Essence
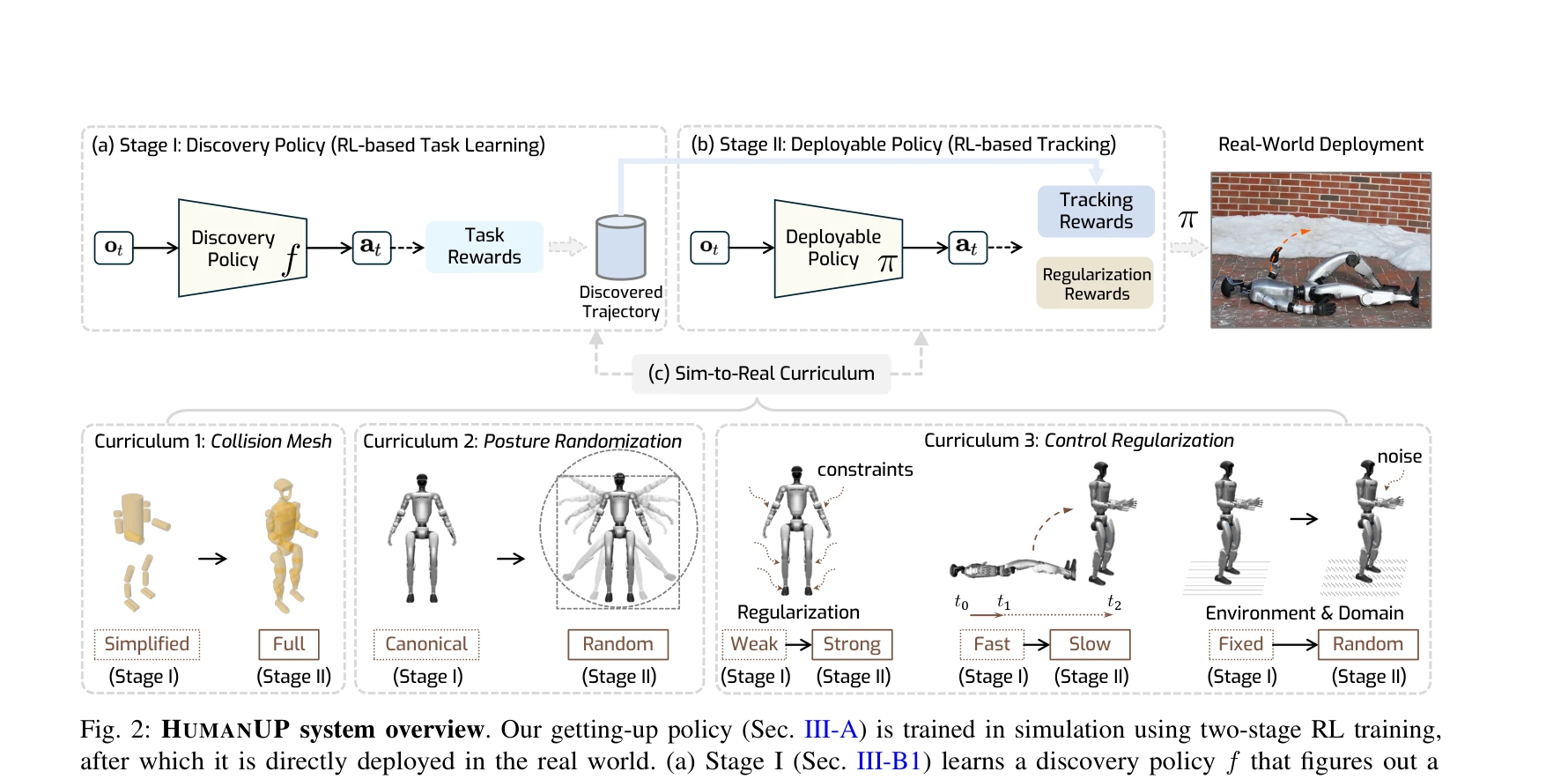
Fig. 2: HUMANUP system overview. Our getting-up policy (Sec. III-A) is trained in simulation using two-stage RL training
휴머노이드 로봇의 낙상 복구를 위해 두 단계 강화학습 프레임워크(HUMANUP)를 제시하여 다양한 자세와 지형에서 일어나는 동작을 학습하고 실제 G1 로봇에 배포했다.
저자: Xialin He, Runpei Dong, Zixuan Chen, Saurabh Gupta | 날짜: 2025-02-17 | URL: https://arxiv.org/abs/2502.12152 📄 PDF
Fig. 2: HUMANUP system overview. Our getting-up policy (Sec. III-A) is trained in simulation using two-stage RL training
휴머노이드 로봇의 낙상 복구를 위해 두 단계 강화학습 프레임워크(HUMANUP)를 제시하여 다양한 자세와 지형에서 일어나는 동작을 학습하고 실제 G1 로봇에 배포했다.

Fig. 1: HUMANUP provides a simple and general two-stage training method for humanoid getting-up tasks, which can be
Fig. 2: HUMANUP system overview. Our getting-up policy (Sec. III-A) is trained in simulation using two-stage RL training
총평: 휴머노이드 로봇 낙상 복구는 중요하면서도 미탐색된 문제이며, 이 논문은 작업 특성을 정확히 파악하고 실용적 커리큘럼 학습을 통해 인간 규모 로봇에서 처음 성공적인 실제 배포를 시연했다. 기술적 기여도 있지만 평가 범위의 한계와 설계 선택의 일반화 가능성에 대한 추가 검증이 필요하다.