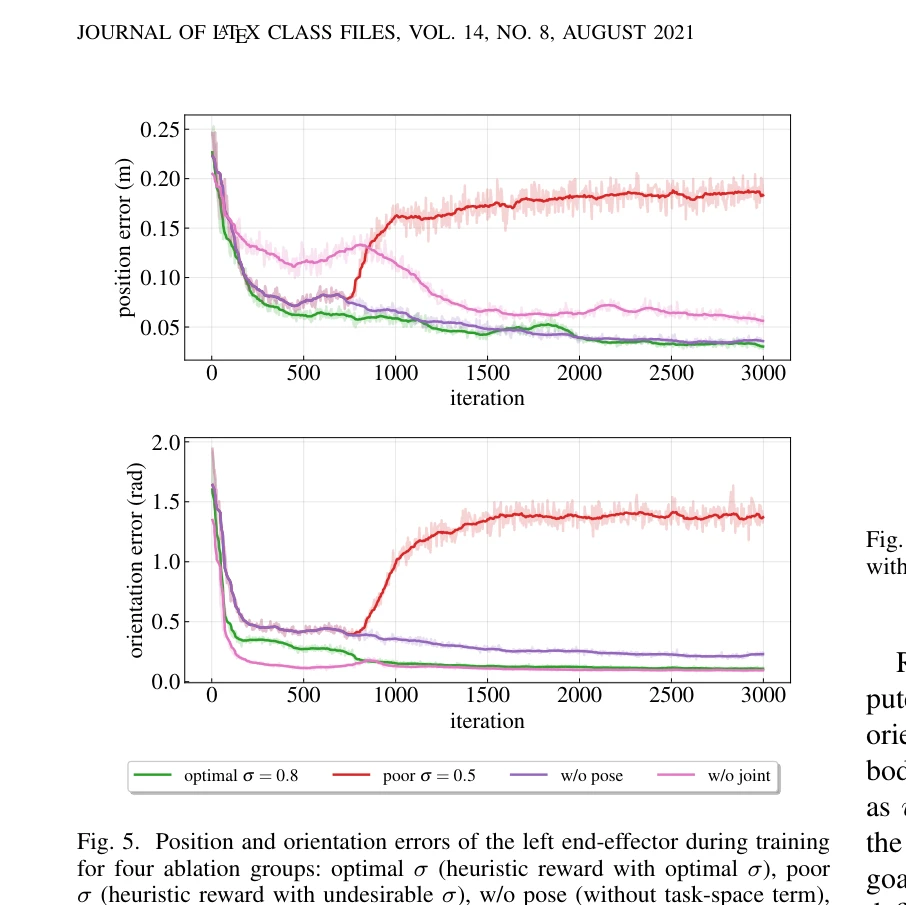
Essence
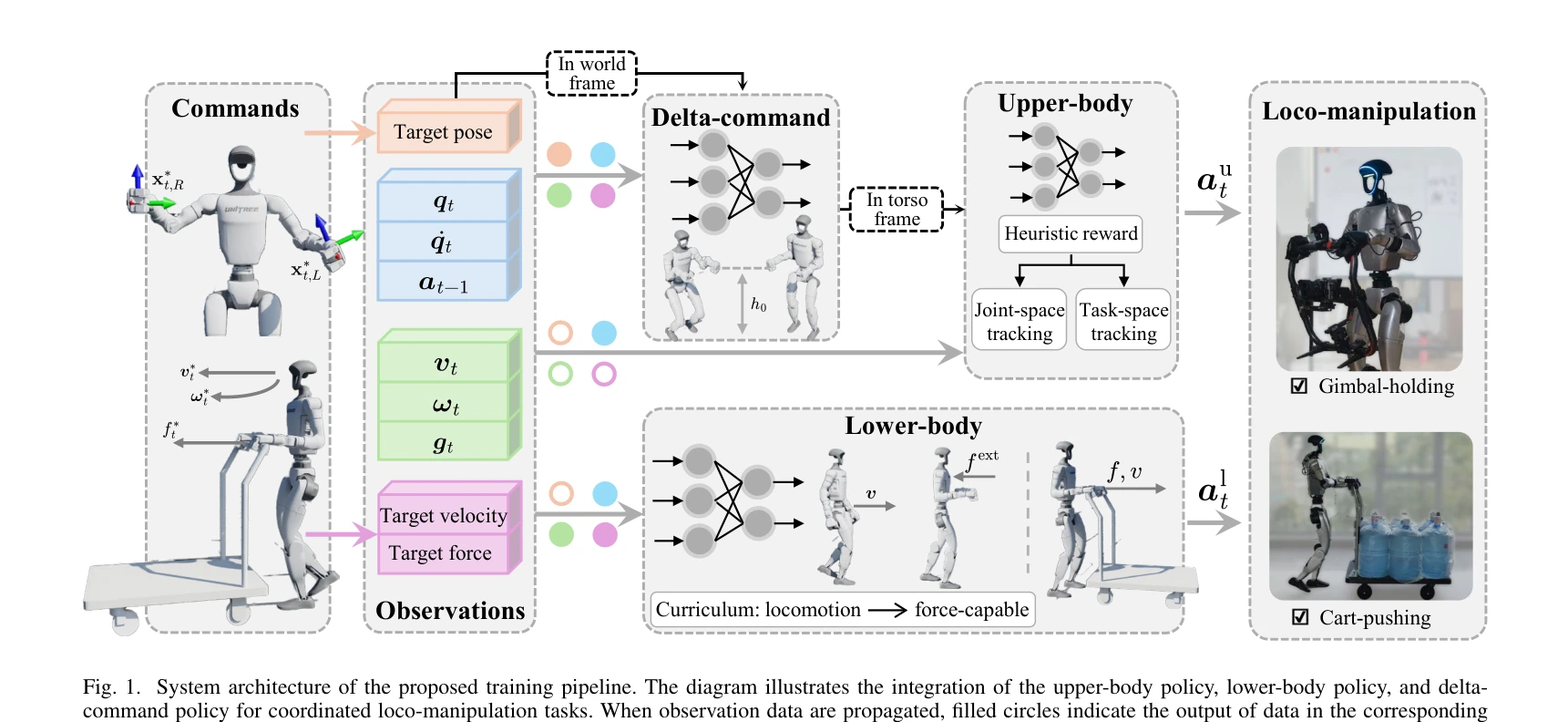
Fig. 1. System architecture of the proposed training pipeline. The diagram illustrates the integration of the upper-body
본 논문은 휴머노이드 로봇의 고부하 산업 작업 수행을 위해 kinematics 사전 정보를 활용한 휴리스틱 보상함수, force-based curriculum learning, delta-command 정책을 통합한 3단계 RL 기반 loco-manipulation 프레임워크를 제안한다.