저자: Wandong Sun, Yongbo Su, Leoric Huang, Alex Zhang, Dwyane Wei, Mu San, Daniel Tian, Ellie Cao, Finn Yan, Ethan Xie, Zongwu Xie | 날짜: 2026-02-06 | URL: https://arxiv.org/abs/2602.06382 📄 PDF
Essence

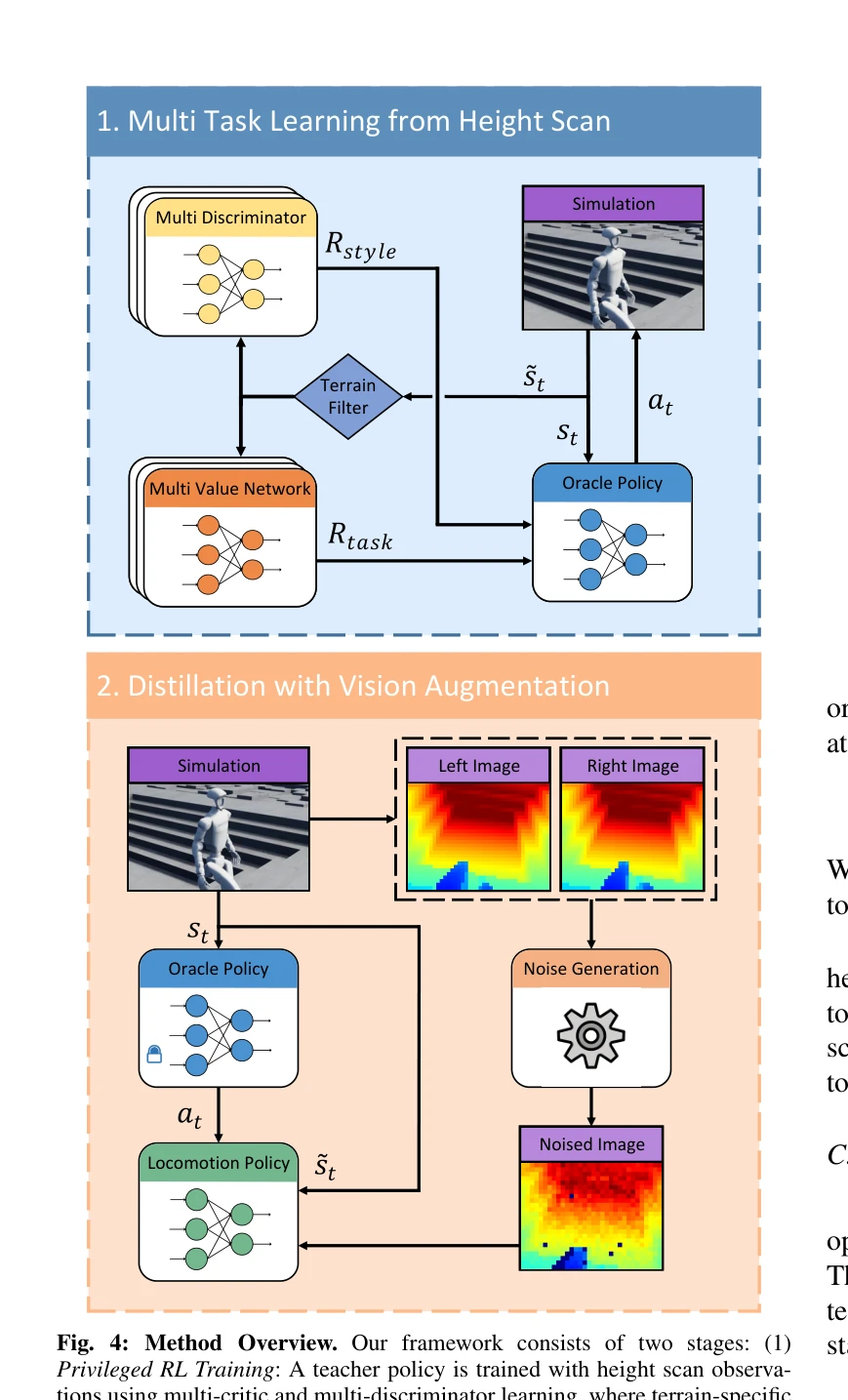
Fig. 1: Overview. Our end-to-end vision-based humanoid locomotion policy enables robust traversal across diverse challen
Raw 깊이 이미지로부터 end-to-end 휴머노이드 로봇 보행을 학습하기 위해, 현실적인 depth 센서 시뮬레이션과 vision-aware behavior distillation, 그리고 terrain-specific multi-critic/multi-discriminator 학습을 결합한 프레임워크를 제시한다.
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 논문은 휴머노이드 로봇의 vision-based 보행에서 sim-to-real gap과 다양한 terrain 통합 학습의 근본적인 두 과제를 체계적으로 해결하며, 현실적인 센서 모델링과 behavior distillation, terrain-specific 학습을 결합한 창의적인 프레임워크를 제시한다. 두 개의 실제 로봇 플랫폼에서 극한 장애물부터 fine-grained 작업까지 광범위한 성능 검증을 통해 학술적·실무적 가치가 높다.