Humanoid — Paper Curation
Research Timeline
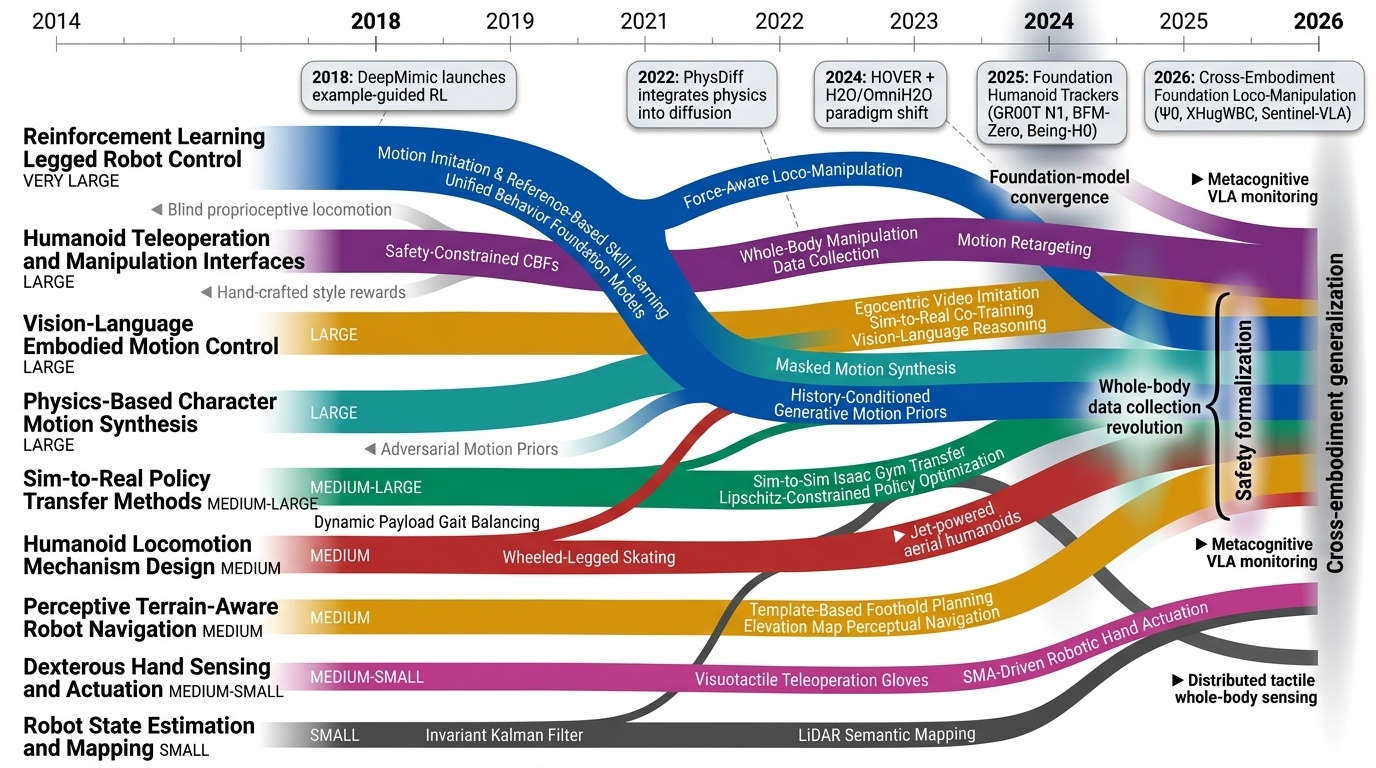
휴머노이드(Humanoid) 연구 분야는 2018년 DeepMimic(Peng et al., 2018)이 모션캡처 기반 예시 유도 강화학습(Example-Guided RL)을 정립하고, 2019년 ANYmal의 학습된 액추에이터 네트워크(Learned Actuator Nets)가 시뮬레이션-실물 전이(Sim-to-Real Transfer)의 표준 경로를 제시하면서 본격적으로 가속화되었다. 이후 2021년 적대적 모션 사전학습(Adversarial Motion Prior, AMP)이 수작업 보상 설계를 대체하였고, 2022년 PhysDiff는 디퓨전 샘플링에 물리 투영을 결합하며 생성 모델과 물리 기반 캐릭터 제어를 융합하는 패러다임 전환을 이끌었다. 2023~2024년에는 PHC가 단일 컨트롤러로 10K 모션 클립을 학습하는 규모 확장을 달성하였고, MaskedMimic(Tessler et al., 2024)이 전신 제어를 마스킹 기반 모션 인페인팅(Inpainting)으로 재정의하였으며, Apple Vision Pro 기반의 Open-TeleVision, Bunny-VisionPro, ARMADA 등이 동시다발적으로 등장하면서 VR 원격조작(Teleoperation)의 폭발적 확산이 일어났다. 같은 시기 HOVER는 15개 이상의 제어 모드를 단일 신경망으로 통합하는 행동 파운데이션 모델(Behavior Foundation Model)의 개념을 제시하였다. 2025년에 들어 GR00T N1, SONIC, FB-CPR, BeyondMimic과 같은 파운데이션급 전신 트래커가 등장하고, FALCON은 0~100N 외력 하 로코-매니퓰레이션(Loco-Manipulation)을 실현하였으며, FastTD3는 단일 GPU에서 15분 학습을 달성해 오프-폴리시 강화학습의 효율성을 극적으로 향상시켰다. 또한 VIRAL, VisualMimic은 RGB 픽셀-투-액션(Pixel-to-Action) 정책의 제로샷 전이를 입증하였고, iRonCub 3는 최초의 제트 추진 휴머노이드 수직 이륙을 시연하며 공중 휴머노이드라는 새로운 영역을 개척하였다. 저비용 의인형 손(RUKA, ORCA, CYJ Hand-0)과 5천 달러대 오픈 플랫폼(Berkeley Humanoid Lite, AGILOped)의 확산은 연구 진입 장벽을 크게 낮추었다. 2026년의 최근 흐름은 XHugWBC, H-Zero 등의 교차 형상(Cross-Embodiment) 일반화, Sentinel-VLA·PaCo-VLA의 메타인지적 안전 추론, Ψ0와 DreamGen 기반 비디오 월드 모델(Video World Model) 공동학습, 그리고 SafeVLA-Bench·SHIELD의 형식적 안전 보장으로 수렴하고 있다. 향후 연구는 에고센트릭 인간 영상 기반 VLA 사전학습, 물리적으로 안전한 언어 조건부 전신 제어, 촉각·시각·고유감각을 통합한 접촉 풍부(Contact-Rich) 매니퓰레이션, 그리고 하드웨어-제어 공동 설계(Co-Design)를 축으로 하여, 인터넷 규모 데이터로부터 실세계에 배포 가능한 범용 휴머노이드 정책을 구축하는 방향으로 진화할 것으로 전망된다.
Research Insights 7 findings
Category Overview
# Humanoid 카테고리: 손재주 손 감지 및 제어 (Dexterous Hand Sensing and Actuation) 인간형 로봇의 손재주 손(dexterous hand) 설계와 제어는 복잡한 조작 작업을 수행하기 위한 핵심 기술이다. 이 분야의 연구들은 강건하고 저비용의 손 구조 설계[1631][1659], 멀티 자유도 구동 메커니즘[1773][1803], 그리고 고급 제어 알고리즘을 통합한 시스템 개발에 집중하고 있다. 촉각 피드백과 시각 정보를 결합한 지각 통합 접근법[1779][2130]은 접촉 기반 조작(contact-rich manipulation)의 정확성을 크게 향상시키고 있으며, 동역학 인식 동작 생성(dynamics-aware motion generation)[1858]과 언어 기반 파지 계획[1717]과 같은 최신 기법들이 로봇의 적응 능력을 강화하고 있다. 전신 다중 접촉 제어[1757], 시뮬레이터 기반 벤치마크[1706], 그리고 시각-촉각 스킬 학습[2075][2083]을 통해 인간형 로봇은 인간 수준의 정교한 조작 능력에 점차 접근하고 있다. 이러한 종합적인 기술 발전은 텔레옵레이션[2113][2129], 인간-로봇 스킬 전이[2130], 그리고 물리 시뮬레이션 최적화[1846][621]를 포함한 다양한 응용 분야로 확장되고 있다.
⚠ 갭: 소프트 물체나 비정형 물체 조작 시 실시간 촉각 피드백을 활용한 적응형 그립력 제어 연구가 하드웨어 발전 속도에 비해 현저히 부족하다.
🏛 정책: 저비용 고성능 로봇 손 핵심 부품(구동기, 촉각 센서)의 국산화 연구개발을 지원하고 관련 특허 풀을 공유하는 오픈 하드웨어 생태계 조성이 필요하다.
BEHAVIOR Robot Suite: Streamlining Real-World Whole-Body Manipulation for Everyday Household Activities

Figure 1: Everyday household activities enabled by BEHAVIOR ROBOT SUITE (BRS), show-
 *Figure 1: Everyday household activities enabled by BEHAVIOR ROBOT SUITE (BRS), show-* BEHAVIOR Robot Suite (BRS)는 가정용 일상 작업을 수행하기 위한 양팔 협력, 안정적 네비게이션, 광범위한 말단 장치 도달성을 갖춘 전신 조작 로봇을 위한 통합 프레임워크를 제시한다. JoyLo 원격 조작 인터페이스와 WB-VIMA 시각운동 정책 학습 알고리즘을 통해 실세계 가정 작업 수행을 가능하게 한다.
BEHAVIOR Robot Suite는 가정용 일상 작업을 위한 전신 조작 로봇의 완전한 생태계를 제시하는 포괄적 연구로, JoyLo의 창의적인 저비용 설계와 WB-VIMA의 계층적 자동회귀 정책 학습이 결합되어 실세계 가정 로봇의 실질적 진전을 이룬다. 특히 하드웨어, 데이터 수집, 알고리즘을 완전히 오픈소스화함으로써 커뮤니티 확산 가능성이 높으며, 다중 도메인의 체계적 통합을 통해 로봇 학습 연구에 의미 있는 기여를 한다.
Quasi-Direct Drive for Low-Cost Compliant Robotic Manipulation

Fig. 1.
 *Fig. 1.* Quasi-Direct Drive 구동방식을 기반으로 한 저비용 7-DOF 로봇 팔 Blue를 제안하여 인간 환경에서 안전하고 힘 제어 가능한 조작을 가능하게 함.
이 논문은 인간 환경에서 필요한 저비용 compliant 로봇의 설계 패러다임을 재정의하고 Quasi-Direct Drive 방식을 통해 이를 실현한 획기적 연구로, AI 기반 로봇 학습의 대규모 보급을 가능하게 하는 중요한 플랫폼을 제시함.
RAPID Hand: A Robust, Affordable, Perception-Integrated, Dexterous Manipulation Platform for Generalist Robot Autonomy
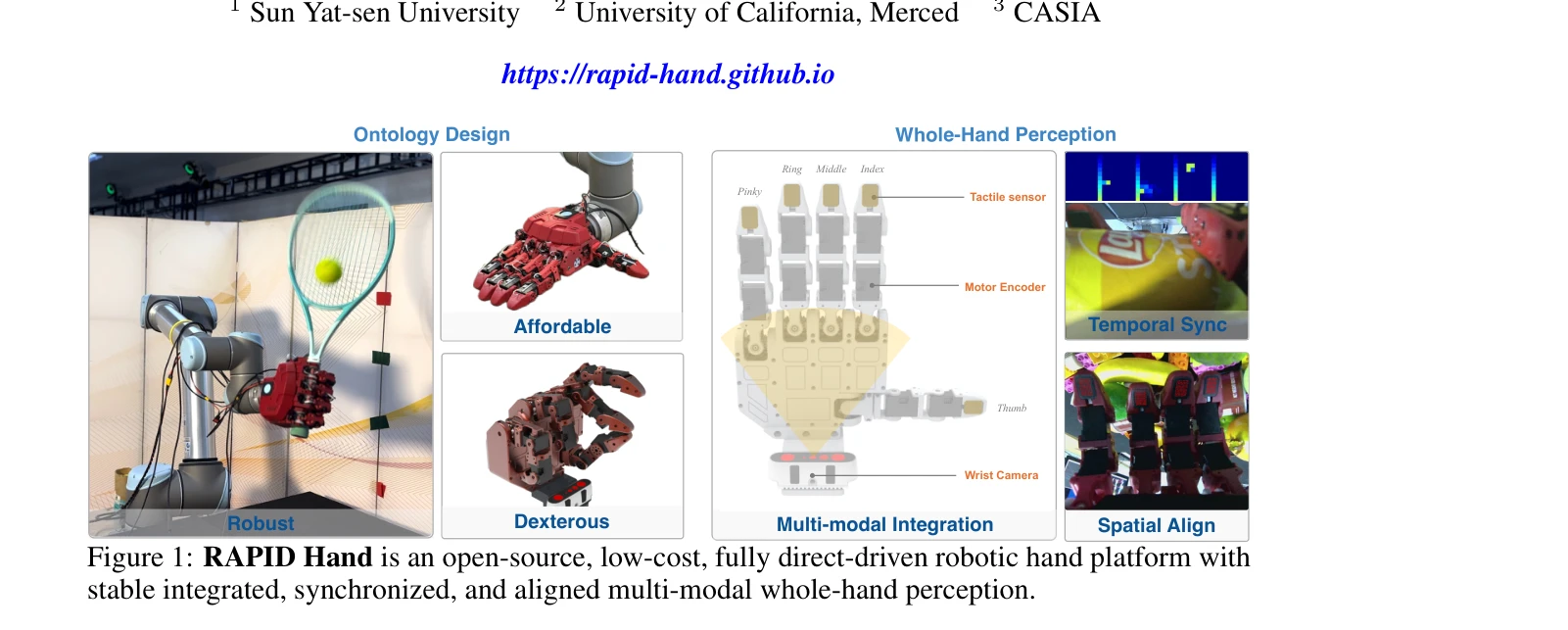
Figure 1: RAPID Hand is an open-source, low-cost, fully direct-driven robotic hand platform with
 *Figure 1: RAPID Hand is an open-source, low-cost, fully direct-driven robotic hand platform with* RAPID Hand는 저비용의 20-DoF 다지형 로봇 손으로, 시각, 촉각, 고유감각을 통합한 멀티모달 인지 시스템과 고-DoF 원격조종 인터페이스를 함께 설계하여 로봇 자율성을 위한 고품질 조작 데이터 수집을 가능하게 한다.
RAPID Hand는 저비용 다지형 로봇 손 설계, 고정밀 멀티모달 인지 통합, 그리고 효과적인 원격조종 인터페이스를 혁신적으로 통합한 오픈소스 플랫폼으로, 일반화된 로봇 자율성 연구에 필요한 고품질 데이터 수집을 가능하게 하는 중요한 기여이다.
TeleOpBench: A Simulator-Centric Benchmark for Dual-Arm Dexterous Teleoperation

Figure 1: We present TeleOpBench, a simulation-based benchmark for bimanual dexterous teleoper-
 *Figure 2: The overview of the proposed TeleOpBench, where we unify four operator interfaces in* TeleOpBench는 쌍팔 민첩한 텔레오퍼레이션을 위한 시뮬레이터 기반 벤치마크로, 30개의 고충실도 작업 환경과 4가지 대표적 텔레오퍼레이션 모달리티(MoCap, VR, 외골격, 비전)를 통합 프레임워크로 제공하며 시뮬레이션과 실제 하드웨어 간의 강한 상관관계를 검증한다.
TeleOpBench는 텔레오퍼레이션 연구의 장기적인 병목인 표준화된 평가 환경의 부재를 해결하는 중요한 기여로, 실제 하드웨어와의 상관관계 검증을 통해 실용성을 입증한 의미 있는 연구이다. 다만 더 많은 로봇 플랫폼 통합과 정성적 사용성 지표 추가로 영향력을 확대할 수 있을 것으로 예상된다.
A Humanoid Visual-Tactile-Action Dataset for Contact-Rich Manipulation
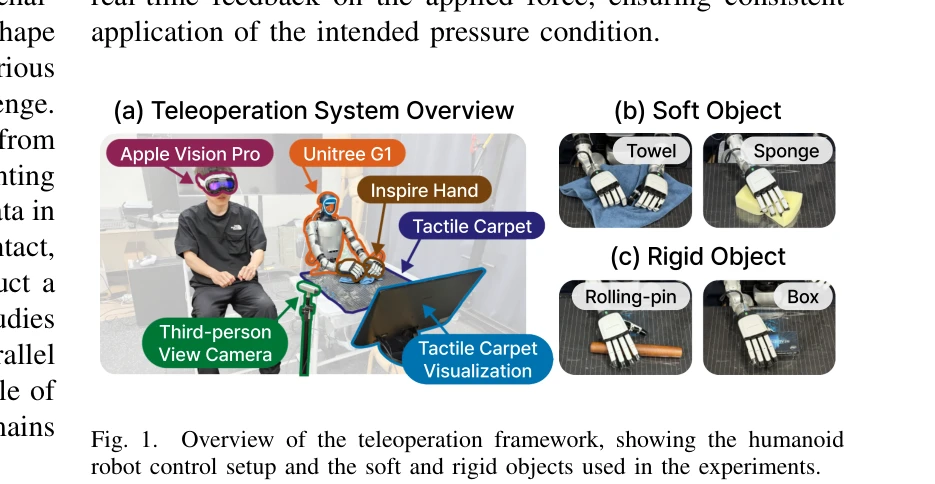
Fig. 1.
 *Fig. 1.* 인형로봇의 시각-촉각-행동 다중모달 데이터셋을 제시하여 접촉 기반 조작, 특히 부드러운 물체 조작을 위한 로봇 학습을 지원한다.
본 논문은 접촉 기반 조작 연구의 중요한 격차를 메우기 위해 인형로봇 기반의 고밀도 시각-촉각-행동 데이터셋을 처음으로 제시하며, 고해상도 촉각 신호의 필요성을 명확하게 입증하는 가치 있는 기여다.
A Rapid Instrument Exchange System for Humanoid Robots in Minimally Invasive Surgery
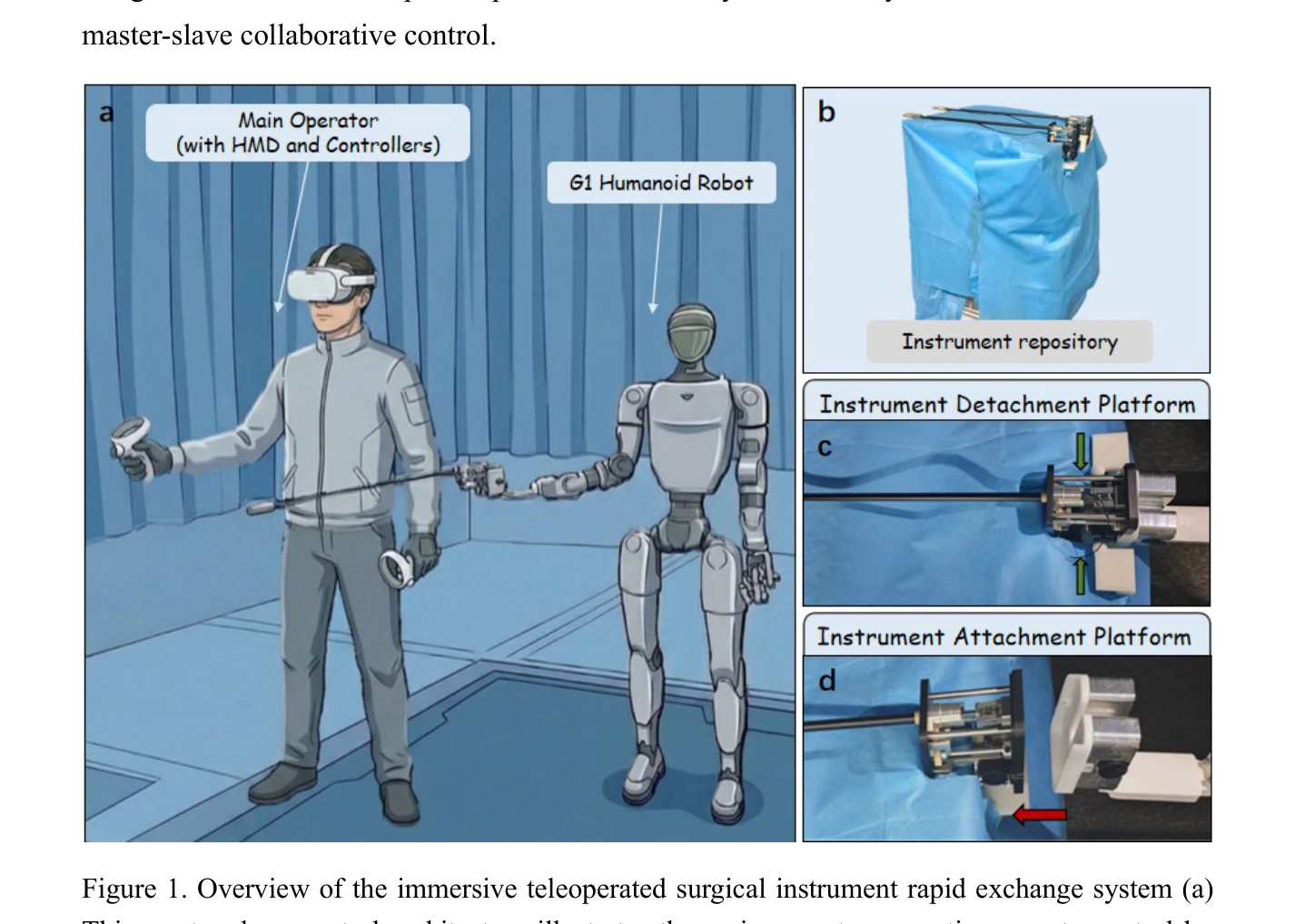
Figure 1. Overview of the immersive teleoperated surgical instrument rapid exchange system (a)
 *Figure 1. Overview of the immersive teleoperated surgical instrument rapid exchange system (a)* 휴머노이드 로봇의 이중 팔 구성을 활용하여 HMD 기반 몰입형 원격조작과 단축 컴플라이언트 도킹 메커니즘을 통합한 최소침습 수술용 고속 기구 교환 시스템을 제안한다.
휴머노이드 로봇을 최소침습 수술에 실질적으로 적용하기 위한 핵심 기술 과제를 체계적으로 해결하였으며, HMD 기반 몰입형 원격조작과 맞춤형 도킹 메커니즘의 통합이 효과적임을 입증한 중요한 연구이다.
ACE: A Cross-Platform Visual-Exoskeletons System for Low-Cost Dexterous Teleoperation

Figure 1: An Overview of the Proposed ACE System. The system consists of two bimanual ex-
 *Figure 1: An Overview of the Proposed ACE System. The system consists of two bimanual ex-* ACE는 3D 프린팅된 이중팔 exoskeleton과 hand-facing 카메라를 결합한 저비용 cross-platform 시각 기반 원격 조종 시스템으로, 다양한 로봇 플랫폼과 end-effector에 대해 정밀한 손과 손목 자세 추적을 가능하게 한다.
ACE는 기존 원격 조종 시스템의 비용-정확도-유연성 trade-off를 효과적으로 해결한 실용적인 솔루션으로, 저비용의 3D 프린팅 exoskeleton과 vision-kinematics 하이브리드 방식을 통해 다양한 로봇 플랫폼에서의 대규모 데이터 수집을 가능하게 한다는 점에서 높은 가치를 제공한다.
Bunny-VisionPro: Real-Time Bimanual Dexterous Teleoperation for Imitation Learning
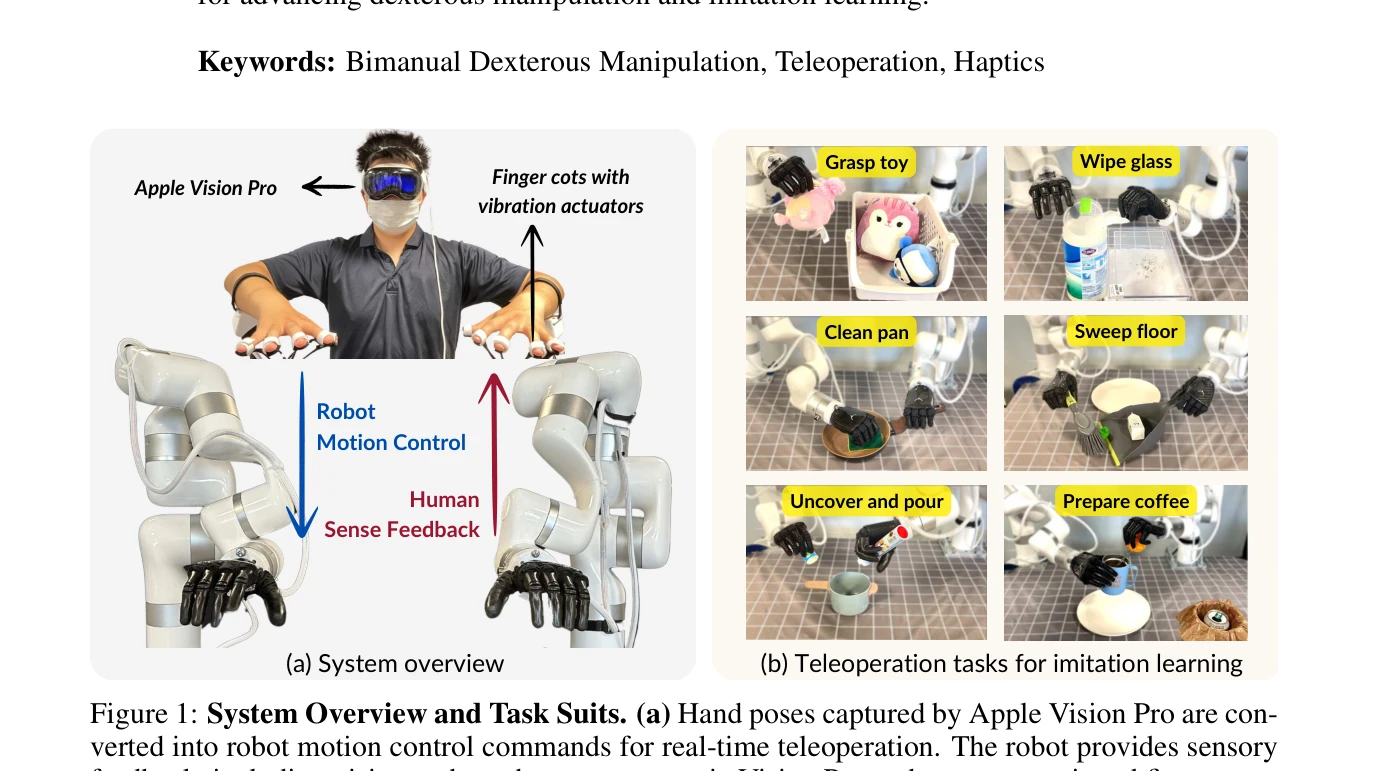
Figure 1: System Overview and Task Suits. (a) Hand poses captured by Apple Vision Pro are con-
 *Figure 1: System Overview and Task Suits. (a) Hand poses captured by Apple Vision Pro are con-* Apple Vision Pro의 손 추적 기능을 활용하여 양손 민첩한 조작이 가능한 실시간 텔레오퍼레이션 시스템 Bunny-VisionPro를 제시하며, 저비용 햅틱 피드백과 충돌/특이점 회피를 통해 모방 학습용 고품질 시연 데이터를 수집한다.
Vision Pro를 활용한 양손 민첩 텔레오퍼레이션에서 실시간 성능, 안전성, 몰입감을 동시에 달성한 혁신적 시스템으로, 장시간 복잡 조작의 시연 수집을 통해 모방 학습의 새로운 가능성을 제시하는 높은 기술적·응용적 가치의 연구다.
Dexterous Teleoperation of 20-DoF ByteDexter Hand via Human Motion Retargeting

Figure 1 Our hand-arm teleoperation system achieves dexterous in-hand manipulation, including multi-object grasping,
 *Figure 2 An overview of the proposed hand-arm teleoperation system. The teleoperation interface consists of a Meta* ByteDexter라는 20-DoF 링크구동 로봇 손과 optimization 기반 motion retargeting을 이용하여 인간의 손 움직임을 실시간으로 로봇에 재현하는 원격조종 시스템을 제시한다.
ByteDexter 시스템은 linkage-driven 손의 mechanical design, fast kinematics solver, 그리고 optimization 기반 motion retargeting을 정교하게 통합하여 고-DoF 로봇 손의 원격조종을 실현하는 의미 있는 기여를 제시한다. 실시간 제어와 고품질 demonstration data 생성이라는 실용적 가치가 높지만, 다양한 task 환경에서의 general robustness와 imitation learning 결과의 실증이 필요하다.
Fauna Sprout: A lightweight, approachable, developer-ready humanoid robot

Fig. 1: Robot in action. (A) Standing and looking up towards a person (B) performing closed-loop high-five interaction
 *Fig. 1: Robot in action. (A) Standing and looking up towards a person (B) performing closed-loop high-five interaction* Sprout는 인간 환경에서의 안전한 배포, 표현성, 개발자 접근성을 강조하는 경량 휴머노이드 로봇 플랫폼이다. 낮은 물리적·기술적 진입장벽으로 구현된 통합 하드웨어-소프트웨어 스택을 제공한다.
Sprout는 로보틱스 분야의 접근성 문제를 정면으로 해결하는 실용적 플랫폼으로, 안전성과 개발자 친화성을 중심으로 한 설계 철학이 명확하다. 인간 환경 배포와 사회적 상호작용이라는 과소 탐색된 영역을 강조함으로써 embodied AI 연구의 새로운 방향을 제시하는 의미 있는 기여이다.
HandX: Scaling Bimanual Motion and Interaction Generation

Figure 1. (a) We introduce HandX, a large-scale dataset of bimanual and dexterous motions paired with fine-grained textu
 *Figure 1. (a) We introduce HandX, a large-scale dataset of bimanual and dexterous motions paired with fine-grained textu* HandX는 양손의 섬세한 움직임과 상호작용을 생성하기 위한 통합 기반을 제공하는 대규모 dataset, annotation 전략, 그리고 평가 방법론을 제시한다.
HandX는 bimanual hand motion generation의 significant gap을 체계적으로 해결하는 comprehensive framework를 제시하며, large-scale dataset, scalable annotation 전략, 그리고 detailed benchmarking을 통해 손 움직임 합성 분야의 새로운 표준을 제시한다. 실제 humanoid deployment까지 입증한 점에서 학술적, 실용적 가치가 높다.
Human-Level Actuation for Humanoids
 *Figure 4: Lower body atlas I: Pelvis and hip degrees of freedom. Pelvic motion is relative to a global* 휴머노이드 로봇의 '인간 수준' 구동을 정량화하고 비교 가능하게 하기 위해 생체역학 기반의 포괄적 평가 프레임워크를 제시하고, DoF atlas, Human-Equivalence Envelopes (HEE), Human-Level Actuation Score (HLAS)의 세 가지 핵심 요소로 구성된다.
이 논문은 휴머노이드 로봇의 '인간 수준' 구동력을 정량화하기 위한 학제적 프레임워크를 제시하며, 생체역학 기반의 엄격한 기준과 표준화된 측정 프로토콜을 결합하여 로봇 개발과 벤치마킹의 투명성과 재현성을 크게 향상시킨다. 구동기 설계 트레이드오프를 명시적으로 노출하고 작업 맥락에 맞춘 평가를 수행한다는 점에서 기존 피크값 기반 사양과 차별화되며, 휴머노이드 로봇 공학 분야에서 중요한 표준화 기여를 한다.
Humanoid Manipulation Interface: Humanoid Whole-Body Manipulation from Robot-Free Demonstrations

Fig. 1: Humanoid Manipulation Interface (HuMI). Left: Our portable, robot-free data collection facilitates skill transfe
 *Fig. 1: Humanoid Manipulation Interface (HuMI). Left: Our portable, robot-free data collection facilitates skill transfe* HuMI는 로봇 없이 휴대용 하드웨어로 수집한 인간 전신 동작 데이터를 이용해 인형형 로봇에게 다양한 전신 조작 기술을 학습시키는 프레임워크이다. 계층적 학습 파이프라인과 IK 기반 적응을 통해 인간-로봇 간 신체형 차이를 극복하고 70% 성공률을 달성한다.
HuMI는 로봇 없는 휴대용 데이터 수집과 계층적 학습을 결합하여 인형형 로봇의 전신 조작을 효율적으로 학습시키는 혁신적인 프레임워크이다. 3배 높은 데이터 수집 효율과 미지 환경에서의 강한 일반화는 로봇 학습의 실용성을 크게 향상시키며, 신체형 차이 극복을 위한 체계적 접근법이 학문적 기여도 크다.
Humanoids in Hospitals: A Technical Study of Humanoid Robot Surrogates for Dexterous Medical Interventions
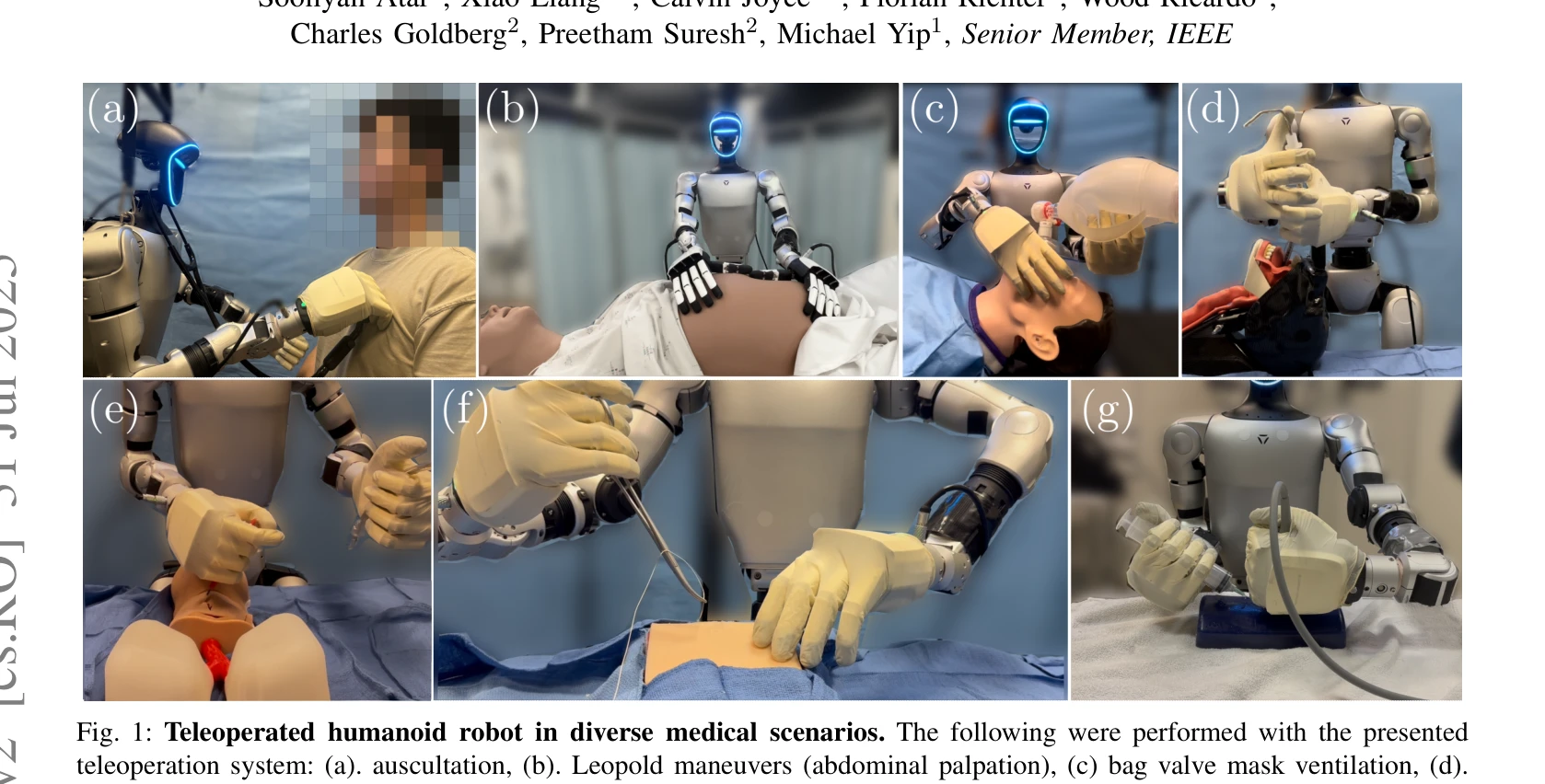
Fig. 1: Teleoperated humanoid robot in diverse medical scenarios. The following were performed with the presented
 *Fig. 1: Teleoperated humanoid robot in diverse medical scenarios. The following were performed with the presented* 본 연구는 Unitree G1 인간형 로봇에 대한 원격조종 시스템을 개발하여 7가지 의료 시술(신체검진, 응급 개입, 정밀 바늘 작업)을 수행할 수 있는 가능성을 탐색적으로 검증했다.
본 연구는 인간형 로봇의 의료 활용 가능성을 처음으로 체계적으로 탐색한 획기적인 연구로, innovative teleoperation 시스템과 실제 임상 작업 검증을 통해 향후 의료 로봇 통합의 토대를 마련했다. 다만 힘 출력과 센서 한계로 인한 현실적 과제 해결이 임상 배포를 위한 핵심 과제이다.
HumDex: Humanoid Dexterous Manipulation Made Easy

Fig. 1: The HumDex System. Our portable teleoperation system enables efficient collection of high-quality dexterous
 *Fig. 1: The HumDex System. Our portable teleoperation system enables efficient collection of high-quality dexterous* IMU 기반 모션 트래킹을 활용한 휴머노이드 전신 손재주 조작 텔레오퍼레이션 시스템으로, learning-based hand retargeting과 human 데이터 사전학습을 통해 최소 데이터로 높은 일반화 성능을 달성한다.
IMU 기반 휴대용 텔레오퍼레이션과 learning-based hand retargeting, human 데이터 활용의 three-pronged 접근으로 humanoid 손재주 조작 데이터 수집의 오래된 병목을 효과적으로 해결한 높은 수준의 시스템 논문이다. 재현성 높은 설계와 충분한 실험 검증으로 실제 영향력이 클 것으로 예상된다.
LapSurgie: Humanoid Robots Performing Surgery via Teleoperated Handheld Laparoscopy
 *Fig. 2: The overview of the humanoid-based laparoscopic framework. The target tool pose Ptt is mapped from the control* LapSurgie는 인문형 로봇이 원격 조종을 통해 상용 복강경 수술 도구를 직접 조작할 수 있게 하는 최초의 텔레오퍼레이션 프레임워크로, 원격 중심 운동(RCM) 제약을 만족하는 역매핑 전략과 스테레오 비전 피드백을 통합한다.
LapSurgie는 인문형 로봇을 수술 영역에 처음 적용하고 RCM 제약 기반 역매핑 제어를 통해 상용 복강경 도구의 직관적 조작을 실현한 혁신적 연구로, 의료 자원 부족 지역에서의 로봇 수술 접근성 확대에 중요한 기여를 한다. 다만 임상 수준의 검증과 기술적 성숙도 향상이 필요하다.
Learning Visuotactile Skills with Two Multifingered Hands
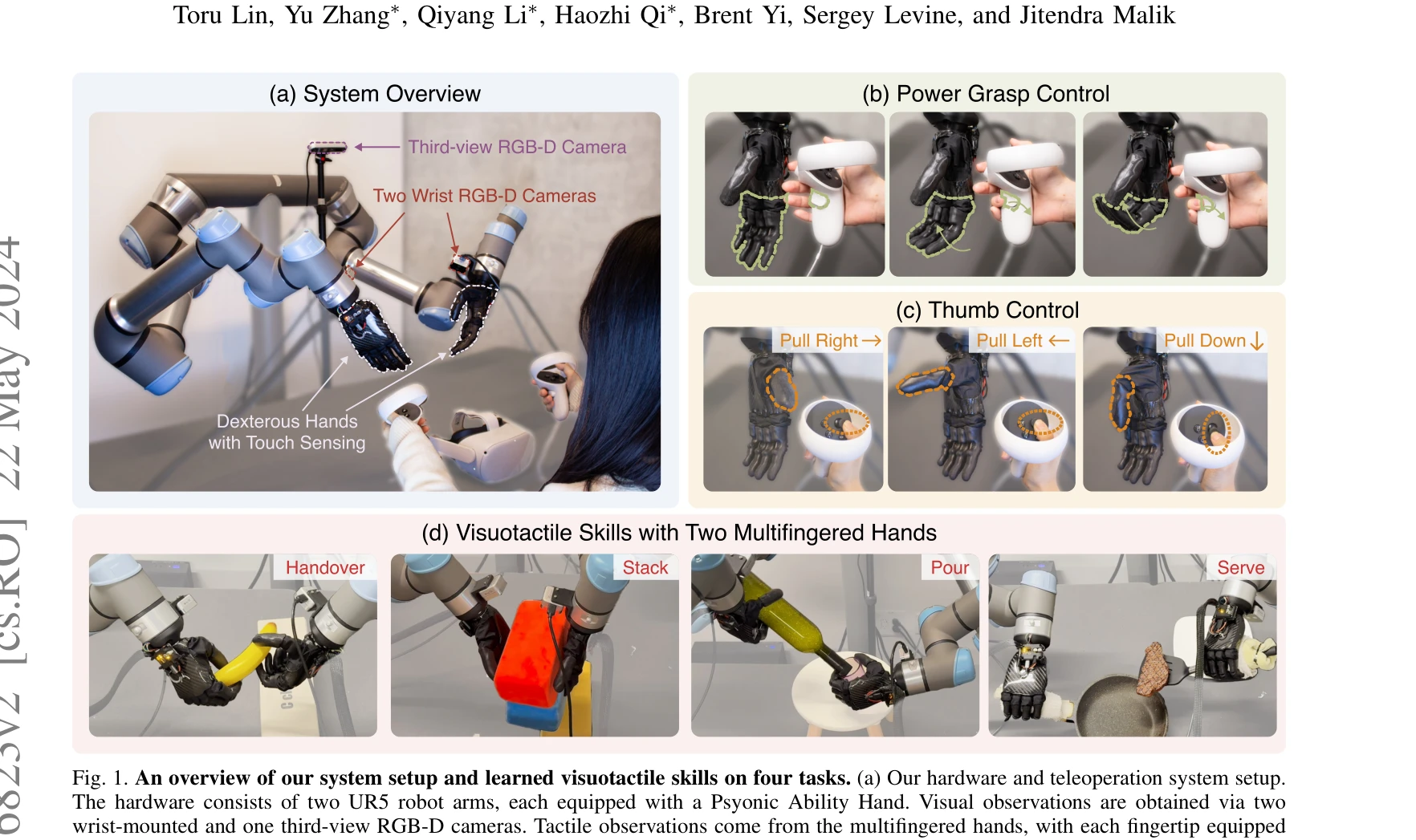
Fig. 1. An overview of our system setup and learned visuotactile skills on four tasks. (a) Our hardware and teleoperatio
 *Fig. 1. An overview of our system setup and learned visuotactile skills on four tasks. (a) Our hardware and teleoperatio* VR 기반 저가형 텔레오퍼레이션 시스템 HATO와 촉각 센서가 장착된 의족 손을 활용하여 양손 다중지 조작 로봇이 시각-촉각 데이터로부터 인간 수준의 민첩한 조작 기술을 학습하는 시스템을 제시한다.
본 논문은 양손 다중지 조작 분야에서 하드웨어 혁신(의족 재목적화)과 접근성 높은 텔레오퍼레이션 시스템(HATO)을 통해 visuotactile learning의 새로운 경계를 개척했다. 촉각 센싱의 중요성을 실증적으로 보여주고 효율적 데이터 수집 및 정책 학습을 달성하여 로봇 조작 분야에 상당한 기여를 한다.
NuExo: A Wearable Exoskeleton Covering all Upper Limb ROM for Outdoor Data Collection and Teleoperation of Humanoid Robots

Fig. 1: NuExo: A backpack-mounted active-joint humanoid robot
 *Fig. 1: NuExo: A backpack-mounted active-joint humanoid robot* 상지의 전체 운동 범위를 커버하면서 야외 환경에서 사용 가능한 경량 웨어러블 외골격계(exoskeleton) NuExo를 개발하여 인간형 로봇의 원격조종과 모션 데이터 수집을 동시에 수행한다.
NuExo는 해부학적으로 영감받은 외골격계 설계와 경량화, multi-modal sensing의 통합을 통해 teleoperation과 로봇 모션 데이터 수집의 네 가지 핵심 목표를 동시에 달성한 혁신적 시스템이다. 야외 환경에서의 실용성과 다양한 로봇 플랫폼 호환성은 인간형 로봇의 imitation learning 분야에 중대한 기여를 한다.
OSMO: Open-Source Tactile Glove for Human-to-Robot Skill Transfer
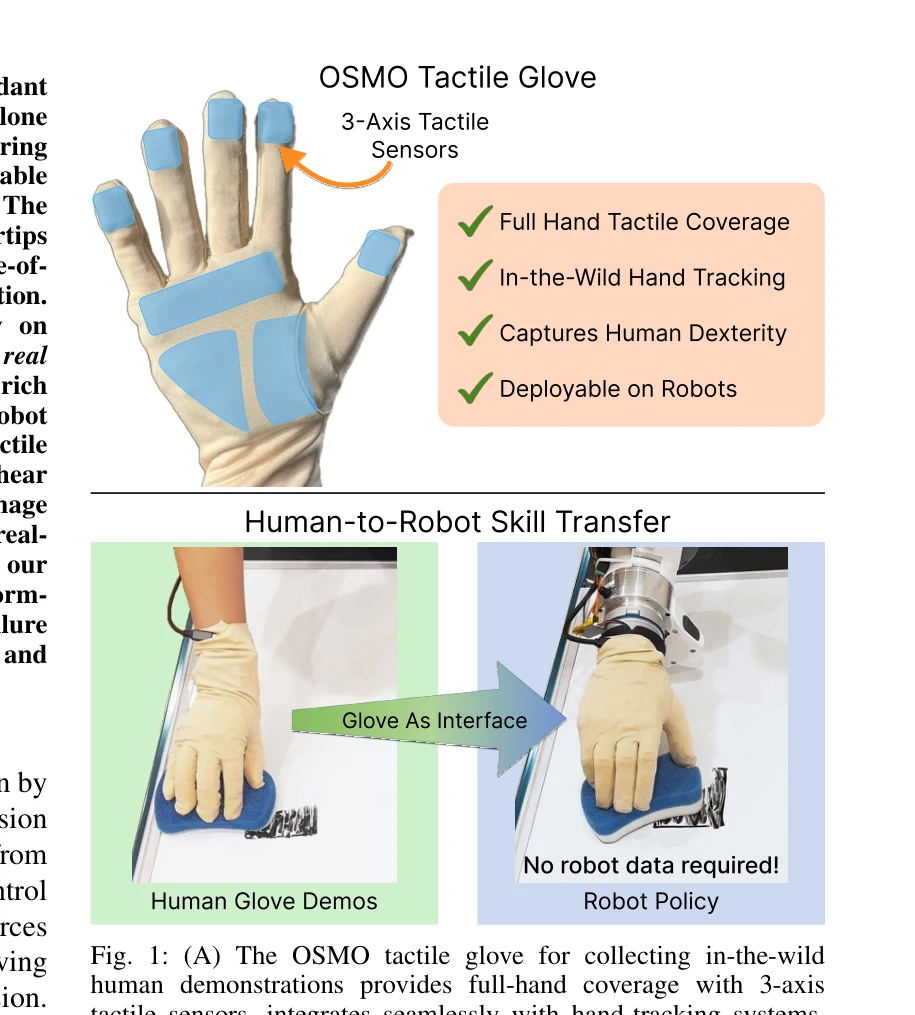
Fig. 1: (A) The OSMO tactile glove for collecting in-the-wild
 *Fig. 1: (A) The OSMO tactile glove for collecting in-the-wild* OSMO는 인간의 촉각 데이터를 캡처하는 오픈소스 웨어러블 촉각 장갑으로, 촉각-시각 embodiment 격차를 최소화하여 인간 시연만으로 로봇 접촉 조작 정책을 학습할 수 있게 한다.
OSMO는 웨어러블 촉각 센싱 분야에서 주목할 만한 하드웨어 기여를 하며, 인간-로봇 skill transfer에서 촉각 정보의 중요성을 실증적으로 입증했다. 완전 공개 설계와 다양한 hand-tracking 호환성은 커뮤니티 영향력을 높일 것으로 예상되나, 단일 작업 평가와 로봇 플랫폼 제한성이 일반화 가능성에 대한 의문을 남긴다.
Alter-Art: Exploring Embodied Artistic Creation through a Robot Avatar

Figure 1: Some snapshots of applications in artistic scenarios: theatre (top),
 *Figure 1: Some snapshots of applications in artistic scenarios: theatre (top),* 본 논문은 반인간형 로봇 Alter-Ego를 통한 원격 몰입 예술 창작 패러다임인 Alter-Art를 제안한다. 무용, 연극, 회화 세 가지 예술 영역에서 전문 예술가들이 로봇 신체에 내재되어 창작하는 경험을 탐구하며, 구체적 현존감 형성과 로봇의 물리적 제약이 창작 과정에 미치는 영향을 분석한다.
본 논문은 로봇 예술의 새로운 패러다임인 Alter-Art를 명확히 정의하고, 실제 예술가들과의 협력을 통해 embodied creative experience의 가능성을 설득력 있게 시연한다. 로봇을 기계가 아닌 신체적 확장으로 재구성하는 철학적 관점과 구체적 기술 플랫폼의 통합이 돋보인다. 다만 표본 규모의 제한, 정성적 방법론의 보강 필요, 기술 세부사항의 추가 설명 등이 개선 과제이나, 사회 로봇과 telepresence 연구에 중요한 개념적 기여를 제시한다.
Human-Level Actuation for Humanoids
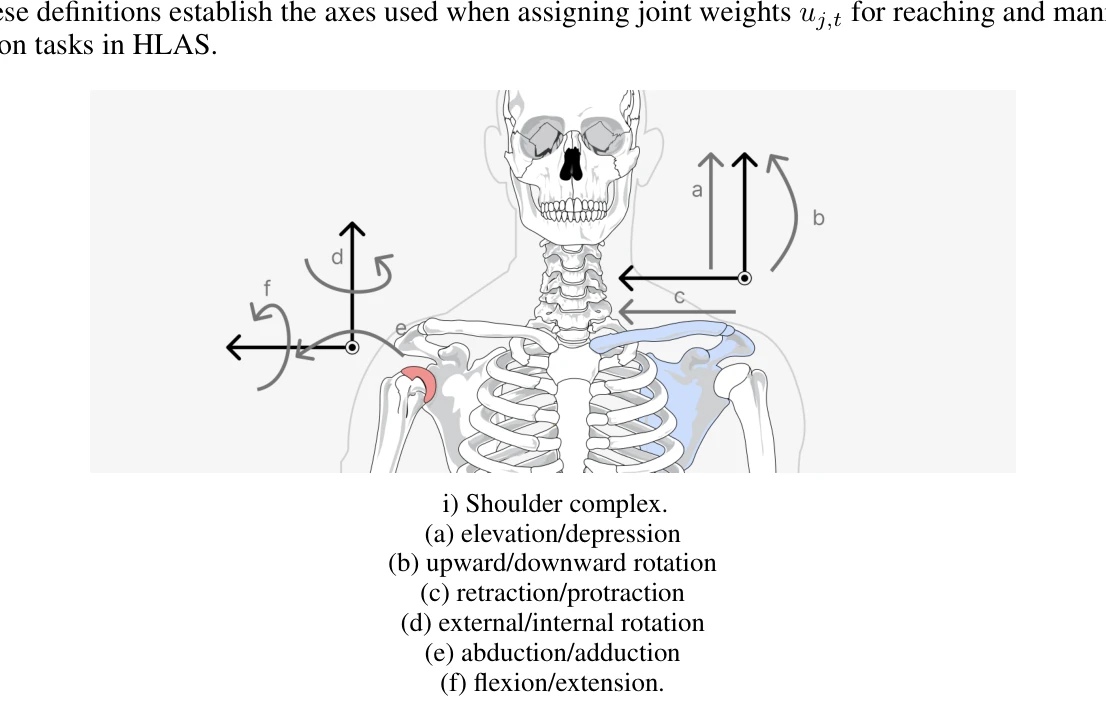
Figure 1: Upper body atlas I: Shoulder complex including scapulothoracic contributions. Origins
 *Figure 1: Upper body atlas I: Shoulder complex including scapulothoracic contributions. Origins* 이 논문은 인간형 로봇의 구동부(actuation)가 인간 수준인지를 객관적으로 측정하고 비교할 수 있는 포괄적 프레임워크를 제시한다. 세 가지 핵심 요소로 구성되는데, 첫째는 ISB 기반 kinematic DoF atlas로 관절 좌표계를 표준화하고, 둘째는 Human-Equivalence Envelopes(HEE)로 특정 관절각도와 각속도에서 인간의 토크와 파워를 동시에 만족하는 요구사항을 정의하며, 셋째는 Human-Level Actuation Score(HLAS)로 workspace coverage, 효율성, 열 지속성 등 여섯 가지 인자를 통합한다.
이 논문은 humanoid robot 개발에서 오래도록 미해결되어 온 정량화 문제를 강력한 이론적 기반(ISB kinematic conventions, human biomechanics 데이터) 위에서 처음으로 체계적으로 해결한다. Human-Equivalence Envelopes와 HLAS는 설계자에게 명확한 목표를 제공하고, task-relevant posture-rate bands에 기반한 가중치 부여는 실무적 타당성을 보장한다. 제안된 측정 프로토콜(dynamometry, thermal testing)은 재현 가능하고 표준화 가능하여 산업 표준으로 채택될 수 있는 잠재력이 크다. 다만 75kg 기준 신체에 대한 의존도와 실험실 기반 biomechanics 데이터의 현장 적용성 한계는 보완이 필요하다. 전반적으로 humanoid actuation 평가에 새로운 표준을 제시하는 중요한 기여로, robotics, biomechanics, benchmarking 커뮤니티에 광범위한 영향을 미칠 것으로 예상된다.
RUKA: Rethinking the Design of Humanoid Hands with Learning

Fig. 1: RUKA is a tendon-driven humanoid hand that is simple,
 *Fig. 1: RUKA is a tendon-driven humanoid hand that is simple,* RUKA는 3D 프린팅과 저가 부품으로 제작한 tendon-driven humanoid hand로, learning-based control을 통해 정밀성, 컴팩트성, 강도, 저비용을 동시에 달성한다.
RUKA는 learning-based control과 실용적 hardware 설계를 결합하여 저비용 대 성능 비율에서 로봇 손 영역의 새로운 기준을 제시하며, open-source 공개로 접근성을 극대화한 의미 있는 기여이다.
A 21-DOF Humanoid Dexterous Hand with Hybrid SMA-Motor Actuation: CYJ Hand-0
 *Figure 3. (a) The overall structural design of the bionic dexterous hand. (b) Components of the bionic dexterous hand. (* CYJ Hand-0는 SMA와 DC 모터의 하이브리드 구동 방식을 결합한 21-DOF 휴머노이드 손으로, 3D 프린팅 AlSi10Mg 금속 프레임과 고강도 낚싯줄 텐던을 활용하여 인간의 손 구조를 생체모방한다.
CYJ Hand-0는 SMA-모터 하이브리드 구동, 정교한 생체모방 설계, 효율적인 3D 프린팅 제조를 통해 경량이면서도 고성능의 휴머노이드 손을 실현한 주목할 만한 연구이며, 특히 모듈화 아키텍처와 포괄적 성능 평가가 강점이다.
Antagonistic Bowden-Cable Actuation of a Lightweight Robotic Hand: Toward Dexterous Manipulation for Payload Constrained Humanoids

Fig. 1: Overview of the proposed Antagonistic Bowden-
 *Fig. 1: Overview of the proposed Antagonistic Bowden-* Bowden 케이블을 이용한 원격 구동 방식의 경량 인간형 로봇 손으로, 길항적 케이블 작동과 rolling-contact joints를 결합하여 20개 DOF를 236g의 극히 낮은 질량으로 구현하였다.
본 논문은 극도로 경량화된 원격 구동 로봇 손의 설계를 통해 payload 제약이 있는 인간형 로봇에 고 dexterity를 부여하는 실용적 솔루션을 제시한다. Rolling-contact joints와 길항적 케이블 구동의 결합은 독창적이며, 3D 프린팅 기반의 완전 제작 가능한 설계로 재현성과 확장성이 우수하다.
Characteristics, Management, and Utilization of Muscles in Musculoskeletal Humanoids: Empirical Study on Kengoro and Musashi
 *Fig. 2. The basic musculoskeletal structure: the components include bones,* 본 논문은 Kengoro와 Musashi 근골격 휴머노이드 로봇의 근육 특성을 5가지 속성(Redundancy, Independency, Anisotropy, Variable Moment Arm, Nonlinear Elasticity)으로 분류하고, 이를 효과적으로 관리·활용하는 방법론을 제시한다.
본 논문은 근골격 휴머노이드의 근육 특성을 처음으로 체계적으로 분류하고 관리·활용 방법을 제시한 중요한 기여이며, 실제 로봇 구현 사례를 바탕으로 높은 실용성을 갖추고 있다. 다만 정량적 성능 평가 및 일반화 가능성에 대한 보완이 필요하다.
Demonstrating Berkeley Humanoid Lite: An Open-source, Accessible, and Customizable 3D-printed Humanoid Robot

Fig. 1.
 *Fig. 1.* Berkeley Humanoid Lite는 3D-printed cycloidal gearbox를 활용한 오픈소스 휴머노이드 로봇으로, $5,000 이하의 저비용으로 데스크톱 3D프린터와 e-commerce 부품으로 제작 가능하며 강화학습 기반 locomotion controller를 통해 sim-to-real transfer를 입증했다.
Berkeley Humanoid Lite는 3D-printed cycloidal gear 기반 저비용 휴머노이드 로봇의 설계와 구현을 통해 로봇 연구의 접근성을 획기적으로 낮추고, 완전 오픈소스 공개 정책으로 커뮤니티 주도의 발전을 가능하게 했다. Reinforcement learning 기반 locomotion control의 성공적인 sim-to-real transfer는 플랫폼의 실용성을 입증하며, 향후 휴머노이드 로봇 연구의 민주화를 주도할 초석이 될 가능성이 크다.
DIAL: Distilling Intent-Aware Latents for Vision-Language-Action on Humanoid Robots
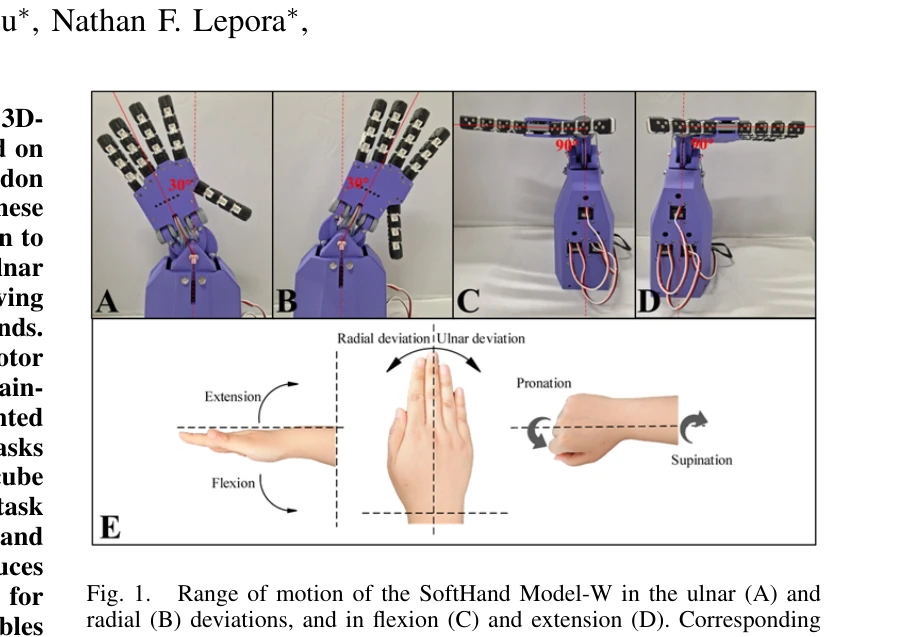
Fig. 1.
 *Fig. 2.* SoftHand Model-W는 3D 프린팅 기반의 인간형 로봇 손으로, 2-DoF 손목을 통합하여 손가락의 underactuated tendon-driven 구조와 손목의 능동적 제어를 결합했다. Carpal tunnel 영감의 힘줄 라우팅을 통해 원격 모터 배치를 가능하게 하면서 compact한 형태를 유지한다.
SoftHand Model-W는 soft robotics의 adaptive synergies 개념을 유지하면서 능동적 손목을 처음 통합한 혁신적 설계이며, 3D 프린팅과 carpal tunnel routing을 통해 실용성과 anthropomorphism을 동시에 달성했다. 손목 추가의 명확한 성능 개선 효과를 입증하여 dexterous manipulation 분야에 의미 있는 기여를 한다.
Exceeding the Maximum Speed Limit of the Joint Angle for the Redundant Tendon-driven Structures of Musculoskeletal Humanoids
 *Fig. 2.* 중복 힘줄 구동 구조를 가진 근골격 인간형 로봇에서 가장 느린 근육에 의해 제한되는 관절 각속도 한계를 초과하는 두 가지 방법을 제안하고 실제 로봇 실험으로 검증한다.
근골격 인간형 로봇의 구동 제약을 새로운 관점에서 분석하고, 실용적이면서도 독창적인 두 가지 해결 방법을 제시했다. 실제 로봇 실험 검증을 통해 이론의 타당성을 입증했으나, 시뮬레이션의 단순화와 적용 조건의 제한이 개선될 여지가 있다.
ORCA: An Open-Source, Reliable, Cost-Effective, Anthropomorphic Robotic Hand for Uninterrupted Dexterous Task Learning

Fig. 1: (A) The ORCA hand closely mimics its human counterpart with
 *Fig. 1: (A) The ORCA hand closely mimics its human counterpart with* ORCA는 2,000 CHF 미만의 재료비로 8시간 내에 조립 가능한 오픈소스 tendon-driven 인간형 로봇 손이며, popping joints와 자동 캘리브레이션 등의 설계로 높은 신뢰성과 정확도를 달성한다.
ORCA는 tendon-driven 로봇 손의 조립 용이성과 신뢰성을 획기적으로 개선하여 dexterous manipulation 연구의 하드웨어 접근 장벽을 크게 낮춘 중요한 공헌이며, 오픈소스 공개를 통해 연구 커뮤니티의 광범위한 채택과 확장을 촉진할 것으로 기대된다.
Multimodal Quad‐Finger Soft Robotic Hand With Dual‐Chamber Origami Actuator for Large‐Workspace Manipulation
 *Figure 5b,c,e,f, respectively, illustrate the 3D fingertip trajectories* 본 연구는 이중 챔버 SCOP actuator를 이용한 4지 소프트 로봇 핸드(QDO hand)를 제시하며, 양압과 음압 조절을 통해 축 방향 신축과 양방향 굽힘 등 다양한 운동 양식을 구현하여 5.2배 확대된 작업 공간을 달성한다.
본 논문은 이중 챔버 SCOP actuator와 DCI-FLMG 제어 방식을 통해 소프트 로봇 핸드의 작업 공간 확대와 다중 운동 양식을 동시에 달성한 혁신적 연구이며, 인간-로봇 협업과 복잡한 환경에서의 조작 능력 향상에 크게 기여할 것으로 기대된다.
Stability-Aware Retargeting for Humanoid Multi-Contact Teleoperation
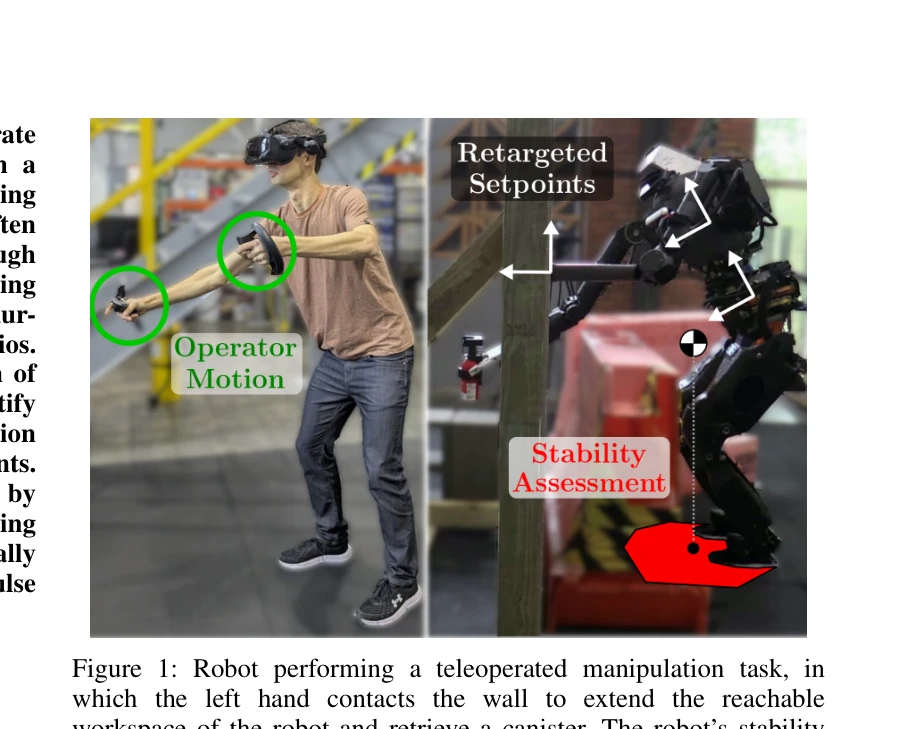
Figure 1: Robot performing a teleoperated manipulation task, in
 *Figure 1: Robot performing a teleoperated manipulation task, in* 휴머노이드 로봇의 다중 접촉 텔레오퍼레이션 중 안정성을 향상시키기 위해 Centroidal stability 기반 retargeting을 제안하며, Linear Program 민감도 분석을 통해 효율적으로 안정성 여유 기울기를 계산한다.
다중 접촉 텔레오퍼레이션에 centroidal 안정성 분석을 효과적으로 통합하고 LP 민감도를 통한 새로운 기울기 계산 방법을 제시하며, 시뮬레이션과 하드웨어 검증으로 실용성을 입증한 견고한 기여.
TACT: Humanoid Whole-body Contact Manipulation through Deep Imitation Learning with Tactile Modality
 *Fig. 2. Humanoid control system for whole-body contact manipulation with tactile feedback.* 인간형 로봇이 촉각 센서를 활용한 모방 학습(imitation learning)을 통해 전신 접촉 조작을 수행할 수 있도록 하는 TACT(tactile-modality extended ACT) 제어 시스템을 제안하였다.
본 연구는 촉각 센서를 Transformer 기반 모방 학습에 성공적으로 통합하여 생활 규모 인간형 로봇의 섬세한 전신 접촉 조작을 최초로 실증했으며, 모델 기반 제어와 학습 기반 제어의 창의적 결합으로 신뢰성과 유연성을 동시에 확보한 의미 있는 기여이다.
Whole-body Multi-contact Motion Control for Humanoid Robots Based on Distributed Tactile Sensors
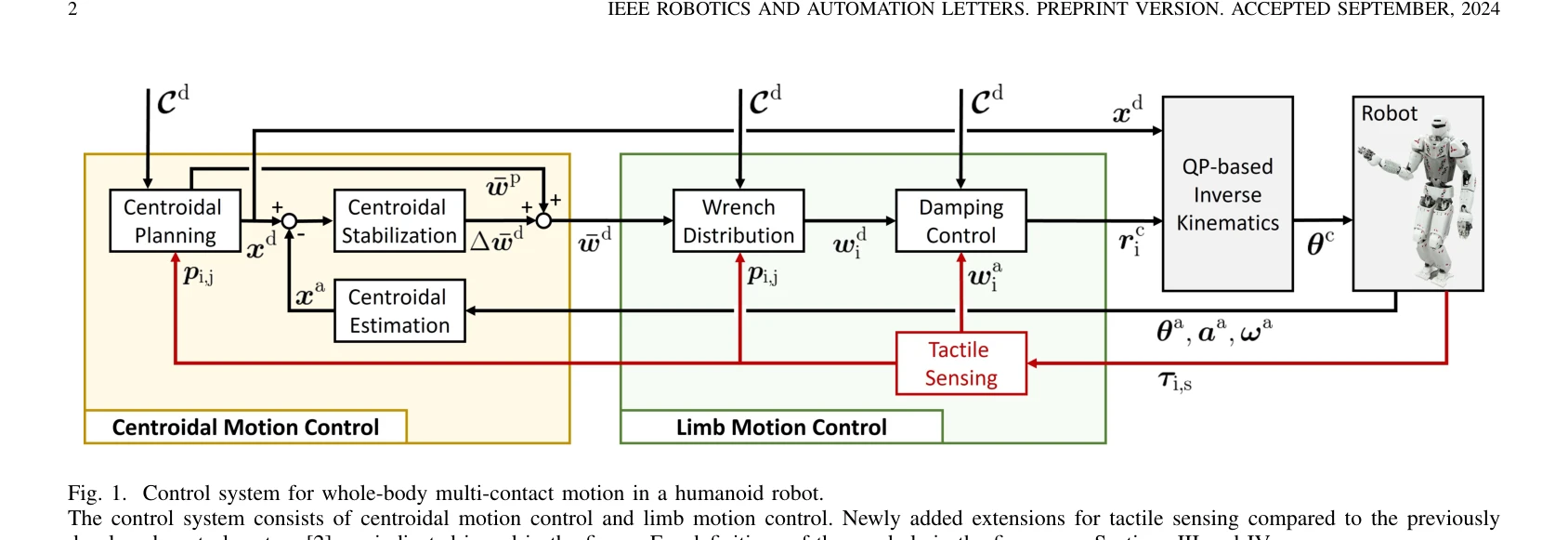
Fig. 1. Control system for whole-body multi-contact motion in a humanoid robot.
 *Fig. 1. Control system for whole-body multi-contact motion in a humanoid robot.* 휴머노이드 로봇이 분산 촉각 센서를 장착하여 팔꿈치, 무릎 등 중간 영역의 접촉을 포함한 전신 다중 접촉 모션을 제어하는 방법을 개발했다.
본 논문은 distributed tactile sensor를 활용하여 휴머노이드 로봇의 전신 다중 접촉 모션을 처음으로 실현한 의미 있는 연구로, 방법론과 검증이 체계적이나 autonomous planning 미흡이 제한적이다.
CHILD (Controller for Humanoid Imitation and Live Demonstration): a Whole-Body Humanoid Teleoperation System
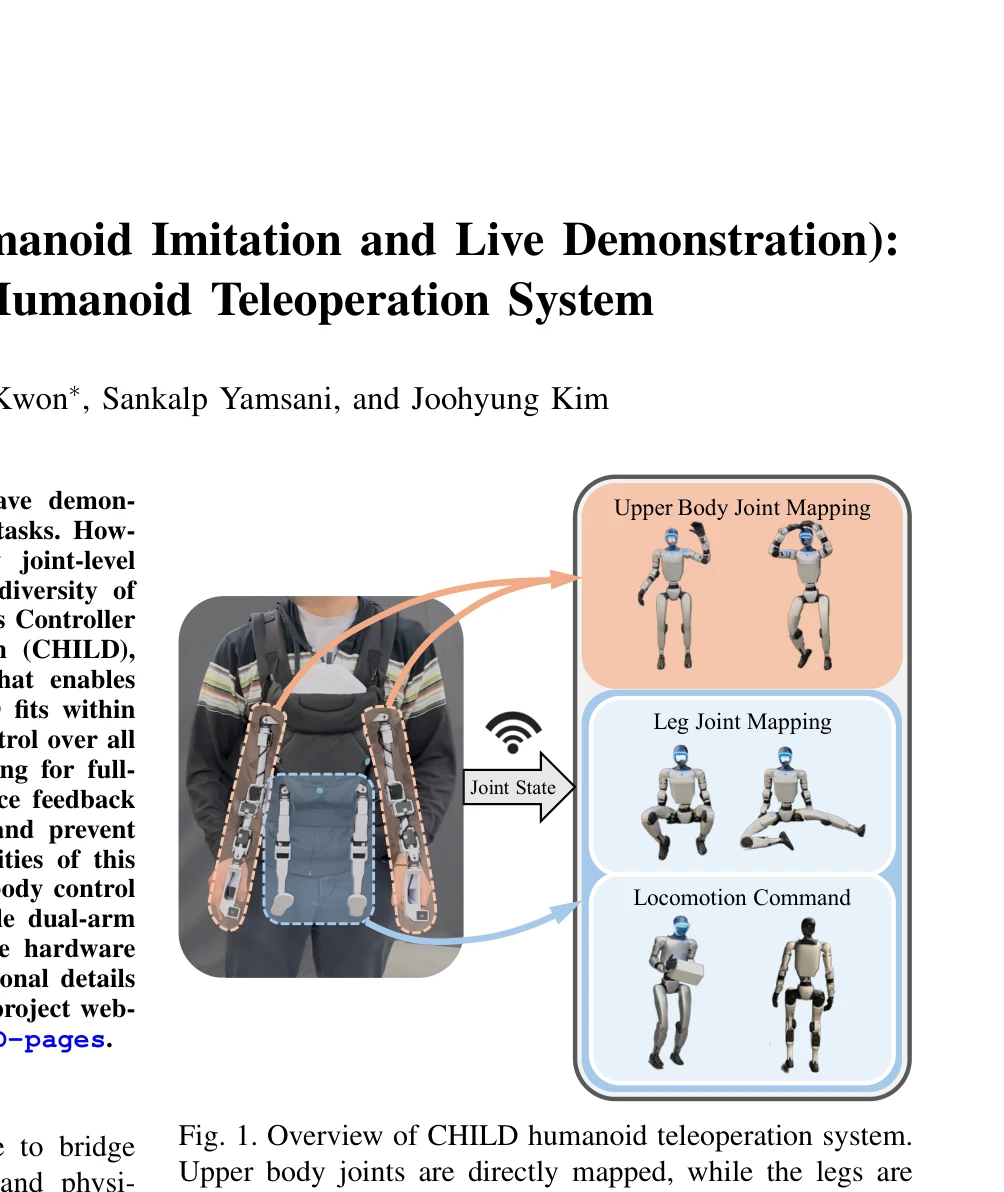
Fig. 1. Overview of CHILD humanoid teleoperation system.
 *Fig. 1. Overview of CHILD humanoid teleoperation system.* CHILD는 베이비 캐리어 크기의 컴팩트한 텔레오퍼레이션 장치로, 직접 관절 매핑을 통해 휴머노이드 로봇의 전신 관절 수준 제어를 가능하게 하는 시스템이다.
이 논문은 전신 humanoid 텔레오퍼레이션을 위한 직접 관절 매핑 방식을 최초로 제시하였으며, 베이비 캐리어를 활용한 혁신적이고 저비용의 하드웨어 설계와 오픈소스 공개를 통해 robotics 커뮤니티에 실질적인 기여를 제공한다.
Embracing Bulky Objects with Humanoid Robots: Whole-Body Manipulation with Reinforcement Learning
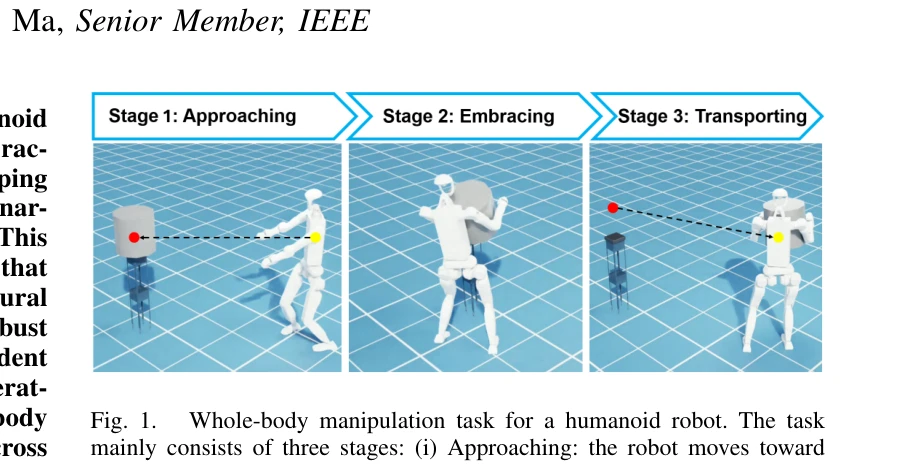
Fig. 1.
 *Fig. 1.* 본 논문은 인간의 동작 사전(human motion prior)과 neural signed distance field(NSDF)를 통합한 강화학습 프레임워크를 제안하여 휴머노이드 로봇이 팔과 몸통을 조율해 부피가 큰 물체를 전신으로 포용하고 운반할 수 있도록 하는 방법을 제시한다.
본 논문은 휴머노이드 로봇의 전신 물체 포용 조작을 위한 최초의 RL 프레임워크를 제시하며, 인간 모션 사전과 NSDF의 통합을 통해 학습 효율성과 접촉 강건성을 동시에 달성한 혁신적인 연구다. 시뮬레이션과 실제 로봇 실험을 통한 검증이 충분하고 실용적 가치가 높다.
Heavy lifting tasks via haptic teleoperation of a wheeled humanoid

Fig. 1.
 *Fig. 1.* 휠형 휴머노이드 로봇의 Dynamic Mobile Manipulation을 위해 햅틱 피드백을 통한 원격 조종 프레임워크를 제시하며, 인간의 전신 모션을 로봇에 재타겟팅하여 무거운 물체 들어올리기를 수행한다.
본 논문은 무거운 물체 들어올리기 작업을 위한 휠형 휴머노이드의 원격 조종에서 높이 조절, 자동 pitch 보상, 햅틱 피드백을 통합한 실질적이고 잘 설계된 시스템을 제시하며, 기존 연구의 명확한 한계를 극복한 의미 있는 기여이다.
Human-Robot Collaboration for the Remote Control of Mobile Humanoid Robots with Torso-Arm Coordination
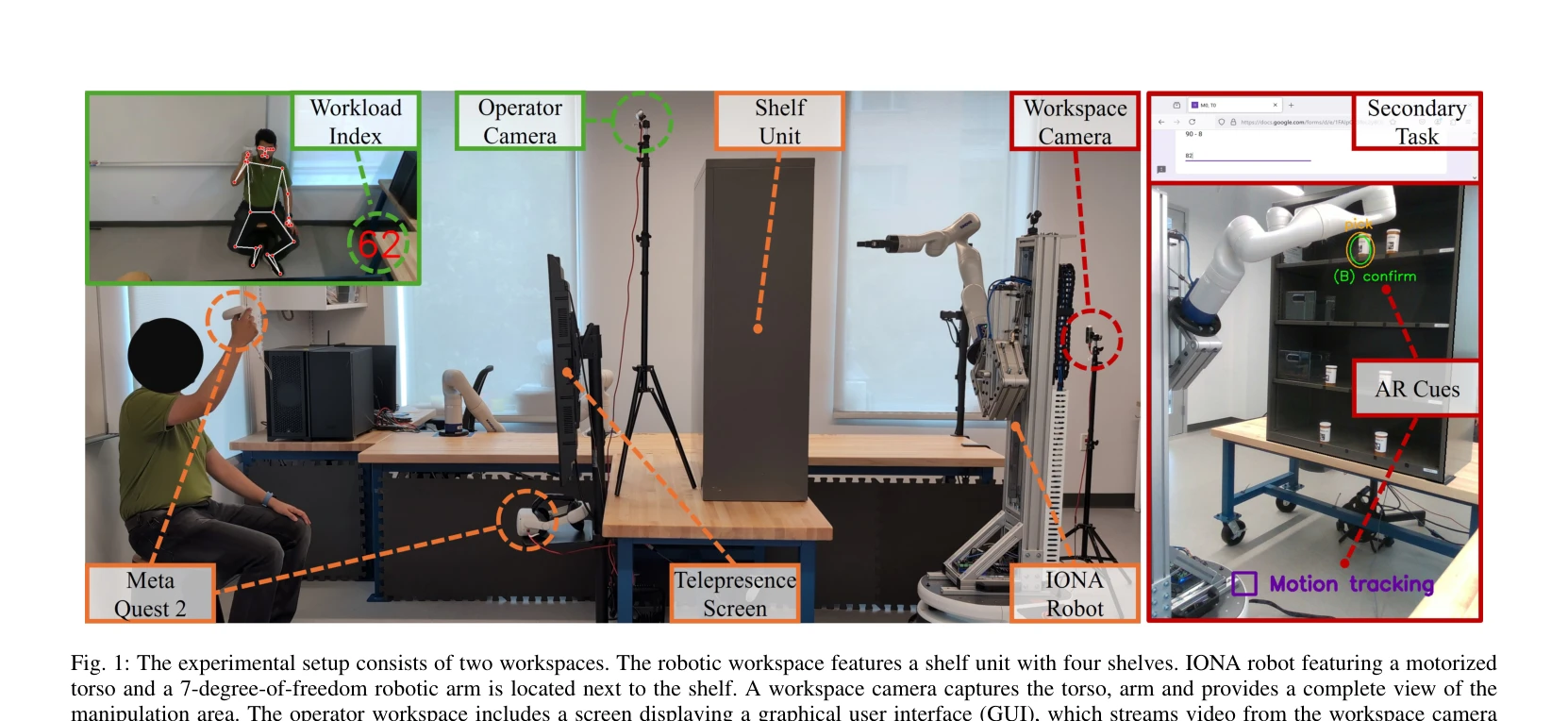
Fig. 1: The experimental setup consists of two workspaces. The robotic workspace features a shelf unit with four shelves
 *Fig. 1: The experimental setup consists of two workspaces. The robotic workspace features a shelf unit with four shelves* 원격 제어되는 모바일 휴머노이드 로봇의 몸통-팔 협력 제어를 위해 인간-로봇 협업(HRC) 방법들을 제안하고, 사용자 연구(N=17)를 통해 자동 및 수동 제어 방식의 효과를 비교 평가한다.
원격 조종 휴머노이드 로봇의 몸통-팔 협력 문제에 대한 체계적이고 실용적인 HRC 솔루션을 제시하며, 사용자 중심의 평가를 통해 상황별 최적 제어 방식을 제공하는 의의 있는 연구이다. 다만 표본 크기와 실제 환경 검증의 확대가 필요하다.
Humanoid Robot Teleoperation for Nonprehensile Transportation: A Multiple-Constraint Safety-Critical Control Framework
 *Figure 2. Dual-arm reachability maps of the custom-built humanoid robot platform.* 본 논문은 인간형 로봇의 비파지형 물체 운반 원격조종 작업에서 다중 제약 조건 간 충돌과 안전 문제를 해결하기 위해 계층적 3단계 구조의 Multiple-Constraint Safety-Critical Control Framework (MC-SCCF)를 제안한다. 상층부는 미분가능한 도달가능성 대리 모델과 개선된 control barrier function 기반 안전 속도 필터로 작업공간 경계에서의 안전성을 보장하고, 중층부는 사용자 명령을 자세 결합 참조 궤적으로 매핑하여 물체의 미끄러짐과 넘어짐을 방지하며, 하층부는 QP 기반 역운동학 해석기로 자체 충돌 회피와 조정된 운동을 달성한다.
본 논문은 인간형 로봇의 복잡한 비파지형 운반 작업에서 다중 충돌 제약을 체계적으로 해결하기 위한 계층적 MC-SCCF를 제시하며, 미분가능한 도달가능성 대리 모델과 개선된 control barrier function 기반의 안전 속도 필터는 기술적 참신성을 보여준다. 시뮬레이션과 물리적 로봇 실험으로 유효성을 입증했으나, 대리 모델의 일반화 가능성, 환경 변수 견고성, 계산 성능 벤치마크 등에 대한 상세 분석이 보완되면 더욱 강화될 수 있다.
GraspSense: 언어 기반 인지와 힘 맵을 활용한 손재주 로봇 파지 계획
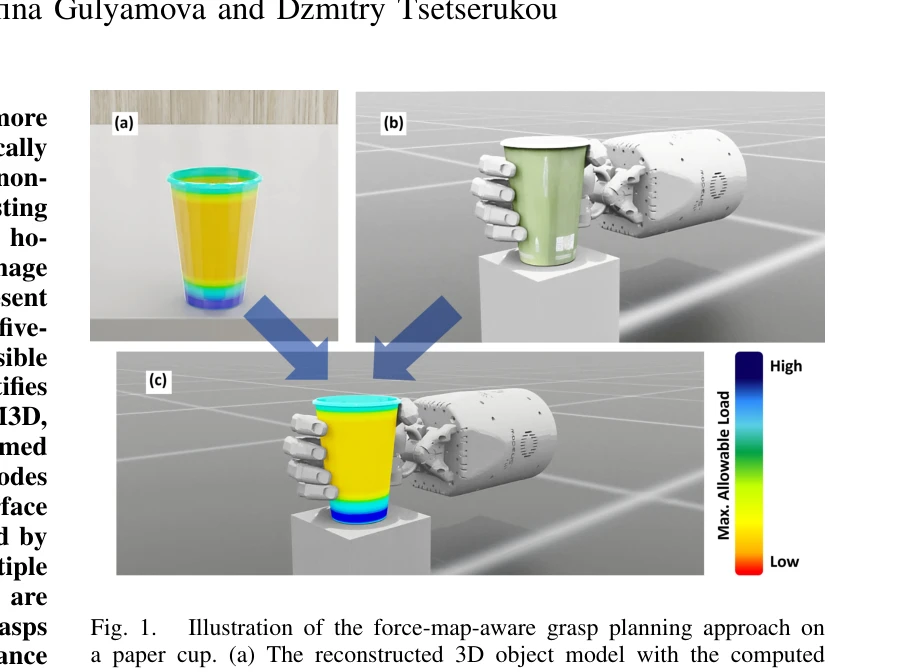
Fig. 1.
 *Fig. 1.* 본 논문은 휴머노이드 손재주 로봇의 파지 계획을 위해 언어 기반 인지, 3D 복원, 물리 기반 구조 해석을 통한 force map 구성, 그리고 임피던스 제어 기반 파지 실행을 통합하는 파이프라인 GraspSense를 제안한다. 기존의 기하학적 파지 계획과 달리, 물체 표면의 공간적으로 비균일한 기계적 특성을 명시적으로 고려하여 파지 선택과 그립 력 조절을 결합하는 물리 기반 접근을 제시한다.
본 논문은 손재주 로봇 파지 계획에 물체의 구조적 기계적 특성을 명시적으로 통합하는 중요한 기여를 제시한다. Force map 기반 파지 선택과 적응형 임피던스 제어를 통해 기존 기하학적 파지 계획의 한계를 극복하는 물리 기반 접근법이 창의적이고 기술적으로 건실하다. 다만 실제 로봇 플랫폼에서의 검증과 더 광범위한 객체 범주에 대한 평가가 필요하며, force map 구성의 정확성 분석이 강화되어야 한다.
ComFree-Sim: A GPU-Parallelized Analytical Contact Physics Engine for Scalable Contact-Rich Robotics Simulation and Control
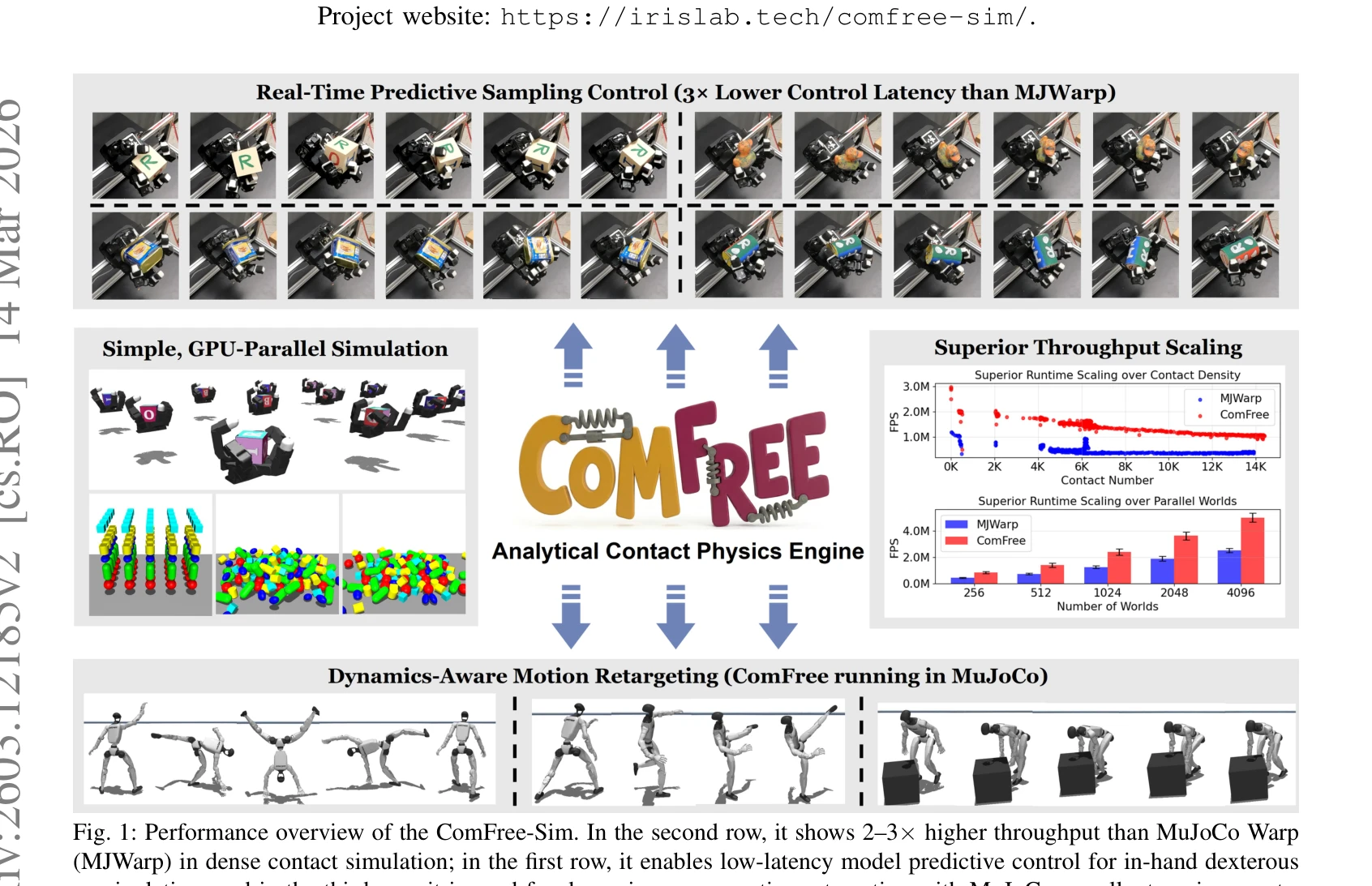
Fig. 1: Performance overview of the ComFree-Sim. In the second row, it shows 2–3× higher throughput than MuJoCo Warp
 *Fig. 1: Performance overview of the ComFree-Sim. In the second row, it shows 2–3× higher throughput than MuJoCo Warp* ComFree-Sim은 여집합-자유(complementarity-free) 접촉 모델링을 기반으로 한 GPU 병렬화 접촉 물리 엔진으로, 폐쇄형 해석해를 통해 접촉 임펄스를 계산하여 접촉 수에 대해 선형적 계산 복잡도를 달성한다.
ComFree-Sim은 complementarity-free 접촉 모델링의 폐쇄형 해석 구조를 효과적으로 GPU 병렬화하고 6D로 확장하여, 기존 iterative solver 기반 접근의 근본적 병목을 해결한 혁신적 접촉 물리 엔진이다. 선형 확장성과 2-3배 향상된 처리량을 실현하면서도 물리 정확도를 유지하고, 실제 로봇 하드웨어에서 고주파 MPC 제어를 성공적으로 구현함으로써 접촉-풍부 로봇 학습과 제어 분야에 상당한 실용적 가치를 제공한다.
cuRoboV2: Dynamics-Aware Motion Generation with Depth-Fused Distance Fields for High-DoF Robots
cuRoboV2는 B-spline 궤적 최적화, GPU 기반 TSDF/ESDF 인식 파이프라인, 확장 가능한 고자유도 로봇 계산을 통합하여 조작기부터 인형로봇까지 안전하고 동역학 인식적인 운동 생성을 제공하는 통합 프레임워크이다.
cuRoboV2는 동역학 인식적 운동 생성, GPU 가속 인식 처리, 고자유도 확장성에서 근본적 한계를 극복한 통합 프레임워크로, 조작 로봇부터 인형로봇까지 대폭 개선된 성능을 달성하여 로봇 자율성의 실용화에 크게 기여한다.
Lightning Grasp: High Performance Procedural Grasp Synthesis with Contact Fields

Figure 1: Lightning Grasp is a high-performance procedural (analytical) grasp synthesis algorithm.
 *Figure 3: Contact Field and Its Interaction with Objects. A contact field is a collection of vectors in* Lightning Grasp는 Contact Field라는 새로운 데이터 구조를 도입하여 기하학적 계산과 최적화 과정을 분리함으로써 다지형 손을 위한 고속의 절차적 파지 합성을 실현한다.
Lightning Grasp는 Contact Field라는 우아한 추상화를 통해 파지 합성의 근본적 병목을 해결하고 획기적인 속도 향상을 달성한 혁신적 기여로, 절차적 파지 합성의 새로운 표준을 제시한다.
OmniRetarget: Interaction-Preserving Data Generation for Humanoid Whole-Body Loco-Manipulation and Scene Interaction

Fig. 1:
 *Fig. 2: OMNIRETARGET overview. Human demonstrations are retargeted to the robot via interaction-mesh–based* OmniRetarget은 interaction mesh 기반의 제약 최적화를 통해 human motion을 humanoid robot을 위한 고품질 kinematic reference로 retarget하며, 상호작용을 보존하면서 단일 시연으로부터 다양한 로봇 구체화, 지형, 물체 설정으로 효율적인 data augmentation을 수행한다.
OmniRetarget은 interaction-preserving motion retargeting과 체계적 data augmentation을 통해 humanoid robot 제어의 데이터 병목을 해결하는 실질적이고 영향력 있는 기여이며, 최소한의 reward engineering으로 complex whole-body loco-manipulation 기술의 zero-shot sim-to-real transfer를 성공적으로 입증하여 로보틱스 커뮤니티에 매우 유용한 공개 도구 및 데이터셋을 제공한다.
Evolving the Complete Muscle: Efficient Morphology-Control Co-design for Musculoskeletal Locomotion
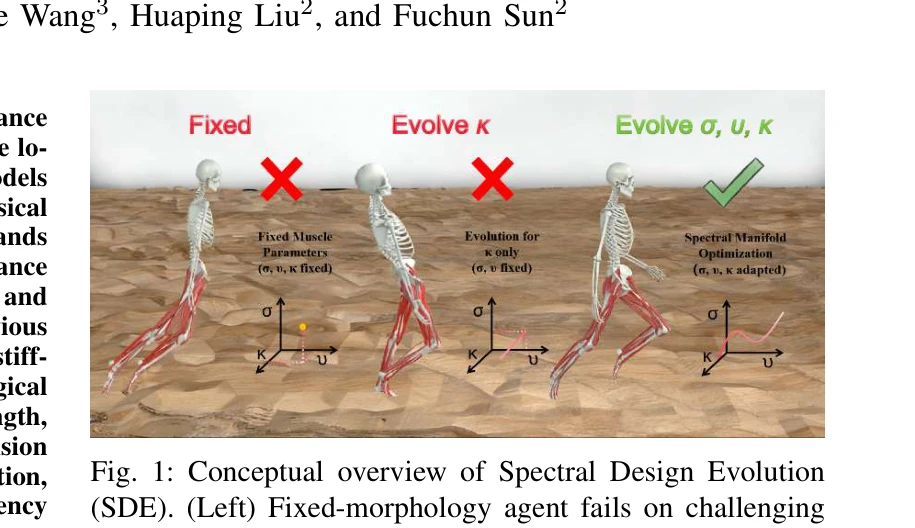
Fig. 1: Conceptual overview of Spectral Design Evolution
 *Fig. 1: Conceptual overview of Spectral Design Evolution* 본 논문은 근육-골격 로봇의 근력, 속도, 경직도를 동시에 진화시키는 Complete Musculoskeletal Morphological Evolution Space를 제시하고, 이를 효율적으로 탐색하기 위해 bilateral symmetry prior와 PCA를 결합한 Spectral Design Evolution(SDE) 프레임워크를 제안한다.
본 논문은 근육-골격 로봇의 형태-제어 공동 설계에 강도, 속도, 경직도의 포괄적 진화를 처음으로 도입하고, SDE의 spectral manifold 접근법으로 차원 폭발 문제를 효과적으로 해결하여 높은 샘플 효율성과 로컬로모션 성능을 달성한 의미있는 기여이나, 다양한 태스크와 형태학에 대한 일반화 검증이 필요하다.
Physics-Informed Neural Networks with Unscented Kalman Filter for Sensorless Joint Torque Estimation in Humanoid Robots
 *Fig. 2: Block diagram of the multi-layer torque control architecture implemented on the ergoCub humanoid robot. The* 본 논문은 Physics-Informed Neural Networks (PINNs)와 Unscented Kalman Filter (UKF)를 결합하여 휴머노이드 로봇의 관절 토크 센서 없이 전신 토크 제어를 수행하는 프레임워크를 제시한다. 이 방식은 마찰 모델링과 토크 추정을 통합하여 실시간 토크 제어 아키텍처를 구현한다.
본 논문은 PINNs과 UKF의 혁신적 통합을 통해 센서 없는 토크 제어라는 실질적 문제를 해결하며, ergoCub에서의 엄밀한 실험 검증과 확장성 시연으로 휴머노이드 로봇의 실시간 준수 제어를 위한 강력한 기초를 제공한다.
Category Overview
휴머노이드 로봇의 보행 메커니즘 설계(Humanoid Locomotion Mechanism Design)는 동적 균형 제어, 관절 구조 최적화, 그리고 에너지 효율적인 이동 방식의 통합을 다루는 분야이다. 이 카테고리는 근골격계 구동(Musculoskeletal Actuation) 기반의 신체 스키마 학습[1618]부터 병렬 발목 구조(Parallel Ankle Structures)를 활용한 설계[1776]까지 다양한 메커니즘 혁신을 포함한다. 동적 페이로드 균형 보행(Dynamic Payload Gait Balancing)을 위한 강화학습 기반 제어[1637], [1656]와 샘플링 기반 모델예측제어(Sampling-Based Model Predictive Control)[1636]는 복잡한 환경에서의 안정적인 이동을 실현한다. 휠-레그 스케이팅 보행(Wheeled-Legged Skating Locomotion)을 통한 고속 이동[1677]과 비선형 전달 관절 메커니즘(Non-Linear Transmission Joint Mechanisms)의 활용[1919], [1920]은 로봇의 성능 한계를 확장한다. 하이브리드 제로 동역학(Hybrid Zero Dynamics) 기반 러닝[1834]과 제트 추진 공중 휴머노이드(Jet-Powered Aerial Humanoid) 설계[1832]는 극한의 운동 능력을 구현하며, 전체 신체 제어기(Whole-Body Controller) 통합[1784], [1759]은 다양한 보행 태스크의 통합 관리를 가능하게 한다.
- Dynamic Payload Gait Balancing: Dynamic Payload Gait Balancing은 인간형 로봇이 동적으로 변화하는 하중(dynamic payload)을 운반하면서 안정적인 보행을 유지하는 메커니즘 설계에 관한 분야입니다. 이는 로봇의 질량 중심(center of mass) 위치가 실시간으로 변화하는 상황에서 균형을 잡고 에너지 효율적인 보행을 실현하는 기술적 과제를 다룹니다. [2397]에서는 선형 역진자 모델(linear inverted pendulum model, LIPM)을 기반으로 적응형 궤적 계획(adaptive trajectory planning)을 제시하여 에너지 효율적 보행을 구현하는 방법을 제안했습니다. [2377]에서는 점근적으로 안정한 보행 생성(asymptotically stable gait generation) 방법론을 통해 변화하는 페이로드 조건에서도 순간적 보행(instantaneous walking)을 가능하게 하는 제어 기법을 개발했습니다. 또한 [2379]에서는 불규칙한 지형(granular terrain) 위에서의 양족 보행 동역학(bipedal walking dynamics)을 모델링하여 실제 환경에서의 하중 변화에 대응하는 연구를 진행했습니다. 이러한 연구들은 다양한 작업 환경에서 인간형 로봇의 실용성을 높이는 데 핵심적인 역할을 합니다.
- Parallel Ankle Humanoid Structures: 인간형 로봇의 발목 구조 설계에서 병렬 메커니즘(Parallel Mechanism)을 활용한 동적 보행 제어는 중요한 연구 분야이다. 강화학습(Reinforcement Learning) 기반의 보행 알고리즘은 로봇의 효율적인 이동성 향상에 필수적이며, 특히 샘플링 기반 시스템 식별(Sampling-Based System Identification)과 능동 탐색(Active Exploration) 기술이 모델 정확도를 개선한다 [1664]. 모델 예측 제어(Model Predictive Control, MPC)와 비용 매칭(Cost-Matching) 알고리즘을 결합하면 강화학습의 수렴 속도와 에너지 효율성을 동시에 증진할 수 있다 [1855]. 대규모 인간형 로봇 훈련에서 물리 정보 신경망(Physics-Informed Neural Networks, PINNs)과 비선형 필터링 기법은 시뮬레이션과 실제 시스템 간의 격차를 줄이는 데 효과적이다 [3359]. 이러한 기술들의 통합을 통해 병렬 발목 구조를 갖춘 인간형 로봇의 보행 안정성과 제어 성능이 크게 향상될 수 있다.
- Wheeled-Legged Skating Locomotion: 휠-다리 복합 스케이팅 로코모션(Wheeled-Legged Skating Locomotion)은 인간형 로봇의 이동 효율성을 극대화하기 위해 바퀴와 다리의 장점을 결합한 혁신적인 이동 메커니즘입니다. 이러한 기술은 에너지 효율성(Energy Efficiency)과 다양한 지형에 대한 적응성을 동시에 달성할 수 있도록 설계되었으며, 동역학 제어(Dynamic Control)와 전신 제어기(Whole-Body Controller) 개발을 통해 구현됩니다 [1709][1784]. SKATER와 같은 합성 운동학(Synthesized Kinematics) 기반의 접근법은 고급 순회 효율성을 제공하며, Foundation Model을 활용한 신체 안정화(Body Stabilization) 기술 [1929]은 불규칙한 지형에서의 로봇 안정성을 향상시킵니다. 좁은 지형 통과(Narrow Terrain Traversal)와 같은 복잡한 환경에서도 동적 제어를 통해 안정적인 로코모션이 가능하도록 발전하고 있습니다 [2004]. 이러한 휠-다리 복합 이동 기술은 인간형 로봇의 실용적 응용성과 이동 성능을 획기적으로 개선할 수 있는 핵심 기술입니다.
- Non-Linear Transmission Joint Mechanisms: # 비선형 전달 관절 메커니즘(Non-Linear Transmission Joint Mechanisms) 인간형 로봇의 관절 설계에서 비선형 전달 메커니즘은 제한된 작동 범위 내에서 최대의 성능을 달성하기 위한 핵심 기술이다. [1776]에서는 발목 관절의 최적 설계 프레임워크를 제시하여 로봇의 안정성과 효율성을 동시에 확보하는 방법을 제안했다. 이러한 메커니즘은 단순한 선형 전달과 달리 회전각도와 토크의 관계를 비선형적으로 제어하여 특정 동작 범위에서 높은 출력을 생성할 수 있게 한다. [1920]에서는 점프 능력 향상을 위해 변동 감속비(Variable Reduction Ratio) 메커니즘을 활용한 폭발적 출력 증대 방법을 제시했으며, [1919]에서는 관절각속도 제한을 초과하는 혁신적인 기법을 제안했다. 평행 메커니즘(Parallel Mechanisms)을 활용한 고성능 제어 기법[1851]과 함께, 이러한 비선형 전달 시스템은 인간형 로봇의 운동 능력을 비약적으로 향상시키는 데 중요한 역할을 한다.
- Musculoskeletal Humanoid Actuation: 근육골격계 인간형 로봇 액추에이션(Musculoskeletal Humanoid Actuation)은 생물학적 근육 구조를 모방하여 인간형 로봇의 움직임을 제어하는 기술 분야입니다. 이러한 접근법은 기존의 강성 액추에이터(rigid actuator) 기반 시스템과 달리, 탄성 요소와 근육의 비선형 특성을 활용하여 더욱 자연스럽고 효율적인 운동을 구현할 수 있습니다. [1618]에서는 신체 스키마 학습(body schema learning)을 통해 근육골격계 로봇의 제어 모델을 효과적으로 습득하는 방법을 제시하고 있으며, [1833]은 복합 로봇 시스템에서 근육을 관리하고 활용하는 특성과 방법론을 다루고 있습니다. [1983]의 동형 외골격계(isomorphic exoskeleton) 기반 접근과 [2381]의 형태-제어 공진화(morphology-control coevolution) 방식은 근육골격 시스템의 효율성을 극대화하기 위한 통합적 설계 전략을 보여줍니다. 이 분야의 연구는 인간형 로봇의 에너지 효율성, 안정성, 그리고 적응 능력을 동시에 향상시키는 데 중요한 역할을 합니다.
- Teacher-Student Bipedal Jumping & Kicking: 교사-학생 양족 점프 및 킹 메커니즘(Teacher-Student Bipedal Jumping & Kicking)은 강화학습(Reinforcement Learning)을 활용하여 인간형 로봇의 동적 이족 보행 능력을 향상시키는 연구 분야입니다. [1637]과 [1656]의 연구들은 강화학습을 통해 로봇이 점프, 회전, 착지 등의 복잡한 동작을 안정적이고 다용도로 수행할 수 있도록 하는 제어 기술을 개발했습니다. [2046]의 연구는 이러한 기술을 축구 로봇의 슈팅 기술 습득으로 확장하여, 인간형 로봇이 다양한 킹 동작을 학습할 수 있음을 입증했습니다. [2407]에서는 다중 작업 적응 제어(Multi-Task Adaptive Control)를 통해 단일 정책(Policy)으로 여러 동작을 동시에 수행할 수 있는 확장성 있는 시스템을 제시했습니다. 이러한 연구들은 교사-학생 학습 패러다임(Teacher-Student Learning Paradigm)을 활용하여 로봇의 일반화 능력(Generalization)과 강건성(Robustness)을 크게 향상시켰습니다.
- Mamba-Based Actuator Dynamics Learning: Mamba 기반 액추에이터 동역학 학습(Mamba-Based Actuator Dynamics Learning)은 휴머노이드 로봇의 복잡한 관절 제어를 위해 Mamba 아키텍처를 활용하여 액추에이터(actuator) 동역학을 학습하는 고급 기법입니다. 이 접근법은 심층 강화학습(deep reinforcement learning) 기반의 엔드-투-엔드(end-to-end) 제어 방식과 함께 적용되어 로봇의 민첩한 움직임(agile motion)을 실현합니다[2045]. 센트로이달 모멘텀(centroidal momentum) 정규화와 같은 물리 기반 제약 조건을 통합하여 휴머노이드 팔의 안정적인 운동 학습을 가능하게 합니다[2054]. 협력적 이질 다중 에이전트 강화학습(cooperative-heterogeneous multi-agent reinforcement learning) 환경에서 액추에이터 동역학 모델을 공동으로 학습함으로써 복수 관절 시스템의 상호작용을 효과적으로 처리합니다[2090]. 이러한 기법은 휴머노이드 로봇이 인간 수준의 동적 운동 기술(dynamic motor skills)을 습득하도록 하는 데 중요한 역할을 합니다[2045]. 결과적으로 Mamba 기반 액추에이터 동역학 학습은 휴머노이드 로봇의 실시간 제어 성능과 일반화 능력을 대폭 향상시킵니다.
- Hybrid Zero Dynamics Running: Hybrid Zero Dynamics Running (3편)은 인간형 로봇의 동적 보행 제어에서 모델 예측 제어(Model Predictive Control, MPC)와 제어 리아푸노프 함수(Control Lyapunov Function, CLF) 기반의 고급 제어 방법론을 다룬다. [1759]에서 제시된 전신 모델 예측 제어(Whole-Body Model-Predictive Control)는 다리 로봇의 복잡한 동역학을 고려하면서 마찰 제약(friction constraint)을 포함한 최적화 문제를 해결한다. [1636]에서 다루어지는 참조값 자유 표본 기반 모델 예측 제어(Reference-Free Sampling-Based Model Predictive Control)는 미리 정의된 보행 궤적 없이 실시간으로 최적의 제어 입력을 생성하는 방식으로, 계산 효율성과 적응성을 향상시킨다. [1834]의 안정성 추적 접근법(Chasing Stability)은 제어 리아푸노프 함수를 활용하여 하이브리드 시스템의 안정성을 보장하면서 동적 보행을 실현한다. 이들 연구는 인간형 로봇이 복잡한 환경에서 안정적이고 에너지 효율적인 달리기 동작을 수행하기 위한 이론적 기반을 제공한다.
- Jet-Powered Aerial Humanoid Dynamics: 제트 추진 공중 인형로봇 동역학(Jet-Powered Aerial Humanoid Dynamics)은 인형로봇에 제트 엔진을 장착하여 비행 능력을 갖추도록 설계하는 분야로, 전통적인 접지 이동성(terrestrial locomotion)을 초월한 3차원 공간 내 동작 제어를 목표로 합니다. 이러한 시스템은 CAD 기반의 동시 설계(co-design) 방법론을 통해 구조 설계와 제어 알고리즘을 통합적으로 최적화하며, iRonCub 3와 같은 실제 비행 가능한 프로토타입 개발에 활용됩니다[1832][2028]. 제트 추진 인형로봇의 공기역학(aerodynamics) 특성 파악은 안정적인 자세 제어(attitude control) 및 궤적 추적(trajectory tracking)에 필수적이며, 기계학습 기반의 공기역학 학습 방법이 실제 비행 환경에서의 제어 성능 향상에 기여합니다[2044]. 이 분야는 항공우주 공학(aerospace engineering)과 로보틱스(robotics)의 융합으로, 극한 환경 탐사(exploration), 재난 구조(disaster rescue), 고정밀 공중 작업(aerial manipulation) 등 다양한 응용 분야를 제시합니다. 제트 추진 인형로봇의 개발은 복합적인 제어 문제, 에너지 효율성, 구조적 안정성 등 여러 도전 과제를 포함하며, 이를 극복하기 위한 지속적인 연구가 진행 중입니다.
⚠ 갭: 실외 장시간 자율 운용 시의 에너지 효율, 열 관리, 구동기 내구성에 대한 정량적 평가 프레임워크가 부재하며 대부분의 연구가 단기 실험에 그친다.
🏛 정책: 휴머노이드 로봇 보행 성능 표준화 및 공인 테스트베드 구축을 통해 기업·연구기관 간 객관적 성능 비교 기반을 마련해야 한다.
PILOT: A Perceptive Integrated Low-level Controller for Loco-manipulation over Unstructured Scenes
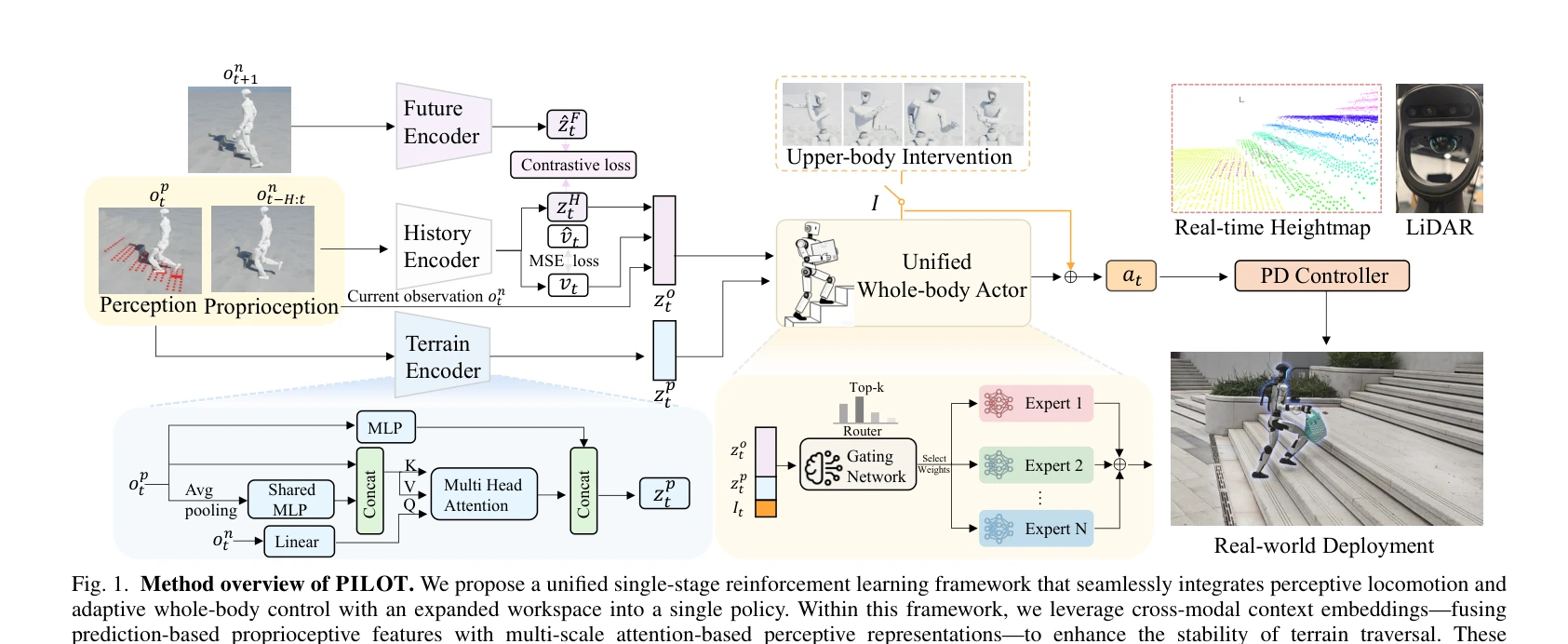
Fig. 1. Method overview of PILOT. We propose a unified single-stage reinforcement learning framework that seamlessly int
 *Fig. 1. Method overview of PILOT. We propose a unified single-stage reinforcement learning framework that seamlessly int* PILOT는 humanoid robot의 loco-manipulation을 위한 통합 단계 RL 프레임워크로, 지각 기반 locomotion과 전신 제어를 단일 policy로 통합하여 비정형 지형에서 안정적인 작업 실행을 가능하게 한다.
PILOT는 humanoid loco-manipulation 문제에 대한 통합적이고 실용적인 해결책을 제시하며, cross-modal perception과 MoE 구조를 통해 기술적 기여와 실제 로봇 구현의 성공적 사례를 보여준다.
Preference-Conditioned Multi-Objective RL for Integrated Command Tracking and Force Compliance in Humanoid Locomotion

Fig. 1: Preference-conditioned locomotion: A single policy realizes behaviors from
 *Fig. 1: Preference-conditioned locomotion: A single policy realizes behaviors from* 인간형 로봇의 명령 추적과 외력 순응을 동시에 달성하기 위해 선호도 조건부 MORL 프레임워크를 제안하며, 단일 정책으로 추적-순응 간의 연속적인 trade-off를 구현한다.
본 논문은 선호도 조건부 MORL을 통해 인간형 로봇 보행의 핵심 trade-off를 명시적으로 해결하는 창의적 접근법을 제시하며, velocity-resistance 모델링이라는 우아한 통합 기법과 실세계 검증을 통해 실제 배치 가능성을 입증한다. 다만 범위 제한(수평 평면, 선형 모델)과 단일 플랫폼 실험이 일반화 가능성에 대한 의문을 남긴다.
Reduced-Order Model-Guided Reinforcement Learning for Demonstration-Free Humanoid Locomotion
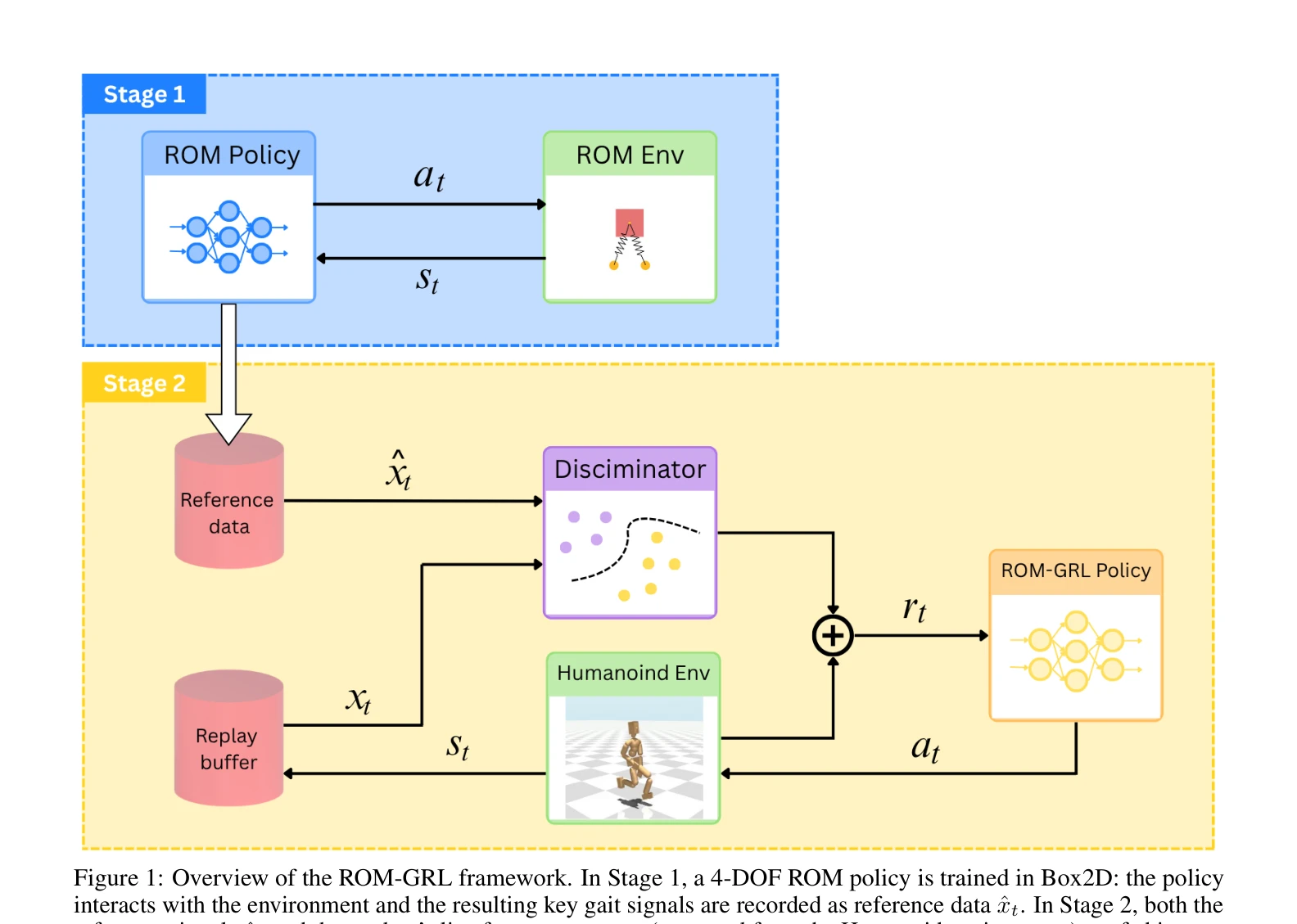
Figure 1: Overview of the ROM-GRL framework. In Stage 1, a 4-DOF ROM policy is trained in Box2D: the policy
 *Figure 1: Overview of the ROM-GRL framework. In Stage 1, a 4-DOF ROM policy is trained in Box2D: the policy* ROM-GRL은 모션캡처 데이터 없이 4-DOF reduced-order model로 생성한 gait template을 이용해 full-body humanoid 정책을 학습하는 2단계 강화학습 프레임워크이다. Adversarial discriminator를 통해 ROM의 5-dimensional gait feature 분포를 따르도록 유도하여 자연스러운 보행을 실현한다.
ROM-GRL은 reduced-order model을 creative하게 활용해 motion capture 의존성을 제거하면서 자연스럽고 안정적인 humanoid 보행을 달성하는 novel 프레임워크이다. 보상 설계와 모방 학습 간 간격을 효과적으로 줄였으나, 제한된 속도 범위와 실제 로봇 검증 부재가 일반화 가능성의 의문을 남긴다.
Reinforcement Learning with Data Bootstrapping for Dynamic Subgoal Pursuit in Humanoid Robot Navigation
 *Fig. 2. Overall structure of the proposed hierarchical framework for humanoid navigation. The high-level RL-based planne* Humanoid robot navigation을 위해 고수준 RL 기반 동적 subgoal 생성기와 저수준 MPC 기반 보행 제어기를 결합한 계층적 프레임워크를 제안하며, data bootstrapping 기법으로 학습을 안정화한다.
Bipedal robot navigation을 위한 RL과 MPC의 계층적 결합은 창의적이며, data bootstrapping을 통한 학습 안정화는 실질적 기여이나, 시뮬레이션 환경만의 검증과 동적 환경 미평가가 실제 적용까지의 간격을 남긴다.
Robot Drummer: Learning Rhythmic Skills for Humanoid Drumming

Fig. 1: The humanoid robot demonstrates expressive drumming skills across three songs: In the top row, the robot plays j
 *Fig. 3: Overview of the Robot Drummer: Starting from a raw MIDI drum track (left), each note-onset is first mapped to a* 본 논문은 인문형 로봇이 MIDI 악보를 기반으로 드럼을 연주하는 기술을 제시하며, Rhythmic Contact Chain 표현과 temporal decomposition을 활용한 reinforcement learning 프레임워크를 제안한다.
본 논문은 humanoid robotics에서 process-driven 창의적 작업으로의 확장을 의미 있게 시연하며, Rhythmic Contact Chain과 temporal decomposition이라는 실용적 기법을 통해 장시간 정밀 제어 문제를 효과적으로 해결한다. 30개 이상의 곡에서의 성공적 성과와 신흥 인간형 전략의 발현은 RL 기반 로봇 제어의 창의적 응용 가능성을 강력하게 보여준다.
Robust and Generalized Humanoid Motion Tracking
 *Fig. 2: Overview of the proposed whole-body control pipeline. A history encoder extracts a dynamics embedding from* 휴머노이드 로봇의 일반적인 전신 제어를 위해 dynamics-conditioned command aggregation 프레임워크를 제안하며, 인과적 temporal encoder와 multi-head cross-attention을 결합하여 노이즈가 있는 참조 동작에 강건하게 대응한다.
본 논문은 dynamics-conditioned command aggregation이라는 우아한 설계를 통해 컴팩트한 데이터셋으로도 강건한 일반화 휴머노이드 전신 제어를 달성하며, 낙하 회복의 통합과 실제 로봇 배포 검증으로 높은 실용성을 보여준다.
RuN: Residual Policy for Natural Humanoid Locomotion
 *Fig. 2: Overview of the RuN framework. (a) Motion Retargeting: Raw human motions are converted into a kinematically feas* RuN은 Conditional Motion Generator를 통한 운동학적 모션 프라이어와 강화학습 기반 residual policy를 분리하여, 인형로봇의 자연스러운 보행-달리기 전환을 실현하는 decoupled residual learning 프레임워크이다.
RuN은 humanoid locomotion 제어의 근본적인 복잡성을 elegant하게 해결한 well-motivated 프레임워크로, decoupled residual learning 접근이 학습 효율성과 최종 성능을 모두 개선하며 실제 로봇에서 검증된 강력한 방법론이다.
SMAP: Self-supervised Motion Adaptation for Physically Plausible Humanoid Whole-body Control
 *Figure 3: Pipeline of SMAP* 본 논문은 인간 모션과 휴머노이드 로봇의 이질적 행동 공간 간 차이를 해결하기 위해 Vector-Quantized Periodic Autoencoder 기반의 Humanoid-Adapter를 제안하여 인간 모션을 물리적으로 타당한 로봇 모션으로 적응시키고, Teacher-Student 증류 학습을 통해 안정적인 전신 제어 정책을 학습한다.
본 논문은 인간-로봇 모션 이질성이라는 실질적 문제를 Vector-Quantized Periodic Autoencoder와 디커플된 보상을 통해 체계적으로 해결하며, 시뮬레이션과 실제 로봇 실험을 통해 방법의 효과성을 충분히 입증한다. 다만 특정 로봇 플랫폼에 한정된 검증과 일반화 가능성에 대한 추가 분석이 있으면 더욱 강력한 논문이 될 것으로 예상된다.
SteadyTray: Learning Object Balancing Tasks in Humanoid Tray Transport via Residual Reinforcement Learning
 *Fig. 2: Overview of the ReST-RL framework. Base Policy Training: A locomotion policy is first trained to carry a tray wh* ReST-RL은 사전학습된 이족 보행 정책에 잔차 모듈을 추가하여 휴머노이드 로봇이 동적 보행 중 트레이 위의 불안정한 물체를 안정적으로 운반할 수 있도록 하는 계층적 강화학습 아키텍처이다.
ReST-RL은 보행 안정성을 보존하면서 payload 안정화를 분리 학습하는 우아한 설계로, 휴머노이드 로봇의 실제 서비스 응용(식음료 배송, 의료 기구 운반)에 필수적인 신뢰성 높은 물체 운반을 처음 성공적으로 시연했다.
VB-Com: Learning Vision-Blind Composite Humanoid Locomotion Against Deficient Perception

Fig. 1: Overview. VB-Com enables humanoid robots (move direction in orange arrorw) to traverse dynamic terrains and obst
 *Fig. 1: Overview. VB-Com enables humanoid robots (move direction in orange arrorw) to traverse dynamic terrains and obst* VB-Com은 휴머노이드 로봇이 시각 정보의 결손에 대응하기 위해 시각 기반 정책과 고유감각 기반의 맹목 정책을 동적으로 전환하는 복합 제어 프레임워크를 제안한다.
VB-Com은 휴머노이드 로봇의 지각 견고성 문제를 정책 합성으로 우아하게 해결하며, return estimator 기반 동적 선택 메커니즘은 창의적이고 실용적이다. 동적 지형 및 지각 노이즈 시나리오의 체계적 구성과 두 휴머노이드 플랫폼에서의 검증이 강점이나, 실제 배포 결과 확장과 일반화 능력 분석이 보강되면 더욱 설득력 있을 것이다.
Walk the PLANC: Physics-Guided RL for Agile Humanoid Locomotion on Constrained Footholds

Fig. 1. Model-guided RL traversing constrained footholds on the Unitree G1
 *Fig. 2. A visual depiction of the model-guided RL architecture used to achieve stepping stones. The left column shows th* 이 논문은 감소된 차수의 발판 계획기와 Control Lyapunov Function (CLF) 기반 보상을 통해 물리학 기반 구조로 강화학습을 안내하여, 제한된 발판에서 인간형 로봇의 정밀한 보행을 달성한다.
본 논문은 물리 기반 구조와 강화학습을 효과적으로 결합하여 stepping-stone 보행의 정밀성과 강건성 문제를 우아하게 해결하였으며, 하드웨어 검증과 오픈소스 공개를 통해 높은 실용적 가치를 제공한다.
Whole-Body Dynamic Throwing with Legged Manipulators

Fig. 1: Our robot throwing policies demonstrated on real hardware (top) and in simulation (bottom) showing complex full-
 *Fig. 1: Our robot throwing policies demonstrated on real hardware (top) and in simulation (bottom) showing complex full-* 다리가 있는 로봇의 전신 동역학을 활용하여 강화학습 기반의 3D 목표지점으로의 정확한 투척을 학습하는 방법을 제시하고, 시뮬레이션에서 학습한 정책을 실제 휴머노이드 로봇으로 전이시켰다.
본 논문은 전신 동역학을 활용한 3D 임의 목표 투척이라는 명확한 혁신과 적응형 커리큘럼이라는 기술적 기여로 로봇 조작 연구의 새로운 방향을 제시했으나, 실제 로봇 전이의 완전성 부족과 일반화 범위 제약이 실용적 임팩트를 다소 제한한다.
Whole-body Humanoid Robot Locomotion with Human Reference

Fig. 1: The top image displays the humanoid robot Adam walking on unseen terrain,
 *Fig. 1: The top image displays the humanoid robot Adam walking on unseen terrain,* 인간의 보행 데이터를 활용한 모방 학습 프레임워크를 통해 풀사이즈 휴머노이드 로봇 Adam이 인간 수준의 보행 성능을 달성하는 방법을 제시한다.
휴머노이드 로봇 제어의 오래된 과제(복잡한 보상 함수, Sim2Real 간극)를 인간 모방 학습으로 효과적으로 해결하고 풀사이즈 로봇에서 첫 성공을 달성한 중요한 연구이다. 다만 정량적 평가 지표 부족과 경쟁 로봇과의 비교 분석이 보강되면 더욱 강력한 논문이 될 수 있다.
X-Loco: Towards Generalist Humanoid Locomotion Control via Synergetic Policy Distillation

Fig. 1: X-Loco achieves vision-based generalist humanoid locomotion control. Relying solely on velocity commands without
 *Fig. 2: Overview of X-Loco. (a) X-Loco integrates the capabilities of three specialist policies into a vision-based gene* X-Loco는 시너지 정책 증류를 통해 세 개의 전문가 정책(upright locomotion, fall recovery, whole-body coordination)을 단일 비전 기반 범용 정책으로 통합하여, 속도 명령만으로 다양한 휴머노이드 보행 스킬을 수행하는 프레임워크이다.
X-Loco는 policy distillation을 통해 다양한 휴머노이드 로콜로모션 스킬을 효과적으로 통합하는 혁신적인 접근법을 제시하며, CASS, SAR, SFI 등의 설계 요소들이 이론적으로 잘 동기부여되고 실제 로봇 배포로 검증되어 휴머노이드 로봇 제어 분야에 중요한 기여를 한다.
Advancing Humanoid Locomotion: Mastering Challenging Terrains with Denoising World Model Learning

Fig. 1: Extensive showcase of locomotion skills using the proposed framework. Displayed is a sequence illustrating a hum
 *Fig. 1: Extensive showcase of locomotion skills using the proposed framework. Displayed is a sequence illustrating a hum* Denoising World Model Learning (DWL)이라는 end-to-end 강화학습 프레임워크를 통해 휴머노이드 로봇이 눈덮인 언덕, 계단, 불규칙한 지형 등 현실의 복잡한 지형을 처음으로 마스터했으며, zero-shot sim-to-real transfer로 같은 신경망을 모든 시나리오에서 구동한다.
DWL은 휴머노이드 로봇의 현실 복잡 지형 보행 문제를 처음으로 해결한 혁신적 연구이며, noisy observation으로부터 true state를 복원하는 encoder-decoder 기반 denoising 접근과 2-DoF ankle mechanism의 하드웨어 혁신이 결합되어 높은 영향력을 기대할 수 있다.
Adversarial Locomotion and Motion Imitation for Humanoid Policy Learning
인간형 로봇의 상반신과 하반신의 서로 다른 역할을 분리하여 학습하는 대적적 학습 프레임워크 ALMI를 제안하고, 시뮬레이션과 실제 로봇에서 강건한 보행과 정확한 모션 추적을 달성한다.
상반신과 하반신의 역할 분리를 adversarial learning으로 구현한 novel framework이며, 이론적 수렴 보장과 실제 로봇 구현의 성공이 결합되어 높은 실용성을 보유하고 있다. 대규모 dataset 공개로 향후 연구의 기반을 제공하는 점도 의미 있다.
AMO: Adaptive Motion Optimization for Hyper-Dexterous Humanoid Whole-Body Control

Fig. 1: AMO enables hyper-dexterous whole-body movements for humanoid robots. (a): The robot picks and places a can on
 *Fig. 2: System overview. The system is decomposed into four stages: 1. AMO module training by collecting AMO dataset* AMO는 sim-to-real RL과 trajectory optimization을 결합하여 29-DoF 인형로봇의 실시간 적응형 전신 제어를 구현하며, hybrid dataset 구성과 O.O.D. 명령에 대한 강건한 일반화를 통해 기존 방법의 운동 공간 제한을 극복한다.
AMO는 hybrid motion synthesis와 O.O.D. robust 정책 학습을 통해 인형로봇의 운동 공간을 획기적으로 확대한 혁신적 연구로, MoCap과 trajectory optimization의 상보적 장점을 효과적으로 결합하며 sim-to-real transfer와 실시간 적응형 제어에서 탁월한 성과를 보여준다.
AMOR: Adaptive Character Control through Multi-Objective Reinforcement Learning
Fig. 1. Our method uses multi-objective reinforcement learning to enable on-the-fly tuning of reward weights post-traini
 *Fig. 1. Our method uses multi-objective reinforcement learning to enable on-the-fly tuning of reward weights post-traini* 본 논문은 Multi-Objective Reinforcement Learning(MORL)을 활용하여 보상 함수의 가중치를 학습 후 조정할 수 있는 AMOR 프레임워크를 제안하며, 이를 통해 물리 기반 캐릭터 제어의 반복 튜닝 시간을 단축하고 실제 로봇으로의 전이를 용이하게 한다.
본 논문은 MORL을 물리 기반 캐릭터 제어에 창의적으로 적용하여 훈련 후 가중치 조정을 가능하게 함으로써 개발 워크플로우를 크게 개선하고, 실제 로봇 적용에서의 sim-to-real 전이를 용이하게 하는 실용적이고 혁신적인 접근법을 제시한다.
Architecture Is All You Need: Diversity-Enabled Sweet Spots for Robust Humanoid Locomotion
 *Fig. 2. Training and Deployment Overview: both actor and critic are two-stage architectures each with their own percepti* 휴머노이드 로봇의 견고한 보행을 위해 빠른 고주파 안정화 제어기와 느린 저주파 지각 정책을 분리하는 계층화 제어 구조(LCA)가 단일 end-to-end 설계보다 우월함을 보였다.
휴머노이드 로봇 제어에서 네트워크 복잡도보다 구조적 설계(계층화 다중 주파수)가 견고성의 핵심임을 명확히 입증한 중요한 연구로, 최소한의 아키텍처로 복잡한 실제 환경 과제를 해결함으로써 로봇 제어 설계의 원칙을 제시한다.
CLOT: Closed-Loop Global Motion Tracking for Whole-Body Humanoid Teleoperation
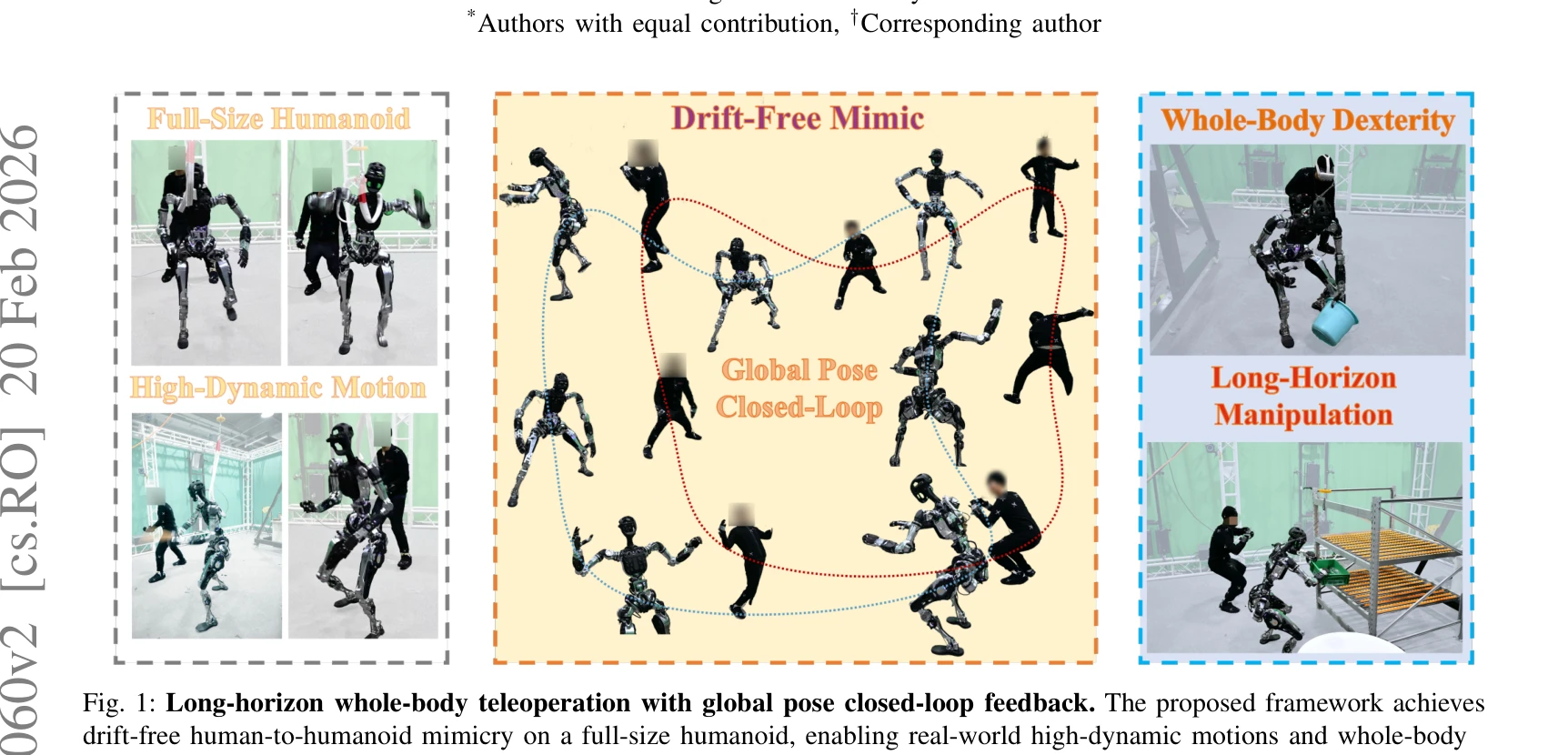
Fig. 1: Long-horizon whole-body teleoperation with global pose closed-loop feedback. The proposed framework achieves
 *Fig. 1: Long-horizon whole-body teleoperation with global pose closed-loop feedback. The proposed framework achieves* CLOT는 고주파 로컬라이제이션 피드백을 통해 폐루프 전역 자세 추적을 달성하는 실시간 인간형 로봇 원격조종 시스템으로, 장시간 운영 중 누적되는 전역 드리프트 문제를 해결한다.
CLOT는 폐루프 전역 제어와 Observation Pre-shift 데이터 기반 무작위화 전략을 통해 장시간 드리프트 없는 인간형 로봇 원격조종을 달성한 혁신적 시스템으로, 실제 인간형 로봇에서의 포괄적 검증과 고품질 데이터셋 공개는 이 분야의 중요한 기여이다.
Distillation-PPO: A Novel Two-Stage Reinforcement Learning Framework for Humanoid Robot Perceptive Locomotion

