Essence
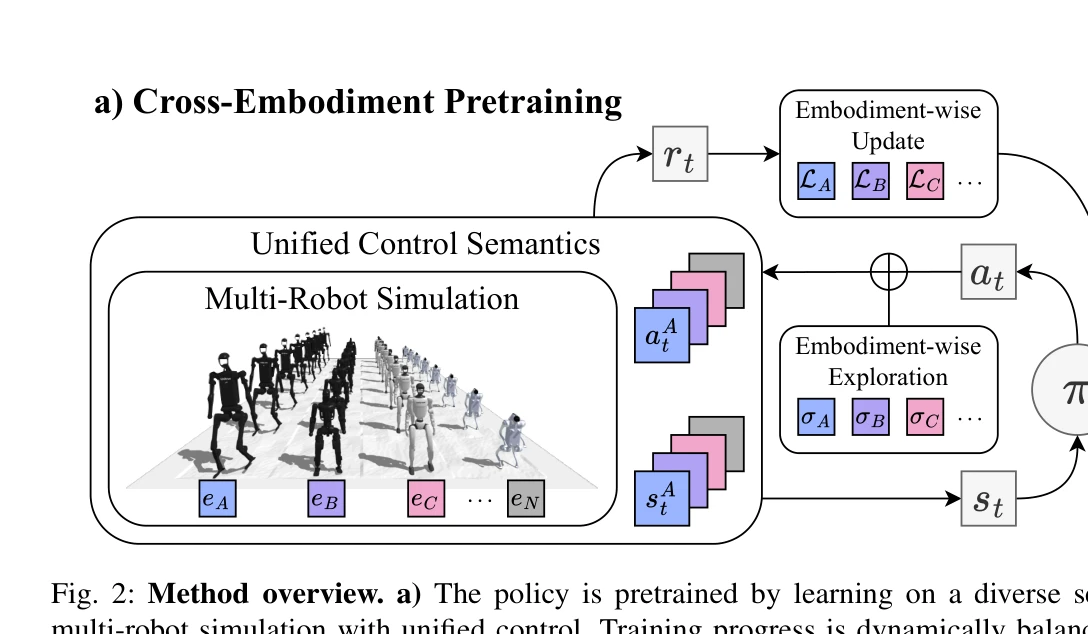
Fig. 2: Method overview. a) The policy is pretrained by learning on a diverse set of humanoid embodiments through
H-Zero는 다양한 휴머노이드 로봇 embodiment에서 사전학습된 일반화된 이동 정책을 학습하여 미지의 로봇으로의 제로샷 및 소수샷 전이를 가능하게 하는 파이프라인이다.
저자: Yunfeng Lin, Minghuan Liu, Yufei Xue, Ming Zhou, Yong Yu, Jiangmiao Pang, Weinan Zhang | 날짜: 2025-11-30 | URL: https://arxiv.org/abs/2512.00971 📄 PDF
Fig. 2: Method overview. a) The policy is pretrained by learning on a diverse set of humanoid embodiments through
H-Zero는 다양한 휴머노이드 로봇 embodiment에서 사전학습된 일반화된 이동 정책을 학습하여 미지의 로봇으로의 제로샷 및 소수샷 전이를 가능하게 하는 파이프라인이다.
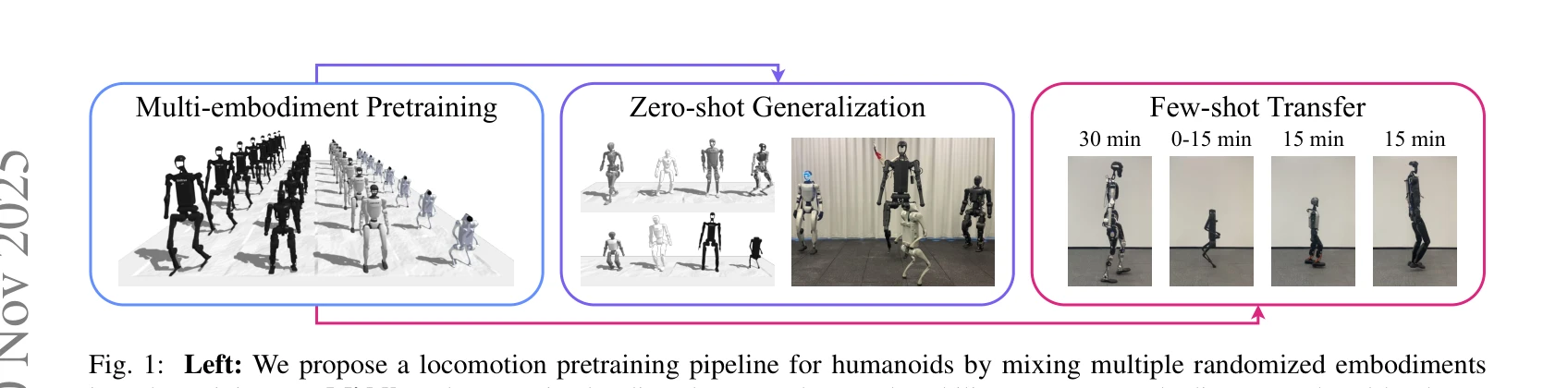
Fig. 1: Left: We propose a locomotion pretraining pipeline for humanoids by mixing multiple randomized embodiments
Fig. 2: Method overview. a) The policy is pretrained by learning on a diverse set of humanoid embodiments through
총평: H-Zero는 unified control semantics를 통해 실용적이고 확장 가능한 cross-embodiment 이동 제어 솔루션을 제시하며, 30분의 미세조정으로 신규 로봇에 적응할 수 있는 점에서 현실 배포 관점에서 큰 의의가 있다. 다만 embodiment 선택의 체계화와 더 다양한 형태의 로봇으로의 일반화 능력 검증이 필요하다.