Essence
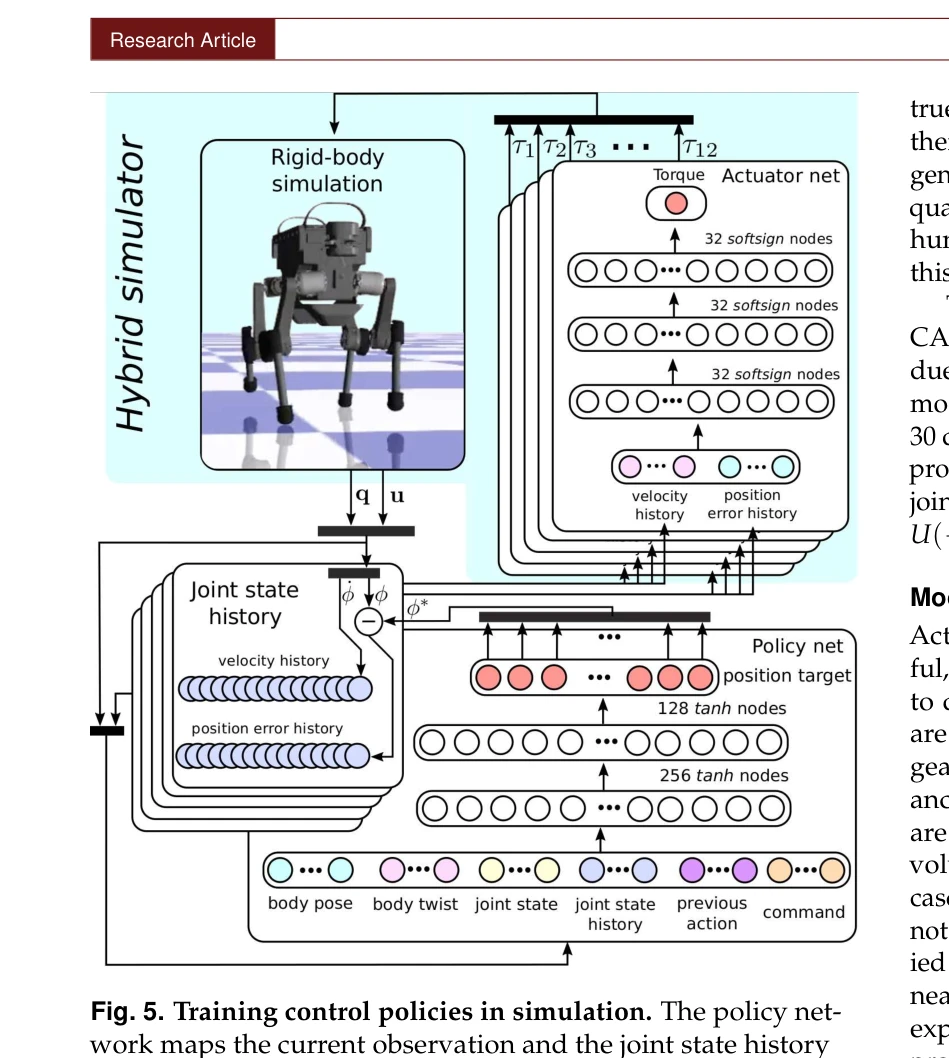
Fig. 5. Training control policies in simulation. The policy net-
본 논문은 시뮬레이션에서 reinforcement learning으로 사족 로봇의 제어 정책을 학습하고 현실의 ANYmal 로봇에 전이하는 방법을 제시하여, 고속 주행과 낙하 복구 등의 동적 운동 기술을 달성했다.
저자: Jemin Hwangbo, Joonho Lee, Alexey Dosovitskiy, Dario Bellicoso, Vassilios Tsounis, Vladlen Koltun, Marco Hutter | 날짜: 2019-01-24 | URL: https://arxiv.org/abs/1901.08652 📄 PDF
Fig. 5. Training control policies in simulation. The policy net-
본 논문은 시뮬레이션에서 reinforcement learning으로 사족 로봇의 제어 정책을 학습하고 현실의 ANYmal 로봇에 전이하는 방법을 제시하여, 고속 주행과 낙하 복구 등의 동적 운동 기술을 달성했다.
총평: 본 논문은 사족 로봇의 동적 제어에 reinforcement learning과 domain randomization을 효과적으로 결합하여 시뮬레이션-현실 전이 문제를 체계적으로 해결했으며, 실제 고급 로봇 플랫폼에서 이전에 달성하지 못한 수준의 운동 기술을 구현함으로써 로봇 제어 분야에 중요한 기여를 했다.