Fig. 1: We demonstrate the walking capabilities of the humanoid robot Tien Kung on
 *Fig. 2: The training framework of Distillation-PPO adopts a symmetric structure for both the teacher and student network* 인문형 로봇의 지각 기반 보행을 위해 교사 정책과 강화학습을 결합한 2단계 프레임워크 Distillation-PPO (D-PPO)를 제안하며, 시뮬레이션에서의 안정성과 실제 로봇의 강건성을 동시에 확보한다.
본 논문은 강화학습과 지식 증류의 강점을 결합한 균형잡힌 접근법으로, 시뮬레이션과 실제 로봇 양쪽에서 검증된 실질적 성과를 보여준다. 다만 이론적 분석이 부족하고 단일 로봇 플랫폼의 실험만 제시된 점이 아쉽지만, 인문형 로봇 보행 제어의 실질적 문제 해결에 기여하는 의미 있는 연구다.
ECO: Energy-Constrained Optimization with Reinforcement Learning for Humanoid Walking
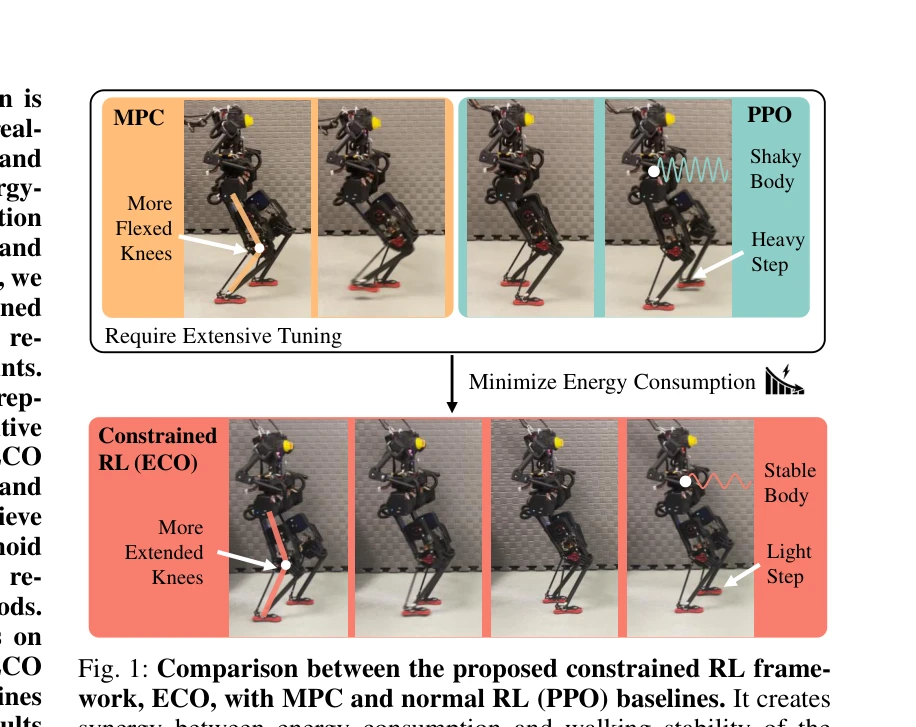
Fig. 1: Comparison between the proposed constrained RL frame-
 *Fig. 1: Comparison between the proposed constrained RL frame-* ECO는 에너지 소비를 보상 함수의 가중치가 아닌 명시적 부등식 제약 조건으로 reformulate한 constrained RL 프레임워크로, 휴머노이드 로봇의 에너지 효율적 보행을 달성한다.
ECO는 에너지 최적화를 constrained RL로 reformulate한 novel한 접근법으로 휴머노이드 보행의 에너지 효율성에서 획기적 성과를 달성했으며, 실제 로봇 플랫폼 검증과 constrained RL에 대한 실증적 분석은 로봇 공학 및 최적 제어 커뮤니티에 중대한 기여를 한다.
Embedding Classical Balance Control Principles in Reinforcement Learning for Humanoid Recovery

Fig. 1.
 *Fig. 1.* 고전적 균형 제어 원리(capture point, center-of-mass, centroidal momentum)를 강화학습의 privileged critic 입력과 보상 형성에 직접 임베딩하여, 인간형 로봇의 낙상 회복을 위한 통합 정책을 학습한다. 단일 정책으로 발목/엉덩이 전략, 보정 스텝, 다중접촉 일어서기를 포괄하며 93.4% 회복률을 달성한다.
본 논문은 고전적 균형 제어 원리를 강화학습에 체계적으로 임베딩하는 creative한 접근으로, ablation을 통해 이 구조의 필수성을 입증하고 93.4% 회복률로 강력한 실증 결과를 제시한다. 다만 하드웨어 검증 규모와 다양한 환경에서의 일반화 평가가 보강되면 더욱 설득력 있을 것이다.
EMP: Executable Motion Prior for Humanoid Robot Standing Upper-body Motion Imitation
 *Fig. 2: Overview of our framework. Motion Retargeting (section III): We train a graph convolution retargeting network to* 휴머노이드 로봇이 서 있는 자세를 유지하면서 인간의 상체 동작을 모방하기 위해 강화학습과 Executable Motion Prior(EMP) 모듈을 결합한 프레임워크를 제안한다.
이 논문은 RL과 동작 prior를 결합하여 휴머노이드 로봇의 안정적인 상체 동작 모방을 실현하는 실용적인 솔루션을 제시하며, 실제 로봇 배포를 통해 그 효과를 입증한 우수한 연구이다.
FALCON: Learning Force-Adaptive Humanoid Loco-Manipulation

Figure 1: FALCON enables versatile forceful loco-manipulation tasks for humanoids: (a) Transporting Pay-
 *Figure 2: Overview of FALCON. (a) Two agents with different sub-tasks are jointly trained with* FALCON은 이중 에이전트 강화학습 프레임워크로, 하체의 안정적 보행과 상체의 정밀한 말단 장치 위치 추적을 분리하여 학습함으로써 휴머노이드 로봇이 0-100N의 큰 외부 힘에 적응하면서 강제적 작업을 수행하도록 한다.
FALCON은 휴머노이드의 강제적 로코-조작 문제를 이중 에이전트 분해와 힘 커리큘럼 설계로 효과적으로 해결하며, 다중 플랫폼 배포와 2배의 추적 정확도 향상을 입증함으로써 실용적 가치가 높다. 다만 sim-to-real 갭 극복 메커니즘과 극단적 환경 강건성에 대한 분석이 더 필요하다.
FastTD3: Simple, Fast, and Capable Reinforcement Learning for Humanoid Control
 *Figure 3: Summary of results. FastTD3 is a simple, fast, and capable RL algorithm that significantly* FastTD3는 병렬 시뮬레이션, 대배치 업데이트, 분포 기반 크리틱 등의 간단한 수정을 통해 TD3를 최적화하여 humanoid 로봇 제어 태스크를 단일 A100 GPU에서 3시간 이내에 학습하는 빠르고 효율적인 오프-정책 강화학습 알고리즘을 제시한다.
FastTD3는 기존 기법의 조합이지만 humanoid robotics에서 실무적으로 매우 유용한 간단하고 빠른 솔루션을 제공하며, 오픈소스 구현을 통해 RL 연구 커뮤니티의 접근성을 크게 향상시킨다. 다만 알고리즘 혁신보다는 엔지니어링 최적화에 중점을 두고 있어 과학적 원창성은 제한적이다.
Flow Matching Imitation Learning for Multi-Support Manipulation
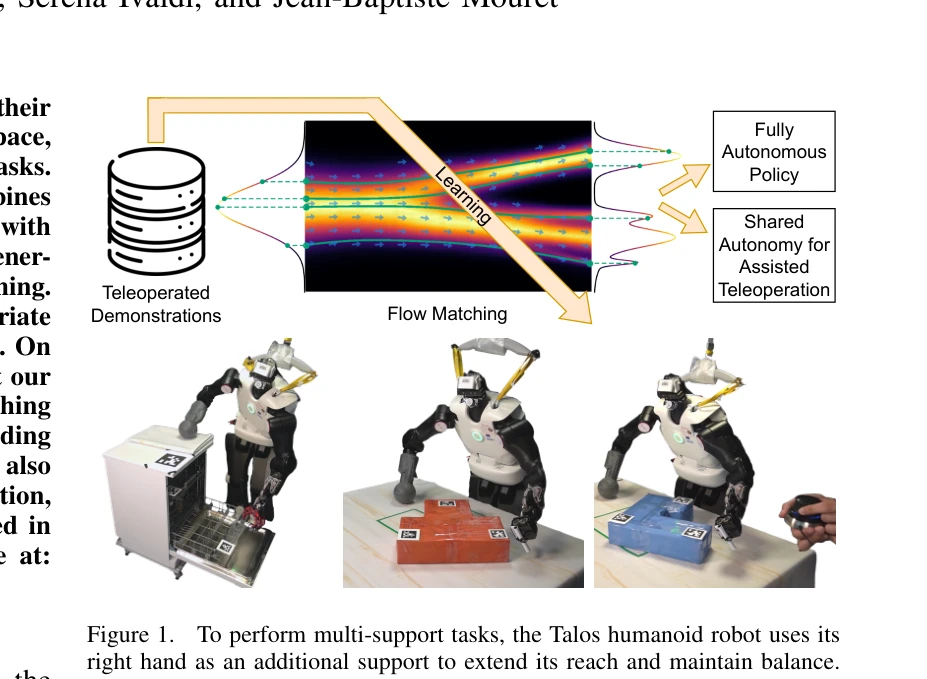
Figure 1.
 *Figure 1.* 본 논문은 Flow Matching 생성 모델을 활용하여 휴머노이드 로봇이 팔을 추가 지지점으로 사용하는 다중 접촉 조작 작업을 모방 학습으로 학습할 수 있는 통합 접근법을 제시한다. Talos 로봇에서 상자 밀기 및 식기세척기 문 닫기 작업을 성공적으로 수행하며, 공유 자율성 모드를 통해 인간 조작자를 지원한다.
본 논문은 Flow Matching을 실제 휴머노이드 로봇의 다중 접촉 조작 학습에 처음 적용한 혁신적 연구로, 이론적 기여와 실제 구현이 잘 결합되어 있다. 공유 자율성 모드를 통한 실용적 응용 가치와 생성 모델의 로봇 적용 가능성을 명확히 입증한다.
Gait-Adaptive Perceptive Humanoid Locomotion with Real-Time Under-Base Terrain Reconstruction
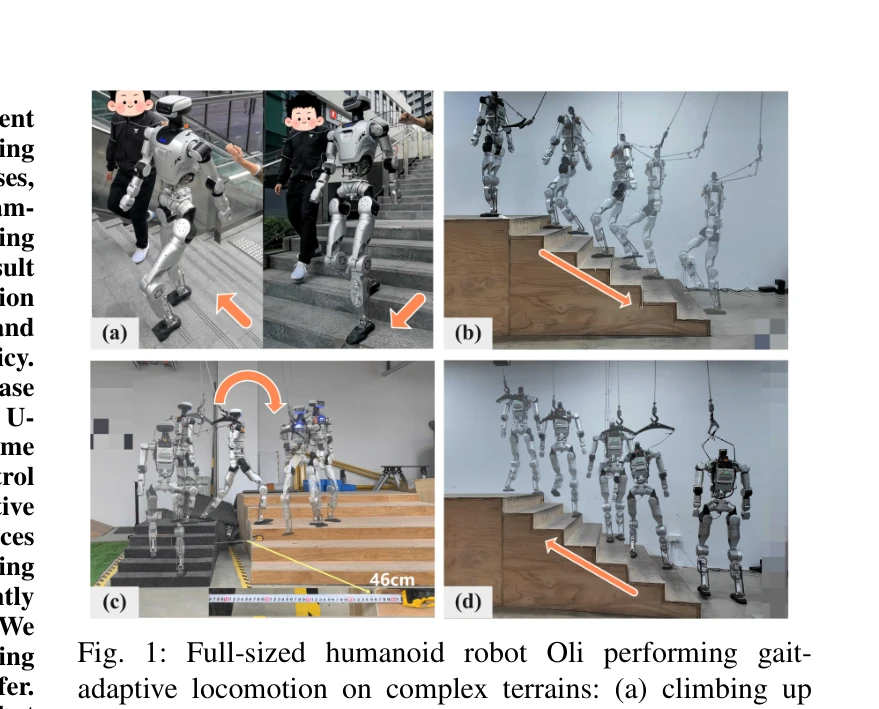
Fig. 1: Full-sized humanoid robot Oli performing gait-
 *Fig. 2: Overview of the proposed Successive Teacher–Student (S-TS) framework and deployment pipeline. A teacher–student* 인간형 로봇의 복잡한 지형 보행을 위해 하향식 깊이 카메라로 촬영한 영상을 U-Net으로 높이맵으로 재구성하고, 이를 통합 정책에 입력하여 관절 제어와 보행 주기를 동시에 적응시키는 지각 기반 보행 프레임워크를 제시한다.
인간형 로봇의 복잡 지형 보행이라는 중요한 문제를 하향식 깊이 카메라와 U-Net 기반 높이맵 재구성, 통합 적응형 정책의 조합으로 창의롭게 해결하였으며, 실제 로봇에서 계단 오르내림과 갭 횡단을 성공적으로 시연하여 높은 실용적 가치를 보인다.
Gait-Conditioned Reinforcement Learning with Multi-Phase Curriculum for Humanoid Locomotion

Fig. 1: Human-like multi-gait locomotion on the Unitree G1
 *Fig. 1: Human-like multi-gait locomotion on the Unitree G1* 인간에게서 영감을 얻은 보상 형성과 gait-conditioned reward routing을 통해 단일 recurrent policy에서 서서기, 걷기, 달리기 및 전환을 학습하는 통합 reference-free RL 프레임워크를 제시한다.
이 논문은 gait-conditioned reward routing과 생물역학 기반 보상 설계를 통해 MoCap 없이 자연스러운 다중 gait 학습을 가능하게 하는 우아한 프레임워크를 제시하며, 실제 인간형 로봇에서의 검증으로 실용성을 입증한다.
GentleHumanoid: Learning Upper-body Compliance for Contact-rich Human and Object Interaction

Fig. 1: GentleHumanoid learns a universal whole-body control policy with upper-body compliance and tunable force limits.
 *Fig. 1: GentleHumanoid learns a universal whole-body control policy with upper-body compliance and tunable force limits.* GentleHumanoid는 impedance control을 whole-body motion tracking 정책에 통합하여 humanoid 로봇의 상체 compliance를 학습하는 프레임워크이다. 이는 human motion data에서 샘플링한 spring-based formulation을 통해 resistive contact와 guiding contact를 통일적으로 모델링한다.
GentleHumanoid는 humanoid 로봇의 안전한 human-robot physical interaction을 위한 실질적이고 창의적인 솔루션을 제시한다. Unified spring-based formulation과 human motion data 기반 contact modeling의 조합은 novel하며, 실제 Unitree G1에서의 검증과 custom pressure-sensing 평가 방법론은 논문의 신뢰성을 높인다.
H2-COMPACT: Human-Humanoid Co-Manipulation via Adaptive Contact Trajectory Policies

Fig. 1: Real-world human–humanoid co-manipulation. The human leads the humanoid robot—unaware of the route or
 *Fig. 2: H²-COMPACT’s pipeline: raw force/torque and RGB inputs are cleaned by SAM2 and WHAM, then passed through* 힘각 센서 기반 haptic intent inference와 reinforcement learning 기반 locomotion policy를 계층적으로 결합하여 인간-휴머노이드 협력 물체 운반을 실현한다.
Haptic-based intent inference와 force-adaptive legged locomotion의 계층적 결합으로 인간-휴머노이드 협력 물체 운반의 새로운 패러다임을 제시하며, motion-capture free 데이터 수집과 sim-to-real 검증을 통해 실용성 높은 연구로 평가된다.
HAFO: A Force-Adaptive Control Framework for Humanoid Robots in Intense Interaction Environments
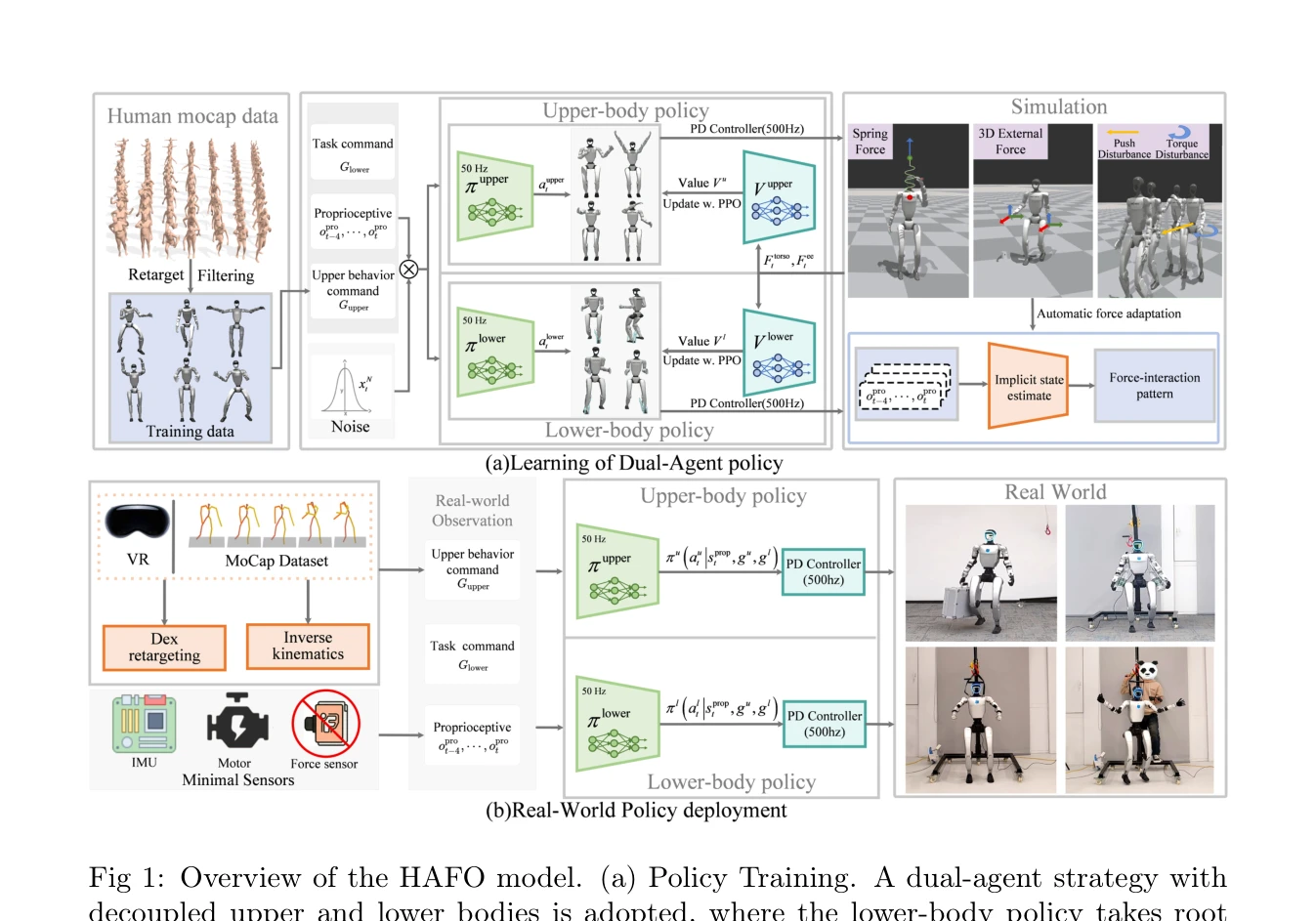
Fig 1: Overview of the HAFO model. (a) Policy Training. A dual-agent strategy with
 *Fig 1: Overview of the HAFO model. (a) Policy Training. A dual-agent strategy with* HAFO는 dual-agent RL 프레임워크를 통해 humanoid robot의 하체 보행과 상체 조작을 동시에 최적화하여 강한 외력 상호작용 환경에서 안정적이고 정밀한 제어를 달성한다.
HAFO는 spring-damper 모델과 dual-agent RL의 결합으로 humanoid robot의 강한 외력 적응 제어에서 새로운 기준을 제시하며, 특히 로프 현수라는 novel 응용에서 안정적 제어를 최초 달성한 의미 있는 연구다.
Hierarchical Vision-Language Planning for Multi-Step Humanoid Manipulation

Fig. 1: Our hierarchical humanoid manipulation system autonomously executes a multi-step rearrangement task. The robot f
 *Fig. 2: Overview of the proposed hierarchical framework for autonomous multi-step humanoid manipulation. The system* 인간형 로봇의 복잡한 다단계 조작 작업을 위해 저수준 RL 추적 제어기, 중수준 모방학습 기반 스킬 정책, 고수준 VLM 기반 계획 및 모니터링으로 구성된 3계층 계층적 프레임워크를 제시한다.
본 논문은 humanoid 로봇의 자율적 다단계 조작을 위해 VLM 기반 계획 및 모니터링을 기존 2계층 제어에 추가하는 실용적인 접근을 제시하며, 실제 로봇 시험으로 기술적 가능성을 입증했다. 다만 73% 성공률과 단일 작업 검증은 추후 개선이 필요한 부분이다.
Hierarchical visuomotor control of humanoids
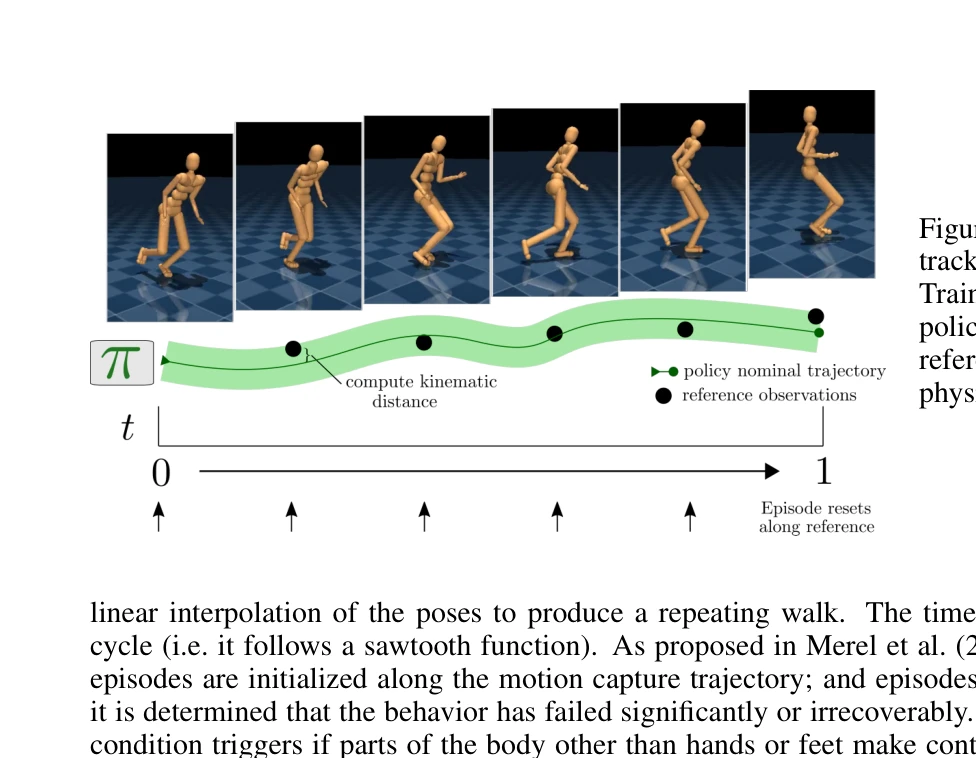
Figure 1:
 *Figure 4: Schematic of the architecture: a high-level controller (HL) selects among multiple low-* 인간형 로봇의 고차원 시각-운동 제어를 위해 저수준 모터 제어기와 고수준 작업 조정기를 계층적으로 구성하는 아키텍처를 제안한다. Motion capture 데이터로 사전학습된 저수준 sub-policy들을 고수준 controller가 시각 정보에 기반해 동적으로 선택하여 복잡한 humanoid 제어를 수행한다.
Motion capture 기반 저수준 제어와 시각-메모리 기반 고수준 조정을 결합하여 고복잡도 humanoid의 integrated visuomotor 제어를 달성한 우수한 연구로, 신경과학적 영감과 실제 구현의 균형이 잘 맞으며 ICLR 발표에 적합한 수준의 기여를 제시한다.
Hold My Beer: Learning Gentle Humanoid Locomotion and End-Effector Stabilization Control

Figure 1: Learning Gentle Humanoid Locomotion and End-Effector Stabilization Control with
 *Figure 1: Learning Gentle Humanoid Locomotion and End-Effector Stabilization Control with* 휴머노이드 로봇이 음료를 들고 걸을 때 흘리지 않도록 상체와 하체를 분리된 에이전트로 제어하는 SoFTA 프레임워크를 제안하여, 느린 보행 제어와 빠른 end-effector 안정화를 동시에 달성한다.
이 논문은 휴머노이드의 보행 중 end-effector 안정화라는 중요하면서도 미해결 문제를 frequency separation과 decoupled control로 우아하게 해결한 창의적 접근법을 제시하며, 실세계 배포로 실용성을 입증한 뛰어난 연구이다.
HOVER: Versatile Neural Whole-Body Controller for Humanoid Robots
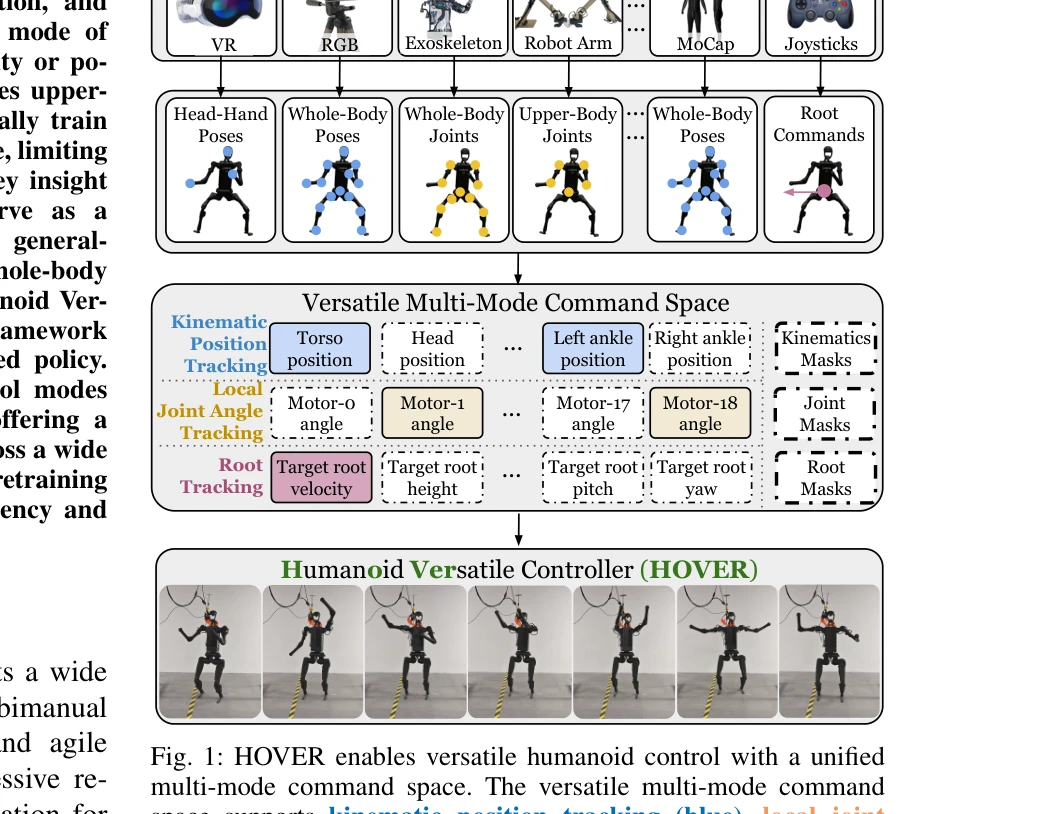
Fig. 1: HOVER enables versatile humanoid control with a unified
 *Fig. 1: HOVER enables versatile humanoid control with a unified* HOVER는 키네매틱 위치 추적, 조인트 각도 추적, 루트 추적을 포함한 15개 이상의 제어 모드를 지원하는 통합 신경망 제어기로, 정책 증류를 통해 다양한 제어 모드를 단일 정책으로 통합하여 휴머노이드 로봇의 다목적 전신 제어를 실현한다.
HOVER는 휴머노이드 전신 제어의 다중 모드 통합이라는 실질적이고 중요한 문제를 정책 증류 기반의 우아한 해결책으로 제시하며, 시뮬레이션과 실제 로봇에서 모두 검증된 견고한 성과를 보여준다. 다만 실제 환경의 복잡한 작업에 대한 적응성과 계산 효율성에 대한 심화 분석이 더해지면 완성도가 높아질 수 있다.
HuMam: Humanoid Motion Control via End-to-End Deep Reinforcement Learning with Mamba
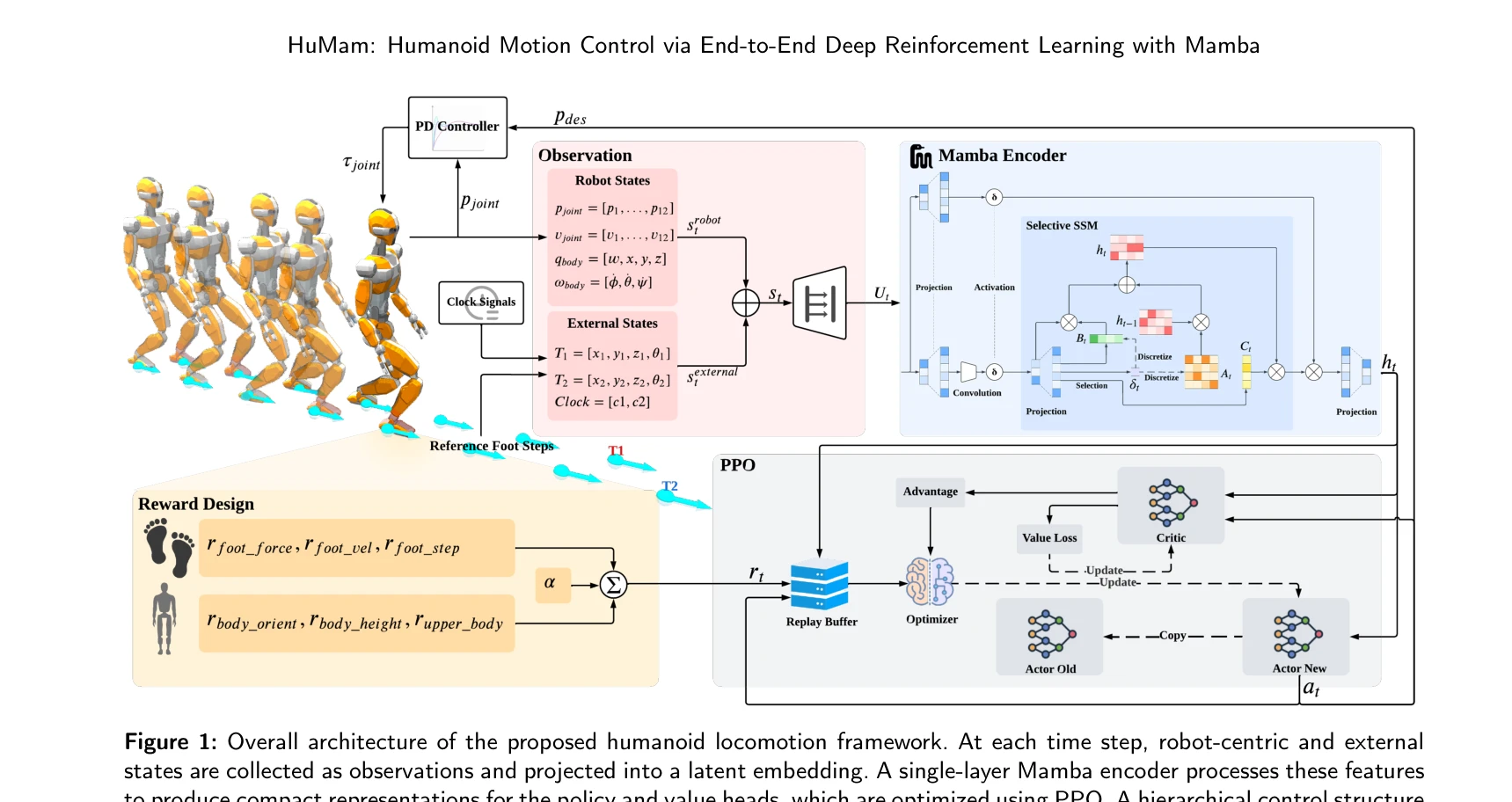
Figure 1: Overall architecture of the proposed humanoid locomotion framework. At each time step, robot-centric and exter
 *Figure 1: Overall architecture of the proposed humanoid locomotion framework. At each time step, robot-centric and exter* HuMam은 Mamba 인코더를 백본으로 사용하는 end-to-end 강화학습 기반 휴머노이드 로봇 보행 제어 프레임워크로, 로봇 중심 상태와 목표 발걸음을 효율적으로 융합하여 안정적이고 에너지 효율적인 제어를 실현한다.
HuMam은 Mamba를 활용한 휴머노이드 보행 제어의 첫 성공 사례로, 학습 효율성과 에너지 효율성을 동시에 개선하는 실질적 기여를 한다. 다만 시뮬레이션 기반 결과와 단일 플랫폼 검증의 제약이 있어 실제 응용 가능성 입증을 위한 추가 연구가 필요하다.
Humanoid Goalkeeper: Learning from Position Conditioned Task-Motion Constraints

Fig. 1: We present Humanoid Goalkeeper, capable of performing goalkeeping tasks across various regions with a wide opera
 *Fig. 2: Method framework: We train our policy using an end-to-end* 인간형 로봇의 골키퍼 역할을 위해 위치 조건부 task-motion constraints를 학습하는 end-to-end RL 프레임워크를 제시하며, 인간 모션 프라이어를 adversarial scheme으로 통합하여 자동화되고 인간다운 전신 동작을 생성한다.
본 논문은 position-conditioned adversarial motion priors를 통해 humanoid 로봇의 자동화되고 인간다운 골키퍼 능력을 처음으로 시연한 의미 있는 연구이며, 실제 하드웨어 배포와 task 일반화를 통해 실용성을 입증했으나, 정량적 분석과 ablation study가 강화될 필요가 있다.
Humanoid Hanoi: Investigating Shared Whole-Body Control for Skill-Based Box Rearrangement
 *Fig. 2: Independently trained high-level skills generate task-level commands that are executed through a shared, task-ag* 휴머노이드 로봇의 장기 박스 재배열 작업을 위해 공유된 task-agnostic WBC를 통해 재사용 가능한 스킬들을 조합하는 skill-based framework를 제안하고, 분포 이동으로 인한 강건성 저하를 데이터 집계를 통해 해결한다.
본 논문은 공유 WBC를 통한 모듈식 스킬 조합 아키텍처의 systematic exploration과 데이터 집계 기반 robustness 개선이라는 실용적 기여를 제시하며, Humanoid Hanoi 벤치마크를 통해 long-horizon 장기 자율 실행의 가능성을 입증한다. 다만 high-level planning, 계산 scalability, sim-to-real gap에 대한 심화 분석은 부족하다.
Humanoid-Gym: Reinforcement Learning for Humanoid Robot with Zero-Shot Sim2Real Transfer

Fig. 1: Humanoid-Gym enables users to train their policies
 *Fig. 2: Pipeline of Humanoid-Gym. Initially, we employ* Humanoid-Gym은 Nvidia Isaac Gym 기반의 강화학습 프레임워크로, 인간형 로봇의 보행 기술을 훈련하고 zero-shot sim-to-real 전이를 통해 실제 환경으로 직접 배포할 수 있도록 설계되었다.
Humanoid-Gym은 인간형 로봇의 zero-shot sim-to-real 전이를 체계적으로 구현한 최초의 공개 프레임워크로, 실제 로봇에서 입증된 높은 실용성과 함께 로봇 학습 커뮤니티에 중요한 기여를 제공한다. 다만 평가 환경과 로봇 종류의 다양성 확대를 통해 결과의 보편성을 강화할 필요가 있다.
HumanoidBench: Simulated Humanoid Benchmark for Whole-Body Locomotion and Manipulation
Fig. 1:
 *Fig. 1:* HumanoidBench는 이족 로봇의 전신 조작과 이동 능력을 평가하기 위한 시뮬레이션 벤치마크로, 손가락이 있는 손과 다양한 27개의 도전적인 작업을 포함한다.
HumanoidBench는 이족 로봇의 전신 제어 문제를 포괄적으로 다루는 첫 번째 벤치마크로서, 로봇 학습 커뮤니티에 중요한 평가 플랫폼을 제공하며, 계층적 학습 접근법의 효과성을 입증하여 향후 이족 로봇 알고리즘 연구의 방향을 제시한다.
HWC-Loco: A Hierarchical Whole-Body Control Approach to Robust Humanoid Locomotion
HWC-Loco는 휴머노이드 로봇의 견고한 이동을 위해 계층적 정책 구조로 목표 추적과 안전 복구 간의 trade-off를 동적으로 해결하는 강화학습 기반 전신 제어 알고리즘이다.
HWC-Loco는 휴머노이드 로봇 제어의 현실적 과제인 sim2real gap과 안전성 대 성능의 trade-off를 효과적으로 해결하는 혁신적인 계층적 제어 프레임워크이며, 광범위한 실험 검증을 통해 실용적 가치를 입증했다.
JAEGER: Dual-Level Humanoid Whole-Body Controller

Figure 1: Some real-world demonstrations of JAEGER deployed on the H1-2. For the root-based
 *Figure 2: The framework of JAEGER. The left shows the retargeting network, which uses an MLP* JAEGER는 인간형 로봇의 상체와 하체를 독립적인 두 개의 컨트롤러로 분리하여 제어하는 dual-level whole-body controller를 제안하며, root velocity tracking(coarse-grained)과 local joint angle tracking(fine-grained) 제어를 모두 지원한다.
JAEGER는 상하체 분리 설계와 MLP 기반 retargeting, 체계화된 curriculum learning을 통해 인간형 로봇의 whole-body control 문제에 대한 실질적이고 창의적인 해결책을 제시하며, 실제 환경에서의 검증을 통해 높은 실용성을 입증한다.
KungfuBot2: Learning Versatile Motion Skills for Humanoid Whole-Body Control

Fig. 1: Humanoid learning versatile motion skills. We deploy VMS on the Unitree G1 humanoid robot, demonstrating its cap
 *Fig. 2: Framework of VMS. The large-scale motion capture dataset is first retargeted to the humanoid skeleton using an I* VMS는 Orthogonal Mixture-of-Experts (OMoE) 아키텍처와 하이브리드 추적 목표를 결합하여 단일 정책으로 다양한 동작을 수행하는 휴머노이드 로봇 제어기를 제시한다. 장시간 시퀀스에서 안정적인 성능과 높은 동작 충실도를 달성한다.
VMS는 OMoE 아키텍처와 하이브리드 추적 목표의 조합으로 실용적 휴머노이드 제어의 주요 과제들을 효과적으로 해결하며, 대규모 데이터 기반의 체계적 방법론과 실로봇 검증을 통해 범용 휴머노이드 제어의 기초 플랫폼으로서 높은 가치를 보여준다.
Learning agile and dynamic motor skills for legged robots
 *Fig. 5. Training control policies in simulation. The policy net-* 본 논문은 시뮬레이션에서 reinforcement learning으로 사족 로봇의 제어 정책을 학습하고 현실의 ANYmal 로봇에 전이하는 방법을 제시하여, 고속 주행과 낙하 복구 등의 동적 운동 기술을 달성했다.
본 논문은 사족 로봇의 동적 제어에 reinforcement learning과 domain randomization을 효과적으로 결합하여 시뮬레이션-현실 전이 문제를 체계적으로 해결했으며, 실제 고급 로봇 플랫폼에서 이전에 달성하지 못한 수준의 운동 기술을 구현함으로써 로봇 제어 분야에 중요한 기여를 했다.
Learning Bipedal Locomotion on Gear-Driven Humanoid Robot Using Foot-Mounted IMUs
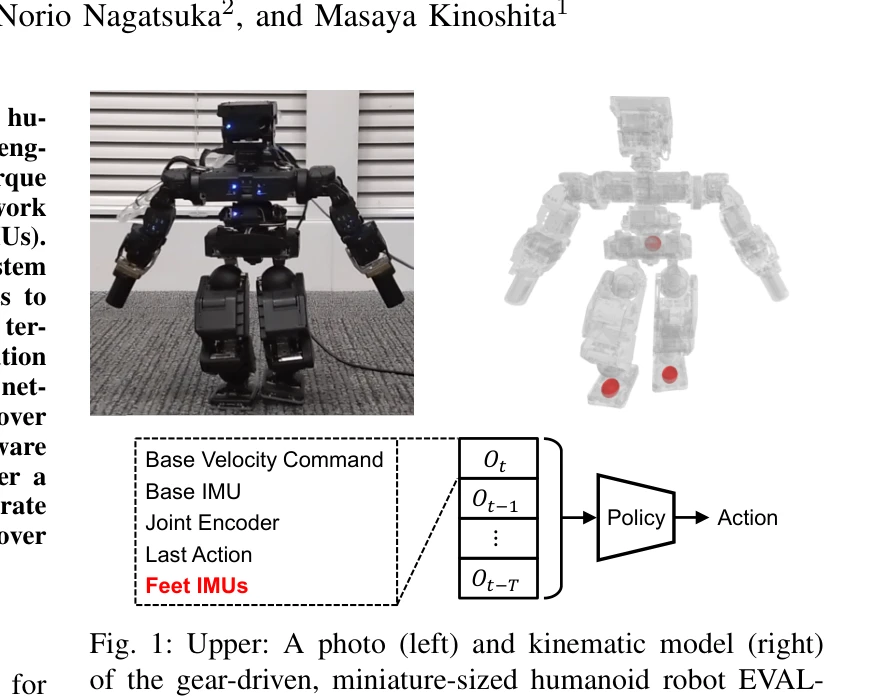
Fig. 1: Upper: A photo (left) and kinematic model (right)
 *Fig. 1: Upper: A photo (left) and kinematic model (right)* 고기어비 액추에이터와 토크 센서가 없는 휴머노이드 로봇의 이족 보행 학습을 위해 발목 장착 IMU를 활용하는 Sim-to-Real RL 프레임워크를 제안하고, 대칭 데이터 증강과 random network distillation을 통해 불규칙한 지형에서의 안정화를 향상시킨다.
본 논문은 저비용 고기어비 액추에이터 로봇의 Sim-to-Real 학습에서 발목 IMU 센서를 혁신적으로 활용하여 복잡한 모델링을 회피하면서도 강건한 이족 보행을 달성한다. 하드웨어 검증과 실제 성능 개선이 입증되었으나, 다양한 로봇 플랫폼으로의 일반화 가능성과 기여도 분석이 향후 강화될 필요가 있다.
Learning Human-Humanoid Coordination for Collaborative Object Carrying

Fig. 1: COLA provides a proprioception-only policy that enables compliant human-humanoid collaboration for carrying dive
 *Fig. 2: Overview of COLA. Our Policy mainly consists of three steps: (i) We train a base whole-body control policy to pr* COLA는 proprioception만을 사용하는 reinforcement learning 기반의 정책으로, humanoid 로봇이 인간과 협력하여 물체를 운반할 때 적응적이고 안정적인 whole-body coordination을 가능하게 한다.
COLA는 humanoid-human collaborative carrying이라는 실용적 과제에 대해 proprioception-only 정책으로 완전한 솔루션을 제시하며, three-step training framework와 implicit force modeling을 통해 높은 독창성을 보여준다. 시뮬레이션과 실제 환경에서 동시에 검증된 결과는 실제 배포 가능성을 시사하며, human user study를 통한 compliant collaboration 확인으로 실무적 가치를 입증한다.
Learning Humanoid Arm Motion via Centroidal Momentum Regularized Multi-Agent Reinforcement Learning
 *Fig. 2: Overview of our limb-level multi-agent reinforcement learning framework with CAM regularization. Separate actor-* 인간의 팔 스윙 운동에서 영감을 받아, centroidal angular momentum (CAM) 추적 보상을 통해 다리와 팔을 별도의 에이전트로 취급하는 multi-agent RL 프레임워크를 제시하여 휴머노이드 로봇의 협응 제어를 달성한다.
본 논문은 centroidal dynamics의 물리적 의미와 생역학적 원리를 CTDE 기반 multi-agent RL과 효과적으로 결합하여, 휴머노이드 로봇의 자연스러운 팔 스윙과 향상된 균형 제어를 달성한 독창적이고 실용적인 연구이다.
Learning Motion Skills with Adaptive Assistive Curriculum Force in Humanoid Robots
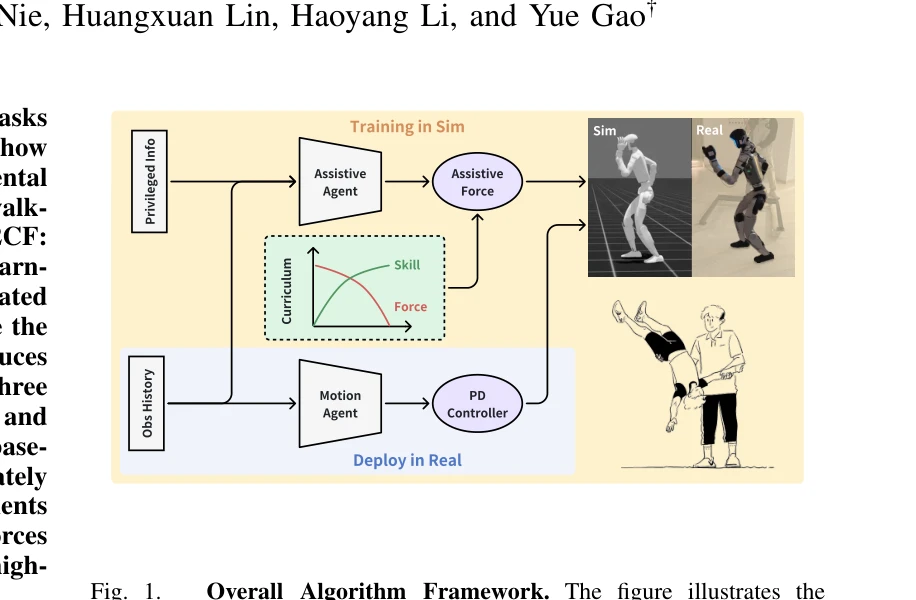
Fig. 1.
 *Fig. 1.* 인간의 학습 방식을 모방한 적응형 보조력(Adaptive Assistive Curriculum Force, A2CF)을 제안하여 휴머노이드 로봇의 복잡한 동작 학습을 가속화하는 이중-에이전트 강화학습 프레임워크를 제시한다.
인간의 자연스러운 학습 과정에서 영감을 얻은 적응형 보조력 메커니즘으로 휴머노이드 로봇의 복잡한 동작 학습을 획기적으로 가속화한 논문이며, 실제 로봇 실험을 통한 검증과 명확한 성과 지표가 높은 실용적 가치를 제공한다.
Learning Sim-to-Real Humanoid Locomotion in 15 Minutes
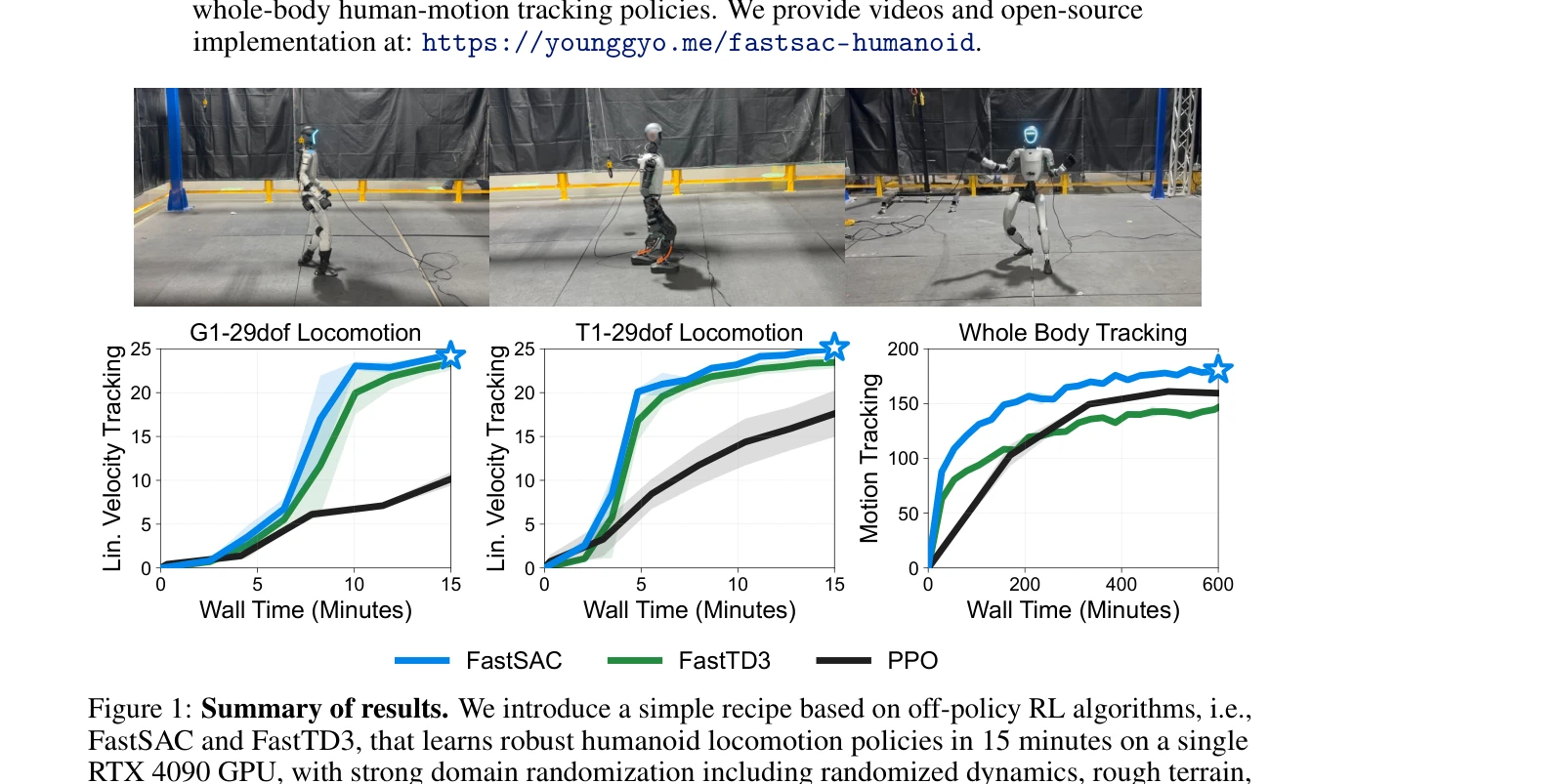
Figure 1: Summary of results. We introduce a simple recipe based on off-policy RL algorithms, i.e.,
 *Figure 1: Summary of results. We introduce a simple recipe based on off-policy RL algorithms, i.e.,* 이 논문은 FastSAC와 FastTD3라는 off-policy RL 알고리즘을 기반으로 단일 RTX 4090 GPU에서 15분 이내에 humanoid 로봇의 보행 정책을 학습할 수 있는 실용적인 레시피를 제시한다.
이 논문은 off-policy RL을 humanoid 제어에 효과적으로 적용하기 위한 실용적이고 체계적인 레시피를 제공하며, 15분의 빠른 훈련 시간과 실제 로봇 배포를 통해 sim-to-real 개발 사이클의 혁신을 보여준다. 오픈소스 구현 제공으로 산업 및 학계에 즉시 영향을 미칠 수 있다.
Learning to Walk and Fly with Adversarial Motion Priors
 *Fig. 2: The discriminator learns to distinguish between samples* 본 논문은 Adversarial Motion Priors(AMP)와 강화학습을 결합하여 항공 인형로봇(aerial humanoid robot)이 인간 같은 보행과 비행 사이를 자동으로 전환하도록 학습하는 방법을 제시한다. 복잡한 보상 함수 없이 동작 데이터셋을 모방하면서 과제를 수행하며, 환경 피드백에 따라 locomotion 모드가 자발적으로 전환된다.
본 논문은 AMP와 강화학습의 결합을 통해 항공 인형로봇의 multimodal locomotion에서 자동 mode-switching이라는 미해결 문제를 우아하게 해결한 높은 수준의 연구이다. 비록 시뮬레이션 환경에 한정되어 있지만, 기술적 혁신성, 문제 해결의 우수성, 그리고 실제 응용 가능성 측면에서 로봇공학 분야에 의미 있는 기여를 한다.
Learning to Walk in Costume: Adversarial Motion Priors for Aesthetically Constrained Humanoids

Fig. 1: Cosmo: an entertainment humanoid robot with covers
 *Fig. 1: Cosmo: an entertainment humanoid robot with covers* 미적 설계 제약이 있는 엔터테인먼트 휴머노이드 로봇 Cosmo를 위해 Adversarial Motion Priors (AMP)를 기반으로 한 강화학습 보행 시스템을 제시하며, 극단적인 질량 분포와 움직임 제약 하에서도 자연스러운 보행 행동을 학습할 수 있음을 보여준다.
본 논문은 엔터테인먼트 로봇의 미적 설계 제약이라는 실제적이고 새로운 도전 문제를 다루면서 AMP 기반 학습을 성공적으로 적용한 의미 있는 연구이다. 극단적인 질량 분포와 제한된 감각 조건에서의 안정적인 sim-to-real 보행 달성은 인상적이지만, 특정 로봇 플랫폼에 대한 높은 맞춤화와 실험의 범위 제한이 일반화 가능성을 감소시킨다.
Load-Aware Locomotion Control for Humanoid Robots in Industrial Transportation Tasks
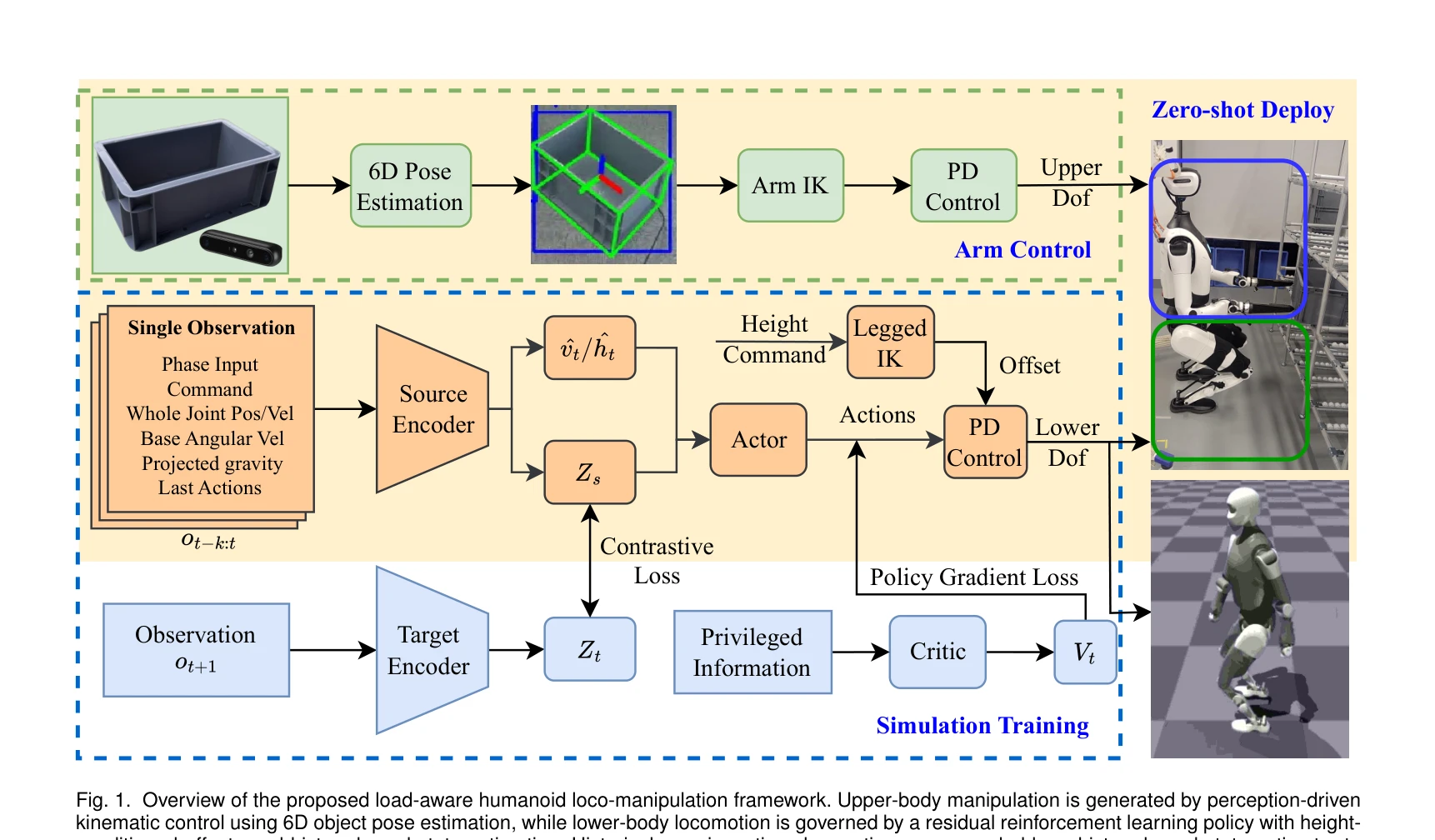
Fig. 1. Overview of the proposed load-aware humanoid loco-manipulation framework. Upper-body manipulation is generated b
 *Fig. 1. Overview of the proposed load-aware humanoid loco-manipulation framework. Upper-body manipulation is generated b* 산업용 휴머노이드 로봇의 다양한 하중 조건에서 안정적 보행을 위해 분리-협조 구조의 로코-매니퓰레이션 아키텍처를 제안하며, RL 기반 하체 제어와 상태 추정기를 통해 시뮬레이션 학습 후 실제 로봇에 파인튜닝 없이 배포 성공.
산업용 휴머노이드의 실질적 과제인 하중 변화 조건에서의 로코-매니퓰레이션을 분리-협조 구조와 상태 추정으로 체계적으로 해결하며, 시뮬레이션 학습 후 무튜닝 실배포 성공은 높은 실무 가치를 입증한다.
MASH: Cooperative-Heterogeneous Multi-Agent Reinforcement Learning for Single Humanoid Robot Locomotion

Fig. 1. MARL model for a single humanoid robot’s locomotion
 *Fig. 1. MARL model for a single humanoid robot’s locomotion* 단일 인간형 로봇의 보행을 위해 각 팔다리를 독립 에이전트로 모델링하여 Cooperative-Heterogeneous MARL을 적용하는 MASH 프레임워크를 제안한다. 이는 전역 비평가를 공유하며 협력학습을 통해 전신 조화 능력을 향상시킨다.
MASH는 MARL 원칙을 단일 인간형 로봇에 창의적으로 적용하여 전신 조화 보행 학습을 효과적으로 개선한 의미 있는 기여이다. 다만 실제 로봇 검증과 알고리즘 세부사항 명확화가 필요하다.
Mechanical Intelligence-Aware Curriculum Reinforcement Learning for Humanoids with Parallel Actuation
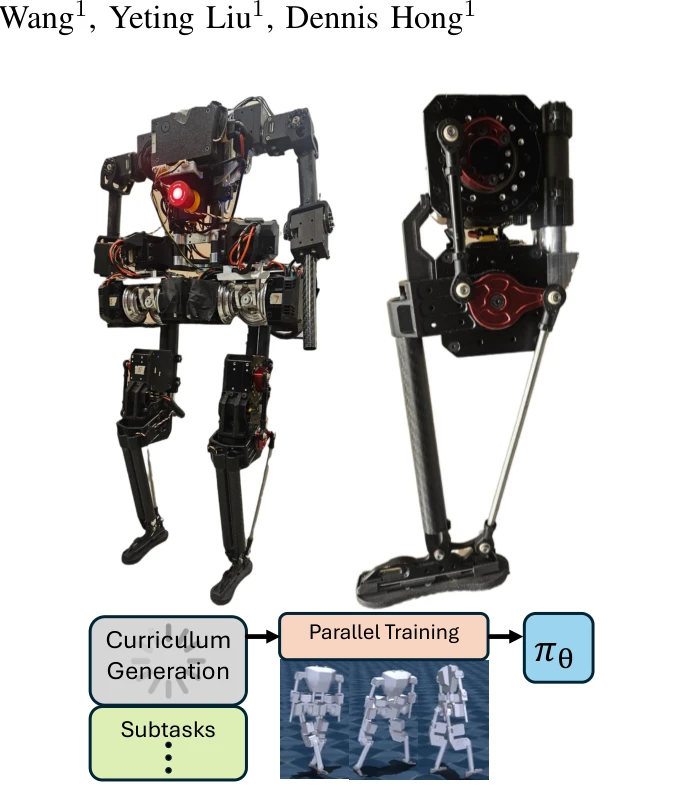
Fig. 1: BRUCE [2] hardware with three distinct parallel mechanisms, which
 *Fig. 1: BRUCE [2] hardware with three distinct parallel mechanisms, which* 본 논문은 병렬 구동 메커니즘을 완전히 시뮬레이션하여 학습한 RL 정책을 휴머노이드 로봇 BRUCE에 배포하며, 기존의 직렬 근사 방식과 달리 폐곡선 운동학 제약을 GPU 가속 MJX로 네이티브 구현한다.
본 논문은 병렬 메커니즘의 기계적 특성을 완전히 시뮬레이션하여 RL 학습에 반영하는 혁신적 접근법을 제시하며, 실제 하드웨어 검증을 통해 이 방식의 실질적 성능 이득을 명확히 보여줌으로써 휴머노이드 로봇 제어 분야에 중요한 기여를 한다.
TokenHSI: Unified Synthesis of Physical Human-Scene Interactions through Task Tokenization
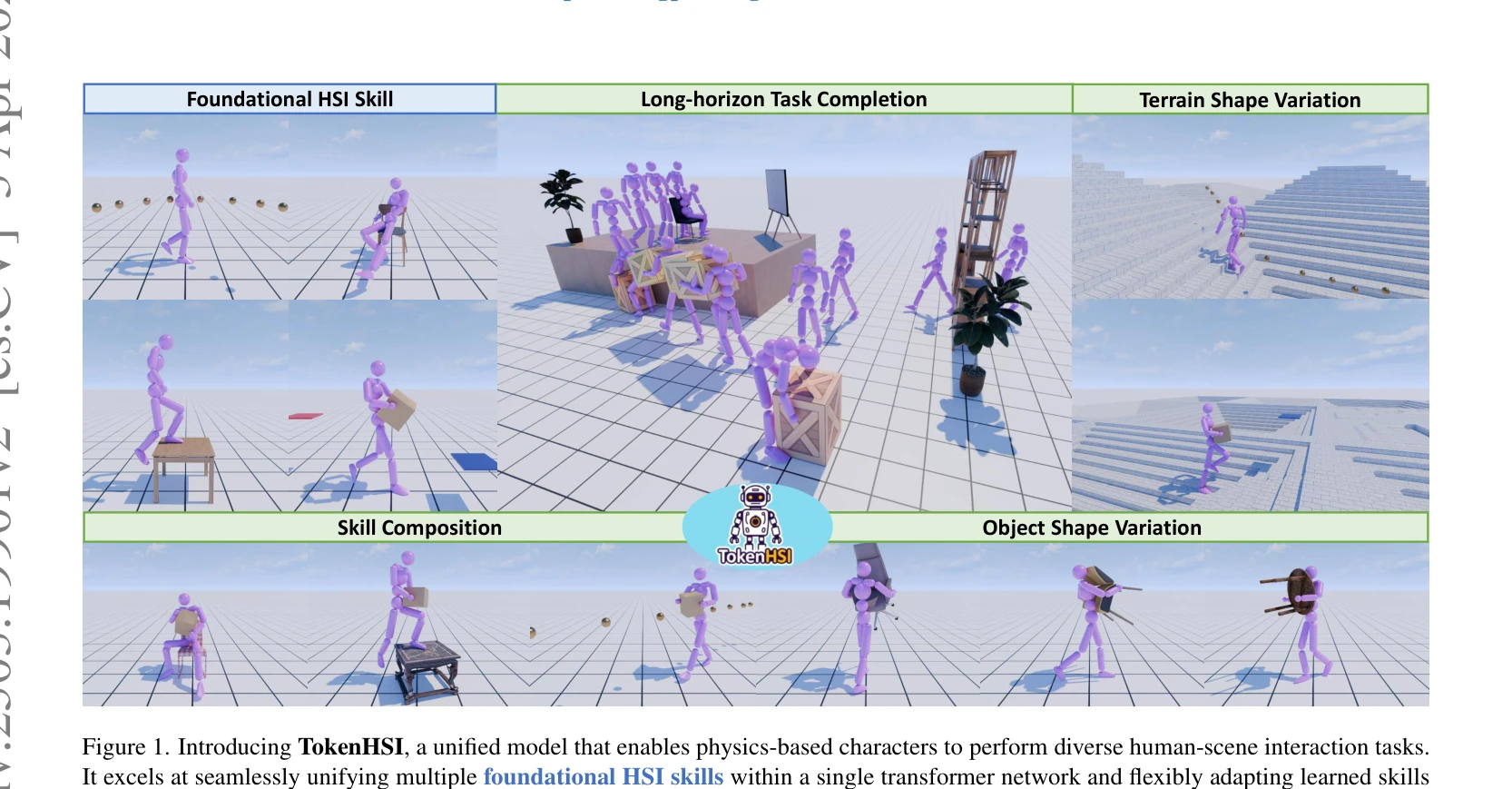
Figure 1. Introducing TokenHSI, a unified model that enables physics-based characters to perform diverse human-scene int
 *Figure 1. Introducing TokenHSI, a unified model that enables physics-based characters to perform diverse human-scene int* TokenHSI는 transformer 기반의 통합 정책으로 humanoid 고유감각을 공유 토큰으로 모델링하고 task 토큰과 masking mechanism으로 결합하여 다양한 인간-장면 상호작용(HSI) 기술을 단일 네트워크에서 통합한다.
TokenHSI는 독립적 proprioception tokenizer와 masking mechanism을 통해 다중 HSI 기술을 단일 네트워크에서 효과적으로 통합하고, 변수 길이 입력을 활용한 효율적 정책 적응까지 실현한 혁신적인 접근법으로, 컴퓨터 애니메이션과 embodied AI 분야에서 실질적인 기여를 한다.
Towards Adaptive Humanoid Control via Multi-Behavior Distillation and Reinforced Fine-Tuning
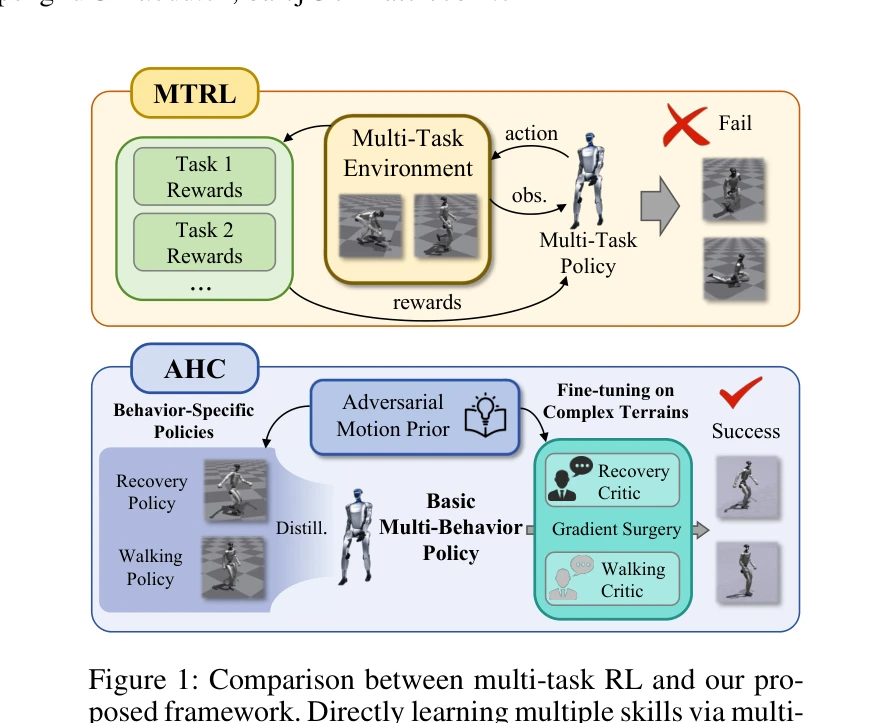
Figure 1: Comparison between multi-task RL and our pro-
 *Figure 2: Overview of the proposed two-stage framework Adaptive Humanoid Control. In the first stage, we train two separ* 휴머노이드 로봇이 다양한 이족보행 행동(서기, 걷기, 뛰기, 점프)을 학습할 수 있도록 다중행동 증류(multi-behavior distillation)와 강화학습 미세조정을 통해 적응형 제어기를 개발한다.
다중행동 증류와 강화학습 미세조정을 결합한 2단계 프레임워크는 휴머노이드 로봇의 적응형 제어라는 중요한 문제에 대한 실용적이고 효과적인 해결책을 제시하며, 시뮬레이션과 실로봇 실험을 통해 그 타당성을 입증했다.
Towards bridging the gap: Systematic sim-to-real transfer for diverse legged robots
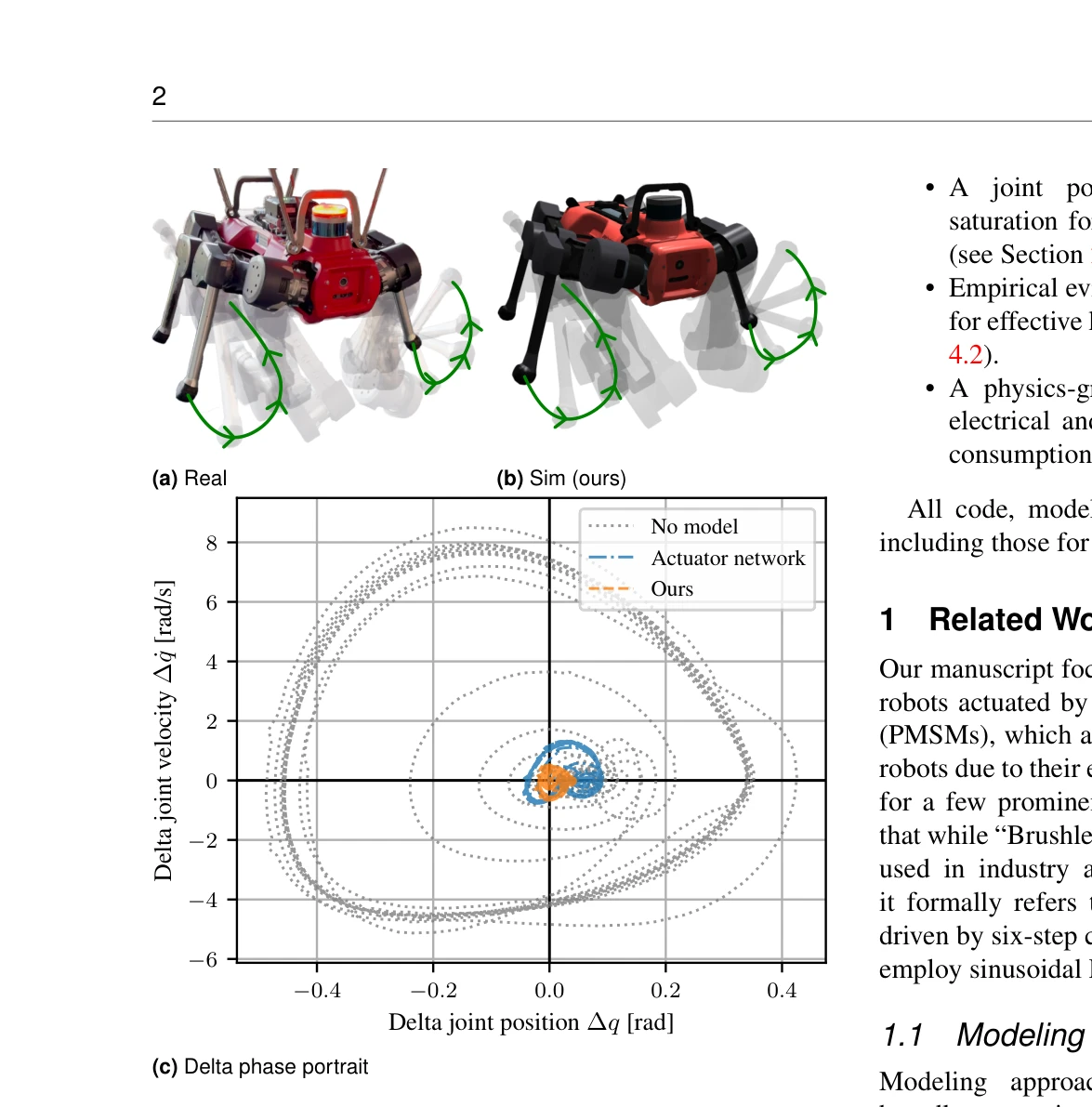
Figure 1. Comparison of real and simulated robot trajectories
 *Figure 1. Comparison of real and simulated robot trajectories* 이족 로봇의 시뮬레이션-실제 전이 문제를 해결하기 위해 강화학습과 영구자석 동기 전동기(PMSM)의 물리 기반 에너지 모델을 통합한 프레임워크를 제안하며, 최소한의 파라미터로 현실성을 확보하면서 에너지 효율성을 달성한다.
이 논문은 물리 기반 모델링과 강화학습을 체계적으로 결합하여 실제 다리 로봇의 시뮬레이션 전이 문제를 효과적으로 해결하며, 광범위한 플랫폼 검증과 에너지 효율성 개선으로 높은 실용성과 신뢰성을 입증한다.
Multi-Gait Learning for Humanoid Robots Using Reinforcement Learning with Selective Adversarial Motion Prior
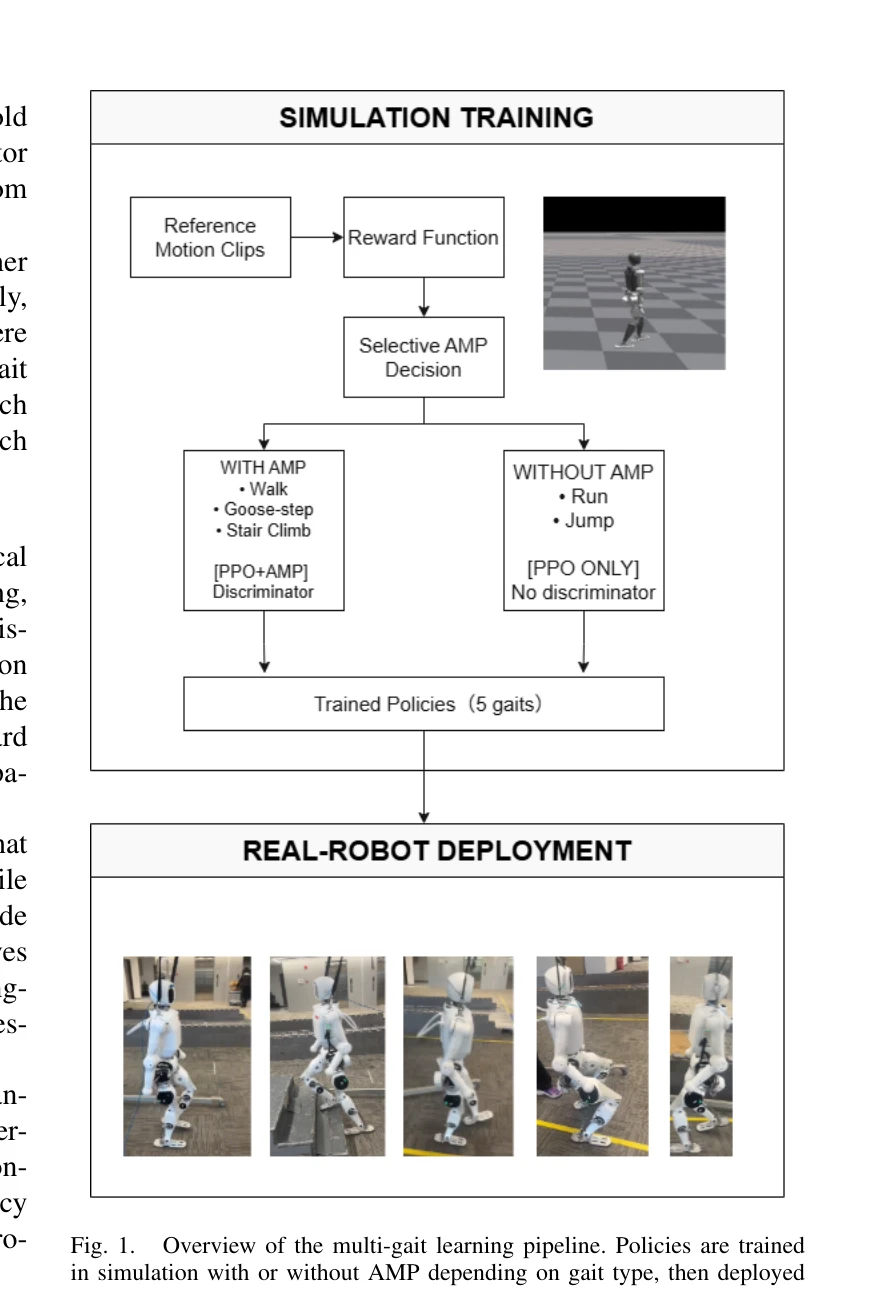
Fig. 1.
 *Fig. 1.* 본 논문은 humanoid robot이 보행, 거위걸음, 달리기, 계단 오르기, 점프 등 5가지 서로 다른 보행 방식을 통일된 강화학습 프레임워크로 학습할 수 있도록 하는 선택적 Adversarial Motion Prior (AMP) 전략을 제안한다.
본 논문은 humanoid robot의 다중 보행 학습에서 AMP의 선택적 적용이라는 창의적인 아이디어를 제시하고, 통일된 강화학습 프레임워크로 5가지 이질적 보행을 성공적으로 학습 및 실로봇 배포한 것으로 실무적 가치가 높다. 다만 선택 기준의 일반화 부족과 단일 로봇 플랫폼 검증이라는 한계가 있어 추가 확장 연구가 필요하다.
X2-N: A Transformable Wheel-legged Humanoid Robot with Dual-mode Locomotion and Manipulation
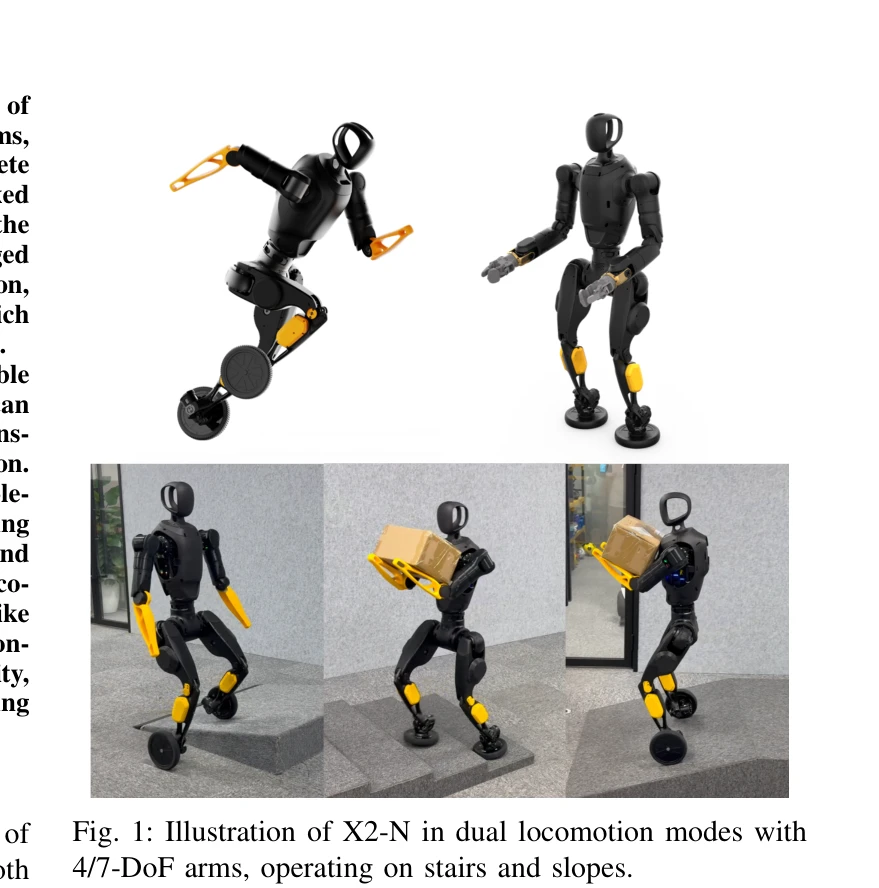
Fig. 1: Illustration of X2-N in dual locomotion modes with
 *Fig. 1: Illustration of X2-N in dual locomotion modes with* X2-N은 휠-레그 하이브리드 모드와 휴머노이드 풋 모드를 유연하게 변환하며 운영할 수 있는 고자유도 로봇으로, RL 기반 통합 제어 프레임워크로 효율적 이동과 정교한 조작을 동시에 수행한다.
X2-N은 휠-레그와 휴머노이드 로봇의 장점을 창의적으로 통합한 혁신적 플랫폼으로, Joint reuse 기반의 우아한 메커니즘 설계와 RL·모델 기반 제어의 효과적 결합을 통해 실용성 높은 솔루션을 제시한다.
Robot Learning from Human Videos: A Survey
 *Figure 2. Taxonomy of robot learning from human videos.* 본 논문은 로봇이 인간 영상 시연으로부터 조작 기술을 습득하는 방법에 대한 포괄적 리뷰로서, task·observation·action 레벨에서의 계층적 전이 경로를 제시하고 데이터 기초를 체계적으로 분석한다. 인간 영상 기반 학습이 기존 로봇 텔레작동에 비해 5-10배 이상의 데이터 효율성을 제공함을 강조한다.
본 survey는 로봇 학습 분야에서 인간 영상 기반 스킬 획득이라는 급성장하는 분야에 대해 처음으로 체계적이고 포괄적인 분류 체계를 제시하며, 다각적인 비교 분석과 대규모 데이터 통계를 바탕으로 현재 연구 경관을 명확히 조망한다. 실제 데이터 효율성 개선(5-10배)이 실증되어 있어 학술적·실무적 중요성이 높으나, 정량적 성능 비교와 새로운 메서드 제시가 없는 순수 리뷰 논문이라는 한계가 있다.
Symphony: A Heuristic Normalized Calibrated Advantage Actor and Critic Algorithm in application for Humanoid Robots
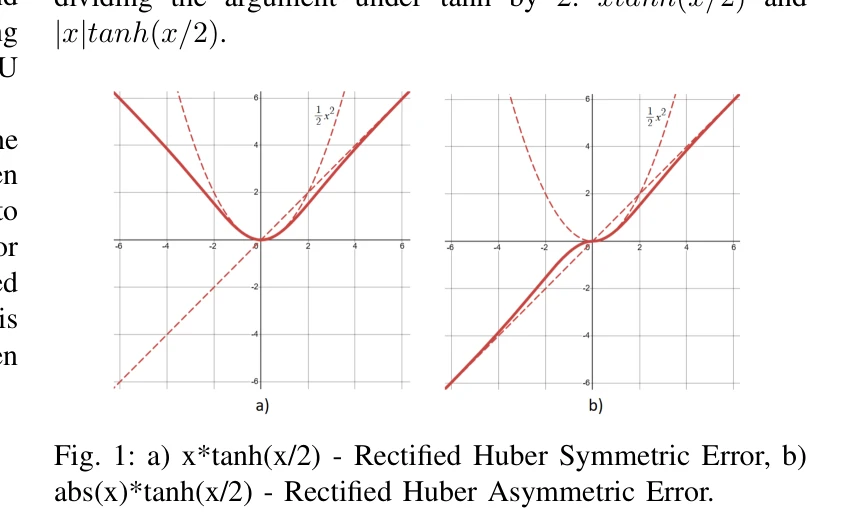
Fig. 1: a) x
 *Fig. 4: Swaddling Regularization with β as temperature.* Symphony는 휴머노이드 로봇을 안전하게 훈련하기 위해 Swaddling 정규화, Fading Replay Buffer, Temporal Advantage를 결합한 결정론적 Actor-Critic 알고리즘이다. 제한된 parametric noise와 action strength 조절을 통해 sample efficiency, safety, smooth motion을 동시에 달성한다.
Symphony는 실제 휴머노이드 로봇 훈련의 실질적 문제들(safety, efficiency, smoothness)을 종합적으로 해결하는 창의적인 heuristic 알고리즘이다. 그러나 이론적 기초와 실증적 검증이 부족하여 학술적 엄밀성과 재현성 면에서 개선이 필요하다.
PIMBS: Efficient Body Schema Learning for Musculoskeletal Humanoids with Physics-Informed Neural Networks
Fig. 1.
 *Fig. 1.* Physics-Informed Neural Networks (PINNs) 개념을 적용하여 근골격 휴머노이드 로봇의 신체 스키마를 적은 데이터로 효율적으로 학습하는 PIMBS 방법을 제안한다.
이 논문은 Physics-Informed Neural Networks를 근골격 로봇의 신체 스키마 학습에 창의적으로 적용하여 적은 데이터로도 효율적인 학습을 가능하게 하는 실용적이고 혁신적인 방법을 제시한다. 시뮬레이션과 실제 로봇 실험을 통한 검증으로 제안 방법의 타당성을 충분히 입증했다.
Characteristics, Management, and Utilization of Muscles in Musculoskeletal Humanoids: Empirical Study on Kengoro and Musashi
 *Fig. 2. The basic musculoskeletal structure: the components include bones,* 본 논문은 Kengoro와 Musashi 근골격 휴머노이드 로봇의 근육 특성을 5가지 속성(Redundancy, Independency, Anisotropy, Variable Moment Arm, Nonlinear Elasticity)으로 분류하고, 이를 효과적으로 관리·활용하는 방법론을 제시한다.
본 논문은 근골격 휴머노이드의 근육 특성을 처음으로 체계적으로 분류하고 관리·활용 방법을 제시한 중요한 기여이며, 실제 로봇 구현 사례를 바탕으로 높은 실용성을 갖추고 있다. 다만 정량적 성능 평가 및 일반화 가능성에 대한 보완이 필요하다.
HOMIE: Humanoid Loco-Manipulation with Isomorphic Exoskeleton Cockpit

Fig. 1: HOMIE empowers the humanoid robot to execute various loco-manipulation tasks in the real world. (a): Squatting t
 *Fig. 2: System Overview. (a): how an operator uses the exoskeleton-based hardware system to control humanoid robots in t* HOMIE는 강화학습 기반 신체 제어, 동형 외골격 팔, 모션센싱 장갑을 통합한 반자율 원격조종 시스템으로, 단일 작업자가 휴머노이드 로봇의 전신 보행-조작 작업을 정밀하게 제어할 수 있게 함
HOMIE는 RL 기반 적응형 보행 제어와 저비용 동형 하드웨어를 혁신적으로 결합하여 휴머노이드 로봇의 전신 원격조종을 현실화한 획기적 시스템으로, 비용 효율성과 성능에서 기존 솔루션을 크게 초월하며 실용적 가치가 높음
Learning Symmetric and Low-energy Locomotion
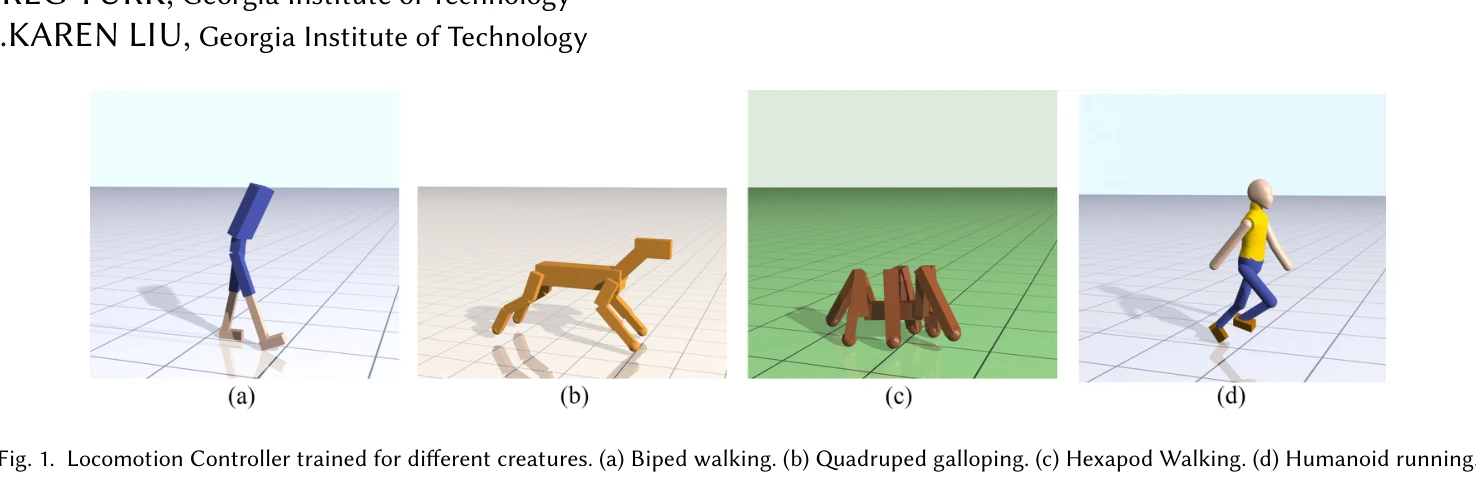
Fig. 1. Locomotion Controller trained for different creatures. (a) Biped walking. (b) Quadruped galloping. (c) Hexapod W
 *Fig. 1. Locomotion Controller trained for different creatures. (a) Biped walking. (b) Quadruped galloping. (c) Hexapod W* Deep Reinforcement Learning에 미러 대칭 손실 함수와 커리큘럼 학습을 적용하여 모션 캡처 데이터 없이 자연스럽고 저에너지의 대칭적인 로코모션을 학습하는 방법을 제안한다.
본 논문은 미러 대칭 손실과 adaptive curriculum learning을 결합하여 DRL 기반 로코모션 학습의 오래된 문제(부자연스러움, 고에너지)를 우아하게 해결하며, 다양한 형태에 일반화 가능한 점에서 높은 독창성과 실용성을 갖춘 우수한 연구이다.
NuExo: A Wearable Exoskeleton Covering all Upper Limb ROM for Outdoor Data Collection and Teleoperation of Humanoid Robots
Fig. 1: NuExo: A backpack-mounted active-joint humanoid robot
 *Fig. 1: NuExo: A backpack-mounted active-joint humanoid robot* 상지의 전체 운동 범위를 커버하면서 야외 환경에서 사용 가능한 경량 웨어러블 외골격계(exoskeleton) NuExo를 개발하여 인간형 로봇의 원격조종과 모션 데이터 수집을 동시에 수행한다.
NuExo는 해부학적으로 영감받은 외골격계 설계와 경량화, multi-modal sensing의 통합을 통해 teleoperation과 로봇 모션 데이터 수집의 네 가지 핵심 목표를 동시에 달성한 혁신적 시스템이다. 야외 환경에서의 실용성과 다양한 로봇 플랫폼 호환성은 인간형 로봇의 imitation learning 분야에 중대한 기여를 한다.
Evolving the Complete Muscle: Efficient Morphology-Control Co-design for Musculoskeletal Locomotion
Fig. 1: Conceptual overview of Spectral Design Evolution
 *Fig. 1: Conceptual overview of Spectral Design Evolution* 본 논문은 근육-골격 로봇의 근력, 속도, 경직도를 동시에 진화시키는 Complete Musculoskeletal Morphological Evolution Space를 제시하고, 이를 효율적으로 탐색하기 위해 bilateral symmetry prior와 PCA를 결합한 Spectral Design Evolution(SDE) 프레임워크를 제안한다.
본 논문은 근육-골격 로봇의 형태-제어 공동 설계에 강도, 속도, 경직도의 포괄적 진화를 처음으로 도입하고, SDE의 spectral manifold 접근법으로 차원 폭발 문제를 효과적으로 해결하여 높은 샘플 효율성과 로컬로모션 성능을 달성한 의미있는 기여이나, 다양한 태스크와 형태학에 대한 일반화 검증이 필요하다.
Physics-Informed Neural Networks with Unscented Kalman Filter for Sensorless Joint Torque Estimation in Humanoid Robots
 *Fig. 2: Block diagram of the multi-layer torque control architecture implemented on the ergoCub humanoid robot. The* 본 논문은 Physics-Informed Neural Networks (PINNs)와 Unscented Kalman Filter (UKF)를 결합하여 휴머노이드 로봇의 관절 토크 센서 없이 전신 토크 제어를 수행하는 프레임워크를 제시한다. 이 방식은 마찰 모델링과 토크 추정을 통합하여 실시간 토크 제어 아키텍처를 구현한다.
본 논문은 PINNs과 UKF의 혁신적 통합을 통해 센서 없는 토크 제어라는 실질적 문제를 해결하며, ergoCub에서의 엄밀한 실험 검증과 확장성 시연으로 휴머노이드 로봇의 실시간 준수 제어를 위한 강력한 기초를 제공한다.
PPF: Pre-training and Preservative Fine-tuning of Humanoid Locomotion via Model-Assumption-based Regularization

Fig. 1.
 *Fig. 1.* 본 연구는 모델 기반 제어기의 모방학습(Pre-training)과 강화학습을 결합하되, 모델 가정이 성립하는 상태에서만 정규화하는 MAR(Model-Assumption-based Regularization)을 통해 인간형 로봇의 보행 정책을 학습하는 PPF 프레임워크를 제안한다.
본 논문은 모델 기반과 학습 기반 제어의 장점을 결합하면서 재앙적 망각을 완화하는 MAR이라는 창신적 정규화 기법을 제안하며, 실제 인간형 로봇에서 1.5 m/s의 고속 보행과 다양한 지형 강건성을 달성하여 실용적 가치가 높다.
Reinforcement Learning for Versatile, Dynamic, and Robust Bipedal Locomotion Control
이족 로봇의 다양한 동적 보행 기술(걷기, 뛰기, 점프)을 통합적으로 제어하기 위해 dual-history 아키텍처를 갖춘 심화강화학습 프레임워크를 제시하고, 시뮬레이션에서 실제 로봇(Cassie)으로 무튜닝 전이 배포를 성공시켰다.
이족 로봇 제어라는 도전적 과제에서 dual-history 아키텍처와 task randomization을 통해 통합 RL 프레임워크를 달성하고, 광범위한 실제 로봇 실험으로 다양한 동적 보행 기술의 강건한 구현을 입증한 우수한 연구이다. 다만 아키텍처 설계 선택의 이론적 근거 강화와 다른 플랫폼으로의 확장성 검증이 필요하다.
Robust and Versatile Bipedal Jumping Control through Reinforcement Learning

Fig. 1: Representative dynamic jumping maneuvers performed by a bipedal robot Cassie using the proposed goal-conditioned
 *Fig. 1: Representative dynamic jumping maneuvers performed by a bipedal robot Cassie using the proposed goal-conditioned* Reinforcement learning과 새로운 정책 구조를 활용하여 이족 로봇 Cassie가 다양한 착지 위치와 방향으로 점프하는 강건하고 다목적인 동적 점프 제어를 실현했다.
이족 로봇의 동적 점프 제어에서 RL과 새로운 정책 구조를 결합하여 기존 방법을 크게 뛰어넘는 실제 세계 성과를 달성한 우수한 연구이며, 다목적 강건한 로봇 제어의 새로운 가능성을 보여준다.
Sim-to-Real of Humanoid Locomotion Policies via Joint Torque Space Perturbation Injection
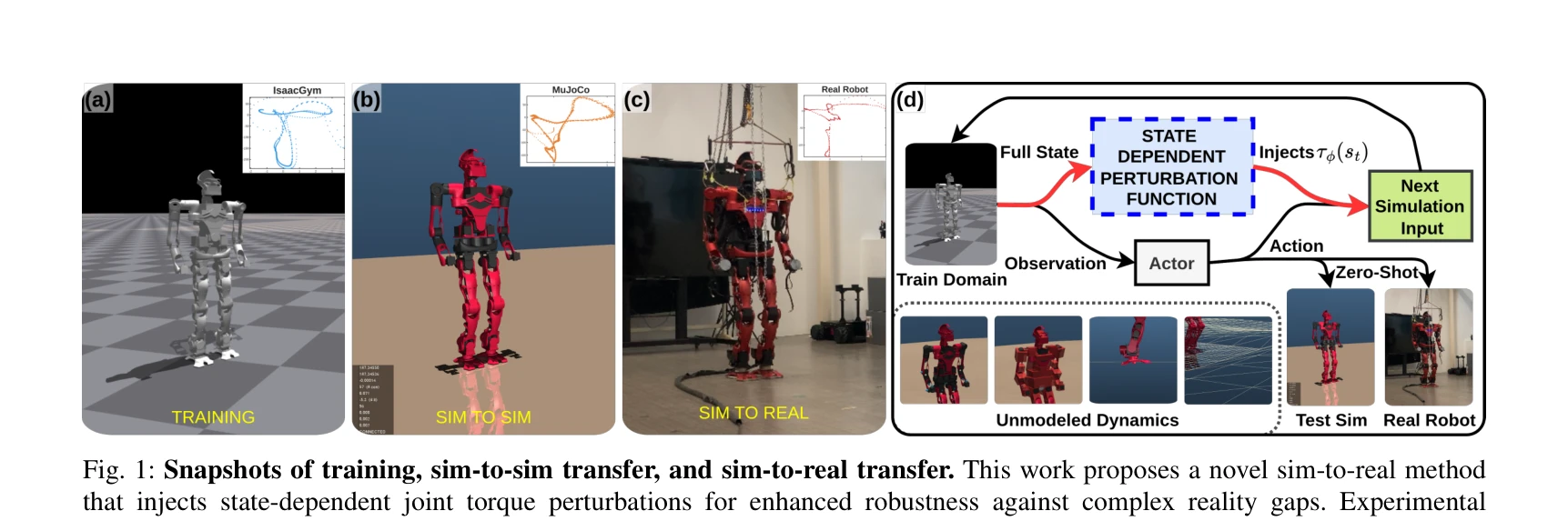
Fig. 1: Snapshots of training, sim-to-sim transfer, and sim-to-real transfer. This work proposes a novel sim-to-real met
 *Fig. 2: Overview of the training framework: The dynamics* 본 논문은 기존 domain randomization의 한계를 극복하기 위해 상태 의존적인 joint torque space perturbation을 주입하여 humanoid 로봇의 sim-to-real 전이를 개선하는 방법을 제안한다.
본 논문은 domain randomization의 근본적 한계를 creative하게 해결하고 full-sized humanoid 로봇에서 실증적 검증을 통해 sim-to-real 전이 분야에 유의미한 기여를 한다. 다만 방법의 일반화 가능성과 실제 배포 시나리오에서의 추가 고려사항에 대한 더 깊은 분석이 있으면 완성도가 높아질 수 있다.
SoccerDiffusion: Toward Learning End-to-End Humanoid Robot Soccer from Gameplay Recordings
SoccerDiffusion은 transformer 기반 diffusion model을 활용하여 RoboCup 경기 녹화 데이터로부터 휴머노이드 로봇 축구의 end-to-end 제어 정책을 학습하고, distillation 기법으로 실시간 추론을 가능하게 한다.
본 논문은 실제 RoboCup 경기 데이터로부터 humanoid robot soccer 정책을 학습하는 실질적 시도로, transformer 기반 diffusion model과 distillation 기법의 조합으로 end-to-end 학습과 실시간 추론을 동시에 달성했다. 고수준 전략 행동은 제한적이지만 저수준 운동 행동의 효과적 학습과 공개 데이터셋 제공으로 향후 로봇 학습 연구의 견고한 기초를 마련했다.
Contrastive Representation Learning for Robust Sim-to-Real Transfer of Adaptive Humanoid Locomotion

Fig. 1: Our policy, trained via contrastive knowledge distillation, enables
 *Fig. 2: Overview of our proposed training framework. An asymmetric Actor-* Contrastive learning을 이용해 시뮬레이션의 특권 정보(terrain heightmap)를 순수 proprioceptive policy에 증류시켜 지각의 선견성을 얻으면서도 배포 시 지각 센서의 비용을 피한다. Adaptive gait clock을 통해 고정된 클럭 보행과 불안정한 자유 클럭 보행 사이의 근본적 trade-off를 해결한다.
이 논문은 contrastive learning을 통해 시뮬레이션 특권 정보를 proprioceptive policy에 효과적으로 증류하여 지각 센서 없이도 선견성 있는 제어를 달성하는 창의적 해결책을 제시한다. Zero-shot sim-to-real 전이로 극도로 도전적인 지형에서의 강건한 보행을 실증함으로써 인간형 로봇 실용화의 중요한 진전을 보여준다.
DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills

Fig. 1. Highly dynamic skills learned by imitating reference motion capture clips using our method, executed by physical
 *Fig. 1. Highly dynamic skills learned by imitating reference motion capture clips using our method, executed by physical* Motion capture 데이터를 활용한 example-guided reinforcement learning으로 물리 기반 캐릭터 애니메이션을 학습하는 방법을 제안하며, 모션 모방과 task 목표를 결합하여 강건하고 다양한 기술을 수행하는 제어 정책을 학습한다.
본 논문은 개별 기술의 novel 한 조합보다는 physics-based character animation에서의 효과적 시스템 설계를 통해 실질적 가치를 제시하며, 광범위한 실증 결과로 방법의 실용성과 확장성을 강력히 입증한 매우 영향력 있는 기여이다.
Design and Control of a Bipedal Robotic Character

Fig. 1.
 *Fig. 2.* 이 논문은 표현력 있는 예술적 동작과 강건한 동적 이동성을 결합한 이족 로봇 캐릭터의 설계 및 제어 시스템을 제시한다. Reinforcement Learning 기반 제어 구조와 실시간 애니메이션 엔진을 통해 로봇이 연극적 성능을 수행할 수 있도록 한다.
이 논문은 이족 로봇의 표현성과 동적 능력을 통합하는 혁신적인 설계 및 제어 파이프라인을 제시하며, 애니메이션과 로봇 공학의 교점에서 새로운 패러다임을 제안한다. 엔터테인ment 로보틱스와 휴먼-로봇 상호작용 분야에 중요한 기여를 하면서도 실제 시스템 구현을 통해 실용성을 입증했다.
Dribble Master: Learning Agile Humanoid Dribbling through Legged Locomotion

Fig. 1: Dribble Master: Humanoid robot learning to dribble under various tasks. (a): The robot receives ball velocity co
 *Fig. 1: Dribble Master: Humanoid robot learning to dribble under various tasks. (a): The robot receives ball velocity co* 두 단계 curriculum learning과 virtual camera 모델을 이용하여 humanoid 로봇이 시뮬레이션에서 학습한 드리블링 정책을 실제 로봇에 성공적으로 전이하는 방법을 제안한다.
본 논문은 humanoid 로봇의 지속적이고 민첩한 드리블링을 최초로 실현한 의미 있는 연구로, 현실적 시각 제약 모델링과 실제 로봇 전이 성공은 높은 가치가 있다. 다만 정량적 평가와 방법의 일반화 가능성 검증이 보강되면 더욱 완성도 있을 것이다.
Evolutionary Continuous Adaptive RL-Powered Co-Design for Humanoid Chin-Up Performance
 *Fig. 2: Overview of the EA-CoRL framework methodology.* EA-CoRL은 진화 알고리즘과 강화학습을 결합하여 휴머노이드 로봇의 하드웨어 설계(기어비)와 제어 정책을 동시에 최적화하는 프레임워크이며, RH5 로봇의 턱걸이 작업 성공을 통해 검증되었다.
EA-CoRL은 continuous adaptive 정책 최적화를 통해 RL 기반 co-design의 실질적 문제를 해결한 창의적 프레임워크이며, 이전 불가능했던 고난도 동적 작업 실현의 가능성을 보였다. 다만 실제 하드웨어 검증과 설계 공간 확장이 이루어진다면 실용적 영향력이 더욱 크게 증대될 것으로 예상된다.
HiFAR: Multi-Stage Curriculum Learning for High-Dynamics Humanoid Fall Recovery
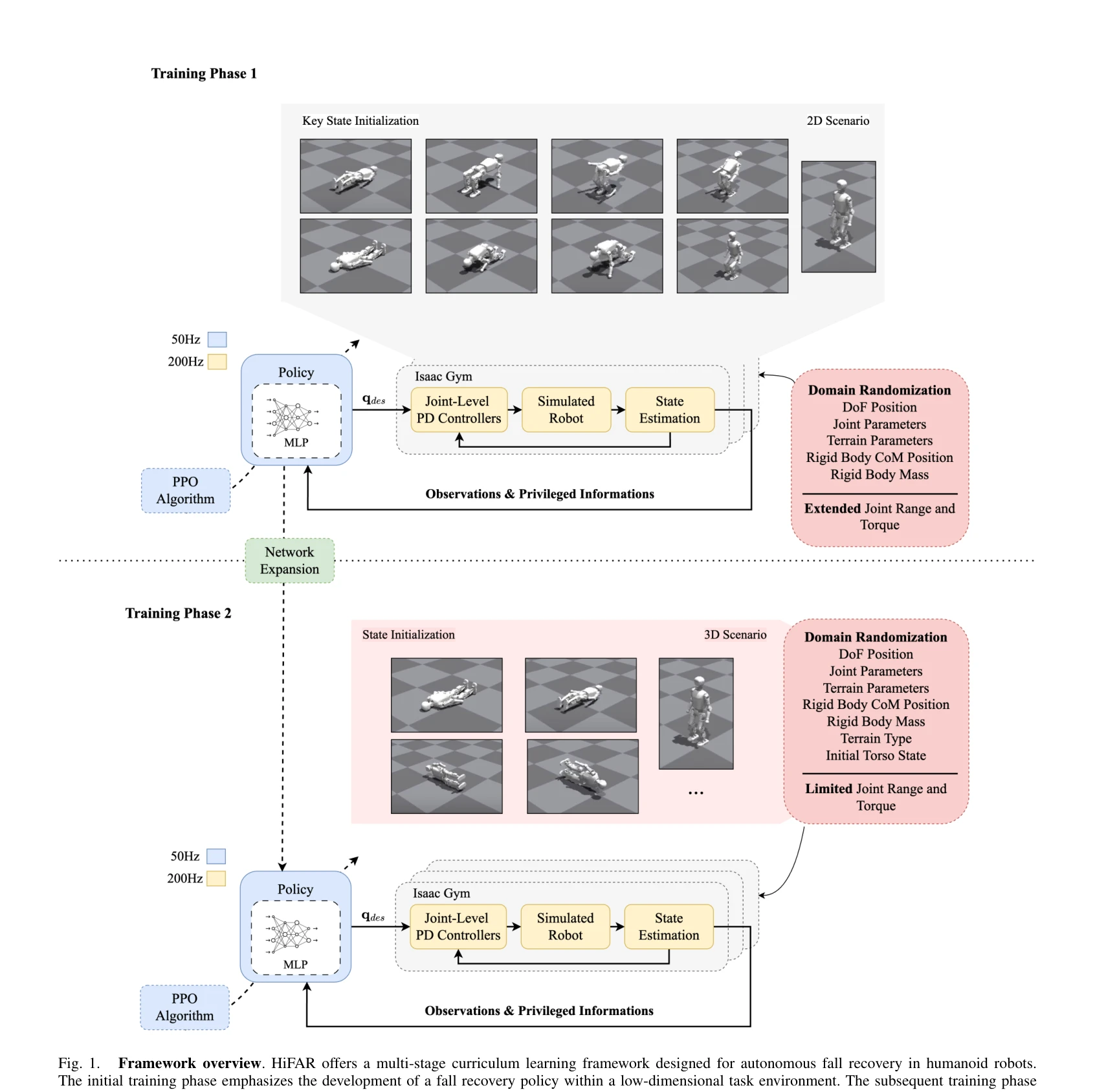
Fig. 1.
 *Fig. 1.* HiFAR는 다단계 커리큘럼 학습 프레임워크를 통해 휴머노이드 로봇의 자율적 낙상 회복을 학습하는 방법을 제시하며, 저차원 태스크에서 시작하여 고차원 배포 시나리오로 점진적으로 확장한다.
HiFAR은 다단계 커리큘럼 학습과 KSI, reward shaping을 효과적으로 결합하여 복잡한 고차원 낙상 회복 문제를 체계적으로 해결하며, 실제 로봇 검증을 통해 높은 실용성과 견고성을 입증한 우수한 연구이다.
Kinematics-Aware Multi-Policy Reinforcement Learning for Force-Capable Humanoid Loco-Manipulation
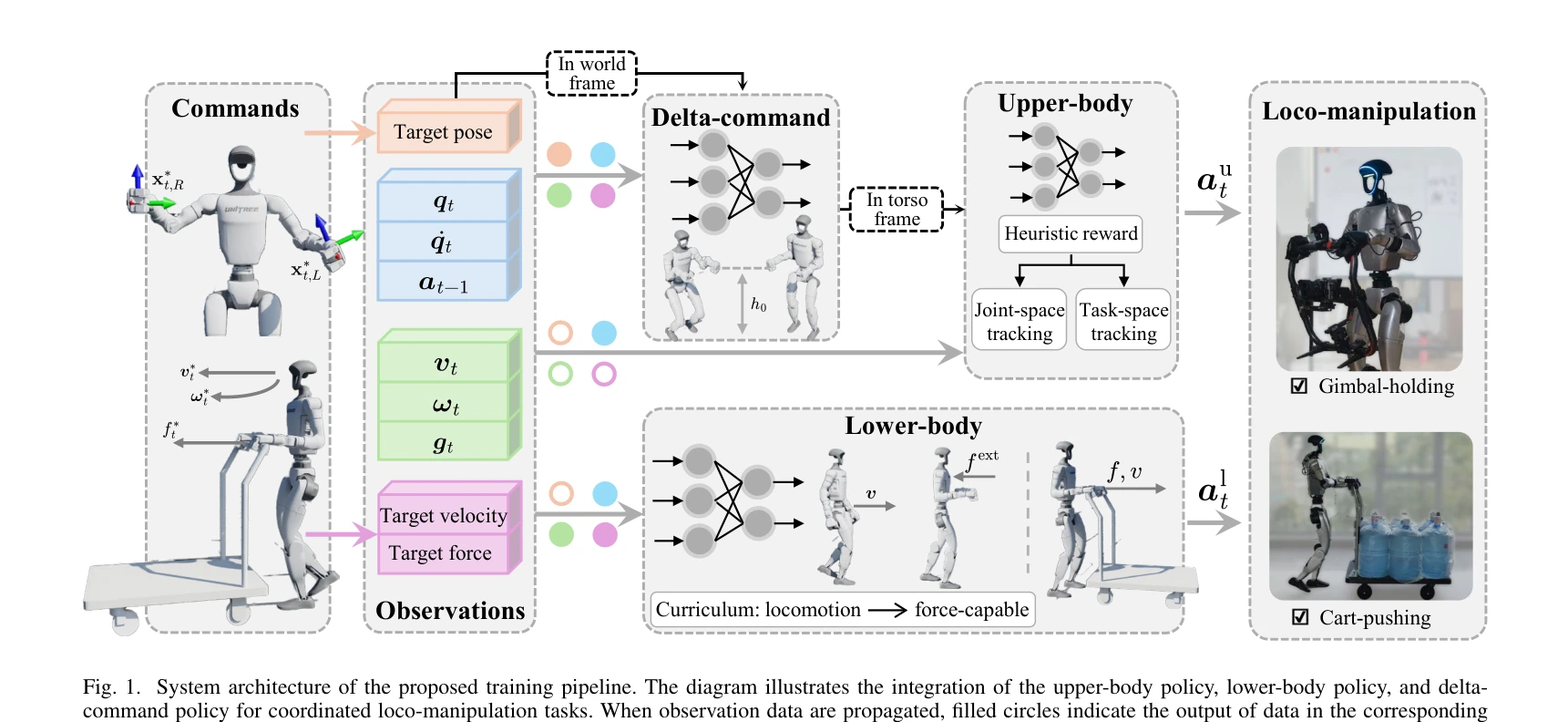
Fig. 1. System architecture of the proposed training pipeline. The diagram illustrates the integration of the upper-body
 *Fig. 1. System architecture of the proposed training pipeline. The diagram illustrates the integration of the upper-body* 본 논문은 휴머노이드 로봇의 고부하 산업 작업 수행을 위해 kinematics 사전 정보를 활용한 휴리스틱 보상함수, force-based curriculum learning, delta-command 정책을 통합한 3단계 RL 기반 loco-manipulation 프레임워크를 제안한다.
본 논문은 휴머노이드 로봇의 고부하 loco-manipulation을 위해 kinematics 정보 활용, curriculum learning, modular 정책 조정을 결합한 체계적이고 실용적인 RL 프레임워크를 제시하며, 실제 로봇 실험으로 강력한 성능을 입증했다. 다만 단일 플랫폼 검증과 실제 산업 환경 적응성 평가 보강이 필요하다.
Learning Agile Striker Skills for Humanoid Soccer Robots from Noisy Sensory Input
 *Fig. 2: Left: The network architectures for the teacher and the student network; Right: Multi-stage training framework: * 이 논문은 reinforcement learning 기반의 4단계 학습 프레임워크를 통해 인간형 로봇이 노이즈가 있는 센서 입력에서도 강건한 볼 킹킹 기술을 습득하도록 하는 시스템을 제시한다.
이 논문은 noisy perception 환경에서 인간형 로봇의 복잡한 동적 기술을 학습하는 현실적이고 체계적인 프레임워크를 제시하며, 4단계 curriculum, 현실적 지각 모델링, constrained RL 적응의 조합으로 sim-to-real gap을 효과적으로 감소시켰다. 실제 로봇 실험 결과와 포괄적 ablation 연구는 제안 방법의 타당성을 잘 입증하고 있으나, 단일 로봇 플랫폼 평가와 66.7% 성공률이 실무 적용성을 위해서는 추가 개선이 필요하다.
Learning to Ball: Composing Policies for Long-Horizon Basketball Moves

Fig. 1. We introduce a novel policy integration framework to enable the composition of drastically different motor skill
 *Fig. 1. We introduce a novel policy integration framework to enable the composition of drastically different motor skill* 농구 동작과 같은 다단계 장기 과제에서 정의되지 않은 중간 상태를 가진 이질적인 스킬들을 seamlessly 합성하기 위해 policy integration framework와 soft routing을 제안한다.
본 논문은 ill-defined 중간 subtask를 다루기 위한 혁신적인 policy integration framework를 제시하며, soft routing과 adaptive fine-tuning을 통해 다단계 장기 과제에서 이질 스킬의 seamless 합성을 실현한다. 실시간 사용자 명령 기반의 자유로운 농구 플레이와 높은 슈팅 정확도는 제안 방법의 유효성을 강력히 입증하나, 시뮬레이션 환경 한정과 방법의 일반화 가능성이 향후 과제이다.
Learning to Get Up Across Morphologies: Zero-Shot Recovery with a Unified Humanoid Policy

Fig. 1. Visual of diverse humanoid morphologies. Ordered by size (left: smallest, right:
 *Fig. 1. Visual of diverse humanoid morphologies. Ordered by size (left: smallest, right:* 7개의 다양한 휴머노이드 로봇(높이 0.48-0.81m, 무게 2.8-7.9kg)에서 낙상 복구를 수행할 수 있는 단일 통합 DRL 정책을 제시하며, 로봇 특화 학습 없이 미학습 로봇에 86±7% 성공률로 제로샷 전이가 가능함을 보였다.
이 논문은 휴머노이드 낙상 복구라는 구체적 과제에서 형태-불가지론적 다중 로봇 제어의 실현 가능성을 처음 입증하며, 포괄적 실험과 높은 제로샷 성능으로 일반화된 로봇 제어의 기초를 마련한다. 다만 시뮬레이션 기반 검증과 실제 전이 실험이 부재한 점이 한계이지만, 오픈소스 공개와 체계적 분석은 해당 분야에 실질적 기여를 한다.
PACE: Physics Augmentation for Coordinated End-to-end Reinforcement Learning toward Versatile Humanoid Table Tennis

Fig. 1.
 *Fig. 2.* 본 논문은 휴머노이드 로봇의 탁구 경기를 위해 학습된 예측기와 물리 기반 보상을 결합한 end-to-end RL 프레임워크 PACE를 제안하여, 전신 협응 제어와 민첩한 풋워크를 동시에 달성한다.
본 논문은 학습된 예측기와 physics-augmented 보상 설계를 통해 휴머노이드 탁구의 end-to-end RL을 성공적으로 구현한 강력한 작업이며, 시뮬레이션과 실제 하드웨어 모두에서 높은 성능을 입증하여 로봇 동적 제어의 실질적 진전을 보여준다.
Reinforcement Learning Enabled Adaptive Multi-Task Control for Bipedal Soccer Robots
 *Fig. 3: Multi-Task RL Control Architecture for Tinker.* 이 논문은 이족 로봇 축구에서 기본 보행과 복잡한 작업(공 찾기, 킥, 낙상 회복)의 깊은 결합 문제를 해결하기 위해 CPG 기반 feedforward oscillator와 RL 기반 residual action을 결합한 모듈식 강화학습 제어 프레임워크를 제안한다.
이 논문은 이족 로봇 축구의 핵심 과제들을 체계적으로 해결하는 효과적인 모듈식 제어 프레임워크를 제시하며, CPG-residual 하이브리드 제어와 posture 기반 상태 전환 메커니즘은 높은 독창성을 보여준다. 다만 실제 하드웨어 검증 부재와 타 방법론과의 비교 분석 부족이 영향력을 제한하며, 이들이 보충된다면 이족 로봇 제어 분야에서 실질적 기여를 할 수 있을 것으로 판단된다.
Stability of Control Lyapunov Function Guided Reinforcement Learning
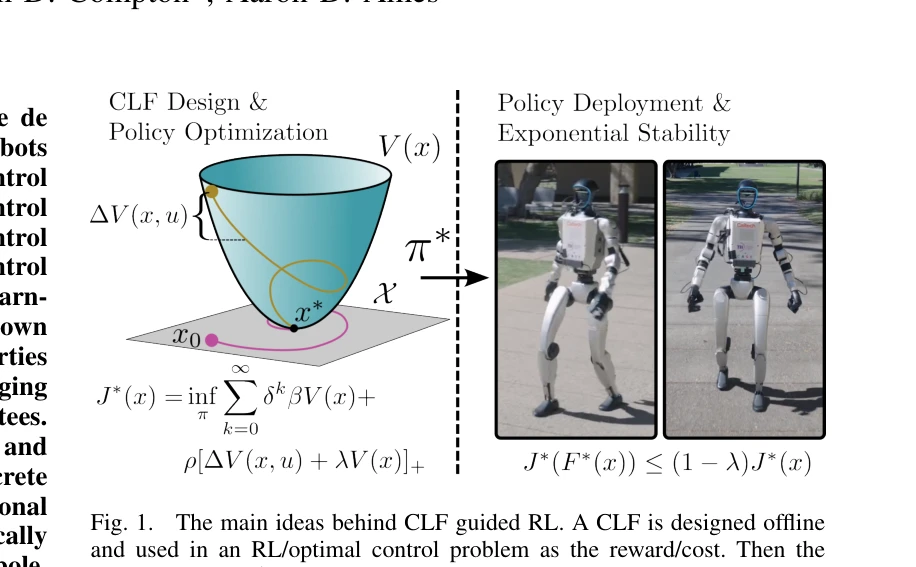
Fig. 1.
 *Fig. 1.* 본 논문은 Control Lyapunov Function (CLF)을 기반으로 한 강화학습(CLF-RL)으로 학습된 제어 정책의 이론적 안정성을 분석한다. 연속·이산 시간 모두에서 최적 제어 문제로 재정의하여 지수 안정성을 증명하고, 이를 수치 검증 및 휴머노이드 로봇의 주기 보행 실험으로 검증한다.
본 논문은 CLF-RL의 실제 성공을 이론으로 뒷받침하는 중요한 기여로, 지수 안정성 증명이 명확하고 연속·이산 시간 모두에서 포괄적으로 다루어졌다. 다만 지역 안정성 한정, CLF 구성 방법의 실용성 부재, 제한된 실험 검증이 한계이나, 제어 이론과 RL의 격차를 줄이는 가치 있는 첫 걸음이다.
Predictive Sampling: Real-time Behaviour Synthesis with MuJoCo
 *Figure 3 | Graphical User Interface. The left tab includes modules for Tasks and the Agent. In the* MuJoCo 물리 엔진 기반의 실시간 예측 제어 프레임워크 MJPC를 소개하고, 간단한 샘플링 기반 알고리즘인 Predictive Sampling이 기존의 더 복잡한 알고리즘들과 경쟁력 있음을 보여준다.
본 논문은 새로운 알고리즘적 기여보다는 실용적이고 접근 가능한 도구의 개발과 제공에 중점을 두며, 예측 제어의 대중화와 연구 생산성 향상이라는 중요한 목표를 달성한다. Predictive Sampling의 실험적 경쟁력은 흥미로우나 이론적 분석이 보완되면 더욱 강력한 기여가 될 것이다.
Reference-Free Sampling-Based Model Predictive Control
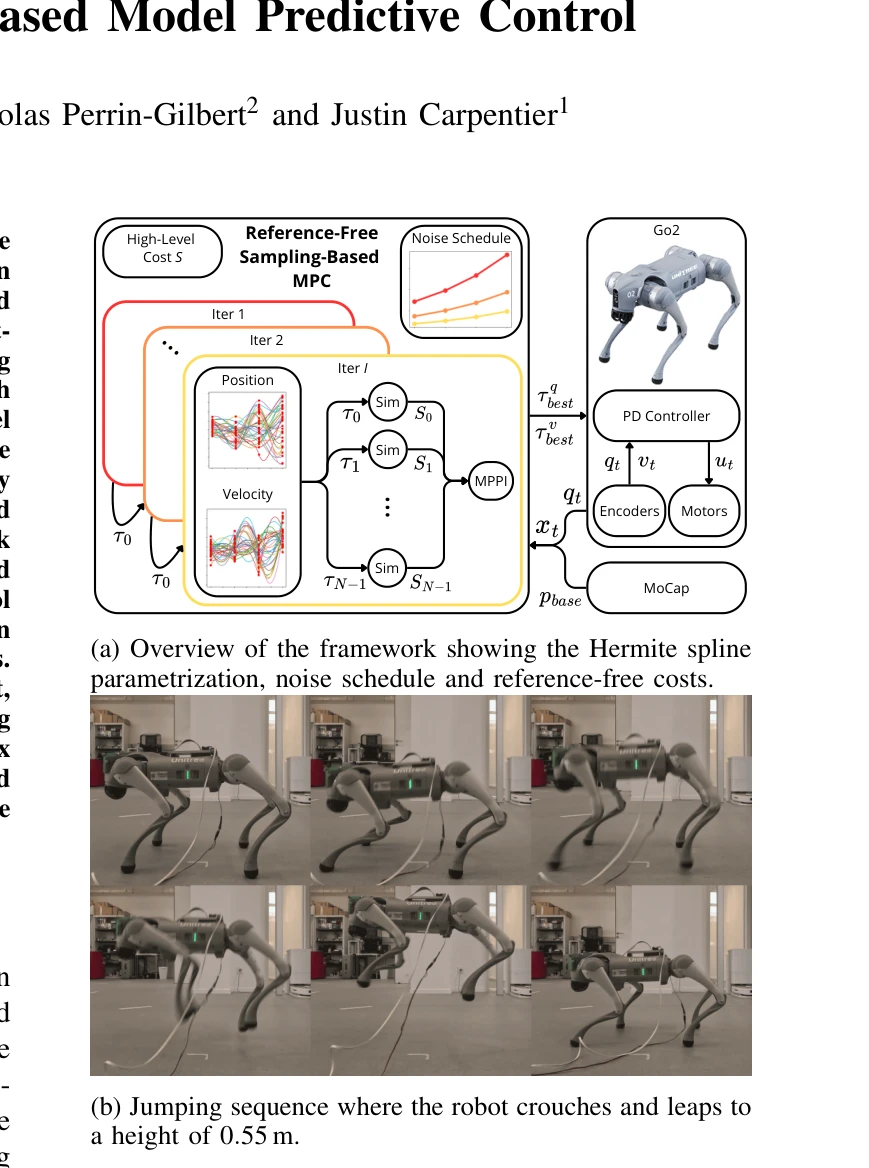
Fig. 1: Our reference-free sampling-based MPC framework
 *Fig. 1: Our reference-free sampling-based MPC framework* 본 논문은 사전정의된 보행 패턴이나 접촉 시퀀스 없이 MPPI 기반의 샘플링 기반 MPC 프레임워크를 제안하여 emergent locomotion을 실현한다. Cubic Hermite spline 파라미터화를 통해 위치와 속도 제어점을 동시에 최적화하여 실시간 CPU 기반 제어를 가능하게 한다.
본 논문은 참조 없는 emergent locomotion 발현, 극도의 샘플 효율성, 그리고 실시간 CPU 제어라는 세 가지 측면에서 우수한 기여를 제시한다. Cubic Hermite spline 파라미터화와 diffusion annealing의 조합은 창의적이며, Go2 로봇의 실제 검증은 신뢰성을 높인다. 다만 현실 로봇 검증의 범위 확대와 sim-to-real 갭 분석이 필요하다.
Whole-Body Model-Predictive Control of Legged Robots with MuJoCo

Fig. 1.
 *Fig. 1.* MuJoCo 물리엔진과 iterative LQR (iLQR) 알고리즘을 결합하여 사족 및 인형로봇의 전신 모델예측제어(MPC)를 실시간으로 수행하고, 간단한 방법으로도 현실 세계에 효과적으로 적용 가능함을 입증하는 연구이다.
이 논문은 복잡한 최적화 이론 대신 표준 도구들의 조합으로 현실 세계 다리로봇 제어를 성공시킨 우수한 실증 연구이며, 공개된 코드와 상세한 구현 정보로 커뮤니티 연구 가속화에 큰 기여할 것으로 기대된다.
Agility Meets Stability: Versatile Humanoid Control with Heterogeneous Data

Fig. 1: Introducing AMS (Agility Meets Stability), one single policy that performs diverse motions with stability and ag
 *Fig. 2: Overview of AMS. (a) The general whole-body tracking pipeline retargets human MoCap data to reference motions* AMS는 휴먼 모션캡처 데이터와 합성 밸런스 데이터를 결합하여 단일 정책으로 민첩한 동작과 극한의 밸런스 유지를 동시에 수행할 수 있는 휴머노이드 제어 프레임워크다.
본 논문은 휴머노이드 로봇 제어의 오랫동안의 과제인 민첩성과 안정성의 통합을 처음으로 체계적으로 해결하며, 이질적 데이터와 하이브리드 보상 설계를 통한 창의적 접근과 실제 로봇에서의 강력한 성과를 보여준다.
Chasing Stability: Humanoid Running via Control Lyapunov Function Guided Reinforcement Learning
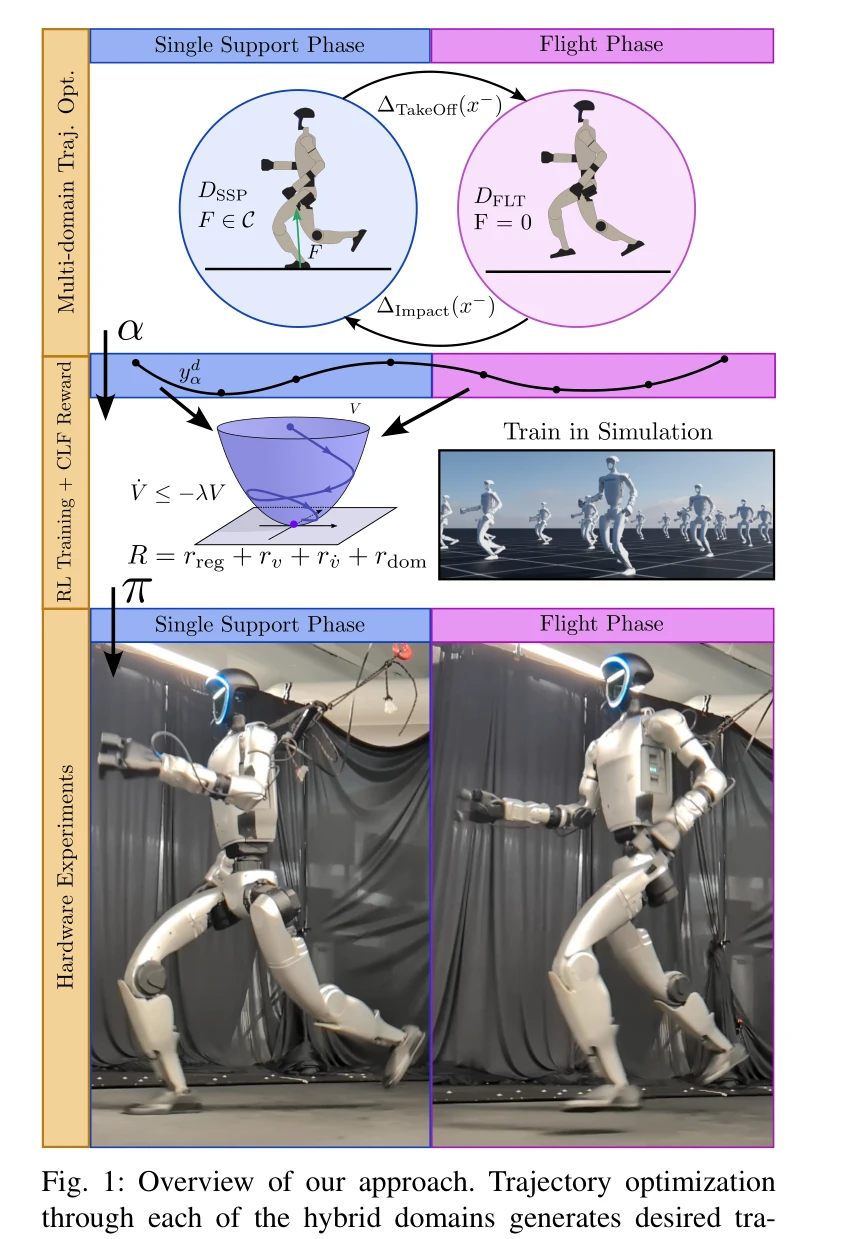
Fig. 1: Overview of our approach. Trajectory optimization
 *Fig. 1: Overview of our approach. Trajectory optimization* 본 논문은 Control Lyapunov Function(CLF)의 안정성 조건을 RL 보상에 임베딩하여 휴머노이드 로봇의 달리기를 실현하는 CLF-RL 방법을 제시한다. 이는 휴머노이드가 비행 및 단일 지지 상(flight and single support phases)를 포함한 동적 달리기를 수행하도록 한다.
본 논문은 고전 제어 이론(CLF)과 최신 RL을 매우 효과적으로 통합하여, 휴머노이드 로봇의 동적 달리기 제어를 위한 원리 기반의 체계적 프레임워크를 제시한다. 실제 하드웨어에서의 안정적 배포와 강건한 추적 성능은 높은 실용적 가치를 입증한다.
ComFree-Sim: A GPU-Parallelized Analytical Contact Physics Engine for Scalable Contact-Rich Robotics Simulation and Control
Fig. 1: Performance overview of the ComFree-Sim. In the second row, it shows 2–3× higher throughput than MuJoCo Warp
 *Fig. 1: Performance overview of the ComFree-Sim. In the second row, it shows 2–3× higher throughput than MuJoCo Warp* ComFree-Sim은 여집합-자유(complementarity-free) 접촉 모델링을 기반으로 한 GPU 병렬화 접촉 물리 엔진으로, 폐쇄형 해석해를 통해 접촉 임펄스를 계산하여 접촉 수에 대해 선형적 계산 복잡도를 달성한다.
ComFree-Sim은 complementarity-free 접촉 모델링의 폐쇄형 해석 구조를 효과적으로 GPU 병렬화하고 6D로 확장하여, 기존 iterative solver 기반 접근의 근본적 병목을 해결한 혁신적 접촉 물리 엔진이다. 선형 확장성과 2-3배 향상된 처리량을 실현하면서도 물리 정확도를 유지하고, 실제 로봇 하드웨어에서 고주파 MPC 제어를 성공적으로 구현함으로써 접촉-풍부 로봇 학습과 제어 분야에 상당한 실용적 가치를 제공한다.
Dexterous Safe Control for Humanoids in Cluttered Environments via Projected Safe Set Algorithm
Figure 1: Application of dexterous safe control for humanoids in cluttered environments. (a) A safe teleoperation task w
 *Figure 1: Application of dexterous safe control for humanoids in cluttered environments. (a) A safe teleoperation task w* 인간형 로봇이 복잡한 환경에서 다중 충돌 회피를 수행할 때 발생하는 제어 제약의 불가능성 문제를 해결하기 위해 Projected Safe Set Algorithm (p-SSA)을 제안한다.
밀집된 환경에서 인간형 로봇의 섬세한 다중 충돌 회피라는 현실적이고 중요한 문제를 처음 체계적으로 다루었으며, p-SSA 알고리즘은 실제 로봇 배포에 즉시 활용 가능한 실용적 해결책을 제시한다. 이론적 보장은 제한적이지만 광범위한 실증 검증과 무매개변수 일반화 능력이 인간형 로봇 안전 제어의 중요한 진전을 보여준다.
Full-Order Sampling-Based MPC for Torque-Level Locomotion Control via Diffusion-Style Annealing
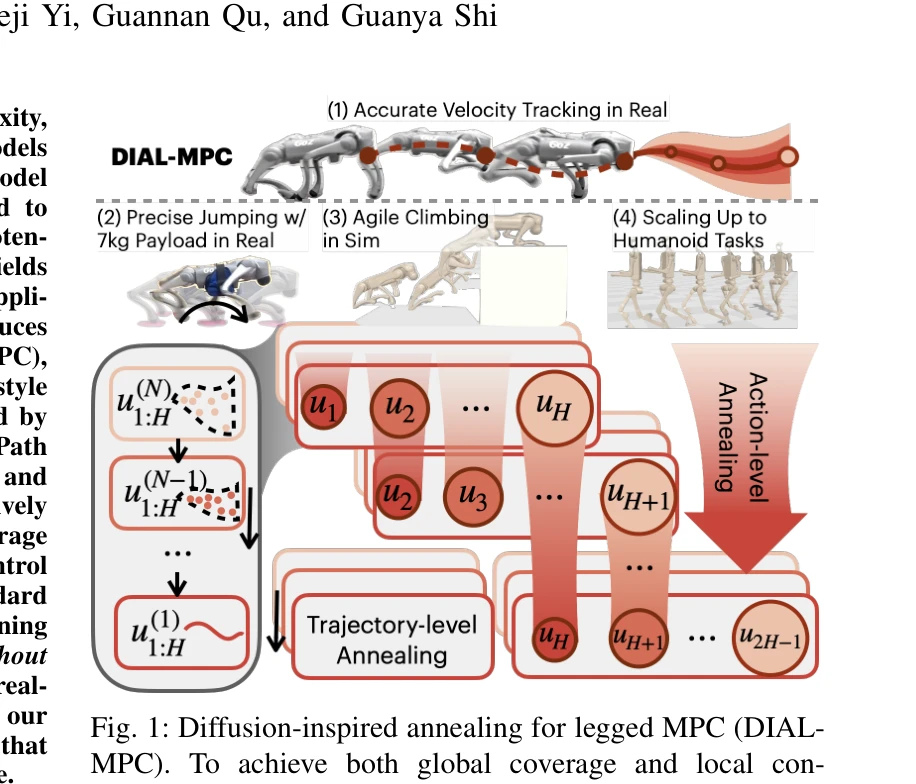
Fig. 1: Diffusion-inspired annealing for legged MPC (DIAL-
 *Fig. 1: Diffusion-inspired annealing for legged MPC (DIAL-* DIAL-MPC는 diffusion 프로세스의 iterative refinement 아이디어를 sampling-based MPC에 적용하여 full-order 사족 로봇의 torque-level 제어를 실시간으로 수행하는 training-free 방법이다.
본 논문은 MPPI와 diffusion의 수학적 연결을 통해 sampling-based MPC의 근본적 한계를 새로운 각도로 접근하며, diffusion-inspired annealing이라는 창의적 방법으로 full-order 사족 로봇의 실시간 제어를 training-free로 달성한 의미있는 기여이다.
Geometry-Aware Predictive Safety Filters on Humanoids: From Poisson Safety Functions to CBF Constrained MPC
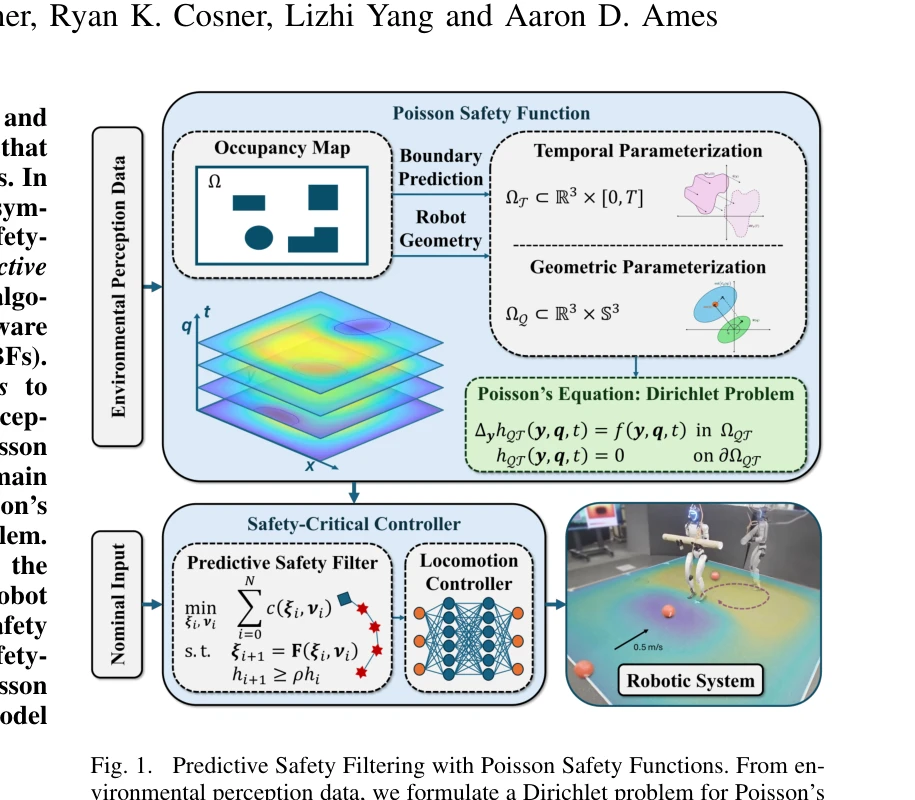
Fig. 1.
 *Fig. 1.* 본 논문은 Poisson safety function을 기반으로 한 geometry-aware predictive safety filter를 제안하며, CBF constrained MPC를 통해 humanoid 및 quadruped 로봇의 실시간 안전한 궤적 생성을 구현한다.
본 논문은 Poisson safety function을 시간-동적 환경과 로봇 기하학에 맞게 확장하고 MPC+CBF와 통합하여 실시간 안전한 자율 네비게이션을 실현한 우수한 연구이다. 이론적 확장과 실제 로봇 검증이 잘 균형을 이루고 있으며, 안전-임계 로봇 제어의 실질적 문제 해결에 기여한다.
Humanoid Robot Acrobatics Utilizing Complete Articulated Rigid Body Dynamics
 *Figure 2: Jump phases. Magenta: Launch phase, blue: flight* 고도화된 동적 동작을 수행하는 휴머노이드 로봇을 위해 완전한 articulated rigid body dynamics를 기반으로 하는 제어 아키텍처를 제시하며, trajectory optimization과 whole-body control을 model abstraction으로 중개하여 아크로바틱 동작을 실현한다.
휴머노이드 로봇의 고도 동적 제어에 대한 개념적·이론적 기여도가 높고 control architecture가 체계적이나, 시뮬레이션 검증에 한정되고 optimization 방법론 세부사항이 부족하여 실질적 영향력에는 제약이 있다.
HUSKY: Humanoid Skateboarding System via Physics-Aware Whole-Body Control

