Essence
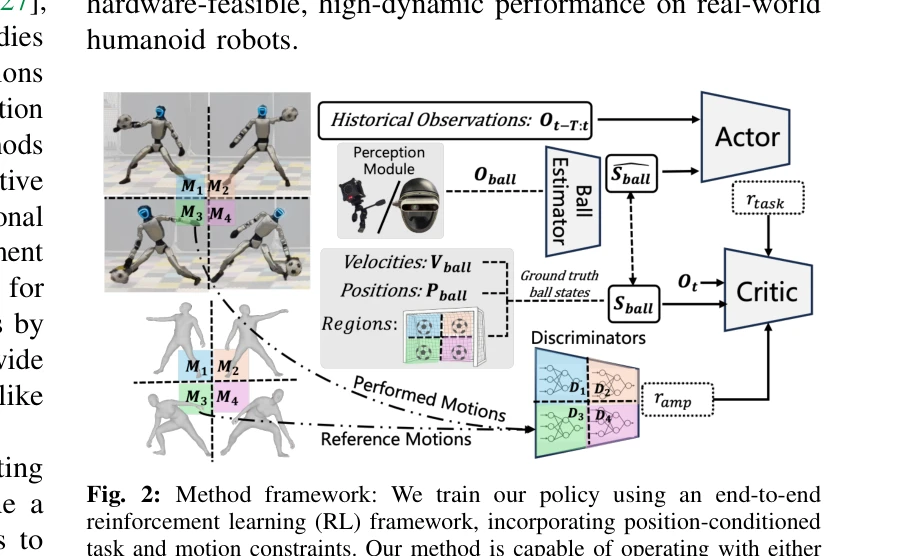
Fig. 2: Method framework: We train our policy using an end-to-end
인간형 로봇의 골키퍼 역할을 위해 위치 조건부 task-motion constraints를 학습하는 end-to-end RL 프레임워크를 제시하며, 인간 모션 프라이어를 adversarial scheme으로 통합하여 자동화되고 인간다운 전신 동작을 생성한다.
저자: Junli Ren, Junfeng Long, Tao Huang, Huayi Wang, Zirui Wang, Feiyu Jia, Wentao Zhang, Jingbo Wang, Ping Luo, Jiangmiao Pang | 날짜: 2026-03-14 | DOI: 10.48550/arXiv.2510.18002 📄 PDF
Fig. 2: Method framework: We train our policy using an end-to-end
인간형 로봇의 골키퍼 역할을 위해 위치 조건부 task-motion constraints를 학습하는 end-to-end RL 프레임워크를 제시하며, 인간 모션 프라이어를 adversarial scheme으로 통합하여 자동화되고 인간다운 전신 동작을 생성한다.

Fig. 1: We present Humanoid Goalkeeper, capable of performing goalkeeping tasks across various regions with a wide opera
Fig. 2: Method framework: We train our policy using an end-to-end
총평: 본 논문은 position-conditioned adversarial motion priors를 통해 humanoid 로봇의 자동화되고 인간다운 골키퍼 능력을 처음으로 시연한 의미 있는 연구이며, 실제 하드웨어 배포와 task 일반화를 통해 실용성을 입증했으나, 정량적 분석과 ablation study가 강화될 필요가 있다.