Essence
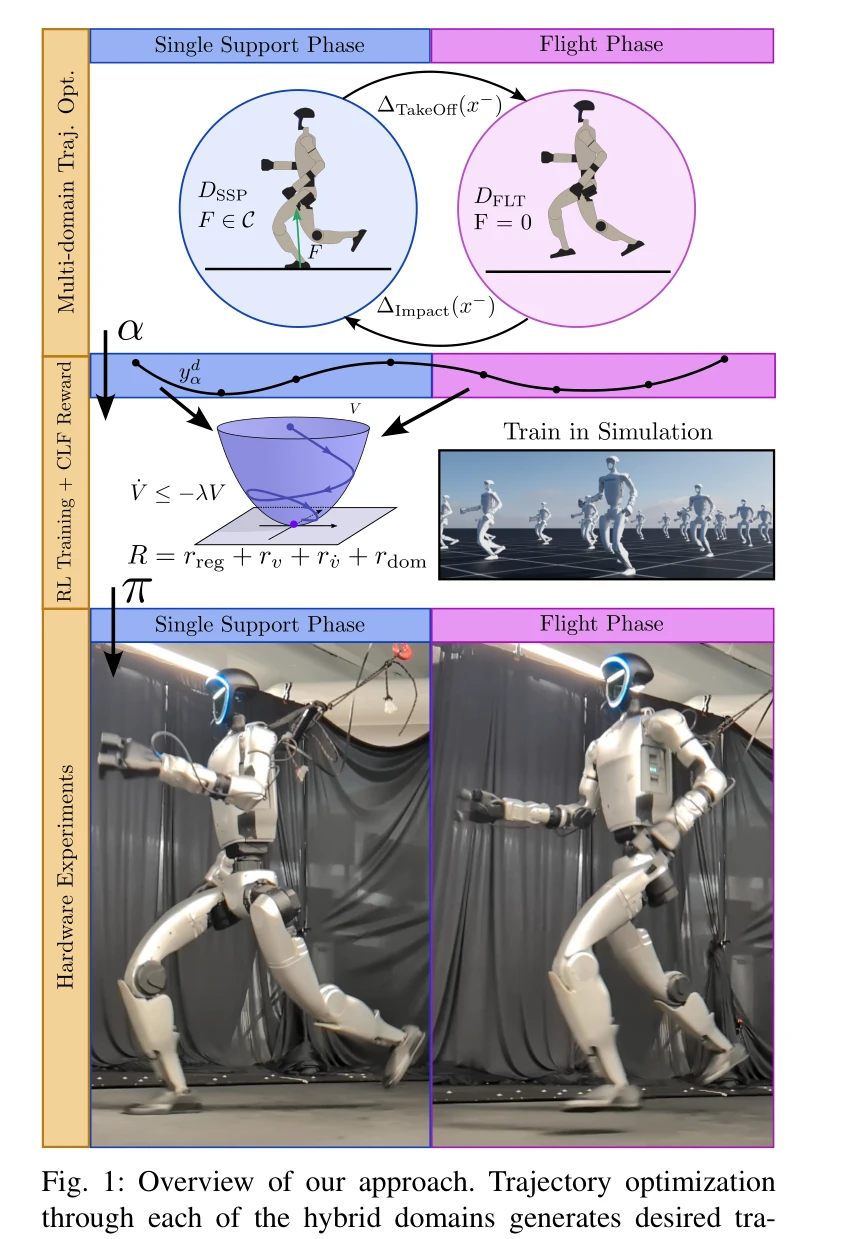
Fig. 1: Overview of our approach. Trajectory optimization
본 논문은 Control Lyapunov Function(CLF)의 안정성 조건을 RL 보상에 임베딩하여 휴머노이드 로봇의 달리기를 실현하는 CLF-RL 방법을 제시한다. 이는 휴머노이드가 비행 및 단일 지지 상(flight and single support phases)를 포함한 동적 달리기를 수행하도록 한다.
저자: Zachary Olkin, Kejun Li, William D. Compton, Aaron D. Ames | 날짜: 2025-09-23 | URL: https://arxiv.org/abs/2509.19573 📄 PDF
Fig. 1: Overview of our approach. Trajectory optimization
본 논문은 Control Lyapunov Function(CLF)의 안정성 조건을 RL 보상에 임베딩하여 휴머노이드 로봇의 달리기를 실현하는 CLF-RL 방법을 제시한다. 이는 휴머노이드가 비행 및 단일 지지 상(flight and single support phases)를 포함한 동적 달리기를 수행하도록 한다.
총평: 본 논문은 고전 제어 이론(CLF)과 최신 RL을 매우 효과적으로 통합하여, 휴머노이드 로봇의 동적 달리기 제어를 위한 원리 기반의 체계적 프레임워크를 제시한다. 실제 하드웨어에서의 안정적 배포와 강건한 추적 성능은 높은 실용적 가치를 입증한다.