Fig. 1: Overview. (a) Our proposed framework HUSKY enables the humanoid robot to perform complete real-world skateboardi
 *Fig. 1: Overview. (a) Our proposed framework HUSKY enables the humanoid robot to perform complete real-world skateboardi* HUSKY는 humanoid 로봇이 skateboard 위에서 안정적으로 skating을 수행하기 위한 physics-aware whole-body control 프레임워크이며, lean-to-steer 제약과 hybrid contact dynamics를 명시적으로 모델링하여 AMP 기반 pushing과 physics-guided steering을 통합한다.
HUSKY는 humanoid skateboarding이라는 도전적인 문제를 physics-aware modeling과 hybrid control framework를 통해 창의적으로 해결한 고품질 연구이며, explicit system modeling과 DRL의 결합으로 real-world에서의 stable skateboarding을 실현한 점에서 significant contribution을 제시한다.
Robot Crash Course: Learning Soft and Stylized Falling
 *Fig. 2: Method Overview. We leverage reinforcement learn-* 이 논문은 양족 로봇의 낙하 현상 자체에 초점을 맞춰, 충격을 최소화하면서 사용자가 지정한 목표 자세에 도달하도록 하는 강화학습 기반 낙하 정책을 제안한다.
이 논문은 로봇 낙하를 예방이 아닌 제어 대상으로 재정의하는 독창적 관점을 제시하며, RL 기반 다목적 보상 함수와 샘플링 전략으로 범용적 해결책을 제공한다. 실제 양족 로봇에서 부드럽고 스타일화된 낙하를 시연한 점에서 높은 의의가 있으나, 정량적 평가 확대와 다양한 로봇 플랫폼 검증이 필요하다.
Robust Humanoid Walking on Compliant and Uneven Terrain with Deep Reinforcement Learning

Fig. 1: HRP-5P humanoid bipedal locomotion (clockwise) on flat rigid
 *Fig. 1: HRP-5P humanoid bipedal locomotion (clockwise) on flat rigid* Deep RL을 이용하여 humanoid robot HRP-5P가 시뮬레이션에서 terrain randomization으로 학습한 정책을 실제 환경의 compliant하고 uneven한 terrain에서도 robust하게 보행하도록 하는 연구이다.
Life-sized humanoid의 challenging terrain 보행을 위한 deep RL 기반 접근법의 실제 구현을 성공적으로 입증했으며, sim-to-real transfer와 adaptive gait control의 효과를 명확히 보여준 의미 있는 연구이다. 다만 clock control 정책의 실제 적용 효과 검증과 failure case 분석이 보강되면 더욱 완성도 높은 작업이 될 수 있다.
Sim-to-Real Learning for Humanoid Box Loco-Manipulation

Fig. 1: We learn box loco-manipulation policies in simulation
 *Fig. 1: We learn box loco-manipulation policies in simulation* 본 연구는 인간형 로봇 Digit의 박스 집기 및 운반 작업을 위해 강화학습 기반의 sim-to-real 접근법을 제시하며, 5가지 분리된 정책(걷기, 서기, 집기, 박스 들고 걷기, 박스 들고 서기)을 학습하여 실제 하드웨어에서 성공적으로 전이했다.
본 논문은 인간형 이족 로봇의 복합적인 loco-manipulation 작업에 대한 첫 sim-to-real RL 성공 사례를 제시하며, 실용적인 보상 함수 설계와 action space 선택을 통해 자연스러운 동작을 학습했다는 점에서 의의가 있다. 다만 phase 관리의 경직성과 박스 pose 추정 오차 등 개선의 여지가 있어 기술적으로는 중간 수준이지만 실제 하드웨어 적용이라는 중요한 성과와 명확한 기여로 높은 가치를 가진다.
SKATER: Synthesized Kinematics for Advanced Traversing Efficiency on a Humanoid Robot via Roller Skate Swizzles
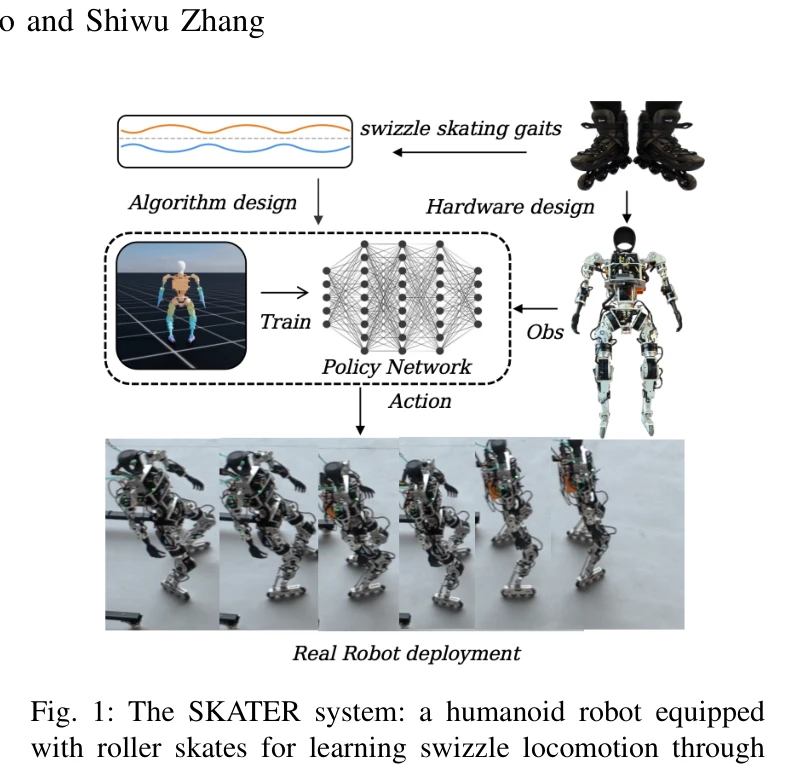
Fig. 1: The SKATER system: a humanoid robot equipped
 *Fig. 1: The SKATER system: a humanoid robot equipped* 휴머노이드 로봇의 발에 4개의 수동 바퀴를 장착하고 Deep Reinforcement Learning을 통해 롤러스케이팅 스위즐 보행을 학습시켜 전통적인 보행 대비 충격력 75.86%, 에너지 소비 63.34% 감소를 달성했다.
휴머노이드 로봇의 에너지 효율과 관절 수명 향상을 위해 롤러스케이팅이라는 창의적인 솔루션을 제시하고, DRL 기반 제어 프레임워크를 통해 현실적인 구현을 달성한 혁신적 연구이다. 85~76% 수준의 높은 성능 개선과 sim-to-real 전이의 성공은 로봇 운동 제어 분야에 실질적 기여를 한다.
SMASH: Mastering Scalable Whole-Body Skills for Humanoid Ping-Pong with Egocentric Vision

Fig. 1: SMASH: Our system enables the first outdoor humanoid ping-pong player and the first whole-body smash on a humano
 *Fig. 2: Overview of SMASH. Our system connects scalable motion generation, task-aligned policy learning, and egocentric* 휴머노이드 로봇의 탁구 게임을 위해 확장 가능한 전신 동작 학습과 자체 에고센트릭 비전을 통합한 SMASH 시스템을 제시하며, 외부 카메라나 모션 캡처 없이 실외에서 연속적인 탁구 스트라이킹을 처음으로 달성했다.
이 논문은 휴머노이드 탁구에서 에고센트릭 온보드 지각과 전신 협응 제어를 통합한 최초의 자율 시스템을 구현함으로써 로봇 동적 상호작용 연구에 중요한 기여를 하였다. Motion VAE 기반 동작 확장과 task-aligned motion matching이라는 확장 가능한 방법론은 다른 동적 로봇 과제에도 적용 가능한 잠재력이 있다.
The Duke Humanoid: Design and Control For Energy Efficient Bipedal Locomotion Using Passive Dynamics

Fig. 1: Duke Humanoid v1.0: a) The frontal plane symmetry
 *Fig. 1: Duke Humanoid v1.0: a) The frontal plane symmetry* Duke Humanoid은 동적 보행이 가능한 오픈소스 10-DoF 인형로봇으로, 패시브 다이내믹스를 활용하는 reinforcement learning 정책을 통해 에너지 효율적인 이족 보행을 달성한다.
이 논문은 오픈소스 인형로봇 플랫폼과 패시브 다이내믹스 기반 에너지 효율 개선을 결합하여 humanoid 보행 연구에 실질적 기여를 한다. 특히 reinforcement learning 내 passive dynamics의 명시적 활용과 zero-shot 배포 검증은 학술적·실용적 가치가 높으나, 속도 범위와 일반화 능력의 검증이 더 필요하다.
A Behavior Architecture for Fast Humanoid Robot Door Traversals

Figure 1: The Nadia humanoid robot performing a right pull lever handle door traversal using cycloidal drive forearms an
 *Figure 2: An all inclusive overview of the parts involved in this work.* 휴머노이드 로봇의 다양한 도어 통과 작업을 수행하기 위해 GPU 가속 인식, Behavior Tree 기반 행동 조정 시스템, 전신 제어기를 통합한 아키텍처를 제시한다. 실제 Nadia 휴머노이드 로봇에서 빠른 도어 통과 성능을 달성했다.
이족 휴머노이드의 도어 통과라는 미개발 영역을 처음 체계적으로 다루고, 실제 로봇에서 동작하는 통합 시스템을 구현한 의미 있는 연구이다. 행동 저작의 속도와 재사용성 향상, 다층적 시스템 설계 관점에서 독창성과 실용성이 우수하나, 단일 플랫폼 검증과 일반화 가능성에 대한 보완이 필요하다.
A Unified and General Humanoid Whole-Body Controller for Versatile Locomotion

Fig. 1: Humanoid capabilities supported by HUGWBC. First row: HUGWBC allows four standard gaits - walking, jumping, stan
HugWBC는 시뮬레이션에서 학습한 통일된 강화학습 기반 정책으로 휴머노이드 로봇이 걷기, 뛰기, 서기, 깡충뛰기 등 다양한 보행 행동을 자유롭게 조절 가능하도록 하며, 상반신 외부 제어 개입도 지원하는 전신 컨트롤러이다.
HugWBC는 확장된 명령 공간과 intervention training 기법을 통해 휴머노이드 로봇의 다양한 보행과 로코-조작을 통합적으로 제어하는 첫 번째 전신 컨트롤러로서, 우수한 추적 성능과 강건성으로 휴머노이드 로봇의 실용 능력을 크게 향상시키는 의미 있는 기여이다.
AGILOped: Agile Open-Source Humanoid Robot for Research
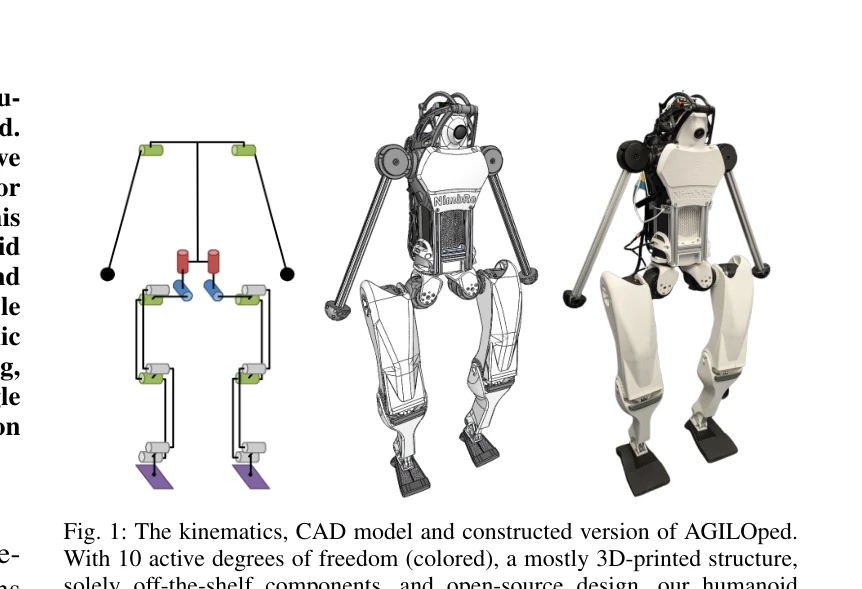
Fig. 1: The kinematics, CAD model and constructed version of AGILOped.
 *Fig. 1: The kinematics, CAD model and constructed version of AGILOped.* AGILOped는 오픈소스 휴머노이드 로봇으로서 높은 성능과 접근성 사이의 간극을 해소하며, 3D 프린팅과 상용 부품을 활용해 6,380 USD의 저렴한 가격으로 동적 운동 능력을 제공한다.
AGILOped는 오픈소스, 저가격, 높은 성능을 결합한 획기적인 휴머노이드 로봇으로, 휴머노이드 로봇 연구의 진입장벽을 크게 낮추고 학계의 민주화를 촉진하는 중요한 기여를 한다.
Berkeley Humanoid: A Research Platform for Learning-based Control

Figure 1: Design, training, and sim-to-real deployment of our custom-built humanoid with a
 *Figure 1: Design, training, and sim-to-real deployment of our custom-built humanoid with a* 학습 기반 제어를 위해 특별히 설계된 저비용 중형 휴머노이드 로봇 플랫폼인 Berkeley Humanoid를 제시하며, 좁은 sim-to-real 갭과 높은 신뢰성으로 다양한 지형에서 동적 보행을 실현한다.
Berkeley Humanoid는 학습 기반 휴머노이드 제어 연구를 위한 실용적이고 비용 효율적인 플랫폼으로, 하드웨어와 제어 알고리즘의 통합 설계를 통해 중요한 sim-to-real 문제를 해결한 가치 있는 기여이다. Open-source 공개 계획은 커뮤니티 연구를 촉진할 것으로 예상된다.
Biomechanical Comparisons Reveal Divergence of Human and Humanoid Gaits
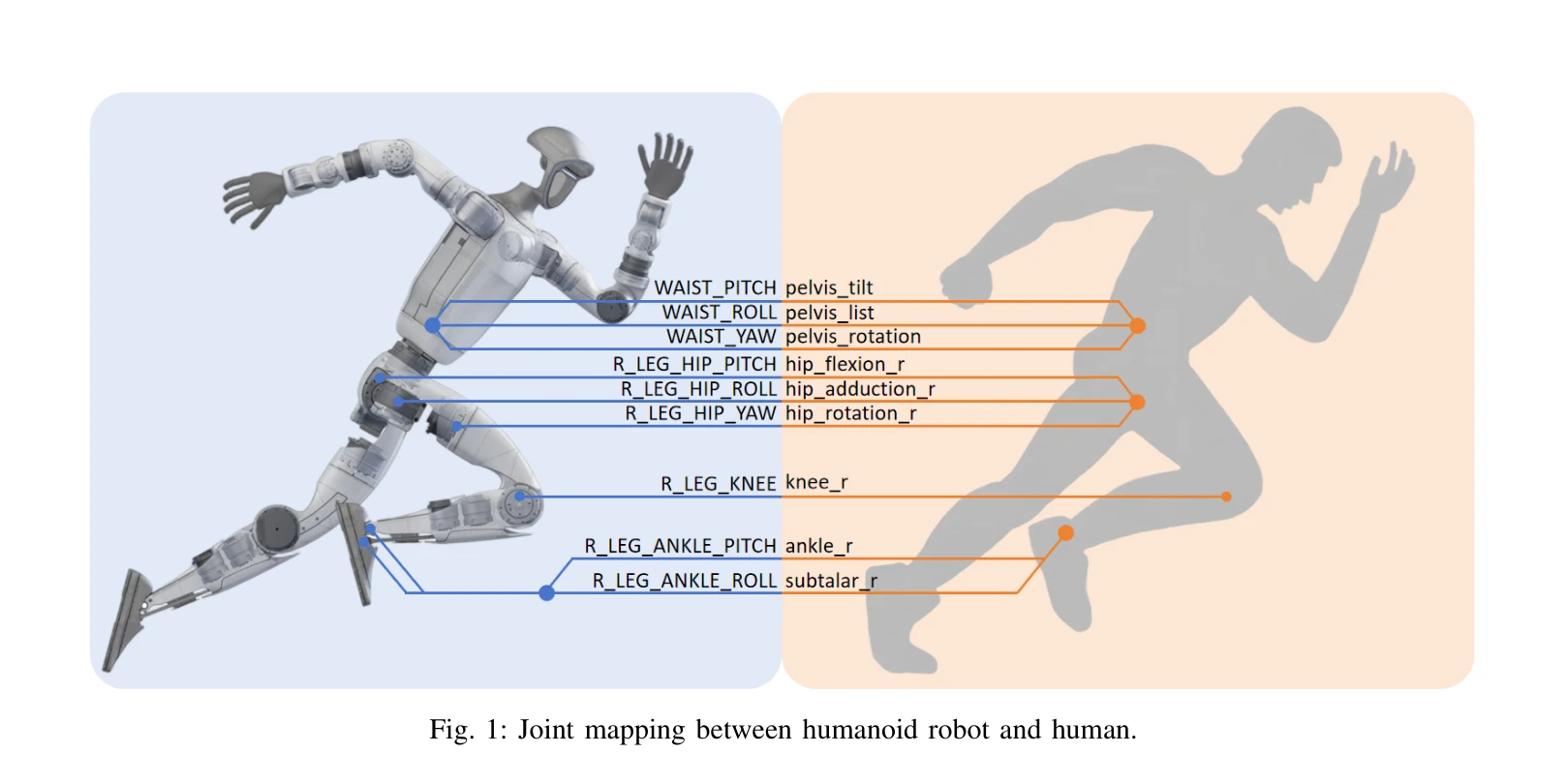
Fig. 1: Joint mapping between humanoid robot and human.
 *Fig. 2: Comparison of lower-limb joint angles, moments, and* 본 논문은 Gait Divergence Analysis Framework (GDAF)를 제안하여 인간과 휴머노이드 로봇의 보행 간 생체역학적 차이를 정량적으로 분석하고, 28개 속도에서 수집한 공개 데이터셋과 분석 도구를 제공한다.
본 논문은 휴머노이드 보행 평가를 위한 첫 번째 체계적 생체역학 분석 프레임워크와 완전 공개 데이터셋을 제시하여 로봇 보행 개선의 정량적 기준과 도구를 확보하게 하는 점에서 의의가 크며, 방법론적 투명성과 재현가능성이 우수하나 단일 플랫폼과 보행 환경 제약이 일반화 가능성을 다소 제한한다.
Deep Whole-body Parkour

Fig. 1: Deep Whole-Body Parkour. Our framework enables a humanoid robot to autonomously traverse challenging obstacles
 *Fig. 2: Data-driven whole-body control framework. Real-world environment scans and human demonstrations are processed an* 본 연구는 외부 센싱(depth perception)을 whole-body motion tracking에 통합하여 인간형 로봇이 불규칙한 지형에서 vaulting, dive-rolling 등의 동적 parkour 움직임을 수행하도록 하는 프레임워크를 제시한다.
본 논문은 두 상충하는 제어 패러다임을 창의적으로 통합하여 humanoid robot의 traversability를 획기적으로 확장했으며, custom motion-terrain dataset과 최적화된 ray-casting algorithm은 기술적 기여도 충실하다. sim-to-real gap 해소와 실제 동작 검증으로 실무적 가치가 높으나, dataset 확장성과 타 robot morphology 적용에 개선 여지가 있다.
FLAM: Foundation Model-Based Body Stabilization for Humanoid Locomotion and Manipulation
Fig. 1.
 *Fig. 1.* FLAM은 인간 동작 재구성 모델 기반의 안정화 보상 함수를 설계하여 휴머노이드 로봇의 전신 제어에서 신체 안정성을 명시적으로 고려하는 강화학습 방법이다. 로봇 자세를 3D 가상 인간 모델에 매핑한 후 안정화된 자세를 재구성하여 보상을 계산함으로써 학습 과정을 가속화한다.
FLAM은 인간 동작 foundation model을 창의적으로 활용하여 휴머노이드 로봇의 안정성 문제를 해결한 효과적인 방법이다. 강화학습의 샘플 효율성 문제를 개선하고 다양한 작업에서 우수한 성능을 보여주며, 향후 로봇 제어의 중요한 기초를 제공할 수 있다.
Heavy lifting tasks via haptic teleoperation of a wheeled humanoid
Fig. 1.
 *Fig. 1.* 휠형 휴머노이드 로봇의 Dynamic Mobile Manipulation을 위해 햅틱 피드백을 통한 원격 조종 프레임워크를 제시하며, 인간의 전신 모션을 로봇에 재타겟팅하여 무거운 물체 들어올리기를 수행한다.
본 논문은 무거운 물체 들어올리기 작업을 위한 휠형 휴머노이드의 원격 조종에서 높이 조절, 자동 pitch 보상, 햅틱 피드백을 통합한 실질적이고 잘 설계된 시스템을 제시하며, 기존 연구의 명확한 한계를 극복한 의미 있는 기여이다.
HITTER: A HumanoId Table TEnnis Robot via Hierarchical Planning and Learning

Fig. 1: Humanoid table tennis rallies. Our system enables both humanoid-humanoid (left) and humanoid-human (right) match
 *Fig. 2: System overview. (a) The racket is mounted on the robot’s right wrist using a 3D-printed connector, and the ball* 휴머노이드 로봇이 탁구를 하기 위한 계층적 프레임워크를 제시하며, model-based planner와 RL 기반 whole-body controller를 통합하여 sub-second 반응 시간 내에 초당 5 m/s 이상의 볼을 처리한다.
본 논문은 humanoid table tennis를 통해 고속 동적 환경에서의 전신 제어 및 상호작용을 처음으로 성공적으로 시연하였으며, 계층적 planning-control 통합과 minimal human references를 통한 우아한 접근법이 인상적이다. 실제 세계 검증(106 연속 샷)은 방법론의 실용성을 강력히 입증한다.
Humanoid Parkour Learning

Figure 1: We present a single vision-based end-to-end whole-body-control parkour policy for humanoid robots
 *Figure 1: We present a single vision-based end-to-end whole-body-control parkour policy for humanoid robots* 본 논문은 시각 기반 end-to-end 제어 정책을 통해 인간형 로봇이 모션 프리어 없이 다양한 파쿠르 기술(점프, 허들 뛰기, 갭 넘기 등)을 수행할 수 있도록 학습하는 통합 프레임워크를 제시한다.
본 논문은 모션 프리어 없이 인간형 로봇이 다양한 파쿠르 기술을 통합적으로 학습하고 실제 배포할 수 있게 하는 혁신적 프레임워크를 제시하며, fractal noise를 통한 자연스러운 보행 유도와 효율적인 vision 정책 증류 기법으로 로봇 운동 능력의 경계를 의미 있게 확장한다.
Humanoid Whole-Body Badminton via Multi-Stage Reinforcement Learning
 *Fig. 2: System overview. (a) Training: PPO learns a single policy πWBC using Privileged Critic Obs together with Actor* 이 논문은 다단계 강화학습 커리큘럼을 통해 휴머노이드 로봇이 배드민턴을 하도록 학습하는 통합 전신 제어기를 제시하며, 시뮬레이션과 실제 로봇 모두에서 1초 이내의 반응 시간으로 19.1 m/s의 셔틀콕 속도를 달성했다.
이 논문은 휴머노이드 로봇의 고속 동적 상호작용 능력을 크게 진전시키며, 잘 설계된 3단계 커리큘럼과 실제 배포 성공이 인상적이다. 다만 예측 없는 변형의 실제 검증 부족과 현재 제한된 시험 환경이 향후 개선 과제이다.
Humanoid Whole-Body Locomotion on Narrow Terrain via Dynamic Balance and Reinforcement Learning

Fig. 1: The locomotion capabilities of full-sized Humanoid without vision or LiDAR sensors. (a) Narrow Path (25cm):
 *Fig. 1: The locomotion capabilities of full-sized Humanoid without vision or LiDAR sensors. (a) Narrow Path (25cm):* ZMP(Zero Moment Point) 기반 리워드와 강화학습을 결합한 동적 균형 메커니즘을 도입하여, 휴머노이드 로봇이 외부 센서 없이 고유감각만으로 좁은 경로와 예상 못한 장애물이 있는 극단적 지형을 안정적으로 통과하도록 하는 전신 보행 알고리즘을 제안한다.
본 논문은 고전적 ZMP 개념을 현대 강화학습에 효과적으로 통합하여 외부 센서 없이 극단적 지형 통과 능력을 확보한 의미 있는 기여를 한다. 실제 full-sized 휴머노이드 로봇에서의 광범위한 실증이 강점이나, 다양한 로봇 플랫폼과 극단적 지형에 대한 일반화 가능성 검증이 필요하다.
Learning Getting-Up Policies for Real-World Humanoid Robots

Fig. 1: HUMANUP provides a simple and general two-stage training method for humanoid getting-up tasks, which can be
 *Fig. 2: HUMANUP system overview. Our getting-up policy (Sec. III-A) is trained in simulation using two-stage RL training* 휴머노이드 로봇의 낙상 복구를 위해 두 단계 강화학습 프레임워크(HUMANUP)를 제시하여 다양한 자세와 지형에서 일어나는 동작을 학습하고 실제 G1 로봇에 배포했다.
휴머노이드 로봇 낙상 복구는 중요하면서도 미탐색된 문제이며, 이 논문은 작업 특성을 정확히 파악하고 실용적 커리큘럼 학습을 통해 인간 규모 로봇에서 처음 성공적인 실제 배포를 시연했다. 기술적 기여도 있지만 평가 범위의 한계와 설계 선택의 일반화 가능성에 대한 추가 검증이 필요하다.
Learning with pyCub: A Simulation and Exercise Framework for Humanoid Robotics
Fig. 1. An example of the simulation environment showing the iCub humanoid robot,
 *Fig. 1. An example of the simulation environment showing the iCub humanoid robot,* pyCub는 humanoid robot iCub의 Python 기반 physics 시뮬레이션 프레임워크로, YARP 미들웨어 없이 학생들이 humanoid robotics의 기초를 배울 수 있는 교육용 연습 문제들을 제공한다.
pyCub는 humanoid robotics 교육 접근성의 실질적 장벽을 Python과 단순화된 아키텍처로 제거한 가치 있는 오픈소스 프레임워크이며, 실제 교육 과정 검증과 완전한 공개를 통해 학술 커뮤니티에 즉시 활용 가능한 자원을 제공한다.
Deep Whole-body Parkour

Fig. 1: Deep Whole-Body Parkour. Our framework enables a humanoid robot to autonomously traverse challenging obstacles
 *Fig. 2: Data-driven whole-body control framework. Real-world environment scans and human demonstrations are processed an* 이 논문은 exteroceptive perception을 whole-body motion tracking에 통합하여 humanoid robot이 복잡한 지형에서 vault, dive-rolling 등의 다중 접촉 parkour 기술을 수행하도록 하는 프레임워크를 제시한다. 기존의 locomotion-centric 접근과 environment-agnostic 동작 추적을 결합하여 지각 기반의 일반적 동작 제어를 실현한다.
이 논문은 humanoid robot 제어의 두 주요 패러다임을 창의적으로 통합하여 지형 인식 능력과 복잡한 전신 동작을 동시에 달성하는 실질적인 솔루션을 제시한다. 커스텀 dataset curation, 최적화된 parallel simulation, 견고한 폐루프 제어 통합을 통해 vault와 dive-rolling 같은 고도로 동적인 parkour 기술을 실제 humanoid에서 구현했다는 점에서 의의가 크다.
Humanoid Parkour Learning

Figure 1: We present a single vision-based end-to-end whole-body-control parkour policy for humanoid robots
 *Figure 1: We present a single vision-based end-to-end whole-body-control parkour policy for humanoid robots* 본 논문은 인간형 로봇이 motion prior 없이 end-to-end vision-based 정책으로 다양한 parkour 기술을 학습할 수 있는 프레임워크를 제시한다. Fractal noise를 활용한 terrain randomization과 DAgger를 통한 vision policy 증류로 sim-to-real transfer를 달성하며, 실제 로봇에서 0.42m 점프, 0.8m gap 통과, 1.8m/s 주행 등을 성공한다.
본 논문은 인간형 로봇의 parkour learning에서 motion prior 제거와 fractal noise 기반 자동 foot-raising 유도라는 중요한 기여를 제시한다. 3단계 훈련 파이프라인과 DAgger 증류를 통한 sim-to-real transfer는 기술적으로 견고하며, 실제 로봇에서의 다양한 성공 사례는 실용적 가치가 높다. 다만 직선 track 제약, 정량적 평가 부족, 일반화 가능성 검증 미흡이 한계이나, 인간형 로봇의 agile locomotion 분야에 상당한 진전을 이루었다.
Sumo: 동적이고 일반화 가능한 전신 이동-조작 제어
 *Fig. 2: System overview: Our method takes a hierarchical* 본 논문은 사전 학습된 전신 제어 정책과 테스트 시점 샘플 기반 계획을 계층적으로 결합하여 사족 로봇과 인형 로봇이 동적으로 대형 무거운 물체를 조작할 수 있게 하는 Sumo 프레임워크를 제시한다. 이 방법은 재학습 없이 다양한 물체와 작업에 일반화되며, 비용 함수만 변경하여 테스트 시점에 유연하게 적응할 수 있다.
본 논문은 강화학습과 샘플 기반 MPC를 계층적으로 결합하는 우아한 방식으로 동적 전신 로코-조작을 처음 구현했으며, Spot 실제 로봇에서의 인상적인 결과와 일반화 가능성은 로봇 조작 분야에 의미 있는 기여를 한다. 테스트 시점 유연성과 훈련 없는 적응은 실무 적용에 큰 가치가 있다.
Sumo: 동적이고 일반화 가능한 전신 이동-조작 제어

 *Fig. 2: System overview: Our method takes a hierarchical* 본 논문은 사전학습된 전신 제어 정책과 테스트 시점 샘플 기반 계획을 계층적으로 결합하는 Sumo 프레임워크를 제안한다. 이를 통해 사족 및 인형 로봇이 동적으로 대형 중량 물체를 조작할 수 있으며, 재학습 없이 다양한 물체와 작업에 일반화된다.
Sumo는 동적 전신 조작이라는 도전적 과제에서 실용적이고 일반화 가능한 해결책을 제시한다. 계층적 프레임워크의 설계가 우수하고 실제 로봇 검증이 설득력 있으며, 재학습 없는 적응 능력이 인상적이다. 다만 인형 로봇 실제 검증과 더 광범위한 물체 기하학적 다양성 시험이 있으면 영향력이 더욱 클 것이다.
Sampling-Based System Identification with Active Exploration for Legged Robot Sim2Real Learning
Figure 1: SPI-Active enables high-fidelity Sim-to-Real transfer across diverse locomotion tasks. To highlight
 *Figure 2: Overview of SPI-Active. Data Collection: Collect real-world trajectories using RL policies or* SPI-Active는 legged robot의 물리 파라미터를 샘플링 기반으로 식별하고 Fisher Information 최대화를 통한 active exploration으로 sim-to-real 갭을 최소화하는 two-stage 프레임워크이다.
이 논문은 legged robot의 sim-to-real 갭 해결을 위한 원리적이고 실용적인 system identification 프레임워크를 제시하며, Fisher Information 기반 active exploration 전략의 창의적 적용으로 고정밀 locomotion 작업에서 현저한 성능 향상을 달성했다.
Spectral Normalization for Lipschitz-Constrained Policies on Learning Humanoid Locomotion

Fig. 1.
 *Fig. 1.* 본 논문은 인간형 로봇의 보행 학습에서 Spectral Normalization (SN)을 사용하여 Lipschitz 연속성을 효율적으로 강제하고, 기존의 gradient penalty 기반 방법보다 GPU 메모리 오버헤드를 줄이면서도 유사한 성능을 달성한다.
본 논문은 Spectral Normalization이라는 기존 기법을 로봇 정책 학습의 대역폭 제약 문제에 창의적으로 적용하여, 계산 효율성과 성능을 모두 달성한 실용적인 솔루션을 제시한다. 시뮬레이션과 실제 로봇 양쪽에서의 검증으로 신뢰성을 높였으며, sim-to-real 전이 문제 해결에 중요한 기여를 한다.
Stabilizing Humanoid Robot Trajectory Generation via Physics-Informed Learning and Control-Informed Steering

Fig. 1: Our method used to execute various walking direc-
 *Fig. 1: Our method used to execute various walking direc-* 인간형 로봇의 궤적 생성에 물리 기반 학습과 제어 기반 보정을 결합하여 모방학습의 안정성을 향상시키는 방법을 제안한다. Physics-informed loss와 PI 제어기를 통해 물리 법칙 위반을 줄이고 실제 로봇에서의 안정성을 개선한다.
본 논문은 물리 기반 학습과 제어 이론을 효과적으로 결합하여 인간형 로봇 궤적 생성의 실제 안정성을 향상시키는 실질적이고 모듈식의 접근법을 제시한다. 특히 미분가능한 물리 제약 인코딩과 추론 단계의 PI 제어 보정은 구현이 간단하면서도 실증적 효과가 크며, 실제 로봇 검증으로 산업 적용 가능성을 보여준다.
The invariant extended Kalman filter as a stable observer
Invariant Extended Kalman Filter (IEKF)를 Lie group 위의 결정론적 비선형 관찰자로 분석하여, 표준 선형 조건 하에서 임의의 궤적 주변에서의 국소 안정성을 증명한다.
본 논문은 IEKF의 수렴성을 엄밀히 증명하고 일반적인 시스템 클래스를 특성화함으로써 비선형 관찰자 이론에 중요한 기여를 하며, navigation 응용에서의 우수한 실제 성능을 이론적으로 정당화한다.
The MIT Humanoid Robot: Design, Motion Planning, and Control For Acrobatic Behaviors
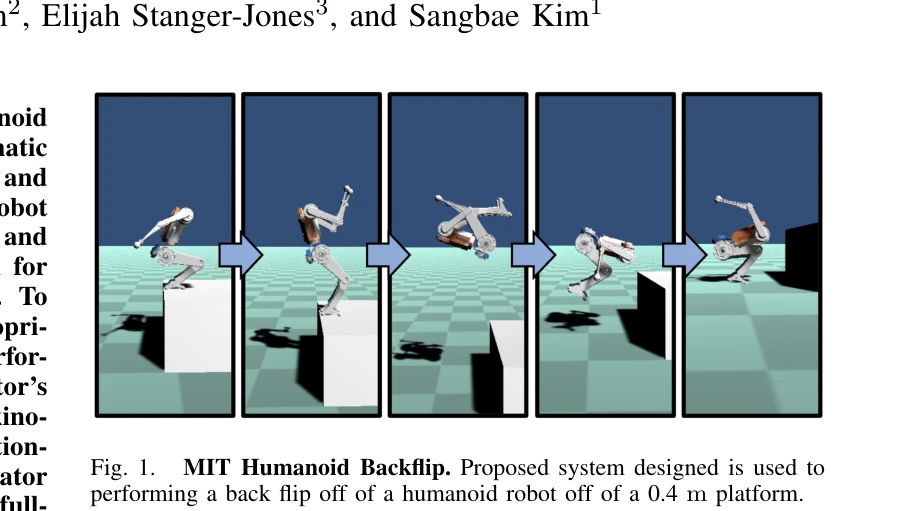
Fig. 1.
 *Fig. 1.* MIT 휴머노이드 로봇이 고도의 동역학 운동(백플립, 전플립, 회전 점프)을 수행하기 위해 맞춤형 액추에이터 설계, actuator-aware kino-dynamic 모션 플래닝, 그리고 MPC와 WBIC을 통합한 착지 제어 시스템을 제시한다.
본 논문은 humanoid 로봇의 고도의 동역학 운동을 실현하기 위해 하드웨어, 모션 플래닝, 제어를 통합적으로 설계한 체계적인 접근법을 제시하며, 맞춤형 액추에이터 개발과 정밀한 검증을 통해 높은 신뢰성을 확보한 우수한 연구이다.
ToddlerBot: Open-Source ML-Compatible Humanoid Platform for Loco-Manipulation

Figure 1: ToddlerBot is an open-source humanoid platform for large-scale, high-quality data collec-
 *Figure 1: ToddlerBot is an open-source humanoid platform for large-scale, high-quality data collec-* ToddlerBot은 머신러닝 기반 로봇 정책 학습을 위해 설계된 저비용, 오픈소스 미니어처 인형로봇으로, 시뮬레이션과 실제 환경 모두에서 고품질 데이터 수집을 가능하게 하며 zero-shot sim-to-real 정책 전이를 지원한다.
ToddlerBot은 ML-compatible 설계, 높은 자유도, 완벽한 재현성, 그리고 저비용이라는 독특한 조합으로 로봇공학 연구를 민주화하는 중요한 플랫폼이며, 시뮬레이션-실제 데이터 수집과 정책 학습을 위한 실질적인 도구를 제공한다.
A Closed-Form Geometric Retargeting Solver for Upper Body Humanoid Robot Teleoperation
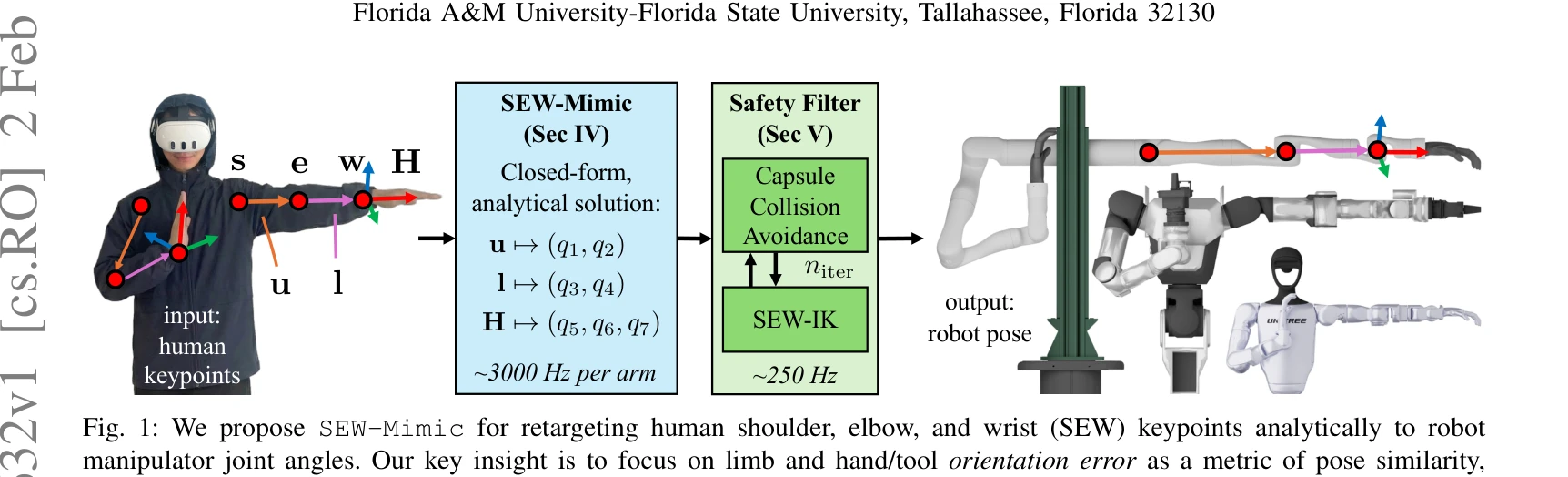
Fig. 1: We propose SEW-Mimic for retargeting human shoulder, elbow, and wrist (SEW) keypoints analytically to robot
 *Fig. 1: We propose SEW-Mimic for retargeting human shoulder, elbow, and wrist (SEW) keypoints analytically to robot* SEW-Mimic은 인간의 어깨, 팔꿈치, 손목(SEW) 키포인트를 7-DoF 로봇 팔의 관절각으로 변환하는 폐형식(closed-form) 기하학적 역운동학 솔버로, 3kHz의 고속 추론과 최적성 보장을 제공한다.
SEW-Mimic은 인간형 로봇 텔레오퍼레이션의 근본적 병목(계산 지연, 팔꿈치 제어 불일치)을 폐형식 기하학적 해석으로 우아하게 해결하며, 실증적 성과와 다중 플랫폼 검증으로 실무 임팩트가 높은 기여이다.
A Gait Driven Reinforcement Learning Framework for Humanoid Robots
 *Fig. 2: A real-time-gait-driven training framework.* 본 논문은 humanoid robot의 bipedal gait 학습을 위해 실시간 gait planner와 structured reward composition을 결합한 reinforcement learning framework를 제시한다.
본 논문은 model-based planning과 data-driven learning을 효과적으로 결합하여 humanoid robot의 bipedal gait 학습을 위한 실용적인 framework를 제시한다. H-LIP 기반 decoupling과 structured reward composition의 조합이 학습 효율성과 periodicity를 동시에 향상시키는 점에서 기술적 독창성이 있으나, 물리 실험 검증과 복잡한 환경 적응성 평가가 추가되면 더욱 강화될 것이다.
A Whole-Body Motion Imitation Framework from Human Data for Full-Size Humanoid Robot
 *Fig. 2.* 전신 동작 모방을 위해 contact-aware 전신 모션 리타겟팅과 비선형 중심 MPC를 결합한 휴머노이드 로봇 제어 프레임워크를 제안한다. 실제 휴머노이드 로봇에서 인간의 다양한 전신 동작을 정확하고 안정적으로 모방할 수 있음을 입증한다.
Contact-aware motion retargeting과 nonlinear centroidal MPC를 체계적으로 결합하여 실제 휴머노이드 로봇에서 정확하고 안정적인 전신 모션 모방을 달성한 강력한 연구이다. 실제 로봇 플랫폼에서의 광범위한 검증은 실용적 가치를 높이나, 고속 동작 확장 및 강건성 분석에서 추가 개선이 필요하다.
AutoOdom: Learning Auto-regressive Proprioceptive Odometry for Legged Locomotion
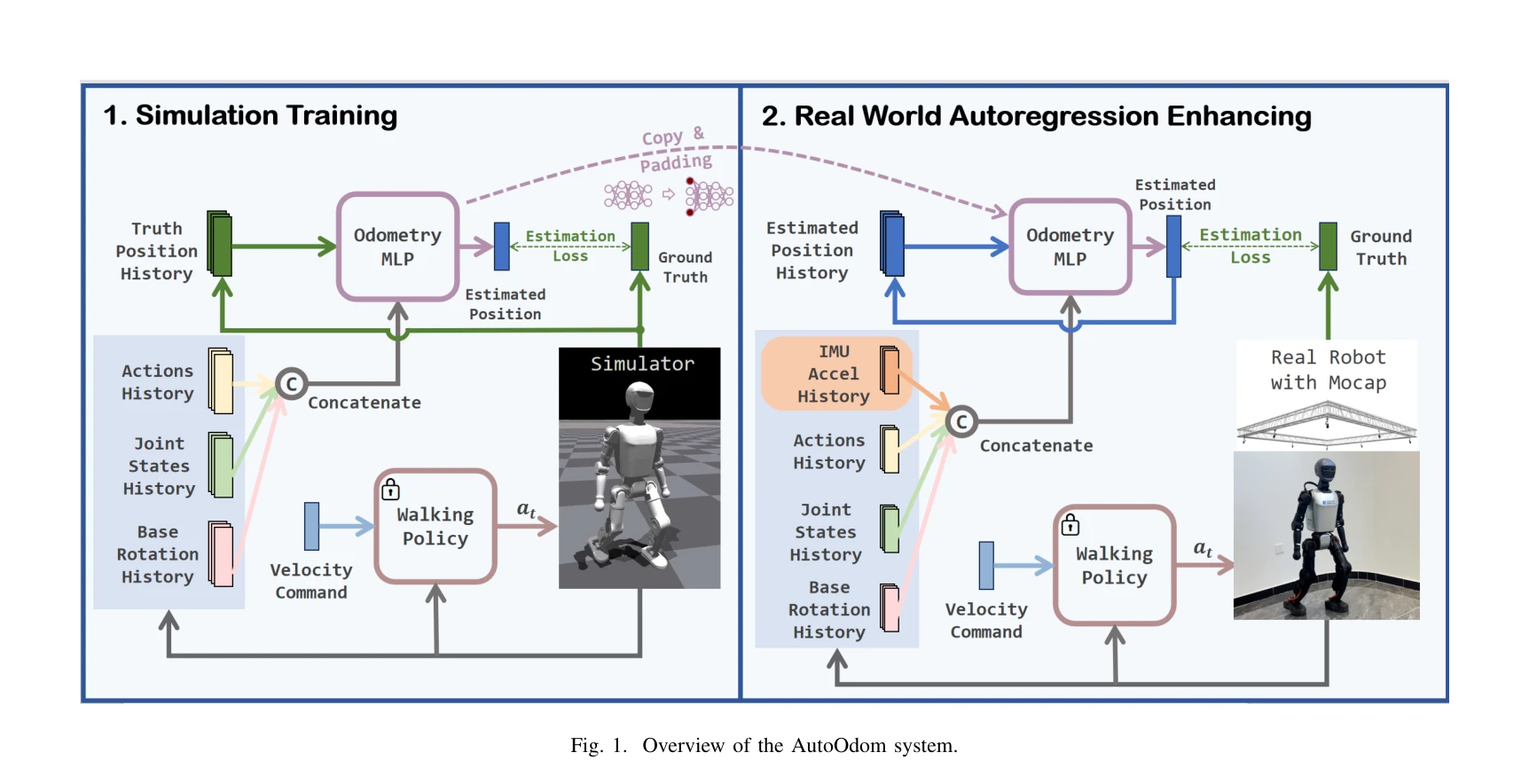
Fig. 1. Overview of the AutoOdom system.
 *Fig. 1. Overview of the AutoOdom system.* AutoOdom은 자동회귀 학습을 기반으로 하는 2단계 훈련 패러다임으로 다리 로봇의 고유감각 주행거리 추정 성능을 크게 향상시킨 시스템이다. 대규모 시뮬레이션 데이터로 비선형 동역학을 학습하고 제한된 실제 데이터로 sim-to-real 갭을 해결한다.
AutoOdom은 자동회귀 학습과 효율적인 2단계 훈련으로 proprioceptive odometry의 중요한 한계를 해결하며, 강력한 실험 결과와 포괄적 ablation 연구로 견고한 기여를 제시한다. 다만 특정 로봇 플랫폼 검증과 다양한 환경으로의 일반화 가능성 확인이 후속 과제다.
Benchmarking Potential Based Rewards for Learning Humanoid Locomotion
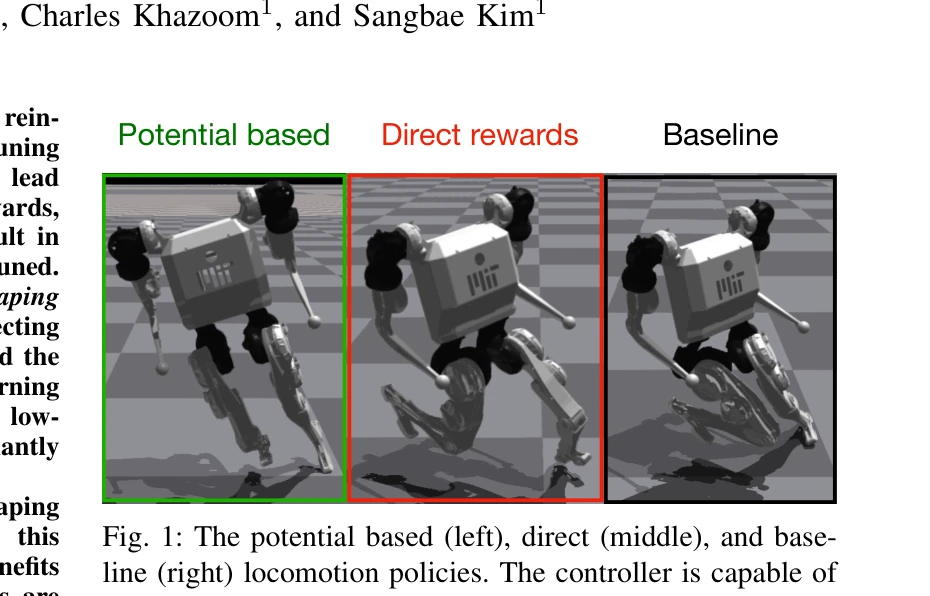
Fig. 1: The potential based (left), direct (middle), and base-
 *Fig. 2: A visualization of a tracking reward in both direct-* 본 논문은 humanoid 로봇의 고차원 보행 학습에서 potential-based reward shaping (PBRS)과 direct reward shaping (DRS)을 벤치마크하여, PBRS가 수렴 속도에서는 한계적 이점만 제공하지만 보상 척도에 대해 훨씬 더 견고하다는 것을 실증적으로 입증한다.
본 논문은 고차원 로보틱 시스템에서 PBRS의 실제 효과를 실증적으로 검증한 중요한 케이스 스터디로, 보상 함수 설계의 실무적 지침(특히 견고성 측면)을 제공한다. 다만 단일 태스크 벤치마크와 이론-실전 간 격차의 원인 분석이 보강된다면 더욱 강력한 기여가 될 것이다.
Cost-Matching Model Predictive Control for Efficient Reinforcement Learning in Humanoid Locomotion
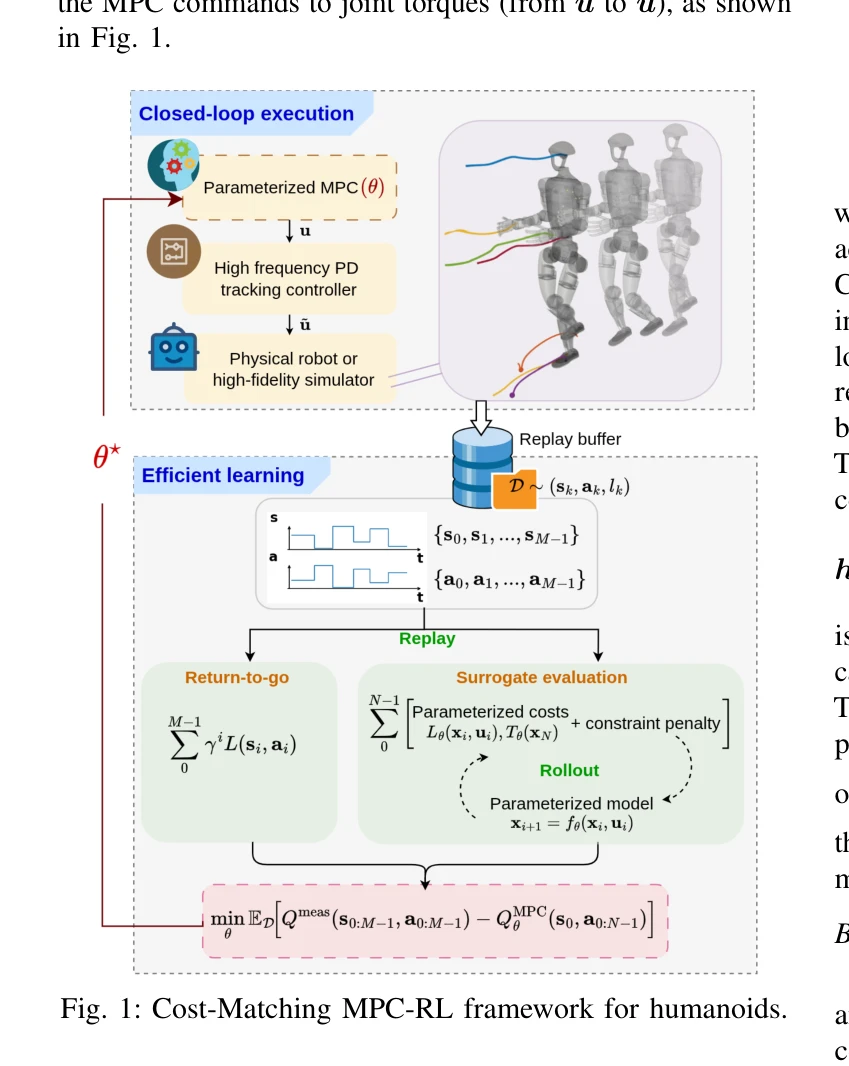
Fig. 1: Cost-Matching MPC-RL framework for humanoids.
 *Fig. 1: Cost-Matching MPC-RL framework for humanoids.* 인간형 로봇 보행 제어를 위해 MPC를 RL로 학습할 때 반복적인 MPC 해결의 계산 부담을 제거하는 Cost-Matching MPC 방법을 제안한다. 매개변수화된 MPC의 비용-미래가치(cost-to-go)와 실제 측정된 리턴값의 불일치를 최소화하여 효율적으로 학습한다.
본 논문은 MPC-RL의 계산 병목을 해결하는 창의적인 cost-matching 방법을 제시하며, 복잡한 인간형 로봇 제어 문제에 체계적으로 적용한 우수한 연구다. 다만 실제 로봇 검증의 부재가 임팩트를 제한하므로, 향후 sim-to-real 전이 연구가 필요하다.
DoublyAware: Dual Planning and Policy Awareness for Temporal Difference Learning in Humanoid Locomotion
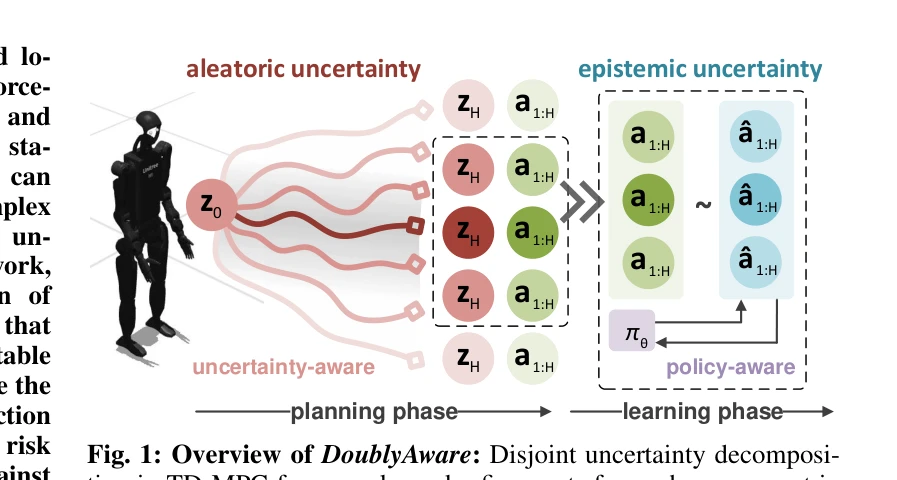
Fig. 1: Overview of DoublyAware: Disjoint uncertainty decomposi-
 *Fig. 1: Overview of DoublyAware: Disjoint uncertainty decomposi-* DoublyAware는 TD-MPC 프레임워크에서 불확실성을 planning uncertainty와 policy uncertainty로 명시적으로 분해하여, conformal prediction과 Group-Relative Policy Constraint를 통해 휴머노이드 로봇의 샘플 효율적이고 안정적인 학습을 실현한다.
본 논문은 MBRL의 핵심 문제인 불확실성을 planning과 policy로 분해하고 각각에 맞는 엄밀한 해법(conformal prediction, GRPC)을 제시함으로써 개념적 명확성과 기술적 우수성을 동시에 달성했다. 휴머노이드 로봇 제어라는 도전적 문제에서 실증적 개선을 보여주었으나, 실제 로봇 검증과 계산 비용 분석이 보완되면 더욱 강력한 기여가 될 것으로 판단된다.
Embrace Collisions: Humanoid Shadowing for Deployable Contact-Agnostics Motions
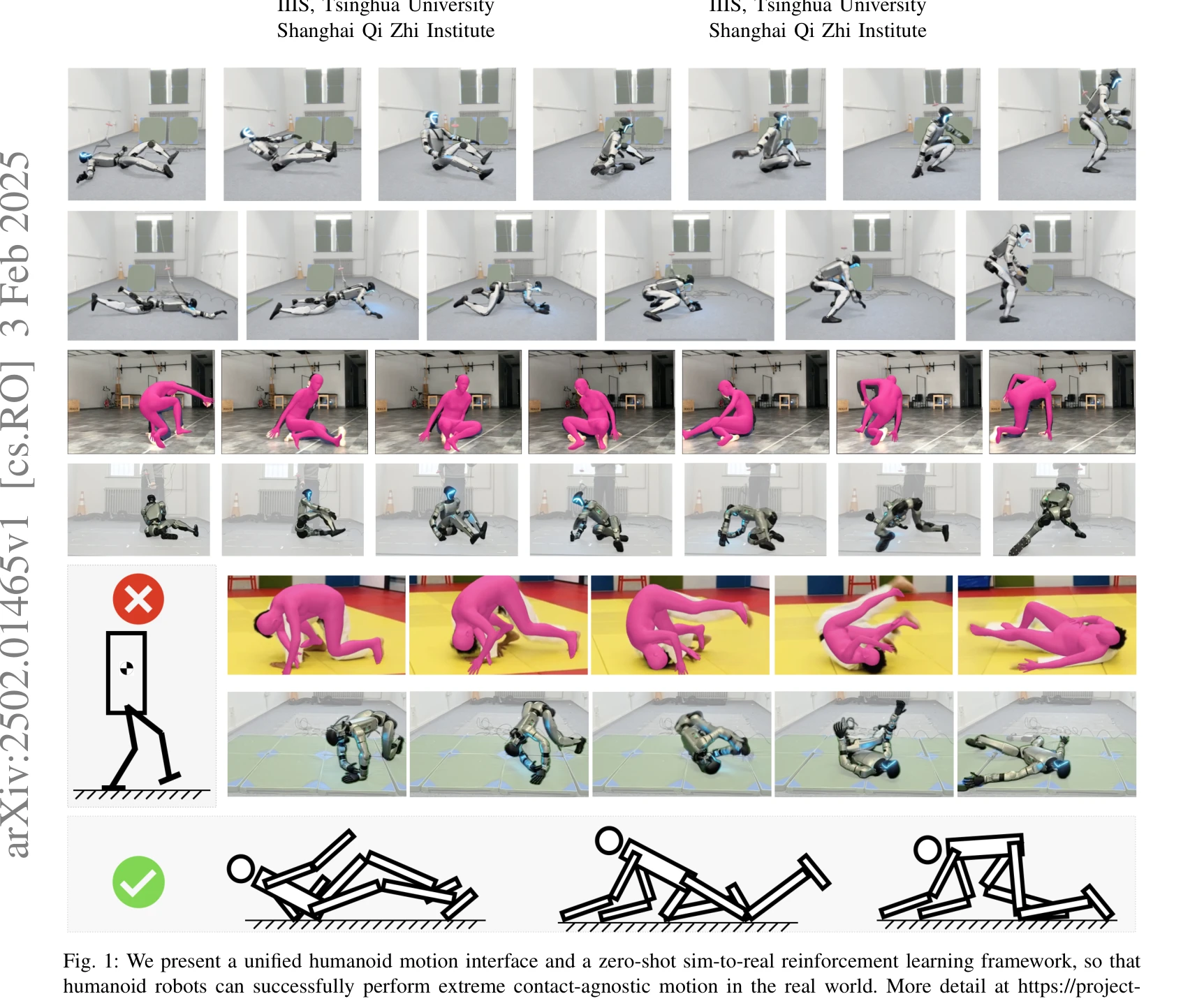
Fig. 1: We present a unified humanoid motion interface and a zero-shot sim-to-real reinforcement learning framework, so
 *Fig. 1: We present a unified humanoid motion interface and a zero-shot sim-to-real reinforcement learning framework, so * 본 논문은 휴머노이드 로봇이 온몸의 모든 신체 부위를 사용하여 환경과 상호작용하는 접촉-무관(contact-agnostic) 동작을 수행할 수 있도록 하는 통합 제어 프레임워크를 제안한다. GPU 가속 rigid-body simulator와 reinforcement learning을 활용하여 시뮬레이션에서 학습한 정책을 실제 로봇에 zero-shot으로 배포할 수 있음을 시연한다.
본 논문은 접촉-무관 극단 동작을 지원하는 humanoid 제어의 중요한 진전을 이루었으며, 새로운 motion interface와 training 기법이 창의적이다. 다만 실험 검증과 기술 상세 설명이 더 필요하고, project website 의존도가 높아 독립적 평가에 제약이 있다.
InEKFormer: A Hybrid State Estimator for Humanoid Robots
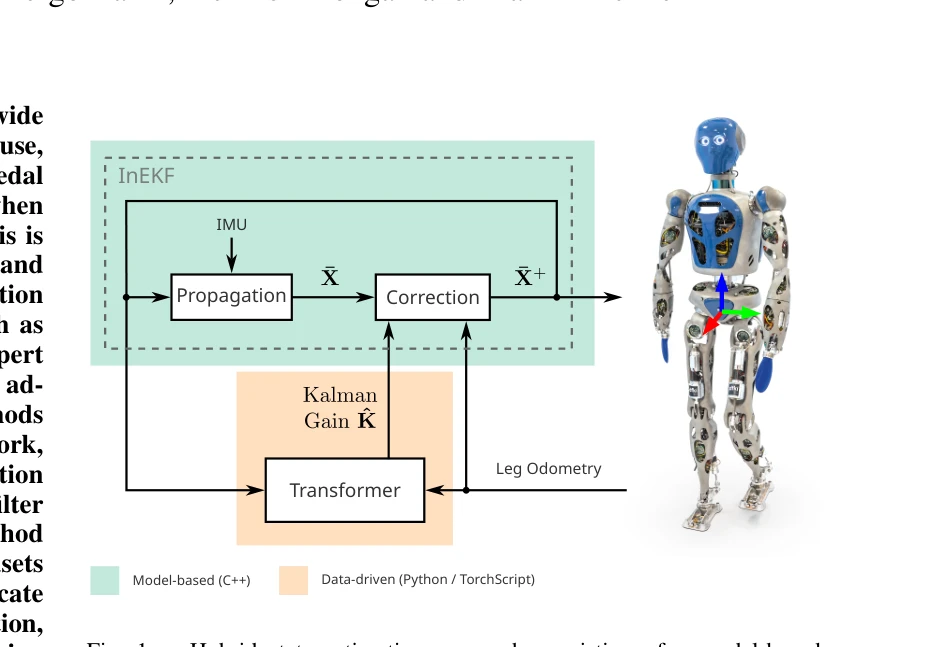
Fig. 1.
 *Fig. 1.* InEKFormer는 Invariant Extended Kalman Filter(InEKF)와 Transformer 네트워크를 결합한 하이브리드 상태 추정 방법으로, 인간형 로봇의 floating base 상태를 정확하게 추정한다.
본 논문은 InEKF와 Transformer를 내부적으로 결합한 novel hybrid 방법을 제시하고 인간형 로봇에 처음 적용함으로써 상태 추정 분야에 기여하나, autoregressive 학습의 안정성 문제와 일반화에 대한 보다 심층적인 분석이 필요하다.
Learning Differentiable Reachability Maps for Optimization-based Humanoid Motion Generation
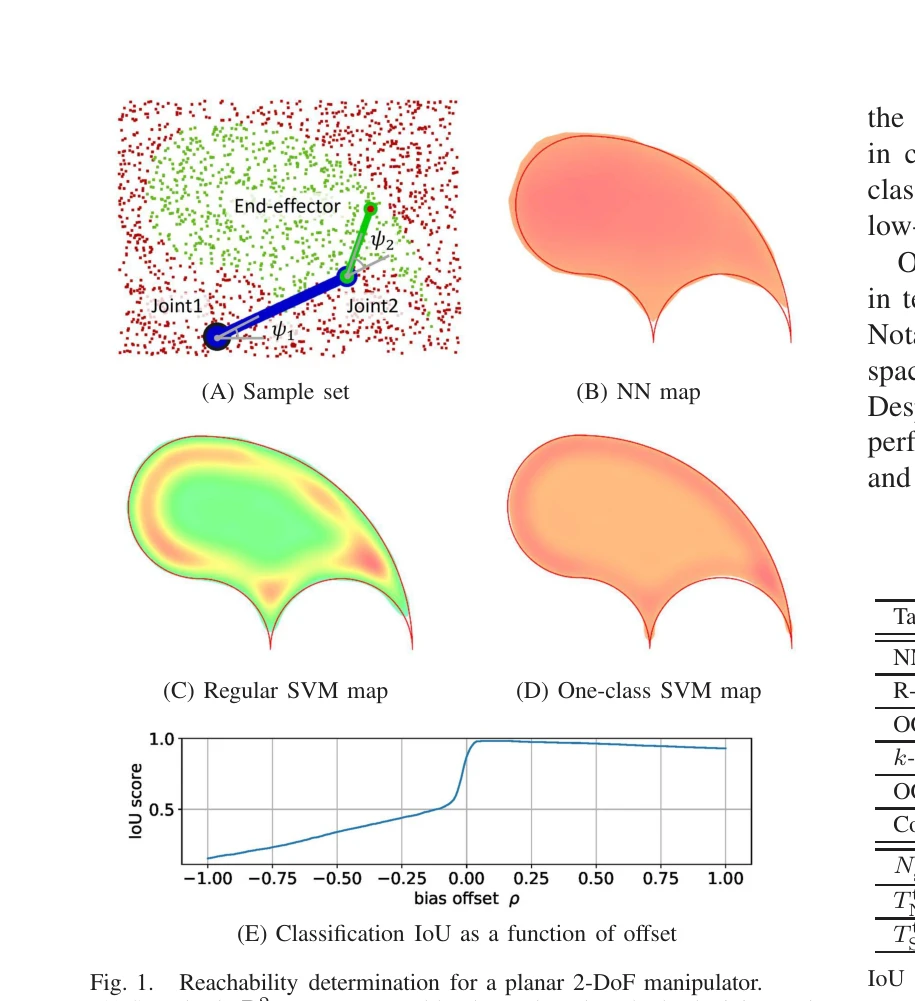
Fig. 1.
 *Fig. 1.* 본 논문은 humanoid robot의 motion generation을 위해 differentiable reachability map을 학습하는 새로운 방법을 제안한다. 이 맵은 task space에서 정의된 스칼라 함수로서, robot end-effector이 도달 가능한 영역에서만 양수값을 가지며, task space 좌표에 대해 미분가능하여 continuous optimization의 제약조건으로 직접 사용될 수 있다.
본 논문은 humanoid motion planning의 computational bottleneck을 해결하기 위해 differentiable reachability map이라는 혁신적 표현을 제안하며, binary classification 기반의 학습 방법론은 기존 방식의 한계를 잘 극복한다. 다만 실제 실험 결과와 성능 평가에 대한 상세한 검증이 필요하다.
Legged Robot State-Estimation Through Combined Forward Kinematic and Preintegrated Contact Factors
 *Fig. 2: An example factor graph for the proposed system. Forward kinematic* 시각 추적 손실 시에도 작동하는 다리 로봇 상태 추정 기법으로, Forward Kinematic 인수와 Preintegrated Contact 인수를 Factor Graph에 통합하여 엔코더 측정과 접촉 정보를 활용한다.
본 논문은 Factor Graph 프레임워크에 Forward Kinematic 및 Preintegrated Contact 인수를 처음 도입하여 시각 손실 상황에서도 다리 로봇의 상태를 추정할 수 있는 실용적 기법을 제시했으며, 이론적 엄밀성과 실제 로봇 구현 양면에서 견고한 기여를 하지만, 실험의 규모가 제한적이고 일반화 가능성 검증이 필요하다.
LiPS: Large-Scale Humanoid Robot Reinforcement Learning with Parallel-Series Structures
 *Fig. 4: Illustration of LiPS Simulation Training and Real-World Deployment Process.* LiPS는 GPU 기반 병렬 훈련 환경에서 URDF 형식의 휴머노이드 로봇을 위한 강화학습 방법으로, 멀티-리지드바디 폐루프 동역학 모델링을 통해 시뮬레이션-현실 간 격차를 줄인다.
LiPS는 휴머노이드 로봇의 GPU 병렬 강화학습에서 sim2real 격차를 크게 줄이는 실질적이고 실용적인 방법으로, URDF 기반 복잡한 로봇 제어 연구에 중요한 기여를 한다. 다만 광범위한 실제 로봇 검증과 다양한 시뮬레이션 플랫폼으로의 확장 연구가 필요하다.
Model-Based Reinforcement Learning Exploits Passive Body Dynamics for High-Performance Biped Robot Locomotion
Figure 1: Biped robot and model. (A) Lower body model based on muscu-
본 연구는 수동적 신체 역학(스프링, 높은 백드라이버빌리티 등)을 가진 이족 로봇이 Model-Based Deep Reinforcement Learning을 통해 고성능 보행·주행 운동을 효율적으로 습득할 수 있음을 보여준다. 수동 요소가 시스템의 어트랙터를 활용하여 안정적이고 에너지 효율적인 운동을 생성한다.
본 논문은 embodied AI의 핵심인 수동 신체 역학의 학습 효율성을 엄밀하게 입증한 중요한 연구로, Model-Based RL과 생체역학 설계의 시너지를 명확히 보여준다. 시뮬레이터 기반 검증이라는 한계가 있지만, 미래 로봇 설계 원칙에 유의미한 통찰을 제공한다.
Tree Learning: A Multi-Skill Continual Learning Framework for Humanoid Robots
 *Figure 2: Tree Learning for Unitree G1.* Tree Learning은 humanoid robot을 위한 multi-skill continual learning 프레임워크로, hierarchical parameter inheritance mechanism을 통해 catastrophic forgetting을 방지하면서 새로운 스킬을 효율적으로 확장한다.
Tree Learning은 biological hierarchy inspired architecture를 통해 humanoid robot의 multi-skill continual learning에서 catastrophic forgetting을 근본적으로 해결하면서 경량 배포를 가능하게 하는 창의적인 솔루션이다. 다만 real-world 환경에서의 실제 검증과 더 복잡한 skill 상호작용에 대한 확장성이 향후 과제이다.
HALO: Hybrid Auto-encoded Locomotion with Learned Latent Dynamics, Poincaré Maps, and Regions of Attraction
Figure 1: Autoencoders enable learning of a reduced-order dynamics model in a latent space.
 *Figure 1: Autoencoders enable learning of a reduced-order dynamics model in a latent space.* HALO는 autoencoder와 Poincaré map을 결합하여 다리 로봇 같은 hybrid 동역학 시스템의 주기적 운동을 저차원 latent space에서 학습하고 분석하는 프레임워크이다. Latent space에서 Lyapunov 분석을 수행하여 region of attraction을 구성하고 이를 전체 시스템으로 복원한다.
HALO는 hybrid locomotion dynamics의 안정성 분석을 위해 autoencoder와 Poincaré map을 창의적으로 결합한 우수한 연구이며, latent space의 안정성 속성이 전체 시스템으로 이전된다는 것을 실험적으로 입증한다. 이론과 실험의 균형이 좋으나, 복잡한 시스템에서의 reconstruction 오차 처리와 robust 안정성 보장에 대한 더 깊은 분석이 필요하다.
Humanoid Robot Teleoperation for Nonprehensile Transportation: A Multiple-Constraint Safety-Critical Control Framework
 *Figure 2. Dual-arm reachability maps of the custom-built humanoid robot platform.* 본 논문은 인간형 로봇의 비파지 운송 작업을 위한 텔레조작 시스템에서 다층적 안전 제약 조건을 동시에 만족하는 Multiple-Constraint Safety-Critical Control Framework (MC-SCCF)를 제안한다. 계층적 3계층 아키텍처를 통해 작업공간 경계, 물체 역학 안전성, 로봇 운동학 제약을 통합하여 관리한다.
본 논문은 인간형 로봇 텔레조작을 위한 실질적이고 중요한 문제를 다루며, 미분 가능한 도달 가능성 평가, 개선된 CBF, 3계층 계층적 제어 프레임워크 등 기술적으로 건실한 해결책을 제시한다. 하드웨어 실증 결과는 실용성을 보여주나, 모델링 불확실성 강건성과 동적 환경 적응성에 대한 깊이 있는 분석이 추가되면 더욱 완성도 높은 연구가 될 것으로 판단된다.
Learning Symmetric and Low-energy Locomotion
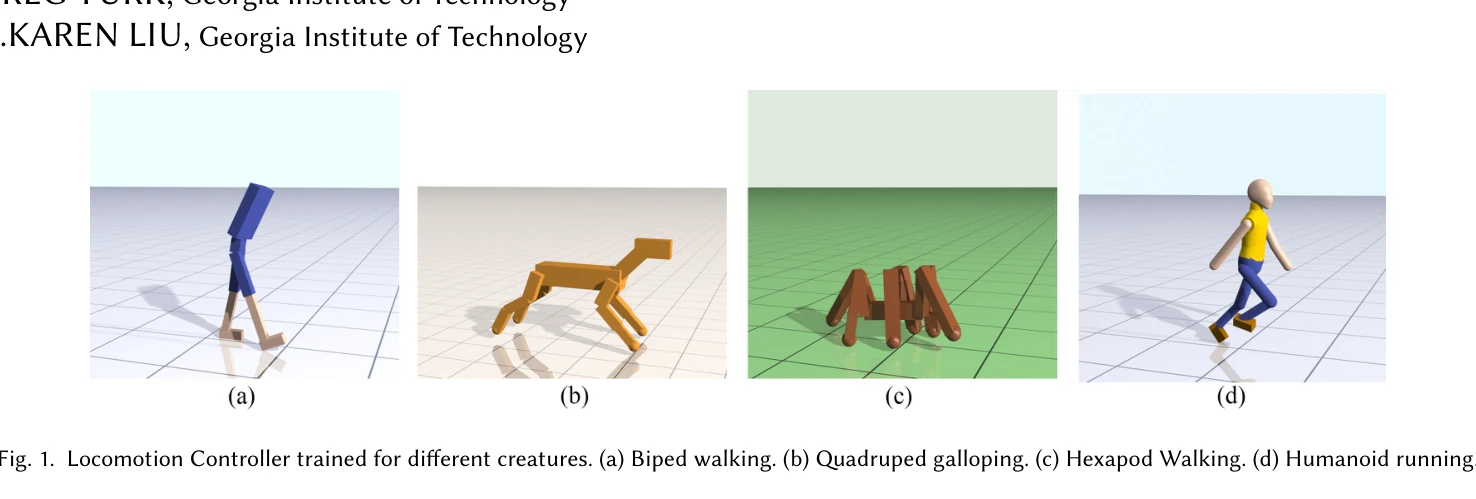
Fig. 1. Locomotion Controller trained for different creatures. (a) Biped walking. (b) Quadruped galloping. (c) Hexapod W
 *Fig. 1. Locomotion Controller trained for different creatures. (a) Biped walking. (b) Quadruped galloping. (c) Hexapod W* 본 논문은 심층 강화학습(DRL)을 사용하여 motion capture나 finite state machine 없이 대칭적이고 저에너지의 자연스러운 로코모션을 학습하는 방법을 제안한다. 손실 함수에 미러 대칭성 손실항을 추가하고, 점진적으로 물리적 보조를 완화하는 curriculum learning 방법을 통해 다양한 형태의 캐릭터(이족, 사족, 육족)에서 효과적인 보행 제어기를 자동으로 생성할 수 있음을 보여준다.
본 논문은 강화학습 기반 로코모션 학습에서 미러 대칭성 손실과 curriculum learning이라는 두 가지 간단하면서도 효과적인 기법을 통해 자연스럽고 에너지 효율적인 보행을 달성한 우수한 연구이다. 특히 motion capture나 형태 특정 지식 없이 다양한 캐릭터에 적용 가능한 일반성과 생물학적으로 타당한 결과는 의미있는 기여이나, 이론적 근거와 더 복잡한 운동에 대한 검증이 보완된다면 더욱 강력한 연구가 될 것이다.
Physics-Informed Neural Networks with Unscented Kalman Filter for Sensorless Joint Torque Estimation in Humanoid Robots
 *Fig. 4: CoM tracking comparison: RNEA-PINN (left) vs. UKF-PINN (right). Green rectangles indicate external contacts.* 본 논문은 휴머노이드 로봇의 joint torque 센서를 사용하지 않고 토크 제어를 수행하기 위해 PINN을 활용한 마찰 모델링과 UKF 기반 joint torque 추정을 통합하는 프레임워크를 제시한다. 이 접근법은 high-ratio harmonic drive를 탑재한 전기 모터 시스템에서 실시간 sensorless torque control을 가능하게 한다.
본 논문은 PINN과 UKF를 통합한 sensorless torque control 프레임워크를 제시하며, 휴머노이드 로봇 제어에서 실질적인 advances를 제공한다. 기술적으로 견고하고 실험적으로 검증되었으나, 실험 범위의 제한과 계산 효율성에 대한 분석 부족이 영향을 미친다. 전반적으로 robotics 커뮤니티에 가치 있는 기여를 한다.
SPARK: Safe Protective and Assistive Robot Kit
 *Figure 3: SPARK system framework.* SPARK는 휴머노이드 로봇의 안전한 자율 제어와 원격 조종을 위한 포괄적인 벤치마크 프레임워크로, 모듈식 안전 제어 알고리즘과 시뮬레이션 환경을 제공하여 비전문가도 안전 컨트롤러를 효율적으로 설계하고 배포할 수 있도록 지원한다.
SPARK는 휴머노이드 로봇의 안전한 제어를 위한 실질적이고 체계적인 프레임워크를 제시하는 높은 가치의 연구로, 모듈식 설계, 벤치마크 제공, 실제 배포 검증을 통해 안전 로봇 연구를 가속화할 수 있는 견고한 기반을 마련했다.
CAD-Driven Co-Design for Flight-Ready Jet-Powered Humanoids
 *Fig. 2: CAD assemblies of the links being modified. 1: Jetpack Turbine Angle; 2: Jetpack Turbine offset distance; 3: Jet* CAD 기반 설계-제어 공동 최적화 프레임워크를 통해 제트 추진 휴머노이드 로봇의 형태와 MPC 제어 파라미터를 동시에 최적화하여 비행 가능한 구성을 도출한다.
본 논문은 CAD 기반 설계-제어 공동 최적화를 제트 추진 항공 휴머노이드에 적용한 것으로, 대규모 형태 공간 탐색과 비행 성능 평가를 체계적으로 통합한 점에서 기여가 크다. 다만 선형화된 제어와 제한된 평가 시나리오는 실제 적용의 견고성을 위해 추가 검증이 필요하다.
Contact-Aided Invariant Extended Kalman Filtering for Robot State Estimation

Figure 1: A Cassie-series biped robot is used for both simulation and experimental results. The robot was developed by A
 *Figure 1: A Cassie-series biped robot is used for both simulation and experimental results. The robot was developed by A* Lie군 이론과 불변 관찰자 설계를 기반으로 IMU와 접촉 센서 데이터를 융합하는 Contact-Aided Invariant Extended Kalman Filter (InEKF)를 개발하여 이족 로봇의 자세와 속도를 추정한다.
이 논문은 Lie군 기반 불변 관찰자 이론을 legged robot의 접촉-관성 상태 추정에 체계적으로 적용하여, 기존 EKF의 수렴성과 일관성 문제를 근본적으로 해결한 중요한 기여를 제시한다. 이론적 엄밀성과 실험적 검증, 오픈소스 구현까지 겸비한 완성도 높은 연구로, 자율 legged robot의 장시간 안정 운영을 위한 핵심 기술이다.
iRonCub 3: The Jet-Powered Flying Humanoid Robot
 *Fig. 2.* iRonCub 3는 제트 터빈 4개를 장착한 완전 인형형 비행 로봇으로, 시뮬레이션 검증 후 최초로 수직 이착륙에 성공했다.
iRonCub 3는 인형형 로봇 비행의 기술적 난제(제어, 추정, 기계 통합)를 체계적으로 해결하고 최초 비행 실증을 달성했으나, 고등 기동과 조작 능력 통합은 향후 과제다.
Learning Aerodynamics for the Control of Flying Humanoid Robots

Fig. 1: Design of the iRonCub-Mk1 physical prototype. Front (a) and rear (b) pictures of the
 *Fig. 1: Design of the iRonCub-Mk1 physical prototype. Front (a) and rear (b) pictures of the* 비행 인간형 로봇의 공기역학 모델링을 위해 CFD 시뮬레이션, 풍동 실험, 딥러닝을 결합한 포괄적 접근 방식을 제시하고, 제트 엔진을 장착한 iRonCub-Mk1 로봇을 설계·제작하여 비행 제어를 구현한다.
인간형 로봇의 비행 능력 확보를 위해 공기역학 모델링과 제어를 종합적으로 다룬 기술적·과학적으로 의미 있는 연구이며, 다중 모드 로봇의 미래 설계에 중요한 기여를 제시한다. 다만 실제 비행 실험 검증과 학습 모델의 일반화 성능 평가가 후속 과제이다.
SPARK: Safe Protective and Assistive Robot Kit
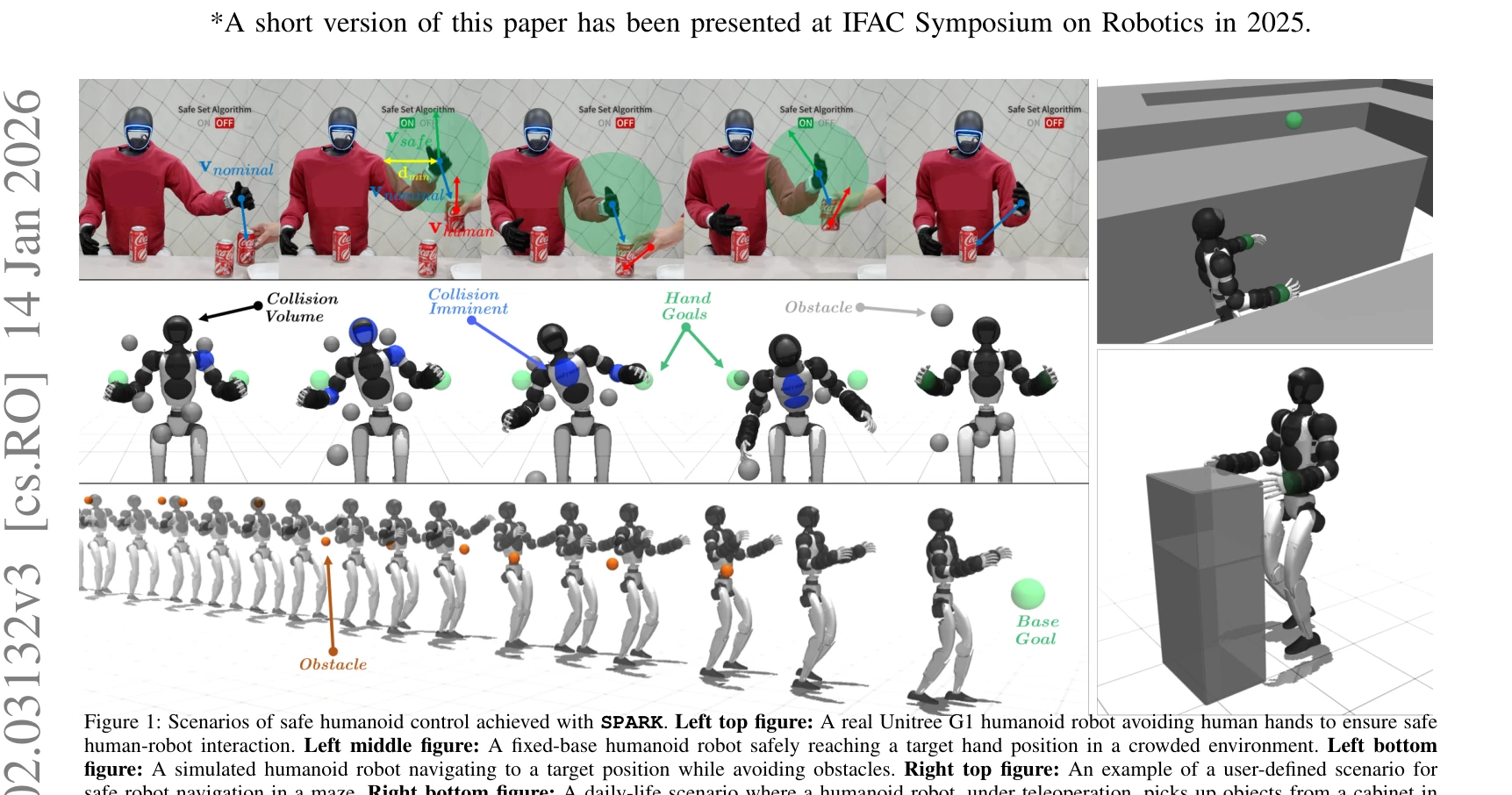
Figure 1: Scenarios of safe humanoid control achieved with SPARK. Left top figure: A real Unitree G1 humanoid robot avoi
 *Figure 1: Scenarios of safe humanoid control achieved with SPARK. Left top figure: A real Unitree G1 humanoid robot avoi* 본 논문은 인형 로봇의 안전한 자율주행 및 원격 조종을 위한 종합적인 벤치마크 및 도구 모음인 SPARK를 제시한다. 모듈 방식의 composable, extensible, deployable 설계를 통해 사용자가 커스텀 안전 조건과 작업 목표를 쉽게 구성하고 실제 로봇에 배포할 수 있도록 한다.
SPARK는 인형 로봇의 안전한 배포를 위한 실질적이고 실용적인 솔루션을 제시하는 고가치의 도구 논문이다. Composable, extensible, deployable 설계 원칙을 통해 기존 개별 알고리즘들의 통합과 재사용성을 크게 향상시켰으며, 시뮬레이션-실제 로봇 간의 연결고리를 제공한다. 다만 새로운 알고리즘 기여보다는 engineering 측면의 도구 개발에 초점이 있으므로 이론적 혁신성은 제한적이다. 로봇 안전 연구 커뮤니티에 실질적인 가치를 제공할 수 있는 고품질의 플랫폼 논문이다.
A 21-DOF Humanoid Dexterous Hand with Hybrid SMA-Motor Actuation: CYJ Hand-0
 *Figure 3. (a) The overall structural design of the bionic dexterous hand. (b) Components of the bionic dexterous hand. (* CYJ Hand-0는 SMA와 DC 모터의 하이브리드 구동 방식을 결합한 21-DOF 휴머노이드 손으로, 3D 프린팅 AlSi10Mg 금속 프레임과 고강도 낚싯줄 텐던을 활용하여 인간의 손 구조를 생체모방한다.
CYJ Hand-0는 SMA-모터 하이브리드 구동, 정교한 생체모방 설계, 효율적인 3D 프린팅 제조를 통해 경량이면서도 고성능의 휴머노이드 손을 실현한 주목할 만한 연구이며, 특히 모듈화 아키텍처와 포괄적 성능 평가가 강점이다.
A Framework for Optimal Ankle Design of Humanoid Robots
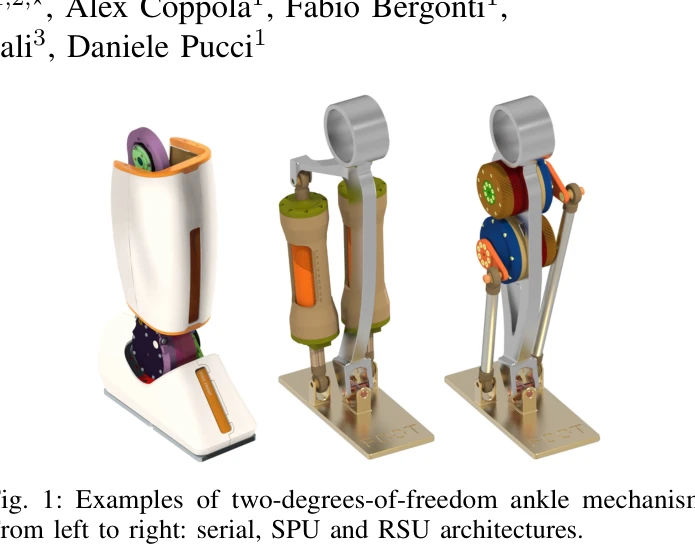
Fig. 1: Examples of two-degrees-of-freedom ankle mechanisms.
 *Fig. 1: Examples of two-degrees-of-freedom ankle mechanisms.* 휴머노이드 로봇의 발목 설계를 위한 통합 프레임워크를 제시하며, SPU 및 RSU 병렬 메커니즘에 대한 다목적 최적화를 통해 최적 구성을 도출한다.
본 논문은 휴머노이드 로봇 발목 설계의 오랜 난제인 아키텍처 선택과 파라미터 최적화를 체계적이고 정량적으로 해결하는 통합 프레임워크를 제시하며, 실제 로봇 재설계를 통한 유의미한 성능 개선으로 실용성을 입증하였다.
A Hierarchical, Model-Based System for High-Performance Humanoid Soccer
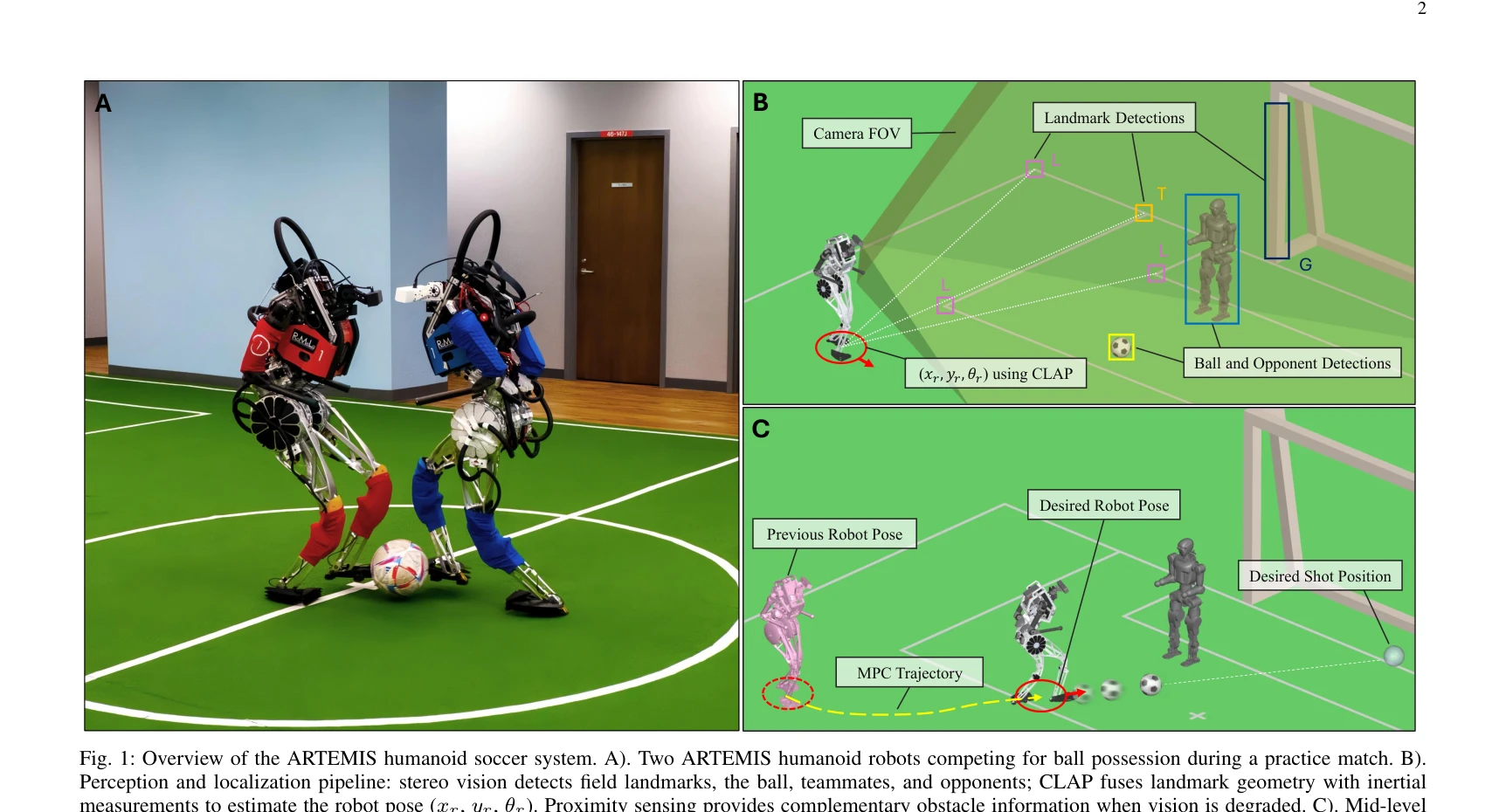
Fig. 1: Overview of the ARTEMIS humanoid soccer system. A). Two ARTEMIS humanoid robots competing for ball possession du
 *Fig. 2: System architecture of the ARTEMIS humanoid platform. The perception layer provides object detections, proximity* RoboCup 2024 우승팀의 완전히 통합된 성인용 휴머노이드 축구 로봇 시스템으로, QDD 액추에이터 기반 하드웨어와 계층적 perception-planning-control 아키텍처를 결합하여 동적이고 전술적으로 효과적인 게임플레이를 실현했다.
QDD 액추에이터 기반 하드웨어와 perception-planning-control의 tight integration을 통해 RoboCup 우승을 달성한 고성숙도의 시스템으로, 동적 휴머노이드 제어와 실시간 자율 네비게이션의 실제 구현 사례로서 상당한 실질적 가치를 제공한다.
Antagonistic Bowden-Cable Actuation of a Lightweight Robotic Hand: Toward Dexterous Manipulation for Payload Constrained Humanoids
Fig. 1: Overview of the proposed Antagonistic Bowden-
 *Fig. 1: Overview of the proposed Antagonistic Bowden-* Bowden 케이블을 이용한 원격 구동 방식의 경량 인간형 로봇 손으로, 길항적 케이블 작동과 rolling-contact joints를 결합하여 20개 DOF를 236g의 극히 낮은 질량으로 구현하였다.
본 논문은 극도로 경량화된 원격 구동 로봇 손의 설계를 통해 payload 제약이 있는 인간형 로봇에 고 dexterity를 부여하는 실용적 솔루션을 제시한다. Rolling-contact joints와 길항적 케이블 구동의 결합은 독창적이며, 3D 프린팅 기반의 완전 제작 가능한 설계로 재현성과 확장성이 우수하다.
Control of Humanoid Robots with Parallel Mechanisms using Differential Actuation Models
 *Fig. 3: Planar 4-bar mechanism, with the serial link rotating* Cassie 영감의 휴머노이드 로봇에 사용되는 병렬 구동 메커니즘에 대한 미분가능한 해석 모델을 제시하여 정확한 비선형 전달 특성을 효율적으로 계산 가능하게 한다.
Parallel actuation 메커니즘의 정확한 모델링을 minimal하고 미분가능한 형식으로 구현하여 현대 제어 및 학습 알고리즘에 실용적으로 통합 가능하게 한 의미 있는 기여다. 하드웨어 검증으로 이론의 실효성을 입증했으나, 보다 일반적인 mechanism 설계에 대한 확장성 검증이 추가로 필요하다.
DIAL: Distilling Intent-Aware Latents for Vision-Language-Action on Humanoid Robots
Fig. 1.
 *Fig. 2.* SoftHand Model-W는 3D 프린팅 기반의 인간형 로봇 손으로, 2-DoF 손목을 통합하여 손가락의 underactuated tendon-driven 구조와 손목의 능동적 제어를 결합했다. Carpal tunnel 영감의 힘줄 라우팅을 통해 원격 모터 배치를 가능하게 하면서 compact한 형태를 유지한다.
SoftHand Model-W는 soft robotics의 adaptive synergies 개념을 유지하면서 능동적 손목을 처음 통합한 혁신적 설계이며, 3D 프린팅과 carpal tunnel routing을 통해 실용성과 anthropomorphism을 동시에 달성했다. 손목 추가의 명확한 성능 개선 효과를 입증하여 dexterous manipulation 분야에 의미 있는 기여를 한다.
Exceeding the Maximum Speed Limit of the Joint Angle for the Redundant Tendon-driven Structures of Musculoskeletal Humanoids
 *Fig. 2.* 중복 힘줄 구동 구조를 가진 근골격 인간형 로봇에서 가장 느린 근육에 의해 제한되는 관절 각속도 한계를 초과하는 두 가지 방법을 제안하고 실제 로봇 실험으로 검증한다.
근골격 인간형 로봇의 구동 제약을 새로운 관점에서 분석하고, 실용적이면서도 독창적인 두 가지 해결 방법을 제시했다. 실제 로봇 실험 검증을 통해 이론의 타당성을 입증했으나, 시뮬레이션의 단순화와 적용 조건의 제한이 개선될 여지가 있다.
Explosive Output to Enhance Jumping Ability: A Variable Reduction Ratio Design Paradigm for Humanoid Robots Knee Joint
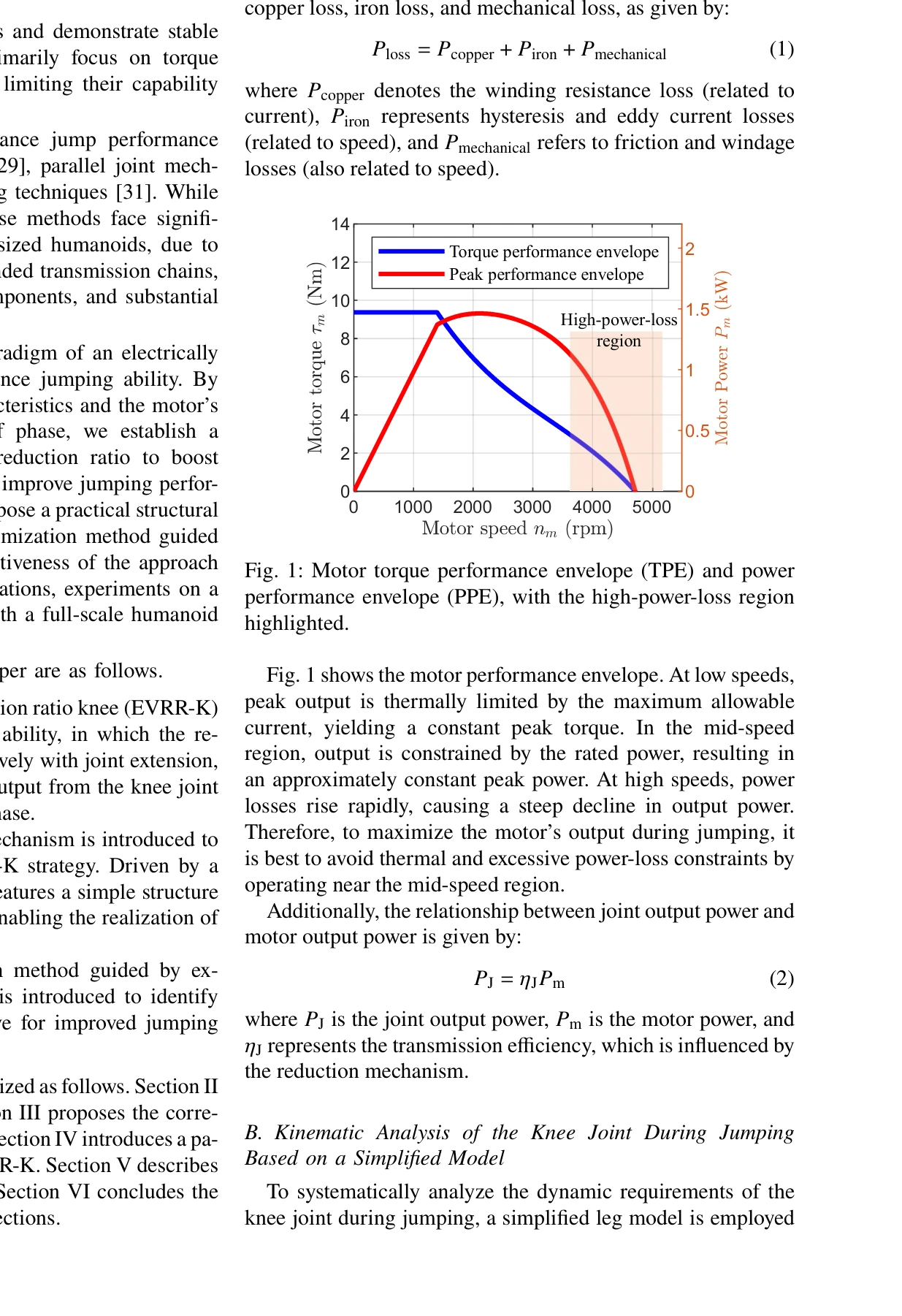
Fig. 1: Motor torque performance envelope (TPE) and power
 *Fig. 1: Motor torque performance envelope (TPE) and power* 휴머노이드 로봇의 점프 능력을 향상시키기 위해 무릎 관절이 신장할수록 감속비가 동적으로 감소하는 EVRR-K(Explosive Variable Reduction Ratio Knee) 설계 패러다임을 제안한다.
무릎 관절의 동적 감속비 개념을 신창의적으로 도입하여 전기 구동 휴머노이드의 점프 성능을 획기적으로 개선한 우수한 연구다. 이론 분석, 메커니즘 설계, 실험 검증이 체계적으로 이루어져 있으며, 달성한 점프 성능(0.5m 수직, 1.1m 수평)은 기존 전기 로봇 대비 최고 수준이다.
ExtremControl: Low-Latency Humanoid Teleoperation with Direct Extremity Control

Fig. 1: The humanoid robot (Unitree G1) demonstrates a diverse set of loco-manipulation tasks under teleoperation: (a) r
 *Fig. 1: The humanoid robot (Unitree G1) demonstrates a diverse set of loco-manipulation tasks under teleoperation: (a) r* ExtremControl은 SE(3) 포즈 기반의 직접 제어와 velocity feedforward 제어를 통해 humanoid teleoperation의 지연시간을 50ms까지 단축하는 저지연 전신 제어 프레임워크이다.
ExtremControl은 velocity feedforward와 direct extremity control을 결합하여 humanoid teleoperation의 지연시간을 4배 단축하고 고속 반응 작업을 실현한 혁신적 연구로, 실제 로봇에서의 높은 응답성 달성과 통합된 시스템 구현으로 실용적 가치가 우수하다.
Fauna Sprout: A lightweight, approachable, developer-ready humanoid robot
Fig. 1: Robot in action. (A) Standing and looking up towards a person (B) performing closed-loop high-five interaction
 *Fig. 1: Robot in action. (A) Standing and looking up towards a person (B) performing closed-loop high-five interaction* Sprout는 인간 환경에서의 안전한 배포, 표현성, 개발자 접근성을 강조하는 경량 휴머노이드 로봇 플랫폼이다. 낮은 물리적·기술적 진입장벽으로 구현된 통합 하드웨어-소프트웨어 스택을 제공한다.
Sprout는 로보틱스 분야의 접근성 문제를 정면으로 해결하는 실용적 플랫폼으로, 안전성과 개발자 친화성을 중심으로 한 설계 철학이 명확하다. 인간 환경 배포와 사회적 상호작용이라는 과소 탐색된 영역을 강조함으로써 embodied AI 연구의 새로운 방향을 제시하는 의미 있는 기여이다.
Human-Level Actuation for Humanoids
 *Figure 4: Lower body atlas I: Pelvis and hip degrees of freedom. Pelvic motion is relative to a global* 휴머노이드 로봇의 '인간 수준' 구동을 정량화하고 비교 가능하게 하기 위해 생체역학 기반의 포괄적 평가 프레임워크를 제시하고, DoF atlas, Human-Equivalence Envelopes (HEE), Human-Level Actuation Score (HLAS)의 세 가지 핵심 요소로 구성된다.
이 논문은 휴머노이드 로봇의 '인간 수준' 구동력을 정량화하기 위한 학제적 프레임워크를 제시하며, 생체역학 기반의 엄격한 기준과 표준화된 측정 프로토콜을 결합하여 로봇 개발과 벤치마킹의 투명성과 재현성을 크게 향상시킨다. 구동기 설계 트레이드오프를 명시적으로 노출하고 작업 맥락에 맞춘 평가를 수행한다는 점에서 기존 피크값 기반 사양과 차별화되며, 휴머노이드 로봇 공학 분야에서 중요한 표준화 기여를 한다.
ORCA: An Open-Source, Reliable, Cost-Effective, Anthropomorphic Robotic Hand for Uninterrupted Dexterous Task Learning
Fig. 1: (A) The ORCA hand closely mimics its human counterpart with
 *Fig. 1: (A) The ORCA hand closely mimics its human counterpart with* ORCA는 2,000 CHF 미만의 재료비로 8시간 내에 조립 가능한 오픈소스 tendon-driven 인간형 로봇 손이며, popping joints와 자동 캘리브레이션 등의 설계로 높은 신뢰성과 정확도를 달성한다.
ORCA는 tendon-driven 로봇 손의 조립 용이성과 신뢰성을 획기적으로 개선하여 dexterous manipulation 연구의 하드웨어 접근 장벽을 크게 낮춘 중요한 공헌이며, 오픈소스 공개를 통해 연구 커뮤니티의 광범위한 채택과 확장을 촉진할 것으로 기대된다.
Constraint-Enhanced Reinforcement Learning Based on Dynamic Decoupled Spherical Radial Squashing
본 논문은 강화학습에서 이질적(heterogeneous) 관절별 액추에이터 속도 제약을 정확히 처리하는 Dynamic Decoupled Spherical Radial Squashing (DD-SRad) 기법을 제안한다. 기존의 isotropic spherical 방법은 ℓ∞ 박스 형태의 제약을 ℓ2 공 형태로 압축하여 실현 가능 집합을 손실하는 반면, DD-SRad는 차원별 적응 반경(per-dimension adaptive radius)을 독립적으로 계산하여 정확한 ℓ∞ 커버리지를 달성한다.
본 논문은 이질적 속도 제약을 가진 강화학습 문제에 대해 이론적으로 건전하고 실무적으로 효과적인 해결책을 제시한다. 기하학적 직관, 엄밀한 정리, 광범위한 실증이 결합되어 있으며, 실 로봇 배포 경로를 명확히 제시하는 점이 돋보인다. 다만 UI=0 미분 불가능성, 제한된 실험 범위, 수렴성 증명 부재가 소수의 약점이나 전반적으로 게재 가치가 충분하다.
Human-Level Actuation for Humanoids
Figure 1: Upper body atlas I: Shoulder complex including scapulothoracic contributions. Origins
 *Figure 1: Upper body atlas I: Shoulder complex including scapulothoracic contributions. Origins* 이 논문은 인간형 로봇의 구동부(actuation)가 인간 수준인지를 객관적으로 측정하고 비교할 수 있는 포괄적 프레임워크를 제시한다. 세 가지 핵심 요소로 구성되는데, 첫째는 ISB 기반 kinematic DoF atlas로 관절 좌표계를 표준화하고, 둘째는 Human-Equivalence Envelopes(HEE)로 특정 관절각도와 각속도에서 인간의 토크와 파워를 동시에 만족하는 요구사항을 정의하며, 셋째는 Human-Level Actuation Score(HLAS)로 workspace coverage, 효율성, 열 지속성 등 여섯 가지 인자를 통합한다.
이 논문은 humanoid robot 개발에서 오래도록 미해결되어 온 정량화 문제를 강력한 이론적 기반(ISB kinematic conventions, human biomechanics 데이터) 위에서 처음으로 체계적으로 해결한다. Human-Equivalence Envelopes와 HLAS는 설계자에게 명확한 목표를 제공하고, task-relevant posture-rate bands에 기반한 가중치 부여는 실무적 타당성을 보장한다. 제안된 측정 프로토콜(dynamometry, thermal testing)은 재현 가능하고 표준화 가능하여 산업 표준으로 채택될 수 있는 잠재력이 크다. 다만 75kg 기준 신체에 대한 의존도와 실험실 기반 biomechanics 데이터의 현장 적용성 한계는 보완이 필요하다. 전반적으로 humanoid actuation 평가에 새로운 표준을 제시하는 중요한 기여로, robotics, biomechanics, benchmarking 커뮤니티에 광범위한 영향을 미칠 것으로 예상된다.
DecARt Leg: Design and Evaluation of a Novel Humanoid Robot Leg with Decoupled Actuation for Agile Locomotion
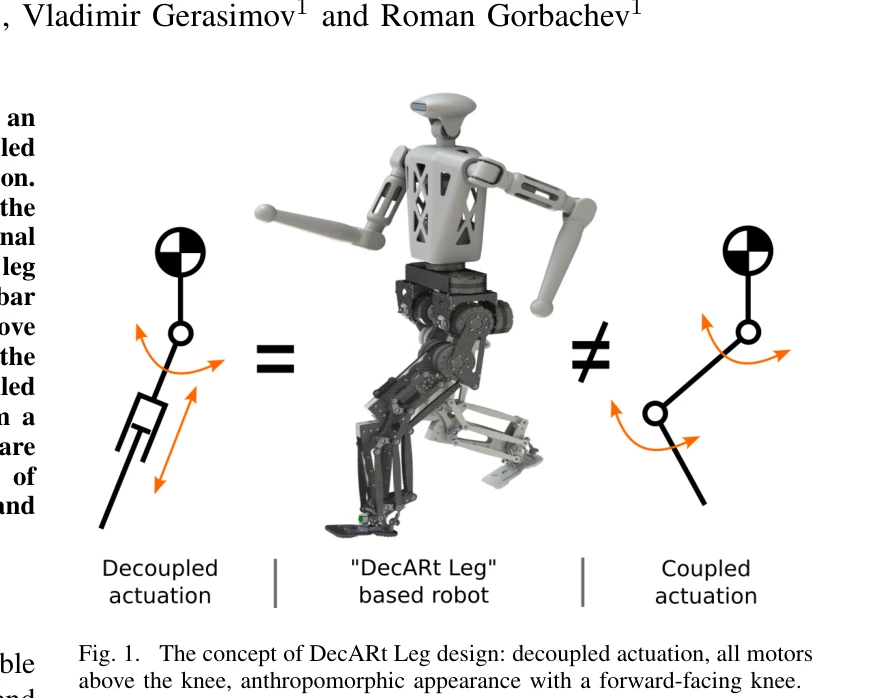
Fig. 1. The concept of DecARt Leg design: decoupled actuation, all motors
 *Fig. 1. The concept of DecARt Leg design: decoupled actuation, all motors* 본 논문은 decoupled actuation을 활용하면서도 인간형 다리의 외형을 유지하는 DecARt Leg을 제안하며, FAST(Fastest Achievable Swing Time) 메트릭을 통해 agile locomotion 능력을 평가한다.
본 논문은 humanoid robotics의 오랜 설계 갈등(efficiency vs. human-like appearance)을 새로운 kinematic approach로 해결하려는 의미 있는 시도이며, FAST 메트릭 제안과 함께 충분한 설계 혁신성을 보여준다. 다만 preliminary hardware 수준의 검증에 그쳐 실제 성능 우위를 완전히 입증하지는 못한 한계가 있다.
Optimizing Bipedal Locomotion for The 100m Dash With Comparison to Human Running
 *Fig. 3: The top 5 most efficient freq (above) and ratio* 이 논문은 이족 로봇 Cassie의 고속 주행 보행을 위해 보행 매개변수(stride frequency, swing ratio)를 체계적으로 최적화하고, 그 결과를 인간의 주행 역학과 비교하며, 최종적으로 100m 대시 기네스 월드레코드를 달성한 완전한 컨트롤러를 제시한다.
이 논문은 이족 로봇의 고속 주행을 위한 보행 매개변수의 첫 체계적 최적화를 제시하고, 인간 주행 역학과의 흥미로운 비교를 통해 이론적 깊이를 제공하며, 기네스 월드레코드 달성으로 실질적 임팩트를 입증한 우수한 연구이다.
A Foot Resistive Force Model for Legged Locomotion on Muddy Terrains
 *Fig. 2 shows a set of snapshots of foot-mud interactions.* 진흙 지형에서 다리 로봇의 발-진흙 상호작용을 모델링하는 저항력 모델을 제시하고, 이를 바탕으로 변형 가능한 로봇 발을 설계하여 이동성과 에너지 효율을 향상시킨다.
본 논문은 진흙 지형에서 다리 로봇의 발-진흙 상호작용에 대한 첫 번째 포괄적 물리 기반 모델을 제시하며, 이를 바탕으로 설계된 변형 발의 성능 향상을 실험으로 검증함으로써 로봇 이동성 연구에 중요한 기여를 한다.
Asymptotically Stable Gait Generation and Instantaneous Walkability Determination for Planar Almost Linear Biped with Knees
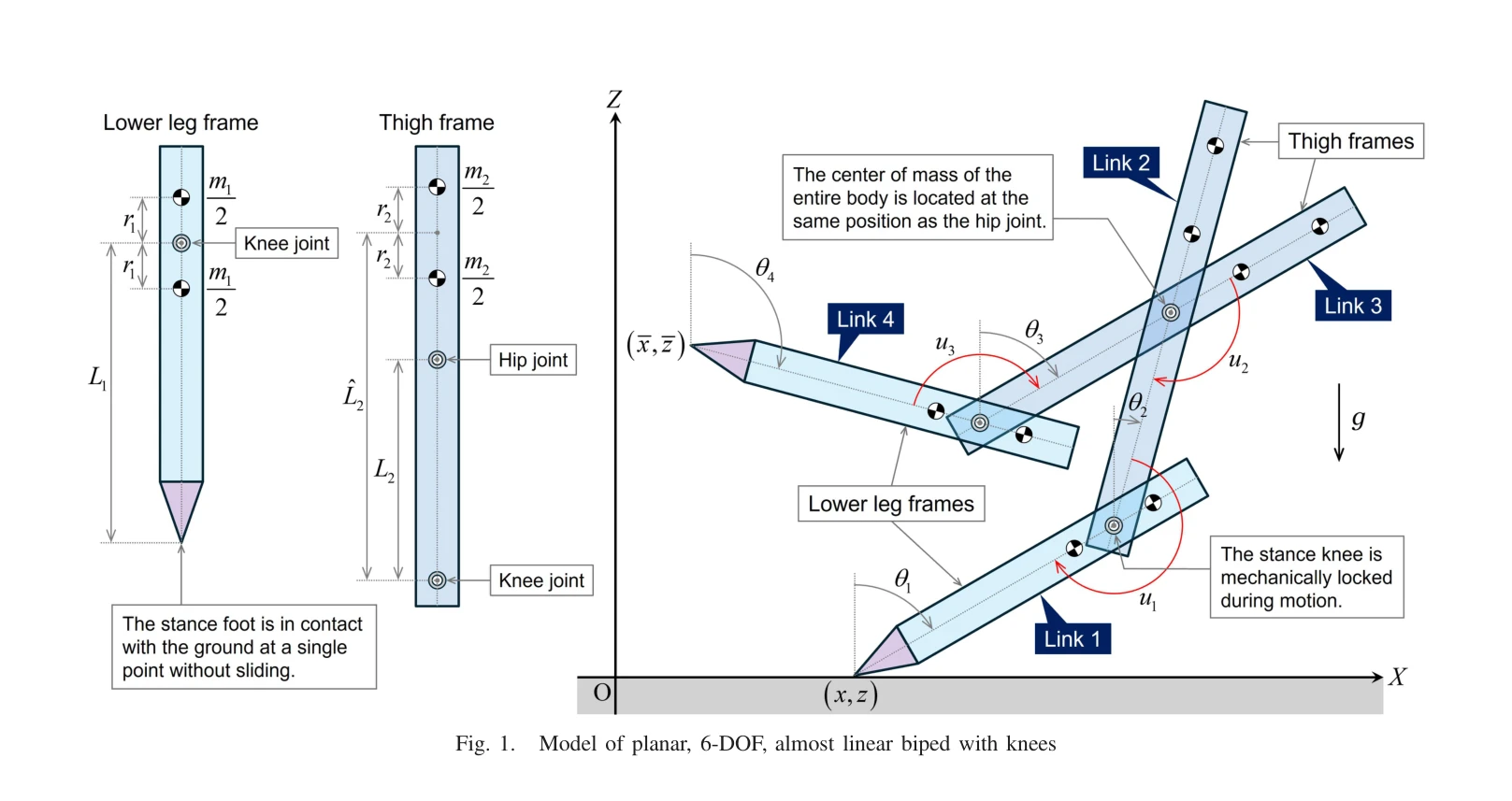
Figure 1 shows the model of the planar 6-DOF biped robot
 *Figure 1 shows the model of the planar 6-DOF biped robot* 거의 선형 역학 모델을 갖는 무릎 관절이 있는 평면 이족보행 로봇에서 Taylor 전개를 이용한 선형화를 통해 수치 적분 없이 점프로 안정적인 보행을 생성하고 즉각적인 보행 가능성 판정을 수행한다.
이 논문은 거의 선형 역학을 갖는 무릎 관절 이족보행 로봇에서 선형화를 통한 실시간 보행 가능성 판정이라는 실용적으로 중요한 문제를 해결하며, 차원 축소 및 근사 정확도 분석에서 상세한 기여를 제공한다. 다만 AL3 로봇의 특수성과 실제 로봇 검증 부족이 일반화 가능성을 제한한다.
Bipedal-Walking-Dynamics Model on Granular Terrains
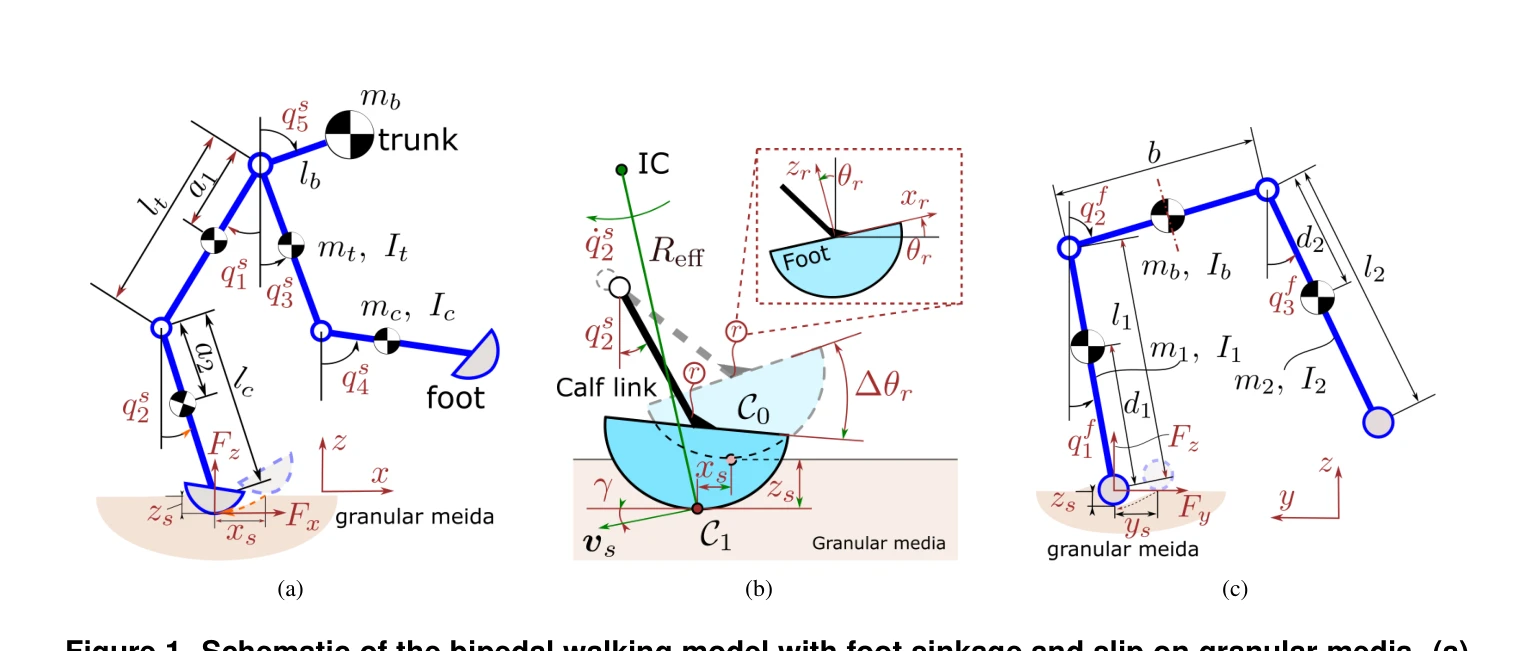
Figure 1. Schematic of the bipedal walking model with foot sinkage and slip on granular media. (a)
 *Figure 1. Schematic of the bipedal walking model with foot sinkage and slip on granular media. (a)* 본 논문은 모래와 같은 입자성 지형에서 이족 로봇의 보행 동역학을 모델링하기 위해 발의 침하(sinkage)와 슬립(slip)을 고려한 3개의 추가 자유도를 도입한 동적 발-지형 상호작용 모델을 제시한다.
본 논문은 입자성 지형에서의 이족 보행 동역학 모델링에 있어 발의 침하와 슬립을 처음으로 명시적으로 다룬 중요한 기여를 제시하며, 실험 검증을 통해 모델의 신뢰성을 입증했다. 제안된 모델은 granular terrain에서의 로봇 보행 제어 및 최적화를 위한 필수적인 기초 도구로서 높은 가치를 가진다.
Adaptive LIPM-based trajectory planning for energy-efficient bipedal locomotion on inclined terrains
 *Fig. 3 Shows the structure and snapshots of the simulation* 경사지면에서 이족 보행 로봇의 안정적이고 에너지 효율적인 보행을 위해 Slope Adaptive LIPM (SA-LIPM)을 기반으로 궤적 계획을 수행하고, 12-DOF 하체 로봇에서 ZMP 안정성, COM 궤적, 관절별 에너지 소비를 상세히 분석한다.
본 논문은 경사지에서 이족 로봇의 보행 안정성과 에너지 효율성을 SA-LIPM 기반으로 체계적으로 분석한 중요한 연구이며, 관절별 에너지 감사를 통해 휴머노이드 로봇 설계에 실질적인 지침을 제공한다. 다만 더 가파른 경사와 실제 하드웨어 검증이 필요하다.
A Hierarchical Framework for Humanoid Locomotion with Supernumerary Limbs
 *Figure 3.1: Training performance of the PPO agent over 500 million environment steps. (a)* 본 논문은 초과 사지(Supernumerary Limbs, SLs)로 증강된 인형로봇(humanoid robot)의 안정적인 보행을 위해 계층적 제어 프레임워크를 제안한다. 학습 기반의 저수준 보행 정책과 모델 기반의 고수준 동적 균형 제어기를 결합한 분리된 접근방식을 통해 SLs로부터의 동적 교란을 효과적으로 완화한다.
본 논문은 계층적 제어 프레임워크를 통해 초과 사지 장착 인형로봇의 안정적 보행 문제를 창의적으로 해결한다. DRL 기반 보행 정책과 model-based 균형 제어의 결합은 기술적으로 타당하며 47% DTW 개선이라는 정량적 성과를 달성한다. 다만 시뮬레이션 한정 평가와 실제 하드웨어 검증 부재가 실용적 기여도를 제한한다.
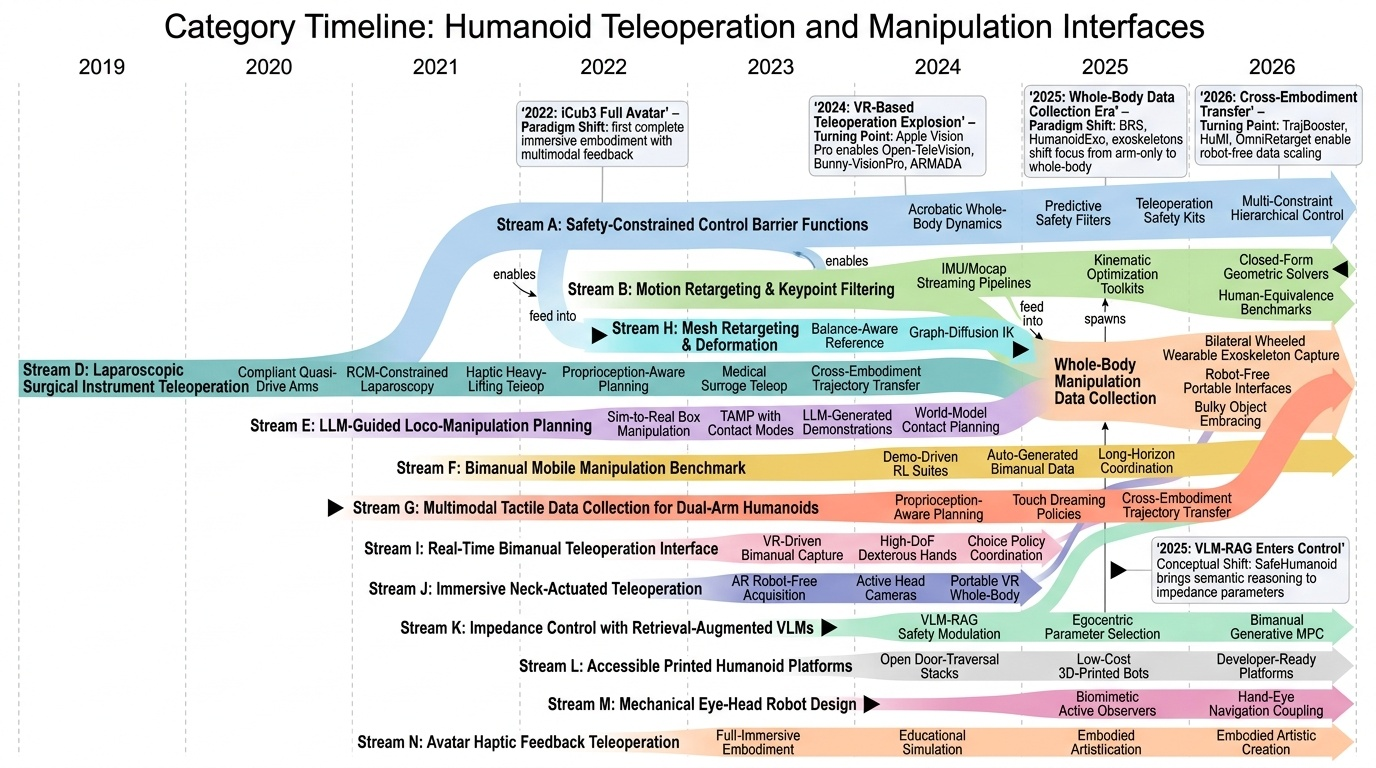
Category Overview
휴머노이드 원격조종 및 조작 인터페이스(Humanoid Teleoperation and Manipulation Interfaces) 카테고리는 인간 조작자가 휴머노이드 로봇을 실시간으로 제어하기 위한 기술과 플랫폼을 다룬다. 이 분야는 동작 재타겟팅(Motion Retargeting), 안전 제약 조건을 고려한 제어(Safety-Constrained Control), 촉각 피드백(Tactile Feedback) 통합 등을 통해 직관적이고 효율적인 원격조종 경험을 제공하는 데 중점을 둔다. [1690], [1775] 등의 연구는 인간의 상체 동작을 휴머노이드에 안정적으로 전달하기 위한 기하학적 해법과 안정성 인식 기법을 제시하고 있다. [1756], [1830]은 양팔 조작(Bimanual Manipulation)을 위한 실시간 원격조종 인터페이스와 몰입형 시각 피드백 시스템을 개발하여 복잡한 다중 대상 작업을 가능하게 한다. [1663], [1824] 등은 대규모 다중양식 데이터 수집(Multimodal Data Collection)과 벤치마크를 구축하여 로봇 학습의 기초를 마련하고 있으며, [1686], [1796] 같은 플랫폼 연구는 접근성 높은 휴머노이드 시스템을 제공함으로써 실제 환경에서의 전신 조작(Whole-Body Manipulation) 연구를 활성화하고 있다.
- Safety-Constrained Control Barrier Functions: 안전 제약 제어 배리어 함수(Safety-Constrained Control Barrier Functions)는 인간형 로봇의 원격 조작 및 물체 조작 작업에서 안전성을 보장하는 핵심 기술입니다. 이 기법은 제어 입력의 실시간 수정을 통해 로봇이 안전 제약(safety constraints)을 위반하지 않도록 하면서도 고도의 조작 작업을 수행할 수 있게 합니다. [1954]에서는 기하학적 정보를 활용한 예측 안전 필터(predictive safety filters)를 통해 인간형 로봇이 복잡한 환경에서 안전하게 작동하도록 제어하며, [1872]는 혼잡한 환경에서의 민첩한 조작(dexterous manipulation)을 위한 안전 제어 방법론을 제시합니다. [1686]의 SPARK 시스템과 [2016]의 HUSKY 플랫폼은 물리 기반의 전신 제어(whole-body control)와 안전 최적화를 결합하여 인간형 로봇이 고난도 동작을 안전하게 수행하도록 지원합니다. 이러한 안전 제약 제어 기술은 실제 산업 환경과 인간-로봇 협업(human-robot collaboration) 상황에서 신뢰할 수 있는 로봇 시스템 구현의 필수 요소입니다.
- Motion Retargeting & Keypoint Filtering: Motion Retargeting & Keypoint Filtering는 원격 조종(teleoperation) 환경에서 인간의 동작을 휴머노이드 로봇으로 변환하고 이를 안정적으로 실행하기 위한 핵심 기술 분야입니다. 이 분야는 인간 조작자의 움직임을 로봇의 운동학적 제약(kinematic constraints)과 물리적 안정성을 고려하여 재타겟팅(retargeting)하고, 필터링(filtering) 과정을 통해 노이즈를 제거하며 실시간 제어 가능성을 확보합니다. [1690]에서는 안정성을 고려한 재타겟팅 기법을, [1775]에서는 상반신 휴머노이드의 기하학적 재타겟팅 솔버(geometric retargeting solver)를 제시하여 정확한 동작 변환을 가능하게 합니다. [1977]과 [2396]은 고속 텔레오퍼레이션(high-speed teleoperation)과 자율 파지(autonomous grasping) 파이프라인을 통해 실제 환경에서의 안정적이고 빠른 조작을 실현합니다. [1990]과 [2079]는 인간 수준의 작동(human-level actuation)과 잠재공간 탐색(latent-space exploration)을 활용하여 로봇의 표현력과 최적화 능력을 향상시킵니다.
- Whole-Body Manipulation Data Collection: 전신 조작 데이터 수집(Whole-Body Manipulation Data Collection)은 인형로봇이 복잡한 작업을 수행하기 위해 필요한 대규모 데이터셋을 효율적으로 구축하는 분야입니다. [1279], [1997]의 연구들은 실제 환경에서 인형로봇의 전신 조작 능력을 학습하기 위한 통합 플랫폼과 인터페이스를 제시하고 있습니다. 특히 [1756], [1909]에서는 양방향 원격조종(Bilateral Teleoperation)과 무거운 물체 취급을 위한 전신 조작 기술을 다루며, 인간의 조작 동작을 로봇이 효과적으로 모방할 수 있도록 하는 데이터 수집 방법론을 제안합니다. [1921], [2008]의 연구는 저지연 원격조종(Low-Latency Teleoperation)과 웨어러블 인터페이스(Wearable Interface)를 활용한 확장성 있는 데이터 수집 기법을 소개하고 있습니다. [2014]에서는 인형로봇의 정밀한 손가락 조작(Dexterous Manipulation) 데이터 수집을 간소화하는 방법론을 제시합니다. 이러한 연구들은 인형로봇의 자율 조작 능력 향상을 위한 고품질의 학습 데이터 확보에 중요한 역할을 하고 있습니다.
- Laparoscopic Surgical Instrument Teleoperation: 복강경 수술 기구 원격 조종(Laparoscopic Surgical Instrument Teleoperation)은 인형로봇(humanoid robot)이 텔레오퍼레이션(teleoperation) 기술을 통해 최소침습 수술을 수행하는 분야입니다. 이 분야는 저비용의 컴플라이언스 매니퓨레이터(compliant manipulator) 개발[1630]과 신속한 기구 교환 시스템(rapid instrument exchange system)[1781]을 통해 수술 로봇의 실용성을 높이고 있습니다. 햅틱 피드백(haptic feedback)을 기반으로 하는 직관적인 제어 인터페이스[1835, 1970]는 원격 환경에서 인간-로봇 협업(human-robot collaboration)의 정확도를 극대화합니다. 병원 환경에서의 기술적 검증[2011]과 실제 수술 수행 연구[2040]를 통해 인형로봇의 의료 분야 적용 가능성이 검증되고 있으며, 이는 의료 접근성 향상과 원격 수술의 혁신적 확대를 가능하게 할 것으로 기대됩니다.
- LLM-Guided Loco-Manipulation Planning: LLM-Guided Loco-Manipulation Planning은 대규모 언어 모델(Large Language Model, LLM)의 고수준 계획 능력을 활용하여 인형로봇의 이동과 조작을 통합적으로 제어하는 기술입니다. 이 분야의 연구들은 자연어 지시사항을 복잡한 로코-조작 태스크(loco-manipulation task)로 변환하고, Task and Motion Planning(TAMP) 기법을 통해 구체적인 실행 경로를 생성합니다[1702]. Sim-to-Real Learning을 통한 시뮬레이션 학습 [1674]과 Ego-Vision World Model을 활용한 접촉 계획[1897]은 현실 세계 적용의 정확도를 높입니다. 또한 인간-인형로봇 협력 조율[2052]과 양손 민첩 조작(bimanual dexterous manipulation)을 위한 데이터 생성[2009], 그리고 동적이고 일반화 가능한 전신 제어(whole-body control)[3370]는 로봇의 적응성과 성능을 크게 향상시킵니다. 이러한 기술들의 통합을 통해 인형로봇은 복잡한 현실 환경에서 자율적으로 다양한 이동-조작 작업을 수행할 수 있게 됩니다.
- Bimanual Mobile Manipulation Benchmark: # Bimanual Mobile Manipulation Benchmark 양팔 모바일 조작 벤치마크(Bimanual Mobile Manipulation Benchmark)는 휴머노이드 로봇이 두 팔을 동시에 조작하면서 이동하는 복잡한 작업을 수행할 수 있도록 평가하고 개선하는 연구 분야입니다. [1824]의 BiGym은 데모 주도 방식으로 양팔 조작 데이터를 수집하는 벤치마크를 제시하며, [1869]의 DexMimicGen은 양팔 정교 조작(Bimanual Dexterous Manipulation)을 위한 자동화된 데이터 생성 방법을 제안합니다. 또한 [2089]의 ManiSkill-HAB는 가정 환경에서의 저수준 조작(Low-Level Manipulation) 능력을 평가하는 벤치마크를 구성하며, [3369]의 BiCoord는 장기간에 걸친 시공간 협응(Spatiotemporal Coordination)이 필요한 양팔 조작 작업을 중점적으로 다룹니다. 이러한 벤치마크들은 로봇의 협응 능력, 이동성, 조작 정확도를 종합적으로 평가함으로써 현실 세계의 다양한 작업 수행을 위한 로봇 기술 발전을 촉진합니다.
- Multimodal Tactile Data Collection for Dual-Arm Humanoids: # Multimodal Tactile Data Collection for Dual-Arm Humanoids 이중팔 휴머노이드 로봇의 다중감각 촉각 데이터 수집(Multimodal Tactile Data Collection)은 로봇의 정교한 조작 능력을 향상시키기 위한 핵심 기술 분야입니다. [1856]의 Cross-modal and Recurrent Fusion (CReF)은 깊이 정보와 여러 감각 모달리티를 융합하여 로봇의 지각 능력을 강화하는 방법을 제시합니다. [2157]과 [2159]는 고유수용감각(Proprioception)을 인식한 신체 계획과 궤적 최적화(Trajectory Optimization)를 통해 이중팔 조작 성능을 개선하는 접근법을 다룹니다. [2166]의 ULTRA 시스템은 통합된 다중모달 제어(Unified Multimodal Control)로 자율 휴머노이드 전신 조작을 가능하게 합니다. [2383]과 [3326]은 촉각 피드백(Tactile Feedback)과 감각운동 경험(Sensorimotor Experience)을 활용한 학습 기반 조작 전략으로, 다양한 과제 적응성을 제공합니다.
- Mesh Retargeting & Deformation: # Mesh Retargeting & Deformation 휴머노이드 로봇의 텔레오퍼레이션(Teleoperation)과 조작(Manipulation) 작업에서 메시 리타게팅(Mesh Retargeting) 및 변형(Deformation) 기술은 인간의 동작을 로봇의 신체 구조에 정확하게 전달하는 핵심 요소이다. [2120]에서는 상호작용 보존 데이터 생성(Interaction-Preserving Data Generation)을 통해 휴머노이드 로봇이 인간의 조작 의도를 유지하면서 동작을 수행할 수 있도록 한다. [2147]에서는 게이트 전문가 혼합(Gated Expert Mixture) 기반의 전신 텔레오퍼레이션(Whole-Body Teleoperation) 방식을 제안하여 복잡한 신체 변형을 효율적으로 처리한다. 이러한 기술들은 그래프 확산(Graph Diffusion) 기반의 역운동학(Inverse Kinematics) [3330]과 결합되어 로봇의 균형 유지(Balance) [1986]와 함께 자연스러운 동작 생성을 가능하게 한다.
- Real-Time Bimanual Teleoperation Interface: # Real-Time Bimanual Teleoperation Interface 실시간 양손 텔레오퍼레이션 인터페이스는 원격 조종자가 인간형 로봇의 두 팔을 동시에 제어하여 복잡한 조작 작업을 수행하는 기술입니다. [1830]에서는 Vision Pro 기반의 실시간 양손 민첩 텔레오퍼레이션 시스템을 제시하여 직관적인 인터페이스를 통한 고정밀 제어를 가능하게 합니다. 이러한 인터페이스는 인간의 시각 피드백(visual feedback)과 운동 학습(motor learning)을 결합하여 [1750]에서 제안한 액티브 퍼셉션(active perception) 능력을 향상시킵니다. [1873]의 20-DoF 다지형 손(dexterous hand) 제어와 [1853]의 협조적 조작(coordinated manipulation)은 양손 간의 동기화된 움직임을 통해 정교한 객체 조작을 실현합니다. 궁극적으로 이러한 기술들은 [1911]에서 보여주는 것처럼 시뮬레이션 환경에서의 학습을 통해 실제 로봇의 신체 능력(embodied dexterity)과 지각 능력을 동시에 발달시키는 것을 목표로 합니다.
- Immersive Neck-Actuated Teleoperation: 몸 전체를 이용한 원격조작 인터페이스에서 목(neck) 부분의 능동적 제어는 사용자의 시각 피드백과 공간 인식을 향상시키는 핵심 요소이다. 이 분야는 사용자가 원격 로봇의 머리와 시선을 직관적으로 제어하면서 주변 환경을 효과적으로 관찰할 수 있는 몰입형(immersive) 경험을 제공한다. [2070]에서는 원격조작 중 향상된 시각 피드백을 통해 학습 효율을 높이는 방법을 다루고 있으며, [2124]에서는 능동 시각 피드백(active visual feedback)을 통합한 텔레오퍼레이션 시스템을 제시하고 있다. 또한 [2164]는 인간형 로봇의 포괄적인 데이터 수집(data collection)을 위한 확장 가능한 플랫폼을 제안하여, 목-구동 텔레오퍼레이션의 실제 적용과 대규모 학습 데이터 확보를 가능하게 한다. 이러한 연구들은 로봇 조작 작업의 정밀도와 사용자 만족도를 동시에 개선하는 데 기여하고 있다.
- Impedance Control with Retrieval-Augmented VLMs: 이 섹션은 휴머노이드 로봇의 임피던스 제어(Impedance Control)와 시각-언어 모델(Vision-Language Model, VLM)을 결합하는 원격 조종 기술을 다룬다. 검색 증강 생성(Retrieval-Augmented Generation, RAG) 기반의 VLM을 활용하여 로봇의 상반신 임피던스 제어 및 전신 조작을 위한 지능형 인터페이스를 구현한다 [1663] [2012]. 이러한 방식은 실시간 시각 피드백(Active Vision)과 자연어 명령을 통해 복잡한 조작 작업(Manipulation Tasks)을 보다 직관적으로 수행할 수 있게 한다 [1902]. 특히 모델 예측 제어(Model Predictive Control, MPC)와 가상 임피던스(Virtual Impedance) 개념을 결합하여 안정성과 적응성을 동시에 확보하는 생성형 제어 기법이 제안되었다 [2399]. 이러한 기술들은 휴머노이드 로봇의 작업 효율성을 높이면서도 사용자의 안전한 원격 제어를 보장하는 핵심 기반 기술이다.
- Accessible Printed Humanoid Platforms: # 접근 가능한 프린트 가능 휴머노이드 플랫폼(Accessible Printed Humanoid Platforms) 접근 가능한 프린트 가능 휴머노이드 플랫폼은 3D 프린팅 기술을 활용하여 제조 비용을 낮추고 누구나 구축할 수 있도록 설계된 오픈소스 휴머노이드 로봇을 의미한다. 이러한 플랫폼들은 연구자, 개발자, 교육 기관 등이 용이하게 접근할 수 있도록 설계 도면과 소스 코드를 공개함으로써 휴머노이드 로봇 연구의 민주화를 추진하고 있다. [1796]의 AGILOped와 [1864]의 Berkeley Humanoid Lite는 오픈소스 기반의 민첩한(Agile) 휴머노이드 플랫폼으로서 빠른 프로토타이핑(Prototyping)과 실시간 제어를 가능하게 한다. 이들 플랫폼은 문 통과(Door Traversal), 복잡한 조작(Manipulation) 작업 등 다양한 실무 작업을 수행할 수 있으며 [1927]의 Fauna Sprout과 같이 개발자 친화적(Developer-ready) 설계로 사용 진입장벽을 최소화하고 있다. 이러한 접근 가능한 프린트 가능 휴머노이드 플랫폼들은 로봇 연구의 진입 장벽을 낮추면서도 실용적인 성능을 제공함으로써 휴머노이드 로봇 기술의 확산에 중요한 역할을 하고 있다.
- Mechanical Eye-Head Robot Design: 휴머노이드 텔레오퍼레이션(Humanoid Teleoperation) 환경에서 기계적 눈-머리 로봇 설계(Mechanical Eye-Head Robot Design)는 원격 조작자의 시각적 피드백과 상황 인식을 향상시키는 핵심 기술입니다. DIJIT 로봇 헤드[1879][3343]는 능동적 관찰자(Active Observer)로서 기능하도록 설계되어, 조작 작업 중 필요한 방향으로 카메라와 센서를 동적으로 제어할 수 있습니다. 이러한 설계는 원격 조작자가 실시간으로 작업 환경을 다양한 각도에서 모니터링하고, 정밀한 매니퓰레이션(Manipulation) 작업을 수행하는 데 필수적입니다. 손-눈 협응(Hand-Eye Coordination) 기반의 자율 배송 시스템[1966]에서도 유사한 기계적 눈-머리 로봇 기술이 휴머노이드 네비게이션(Humanoid Navigation)과 통합되어 활용됩니다. 이러한 기술은 복잡한 환경에서의 적응적 시각 제어와 조작 성능을 동시에 만족시키기 위해 지속적으로 발전하고 있습니다.
- Avatar Haptic Feedback Teleoperation: # Avatar Haptic Feedback Teleoperation (3편) 아바타 햅틱 피드백 텔레오퍼레이션(Avatar Haptic Feedback Teleoperation)은 원격 로봇 조작 환경에서 사용자의 촉각 감각을 구현하는 기술을 의미합니다. [2019]의 iCub3 아바타 시스템은 완전한 몰입형 원격 제어(fully-immersive teleoperation)를 가능하게 하여 사용자가 물리적으로 떨어진 위치에서 휴머노이드 로봇을 자신의 신체 확장으로 경험할 수 있습니다. [3305]의 Alter-Art 프로젝트는 구현된 촉각 피드백(embodied haptic feedback)을 예술 창작에 활용하여 원격 로봇 조작의 활용 범위를 창의적 표현으로 확대하고 있습니다. 시뮬레이션 기반의 학습 프레임워크와 실제 로봇 시스템의 통합을 통해 사용자는 더욱 직관적이고 자연스러운 인터페이스(intuitive interface)로 원격 작업을 수행할 수 있습니다. 이러한 기술들은 로봇 조작의 정밀도와 사용자 만족도를 동시에 향상시키는 중요한 진전을 나타냅니다.
⚠ 갭: 통신 지연, 시스템 신뢰성, 사용자 피로도 등 실제 산업 현장 배포에 직결된 공학적 요인에 대한 체계적 연구가 부족하며 대부분의 연구가 이상적인 실험실 환경에서 수행된다.
🏛 정책: 원격 의료·재난 대응·위험 작업 현장에서의 휴머노이드 텔레오퍼레이션 실증 프로그램을 지원하고 관련 안전 규격을 마련해야 한다.
BEHAVIOR Robot Suite: Streamlining Real-World Whole-Body Manipulation for Everyday Household Activities
Figure 1: Everyday household activities enabled by BEHAVIOR ROBOT SUITE (BRS), show-
 *Figure 1: Everyday household activities enabled by BEHAVIOR ROBOT SUITE (BRS), show-* BEHAVIOR Robot Suite (BRS)는 가정용 일상 작업을 수행하기 위한 양팔 협력, 안정적 네비게이션, 광범위한 말단 장치 도달성을 갖춘 전신 조작 로봇을 위한 통합 프레임워크를 제시한다. JoyLo 원격 조작 인터페이스와 WB-VIMA 시각운동 정책 학습 알고리즘을 통해 실세계 가정 작업 수행을 가능하게 한다.
BEHAVIOR Robot Suite는 가정용 일상 작업을 위한 전신 조작 로봇의 완전한 생태계를 제시하는 포괄적 연구로, JoyLo의 창의적인 저비용 설계와 WB-VIMA의 계층적 자동회귀 정책 학습이 결합되어 실세계 가정 로봇의 실질적 진전을 이룬다. 특히 하드웨어, 데이터 수집, 알고리즘을 완전히 오픈소스화함으로써 커뮤니티 확산 가능성이 높으며, 다중 도메인의 체계적 통합을 통해 로봇 학습 연구에 의미 있는 기여를 한다.
Learning Human-to-Humanoid Real-Time Whole-Body Teleoperation

