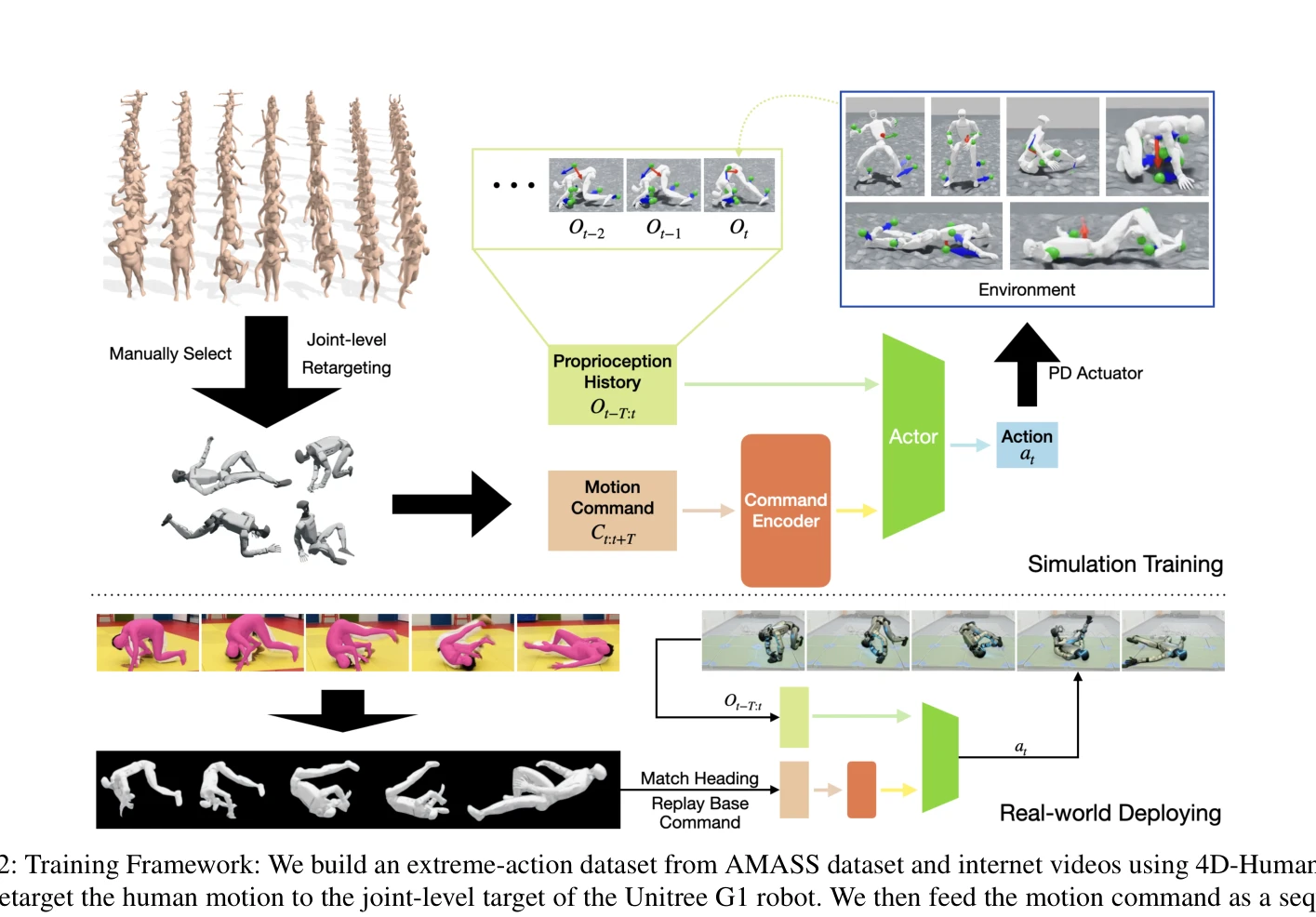
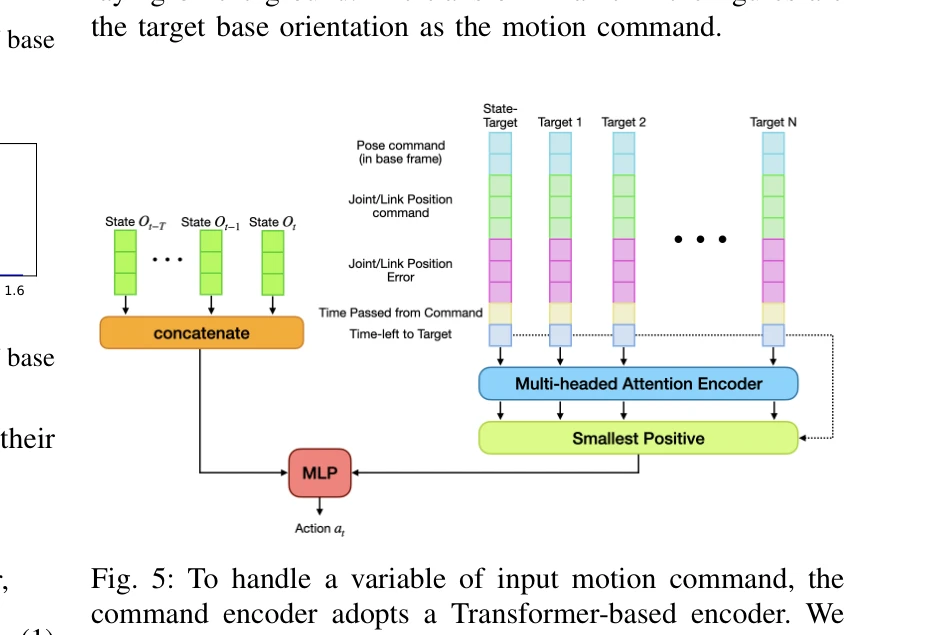
Essence
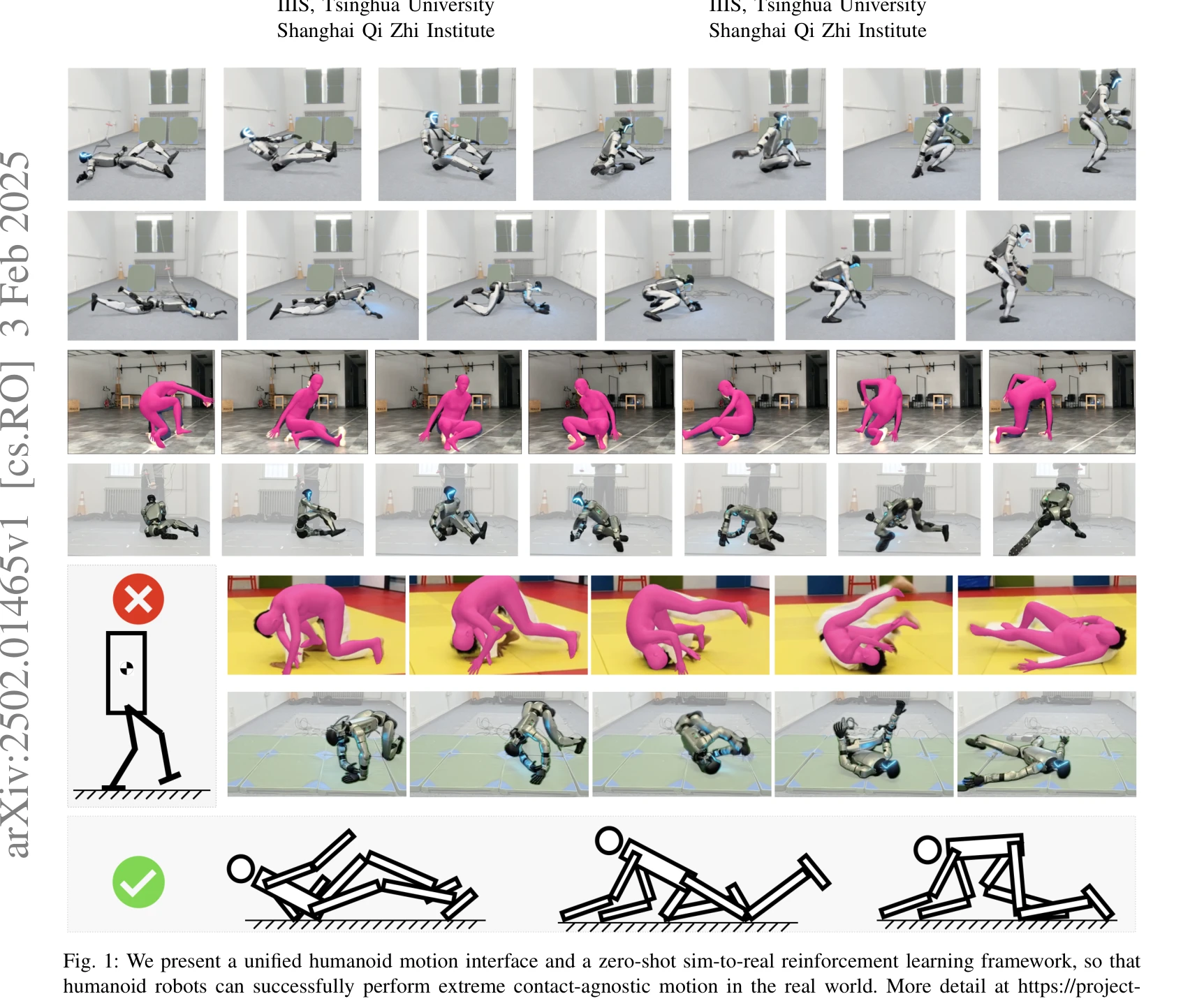
Fig. 1: We present a unified humanoid motion interface and a zero-shot sim-to-real reinforcement learning framework, so
본 논문은 휴머노이드 로봇이 온몸의 모든 신체 부위를 사용하여 환경과 상호작용하는 접촉-무관(contact-agnostic) 동작을 수행할 수 있도록 하는 통합 제어 프레임워크를 제안한다. GPU 가속 rigid-body simulator와 reinforcement learning을 활용하여 시뮬레이션에서 학습한 정책을 실제 로봇에 zero-shot으로 배포할 수 있음을 시연한다.