Fig. 1:
 *Fig. 4: Overview of H2O: (a) Retargeting (Section IV): H2O first aligns the SMPL body model to a humanoid’s structure* RGB 카메라만을 사용하여 실시간으로 전신 휴머노이드 로봇을 원격조종할 수 있는 RL 기반 프레임워크 H2O를 제시하며, 'sim-to-data' 프로세스로 인간 동작을 로봇 친화적으로 필터링하고 sim-to-real 전이를 달성했다.
본 논문은 인간-휴머노이드 상호작용의 새로운 패러다임을 제시하며, 'sim-to-data' 필터링과 효과적인 sim-to-real 전이를 통해 RL 기반 전신 원격조종을 처음 실현했다는 점에서 획기적 기여이다. 대규모 데이터셋 생성, RGB 카메라 기반 제어, 다양한 동작 실현 등에서 높은 완성도를 보여주며, 향후 로봇 원격조종 및 자율 시스템 학습의 중요한 토대가 될 것으로 예상된다.
PIMBS: Efficient Body Schema Learning for Musculoskeletal Humanoids with Physics-Informed Neural Networks
Fig. 1.
 *Fig. 1.* Physics-Informed Neural Networks (PINNs) 개념을 적용하여 근골격 휴머노이드 로봇의 신체 스키마를 적은 데이터로 효율적으로 학습하는 PIMBS 방법을 제안한다.
이 논문은 Physics-Informed Neural Networks를 근골격 로봇의 신체 스키마 학습에 창의적으로 적용하여 적은 데이터로도 효율적인 학습을 가능하게 하는 실용적이고 혁신적인 방법을 제시한다. 시뮬레이션과 실제 로봇 실험을 통한 검증으로 제안 방법의 타당성을 충분히 입증했다.
RUKA: Rethinking the Design of Humanoid Hands with Learning
Fig. 1: RUKA is a tendon-driven humanoid hand that is simple,
 *Fig. 1: RUKA is a tendon-driven humanoid hand that is simple,* RUKA는 3D 프린팅과 저가 부품으로 제작한 tendon-driven humanoid hand로, learning-based control을 통해 정밀성, 컴팩트성, 강도, 저비용을 동시에 달성한다.
RUKA는 learning-based control과 실용적 hardware 설계를 결합하여 저비용 대 성능 비율에서 로봇 손 영역의 새로운 기준을 제시하며, open-source 공개로 접근성을 극대화한 의미 있는 기여이다.
SMASH: Mastering Scalable Whole-Body Skills for Humanoid Ping-Pong with Egocentric Vision
Fig. 1: SMASH: Our system enables the first outdoor humanoid ping-pong player and the first whole-body smash on a humano
 *Fig. 2: Overview of SMASH. Our system connects scalable motion generation, task-aligned policy learning, and egocentric* 휴머노이드 로봇의 탁구 게임을 위해 확장 가능한 전신 동작 학습과 자체 에고센트릭 비전을 통합한 SMASH 시스템을 제시하며, 외부 카메라나 모션 캡처 없이 실외에서 연속적인 탁구 스트라이킹을 처음으로 달성했다.
이 논문은 휴머노이드 탁구에서 에고센트릭 온보드 지각과 전신 협응 제어를 통합한 최초의 자율 시스템을 구현함으로써 로봇 동적 상호작용 연구에 중요한 기여를 하였다. Motion VAE 기반 동작 확장과 task-aligned motion matching이라는 확장 가능한 방법론은 다른 동적 로봇 과제에도 적용 가능한 잠재력이 있다.
SoftMimic: Learning Compliant Whole-body Control from Examples
 *Fig. 2: Soft Whole-body Control via Compliant Motion Augmentation. Left: Given an original reference motion (qref) and a* SoftMimic은 역기구학 솔버를 이용해 순응적 동작 데이터셋을 생성하고 강화학습으로 학습하여, 인간형 로봇이 외부 힘에 순응하면서도 균형을 유지하는 제어 정책을 학습하는 프레임워크이다.
SoftMimic은 역기구학 기반 데이터 증강과 강화학습을 창의적으로 결합하여 인간형 로봇의 순응적 제어라는 중요한 문제를 체계적으로 해결하며, 이론과 실제 로봇 실험으로 그 효과를 입증한 우수한 연구이다.
TACT: Humanoid Whole-body Contact Manipulation through Deep Imitation Learning with Tactile Modality
 *Fig. 2. Humanoid control system for whole-body contact manipulation with tactile feedback.* 인간형 로봇이 촉각 센서를 활용한 모방 학습(imitation learning)을 통해 전신 접촉 조작을 수행할 수 있도록 하는 TACT(tactile-modality extended ACT) 제어 시스템을 제안하였다.
본 연구는 촉각 센서를 Transformer 기반 모방 학습에 성공적으로 통합하여 생활 규모 인간형 로봇의 섬세한 전신 접촉 조작을 최초로 실증했으며, 모델 기반 제어와 학습 기반 제어의 창의적 결합으로 신뢰성과 유연성을 동시에 확보한 의미 있는 기여이다.
The Duke Humanoid: Design and Control For Energy Efficient Bipedal Locomotion Using Passive Dynamics
Fig. 1: Duke Humanoid v1.0: a) The frontal plane symmetry
 *Fig. 1: Duke Humanoid v1.0: a) The frontal plane symmetry* Duke Humanoid은 동적 보행이 가능한 오픈소스 10-DoF 인형로봇으로, 패시브 다이내믹스를 활용하는 reinforcement learning 정책을 통해 에너지 효율적인 이족 보행을 달성한다.
이 논문은 오픈소스 인형로봇 플랫폼과 패시브 다이내믹스 기반 에너지 효율 개선을 결합하여 humanoid 보행 연구에 실질적 기여를 한다. 특히 reinforcement learning 내 passive dynamics의 명시적 활용과 zero-shot 배포 검증은 학술적·실용적 가치가 높으나, 속도 범위와 일반화 능력의 검증이 더 필요하다.
Thor: Towards Human-Level Whole-Body Reactions for Intense Contact-Rich Environments

Fig. 1. Humanoids performing tasks involving forceful interactions with the
 *Fig. 2.* Thor는 humanoid 로봇이 강한 접촉 상호작용 환경에서 인간 수준의 전신 반응을 생성하도록 하는 프레임워크로, force-adaptive torso-tilt (FAT2) 보상 함수와 decoupled reinforcement learning 아키텍처를 제안한다.
Thor는 decoupled RL 아키텍처와 인간 생체역학 기반 FAT2 보상 함수를 통해 humanoid의 강력한 힘 상호작용 능력을 크게 향상시킨 우수한 연구로, 실세계 성능 검증과 다양한 작업 시연을 통해 높은 실용적 가치를 입증했다.
Whole-Body Bilateral Teleoperation with Multi-Stage Object Parameter Estimation for Wheeled Humanoid Locomanipulation

Fig. 1: Lifting and delivering a heavy water bottle (∼1/3 of robot’s weight)
 *Fig. 2: Overview of the whole-body bilateral teleoperation framework. (Left) A human pilot controls a wheeled humanoid w* 휠 달린 인간형 로봇의 원격조종 시스템에 다단계 물체 관성 매개변수 온라인 추정을 통합하여, 무거운 물체의 들기·운반 작업을 동적으로 수행할 수 있는 프레임워크를 제시한다.
본 논문은 VLM과 hierarchical sampling을 결합한 혁신적 물체 매개변수 추정과 이를 bilateral teleoperation에 통합함으로써 로봇의 무거운 부하 취급 능력을 획기적으로 향상시켰다. 시스템 설계, 기술 구현, 실험 검증 모두 우수하며 로봇 조작 작업의 실용화에 중요한 기여를 한다.
WoCoCo: Learning Whole-Body Humanoid Control with Sequential Contacts

Figure 1: An overview of WoCoCo and tasks. (A) We decompose the task into separate contact
 *Figure 1: An overview of WoCoCo and tasks. (A) We decompose the task into separate contact* WoCoCo는 순차적 접촉(sequential contacts)을 포함한 전신 휴머노이드 제어를 학습하기 위한 통합 RL 프레임워크로, 작업을 접촉 단계별로 분해하여 task-agnostic 보상 설계와 sim-to-real 파이프라인을 제시한다.
WoCoCo는 순차적 접촉을 포함한 휴머노이드 제어 문제에 대해 개념적으로 우아하고 실용적인 RL 프레임워크를 제시하며, 4가지 도전적 작업의 현실 검증을 통해 높은 응용 가치를 입증한다. 다만 접촉 계획의 자동 생성 및 더 복잡한 작업 환경으로의 확장은 향후 연구 방향이다.
ZEST: Zero-shot Embodied Skill Transfer for Athletic Robot Control

Fig. 1. Hardware deployment of ZEST across diverse data sources and robot morphologies. In order of appearance from top
 *Fig. 3. Overview of ZEST, which consists of three main stages. (1) Reference data: A diverse set of motions from MoCap, * ZEST는 모션 캡처, 비디오, 애니메이션 등 다양한 출처의 데이터로부터 RL을 통해 인간형 로봇 제어 정책을 학습하고, 시뮬레이션에서만 훈련하여 하드웨어에 Zero-shot 배포하는 motion-imitation 프레임워크이다.
ZEST는 다양한 비정형 데이터 소스로부터 인간형 로봇의 일반적 제어 정책을 학습하고 zero-shot 배포하는 혁신적 프레임워크로, 실제 하드웨어에서의 광범위한 성공적 검증을 통해 로봇 제어의 실용성과 확장성을 크게 향상시킨 매우 중요한 기여이다.
A Humanoid Visual-Tactile-Action Dataset for Contact-Rich Manipulation
Fig. 1.
 *Fig. 1.* 인형로봇의 시각-촉각-행동 다중모달 데이터셋을 제시하여 접촉 기반 조작, 특히 부드러운 물체 조작을 위한 로봇 학습을 지원한다.
본 논문은 접촉 기반 조작 연구의 중요한 격차를 메우기 위해 인형로봇 기반의 고밀도 시각-촉각-행동 데이터셋을 처음으로 제시하며, 고해상도 촉각 신호의 필요성을 명확하게 입증하는 가치 있는 기여다.
A Unified and General Humanoid Whole-Body Controller for Versatile Locomotion
Fig. 1: Humanoid capabilities supported by HUGWBC. First row: HUGWBC allows four standard gaits - walking, jumping, stan
HugWBC는 시뮬레이션에서 학습한 통일된 강화학습 기반 정책으로 휴머노이드 로봇이 걷기, 뛰기, 서기, 깡충뛰기 등 다양한 보행 행동을 자유롭게 조절 가능하도록 하며, 상반신 외부 제어 개입도 지원하는 전신 컨트롤러이다.
HugWBC는 확장된 명령 공간과 intervention training 기법을 통해 휴머노이드 로봇의 다양한 보행과 로코-조작을 통합적으로 제어하는 첫 번째 전신 컨트롤러로서, 우수한 추적 성능과 강건성으로 휴머노이드 로봇의 실용 능력을 크게 향상시키는 의미 있는 기여이다.
A Whole-Body Motion Imitation Framework from Human Data for Full-Size Humanoid Robot
 *Fig. 2.* 전신 동작 모방을 위해 contact-aware 전신 모션 리타겟팅과 비선형 중심 MPC를 결합한 휴머노이드 로봇 제어 프레임워크를 제안한다. 실제 휴머노이드 로봇에서 인간의 다양한 전신 동작을 정확하고 안정적으로 모방할 수 있음을 입증한다.
Contact-aware motion retargeting과 nonlinear centroidal MPC를 체계적으로 결합하여 실제 휴머노이드 로봇에서 정확하고 안정적인 전신 모션 모방을 달성한 강력한 연구이다. 실제 로봇 플랫폼에서의 광범위한 검증은 실용적 가치를 높이나, 고속 동작 확장 및 강건성 분석에서 추가 개선이 필요하다.
Adversarial Locomotion and Motion Imitation for Humanoid Policy Learning
인간형 로봇의 상반신과 하반신의 서로 다른 역할을 분리하여 학습하는 대적적 학습 프레임워크 ALMI를 제안하고, 시뮬레이션과 실제 로봇에서 강건한 보행과 정확한 모션 추적을 달성한다.
상반신과 하반신의 역할 분리를 adversarial learning으로 구현한 novel framework이며, 이론적 수렴 보장과 실제 로봇 구현의 성공이 결합되어 높은 실용성을 보유하고 있다. 대규모 dataset 공개로 향후 연구의 기반을 제공하는 점도 의미 있다.
Biomechanical Comparisons Reveal Divergence of Human and Humanoid Gaits
Fig. 1: Joint mapping between humanoid robot and human.
 *Fig. 2: Comparison of lower-limb joint angles, moments, and* 본 논문은 Gait Divergence Analysis Framework (GDAF)를 제안하여 인간과 휴머노이드 로봇의 보행 간 생체역학적 차이를 정량적으로 분석하고, 28개 속도에서 수집한 공개 데이터셋과 분석 도구를 제공한다.
본 논문은 휴머노이드 보행 평가를 위한 첫 번째 체계적 생체역학 분석 프레임워크와 완전 공개 데이터셋을 제시하여 로봇 보행 개선의 정량적 기준과 도구를 확보하게 하는 점에서 의의가 크며, 방법론적 투명성과 재현가능성이 우수하나 단일 플랫폼과 보행 환경 제약이 일반화 가능성을 다소 제한한다.
Characteristics, Management, and Utilization of Muscles in Musculoskeletal Humanoids: Empirical Study on Kengoro and Musashi
 *Fig. 2. The basic musculoskeletal structure: the components include bones,* 본 논문은 Kengoro와 Musashi 근골격 휴머노이드 로봇의 근육 특성을 5가지 속성(Redundancy, Independency, Anisotropy, Variable Moment Arm, Nonlinear Elasticity)으로 분류하고, 이를 효과적으로 관리·활용하는 방법론을 제시한다.
본 논문은 근골격 휴머노이드의 근육 특성을 처음으로 체계적으로 분류하고 관리·활용 방법을 제시한 중요한 기여이며, 실제 로봇 구현 사례를 바탕으로 높은 실용성을 갖추고 있다. 다만 정량적 성능 평가 및 일반화 가능성에 대한 보완이 필요하다.
CHIP: Adaptive Compliance for Humanoid Control through Hindsight Perturbation

Fig. 1: CHIP enables humanoid robots to perform manipulation tasks that require force control, such as wiping a whiteboa
 *Fig. 1: CHIP enables humanoid robots to perform manipulation tasks that require force control, such as wiping a whiteboa* CHIP는 hindsight perturbation을 통해 humanoid robot이 민첩한 움직임을 유지하면서도 적응적 compliance를 갖춘 forceful manipulation을 수행할 수 있게 하는 plug-and-play 모듈이다.
CHIP는 humanoid의 agile motion과 compliant manipulation을 양립시키는 우아한 해결책으로, hindsight perturbation이라는 핵심 아이디어의 단순함과 기존 framework와의 호환성이 강점이다. 다만 실제 로봇 검증과 force control의 정량적 분석이 보완되면 더욱 완성도 있는 연구가 될 것이다.
ClimbingCap: Multi-Modal Dataset and Method for Rock Climbing in World Coordinate

Figure 1. Overview. To address the challenging problem of global climbing motion recovery, we collect the dataset Ascend
 *Figure 1. Overview. To address the challenging problem of global climbing motion recovery, we collect the dataset Ascend* ClimbingCap은 RGB와 LiDAR 멀티모달 데이터를 활용하여 암벽 등반 동작을 글로벌 좌표계에서 정확하게 복원하는 방법을 제안하며, 대규모 도전적 등반 동작 데이터셋 AscendMotion을 구축했다.
ClimbingCap은 미개발 분야인 등반 동작 캡처에 대해 대규모 고품질 데이터셋과 멀티모달 별도 좌표 복원 방식의 창의적 방법론을 제시하여 높은 독창성과 실질적 기여도를 보여준다. 광범위한 실험 검증과 공개 예정인 데이터셋·코드는 커뮤니티 기여도 높으나, 환경 일반화와 단일 모달 방식의 개발이 후속 과제다.
CLONE: Closed-Loop Whole-Body Humanoid Teleoperation for Long-Horizon Tasks
CLONE은 MoE 기반 폐루프 제어 시스템으로 MR 헤드셋의 헤드와 손 추적만으로 휴머노이드 로봇의 전신 협응 동작을 정밀하게 원격 조종하고 장시간 작업에서 위치 드리프트를 최소화한다.
CLONE은 MoE 기반 폐루프 제어와 최소 입력 인터페이스를 결합하여 휴머노이드 텔레오퍼레이션의 근본적 제약을 해결한 선도적 연구로, 전신 협응과 장시간 정밀 제어를 동시에 달성한 최초의 실제 시스템 구현이다.
CLOT: Closed-Loop Global Motion Tracking for Whole-Body Humanoid Teleoperation
Fig. 1: Long-horizon whole-body teleoperation with global pose closed-loop feedback. The proposed framework achieves
 *Fig. 1: Long-horizon whole-body teleoperation with global pose closed-loop feedback. The proposed framework achieves* CLOT는 고주파 로컬라이제이션 피드백을 통해 폐루프 전역 자세 추적을 달성하는 실시간 인간형 로봇 원격조종 시스템으로, 장시간 운영 중 누적되는 전역 드리프트 문제를 해결한다.
CLOT는 폐루프 전역 제어와 Observation Pre-shift 데이터 기반 무작위화 전략을 통해 장시간 드리프트 없는 인간형 로봇 원격조종을 달성한 혁신적 시스템으로, 실제 인간형 로봇에서의 포괄적 검증과 고품질 데이터셋 공개는 이 분야의 중요한 기여이다.
Deep Imitation Learning for Humanoid Loco-manipulation through Human Teleoperation

Fig. 1: Overview of TRILL. TRILL addresses the challenge of learning
 *Fig. 1: Overview of TRILL. TRILL addresses the challenge of learning* 본 논문은 VR 텔레오퍼레이션을 통해 수집한 인간 시연 데이터로부터 humanoid 로봇의 loco-manipulation 능력을 deep imitation learning으로 학습하는 TRILL 프레임워크를 제시한다. Whole-body control 기반의 계층적 정책 구조를 통해 높은 자유도 humanoid의 복잡한 동작을 데이터 효율적으로 학습할 수 있다.
본 논문은 humanoid loco-manipulation을 위한 데이터 효율적 deep imitation learning 방법을 제시하며, whole-body control과의 영리한 결합을 통해 높은 자유도 시스템의 안정성과 학습 효율성을 동시에 달성했다. 실제 humanoid 로봇에서 처음으로 성공적으로 복잡한 manipulation을 학습한 선도적 성과로, 앞으로 humanoid의 자율 능력 향상에 중요한 기여를 할 것으로 예상된다.
DemoHLM: From One Demonstration to Generalizable Humanoid Loco-Manipulation
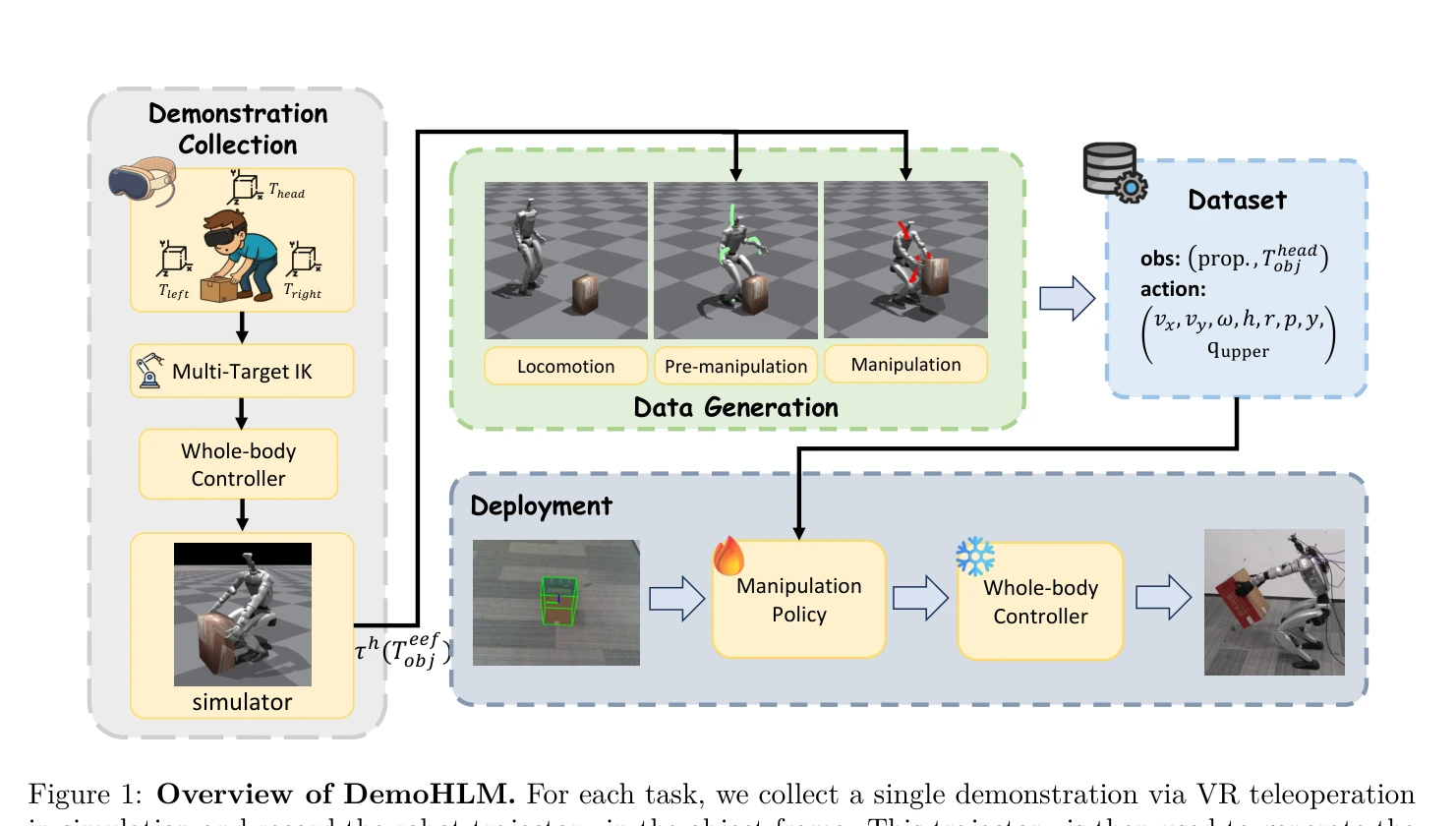
Figure 1: Overview of DemoHLM. For each task, we collect a single demonstration via VR teleoperation
 *Figure 1: Overview of DemoHLM. For each task, we collect a single demonstration via VR teleoperation* DemoHLM은 단일 시뮬레이션 데모로부터 합성 데이터를 생성하여 휴머노이드 로봇의 일반화된 로코-매니퓰레이션 정책을 학습하는 프레임워크이다. 계층적 제어 구조를 통해 저수준 전신 제어기와 고수준 조작 정책을 통합하여 실제 로봇에 시뮬레이션-현실 전이를 달성한다.
본 논문은 MimicGen 개념을 휴머노이드 로코-매니퓰레이션으로 확장하여 단일 데모로부터 확장 가능한 데이터 생성을 실현하고, 계층적 제어 구조를 통해 현실 로봇에 효과적인 시뮬레이션-현실 전이를 달성했다. 데이터 효율성과 다중 작업 일반화 측면에서 강력한 기여를 제공하며, 실제 로봇 검증이 완전하여 실질적 가치가 높다.
EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video
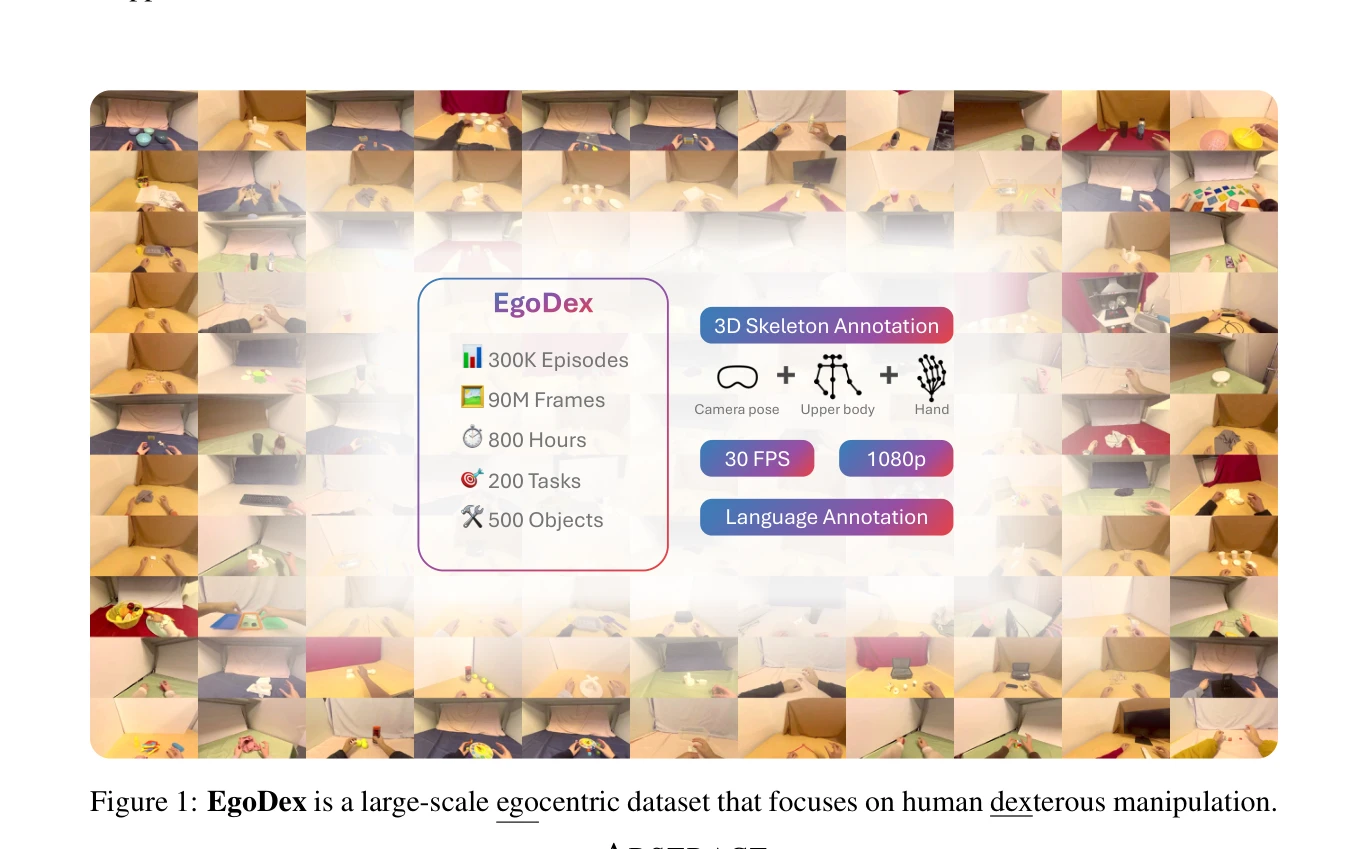
Figure 1: EgoDex is a large-scale egocentric dataset that focuses on human dexterous manipulation.
 *Figure 1: EgoDex is a large-scale egocentric dataset that focuses on human dexterous manipulation.* Apple Vision Pro를 활용하여 829시간의 3D 손 추적 주석이 포함된 대규모 자아중심 비디오 데이터셋 EgoDex를 수집하고, 이를 통해 기술적 조작 모방 학습을 위한 벤치마크를 제시한다.
EgoDex는 기술적 조작 학습을 위한 획기적인 대규모 데이터셋을 제공하며, 웨어러블 기술의 실제 활용을 통해 로봇 조작 분야의 '인터넷 규모 데이터' 시대를 개척한다. 데이터셋의 규모와 정밀도는 탁월하나, 실제 로봇 정책 전이의 실효성 검증이 후속 과제로 남아있다.
Embracing Bulky Objects with Humanoid Robots: Whole-Body Manipulation with Reinforcement Learning
Fig. 1.
 *Fig. 1.* 본 논문은 인간의 동작 사전(human motion prior)과 neural signed distance field(NSDF)를 통합한 강화학습 프레임워크를 제안하여 휴머노이드 로봇이 팔과 몸통을 조율해 부피가 큰 물체를 전신으로 포용하고 운반할 수 있도록 하는 방법을 제시한다.
본 논문은 휴머노이드 로봇의 전신 물체 포용 조작을 위한 최초의 RL 프레임워크를 제시하며, 인간 모션 사전과 NSDF의 통합을 통해 학습 효율성과 접촉 강건성을 동시에 달성한 혁신적인 연구다. 시뮬레이션과 실제 로봇 실험을 통한 검증이 충분하고 실용적 가치가 높다.
ExBody2: Advanced Expressive Humanoid Whole-Body Control

Fig. 1: Humanoid robot executing various expressive whole-body motions in the real world. The robot can (a) walk with a
 *Fig. 1: Humanoid robot executing various expressive whole-body motions in the real world. The robot can (a) walk with a * ExBody2는 휴머노이드 로봇이 인간의 모션 캡처 데이터와 시뮬레이션 데이터를 학습하여 표현력 있는 전신 동작을 수행하도록 하는 프레임워크이며, 자동화된 데이터 필터링과 teacher-student 기반의 decoupled motion-velocity 제어 전략을 통해 실제 로봇에 배포 가능하게 함.
ExBody2는 자동화된 데이터 필터링, generalist-specialist 파이프라인, decoupled motion-velocity 제어라는 세 가지 명확한 혁신을 통해 휴머노이드 로봇의 표현력 있는 전신 제어 문제를 체계적으로 해결하며, 실제 로봇에서의 다양한 동작 성공 시연으로 실질적 기여를 입증한 우수한 연구임.
ExtremControl: Low-Latency Humanoid Teleoperation with Direct Extremity Control
Fig. 1: The humanoid robot (Unitree G1) demonstrates a diverse set of loco-manipulation tasks under teleoperation: (a) r
 *Fig. 1: The humanoid robot (Unitree G1) demonstrates a diverse set of loco-manipulation tasks under teleoperation: (a) r* ExtremControl은 SE(3) 포즈 기반의 직접 제어와 velocity feedforward 제어를 통해 humanoid teleoperation의 지연시간을 50ms까지 단축하는 저지연 전신 제어 프레임워크이다.
ExtremControl은 velocity feedforward와 direct extremity control을 결합하여 humanoid teleoperation의 지연시간을 4배 단축하고 고속 반응 작업을 실현한 혁신적 연구로, 실제 로봇에서의 높은 응답성 달성과 통합된 시스템 구현으로 실용적 가치가 우수하다.
FALCON: Learning Force-Adaptive Humanoid Loco-Manipulation
Figure 1: FALCON enables versatile forceful loco-manipulation tasks for humanoids: (a) Transporting Pay-
 *Figure 2: Overview of FALCON. (a) Two agents with different sub-tasks are jointly trained with* FALCON은 이중 에이전트 강화학습 프레임워크로, 하체의 안정적 보행과 상체의 정밀한 말단 장치 위치 추적을 분리하여 학습함으로써 휴머노이드 로봇이 0-100N의 큰 외부 힘에 적응하면서 강제적 작업을 수행하도록 한다.
FALCON은 휴머노이드의 강제적 로코-조작 문제를 이중 에이전트 분해와 힘 커리큘럼 설계로 효과적으로 해결하며, 다중 플랫폼 배포와 2배의 추적 정확도 향상을 입증함으로써 실용적 가치가 높다. 다만 sim-to-real 갭 극복 메커니즘과 극단적 환경 강건성에 대한 분석이 더 필요하다.
FAME: Force-Adaptive RL for Expanding the Manipulation Envelope of a Full-Scale Humanoid
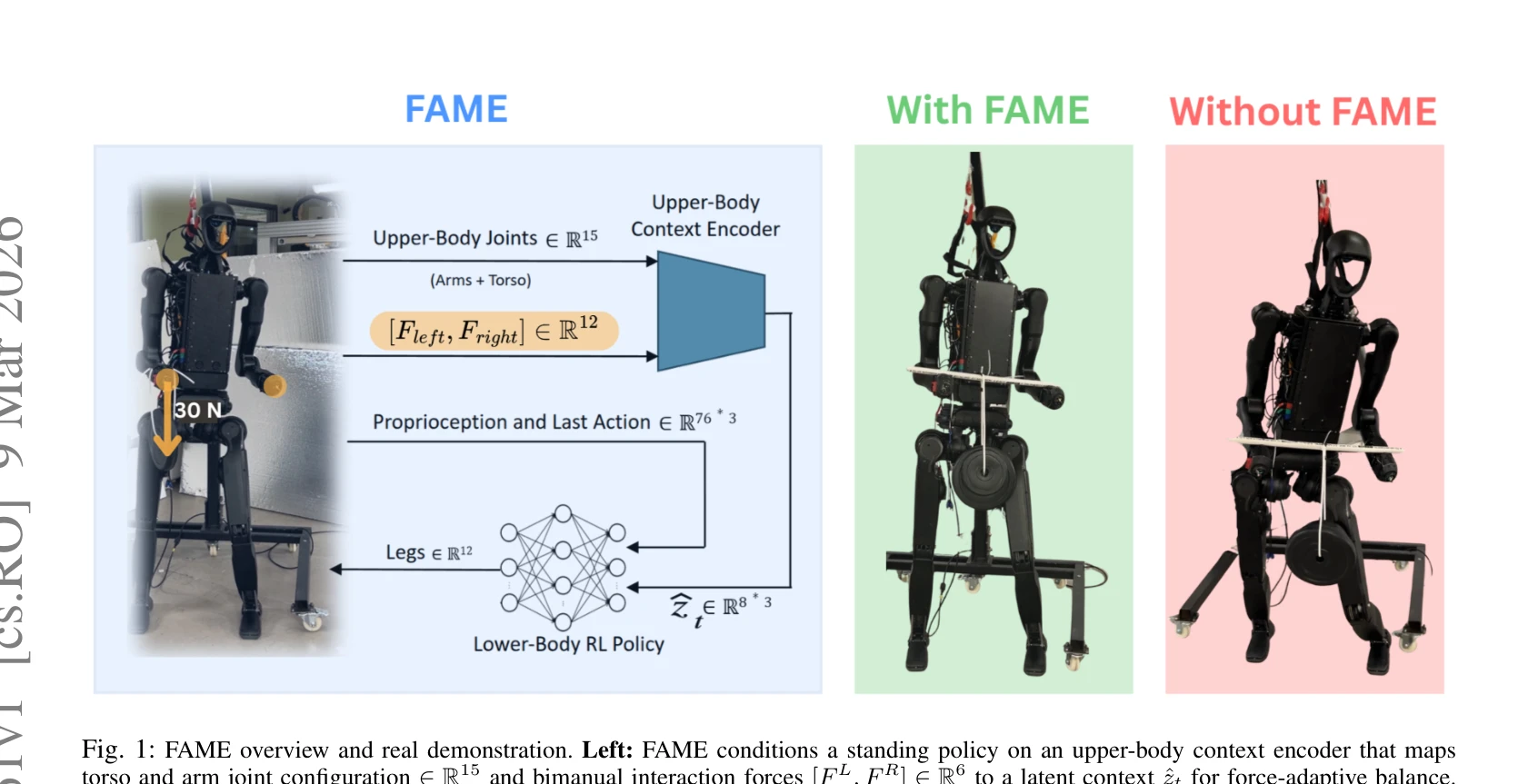
Fig. 1: FAME overview and real demonstration. Left: FAME conditions a standing policy on an upper-body context encoder t
 *Fig. 2: Overview of the proposed standing framework. During training (top), an upper-body dynamics encoder processes* FAME는 양팔 조작 시 외부 손 힘으로 인한 균형 교란을 해결하기 위해, 상체 관절 구성과 양팔 상호작용 힘을 인코딩하는 latent context에 조건화된 RL 정책을 학습한다.
FAME는 latent context adaptation을 양팔 조작 중 balance 문제에 창의적으로 적용하며, 센서 불필요 배포와 실세계 검증으로 실용적 기여를 한다. 다만 sim-to-real 격차와 힘 추정 정확도 분석이 보강되면 더욱 강력해질 것이다.
FLAM: Foundation Model-Based Body Stabilization for Humanoid Locomotion and Manipulation
Fig. 1.
 *Fig. 1.* FLAM은 인간 동작 재구성 모델 기반의 안정화 보상 함수를 설계하여 휴머노이드 로봇의 전신 제어에서 신체 안정성을 명시적으로 고려하는 강화학습 방법이다. 로봇 자세를 3D 가상 인간 모델에 매핑한 후 안정화된 자세를 재구성하여 보상을 계산함으로써 학습 과정을 가속화한다.
FLAM은 인간 동작 foundation model을 창의적으로 활용하여 휴머노이드 로봇의 안정성 문제를 해결한 효과적인 방법이다. 강화학습의 샘플 효율성 문제를 개선하고 다양한 작업에서 우수한 성능을 보여주며, 향후 로봇 제어의 중요한 기초를 제공할 수 있다.
Flow Matching Imitation Learning for Multi-Support Manipulation
Figure 1.
 *Figure 1.* 본 논문은 Flow Matching 생성 모델을 활용하여 휴머노이드 로봇이 팔을 추가 지지점으로 사용하는 다중 접촉 조작 작업을 모방 학습으로 학습할 수 있는 통합 접근법을 제시한다. Talos 로봇에서 상자 밀기 및 식기세척기 문 닫기 작업을 성공적으로 수행하며, 공유 자율성 모드를 통해 인간 조작자를 지원한다.
본 논문은 Flow Matching을 실제 휴머노이드 로봇의 다중 접촉 조작 학습에 처음 적용한 혁신적 연구로, 이론적 기여와 실제 구현이 잘 결합되어 있다. 공유 자율성 모드를 통한 실용적 응용 가치와 생성 모델의 로봇 적용 가능성을 명확히 입증한다.
General Humanoid Whole-Body Control via Pretraining and Fast Adaptation
 *Figure 2: An overview of FAST. Our framework consists of three stages. (1) We construct a curated* FAST는 대규모 사전학습과 경량 잔여 정책 적응을 결합하여 인간형 로봇의 일반적인 전신 제어를 가능하게 하는 프레임워크이다. Center-of-Mass-Aware Control과 Parseval-Guided Residual Policy Adaptation을 통해 분포 외 동작에 대한 빠른 적응과 안정적인 균형을 동시에 달성한다.
FAST는 실용적인 제약 조건 하에서 인간형 로봇의 일반적이고 견고한 전신 제어를 달성하는 잘 설계된 프레임워크이며, Center-of-Mass-Aware 제어와 Parseval-Guided 잔여 적응의 조합은 분포 외 동작 적응에서 새로운 접근 방식을 제시한다.
GentleHumanoid: Learning Upper-body Compliance for Contact-rich Human and Object Interaction
Fig. 1: GentleHumanoid learns a universal whole-body control policy with upper-body compliance and tunable force limits.
 *Fig. 1: GentleHumanoid learns a universal whole-body control policy with upper-body compliance and tunable force limits.* GentleHumanoid는 impedance control을 whole-body motion tracking 정책에 통합하여 humanoid 로봇의 상체 compliance를 학습하는 프레임워크이다. 이는 human motion data에서 샘플링한 spring-based formulation을 통해 resistive contact와 guiding contact를 통일적으로 모델링한다.
GentleHumanoid는 humanoid 로봇의 안전한 human-robot physical interaction을 위한 실질적이고 창의적인 솔루션을 제시한다. Unified spring-based formulation과 human motion data 기반 contact modeling의 조합은 novel하며, 실제 Unitree G1에서의 검증과 custom pressure-sensing 평가 방법론은 논문의 신뢰성을 높인다.
HAFO: A Force-Adaptive Control Framework for Humanoid Robots in Intense Interaction Environments
Fig 1: Overview of the HAFO model. (a) Policy Training. A dual-agent strategy with
 *Fig 1: Overview of the HAFO model. (a) Policy Training. A dual-agent strategy with* HAFO는 dual-agent RL 프레임워크를 통해 humanoid robot의 하체 보행과 상체 조작을 동시에 최적화하여 강한 외력 상호작용 환경에서 안정적이고 정밀한 제어를 달성한다.
HAFO는 spring-damper 모델과 dual-agent RL의 결합으로 humanoid robot의 강한 외력 적응 제어에서 새로운 기준을 제시하며, 특히 로프 현수라는 novel 응용에서 안정적 제어를 최초 달성한 의미 있는 연구다.
Hierarchical Vision-Language Planning for Multi-Step Humanoid Manipulation
Fig. 1: Our hierarchical humanoid manipulation system autonomously executes a multi-step rearrangement task. The robot f
 *Fig. 2: Overview of the proposed hierarchical framework for autonomous multi-step humanoid manipulation. The system* 인간형 로봇의 복잡한 다단계 조작 작업을 위해 저수준 RL 추적 제어기, 중수준 모방학습 기반 스킬 정책, 고수준 VLM 기반 계획 및 모니터링으로 구성된 3계층 계층적 프레임워크를 제시한다.
본 논문은 humanoid 로봇의 자율적 다단계 조작을 위해 VLM 기반 계획 및 모니터링을 기존 2계층 제어에 추가하는 실용적인 접근을 제시하며, 실제 로봇 시험으로 기술적 가능성을 입증했다. 다만 73% 성공률과 단일 작업 검증은 추후 개선이 필요한 부분이다.
HOMIE: Humanoid Loco-Manipulation with Isomorphic Exoskeleton Cockpit
Fig. 1: HOMIE empowers the humanoid robot to execute various loco-manipulation tasks in the real world. (a): Squatting t
 *Fig. 2: System Overview. (a): how an operator uses the exoskeleton-based hardware system to control humanoid robots in t* HOMIE는 강화학습 기반 신체 제어, 동형 외골격 팔, 모션센싱 장갑을 통합한 반자율 원격조종 시스템으로, 단일 작업자가 휴머노이드 로봇의 전신 보행-조작 작업을 정밀하게 제어할 수 있게 함
HOMIE는 RL 기반 적응형 보행 제어와 저비용 동형 하드웨어를 혁신적으로 결합하여 휴머노이드 로봇의 전신 원격조종을 현실화한 획기적 시스템으로, 비용 효율성과 성능에서 기존 솔루션을 크게 초월하며 실용적 가치가 높음
Humanoid Manipulation Interface: Humanoid Whole-Body Manipulation from Robot-Free Demonstrations
Fig. 1: Humanoid Manipulation Interface (HuMI). Left: Our portable, robot-free data collection facilitates skill transfe
 *Fig. 1: Humanoid Manipulation Interface (HuMI). Left: Our portable, robot-free data collection facilitates skill transfe* HuMI는 로봇 없이 휴대용 하드웨어로 수집한 인간 전신 동작 데이터를 이용해 인형형 로봇에게 다양한 전신 조작 기술을 학습시키는 프레임워크이다. 계층적 학습 파이프라인과 IK 기반 적응을 통해 인간-로봇 간 신체형 차이를 극복하고 70% 성공률을 달성한다.
HuMI는 로봇 없는 휴대용 데이터 수집과 계층적 학습을 결합하여 인형형 로봇의 전신 조작을 효율적으로 학습시키는 혁신적인 프레임워크이다. 3배 높은 데이터 수집 효율과 미지 환경에서의 강한 일반화는 로봇 학습의 실용성을 크게 향상시키며, 신체형 차이 극복을 위한 체계적 접근법이 학문적 기여도 크다.
Humanoid Policy ~ Human Policy

Figure 1: This paper advocates high-quality human data as a data source for cross-embodiment
 *Figure 1: This paper advocates high-quality human data as a data source for cross-embodiment* 휴머노이드 로봇 조작 정책 학습을 위해 대규모 자아중심 인간 데모를 cross-embodiment 학습 데이터로 활용하고, Human Action Transformer (HAT)를 통해 인간과 로봇을 통합된 상태-행동 공간에서 다양한 embodiment으로 모델링한다.
로봇 조작 학습에서 대규모 인간 데이터 활용의 실질적 가치를 입증한 의미 있는 연구로, 통합된 state-action space와 체계적인 co-training 전략을 통해 embodiment 간극을 효과적으로 해소했으며, PH2D 데이터셋과 HAT 모델의 공개를 통해 cross-embodiment 학습 커뮤니티에 중요한 기여를 할 것으로 기대된다.
Humanoid Whole-Body Badminton via Multi-Stage Reinforcement Learning
 *Fig. 2: System overview. (a) Training: PPO learns a single policy πWBC using Privileged Critic Obs together with Actor* 이 논문은 다단계 강화학습 커리큘럼을 통해 휴머노이드 로봇이 배드민턴을 하도록 학습하는 통합 전신 제어기를 제시하며, 시뮬레이션과 실제 로봇 모두에서 1초 이내의 반응 시간으로 19.1 m/s의 셔틀콕 속도를 달성했다.
이 논문은 휴머노이드 로봇의 고속 동적 상호작용 능력을 크게 진전시키며, 잘 설계된 3단계 커리큘럼과 실제 배포 성공이 인상적이다. 다만 예측 없는 변형의 실제 검증 부족과 현재 제한된 시험 환경이 향후 개선 과제이다.
HumanoidExo: Scalable Whole-Body Humanoid Manipulation via Wearable Exoskeleton

Figure 1. HumanoidExo, a wearable exoskeleton system that transfers human motion to whole-body humanoid data. HumanoidEx
 *Figure 1. HumanoidExo, a wearable exoskeleton system that transfers human motion to whole-body humanoid data. HumanoidEx* 웨어러블 외골격(exoskeleton)을 통해 인간의 전신 동작을 휴머노이드 로봇 데이터로 변환하는 HumanoidExo 시스템을 제안하여, 휴머노이드 정책 학습을 위한 대규모 다양한 데이터셋 수집의 병목을 해결한다.
HumanoidExo는 웨어러블 외골격을 통한 전신 휴머노이드 데이터 수집의 첫 성공적 사례로, 기존 방법의 상지 집중 문제를 극복하고 embodiment gap을 최소화한 혁신적 접근이다. 실험 결과가 제한적이고 기술적 깊이가 다소 부족하지만, 휴머노이드 정책 학습의 데이터 병목 문제 해결이라는 실질적 기여와 높은 실용성으로 인해 로보틱스 분야에 의미 있는 진전을 제시한다.
HumDex: Humanoid Dexterous Manipulation Made Easy
Fig. 1: The HumDex System. Our portable teleoperation system enables efficient collection of high-quality dexterous
 *Fig. 1: The HumDex System. Our portable teleoperation system enables efficient collection of high-quality dexterous* IMU 기반 모션 트래킹을 활용한 휴머노이드 전신 손재주 조작 텔레오퍼레이션 시스템으로, learning-based hand retargeting과 human 데이터 사전학습을 통해 최소 데이터로 높은 일반화 성능을 달성한다.
IMU 기반 휴대용 텔레오퍼레이션과 learning-based hand retargeting, human 데이터 활용의 three-pronged 접근으로 humanoid 손재주 조작 데이터 수집의 오래된 병목을 효과적으로 해결한 높은 수준의 시스템 논문이다. 재현성 높은 설계와 충분한 실험 검증으로 실제 영향력이 클 것으로 예상된다.
Learning Humanoid Arm Motion via Centroidal Momentum Regularized Multi-Agent Reinforcement Learning
 *Fig. 2: Overview of our limb-level multi-agent reinforcement learning framework with CAM regularization. Separate actor-* 인간의 팔 스윙 운동에서 영감을 받아, centroidal angular momentum (CAM) 추적 보상을 통해 다리와 팔을 별도의 에이전트로 취급하는 multi-agent RL 프레임워크를 제시하여 휴머노이드 로봇의 협응 제어를 달성한다.
본 논문은 centroidal dynamics의 물리적 의미와 생역학적 원리를 CTDE 기반 multi-agent RL과 효과적으로 결합하여, 휴머노이드 로봇의 자연스러운 팔 스윙과 향상된 균형 제어를 달성한 독창적이고 실용적인 연구이다.
Learning Humanoid Standing-up Control across Diverse Postures

Fig. 1: Overview. (a) Our proposed framework HOST enables the humanoid robot to learn standing-up control via reinforcem
 *Fig. 1: Overview. (a) Our proposed framework HOST enables the humanoid robot to learn standing-up control via reinforcem* HoST는 강화학습 기반 프레임워크로 휴머노이드 로봇이 다양한 자세에서 일어서는 동작을 학습하고 실제 환경에서 robust하게 수행할 수 있도록 한다.
이 논문은 휴머노이드 로봇의 standing-up control이라는 실질적 문제를 RL 기반으로 체계적으로 해결하며, 사전 궤적 없이 diverse posture에서의 실제 배포를 성공적으로 달성한 의미 있는 기여로, 실제 로봇 시스템의 자율성 향상에 중요한 발걸음이다.
Learning Motion Skills with Adaptive Assistive Curriculum Force in Humanoid Robots
Fig. 1.
 *Fig. 1.* 인간의 학습 방식을 모방한 적응형 보조력(Adaptive Assistive Curriculum Force, A2CF)을 제안하여 휴머노이드 로봇의 복잡한 동작 학습을 가속화하는 이중-에이전트 강화학습 프레임워크를 제시한다.
인간의 자연스러운 학습 과정에서 영감을 얻은 적응형 보조력 메커니즘으로 휴머노이드 로봇의 복잡한 동작 학습을 획기적으로 가속화한 논문이며, 실제 로봇 실험을 통한 검증과 명확한 성과 지표가 높은 실용적 가치를 제공한다.
Load-Aware Locomotion Control for Humanoid Robots in Industrial Transportation Tasks
Fig. 1. Overview of the proposed load-aware humanoid loco-manipulation framework. Upper-body manipulation is generated b
 *Fig. 1. Overview of the proposed load-aware humanoid loco-manipulation framework. Upper-body manipulation is generated b* 산업용 휴머노이드 로봇의 다양한 하중 조건에서 안정적 보행을 위해 분리-협조 구조의 로코-매니퓰레이션 아키텍처를 제안하며, RL 기반 하체 제어와 상태 추정기를 통해 시뮬레이션 학습 후 실제 로봇에 파인튜닝 없이 배포 성공.
산업용 휴머노이드의 실질적 과제인 하중 변화 조건에서의 로코-매니퓰레이션을 분리-협조 구조와 상태 추정으로 체계적으로 해결하며, 시뮬레이션 학습 후 무튜닝 실배포 성공은 높은 실무 가치를 입증한다.
Mobile-TeleVision: Predictive Motion Priors for Humanoid Whole-Body Control

Fig. 1: Humanoid robot doing whole-body tasks that require both precise manipulation and robust locomotion. The robot
 *Fig. 2: The training pipeline consists of three stages: (a) preprocessing of the motion dataset by mapping local rotatio* 휴머노이드 로봇의 전신 제어를 위해 상체 조작과 하체 보행을 분리하고, CVAE 기반 Predictive Motion Priors (PMP)를 사용하여 상체의 정밀한 조작과 하체의 강건한 보행을 동시에 달성한다.
상체 정밀 조작과 하체 강건 보행이라는 근본적으로 다른 요구를 효과적으로 분리하면서도 CVAE 기반 motion prior를 통해 통합하는 창의적 접근으로, 고 DoF 팔 제어에서 기존 전신 RL 방법을 명확히 능가한다. 실세계 텔레오퍼레이션 가능성까지 보여주어 실용성이 높은 연구이다.
MobileH2R: Learning Generalizable Human to Mobile Robot Handover Exclusively from Scalable and Diverse Synthetic Data
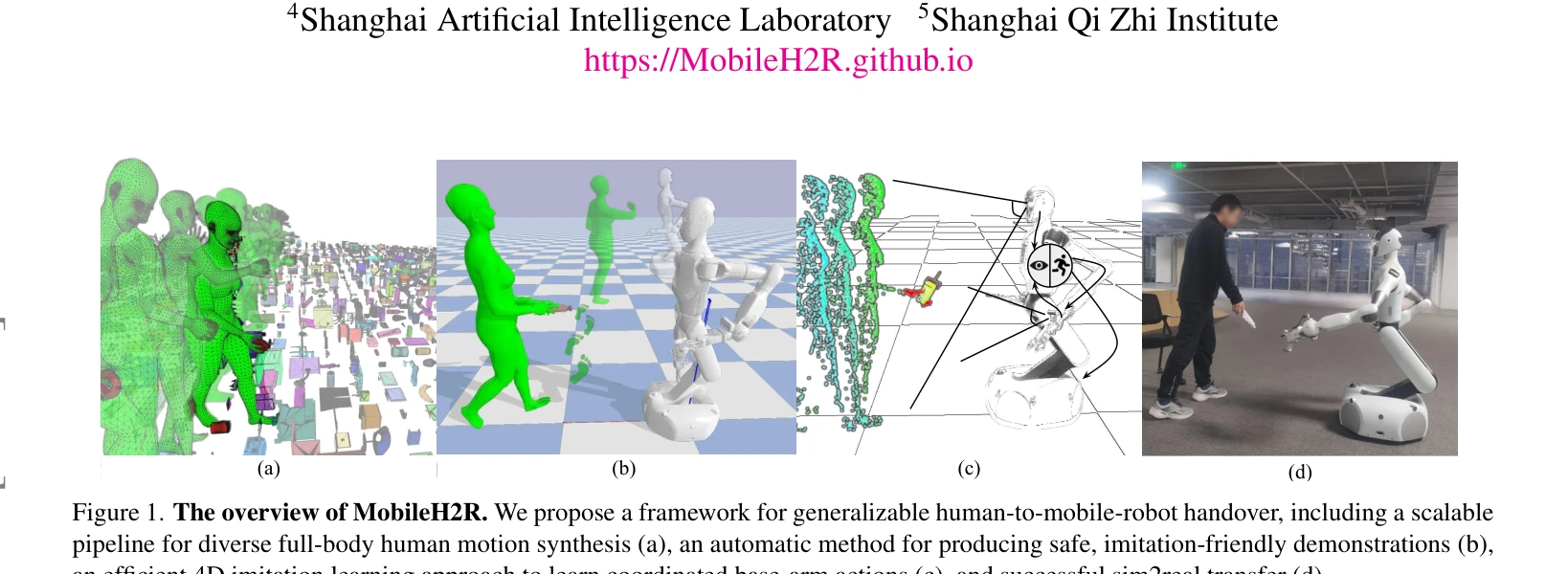
Figure 1. The overview of MobileH2R. We propose a framework for generalizable human-to-mobile-robot handover, including
 *Figure 1. The overview of MobileH2R. We propose a framework for generalizable human-to-mobile-robot handover, including * MobileH2R는 대규모 다양한 합성 데이터만을 사용하여 모바일 로봇이 인간으로부터 물체를 받을 수 있도록 학습하는 프레임워크를 제시한다. 인간의 전신 동작 생성, 안전한 시연 자동 생성, 4D imitation learning을 통합하여 베이스-암 협조 제어가 가능한 일반화된 정책을 학습한다.
MobileH2R는 모바일 로봇의 인간-로봇 handover 문제를 체계적으로 해결하는 포괄적이고 확장 가능한 프레임워크를 제시한다. 합성 데이터의 생성, 안전한 시연 자동 생성, 통합 학습이라는 세 요소를 정교하게 설계하여 +15% 이상의 성능 향상을 달성했으며, 대규모 데이터의 효과를 실증한 점에서 실무적 가치가 높다.
OmniClone: Engineering a Robust, All-Rounder Whole-Body Humanoid Teleoperation System
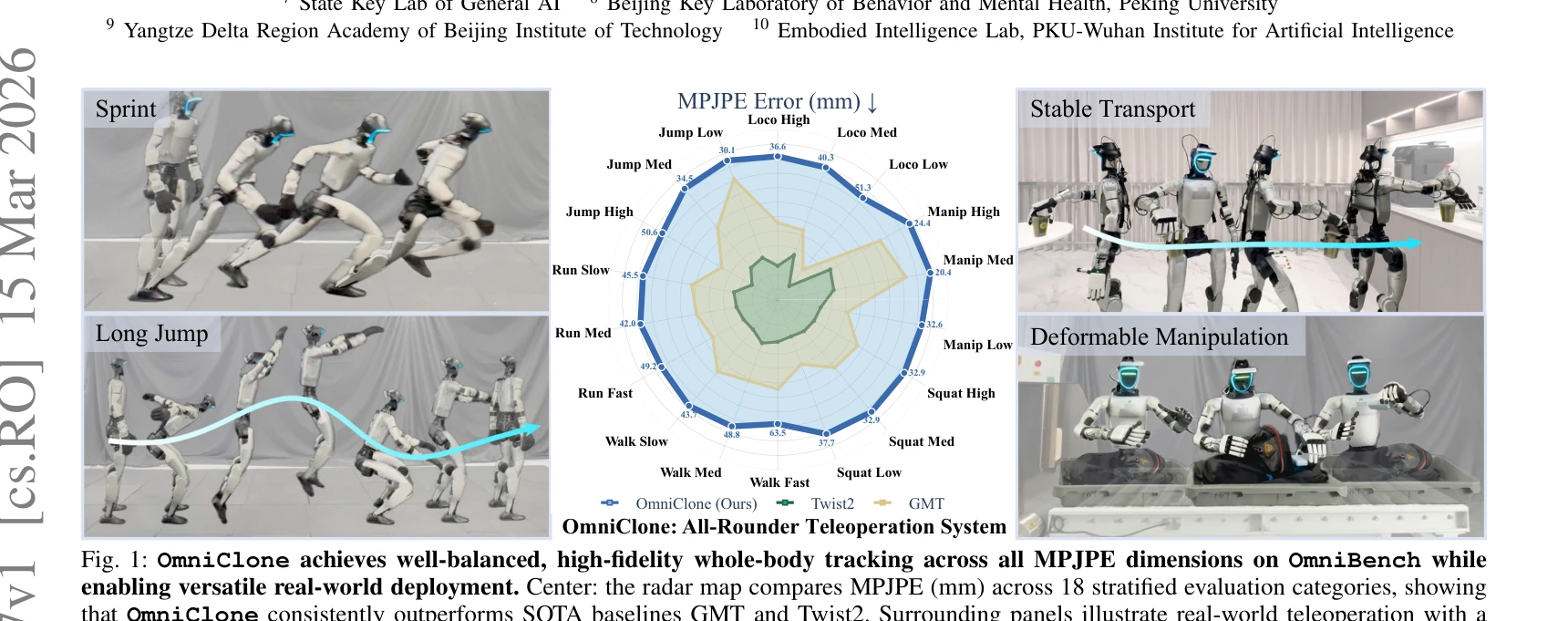
Fig. 1: OmniClone achieves well-balanced, high-fidelity whole-body tracking across all MPJPE dimensions on OmniBench whi
 *Fig. 1: OmniClone achieves well-balanced, high-fidelity whole-body tracking across all MPJPE dimensions on OmniBench whi* OmniClone은 단일 소비자 GPU에서 전신 휴머노이드 텔레오퍼레이션을 실현하는 시스템으로, OmniBench 진단 벤치마크를 통해 기존 시스템의 동작별 성능 격차를 노출하고 이를 바탕으로 최적화된 정책과 시스템 기술을 통합하여 MPJPE를 66% 이상 감소시켰다.
OmniClone은 진단적 벤치마킹과 시스템 공학을 결합하여 실용적이면서도 강력한 휴머노이드 텔레오퍼레이션 시스템을 제시한다. OmniBench는 기존 평가 방식의 근본적 한계를 지적하고 이를 기반으로 한 체계적 개선이 뒤따르는 점, 그리고 소비자 GPU로 SOTA 성능을 달성하면서도 높은 접근성을 제공하는 점에서 학술적, 실용적 가치가 모두 높다.
Opt2Skill: Imitating Dynamically-feasible Whole-Body Trajectories for Versatile Humanoid Loco-Manipulation

Fig. 1. The proposed Opt2Skill framework enables a Digit humanoid robot to
 *Fig. 1. The proposed Opt2Skill framework enables a Digit humanoid robot to* Opt2Skill은 Differential Dynamic Programming (DDP)로 생성한 동역학적으로 실현 가능한 궤적을 Reinforcement Learning (RL)으로 모방하게 함으로써 인간형 로봇의 다양한 로코-조작 작업을 효과적으로 수행하는 통합 파이프라인이다.
Opt2Skill은 model-based trajectory optimization과 reinforcement learning을 효과적으로 결합하여 인간형 로봇의 동역학적으로 실현 가능한 다양한 로코-조작 작업을 체계적으로 해결하며, 실제 하드웨어 전이까지 성공한 중요한 기여로, 토크 정보 활용과 광범위한 실험 검증을 통해 높은 과학적 가치를 갖춘다.
TOP: Time Optimization Policy for Stable and Accurate Standing Manipulation with Humanoid Robots
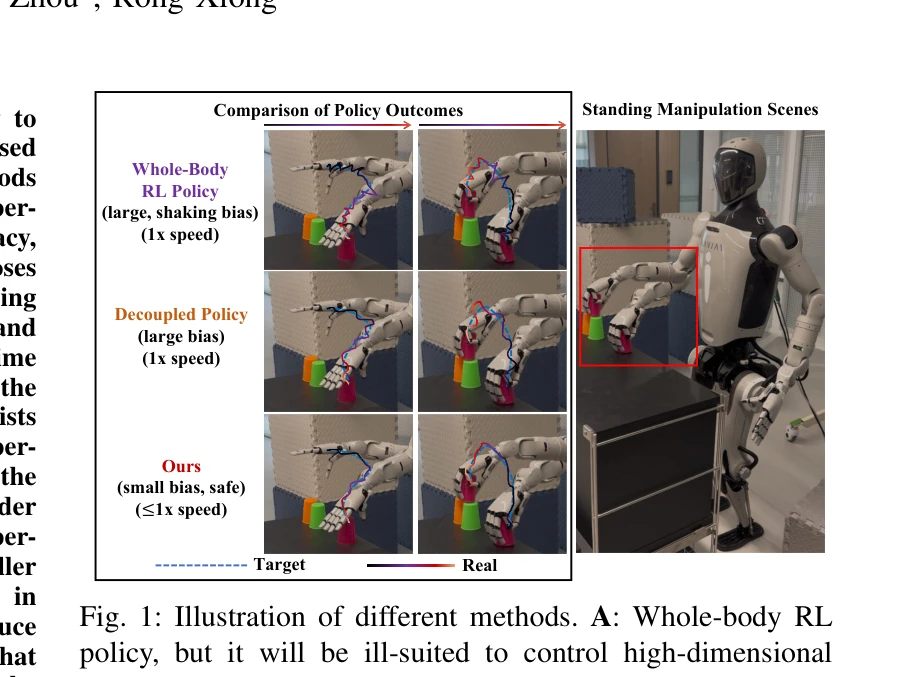
Fig. 1: Illustration of different methods. A: Whole-body RL
 *Fig. 2: The overall architecture. (A) Training a latent code zt based on VAE structure to represent diverse upper-body m* 이 논문은 휴머노이드 로봇의 안정적인 서서하기 조작을 위해 상체 동작의 시간 궤적을 최적화하는 Time Optimization Policy (TOP)을 제안한다. 상체의 빠른 움직임으로 인한 모멘텀을 줄여 균형, 정확성, 시간 효율성을 동시에 달성한다.
이 논문은 상체 동작 시간 최적화라는 직관적이면서도 효과적인 아이디어로 휴머노이드 서서하기 조작의 안정성-정확성-효율성 trade-off 문제를 창의적으로 해결한다. 이론과 실험이 잘 결합되어 있으며, humanoid 로봇 제어 분야에 실질적인 기여를 제공한다.
Toward Humanoid Brain-Body Co-design: Joint Optimization of Control and Morphology for Fall Recovery
 *Fig. 2: The RoboCraft framework.* 본 논문은 humanoid 로봇의 fall recovery 능력을 향상시키기 위해 제어 정책과 신체 형태를 동시에 최적화하는 RoboCraft 프레임워크를 제안한다. 공유 제어 정책의 사전학습과 설계 공간 탐색을 결합하여 효율적인 co-design을 실현한다.
본 논문은 복잡한 humanoid 로봇에 대한 실질적이고 확장 가능한 co-design 프레임워크를 처음 제시하며, 다중 설계 사전학습 정책과 우선순위 버퍼를 통한 효율적 최적화로 형태 최적화의 중요성을 명확히 입증했다. 시뮬레이션 기반 한계에도 불구하고 embodied AI 분야의 중요한 진전을 나타낸다.
TWIST: Teleoperated Whole-Body Imitation System

Figure 1: The Teleoperated Whole-Body Imitation System (TWIST) is a system that teleoperates humanoid
 *Figure 1: The Teleoperated Whole-Body Imitation System (TWIST) is a system that teleoperates humanoid* TWIST는 모션 캡처 데이터의 실시간 리타겟팅과 RL+BC 기반의 통합 신경망 컨트롤러를 통해 휴머노이드 로봇의 전신 협응 제어를 실현하는 원격 조종 시스템이다.
TWIST는 전신 협응 휴머노이드 원격 조종의 오래된 과제를 teacher-student 프레임워크와 데이터 혼합 전략으로 우아하게 해결하며, 단일 신경망으로 다양한 협응 기술을 실현한 의미 있는 기여이다.
Safe Human-to-Humanoid Motion Imitation Using Control Barrier Functions
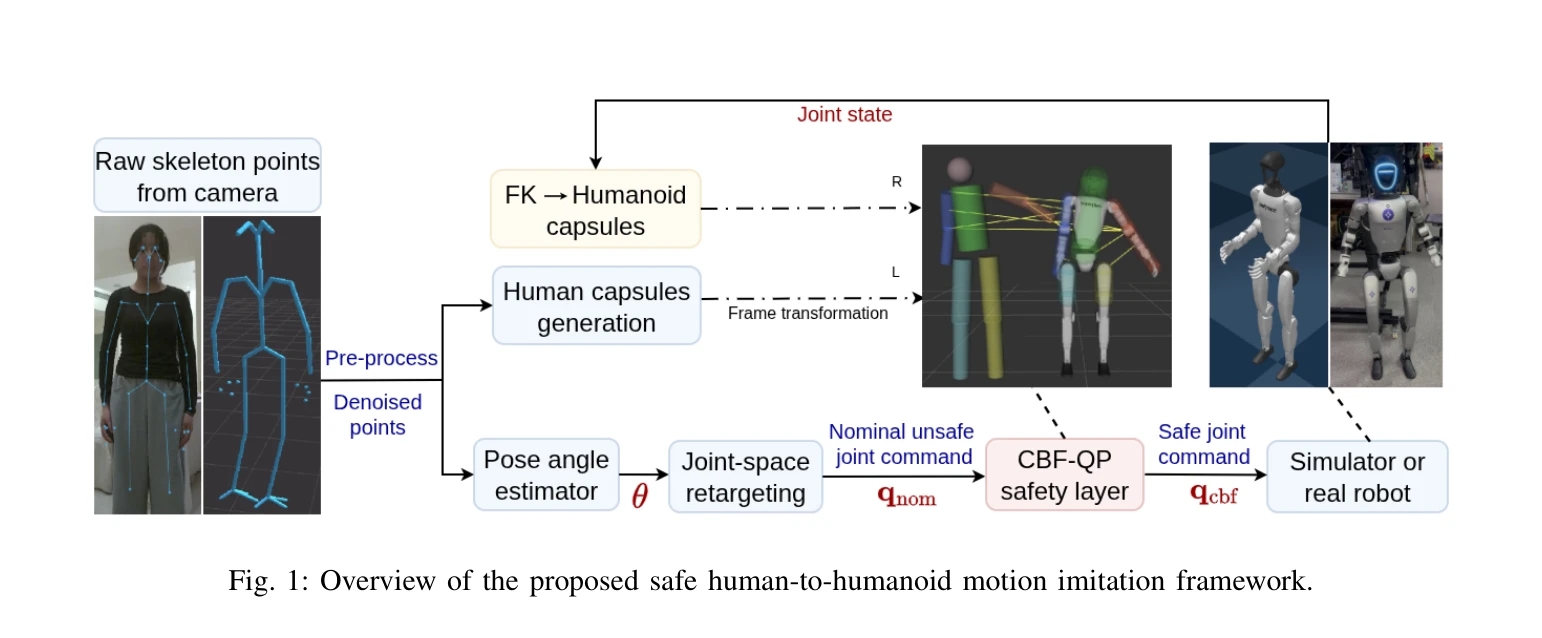
Fig. 1: Overview of the proposed safe human-to-humanoid motion imitation framework.
 *Fig. 1: Overview of the proposed safe human-to-humanoid motion imitation framework.* 비전 기반 motion retargeting과 Control Barrier Function을 결합하여 휴머노이드 로봇이 인간의 동작을 모방하면서 자기 충돌과 인간-로봇 충돌을 실시간으로 회피할 수 있는 안전 프레임워크를 제시한다.
비전 기반 motion imitation에 CBF를 체계적으로 도입하여 실시간 안전 필터링을 구현한 실질적 기여이며, 충돌 회피와 responsiveness의 균형을 QP로 효과적으로 달성했다. 다만 시뮬레이션만 제시되고 하드웨어 검증이 필요하며, 설계 parameter 튜닝과 일반화 가능성 개선이 추후 과제이다.
Switch: Learning Agile Skills Switching for Humanoid Robots
 *Fig. 2: The Switch system: (a) We retarget human motion capture skills onto the robot. We then construct a skill graph w* Switch는 Skill Graph를 기반으로 humanoid robot이 임의의 시점에서 다양한 동작 기술들 사이를 자유롭게 전환할 수 있는 계층적 전신 제어 시스템을 제시한다.
Switch는 Skill Graph라는 단순하면서도 효과적인 구조와 online graph search 기반의 동적 재계획을 통해 humanoid robot의 skill switching 문제를 실용적으로 해결한 의미 있는 연구이며, 실제 로봇 플랫폼에서의 검증으로 높은 적용 가치를 보여준다.
X2-N: A Transformable Wheel-legged Humanoid Robot with Dual-mode Locomotion and Manipulation
Fig. 1: Illustration of X2-N in dual locomotion modes with
 *Fig. 1: Illustration of X2-N in dual locomotion modes with* X2-N은 휠-레그 하이브리드 모드와 휴머노이드 풋 모드를 유연하게 변환하며 운영할 수 있는 고자유도 로봇으로, RL 기반 통합 제어 프레임워크로 효율적 이동과 정교한 조작을 동시에 수행한다.
X2-N은 휠-레그와 휴머노이드 로봇의 장점을 창의적으로 통합한 혁신적 플랫폼으로, Joint reuse 기반의 우아한 메커니즘 설계와 RL·모델 기반 제어의 효과적 결합을 통해 실용성 높은 솔루션을 제시한다.
Humanoid Policy ~ Human Policy

Figure 1: This paper advocates high-quality human data as a data source for cross-embodiment
 *Figure 3: Overview of HAT. Human Action Transformer (HAT) learns a robot policy by modeling* 이 논문은 humanoid 로봇의 조작 정책 학습에 대규모 egocentric human demonstration을 활용하는 cross-embodiment 학습 방법을 제안한다. PH2D 데이터셋과 Human Action Transformer (HAT)를 통해 human과 robot 간의 embodiment gap을 완화하고 데이터 수집 효율을 크게 개선한다.
이 논문은 humanoid robot manipulation 학습을 위해 대규모 human data를 효율적으로 활용하는 실용적이고 창의적인 방안을 제시한다. PH2D 데이터셋의 규모와 품질, HAT의 unified design, 그리고 실로봇 검증이 기여도 있으나, 평가 범위 확장과 다양한 플랫폼으로의 일반화 검증이 필요하다.
Deep Reinforcement Learning for Bipedal Locomotion: A Brief Survey
Fig. 1: Representative bipedal and humanoid robots illustrat-
본 논문은 bipedal robot의 locomotion을 위한 Deep Reinforcement Learning(DRL) 기반 프레임워크를 체계적으로 분류, 비교, 분석하는 survey이며, end-to-end와 hierarchical 제어 방식으로 구분하여 각 프레임워크의 구성, 강점, 한계를 평가한다.
본 survey는 DRL 기반 bipedal locomotion 분야의 fragmented 연구를 체계적으로 정리하고 unified framework을 향한 명확한 research agenda를 제시하는 가치 있는 종합 분석이다. End-to-end와 hierarchical 분류 체계, learning paradigm 비교, hybrid 아키텍처 평가는 이 분야의 종사자들에게 실질적인 guidance를 제공하며, 향후 generalisable bipedal locomotion 개발의 기초를 마련한다.
Teleoperation of Humanoid Robots: A Survey
 *Fig. 2: Schematic architecture for teleoperating a humanoid.* 이 논문은 인간형 로봇의 원격 조종(teleoperation) 분야에 대한 포괄적인 서베이로, 시스템 아키텍처, 기술 및 방법론적 진전, 실제 응용 분야를 종합적으로 분석한다.
이 서베이는 humanoid robot teleoperation의 포괄적이고 최신의 개요를 제공하며, 복잡한 시스템을 명확한 아키텍처로 정리하고 다양한 기술적 도전과 솔루션을 체계적으로 분석한다. 해당 분야의 연구자와 실무자들에게 매우 유용한 참고 자료이지만, 구체적인 기술 혁신보다는 기존 연구의 종합과 정리에 초점을 두고 있다.
A Behavior Architecture for Fast Humanoid Robot Door Traversals
Figure 1: The Nadia humanoid robot performing a right pull lever handle door traversal using cycloidal drive forearms an
 *Figure 2: An all inclusive overview of the parts involved in this work.* 휴머노이드 로봇의 다양한 도어 통과 작업을 수행하기 위해 GPU 가속 인식, Behavior Tree 기반 행동 조정 시스템, 전신 제어기를 통합한 아키텍처를 제시한다. 실제 Nadia 휴머노이드 로봇에서 빠른 도어 통과 성능을 달성했다.
이족 휴머노이드의 도어 통과라는 미개발 영역을 처음 체계적으로 다루고, 실제 로봇에서 동작하는 통합 시스템을 구현한 의미 있는 연구이다. 행동 저작의 속도와 재사용성 향상, 다층적 시스템 설계 관점에서 독창성과 실용성이 우수하나, 단일 플랫폼 검증과 일반화 가능성에 대한 보완이 필요하다.
AGILOped: Agile Open-Source Humanoid Robot for Research
Fig. 1: The kinematics, CAD model and constructed version of AGILOped.
 *Fig. 1: The kinematics, CAD model and constructed version of AGILOped.* AGILOped는 오픈소스 휴머노이드 로봇으로서 높은 성능과 접근성 사이의 간극을 해소하며, 3D 프린팅과 상용 부품을 활용해 6,380 USD의 저렴한 가격으로 동적 운동 능력을 제공한다.
AGILOped는 오픈소스, 저가격, 높은 성능을 결합한 획기적인 휴머노이드 로봇으로, 휴머노이드 로봇 연구의 진입장벽을 크게 낮추고 학계의 민주화를 촉진하는 중요한 기여를 한다.
Beyond Tools and Persons: Who Are They? Classifying Robots and AI Agents for Proportional Governance
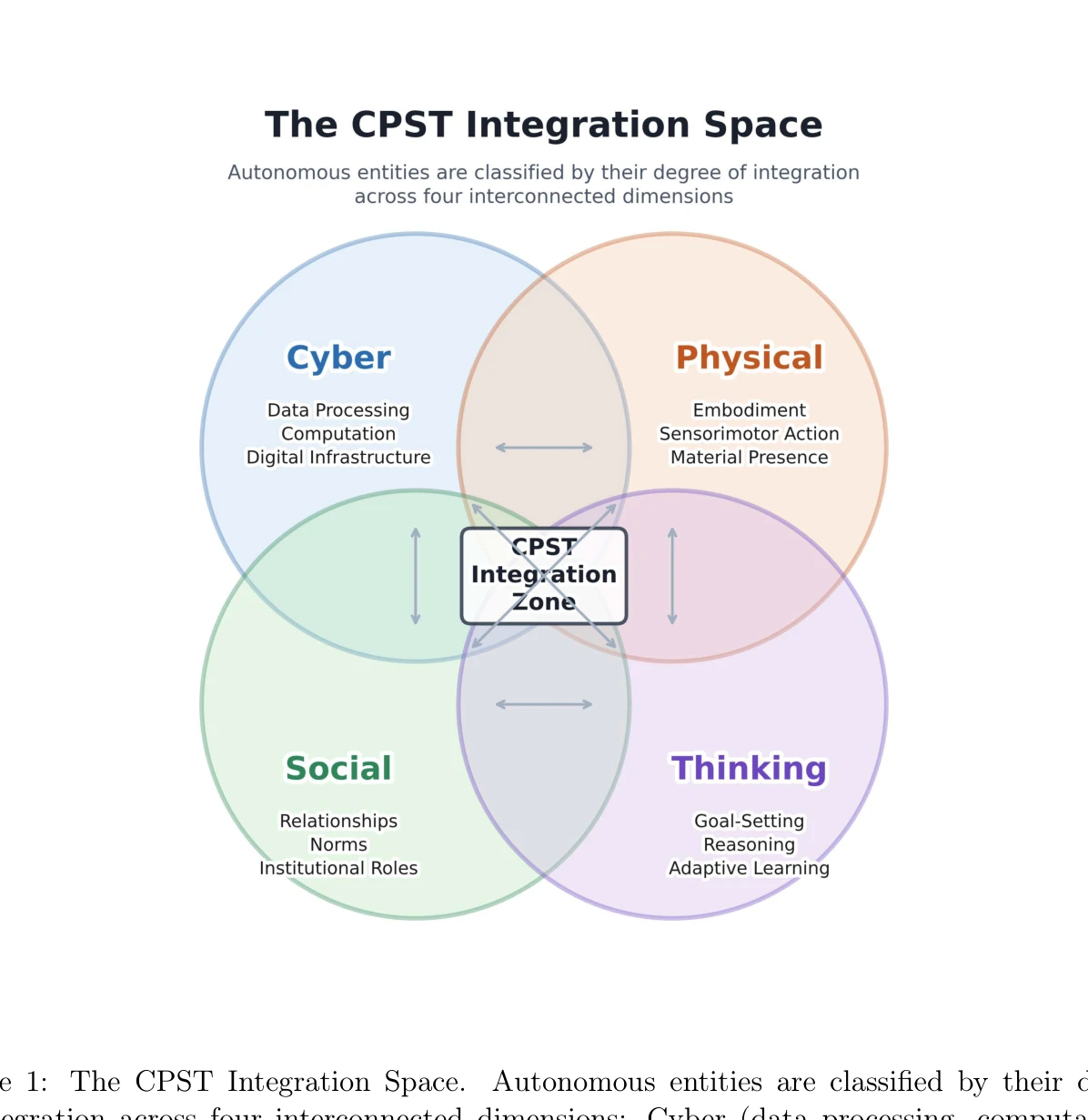
Figure 1: The CPST Integration Space.
 *Figure 1: The CPST Integration Space.* CPST(Cyber-Physical-Social-Thinking) 공간 이론에 기반한 로봇과 AI 에이전트의 분류 프레임워크를 제안하여, 기존의 '도구' vs '인격' 이분법적 법적 범주의 한계를 극복하고 비례적 거버넌스를 위한 온톨로지를 제시한다.
본 논문은 AI 및 로봇 거버넌스의 근본적 온톨로지 문제를 CPST 이론으로 해결하려는 야심찬 시도로, 기존 위험도/안전성 중심의 규제에서 엔티티 특성 중심으로의 패러다임 전환을 제시한다. 다만 평가 지표의 정량화, 국제 표준화의 현실성, 신기술 추적 메커니즘에 대한 더 깊은 논의가 필요하다.
Demonstrating Berkeley Humanoid Lite: An Open-source, Accessible, and Customizable 3D-printed Humanoid Robot
Fig. 1.
 *Fig. 1.* Berkeley Humanoid Lite는 3D-printed cycloidal gearbox를 활용한 오픈소스 휴머노이드 로봇으로, $5,000 이하의 저비용으로 데스크톱 3D프린터와 e-commerce 부품으로 제작 가능하며 강화학습 기반 locomotion controller를 통해 sim-to-real transfer를 입증했다.
Berkeley Humanoid Lite는 3D-printed cycloidal gear 기반 저비용 휴머노이드 로봇의 설계와 구현을 통해 로봇 연구의 접근성을 획기적으로 낮추고, 완전 오픈소스 공개 정책으로 커뮤니티 주도의 발전을 가능하게 했다. Reinforcement learning 기반 locomotion control의 성공적인 sim-to-real transfer는 플랫폼의 실용성을 입증하며, 향후 휴머노이드 로봇 연구의 민주화를 주도할 초석이 될 가능성이 크다.
Fauna Sprout: A lightweight, approachable, developer-ready humanoid robot
Fig. 1: Robot in action. (A) Standing and looking up towards a person (B) performing closed-loop high-five interaction
 *Fig. 1: Robot in action. (A) Standing and looking up towards a person (B) performing closed-loop high-five interaction* Sprout는 인간 환경에서의 안전한 배포, 표현성, 개발자 접근성을 강조하는 경량 휴머노이드 로봇 플랫폼이다. 낮은 물리적·기술적 진입장벽으로 구현된 통합 하드웨어-소프트웨어 스택을 제공한다.
Sprout는 로보틱스 분야의 접근성 문제를 정면으로 해결하는 실용적 플랫폼으로, 안전성과 개발자 친화성을 중심으로 한 설계 철학이 명확하다. 인간 환경 배포와 사회적 상호작용이라는 과소 탐색된 영역을 강조함으로써 embodied AI 연구의 새로운 방향을 제시하는 의미 있는 기여이다.
Hierarchical Planning and Control for Box Loco-Manipulation

Fig. 1. We develop loco-manipulation skills for box-carrying physics-based characters. This is achieved via a
 *Fig. 2. System overview. We design four motion primitives for locomotion and manipulation which can be* 물리 기반 시뮬레이션 인간 캐릭터가 box rearrangement 작업을 수행하기 위해 계획, diffusion model, 강화학습을 계층적으로 조합하는 시스템을 제시한다.
본 논문은 물리 기반 캐릭터 애니메이션에서 loco-manipulation의 도전적인 문제를 diffusion model과 RL을 계층적으로 조합하여 우아하게 해결하며, 높은 기술적 완성도와 실용적 가치를 동시에 갖춘 우수한 연구이다.
Teleoperation of Humanoid Robots: A Survey
 *Fig. 2: Schematic architecture for teleoperating a humanoid.* 본 논문은 humanoid robot teleoperation에 대한 포괄적인 survey로, 원격 환경에서 인간의 인지 능력과 humanoid robot의 물리적 능력을 통합하는 teleoperation 시스템의 아키텍처, 기술적 조화, 그리고 응용 분야를 체계적으로 분석한다. Teleoperation system의 전체 파이프라인과 각 구성 요소를 상세히 제시하며, 통신 지연, 제어, retargeting, 인간-로봇 상호작용 등 다층적 도전 과제들을 다룬다.
본 논문은 humanoid robot teleoperation 분야의 첫 번째 포괄적 survey로, 시스템 아키텍처, 기술적 도전 과제, 그리고 실제 응용을 통합적으로 다룬다. 웹 기반 자료까지 제공하여 학계의 접근성을 높였으나, 이론적 깊이와 정량적 성능 비교 분석이 추가되면 더욱 강화될 수 있다. 고위험 원격 작업의 안전성과 효율성이 중요해지는 시대에 매우 시의적절하고 가치 있는 기여이다.
Physically Consistent Humanoid Loco-Manipulation using Latent Diffusion Models
Fig. 1: A loco-manipulation task achieved with our approach.
 *Fig. 2: Pipeline overview.* 본 논문은 Latent Diffusion Model(LDM)을 활용하여 인간-물체 상호작용 장면을 생성하고, 이로부터 추출한 접촉 위치와 로봇 구성을 whole-body trajectory optimization에 활용하여 인형로봇의 물리적으로 일관성 있는 장기 조작 계획을 수립한다.
본 논문은 LDM과 foundation model을 창의적으로 결합하여 인형로봇의 장기 로코-조작 계획 문제를 새로운 방식으로 접근하며, 광범위한 실험과 분석을 통해 방법론의 유효성을 입증했다. 다만 실제 로봇 검증과 일부 모듈의 정확성 개선이 필요하다.
PolygMap: A Perceptive Locomotion Framework for Humanoid Robot Stair Climbing
 *Fig. 2: The system integrates joint recorders, depth sensing and LIO estimator. Robot pose is obtained via fusing forwar* PolygMap은 LiDAR, RGB-D 카메라, IMU를 융합하여 실시간 다각형 계단 평면 의미지도를 구축하고, 이를 기반으로 인간형 로봇의 계단 등반을 위한 발디딤 계획을 수행하는 지각 기반 보행 계획 프레임워크이다.
PolygMap은 다중 센서 융합을 통해 계단 환경의 인식 불확실성을 효과적으로 대응하고, 실시간 의미지도 생성과 안전 제약 기반 발디딤 계획을 실현함으로써 인간형 로봇의 신뢰성 있는 계단 등반을 달성했다. 실제 환경 검증과 NVIDIA Orin 구현을 통해 실용성을 입증한 점에서 높은 가치가 있으나, 특정 표면 재질에 대한 견고성 개선과 더 높은 갱신률이 향후 과제이다.
Reference-Free Sampling-Based Model Predictive Control
Fig. 1: Our reference-free sampling-based MPC framework
 *Fig. 1: Our reference-free sampling-based MPC framework* 본 논문은 사전정의된 보행 패턴이나 접촉 시퀀스 없이 MPPI 기반의 샘플링 기반 MPC 프레임워크를 제안하여 emergent locomotion을 실현한다. Cubic Hermite spline 파라미터화를 통해 위치와 속도 제어점을 동시에 최적화하여 실시간 CPU 기반 제어를 가능하게 한다.
본 논문은 참조 없는 emergent locomotion 발현, 극도의 샘플 효율성, 그리고 실시간 CPU 제어라는 세 가지 측면에서 우수한 기여를 제시한다. Cubic Hermite spline 파라미터화와 diffusion annealing의 조합은 창의적이며, Go2 로봇의 실제 검증은 신뢰성을 높인다. 다만 현실 로봇 검증의 범위 확대와 sim-to-real 갭 분석이 필요하다.
Reinforcement Learning with Data Bootstrapping for Dynamic Subgoal Pursuit in Humanoid Robot Navigation
 *Fig. 2. Overall structure of the proposed hierarchical framework for humanoid navigation. The high-level RL-based planne* Humanoid robot navigation을 위해 고수준 RL 기반 동적 subgoal 생성기와 저수준 MPC 기반 보행 제어기를 결합한 계층적 프레임워크를 제안하며, data bootstrapping 기법으로 학습을 안정화한다.
Bipedal robot navigation을 위한 RL과 MPC의 계층적 결합은 창의적이며, data bootstrapping을 통한 학습 안정화는 실질적 기여이나, 시뮬레이션 환경만의 검증과 동적 환경 미평가가 실제 적용까지의 간격을 남긴다.
Sim-to-Real Learning for Humanoid Box Loco-Manipulation
Fig. 1: We learn box loco-manipulation policies in simulation
 *Fig. 1: We learn box loco-manipulation policies in simulation* 본 연구는 인간형 로봇 Digit의 박스 집기 및 운반 작업을 위해 강화학습 기반의 sim-to-real 접근법을 제시하며, 5가지 분리된 정책(걷기, 서기, 집기, 박스 들고 걷기, 박스 들고 서기)을 학습하여 실제 하드웨어에서 성공적으로 전이했다.
본 논문은 인간형 이족 로봇의 복합적인 loco-manipulation 작업에 대한 첫 sim-to-real RL 성공 사례를 제시하며, 실용적인 보상 함수 설계와 action space 선택을 통해 자연스러운 동작을 학습했다는 점에서 의의가 있다. 다만 phase 관리의 경직성과 박스 pose 추정 오차 등 개선의 여지가 있어 기술적으로는 중간 수준이지만 실제 하드웨어 적용이라는 중요한 성과와 명확한 기여로 높은 가치를 가진다.
Success in Humanoid Reinforcement Learning under Partial Observation
Figure 1 summarizes the training performance under three partial observability configurations:
 *Figure 1 summarizes the training performance under three partial observability configurations:* 부분 관찰 환경에서 고정 길이 과거 관찰 시퀀스를 병렬로 처리하는 novel history encoder를 제안하여, Gymnasium Humanoid-v4 환경에서 부분 관찰 하에서의 안정적인 humanoid 정책 학습을 처음으로 성공시켰다.
본 연구는 부분 관찰 환경에서의 고차원 humanoid 제어라는 미해결 문제를 처음으로 성공적으로 해결하며, 병렬 history encoder를 통해 기존 RNN 기반 메모리 방법들을 압도적으로 능가한다. 다만 방법론의 구체적 설명이 부족하고 실제 로봇 검증이 필요하다.
Task and Motion Planning for Humanoid Loco-manipulation
Fig. 1: Overview of the proposed framework. Second panel: the task and the scene are translated into our symbolic framew
 *Fig. 1: Overview of the proposed framework. Second panel: the task and the scene are translated into our symbolic framew* 본 논문은 접촉 모드의 통일된 표현을 통해 로봇 이동과 조작을 함께 계획하는 최적화 기반 TAMP 프레임워크를 제시하며, 인형로봇의 장시간 복잡한 로코-조작 행동 생성을 가능하게 한다.
본 논문은 인형로봇의 동적 로코-조작 계획이라는 도전적 문제에 대해 접촉 수준의 통일된 기호 표현을 통해 이론적으로 견고한 TAMP 솔루션을 제시하며, 전신 동역학과 구동 제약을 포함한 점에서 학술적 기여도가 높다. 다만 실제 로봇 실험 검증과 대규모 문제에 대한 계산 효율 평가가 추가되면 영향력을 더욱 높일 수 있을 것으로 판단된다.
X-Loco: Towards Generalist Humanoid Locomotion Control via Synergetic Policy Distillation
Fig. 1: X-Loco achieves vision-based generalist humanoid locomotion control. Relying solely on velocity commands without
 *Fig. 2: Overview of X-Loco. (a) X-Loco integrates the capabilities of three specialist policies into a vision-based gene* X-Loco는 시너지 정책 증류를 통해 세 개의 전문가 정책(upright locomotion, fall recovery, whole-body coordination)을 단일 비전 기반 범용 정책으로 통합하여, 속도 명령만으로 다양한 휴머노이드 보행 스킬을 수행하는 프레임워크이다.
X-Loco는 policy distillation을 통해 다양한 휴머노이드 로콜로모션 스킬을 효과적으로 통합하는 혁신적인 접근법을 제시하며, CASS, SAR, SFI 등의 설계 요소들이 이론적으로 잘 동기부여되고 실제 로봇 배포로 검증되어 휴머노이드 로봇 제어 분야에 중요한 기여를 한다.
APEX: Learning Adaptive High-Platform Traversal for Humanoid Robots

Fig. 1: The robot adaptively traverses high platforms of up to 0.8 m (≈114% of leg length) by leveraging diverse full-bo
 *Fig. 1: The robot adaptively traverses high platforms of up to 0.8 m (≈114% of leg length) by leveraging diverse full-bo* APEX는 humanoid 로봇이 다리 길이의 114%에 달하는 높은 플랫폼을 traversal할 수 있도록 하는 시스템으로, ratchet progress reward를 통해 학습한 6가지 기술(climb-up, climb-down, stand-up, lie-down, walking, crawling)을 하나의 정책으로 통합한다.
APEX는 humanoid 로봇의 고플랫폼 traversal에 대한 실질적 해결책을 제시하는 논문으로, 새로운 ratchet progress reward 공식과 다중기술 통합 framework가 창의적이며, 실제 로봇에서 다리 길이의 114%에 달하는 높이를 달성한 점이 매우 인상적이다. 다만 평가 환경이 상대적으로 제한적이고 더 복잡한 실제 환경으로의 확장성에 대한 검증이 필요하다.
Collision-Free Humanoid Traversal in Cluttered Indoor Scenes

Fig. 1: Using a single generalist policy, our humanoid robot achieves collision-free traversal in cluttered indoor envir
 *Fig. 2: Overall pipeline. We learn a visuomotor policy that maps diverse obstacle geometries and spatial layouts to* 인간형 로봇이 어수선한 실내 환경에서 장애물을 피하며 이동할 수 있도록 Humanoid Potential Field (HumanoidPF)를 제안하고, 하이브리드 장면 생성 방식과 RL 기반 학습으로 현실 세계에 성공적으로 전이시킨 연구이다.
이 논문은 humanoid 로봇의 현실적 실내 이동이라는 중요한 문제를 체계적으로 처음 다루면서, HumanoidPF라는 창의적이고 효과적인 표현 방식과 하이브리드 scene generation을 통해 실제 로봇에의 성공적 전이를 보여준다. 기술적 깊이, 실험의 포괄성, 그리고 실용적 가치 측면에서 humanoid robotics 분야에 상당한 기여를 하는 우수한 연구이다.
Ego-Vision World Model for Humanoid Contact Planning
 *Fig. 2: World Model Training Pipeline. The pipeline begins with the offline data collection process shown in (a), where * 휴머노이드 로봇이 접촉을 활용하는 지능형 계획을 수립하기 위해 학습된 world model을 sampling-based MPC와 결합한 프레임워크를 제안하며, 오프라인 데이터셋으로부터 압축된 latent space에서 미래 결과를 예측한다.
휴머노이드의 접촉 활용 계획을 위해 world model과 value-guided MPC를 효과적으로 결합하여 샘플 효율성과 다중 작업 능력을 동시에 달성한 우수한 연구로, 실제 로봇 배포를 통해 실용성을 입증했으나 계획 수평선 제약과 시뮬-현실 갭에 대한 추가 분석이 필요하다.
H2-COMPACT: Human-Humanoid Co-Manipulation via Adaptive Contact Trajectory Policies
Fig. 1: Real-world human–humanoid co-manipulation. The human leads the humanoid robot—unaware of the route or
 *Fig. 2: H²-COMPACT’s pipeline: raw force/torque and RGB inputs are cleaned by SAM2 and WHAM, then passed through* 힘각 센서 기반 haptic intent inference와 reinforcement learning 기반 locomotion policy를 계층적으로 결합하여 인간-휴머노이드 협력 물체 운반을 실현한다.
Haptic-based intent inference와 force-adaptive legged locomotion의 계층적 결합으로 인간-휴머노이드 협력 물체 운반의 새로운 패러다임을 제시하며, motion-capture free 데이터 수집과 sim-to-real 검증을 통해 실용성 높은 연구로 평가된다.
HITTER: A HumanoId Table TEnnis Robot via Hierarchical Planning and Learning
Fig. 1: Humanoid table tennis rallies. Our system enables both humanoid-humanoid (left) and humanoid-human (right) match
 *Fig. 2: System overview. (a) The racket is mounted on the robot’s right wrist using a 3D-printed connector, and the ball* 휴머노이드 로봇이 탁구를 하기 위한 계층적 프레임워크를 제시하며, model-based planner와 RL 기반 whole-body controller를 통합하여 sub-second 반응 시간 내에 초당 5 m/s 이상의 볼을 처리한다.
본 논문은 humanoid table tennis를 통해 고속 동적 환경에서의 전신 제어 및 상호작용을 처음으로 성공적으로 시연하였으며, 계층적 planning-control 통합과 minimal human references를 통한 우아한 접근법이 인상적이다. 실제 세계 검증(106 연속 샷)은 방법론의 실용성을 강력히 입증한다.
Humanoid Goalkeeper: Learning from Position Conditioned Task-Motion Constraints
Fig. 1: We present Humanoid Goalkeeper, capable of performing goalkeeping tasks across various regions with a wide opera
 *Fig. 2: Method framework: We train our policy using an end-to-end* 인간형 로봇의 골키퍼 역할을 위해 위치 조건부 task-motion constraints를 학습하는 end-to-end RL 프레임워크를 제시하며, 인간 모션 프라이어를 adversarial scheme으로 통합하여 자동화되고 인간다운 전신 동작을 생성한다.
본 논문은 position-conditioned adversarial motion priors를 통해 humanoid 로봇의 자동화되고 인간다운 골키퍼 능력을 처음으로 시연한 의미 있는 연구이며, 실제 하드웨어 배포와 task 일반화를 통해 실용성을 입증했으나, 정량적 분석과 ablation study가 강화될 필요가 있다.
Humanoid Hanoi: Investigating Shared Whole-Body Control for Skill-Based Box Rearrangement
 *Fig. 2: Independently trained high-level skills generate task-level commands that are executed through a shared, task-ag* 휴머노이드 로봇의 장기 박스 재배열 작업을 위해 공유된 task-agnostic WBC를 통해 재사용 가능한 스킬들을 조합하는 skill-based framework를 제안하고, 분포 이동으로 인한 강건성 저하를 데이터 집계를 통해 해결한다.
본 논문은 공유 WBC를 통한 모듈식 스킬 조합 아키텍처의 systematic exploration과 데이터 집계 기반 robustness 개선이라는 실용적 기여를 제시하며, Humanoid Hanoi 벤치마크를 통해 long-horizon 장기 자율 실행의 가능성을 입증한다. 다만 high-level planning, 계산 scalability, sim-to-real gap에 대한 심화 분석은 부족하다.
Humanoid Parkour Learning
Figure 1: We present a single vision-based end-to-end whole-body-control parkour policy for humanoid robots
 *Figure 1: We present a single vision-based end-to-end whole-body-control parkour policy for humanoid robots* 본 논문은 시각 기반 end-to-end 제어 정책을 통해 인간형 로봇이 모션 프리어 없이 다양한 파쿠르 기술(점프, 허들 뛰기, 갭 넘기 등)을 수행할 수 있도록 학습하는 통합 프레임워크를 제시한다.
본 논문은 모션 프리어 없이 인간형 로봇이 다양한 파쿠르 기술을 통합적으로 학습하고 실제 배포할 수 있게 하는 혁신적 프레임워크를 제시하며, fractal noise를 통한 자연스러운 보행 유도와 효율적인 vision 정책 증류 기법으로 로봇 운동 능력의 경계를 의미 있게 확장한다.
Humanoid Whole-Body Locomotion on Narrow Terrain via Dynamic Balance and Reinforcement Learning
Fig. 1: The locomotion capabilities of full-sized Humanoid without vision or LiDAR sensors. (a) Narrow Path (25cm):
 *Fig. 1: The locomotion capabilities of full-sized Humanoid without vision or LiDAR sensors. (a) Narrow Path (25cm):* ZMP(Zero Moment Point) 기반 리워드와 강화학습을 결합한 동적 균형 메커니즘을 도입하여, 휴머노이드 로봇이 외부 센서 없이 고유감각만으로 좁은 경로와 예상 못한 장애물이 있는 극단적 지형을 안정적으로 통과하도록 하는 전신 보행 알고리즘을 제안한다.
본 논문은 고전적 ZMP 개념을 현대 강화학습에 효과적으로 통합하여 외부 센서 없이 극단적 지형 통과 능력을 확보한 의미 있는 기여를 한다. 실제 full-sized 휴머노이드 로봇에서의 광범위한 실증이 강점이나, 다양한 로봇 플랫폼과 극단적 지형에 대한 일반화 가능성 검증이 필요하다.
HumanoidGen: Data Generation for Bimanual Dexterous Manipulation via LLM Reasoning
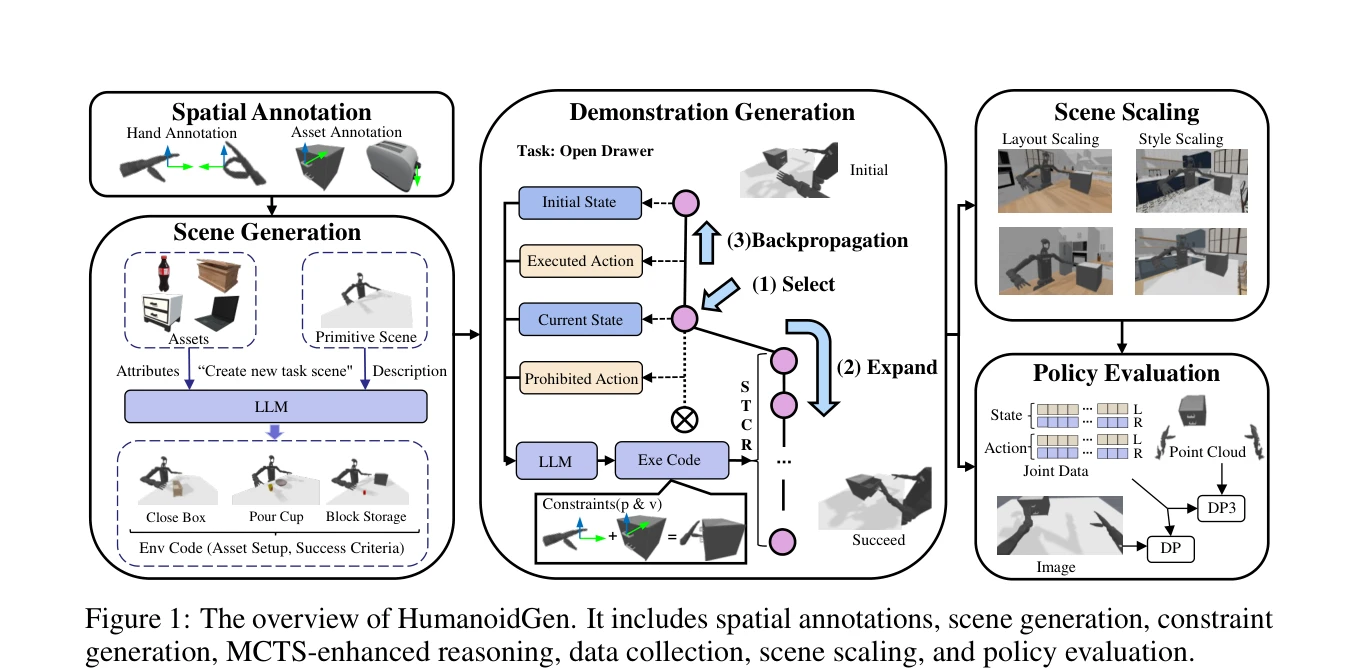
Figure 1: The overview of HumanoidGen. It includes spatial annotations, scene generation, constraint
 *Figure 1: The overview of HumanoidGen. It includes spatial annotations, scene generation, constraint* HumanoidGen은 LLM 추론과 원자적 손 동작을 활용하여 휴머노이드 로봇의 양손 정교한 조작을 위한 시뮬레이션 데이터와 시연을 자동으로 생성하는 프레임워크이다. MCTS 기반 추론 강화를 통해 장시간 작업과 불충분한 주석에서의 계획 능력을 개선한다.
HumanoidGen은 LLM 기반 자동화, 원자적 손 동작 설계, MCTS 강화 추론의 조합으로 휴머노이드 로봇의 양손 정교한 조작 데이터 생성에 새로운 접근법을 제시하며, HGen-Bench 벤치마크와 함께 데이터 스케일링의 성능 향상을 실증하여 실무적 가치가 높다. 다만 공간 주석의 수동 작성 부담과 sim-to-real 검증 부재가 확장성을 제한한다.
HYPERmotion: Learning Hybrid Behavior Planning for Autonomous Loco-manipulation
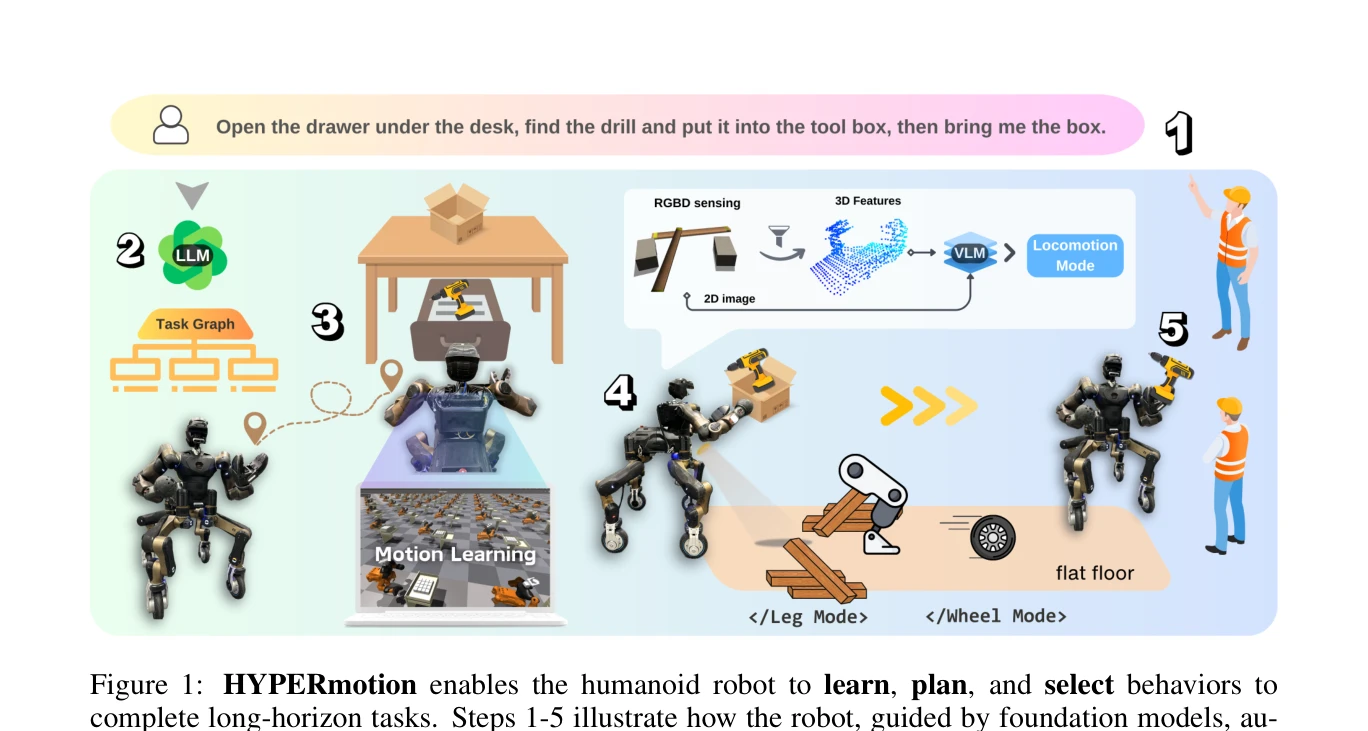
Figure 1: HYPERmotion enables the humanoid robot to learn, plan, and select behaviors to
 *Figure 2: Overview of HYPERmotion.We decompose the framework into four sectors: Motion* HYPERmotion은 강화학습과 최적화를 결합하여 휴머노이드 로봇이 자연어 명령으로부터 복잡한 로코-조작 작업을 자율적으로 수행할 수 있도록 하는 계층적 행동 계획 프레임워크이다. LLM과 VLM을 활용하여 의미론적 지시를 원시 행동 기술로 변환하고 동적 환경에서 형태론적 선택을 수행한다.
HYPERmotion은 고자유도 휴머노이드 로봇의 자율적 로코-조작을 자연어 명령으로부터 수행하는 포괄적이고 실용적인 프레임워크를 제시하며, 특히 LLM/VLM과 로봇 제어의 통합, 실제 로봇 배포 실현은 해당 분야에서 의미 있는 진전을 보여준다. 다만 계산 복잡도, 환경 적응성, 완전한 자동화 측면에서 개선 여지가 있다.
Learning Getting-Up Policies for Real-World Humanoid Robots
Fig. 1: HUMANUP provides a simple and general two-stage training method for humanoid getting-up tasks, which can be
 *Fig. 2: HUMANUP system overview. Our getting-up policy (Sec. III-A) is trained in simulation using two-stage RL training* 휴머노이드 로봇의 낙상 복구를 위해 두 단계 강화학습 프레임워크(HUMANUP)를 제시하여 다양한 자세와 지형에서 일어나는 동작을 학습하고 실제 G1 로봇에 배포했다.
휴머노이드 로봇 낙상 복구는 중요하면서도 미탐색된 문제이며, 이 논문은 작업 특성을 정확히 파악하고 실용적 커리큘럼 학습을 통해 인간 규모 로봇에서 처음 성공적인 실제 배포를 시연했다. 기술적 기여도 있지만 평가 범위의 한계와 설계 선택의 일반화 가능성에 대한 추가 검증이 필요하다.
Learning Human-Humanoid Coordination for Collaborative Object Carrying
Fig. 1: COLA provides a proprioception-only policy that enables compliant human-humanoid collaboration for carrying dive
 *Fig. 2: Overview of COLA. Our Policy mainly consists of three steps: (i) We train a base whole-body control policy to pr* COLA는 proprioception만을 사용하는 reinforcement learning 기반의 정책으로, humanoid 로봇이 인간과 협력하여 물체를 운반할 때 적응적이고 안정적인 whole-body coordination을 가능하게 한다.
COLA는 humanoid-human collaborative carrying이라는 실용적 과제에 대해 proprioception-only 정책으로 완전한 솔루션을 제시하며, three-step training framework와 implicit force modeling을 통해 높은 독창성을 보여준다. 시뮬레이션과 실제 환경에서 동시에 검증된 결과는 실제 배포 가능성을 시사하며, human user study를 통한 compliant collaboration 확인으로 실무적 가치를 입증한다.
LHM-Humanoid: Learning a Unified Policy for Long-Horizon Humanoid Whole-Body Loco-Manipulation in Diverse Messy Environments
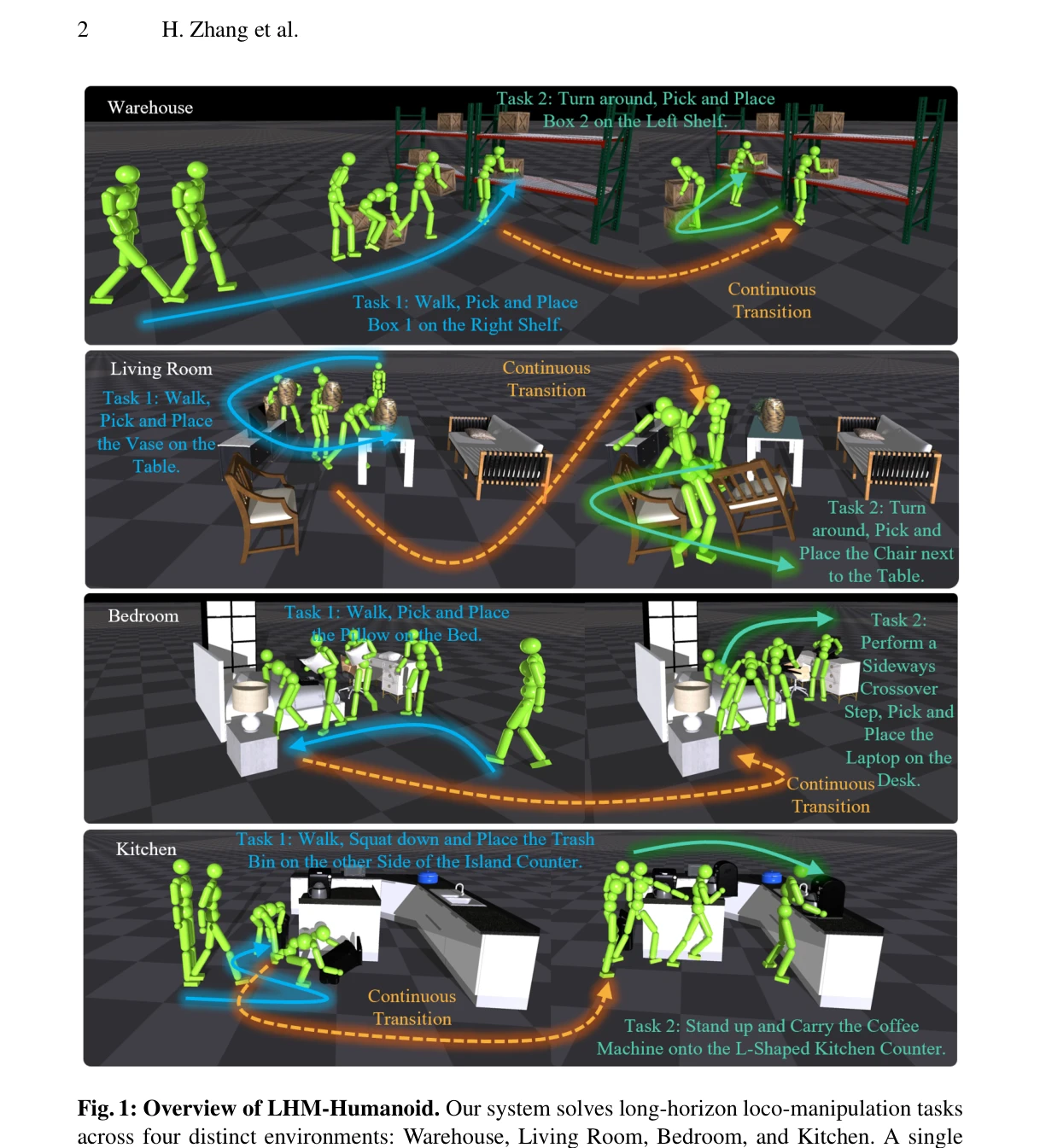
Fig. 1: Overview of LHM-Humanoid. Our system solves long-horizon loco-manipulation tasks
 *Fig. 1: Overview of LHM-Humanoid. Our system solves long-horizon loco-manipulation tasks* LHM-Humanoid는 다양한 혼란스러운 환경에서 장시간 인간형 로봇이 복수 객체를 반복적으로 집기, 운반, 배치하는 작업을 단일 통합 정책으로 수행하는 벤치마크와 학습 프레임워크를 제시한다.
본 논문은 장시간 혼란스러운 환경에서의 인간형 로봇 로코-조작이라는 도전적인 새로운 문제를 정의하고 이중 교사 증류 프레임워크로 효과적으로 해결하며, 350개 다양한 장면의 종합 벤치마크를 제공하여 로봇 일반화 연구에 의미 있는 기여를 한다.
Olaf: Bringing an Animated Character to Life in the Physical World

Fig. 1: Olaf Robot.
 *Fig. 1: Olaf Robot.* 애니메이션 캐릭터 올라프를 실제 물리 로봇으로 구현하기 위해 RL 기반 제어와 혁신적인 기계설계를 결합한 연구이다. 비물리적 움직임과 부자연스러운 비율을 가진 캐릭터를 believable하게 현실화했다.
애니메이션 캐릭터를 물리 로봇으로 현실화하는 문제에 대해 기계설계와 제어 알고리즘을 창의적으로 결합한 우수한 연구이며, thermal awareness와 impact reduction 같은 실무적 고려사항을 RL에 반영한 점이 특히 주목할 만하다.
Traversing Narrow Paths: A Two-Stage Reinforcement Learning Framework for Robust and Safe Humanoid Walking

Fig. 1: Overview. The proposed framework uses 3D-LIPM
 *Fig. 1: Overview. The proposed framework uses 3D-LIPM* 이 논문은 humanoid 로봇이 좁은 경로를 안전하게 통과하도록 하는 두 단계 reinforcement learning 프레임워크를 제안하며, physics-기반 LIPM foothold planner와 RL 기반 foothold tracker/modifier를 결합한다.
이 논문은 physics-기반 모델과 reinforcement learning을 창의적으로 결합하여 안전하고 해석 가능한 narrow path traversal을 달성했으며, 실제 humanoid robot에서 높은 성공률로 검증함으로써 로봇 제어의 실질적 응용 가치를 입증했다.
ULC: A Unified and Fine-Grained Controller for Humanoid Loco-Manipulation

Fig. 1: Diverse loco-manipulation capabilities enabled by ULC. The humanoid robot demonstrates various coordinated whole
 *Fig. 1: Diverse loco-manipulation capabilities enabled by ULC. The humanoid robot demonstrates various coordinated whole* ULC는 인간형 로봇의 보행-조작을 위해 상체와 하체 제어를 통합한 단일 정책 프레임워크로, sequential skill acquisition, residual action modeling, 다항식 보간 등의 기술을 통해 추적 정확도, 넓은 작업 공간, 견고성을 동시에 달성한다.
ULC는 humanoid loco-manipulation 분야에서 통합 제어의 실행 가능성을 처음으로 대규모 실험으로 입증한 의미 있는 논문이며, sequential skill acquisition, residual action modeling, deployment-realistic training 등의 체계적인 기술 조합으로 높은 추적 성능과 넓은 작업 공간을 동시에 달성했다. 다만 단일 하드웨어 플랫폼에만 검증되었고 시뮬레이션 기반 훈련의 현실 일반화 가능성에 대한 상세 분석이 부족한 점이 한계이다.
Unified Humanoid Fall-Safety Policy from a Few Demonstrations
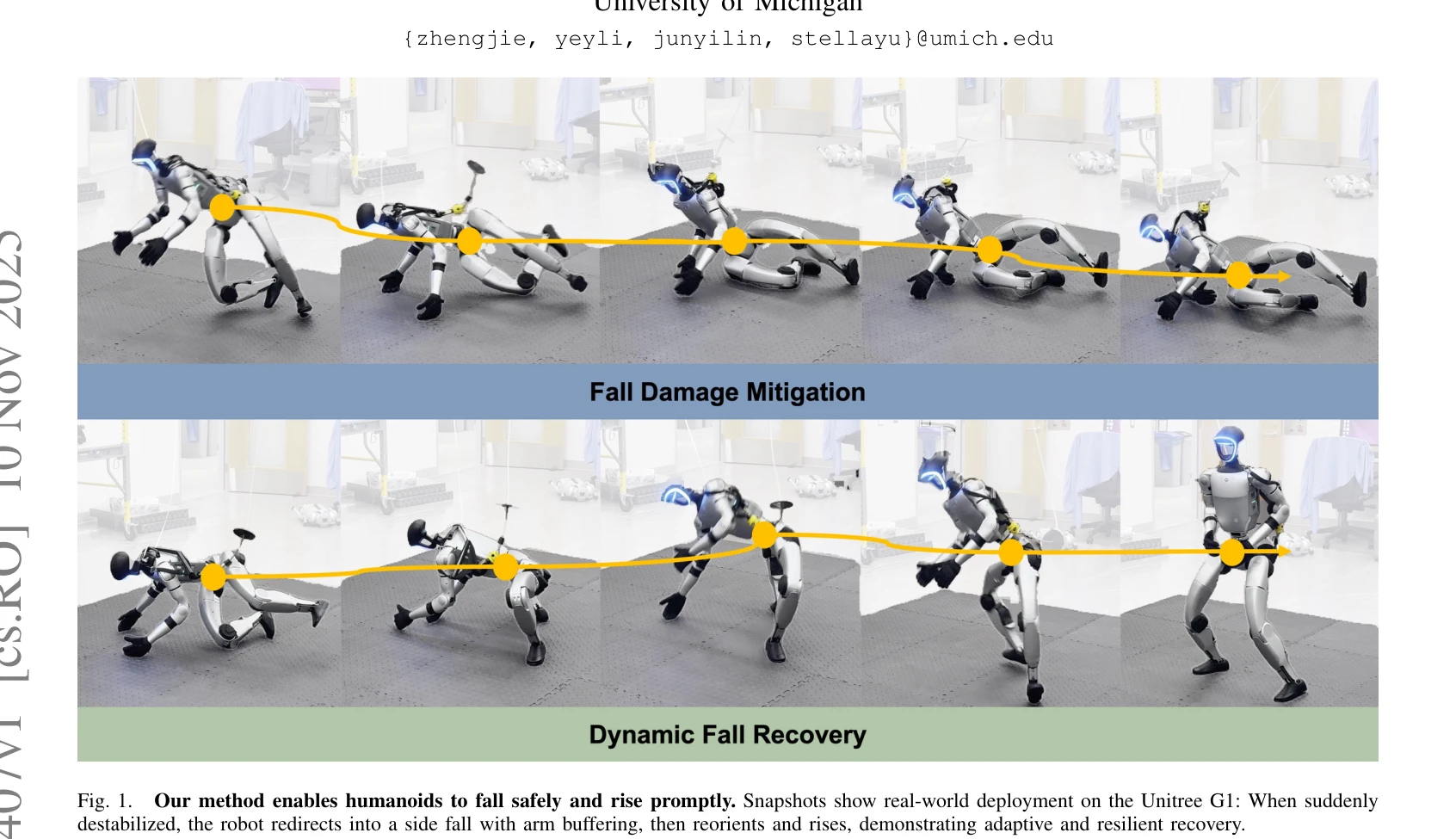
Fig. 1.
 *Fig. 1.* 휴머노이드 로봇이 균형을 잃었을 때 안전하게 넘어지고 빠르게 일어날 수 있도록, 스파스한 인간 시연과 reinforcement learning, diffusion 기반 메모리를 결합하여 낙상 예방·충격 완화·회복을 통합하는 단일 정책을 학습한다.
본 논문은 휴머노이드 낙상 완화와 회복을 명시적으로 통합하는 첫 성공적인 통합 정책을 제시하며, 스파스 인간 시연과 RL, diffusion model을 창의적으로 결합하여 안전한 다중 모달 행동을 학습한다. Unitree G1에서의 견고한 sim-to-real 전이와 일관된 성능은 실제 환경에서의 로봇 안전성을 크게 향상시킬 가능성을 보여준다.
CART: Context-Aware Terrain Adaptation using Temporal Sequence Selection for Legged Robots
 *Fig. 2: Overview of the Pipeline: CART inputs a stream of RGBD images Sv, friction meshes Sm using [19], and propriocept* CART는 사족 로봇의 지형 적응을 위해 시각 정보와 고유감각(proprioception)을 통합하여 맥락을 파악하고, 시간 수열 선택을 통해 로봇의 안정성을 향상시키는 고수준 제어기이다.
CART는 시각과 고유감각의 불일치 문제를 명시적으로 인식하고 이를 해결하기 위한 창의적인 맥락 기반 제어 프레임워크를 제시하며, 시뮬레이션과 실제 환경 모두에서 안정성 개선을 입증한 의미 있는 연구이다. 다만 평가 범위 확대와 방법론의 일반화 가능성 검증이 필요하다.
HOIST: Humanoid Optimization with Imitation and Sample-efficient Tuning for Manipulating Suspended Loads
 *Figure 4: Overview of the HOIST pipeline. VR teleoperation provides hoisting demonstrations to* 본 논문은 인도형(underactuated) 부유 하중(suspended load)을 조작하는 휴머노이드 로봇을 위한 HOIST를 제시한다. VR 원격 조종 데이터로부터 vision-language-action(VLA) 정책을 미세조정하고, whole-body controller를 통해 실행한 후, iterative batched reinforcement learning으로 배치 정확도와 정지 행동을 개선한다.
HOIST는 휴머노이드 로봇을 이용한 underactuated material-handling이라는 새로운 실제 문제를 잘 정의하고, imitation learning과 reinforcement learning을 실용적으로 결합한 효과적인 해결 방안을 제시한다. VR teleoperation 기반의 데이터 수집부터 whole-body control과 sample-efficient RL까지 완전한 파이프라인을 구현하고, 시뮬레이션과 실제 로봇 모두에서 검증한 점이 강점이다. 다만 일반화 능력 검증과 안전 보장의 명시적 분석이 부족하고, 더 다양한 시나리오에서의 평가가 필요하다.
World Models for Robotic Manipulation: A Survey
 *Fig. 2. Representation spectrum of world models. The five families are ordered by increasing structured inductive bias, * 로봇 조작을 위한 world model에 대한 포괄적 서베이다. 세 가지 질문(어떤 미래 표현을 예측하는가, 예측을 행동에 어떻게 연결하는가, 학습 파이프라인의 어느 단계에서 사용되는가)을 중심으로 action-conditioned predictive system으로서의 world model을 정의하고, 다섯 가지 표현 계열과 기능적 분류를 제시한다.
이 서베이는 로봇 조작 분야에서 fragmented된 world model 문헌을 통합하는 중요한 기여다. 세 가지 직교 축의 framework와 명확한 operational definition은 향후 연구의 설계 선택을 가이드할 수 있으며, 34개 dataset 검토와 종합 평가 프로토콜은 실질적 가치를 제공한다. 다만 closed-loop 평가 부족과 contact modeling 등 조작 고유의 도전이 여전히 미해결되어 있고, 개념적 경계의 모호성도 완전히 제거되지 않았다. 전체적으로 조작 중심의 predictive modeling을 이해하는 데 필수적인 참고문헌이지만, 구체적인 기술 혁신보다는 종합 정리의 성격이 강하다.
Humanoid Parkour Learning
Figure 1: We present a single vision-based end-to-end whole-body-control parkour policy for humanoid robots
 *Figure 1: We present a single vision-based end-to-end whole-body-control parkour policy for humanoid robots* 본 논문은 인간형 로봇이 motion prior 없이 end-to-end vision-based 정책으로 다양한 parkour 기술을 학습할 수 있는 프레임워크를 제시한다. Fractal noise를 활용한 terrain randomization과 DAgger를 통한 vision policy 증류로 sim-to-real transfer를 달성하며, 실제 로봇에서 0.42m 점프, 0.8m gap 통과, 1.8m/s 주행 등을 성공한다.
본 논문은 인간형 로봇의 parkour learning에서 motion prior 제거와 fractal noise 기반 자동 foot-raising 유도라는 중요한 기여를 제시한다. 3단계 훈련 파이프라인과 DAgger 증류를 통한 sim-to-real transfer는 기술적으로 견고하며, 실제 로봇에서의 다양한 성공 사례는 실용적 가치가 높다. 다만 직선 track 제약, 정량적 평가 부족, 일반화 가능성 검증 미흡이 한계이나, 인간형 로봇의 agile locomotion 분야에 상당한 진전을 이루었다.
Sumo: 동적이고 일반화 가능한 전신 이동-조작 제어
 *Fig. 2: System overview: Our method takes a hierarchical* 본 논문은 사전 학습된 전신 제어 정책과 테스트 시점 샘플 기반 계획을 계층적으로 결합하여 사족 로봇과 인형 로봇이 동적으로 대형 무거운 물체를 조작할 수 있게 하는 Sumo 프레임워크를 제시한다. 이 방법은 재학습 없이 다양한 물체와 작업에 일반화되며, 비용 함수만 변경하여 테스트 시점에 유연하게 적응할 수 있다.
본 논문은 강화학습과 샘플 기반 MPC를 계층적으로 결합하는 우아한 방식으로 동적 전신 로코-조작을 처음 구현했으며, Spot 실제 로봇에서의 인상적인 결과와 일반화 가능성은 로봇 조작 분야에 의미 있는 기여를 한다. 테스트 시점 유연성과 훈련 없는 적응은 실무 적용에 큰 가치가 있다.
Sumo: 동적이고 일반화 가능한 전신 이동-조작 제어
 *Fig. 2: System overview: Our method takes a hierarchical* 본 논문은 사전학습된 전신 제어 정책과 테스트 시점 샘플 기반 계획을 계층적으로 결합하는 Sumo 프레임워크를 제안한다. 이를 통해 사족 및 인형 로봇이 동적으로 대형 중량 물체를 조작할 수 있으며, 재학습 없이 다양한 물체와 작업에 일반화된다.
Sumo는 동적 전신 조작이라는 도전적 과제에서 실용적이고 일반화 가능한 해결책을 제시한다. 계층적 프레임워크의 설계가 우수하고 실제 로봇 검증이 설득력 있으며, 재학습 없는 적응 능력이 인상적이다. 다만 인형 로봇 실제 검증과 더 광범위한 물체 기하학적 다양성 시험이 있으면 영향력이 더욱 클 것이다.
PICO: Reconstructing 3D People In Contact with Objects

Figure 1. We present PICO, a novel framework for joint human-object reconstruction in 3D. PICO includes PICO-db, a uniqu
 *Figure 1. We present PICO, a novel framework for joint human-object reconstruction in 3D. PICO includes PICO-db, a uniqu* 단일 이미지에서 신체-물체 접촉 정보를 활용하여 3D 인간-물체 상호작용을 복원하는 PICO 프레임워크를 제시하며, 이를 위해 신체와 물체 모두에 밀집된 3D 접촉 주석이 있는 PICO-db 데이터셋을 수집했다.
본 논문은 신체-물체 접촉이라는 새로운 관점에서 3D HOI 문제를 체계적으로 다루며, PICO-db라는 고가치 데이터셋과 확장 가능한 PICO-fit 방법을 통해 현실의 다양한 물체 클래스에 일반화되는 실용적인 해결책을 제시한다.
Guided Motion Diffusion for Controllable Human Motion Synthesis

Figure 1. Our proposed Guided Motion Diffusion (GMD) can generate high-quality and diverse motions given a text prompt a
 *Figure 2. We tackle the problem of spatially conditioned motion* Guided Motion Diffusion (GMD)는 자연어 설명과 공간적 제약(궤적, 키프레임, 장애물 회피)을 동시에 고려하여 인간의 모션을 합성하는 diffusion model 기반 방법을 제안한다.
GMD는 모션 생성의 중요한 미충족 요구(공간적 제약 통합)를 새로운 관점에서 해결하며, emphasis projection과 dense signal propagation이라는 두 가지 우아하고 일반적인 기법으로 강력한 성과를 달성한 고품질의 논문이다.
HuB: Learning Extreme Humanoid Balance

Figure 1: Extreme Balance Tasks. HuB enables humanoids to perform extreme quasi-static balance tasks
 *Figure 2: HuB Overview. To tackle the challenges of extreme balance tasks on humanoids, HuB integrates* HuB는 휴머노이드 로봇이 제한된 한 발로 서기나 높은 킥과 같은 극도의 준정적 균형 작업을 수행할 수 있도록 하는 통합 프레임워크이며, 참조 동작 정제, 균형 인식 정책 학습, sim-to-real 강건성 훈련의 세 가지 구성 요소로 이루어져 있다.
HuB는 휴머노이드의 극한 균형 제어라는 도전적 문제에 대해 참조 정제, 정책 학습, sim-to-real 전이의 세 가지 핵심 요소를 체계적으로 통합한 포괄적 솔루션을 제시하며, 실제 하드웨어에서 인상적인 성능을 달성하여 로봇 제어 분야에 의미 있는 기여를 한다.
MorphoGuard: A Morphology-Based Whole-Body Interactive Motion Controller
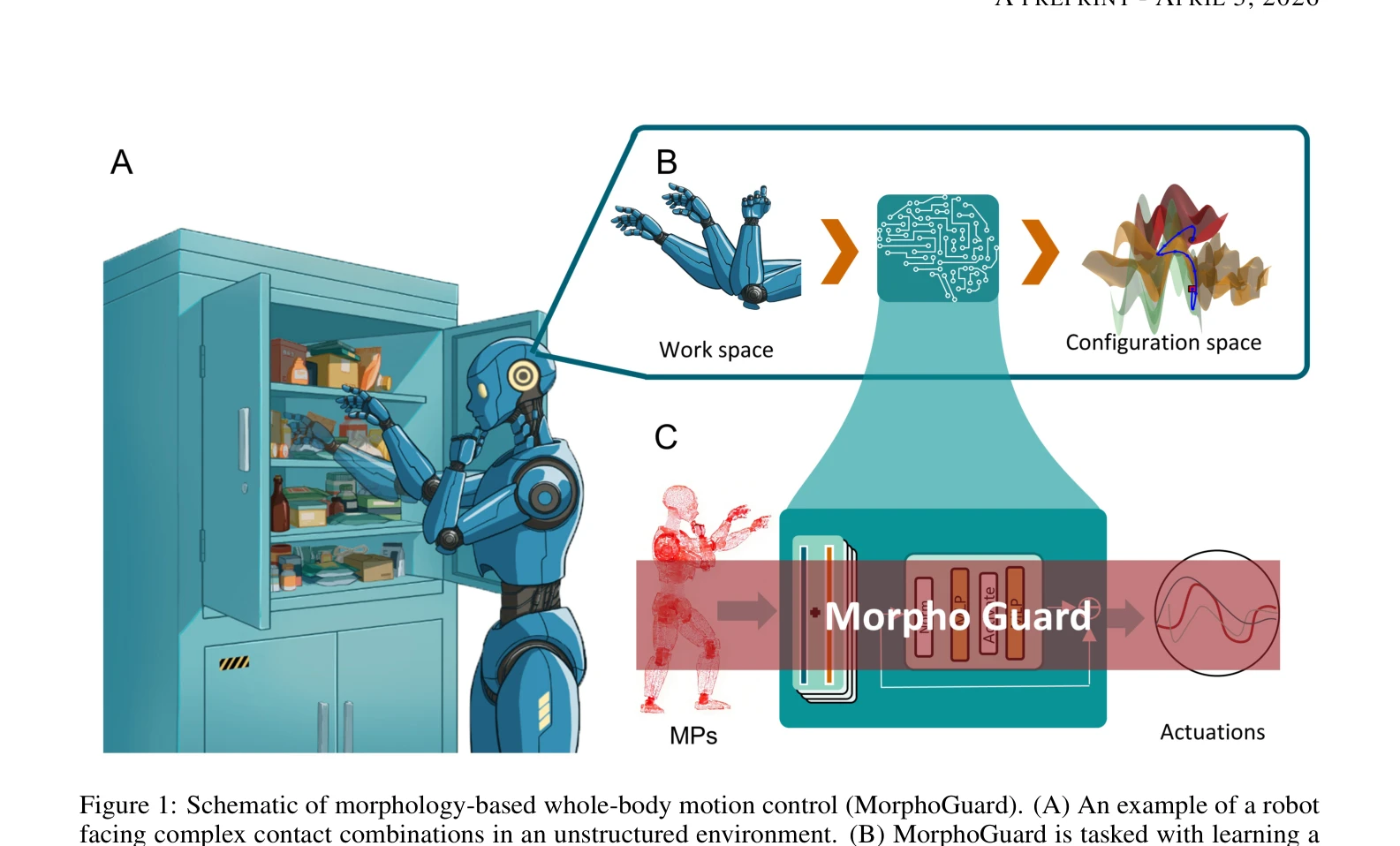
Figure 1: Schematic of morphology-based whole-body motion control (MorphoGuard). (A) An example of a robot
 *Figure 1: Schematic of morphology-based whole-body motion control (MorphoGuard). (A) An example of a robot* 로봇의 형태학적 표현을 기반으로 Material Point Method를 활용하여 전신 제어 네트워크 MorphoGuard를 제안. 복잡한 다중 접촉 조합을 명시적으로 관리하며 1cm의 접촉점 관리 오차를 달성.
복잡한 다중 접촉 조합을 관리하는 로봇 전신 제어의 미해결 문제를 형태학적 표현과 Material Point Method의 창의적 결합으로 우아하게 해결했으며, 높은 정확도의 실험 결과를 보여준다. 다만 단일 플랫폼 실험과 일반화 가능성에 대한 검증이 보완되면 더욱 강력한 기여가 될 것으로 기대된다.
OmniRetarget: Interaction-Preserving Data Generation for Humanoid Whole-Body Loco-Manipulation and Scene Interaction
Fig. 1:
 *Fig. 2: OMNIRETARGET overview. Human demonstrations are retargeted to the robot via interaction-mesh–based* OmniRetarget은 interaction mesh 기반의 제약 최적화를 통해 human motion을 humanoid robot을 위한 고품질 kinematic reference로 retarget하며, 상호작용을 보존하면서 단일 시연으로부터 다양한 로봇 구체화, 지형, 물체 설정으로 효율적인 data augmentation을 수행한다.
OmniRetarget은 interaction-preserving motion retargeting과 체계적 data augmentation을 통해 humanoid robot 제어의 데이터 병목을 해결하는 실질적이고 영향력 있는 기여이며, 최소한의 reward engineering으로 complex whole-body loco-manipulation 기술의 zero-shot sim-to-real transfer를 성공적으로 입증하여 로보틱스 커뮤니티에 매우 유용한 공개 도구 및 데이터셋을 제공한다.
TeleGate: Whole-Body Humanoid Teleoperation via Gated Expert Selection with Motion Prior

Fig. 1.
 *Fig. 1.* TeleGate는 가벼운 gating network를 통해 multiple domain-specific expert policies를 동적으로 선택하여 humanoid robot의 real-time whole-body teleoperation을 수행하며, VAE 기반 motion prior를 도입하여 미래 정보 없이도 점프나 일어서기 같은 동적 동작을 예측적으로 제어한다.
TeleGate는 gated expert selection과 VAE 기반 motion prior를 결합하여 제한된 데이터로도 높은 정밀도의 real-time whole-body humanoid teleoperation을 실현하는 혁신적인 프레임워크이며, Unitree G1에서의 성공적인 physical deployment로 실제 적용 가능성을 입증했다.
Learn Weightlessness: Imitate Non-Self-Stabilizing Motions on Humanoid Robot

Fig. 1: Our work introduces a human-inspired weightlessness mechanism that controls robot joints to selectively relax wh
 *Fig. 1: Our work introduces a human-inspired weightlessness mechanism that controls robot joints to selectively relax wh* 휴머노이드 로봇이 비자기안정화(non-self-stabilizing) 동작을 수행할 때 인간의 '무중력 상태' 메커니즘을 모방하여 특정 관절을 선택적으로 이완시킴으로써 환경과의 물리적 접촉을 통해 동작을 완성하는 방법을 제안한다.
본 논문은 인간의 생물학적 메커니즘을 로봇 제어에 창의적으로 적용하여 비자기안정화 동작이라는 미해결 문제를 해결하는 우수한 연구이며, Unitree G1에서의 실제 검증과 다양한 환경에 대한 일반화 성능은 로봇 공학의 실질적 진전을 보여준다.
SynAgent: Generalizable Cooperative Humanoid Manipulation via Solo-to-Cooperative Agent Synergy
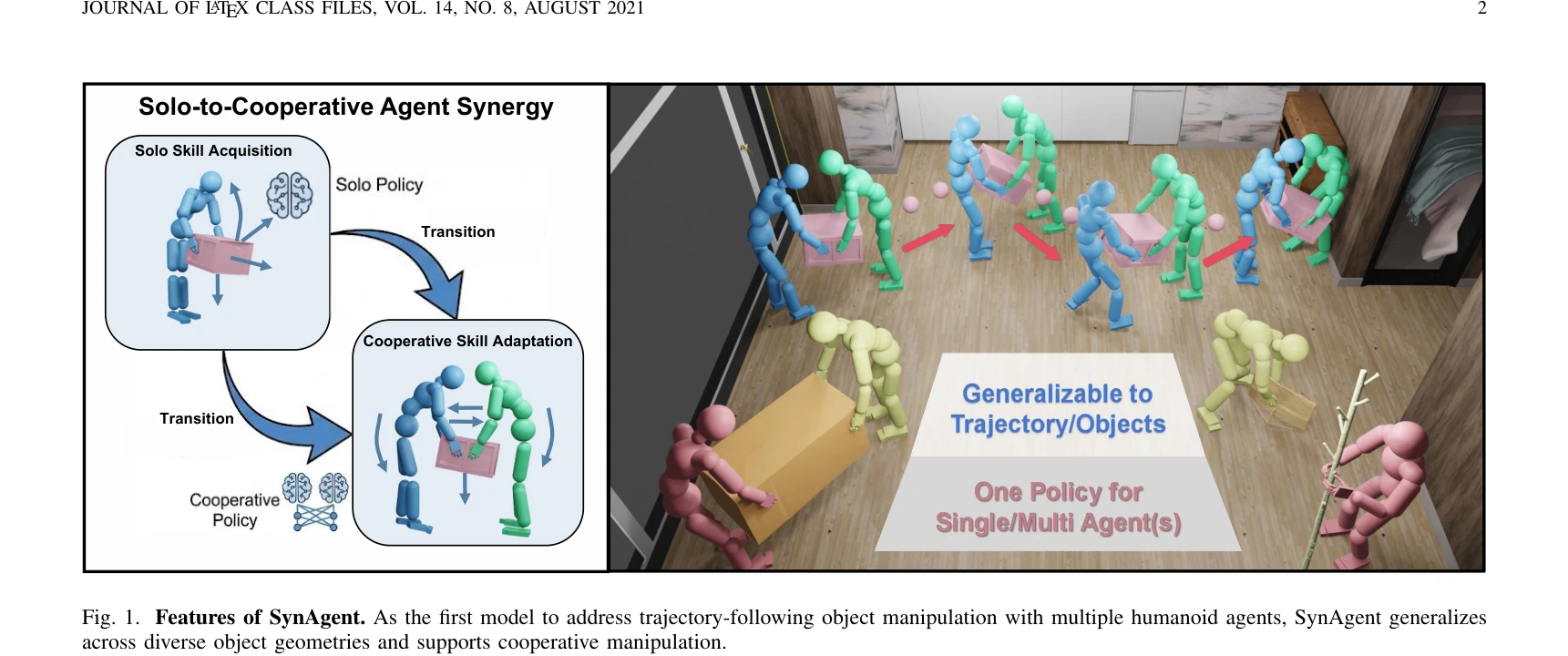
Fig. 1. Features of SynAgent. As the first model to address trajectory-following object manipulation with multiple human
 *Fig. 1. Features of SynAgent. As the first model to address trajectory-following object manipulation with multiple human* SynAgent는 단일 에이전트 기술을 다중 에이전트 협력 조작으로 전이하는 Solo-to-Cooperative Agent Synergy 패러다임을 통해, 휴머노이드 로봇의 협력 조작 학습 데이터 부족 문제를 해결하고 다양한 물체 기하학에 일반화하는 통합 프레임워크를 제시한다.
SynAgent는 HOHI 데이터 부족 문제를 창의적으로 해결하고, Solo-to-Cooperative Agent Synergy 패러다임을 통해 다중 에이전트 협력 조작의 확장성과 일반화를 크게 향상시킨 중요한 기여를 한다. 다만 실제 로봇 환경 검증과 더 많은 에이전트로의 확장성 증명이 필요하다.
Whole-Body Inverse Kinematics with Graph Diffusion
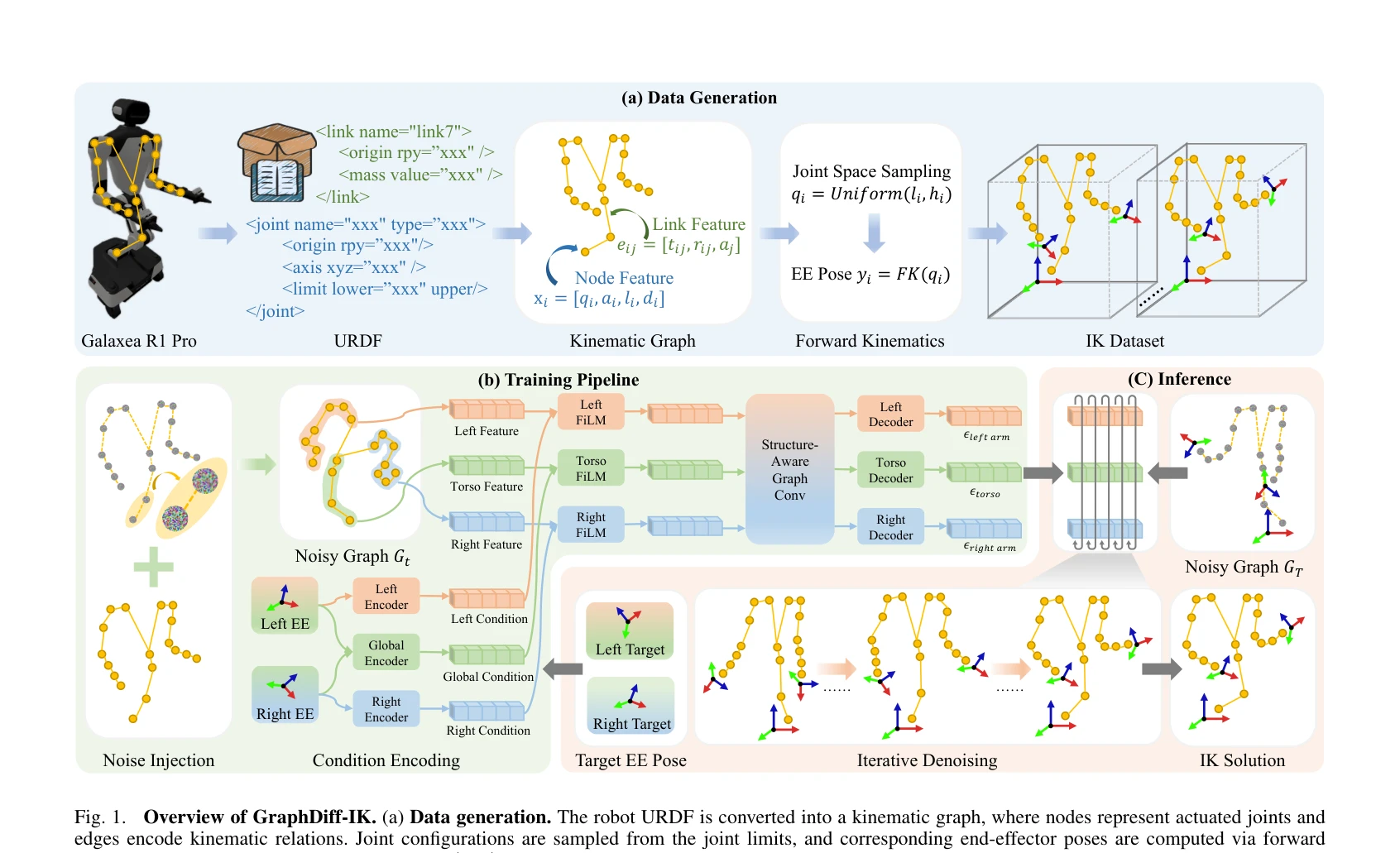
Fig. 1.
 *Fig. 1.* 이 논문은 역기구학(inverse kinematics) 문제를 구조-인식형 그래프 확산 프레임워크인 GraphDiff-IK로 해결한다. 로봇의 URDF로부터 구성한 kinematic graph를 기반으로 조건부 그래프 diffusion process를 통해 직접 joint configuration을 생성하며, 단일 팔 로봇부터 dual-arm, 토소를 가진 전신 로봇까지 통일된 방식으로 지원한다.
GraphDiff-IK는 구조-인식형 graph diffusion을 IK에 적용하여 다양한 로봇 형태의 통일된 처리, 다중 해 생성, 높은 정확도를 동시에 달성한 혁신적 접근법이다. 실제 로봇 플랫폼에서의 광범위한 검증과 우수한 성능으로, 현대 고도-자유도 로봇 제어에 실질적 기여가 기대된다.
HuB: Learning Extreme Humanoid Balance

Figure 1: Extreme Balance Tasks. HuB enables humanoids to perform extreme quasi-static balance tasks
 *Figure 1: Extreme Balance Tasks. HuB enables humanoids to perform extreme quasi-static balance tasks* 본 논문은 휴머노이드 로봇이 극단적인 균형 잡기 태스크(Swallow Balance, Bruce Lee's Kick 등)를 수행하도록 하기 위해 세 가지 핵심 문제(참조 동작 오류, 형태학적 불일치, sim-to-real 갭)를 각각 해결하는 통합 프레임워크 HuB를 제시한다. 이를 통해 Unitree G1 휴머노이드 로봇에서 강한 외부 충격에도 안정적으로 균형을 유지하는 정책을 학습할 수 있음을 입증했다.
본 논문은 휴머노이드의 극단적 균형 제어라는 도전적인 문제에 대해 잘 동기부여되고 체계적으로 설계된 솔루션을 제시한다. 세 가지 핵심 장애물(참조 오류, morphological mismatch, sim-to-real 갭)을 각각 겨냥한 모듈식 접근법과 실제 하드웨어에서의 강력한 실험 검증이 강점이다. 다만 다른 휴머노이드 플랫폼으로의 일반화 가능성과 학습 효율성 측면에서 추가 논의가 필요하다.
PyRoki: A Modular Toolkit for Robot Kinematic Optimization
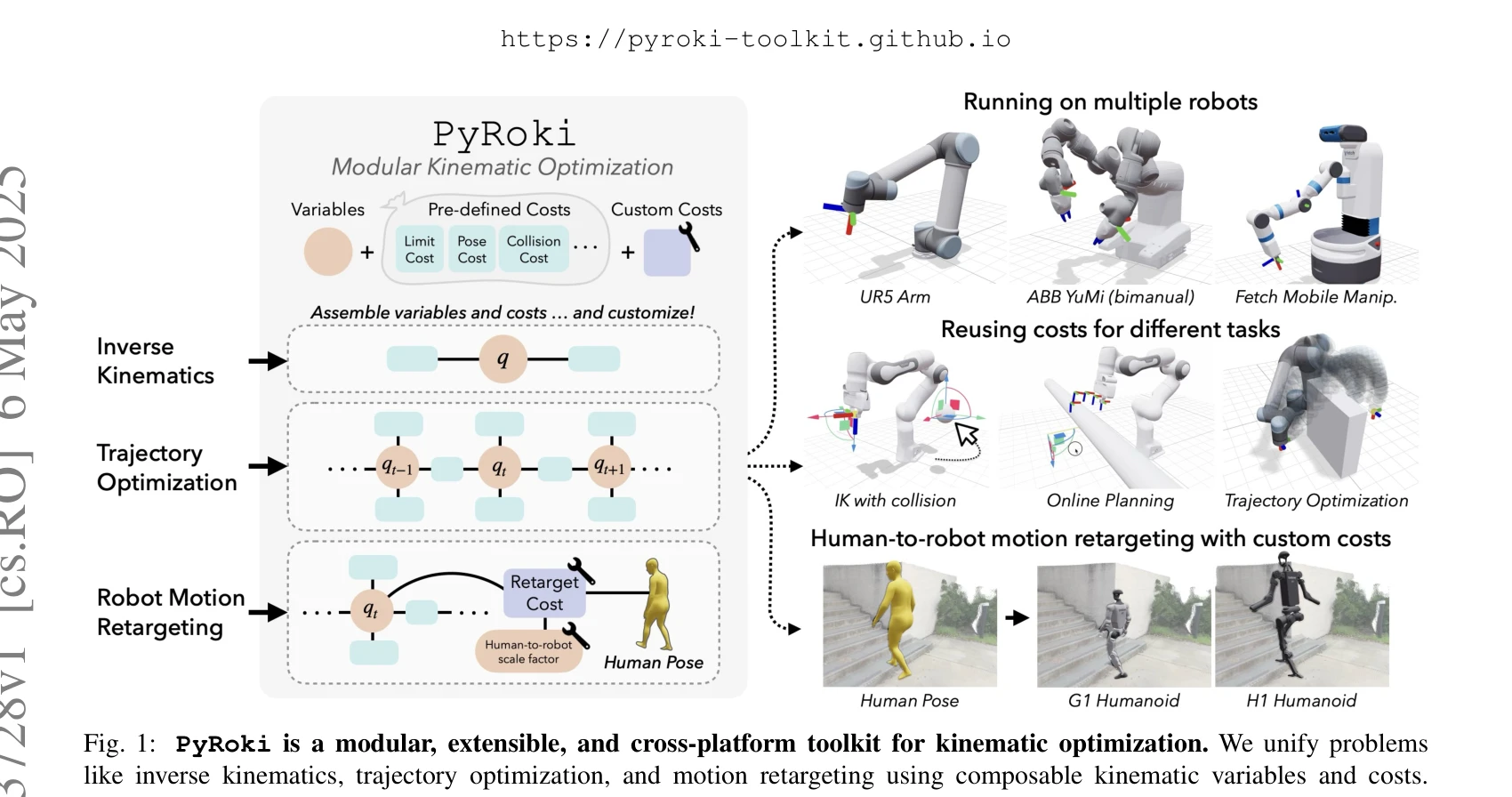
Fig. 1: PyRoki is a modular, extensible, and cross-platform toolkit for kinematic optimization. We unify problems
 *Fig. 1: PyRoki is a modular, extensible, and cross-platform toolkit for kinematic optimization. We unify problems* PyRoki는 역기구학, 궤적 최적화, 모션 리타게팅 등 다양한 로봇 운동학 최적화 문제를 통합적으로 해결하는 모듈식, 확장 가능하며 CPU/GPU/TPU에서 실행되는 크로스 플랫폼 툴킷이다.
PyRoki는 로봇 운동학 최적화를 위한 통합된 모듈식 프레임워크로서 파편화된 기존 도구들의 문제를 효과적으로 해결하고, CPU/GPU/TPU 크로스 플랫폼 지원과 cuRobo 대비 1.4-1.7배 성능 향상을 달성하였다. 인터랙티브 시각화와 사용 편의성을 갖춘 실용적인 오픈소스 도구로서 높은 연구 및 산업 가치가 있다.
Stability-Aware Retargeting for Humanoid Multi-Contact Teleoperation
Figure 1: Robot performing a teleoperated manipulation task, in
 *Figure 1: Robot performing a teleoperated manipulation task, in* 휴머노이드 로봇의 다중 접촉 텔레오퍼레이션 중 안정성을 향상시키기 위해 Centroidal stability 기반 retargeting을 제안하며, Linear Program 민감도 분석을 통해 효율적으로 안정성 여유 기울기를 계산한다.
다중 접촉 텔레오퍼레이션에 centroidal 안정성 분석을 효과적으로 통합하고 LP 민감도를 통한 새로운 기울기 계산 방법을 제시하며, 시뮬레이션과 하드웨어 검증으로 실용성을 입증한 견고한 기여.
ToddlerBot: Open-Source ML-Compatible Humanoid Platform for Loco-Manipulation
Figure 1: ToddlerBot is an open-source humanoid platform for large-scale, high-quality data collec-
 *Figure 1: ToddlerBot is an open-source humanoid platform for large-scale, high-quality data collec-* ToddlerBot은 머신러닝 기반 로봇 정책 학습을 위해 설계된 저비용, 오픈소스 미니어처 인형로봇으로, 시뮬레이션과 실제 환경 모두에서 고품질 데이터 수집을 가능하게 하며 zero-shot sim-to-real 정책 전이를 지원한다.
ToddlerBot은 ML-compatible 설계, 높은 자유도, 완벽한 재현성, 그리고 저비용이라는 독특한 조합으로 로봇공학 연구를 민주화하는 중요한 플랫폼이며, 시뮬레이션-실제 데이터 수집과 정책 학습을 위한 실질적인 도구를 제공한다.
GraspSense: 언어 기반 인지와 힘 맵을 활용한 손재주 로봇 파지 계획
Fig. 1.
 *Fig. 1.* 본 논문은 휴머노이드 손재주 로봇의 파지 계획을 위해 언어 기반 인지, 3D 복원, 물리 기반 구조 해석을 통한 force map 구성, 그리고 임피던스 제어 기반 파지 실행을 통합하는 파이프라인 GraspSense를 제안한다. 기존의 기하학적 파지 계획과 달리, 물체 표면의 공간적으로 비균일한 기계적 특성을 명시적으로 고려하여 파지 선택과 그립 력 조절을 결합하는 물리 기반 접근을 제시한다.
본 논문은 손재주 로봇 파지 계획에 물체의 구조적 기계적 특성을 명시적으로 통합하는 중요한 기여를 제시한다. Force map 기반 파지 선택과 적응형 임피던스 제어를 통해 기존 기하학적 파지 계획의 한계를 극복하는 물리 기반 접근법이 창의적이고 기술적으로 건실하다. 다만 실제 로봇 플랫폼에서의 검증과 더 광범위한 객체 범주에 대한 평가가 필요하며, force map 구성의 정확성 분석이 강화되어야 한다.
A Closed-Form Geometric Retargeting Solver for Upper Body Humanoid Robot Teleoperation
Fig. 1: We propose SEW-Mimic for retargeting human shoulder, elbow, and wrist (SEW) keypoints analytically to robot
 *Fig. 1: We propose SEW-Mimic for retargeting human shoulder, elbow, and wrist (SEW) keypoints analytically to robot* SEW-Mimic은 인간의 어깨, 팔꿈치, 손목(SEW) 키포인트를 7-DoF 로봇 팔의 관절각으로 변환하는 폐형식(closed-form) 기하학적 역운동학 솔버로, 3kHz의 고속 추론과 최적성 보장을 제공한다.
SEW-Mimic은 인간형 로봇 텔레오퍼레이션의 근본적 병목(계산 지연, 팔꿈치 제어 불일치)을 폐형식 기하학적 해석으로 우아하게 해결하며, 실증적 성과와 다중 플랫폼 검증으로 실무 임팩트가 높은 기여이다.
A Framework for Optimal Ankle Design of Humanoid Robots
Fig. 1: Examples of two-degrees-of-freedom ankle mechanisms.
 *Fig. 1: Examples of two-degrees-of-freedom ankle mechanisms.* 휴머노이드 로봇의 발목 설계를 위한 통합 프레임워크를 제시하며, SPU 및 RSU 병렬 메커니즘에 대한 다목적 최적화를 통해 최적 구성을 도출한다.
본 논문은 휴머노이드 로봇 발목 설계의 오랜 난제인 아키텍처 선택과 파라미터 최적화를 체계적이고 정량적으로 해결하는 통합 프레임워크를 제시하며, 실제 로봇 재설계를 통한 유의미한 성능 개선으로 실용성을 입증하였다.
A Hierarchical, Model-Based System for High-Performance Humanoid Soccer
Fig. 1: Overview of the ARTEMIS humanoid soccer system. A). Two ARTEMIS humanoid robots competing for ball possession du
 *Fig. 2: System architecture of the ARTEMIS humanoid platform. The perception layer provides object detections, proximity* RoboCup 2024 우승팀의 완전히 통합된 성인용 휴머노이드 축구 로봇 시스템으로, QDD 액추에이터 기반 하드웨어와 계층적 perception-planning-control 아키텍처를 결합하여 동적이고 전술적으로 효과적인 게임플레이를 실현했다.
QDD 액추에이터 기반 하드웨어와 perception-planning-control의 tight integration을 통해 RoboCup 우승을 달성한 고성숙도의 시스템으로, 동적 휴머노이드 제어와 실시간 자율 네비게이션의 실제 구현 사례로서 상당한 실질적 가치를 제공한다.
An Empirical Evaluation of Four Off-the-Shelf Proprietary Visual-Inertial Odometry Systems

Fig. 1. The custom-built capture rig for benchmarking 6-DoF motion tracking
 *Fig. 1. The custom-built capture rig for benchmarking 6-DoF motion tracking* Apple ARKit, Google ARCore, Intel RealSense T265, Stereolabs ZED 2 등 4개의 상용 VIO 시스템을 실내외 환경에서 실험하여 6-DoF 위치 추정 성능을 벤치마크 비교한 연구이다.
본 연구는 산업 및 로봇 분야에서 광범위하게 사용되는 상용 VIO 시스템의 실제 성능을 최초로 체계적으로 벤치마킹한 중요한 기여이며, 실내외 도전적 환경에서의 포괄적 평가를 통해 연구자와 엔지니어에게 실용적인 참고 자료를 제공한다.
Antagonistic Bowden-Cable Actuation of a Lightweight Robotic Hand: Toward Dexterous Manipulation for Payload Constrained Humanoids
Fig. 1: Overview of the proposed Antagonistic Bowden-
 *Fig. 1: Overview of the proposed Antagonistic Bowden-* Bowden 케이블을 이용한 원격 구동 방식의 경량 인간형 로봇 손으로, 길항적 케이블 작동과 rolling-contact joints를 결합하여 20개 DOF를 236g의 극히 낮은 질량으로 구현하였다.
본 논문은 극도로 경량화된 원격 구동 로봇 손의 설계를 통해 payload 제약이 있는 인간형 로봇에 고 dexterity를 부여하는 실용적 솔루션을 제시한다. Rolling-contact joints와 길항적 케이블 구동의 결합은 독창적이며, 3D 프린팅 기반의 완전 제작 가능한 설계로 재현성과 확장성이 우수하다.
ComFree-Sim: A GPU-Parallelized Analytical Contact Physics Engine for Scalable Contact-Rich Robotics Simulation and Control
Fig. 1: Performance overview of the ComFree-Sim. In the second row, it shows 2–3× higher throughput than MuJoCo Warp
 *Fig. 1: Performance overview of the ComFree-Sim. In the second row, it shows 2–3× higher throughput than MuJoCo Warp* ComFree-Sim은 여집합-자유(complementarity-free) 접촉 모델링을 기반으로 한 GPU 병렬화 접촉 물리 엔진으로, 폐쇄형 해석해를 통해 접촉 임펄스를 계산하여 접촉 수에 대해 선형적 계산 복잡도를 달성한다.
ComFree-Sim은 complementarity-free 접촉 모델링의 폐쇄형 해석 구조를 효과적으로 GPU 병렬화하고 6D로 확장하여, 기존 iterative solver 기반 접근의 근본적 병목을 해결한 혁신적 접촉 물리 엔진이다. 선형 확장성과 2-3배 향상된 처리량을 실현하면서도 물리 정확도를 유지하고, 실제 로봇 하드웨어에서 고주파 MPC 제어를 성공적으로 구현함으로써 접촉-풍부 로봇 학습과 제어 분야에 상당한 실용적 가치를 제공한다.
Control of Humanoid Robots with Parallel Mechanisms using Differential Actuation Models
 *Fig. 3: Planar 4-bar mechanism, with the serial link rotating* Cassie 영감의 휴머노이드 로봇에 사용되는 병렬 구동 메커니즘에 대한 미분가능한 해석 모델을 제시하여 정확한 비선형 전달 특성을 효율적으로 계산 가능하게 한다.
Parallel actuation 메커니즘의 정확한 모델링을 minimal하고 미분가능한 형식으로 구현하여 현대 제어 및 학습 알고리즘에 실용적으로 통합 가능하게 한 의미 있는 기여다. 하드웨어 검증으로 이론의 실효성을 입증했으나, 보다 일반적인 mechanism 설계에 대한 확장성 검증이 추가로 필요하다.
cuRoboV2: Dynamics-Aware Motion Generation with Depth-Fused Distance Fields for High-DoF Robots
cuRoboV2는 B-spline 궤적 최적화, GPU 기반 TSDF/ESDF 인식 파이프라인, 확장 가능한 고자유도 로봇 계산을 통합하여 조작기부터 인형로봇까지 안전하고 동역학 인식적인 운동 생성을 제공하는 통합 프레임워크이다.
cuRoboV2는 동역학 인식적 운동 생성, GPU 가속 인식 처리, 고자유도 확장성에서 근본적 한계를 극복한 통합 프레임워크로, 조작 로봇부터 인형로봇까지 대폭 개선된 성능을 달성하여 로봇 자율성의 실용화에 크게 기여한다.
Explosive Output to Enhance Jumping Ability: A Variable Reduction Ratio Design Paradigm for Humanoid Robots Knee Joint
Fig. 1: Motor torque performance envelope (TPE) and power
 *Fig. 1: Motor torque performance envelope (TPE) and power* 휴머노이드 로봇의 점프 능력을 향상시키기 위해 무릎 관절이 신장할수록 감속비가 동적으로 감소하는 EVRR-K(Explosive Variable Reduction Ratio Knee) 설계 패러다임을 제안한다.
무릎 관절의 동적 감속비 개념을 신창의적으로 도입하여 전기 구동 휴머노이드의 점프 성능을 획기적으로 개선한 우수한 연구다. 이론 분석, 메커니즘 설계, 실험 검증이 체계적으로 이루어져 있으며, 달성한 점프 성능(0.5m 수직, 1.1m 수평)은 기존 전기 로봇 대비 최고 수준이다.
FRAME: Floor-aligned Representation for Avatar Motion from Egocentric Video
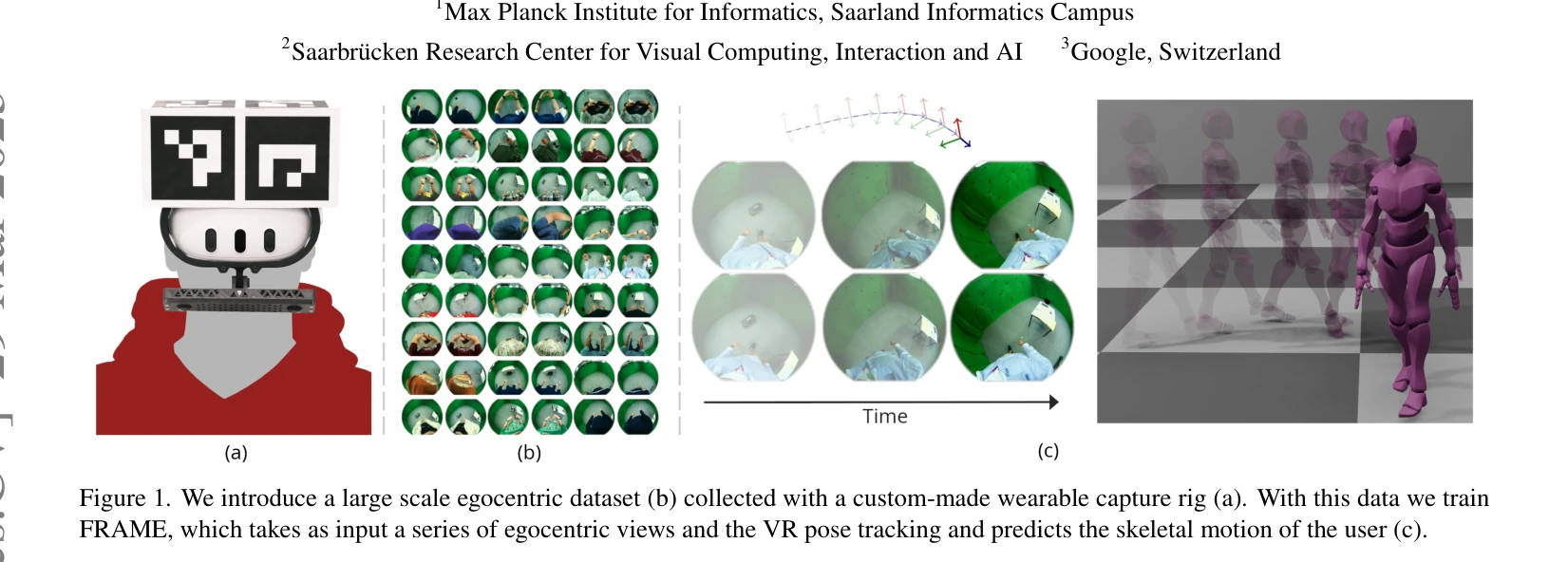
Figure 1. We introduce a large scale egocentric dataset (b) collected with a custom-made wearable capture rig (a). With
 *Figure 1. We introduce a large scale egocentric dataset (b) collected with a custom-made wearable capture rig (a). With * VR/AR 환경에서 일인칭 시점의 스테레오 카메라와 헤드 트래킹을 활용하여 신체 자세를 추정하는 FRAME 아키텍처를 제안하며, 대규모 실제 데이터셋을 수집하여 합성 데이터 사전학습의 필요성을 제거했다.
일인칭 모션 캡처의 핵심 문제들(합성 데이터 의존성, 하지 정확도, 아티팩트)을 대규모 실제 데이터셋과 기하학적으로 명시적인 아키텍처로 체계적으로 해결하며, 실시간 성능과 높은 일반화 능력을 동시에 달성한 실용성 높은 연구다.
High-Speed and Impact Resilient Teleoperation of Humanoid Robots

Fig. 1.
 *Fig. 1.* 본 논문은 7개의 IMU 기반 캘리브레이션 무료 모션 캡처, low-latency kinematics streaming toolbox, 고대역폭 cycloidal actuator를 통합하여 휴머노이드 로봇의 고속 및 충격 강건 텔레오퍼레이션을 실현한다.
본 논문은 최소 센서 기반 모션 캡처, low-latency streaming, cycloidal actuator를 통합하여 휴머노이드 로봇의 고속 충격 강건 텔레오퍼레이션을 처음으로 실제 구현 및 검증했으며, 간단하면서도 효과적인 설계로 실용적 가치가 높다. 다만 플랫폼 특화성과 환경 다양성 평가 부재가 한계이다.
Human-Level Actuation for Humanoids
 *Figure 4: Lower body atlas I: Pelvis and hip degrees of freedom. Pelvic motion is relative to a global* 휴머노이드 로봇의 '인간 수준' 구동을 정량화하고 비교 가능하게 하기 위해 생체역학 기반의 포괄적 평가 프레임워크를 제시하고, DoF atlas, Human-Equivalence Envelopes (HEE), Human-Level Actuation Score (HLAS)의 세 가지 핵심 요소로 구성된다.
이 논문은 휴머노이드 로봇의 '인간 수준' 구동력을 정량화하기 위한 학제적 프레임워크를 제시하며, 생체역학 기반의 엄격한 기준과 표준화된 측정 프로토콜을 결합하여 로봇 개발과 벤치마킹의 투명성과 재현성을 크게 향상시킨다. 구동기 설계 트레이드오프를 명시적으로 노출하고 작업 맥락에 맞춘 평가를 수행한다는 점에서 기존 피크값 기반 사양과 차별화되며, 휴머노이드 로봇 공학 분야에서 중요한 표준화 기여를 한다.
Legged Robot State-Estimation Through Combined Forward Kinematic and Preintegrated Contact Factors
 *Fig. 2: An example factor graph for the proposed system. Forward kinematic* 시각 추적 손실 시에도 작동하는 다리 로봇 상태 추정 기법으로, Forward Kinematic 인수와 Preintegrated Contact 인수를 Factor Graph에 통합하여 엔코더 측정과 접촉 정보를 활용한다.
본 논문은 Factor Graph 프레임워크에 Forward Kinematic 및 Preintegrated Contact 인수를 처음 도입하여 시각 손실 상황에서도 다리 로봇의 상태를 추정할 수 있는 실용적 기법을 제시했으며, 이론적 엄밀성과 실제 로봇 구현 양면에서 견고한 기여를 하지만, 실험의 규모가 제한적이고 일반화 가능성 검증이 필요하다.
LEGO: Latent-space Exploration for Geometry-aware Optimization of Humanoid Kinematic Design
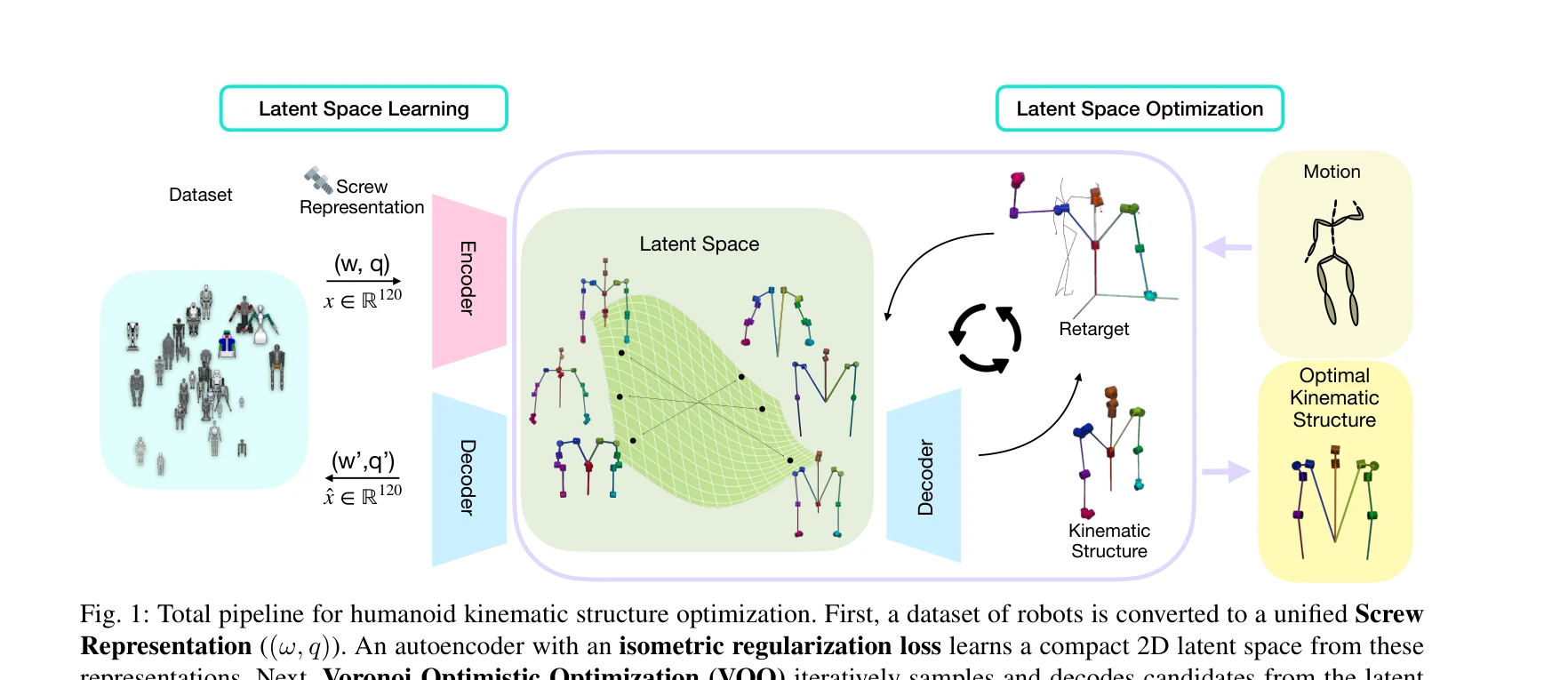
Fig. 1: Total pipeline for humanoid kinematic structure optimization. First, a dataset of robots is converted to a unifi
 *Fig. 1: Total pipeline for humanoid kinematic structure optimization. First, a dataset of robots is converted to a unifi* LEGO는 기존 로봇 설계 데이터와 인간 모션 데이터를 활용하여 humanoid 로봇의 kinematic 구조를 자동으로 최적화하는 데이터 기반 설계 프레임워크이다. Screw theory 기반 표현과 isometric manifold learning을 통해 compact한 latent space를 구성하고 gradient-free optimization으로 최적 설계를 탐색한다.
본 논문은 screw theory, isometric manifold learning, motion retargeting을 통합한 혁신적인 data-driven 로봇 설계 프레임워크를 제시하며, 실제 하드웨어 프로토타입 검증으로 실용성을 입증한 의미 있는 연구이다. 다만 제한된 학습 데이터와 특정 morphology에의 국한이 일반화 관점에서의 한계이나, 로봇 설계 자동화 분야에 중요한 기여를 제공한다.
Optimizing Bipedal Locomotion for The 100m Dash With Comparison to Human Running
 *Fig. 3: The top 5 most efficient freq (above) and ratio* 이 논문은 이족 로봇 Cassie의 고속 주행 보행을 위해 보행 매개변수(stride frequency, swing ratio)를 체계적으로 최적화하고, 그 결과를 인간의 주행 역학과 비교하며, 최종적으로 100m 대시 기네스 월드레코드를 달성한 완전한 컨트롤러를 제시한다.
이 논문은 이족 로봇의 고속 주행을 위한 보행 매개변수의 첫 체계적 최적화를 제시하고, 인간 주행 역학과의 흥미로운 비교를 통해 이론적 깊이를 제공하며, 기네스 월드레코드 달성으로 실질적 임팩트를 입증한 우수한 연구이다.
ORCA: An Open-Source, Reliable, Cost-Effective, Anthropomorphic Robotic Hand for Uninterrupted Dexterous Task Learning
Fig. 1: (A) The ORCA hand closely mimics its human counterpart with
 *Fig. 1: (A) The ORCA hand closely mimics its human counterpart with* ORCA는 2,000 CHF 미만의 재료비로 8시간 내에 조립 가능한 오픈소스 tendon-driven 인간형 로봇 손이며, popping joints와 자동 캘리브레이션 등의 설계로 높은 신뢰성과 정확도를 달성한다.
ORCA는 tendon-driven 로봇 손의 조립 용이성과 신뢰성을 획기적으로 개선하여 dexterous manipulation 연구의 하드웨어 접근 장벽을 크게 낮춘 중요한 공헌이며, 오픈소스 공개를 통해 연구 커뮤니티의 광범위한 채택과 확장을 촉진할 것으로 기대된다.
Simulator Adaptation for Sim-to-Real Learning of Legged Locomotion via Proprioceptive Distribution Matching
 *Fig. 3: A Unitree Go2 quadruped used in sim-to-real experiments.* 본 논문은 Sim-to-Real 학습에서 시뮬레이터를 적응시키기 위해 proprioceptive distribution matching을 제안하며, 모션 캡처나 시간 정렬 없이 hardware와 simulation의 dynamics 불일치를 해결한다.
본 논문은 실무적 제약을 해결하는 실용적이고 우아한 솔루션을 제시하며, proprioceptive distribution matching은 기존의 복잡한 state-matching 방식을 효과적으로 대체할 수 있는 가치 있는 기여다. 다만 평가가 단일 로봇 플랫폼과 제한된 hardware data에서만 수행되어 일반화 가능성을 더 광범위하게 검증할 필요가 있다.
A Rapid Deployment Pipeline for Autonomous Humanoid Grasping Based on Foundation Models
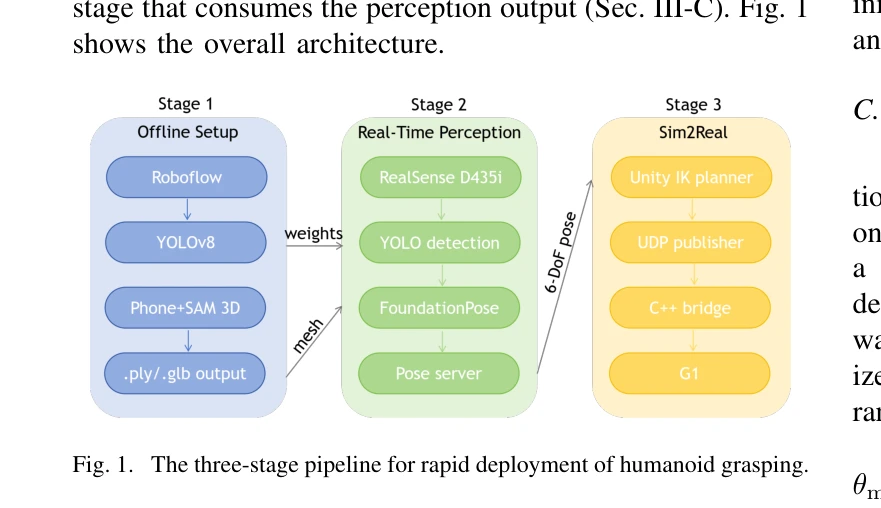
Fig. 1. The three-stage pipeline for rapid deployment of humanoid grasping.
 *Fig. 1. The three-stage pipeline for rapid deployment of humanoid grasping.* Foundation model들(YOLOv8, SAM 3D, FoundationPose)을 통합하여 휴머노이드 로봇의 새로운 물체 조작 배포 시간을 1-2일에서 약 30분으로 단축하는 end-to-end 파이프라인을 제시한다.
Foundation model들의 효과적 통합으로 휴머노이드 로봇 배포 시간을 획기적으로 단축한 실용적이고 우수한 논문이며, 자동 주석, zero-shot 3D 재구성, zero-shot pose tracking을 연계한 modular 설계가 산업 적용성을 높인다. 다만 제한된 물체 유형과 환경 조건에서의 검증이 일반화 가능성을 판단하기 위해 추가 필요하다.
Constraint-Enhanced Reinforcement Learning Based on Dynamic Decoupled Spherical Radial Squashing
본 논문은 강화학습에서 이질적(heterogeneous) 관절별 액추에이터 속도 제약을 정확히 처리하는 Dynamic Decoupled Spherical Radial Squashing (DD-SRad) 기법을 제안한다. 기존의 isotropic spherical 방법은 ℓ∞ 박스 형태의 제약을 ℓ2 공 형태로 압축하여 실현 가능 집합을 손실하는 반면, DD-SRad는 차원별 적응 반경(per-dimension adaptive radius)을 독립적으로 계산하여 정확한 ℓ∞ 커버리지를 달성한다.
본 논문은 이질적 속도 제약을 가진 강화학습 문제에 대해 이론적으로 건전하고 실무적으로 효과적인 해결책을 제시한다. 기하학적 직관, 엄밀한 정리, 광범위한 실증이 결합되어 있으며, 실 로봇 배포 경로를 명확히 제시하는 점이 돋보인다. 다만 UI=0 미분 불가능성, 제한된 실험 범위, 수렴성 증명 부재가 소수의 약점이나 전반적으로 게재 가치가 충분하다.
A Hierarchical Framework for Humanoid Locomotion with Supernumerary Limbs
 *Figure 3.1: Training performance of the PPO agent over 500 million environment steps. (a)* 본 논문은 초과 사지(Supernumerary Limbs, SLs)로 증강된 인형로봇(humanoid robot)의 안정적인 보행을 위해 계층적 제어 프레임워크를 제안한다. 학습 기반의 저수준 보행 정책과 모델 기반의 고수준 동적 균형 제어기를 결합한 분리된 접근방식을 통해 SLs로부터의 동적 교란을 효과적으로 완화한다.
본 논문은 계층적 제어 프레임워크를 통해 초과 사지 장착 인형로봇의 안정적 보행 문제를 창의적으로 해결한다. DRL 기반 보행 정책과 model-based 균형 제어의 결합은 기술적으로 타당하며 47% DTW 개선이라는 정량적 성과를 달성한다. 다만 시뮬레이션 한정 평가와 실제 하드웨어 검증 부재가 실용적 기여도를 제한한다.
Human-Level Actuation for Humanoids
Figure 1: Upper body atlas I: Shoulder complex including scapulothoracic contributions. Origins
 *Figure 1: Upper body atlas I: Shoulder complex including scapulothoracic contributions. Origins* 이 논문은 인간형 로봇의 구동부(actuation)가 인간 수준인지를 객관적으로 측정하고 비교할 수 있는 포괄적 프레임워크를 제시한다. 세 가지 핵심 요소로 구성되는데, 첫째는 ISB 기반 kinematic DoF atlas로 관절 좌표계를 표준화하고, 둘째는 Human-Equivalence Envelopes(HEE)로 특정 관절각도와 각속도에서 인간의 토크와 파워를 동시에 만족하는 요구사항을 정의하며, 셋째는 Human-Level Actuation Score(HLAS)로 workspace coverage, 효율성, 열 지속성 등 여섯 가지 인자를 통합한다.
이 논문은 humanoid robot 개발에서 오래도록 미해결되어 온 정량화 문제를 강력한 이론적 기반(ISB kinematic conventions, human biomechanics 데이터) 위에서 처음으로 체계적으로 해결한다. Human-Equivalence Envelopes와 HLAS는 설계자에게 명확한 목표를 제공하고, task-relevant posture-rate bands에 기반한 가중치 부여는 실무적 타당성을 보장한다. 제안된 측정 프로토콜(dynamometry, thermal testing)은 재현 가능하고 표준화 가능하여 산업 표준으로 채택될 수 있는 잠재력이 크다. 다만 75kg 기준 신체에 대한 의존도와 실험실 기반 biomechanics 데이터의 현장 적용성 한계는 보완이 필요하다. 전반적으로 humanoid actuation 평가에 새로운 표준을 제시하는 중요한 기여로, robotics, biomechanics, benchmarking 커뮤니티에 광범위한 영향을 미칠 것으로 예상된다.
Physics-Informed Neural Networks with Unscented Kalman Filter for Sensorless Joint Torque Estimation in Humanoid Robots
 *Fig. 4: CoM tracking comparison: RNEA-PINN (left) vs. UKF-PINN (right). Green rectangles indicate external contacts.* 본 논문은 휴머노이드 로봇의 joint torque 센서를 사용하지 않고 토크 제어를 수행하기 위해 PINN을 활용한 마찰 모델링과 UKF 기반 joint torque 추정을 통합하는 프레임워크를 제시한다. 이 접근법은 high-ratio harmonic drive를 탑재한 전기 모터 시스템에서 실시간 sensorless torque control을 가능하게 한다.
본 논문은 PINN과 UKF를 통합한 sensorless torque control 프레임워크를 제시하며, 휴머노이드 로봇 제어에서 실질적인 advances를 제공한다. 기술적으로 견고하고 실험적으로 검증되었으나, 실험 범위의 제한과 계산 효율성에 대한 분석 부족이 영향을 미친다. 전반적으로 robotics 커뮤니티에 가치 있는 기여를 한다.
Quasi-Direct Drive for Low-Cost Compliant Robotic Manipulation
Fig. 1.
 *Fig. 1.* Quasi-Direct Drive 구동방식을 기반으로 한 저비용 7-DOF 로봇 팔 Blue를 제안하여 인간 환경에서 안전하고 힘 제어 가능한 조작을 가능하게 함.
이 논문은 인간 환경에서 필요한 저비용 compliant 로봇의 설계 패러다임을 재정의하고 Quasi-Direct Drive 방식을 통해 이를 실현한 획기적 연구로, AI 기반 로봇 학습의 대규모 보급을 가능하게 하는 중요한 플랫폼을 제시함.
TeleOpBench: A Simulator-Centric Benchmark for Dual-Arm Dexterous Teleoperation
Figure 1: We present TeleOpBench, a simulation-based benchmark for bimanual dexterous teleoper-
 *Figure 2: The overview of the proposed TeleOpBench, where we unify four operator interfaces in* TeleOpBench는 쌍팔 민첩한 텔레오퍼레이션을 위한 시뮬레이터 기반 벤치마크로, 30개의 고충실도 작업 환경과 4가지 대표적 텔레오퍼레이션 모달리티(MoCap, VR, 외골격, 비전)를 통합 프레임워크로 제공하며 시뮬레이션과 실제 하드웨어 간의 강한 상관관계를 검증한다.
TeleOpBench는 텔레오퍼레이션 연구의 장기적인 병목인 표준화된 평가 환경의 부재를 해결하는 중요한 기여로, 실제 하드웨어와의 상관관계 검증을 통해 실용성을 입증한 의미 있는 연구이다. 다만 더 많은 로봇 플랫폼 통합과 정성적 사용성 지표 추가로 영향력을 확대할 수 있을 것으로 예상된다.
Whole-body Multi-contact Motion Control for Humanoid Robots Based on Distributed Tactile Sensors
Fig. 1. Control system for whole-body multi-contact motion in a humanoid robot.
 *Fig. 1. Control system for whole-body multi-contact motion in a humanoid robot.* 휴머노이드 로봇이 분산 촉각 센서를 장착하여 팔꿈치, 무릎 등 중간 영역의 접촉을 포함한 전신 다중 접촉 모션을 제어하는 방법을 개발했다.
본 논문은 distributed tactile sensor를 활용하여 휴머노이드 로봇의 전신 다중 접촉 모션을 처음으로 실현한 의미 있는 연구로, 방법론과 검증이 체계적이나 autonomous planning 미흡이 제한적이다.
A 21-DOF Humanoid Dexterous Hand with Hybrid SMA-Motor Actuation: CYJ Hand-0
 *Figure 3. (a) The overall structural design of the bionic dexterous hand. (b) Components of the bionic dexterous hand. (* CYJ Hand-0는 SMA와 DC 모터의 하이브리드 구동 방식을 결합한 21-DOF 휴머노이드 손으로, 3D 프린팅 AlSi10Mg 금속 프레임과 고강도 낚싯줄 텐던을 활용하여 인간의 손 구조를 생체모방한다.
CYJ Hand-0는 SMA-모터 하이브리드 구동, 정교한 생체모방 설계, 효율적인 3D 프린팅 제조를 통해 경량이면서도 고성능의 휴머노이드 손을 실현한 주목할 만한 연구이며, 특히 모듈화 아키텍처와 포괄적 성능 평가가 강점이다.
A Rapid Instrument Exchange System for Humanoid Robots in Minimally Invasive Surgery
Figure 1. Overview of the immersive teleoperated surgical instrument rapid exchange system (a)
 *Figure 1. Overview of the immersive teleoperated surgical instrument rapid exchange system (a)* 휴머노이드 로봇의 이중 팔 구성을 활용하여 HMD 기반 몰입형 원격조작과 단축 컴플라이언트 도킹 메커니즘을 통합한 최소침습 수술용 고속 기구 교환 시스템을 제안한다.
휴머노이드 로봇을 최소침습 수술에 실질적으로 적용하기 위한 핵심 기술 과제를 체계적으로 해결하였으며, HMD 기반 몰입형 원격조작과 맞춤형 도킹 메커니즘의 통합이 효과적임을 입증한 중요한 연구이다.
ACE: A Cross-Platform Visual-Exoskeletons System for Low-Cost Dexterous Teleoperation
Figure 1: An Overview of the Proposed ACE System. The system consists of two bimanual ex-
 *Figure 1: An Overview of the Proposed ACE System. The system consists of two bimanual ex-* ACE는 3D 프린팅된 이중팔 exoskeleton과 hand-facing 카메라를 결합한 저비용 cross-platform 시각 기반 원격 조종 시스템으로, 다양한 로봇 플랫폼과 end-effector에 대해 정밀한 손과 손목 자세 추적을 가능하게 한다.
ACE는 기존 원격 조종 시스템의 비용-정확도-유연성 trade-off를 효과적으로 해결한 실용적인 솔루션으로, 저비용의 3D 프린팅 exoskeleton과 vision-kinematics 하이브리드 방식을 통해 다양한 로봇 플랫폼에서의 대규모 데이터 수집을 가능하게 한다는 점에서 높은 가치를 제공한다.
CHILD (Controller for Humanoid Imitation and Live Demonstration): a Whole-Body Humanoid Teleoperation System
Fig. 1. Overview of CHILD humanoid teleoperation system.
 *Fig. 1. Overview of CHILD humanoid teleoperation system.* CHILD는 베이비 캐리어 크기의 컴팩트한 텔레오퍼레이션 장치로, 직접 관절 매핑을 통해 휴머노이드 로봇의 전신 관절 수준 제어를 가능하게 하는 시스템이다.
이 논문은 전신 humanoid 텔레오퍼레이션을 위한 직접 관절 매핑 방식을 최초로 제시하였으며, 베이비 캐리어를 활용한 혁신적이고 저비용의 하드웨어 설계와 오픈소스 공개를 통해 robotics 커뮤니티에 실질적인 기여를 제공한다.
DecARt Leg: Design and Evaluation of a Novel Humanoid Robot Leg with Decoupled Actuation for Agile Locomotion
Fig. 1. The concept of DecARt Leg design: decoupled actuation, all motors
 *Fig. 1. The concept of DecARt Leg design: decoupled actuation, all motors* 본 논문은 decoupled actuation을 활용하면서도 인간형 다리의 외형을 유지하는 DecARt Leg을 제안하며, FAST(Fastest Achievable Swing Time) 메트릭을 통해 agile locomotion 능력을 평가한다.
본 논문은 humanoid robotics의 오랜 설계 갈등(efficiency vs. human-like appearance)을 새로운 kinematic approach로 해결하려는 의미 있는 시도이며, FAST 메트릭 제안과 함께 충분한 설계 혁신성을 보여준다. 다만 preliminary hardware 수준의 검증에 그쳐 실제 성능 우위를 완전히 입증하지는 못한 한계가 있다.
DIAL: Distilling Intent-Aware Latents for Vision-Language-Action on Humanoid Robots
Fig. 1.
 *Fig. 2.* SoftHand Model-W는 3D 프린팅 기반의 인간형 로봇 손으로, 2-DoF 손목을 통합하여 손가락의 underactuated tendon-driven 구조와 손목의 능동적 제어를 결합했다. Carpal tunnel 영감의 힘줄 라우팅을 통해 원격 모터 배치를 가능하게 하면서 compact한 형태를 유지한다.
SoftHand Model-W는 soft robotics의 adaptive synergies 개념을 유지하면서 능동적 손목을 처음 통합한 혁신적 설계이며, 3D 프린팅과 carpal tunnel routing을 통해 실용성과 anthropomorphism을 동시에 달성했다. 손목 추가의 명확한 성능 개선 효과를 입증하여 dexterous manipulation 분야에 의미 있는 기여를 한다.
Exceeding the Maximum Speed Limit of the Joint Angle for the Redundant Tendon-driven Structures of Musculoskeletal Humanoids
 *Fig. 2.* 중복 힘줄 구동 구조를 가진 근골격 인간형 로봇에서 가장 느린 근육에 의해 제한되는 관절 각속도 한계를 초과하는 두 가지 방법을 제안하고 실제 로봇 실험으로 검증한다.
근골격 인간형 로봇의 구동 제약을 새로운 관점에서 분석하고, 실용적이면서도 독창적인 두 가지 해결 방법을 제시했다. 실제 로봇 실험 검증을 통해 이론의 타당성을 입증했으나, 시뮬레이션의 단순화와 적용 조건의 제한이 개선될 여지가 있다.
Heavy lifting tasks via haptic teleoperation of a wheeled humanoid
Fig. 1.
 *Fig. 1.* 휠형 휴머노이드 로봇의 Dynamic Mobile Manipulation을 위해 햅틱 피드백을 통한 원격 조종 프레임워크를 제시하며, 인간의 전신 모션을 로봇에 재타겟팅하여 무거운 물체 들어올리기를 수행한다.
본 논문은 무거운 물체 들어올리기 작업을 위한 휠형 휴머노이드의 원격 조종에서 높이 조절, 자동 pitch 보상, 햅틱 피드백을 통합한 실질적이고 잘 설계된 시스템을 제시하며, 기존 연구의 명확한 한계를 극복한 의미 있는 기여이다.
Human-Robot Collaboration for the Remote Control of Mobile Humanoid Robots with Torso-Arm Coordination
Fig. 1: The experimental setup consists of two workspaces. The robotic workspace features a shelf unit with four shelves
 *Fig. 1: The experimental setup consists of two workspaces. The robotic workspace features a shelf unit with four shelves* 원격 제어되는 모바일 휴머노이드 로봇의 몸통-팔 협력 제어를 위해 인간-로봇 협업(HRC) 방법들을 제안하고, 사용자 연구(N=17)를 통해 자동 및 수동 제어 방식의 효과를 비교 평가한다.
원격 조종 휴머노이드 로봇의 몸통-팔 협력 문제에 대한 체계적이고 실용적인 HRC 솔루션을 제시하며, 사용자 중심의 평가를 통해 상황별 최적 제어 방식을 제공하는 의의 있는 연구이다. 다만 표본 크기와 실제 환경 검증의 확대가 필요하다.
Humanoids in Hospitals: A Technical Study of Humanoid Robot Surrogates for Dexterous Medical Interventions
Fig. 1: Teleoperated humanoid robot in diverse medical scenarios. The following were performed with the presented
 *Fig. 1: Teleoperated humanoid robot in diverse medical scenarios. The following were performed with the presented* 본 연구는 Unitree G1 인간형 로봇에 대한 원격조종 시스템을 개발하여 7가지 의료 시술(신체검진, 응급 개입, 정밀 바늘 작업)을 수행할 수 있는 가능성을 탐색적으로 검증했다.
본 연구는 인간형 로봇의 의료 활용 가능성을 처음으로 체계적으로 탐색한 획기적인 연구로, innovative teleoperation 시스템과 실제 임상 작업 검증을 통해 향후 의료 로봇 통합의 토대를 마련했다. 다만 힘 출력과 센서 한계로 인한 현실적 과제 해결이 임상 배포를 위한 핵심 과제이다.
LapSurgie: Humanoid Robots Performing Surgery via Teleoperated Handheld Laparoscopy
 *Fig. 2: The overview of the humanoid-based laparoscopic framework. The target tool pose Ptt is mapped from the control* LapSurgie는 인문형 로봇이 원격 조종을 통해 상용 복강경 수술 도구를 직접 조작할 수 있게 하는 최초의 텔레오퍼레이션 프레임워크로, 원격 중심 운동(RCM) 제약을 만족하는 역매핑 전략과 스테레오 비전 피드백을 통합한다.
LapSurgie는 인문형 로봇을 수술 영역에 처음 적용하고 RCM 제약 기반 역매핑 제어를 통해 상용 복강경 도구의 직관적 조작을 실현한 혁신적 연구로, 의료 자원 부족 지역에서의 로봇 수술 접근성 확대에 중요한 기여를 한다. 다만 임상 수준의 검증과 기술적 성숙도 향상이 필요하다.
NuExo: A Wearable Exoskeleton Covering all Upper Limb ROM for Outdoor Data Collection and Teleoperation of Humanoid Robots
Fig. 1: NuExo: A backpack-mounted active-joint humanoid robot
 *Fig. 1: NuExo: A backpack-mounted active-joint humanoid robot* 상지의 전체 운동 범위를 커버하면서 야외 환경에서 사용 가능한 경량 웨어러블 외골격계(exoskeleton) NuExo를 개발하여 인간형 로봇의 원격조종과 모션 데이터 수집을 동시에 수행한다.
NuExo는 해부학적으로 영감받은 외골격계 설계와 경량화, multi-modal sensing의 통합을 통해 teleoperation과 로봇 모션 데이터 수집의 네 가지 핵심 목표를 동시에 달성한 혁신적 시스템이다. 야외 환경에서의 실용성과 다양한 로봇 플랫폼 호환성은 인간형 로봇의 imitation learning 분야에 중대한 기여를 한다.
Multimodal Quad‐Finger Soft Robotic Hand With Dual‐Chamber Origami Actuator for Large‐Workspace Manipulation
 *Figure 5b,c,e,f, respectively, illustrate the 3D fingertip trajectories* 본 연구는 이중 챔버 SCOP actuator를 이용한 4지 소프트 로봇 핸드(QDO hand)를 제시하며, 양압과 음압 조절을 통해 축 방향 신축과 양방향 굽힘 등 다양한 운동 양식을 구현하여 5.2배 확대된 작업 공간을 달성한다.
본 논문은 이중 챔버 SCOP actuator와 DCI-FLMG 제어 방식을 통해 소프트 로봇 핸드의 작업 공간 확대와 다중 운동 양식을 동시에 달성한 혁신적 연구이며, 인간-로봇 협업과 복잡한 환경에서의 조작 능력 향상에 크게 기여할 것으로 기대된다.
RAPID Hand: A Robust, Affordable, Perception-Integrated, Dexterous Manipulation Platform for Generalist Robot Autonomy
Figure 1: RAPID Hand is an open-source, low-cost, fully direct-driven robotic hand platform with
 *Figure 1: RAPID Hand is an open-source, low-cost, fully direct-driven robotic hand platform with* RAPID Hand는 저비용의 20-DoF 다지형 로봇 손으로, 시각, 촉각, 고유감각을 통합한 멀티모달 인지 시스템과 고-DoF 원격조종 인터페이스를 함께 설계하여 로봇 자율성을 위한 고품질 조작 데이터 수집을 가능하게 한다.
RAPID Hand는 저비용 다지형 로봇 손 설계, 고정밀 멀티모달 인지 통합, 그리고 효과적인 원격조종 인터페이스를 혁신적으로 통합한 오픈소스 플랫폼으로, 일반화된 로봇 자율성 연구에 필요한 고품질 데이터 수집을 가능하게 하는 중요한 기여이다.
Vision in Action: Learning Active Perception from Human Demonstrations
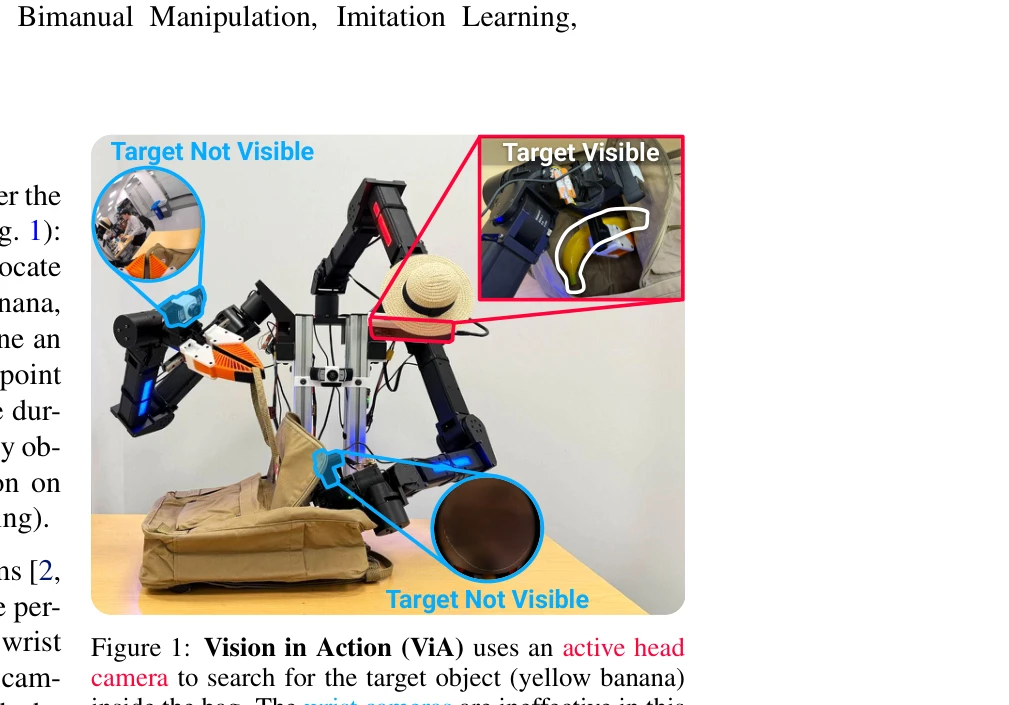
Figure 1: Vision in Action (ViA) uses an active head
 *Figure 1: Vision in Action (ViA) uses an active head* ViA는 6-DoF 로봇 넥과 VR 텔레오퍼레이션 인터페이스를 통해 인간의 능동적 지각 전략을 직접 학습하여 이중팔 조작 로봇의 성능을 향상시키는 시스템이다.
ViA는 능동적 지각, VR 텔레오퍼레이션, 이중팔 조작을 효과적으로 통합한 혁신적 시스템으로, 중간 3D 표현을 통한 지연 시간 해결과 공유 관찰 공간 개념이 특히 창의적이며, 시각적 폐색이 있는 복잡한 실제 작업에서 실질적인 성능 향상을 달성했다.
Bunny-VisionPro: Real-Time Bimanual Dexterous Teleoperation for Imitation Learning
Figure 1: System Overview and Task Suits. (a) Hand poses captured by Apple Vision Pro are con-
 *Figure 1: System Overview and Task Suits. (a) Hand poses captured by Apple Vision Pro are con-* Apple Vision Pro의 손 추적 기능을 활용하여 양손 민첩한 조작이 가능한 실시간 텔레오퍼레이션 시스템 Bunny-VisionPro를 제시하며, 저비용 햅틱 피드백과 충돌/특이점 회피를 통해 모방 학습용 고품질 시연 데이터를 수집한다.
Vision Pro를 활용한 양손 민첩 텔레오퍼레이션에서 실시간 성능, 안전성, 몰입감을 동시에 달성한 혁신적 시스템으로, 장시간 복잡 조작의 시연 수집을 통해 모방 학습의 새로운 가능성을 제시하는 높은 기술적·응용적 가치의 연구다.
Cognition to Control - Multi-Agent Learning for Human-Humanoid Collaborative Transport

Fig. 1: Demonstration of human-robot collaboration via cognition-to-control hierarchy: (a) the humanoid and human partne
 *Fig. 3: The proposed hierarchical HRC framework for humanoid-object coordination, partitioning decision-making into thre* 인간-휴머노이드 협업 운반을 위한 3계층 Cognition-to-Control 프레임워크로, VLM 기반 의미론적 추론, Markov potential game 기반 MARL 조정, 전신 제어를 통합하여 역할의 자동 형성과 강건한 협업을 실현한다.
인간-로봇 협업의 근본적인 인지-제어 단절 문제를 3계층 구조로 체계적으로 해결하고, Markov potential game MARL을 통해 명시적 역할 할당 없이 협업 역할이 자동 형성되는 novel 접근법을 제시한다. 실험 결과는 강건성과 유효성을 잘 보여주지만, 작업 다양성 및 환경 조건 범위 확대가 필요하다.
Coordinated Humanoid Manipulation with Choice Policies

Fig. 1: Coordinated Humanoid Manipulation. We present a teleoperation system and a policy learning framework for
 *Fig. 1: Coordinated Humanoid Manipulation. We present a teleoperation system and a policy learning framework for* 휴머노이드 로봇의 전신 협조 조작을 위해 모듈식 텔레오퍼레이션 인터페이스와 Choice Policy라는 모방 학습 방식을 결합한 시스템을 제시한다. Choice Policy는 다중 후보 행동을 생성하고 점수를 학습하여 멀티모달 행동을 효율적으로 모델링한다.
이 논문은 휴머노이드 전신 조작을 위한 실용적이고 확장 가능한 시스템을 제시하며, Choice Policy는 멀티모달 행동 모델링에서 효율성과 표현력의 균형을 잘 달성했다. 모듈식 텔레오퍼레이션과 함께 실제 로봇 작업에서의 성공적 검증은 고가치의 실제 기여를 보여준다.
DexterCap: An Affordable and Automated System for Capturing Dexterous Hand-Object Manipulation
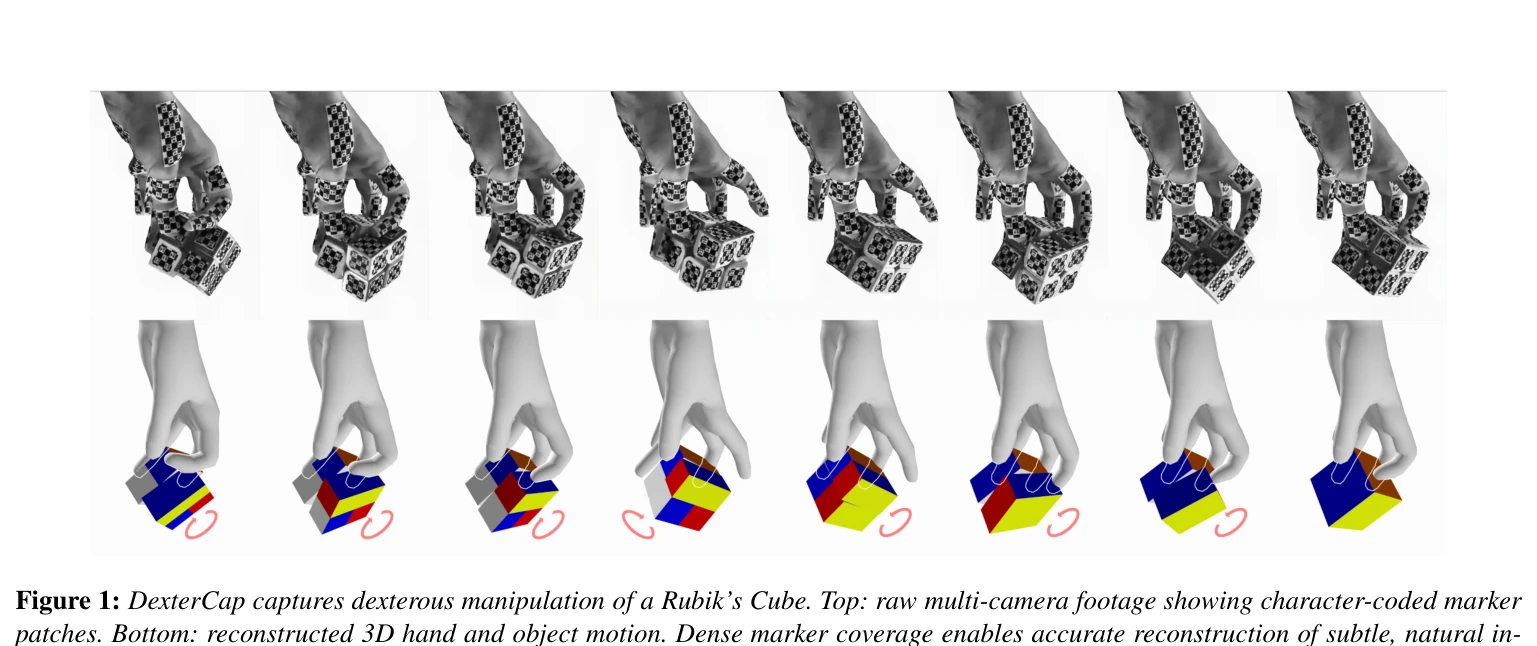
Figure 1: DexterCap captures dexterous manipulation of a Rubik’s Cube. Top: raw multi-camera footage showing character-c
 *Figure 1: DexterCap captures dexterous manipulation of a Rubik’s Cube. Top: raw multi-camera footage showing character-c* DexterCap는 문자 코드화된 마커 패치를 사용하는 저비용 광학 모션 캡처 시스템으로, 심한 자기 폐색 상황에서도 손가락의 섬세한 조작 동작을 정확하게 추적하며 최소한의 수동 작업으로 자동 재구성 파이프라인을 제공한다.
DexterCap은 문자 코드화 마커와 자동화 파이프라인을 통해 저비용으로도 섬세한 손 조작을 정확하게 캡처할 수 있음을 보여주며, 공개된 DexterHand 데이터셋과 함께 손-물체 상호작용 연구의 중요한 리소스로 기여한다.
Dexterous Teleoperation of 20-DoF ByteDexter Hand via Human Motion Retargeting
Figure 1 Our hand-arm teleoperation system achieves dexterous in-hand manipulation, including multi-object grasping,
 *Figure 2 An overview of the proposed hand-arm teleoperation system. The teleoperation interface consists of a Meta* ByteDexter라는 20-DoF 링크구동 로봇 손과 optimization 기반 motion retargeting을 이용하여 인간의 손 움직임을 실시간으로 로봇에 재현하는 원격조종 시스템을 제시한다.
ByteDexter 시스템은 linkage-driven 손의 mechanical design, fast kinematics solver, 그리고 optimization 기반 motion retargeting을 정교하게 통합하여 고-DoF 로봇 손의 원격조종을 실현하는 의미 있는 기여를 제시한다. 실시간 제어와 고품질 demonstration data 생성이라는 실용적 가치가 높지만, 다양한 task 환경에서의 general robustness와 imitation learning 결과의 실증이 필요하다.
Emergent Active Perception and Dexterity of Simulated Humanoids from Visual Reinforcement Learning

Figure 1. Perceptive Dexterous Control (PDC) enables a humanoid equipped with egocentric vision to search for, reach, gr
 *Figure 1. Perceptive Dexterous Control (PDC) enables a humanoid equipped with egocentric vision to search for, reach, gr* 본 논문은 egocentric vision만을 사용하여 simulated humanoid가 복잡한 household tasks를 수행하도록 하는 Perceptive Dexterous Control (PDC) 프레임워크를 제안하며, visual perception을 task specification의 인터페이스로 활용하여 active search 등의 emergent behaviors를 유도한다.
본 논문은 egocentric vision을 유일한 정보원으로 하는 humanoid whole-body dexterous control의 실현이라는 도전적 문제를 perception-as-interface 패러다임과 hierarchical RL을 통해 창의적으로 해결하며, emergent active search behaviors의 명시적 입증을 통해 vision-driven control의 이점을 새롭게 조명한다.
Learning Soccer Skills for Humanoid Robots: A Progressive Perception-Action Framework
 *Fig. 2: Overview of the Perception-Action integrated Decision-making (PAiD) framework. Our pipeline progressively acquir* 본 논문은 humanoid robot이 human-like kicking과 whole-body balance를 동시에 수행하는 soccer skill을 습득하기 위해, 세 단계로 구성된 Perception-Action integrated Decision-making (PAiD) 프레임워크를 제안한다.
본 논문은 humanoid robot의 복잡한 embodied skill 습득을 위한 체계적인 progressive framework를 제시하며, motion tracking-perception integration-sim-to-real transfer의 세 단계 분해를 통해 기존 방식의 training instability와 reward conflict를 효과적으로 해결한다. 91.3% 성공률의 robust real-world kicking 성능과 diverse condition에서의 일관성은 제안 방법의 효과를 입증하며, divide-and-conquer 전략은 향후 complex embodied skill 습득의 scalable framework로 활용 가능하다.
Learning Visuotactile Skills with Two Multifingered Hands
Fig. 1. An overview of our system setup and learned visuotactile skills on four tasks. (a) Our hardware and teleoperatio
 *Fig. 1. An overview of our system setup and learned visuotactile skills on four tasks. (a) Our hardware and teleoperatio* VR 기반 저가형 텔레오퍼레이션 시스템 HATO와 촉각 센서가 장착된 의족 손을 활용하여 양손 다중지 조작 로봇이 시각-촉각 데이터로부터 인간 수준의 민첩한 조작 기술을 학습하는 시스템을 제시한다.
본 논문은 양손 다중지 조작 분야에서 하드웨어 혁신(의족 재목적화)과 접근성 높은 텔레오퍼레이션 시스템(HATO)을 통해 visuotactile learning의 새로운 경계를 개척했다. 촉각 센싱의 중요성을 실증적으로 보여주고 효율적 데이터 수집 및 정책 학습을 달성하여 로봇 조작 분야에 상당한 기여를 한다.
OKAMI: Teaching Humanoid Robots Manipulation Skills through Single Video Imitation
 *Figure 2: Overview of OKAMI. OKAMI is a two-staged method that enables a humanoid robot to imitate a* OKAMI는 단일 RGB-D 비디오 시연으로부터 인형 로봇의 조작 기술을 학습하도록 하는 방법으로, object-aware retargeting을 통해 인간의 움직임을 로봇 기구학에 맞게 변환하면서 테스트 시 객체 위치에 적응한다.
OKAMI는 object-aware retargeting이라는 핵심 개념으로 단일 비디오로부터 인형 로봇의 조작 학습을 효과적으로 해결하며, 실제 하드웨어에서 강한 일반화 능력을 입증하여 로봇 학습의 실용성을 크게 향상시킨다.
OSMO: Open-Source Tactile Glove for Human-to-Robot Skill Transfer
Fig. 1: (A) The OSMO tactile glove for collecting in-the-wild
 *Fig. 1: (A) The OSMO tactile glove for collecting in-the-wild* OSMO는 인간의 촉각 데이터를 캡처하는 오픈소스 웨어러블 촉각 장갑으로, 촉각-시각 embodiment 격차를 최소화하여 인간 시연만으로 로봇 접촉 조작 정책을 학습할 수 있게 한다.
OSMO는 웨어러블 촉각 센싱 분야에서 주목할 만한 하드웨어 기여를 하며, 인간-로봇 skill transfer에서 촉각 정보의 중요성을 실증적으로 입증했다. 완전 공개 설계와 다양한 hand-tracking 호환성은 커뮤니티 영향력을 높일 것으로 예상되나, 단일 작업 평가와 로봇 플랫폼 제한성이 일반화 가능성에 대한 의문을 남긴다.
Realistic Lip Motion Generation Based on 3D Dynamic Viseme and Coarticulation Modeling for Human-Robot Interaction
Fig. 1.
 *Fig. 1.* 인간-로봇 상호작용을 위해 3D 동적 비셈(viseme)과 공명음현상(coarticulation) 모델링 기반의 입술 운동 생성 프레임워크를 제안하며, 고차원 공간 입술 운동을 14-DOF 로봇 입술 구동 시스템으로 변환한다.
본 연구는 3D 동적 비셈과 중국어 언어학적 특성을 결합하여 입술 동기화의 근본적 한계를 해결한 학제적 기여로, 경량하고 실용적인 로봇 배포 프레임워크를 통해 인간-로봇 상호작용의 자연성을 크게 향상시킨다.
Robust and Generalized Humanoid Motion Tracking
 *Fig. 2: Overview of the proposed whole-body control pipeline. A history encoder extracts a dynamics embedding from* 휴머노이드 로봇의 일반적인 전신 제어를 위해 dynamics-conditioned command aggregation 프레임워크를 제안하며, 인과적 temporal encoder와 multi-head cross-attention을 결합하여 노이즈가 있는 참조 동작에 강건하게 대응한다.
본 논문은 dynamics-conditioned command aggregation이라는 우아한 설계를 통해 컴팩트한 데이터셋으로도 강건한 일반화 휴머노이드 전신 제어를 달성하며, 낙하 회복의 통합과 실제 로봇 배포 검증으로 높은 실용성을 보여준다.
VisualMimic: Visual Humanoid Loco-Manipulation via Motion Tracking and Generation
 *Fig. 2: VisualMimic consists of two training stages: 1) training a general keypoint tracker, where a teacher motion trac* VisualMimic은 egocentric vision과 hierarchical whole-body control을 결합한 sim-to-real 프레임워크로, 인간의 동작 데이터로 학습한 task-agnostic keypoint tracker와 task-specific visuomotor policy를 통해 humanoid robot의 loco-manipulation을 실현한다.
VisualMimic은 teacher-student distillation의 창의적 이중 적용과 human motion statistics 기반 제약으로 humanoid loco-manipulation의 현실적 과제를 효과적으로 해결하며, 다양한 작업에서 zero-shot real-world transfer를 입증한 매우 의미 있는 연구이다.
CReF: Cross-modal and Recurrent Fusion for Depth-conditioned Humanoid Locomotion

Fig. 1.
 *Fig. 2.* CReF는 cross-modal attention과 gated residual fusion을 활용하여 raw depth 입력으로부터 직접 locomotion-relevant 특징을 학습하는 단일 단계 depth-conditioned humanoid locomotion 프레임워크로, 명시적 기하학적 중간 표현 없이 zero-shot sim-to-real transfer를 달성한다.
CReF는 명시적 기하학적 중간 표현을 제거하고 cross-modal attention과 gated recurrent fusion을 통해 raw depth로부터 직접 locomotion-relevant features를 학습하는 혁신적 접근법으로, zero-shot sim-to-real transfer와 다양한 실제 환경에서의 강건한 성능을 통해 humanoid locomotion 분야에 significant contribution을 제시한다.
EgoHumanoid: Unlocking In-the-Wild Loco-Manipulation with Robot-Free Egocentric Demonstration
Fig. 1: Introducing EGOHUMANOID, the first investigation on human-to-humanoid transfer for whole-body loco-manipulation.
 *Fig. 1: Introducing EGOHUMANOID, the first investigation on human-to-humanoid transfer for whole-body loco-manipulation.* EgoHumanoid는 로봇 없이 수집한 대규모 인간 egocentric 시연과 제한된 로봇 데이터를 co-train하여 휴머노이드 로봇이 다양한 현실 환경에서 loco-manipulation을 수행하도록 하는 첫 번째 프레임워크이다. View alignment와 action alignment로 구성된 embodiment 정렬 파이프라인을 통해 인간-로봇 간의 신체 형태, 관점, 동역학의 차이를 극복한다.
EgoHumanoid는 휴머노이드 loco-manipulation 분야에서 human egocentric data 활용의 새로운 가능성을 체계적으로 보여주는 획기적인 작업이다. Practical embodiment alignment pipeline, 현실 환경에서의 강력한 성능 개선(51%), 그리고 scalability 분석은 향후 humanoid 로봇 학습의 중요한 방향을 제시한다.
Endowing GPT-4 with a Humanoid Body: Building the Bridge Between Off-the-Shelf VLMs and the Physical World
Figure 1: BiBo is a humanoid agent powered by an off-the-shelf VLM. It consists of an embodied
 *Figure 1: BiBo is a humanoid agent powered by an off-the-shelf VLM. It consists of an embodied* off-the-shelf VLM(GPT-4)을 humanoid agent의 제어에 활용하기 위해 embodied instruction compiler와 diffusion-based motion executor로 구성된 BiBo 프레임워크를 제안하고, 이를 통해 대규모 데이터 수집 없이 개방형 환경에서의 유연한 상호작용을 가능하게 함.
본 논문은 off-the-shelf VLM과 humanoid control을 연결하는 창의적인 프레임워크를 제시하고, structured representation과 LDM의 novel application을 통해 기술적 기여를 하였으며, 실제 데이터 수집의 병목을 해소하려는 실질적 의의가 있음. 다만 실제 물리 환경에서의 검증과 robustness 분석이 보강된다면 더욱 강력한 작업이 될 것으로 예상됨.
Flexible Motion In-betweening with Diffusion Models
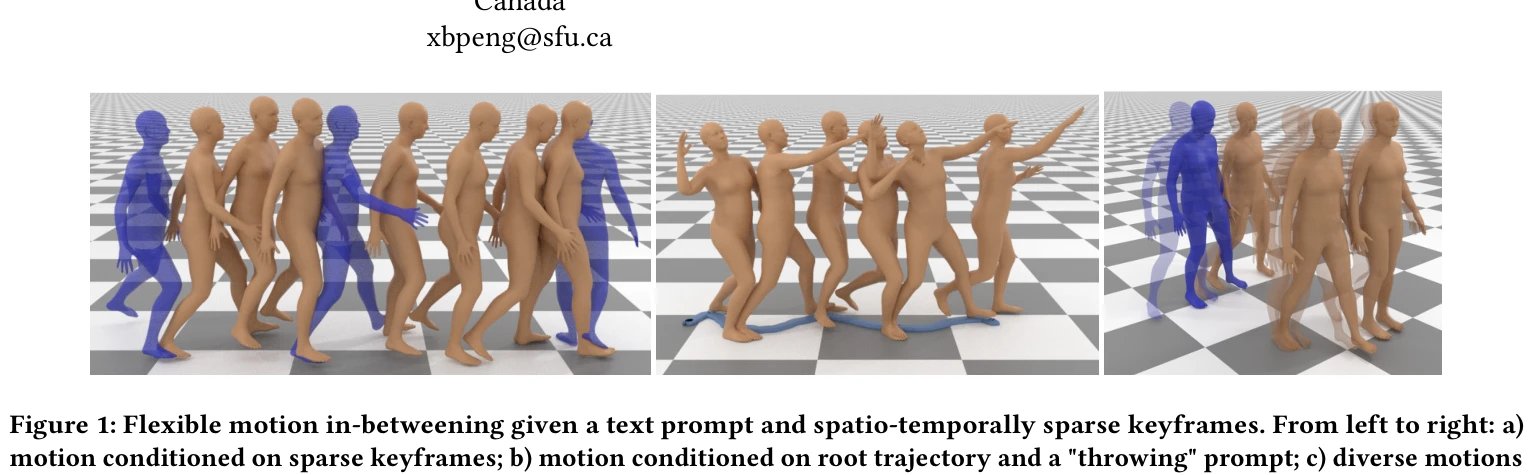
Figure 1: Flexible motion in-betweening given a text prompt and spatio-temporally sparse keyframes. From left to right:
 *Figure 1: Flexible motion in-betweening given a text prompt and spatio-temporally sparse keyframes. From left to right: * CondMDI는 diffusion model 기반의 통합된 모션 인-비트위닝 방법으로, 텍스트 조건과 함께 유연한 keyframe 제약을 받아 다양하고 정밀한 인간 모션을 생성한다.
CondMDI는 masked conditional diffusion model을 통해 motion in-betweening의 오랜 한계를 효과적으로 해결하며, 유연한 제약 처리와 텍스트 조건의 통합으로 실무적 가치가 높고 기술적으로도 우수한 기여를 제시한다.
Harmon: Whole-Body Motion Generation of Humanoid Robots from Language Descriptions
 *Fig. 2 depicts our proposed method, HARMON. Firstly, we generate human motion based on the* 인간 모션 데이터셋으로부터 사전학습된 프라이어를 활용하고 Vision Language Model을 통해 손가락과 머리 모션을 생성·편집하여 휴머노이드 로봇의 자연스러운 전신 모션을 언어 설명으로부터 생성한다.
이 논문은 인간 모션 프라이어와 VLM의 상식적 추론을 창의적으로 결합하여 언어로부터 자연스러운 휴머노이드 모션을 생성하는 실용적인 방법을 제시하며, 실제 로봇 실험과 높은 사용자 평가로 그 유효성을 입증했다.
Hierarchical visuomotor control of humanoids
Figure 1:
 *Figure 4: Schematic of the architecture: a high-level controller (HL) selects among multiple low-* 인간형 로봇의 고차원 시각-운동 제어를 위해 저수준 모터 제어기와 고수준 작업 조정기를 계층적으로 구성하는 아키텍처를 제안한다. Motion capture 데이터로 사전학습된 저수준 sub-policy들을 고수준 controller가 시각 정보에 기반해 동적으로 선택하여 복잡한 humanoid 제어를 수행한다.
Motion capture 기반 저수준 제어와 시각-메모리 기반 고수준 조정을 결합하여 고복잡도 humanoid의 integrated visuomotor 제어를 달성한 우수한 연구로, 신경과학적 영감과 실제 구현의 균형이 잘 맞으며 ICLR 발표에 적합한 수준의 기여를 제시한다.
HuBE: Cross-Embodiment Human-like Behavior Execution for Humanoid Robots
Fig. 1.
 *Fig. 1.* HuBE는 인간 행동의 유사성(similarity)과 적절성(appropriateness)을 모두 만족하는 이족 로봇용 양단계 폐루프 프레임워크를 제안하며, 뼈 스케일링 기반 데이터 증강을 통해 이기종 로봇 간 교차-구현체(cross-embodiment) 적응을 실현한다.
HuBE는 인간형 로봇 행동 생성에 행동 적절성 개념을 처음 체계적으로 도입하고, 폐루프 아키텍처와 bone scaling 기반 교차-구현체 적응을 통해 실무적 가치 높은 솔루션을 제시한다. 다만 LLM 주석 신뢰성 검증과 더 광범위한 플랫폼 실험이 진행된다면 영향력이 한층 강화될 것으로 예상된다.
Humanoid Agent via Embodied Chain-of-Action Reasoning with Multimodal Foundation Models for Zero-Shot Loco-Manipulation
Fig. 1.
 *Fig. 1.* 인형로봇의 전신 보행-조작을 위해 기초 모델의 추론 능력과 Embodied Chain-of-Action (CoA) 메커니즘을 통합한 제로샷 에이전트 프레임워크를 제시한다. 고수준 인간 지시를 affordance 분석, 공간 추론, 전신 동작 추론을 통해 체계적인 보행 및 조작 원시 동작 수열로 분해한다.
본 논문은 Foundation model의 추론 능력을 인형로봇 보행-조작에 처음 통합한 의미 있는 기여이며, CoA Reasoning 메커니즘을 통해 자연어 지시를 물리적으로 실현 가능한 동작 수열로 변환하는 새로운 접근을 제시한다. 실제 인형로봇에서 강건한 제로샷 일반화를 입증한 점에서 높은 실용적 가치를 갖는다.
Humanoid Locomotion as Next Token Prediction

Figure 1: A humanoid that walks in San Francisco. We deploy our policy to various locations in San Francisco over
 *Figure 2: Humanoid locomotion as next token prediction. We collect a dataset on trajectories from various sources, such* Humanoid 로봇 제어를 언어 모델의 next token prediction처럼 다루어, causal transformer를 통해 sensorimotor 궤적을 자동 회귀적으로 예측한다. 시뮬레이션, 모션캡처, 유튜브 영상 등 다양한 소스의 불완전한 데이터로 학습하여 실제 humanoid 로봇이 zero-shot으로 샌프란시스코에서 보행할 수 있게 한다.
본 논문은 언어 모델의 next token prediction 패러다임을 humanoid 제어에 창의적으로 적용하여, 불완전한 다중 소스 데이터로 학습한 모델이 실제 환경에서 zero-shot 보행을 가능하게 함을 입증했다. 생성 모델 기반의 로봇 제어 학습에 대한 유망한 방향을 제시하며, 실제 배포 결과는 매우 인상적이다.
HUMOTO: A 4D Dataset of Mocap Human Object Interactions
Figure 1. Overview of the HUMOTO dataset. The dataset contains mocap 4D human-object interaction animations with multipl
 *Figure 1. Overview of the HUMOTO dataset. The dataset contains mocap 4D human-object interaction animations with multipl* HUMOTO는 735개 시퀀스(7,875초)의 고충실도 모션캡처 4D 인간-객체 상호작용 데이터셋으로, 63개의 정밀 모델링 객체와 상세한 손 동작을 포함하며 LLM 기반 스크립팅과 다중센서 캡처로 복잡한 다중-객체 상호작용을 정확히 기록한다.
HUMOTO는 고충실도 다중-객체 인간-객체 상호작용 데이터셋으로서, Scene-Driven LLM Scripting과 다중센서 캡처 기술의 창의적 결합을 통해 기존 데이터셋의 한계를 효과적으로 해결하였으며, 정량적 평가 메트릭 도입으로 HOI 데이터셋 분야에 기여한 가치 있는 자산이다.
It Takes Two: Learning Interactive Whole-Body Control Between Humanoid Robots
 *Figure 2: Overview of the proposed Harmanoid framework. It contains two key components: (i) contact-aware motion retarge* Harmanoid는 두 개의 휴머노이드 로봇 간 상호작용 동작을 모방하는 프레임워크로, 접촉 인식 motion retargeting과 상호작용 기반 motion controller를 통해 키네마틱 충실도와 물리적 현실성을 동시에 보존한다.
Harmanoid는 다중 휴머노이드 상호작용 동작 모방의 명확한 문제를 체계적으로 해결하며, contact-aware retargeting과 interaction-aware control의 결합으로 고립 문제를 효과적으로 극복하는 첫 프레임워크이다. 종합적인 실험과 우수한 성능으로 humanoid robotics 분야에 중요한 기여를 하나, sim-to-real 검증 부재와 2-agent 제한이 실제 적용의 완전성을 제약한다.
Let Humanoids Hike! Integrative Skill Development on Complex Trails

Figure 1. We propose training humanoids to hike complex trails, driving integrative skill development across visual perc
 *Figure 1. We propose training humanoids to hike complex trails, driving integrative skill development across visual perc* 휴머노이드 로봇이 복잡한 산길을 자율적으로 하이킹하도록 학습시키기 위해 시각 인식, 의사결정, 운동 실행을 통합하는 LEGO-H 프레임워크를 제안한다. TC-ViT와 Hierarchical Latent Matching을 통해 네비게이션과 로코모션을 단일 학습 체계로 통합한다.
본 논문은 하이킹을 새로운 벤치마크로 제시하고 TC-ViT와 HLM 기반 LEGO-H 프레임워크를 통해 네비게이션과 로코모션의 통합이라는 오래된 문제에 혁신적으로 접근한다. 다만 시뮬레이션 중심의 평가가 실제 배포 가능성의 의문을 남기지만, 휴머노이드 로봇 자율성 개발을 위한 강력한 기초 제시로서 충분히 의미 있는 기여이다.
Mimicking-Bench: A Benchmark for Generalizable Humanoid-Scene Interaction Learning via Human Mimicking
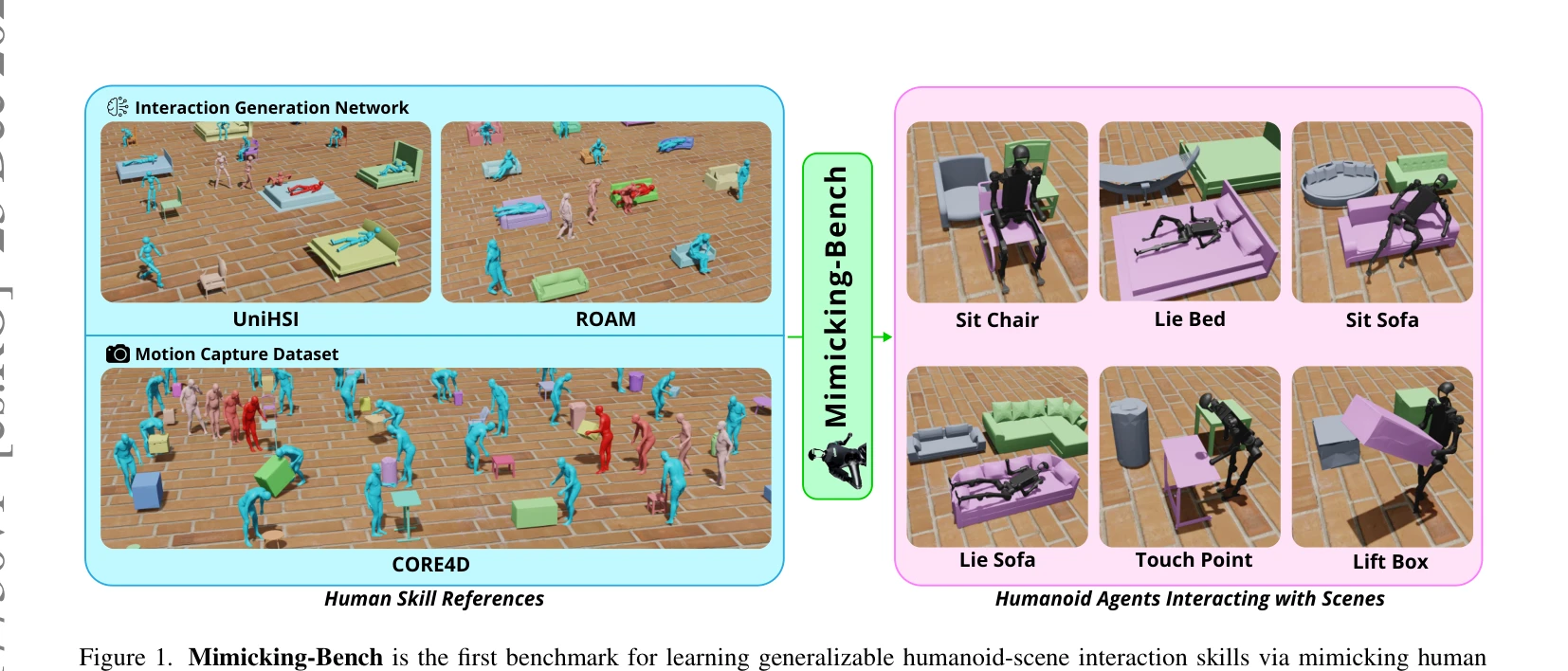
Figure 1. Mimicking-Bench is the first benchmark for learning generalizable humanoid-scene interaction skills via mimick
 *Figure 1. Mimicking-Bench is the first benchmark for learning generalizable humanoid-scene interaction skills via mimick* 인간의 모션 데이터를 활용한 휴머노이드 로봇의 3D 장면 상호작용 학습을 위한 첫 번째 종합 벤치마크인 Mimicking-Bench를 제시하며, 23K개의 인간 상호작용 모션과 11K개의 다양한 객체 형상을 포함한다.
Mimicking-Bench는 인간 모션 데이터의 대규모 다양성을 활용한 휴머노이드-장면 상호작용 학습을 위한 첫 종합 벤치마크로, 신체 모방 기반의 로봇 스킬 학습 연구를 체계적으로 진행할 수 있는 중요한 기여를 제공한다.
MOSAIC: Bridging the Sim-to-Real Gap in Generalist Humanoid Motion Tracking and Teleoperation with Rapid Residual Adaptation
 *Fig. 2: MOSAIC System Overview. MOSAIC consists of a unified training–deployment pipeline for humanoid motion tracking* MOSAIC는 강화학습을 통해 학습한 범용 humanoid 동작 추적기와 빠른 residual 적응 메커니즘을 결합하여 시뮬레이션과 실제 로봇 간의 gap을 줄이고 장시간의 텔레오퍼레이션을 안정적으로 지원하는 시스템이다.
MOSAIC는 시뮬레이션-실제 로봇 간 격차를 체계적으로 해결하기 위해 텔레오퍼레이션 지향의 RL 설계와 residual adaptation을 결합한 실용적이고 잘 설계된 시스템으로, RobotBridge 프레임워크와 함께 공개되어 재현성과 확장성을 크게 향상시킨다. 다만 완전한 zero-shot adaptation과 다양한 embodiment에 대한 더욱 강력한 일반화가 향후 과제이다.
PHUMA: Physically-Grounded Humanoid Locomotion Dataset
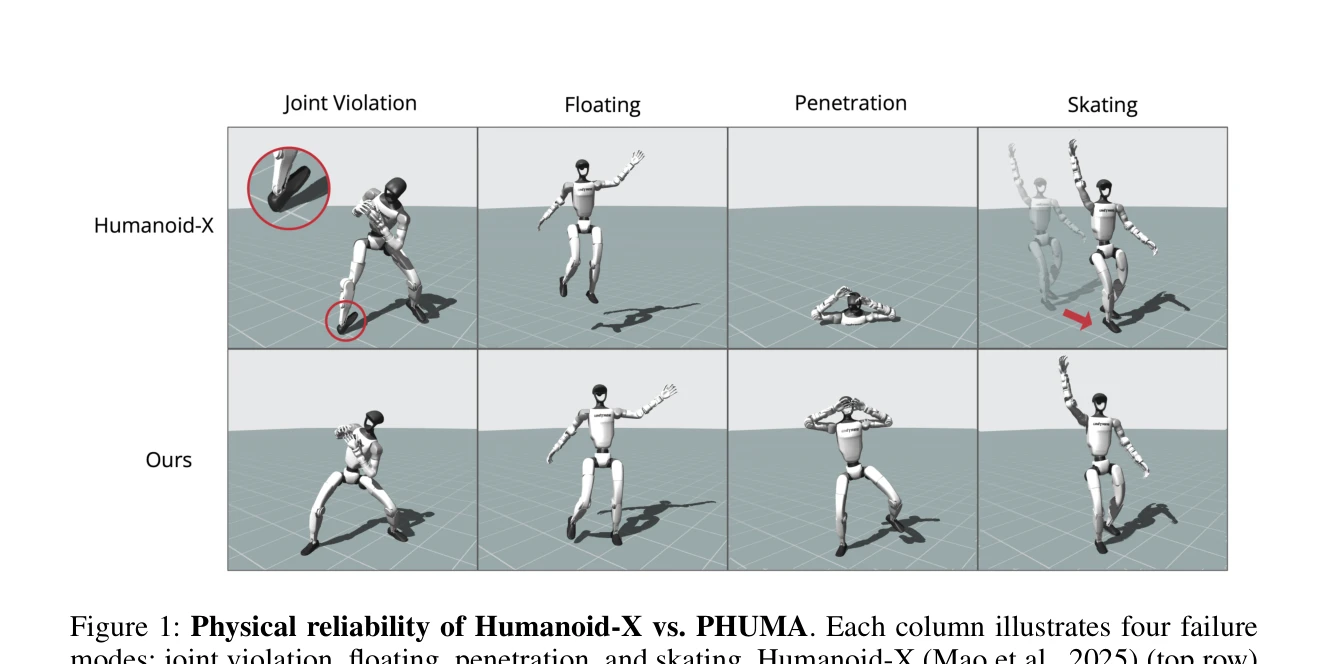
Figure 1: Physical reliability of Humanoid-X vs. PHUMA. Each column illustrates four failure
 *Figure 1: Physical reliability of Humanoid-X vs. PHUMA. Each column illustrates four failure* PHUMA는 대규모 인터넷 비디오로부터 인간다운 보행을 위한 물리적으로 타당한 휴머노이드 모션 데이터셋을 구축하며, 데이터 큐레이션과 physics-constrained retargeting을 통해 floating, penetration, foot skating 등의 물리적 artifacts를 제거한다.
PHUMA는 대규모 비디오 기반 모션 데이터의 물리적 신뢰성 문제를 체계적으로 해결하는 실용적인 데이터셋이며, physics-constrained retargeting 방법론과 실증적 성능 향상을 통해 휴머노이드 보행 학습 분야에 명확한 기여를 제시한다.
Towards Motion Turing Test: Evaluating Human-Likeness in Humanoid Robots
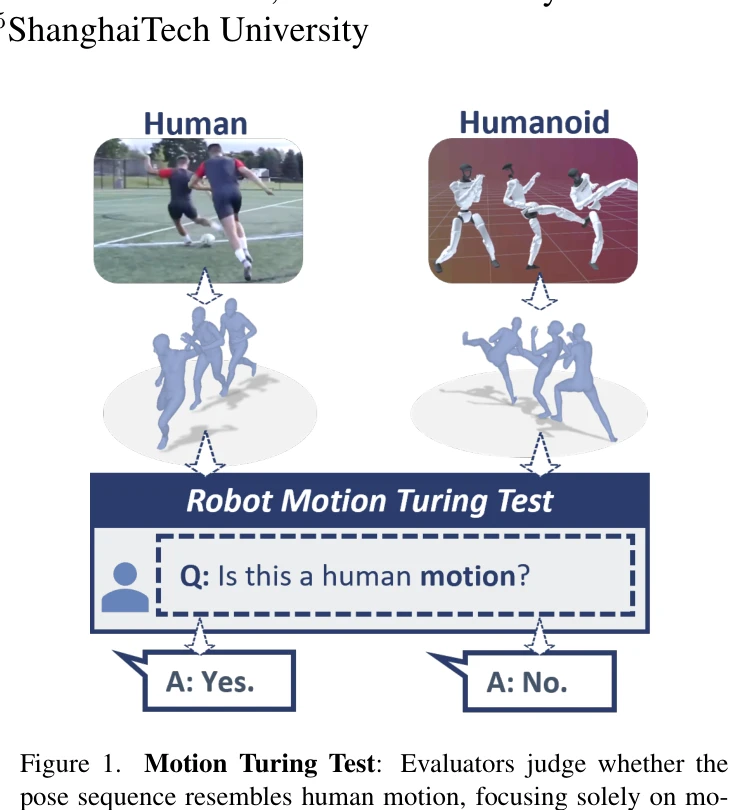
Figure 1.
 *Figure 1.* Motion Turing Test라는 개념을 제시하여 인간관찰자가 키네마틱 정보만으로 휴머노이드 로봇과 인간의 자세를 구분할 수 있는지를 평가하고, 이를 위해 1,000개의 모션 시퀀스로 구성된 HHMotion 데이터셋과 human-likeness 예측 기준선 모델을 제안한다.
Motion Turing Test라는 명확한 개념 정의와 이를 뒷받침하는 포괄적인 HHMotion 데이터셋은 휴머노이드 로봇 모션 평가 분야에 중요한 기여를 한다. SMPL-X 기반 appearance-agnostic 평가 방식과 500시간의 대규모 인간 주석은 높은 신뢰성을 제공하며, 제안된 PTR-Net이 VLM 기반 방법들을 능가한 결과는 전문화된 모션 평가 모델의 필요성을 입증한다.
Towards Proprioception-Aware Embodied Planning for Dual-Arm Humanoid Robots

Fig. 1: DualTHOR is a novel simulator specifically tai-
 *Fig. 1: DualTHOR is a novel simulator specifically tai-* 이 논문은 이중팔 휴머노이드 로봇의 장기 계획을 위해 DualTHOR 시뮬레이터와 고유감각(proprioception)을 인식하는 Proprio-MLLM을 제안하며, 기존 MLLM의 구현화 인식 부족을 해결한다.
이 논문은 이중팔 휴머노이드 로봇의 장기 계획을 위한 체계적인 시뮬레이션 플랫폼과 고유감각 기반 MLLM을 제시함으로써 구현화 AI 분야에 중요한 기여를 한다. 실제 로봇에서의 성능 검증과 더 복잡한 협력 작업 확장이 이루어진다면 더욱 영향력 있는 연구가 될 것이다.
TrajBooster: Boosting Humanoid Whole-Body Manipulation via Trajectory-Centric Learning
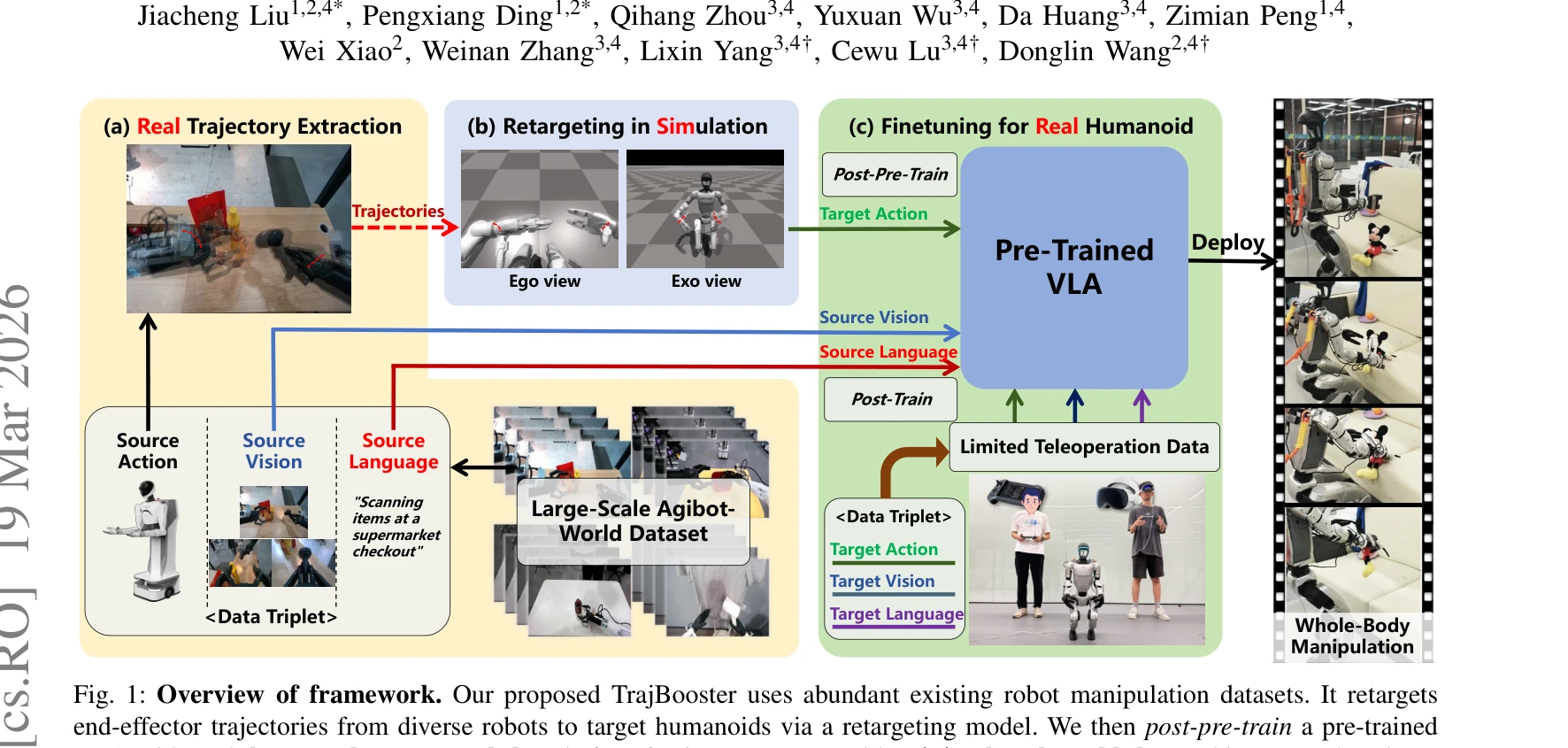
Fig. 1: Overview of framework. Our proposed TrajBooster uses abundant existing robot manipulation datasets. It retargets
 *Fig. 1: Overview of framework. Our proposed TrajBooster uses abundant existing robot manipulation datasets. It retargets* TrajBooster는 휠드 휴머노이드에서 추출한 다양한 궤적 데이터를 이족 휴머노이드(Unitree G1)로 전이학습하여, 부족한 이족 휴머노이드 데이터를 보충하고 Vision-Language-Action 모델의 성능을 향상시키는 실시간-시뮬레이션-실시간 파이프라인이다.
TrajBooster는 형태학적으로 다른 로봇 간 전이학습이라는 어려운 문제에 대해 실용적이고 효과적인 해결책을 제시한다. 최소한의 실제 데이터만으로도 이족 휴머노이드의 광범위한 전신 조작을 가능하게 한 점에서 로봇 학습의 실용성 측면에서 매우 중요한 기여를 한다.
Trinity: A Modular Humanoid Robot AI System
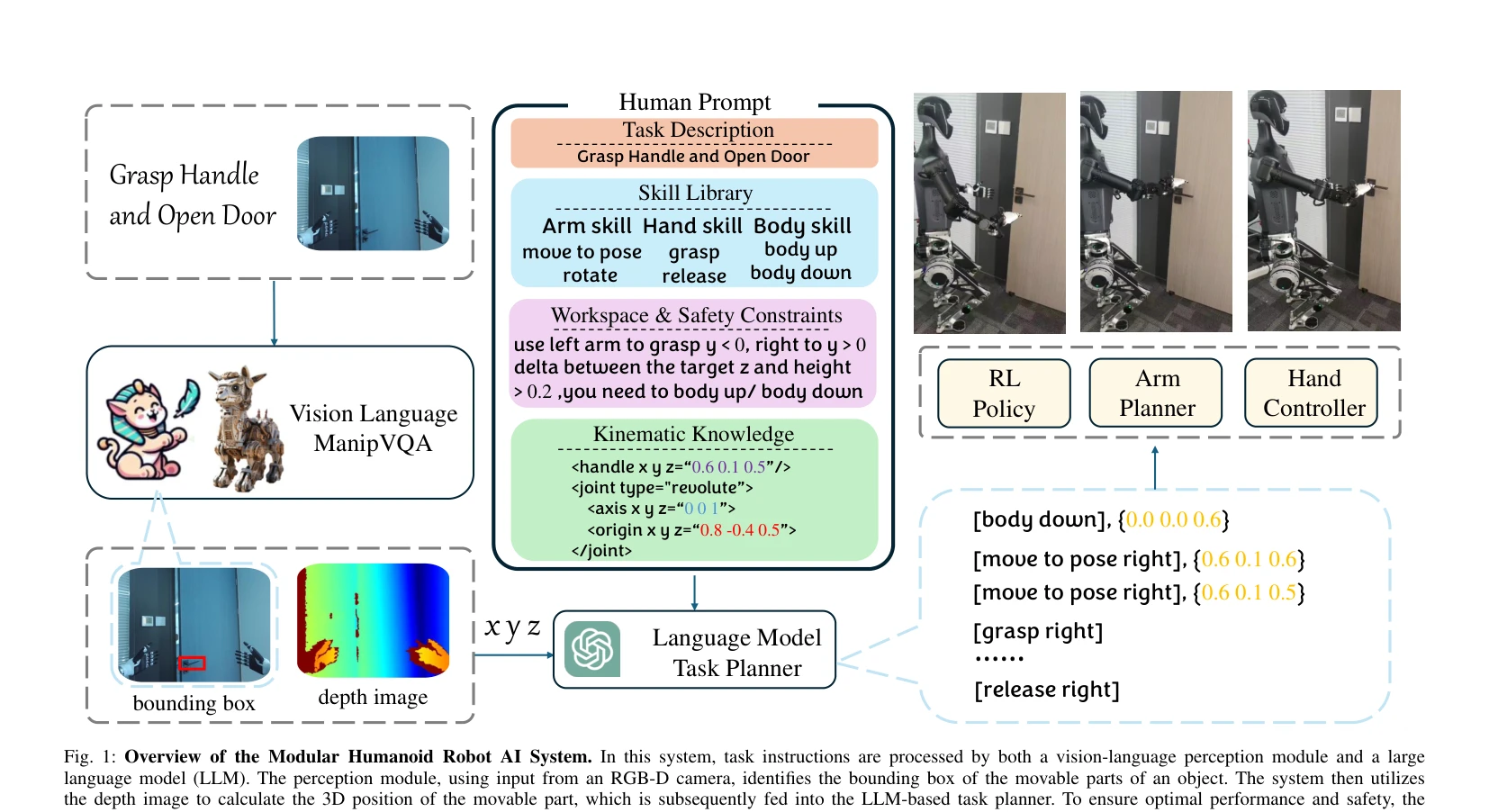
Fig. 1: Overview of the Modular Humanoid Robot AI System. In this system, task instructions are processed by both a visi
 *Fig. 1: Overview of the Modular Humanoid Robot AI System. In this system, task instructions are processed by both a visi* LLM, VLM, RL을 통합한 모듈식 인간형 로봇 AI 시스템 Trinity를 제안하여 복잡한 환경에서 효율적인 제어를 실현한다. 계층적 아키텍처를 통해 언어 이해, 시각 인식, 동작 제어를 조화롭게 수행한다.
Trinity는 RL, LLM, VLM을 효과적으로 통합한 혁신적 인간형 로봇 AI 시스템으로, 모듈식 설계를 통해 유연성과 해석성을 확보하고 실제 로봇에서의 동작을 입증함으로써 구현적 가치가 높다. 다만 sim-to-real 갭과 모듈 간 상호작용의 견고성에 대한 심화 분석이 필요하다.
ULTRA: Unified Multimodal Control for Autonomous Humanoid Whole-Body Loco-Manipulation

Fig. 1: ULTRA is an all-in-one controller for humanoid loco-manipulation that supports: Top. dense motion tracking
 *Fig. 1: ULTRA is an all-in-one controller for humanoid loco-manipulation that supports: Top. dense motion tracking* 물리 기반 신경 retargeting과 unified multimodal controller를 결합하여 humanoid 로봇이 dense reference tracking과 sparse goal-conditioning을 모두 지원하며, egocentric 시각 인지 기반 자율적 전신 loco-manipulation을 수행할 수 있는 프레임워크이다.
이 논문은 humanoid loco-manipulation의 두 가지 근본적인 병목(물리적 retargeting과 통합 컨트롤)을 체계적으로 해결하며, physics-driven retargeting과 multimodal distillation의 조합으로 실제 배포 환경에서의 자율성을 크게 향상시킨다. 특히 unified framework로 diverse 조건 신호를 처리하고 real-world 평가를 제시한 점에서 학술적 및 실용적 의의가 높다.
Learning Versatile Humanoid Manipulation with Touch Dreaming

Fig. 1: Our system enables versatile, contact-rich, and dexterous humanoid manipulation. A: long-horizon, multi-stage ma
 *Fig. 1: Our system enables versatile, contact-rich, and dexterous humanoid manipulation. A: long-horizon, multi-stage ma* 휴머노이드 로봇의 접촉-풍부한 조작을 위해 VR 텔레오퍼레이션 기반 데이터 수집과 터치 감각을 핵심 모달리티로 하는 Humanoid Transformer with Touch Dreaming (HTD)을 제안한다.
본 논문은 터치를 핵심 모달리티로 하는 Touch Dreaming 기법과 통합된 실세계 데이터 수집 시스템으로 휴머노이드 접촉-풍부한 조작의 실현 가능성을 강력하게 입증한다. 다섯 가지 다양한 실제 작업에서 90.9% 성능 개선을 달성하며, 잠재 공간 예측의 효과성을 명확히 보여주는 높은 질의 연구이다.
Simulating Infant First-Person Sensorimotor Experience via Motion Retargeting from Babies to Humanoids
 *Fig. 2.* 본 논문은 영아의 단일 비디오로부터 3D 신체 자세를 추정하고 이를 iCub, pyCub, EMFANT, MIMo 등의 휴머노이드 로봇에 매핑하여 고유수용감각, 촉각, 시각 등 다중감각 스트림을 시뮬레이션하는 motion retargeting 프레임워크를 제시한다.
본 논문은 영아 발달 연구와 로보틱스의 교점에서 motion retargeting에 다중감각 시뮬레이션을 결합한 창의적이고 기술적으로 건전한 작업이다. Sub-centimeter 정확도와 실제 및 가상 휴머노이드 플랫폼에서의 입증은 강점이나, 단일 영상 검증과 영아 모델 부재로 인한 일반화 가능성 제약이 한계이다. 코드 공개 및 명확한 방법론 제시는 높이 평가되며, 발달과학과 신경발달 진단 응용의 미래 잠재력이 있다.
Humanoid Locomotion as Next Token Prediction
 *Figure 2: Humanoid locomotion as next token prediction. We collect a dataset on trajectories from various sources, such* 이 논문은 인간형 로봇의 보행 제어를 언어 모델링의 next token prediction 문제로 재해석한 연구이다. causal transformer를 이용해 sensorimotor trajectories를 자동회귀적으로 예측하되, 불완전한 모달리티(예: 액션 없는 비디오)도 활용할 수 있도록 설계했다.
이 논문은 언어 모델링 패러다임을 로봇 제어에 효과적으로 적용한 강력한 연구이다. 제로샷 실제 환경 배포, 불완전한 데이터의 창의적 활용, 다양한 소스 통합 등에서 명확한 기여를 보여주며, 기술적으로도 건전하고 실험 결과도 설득력 있다.
Trinity: A Modular Humanoid Robot AI System
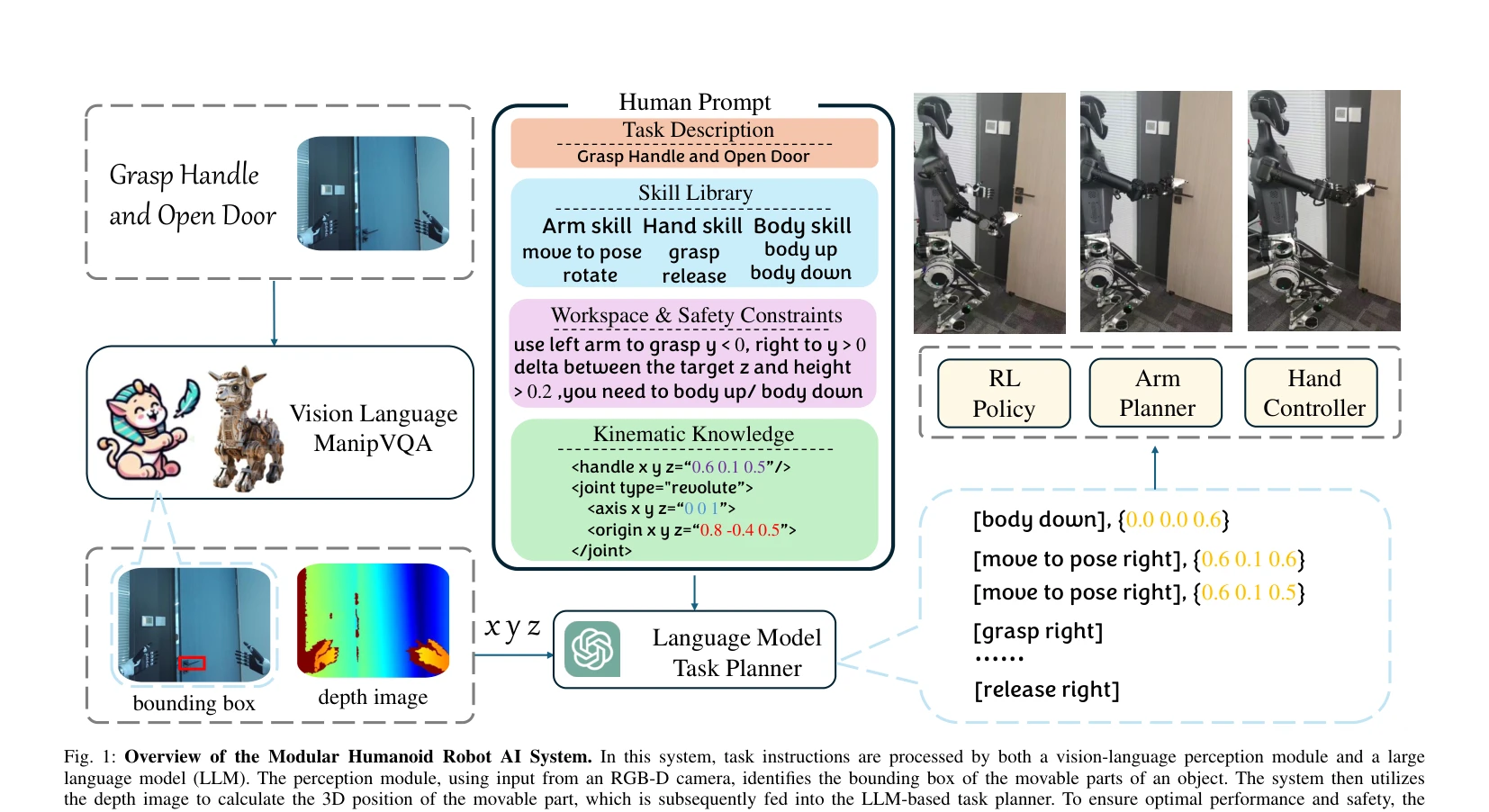
Fig. 1: Overview of the Modular Humanoid Robot AI System. In this system, task instructions are processed by both a visi
 *Fig. 1: Overview of the Modular Humanoid Robot AI System. In this system, task instructions are processed by both a visi* Trinity는 LLM, VLM, RL을 모듈식 계층 구조로 통합하여 humanoid robot을 제어하는 종합 AI 시스템이다. 각 모듈이 독립적으로 최적화되면서도 협력하여 복잡한 환경에서 humanoid robot의 효율적인 제어를 실현한다.
Trinity는 RL, LLM, VLM을 모듈식 계층 구조로 통합하여 humanoid robot의 복잡한 제어 문제를 체계적으로 해결하는 혁신적인 접근법을 제시한다. Full-scale humanoid robot에 대한 종합 검증과 loco-manipulation 성능이 주요 강점이나, 더 광범위한 작업에 대한 평가와 sim-to-real transfer 성능의 명확한 분석이 필요하다. 전반적으로 humanoid robotics 분야의 중요한 진전을 대표하는 양질의 시스템 논문이다.
RoboPlayground: 구조화된 물리 도메인을 통한 로봇 평가 민주화
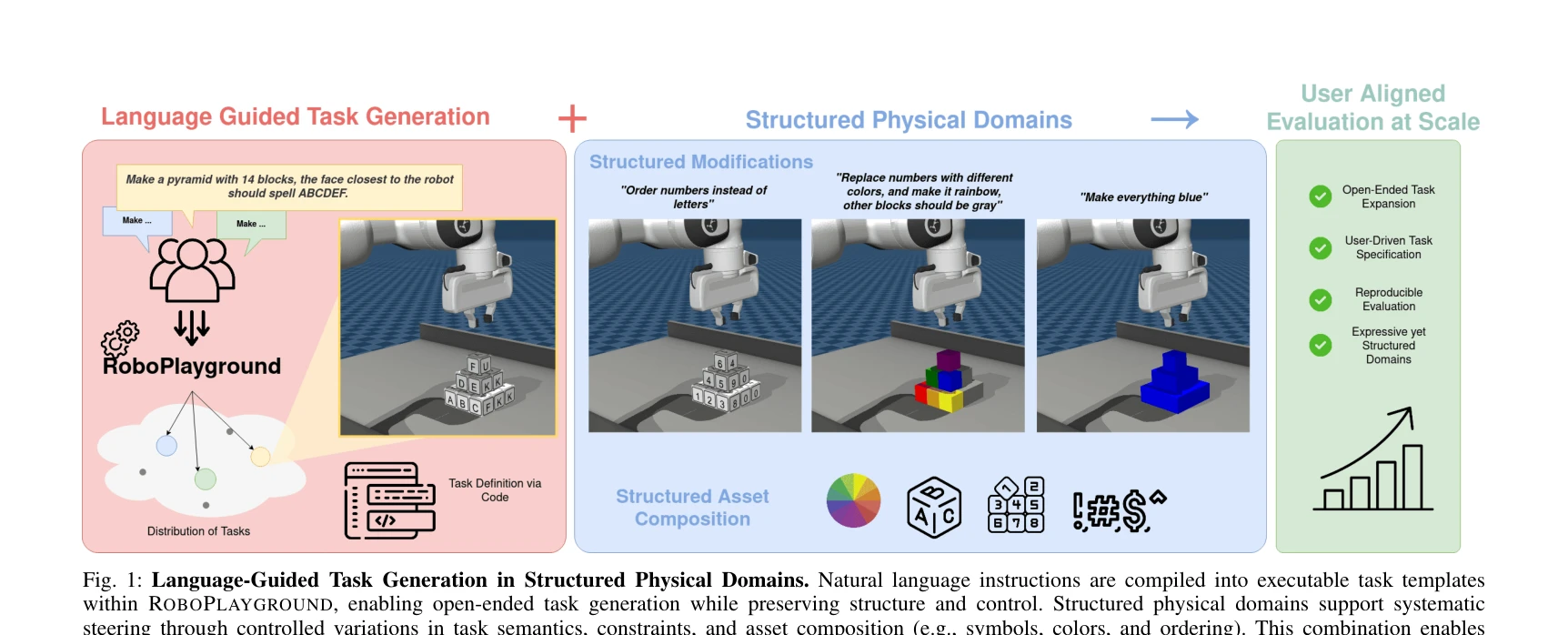
Fig. 1: Language-Guided Task Generation in Structured Physical Domains. Natural language instructions are compiled into
 *Fig. 1: Language-Guided Task Generation in Structured Physical Domains. Natural language instructions are compiled into * 자연어로 로봇 조작 작업을 정의하고 재현 가능한 작업 명세로 컴파일하는 RoboPlayground 프레임워크를 제안하며, 고정 벤치마크에서 드러나지 않는 일반화 실패를 언어 기반 작업 변형을 통해 발견한다.
RoboPlayground는 로봇 평가의 민주화와 접근성을 크게 향상시키는 혁신적 접근법으로, 언어 기반 구조화된 작업 변형을 통해 고정 벤치마크가 놓치는 정책의 실제 약점을 드러낸다는 점에서 중요한 기여다. 다만 도메인 제한과 대규모 crowd-sourced 평가의 품질 관리가 실무 적용의 과제다.
Sim-and-Real Co-Training: A Simple Recipe for Vision-Based Robotic Manipulation
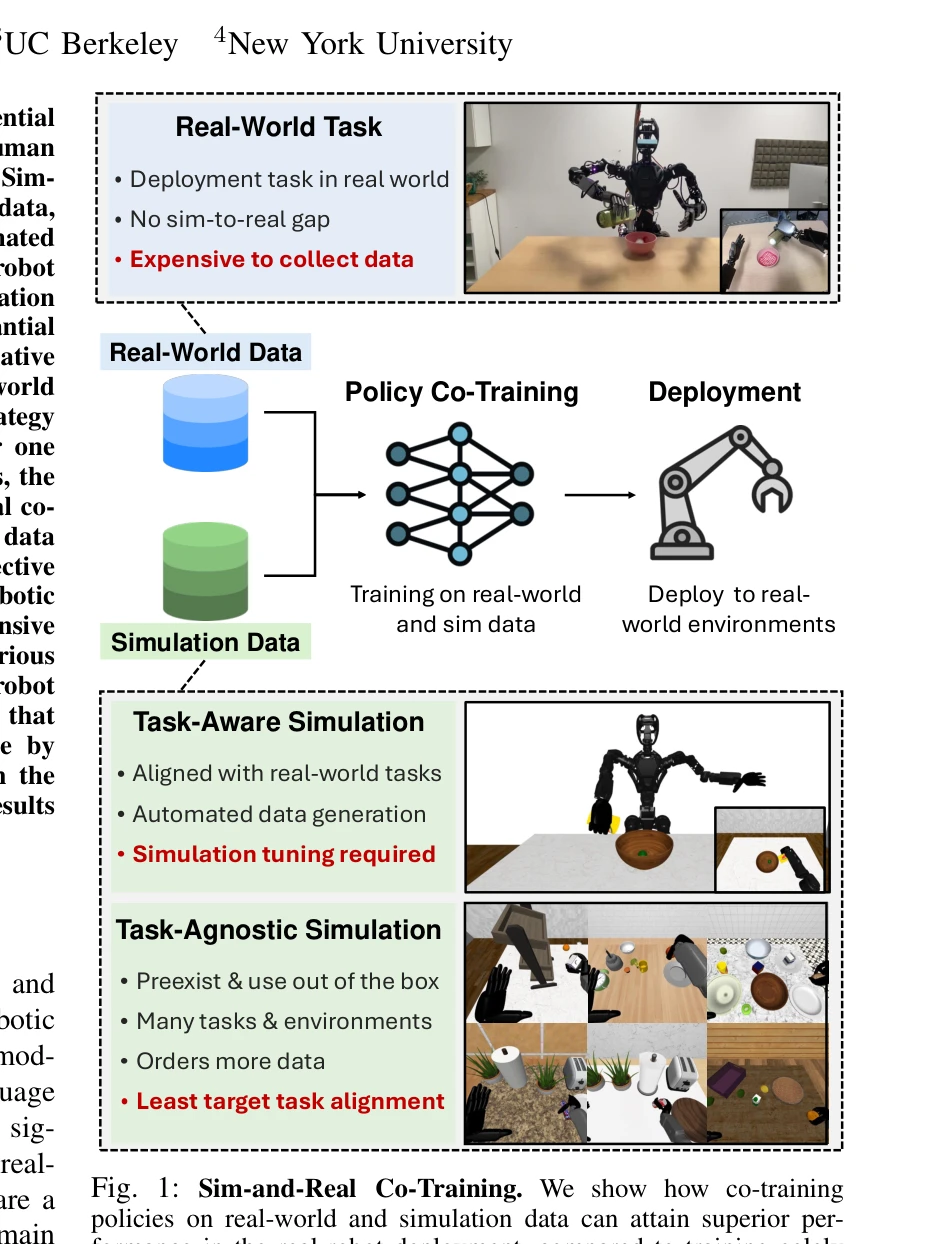
Fig. 1: Sim-and-Real Co-Training. We show how co-training
 *Fig. 1: Sim-and-Real Co-Training. We show how co-training* 시뮬레이션 데이터와 실제 로봇 데이터를 혼합하여 학습하는 sim-and-real co-training 전략을 체계적으로 연구하고, 비전 기반 로봇 조작 작업에서 실제 데이터만 사용하는 것 대비 평균 38% 성능 향상을 달성했다.
본 논문은 sim-and-real co-training의 실용성을 체계적으로 검증하여 실제 로봇 학습의 데이터 효율성 문제에 직접적인 해결책을 제시하며, 명확한 실험 설계와 실무적 가이드라인으로 로봇 커뮤니티에 높은 가치를 제공한다.
SkillBlender: Towards Versatile Humanoid Whole-Body Loco-Manipulation via Skill Blending
 *Figure 2: Overview of SkillBlender. We first pretrain goal-conditioned primitive expert skills that are* SkillBlender는 사전학습된 목표조건부 원시 기술들을 동적으로 혼합하여 휴머노이드 로봇이 복잡한 전신 조작-이동 작업을 최소한의 보상 엔지니어링으로 수행할 수 있게 하는 계층적 강화학습 프레임워크이다.
SkillBlender는 휴머노이드 로봇의 다용도적 조작-이동 능력 개발에 대한 우아하고 실용적인 해결책을 제시하며, 포괄적인 벤치마크와 함께 향후 휴머노이드 연구의 중요한 기초가 될 가능성이 높다.
Whole-Body Dynamic Throwing with Legged Manipulators
Fig. 1: Our robot throwing policies demonstrated on real hardware (top) and in simulation (bottom) showing complex full-
 *Fig. 1: Our robot throwing policies demonstrated on real hardware (top) and in simulation (bottom) showing complex full-* 다리가 있는 로봇의 전신 동역학을 활용하여 강화학습 기반의 3D 목표지점으로의 정확한 투척을 학습하는 방법을 제시하고, 시뮬레이션에서 학습한 정책을 실제 휴머노이드 로봇으로 전이시켰다.
본 논문은 전신 동역학을 활용한 3D 임의 목표 투척이라는 명확한 혁신과 적응형 커리큘럼이라는 기술적 기여로 로봇 조작 연구의 새로운 방향을 제시했으나, 실제 로봇 전이의 완전성 부족과 일반화 범위 제약이 실용적 임팩트를 다소 제한한다.
BiGym: A Demo-Driven Mobile Bi-Manual Manipulation Benchmark

Figure 1: BiGym focuses on mobile manipulation with home assistance humanoids. We provide 40
 *Figure 1: BiGym focuses on mobile manipulation with home assistance humanoids. We provide 40* BiGym은 인간이 수집한 데모를 포함한 40개의 다양한 이족 이족 조작 작업을 제공하는 모바일 휴머노이드 로봇 학습 벤치마크로, Imitation Learning과 Demo-Driven RL 알고리즘을 평가할 수 있게 설계되었다.
BiGym은 인간이 수집한 현실적 다중양식 데모와 모바일 이족 조작의 복잡성을 체계적으로 다루는 최초의 종합 벤치마크로, Imitation Learning과 Demo-Driven RL 연구에 중요한 기여를 한다. 다만 실제 로봇 검증과 환경 다양성 확대가 향후 영향력 확대를 위해 필요하다.
Bridging the Sim-to-Real Gap for Athletic Loco-Manipulation
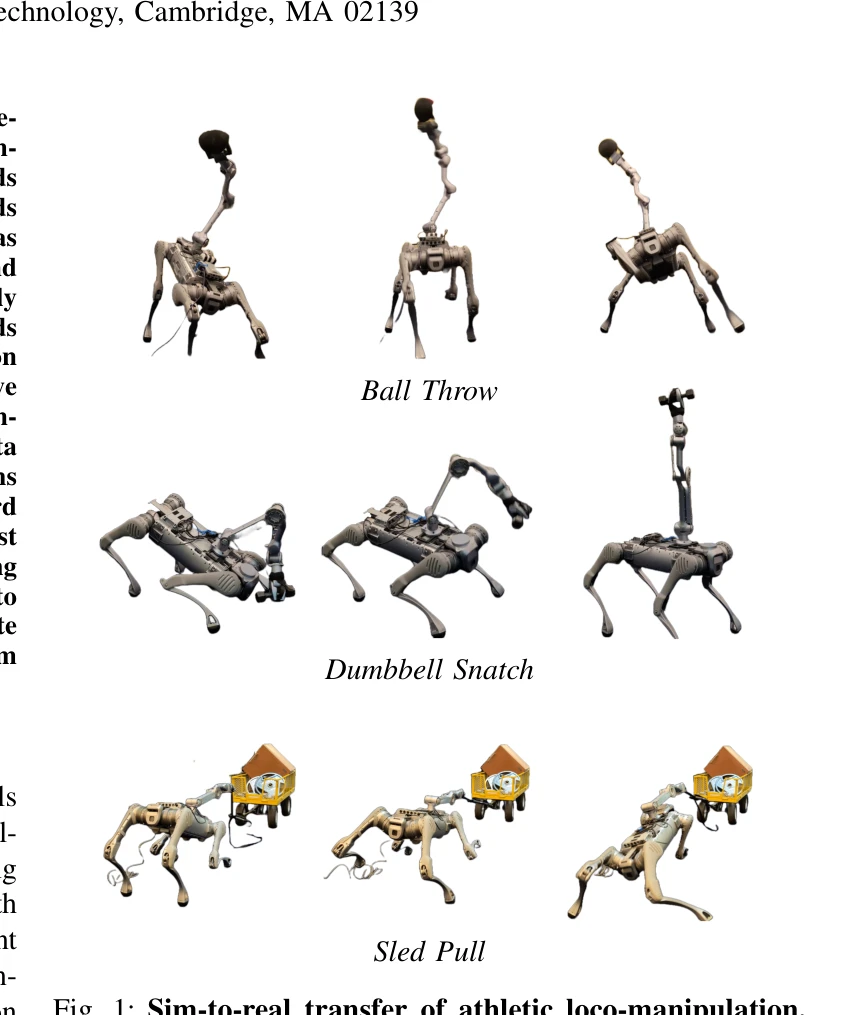
Fig. 1: Sim-to-real transfer of athletic loco-manipulation.
 *Fig. 2: Unsupervised Actuator Network (UAN) approach for real-to-sim-to-real. Our training pipeline involves three steps* 로봇의 운동 조작 작업에서 시뮬레이션-현실 간 격차를 줄이기 위해 실제 데이터로부터 액추에이터 동역학을 학습하는 Unsupervised Actuator Net (UAN)과 참조 궤적을 탐색 힌트로 활용하는 두 단계 학습 파이프라인을 제안한다.
본 논문은 토크 센싱 없는 UAN으로 복잡한 액추에이터 동역학을 학습하고, 참조 궤적을 탐색 힌트로 활용하는 우아한 두 단계 파이프라인으로 운동 로봇의 시뮬-현실 전이 문제를 체계적으로 해결했다. 실제 사족 조작 로봇에서 다양한 운동 작업의 성공적 구현으로 높은 실용성을 보여주며, RL 기반 로보틱스 분야에 기여도 높은 연구이다.
DexMimicGen: Automated Data Generation for Bimanual Dexterous Manipulation via Imitation Learning

Fig. 1: DexMimicGen Overview. DexMimicGen offers an efficient pipeline
 *Fig. 1: DexMimicGen Overview. DexMimicGen offers an efficient pipeline* DexMimicGen은 소수의 인간 시연으로부터 simulation에서 자동으로 대규모 궤적 데이터를 생성하여 양손 dexterous 로봇 조작 학습을 위한 imitation learning 데이터 수집 병목을 해결하는 시스템이다.
DexMimicGen은 양손 dexterous 로봇 조작을 위한 자동 데이터 생성의 실질적인 해결책을 제시하며, MimicGen을 의미 있게 확장하고 실제 humanoid 배포로 그 효과를 입증했으나, 한계된 실제 작업 검증과 일반화 능력 평가가 필요하다.
EgoMimic: Scaling Imitation Learning via Egocentric Video
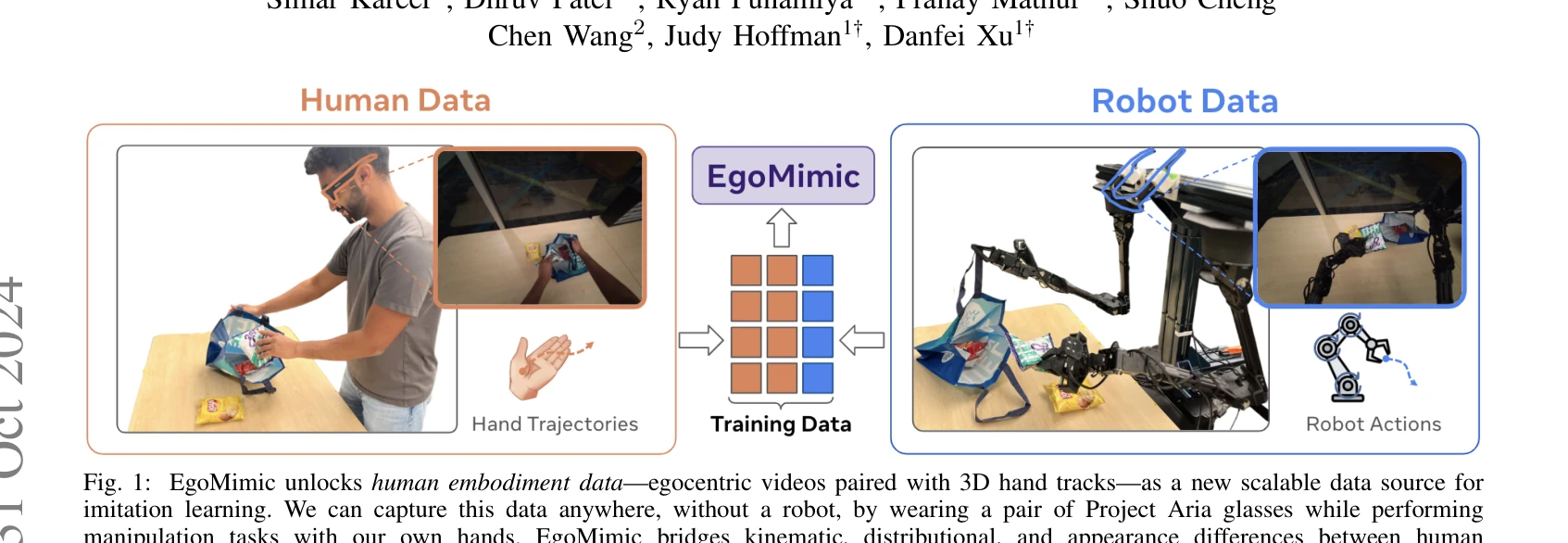
Fig. 1: EgoMimic unlocks human embodiment data—egocentric videos paired with 3D hand tracks—as a new scalable data sourc
 *Fig. 1: EgoMimic unlocks human embodiment data—egocentric videos paired with 3D hand tracks—as a new scalable data sourc* EgoMimic은 Project Aria 안경을 통해 수집한 인간의 일인칭 시점 비디오와 3D 손 추적 데이터를 로봇 조작 학습에 활용하는 전체 스택 프레임워크로, 인간과 로봇 데이터를 동등한 embodied demonstration으로 취급하여 통합 정책을 학습한다.
EgoMimic은 인간의 일인칭 시점 데이터를 로봇 학습에 동등하게 활용하는 혁신적 접근으로, 실제 조작 작업에서 뛰어난 성능 개선과 일반화를 입증했으며, 수동적 대규모 데이터 수집의 가능성을 열어 로봇 학습의 확장성 문제 해결에 크게 기여한다.
EgoVLA: Learning Vision-Language-Action Models from Egocentric Human Videos
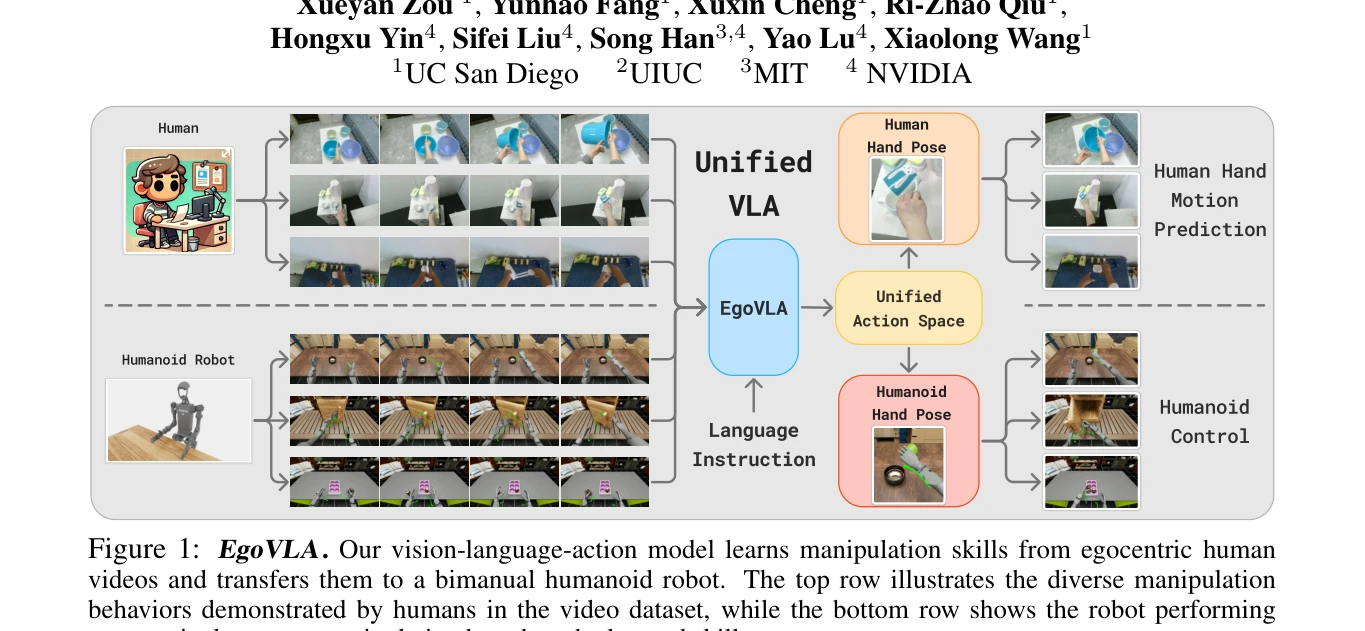
Figure 1: EgoVLA. Our vision-language-action model learns manipulation skills from egocentric human
 *Figure 1: EgoVLA. Our vision-language-action model learns manipulation skills from egocentric human* egocentric human 비디오로부터 Vision-Language-Action (VLA) 모델을 학습하여 로봇 조작 정책을 획득하고, Inverse Kinematics과 retargeting을 통해 인간 행동을 로봇 행동으로 변환한다.
본 논문은 egocentric human 비디오를 활용한 VLA 학습이라는 혁신적 접근으로 로봇 데이터 수집의 확장성 문제를 효과적으로 해결하며, unified action space 설계와 종합적인 벤치마크 제안을 통해 높은 실용성과 학술적 기여를 제시한다.
Genie Sim 3.0 : A High-Fidelity Comprehensive Simulation Platform for Humanoid Robot

Fig. 1: Overview of Genie Sim 3.0. Genie Sim 3.0 is a full-cycle robotic simulation platform that integrates environment
 *Fig. 1: Overview of Genie Sim 3.0. Genie Sim 3.0 is a full-cycle robotic simulation platform that integrates environment* Genie Sim 3.0은 LLM 기반 장면 생성, VLM 기반 자동 평가, 10,000시간 이상의 합성 데이터를 제공하는 휴머노이드 로봇 통합 시뮬레이션 플랫폼이다.
Genie Sim 3.0은 LLM/VLM과 로봇 시뮬레이션을 통합한 혁신적 플랫폼으로, 자동화된 장면 생성, 대규모 합성 데이터, 다차원 평가 벤치마크를 통해 로봇 학습 개발 사이클을 크게 가속화할 수 있는 높은 기여도의 연구이다.
HiWET: Hierarchical World-Frame End-Effector Tracking for Long-Horizon Humanoid Loco-Manipulation

Fig. 1.
 *Fig. 2.* HiWET는 휴머노이드 로봇의 장기 조작 작업을 위해 세계 좌표계 기준 end-effector 추적을 명시적으로 수행하는 계층적 강화학습 프레임워크를 제안한다. Kinematic Manifold Prior를 통해 탐색 공간을 감소시키고 동역학적 안정성을 유지하면서 정밀한 추적을 달성한다.
HiWET는 world-frame 중심 재정의와 Kinematic Manifold Prior를 통해 휴머노이드 조작에서 정밀하고 안정적인 추적을 실현한 창의적 연구이다. 실제 로봇 검증과 12.4 mm의 추적 정확도로 실질적 기여를 입증하였으며, 계층적 설계와 명시적 공간 인터페이스는 장기 로컬로조작 문제의 효과적 해결 방안을 제시한다.
HMC: Learning Heterogeneous Meta-Control for Contact-Rich Loco-Manipulation

Fig. 1: Rolling out HMC for contact-rich tasks on a humanoid robot. Compared to na¨ıve position-only policies [5, 26,
 *Fig. 2: System overview. HMC-Controller accepts inputs from either a VR-based teleoperation system or HMC-Policy* 로봇의 접촉이 많은 조작 작업을 위해 위치, 임피던스, 하이브리드 힘-위치 제어를 적응적으로 혼합하는 HMC(Heterogeneous Meta-Control) 프레임워크를 제안하며, mixture-of-experts 라우팅을 통해 대규모 위치 데이터와 미세한 힘 인식 시연으로부터 학습한다.
HMC는 실제 접촉이 많은 조작 작업의 도전을 체계적으로 해결하는 실용적이고 혁신적인 프레임워크로, 통합된 제어 인터페이스와 이질적 정책 설계가 50% 이상의 성능 향상을 달성하며 로코-조작 분야에 의미 있는 기여를 제시한다.
Lightning Grasp: High Performance Procedural Grasp Synthesis with Contact Fields
Figure 1: Lightning Grasp is a high-performance procedural (analytical) grasp synthesis algorithm.
 *Figure 3: Contact Field and Its Interaction with Objects. A contact field is a collection of vectors in* Lightning Grasp는 Contact Field라는 새로운 데이터 구조를 도입하여 기하학적 계산과 최적화 과정을 분리함으로써 다지형 손을 위한 고속의 절차적 파지 합성을 실현한다.
Lightning Grasp는 Contact Field라는 우아한 추상화를 통해 파지 합성의 근본적 병목을 해결하고 획기적인 속도 향상을 달성한 혁신적 기여로, 절차적 파지 합성의 새로운 표준을 제시한다.
ManiSkill-HAB: A Benchmark for Low-Level Manipulation in Home Rearrangement Tasks
 *Figure 2: Interact benchmark comparing MS-HAB (ours) with Habitat. Each data point is annotated* MS-HAB는 GPU 가속화된 Home Assistant Benchmark의 구현으로, 현실적인 저수준 조작과 빠른 시뮬레이션 속도(4300 SPS)를 지원하며 대규모 데이터셋 생성을 위한 자동화된 궤적 필터링 시스템을 제공한다.
MS-HAB는 현실적인 저수준 조작 제어, 고속 GPU 시뮬레이션, 그리고 자동화된 데이터 생성을 통합하여 가정용 로봇 조작 연구의 중요한 벤치마크를 제공하며, 광범위한 기반선과 투명한 평가 지표는 후속 연구에 큰 가치를 제공한다.
MolmoSpaces: A Large-Scale Open Ecosystem for Robot Navigation and Manipulation
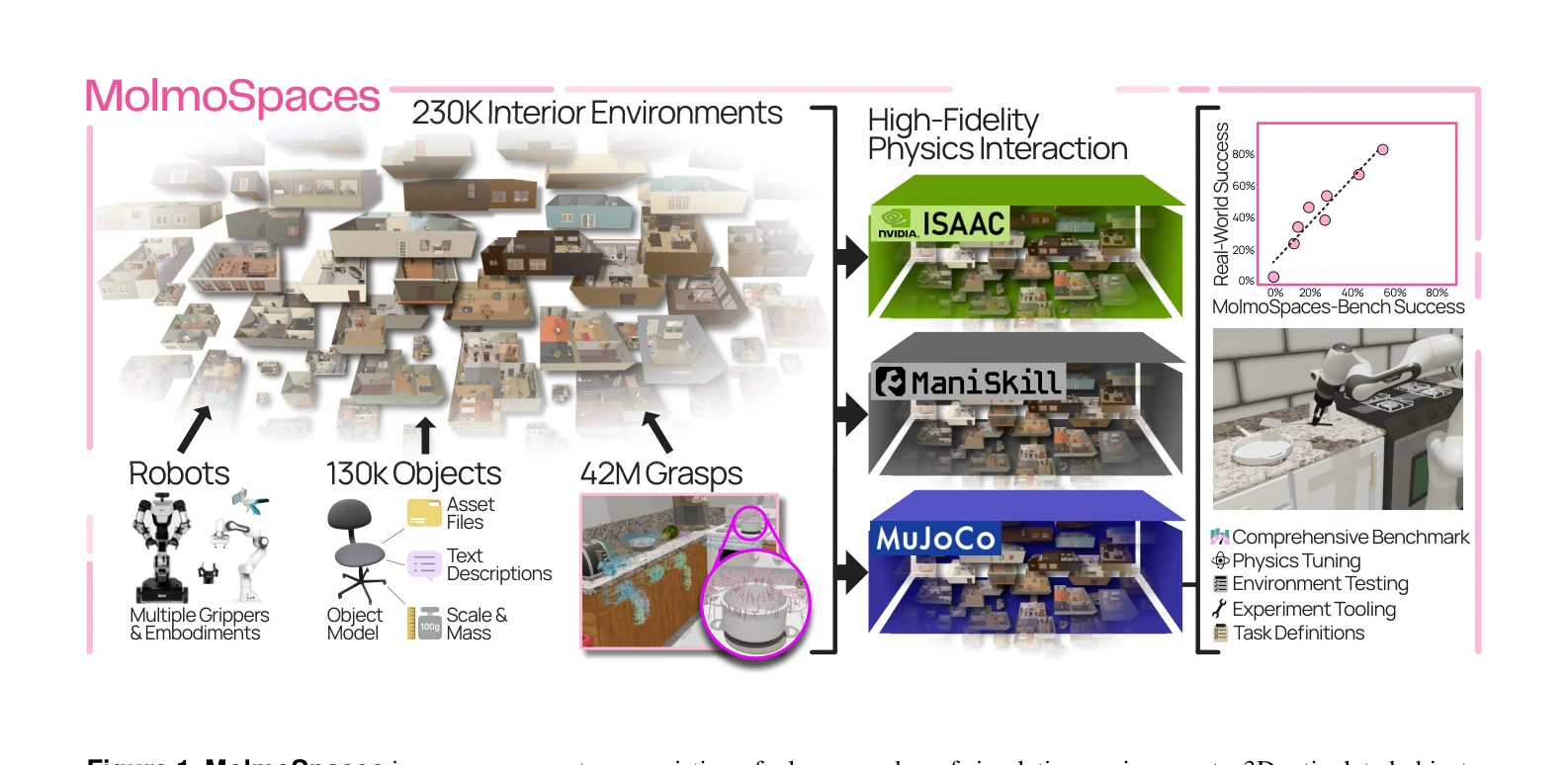
Figure 1 MolmoSpaces is an open ecosystem consisting of a large number of simulation environments, 3D articulated object
 *Figure 1 MolmoSpaces is an open ecosystem consisting of a large number of simulation environments, 3D articulated object* 로봇 네비게이션과 매니퓰레이션을 위한 230k개 이상의 다양한 실내 환경, 130k개의 주석이 달린 객체 자산, 42M개의 안정적인 그래스프를 포함하는 대규모 오픈 에코시스템 MolmoSpaces를 제시하고, 이를 통해 로봇 정책의 일반화 능력을 평가할 수 있는 벤치마크를 구축했다.
MolmoSpaces는 로봇 학습의 평가 기준이 되어 왔던 장면과 객체의 규모 제약을 크게 확장하며, simulator-agnostic 설계와 강한 시뮬-투-리얼 상관관계 검증으로 실무적 신뢰성을 확보한 중요한 오픈 인프라이다. 다만 task 복잡도와 시각적 현실성에서 아직 개선의 여지가 있다.
Object-Centric Dexterous Manipulation from Human Motion Data

Figure 1: Our system uses human hand motion capture data and deep reinforcement learning to train
 *Figure 2: Overview of our framework. (A) Training: Firstly, we use human motion capture data to* 인간의 손 모션 캡처 데이터를 활용하여 로봇 다지털 조작을 학습하는 계층적 정책 학습 프레임워크를 제안한다. 고수준의 손목 궤적 생성 모델과 저수준의 손가락 제어기를 조합하여 embodiment gap을 극복한다.
본 논문은 인간 wrist 모션의 embodiment 불변성을 창의적으로 활용하여 embodiment gap 문제를 해결하고, 계층적 학습 프레임워크로 복잡한 다지털 조작을 효과적으로 학습한다. 실세계 전이와 일반화 능력 모두 입증하여 로봇 조작 분야에 significant한 기여를 한다.
Toward Reliable Sim-to-Real Predictability for MoE-based Robust Quadrupedal Locomotion
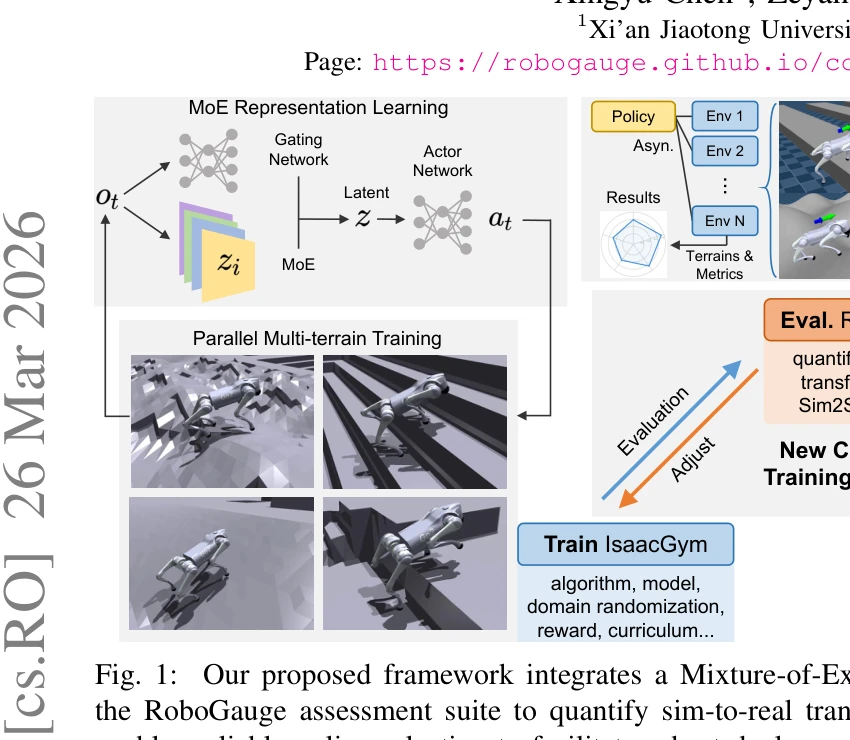
Fig. 1:
 *Fig. 1:* 본 논문은 Mixture-of-Experts (MoE) 기반 사족 로봇 이동 정책과 sim-to-real 전이 가능성을 정량화하는 RoboGauge 평가 프레임워크를 통합하여 신뢰할 수 있는 시뮬레이션-실제 간 갭을 해소하는 통합 프레임워크를 제시한다.
본 논문은 MoE 기반 정책과 RoboGauge 평가 프레임워크를 통합하여 sim-to-real 갭 문제를 체계적으로 해결하고, 극한 지형에서 4 m/s의 견고한 이동 성능을 입증함으로써 사족 로봇 이동 제어 분야에 유의미한 기여를 한다.
BiCoord: 장기간 시공간 협응 양팔 조작 벤치마크
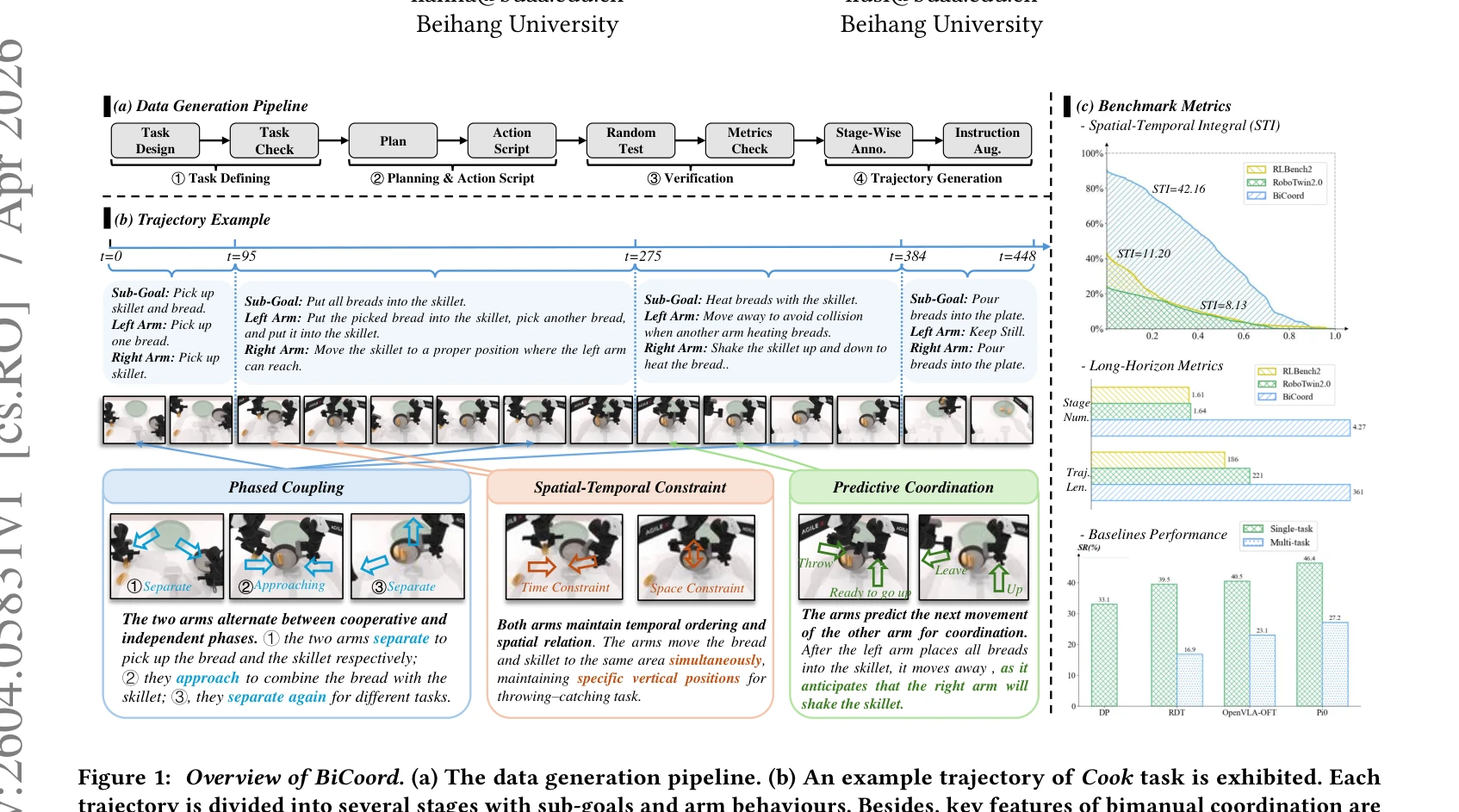
Figure 1: Overview of BiCoord. (a) The data generation pipeline. (b) An example trajectory of Cook task is exhibited. Ea
 *Figure 1: Overview of BiCoord. (a) The data generation pipeline. (b) An example trajectory of Cook task is exhibited. Ea* 본 논문은 장기간 고도로 협응되는 양팔 조작 작업을 평가하기 위한 벤치마크 BiCoord를 제안한다. 기존 벤치마크는 단기간의 느슨한 협응 작업만 포함하는 반면, BiCoord는 연속적 팔 의존성과 동적 역할 교환이 필요한 복잡한 다단계 작업들을 제공한다.
본 논문은 양팔 조작 연구의 중요한 공백을 채우는 포괄적이고 잘 설계된 벤치마크를 제시한다. 장기간 고결합 작업, 명시적인 협응 특성 정의, 다각적 정량 메트릭 등이 커뮤니티에 상당한 기여를 할 것으로 기대된다.
BiCoord: 장기간 시공간 협응 양팔 조작 벤치마크
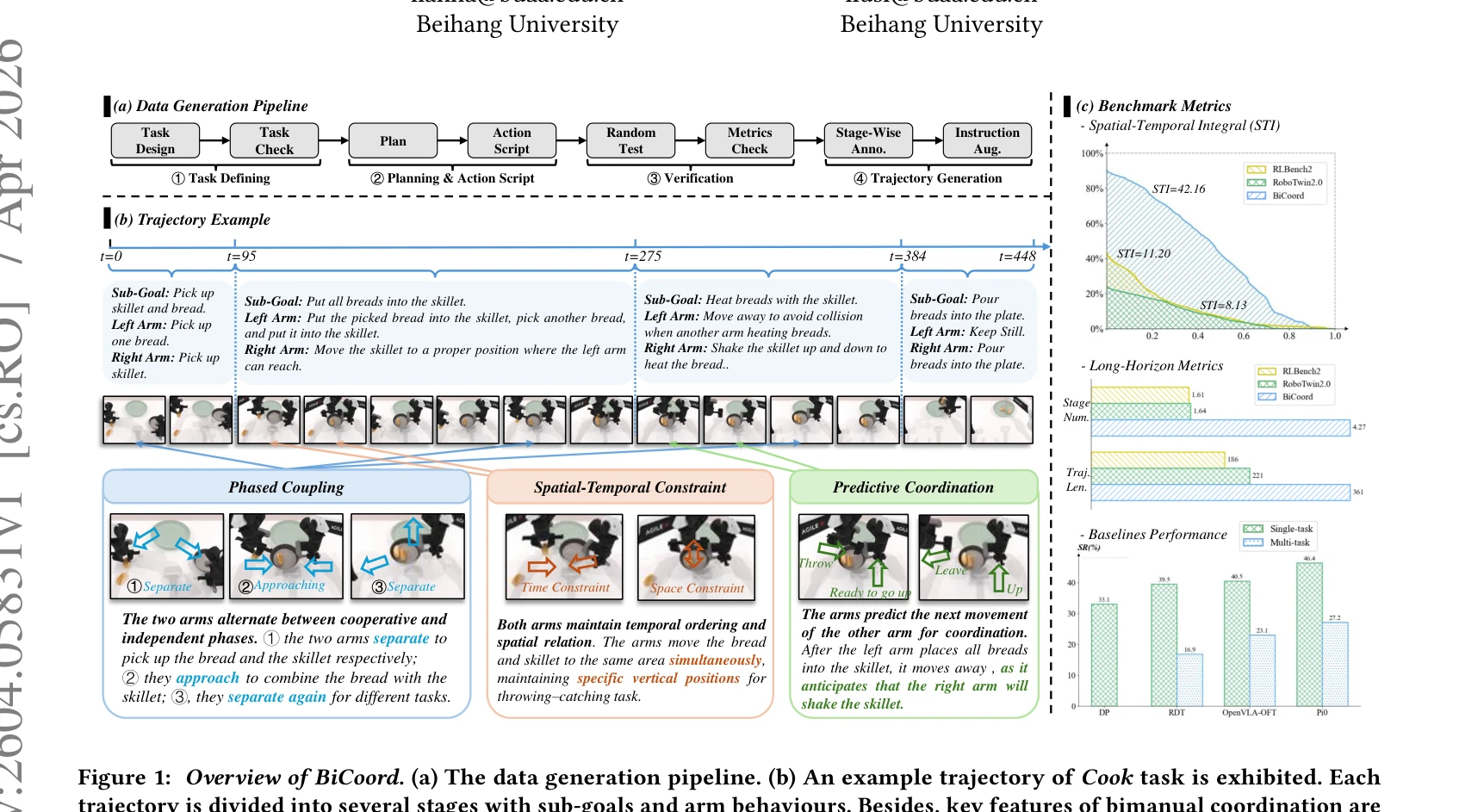
Figure 1: Overview of BiCoord. (a) The data generation pipeline. (b) An example trajectory of Cook task is exhibited. Ea
 *Figure 1: Overview of BiCoord. (a) The data generation pipeline. (b) An example trajectory of Cook task is exhibited. Ea* 본 논문은 장시간의 강한 시공간 협응을 요구하는 양팔 조작 작업을 평가하기 위한 BiCoord 벤치마크를 제시한다. 기존 벤치마크의 단기 및 약결합 작업의 한계를 극복하고자 phased coupling, spatial-temporal constraint, predictive coordination 특성을 반영한 과제를 설계했으며, 시간적·공간적·시공간 복합 메트릭을 제안한다.
BiCoord는 양팔 로봇 조작 분야에서 기존의 단기 약결합 벤치마크의 공백을 효과적으로 메우며, 장시간 강결합 협응 작업 평가를 위한 체계적 프레임워크를 제공한다. 새로운 메트릭과 포괄적 실험을 통해 현존 정책의 한계를 명확히 드러내고 향후 협응 인식 모델 개발에 의미 있는 기준점을 제시한다. 다만 시뮬레이션의 물리적 한계, 실제 로봇으로의 전이 가능성 검증, 그리고 협응 특화 학습 방법의 부재는 보완이 필요한 부분이다.
Robot Crash Course: Learning Soft and Stylized Falling
 *Fig. 2: Method Overview. We leverage reinforcement learn-* 이 논문은 양족 로봇의 낙하 현상 자체에 초점을 맞춰, 충격을 최소화하면서 사용자가 지정한 목표 자세에 도달하도록 하는 강화학습 기반 낙하 정책을 제안한다.
이 논문은 로봇 낙하를 예방이 아닌 제어 대상으로 재정의하는 독창적 관점을 제시하며, RL 기반 다목적 보상 함수와 샘플링 전략으로 범용적 해결책을 제공한다. 실제 양족 로봇에서 부드럽고 스타일화된 낙하를 시연한 점에서 높은 의의가 있으나, 정량적 평가 확대와 다양한 로봇 플랫폼 검증이 필요하다.
SafeFall: Learning Protective Control for Humanoid Robots

Fig. 1.
 *Fig. 1.* SafeFall은 휴머노이드 로봇의 낙상을 예측하고 손상 최소화 제어를 학습하는 프레임워크로, GRU 기반 낙상 예측기와 강화학습 정책을 결합하여 로봇의 구조적 취약성을 고려한 보호 행동을 실행한다.
SafeFall은 휴머노이드 로봇의 실제 배포를 가로막던 낙상 손상 문제를 처음으로 체계적으로 해결하는 프레임워크로, 강화학습과 손상 인식 설계를 결합하여 의미 있는 성능 개선을 달성했으며, 기존 제어기와의 무간섭 통합으로 즉시 실용성이 높다.
SEEC: Stable End-Effector Control with Model-Enhanced Residual Learning for Humanoid Loco-Manipulation
 *Fig. 2: System framework overview of SEEC. Our SEEC framework decouples the humanoid loco-manipulation controller into u* SEEC는 model-enhanced residual learning을 통해 휴머노이드 로봇의 보행 중 팔 end-effector를 안정적으로 제어하는 프레임워크로, 하지 유도 교란에 대해 모델 기반 보상 신호를 RL 정책에 통합한다.
SEEC는 모델 기반 제어의 정밀성과 RL의 적응성을 효과적으로 결합하며, perturbation 생성을 통한 모듈식 설계로 미학습 제어기에도 robust하게 전이되는 점에서 높은 독창성을 보인다. 실제 휴머노이드 로봇 배포와 다양한 loco-manipulation 작업 검증으로 실용성도 입증하였다.
SHIELD: Safety on Humanoids via CBFs In Expectation on Learned Dynamics
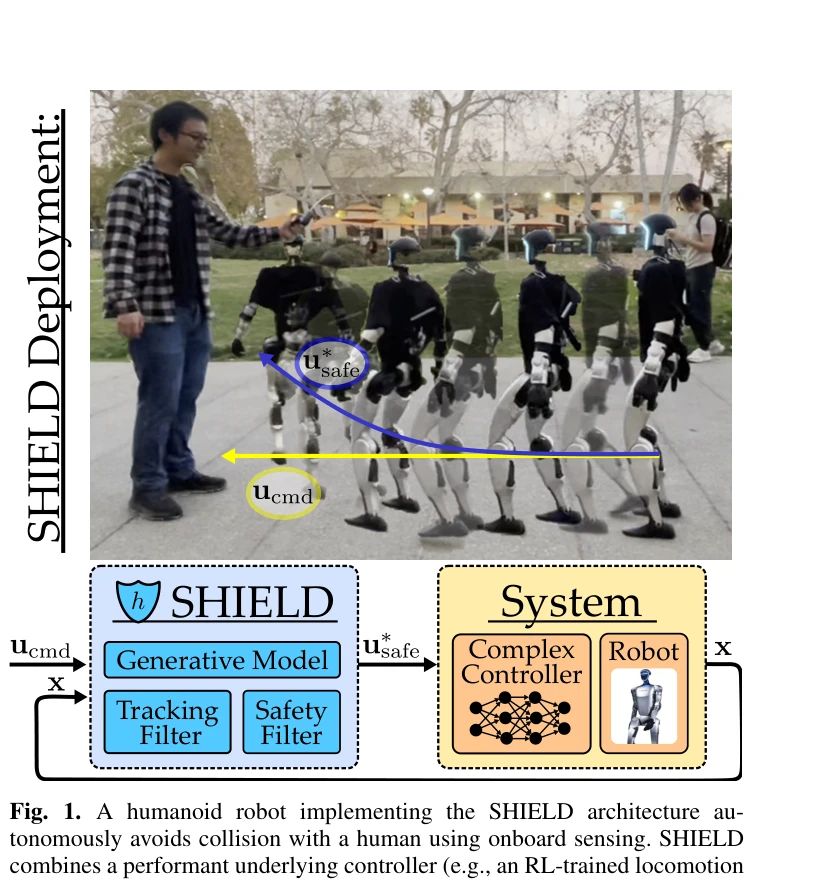
Fig. 1. A humanoid robot implementing the SHIELD architecture au-
 *Fig. 1. A humanoid robot implementing the SHIELD architecture au-* SHIELD는 학습 기반 휴머노이드 로봇 컨트롤러에 안전 계층을 추가하여 실시간 제약 조건 명시와 확률적 안전 보장을 동시에 제공하는 프레임워크이다. 동적 잔차 모델과 확률적 이산 시간 제어 배리어 함수(S-DTCBF)를 통해 기존 블랙박스 RL 정책을 재학습 없이 안전화한다.
SHIELD는 학습 기반 humanoid 컨트롤러의 실제 배포를 위한 현실적이고 실용적인 안전 보장 방법을 제시하며, 데이터 기반과 모델 기반 방법의 간격을 효과적으로 연결한다. 실제 로봇 실험 검증과 함께 이론적 안전 보장을 제공하여 로봇 안전 연구에 상당한 기여를 한다.
SPARK: Safe Protective and Assistive Robot Kit
 *Figure 3: SPARK system framework.* SPARK는 휴머노이드 로봇의 안전한 자율 제어와 원격 조종을 위한 포괄적인 벤치마크 프레임워크로, 모듈식 안전 제어 알고리즘과 시뮬레이션 환경을 제공하여 비전문가도 안전 컨트롤러를 효율적으로 설계하고 배포할 수 있도록 지원한다.
SPARK는 휴머노이드 로봇의 안전한 제어를 위한 실질적이고 체계적인 프레임워크를 제시하는 높은 가치의 연구로, 모듈식 설계, 벤치마크 제공, 실제 배포 검증을 통해 안전 로봇 연구를 가속화할 수 있는 견고한 기반을 마련했다.
STATE-NAV: Stability-Aware Traversability Estimation for Bipedal Navigation on Rough Terrain
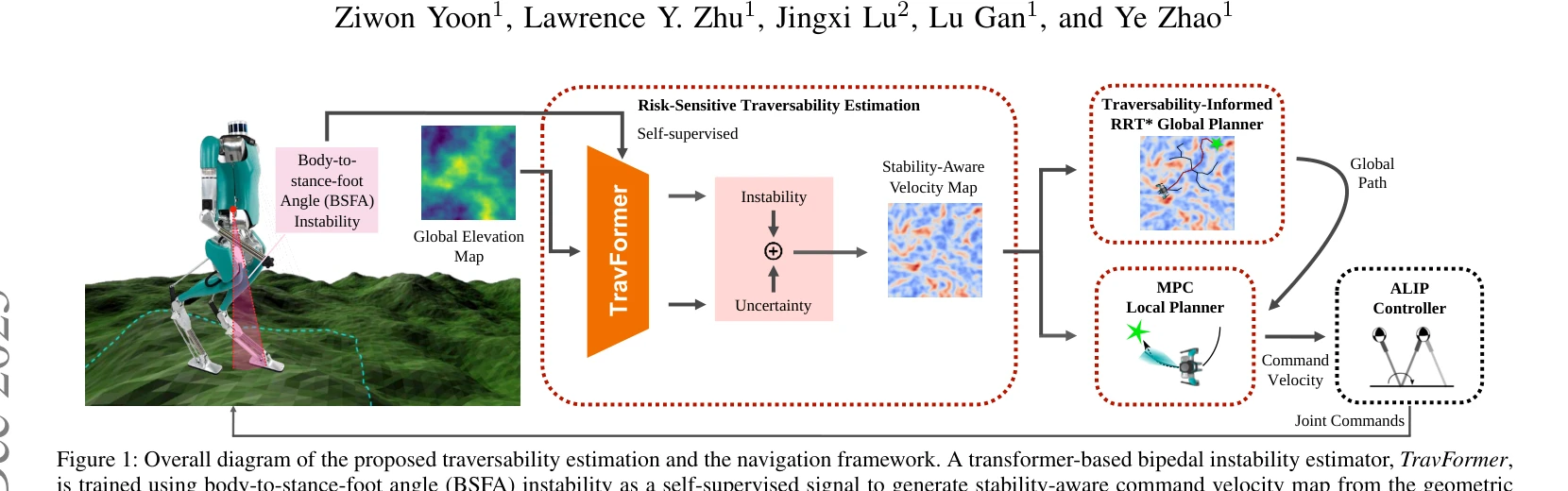
Figure 1: Overall diagram of the proposed traversability estimation and the navigation framework. A transformer-based bi
 *Figure 1: Overall diagram of the proposed traversability estimation and the navigation framework. A transformer-based bi* 이족 로봇의 불안정성을 예측하는 TravFormer 신경망을 개발하고, 안정성 기반 명령 속도를 traversability로 정의하여 거친 지형에서의 안전하고 효율적인 네비게이션을 실현한다.
이 논문은 이족 로봇의 안정성 기반 traversability 추정이라는 중요하면서도 미개척된 문제를 처음 체계적으로 다루며, BSFA 특성 식별부터 TravFormer 개발, 계층적 네비게이션 프레임워크까지 일관된 기술적 기여를 제시한다. 시뮬레이션과 실제 로봇 실험을 통한 검증이 견고하고, 안정성 기반 속도 표현이라는 혁신적 설계로 가중치 재조정 문제를 해결하여 실용적 가치가 높다.
The invariant extended Kalman filter as a stable observer
Invariant Extended Kalman Filter (IEKF)를 Lie group 위의 결정론적 비선형 관찰자로 분석하여, 표준 선형 조건 하에서 임의의 궤적 주변에서의 국소 안정성을 증명한다.
본 논문은 IEKF의 수렴성을 엄밀히 증명하고 일반적인 시스템 클래스를 특성화함으로써 비선형 관찰자 이론에 중요한 기여를 하며, navigation 응용에서의 우수한 실제 성능을 이론적으로 정당화한다.
The MIT Humanoid Robot: Design, Motion Planning, and Control For Acrobatic Behaviors
Fig. 1.
 *Fig. 1.* MIT 휴머노이드 로봇이 고도의 동역학 운동(백플립, 전플립, 회전 점프)을 수행하기 위해 맞춤형 액추에이터 설계, actuator-aware kino-dynamic 모션 플래닝, 그리고 MPC와 WBIC을 통합한 착지 제어 시스템을 제시한다.
본 논문은 humanoid 로봇의 고도의 동역학 운동을 실현하기 위해 하드웨어, 모션 플래닝, 제어를 통합적으로 설계한 체계적인 접근법을 제시하며, 맞춤형 액추에이터 개발과 정밀한 검증을 통해 높은 신뢰성을 확보한 우수한 연구이다.
VIGOR: Visual Goal-In-Context Inference for Unified Humanoid Fall Safety

Fig. 1. Vision-enabled unified fall safety for humanoids. A single learned policy integrates fall mitigation and stand-u
 *Fig. 1. Vision-enabled unified fall safety for humanoids. A single learned policy integrates fall mitigation and stand-u* 휴머노이드 로봇의 넘어짐 안전성을 위해 teacher-student 증류 방식으로 egocentric depth와 proprioception만 사용하여 시각적 goal-in-context 표현을 학습하는 통합 접근법을 제시한다.
휴머노이드의 통합적 fall safety를 시각 기반으로 해결하는 창의적 접근으로, factorized data generation과 goal-in-context representation의 개념이 우수하며 zero-shot transfer 결과가 인상적이다. 다만 실제 환경 적용성을 더 광범위하게 검증할 필요가 있다.
Whole-Body Model-Predictive Control of Legged Robots with MuJoCo
Fig. 1.
 *Fig. 1.* MuJoCo 물리엔진과 iterative LQR (iLQR) 알고리즘을 결합하여 사족 및 인형로봇의 전신 모델예측제어(MPC)를 실시간으로 수행하고, 간단한 방법으로도 현실 세계에 효과적으로 적용 가능함을 입증하는 연구이다.
이 논문은 복잡한 최적화 이론 대신 표준 도구들의 조합으로 현실 세계 다리로봇 제어를 성공시킨 우수한 실증 연구이며, 공개된 코드와 상세한 구현 정보로 커뮤니티 연구 가속화에 큰 기여할 것으로 기대된다.
A Gait Driven Reinforcement Learning Framework for Humanoid Robots
 *Fig. 2: A real-time-gait-driven training framework.* 본 논문은 humanoid robot의 bipedal gait 학습을 위해 실시간 gait planner와 structured reward composition을 결합한 reinforcement learning framework를 제시한다.
본 논문은 model-based planning과 data-driven learning을 효과적으로 결합하여 humanoid robot의 bipedal gait 학습을 위한 실용적인 framework를 제시한다. H-LIP 기반 decoupling과 structured reward composition의 조합이 학습 효율성과 periodicity를 동시에 향상시키는 점에서 기술적 독창성이 있으나, 물리 실험 검증과 복잡한 환경 적응성 평가가 추가되면 더욱 강화될 것이다.
CAD-Driven Co-Design for Flight-Ready Jet-Powered Humanoids
 *Fig. 2: CAD assemblies of the links being modified. 1: Jetpack Turbine Angle; 2: Jetpack Turbine offset distance; 3: Jet* CAD 기반 설계-제어 공동 최적화 프레임워크를 통해 제트 추진 휴머노이드 로봇의 형태와 MPC 제어 파라미터를 동시에 최적화하여 비행 가능한 구성을 도출한다.
본 논문은 CAD 기반 설계-제어 공동 최적화를 제트 추진 항공 휴머노이드에 적용한 것으로, 대규모 형태 공간 탐색과 비행 성능 평가를 체계적으로 통합한 점에서 기여가 크다. 다만 선형화된 제어와 제한된 평가 시나리오는 실제 적용의 견고성을 위해 추가 검증이 필요하다.
Chasing Stability: Humanoid Running via Control Lyapunov Function Guided Reinforcement Learning
Fig. 1: Overview of our approach. Trajectory optimization
 *Fig. 1: Overview of our approach. Trajectory optimization* 본 논문은 Control Lyapunov Function(CLF)의 안정성 조건을 RL 보상에 임베딩하여 휴머노이드 로봇의 달리기를 실현하는 CLF-RL 방법을 제시한다. 이는 휴머노이드가 비행 및 단일 지지 상(flight and single support phases)를 포함한 동적 달리기를 수행하도록 한다.
본 논문은 고전 제어 이론(CLF)과 최신 RL을 매우 효과적으로 통합하여, 휴머노이드 로봇의 동적 달리기 제어를 위한 원리 기반의 체계적 프레임워크를 제시한다. 실제 하드웨어에서의 안정적 배포와 강건한 추적 성능은 높은 실용적 가치를 입증한다.
Contact-Aided Invariant Extended Kalman Filtering for Robot State Estimation
Figure 1: A Cassie-series biped robot is used for both simulation and experimental results. The robot was developed by A
 *Figure 1: A Cassie-series biped robot is used for both simulation and experimental results. The robot was developed by A* Lie군 이론과 불변 관찰자 설계를 기반으로 IMU와 접촉 센서 데이터를 융합하는 Contact-Aided Invariant Extended Kalman Filter (InEKF)를 개발하여 이족 로봇의 자세와 속도를 추정한다.
이 논문은 Lie군 기반 불변 관찰자 이론을 legged robot의 접촉-관성 상태 추정에 체계적으로 적용하여, 기존 EKF의 수렴성과 일관성 문제를 근본적으로 해결한 중요한 기여를 제시한다. 이론적 엄밀성과 실험적 검증, 오픈소스 구현까지 겸비한 완성도 높은 연구로, 자율 legged robot의 장시간 안정 운영을 위한 핵심 기술이다.
Development of an Intuitive GUI for Non-Expert Teleoperation of Humanoid Robots

Figure 1: Visual of kid-size humanoid robot navigating a replica of the FIRA obstacle run event.
 *Figure 1: Visual of kid-size humanoid robot navigating a replica of the FIRA obstacle run event.* FIRA HuroCup 경기에서 비전문가 운영자가 인형형 로봇을 텔레조작할 수 있도록 사용자 친화적인 GUI를 개발했다. HTML, CSS, JavaScript를 사용하여 직관적인 인터페이스를 반복적으로 설계하고 테스트했다.
본 연구는 경합 환경에서 실제로 필요한 비전문가 중심의 텔로봇 GUI를 반복적 개발 방식으로 체계적으로 구축한 의미 있는 실무 기여이다. 다만 외부 사용자 평가 부재로 주장의 일반화 가능성이 제한되며, 향후 형식적인 사용성 평가를 통한 정량적 검증이 필요하다.
Dexterous Safe Control for Humanoids in Cluttered Environments via Projected Safe Set Algorithm
Figure 1: Application of dexterous safe control for humanoids in cluttered environments. (a) A safe teleoperation task w
 *Figure 1: Application of dexterous safe control for humanoids in cluttered environments. (a) A safe teleoperation task w* 인간형 로봇이 복잡한 환경에서 다중 충돌 회피를 수행할 때 발생하는 제어 제약의 불가능성 문제를 해결하기 위해 Projected Safe Set Algorithm (p-SSA)을 제안한다.
밀집된 환경에서 인간형 로봇의 섬세한 다중 충돌 회피라는 현실적이고 중요한 문제를 처음 체계적으로 다루었으며, p-SSA 알고리즘은 실제 로봇 배포에 즉시 활용 가능한 실용적 해결책을 제시한다. 이론적 보장은 제한적이지만 광범위한 실증 검증과 무매개변수 일반화 능력이 인간형 로봇 안전 제어의 중요한 진전을 보여준다.
Embrace Collisions: Humanoid Shadowing for Deployable Contact-Agnostics Motions
Fig. 1: We present a unified humanoid motion interface and a zero-shot sim-to-real reinforcement learning framework, so
 *Fig. 1: We present a unified humanoid motion interface and a zero-shot sim-to-real reinforcement learning framework, so * 본 논문은 휴머노이드 로봇이 온몸의 모든 신체 부위를 사용하여 환경과 상호작용하는 접촉-무관(contact-agnostic) 동작을 수행할 수 있도록 하는 통합 제어 프레임워크를 제안한다. GPU 가속 rigid-body simulator와 reinforcement learning을 활용하여 시뮬레이션에서 학습한 정책을 실제 로봇에 zero-shot으로 배포할 수 있음을 시연한다.
본 논문은 접촉-무관 극단 동작을 지원하는 humanoid 제어의 중요한 진전을 이루었으며, 새로운 motion interface와 training 기법이 창의적이다. 다만 실험 검증과 기술 상세 설명이 더 필요하고, project website 의존도가 높아 독립적 평가에 제약이 있다.
FocusNav: Spatial Selective Attention with Waypoint Guidance for Humanoid Local Navigation
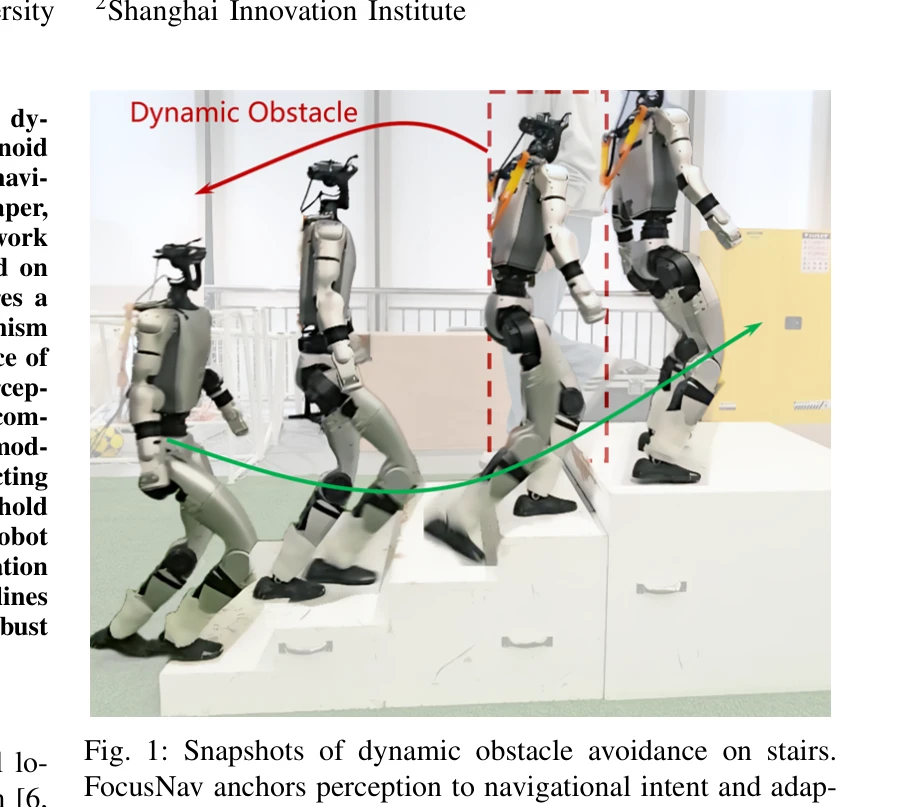
Fig. 1: Snapshots of dynamic obstacle avoidance on stairs.
 *Fig. 4: Overview of the FocusNav framework. (a) Multi-modal perception encoder fuses spatially aligned LiDAR and depth* FocusNav는 인간형 로봇의 국소 항법을 위해 Waypoint-Guided Spatial Cross-Attention (WGSCA)와 Stability-Aware Selective Gating (SASG) 모듈을 결합한 공간 선택적 주의 프레임워크를 제안한다. 예측된 무충돌 경로점을 기준으로 환경 지각을 동적으로 조정하여 불안정 시 원거리 정보를 제거함으로써 동적·복잡한 환경에서의 견고한 항법을 달성한다.
FocusNav는 생물학적 영감과 기술적 혁신을 결합하여 인간형 로봇의 복잡한 동적 환경 항법이라는 중대한 과제를 체계적으로 해결한다. WGSCA와 SASG 모듈의 설계가 우수하고 실제 로봇 실험으로 검증되었으나, 단일 플랫폼 실험과 수동 파라미터 조정이라는 제약이 있다.
Geometry-Aware Predictive Safety Filters on Humanoids: From Poisson Safety Functions to CBF Constrained MPC
Fig. 1.
 *Fig. 1.* 본 논문은 Poisson safety function을 기반으로 한 geometry-aware predictive safety filter를 제안하며, CBF constrained MPC를 통해 humanoid 및 quadruped 로봇의 실시간 안전한 궤적 생성을 구현한다.
본 논문은 Poisson safety function을 시간-동적 환경과 로봇 기하학에 맞게 확장하고 MPC+CBF와 통합하여 실시간 안전한 자율 네비게이션을 실현한 우수한 연구이다. 이론적 확장과 실제 로봇 검증이 잘 균형을 이루고 있으며, 안전-임계 로봇 제어의 실질적 문제 해결에 기여한다.
HAIC: Humanoid Agile Object Interaction Control via Dynamics-Aware World Model
 *Fig. 3: Overview of our Dynamics-aware World Model. It predicts object* HAIC는 humanoid 로봇이 독립적인 동역학을 가진 미작동(underactuated) 물체와 상호작용할 수 있도록 dynamics-aware world model을 통해 proprioception만으로 고차 가속도를 예측하고 기하학적 projection을 통해 시각 blind spot에서도 강건한 제어를 실현한다.
본 논문은 humanoid 로봇의 underactuated 물체 상호작용이라는 현실적으로 중요한 문제를 proprioception 기반의 창의적인 dynamics prediction과 geometric projection으로 우아하게 해결하며, 실제 로봇에서 SOTA 성능을 입증한 매우 강력한 기여이다.
Humanoid Robot Acrobatics Utilizing Complete Articulated Rigid Body Dynamics
 *Figure 2: Jump phases. Magenta: Launch phase, blue: flight* 고도화된 동적 동작을 수행하는 휴머노이드 로봇을 위해 완전한 articulated rigid body dynamics를 기반으로 하는 제어 아키텍처를 제시하며, trajectory optimization과 whole-body control을 model abstraction으로 중개하여 아크로바틱 동작을 실현한다.
휴머노이드 로봇의 고도 동적 제어에 대한 개념적·이론적 기여도가 높고 control architecture가 체계적이나, 시뮬레이션 검증에 한정되고 optimization 방법론 세부사항이 부족하여 실질적 영향력에는 제약이 있다.
HUSKY: Humanoid Skateboarding System via Physics-Aware Whole-Body Control
Fig. 1: Overview. (a) Our proposed framework HUSKY enables the humanoid robot to perform complete real-world skateboardi
 *Fig. 1: Overview. (a) Our proposed framework HUSKY enables the humanoid robot to perform complete real-world skateboardi* HUSKY는 humanoid 로봇이 skateboard 위에서 안정적으로 skating을 수행하기 위한 physics-aware whole-body control 프레임워크이며, lean-to-steer 제약과 hybrid contact dynamics를 명시적으로 모델링하여 AMP 기반 pushing과 physics-guided steering을 통합한다.
HUSKY는 humanoid skateboarding이라는 도전적인 문제를 physics-aware modeling과 hybrid control framework를 통해 창의적으로 해결한 고품질 연구이며, explicit system modeling과 DRL의 결합으로 real-world에서의 stable skateboarding을 실현한 점에서 significant contribution을 제시한다.
HWC-Loco: A Hierarchical Whole-Body Control Approach to Robust Humanoid Locomotion
HWC-Loco는 휴머노이드 로봇의 견고한 이동을 위해 계층적 정책 구조로 목표 추적과 안전 복구 간의 trade-off를 동적으로 해결하는 강화학습 기반 전신 제어 알고리즘이다.
HWC-Loco는 휴머노이드 로봇 제어의 현실적 과제인 sim2real gap과 안전성 대 성능의 trade-off를 효과적으로 해결하는 혁신적인 계층적 제어 프레임워크이며, 광범위한 실험 검증을 통해 실용적 가치를 입증했다.
iRonCub 3: The Jet-Powered Flying Humanoid Robot
 *Fig. 2.* iRonCub 3는 제트 터빈 4개를 장착한 완전 인형형 비행 로봇으로, 시뮬레이션 검증 후 최초로 수직 이착륙에 성공했다.
iRonCub 3는 인형형 로봇 비행의 기술적 난제(제어, 추정, 기계 통합)를 체계적으로 해결하고 최초 비행 실증을 달성했으나, 고등 기동과 조작 능력 통합은 향후 과제다.
Learning Aerodynamics for the Control of Flying Humanoid Robots
Fig. 1: Design of the iRonCub-Mk1 physical prototype. Front (a) and rear (b) pictures of the
 *Fig. 1: Design of the iRonCub-Mk1 physical prototype. Front (a) and rear (b) pictures of the* 비행 인간형 로봇의 공기역학 모델링을 위해 CFD 시뮬레이션, 풍동 실험, 딥러닝을 결합한 포괄적 접근 방식을 제시하고, 제트 엔진을 장착한 iRonCub-Mk1 로봇을 설계·제작하여 비행 제어를 구현한다.
인간형 로봇의 비행 능력 확보를 위해 공기역학 모델링과 제어를 종합적으로 다룬 기술적·과학적으로 의미 있는 연구이며, 다중 모드 로봇의 미래 설계에 중요한 기여를 제시한다. 다만 실제 비행 실험 검증과 학습 모델의 일반화 성능 평가가 후속 과제이다.
Learning Differentiable Reachability Maps for Optimization-based Humanoid Motion Generation
Fig. 1.
 *Fig. 1.* 본 논문은 humanoid robot의 motion generation을 위해 differentiable reachability map을 학습하는 새로운 방법을 제안한다. 이 맵은 task space에서 정의된 스칼라 함수로서, robot end-effector이 도달 가능한 영역에서만 양수값을 가지며, task space 좌표에 대해 미분가능하여 continuous optimization의 제약조건으로 직접 사용될 수 있다.
본 논문은 humanoid motion planning의 computational bottleneck을 해결하기 위해 differentiable reachability map이라는 혁신적 표현을 제안하며, binary classification 기반의 학습 방법론은 기존 방식의 한계를 잘 극복한다. 다만 실제 실험 결과와 성능 평가에 대한 상세한 검증이 필요하다.
A Foot Resistive Force Model for Legged Locomotion on Muddy Terrains
 *Fig. 2 shows a set of snapshots of foot-mud interactions.* 진흙 지형에서 다리 로봇의 발-진흙 상호작용을 모델링하는 저항력 모델을 제시하고, 이를 바탕으로 변형 가능한 로봇 발을 설계하여 이동성과 에너지 효율을 향상시킨다.
본 논문은 진흙 지형에서 다리 로봇의 발-진흙 상호작용에 대한 첫 번째 포괄적 물리 기반 모델을 제시하며, 이를 바탕으로 설계된 변형 발의 성능 향상을 실험으로 검증함으로써 로봇 이동성 연구에 중요한 기여를 한다.
Asymptotically Stable Gait Generation and Instantaneous Walkability Determination for Planar Almost Linear Biped with Knees
Figure 1 shows the model of the planar 6-DOF biped robot
 *Figure 1 shows the model of the planar 6-DOF biped robot* 거의 선형 역학 모델을 갖는 무릎 관절이 있는 평면 이족보행 로봇에서 Taylor 전개를 이용한 선형화를 통해 수치 적분 없이 점프로 안정적인 보행을 생성하고 즉각적인 보행 가능성 판정을 수행한다.
이 논문은 거의 선형 역학을 갖는 무릎 관절 이족보행 로봇에서 선형화를 통한 실시간 보행 가능성 판정이라는 실용적으로 중요한 문제를 해결하며, 차원 축소 및 근사 정확도 분석에서 상세한 기여를 제공한다. 다만 AL3 로봇의 특수성과 실제 로봇 검증 부족이 일반화 가능성을 제한한다.
Humanoid Robot Teleoperation for Nonprehensile Transportation: A Multiple-Constraint Safety-Critical Control Framework
 *Figure 2. Dual-arm reachability maps of the custom-built humanoid robot platform.* 본 논문은 인간형 로봇의 비파지형 물체 운반 원격조종 작업에서 다중 제약 조건 간 충돌과 안전 문제를 해결하기 위해 계층적 3단계 구조의 Multiple-Constraint Safety-Critical Control Framework (MC-SCCF)를 제안한다. 상층부는 미분가능한 도달가능성 대리 모델과 개선된 control barrier function 기반 안전 속도 필터로 작업공간 경계에서의 안전성을 보장하고, 중층부는 사용자 명령을 자세 결합 참조 궤적으로 매핑하여 물체의 미끄러짐과 넘어짐을 방지하며, 하층부는 QP 기반 역운동학 해석기로 자체 충돌 회피와 조정된 운동을 달성한다.
본 논문은 인간형 로봇의 복잡한 비파지형 운반 작업에서 다중 충돌 제약을 체계적으로 해결하기 위한 계층적 MC-SCCF를 제시하며, 미분가능한 도달가능성 대리 모델과 개선된 control barrier function 기반의 안전 속도 필터는 기술적 참신성을 보여준다. 시뮬레이션과 물리적 로봇 실험으로 유효성을 입증했으나, 대리 모델의 일반화 가능성, 환경 변수 견고성, 계산 성능 벤치마크 등에 대한 상세 분석이 보완되면 더욱 강화될 수 있다.
Adaptive LIPM-based trajectory planning for energy-efficient bipedal locomotion on inclined terrains
 *Fig. 3 Shows the structure and snapshots of the simulation* 경사지면에서 이족 보행 로봇의 안정적이고 에너지 효율적인 보행을 위해 Slope Adaptive LIPM (SA-LIPM)을 기반으로 궤적 계획을 수행하고, 12-DOF 하체 로봇에서 ZMP 안정성, COM 궤적, 관절별 에너지 소비를 상세히 분석한다.
본 논문은 경사지에서 이족 로봇의 보행 안정성과 에너지 효율성을 SA-LIPM 기반으로 체계적으로 분석한 중요한 연구이며, 관절별 에너지 감사를 통해 휴머노이드 로봇 설계에 실질적인 지침을 제공한다. 다만 더 가파른 경사와 실제 하드웨어 검증이 필요하다.
Humanoid Robot Teleoperation for Nonprehensile Transportation: A Multiple-Constraint Safety-Critical Control Framework
 *Figure 2. Dual-arm reachability maps of the custom-built humanoid robot platform.* 본 논문은 인간형 로봇의 비파지 운송 작업을 위한 텔레조작 시스템에서 다층적 안전 제약 조건을 동시에 만족하는 Multiple-Constraint Safety-Critical Control Framework (MC-SCCF)를 제안한다. 계층적 3계층 아키텍처를 통해 작업공간 경계, 물체 역학 안전성, 로봇 운동학 제약을 통합하여 관리한다.
본 논문은 인간형 로봇 텔레조작을 위한 실질적이고 중요한 문제를 다루며, 미분 가능한 도달 가능성 평가, 개선된 CBF, 3계층 계층적 제어 프레임워크 등 기술적으로 건실한 해결책을 제시한다. 하드웨어 실증 결과는 실용성을 보여주나, 모델링 불확실성 강건성과 동적 환경 적응성에 대한 깊이 있는 분석이 추가되면 더욱 완성도 높은 연구가 될 것으로 판단된다.
Constrained Whole-Body Tracking for Humanoid Robots
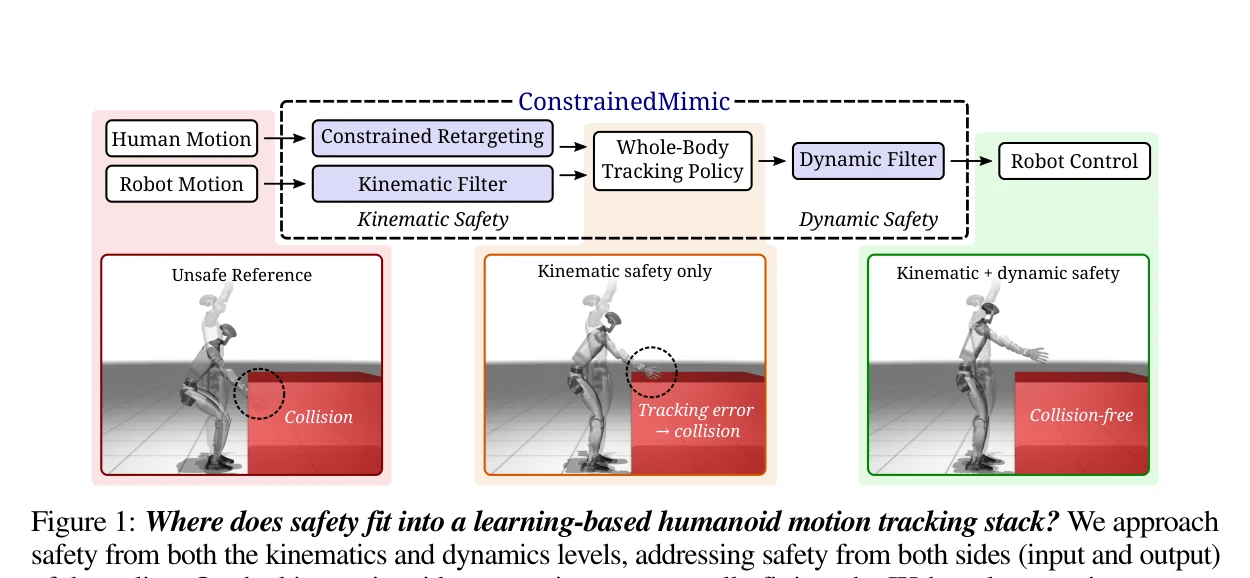
Figure 1: Where does safety fit into a learning-based humanoid motion tracking stack? We approach
 *Figure 1: Where does safety fit into a learning-based humanoid motion tracking stack? We approach* 본 논문은 강화학습 기반 인간형 로봇의 전신 모션 추적 제어에서 안전 제약조건을 실시간으로 강제하는 ConstrainedMimic 프레임워크를 제시한다. operational space control과 control barrier functions을 결합하여 kinematics와 dynamics 차원에서 실행시간 제약조건을 만족시킨다.
본 논문은 humanoid 전신 제어에서 contact-constrained 동역학을 통한 체계적이고 실용적인 안전 강제 방법을 제시한다. Kinematics와 dynamics 양단 필터링, task-consistent 설계, 실시간 실행 가능성은 주목할 만하나, 실하드웨어 검증과 충돌 모델 확장이 필요하다.
SafeVLA-Bench: A Benchmark for the Success-Safety Gap in Vision-Language-Action Models

Figure 1: SafeVLA-Bench overview. SafeVLA-Bench combines task-aware STL safety specifica-
 *Figure 1: SafeVLA-Bench overview. SafeVLA-Bench combines task-aware STL safety specifica-* 본 논문은 VLA 벤치마크에서 높은 작업 성공률이 안전한 실행을 보장하지 않는 문제를 지적하고, SafeVLA-Bench를 제시하여 Signal Temporal Logic (STL) 기반의 형식화된 안전 사양과 Success-But-Unsafe (SBU), Violation Severity Index (VSI) 메트릭을 통해 성공-안전 간극을 정량화한다.
SafeVLA-Bench는 VLA 벤치마크에서 간과되어 온 성공-안전 간극을 명확히 드러내고, 형식화되고 이식 가능한 평가 프레임워크를 제공함으로써 로봇 안전 연구에 중요한 기여를 한다. 다만 시뮬레이터 충실도, 임계값 보정의 한계, 현실 환경 검증 부재 등의 제약이 있다.
SPARK: Safe Protective and Assistive Robot Kit
Figure 1: Scenarios of safe humanoid control achieved with SPARK. Left top figure: A real Unitree G1 humanoid robot avoi
 *Figure 1: Scenarios of safe humanoid control achieved with SPARK. Left top figure: A real Unitree G1 humanoid robot avoi* 본 논문은 인형 로봇의 안전한 자율주행 및 원격 조종을 위한 종합적인 벤치마크 및 도구 모음인 SPARK를 제시한다. 모듈 방식의 composable, extensible, deployable 설계를 통해 사용자가 커스텀 안전 조건과 작업 목표를 쉽게 구성하고 실제 로봇에 배포할 수 있도록 한다.
SPARK는 인형 로봇의 안전한 배포를 위한 실질적이고 실용적인 솔루션을 제시하는 고가치의 도구 논문이다. Composable, extensible, deployable 설계 원칙을 통해 기존 개별 알고리즘들의 통합과 재사용성을 크게 향상시켰으며, 시뮬레이션-실제 로봇 간의 연결고리를 제공한다. 다만 새로운 알고리즘 기여보다는 engineering 측면의 도구 개발에 초점이 있으므로 이론적 혁신성은 제한적이다. 로봇 안전 연구 커뮤니티에 실질적인 가치를 제공할 수 있는 고품질의 플랫폼 논문이다.
SafeHumanoid: VLM-RAG-driven Control of Upper Body Impedance for Humanoid Robot
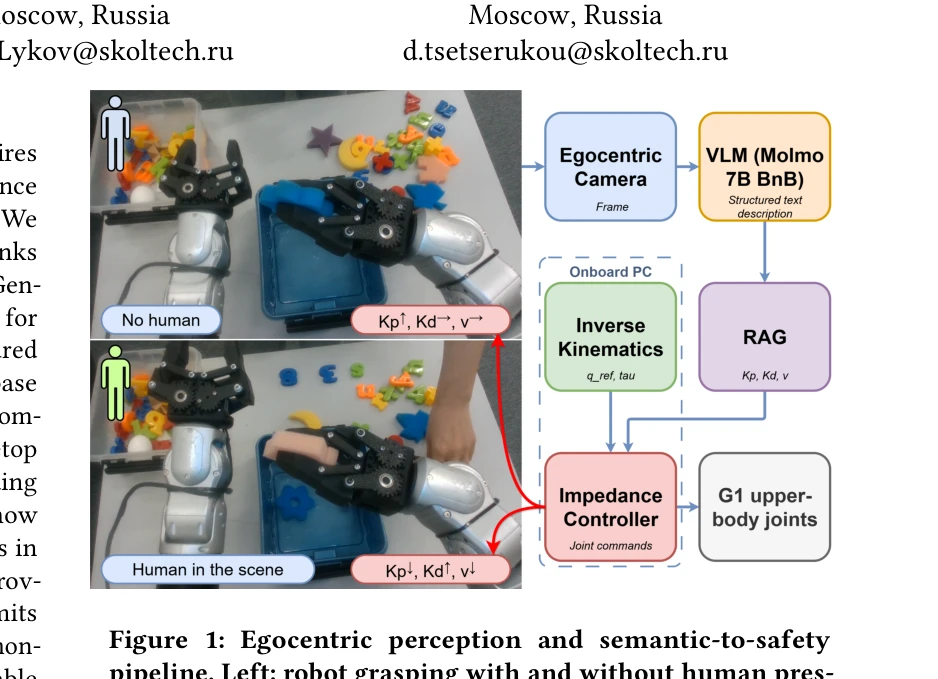
Figure 1: Egocentric perception and semantic-to-safety
 *Figure 1: Egocentric perception and semantic-to-safety* SafeHumanoid는 Vision Language Model(VLM)과 Retrieval-Augmented Generation(RAG)을 활용하여 휴머노이드 로봇의 임피던스와 속도를 동적으로 조정하는 시스템으로, 인간-로봇 상호작용 시 안전성과 작업 완료를 동시에 달성한다.
SafeHumanoid는 의미론적 추론과 임피던스 제어의 혁신적 결합으로 인간-로봇 협력의 안전성을 크게 향상시키는 제안이지만, 추론 지연시간과 실시간성은 실제 배포를 위해 해결해야 할 주요 과제이다.
EgoActor: Grounding Task Planning into Spatial-aware Egocentric Actions for Humanoid Robots via Visual-Language Models
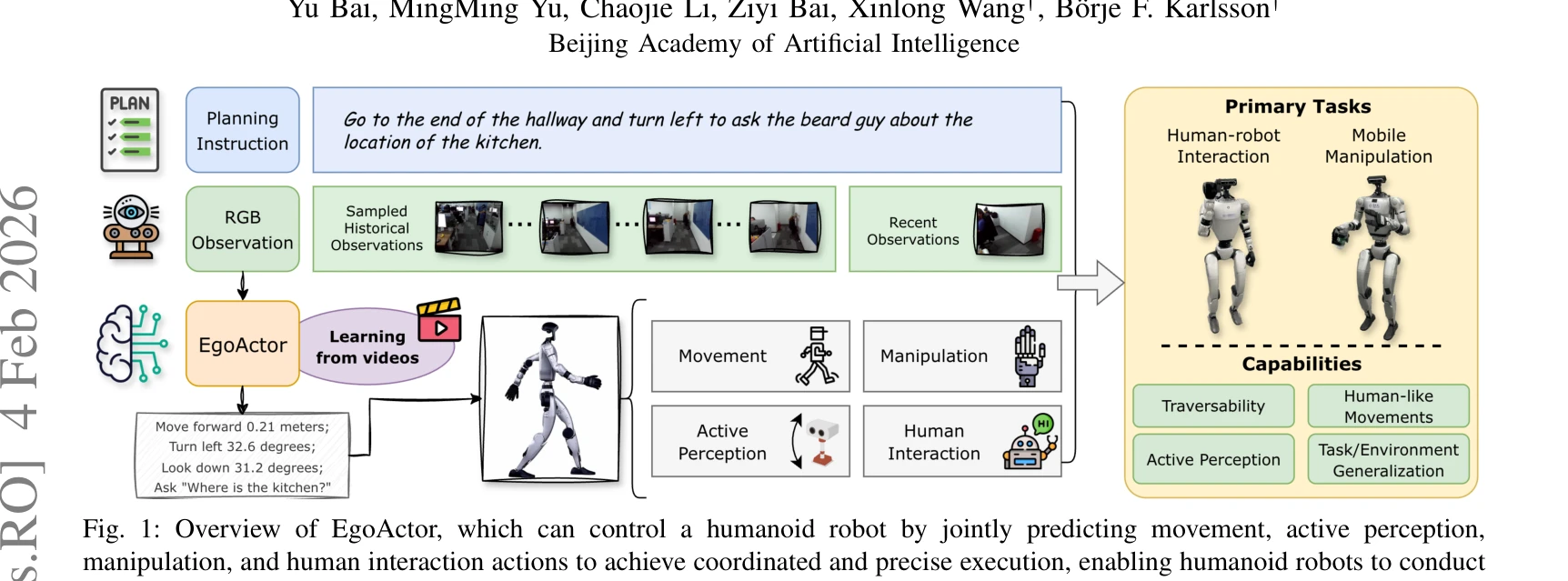
Fig. 1: Overview of EgoActor, which can control a humanoid robot by jointly predicting movement, active perception,
 *Fig. 1: Overview of EgoActor, which can control a humanoid robot by jointly predicting movement, active perception,* EgoActor는 VLM 기반의 통합 모델로서 고수준 자연어 명령어를 휴머노이드 로봇의 저수준 공간 인식 동작(보행, 조작, 지각, 인간-로봇 상호작용)으로 직접 변환하는 EgoActing 태스크를 제안한다.
EgoActor는 VLM을 활용한 휴머노이드 로봇 제어에서 보행, 조작, 지각, 상호작용을 통합하는 새로운 접근을 제시하며, 광범위한 실제 및 시뮬레이션 검증을 통해 그 가능성을 입증한다. 오픈소스 공개와 함께 휴머노이드 구체화 AI의 실질적 발전에 기여할 것으로 예상된다.
EgoMI: Learning Active Vision and Whole-Body Manipulation from Egocentric Human Demonstrations
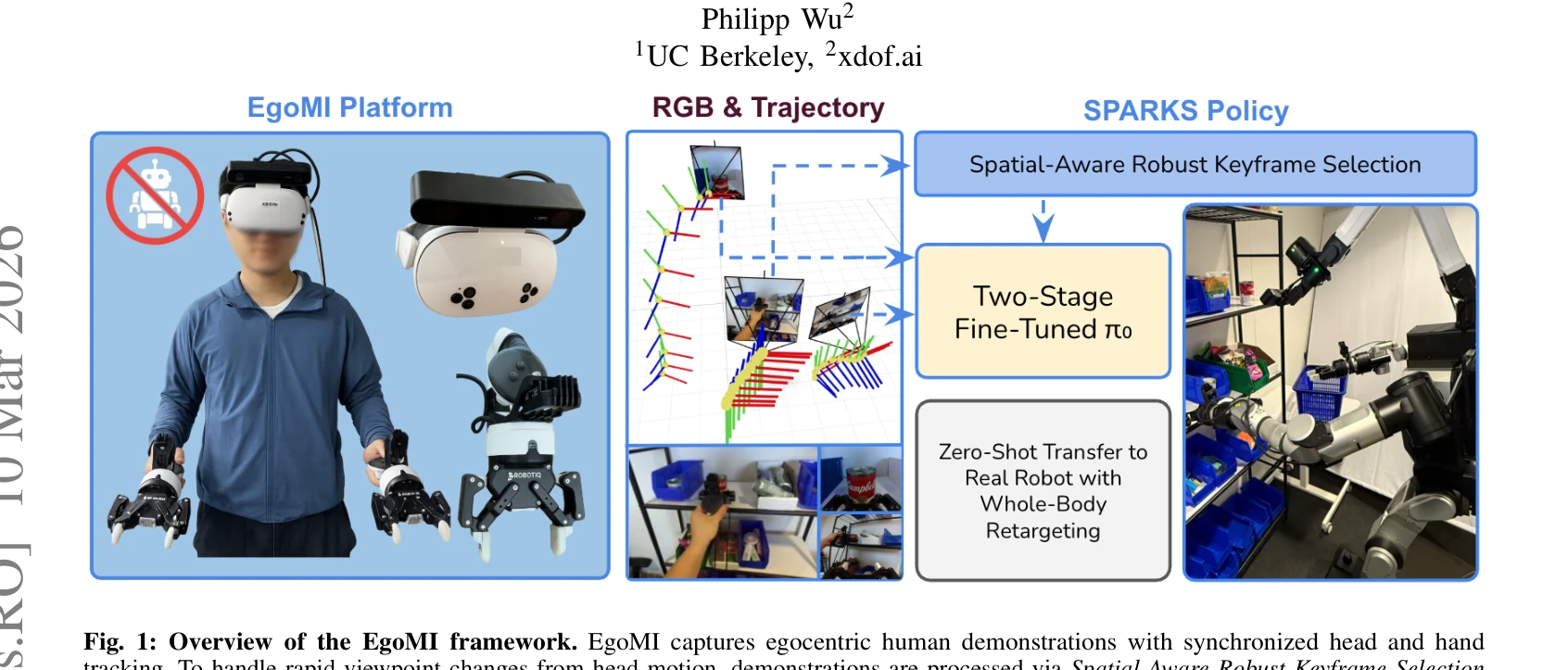
Fig. 1: Overview of the EgoMI framework. EgoMI captures egocentric human demonstrations with synchronized head and hand
 *Fig. 1: Overview of the EgoMI framework. EgoMI captures egocentric human demonstrations with synchronized head and hand* EgoMI는 인간의 동시화된 머리 및 손 움직임을 포착하는 egocentric 데이터 수집 프레임워크로, SPARKS 메모리 메커니즘을 통해 급속한 시점 변화를 처리하여 반인간형 로봇으로 zero-shot 전이를 달성한다.
EgoMI는 인간의 active vision과 manipulation을 동시에 포착하는 창의적 프레임워크로, SPARKS 메커니즘을 통해 급속한 시점 변화를 우아하게 처리하며 zero-shot transfer를 달성해 imitation learning의 embodiment gap 문제에 실질적 솔루션을 제시한다.
Humanoid Occupancy: Enabling A Generalized Multimodal Occupancy Perception System on Humanoid Robots

Figure 1: Schematic diagram of the Humanoid Occupancy system.
 *Figure 1: Schematic diagram of the Humanoid Occupancy system.* 휴머노이드 로봇을 위한 일반화된 다중모달 occupancy 인식 시스템을 제시하며, 하드웨어 설계, 데이터셋 구축, 다중모달 fusion 네트워크를 통합한 완전한 환경 인식 프레임워크를 제공한다.
본 논문은 휴머노이드 로봇의 독특한 구조적 도전과제를 해결하는 실질적이고 포괄적인 occupancy 기반 인식 시스템을 제시하며, 첫 번째 휴머노이드 로봇 특화 데이터셋 제공으로 해당 분야에 중요한 기여를 한다.
HumanoidVLM: Vision-Language-Guided Impedance Control for Contact-Rich Humanoid Manipulation
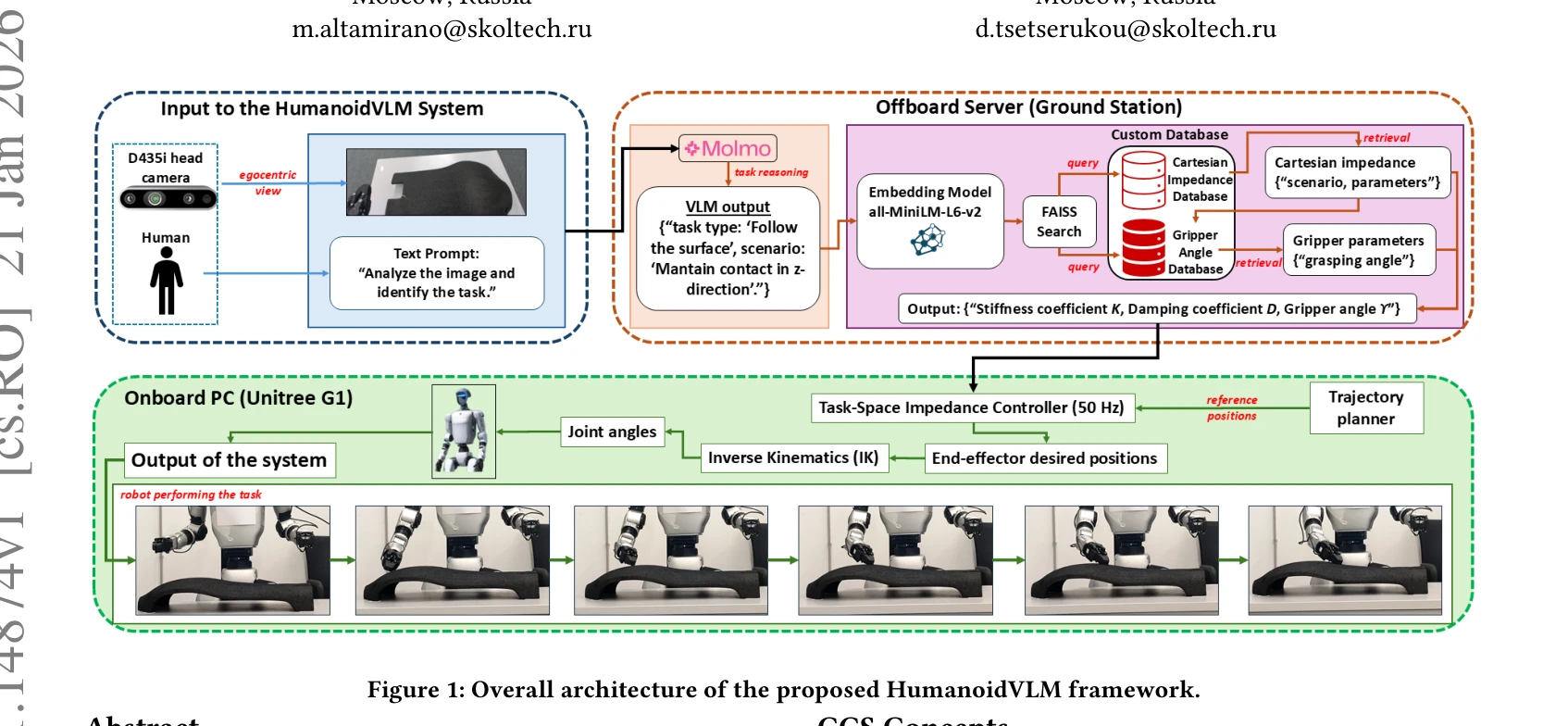
Figure 1: Overall architecture of the proposed HumanoidVLM framework.
 *Figure 1: Overall architecture of the proposed HumanoidVLM framework.* HumanoidVLM은 vision-language model과 retrieval-augmented generation을 결합하여 휴머노이드 로봇이 egocentric 이미지로부터 task-specific impedance parameters와 gripper configuration을 자동으로 선택하는 적응형 조작 프레임워크이다.
본 논문은 VLM과 RAG를 humanoid manipulation에 효과적으로 적용하여 semantic perception과 compliant control을 처음 체계적으로 연결했으며, 높은 retrieval 정확도와 실제 로봇 실험을 통해 타당성을 입증했다. 다만 고정된 database 규모와 sensor 제약이 향후 확장성을 제한하는 점이 개선 대상이다.
INTENTION: Inferring Tendencies of Humanoid Robot Motion Through Interactive Intuition and Grounded VLM
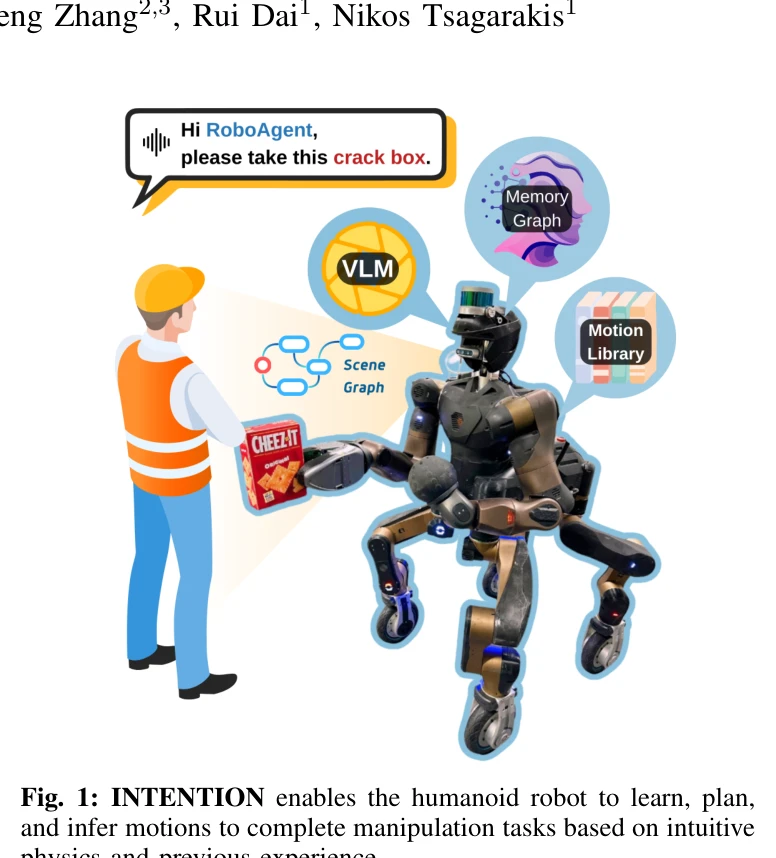
Fig. 1: INTENTION enables the humanoid robot to learn, plan,
 *Fig. 1: INTENTION enables the humanoid robot to learn, plan,* INTENTION은 Vision-Language Models 기반의 Intuitive Perceptor와 Memory Graph를 통합하여 휴머노이드 로봇이 상호작용 경험으로부터 직관적 물리 이해를 학습하고 새로운 조작 작업에 자율적으로 적응하는 프레임워크를 제안한다.
INTENTION은 VLM 기반 지각과 상호작용 메모리를 결합하여 휴머노이드 로봇의 적응형 조작을 혁신적으로 제시하는 연구로, 개념과 설계는 우수하나 실험적 검증과 기술적 세부 구현의 엄밀성 강화가 필요하다.
Unified Human-Scene Interaction via Prompted Chain-of-Contacts
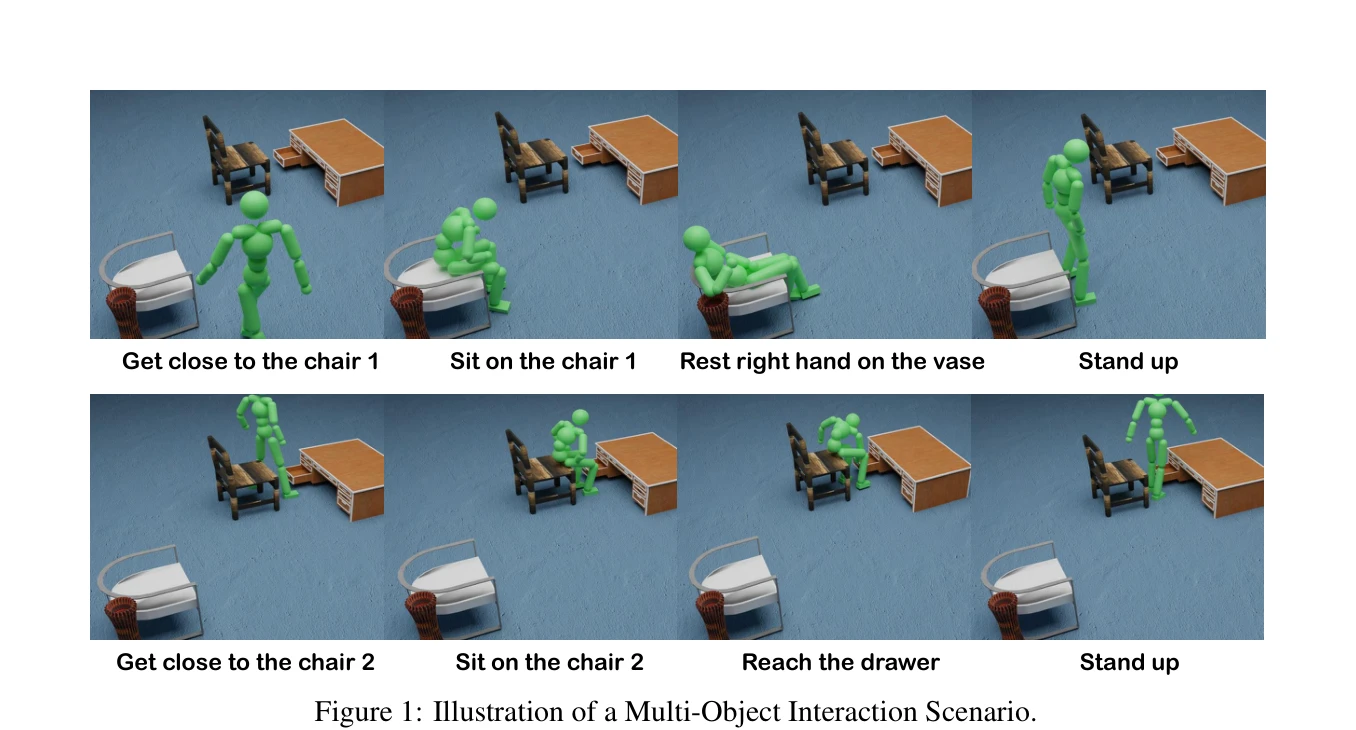
Figure 1: UniHSI facilitates unified and long-horizon control in response to natural language com-
 *Figure 2: Comprehensive Overview of UniHSI. The entire pipeline comprises two principal com-* UniHSI는 Large Language Model을 활용하여 자연어 명령을 Chain of Contacts (CoC)로 변환하고, 통합 컨트롤러를 통해 다양한 인간-장면 상호작용을 물리적으로 타당하게 수행하는 프레임워크를 제안한다.
UniHSI는 Chain of Contacts라는 새로운 상호작용 표현과 LLM 기반 계획 생성으로 자연어 명령 기반의 다양하고 장기간의 인간-장면 상호작용을 통합적으로 제어하는 혁신적 프레임워크이며, ICLR 2024 발표 논문으로서 embodied AI 분야에 의미 있는 기여를 제시한다.
GenerativeMPC: VLM-RAG-guided Whole-Body MPC with Virtual Impedance for Bimanual Mobile Manipulation
 *Fig. 3.* GenerativeMPC는 Vision-Language Model과 Retrieval-Augmented Generation을 활용하여 의미론적 장면 이해를 물리적 제어 파라미터로 변환하고, Whole-Body MPC와 통합 임피던스-어드미턴스 제어기를 통해 양팔 이동형 조작 로봇의 안전하고 맥락인식적인 제어를 실현한다.
GenerativeMPC는 의미론적 이해와 물리적 안전성을 체계적으로 통합하는 창의적 접근으로, VLM-RAG 기반 파라미터 생성과 경험 메모리의 신규 활용을 통해 양팔 이동형 조작 로봇의 인간중심 자율성을 크게 향상시킨다. 광범위한 시뮬레이션 및 실제 검증으로 신뢰성을 입증했으나, 실제 플랫폼 실험 확대와 분포 외 robustness 분석이 추가 필요하다.
Thinking in 360°: Humanoid Visual Search in the Wild
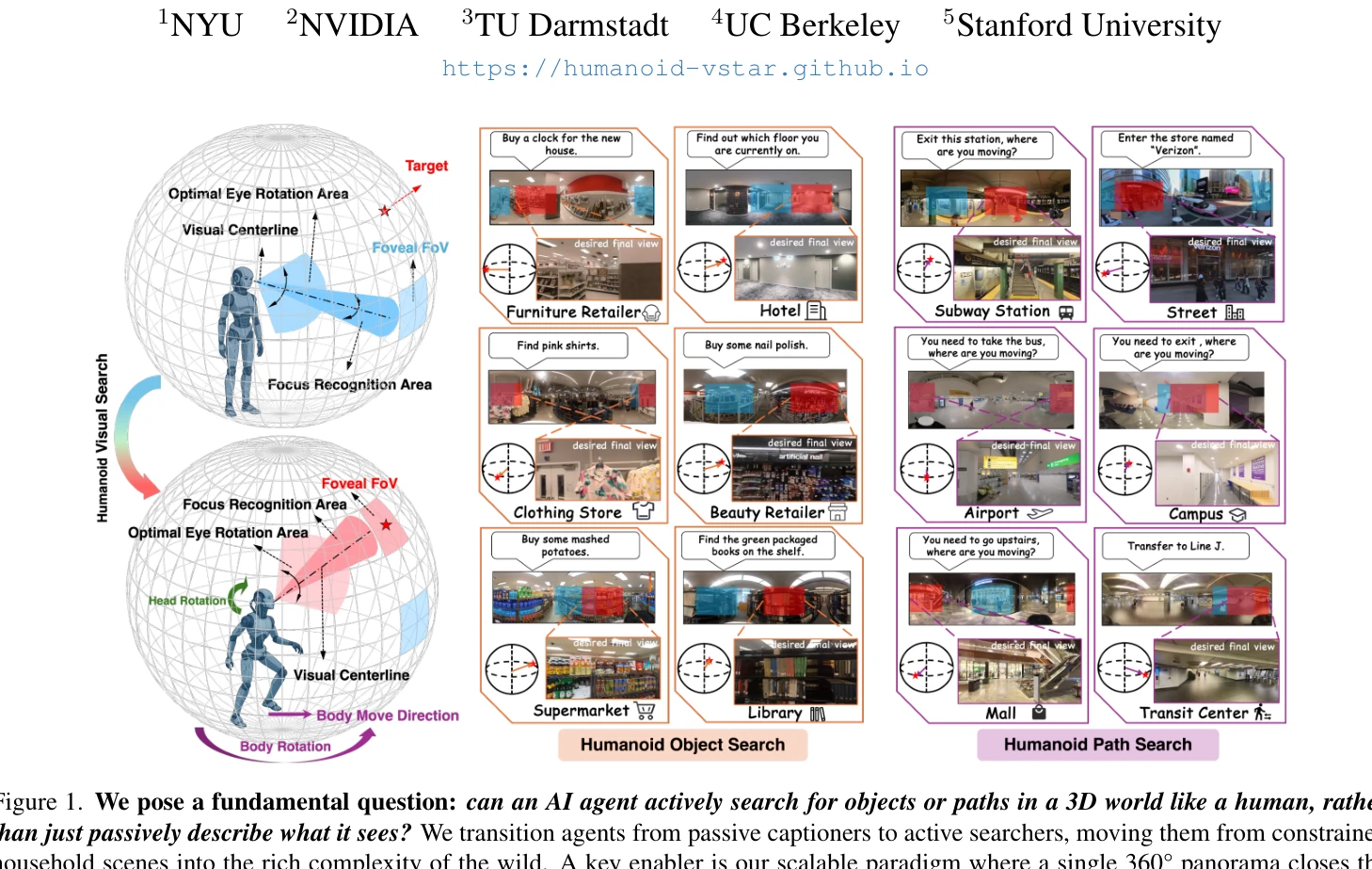
Figure 1. We pose a fundamental question: can an AI agent actively search for objects or paths in a 3D world like a huma
 *Figure 1. We pose a fundamental question: can an AI agent actively search for objects or paths in a 3D world like a huma* 인간처럼 360° 파노라마 환경에서 머리 회전을 통해 능동적으로 물체를 탐색하거나 경로를 찾는 embodied 시각 탐색 에이전트를 제안하고, 실내 장면을 넘어 지하철역·쇼핑몰·거리 등 복잡한 현실 환경을 대상으로 한 H*Bench 벤치마크를 구축했다.
humanoid visual search라는 새로운 embodied AI 문제를 정의하고 현실적이고 도전적인 H*Bench 벤치마크를 제시함으로써 MLLM 기반 에이전트의 공간 추론 능력을 체계적으로 평가할 수 있는 기틀을 마련했으며, SFT와 RL을 통한 성능 향상을 보여주되 남은 큰 도전과제도 명확히 규명한 높은 가치의 연구이다.
DIJIT: A Robotic Head for an Active Observer

Fig. 1.
 *Fig. 1.* 인간의 시각 체계를 모방한 생체모방 쌍안 로봇 헤드 DIJIT를 제시하며, 9개의 기계적 자유도와 4개의 광학적 자유도를 통해 능동적 시각 연구와 인간 시각의 안구-머리 운동을 탐구한다.
DIJIT은 인간 시각의 핵심 특성을 종합적으로 구현한 최초의 로봇 헤드로, 생체모방 설계와 실제 saccade 성능 평가를 통해 능동 시각 연구의 새로운 플랫폼을 제공한다. 완전 공개된 설계와 체계적인 비교 분석은 후속 로봇 시각 연구에 중요한 기여를 할 수 있다.
Hand-Eye Autonomous Delivery: Learning Humanoid Navigation, Locomotion and Reaching
 *Figure 2: System overview: HEAD consists of a high-level policy with two modules, navigation* 인간 모션 캡처와 에고센트릭 비전 데이터로부터 휴머노이드 로봇의 네비게이션, 로코모션, 리칭 능력을 학습하는 HEAD 프레임워크를 제안한다. 고수준 정책이 손과 눈의 목표 위치를 명령하고 저수준 whole-body controller가 추적하는 모듈식 접근법을 채택한다.
HEAD는 모듈식 설계와 sparse 3-point tracking을 통해 휴머노이드 로봇의 통합적 navigation, locomotion, reaching을 효과적으로 학습하는 창의적인 접근을 제시하며, 실제 로봇에서의 동작 검증으로 실용성을 입증한다. 다만 human 데이터 의존성과 정제 비용, 환경 일반화 가능성에 대한 추가 분석이 필요하다.
DIJIT: A Robotic Head for an Active Observer

Fig. 1.
 *Fig. 1.* 본 논문은 능동적 관찰자 역할을 수행하는 이동형 로봇을 위해 설계된 이중 카메라 로봇 헤드 DIJIT를 제시한다. DIJIT는 9개의 기계적 자유도와 4개의 광학적 자유도를 갖추고 있으며, 인간의 시각 체계와 유사한 범위와 속도의 카메라 운동이 가능하다.
DIJIT는 인간의 시각 체계를 포괄적으로 모방한 잘 설계된 로봇 헤드로, active vision 연구와 인간-기계 시각 비교를 위한 가치 있는 플랫폼을 제공한다. 특히 완전한 자유도 구현과 실용적인 saccade 제어 방법은 주목할 만하며, 오픈소스 공개로 인한 접근성도 강점이다.
ARMADA: Augmented Reality for Robot Manipulation and Robot-Free Data Acquisition

Fig. 1: Overview. (A) Human demonstrators wearing Apple Vision Pro can
 *Fig. 1: Overview. (A) Human demonstrators wearing Apple Vision Pro can* Apple Vision Pro의 AR을 활용하여 물리적 로봇 없이 로봇 조작 데이터를 수집하는 ARMADA 시스템을 제시하며, 실시간 로봇 피드백이 데이터 품질을 1.3%에서 71.1%로 향상시킨다.
ARMADA는 AR 기술을 창의적으로 활용하여 로봇 데이터 수집의 실제적 병목을 해결하는 혁신적 시스템을 제시하며, 실시간 피드백의 극적인 효과를 실증함으로써 대규모 로봇 학습의 새로운 가능성을 열었다.
ARMOR: Egocentric Perception for Humanoid Robot Collision Avoidance and Motion Planning

Fig. 1: ARMOR presents a novel egocentric wearable perception hardware and software system for humanoid robots (left).
 *Fig. 3: ARMOR’s egocentric perception hardware in simu-* 휴머노이드 로봇의 팔과 손에 분산 배치된 ToF 센서 기반의 자아중심 지각 시스템 ARMOR과 transformer 기반 모방학습 정책을 제시하여 밀집 환경에서의 충돌 회피 및 동작 계획을 수행한다.
휴머노이드 로봇의 지각-계획 문제를 분산 ToF 센서와 인간 중심의 imitation learning으로 창의적으로 해결하며, 실제 배포와 의미 있는 성능 향상으로 실용성 높은 연구이다. 다만 센서 배치 최적화와 sim-to-real gap 논의 강화가 필요하다.
DexHub and DART: Towards Internet Scale Robot Data Collection
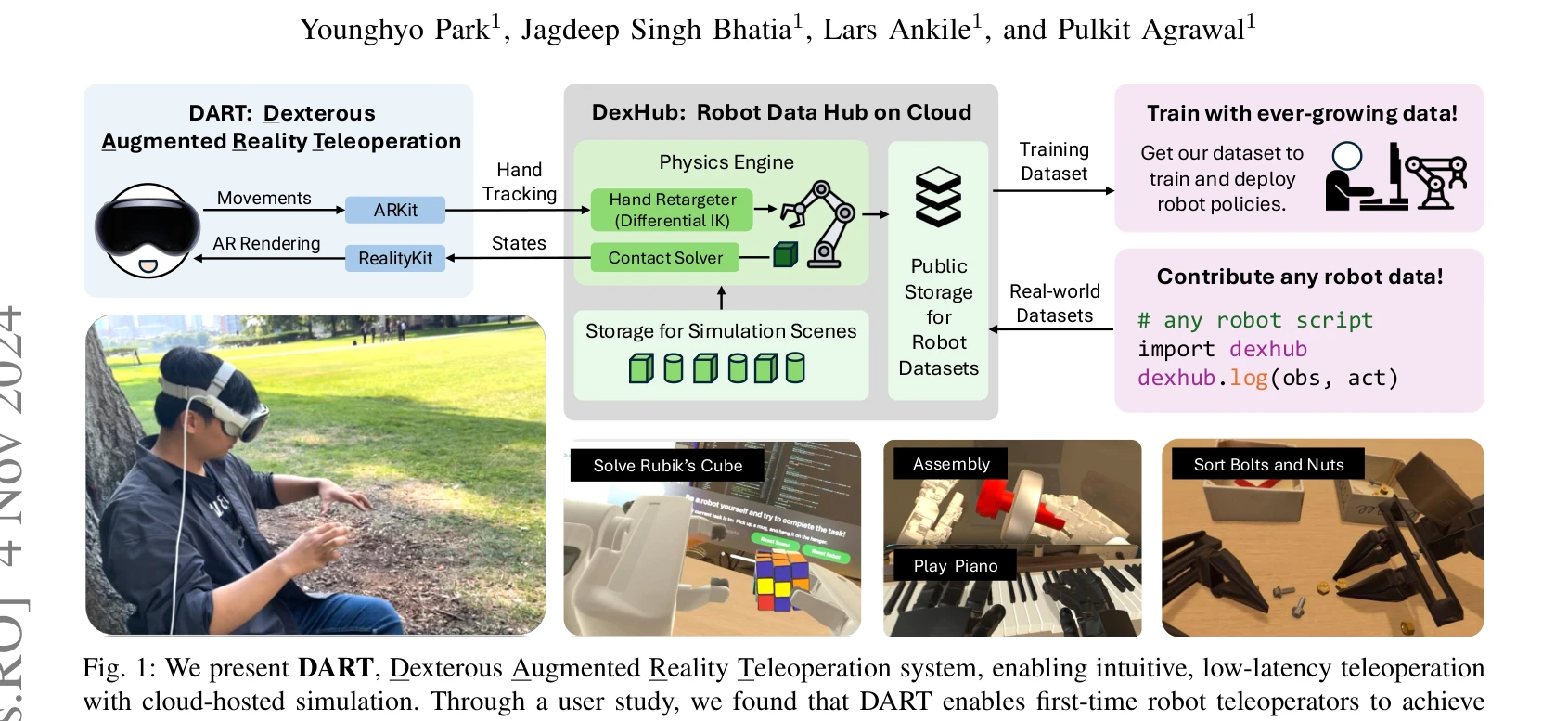
Fig. 1: We present DART, Dexterous Augmented Reality Teleoperation system, enabling intuitive, low-latency teleoperation
 *Fig. 1: We present DART, Dexterous Augmented Reality Teleoperation system, enabling intuitive, low-latency teleoperation* DART는 클라우드 기반 시뮬레이션과 AR을 활용한 군중기반 로봇 데이터 수집 플랫폼이며, DexHub는 수집된 데이터를 저장하는 공개 클라우드 데이터베이스이다.
본 논문은 AR과 클라우드 시뮬레이션을 창의적으로 결합하여 로봇 데이터 수집의 실질적 문제(지연, 피로, 확장성)를 해결하는 DART 플랫폼을 제시하며, DexHub를 통해 커뮤니티 규모의 데이터 생태계 구축을 시도한 점에서 높은 기여도를 가진다.
Learning Adaptive Neural Teleoperation for Humanoid Robots: From Inverse Kinematics to End-to-End Control
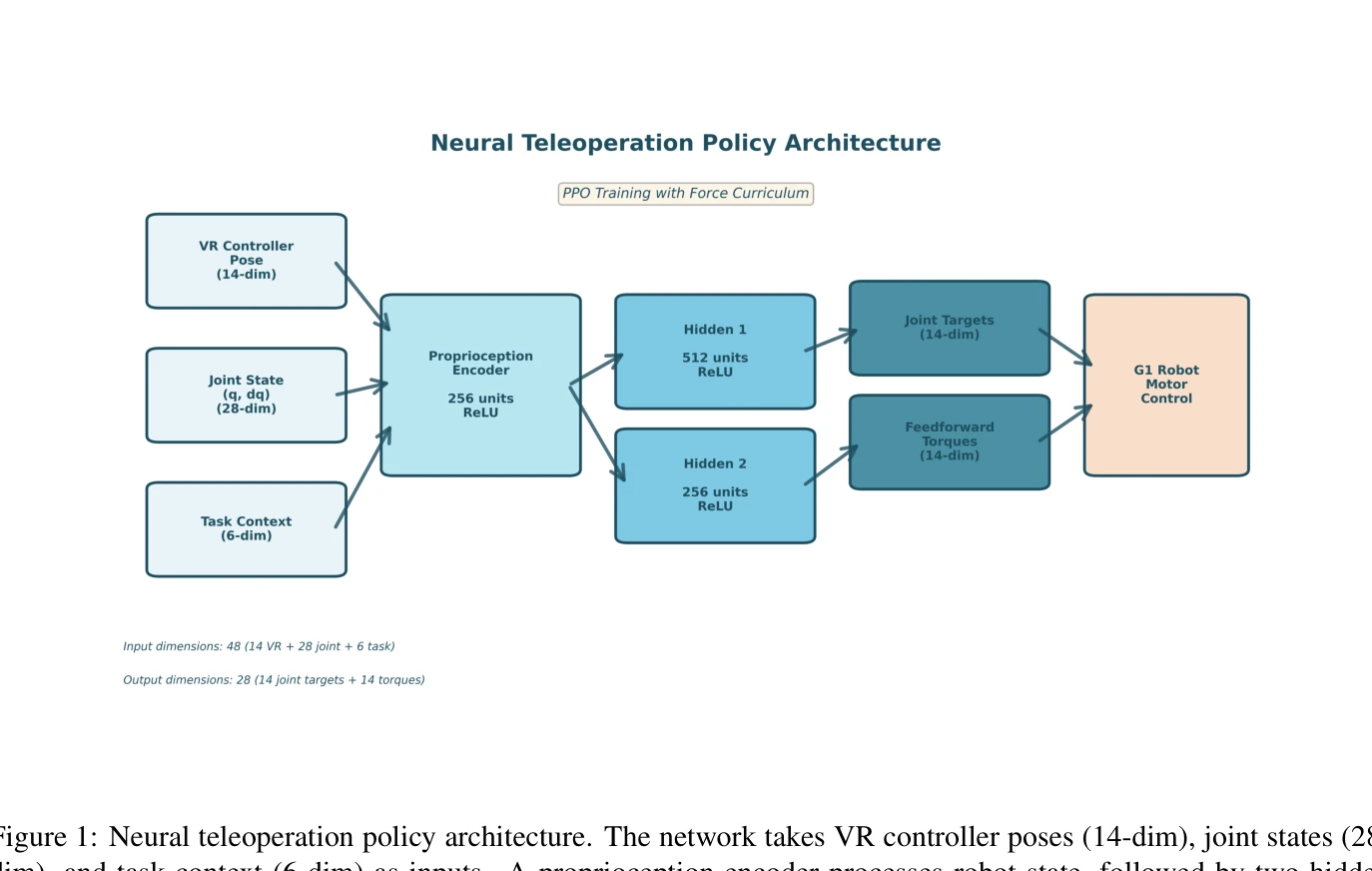
Figure 1: Neural teleoperation policy architecture. The network takes VR controller poses (14-dim), joint states (28-
 *Figure 1: Neural teleoperation policy architecture. The network takes VR controller poses (14-dim), joint states (28-* VR 텔레오퍼레이션에서 전통적인 IK+PD 파이프라인을 RL 기반 신경망 정책으로 대체하여 힘 적응, 궤적 부드러움, 사용자 적응을 동시에 달성하는 학습 기반 프레임워크를 제안한다.
학습 기반 신경망 정책으로 VR 텔레오퍼레이션의 근본적 한계를 해결하고 명확한 성능 향상을 보여주는 실질적으로 가치 있는 연구이며, 모방 학습과 교과 학습의 조합 설계가 우수하다.
Learning to Look Around: Enhancing Teleoperation and Learning with a Human-like Actuated Neck

Figure 1: A teleoperation system featuring an actuated neck and dexterous arms, enabling human-like manipu-
 *Figure 1: A teleoperation system featuring an actuated neck and dexterous arms, enabling human-like manipu-* 인간의 자연스러운 머리 움직임을 모방하는 5-DOF actuated neck을 원격 조종 시스템에 통합하여 작업자의 직관성 향상, 인지 부하 감소, 자율 정책 학습 개선을 달성하는 연구이다.
이 논문은 인간의 자연스러운 지각 능력을 원격 조종 시스템에 구현한 혁신적 접근으로, 직관성 향상과 자율 정책 학습 개선에 대한 실증적 증거를 제시한다. 다만 평가 작업의 범위 확대와 기술적 한계 개선을 통해 더욱 강화될 수 있다.
Open-TeleVision: Teleoperation with Immersive Active Visual Feedback

Figure 1: Autonomous and teleoperated sessions using our setup. a-e: robots executing long-
 *Figure 2: Teleoperated data collection and learning setup. Left: our teleoperation system. VR* Apple VisionPro 등 VR 기기를 활용하여 스테레오 영상 피드백과 로봇 헤드의 능동적 카메라 제어를 통해 직관적이고 몰입감 있는 원격 조종 시스템을 구현하고, 이를 통해 수집한 데이터로 모방 학습 정책을 훈련하여 복잡한 조작 작업을 자동화함.
본 논문은 VR 기반 능동적 헤드 카메라와 스테레오 영상 피드백을 통해 직관적이고 몰입감 있는 원격 조종 시스템을 제시하며, 이를 통해 수집한 데이터로 복잡한 조작 작업을 성공적으로 자동화할 수 있음을 입증함으로써 로봇 학습 데이터 수집 분야에 실질적인 기여를 함.
TWIST2: Scalable, Portable, and Holistic Humanoid Data Collection System

Fig. 1: We introduce TWIST2, a holistic humanoid data collection system designed with scalability and portability. TWIST
 *Fig. 1: We introduce TWIST2, a holistic humanoid data collection system designed with scalability and portability. TWIST* TWIST2는 mocap 없이 VR 기반의 포터블한 휴머노이드 텔레오퍼레이션 시스템으로, 전신 제어를 유지하면서 확장 가능한 데이터 수집을 가능하게 한다. 수집한 데이터로 hierarchical visuomotor policy를 학습하여 자율적인 전신 제어를 구현한다.
TWIST2는 휴머노이드 로봇의 대규모 데이터 수집 병목을 실질적으로 해결하는 혁신적인 시스템으로, 포터블성과 전신 제어의 오래된 trade-off를 극복했다. 완전 오픈소스 공개와 실증적 성과(whole-body dexterous manipulation, kick-T task)는 휴머노이드 로봇 학습 커뮤니티에 즉각적인 영향을 미칠 수 있는 중대한 기여다.
Design and Control of a Bipedal Robotic Character
Fig. 1.
 *Fig. 2.* 이 논문은 표현력 있는 예술적 동작과 강건한 동적 이동성을 결합한 이족 로봇 캐릭터의 설계 및 제어 시스템을 제시한다. Reinforcement Learning 기반 제어 구조와 실시간 애니메이션 엔진을 통해 로봇이 연극적 성능을 수행할 수 있도록 한다.
이 논문은 이족 로봇의 표현성과 동적 능력을 통합하는 혁신적인 설계 및 제어 파이프라인을 제시하며, 애니메이션과 로봇 공학의 교점에서 새로운 패러다임을 제안한다. 엔터테인ment 로보틱스와 휴먼-로봇 상호작용 분야에 중요한 기여를 하면서도 실제 시스템 구현을 통해 실용성을 입증했다.
iCub3 Avatar System: Enabling Remote Fully-Immersive Embodiment of Humanoid Robots
원격 위치에서 휴머노이드 로봇 iCub3을 구현화(embodiment)하는 완전한 아바타 시스템을 제시하며, 수백 km 떨어진 위치에서의 이동, 조작, 음성, 표정 제어와 시각, 청각, 촉각, 무게감 피드백을 통합한다.
본 논문은 휴머노이드 아바타의 완전한 신체 제어와 다중 감각 피드백을 통합하여 원격 현존감을 실현한 획기적인 시스템을 제시하며, 실제 환경에서의 대규모 검증을 통해 그 실용성을 입증했다. 네트워크 지연 처리와 embodiment 평가의 정량화 측면에서 개선의 여지가 있으나, 전체적으로 로보틱스와 텔레현존 분야에 중요한 기여를 한다.
Learning with pyCub: A Simulation and Exercise Framework for Humanoid Robotics
Fig. 1. An example of the simulation environment showing the iCub humanoid robot,
 *Fig. 1. An example of the simulation environment showing the iCub humanoid robot,* pyCub는 humanoid robot iCub의 Python 기반 physics 시뮬레이션 프레임워크로, YARP 미들웨어 없이 학생들이 humanoid robotics의 기초를 배울 수 있는 교육용 연습 문제들을 제공한다.
pyCub는 humanoid robotics 교육 접근성의 실질적 장벽을 Python과 단순화된 아키텍처로 제거한 가치 있는 오픈소스 프레임워크이며, 실제 교육 과정 검증과 완전한 공개를 통해 학술 커뮤니티에 즉시 활용 가능한 자원을 제공한다.
Alter-Art: Exploring Embodied Artistic Creation through a Robot Avatar
Figure 1: Some snapshots of applications in artistic scenarios: theatre (top),
 *Figure 1: Some snapshots of applications in artistic scenarios: theatre (top),* 본 논문은 반인간형 로봇 Alter-Ego를 통한 원격 몰입 예술 창작 패러다임인 Alter-Art를 제안한다. 무용, 연극, 회화 세 가지 예술 영역에서 전문 예술가들이 로봇 신체에 내재되어 창작하는 경험을 탐구하며, 구체적 현존감 형성과 로봇의 물리적 제약이 창작 과정에 미치는 영향을 분석한다.
본 논문은 로봇 예술의 새로운 패러다임인 Alter-Art를 명확히 정의하고, 실제 예술가들과의 협력을 통해 embodied creative experience의 가능성을 설득력 있게 시연한다. 로봇을 기계가 아닌 신체적 확장으로 재구성하는 철학적 관점과 구체적 기술 플랫폼의 통합이 돋보인다. 다만 표본 규모의 제한, 정성적 방법론의 보강 필요, 기술 세부사항의 추가 설명 등이 개선 과제이나, 사회 로봇과 telepresence 연구에 중요한 개념적 기여를 제시한다.
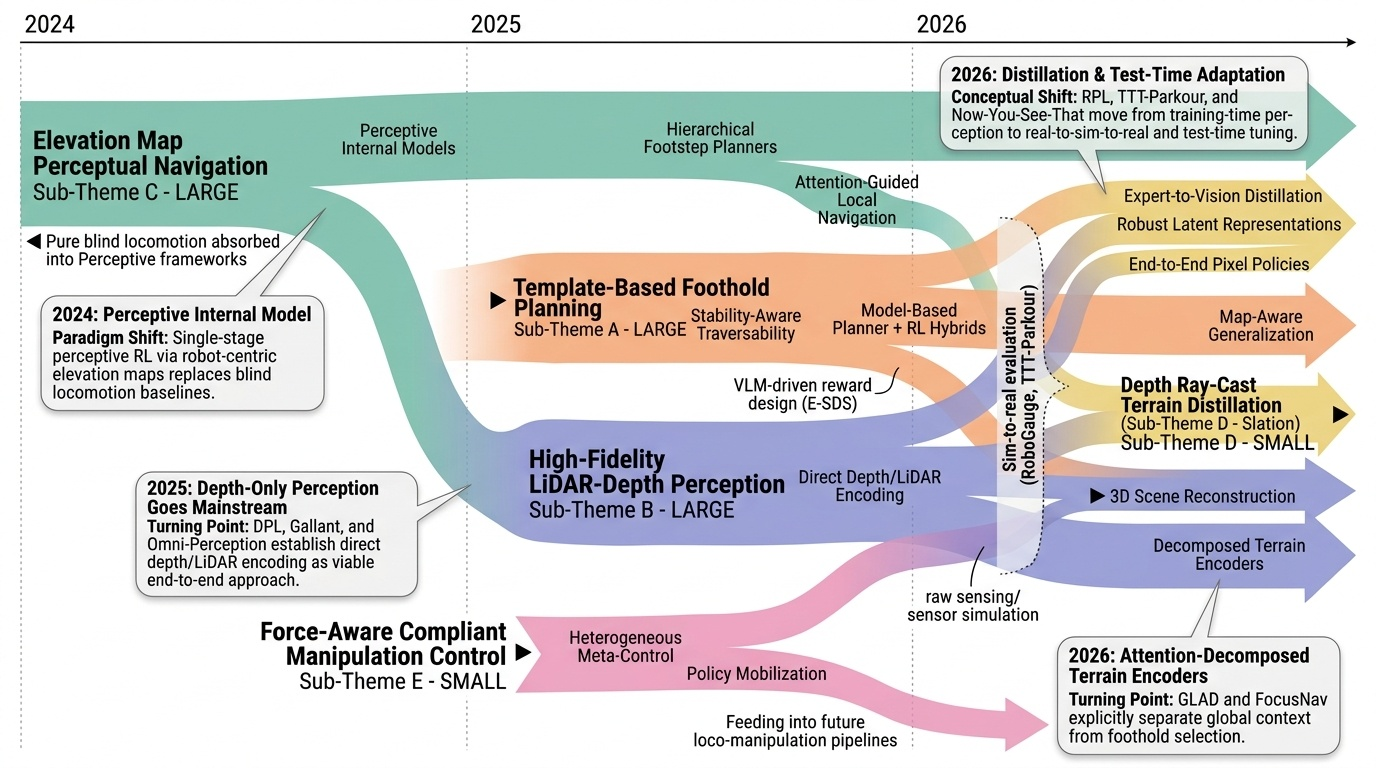
Category Overview
# Perceptive Terrain-Aware Robot Navigation 이 카테고리는 인간형 로봇이 복잡한 지형을 지각(perception)하고 안정적으로 이동하는 기술에 관한 연구를 다룬다. 로봇의 시각 센서와 내부 모델(internal model)을 활용하여 실시간으로 지형의 통과가능성(traversability)을 판단하고 보행 경로를 계획하는 방식이 핵심이다[1693][2056]. 계단 오르기, 좁은 길 통행, 플랫폼 점프 등 다양한 지형 조건에서 로봇의 이동성을 향상시키기 위해 강화학습(reinforcement learning)과 시뮬레이션(simulation) 기반 학습이 광범위하게 활용된다[1925][1804][2160]. 주목할 점은 sim-to-real 전이(transfer) 문제를 해결하기 위해 현실적인 깊이 카메라 시뮬레이션(depth camera simulation)과 메시 기반 모방 학습(mesh-based mimic learning) 등 기하학적 접근법이 도입되었다는 것이다[1884][2095]. 또한 메타 학습(meta-learning)과 혼합 전문가 모델(mixture of experts, MoE) 같은 고급 방식들이 다양한 환경 조건에 대한 적응성(generalization)을 개선하는 데 적용되고 있다[1843][1981][2151].
⚠ 갭: 야외 비정형 환경(비·안개·야간 등 악천후 조건)에서의 강건성 연구와 인간 군집 속에서의 사회적 내비게이션 능력을 결합한 연구가 거의 없다.
🏛 정책: 실외 복잡 환경 대응 자율 보행 기술 개발을 위한 다양한 실외 테스트 환경 구축과 공공 데이터셋 수집을 국가 차원에서 지원해야 한다.
Physics-Based Motion Imitation with Adversarial Differential Discriminators

Fig. 1. We propose an adversarial multi-objective optimization technique that enables physically simulated characters to
 *Fig. 1. We propose an adversarial multi-objective optimization technique that enables physically simulated characters to* Physics-based 캐릭터 애니메이션을 위해 Adversarial Differential Discriminator (ADD)를 통해 수동 보상 함수 설계 없이 다중 목표 최적화를 자동으로 수행하는 방법을 제시한다. 단일 positive sample(영점 벡터)만으로도 효과적으로 여러 목표를 동적으로 균형잡아 고난도 동작을 모방할 수 있다.
본 논문은 다중 목표 최적화의 자동화를 위해 창의적인 adversarial discriminator 설계를 제시하며, physics-based 캐릭터 애니메이션에서 수동 보상 함수 설계 제거를 통해 일반화 가능성을 크게 향상시킨다. 핵심 아이디어의 단순성과 광범위한 적용 가능성이 강점이다.
PILOT: A Perceptive Integrated Low-level Controller for Loco-manipulation over Unstructured Scenes
Fig. 1. Method overview of PILOT. We propose a unified single-stage reinforcement learning framework that seamlessly int
 *Fig. 1. Method overview of PILOT. We propose a unified single-stage reinforcement learning framework that seamlessly int* PILOT는 humanoid robot의 loco-manipulation을 위한 통합 단계 RL 프레임워크로, 지각 기반 locomotion과 전신 제어를 단일 policy로 통합하여 비정형 지형에서 안정적인 작업 실행을 가능하게 한다.
PILOT는 humanoid loco-manipulation 문제에 대한 통합적이고 실용적인 해결책을 제시하며, cross-modal perception과 MoE 구조를 통해 기술적 기여와 실제 로봇 구현의 성공적 사례를 보여준다.
PolySim: Bridging the Sim-to-Real Gap for Humanoid Control via Multi-Simulator Dynamics Randomization
 *Fig. 2: Visual illustration of PolySim. The pink star denotes* PolySim은 여러 이질적인 시뮬레이터를 병렬로 활용하여 훈련하는 플랫폼으로, 단일 시뮬레이터의 귀납적 편향을 완화하고 현실 세계로의 전이 갭을 줄인다.
PolySim은 다중 시뮬레이터 병렬 훈련을 통해 simulator inductive bias를 근본적으로 완화하는 혁신적 접근법이며, 견고한 이론적 근거와 실제 배포 성공으로 humanoid control의 현실 전이 문제 해결에 중요한 기여를 한다.
PPF: Pre-training and Preservative Fine-tuning of Humanoid Locomotion via Model-Assumption-based Regularization
Fig. 1.
 *Fig. 1.* 본 연구는 모델 기반 제어기의 모방학습(Pre-training)과 강화학습을 결합하되, 모델 가정이 성립하는 상태에서만 정규화하는 MAR(Model-Assumption-based Regularization)을 통해 인간형 로봇의 보행 정책을 학습하는 PPF 프레임워크를 제안한다.
본 논문은 모델 기반과 학습 기반 제어의 장점을 결합하면서 재앙적 망각을 완화하는 MAR이라는 창신적 정규화 기법을 제안하며, 실제 인간형 로봇에서 1.5 m/s의 고속 보행과 다양한 지형 강건성을 달성하여 실용적 가치가 높다.
Retargeting Matters: General Motion Retargeting for Humanoid Motion Tracking
 *Fig. 2: General Motion Retargeting (GMR) Pipeline.* 인간-휴머노이드 로봇 간 embodiment gap을 해결하기 위해 모션 retargeting 품질이 정책 성능에 미치는 영향을 체계적으로 평가하고, retargeting artifacts를 줄이는 새로운 방법 GMR을 제안한다.
본 연구는 humanoid motion tracking에서 그동안 간과되어온 retargeting 품질의 중요성을 체계적으로 입증하고, GMR을 통해 실질적 개선을 달성했다. 광범위한 평가 프레임워크와 명확한 발견은 향후 humanoid 학습 연구에 중요한 지침을 제공한다.
STATE-NAV: Stability-Aware Traversability Estimation for Bipedal Navigation on Rough Terrain
Figure 1: Overall diagram of the proposed traversability estimation and the navigation framework. A transformer-based bi
 *Figure 1: Overall diagram of the proposed traversability estimation and the navigation framework. A transformer-based bi* 이족 로봇의 불안정성을 예측하는 TravFormer 신경망을 개발하고, 안정성 기반 명령 속도를 traversability로 정의하여 거친 지형에서의 안전하고 효율적인 네비게이션을 실현한다.
이 논문은 이족 로봇의 안정성 기반 traversability 추정이라는 중요하면서도 미개척된 문제를 처음 체계적으로 다루며, BSFA 특성 식별부터 TravFormer 개발, 계층적 네비게이션 프레임워크까지 일관된 기술적 기여를 제시한다. 시뮬레이션과 실제 로봇 실험을 통한 검증이 견고하고, 안정성 기반 속도 표현이라는 혁신적 설계로 가중치 재조정 문제를 해결하여 실용적 가치가 높다.
SteadyTray: Learning Object Balancing Tasks in Humanoid Tray Transport via Residual Reinforcement Learning
 *Fig. 2: Overview of the ReST-RL framework. Base Policy Training: A locomotion policy is first trained to carry a tray wh* ReST-RL은 사전학습된 이족 보행 정책에 잔차 모듈을 추가하여 휴머노이드 로봇이 동적 보행 중 트레이 위의 불안정한 물체를 안정적으로 운반할 수 있도록 하는 계층적 강화학습 아키텍처이다.
ReST-RL은 보행 안정성을 보존하면서 payload 안정화를 분리 학습하는 우아한 설계로, 휴머노이드 로봇의 실제 서비스 응용(식음료 배송, 의료 기구 운반)에 필수적인 신뢰성 높은 물체 운반을 처음 성공적으로 시연했다.
Success in Humanoid Reinforcement Learning under Partial Observation
Figure 1 summarizes the training performance under three partial observability configurations:
 *Figure 1 summarizes the training performance under three partial observability configurations:* 부분 관찰 환경에서 고정 길이 과거 관찰 시퀀스를 병렬로 처리하는 novel history encoder를 제안하여, Gymnasium Humanoid-v4 환경에서 부분 관찰 하에서의 안정적인 humanoid 정책 학습을 처음으로 성공시켰다.
본 연구는 부분 관찰 환경에서의 고차원 humanoid 제어라는 미해결 문제를 처음으로 성공적으로 해결하며, 병렬 history encoder를 통해 기존 RNN 기반 메모리 방법들을 압도적으로 능가한다. 다만 방법론의 구체적 설명이 부족하고 실제 로봇 검증이 필요하다.
Unleashing Humanoid Reaching Potential via Real-world-Ready Skill Space

Fig. 1: (a) The humanoid showcases multiple real-world-ready primitive skills, including locomotion and body-pose-adjust
 *Fig. 1: (a) The humanoid showcases multiple real-world-ready primitive skills, including locomotion and body-pose-adjust* 휴머노이드 로봇의 대규모 도달 공간 확보를 위해 사전 학습된 원시 스킬들을 통합하는 Real-world-Ready Skill Space (R2S2)를 제안하며, CVAE 기반의 통일된 신경 스킬 표현을 통해 효율적이고 sim2real 전이 가능한 전신 제어를 실현한다.
이 논문은 휴머노이드 로봇의 대규모 도달 공간 실현이라는 중요한 문제를 실용적 관점에서 해결하며, 이질적 스킬 통합과 CVAE 기반 신경 스킬 표현이라는 참신한 기술을 통해 보상 엔지니어링 최소화와 강한 sim2real 전이를 동시에 달성한 우수한 연구이다.
AME-2: Agile and Generalized Legged Locomotion via Attention-Based Neural Map Encoding

Fig. 1. Our method enables agile and generalized legged locomotion across diverse terrains with onboard sensing and comp
 *Fig. 1. Our method enables agile and generalized legged locomotion across diverse terrains with onboard sensing and comp* AME-2는 Attention 기반 맵 인코더를 통합한 통합 RL 프레임워크로, 민첩성과 일반화를 동시에 달성하는 사족/이족 로봇 보행 제어 방법이다. 학습 기반의 불확실성 인식 elevation mapping 파이프라인과 teacher-student 학습 체계를 통해 sim-to-real 이전을 개선한다.
AME-2는 Attention 기반 맵 인코더와 불확실성 인식 elevation mapping을 통해 agile과 generalized 보행을 통합적으로 달성하는 우수한 프레임워크이며, quadruped과 biped 양쪽에서 실증된 강력한 일반화 능력과 sim-to-real 이전 효과를 입증함으로써 legged locomotion 분야에 중요한 기여를 한다.
APEX: Learning Adaptive High-Platform Traversal for Humanoid Robots
Fig. 1: The robot adaptively traverses high platforms of up to 0.8 m (≈114% of leg length) by leveraging diverse full-bo
 *Fig. 1: The robot adaptively traverses high platforms of up to 0.8 m (≈114% of leg length) by leveraging diverse full-bo* APEX는 humanoid 로봇이 다리 길이의 114%에 달하는 높은 플랫폼을 traversal할 수 있도록 하는 시스템으로, ratchet progress reward를 통해 학습한 6가지 기술(climb-up, climb-down, stand-up, lie-down, walking, crawling)을 하나의 정책으로 통합한다.
APEX는 humanoid 로봇의 고플랫폼 traversal에 대한 실질적 해결책을 제시하는 논문으로, 새로운 ratchet progress reward 공식과 다중기술 통합 framework가 창의적이며, 실제 로봇에서 다리 길이의 114%에 달하는 높이를 달성한 점이 매우 인상적이다. 다만 평가 환경이 상대적으로 제한적이고 더 복잡한 실제 환경으로의 확장성에 대한 검증이 필요하다.
BeamDojo: Learning Agile Humanoid Locomotion on Sparse Footholds

Fig. 1: Our proposed framework, BEAMDOJO, enables agile and robust humanoid locomotion across challenging sparse foothol
 *Fig. 1: Our proposed framework, BEAMDOJO, enables agile and robust humanoid locomotion across challenging sparse foothol* BeamDojo는 샘플링 기반의 다각형 발 보상 함수와 이중 critic 아키텍처를 결합한 2단계 강화학습 프레임워크로, 휴머노이드 로봇이 디딤돌과 같은 드문 디딤점을 가진 복잡한 지형에서 민첩하고 정밀한 보행을 학습하게 한다.
BeamDojo는 휴머노이드 로봇의 다각형 발 기하학을 명시적으로 처리하고 2단계 훈련으로 표본 효율성을 높인 혁신적인 프레임워크로, 시뮬레이션과 실제 로봇 실험을 통해 sparse foothold에서의 민첩한 보행 능력을 입증하여 로봇 보행 제어 분야에 중요한 기여를 한다.
Booster Gym: An End-to-End Reinforcement Learning Framework for Humanoid Robot Locomotion

Fig. 1: Training, testing, and deployment on Booster T1
 *Fig. 1: Training, testing, and deployment on Booster T1* Booster Gym은 시뮬레이션에서 실제 로봇까지 humanoid robot locomotion을 위한 RL 기반 정책을 훈련하고 배포하는 end-to-end 프레임워크를 제시한다. 이 프레임워크는 domain randomization, 보상 함수 설계, parallel structures 처리 등을 포함하며 Booster T1 로봇에서 omnidirectional walking, disturbance resistance, terrain adaptability를 달성했다.
이 논문은 humanoid robot locomotion의 RL 기반 훈련과 배포를 위한 실용적이고 완전한 오픈소스 프레임워크를 제시하며, 다중 시뮬레이터 검증과 실제 로봇 배포를 통해 실용성을 입증한다. 학술적 기여는 제한적이지만 로보틱스 커뮤니티에 즉시 활용 가능한 도구를 제공하는 점에서 가치 있다.
Collision-Free Humanoid Traversal in Cluttered Indoor Scenes
Fig. 1: Using a single generalist policy, our humanoid robot achieves collision-free traversal in cluttered indoor envir
 *Fig. 2: Overall pipeline. We learn a visuomotor policy that maps diverse obstacle geometries and spatial layouts to* 인간형 로봇이 어수선한 실내 환경에서 장애물을 피하며 이동할 수 있도록 Humanoid Potential Field (HumanoidPF)를 제안하고, 하이브리드 장면 생성 방식과 RL 기반 학습으로 현실 세계에 성공적으로 전이시킨 연구이다.
이 논문은 humanoid 로봇의 현실적 실내 이동이라는 중요한 문제를 체계적으로 처음 다루면서, HumanoidPF라는 창의적이고 효과적인 표현 방식과 하이브리드 scene generation을 통해 실제 로봇에의 성공적 전이를 보여준다. 기술적 깊이, 실험의 포괄성, 그리고 실용적 가치 측면에서 humanoid robotics 분야에 상당한 기여를 하는 우수한 연구이다.
DiffCoTune: Differentiable Co-Tuning for Cross-domain Robot Control
Fig. 1: Overview of the proposed automated co-tuning approach for
 *Fig. 1: Overview of the proposed automated co-tuning approach for* 로봇 컨트롤러의 시뮬레이션-실제 환경 간 성능 격차를 해결하기 위해 differentiable simulator를 활용한 gradient 기반 co-tuning 프레임워크를 제안하며, 컨트롤러와 시뮬레이터 매개변수를 동시에 최적화하여 적은 시행횟수로 체계적인 도메인 전이를 가능하게 한다.
본 논문은 로봇 도메인 전이의 실질적 문제를 differentiable simulator 기반의 우아한 co-tuning 프레임워크로 해결하며, 다양한 컨트롤러와 시스템에서의 광범위한 실험을 통해 실용성을 입증한 기여도 높은 연구이다.
Ego-Vision World Model for Humanoid Contact Planning
 *Fig. 2: World Model Training Pipeline. The pipeline begins with the offline data collection process shown in (a), where * 휴머노이드 로봇이 접촉을 활용하는 지능형 계획을 수립하기 위해 학습된 world model을 sampling-based MPC와 결합한 프레임워크를 제안하며, 오프라인 데이터셋으로부터 압축된 latent space에서 미래 결과를 예측한다.
휴머노이드의 접촉 활용 계획을 위해 world model과 value-guided MPC를 효과적으로 결합하여 샘플 효율성과 다중 작업 능력을 동시에 달성한 우수한 연구로, 실제 로봇 배포를 통해 실용성을 입증했으나 계획 수평선 제약과 시뮬-현실 갭에 대한 추가 분석이 필요하다.
End-to-End Humanoid Robot Safe and Comfortable Locomotion Policy
Fig. 1.
 *Fig. 1.* 휴머노이드 로봇의 안전하고 편안한 네비게이션을 위해 LiDAR 포인트 클라우드를 모터 커맨드로 직접 매핑하는 end-to-end 정책을 제시하며, CMDP 프레임워크에서 CBF 원리를 비용 함수로 변환하여 P3O로 안전 제약을 강제한다.
본 논문은 LiDAR 기반 end-to-end 정책, CBF-CMDP-P3O 통합 프레임워크, HRI 기반 편안함 설계를 통해 휴머노이드 로봇의 안전하고 사회적으로 수용 가능한 네비게이션 문제를 종합적으로 해결한 강력한 기여를 제시한다. 형식적 안전 보장과 실제 배포의 균형을 잘 맞추었으며, 다만 비선형 동역학과 도메인 갭 분석 강화가 필요하다.
FastStair: Learning to Run Up Stairs with Humanoid Robots

Fig. 1.
 *Fig. 2.* FastStair는 model-based foothold planner와 model-free RL을 통합하여 humanoid robot의 고속 계단 등반을 실현하는 다단계 학습 프레임워크이다. DCM 기반 planner로 탐색을 안내하고 speed-specialized experts와 LoRA를 통해 보수성을 완화한다.
FastStair는 model-based 안정성과 learning-based 민첩성의 근본적 상충을 다단계 학습과 LoRA 기반 통합으로 우아하게 해결한 혁신적 프레임워크이다. 실제 로봇 배포와 경쟁 우승으로 실용성이 입증되었다.
Geometry-Aware Predictive Safety Filters on Humanoids: From Poisson Safety Functions to CBF Constrained MPC
Fig. 1.
 *Fig. 1.* 본 논문은 Poisson safety function을 기반으로 한 geometry-aware predictive safety filter를 제안하며, CBF constrained MPC를 통해 humanoid 및 quadruped 로봇의 실시간 안전한 궤적 생성을 구현한다.
본 논문은 Poisson safety function을 시간-동적 환경과 로봇 기하학에 맞게 확장하고 MPC+CBF와 통합하여 실시간 안전한 자율 네비게이션을 실현한 우수한 연구이다. 이론적 확장과 실제 로봇 검증이 잘 균형을 이루고 있으며, 안전-임계 로봇 제어의 실질적 문제 해결에 기여한다.
HiFAR: Multi-Stage Curriculum Learning for High-Dynamics Humanoid Fall Recovery
Fig. 1.
 *Fig. 1.* HiFAR는 다단계 커리큘럼 학습 프레임워크를 통해 휴머노이드 로봇의 자율적 낙상 회복을 학습하는 방법을 제시하며, 저차원 태스크에서 시작하여 고차원 배포 시나리오로 점진적으로 확장한다.
HiFAR은 다단계 커리큘럼 학습과 KSI, reward shaping을 효과적으로 결합하여 복잡한 고차원 낙상 회복 문제를 체계적으로 해결하며, 실제 로봇 검증을 통해 높은 실용성과 견고성을 입증한 우수한 연구이다.
Learning Soccer Skills for Humanoid Robots: A Progressive Perception-Action Framework
 *Fig. 2: Overview of the Perception-Action integrated Decision-making (PAiD) framework. Our pipeline progressively acquir* 본 논문은 humanoid robot이 human-like kicking과 whole-body balance를 동시에 수행하는 soccer skill을 습득하기 위해, 세 단계로 구성된 Perception-Action integrated Decision-making (PAiD) 프레임워크를 제안한다.
본 논문은 humanoid robot의 복잡한 embodied skill 습득을 위한 체계적인 progressive framework를 제시하며, motion tracking-perception integration-sim-to-real transfer의 세 단계 분해를 통해 기존 방식의 training instability와 reward conflict를 효과적으로 해결한다. 91.3% 성공률의 robust real-world kicking 성능과 diverse condition에서의 일관성은 제안 방법의 효과를 입증하며, divide-and-conquer 전략은 향후 complex embodied skill 습득의 scalable framework로 활용 가능하다.
MoRE: Mixture of Residual Experts for Humanoid Lifelike Gaits Learning on Complex Terrains

Fig. 1. Our framework leverages a two-stage training pipeline and the mixture
 *Fig. 2.* 휴머노이드 로봇이 복잡한 지형을 인간다운 보행으로 횡단하기 위해 Mixture of Residual Experts (MoRE)와 다중 판별자를 활용한 2단계 RL 학습 프레임워크를 제안한다.
본 논문은 복잡 지형 횡단과 인간다운 다중 보행 학습을 동시에 달성하는 통합적 프레임워크를 제시하며, MoE 기반 residual 접근법과 다중 판별자 활용으로 방법론적 독창성을 보인다. 실제 로봇 배포 검증과 함께 기술적으로 견고하고 실무적 중요성이 높은 연구이다.
No More Marching: Learning Humanoid Locomotion for Short-Range SE(2) Targets

Fig. 1: Overview of our approach for short-range SE(2)-target
 *Fig. 1: Overview of our approach for short-range SE(2)-target* 본 논문은 휴머노이드 로봇의 단거리 SE(2) 목표 위치 도달을 위해 constellation 기반 보상 함수를 활용한 강화학습 접근법을 제시하며, 속도 추적 기반의 기존 방법들이 생성하는 비효율적인 행진 동작을 제거한다.
이 논문은 단거리 SE(2) 목표 도달이라는 실제 작업에 특화된 새로운 보상 함수와 RL 접근법을 제시하며, 직관적인 설계와 sim-to-real 전이 성공으로 휴머노이드 로봇의 실무 적용 가능성을 크게 향상시킨다.
OmniRetarget: Interaction-Preserving Data Generation for Humanoid Whole-Body Loco-Manipulation and Scene Interaction
Fig. 1:
 *Fig. 2: OMNIRETARGET overview. Human demonstrations are retargeted to the robot via interaction-mesh–based* OmniRetarget은 interaction mesh 기반의 제약 최적화를 통해 human motion을 humanoid robot을 위한 고품질 kinematic reference로 retarget하며, 상호작용을 보존하면서 단일 시연으로부터 다양한 로봇 구체화, 지형, 물체 설정으로 효율적인 data augmentation을 수행한다.
OmniRetarget은 interaction-preserving motion retargeting과 체계적 data augmentation을 통해 humanoid robot 제어의 데이터 병목을 해결하는 실질적이고 영향력 있는 기여이며, 최소한의 reward engineering으로 complex whole-body loco-manipulation 기술의 zero-shot sim-to-real transfer를 성공적으로 입증하여 로보틱스 커뮤니티에 매우 유용한 공개 도구 및 데이터셋을 제공한다.
Toward Reliable Sim-to-Real Predictability for MoE-based Robust Quadrupedal Locomotion
Fig. 1:
 *Fig. 1:* 본 논문은 Mixture-of-Experts (MoE) 기반 사족 로봇 이동 정책과 sim-to-real 전이 가능성을 정량화하는 RoboGauge 평가 프레임워크를 통합하여 신뢰할 수 있는 시뮬레이션-실제 간 갭을 해소하는 통합 프레임워크를 제시한다.
본 논문은 MoE 기반 정책과 RoboGauge 평가 프레임워크를 통합하여 sim-to-real 갭 문제를 체계적으로 해결하고, 극한 지형에서 4 m/s의 견고한 이동 성능을 입증함으로써 사족 로봇 이동 제어 분야에 유의미한 기여를 한다.
Traversing Narrow Paths: A Two-Stage Reinforcement Learning Framework for Robust and Safe Humanoid Walking
Fig. 1: Overview. The proposed framework uses 3D-LIPM
 *Fig. 1: Overview. The proposed framework uses 3D-LIPM* 이 논문은 humanoid 로봇이 좁은 경로를 안전하게 통과하도록 하는 두 단계 reinforcement learning 프레임워크를 제안하며, physics-기반 LIPM foothold planner와 RL 기반 foothold tracker/modifier를 결합한다.
이 논문은 physics-기반 모델과 reinforcement learning을 창의적으로 결합하여 안전하고 해석 가능한 narrow path traversal을 달성했으며, 실제 humanoid robot에서 높은 성공률로 검증함으로써 로봇 제어의 실질적 응용 가치를 입증했다.
BiCoord: 장기간 시공간 협응 양팔 조작 벤치마크
Figure 1: Overview of BiCoord. (a) The data generation pipeline. (b) An example trajectory of Cook task is exhibited. Ea
 *Figure 1: Overview of BiCoord. (a) The data generation pipeline. (b) An example trajectory of Cook task is exhibited. Ea* 본 논문은 장기간 고도로 협응되는 양팔 조작 작업을 평가하기 위한 벤치마크 BiCoord를 제안한다. 기존 벤치마크는 단기간의 느슨한 협응 작업만 포함하는 반면, BiCoord는 연속적 팔 의존성과 동적 역할 교환이 필요한 복잡한 다단계 작업들을 제공한다.
본 논문은 양팔 조작 연구의 중요한 공백을 채우는 포괄적이고 잘 설계된 벤치마크를 제시한다. 장기간 고결합 작업, 명시적인 협응 특성 정의, 다각적 정량 메트릭 등이 커뮤니티에 상당한 기여를 할 것으로 기대된다.
BiCoord: 장기간 시공간 협응 양팔 조작 벤치마크
Figure 1: Overview of BiCoord. (a) The data generation pipeline. (b) An example trajectory of Cook task is exhibited. Ea
 *Figure 1: Overview of BiCoord. (a) The data generation pipeline. (b) An example trajectory of Cook task is exhibited. Ea* 본 논문은 장시간의 강한 시공간 협응을 요구하는 양팔 조작 작업을 평가하기 위한 BiCoord 벤치마크를 제시한다. 기존 벤치마크의 단기 및 약결합 작업의 한계를 극복하고자 phased coupling, spatial-temporal constraint, predictive coordination 특성을 반영한 과제를 설계했으며, 시간적·공간적·시공간 복합 메트릭을 제안한다.
BiCoord는 양팔 로봇 조작 분야에서 기존의 단기 약결합 벤치마크의 공백을 효과적으로 메우며, 장시간 강결합 협응 작업 평가를 위한 체계적 프레임워크를 제공한다. 새로운 메트릭과 포괄적 실험을 통해 현존 정책의 한계를 명확히 드러내고 향후 협응 인식 모델 개발에 의미 있는 기준점을 제시한다. 다만 시뮬레이션의 물리적 한계, 실제 로봇으로의 전이 가능성 검증, 그리고 협응 특화 학습 방법의 부재는 보완이 필요한 부분이다.
PolygMap: A Perceptive Locomotion Framework for Humanoid Robot Stair Climbing
 *Fig. 2: The system integrates joint recorders, depth sensing and LIO estimator. Robot pose is obtained via fusing forwar* PolygMap은 LiDAR, RGB-D 카메라, IMU를 융합하여 실시간 다각형 계단 평면 의미지도를 구축하고, 이를 기반으로 인간형 로봇의 계단 등반을 위한 발디딤 계획을 수행하는 지각 기반 보행 계획 프레임워크이다.
PolygMap은 다중 센서 융합을 통해 계단 환경의 인식 불확실성을 효과적으로 대응하고, 실시간 의미지도 생성과 안전 제약 기반 발디딤 계획을 실현함으로써 인간형 로봇의 신뢰성 있는 계단 등반을 달성했다. 실제 환경 검증과 NVIDIA Orin 구현을 통해 실용성을 입증한 점에서 높은 가치가 있으나, 특정 표면 재질에 대한 견고성 개선과 더 높은 갱신률이 향후 과제이다.
Real-Time Polygonal Semantic Mapping for Humanoid Robot Stair Climbing

Fig. 1: Planar polygon semantic mapping results of spiral
 *Fig. 2: Overview of the Planar Polygonal Semantic Mapping System Framework. The system inputs are depth images and* 인형로봇의 계단 등반을 위해 GPU 가속 anisotropic diffusion 필터링과 RANSAC 기반 평면 추출을 활용한 실시간 다각형 의미 맵핑 알고리즘을 제시한다.
본 논문은 GPU 가속을 활용한 anisotropic diffusion 필터링과 RANSAC 기반 다각형 추출을 결합하여 인형로봇의 복잡한 지형 네비게이션을 위한 실시간 의미 맵핑 문제를 효과적으로 해결했다. 시뮬레이션과 실제 센서 데이터 간의 성능 격차를 줄이고 로봇의 안전한 보행 계획을 지원하는 실용적인 시스템으로서의 가치가 크다.
RGMP: Recurrent Geometric-prior Multimodal Policy for Generalizable Humanoid Robot Manipulation
Figure 1: Overview of our framework. By applying seman-
 *Figure 2: Pipeline of RGMP. Upon receiving a speech command, the robot utilizes GSS to identify and localize the target* 기하학적 추론과 데이터 효율성을 결합한 RGMP는 humanoid robot 조작을 위해 Geometric-prior Skill Selector와 Adaptive Recursive Gaussian Network를 통합하여 87% 성공률과 5배 데이터 효율을 달성한다.
RGMP는 기하학적 추론과 데이터 효율성의 결합을 통해 humanoid robot 조작의 중요한 문제를 해결하며, GSS와 ARGN의 설계가 정교하고 실제 로봇에서 strong empirical result를 달성한 우수한 연구이다. 다만 기하학적 제약의 자동화와 더 광범위한 실증 평가가 이루어진다면 더욱 강력할 것으로 판단된다.
ARMOR: Egocentric Perception for Humanoid Robot Collision Avoidance and Motion Planning
Fig. 1: ARMOR presents a novel egocentric wearable perception hardware and software system for humanoid robots (left).
 *Fig. 3: ARMOR’s egocentric perception hardware in simu-* 휴머노이드 로봇의 팔과 손에 분산 배치된 ToF 센서 기반의 자아중심 지각 시스템 ARMOR과 transformer 기반 모방학습 정책을 제시하여 밀집 환경에서의 충돌 회피 및 동작 계획을 수행한다.
휴머노이드 로봇의 지각-계획 문제를 분산 ToF 센서와 인간 중심의 imitation learning으로 창의적으로 해결하며, 실제 배포와 의미 있는 성능 향상으로 실용성 높은 연구이다. 다만 센서 배치 최적화와 sim-to-real gap 논의 강화가 필요하다.
DPL: Depth-only Perceptive Humanoid Locomotion via Realistic Depth Synthesis and Cross-Attention Terrain Reconstruction
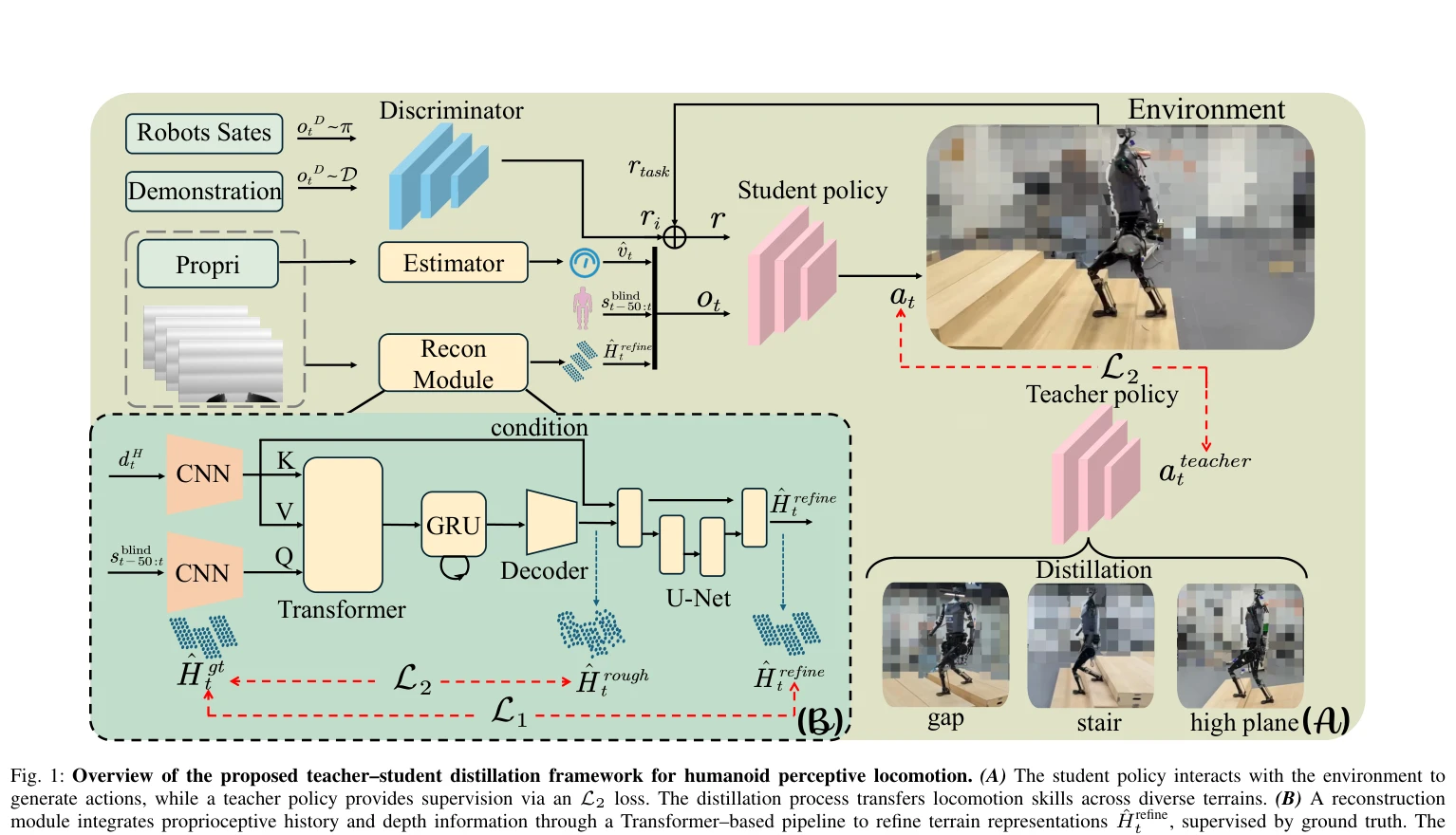
Fig. 1: Overview of the proposed teacher–student distillation framework for humanoid perceptive locomotion. (A) The stud
 *Fig. 1: Overview of the proposed teacher–student distillation framework for humanoid perceptive locomotion. (A) The stud* 휴머노이드 로봇의 깊이 이미지만을 사용한 지형 인식 보행을 위해, 현실적인 깊이 합성과 cross-attention transformer를 결합하여 사전 학습된 blind policy를 기반으로 효율적인 정책 학습을 가능하게 한다.
이 논문은 humanoid 로봇의 깊이 기반 보행에서 sim-to-real gap과 효율성 문제를 체계적으로 해결하는 통합 프레임워크를 제시하며, self-occlusion-aware 깊이 합성, cross-modal transformer, end-to-end fine-tuning의 조합으로 높은 독창성과 실용성을 달성했다. 실제 로봇 검증과 명확한 기술 기여가 돋보이는 우수한 연구이다.
Gallant: Voxel Grid-based Humanoid Locomotion and Local-navigation across 3D Constrained Terrains
Figure 1. Overview. Gallant enables a single policy with voxel grids to traverse diverse 3D constrained terrains: (a) as
 *Figure 1. Overview. Gallant enables a single policy with voxel grids to traverse diverse 3D constrained terrains: (a) as* Gallant는 Voxel Grid 기반의 LiDAR 인식과 z-grouped 2D CNN을 활용하여 인간형 로봇이 계단, 천장, 측면 장애물 등 3D 제약 지형을 단일 정책으로 횡단할 수 있게 하는 프레임워크이다.
Gallant는 Voxel Grid와 효율적 CNN을 결합하여 인간형 로봇의 3D 지형 인식 문제를 체계적으로 해결하고, 고충실도 시뮬레이션과 end-to-end 최적화로 sim-to-real 일관성을 달성한 임팩트 있는 연구이다. 다만 실시간 성능과 지형 일반화의 추가 검증이 필요하다.
GaussGym: An open-source real-to-sim framework for learning locomotion from pixels
Figure 1: GaussGym constructs photorealistic worlds from various data sources and renders them
 *Figure 1: GaussGym constructs photorealistic worlds from various data sources and renders them* 3D Gaussian Splatting을 IsaacGym 같은 벡터화된 물리 시뮬레이터에 통합하여 초당 100,000스텝 이상의 고속 시뮬레이션과 높은 시각적 충실도를 동시에 달성하는 포토리얼리스틱 로봇 시뮬레이션 프레임워크를 제시한다.
본 논문은 3D Gaussian Splatting을 물리 시뮬레이터와 통합하여 고속성과 시각적 충실도를 동시에 달성한 획기적인 작업으로, 포토리얼리스틱 로봇 학습에 새로운 가능성을 열었다. 오픈소스 공개와 광범위한 데이터 지원으로 향후 연구의 기반이 될 것으로 기대된다.
Generalizable Geometric Prior and Recurrent Spiking Feature Learning for Humanoid Robot Manipulation
Fig. 1. Overview of our framework. By integrating geometric common-
 *Fig. 1. Overview of our framework. By integrating geometric common-* RGMP-S는 기하학적 선행 정보와 spiking 신경망을 결합하여 인간형 로봇 조작을 위한 고수준 의미론적 추론과 저수준 동작 생성을 동시에 달성하는 프레임워크다.
RGMP-S는 기하학적 추론과 spiking neural network을 창의적으로 결합하여 인간형 로봇 조작에서 기술 가능성 검증과 데이터 효율성이라는 두 가지 근본적 도전을 동시에 해결한다. 다양한 실제 로봇 플랫폼에서의 광범위한 검증과 19% 성능 향상, 5배 데이터 효율성 개선은 높은 실용적 가치를 입증한다.
Hiking in the Wild: A Scalable Perceptive Parkour Framework for Humanoids

Fig. 1: Hiking in the Wild. Our framework enables a humanoid robot to traverse diverse terrains in both indoor and outdo
 *Fig. 2: System overview. Our framework trains an end-to-end policy using simulated depth and proprioception. To ensure* 이 논문은 깊이 카메라와 proprioception을 직접 joint actions으로 변환하는 end-to-end RL 프레임워크를 제시하여, 외부 상태 추정 없이 humanoid 로봇이 복잡한 비정형 지형에서 최대 2.5 m/s의 속도로 안전하게 이동할 수 있게 한다.
이 논문은 humanoid 로봇의 야외 주행을 위한 실용적이고 확장 가능한 end-to-end RL 프레임워크를 제시하며, Terrain Edge Detection, Foot Volume Points, Flat Patch Sampling 등 novel 메커니즘으로 safety와 reward hacking 문제를 효과적으로 해결한다. Open-source 배포와 실제 로봇 검증을 통해 높은 재현성과 실용성을 입증한 우수한 연구이다.
Humanoid Occupancy: Enabling A Generalized Multimodal Occupancy Perception System on Humanoid Robots
Figure 1: Schematic diagram of the Humanoid Occupancy system.
 *Figure 1: Schematic diagram of the Humanoid Occupancy system.* 휴머노이드 로봇을 위한 일반화된 다중모달 occupancy 인식 시스템을 제시하며, 하드웨어 설계, 데이터셋 구축, 다중모달 fusion 네트워크를 통합한 완전한 환경 인식 프레임워크를 제공한다.
본 논문은 휴머노이드 로봇의 독특한 구조적 도전과제를 해결하는 실질적이고 포괄적인 occupancy 기반 인식 시스템을 제시하며, 첫 번째 휴머노이드 로봇 특화 데이터셋 제공으로 해당 분야에 중요한 기여를 한다.
HumanoidPano: Hybrid Spherical Panoramic-LiDAR Cross-Modal Perception for Humanoid Robots

Figure 1. The humanoid robot autonomously navigates complex environments using HumanoidPano, which fuses panoramic visio
 *Figure 1. The humanoid robot autonomously navigates complex environments using HumanoidPano, which fuses panoramic visio* 인간형 로봇의 자아-폐색 및 제한된 시야 문제를 해결하기 위해 파노라마 비전과 LiDAR를 융합하는 HumanoidPano 프레임워크를 제안하며, Spherical Geometry-aware Constraints와 Spatial Deformable Attention을 통해 기하학적으로 정렬된 크로스모달 인식을 구현한다.
HumanoidPano는 인간형 로봇의 고유한 구조적 제약을 심층적으로 고려하여 panoramic vision과 LiDAR를 기하학적으로 정렬하는 혁신적인 프레임워크로, 실제 로봇 플랫폼에서의 검증과 state-of-the-art 성능으로 embodied AI 분야에 새로운 패러다임을 제시한다.
Learning Humanoid Navigation from Human Data

Fig. 1.
 *Fig. 1.* 인간 보행 데이터 5시간으로만 학습하여 휴머노이드 로봇이 미지의 환경을 자율 내비게이션할 수 있는 EgoNav 시스템을 제안. 360° 시각 메모리와 diffusion model을 통해 다중모달 궤적 분포를 생성하고 로봇에 직접 배포 가능.
인간 보행 데이터로부터 로봇 데이터 없이 휴머노이드 내비게이션을 학습하는 혁신적 접근으로, 360° visual memory와 diffusion model의 조합으로 다중모달 예측과 실시간 성능을 동시에 달성했다. 실제 로봇 배포 데모는 임팩트 있지만 정량적 성능 평가 확대와 다양한 로봇 및 환경에서의 일반화 검증이 필요하다.
MeshMimic: Geometry-Aware Humanoid Motion Learning through 3D Scene Reconstruction

Figure 1: MeshMimic: monocular video-to-humanoid robots. From ordinary consumer monocular videos (no
 *Figure 1: MeshMimic: monocular video-to-humanoid robots. From ordinary consumer monocular videos (no* MeshMimic은 단일 모노큘러 비디오에서 3D 장면 재구성을 통해 휴머노이드 로봇이 복잡한 지형과의 상호작용을 학습할 수 있는 프레임워크이다. Kinematic Consistency Optimization과 contact-aware retargeting을 통해 모션-지형 결합 상호작용을 정확하게 전달한다.
MeshMimic은 3D 비전과 구체화된 지능을 창의적으로 결합하여 비용 효율적이고 확장 가능한 휴머노이드 로봇 훈련 방식을 제시한다. 물리적 일관성 최적화와 접촉 인식 retargeting을 통해 복잡한 지형에서의 안정적인 상호작용을 실현함으로써 로봇 제어 분야에 상당한 기여를 한다.
Omni-Perception: Omnidirectional Collision Avoidance for Legged Locomotion in Dynamic Environments
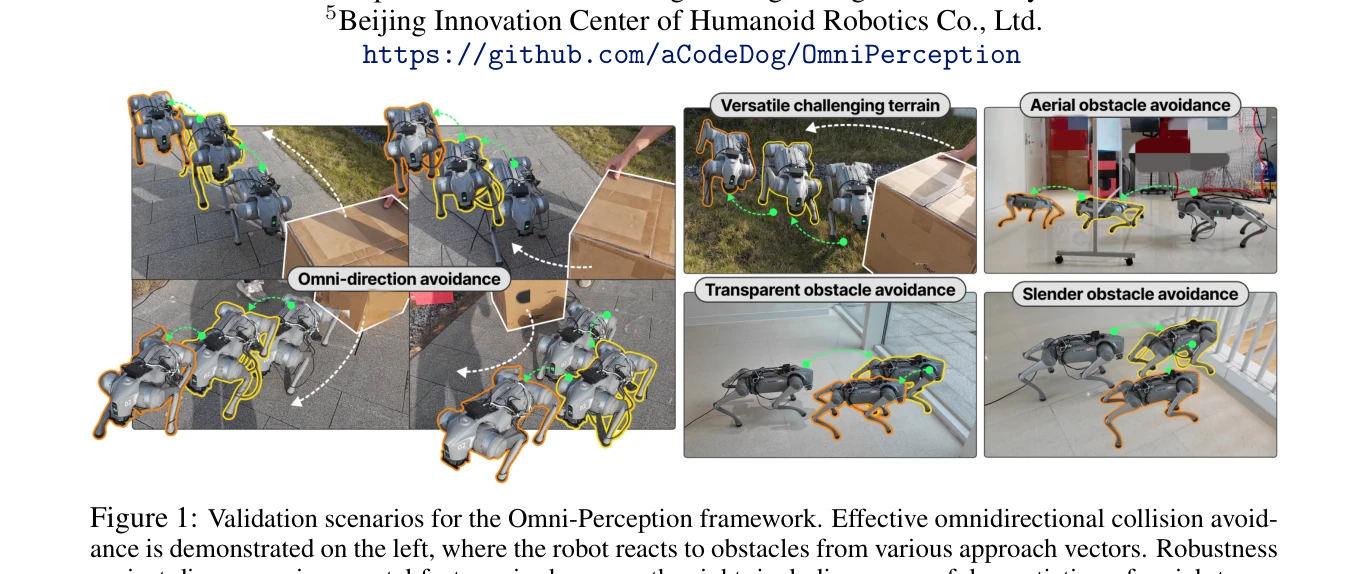
Figure 1: Validation scenarios for the Omni-Perception framework. Effective omnidirectional collision avoid-
 *Figure 1: Validation scenarios for the Omni-Perception framework. Effective omnidirectional collision avoid-* 본 논문은 LiDAR 포인트 클라우드를 직접 처리하는 end-to-end 강화학습 정책 Omni-Perception을 제안하여 동적 환경에서 다리 로봇의 전방향 충돌 회피를 실현한다. PD-RiskNet이라는 새로운 지각 모듈을 통해 시공간적 LiDAR 데이터를 해석하여 환경 위험을 평가한다.
본 논문은 다리 로봇의 동적 환경 네비게이션에 LiDAR을 직접 활용한 end-to-end 학습 프레임워크라는 참신한 접근을 제시하며, 실용적인 시뮬레이션 툴킷과 함께 강건한 sim-to-real 전이를 입증한다. 다만 기술 상세 공개 수준과 극단 환경 검증 보강이 필요하다.
TTT-Parkour: Rapid Test-Time Training for Perceptive Robot Parkour
 *Fig. 2: TTT-Parkour. Our framework consists of three stages: (1) Pre-training: A general policy is pre-trained on divers* 본 논문은 RGB-D 입력으로부터 고충실도 메시 재구성을 통해 미지의 복잡한 지형에서 휴머노이드 로봇의 빠른 테스트 시간 파인튜닝(TTT)을 가능하게 하는 real-to-sim-to-real 프레임워크를 제안한다.
본 논문은 피드포워드 기하 재구성과 빠른 테스트 시간 파인튜닝을 통합하여 휴머노이드 로봇의 미지 복잡 지형 순회 능력을 획기적으로 향상시키는 실용적이고 혁신적인 프레임워크를 제시한다. 10분 이내의 완전 파이프라인과 강건한 sim-to-real 전이는 로봇 배포의 현실성을 크게 높인다.
Global-Local Attention Decomposition for Terrain Encoding in Humanoid Perceptive Locomotion

Fig. 1. Real-world locomotion results on the Unitree G1 humanoid robot. A
 *Fig. 2.* 본 논문은 인간형 로봇의 지형 인식 보행을 위해 Global-Local Attention Decomposition (GLAD)이라는 새로운 terrain encoder를 제안한다. 광범위한 지형 맥락 이해와 정확한 발판 선택이라는 두 가지 지각 목표를 명시적으로 분리함으로써 sparse-foothold terrain에서의 안정적인 보행을 달성한다.
본 논문은 인간형 로봇의 sparse-foothold 보행을 위해 attention mechanism의 역할을 명시적으로 분리하는 GLAD를 제안하며, 이론적 동기부여가 명확하고 실제 로봇 배포에서 우수한 성능을 달성했다는 점에서 의미 있는 기여를 한다. 다만, 더 철저한 ablation study와 기존 방법과의 정량적 비교가 보충되면 더욱 강력한 논문이 될 것이다.
Learning Humanoid Navigation from Human Data

Fig. 1.
 *Fig. 2. Overview of the proposed method: A rolling buffer of 32 segmented* 본 논문은 인간의 보행 데이터 5시간만을 활용하여 휴머노이드 로봇이 미지의 환경에서 자율적으로 내비게이션할 수 있는 EgoNav 시스템을 제안한다. 로봇 데이터 없이 순수 인간 데이터만으로 학습한 모델을 Unitree G1 휴머노이드에 제로샷 배포하여 실제 환경에서의 효과를 입증한다.
EgoNav는 인간 보행 데이터만으로 휴머노이드 로봇 내비게이션을 가능하게 하는 혁신적 접근을 제시하며, diffusion model 기반 다중 모달 궤적 생성과 실시간 추론의 결합, 실제 미지 환경에서의 제로샷 배포 성공은 로봇 내비게이션 분야에 상당한 기여를 한다. 다만 학습 데이터 규모와 극한 환경 견고성의 검증이 추가되면 더욱 강력한 논문이 될 수 있다.
A Hybrid Autoencoder for Robust Heightmap Generation from Fused Lidar and Depth Data for Humanoid Robot Locomotion
 *Figure 3. The structure is designed to bridge this gap by ex-* 이 논문은 humanoid robot의 unstructured environment 이동을 위해 LiDAR과 depth camera 데이터를 fuse하여 heightmap을 생성하는 hybrid encoder-decoder 아키텍처를 제안한다. CNN 기반 spatial feature extraction과 GRU 기반 temporal consistency를 결합한 접근으로, multimodal fusion이 단일 센서 대비 7.2~9.9% 재구성 정확도 개선을 달성한다.
이 논문은 multimodal sensor fusion과 temporal modeling을 통해 humanoid robot의 heightmap 재구성 정확도를 체계적으로 개선하며, spherical projection 기반 LiDAR 처리와 heightmap 그리드 해상도 최적화 등의 실질적 contribution을 제공한다. 다만 실제 robot platform에서의 locomotion 성능 향상을 정량적으로 입증하고, 다양한 환경 및 센서 조합에 대한 robust성을 검증해야 impact가 높아질 수 있다.
RPL: Learning Robust Humanoid Perceptive Locomotion on Challenging Terrains

Fig. 1.
 *Fig. 2.* RPL은 두 단계 학습 프레임워크로 terrain-specific 전문가 정책을 depth 카메라 기반 transformer 정책으로 증류하여, 복잡한 지형에서 payload를 탑재한 상태의 견고한 다방향 인형로봇 보행을 실현한다.
본 논문은 다단계 학습과 효율적 시뮬레이션을 통해 인형로봇의 복잡 지형 다방향 보행 문제를 체계적으로 해결하며, 특히 비대칭 다중 센서 입력 처리 기법과 payload 견고성 검증에서 실질적 기여를 제시한다.
CMR: Contractive Mapping Embeddings for Robust Humanoid Locomotion on Unstructured Terrains
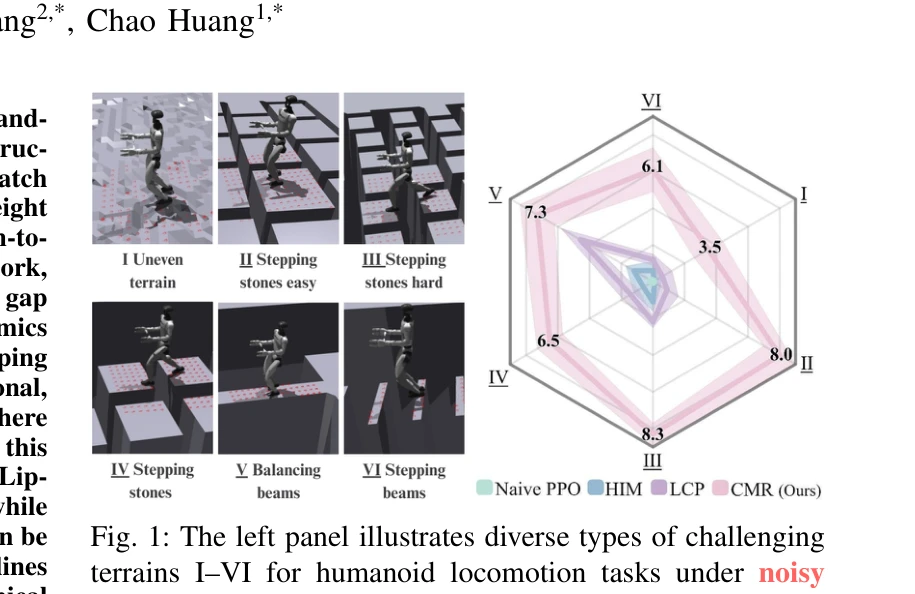
Fig. 1: The left panel illustrates diverse types of challenging
 *Fig. 2: Overview of the CMR framework. Noisy ob-* CMR은 관찰 노이즈에 강건한 휴머노이드 로봇 보행을 위해 contrastive representation learning과 Lipschitz regularization을 결합하여 disturbance를 attenuate하는 latent space를 학습하는 프레임워크이다.
CMR은 contraction mapping theorem을 휴머노이드 로봇 제어에 엄밀하게 도입하여 이론적 근거와 실증적 성능을 모두 제시한 강한 논문이다. 다양한 지형에서의 노이즈 robustness 개선과 기존 파이프라인과의 용이한 통합이 주요 강점이나, 실제 로봇 검증과 노이즈 모델 확장이 필요하다.
Keep on Going: Learning Robust Humanoid Motion Skills via Selective Adversarial Training
 *Figure 2: Overview of the SA2RT. The SAP identifies vulnerabilities in motion states and generates adversarial samples b* 인간형 로봇의 장시간 안정적 운영을 위해 선택적 적대적 공격(SA2RT)을 통한 견고한 동작 제어 정책을 학습하는 방법을 제안한다. 공격 예산 제약 하에서 취약한 상태와 행동을 찾아 표적화된 섭동을 가하여 정책을 강화한다.
본 논문은 선택적 적대적 공격을 통해 인간형 로봇의 동작 견고성을 체계적으로 강화하는 혁신적인 방법을 제시하며, 실제 로봇 플랫폼에서 40% 성공률 향상 등 괄목할 만한 성과를 입증했다. 다만 단일 로봇 플랫폼 실험과 공격 예산 설정의 일반화 측면에서 개선의 여지가 있다.
Now You See That: Learning End-to-End Humanoid Locomotion from Raw Pixels

Fig. 1: Overview. Our end-to-end vision-based humanoid locomotion policy enables robust traversal across diverse challen
 *Fig. 1: Overview. Our end-to-end vision-based humanoid locomotion policy enables robust traversal across diverse challen* Raw 깊이 이미지로부터 end-to-end 휴머노이드 로봇 보행을 학습하기 위해, 현실적인 depth 센서 시뮬레이션과 vision-aware behavior distillation, 그리고 terrain-specific multi-critic/multi-discriminator 학습을 결합한 프레임워크를 제시한다.
본 논문은 휴머노이드 로봇의 vision-based 보행에서 sim-to-real gap과 다양한 terrain 통합 학습의 근본적인 두 과제를 체계적으로 해결하며, 현실적인 센서 모델링과 behavior distillation, terrain-specific 학습을 결합한 창의적인 프레임워크를 제시한다. 두 개의 실제 로봇 플랫폼에서 극한 장애물부터 fine-grained 작업까지 광범위한 성능 검증을 통해 학술적·실무적 가치가 높다.
SafeFall: Learning Protective Control for Humanoid Robots
Fig. 1.
 *Fig. 1.* SafeFall은 휴머노이드 로봇의 낙상을 예측하고 손상 최소화 제어를 학습하는 프레임워크로, GRU 기반 낙상 예측기와 강화학습 정책을 결합하여 로봇의 구조적 취약성을 고려한 보호 행동을 실행한다.
SafeFall은 휴머노이드 로봇의 실제 배포를 가로막던 낙상 손상 문제를 처음으로 체계적으로 해결하는 프레임워크로, 강화학습과 손상 인식 설계를 결합하여 의미 있는 성능 개선을 달성했으며, 기존 제어기와의 무간섭 통합으로 즉시 실용성이 높다.
VB-Com: Learning Vision-Blind Composite Humanoid Locomotion Against Deficient Perception
Fig. 1: Overview. VB-Com enables humanoid robots (move direction in orange arrorw) to traverse dynamic terrains and obst
 *Fig. 1: Overview. VB-Com enables humanoid robots (move direction in orange arrorw) to traverse dynamic terrains and obst* VB-Com은 휴머노이드 로봇이 시각 정보의 결손에 대응하기 위해 시각 기반 정책과 고유감각 기반의 맹목 정책을 동적으로 전환하는 복합 제어 프레임워크를 제안한다.
VB-Com은 휴머노이드 로봇의 지각 견고성 문제를 정책 합성으로 우아하게 해결하며, return estimator 기반 동적 선택 메커니즘은 창의적이고 실용적이다. 동적 지형 및 지각 노이즈 시나리오의 체계적 구성과 두 휴머노이드 플랫폼에서의 검증이 강점이나, 실제 배포 결과 확장과 일반화 능력 분석이 보강되면 더욱 설득력 있을 것이다.
An Empirical Evaluation of Four Off-the-Shelf Proprietary Visual-Inertial Odometry Systems
Fig. 1. The custom-built capture rig for benchmarking 6-DoF motion tracking
 *Fig. 1. The custom-built capture rig for benchmarking 6-DoF motion tracking* Apple ARKit, Google ARCore, Intel RealSense T265, Stereolabs ZED 2 등 4개의 상용 VIO 시스템을 실내외 환경에서 실험하여 6-DoF 위치 추정 성능을 벤치마크 비교한 연구이다.
본 연구는 산업 및 로봇 분야에서 광범위하게 사용되는 상용 VIO 시스템의 실제 성능을 최초로 체계적으로 벤치마킹한 중요한 기여이며, 실내외 도전적 환경에서의 포괄적 평가를 통해 연구자와 엔지니어에게 실용적인 참고 자료를 제공한다.
AutoOdom: Learning Auto-regressive Proprioceptive Odometry for Legged Locomotion
Fig. 1. Overview of the AutoOdom system.
 *Fig. 1. Overview of the AutoOdom system.* AutoOdom은 자동회귀 학습을 기반으로 하는 2단계 훈련 패러다임으로 다리 로봇의 고유감각 주행거리 추정 성능을 크게 향상시킨 시스템이다. 대규모 시뮬레이션 데이터로 비선형 동역학을 학습하고 제한된 실제 데이터로 sim-to-real 갭을 해결한다.
AutoOdom은 자동회귀 학습과 효율적인 2단계 훈련으로 proprioceptive odometry의 중요한 한계를 해결하며, 강력한 실험 결과와 포괄적 ablation 연구로 견고한 기여를 제시한다. 다만 특정 로봇 플랫폼 검증과 다양한 환경으로의 일반화 가능성 확인이 후속 과제다.
E-SDS: Environment-aware See it, Do it, Sorted - Automated Environment-Aware Reinforcement Learning for Humanoid Locomotion
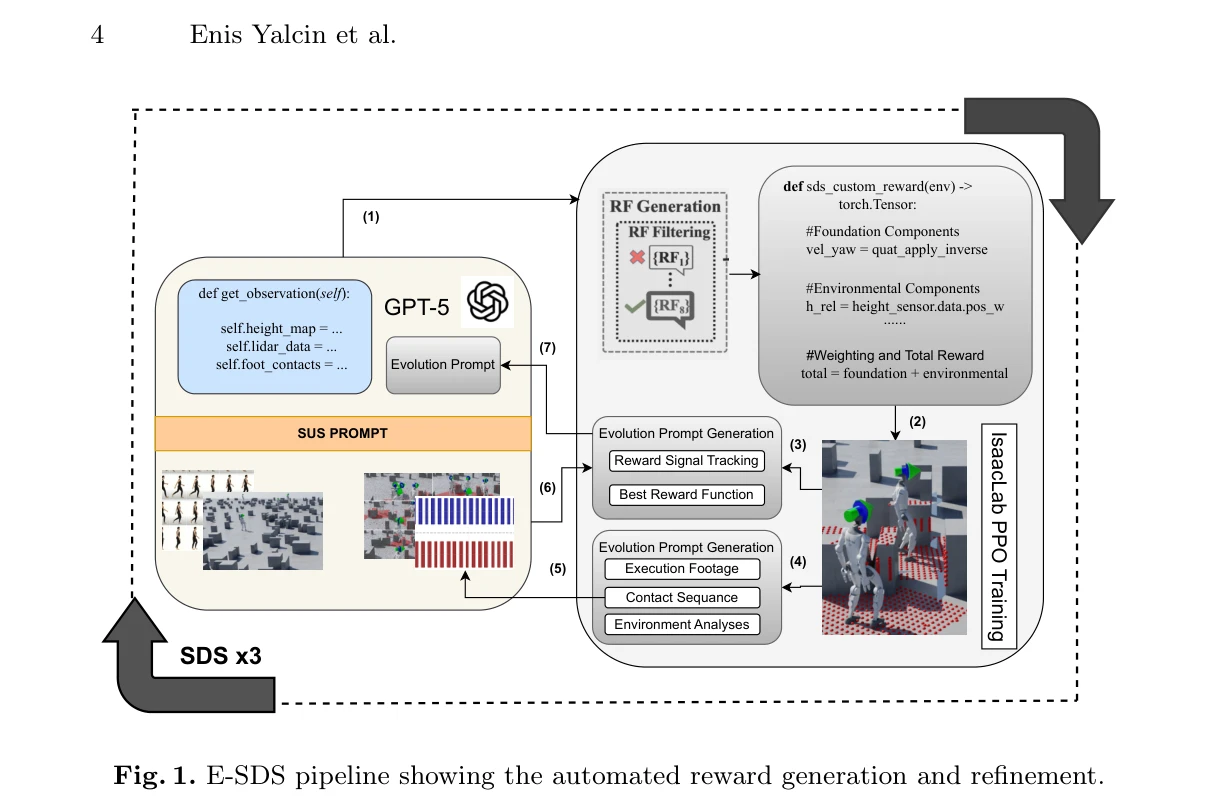
Fig. 1. E-SDS pipeline showing the automated reward generation and refinement.
 *Fig. 1. E-SDS pipeline showing the automated reward generation and refinement.* E-SDS는 Vision-Language Model과 실시간 지형 센서 분석을 통합하여 휴머노이드 로봇의 환경 인식 보행 정책을 자동으로 학습할 수 있는 프레임워크를 제시한다. 환경 통계 기반 보상 함수 자동 생성으로 수동 엔지니어링 시간을 대폭 단축하면서도 더 강건한 보행 정책을 실현한다.
E-SDS는 VLM 기반 자동 보상 설계와 환경 인식 지각형 제어를 혁신적으로 통합하여 휴머노이드 보행의 자동화 및 강건성을 획기적으로 개선했다. 다만 최신 VLM 모델 의존성, 계산 비용, 실제 하드웨어 검증 부재 등은 실용화를 위한 과제로 남아있다.
FocusNav: Spatial Selective Attention with Waypoint Guidance for Humanoid Local Navigation
Fig. 1: Snapshots of dynamic obstacle avoidance on stairs.
 *Fig. 4: Overview of the FocusNav framework. (a) Multi-modal perception encoder fuses spatially aligned LiDAR and depth* FocusNav는 인간형 로봇의 국소 항법을 위해 Waypoint-Guided Spatial Cross-Attention (WGSCA)와 Stability-Aware Selective Gating (SASG) 모듈을 결합한 공간 선택적 주의 프레임워크를 제안한다. 예측된 무충돌 경로점을 기준으로 환경 지각을 동적으로 조정하여 불안정 시 원거리 정보를 제거함으로써 동적·복잡한 환경에서의 견고한 항법을 달성한다.
FocusNav는 생물학적 영감과 기술적 혁신을 결합하여 인간형 로봇의 복잡한 동적 환경 항법이라는 중대한 과제를 체계적으로 해결한다. WGSCA와 SASG 모듈의 설계가 우수하고 실제 로봇 실험으로 검증되었으나, 단일 플랫폼 실험과 수동 파라미터 조정이라는 제약이 있다.
Gait-Adaptive Perceptive Humanoid Locomotion with Real-Time Under-Base Terrain Reconstruction
Fig. 1: Full-sized humanoid robot Oli performing gait-
 *Fig. 2: Overview of the proposed Successive Teacher–Student (S-TS) framework and deployment pipeline. A teacher–student* 인간형 로봇의 복잡한 지형 보행을 위해 하향식 깊이 카메라로 촬영한 영상을 U-Net으로 높이맵으로 재구성하고, 이를 통합 정책에 입력하여 관절 제어와 보행 주기를 동시에 적응시키는 지각 기반 보행 프레임워크를 제시한다.
인간형 로봇의 복잡 지형 보행이라는 중요한 문제를 하향식 깊이 카메라와 U-Net 기반 높이맵 재구성, 통합 적응형 정책의 조합으로 창의롭게 해결하였으며, 실제 로봇에서 계단 오르내림과 갭 횡단을 성공적으로 시연하여 높은 실용적 가치를 보인다.
Learning a Vision-Based Footstep Planner for Hierarchical Walking Control

Fig. 1.
 *Fig. 2.* 본 논문은 단일 깊이 카메라와 reinforcement learning 기반의 계층적 제어 프레임워크를 통해 쌍족 로봇이 비정형 지형에서 실시간 발걸음 계획을 수행하도록 하는 시각 기반 발걸음 계획기를 제시한다. Angular Momentum Linear Inverted Pendulum 모델을 활용하여 저차원 상태 표현을 구성하고 상위 레벨의 RL 발걸음 계획기와 하위 레벨의 Operational Space Controller를 통합한다.
본 논문은 RL 기반 발걸음 계획을 ALIP 모델과 깊이 카메라 vision으로 통합한 실질적인 계층적 제어 프레임워크를 제시하며, 실제 로봇 하드웨어에서의 검증을 통해 실용성을 입증한다. 다만 ALIP 모델의 표현력 한계와 복잡한 지형에서의 성능 저하가 명확하게 드러나 향후 더 정교한 모델이나 end-to-end 학습 접근의 필요성을 시사한다.
Learning Humanoid Locomotion with Perceptive Internal Model

Fig. 1: We propose a perceptive humanoid locomotion policy capable of mastering various challenging terrains. This polic
 *Fig. 2: Overview of our framework. Within PIM, we integrate perceptive information into the state predictor to achieve m* 인간형 로봇의 안정적인 이동을 위해 온보드 elevation map을 기반으로 한 Perceptive Internal Model (PIM)을 제안하며, HIM을 확장하여 지각 정보를 통합한 단일 단계 학습 방법을 제시한다.
본 논문은 elevation map 기반 지각 모듈을 HIM과 통합하여 인간형 로봇의 복잡한 지형 네비게이션을 단일 단계로 효율적으로 학습하는 실질적이고 우수한 방법을 제시하며, 다양한 로봇과 지형에서의 광범위한 검증을 통해 실용성을 입증한다.
Learning Social Navigation from Positive and Negative Demonstrations and Rule-Based Specifications
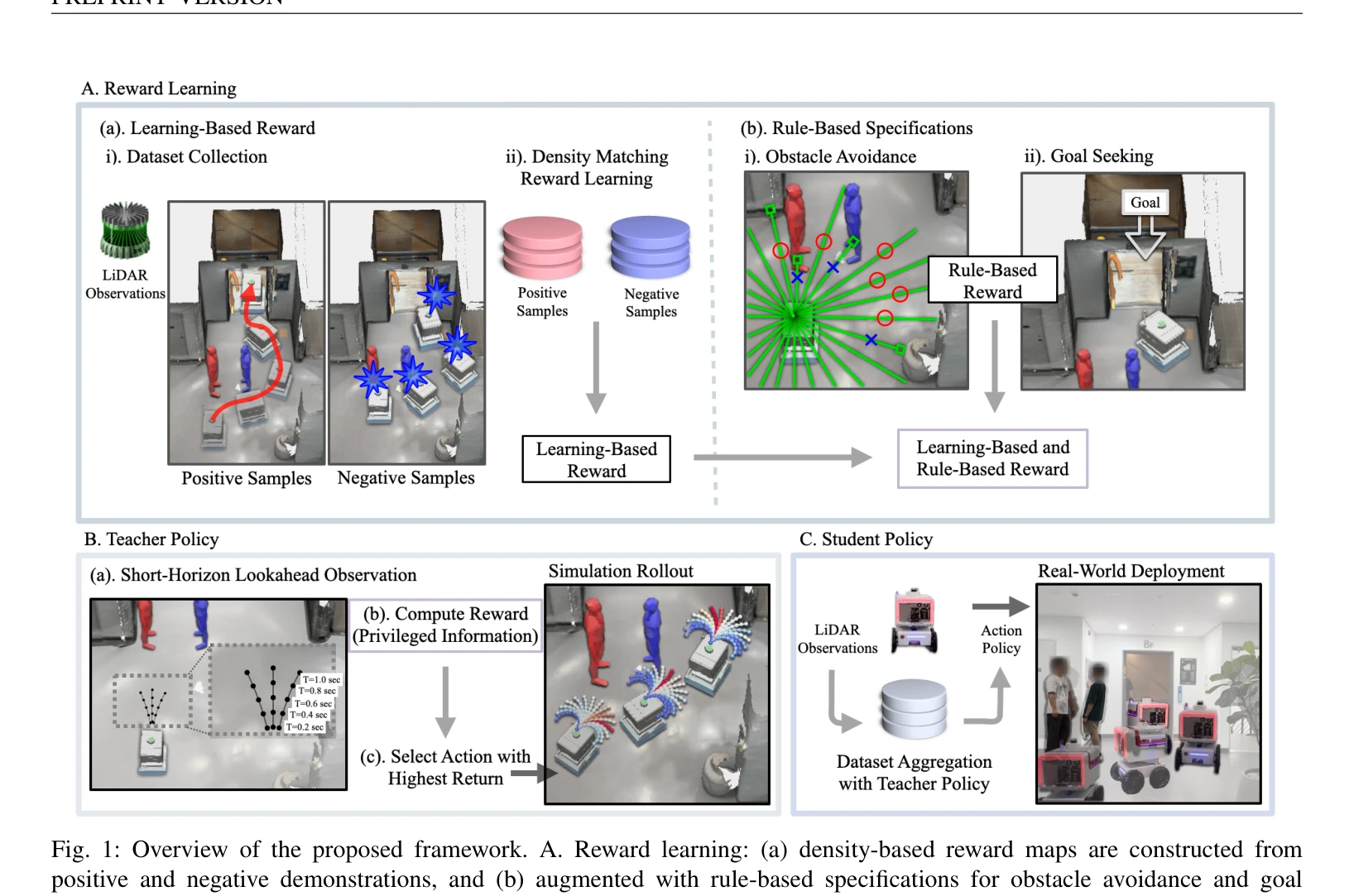
Fig. 1: Overview of the proposed framework. A. Reward learning: (a) density-based reward maps are constructed from
 *Fig. 1: Overview of the proposed framework. A. Reward learning: (a) density-based reward maps are constructed from* 본 논문은 긍정적 및 부정적 시연과 규칙 기반 명세로부터 학습한 밀도 기반 보상을 결합하여 동적 인간 환경에서 안전성과 적응성의 균형을 맞춘 모바일 로봇 네비게이션 정책을 개발한다.
본 논문은 데이터 기반 보상과 규칙 기반 안전 명제의 효과적인 통합을 통해 동적 인간 환경에서의 로봇 네비게이션을 다루는 실용적이고 신뢰할 수 있는 해결책을 제시하며, teacher-student 증류 및 불확실성 추정 기법을 포함한 방법론적 기여와 함께 실제 인간 참여자 실험으로 검증한 점에서 높은 가치를 갖는다.
CART: Context-Aware Terrain Adaptation using Temporal Sequence Selection for Legged Robots
 *Fig. 2: Overview of the Pipeline: CART inputs a stream of RGBD images Sv, friction meshes Sm using [19], and propriocept* CART는 사족 로봇의 지형 적응을 위해 시각 정보와 고유감각(proprioception)을 통합하여 맥락을 파악하고, 시간 수열 선택을 통해 로봇의 안정성을 향상시키는 고수준 제어기이다.
CART는 시각과 고유감각의 불일치 문제를 명시적으로 인식하고 이를 해결하기 위한 창의적인 맥락 기반 제어 프레임워크를 제시하며, 시뮬레이션과 실제 환경 모두에서 안정성 개선을 입증한 의미 있는 연구이다. 다만 평가 범위 확대와 방법론의 일반화 가능성 검증이 필요하다.
Learning Humanoid Locomotion with Perceptive Internal Model

Fig. 1: We propose a perceptive humanoid locomotion policy capable of mastering various challenging terrains. This polic
 *Fig. 1: We propose a perceptive humanoid locomotion policy capable of mastering various challenging terrains. This polic* 본 논문은 휴머노이드 로봇의 불안정한 형태학적 특성으로 인해 필수적인 지각 정보를 효과적으로 통합하기 위해 Perceptive Internal Model (PIM)을 제안한다. 로봇 중심의 elevation map을 기반으로 하는 이 방법은 깊이 맵이나 포인트 클라우드 직접 인코딩과 달리 시뮬레이션에서 최소한의 계산 비용으로 3시간 내에 정책 학습을 완료할 수 있다.
본 논문은 로봇 중심 elevation map 기반 지각 정보 통합을 통해 휴머노이드 로봇의 안정적인 복잡 지형 주행을 실현하는 실질적이고 효율적인 방법을 제시한다. 단일 단계 훈련으로 우수한 성능을 달성하며 다양한 로봇 플랫폼에 검증된 점이 강점이나, 실제 환경 적용 시 elevation map 구성 오류에 대한 견고성 분석이 보완되면 더욱 완성도 있는 연구가 될 것이다.
HMC: Learning Heterogeneous Meta-Control for Contact-Rich Loco-Manipulation
Fig. 1: Rolling out HMC for contact-rich tasks on a humanoid robot. Compared to na¨ıve position-only policies [5, 26,
 *Fig. 2: System overview. HMC-Controller accepts inputs from either a VR-based teleoperation system or HMC-Policy* 로봇의 접촉이 많은 조작 작업을 위해 위치, 임피던스, 하이브리드 힘-위치 제어를 적응적으로 혼합하는 HMC(Heterogeneous Meta-Control) 프레임워크를 제안하며, mixture-of-experts 라우팅을 통해 대규모 위치 데이터와 미세한 힘 인식 시연으로부터 학습한다.
HMC는 실제 접촉이 많은 조작 작업의 도전을 체계적으로 해결하는 실용적이고 혁신적인 프레임워크로, 통합된 제어 인터페이스와 이질적 정책 설계가 50% 이상의 성능 향상을 달성하며 로코-조작 분야에 의미 있는 기여를 제시한다.
Mobi-$π$: Mobilizing Your Robot Learning Policy

Figure 1: Introducing policy mobilization. (a) Assume a visuomotor policy π trained from one or a set of limited camera
 *Figure 1: Introducing policy mobilization. (a) Assume a visuomotor policy π trained from one or a set of limited camera * 모바일 로봇에서 제한된 관점으로 학습된 조작 정책을 배포할 때 발생하는 분포 외 문제를 해결하기 위해, 정책과 호환되는 로봇 베이스 포즈를 찾는 '정책 모빌라이제이션' 문제를 제시하고 3D Gaussian Splatting과 샘플링 기반 최적화를 통해 해결한다.
본 논문은 모바일 조작 로봇에서 기존 정책의 재사용성을 크게 향상시키는 정책 모빌라이제이션이라는 새로운 문제를 정의하고, 3D Gaussian Splatting과 최적화 기법을 활용한 실용적 해법을 제시했다. 시뮬레이션과 실제 환경에서의 광범위한 검증을 통해 방법론의 유효성을 입증하였으며, 제시된 프레임워크는 향후 모바일 조작 연구의 중요한 기준이 될 것으로 기대된다.
ULC: A Unified and Fine-Grained Controller for Humanoid Loco-Manipulation
Fig. 1: Diverse loco-manipulation capabilities enabled by ULC. The humanoid robot demonstrates various coordinated whole
 *Fig. 1: Diverse loco-manipulation capabilities enabled by ULC. The humanoid robot demonstrates various coordinated whole* ULC는 인간형 로봇의 보행-조작을 위해 상체와 하체 제어를 통합한 단일 정책 프레임워크로, sequential skill acquisition, residual action modeling, 다항식 보간 등의 기술을 통해 추적 정확도, 넓은 작업 공간, 견고성을 동시에 달성한다.
ULC는 humanoid loco-manipulation 분야에서 통합 제어의 실행 가능성을 처음으로 대규모 실험으로 입증한 의미 있는 논문이며, sequential skill acquisition, residual action modeling, deployment-realistic training 등의 체계적인 기술 조합으로 높은 추적 성능과 넓은 작업 공간을 동시에 달성했다. 다만 단일 하드웨어 플랫폼에만 검증되었고 시뮬레이션 기반 훈련의 현실 일반화 가능성에 대한 상세 분석이 부족한 점이 한계이다.
Mobi-$π$: Mobilizing Your Robot Learning Policy

Figure 1: Introducing policy mobilization. (a) Assume a visuomotor policy π trained from one or a set of limited camera
 *Figure 1: Introducing policy mobilization. (a) Assume a visuomotor policy π trained from one or a set of limited camera * 본 논문은 제한된 카메라 뷰포인트에서 학습된 visuomotor 조작 정책을 모바일 로봇 플랫폼에서 실행 가능하게 하는 "policy mobilization" 문제를 정의하고, 3D Gaussian Splatting과 sampling-based optimization을 활용하여 최적의 로봇 베이스 포즈를 찾는 방법을 제안한다.
Policy mobilization을 명확히 정의하고 3D Gaussian Splatting 기반의 실질적 해결책을 제시한 우수한 연구이다. 기존 stationary robot 정책의 모바일 로봇 배포 문제를 elegant하게 해결하며, Mobi-π 프레임워크를 통해 체계적 평가가 가능하도록 한 점이 특히 가치있다. 다만 실환경 실험 규모 확대와 더 정교한 method 개발이 추가되면 영향력을 더욱 높일 수 있을 것으로 기대된다.
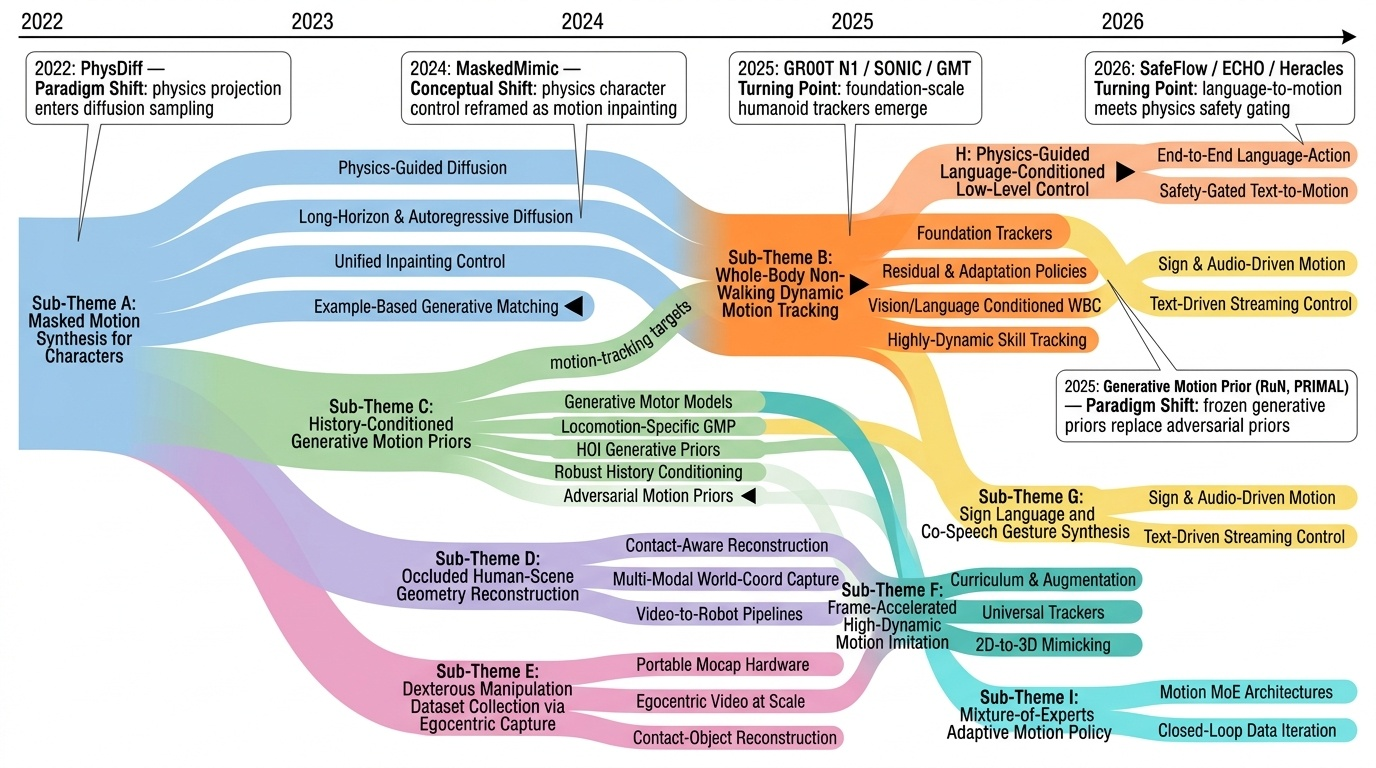
Category Overview
# Physics-Based Character Motion Synthesis 개요 본 카테고리는 물리 기반 인간형 로봇(humanoid robot)의 동작 합성 및 추적 기술을 다루는 58편의 연구를 포괄한다. 마스크된 모션 합성(masked motion synthesis), 전신 비보행 동작 추적(whole-body non-walking dynamic motion tracking), 역사 조건부 생성 모션 사전(history-conditioned generative motion priors) 등 다양한 세부 주제를 통해 인간형 로봇의 자연스러운 동작 생성 문제를 해결한다. 특히 언어 조건부 제어(language-conditioned control), 물리 기반 모방 학습(physics-guided imitation learning), 멀티모달 데이터 수집 기술이 중점적으로 다루어진다. 텍스트 기반 실시간 제어[1662, 1708], 기초 모델 개발[1412], 손동작 데이터 수집[1867, 1870] 등의 연구들이 실제 로봇 응용에 필요한 기술적 기반을 제공한다. 모션 추적기(motion tracker) 통합[1743, 1685], 접촉 기반 복원(contact-guided reconstruction)[1857], 전문가 혼합 정책(mixture-of-experts adaptive motion policy) 등의 고급 기법들이 동작 합성의 정확성과 자연성을 향상시킨다. 이러한 연구들은 인간형 로봇이 복잡한 환경에서 인간과 유사한 동작을 수행할 수 있도록 하는 통합적인 기술 체계를 구축한다.
- Masked Motion Synthesis for Characters: # Masked Motion Synthesis for Characters (마스킹된 모션 합성) 마스킹된 모션 합성(Masked Motion Synthesis)은 물리 기반 캐릭터 모션 생성에서 부분적으로 가려진 모션 데이터를 활용하여 완전한 캐릭터 동작을 생성하는 기술이다. 이 방식은 Diffusion Model을 기반으로 하며, 주어진 제약 조건(Constraint) 하에서 자연스럽고 제어 가능한 모션을 합성할 수 있다. [1701]과 [1960]에서는 확산 확률 모델(Diffusion Probabilistic Models)을 캐릭터 제어에 적용하여 조건부 모션 생성(Conditional Motion Generation)을 실현했으며, [2035]에서는 대규모 제어 가능한 인간 모션 생성(Controllable Human Motion Generation)으로 확장하였다. [1930]과 [1917]은 부분적 모션 정보로부터 누락된 프레임을 채우는 인-비트위닝(In-betweening) 및 제너러티브 모션 매칭(Generative Motion Matching) 기법을 제시했다. 마스킹된 모션 합성은 게임, 애니메이션, 로봇틱스 등 다양한 분야에서 고품질의 캐릭터 애니메이션 생성을 가능하게 한다.
- Whole-Body Non-Walking Dynamic Motion Tracking: 전신 비보행 동적 동작 추적(Whole-Body Non-Walking Dynamic Motion Tracking)은 휴머노이드 로봇이 보행 이외의 복잡한 전신 동작을 물리 기반 제어를 통해 수행하고 추적하는 기술입니다. 이 분야는 일반화된 기초 모델(Foundation Model)과 사전학습(Pretraining) 기법을 활용하여 다양한 동작에 대한 적응력을 높이는 데 중점을 두고 있습니다[1640][1944]. 비전-언어 제어(Visuomotor Control)와 영상 정보를 결합하여 로봇이 자연스러운 동작을 직접 학습할 수 있는 방식들이 제안되고 있으며[2037][2081], 원샷 적응(One-shot Adaptation) 등의 빠른 학습 기법을 통해 신규 동작에 대한 즉각적인 적응이 가능해지고 있습니다. 이러한 기술들은 휴머노이드 로봇의 운동 제어를 보다 자연스럽고 효율적으로 만들어 인간과 유사한 동적 동작 수행을 실현하는 데 기여합니다.
- History-Conditioned Generative Motion Priors: History-Conditioned Generative Motion Priors는 물리 기반 인간형 로봇의 운동 합성에서 과거 상태 정보를 활용하여 자연스러운 동작을 생성하는 기술입니다. 이 접근법은 reinforcement learning과 generative model을 결합하여 로봇이 복잡한 환경에서 적응적으로 움직일 수 있도록 학습합니다. [1660]과 [2109]에서 보듯이 humanoid locomotion의 자연성을 향상시키기 위해 역사 정보를 조건(history-conditioned)으로 활용하는 방식이 주목받고 있습니다. 또한 [1984]와 [2091]은 이러한 조건부 생성 모델이 객체 조작(object interaction)과 강화학습 기반 제어에서 강건한 성능을 발휘함을 보여줍니다. 이러한 연구들은 물리 시뮬레이션 환경에서 학습된 운동 선행 지식(motion priors)을 실제 로봇 제어에 적용하는 것을 목표로 합니다.
- Occluded Human-Scene Geometry Reconstruction: Occluded Human-Scene Geometry Reconstruction (폐색된 인간-장면 기하학 재구성)은 물리 기반 캐릭터 모션 합성에서 인간과 환경의 복잡한 상호작용을 정확하게 모델링하기 위한 핵심 기술 분야입니다. 이 분야는 모노큘러 비디오(monocular video)나 제한된 센서 정보로부터 인간의 신체와 주변 환경이 겹쳐있는 상황에서도 정확한 3D 기하학 정보를 복원하는 것을 목표로 합니다. [1857]의 Contact-Guided Real2Sim 방식이나 [1895]의 Human-Object Interaction 모델링과 같이, 접촉 정보(contact information)와 상호작용 제약 조건을 활용하여 실제 환경에서의 인간 동작을 시뮬레이션 환경으로 변환합니다. [1907]의 4D Human-Scene Reconstruction과 [1933]의 Floor-aligned Representation 기법들은 동적 환경에서의 포즈 추정(pose estimation)과 모션 캡처(motion capture)를 통해 더욱 정교한 재구성을 가능하게 합니다. [1838]과 [2136]과 같은 멀티모달 데이터셋(multi-modal dataset) 기반의 접근법들은 암벽 등반이나 인간형 로봇 이동(humanoid locomotion) 같은 특수한 시나리오에서의 모션 합성 성능을 향상시킵니다.
- Dexterous Manipulation Dataset Collection via Egocentric Capture: 민첩한 조작(Dexterous Manipulation) 데이터셋 수집은 손가락의 세밀한 움직임을 포착하기 위해 일인칭 시점(Egocentric Capture)을 활용하는 기술 분야입니다. [1867]과 [1870]에서 제시된 모션캡처(Mocap) 데이터 수집 시스템들은 확장 가능하고 저비용의 자동화된 방식으로 대규모 손 조작 데이터를 수집할 수 있도록 설계되었습니다. [1900]과 [1967]은 수집된 데이터를 바탕으로 심화학습(Deep Learning) 기반의 조작 제어 및 양손 상호작용(Bimanual Interaction) 생성 모델을 개발하였습니다. [1616]과 [2169]는 객체와의 접촉(Contact) 상황을 3D로 재구성하거나 로봇 기초 모델(Robot Foundation Suite)을 통해 범용적인 민첩한 손 작업을 수행하는 기술을 제시합니다. 이러한 일인칭 기반의 데이터 수집 방식은 현실감 있는 조작 동작 학습의 핵심 기반이 되고 있습니다.
- Frame-Accelerated High-Dynamic Motion Imitation: # Frame-Accelerated High-Dynamic Motion Imitation 프레임-가속화된 고역동 모션 모방(Frame-Accelerated High-Dynamic Motion Imitation)은 물리 기반 캐릭터 제어에서 복잡한 움직임을 효율적으로 학습하고 재현하는 기술이다. 이 분야는 강화학습(Reinforcement Learning)과 모션 캡처(Motion Capture) 데이터를 결합하여 자연스럽고 동적으로 풍부한 캐릭터 애니메이션을 생성하는 데 중점을 둔다. [1896]과 [2026]의 연구들은 범용 모션 추적 정책(Universal Motion Tracking Policy)을 개발하여 다양한 신체 부위의 움직임을 통합적으로 제어하는 방법을 제시했다. [1924]의 프레임 가속화 기법(Frame Acceleration)은 학습 효율을 크게 향상시켜 제한된 계산 자원에서도 고품질의 모션 모방을 가능하게 한다. 이러한 접근법들은 게임, 애니메이션, 로보틱스 등 다양한 분야에서 실시간 캐릭터 제어의 성능을 현저히 개선하고 있다.
- Sign Language and Co-Speech Gesture Synthesis: # Sign Language and Co-Speech Gesture Synthesis 수화(Sign Language)와 음성 동반 제스처(Co-Speech Gesture) 합성은 물리 기반 캐릭터 모션 합성의 중요한 분야로, 인간과 로봇 간의 자연스러운 상호작용을 실현하기 위한 기술들을 포함합니다. [1672]의 SignBot은 인간-휴머노이드 간 수화 상호작용 학습을 통해 로봇이 자연스러운 손 모양과 움직임을 생성하도록 합니다. [1708]의 TextOp는 텍스트 기반 실시간 상호작용(Real-time Interactive)을 통해 휴머노이드 로봇의 모션을 직접 제어하는 기술을 제시합니다. [1634]에서는 3D 동적 비즈음(3D Dynamic Viseme)을 기반으로 한 입술 모션(Lip Motion) 생성을 다루어 음성 합성에 필요한 자연스러운 입술 움직임을 구현합니다. [1882]의 연구는 자동 음성 인식(Automatic Speech Recognition)을 활용하여 표현력 있는 휴머노이드 보행(Expressive Humanoid Locomotion)을 실현하는 방법을 제안합니다.
- Physics-Guided Language-Conditioned Low-Level Control: 물리 기반 캐릭터 모션 합성에서 물리 가이드 언어 조건부 저수준 제어(Physics-Guided Language-Conditioned Low-Level Control)는 자연언어 명령을 직접 휴머노이드 로봇의 모터 제어 신호로 변환하는 기술입니다. [1662]의 SafeFlow는 실시간(Real-Time) 텍스트 기반 휴머노이드 전신 제어(Whole-Body Control)를 구현하여 안정적인 물리 시뮬레이션 환경에서 복잡한 동작을 생성합니다. [1670]의 SENTINEL과 [1893]의 ECHO는 엔드-투-엔드(End-to-End) 언어-행동 모델(Language-Action Model)을 통해 고수준의 의미 정보를 저수준의 제어 신호로 직접 매핑하는 방식을 제시합니다. [1971]의 Heracles는 정밀한 추적(Precise Tracking) 성능과 생성 모델(Generative Synthesis)의 유연성을 결합하여 언어 조건부 모션 제어의 정확성을 향상시킵니다. 이러한 접근법들은 물리적 제약 조건을 만족하면서도 자연스럽고 제어 가능한 휴머노이드 동작 합성을 가능하게 합니다.
- Mixture-of-Experts Adaptive Motion Policy: Mixture-of-Experts Adaptive Motion Policy는 복잡한 휴머노이드 로봇의 동작 제어를 위해 여러 전문화된 정책(specialized policies)을 조합하여 다양한 움직임을 효율적으로 학습하는 기술입니다. [1955]의 General Motion Tracking (GMT) 방식은 전신 제어(whole-body control)를 위해 추적 기반의 통합 정책을 제안하며, [2031]의 반복적 폐루프 동작 합성(iterative closed-loop motion synthesis) 방법은 모션 생성 능력을 확장하는 데 중점을 둡니다. [2038]의 KungfuBot2는 혼합 전문가 구조(mixture-of-experts architecture)를 통해 무술과 같은 고난도의 다양한 동작 기술(motion skills)을 학습함으로써 휴머노이드 로봇의 운동 능력을 한 단계 높입니다. 이러한 접근 방식은 개별 정책의 강점을 활용하면서 동시에 새로운 동작으로의 적응성(adaptability)을 향상시킵니다. 물리 기반 캐릭터 동작 합성(physics-based character motion synthesis) 분야에서 Mixture-of-Experts 방식은 휴머노이드 로봇이 다양한 환경과 작업에서 안정적으로 동작할 수 있도록 하는 핵심 기술입니다.
⚠ 갭: 생성된 모션의 인간-유사성(human-likeness)을 객관적으로 평가하는 표준 지표가 부재하며, Motion Turing Test처럼 사용자 연구 기반 평가 방법론의 발전이 기술 발전 속도를 따라가지 못하고 있다.
🏛 정책: 물리 기반 모션 합성 기술의 엔터테인먼트·재활·스포츠 분야 응용을 위한 기술 이전 프로그램과 표준 평가 지표 개발을 지원해야 한다.
A Hierarchical Framework for Humanoid Locomotion with Supernumerary Limbs
 *Figure 2.1: The composite robot model used in the simulation, illustrating (a) the Unitree H1* 초과 사지(Supernumerary Limbs)가 장착된 인형형 로봇의 안정적인 보행을 위해 학습 기반 저수준 보행 제어와 모델 기반 고수준 동적 평형 제어를 결합한 계층적 제어 아키텍처를 제시한다.
본 논문은 초과 사지가 장착된 인형형 로봇의 보행 안정성 문제를 해결하기 위해 계층적 제어 구조를 통해 학습 기반과 모델 기반 제어를 효과적으로 결합한 독창적인 접근법을 제시하며, 47% DTW 거리 감소 등 정량적 성과를 입증했다. 다만 실제 하드웨어 검증과 복잡한 환경에서의 평가가 필요하다.
Realistic Lip Motion Generation Based on 3D Dynamic Viseme and Coarticulation Modeling for Human-Robot Interaction
Fig. 1.
 *Fig. 1.* 인간-로봇 상호작용을 위해 3D 동적 비셈(viseme)과 공명음현상(coarticulation) 모델링 기반의 입술 운동 생성 프레임워크를 제안하며, 고차원 공간 입술 운동을 14-DOF 로봇 입술 구동 시스템으로 변환한다.
본 연구는 3D 동적 비셈과 중국어 언어학적 특성을 결합하여 입술 동기화의 근본적 한계를 해결한 학제적 기여로, 경량하고 실용적인 로봇 배포 프레임워크를 통해 인간-로봇 상호작용의 자연성을 크게 향상시킨다.
Semantic Co-Speech Gesture Synthesis and Real-Time Control for Humanoid Robots
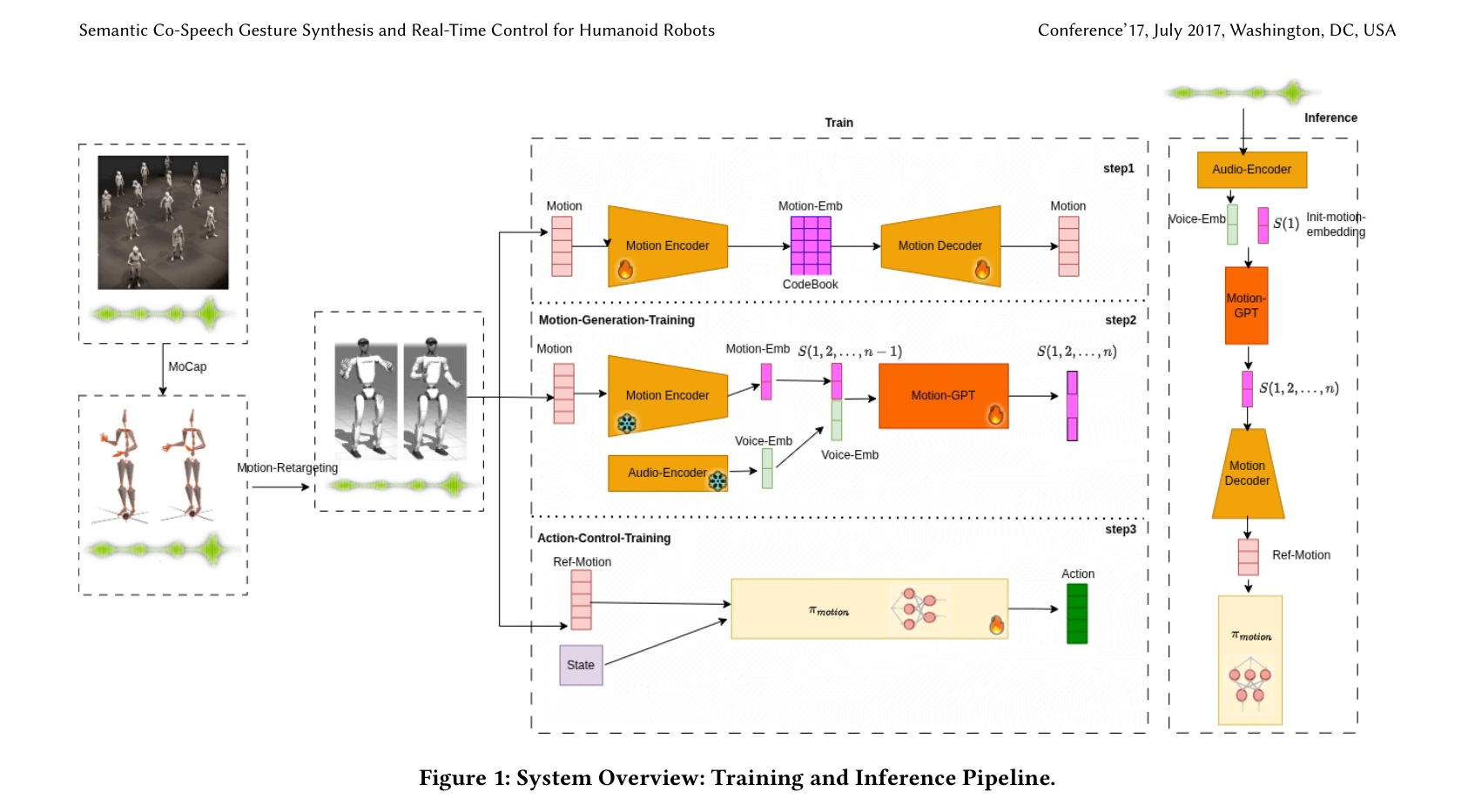
Figure 1: System Overview: Training and Inference Pipeline.
 *Figure 1: System Overview: Training and Inference Pipeline.* 이 연구는 음성 입력으로부터 의미론적으로 적절한 제스처를 생성하고 실시간으로 휴머노이드 로봇에 배포하는 end-to-end 프레임워크를 제시한다. LLM과 Motion-GPT를 활용한 제스처 생성과 imitation learning 기반의 MotionTracker 제어 정책을 통합하여 의미 있는 비언어적 소통을 실현한다.
이 논문은 음성 기반 의미론적 제스처 생성과 실시간 로봇 배포를 통합한 의미 있는 연구로, LLM, Motion-GPT, imitation learning을 창의적으로 결합하여 완전한 end-to-end 파이프라인을 실현했다. 다만 평가의 정량성 강화와 다양한 환경에서의 robustness 검증이 필요하다.
SignBot: Learning Human-to-Humanoid Sign Language Interaction
 *Fig. 2: Overview of SignBot: The framework consists of three stages: (1) Motion Retargeting aligns human sign language* SignBot은 수화 언어를 인식하고 생성할 수 있는 인간형 로봇을 위한 프레임워크로, motion retargeting, policy training, 그리고 generative interaction을 통합하여 청각장애인과의 자연스러운 상호작용을 실현한다.
SignBot은 embodied humanoid robot에서 처음으로 자동화된 sign language interaction을 구현한 혁신적 연구로, 청각장애인 커뮤니티의 의사소통 접근성 향상에 실질적 기여를 한다. 다만 hand retargeting 기술의 상세 설명과 더 광범위한 실세계 평가가 보완되면 영향력이 더욱 증대될 것으로 예상된다.
TextOp: Real-time Interactive Text-Driven Humanoid Robot Motion Generation and Control
 *Fig. 2: Overview of TextOp’s framework. The framework consists of three main parts: (a) Interactive Motion Generation,* TextOp는 streaming 자연어 명령으로 인간형 로봇의 운동을 실시간으로 생성하고 제어하는 프레임워크로, 고수준의 autoregressive motion diffusion 모델과 저수준의 motion tracking policy를 결합하여 실행 중 동적으로 명령 수정을 지원한다.
TextOp는 실시간 interactive motion generation과 robust physical control을 성공적으로 통합하여 자연어 기반 humanoid 제어의 새로운 paradigm을 제시한 뛰어난 연구이며, 실제 로봇 실험을 통해 실현 가능성을 검증했다. 다만 플랫폼 특화성과 데이터셋 의존성을 개선한다면 더욱 광범위한 영향을 미칠 수 있을 것으로 예상된다.
Do You Have Freestyle? Expressive Humanoid Locomotion via Audio Control

Figure 1.
 *Figure 1.* RoboPerform은 오디오를 직접 제어 신호로 사용하여 음악에 맞춰 춤을 추거나 음성에 맞춰 제스처를 생성하는 휴머노이드 로봇 제어 프레임워크로, 명시적 모션 재구성을 제거하여 저지연 및 고충실도를 달성한다.
RoboPerform은 오디오 제어 신호를 휴머노이드 로봇 모션에 직접 통합하는 novel한 접근으로, retargeting-free 설계와 content-style decomposition을 통해 저지연 고충실도 실시간 성능을 달성한 의미 있는 기여이다. 다만 실제 로봇 배포 및 sim-to-real 검증이 추가되면 실용성이 더욱 강화될 것이다.
EMOTION: Expressive Motion Sequence Generation for Humanoid Robots with In-Context Learning
Fig. 1. Overview of the EMOTION framework.
 *Fig. 1. Overview of the EMOTION framework.* EMOTION은 대규모 언어 모델(LLM)의 문맥 학습 능력을 활용하여 인간형 로봇이 표정, 제스처, 신체 움직임 등 자연스러운 비언어적 의사소통을 수행할 수 있도록 하는 프레임워크이다. 온라인 사용자 연구를 통해 생성된 모션이 인간 수행자와 동등하거나 우수함을 입증했다.
EMOTION은 LLM의 in-context learning을 창의적으로 활용하여 인간형 로봇의 표현적 모션 생성을 자동화한 실질적 솔루션을 제시한다. 사용자 연구를 통한 검증과 인간 피드백 통합 방식은 실용성을 높이나, 다양한 제스처에 대한 성능 편차와 실제 상호작용 환경 테스트의 필요성이 향후 과제로 남아 있다.
Harmon: Whole-Body Motion Generation of Humanoid Robots from Language Descriptions
 *Fig. 2 depicts our proposed method, HARMON. Firstly, we generate human motion based on the* 인간 모션 데이터셋으로부터 사전학습된 프라이어를 활용하고 Vision Language Model을 통해 손가락과 머리 모션을 생성·편집하여 휴머노이드 로봇의 자연스러운 전신 모션을 언어 설명으로부터 생성한다.
이 논문은 인간 모션 프라이어와 VLM의 상식적 추론을 창의적으로 결합하여 언어로부터 자연스러운 휴머노이드 모션을 생성하는 실용적인 방법을 제시하며, 실제 로봇 실험과 높은 사용자 평가로 그 유효성을 입증했다.
Hierarchical Intention-Aware Expressive Motion Generation for Humanoid Robots
Fig. 1: Overall framework of the proposed work. (a) The high-level system architecture. Multimodal inputs XI = (Vin, Lin
 *Fig. 1: Overall framework of the proposed work. (a) The high-level system architecture. Multimodal inputs XI = (Vin, Lin* 본 논문은 Vision Language Model의 의도 추론과 diffusion 기반 동작 생성을 결합한 계층적 프레임워크 HIAER을 제안하여, 인간의 사회적 의도와 감정 맥락을 파악하고 실시간으로 표현적인 로봇 동작을 생성한다.
본 논문은 VLM의 고수준 사회적 추론과 diffusion 기반 동작 생성을 의도적으로 결합하여 인간-로봇 상호작용의 폐쇄 루프를 완성한 점에서 높은 가치를 지니며, 물리 로봇 실증을 통해 실현 가능성을 보여준다.
DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
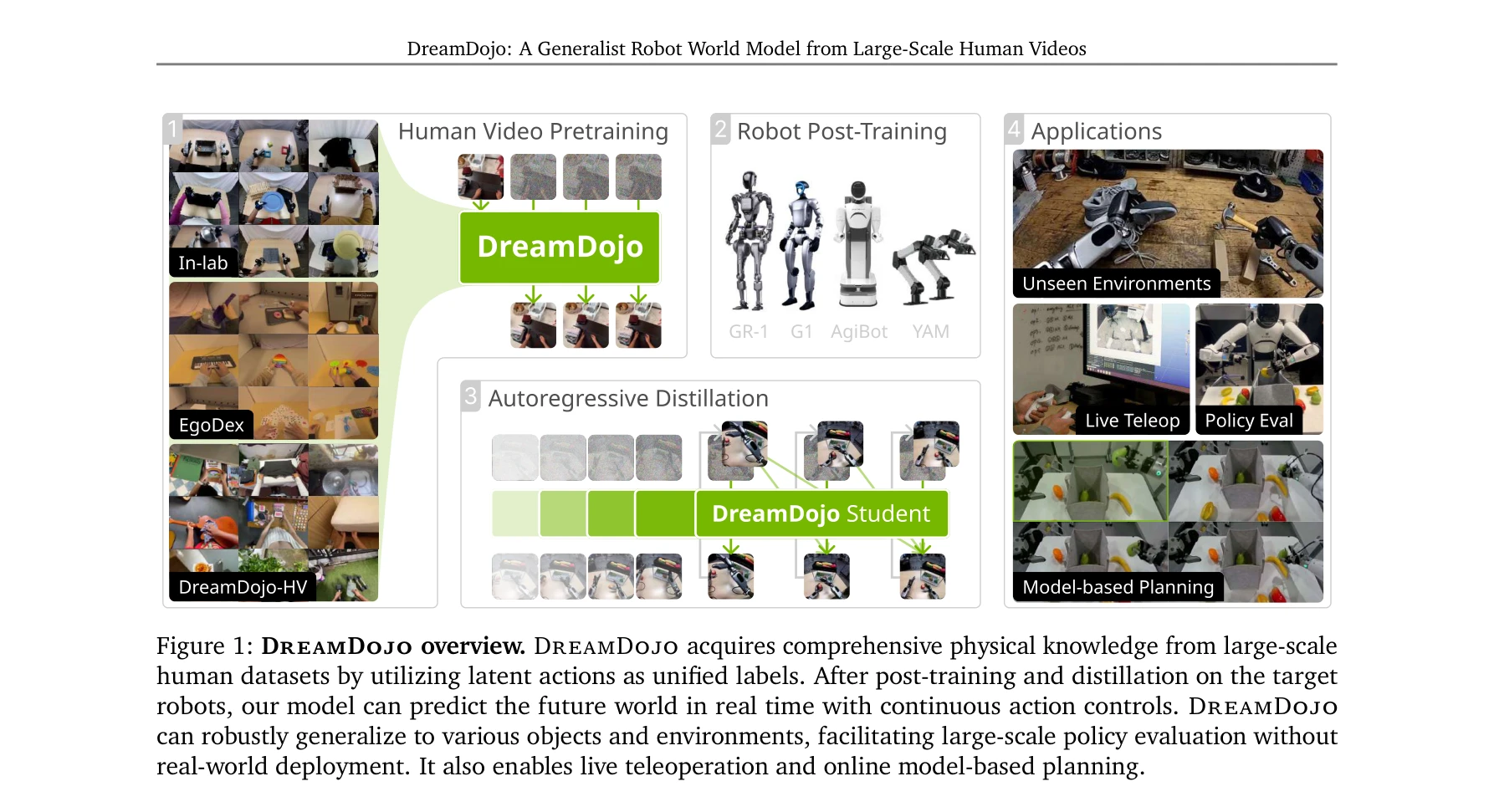
Figure 1: DreamDojo overview. DreamDojo acquires comprehensive physical knowledge from large-scale
 *Figure 1: DreamDojo overview. DreamDojo acquires comprehensive physical knowledge from large-scale* 44k시간의 대규모 인간 동영상으로부터 연속 잠재 행동(continuous latent actions)을 통일된 프록시로 사용하여 학습한 DreamDojo는 로봇의 손재주 제어와 물리 이해를 갖춘 기초 세계 모델로, 실시간 텔레오퍼레이션과 모델 기반 계획을 가능하게 한다.
DreamDojo는 대규모 인간 동영상과 연속 잠재 행동의 혁신적 결합으로 로봇 세계 모델의 스케일과 일반화 능력을 획기적으로 향상시킨 중요한 기여이다. 실시간 성능과 다양한 실제 응용 가능성이 입증되었으나, embodiment gap 완전 해결과 극도의 장기 예측에 대한 추가 검증이 필요하다.
Expressive Whole-Body Control for Humanoid Robots

Fig. 1: Our Robot demonstrates diverse and expressive whole-body movements in different scenarios. Top Row: The robot is
 *Fig. 2: Overview of our framework. Our framework is able to train on data from various sources such as static human moti* 인간형 로봇이 인간의 모션 캡처 데이터를 학습하여 표현력 있는 전신 움직임을 수행하도록 강화학습 기반의 제어 정책을 제안하며, 상체는 참조 모션을 모방하되 하체는 속도 명령만 따르도록 제약을 완화하여 실제 로봇에서의 동작을 가능하게 함.
본 논문은 인간 모션 캡처 데이터를 실제 인간형 로봇에 효과적으로 적용하는 창의적인 문제 분해 방식과 차등적 제약 설계로, 학습 기반 인간형 로봇 제어 분야에서 처음으로 다양한 표현력 있는 동작을 실현함. 명확한 동기, 실제 로봇 검증, 그리고 우수한 성과에도 불구하고 기술적 신규성이 개별 컴포넌트 수준에서는 제한적이며, 하체 표현력과 다양한 작업 확장에 대한 연구가 필요함.
HumanPlus: Humanoid Shadowing and Imitation from Humans

Figure 1: Stanford HumanPlus Robot. We present a full-stack system for humanoid robots to learn motion and
 *Figure 3: Shadowing and Retargeting. Our system uses one RGB camera for body and hand pose estimation.* 휴머노이드 로봇이 단일 RGB 카메라를 사용하여 인간의 동작을 실시간으로 따라할 수 있는 shadowing 시스템과, 수집된 데이터로부터 자율적인 작업 기술을 학습하는 imitation learning 파이프라인을 제시하는 전체 스택 시스템이다.
본 논문은 휴머노이드 로봇의 인간 데이터 활용이라는 오랫동안의 과제에 대해 실용적이고 완성도 높은 end-to-end 시스템을 제시했으며, RGB 카메라 기반 shadowing의 단순성과 효율성, 그리고 다양한 자율 작업의 성공적 구현은 로봇 공학 분야에 실질적인 기여를 한다.
PhysHMR: Learning Humanoid Control Policies from Vision for Physically Plausible Human Motion Reconstruction
Fig. 1. Given a monocular video (a), (b) kinematic-based methods (e.g., GVHMR [Shen et al. 2024]) often cannot produce p
 *Fig. 1. Given a monocular video (a), (b) kinematic-based methods (e.g., GVHMR [Shen et al. 2024]) often cannot produce p* PhysHMR은 모노큘러 비디오로부터 물리적으로 타당한 인간 동작 재구성을 위해 비전-기반 휴머노이드 제어 정책을 직접 학습하는 통합 프레임워크이다. 기존의 두 단계 방식(운동학 기반 추정 + 물리 후처리)과 달리, 시각 정보와 물리 제약을 단일 정책 네트워크에서 함께 추론한다.
PhysHMR은 시각-기반 제어와 물리 추론을 통합하는 창의적 접근으로 모노큘러 비디오 기반 인간 동작 재구성의 근본적 문제를 해결한다. 우수한 물리적 타당성 개선과 실질적 응용 가치로 컴퓨터 비전과 그래픽스 분야에 의미 있는 기여를 한다.
PhysHSI: Towards a Real-World Generalizable and Natural Humanoid-Scene Interaction System

Fig. 1: Our system PhysHSI enables humanoid robots to perform diverse real-world interactions indoors and outdoors with
 *Fig. 2: Overview of PhysHSI. (a) Dataset Preparation: Human motions from a MoCap dataset are retargeted to humanoid moti* PhysHSI는 humanoid 로봇이 실제 환경에서 물체 운반, 앉기, 누우기 등 다양한 상호작용을 자연스럽고 일반화 가능하게 수행할 수 있도록 하는 통합 시스템으로, simulation 기반 AMP 정책 학습과 실시간 LiDAR-camera 기반 객체 인식 모듈을 결합한다.
PhysHSI는 AMP 기반 motion learning과 hybrid sensor fusion을 통합하여 humanoid의 실세계 scene interaction을 처음 실현한 high-impact system으로, 자연스러운 동작과 robust generalization을 동시에 달성했으나, annotation 자동화와 marker-free perception 확대가 실용 배포의 과제이다.
PRIMAL: Physically Reactive and Interactive Motor Model for Avatar Learning
Figure 1. PRIMAL is a novel generative real-time 3D character animation system that works in Unreal Engine. The avatar r
 *Figure 1. PRIMAL is a novel generative real-time 3D character animation system that works in Unreal Engine. The avatar r* PRIMAL은 두 단계 학습 패러다임으로 아바타의 모터 시스템을 generative motion model로 구현하여, 물리적으로 반응성 있고 제어 가능하며 실시간 상호작용이 가능한 3D 캐릭터 애니메이션을 실현한다.
PRIMAL은 짧은 시간 척도에서의 physics 지배성이라는 통찰력으로 unsupervised diffusion model을 통해 실시간 반응성과 물리적 사실성을 동시에 달성한 혁신적 접근이며, Unreal Engine 구현으로 실제 응용 가능성을 입증한 탁월한 연구이다.
Reduced-Order Model-Guided Reinforcement Learning for Demonstration-Free Humanoid Locomotion
Figure 1: Overview of the ROM-GRL framework. In Stage 1, a 4-DOF ROM policy is trained in Box2D: the policy
 *Figure 1: Overview of the ROM-GRL framework. In Stage 1, a 4-DOF ROM policy is trained in Box2D: the policy* ROM-GRL은 모션캡처 데이터 없이 4-DOF reduced-order model로 생성한 gait template을 이용해 full-body humanoid 정책을 학습하는 2단계 강화학습 프레임워크이다. Adversarial discriminator를 통해 ROM의 5-dimensional gait feature 분포를 따르도록 유도하여 자연스러운 보행을 실현한다.
ROM-GRL은 reduced-order model을 creative하게 활용해 motion capture 의존성을 제거하면서 자연스럽고 안정적인 humanoid 보행을 달성하는 novel 프레임워크이다. 보상 설계와 모방 학습 간 간격을 효과적으로 줄였으나, 제한된 속도 범위와 실제 로봇 검증 부재가 일반화 가능성의 의문을 남긴다.
Robot Trains Robot: Automatic Real-World Policy Adaptation and Learning for Humanoids

Figure 1: Robot Trains Robot (RTR). We pro-
 *Figure 1: Robot Trains Robot (RTR). We pro-* 로봇 팔(teacher)이 휴머노이드 로봇(student)을 지원하고 가이드하는 Robot-Trains-Robot(RTR) 프레임워크를 제안하여, 안전하고 효율적인 실제 환경에서의 휴머노이드 학습을 가능하게 한다. Dynamics-encoded latent variable 최적화를 통한 sim-to-real 전이 방법을 함께 제안한다.
실제 환경에서의 휴머노이드 학습이라는 중요하면서도 실제로 구현되지 않았던 문제에 대해, 혁신적인 teacher-robot 지원 방식과 효율적 sim-to-real 알고리즘을 결합하여 실질적인 해결책을 제시한다. 실험적 검증과 전반적 설계의 견고성이 우수하지만, 제한된 플랫폼과 태스크에서의 검증이라는 한계가 있다.
RobotDancing: Residual-Action Reinforcement Learning Enables Robust Long-Horizon Humanoid Motion Tracking
Fig. 1.
 *Fig. 1.* RobotDancing은 잔차 동작(residual action) 강화학습을 통해 인간형 로봇이 장기간 고역동 춤 동작을 추적할 수 있도록 하는 프레임워크로, 모델-실제 간의 동역학 불일치를 명시적으로 보정한다.
RobotDancing은 잔차 동작 학습과 이원 샘플링 전략을 통해 인간형 로봇의 장기 고역동 모션 추적 문제를 우아하게 해결하며, 실제 로봇으로의 영점 전달 성공은 실무적 가치가 높다.
RuN: Residual Policy for Natural Humanoid Locomotion
 *Fig. 2: Overview of the RuN framework. (a) Motion Retargeting: Raw human motions are converted into a kinematically feas* RuN은 Conditional Motion Generator를 통한 운동학적 모션 프라이어와 강화학습 기반 residual policy를 분리하여, 인형로봇의 자연스러운 보행-달리기 전환을 실현하는 decoupled residual learning 프레임워크이다.
RuN은 humanoid locomotion 제어의 근본적인 복잡성을 elegant하게 해결한 well-motivated 프레임워크로, decoupled residual learning 접근이 학습 효율성과 최종 성능을 모두 개선하며 실제 로봇에서 검증된 강력한 방법론이다.
Scalable and General Whole-Body Control for Cross-Humanoid Locomotion

Figure 1. Zero-shot generalization and real-world humanoid capabilities enabled by XHugWBC’s generalist policy. First ro
 *Figure 2. Training framework of XHugWBC. (a) Data generation: physics-consistent morphological randomization produces di* XHugWBC는 물리적으로 일관성 있는 형태학적 랜덤화, 의미론적으로 정렬된 관찰-행동 공간, 그래프 기반 정책 아키텍처를 통해 단일 정책으로 다양한 인간형 로봇에 대한 제로샷 제너럴화를 실현하는 교차-신체 전신 제어 프레임워크이다.
본 논문은 물리적으로 일관성 있는 형태 랜덤화와 의미론적 정렬을 통해 단일 정책의 다중 인간형 로봇 제너럴화를 처음으로 달성했으며, 7개 실제 로봇에서의 강건한 제로샷 성능과 시뮬레이션 확장성으로 로봇 학습의 현실적 가치를 입증했다.
SCDP: Learning Humanoid Locomotion from Partial Observations via Mixed-Observation Distillation
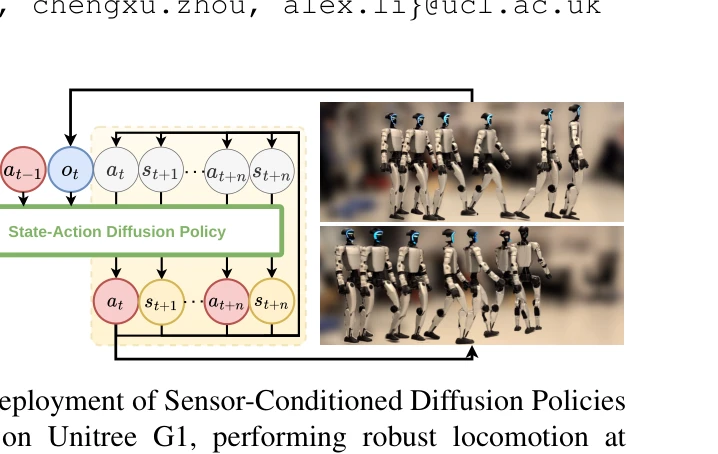
Fig. 1: Deployment of Sensor-Conditioned Diffusion Policies
 *Fig. 2: Sensor-Conditioned Diffusion Policies (SCDP) architecture and training framework. The state-action diffusion* 온보드 센서만으로 휴머노이드 보행을 학습하기 위해 mixed-observation distillation을 사용하는 SCDP(Sensor-Conditioned Diffusion Policies)를 제안하며, diffusion model이 센서 이력에 조건화되면서 privileged 미래 상태-행동 궤적을 예측하도록 학습한다.
Mixed-observation distillation은 개념적으로 우수한 해결책이며, 실로봇 배포까지 달성한 점이 높게 평가된다. 다만 일반화 범위와 센서 robustness 측면의 추가 검증이 필요하며, IROS 채택으로 인정된 견고한 연구이다.
SimGenHOI: Physically Realistic Whole-Body Humanoid-Object Interaction via Generative Modeling and Reinforcement Learning

Figure 1: With the condition of text prompt, object geometry,
 *Figure 2: Our proposed framework uses a diffusion model for key action generation and reinforcement learning to train* SimGenHOI는 Diffusion Transformers 기반의 생성 모델과 강화학습 기반의 접촉-인식 제어 정책을 결합하여 물리적으로 현실적인 인간형 로봇-객체 상호작용을 생성하는 통합 프레임워크이다. 상호 미세조정 전략을 통해 생성 모델과 제어 정책이 반복적으로 서로를 개선하여 장기 조작 과제의 성공률을 높인다.
본 논문은 생성 모델과 강화학습의 상호 보완적 강점을 효과적으로 결합하여 물리적으로 현실적인 장기 인간형 로봇-객체 상호작용 생성이라는 중요한 문제를 해결하였다. 특히 상호 미세조정 전략과 key action 기반 패러다임은 높은 독창성을 보여주며, 광범위한 실험을 통해 방법의 효과를 입증했으나 sim-to-real 검증이 부족한 점이 아쉽다.
The Role of Domain Randomization in Training Diffusion Policies for Whole-Body Humanoid Control
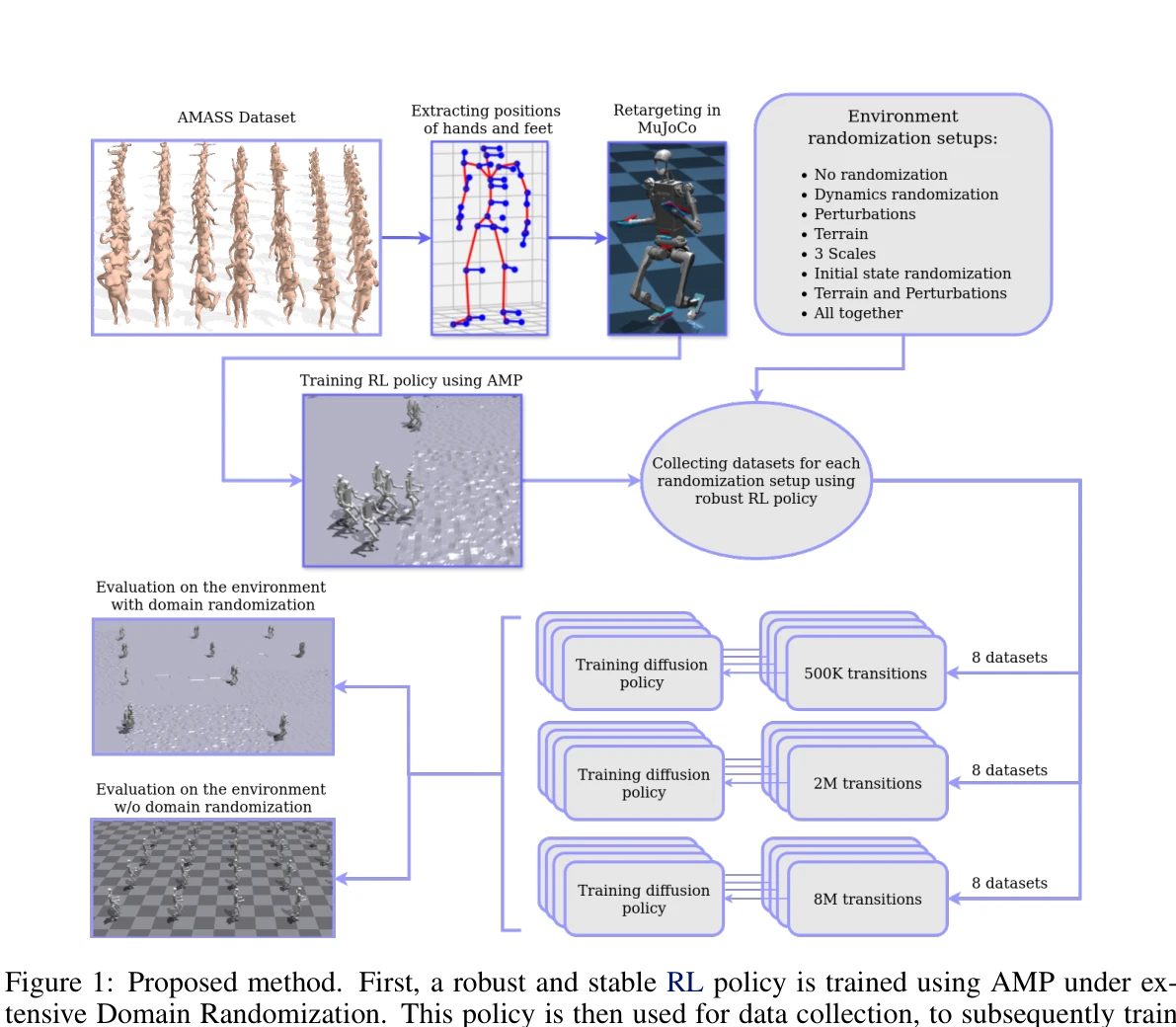
Figure 1: Proposed method. First, a robust and stable RL policy is trained using AMP under ex-
 *Figure 2: Evaluation of Diffusion Policies in a non-randomized target environment. Top: A plot dis-* 본 논문은 Humanoid 로봇의 전신 제어를 위해 Diffusion Policies를 훈련할 때 Domain Randomization의 역할을 조사하며, 조작 작업보다 보행 작업이 훨씬 더 큰 규모와 다양성의 데이터셋을 요구함을 보여준다.
본 논문은 humanoid 제어를 위한 Diffusion Policies의 데이터 요구사항에 대한 첫 체계적 ablation 연구로서, Domain Randomization의 중요성을 명확히 입증하고 조작-보행 작업 간의 근본적 차이를 정량화한다. 다만 실제 로봇 검증과 복잡한 작업으로의 확장이 필요하다.
Thor: Towards Human-Level Whole-Body Reactions for Intense Contact-Rich Environments
Fig. 1. Humanoids performing tasks involving forceful interactions with the
 *Fig. 2.* Thor는 humanoid 로봇이 강한 접촉 상호작용 환경에서 인간 수준의 전신 반응을 생성하도록 하는 프레임워크로, force-adaptive torso-tilt (FAT2) 보상 함수와 decoupled reinforcement learning 아키텍처를 제안한다.
Thor는 decoupled RL 아키텍처와 인간 생체역학 기반 FAT2 보상 함수를 통해 humanoid의 강력한 힘 상호작용 능력을 크게 향상시킨 우수한 연구로, 실세계 성능 검증과 다양한 작업 시연을 통해 높은 실용적 가치를 입증했다.
Unveiling the Impact of Data and Model Scaling on High-Level Control for Humanoid Robots

Fig. 1. We present the large-scale, high-quality robot motion dataset
 *Fig. 1. We present the large-scale, high-quality robot motion dataset* 대규모 인간 모션 데이터를 활용하여 자동 파이프라인으로 생성한 Humanoid-Union 데이터셋(260시간)과 이를 기반으로 하는 SCHUR 프레임워크를 제안하여 텍스트 기반 휴머노이드 로봇 모션 생성의 확장성을 달성했다.
본 논문은 대규모 자동화 파이프라인으로 고품질 로봇 모션 데이터셋을 구축하고, FSQ VAE 및 LLaMA 기반 SCHUR 프레임워크로 효과적인 data/model scaling을 달성하여 휴머노이드 로봇의 텍스트 기반 고수준 제어의 실질적 발전을 보여준다.
Visual Imitation Enables Contextual Humanoid Control
 *Figure 2: VideoMimic Real-to-Sim. A casually captured phone video provides the only input. We first* VIDEOMIMIC는 단순한 휴대폰 영상에서 인간-환경 4D 기하학을 공동 재구성하고, 이를 시뮬레이션에서 RL 정책으로 학습한 후 실제 휴머노이드 로봇에 배포하는 real-to-sim-to-real 파이프라인이다.
이 논문은 일상 영상으로부터 휴머노이드 로봇의 문맥-인식 제어를 가능하게 하는 실용적이고 확장 가능한 파이프라인을 제시하며, 공동 4D 재구성과 RL 기반 정책 증류의 조합으로 높은 독창성을 보인다. 실제 로봇 배포 성공은 연구의 가치를 크게 높이나, 환경 표현의 제한성과 동역학 정확도 측면에서 개선 여지가 있다.
Zero-Shot Whole-Body Humanoid Control via Behavioral Foundation Models

Figure 1 META MOTIVO is the first behavioral foundation model for humanoid agents that can solve whole-body control task
 *Figure 1 META MOTIVO is the first behavioral foundation model for humanoid agents that can solve whole-body control task* Forward-Backward representations with Conditional-Policy Regularization (FB-CPR)을 통해 unlabeled behavior dataset으로 unsupervised RL을 정규화하여, humanoid agent의 zero-shot whole-body control을 가능하게 하는 behavioral foundation model Meta Motivo를 개발했다.
FB-CPR은 unsupervised RL의 exploration 한계를 behavior dataset 정규화로 창의적으로 해결하고, 복잡한 humanoid 제어에서 zero-shot generalization을 달성한 기술적으로 견실하고 의미 있는 연구이다. 재현성 보장과 다양한 평가는 강점이나, 데이터셋 의존성과 실제 로봇 검증 부재는 향후 개선이 필요하다.
$Ψ_0$: An Open Foundation Model Towards Universal Humanoid Loco-Manipulation
 *Fig. 2: Model Training and Deployment: First, we pre-train the VLM on the EgoDex [20] dataset to autoregressively predic* Ψ0는 인간 중심 egocentric 비디오로 VLM을 사전학습한 후 humanoid 로봇 데이터로 flow-based action expert를 post-train하는 2단계 학습 패러다임을 통해 humanoid loco-manipulation을 위한 foundation model을 제안한다.
Ψ0는 인간-humanoid embodiment gap을 극복하기 위한 명확한 2단계 학습 패러다임과 고품질 데이터 선택의 중요성을 새롭게 제시하며, 10배 이상의 데이터 효율 개선으로 humanoid loco-manipulation 분야에 significant contribution을 제공한다.
AMP: Adversarial Motion Priors for Stylized Physics-Based Character Control
 *Fig. 2. Schematic overview of the system. Given a motion dataset defining a* 물리 기반 캐릭터 애니메이션에서 adversarial motion prior를 학습하여 비구조화된 모션 클립 데이터셋으로부터 자동으로 스타일을 추출하고, 간단한 보상 함수로 정의된 고수준 태스크 목표를 달성하면서도 자연스러운 움직임을 생성하는 방법을 제안한다.
본 논문은 adversarial motion prior를 통해 비구조화 모션 데이터의 자동 활용을 실현한 물리 기반 캐릭터 애니메이션 분야의 중요한 기여로, 모션 선택 메커니즘 설계의 부담을 제거하면서도 최첨단 성능을 달성하며 게임, 영상, 로봇 등 다양한 응용 분야에 실질적 가치를 제공한다.
Behavior Foundation Model for Humanoid Robots

Fig. 1: Behavior Foundation Model enables humanoid robots to perform a variety of behaviors in a zero-shot manner,
 *Fig. 2: Overview of BFM Implementation. (a) Human motion dataset is retargeted to humanoid robots for proxy agent* 본 논문은 휴머노이드 로봇의 다양한 제어 태스크에 일반화 가능한 행동 기반 파운데이션 모델(BFM)을 제안하며, masked online distillation과 CVAE를 결합하여 대규모 행동 데이터셋으로 사전학습한다.
본 논문은 휴머노이드 로봇 제어의 통합 행동 학습 패러다임을 명확히 제시하고 masked online distillation과 CVAE를 통한 실제적 구현으로 다양한 제어 모드 지원과 빠른 신행동 습득을 실현했으며, 시뮬레이션과 실제 플랫폼 양쪽에서 광범위하게 검증하여 범용 휴머노이드 제어의 새로운 방향을 제시한다.
Being-M0.5: A Real-Time Controllable Vision-Language-Motion Model

Figure 1: Leveraging our million-scale dataset HuMo100M, we present Being-M0.5, the first real-time, control-
 *Figure 1: Leveraging our million-scale dataset HuMo100M, we present Being-M0.5, the first real-time, control-* Being-M0.5는 HuMo100M이라는 백만 규모의 대규모 데이터셋을 기반으로 한 최초의 실시간 제어 가능 vision-language-motion model로, part-aware residual quantization을 통해 신체 각 부위에 대한 세밀한 제어를 가능하게 한다.
Being-M0.5는 HuMo100M과 part-aware residual quantization이라는 두 가지 주요 혁신을 통해 motion generation의 제어 가능성과 실시간 성능 문제를 동시에 해결하며, 대규모 데이터셋과 모델 설계 통찰력으로 실제 응용 배포의 새로운 기준을 제시한다.
Benchmarking Humanoid Imitation Learning with Motion Difficulty
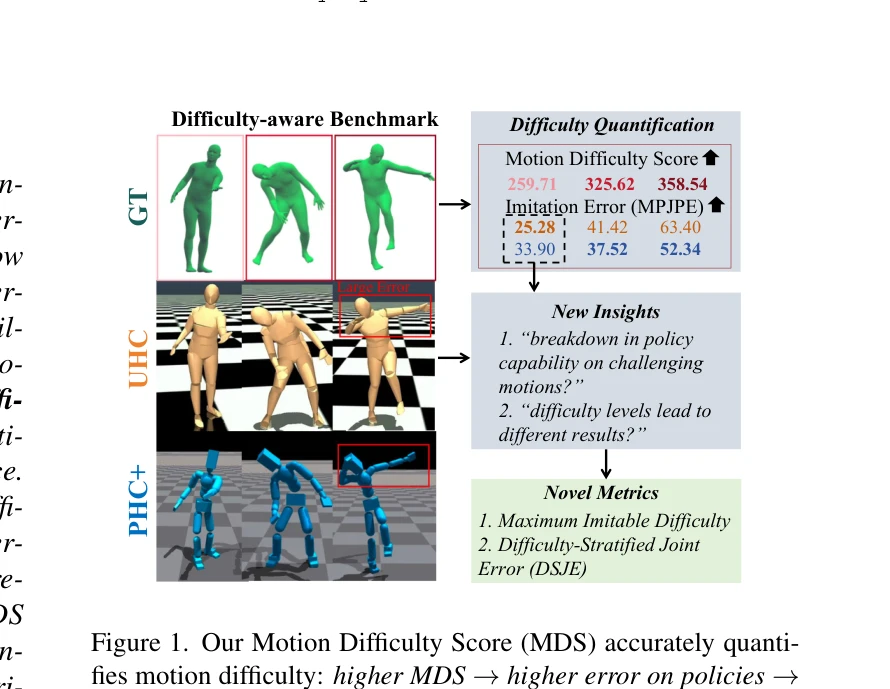
Figure 1. Our Motion Difficulty Score (MDS) accurately quanti-
 *Figure 1. Our Motion Difficulty Score (MDS) accurately quanti-* 본 논문은 인간형 로봇의 동작 모방 학습에서 정책 성능과 동작 난이도를 분리하여 평가하기 위해 Motion Difficulty Score (MDS)를 제안하며, 이를 통해 실패가 학습 부족인지 본질적으로 어려운 동작인지를 구분할 수 있게 한다.
본 논문은 동작 모방 학습에서 오래된 문제(정책 성능 vs 동작 난이도의 혼동)를 처음으로 명확히 정의하고 수학적으로 해결하는 창의적인 접근을 제시하며, MD-AMASS 구성과 광범위한 실증 검증을 통해 실용적 가치를 입증한다. 다만 실제 로봇 환경으로의 확장과 일반화 가능성에 대한 추가 검증이 요구된다.
BFM-Zero: A Promptable Behavioral Foundation Model for Humanoid Control Using Unsupervised Reinforcement Learning

Figure 1: BFM-Zero enables versatile and robust whole-body skills. (A-C) Diverse zero-shot inference
 *Figure 2: An overview of the BFM-Zero framework. After the pre-training stage, BFM-Zero forms a latent* BFM-Zero는 unsupervised RL과 Forward-Backward 모델을 활용하여 휴머노이드 로봇의 다양한 제어 작업을 단일 정책으로 수행할 수 있는 promptable behavioral foundation model을 제시한다. 공유 잠재 공간에 모션, 목표, 보상을 임베딩하여 zero-shot 추론과 few-shot 적응을 가능하게 한다.
BFM-Zero는 unsupervised RL을 통해 휴머노이드 로봇의 실제 배포에서 처음으로 promptable foundation model을 성공적으로 구현하였으며, zero-shot 다중 작업 수행과 few-shot 적응의 균형을 이루는 실용적 솔루션을 제시한다. 이는 로봇 제어의 패러다임 전환을 제시하는 중요한 기여이다.
CMR: Contractive Mapping Embeddings for Robust Humanoid Locomotion on Unstructured Terrains
Fig. 1: The left panel illustrates diverse types of challenging
 *Fig. 2: Overview of the CMR framework. Noisy ob-* CMR은 관찰 노이즈에 강건한 휴머노이드 로봇 보행을 위해 contrastive representation learning과 Lipschitz regularization을 결합하여 disturbance를 attenuate하는 latent space를 학습하는 프레임워크이다.
CMR은 contraction mapping theorem을 휴머노이드 로봇 제어에 엄밀하게 도입하여 이론적 근거와 실증적 성능을 모두 제시한 강한 논문이다. 다양한 지형에서의 노이즈 robustness 개선과 기존 파이프라인과의 용이한 통합이 주요 강점이나, 실제 로봇 검증과 노이즈 모델 확장이 필요하다.
Coordinated Humanoid Robot Locomotion with Symmetry Equivariant Reinforcement Learning Policy
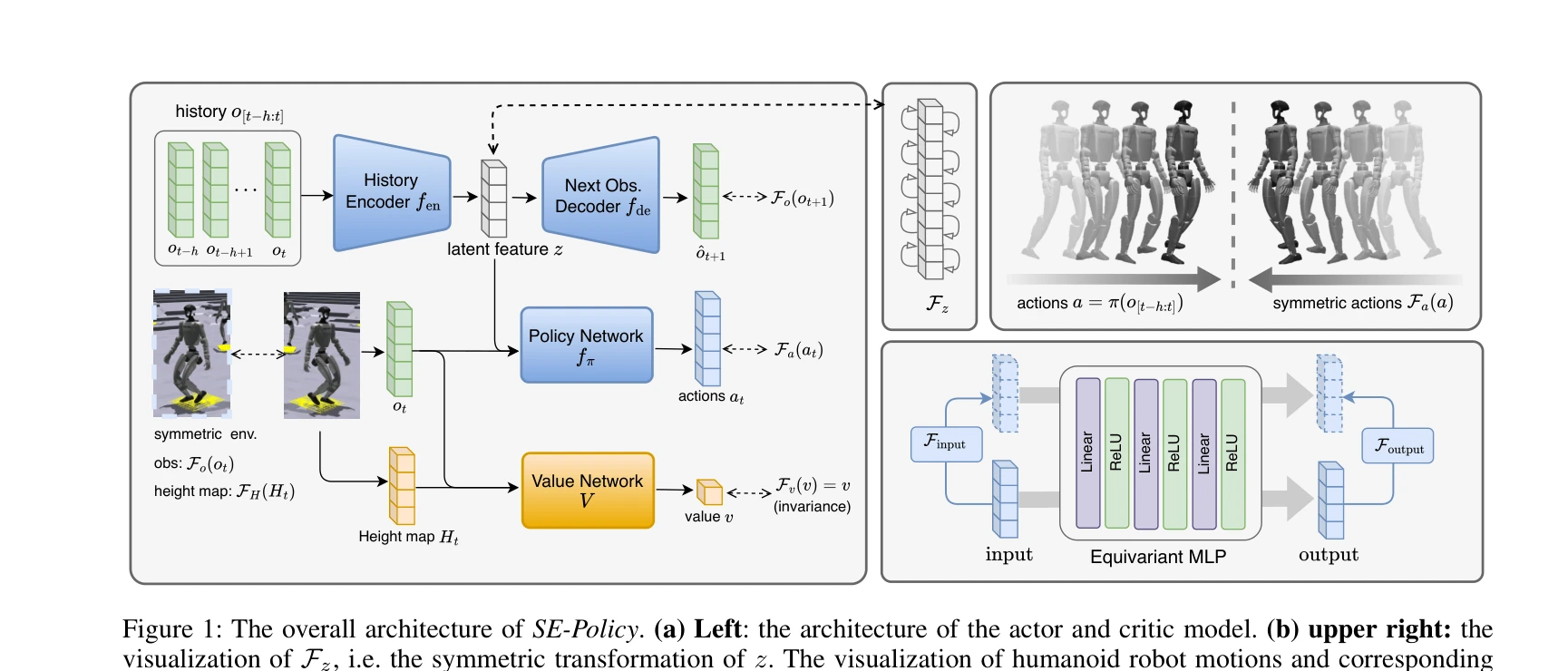
Figure 1: The overall architecture of SE-Policy. (a) Left: the architecture of the actor and critic model. (b) upper rig
 *Figure 1: The overall architecture of SE-Policy. (a) Left: the architecture of the actor and critic model. (b) upper rig* 인간의 신경계에서 영감을 받은 Symmetry Equivariant Policy (SE-Policy)를 제안하여, 휴머노이드 로봇의 형태적 대칭성을 DRL 프레임워크에 엄격하게 임베딩함으로써 조정되고 균형잡힌 보행을 실현한다.
SE-Policy는 휴머노이드 로봇의 형태적 대칭성을 엄격한 네트워크 제약으로 구현하여 추가 하이퍼파라미터 없이 40% 성능 향상을 달성한 혁신적인 방법이며, 실제 로봇 배포를 통해 실용성을 입증했다는 점에서 높은 기여도를 가진다.
DreamControl-v2: Simpler and Scalable Autonomous Humanoid Skills via Trainable Guided Diffusion Priors

Fig. 1: DreamControl-v2 enables scalable and autonomous humanoid skill acquisition. We demonstrate diverse real-world sk
 *Fig. 2: DreamControl-v2 Overview. Our four-stage pipeline enables humanoid whole-body manipulation: (1) large-scale huma* humanoid 로봇의 복잡한 manipulation 작업을 위해 guided diffusion 모델을 로봇의 motion space에 직접 학습하여, 다양한 인간과 로봇 데이터를 통합하고 RL 정책을 자동으로 생성하는 확장 가능한 프레임워크를 제시한다.
DreamControl-v2는 robot-space diffusion prior 훈련이라는 명확한 아이디어로 기존의 확장성 문제를 근본적으로 해결하며, 자동화된 파이프라인과 다양한 skill 습득을 통해 humanoid 로봇의 자율적 loco-manipulation에 실질적인 진전을 이루었다. 다만 다중 로봇 embodiment 일반화와 실제 환경에서의 광범위한 검증이 추가되면 더욱 강력한 기여가 될 것이다.
DreamControl: Human-Inspired Whole-Body Humanoid Control for Scene Interaction via Guided Diffusion

Fig. 1: Unitree G1 humanoid performing various skills trained via
 *Fig. 2: DreamControl Overview: (A) we first generate text and spatiotemporally guided human motion trajectories using di* DreamControl은 human motion 기반 diffusion prior를 RL과 결합하여 humanoid robot의 whole-body 조작 작업을 학습하는 방법론을 제안한다.
DreamControl은 human motion diffusion prior와 RL의 장점을 효과적으로 결합하여 humanoid robot의 whole-body manipulation을 학습하는 창의적이고 실용적인 방법론을 제시하며, 실제 로봇에서의 다양한 작업 수행으로 그 가치를 입증했다.
DreamGen: Unlocking Generalization in Robot Learning through Video World Models
 *Figure 2: DREAMGEN Overview. We begin by fine-tuning a video world model on teleoperated robot trajectories.* DreamGen은 비디오 월드 모델(video world model)을 활용하여 최소한의 원격조종 데이터로부터 로봇 정책을 학습하는 4단계 파이프라인으로, 신규 행동과 환경에 대한 일반화를 달성한다.
DreamGen은 비디오 월드 모델을 로봇 학습의 효율적인 데이터 생성 도구로 재정의하여, 최소한의 원격조종 데이터로 다양한 행동과 환경 일반화를 달성하는 혁신적이고 실용적인 접근법을 제시한다. 다중 embodiment 실세계 검증과 DreamGen Bench라는 체계적 평가 도구까지 제공하여 로봇 학습 확장의 새로운 방향을 제시한다.
DynaRetarget: Dynamically-Feasible Retargeting using Sampling-Based Trajectory Optimization

Fig. 1: Real-world humanoid loco-manipulation behaviors enabled by DynaRetarget. Demonstrations retargeted using our fra
 *Fig. 2: DynaRetarget overview. Given a human–object demonstration, we first perform IK-based retargeting to obtain a kin* DynaRetarget은 Sampling-Based Trajectory Optimization (SBTO)을 통해 운동학적으로 부정확한 인간 동작을 휴머노이드 로봇이 동적으로 실행 가능한 loco-manipulation 행동으로 변환하는 완전한 파이프라인을 제시한다.
DynaRetarget은 sampling-based trajectory optimization의 incremental horizon 확장 개념을 통해 humanoid loco-manipulation retargeting의 동적 실행 가능성 문제를 효과적으로 해결하며, 광범위한 실험과 실제 로봇 배포를 통해 그 효과를 입증한 의미 있는 기여이다.
EgoDemoGen: Egocentric Demonstration Generation for Viewpoint Generalization in Robotic Manipulation
 *Figure 2. Overview of EgoDemoGen. Given source demonstrations from a standard egocentric viewpoint, we generate novel de* EgoDemoGen은 egocentric viewpoint 변화에 대응하는 로봇 조작 정책의 일반화를 위해, 궤적 전송과 영상 합성을 통해 새로운 egocentric 관점에서 정렬된 observation-action 시연을 생성하는 프레임워크이다.
본 논문은 egocentric viewpoint 변화의 특수성을 명확히 인식하고, 궤적 전송과 영상 합성을 통합하는 EgoDemoGen 프레임워크를 제시하여 로봇 조작의 viewpoint 일반화 문제를 근본적으로 해결한다. 실험적으로 시뮬레이션과 실제 로봇 환경에서 일관된 성능 향상을 보여주며, 로봇 학습의 실용적 적용에 중요한 기여를 한다.
Embodiment-Aware Generalist Specialist Distillation for Unified Humanoid Whole-Body Control

Fig. 1: In this work, we propose a distillation framework that yields a single whole-body controller that runs on hetero
 *Fig. 2: Method Overview. (a) Unified command interface. The command vector ct comprises task commands vt (linear* EAGLE는 다양한 휴머노이드 로봇을 단일 정책으로 제어하기 위한 embodiment-aware generalist-specialist distillation 프레임워크로, 반복적인 전문가 미세조정과 일반화 정책으로의 지식 증류를 통해 여러 이종 로봇에서 보행, 스쿼팅, 기울임 등 다양한 whole-body 제어를 가능하게 한다.
EAGLE는 generalist-specialist distillation을 통해 이종 휴머노이드의 통합 제어라는 어려운 문제에 대한 실증적 해결책을 제시하며, 시뮬레이션과 실제 하드웨어에서의 광범위한 검증으로 fleet-level 휴머노이드 제어의 실현 가능성을 보여주는 의미 있는 기여다.
FAME: Force-Adaptive RL for Expanding the Manipulation Envelope of a Full-Scale Humanoid
Fig. 1: FAME overview and real demonstration. Left: FAME conditions a standing policy on an upper-body context encoder t
 *Fig. 2: Overview of the proposed standing framework. During training (top), an upper-body dynamics encoder processes* FAME는 양팔 조작 시 외부 손 힘으로 인한 균형 교란을 해결하기 위해, 상체 관절 구성과 양팔 상호작용 힘을 인코딩하는 latent context에 조건화된 RL 정책을 학습한다.
FAME는 latent context adaptation을 양팔 조작 중 balance 문제에 창의적으로 적용하며, 센서 불필요 배포와 실세계 검증으로 실용적 기여를 한다. 다만 sim-to-real 격차와 힘 추정 정확도 분석이 보강되면 더욱 강력해질 것이다.
GraspDreamer: 생성형 인간 시연 기반 기능적 파지 모방 학습

Fig. 1: GraspDreamer leverages human demonstrations syn-
 *Fig. 1: GraspDreamer leverages human demonstrations syn-* Visual Generative Model (VGM)으로 생성한 인간 시연 비디오로부터 기능적 파지를 학습하여 실제 데이터 수집 없이 제로샷 로봇 파지를 가능하게 하는 GraspDreamer 방법을 제안한다. 인터넷 규모의 사전학습 데이터에 인코딩된 인간-물체 상호작용 프라이어를 활용하여 데이터 효율성과 일반화 성능을 동시에 달성한다.
GraspDreamer는 VGM의 생성 능력을 창의적으로 활용하여 기능적 파지의 데이터 수집 부담을 획기적으로 감소시키면서도 다양한 로봇 플랫폼에 일반화되는 실용적 솔루션을 제시한다. 공개 벤치마크와 실세계 실험의 광범위한 검증으로 방법의 유효성을 충실히 입증하였다.
H-RDT: Human Manipulation Enhanced Bimanual Robotic Manipulation
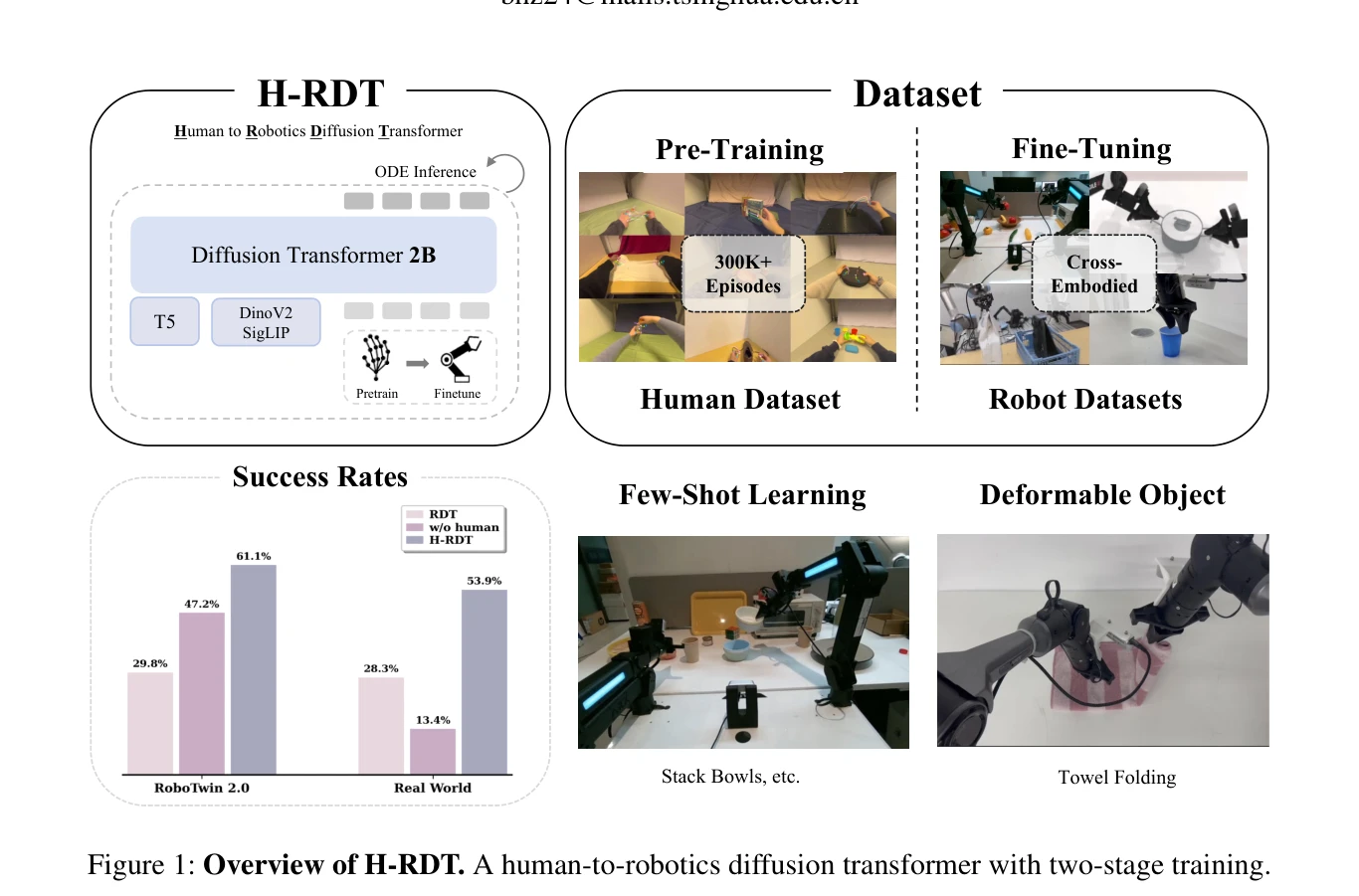
Figure 1: Overview of H-RDT. A human-to-robotics diffusion transformer with two-stage training.
 *Figure 1: Overview of H-RDT. A human-to-robotics diffusion transformer with two-stage training.* H-RDT는 대규모 egocentric 인간 조작 데이터로 사전학습하고 모듈식 action encoder/decoder를 통해 다양한 로봇에 fine-tuning하는 두 단계 diffusion transformer 기반 접근법으로, 로봇 조작 학습을 향상시킨다.
H-RDT는 대규모 egocentric human manipulation 데이터의 가치를 체계적으로 입증하면서, 모듈식 전이 구조를 통해 diverse robot platform으로의 확장 가능성을 보여준 혁신적 연구이다. 광범위한 실험과 강력한 empirical 결과가 robotic manipulation 학습의 data scarcity 문제 해결에 실질적인 기여를 하고 있다.
H-Zero: Cross-Humanoid Locomotion Pretraining Enables Few-shot Novel Embodiment Transfer
Fig. 1: Left: We propose a locomotion pretraining pipeline for humanoids by mixing multiple randomized embodiments
 *Fig. 2: Method overview. a) The policy is pretrained by learning on a diverse set of humanoid embodiments through* H-Zero는 다양한 휴머노이드 로봇 embodiment에서 사전학습된 일반화된 이동 정책을 학습하여 미지의 로봇으로의 제로샷 및 소수샷 전이를 가능하게 하는 파이프라인이다.
H-Zero는 unified control semantics를 통해 실용적이고 확장 가능한 cross-embodiment 이동 제어 솔루션을 제시하며, 30분의 미세조정으로 신규 로봇에 적응할 수 있는 점에서 현실 배포 관점에서 큰 의의가 있다. 다만 embodiment 선택의 체계화와 더 다양한 형태의 로봇으로의 일반화 능력 검증이 필요하다.
HDMI: Learning Interactive Humanoid Whole-Body Control from Human Videos

Fig. 1: HDMI enables humanoid robots to acquire diverse whole-body interaction skills directly from human videos. (a)
 *Fig. 2: HDMI is a general framework for interactive skill learning. Monocular RGB videos are processed into a structured* HDMI는 단일 모노큘러 RGB 비디오에서 인간의 상호작용을 추출하여 휴머노이드 로봇이 물체와의 전신 상호작용 기술을 학습하는 프레임워크이다. Robot-object co-tracking을 통해 강화학습 정책을 훈련하고 실제 로봇에 제로샷 배포한다.
HDMI는 휴머노이드 로봇의 전신 물체 상호작용을 위한 일반적이고 실용적인 프레임워크로, 인간 비디오 활용이라는 확장 가능한 데이터 소스와 함께 robot-object co-tracking이라는 우아한 문제 설정을 통해 실제 로봇에서 강력한 성능을 달성했으며, 휴머노이드 로보틱스 분야에 의미 있는 기여를 한다.
HoRD: Robust Humanoid Control via History-Conditioned Reinforcement Learning and Online Distillation
Figure 1. Framework overview. Two-stage teacher–student learning pipeline for robust humanoid control under partial obse
 *Figure 1. Framework overview. Two-stage teacher–student learning pipeline for robust humanoid control under partial obse* HoRD는 history-conditioned reinforcement learning과 online distillation을 결합한 두 단계 학습 프레임워크로, 휴머노이드 로봇이 도메인 시프트 상황에서 강건한 제어를 수행하도록 한다.
HoRD는 history-conditioned 동역학 추론과 sparse 명령 처리라는 두 가지 핵심 혁신을 통해 휴머노이드 제어의 강건성과 일반화 문제를 효과적으로 해결하며, 광범위한 실험 검증과 데이터셋 공개로 실용적 가치를 입증한다.
HOVER: Versatile Neural Whole-Body Controller for Humanoid Robots
Fig. 1: HOVER enables versatile humanoid control with a unified
 *Fig. 1: HOVER enables versatile humanoid control with a unified* HOVER는 키네매틱 위치 추적, 조인트 각도 추적, 루트 추적을 포함한 15개 이상의 제어 모드를 지원하는 통합 신경망 제어기로, 정책 증류를 통해 다양한 제어 모드를 단일 정책으로 통합하여 휴머노이드 로봇의 다목적 전신 제어를 실현한다.
HOVER는 휴머노이드 전신 제어의 다중 모드 통합이라는 실질적이고 중요한 문제를 정책 증류 기반의 우아한 해결책으로 제시하며, 시뮬레이션과 실제 로봇에서 모두 검증된 견고한 성과를 보여준다. 다만 실제 환경의 복잡한 작업에 대한 적응성과 계산 효율성에 대한 심화 분석이 더해지면 완성도가 높아질 수 있다.
Human-Humanoid Robots Cross-Embodiment Behavior-Skill Transfer Using Decomposed Adversarial Learning from Demonstration

Fig. 1: Human can serve as the prototype of diverse humanoid robots, efficiently learning generalized loco-manipulation
 *Fig. 2: Schematic overview of the cross-embodiment loco-manipulation skill transfer framework. 1) Human embodiment* Unified Digital Human (UDH) 모델을 공통 프로토타입으로 사용하여 인간 시연에서 행동 원시 요소를 학습하고, 분해된 adversarial imitation learning과 kinematic motion retargeting을 통해 다양한 휴머노이드 로봇 플랫폼으로 로코-매니퓰레이션 스킬을 효율적으로 전이한다.
본 논문은 UDH를 중심으로 한 창의적인 교차 embodiment 프레임워크를 제시하며, functional decomposition과 adversarial imitation learning의 결합, 그리고 interaction graph 기반 계획을 통해 휴머노이드 로봇의 로코-매니퓰레이션 스킬 전이 문제를 실질적으로 해결하는 중요한 기여를 한다.
HumanX: Toward Agile and Generalizable Humanoid Interaction Skills from Human Videos
Fig. 1: HumanX enables diverse interaction skills through two core components. XGen synthesizes and augments humanoid in
 *Fig. 1: HumanX enables diverse interaction skills through two core components. XGen synthesizes and augments humanoid in* HumanX는 인간 비디오로부터 휴머노이드 로봇의 상호작용 스킬을 학습하는 전체 스택 프레임워크로, XGen 데이터 생성 파이프라인과 XMimic 모방 학습 프레임워크의 두 가지 핵심 컴포넌트를 통합하여 과제별 보상 설계 없이 일반화 가능한 현실 세계 스킬을 습득한다.
HumanX는 물리 기반 데이터 합성과 일반화 우선 모방 학습을 결합하여 단일 비디오로부터 현실 세계 휴머노이드 로봇의 다양한 상호작용 스킬을 효율적으로 습득하는 획기적인 방법론을 제시하며, 8배 이상의 일반화 성능 향상과 적응형 행동 시연으로 로보틱스 분야에 상당한 기여를 한다.
Implicit Kinodynamic Motion Retargeting for Human-to-humanoid Imitation Learning
 *Fig. 2: Overall pipeline for our proposed framework. We model motion retargeting as a sequence-to-sequence mapping from * 본 논문은 인간의 모션을 휴머노이드 로봇이 실행 가능한 모션으로 변환하는 Implicit Kinodynamic Motion Retargeting (IKMR) 프레임워크를 제안하며, 기존 frame-by-frame 방식의 비효율성을 극복하고 대규모 모션을 실시간으로 처리한다.
본 논문은 motion retargeting에 implicit neural network을 처음 도입하여 scalability 문제를 혁신적으로 해결하고, kinematics과 dynamics를 체계적으로 통합함으로써 physically feasible한 대규모 모션 자동 변환을 실현한 의미 있는 기여이며, 실제 휴머노이드 로봇 배포 검증으로 실용성을 입증했다.
In-N-On: Scaling Egocentric Manipulation with in-the-wild and on-task Data
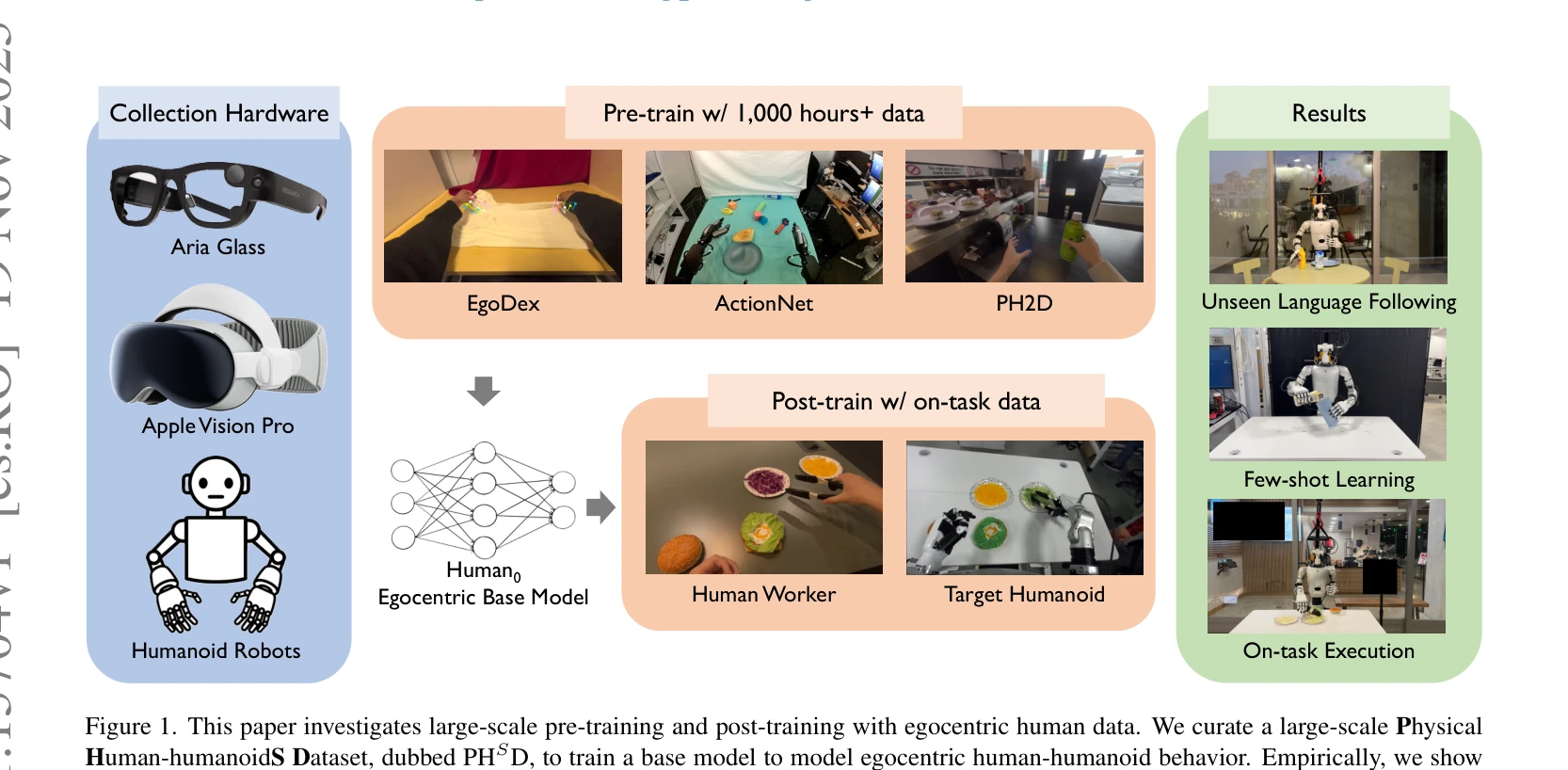
Figure 1. This paper investigates large-scale pre-training and post-training with egocentric human data. We curate a lar
 *Figure 1. This paper investigates large-scale pre-training and post-training with egocentric human data. We curate a lar* 이 논문은 1,000시간 이상의 in-the-wild 에고센트릭 데이터와 on-task 데이터를 결합하여 대규모 휴머노이드 조작 정책 Human0을 학습하고, domain adaptation을 통해 인간과 로봇 간의 도메인 갭을 최소화한다.
이 논문은 in-the-wild와 on-task 인간 데이터를 체계적으로 결합하는 새로운 data recipe를 제시하고, 대규모 PHSD 데이터셋과 Human0 모델을 통해 실제 휴머노이드 로봇에서 language following, few-shot learning, robustness 개선을 달성함으로써 로봇 조작 학습의 확장성에 중요한 기여를 한다.
InterPrior: Scaling Generative Control for Physics-Based Human-Object Interactions
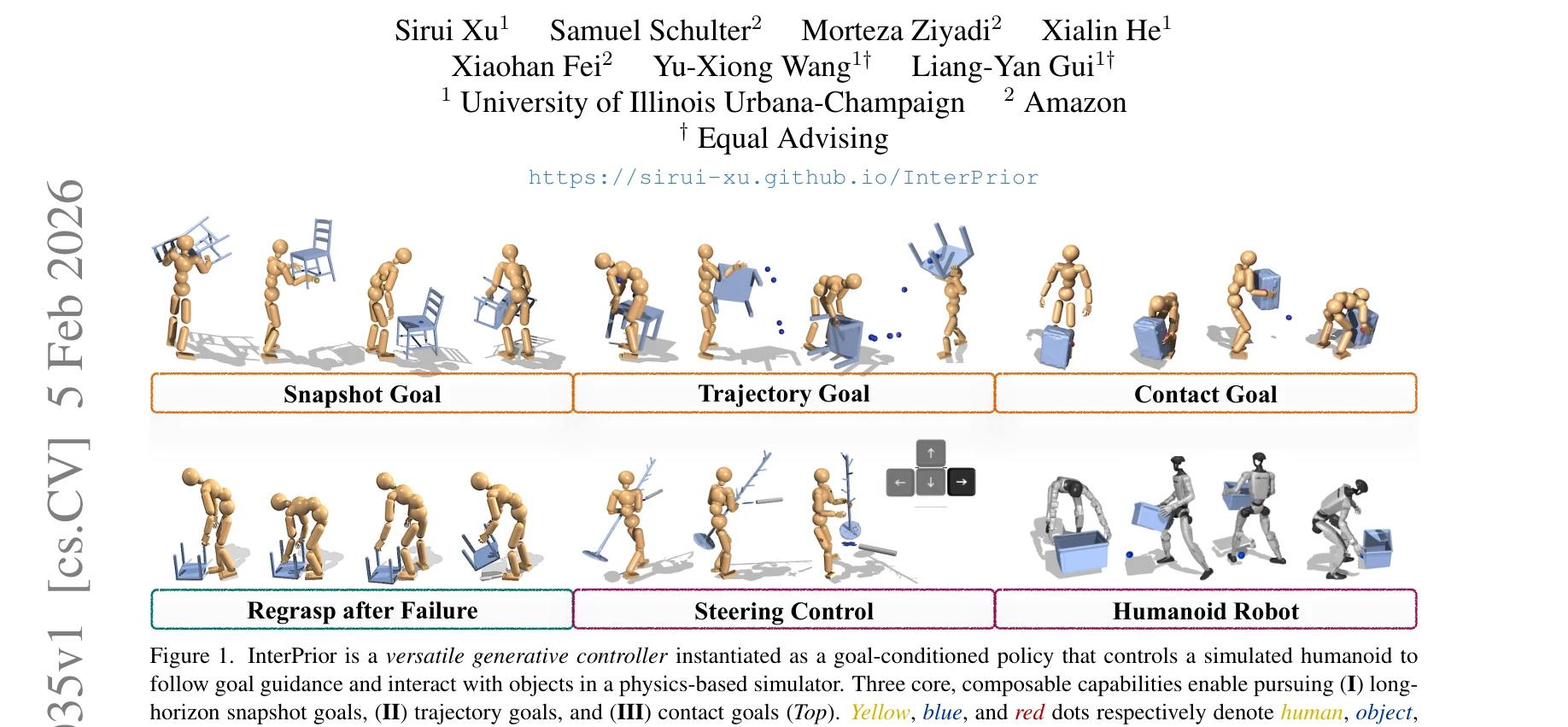
Figure 1. InterPrior is a versatile generative controller instantiated as a goal-conditioned policy that controls a simu
 *Figure 1. InterPrior is a versatile generative controller instantiated as a goal-conditioned policy that controls a simu* InterPrior는 대규모 모방 사전학습과 강화학습 미세조정을 통해 물리 기반 인간-객체 상호작용을 위한 확장 가능한 생성형 제어기를 학습하는 프레임워크로, 고수준 의도로부터 자연스러운 전신 협응과 조작을 생성한다.
InterPrior는 distillation과 RL의 시너지를 통해 물리 기반 인간-객체 상호작용의 확장 가능한 생성형 제어 문제를 우아하게 해결하며, 다양한 목표 형식 지원, 강력한 실패 회복, 미분포 일반화 능력으로 인해 휴머노이드 로봇 제어 분야의 실질적 진전을 이루었다.
Learning from Massive Human Videos for Universal Humanoid Pose Control
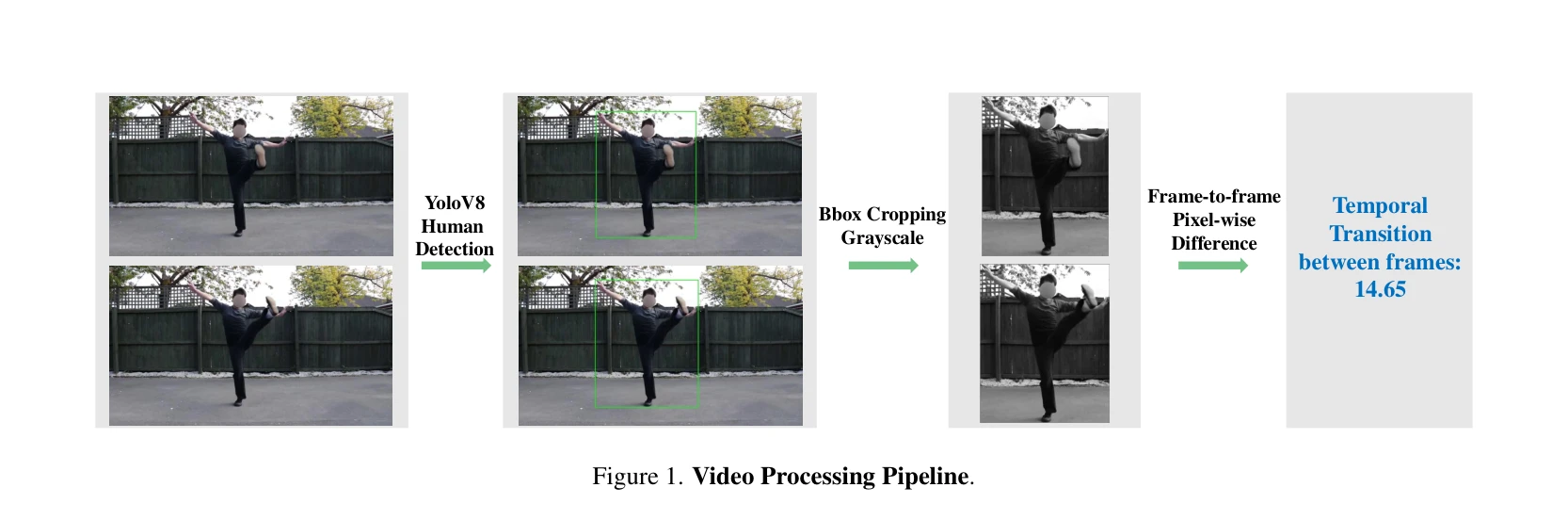
Figure 1. Overview. We introduce Humanoid-X, a large-scale dataset to facilitate humanoid robot learning from massive hu
 *Figure 2. Learning Humanoid Pose Control from Massive Videos. We mine massive human-centric video clips V from the Inter* Humanoid-X는 인터넷의 160,000개 이상의 인간 동영상으로부터 20백만 개의 휴머노이드 로봇 동작을 수집한 대규모 데이터셋이며, UH-1 모델을 통해 텍스트 명령을 휴머노이드 로봇의 제어 신호로 변환하는 범용 언어 조건부 제어를 실현한다.
본 논문은 휴머노이드 로봇 제어에 인터넷 비디오 빅데이터를 최초로 체계적으로 적용하고, 대규모 데이터셋과 범용 모델을 구축함으로써 로봇 학습의 확장성 문제를 실질적으로 해결한 중요한 기여를 한다. 시뮬레이션과 실세계 실험을 통한 검증이 충분하며 기술적·실무적 가치가 높다.
Learning Human-Like Badminton Skills for Humanoid Robots

Fig. 1: Real-world Deployment of the System. We present a learning-based framework that enables a humanoid to perform ag
 *Fig. 2: Overview of the Framework. The pipeline progressively transforms a kinematic imitator into a dynamic striker thr* 휴머노이드 로봇이 배드민턴 기술을 습득하도록 하는 Imitation-to-Interaction 점진적 강화학습 프레임워크를 제안하며, 시뮬레이션에서 실제 로봇으로의 제로샷 sim-to-real 전이를 달성했다.
휴머노이드 로봇 스포츠 제어의 새로운 경계를 개척한 혁신적 연구로, Imitation-to-Interaction 프레임워크와 manifold expansion 전략은 희소한 전문가 데이터에서 고도로 정밀하고 인간다운 운동을 학습하는 강력한 솔루션을 제시한다. 제로샷 sim-to-real 전이의 성공은 실용적 가치가 높으나, 상대방 상호작용과 환경 변동성 측면의 제한이 남아 있다.
Learning to Walk and Fly with Adversarial Motion Priors
 *Fig. 2: The discriminator learns to distinguish between samples* 본 논문은 Adversarial Motion Priors(AMP)와 강화학습을 결합하여 항공 인형로봇(aerial humanoid robot)이 인간 같은 보행과 비행 사이를 자동으로 전환하도록 학습하는 방법을 제시한다. 복잡한 보상 함수 없이 동작 데이터셋을 모방하면서 과제를 수행하며, 환경 피드백에 따라 locomotion 모드가 자발적으로 전환된다.
본 논문은 AMP와 강화학습의 결합을 통해 항공 인형로봇의 multimodal locomotion에서 자동 mode-switching이라는 미해결 문제를 우아하게 해결한 높은 수준의 연구이다. 비록 시뮬레이션 환경에 한정되어 있지만, 기술적 혁신성, 문제 해결의 우수성, 그리고 실제 응용 가능성 측면에서 로봇공학 분야에 의미 있는 기여를 한다.
Learning Vision-Driven Reactive Soccer Skills for Humanoid Robots
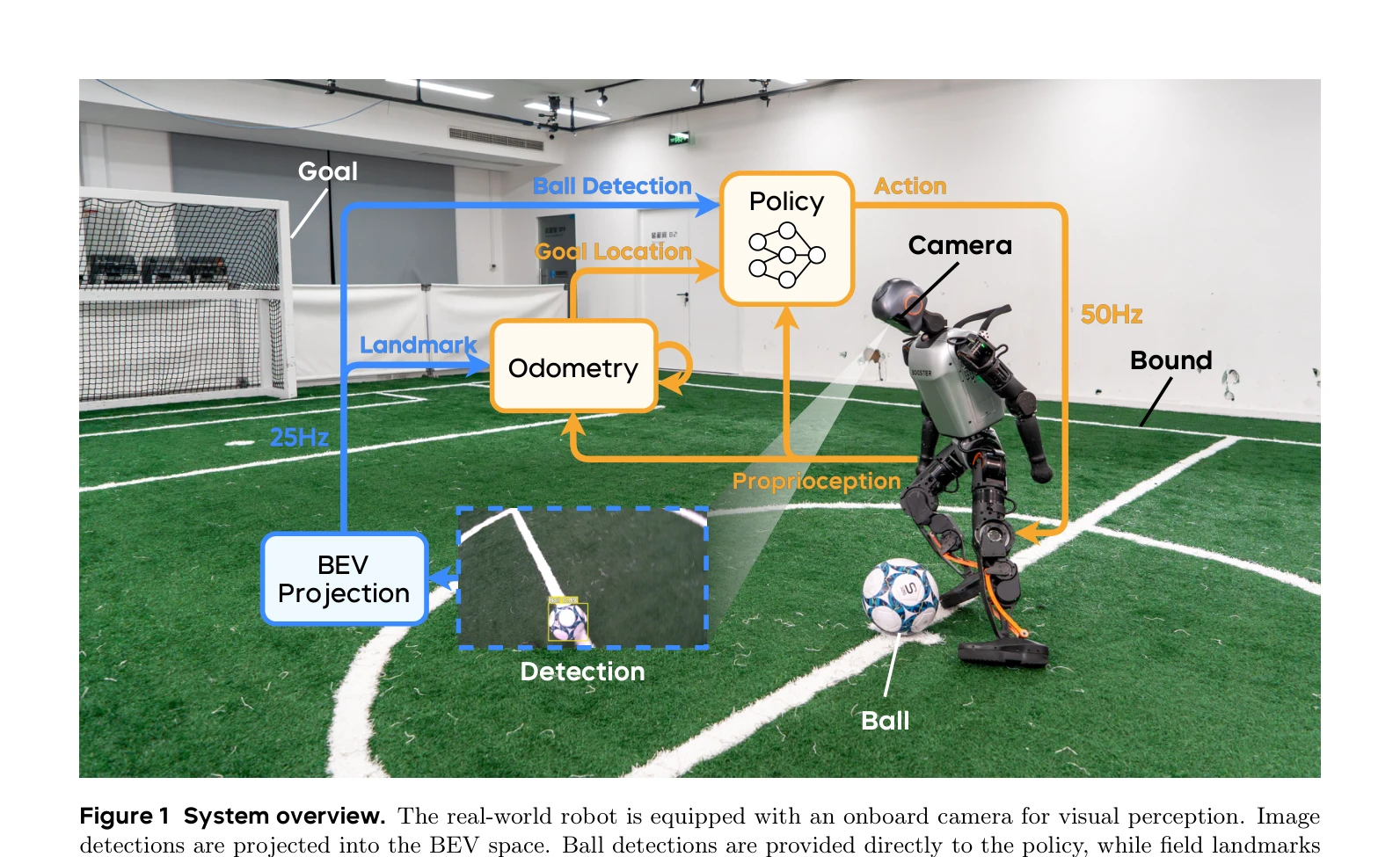
Figure 1 System overview. The real-world robot is equipped with an onboard camera for visual perception. Image
 *Figure 1 System overview. The real-world robot is equipped with an onboard camera for visual perception. Image* 본 논문은 시각 인식과 모션 제어를 직접 통합한 통합 강화학습 기반 컨트롤러를 통해 인형 로봇이 반응형 축구 기술을 습득할 수 있도록 하는 방법을 제시한다. Adversarial Motion Priors를 시각 기반 동적 제어 환경으로 확장하여 실제 RoboCup 경기에서 강력한 반응성을 보여준다.
본 논문은 Adversarial Motion Priors를 시각 기반 동적 제어로 성공적으로 확장하여, 강화학습 기반 인형 로봇이 실세계 축구 환경에서 반응형 행동을 자동으로 습득할 수 있음을 처음으로 입증했다. RoboCup 2025 우승이라는 실제 경쟁 성과는 제시된 방법론의 실용성과 견고성을 강력하게 검증한다.
Learning Whole-Body Human-Humanoid Interaction from Human-Human Demonstrations

Figure 1. From HHI to HHoI with simulation and real-robot results. Left: PAIR (Physics-Aware Interaction Retargeting) co
 *Figure 2. PAIR preserves physical consistency where naive meth-* 휴먼-휴먼 인터랙션(HHI) 데이터를 물리적 일관성을 보존하면서 휴먼-휴모이드 인터랙션(HHoI)으로 변환하는 PAIR와, 시간적 의도와 공간적 선택을 분리하여 상호작용적 이해를 갖춘 D-STAR 정책을 제안한다.
이 논문은 HHI에서 HHoI로의 데이터 변환 문제를 물리적 일관성 관점에서 체계적으로 해결하고, 시공간 분리를 통해 상호작용 정책의 반응성을 크게 향상시키는 혁신적인 접근을 제시한다. 시뮬레이션과 실제 로봇 검증을 통해 실용성을 입증하였으나, 더 다양한 상호작용 시나리오와 플랫폼으로의 확장이 필요하다.
LEGO: Latent-space Exploration for Geometry-aware Optimization of Humanoid Kinematic Design
Fig. 1: Total pipeline for humanoid kinematic structure optimization. First, a dataset of robots is converted to a unifi
 *Fig. 1: Total pipeline for humanoid kinematic structure optimization. First, a dataset of robots is converted to a unifi* LEGO는 기존 로봇 설계 데이터와 인간 모션 데이터를 활용하여 humanoid 로봇의 kinematic 구조를 자동으로 최적화하는 데이터 기반 설계 프레임워크이다. Screw theory 기반 표현과 isometric manifold learning을 통해 compact한 latent space를 구성하고 gradient-free optimization으로 최적 설계를 탐색한다.
본 논문은 screw theory, isometric manifold learning, motion retargeting을 통합한 혁신적인 data-driven 로봇 설계 프레임워크를 제시하며, 실제 하드웨어 프로토타입 검증으로 실용성을 입증한 의미 있는 연구이다. 다만 제한된 학습 데이터와 특정 morphology에의 국한이 일반화 관점에서의 한계이나, 로봇 설계 자동화 분야에 중요한 기여를 제공한다.
MaskedManipulator: Versatile Whole-Body Manipulation

Figure 1: MaskedManipulator enables physics-based humanoids to perform intricate, object interactions from sparse spatio
 *Figure 1: MaskedManipulator enables physics-based humanoids to perform intricate, object interactions from sparse spatio* MaskedManipulator는 대규모 모션 캡처 데이터로 학습한 추적 컨트롤러에서 증류한 생성적 제어 정책으로, 사용자가 객체 포즈나 신체 포즈 같은 고수준 목표를 지정하여 물리 기반 전신 조작 행동을 생성한다.
MaskedManipulator는 두 단계 증류 프레임워크를 통해 정교한 물리 기반 전신 조작을 희소한 고수준 목표로 제어 가능하도록 함으로써, 캐릭터 애니메이션과 인간형 로봇 제어 분야의 중요한 진전을 이룬다. 대규모 모션 캡처 데이터 활용과 유연성-정밀도 균형 달성이 특히 주목할 만하나, 실제 로봇 적용 평가와 일반화 성능 분석이 보완되면 더욱 완성도 높은 기여가 될 것이다.
Masquerade: Learning from In-the-wild Human Videos using Data-Editing

Fig. 1: Overview of Masquerade. Left: Large-scale in-the-wild egocentric human videos are edited to obtain “robotized”
 *Fig. 1: Overview of Masquerade. Left: Large-scale in-the-wild egocentric human videos are edited to obtain “robotized”* Masquerade는 in-the-wild 인간 영상을 데이터 편집을 통해 로봇화된 시연으로 변환하고, 이를 통해 사전학습된 visual encoder로 로봇 조작 정책을 학습하는 방법을 제안한다. 675K 프레임의 편집된 인간 영상으로 사전학습 후 50개의 로봇 시연으로 fine-tuning하여 기존 방법 대비 5-6배 향상된 성능을 달성한다.
Masquerade는 visual embodiment gap을 명시적으로 해결하면서 대규모 in-the-wild 인간 영상을 로봇 학습에 활용하는 창의적이고 실용적인 방법론을 제시한다. 적절한 평가와 ablation으로 핵심 설계 선택의 효과를 입증했으며, 로봇 데이터 부족 문제를 완화하는 데 의미 있는 기여를 한다.
MetaWorld-X: Hierarchical World Modeling via VLM-Orchestrated Experts for Humanoid Loco-Manipulation
 *Fig. 2: MetaWorld-X achieves natural humanoid control through the dynamic orchestration of expert policies guided by a* 휴머노이드 로봇의 복잡한 로코-매니퓰레이션 제어를 Specialized Expert Policy(SEP)와 VLM 기반 Intelligent Routing Mechanism(IRM)으로 분해-통합하는 계층적 프레임워크를 제안한다. 인간 모션 프라이어와 의미적 라우팅을 결합하여 자연스럽고 안정적인 동작을 생성한다.
MetaWorld-X는 human motion priors, world models, VLM 기반 의미적 라우팅을 창의적으로 결합하여 고자유도 휴머노이드 로코-매니퓰레이션 제어의 중요한 문제(스킬 간섭, 부자연스러운 동작, 낮은 일반화)를 효과적으로 해결한다. Humanoid-bench에서의 강력한 실험 결과와 명확한 방법론 제시에도 불구하고, 실제 로봇 검증 부재가 임팩트를 제한한다.
MimicDroid: In-Context Learning for Humanoid Robot Manipulation from Human Play Videos
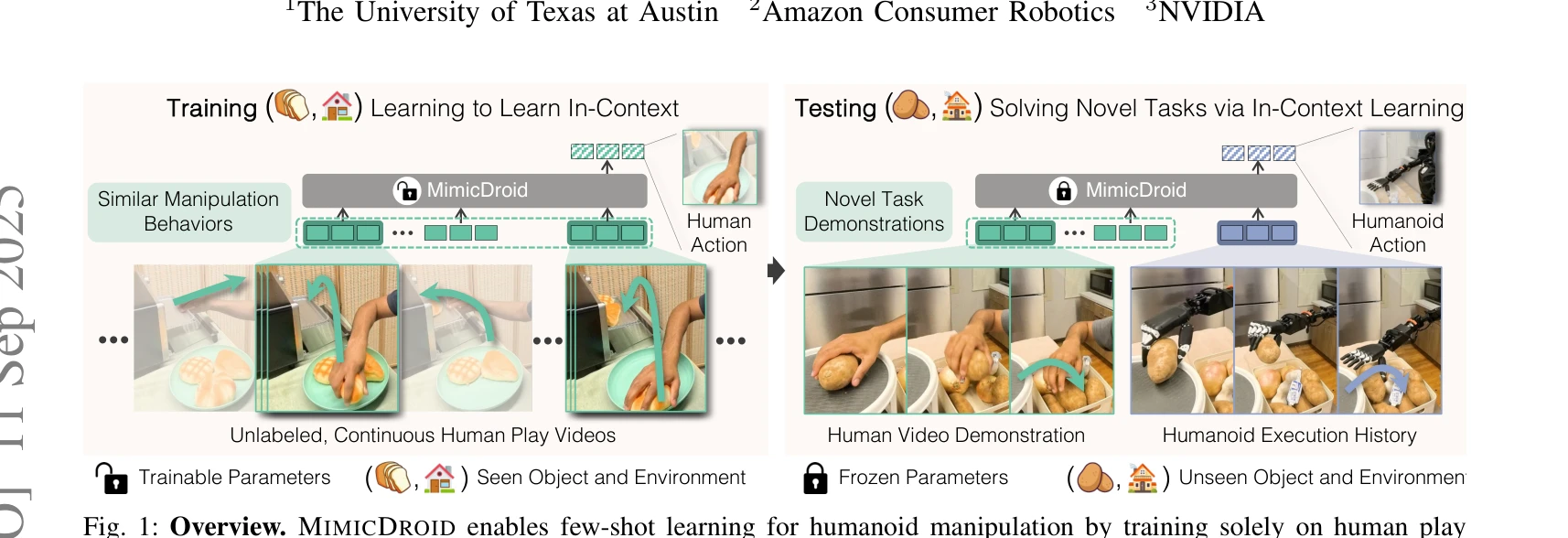
Fig. 1: Overview. MIMICDROID enables few-shot learning for humanoid manipulation by training solely on human play
 *Fig. 1: Overview. MIMICDROID enables few-shot learning for humanoid manipulation by training solely on human play* MimicDroid는 인간의 자유로운 상호작용 비디오(human play videos)만을 학습 데이터로 사용하여 휴머노이드 로봇이 In-Context Learning(ICL)을 통해 새로운 조작 작업을 효율적으로 수행하도록 한다.
MimicDroid는 human play videos라는 현실적이고 확장 가능한 데이터 소스를 활용하여 휴머노이드 로봇의 In-Context Learning 기반 조작을 실현한 혁신적인 연구이며, 명확한 방법론, 강력한 실증적 결과, 그리고 공개 벤치마크를 통해 로봇 학습 분야에 실질적인 기여를 한다.
Mobile-TeleVision: Predictive Motion Priors for Humanoid Whole-Body Control
Fig. 1: Humanoid robot doing whole-body tasks that require both precise manipulation and robust locomotion. The robot
 *Fig. 2: The training pipeline consists of three stages: (a) preprocessing of the motion dataset by mapping local rotatio* 휴머노이드 로봇의 전신 제어를 위해 상체 조작과 하체 보행을 분리하고, CVAE 기반 Predictive Motion Priors (PMP)를 사용하여 상체의 정밀한 조작과 하체의 강건한 보행을 동시에 달성한다.
상체 정밀 조작과 하체 강건 보행이라는 근본적으로 다른 요구를 효과적으로 분리하면서도 CVAE 기반 motion prior를 통해 통합하는 창의적 접근으로, 고 DoF 팔 제어에서 기존 전신 RL 방법을 명확히 능가한다. 실세계 텔레오퍼레이션 가능성까지 보여주어 실용성이 높은 연구이다.
MoRE: Mixture of Residual Experts for Humanoid Lifelike Gaits Learning on Complex Terrains
Fig. 1. Our framework leverages a two-stage training pipeline and the mixture
 *Fig. 2.* 휴머노이드 로봇이 복잡한 지형을 인간다운 보행으로 횡단하기 위해 Mixture of Residual Experts (MoRE)와 다중 판별자를 활용한 2단계 RL 학습 프레임워크를 제안한다.
본 논문은 복잡 지형 횡단과 인간다운 다중 보행 학습을 동시에 달성하는 통합적 프레임워크를 제시하며, MoE 기반 residual 접근법과 다중 판별자 활용으로 방법론적 독창성을 보인다. 실제 로봇 배포 검증과 함께 기술적으로 견고하고 실무적 중요성이 높은 연구이다.
Natural Humanoid Robot Locomotion with Generative Motion Prior
본 논문은 Generative Motion Prior (GMP)를 활용하여 인간의 자연스러운 보행 데이터로부터 휴머노이드 로봇의 자연스러운 보행을 학습하는 방법을 제안한다. 기존의 adversarial motion prior 대신 frozen generative model을 사용하여 fine-grained motion-level 감독을 제공함으로써 학습 안정성과 해석 가능성을 향상시킨다.
본 논문은 generative motion prior를 활용한 혁신적 접근으로 humanoid robot의 자연스러운 보행 학습 문제를 효과적으로 해결하며, adversarial training의 불안정성을 제거하고 fine-grained guidance를 제공함으로써 motion naturalness에서 SOTA 성능을 달성한다. 다만 real-world 실험 확대와 다양한 환경에서의 일반화 능력 검증이 필요하다.
One Policy but Many Worlds: A Scalable Unified Policy for Versatile Humanoid Locomotion
 *Figure 2: Framework of DreamPolicy. The system is decomposed into two parts: (1) Terrain-aware* DreamPolicy는 Humanoid Motion Imagery (HMI)를 생성하는 terrain-aware autoregressive diffusion planner와 HMI-conditioned RL policy를 결합하여, 단일 정책으로 다양한 지형에서 humanoid 로봇의 이동을 학습하고 미지의 시나리오로 zero-shot 일반화를 달성하는 통합 프레임워크이다.
DreamPolicy는 offline data와 diffusion-based trajectory synthesis를 통합하여 humanoid 이동의 확장성 문제를 창의적으로 해결하고, 실제 로봇 응용에 실질적 가치를 제공하는 강력한 프레임워크이다. 다만 sim-to-real 검증과 computational 효율성 분석이 보완되면 더욱 견고한 기여가 될 것이다.
Opening the Sim-to-Real Door for Humanoid Pixel-to-Action Policy Transfer
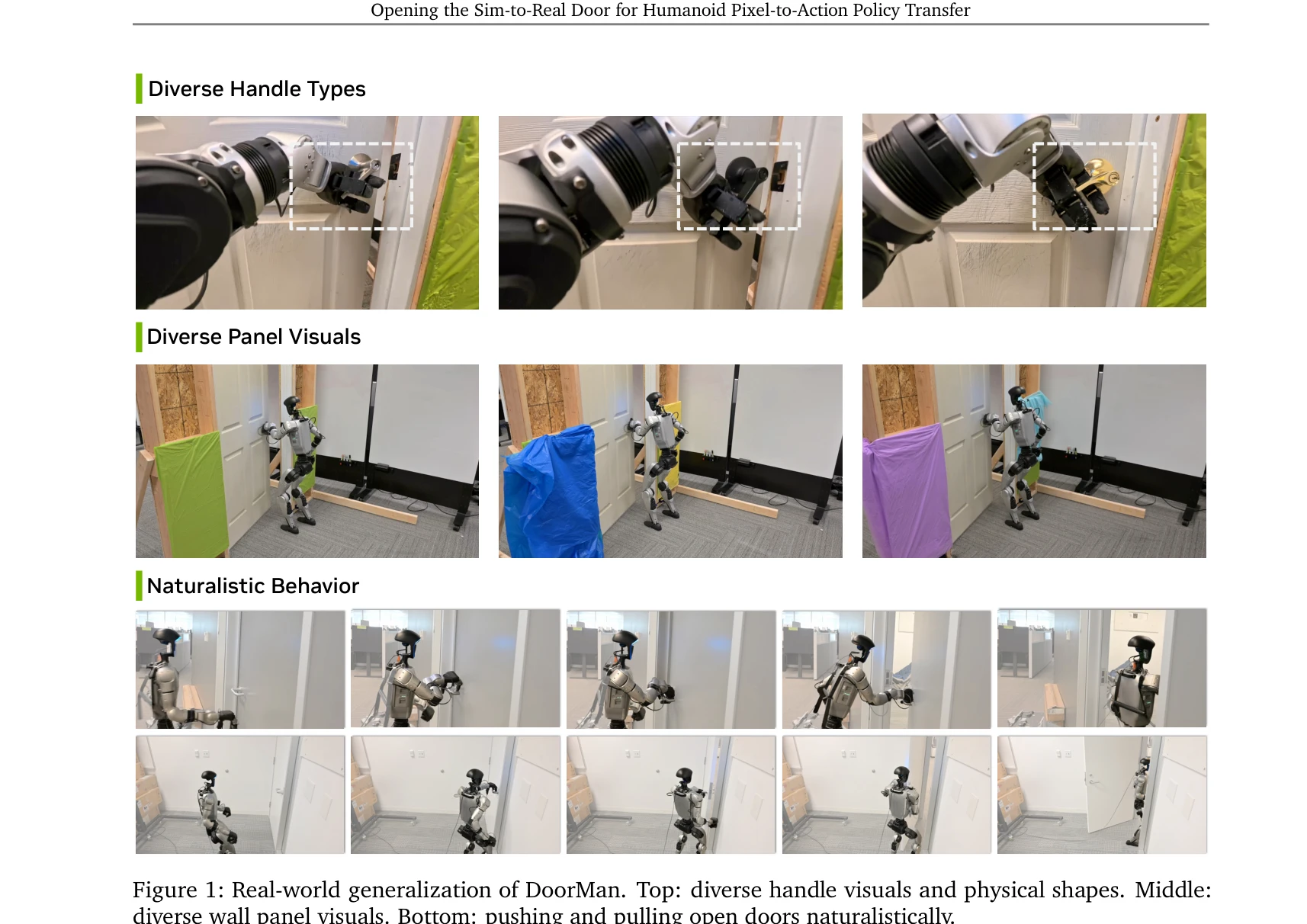
Figure 1: DoorMan, a simulation-trained, RGB-only humanoid loco-manipulation policy, opens diverse, real-world doors.
 *Figure 2: DoorMan training pipeline. All phases are done interactively with IsaacLab. In Phase 1, we train a* GPU 가속 포토리얼리스틱 시뮬레이션과 teacher-student-bootstrap 학습 프레임워크를 통해 순수 RGB 시각만 사용하여 인간형 로봇이 다양한 문을 열 수 있는 sim-to-real 정책을 개발했다.
순수 RGB 시각만을 사용하여 다양한 실제 문을 여는 인간형 로봇 정책을 시뮬레이션에서만 훈련하여 영점 샷 전이에 성공한 획기적인 연구로, staged-reset 탐색과 GRPO 기반 bootstrapping 등의 novel 방법론이 실질적 성능 개선을 입증한다.
Opt2Skill: Imitating Dynamically-feasible Whole-Body Trajectories for Versatile Humanoid Loco-Manipulation
Fig. 1. The proposed Opt2Skill framework enables a Digit humanoid robot to
 *Fig. 1. The proposed Opt2Skill framework enables a Digit humanoid robot to* Opt2Skill은 Differential Dynamic Programming (DDP)로 생성한 동역학적으로 실현 가능한 궤적을 Reinforcement Learning (RL)으로 모방하게 함으로써 인간형 로봇의 다양한 로코-조작 작업을 효과적으로 수행하는 통합 파이프라인이다.
Opt2Skill은 model-based trajectory optimization과 reinforcement learning을 효과적으로 결합하여 인간형 로봇의 동역학적으로 실현 가능한 다양한 로코-조작 작업을 체계적으로 해결하며, 실제 하드웨어 전이까지 성공한 중요한 기여로, 토크 정보 활용과 광범위한 실험 검증을 통해 높은 과학적 가치를 갖춘다.
PDF-HR: Pose Distance Fields for Humanoid Robots
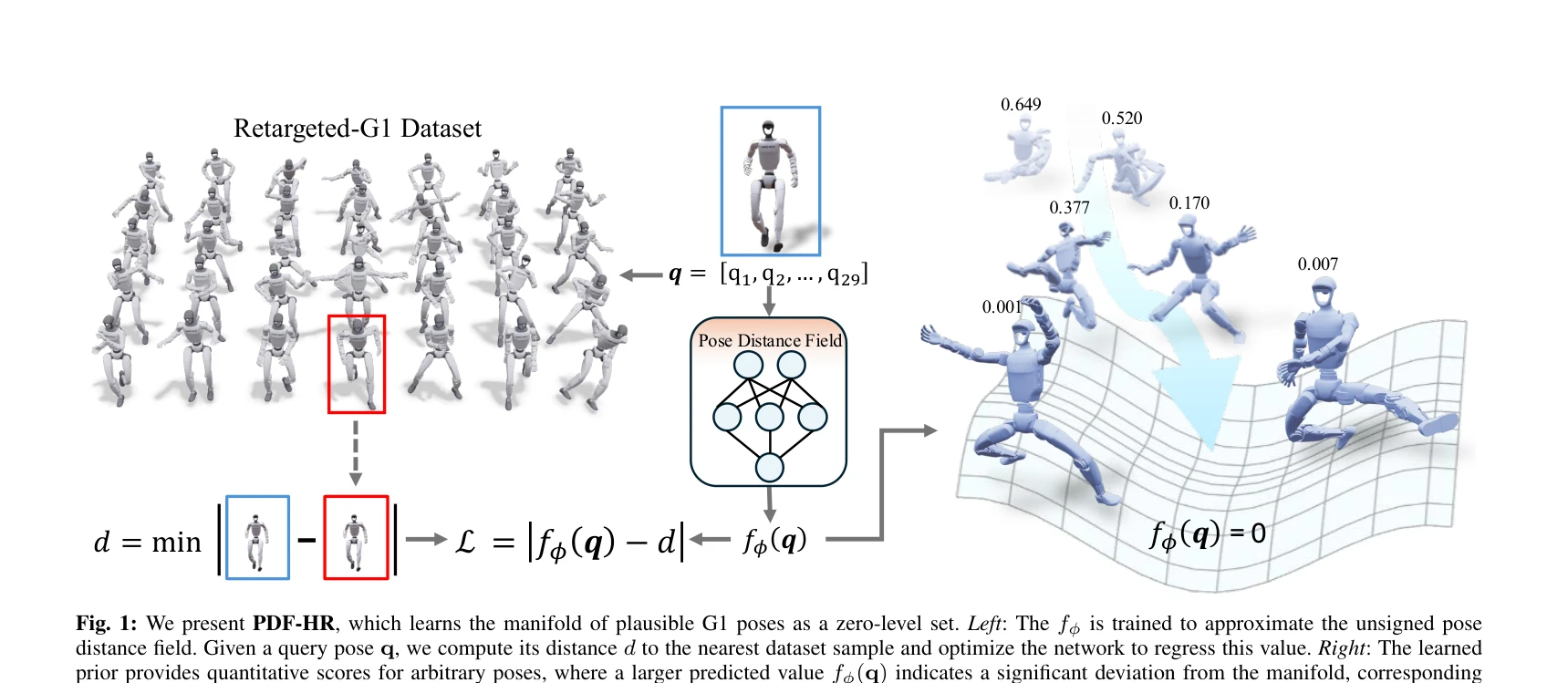
Fig. 1: We present PDF-HR, which learns the manifold of plausible G1 poses as a zero-level set. Left: The fϕ is trained
 *Fig. 1: We present PDF-HR, which learns the manifold of plausible G1 poses as a zero-level set. Left: The fϕ is trained * Humanoid 로봇을 위한 pose distance field인 PDF-HR을 제안하여, 학습된 로봇 포즈 분포를 연속 미분 가능한 manifold로 표현하고 포즈의 plausibility를 평가한다.
이 논문은 humanoid robotics에 implicit manifold representation을 처음 적용하여 scarce data 문제를 효과적으로 해결하고, lightweight하면서도 재사용 가능한 pose prior를 제안한 점에서 높은 학술적 기여를 한다. 다양한 task에서 일관된 성능 향상을 보이며 실용적 가치도 우수하나, corpus 의존성과 temporal modeling의 미흡이 향후 개선 과제이다.
Multi-Gait Learning for Humanoid Robots Using Reinforcement Learning with Selective Adversarial Motion Prior
Fig. 1.
 *Fig. 1.* 본 논문은 humanoid robot이 보행, 거위걸음, 달리기, 계단 오르기, 점프 등 5가지 서로 다른 보행 방식을 통일된 강화학습 프레임워크로 학습할 수 있도록 하는 선택적 Adversarial Motion Prior (AMP) 전략을 제안한다.
본 논문은 humanoid robot의 다중 보행 학습에서 AMP의 선택적 적용이라는 창의적인 아이디어를 제시하고, 통일된 강화학습 프레임워크로 5가지 이질적 보행을 성공적으로 학습 및 실로봇 배포한 것으로 실무적 가치가 높다. 다만 선택 기준의 일반화 부족과 단일 로봇 플랫폼 검증이라는 한계가 있어 추가 확장 연구가 필요하다.
RPG: Robust Policy Gating for Smooth Multi-Skill Transitions in Humanoid Fighting

Fig. 1.
 *Fig. 1.* 본 논문은 RPG(Robust Policy Gating)라는 하이브리드 전문가 정책 프레임워크를 제안하여 인형형 로봇이 다양한 격투 기술 간 매끄럽고 안정적인 전환을 통해 장시간 동적 격투를 수행할 수 있도록 함.
본 논문은 RPG 프레임워크를 통해 인형형 로봇의 다중 격투 기술 매끄러운 전환 문제를 효과적으로 해결하였으며, policy-transition randomization과 temporal randomization의 결합은 기술 전환 강건성 확보에 창의적 기여를 함. 실세계 로봇 검증과 게임 인터페이스 설계로 실용성이 높으나, 기술 범주 확장 및 다양한 로봇 플랫폼 검증이 필요함.
CF-VLA: Efficient Coarse-to-Fine Action Generation for Vision-Language-Action Policies
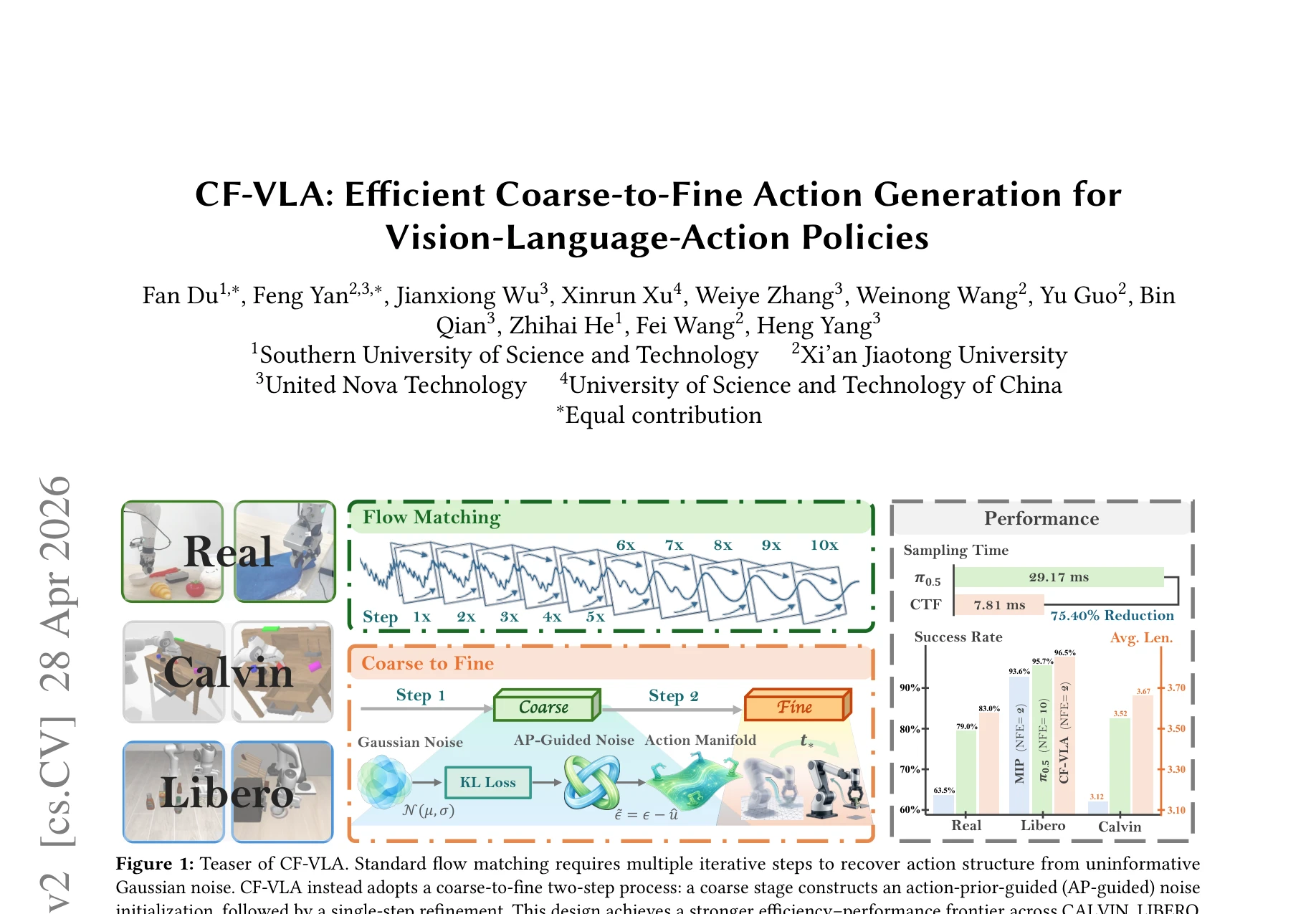
Figure 1: Teaser of CF-VLA. Standard flow matching requires multiple iterative steps to recover action structure from un
 *Figure 1: Teaser of CF-VLA. Standard flow matching requires multiple iterative steps to recover action structure from un* 본 논문은 flow matching 기반 VLA 정책의 비효율성을 해결하기 위해 coarse-to-fine 두 단계 생성 프레임워크를 제안한다. 첫 번째 단계에서는 Gaussian 노이즈를 action-prior-guided 초기화로 변환하고, 두 번째 단계에서는 단일 스텝 국소 정교화를 수행하여 추론 지연시간을 75.4% 감소시키면서 성능을 유지한다.
CF-VLA는 flow-based VLA 정책의 구조적 비효율성을 명확하게 파악하고, coarse-to-fine 분해를 통해 실용적이고 효과적인 해결책을 제시한다. 75.4%의 지연시간 감소와 실로봇 83.0% 성공률은 강력한 경험적 검증을 보여주며, 방법의 플러그-앤-플레이 특성으로 인해 광범위한 적용성을 가진다. 다만 이론적 분석과 더 깊은 통찰이 추가되면 더욱 완성도 있는 연구가 될 것이다.
HumanEgo: Zero-Shot Robot Learning from Minutes of Human Egocentric Videos
HumanEgo는 인간의 자아중심 영상(egocentric video)으로부터 로봇 조작 정책을 학습하는 프레임워크로서, Interaction-Centric Tokens(ICT)를 통해 구체화 격차(embodiment gap)를 해결하고 flow matching 정책과 조밀한 보조 목표들을 결합하여 30분의 인간 영상만으로 92.5% 성공률을 달성한다.
HumanEgo는 인간 자아중심 영상으로부터 로봇 정책을 학습하는 문제에 명확한 해결책을 제시한다. Interaction-Centric Tokens를 통한 혁신적 표현과 조밀한 보조 감시의 조합은 기술적으로 타당하며, 30분 영상으로 92.5% 성공률과 zero-shot 전이 능력은 실용적 의의가 크다. 다만 Aria 센서 의존도와 제한된 작업 평가 범위가 일반화 가능성에 의문을 제기한다.
Learning Human-Intention Priors from Large-Scale Human Demonstrations for Robotic Manipulation
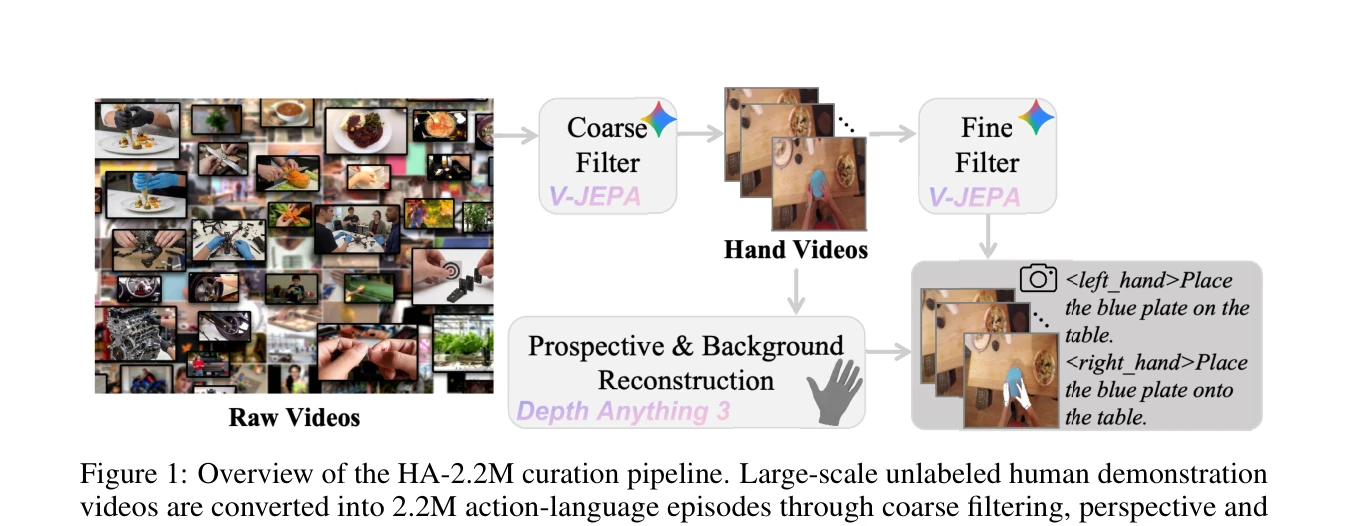
Figure 1: Overview of the HA-2.2M curation pipeline. Large-scale unlabeled human demonstration
 *Figure 1: Overview of the HA-2.2M curation pipeline. Large-scale unlabeled human demonstration* 본 논문은 대규모 인간 시연 영상으로부터 로봇 조작을 위한 인간-의도 사전을 학습하는 MoT-HRA 프레임워크를 제안한다. 220만 에피소드의 HA-2.2M 데이터셋을 구성하고, 3D 궤적 예측, MANO 스타일 손 모션 모델링, 로봇 행동 변환의 3단계 계층적 구조로 인간 시연의 재사용 가능한 부분을 보존하면서 로봇 특화 제어를 학습한다.
본 논문은 대규모 인간 시연으로부터 로봇 조작을 학습하는 실질적 도전에 대해 잘 정의된 계층적 접근을 제시한다. 220만 에피소드 HA-2.2M 데이터셋과 MoT-HRA의 knowledge insulation 설계는 인간 행동의 재사용 가능한 구조를 보존하면서 로봇 특화 제어를 학습하는 점에서 기여도가 있다. 다만 데이터셋 필터링 정확성, 실제 로봇 평가의 포괄성, 계산 효율성 분석이 강화될 필요가 있다.
MuGen: Multi-Skill Generative Locomotion Controller for Humanoid Robots
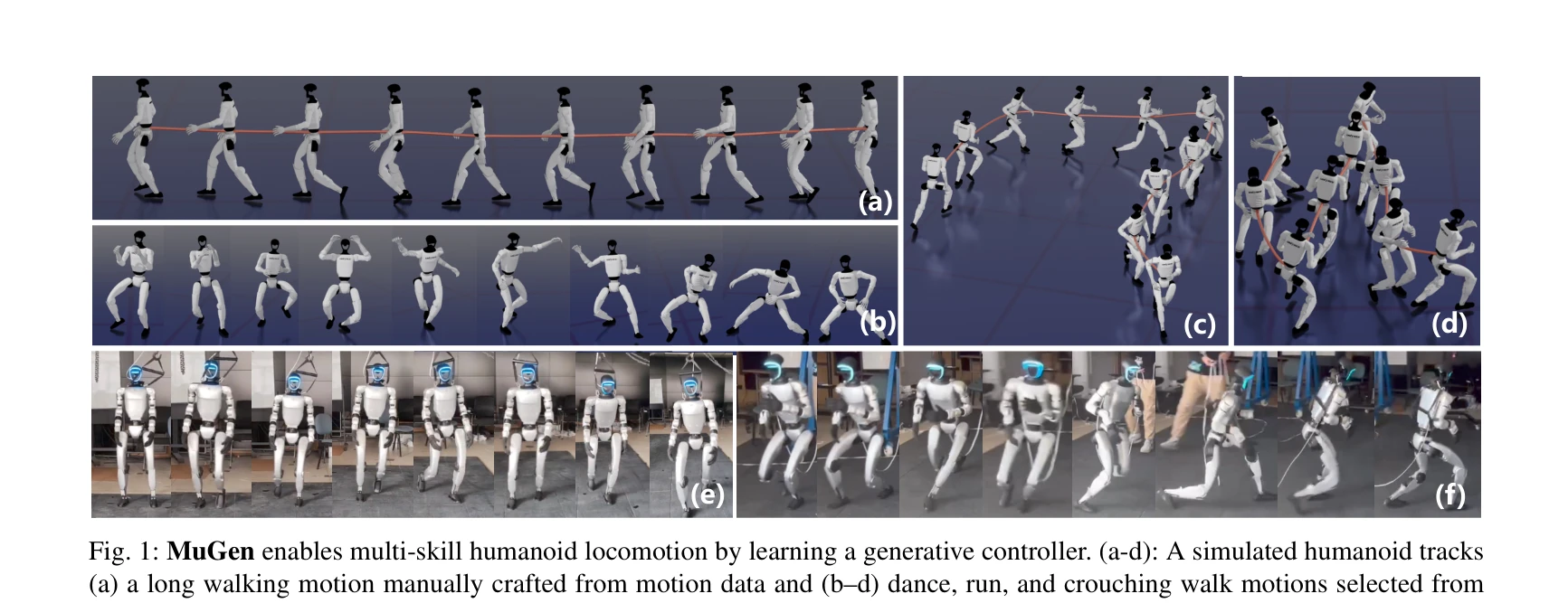
Fig. 1: MuGen enables multi-skill humanoid locomotion by learning a generative controller. (a-d): A simulated humanoid t
 *Fig. 2: System overview 1) Motion Skill Embedding: states and reference motions are encoded into continuous representati* MuGen은 VQ-VAE와 model-based reinforcement learning을 결합하여 인간의 모션 데이터로부터 인형형 로봇의 다중 기술 보행 제어기를 학습하는 데이터 기반 프레임워크이다. Teacher-student learning과 새로운 policy distillation 전략을 통해 시뮬레이션에서 학습한 모션을 실제 로봇에 배포할 수 있게 한다.
MuGen은 VQ-VAE, model-based RL, teacher-student learning을 통합하여 인형형 로봇의 다중 기술 보행을 학습하고 배포하는 체계적이고 기술적으로 건전한 접근을 제시한다. 실제 Unitree G1 로봇에서의 검증과 미학습 모션에 대한 강건한 일반화 능력을 보여주었으나, sim-to-real gap의 완전한 해결, 데이터셋 규모/다양성의 상세 분석, 계산 복잡도 평가 등에서 개선이 필요하다. 전반적으로 인형형 로봇 제어 분야에 의미 있는 기여를 한 견실한 연구이다.
ReActor: Reinforcement Learning for Physics-Aware Motion Retargeting

Fig. 1. Physics-aware retargeting of human motion (left) onto two humanoid robots (middle) and a quadruped (right) with
 *Fig. 1. Physics-aware retargeting of human motion (left) onto two humanoid robots (middle) and a quadruped (right) with * 본 논문은 인간의 모션캡처 데이터를 상이한 형태의 휴머노이드 및 사족로봇으로 리타게팅하기 위한 이중수준 최적화 프레임워크를 제안한다. 상단 수준에서는 리타게팅 매개변수를 최적화하고, 하단 수준에서는 reinforcement learning을 통해 tracking policy를 학습하여 물리 기반의 artifact-free한 모션을 생성한다.
본 논문은 motion retargeting을 bilevel optimization과 RL의 조합으로 재정의하여 물리적으로 타당하고 artifact-free한 모션을 생성하는 강력한 프레임워크를 제시한다. Sparse correspondence만으로 다양한 morphology를 지원하며, 시뮬레이션 기반 검증과 제한적 hardware 결과를 제공한다. 계산 효율성과 hardware 검증의 확장이 향후 과제이지만, 로보틱스와 애니메이션 분야의 motion retargeting 문제에 대한 중요한 기여로 평가된다.
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
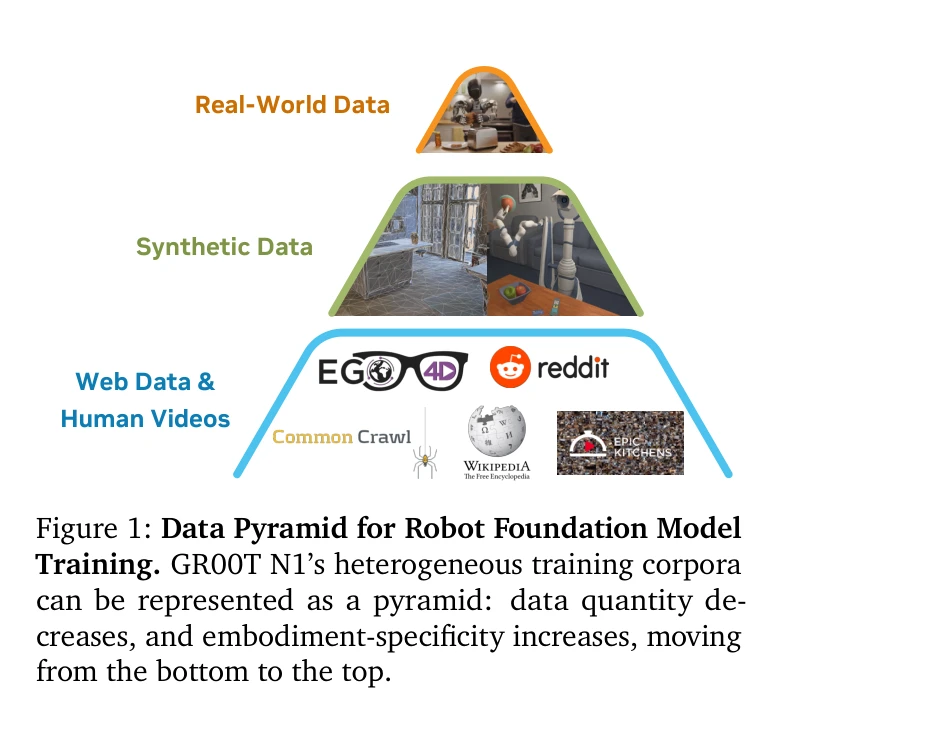
Figure 1: Data Pyramid for Robot Foundation Model
 *Figure 1: Data Pyramid for Robot Foundation Model* GR00T N1은 Vision-Language-Action (VLA) 모델로, dual-system 아키텍처를 통해 다양한 휴머노이드 로봇을 제어할 수 있는 오픈 소스 기초 모델이다. 웹 데이터, 인간 비디오, 합성 데이터, 실제 로봇 궤적을 계층적으로 조합하여 학습한다.
GR00T N1은 휴머노이드 로봇 기초 모델 개발에서 중요한 진전을 이루었으며, data pyramid 전략과 dual-system 아키텍처의 혁신적 설계가 돋보인다. 오픈소스 공개와 실제 로봇 검증을 통해 로봇 학습 커뮤니티에 실질적 기여를 할 것으로 기대된다.
Learning Human-to-Humanoid Real-Time Whole-Body Teleoperation
Fig. 1:
 *Fig. 4: Overview of H2O: (a) Retargeting (Section IV): H2O first aligns the SMPL body model to a humanoid’s structure* RGB 카메라만을 사용하여 실시간으로 전신 휴머노이드 로봇을 원격조종할 수 있는 RL 기반 프레임워크 H2O를 제시하며, 'sim-to-data' 프로세스로 인간 동작을 로봇 친화적으로 필터링하고 sim-to-real 전이를 달성했다.
본 논문은 인간-휴머노이드 상호작용의 새로운 패러다임을 제시하며, 'sim-to-data' 필터링과 효과적인 sim-to-real 전이를 통해 RL 기반 전신 원격조종을 처음 실현했다는 점에서 획기적 기여이다. 대규모 데이터셋 생성, RGB 카메라 기반 제어, 다양한 동작 실현 등에서 높은 완성도를 보여주며, 향후 로봇 원격조종 및 자율 시스템 학습의 중요한 토대가 될 것으로 예상된다.
OmniH2O: Universal and Dexterous Human-to-Humanoid Whole-Body Teleoperation and Learning

Figure 1: (a) OmniH2O enables teleoperating a full-size humanoid robot (Unitree H1) to complete tasks that
 *Figure 1: (a) OmniH2O enables teleoperating a full-size humanoid robot (Unitree H1) to complete tasks that* OmniH2O는 kinematic pose를 보편적 제어 인터페이스로 사용하여 VR, RGB 카메라, 음성 명령 등 다양한 입력을 통해 전신 인형 로봇을 조작하고 자율 작업을 수행할 수 있는 학습 기반 시스템이다.
OmniH2O는 kinematic pose 기반의 보편적 제어 인터페이스와 정교한 sim-to-real 파이프라인을 통해 인형 로봇의 전신 로코-조작을 처음으로 체계적으로 해결한 연구이며, 공개 데이터셋과 다양한 실제 작업 시연으로 높은 실무 가치를 제공한다.
Preference-Conditioned Multi-Objective RL for Integrated Command Tracking and Force Compliance in Humanoid Locomotion
Fig. 1: Preference-conditioned locomotion: A single policy realizes behaviors from
 *Fig. 1: Preference-conditioned locomotion: A single policy realizes behaviors from* 인간형 로봇의 명령 추적과 외력 순응을 동시에 달성하기 위해 선호도 조건부 MORL 프레임워크를 제안하며, 단일 정책으로 추적-순응 간의 연속적인 trade-off를 구현한다.
본 논문은 선호도 조건부 MORL을 통해 인간형 로봇 보행의 핵심 trade-off를 명시적으로 해결하는 창의적 접근법을 제시하며, velocity-resistance 모델링이라는 우아한 통합 기법과 실세계 검증을 통해 실제 배치 가능성을 입증한다. 다만 범위 제한(수평 평면, 선형 모델)과 단일 플랫폼 실험이 일반화 가능성에 대한 의문을 남긴다.
ResMimic: From General Motion Tracking to Humanoid Whole-body Loco-Manipulation via Residual Learning

Fig. 1: We deploy ResMimic on a Unitree G1 humanoid to demonstrate diverse whole-body loco-manipulation capabilities.
 *Fig. 3: Overview of ResMimic : (1) A general motion tracking policy is trained on large-scale human motion data to serve* ResMimic는 일반 모션 추적(GMT) 정책을 기반으로 효율적인 잔차 정책(residual policy)을 학습하여 인간형 로봇의 정밀한 전신 이동-조작 능력을 실현하는 이단계 잔차학습 프레임워크이다.
ResMimic는 대규모 사전훈련 GMT 정책과 효율적 잔차 정책의 결합으로 인간형 로봇의 정밀한 전신 이동-조작을 실현한 혁신적 프레임워크이며, 맞춤형 보상 설계와 광범위한 실증으로 인간형 로봇 제어 분야에 중요한 기여를 한다.
SMAP: Self-supervised Motion Adaptation for Physically Plausible Humanoid Whole-body Control
 *Figure 3: Pipeline of SMAP* 본 논문은 인간 모션과 휴머노이드 로봇의 이질적 행동 공간 간 차이를 해결하기 위해 Vector-Quantized Periodic Autoencoder 기반의 Humanoid-Adapter를 제안하여 인간 모션을 물리적으로 타당한 로봇 모션으로 적응시키고, Teacher-Student 증류 학습을 통해 안정적인 전신 제어 정책을 학습한다.
본 논문은 인간-로봇 모션 이질성이라는 실질적 문제를 Vector-Quantized Periodic Autoencoder와 디커플된 보상을 통해 체계적으로 해결하며, 시뮬레이션과 실제 로봇 실험을 통해 방법의 효과성을 충분히 입증한다. 다만 특정 로봇 플랫폼에 한정된 검증과 일반화 가능성에 대한 추가 분석이 있으면 더욱 강력한 논문이 될 것으로 예상된다.
SoftMimic: Learning Compliant Whole-body Control from Examples
 *Fig. 2: Soft Whole-body Control via Compliant Motion Augmentation. Left: Given an original reference motion (qref) and a* SoftMimic은 역기구학 솔버를 이용해 순응적 동작 데이터셋을 생성하고 강화학습으로 학습하여, 인간형 로봇이 외부 힘에 순응하면서도 균형을 유지하는 제어 정책을 학습하는 프레임워크이다.
SoftMimic은 역기구학 기반 데이터 증강과 강화학습을 창의적으로 결합하여 인간형 로봇의 순응적 제어라는 중요한 문제를 체계적으로 해결하며, 이론과 실제 로봇 실험으로 그 효과를 입증한 우수한 연구이다.
SONIC: Supersizing Motion Tracking for Natural Humanoid Whole-Body Control

Figure 1: SONIC enables diverse humanoid tasks through a universal control policy that handles diverse input
 *Figure 1: SONIC enables diverse humanoid tasks through a universal control policy that handles diverse input* 인간의 모션 캡처 데이터를 활용한 motion tracking을 기반 작업으로 삼아 42M 파라미터의 대규모 humanoid controller를 학습하고, kinematic planner와 unified token space를 통해 다양한 제어 인터페이스를 지원하는 자연스러운 전신 움직임 제어 시스템을 제시한다.
이 논문은 humanoid control에 대규모 스케일링을 성공적으로 적용한 첫 사례로, motion tracking을 foundation task로 선정하고 100M 프레임 데이터와 42M 파라미터로 학습하여 강력한 generalization을 보인다. Kinematic planner와 unified token space를 통해 다양한 제어 인터페이스를 단일 정책으로 통합함으로써 실제 응용 가능성을 입증했으며, 체계적인 ablation과 comprehensive evaluation은 연구의 엄밀성을 보강한다.
WoCoCo: Learning Whole-Body Humanoid Control with Sequential Contacts
Figure 1: An overview of WoCoCo and tasks. (A) We decompose the task into separate contact
 *Figure 1: An overview of WoCoCo and tasks. (A) We decompose the task into separate contact* WoCoCo는 순차적 접촉(sequential contacts)을 포함한 전신 휴머노이드 제어를 학습하기 위한 통합 RL 프레임워크로, 작업을 접촉 단계별로 분해하여 task-agnostic 보상 설계와 sim-to-real 파이프라인을 제시한다.
WoCoCo는 순차적 접촉을 포함한 휴머노이드 제어 문제에 대해 개념적으로 우아하고 실용적인 RL 프레임워크를 제시하며, 4가지 도전적 작업의 현실 검증을 통해 높은 응용 가치를 입증한다. 다만 접촉 계획의 자동 생성 및 더 복잡한 작업 환경으로의 확장은 향후 연구 방향이다.
ZeroWBC: Learning Natural Visuomotor Humanoid Control Directly from Human Egocentric Video

Fig. 1: Overview of the ZeroWBC framework. We propose a novel framework that learns natural humanoid visuomotor control
 *Fig. 1: Overview of the ZeroWBC framework. We propose a novel framework that learns natural humanoid visuomotor control* ZeroWBC는 인간의 일인칭 비디오와 모션 캡처 데이터로부터 휴머노이드 로봇의 전신 제어 정책을 직접 학습하는 프레임워크로, 로봇 원격조종 데이터 수집 없이 자연스러운 장면 상호작용을 가능하게 한다.
ZeroWBC는 휴머노이드 로봇의 원격조종 데이터 수집 문제를 근본적으로 해결하며, 인간 영상 데이터로부터 자연스럽고 다양한 전신 제어를 구현하는 혁신적인 프레임워크이다. 강력한 실험 검증과 실제 로봇 성공사례는 제시되어 있으나, 추가 플랫폼 일반화와 동적 환경 적응성에 대한 평가가 향후 필요하다.
ASE: Large-Scale Reusable Adversarial Skill Embeddings for Physically Simulated Characters

Fig. 1. Our framework enables physically simulated characters to learn versatile and reusable skill embeddings from larg
 *Fig. 1. Our framework enables physically simulated characters to learn versatile and reusable skill embeddings from larg* 대규모 비정형 모션 데이터셋으로부터 adversarial imitation learning과 unsupervised reinforcement learning을 결합하여 물리 시뮬레이션 캐릭터의 재사용 가능한 스킬 임베딩을 학습하는 데이터 기반 프레임워크를 제시한다. 학습된 스킬 임베딩은 다양한 새로운 과제에 효과적으로 전이되며 자연스러운 행동을 합성한다.
본 논문은 adversarial imitation learning과 information maximization을 결합하여 대규모 비정형 모션 데이터로부터 재사용 가능한 스킬 임베딩을 학습하는 혁신적인 프레임워크를 제시한다. 십 년 규모의 대규모 사전 학습과 탁월한 전이 성능으로 물리 기반 캐릭터 애니메이션 분야에 significant contribution을 제공한다.
BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion

Figure 1: Overview of the proposed versatile humanoid control framework. (A) Scalable
 *Figure 1: Overview of the proposed versatile humanoid control framework. (A) Scalable* BeyondMimic은 인간 모션 데이터로부터 학습한 compact motion-tracking 공식과 classifier guidance를 활용한 diffusion model을 결합하여, 휴머노이드 로봇이 학습 중 보지 못한 다양한 작업을 zero-shot으로 수행할 수 있는 통합 제어 프레임워크를 제시한다.
BeyondMimic은 motion tracking RL의 민첩성과 diffusion 모델의 유연성을 효과적으로 결합하여, 휴머노이드 로봇 제어의 장기적 과제인 자연스러움, 민첩성, versatility를 동시에 달성하는 강력한 프레임워크를 제시한다. 실제 로봇 배포와 zero-shot task 일반화 시연은 로보틱스 커뮤니티에 상당한 기여를 한다.
CHIP: Adaptive Compliance for Humanoid Control through Hindsight Perturbation
Fig. 1: CHIP enables humanoid robots to perform manipulation tasks that require force control, such as wiping a whiteboa
 *Fig. 1: CHIP enables humanoid robots to perform manipulation tasks that require force control, such as wiping a whiteboa* CHIP는 hindsight perturbation을 통해 humanoid robot이 민첩한 움직임을 유지하면서도 적응적 compliance를 갖춘 forceful manipulation을 수행할 수 있게 하는 plug-and-play 모듈이다.
CHIP는 humanoid의 agile motion과 compliant manipulation을 양립시키는 우아한 해결책으로, hindsight perturbation이라는 핵심 아이디어의 단순함과 기존 framework와의 호환성이 강점이다. 다만 실제 로봇 검증과 force control의 정량적 분석이 보완되면 더욱 완성도 있는 연구가 될 것이다.
Deep Whole-body Parkour
Fig. 1: Deep Whole-Body Parkour. Our framework enables a humanoid robot to autonomously traverse challenging obstacles
 *Fig. 2: Data-driven whole-body control framework. Real-world environment scans and human demonstrations are processed an* 본 연구는 외부 센싱(depth perception)을 whole-body motion tracking에 통합하여 인간형 로봇이 불규칙한 지형에서 vaulting, dive-rolling 등의 동적 parkour 움직임을 수행하도록 하는 프레임워크를 제시한다.
본 논문은 두 상충하는 제어 패러다임을 창의적으로 통합하여 humanoid robot의 traversability를 획기적으로 확장했으며, custom motion-terrain dataset과 최적화된 ray-casting algorithm은 기술적 기여도 충실하다. sim-to-real gap 해소와 실제 동작 검증으로 실무적 가치가 높으나, dataset 확장성과 타 robot morphology 적용에 개선 여지가 있다.
ExBody2: Advanced Expressive Humanoid Whole-Body Control
Fig. 1: Humanoid robot executing various expressive whole-body motions in the real world. The robot can (a) walk with a
 *Fig. 1: Humanoid robot executing various expressive whole-body motions in the real world. The robot can (a) walk with a * ExBody2는 휴머노이드 로봇이 인간의 모션 캡처 데이터와 시뮬레이션 데이터를 학습하여 표현력 있는 전신 동작을 수행하도록 하는 프레임워크이며, 자동화된 데이터 필터링과 teacher-student 기반의 decoupled motion-velocity 제어 전략을 통해 실제 로봇에 배포 가능하게 함.
ExBody2는 자동화된 데이터 필터링, generalist-specialist 파이프라인, decoupled motion-velocity 제어라는 세 가지 명확한 혁신을 통해 휴머노이드 로봇의 표현력 있는 전신 제어 문제를 체계적으로 해결하며, 실제 로봇에서의 다양한 동작 성공 시연으로 실질적 기여를 입증한 우수한 연구임.
General Humanoid Whole-Body Control via Pretraining and Fast Adaptation
 *Figure 2: An overview of FAST. Our framework consists of three stages. (1) We construct a curated* FAST는 대규모 사전학습과 경량 잔여 정책 적응을 결합하여 인간형 로봇의 일반적인 전신 제어를 가능하게 하는 프레임워크이다. Center-of-Mass-Aware Control과 Parseval-Guided Residual Policy Adaptation을 통해 분포 외 동작에 대한 빠른 적응과 안정적인 균형을 동시에 달성한다.
FAST는 실용적인 제약 조건 하에서 인간형 로봇의 일반적이고 견고한 전신 제어를 달성하는 잘 설계된 프레임워크이며, Center-of-Mass-Aware 제어와 Parseval-Guided 잔여 적응의 조합은 분포 외 동작 적응에서 새로운 접근 방식을 제시한다.
HuB: Learning Extreme Humanoid Balance
Figure 1: Extreme Balance Tasks. HuB enables humanoids to perform extreme quasi-static balance tasks
 *Figure 2: HuB Overview. To tackle the challenges of extreme balance tasks on humanoids, HuB integrates* HuB는 휴머노이드 로봇이 제한된 한 발로 서기나 높은 킥과 같은 극도의 준정적 균형 작업을 수행할 수 있도록 하는 통합 프레임워크이며, 참조 동작 정제, 균형 인식 정책 학습, sim-to-real 강건성 훈련의 세 가지 구성 요소로 이루어져 있다.
HuB는 휴머노이드의 극한 균형 제어라는 도전적 문제에 대해 참조 정제, 정책 학습, sim-to-real 전이의 세 가지 핵심 요소를 체계적으로 통합한 포괄적 솔루션을 제시하며, 실제 하드웨어에서 인상적인 성능을 달성하여 로봇 제어 분야에 의미 있는 기여를 한다.
It Takes Two: Learning Interactive Whole-Body Control Between Humanoid Robots
 *Figure 2: Overview of the proposed Harmanoid framework. It contains two key components: (i) contact-aware motion retarge* Harmanoid는 두 개의 휴머노이드 로봇 간 상호작용 동작을 모방하는 프레임워크로, 접촉 인식 motion retargeting과 상호작용 기반 motion controller를 통해 키네마틱 충실도와 물리적 현실성을 동시에 보존한다.
Harmanoid는 다중 휴머노이드 상호작용 동작 모방의 명확한 문제를 체계적으로 해결하며, contact-aware retargeting과 interaction-aware control의 결합으로 고립 문제를 효과적으로 극복하는 첫 프레임워크이다. 종합적인 실험과 우수한 성능으로 humanoid robotics 분야에 중요한 기여를 하나, sim-to-real 검증 부재와 2-agent 제한이 실제 적용의 완전성을 제약한다.
JAEGER: Dual-Level Humanoid Whole-Body Controller
Figure 1: Some real-world demonstrations of JAEGER deployed on the H1-2. For the root-based
 *Figure 2: The framework of JAEGER. The left shows the retargeting network, which uses an MLP* JAEGER는 인간형 로봇의 상체와 하체를 독립적인 두 개의 컨트롤러로 분리하여 제어하는 dual-level whole-body controller를 제안하며, root velocity tracking(coarse-grained)과 local joint angle tracking(fine-grained) 제어를 모두 지원한다.
JAEGER는 상하체 분리 설계와 MLP 기반 retargeting, 체계화된 curriculum learning을 통해 인간형 로봇의 whole-body control 문제에 대한 실질적이고 창의적인 해결책을 제시하며, 실제 환경에서의 검증을 통해 높은 실용성을 입증한다.
KungfuBot: Physics-Based Humanoid Whole-Body Control for Learning Highly-Dynamic Skills
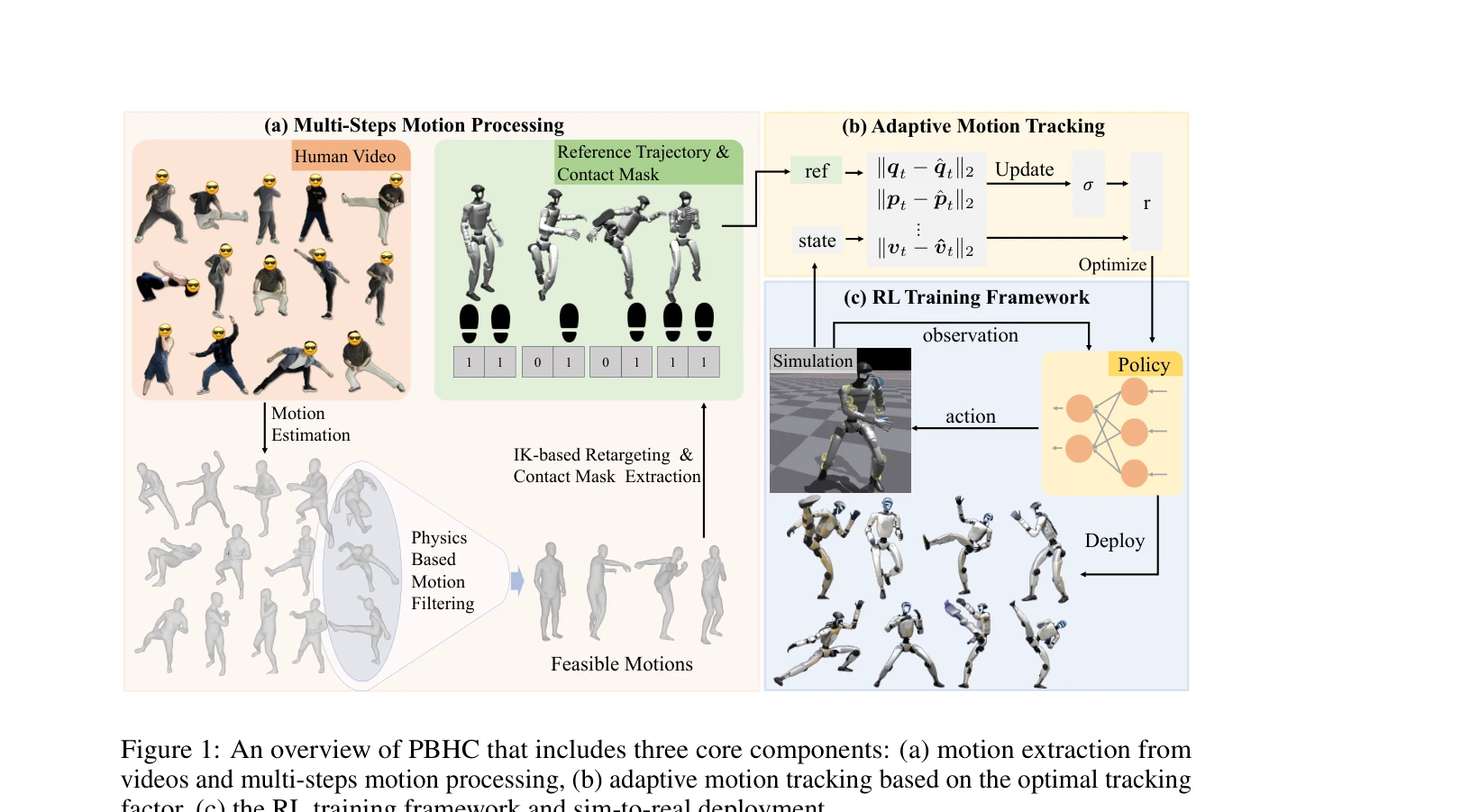
Figure 1: An overview of PBHC that includes three core components: (a) motion extraction from
 *Figure 1: An overview of PBHC that includes three core components: (a) motion extraction from* 본 논문은 물리 기반 인간형 로봇 제어 프레임워크(PBHC)를 제안하여 쿵푸, 댄싱 등 고도로 동적인 인간 행동을 모방하도록 학습하는 방법을 제시한다. 다단계 모션 처리와 적응형 모션 추적을 통해 기존 방법보다 현저히 낮은 추적 오차를 달성하고 실제 로봇에 배포된다.
본 논문은 물리 기반 모션 처리, 적응형 bi-level optimization 커리큘럼, 비대칭 actor-critic 구조를 결합한 포괄적 프레임워크로 고도로 동적인 인간형 로봇 제어 문제를 체계적으로 해결한다. 실제 로봇 배포 성공과 기존 방법 대비 현저한 성능 향상은 강력한 기술적 기여를 입증하며, 인간형 로봇의 동적 행동 학습 분야에서 중요한 진전을 이룬다.
Learning Athletic Humanoid Tennis Skills from Imperfect Human Motion Data (LATENT)

Figure 1 (a) The humanoid performs multi-shot rallies with a human player using different stroke types across various co
 *Figure 2 Overview of LATENT. (a) We pre-train a motion tracker on collected imperfect human motion data. (b) We construc* LATENT는 불완전한 인간 모션 데이터(5시간 분량의 테니스 프리미브)로부터 수정 가능한 잠재 행동 공간을 구성하고, 고수준 정책으로 이를 보정·합성하여 휴머노이드 로봇이 인간과의 멀티샷 테니스 랠리를 수행하도록 학습하는 시스템이다.
본 논문은 불완전한 모션 데이터로부터 athletic humanoid 스포츠 기술을 학습하는 실질적이고 창의적인 시스템을 제시하며, correctable latent space와 latent action barrier라는 두 가지 novel design으로 imperfect data의 한계를 효과적으로 극복했다. Real-world humanoid 로봇에서 인간과의 멀티샷 테니스 랠리를 성공적으로 구현한 점이 이 분야의 중요한 이정표이다.
Learning Humanoid Standing-up Control across Diverse Postures
Fig. 1: Overview. (a) Our proposed framework HOST enables the humanoid robot to learn standing-up control via reinforcem
 *Fig. 1: Overview. (a) Our proposed framework HOST enables the humanoid robot to learn standing-up control via reinforcem* HoST는 강화학습 기반 프레임워크로 휴머노이드 로봇이 다양한 자세에서 일어서는 동작을 학습하고 실제 환경에서 robust하게 수행할 수 있도록 한다.
이 논문은 휴머노이드 로봇의 standing-up control이라는 실질적 문제를 RL 기반으로 체계적으로 해결하며, 사전 궤적 없이 diverse posture에서의 실제 배포를 성공적으로 달성한 의미 있는 기여로, 실제 로봇 시스템의 자율성 향상에 중요한 발걸음이다.
LeVERB: Humanoid Whole-Body Control with Latent Vision-Language Instruction

Figure 1: Overview of our contributions. Top: we create a photorealistic and dynamically accurate
 *Figure 1: Overview of our contributions. Top: we create a photorealistic and dynamically accurate* LeVERB는 humanoid 로봇의 전신 제어를 위해 vision-language 입력을 latent action 공간으로 인코딩하는 계층적 프레임워크를 제안하며, 150개 이상의 task로 구성된 첫 번째 sim-to-real 준비 벤치마크를 제시한다.
LeVERB는 humanoid WBC를 위한 vision-language 제어에서 중요한 진전을 이루었으며, 첫 latent instruction-following framework와 comprehensive sim-to-real 벤치마크를 제시하여 이 분야의 기초를 다졌다. 다만 실제 배포 성능의 추가 개선과 더 광범위한 task 평가를 통한 검증이 필요하다.
Mimicking-Bench: A Benchmark for Generalizable Humanoid-Scene Interaction Learning via Human Mimicking
Figure 1. Mimicking-Bench is the first benchmark for learning generalizable humanoid-scene interaction skills via mimick
 *Figure 1. Mimicking-Bench is the first benchmark for learning generalizable humanoid-scene interaction skills via mimick* 인간의 모션 데이터를 활용한 휴머노이드 로봇의 3D 장면 상호작용 학습을 위한 첫 번째 종합 벤치마크인 Mimicking-Bench를 제시하며, 23K개의 인간 상호작용 모션과 11K개의 다양한 객체 형상을 포함한다.
Mimicking-Bench는 인간 모션 데이터의 대규모 다양성을 활용한 휴머노이드-장면 상호작용 학습을 위한 첫 종합 벤치마크로, 신체 모방 기반의 로봇 스킬 학습 연구를 체계적으로 진행할 수 있는 중요한 기여를 제공한다.
MOSAIC: Bridging the Sim-to-Real Gap in Generalist Humanoid Motion Tracking and Teleoperation with Rapid Residual Adaptation
 *Fig. 2: MOSAIC System Overview. MOSAIC consists of a unified training–deployment pipeline for humanoid motion tracking* MOSAIC는 강화학습을 통해 학습한 범용 humanoid 동작 추적기와 빠른 residual 적응 메커니즘을 결합하여 시뮬레이션과 실제 로봇 간의 gap을 줄이고 장시간의 텔레오퍼레이션을 안정적으로 지원하는 시스템이다.
MOSAIC는 시뮬레이션-실제 로봇 간 격차를 체계적으로 해결하기 위해 텔레오퍼레이션 지향의 RL 설계와 residual adaptation을 결합한 실용적이고 잘 설계된 시스템으로, RobotBridge 프레임워크와 함께 공개되어 재현성과 확장성을 크게 향상시킨다. 다만 완전한 zero-shot adaptation과 다양한 embodiment에 대한 더욱 강력한 일반화가 향후 과제이다.
One-shot Adaptation of Humanoid Whole-body Motion with Walking Priors

Figure 1. Sampled frames from motion sequences of a humanoid (Unitree H1) performing four distinct actions in sim-to-sim
 *Figure 2. Given a sequence of walking motion pose skeletons and a target sequence comprising non-walking motions, we emp* 단일 비보행 대상 샘플과 보행 사전 지식을 활용하여 휴머노이드 전신 운동을 원샷 적응하는 데이터 효율적 방법을 제안한다. Order-preserving optimal transport를 통해 보행과 비보행 시퀀스 간 거리를 계산하고 geodesic 보간으로 중간 포즈를 생성한 후 강화학습으로 정책을 적응한다.
휴머노이드 전신 운동에 원샷 학습을 효과적으로 적용하고, order-preserving optimal transport와 manifold 최적화를 통해 경량의 데이터 효율적 솔루션을 제시하는 높은 가치의 연구이다. 다만 실제 로봇 검증과 더 다양한 보조 모션 확장이 후속 과제이다.
Perceptive Humanoid Parkour: Chaining Dynamic Human Skills via Motion Matching

Fig. 1: Perceptive Humanoid Parkour (PHP) enables a Unitree G1 humanoid robot to execute highly dynamic, long-horizon
 *Fig. 2: Perceptive Humanoid Parkour overview. Atomic parkour skills are composed into long-horizon kinematic reference* Motion matching을 통해 인간의 동작 데이터를 원자적 기술로 합성하고, DAgger와 RL을 결합한 teacher-student 파이프라인으로 단일 깊이 기반 정책으로 증류하여 휴머노이드 로봇이 복잡한 장애물 코스에서 자율적으로 장시간 파쿠르를 수행하도록 한다.
본 연구는 motion matching과 hybrid DAgger-RL 증류를 통해 희소한 인간 동작 데이터로부터 복잡한 파쿠르 기술을 효과적으로 합성 및 학습하여 휴머노이드 로봇의 동적 환경 적응 능력을 획기적으로 향상시켰으며, 실제 로봇에서의 강인한 구현과 zero-shot sim-to-real 전이는 높은 실용적 가치를 입증한다.
Perpetual Humanoid Control for Real-time Simulated Avatars

Figure 1: We propose a motion imitator that can naturally recover from falls and walk to far-away reference motion, perp
 *Figure 1: We propose a motion imitator that can naturally recover from falls and walk to far-away reference motion, perp* Physics 기반 humanoid controller인 Perpetual Humanoid Controller (PHC)는 noisy input과 unexpected falls에 강건하면서 10,000개의 motion clips을 학습할 수 있으며, 새로운 Progressive Multiplicative Control Policy (PMCP)를 통해 catastrophic forgetting 없이 대규모 motion database에서 학습 가능하다.
이 논문은 external force 제거와 PMCP라는 novel mechanism으로 physics-based motion imitation의 scalability 문제를 효과적으로 해결하며, natural fail-state recovery와 noisy input 강건성으로 실제 video 기반 avatar application에 처음으로 실용적인 solution을 제공한다.
Toward Humanoid Brain-Body Co-design: Joint Optimization of Control and Morphology for Fall Recovery
 *Fig. 2: The RoboCraft framework.* 본 논문은 humanoid 로봇의 fall recovery 능력을 향상시키기 위해 제어 정책과 신체 형태를 동시에 최적화하는 RoboCraft 프레임워크를 제안한다. 공유 제어 정책의 사전학습과 설계 공간 탐색을 결합하여 효율적인 co-design을 실현한다.
본 논문은 복잡한 humanoid 로봇에 대한 실질적이고 확장 가능한 co-design 프레임워크를 처음 제시하며, 다중 설계 사전학습 정책과 우선순위 버퍼를 통한 효율적 최적화로 형태 최적화의 중요성을 명확히 입증했다. 시뮬레이션 기반 한계에도 불구하고 embodied AI 분야의 중요한 진전을 나타낸다.
Towards Adaptable Humanoid Control via Adaptive Motion Tracking

Fig. 1: Overview. Our method, AdaMimic (adaptive motion tracking), achieves agile humanoid whole-body adaptation from on
 *Fig. 2: Method overview. (a) Human motions are reconstructed into SMPL motions via GVHMR [21] and retargeted to the huma* AdaMimic은 단일 참조 동작으로부터 휴머노이드 로봇의 적응형 제어를 가능하게 하는 동작 추적 알고리즘으로, 키프레임 기반 데이터 증강과 단계적 어댑터 학습을 통해 정확한 모방과 광범위한 적응성을 동시에 달성한다.
AdaMimic은 단일 참조 동작으로부터 고정밀 모방과 광범위 적응성을 동시에 달성하는 혁신적 접근으로, 두 단계 학습과 이중 어댑터 구조의 새로운 설계가 의미 있으며, 실제 로봇에서의 광범위한 검증이 제시되어 실용성이 높다.
Towards Adaptive Humanoid Control via Multi-Behavior Distillation and Reinforced Fine-Tuning
Figure 1: Comparison between multi-task RL and our pro-
 *Figure 2: Overview of the proposed two-stage framework Adaptive Humanoid Control. In the first stage, we train two separ* 휴머노이드 로봇이 다양한 이족보행 행동(서기, 걷기, 뛰기, 점프)을 학습할 수 있도록 다중행동 증류(multi-behavior distillation)와 강화학습 미세조정을 통해 적응형 제어기를 개발한다.
다중행동 증류와 강화학습 미세조정을 결합한 2단계 프레임워크는 휴머노이드 로봇의 적응형 제어라는 중요한 문제에 대한 실용적이고 효과적인 해결책을 제시하며, 시뮬레이션과 실로봇 실험을 통해 그 타당성을 입증했다.
ULTRA: Unified Multimodal Control for Autonomous Humanoid Whole-Body Loco-Manipulation
Fig. 1: ULTRA is an all-in-one controller for humanoid loco-manipulation that supports: Top. dense motion tracking
 *Fig. 1: ULTRA is an all-in-one controller for humanoid loco-manipulation that supports: Top. dense motion tracking* 물리 기반 신경 retargeting과 unified multimodal controller를 결합하여 humanoid 로봇이 dense reference tracking과 sparse goal-conditioning을 모두 지원하며, egocentric 시각 인지 기반 자율적 전신 loco-manipulation을 수행할 수 있는 프레임워크이다.
이 논문은 humanoid loco-manipulation의 두 가지 근본적인 병목(물리적 retargeting과 통합 컨트롤)을 체계적으로 해결하며, physics-driven retargeting과 multimodal distillation의 조합으로 실제 배포 환경에서의 자율성을 크게 향상시킨다. 특히 unified framework로 diverse 조건 신호를 처리하고 real-world 평가를 제시한 점에서 학술적 및 실용적 의의가 높다.
UniAct: Unified Motion Generation and Action Streaming for Humanoid Robots

Figure 1. UniAct, a unified framework for multimodal motion generation and action streaming. UniAct enables humanoid rob
 *Figure 1. UniAct, a unified framework for multimodal motion generation and action streaming. UniAct enables humanoid rob* UniAct는 MLLM과 causal streaming pipeline을 결합한 두 단계 프레임워크로, 인간형 로봇이 언어, 음악, 궤적 등 다양한 multimodal 명령을 sub-500ms 지연시간으로 실행할 수 있게 한다.
UniAct는 MLLM과 robust tracking을 unified framework로 통합하여 실제 humanoid robot에서 multimodal instruction following을 low latency로 달성한 의미 있는 연구이며, UA-Net 데이터셋 기여와 함께 embodied AI 분야에서 중요한 진전을 나타낸다.
Safe Human-to-Humanoid Motion Imitation Using Control Barrier Functions
Fig. 1: Overview of the proposed safe human-to-humanoid motion imitation framework.
 *Fig. 1: Overview of the proposed safe human-to-humanoid motion imitation framework.* 비전 기반 motion retargeting과 Control Barrier Function을 결합하여 휴머노이드 로봇이 인간의 동작을 모방하면서 자기 충돌과 인간-로봇 충돌을 실시간으로 회피할 수 있는 안전 프레임워크를 제시한다.
비전 기반 motion imitation에 CBF를 체계적으로 도입하여 실시간 안전 필터링을 구현한 실질적 기여이며, 충돌 회피와 responsiveness의 균형을 QP로 효과적으로 달성했다. 다만 시뮬레이션만 제시되고 하드웨어 검증이 필요하며, 설계 parameter 튜닝과 일반화 가능성 개선이 추후 과제이다.
Tree Learning: A Multi-Skill Continual Learning Framework for Humanoid Robots
 *Figure 2: Tree Learning for Unitree G1.* Tree Learning은 humanoid robot을 위한 multi-skill continual learning 프레임워크로, hierarchical parameter inheritance mechanism을 통해 catastrophic forgetting을 방지하면서 새로운 스킬을 효율적으로 확장한다.
Tree Learning은 biological hierarchy inspired architecture를 통해 humanoid robot의 multi-skill continual learning에서 catastrophic forgetting을 근본적으로 해결하면서 경량 배포를 가능하게 하는 창의적인 솔루션이다. 다만 real-world 환경에서의 실제 검증과 더 복잡한 skill 상호작용에 대한 확장성이 향후 과제이다.
Learning Whole-Body Humanoid Locomotion via Motion Generation and Motion Tracking
 *Fig. 2. Overview of the training framework. (a) Data Collection & Curation: whole-body robot motions are obtained from h* Diffusion 기반 motion generation과 RL 기반 motion tracking을 결합하여 지형 인식 whole-body humanoid locomotion을 실현하고 Unitree G1 로봇에 실제 배포했다.
이 논문은 diffusion-based motion generation과 RL-based tracking을 결합하여 실제 humanoid 로봇에서 처음으로 whole-body terrain-aware locomotion을 성공적으로 구현한 획기적 연구이다. 강력한 hardware 검증과 명확한 방법론을 통해 높은 수준의 완성도를 보여주며, humanoid 로봇 제어 분야에 의미 있는 기여를 제시한다.
Deep Whole-body Parkour
Fig. 1: Deep Whole-Body Parkour. Our framework enables a humanoid robot to autonomously traverse challenging obstacles
 *Fig. 2: Data-driven whole-body control framework. Real-world environment scans and human demonstrations are processed an* 이 논문은 exteroceptive perception을 whole-body motion tracking에 통합하여 humanoid robot이 복잡한 지형에서 vault, dive-rolling 등의 다중 접촉 parkour 기술을 수행하도록 하는 프레임워크를 제시한다. 기존의 locomotion-centric 접근과 environment-agnostic 동작 추적을 결합하여 지각 기반의 일반적 동작 제어를 실현한다.
이 논문은 humanoid robot 제어의 두 주요 패러다임을 창의적으로 통합하여 지형 인식 능력과 복잡한 전신 동작을 동시에 달성하는 실질적인 솔루션을 제시한다. 커스텀 dataset curation, 최적화된 parallel simulation, 견고한 폐루프 제어 통합을 통해 vault와 dive-rolling 같은 고도로 동적인 parkour 기술을 실제 humanoid에서 구현했다는 점에서 의의가 크다.
HuB: Learning Extreme Humanoid Balance
Figure 1: Extreme Balance Tasks. HuB enables humanoids to perform extreme quasi-static balance tasks
 *Figure 1: Extreme Balance Tasks. HuB enables humanoids to perform extreme quasi-static balance tasks* 본 논문은 휴머노이드 로봇이 극단적인 균형 잡기 태스크(Swallow Balance, Bruce Lee's Kick 등)를 수행하도록 하기 위해 세 가지 핵심 문제(참조 동작 오류, 형태학적 불일치, sim-to-real 갭)를 각각 해결하는 통합 프레임워크 HuB를 제시한다. 이를 통해 Unitree G1 휴머노이드 로봇에서 강한 외부 충격에도 안정적으로 균형을 유지하는 정책을 학습할 수 있음을 입증했다.
본 논문은 휴머노이드의 극단적 균형 제어라는 도전적인 문제에 대해 잘 동기부여되고 체계적으로 설계된 솔루션을 제시한다. 세 가지 핵심 장애물(참조 오류, morphological mismatch, sim-to-real 갭)을 각각 겨냥한 모듈식 접근법과 실제 하드웨어에서의 강력한 실험 검증이 강점이다. 다만 다른 휴머노이드 플랫폼으로의 일반화 가능성과 학습 효율성 측면에서 추가 논의가 필요하다.
Learning Humanoid Locomotion with World Model Reconstruction

Fig. 1: Deployment to outdoor environments. We deployed the model in an outdoor environment covered in ice and snow.
 *Fig. 2: Illustration of the World Model Reconstruction framework. Our framework explicitly reconstructs world state from* 본 논문은 humanoid robot의 blind locomotion을 위해 World Model Reconstruction (WMR)을 제안한다. 센서 노이즈로부터 world state를 명시적으로 재구성하고, gradient cutoff를 통해 estimator와 policy를 독립적으로 학습시킴으로써 실제 복잡한 지형에서의 견고한 주행을 실현한다.
본 논문은 humanoid 로봇의 blind locomotion을 위한 명시적 world model reconstruction의 효과를 체계적으로 입증하고, gradient cutoff 메커니즘을 통해 estimation과 policy learning의 충돌을 창의적으로 해결한다. 단일 학습 단계로 복잡한 실제 지형에서의 장거리 주행을 달성한 것은 실질적 임팩트가 크며, 3.2 km hike의 구체적 성과는 방법의 실효성을 명확히 보여준다. 다만 단일 로봇 플랫폼 실험과 failure case 분석의 부족이 아쉬우나, 전체적으로 humanoid locomotion 분야에 의미있는 기여를 하는 고품질 연구이다.
PICO: Reconstructing 3D People In Contact with Objects
Figure 1. We present PICO, a novel framework for joint human-object reconstruction in 3D. PICO includes PICO-db, a uniqu
 *Figure 1. We present PICO, a novel framework for joint human-object reconstruction in 3D. PICO includes PICO-db, a uniqu* 단일 이미지에서 신체-물체 접촉 정보를 활용하여 3D 인간-물체 상호작용을 복원하는 PICO 프레임워크를 제시하며, 이를 위해 신체와 물체 모두에 밀집된 3D 접촉 주석이 있는 PICO-db 데이터셋을 수집했다.
본 논문은 신체-물체 접촉이라는 새로운 관점에서 3D HOI 문제를 체계적으로 다루며, PICO-db라는 고가치 데이터셋과 확장 가능한 PICO-fit 방법을 통해 현실의 다양한 물체 클래스에 일반화되는 실용적인 해결책을 제시한다.
RAPID Hand: A Robust, Affordable, Perception-Integrated, Dexterous Manipulation Platform for Generalist Robot Autonomy
Figure 1: RAPID Hand is an open-source, low-cost, fully direct-driven robotic hand platform with
 *Figure 1: RAPID Hand is an open-source, low-cost, fully direct-driven robotic hand platform with* RAPID Hand는 저비용의 20-DoF 다지형 로봇 손으로, 시각, 촉각, 고유감각을 통합한 멀티모달 인지 시스템과 고-DoF 원격조종 인터페이스를 함께 설계하여 로봇 자율성을 위한 고품질 조작 데이터 수집을 가능하게 한다.
RAPID Hand는 저비용 다지형 로봇 손 설계, 고정밀 멀티모달 인지 통합, 그리고 효과적인 원격조종 인터페이스를 혁신적으로 통합한 오픈소스 플랫폼으로, 일반화된 로봇 자율성 연구에 필요한 고품질 데이터 수집을 가능하게 하는 중요한 기여이다.
RUKA: Rethinking the Design of Humanoid Hands with Learning
Fig. 1: RUKA is a tendon-driven humanoid hand that is simple,
 *Fig. 1: RUKA is a tendon-driven humanoid hand that is simple,* RUKA는 3D 프린팅과 저가 부품으로 제작한 tendon-driven humanoid hand로, learning-based control을 통해 정밀성, 컴팩트성, 강도, 저비용을 동시에 달성한다.
RUKA는 learning-based control과 실용적 hardware 설계를 결합하여 저비용 대 성능 비율에서 로봇 손 영역의 새로운 기준을 제시하며, open-source 공개로 접근성을 극대화한 의미 있는 기여이다.
TeleOpBench: A Simulator-Centric Benchmark for Dual-Arm Dexterous Teleoperation
Figure 1: We present TeleOpBench, a simulation-based benchmark for bimanual dexterous teleoper-
 *Figure 2: The overview of the proposed TeleOpBench, where we unify four operator interfaces in* TeleOpBench는 쌍팔 민첩한 텔레오퍼레이션을 위한 시뮬레이터 기반 벤치마크로, 30개의 고충실도 작업 환경과 4가지 대표적 텔레오퍼레이션 모달리티(MoCap, VR, 외골격, 비전)를 통합 프레임워크로 제공하며 시뮬레이션과 실제 하드웨어 간의 강한 상관관계를 검증한다.
TeleOpBench는 텔레오퍼레이션 연구의 장기적인 병목인 표준화된 평가 환경의 부재를 해결하는 중요한 기여로, 실제 하드웨어와의 상관관계 검증을 통해 실용성을 입증한 의미 있는 연구이다. 다만 더 많은 로봇 플랫폼 통합과 정성적 사용성 지표 추가로 영향력을 확대할 수 있을 것으로 예상된다.
GraspSense: 언어 기반 인지와 힘 맵을 활용한 손재주 로봇 파지 계획
Fig. 1.
 *Fig. 1.* 본 논문은 휴머노이드 손재주 로봇의 파지 계획을 위해 언어 기반 인지, 3D 복원, 물리 기반 구조 해석을 통한 force map 구성, 그리고 임피던스 제어 기반 파지 실행을 통합하는 파이프라인 GraspSense를 제안한다. 기존의 기하학적 파지 계획과 달리, 물체 표면의 공간적으로 비균일한 기계적 특성을 명시적으로 고려하여 파지 선택과 그립 력 조절을 결합하는 물리 기반 접근을 제시한다.
본 논문은 손재주 로봇 파지 계획에 물체의 구조적 기계적 특성을 명시적으로 통합하는 중요한 기여를 제시한다. Force map 기반 파지 선택과 적응형 임피던스 제어를 통해 기존 기하학적 파지 계획의 한계를 극복하는 물리 기반 접근법이 창의적이고 기술적으로 건실하다. 다만 실제 로봇 플랫폼에서의 검증과 더 광범위한 객체 범주에 대한 평가가 필요하며, force map 구성의 정확성 분석이 강화되어야 한다.
ACE: A Cross-Platform Visual-Exoskeletons System for Low-Cost Dexterous Teleoperation
Figure 1: An Overview of the Proposed ACE System. The system consists of two bimanual ex-
 *Figure 1: An Overview of the Proposed ACE System. The system consists of two bimanual ex-* ACE는 3D 프린팅된 이중팔 exoskeleton과 hand-facing 카메라를 결합한 저비용 cross-platform 시각 기반 원격 조종 시스템으로, 다양한 로봇 플랫폼과 end-effector에 대해 정밀한 손과 손목 자세 추적을 가능하게 한다.
ACE는 기존 원격 조종 시스템의 비용-정확도-유연성 trade-off를 효과적으로 해결한 실용적인 솔루션으로, 저비용의 3D 프린팅 exoskeleton과 vision-kinematics 하이브리드 방식을 통해 다양한 로봇 플랫폼에서의 대규모 데이터 수집을 가능하게 한다는 점에서 높은 가치를 제공한다.
Being-H0: Vision-Language-Action Pretraining from Large-Scale Human Videos

Figure 1: Being-H0 acquires dexterous manipulation skills by learning from large-scale human videos in the
 *Figure 1: Being-H0 acquires dexterous manipulation skills by learning from large-scale human videos in the* Being-H0는 대규모 인간 비디오로부터 학습한 민첩한 Vision-Language-Action 모델로, physical instruction tuning 패러다임을 통해 인간의 손 동작을 명시적으로 모델링하여 로봇 조작 작업으로 전이한다.
Being-H0는 대규모 인간 비디오로부터 민첩한 로봇 조작을 학습하는 새로운 패러다임을 제시하며, physical instruction tuning과 part-level motion tokenization을 통해 기존 VLA의 데이터 부족 문제를 혁신적으로 해결한다. 명시적 동작 모델링 접근법과 UniHand 데이터셋은 로봇 공학 분야에 중요한 기여를 제공한다.
cuRoboV2: Dynamics-Aware Motion Generation with Depth-Fused Distance Fields for High-DoF Robots
cuRoboV2는 B-spline 궤적 최적화, GPU 기반 TSDF/ESDF 인식 파이프라인, 확장 가능한 고자유도 로봇 계산을 통합하여 조작기부터 인형로봇까지 안전하고 동역학 인식적인 운동 생성을 제공하는 통합 프레임워크이다.
cuRoboV2는 동역학 인식적 운동 생성, GPU 가속 인식 처리, 고자유도 확장성에서 근본적 한계를 극복한 통합 프레임워크로, 조작 로봇부터 인형로봇까지 대폭 개선된 성능을 달성하여 로봇 자율성의 실용화에 크게 기여한다.
DexCap: Scalable and Portable Mocap Data Collection System for Dexterous Manipulation

Fig. 1: DEXCAP facilitates the in-the-wild collection of high-quality human hand motion capture data and 3D observations
 *Fig. 1: DEXCAP facilitates the in-the-wild collection of high-quality human hand motion capture data and 3D observations* DexCap은 SLAM과 전자기장을 활용한 휴대용 손 모션캡처 시스템이며, DexIL은 이 데이터로부터 역운동학과 point cloud 기반 모방학습을 통해 로봇이 손가락 조작을 직접 학습하도록 하는 알고리즘이다.
DexCap과 DexIL은 휴대용 mocap 시스템과 embodiment gap을 극복하는 imitation learning을 처음으로 통합하여 in-the-wild 환경에서 로봇 손가락 조작 학습을 가능하게 한 우수한 기여이며, 6가지 조작 작업에서 일관된 성과를 보여준다.
DexterCap: An Affordable and Automated System for Capturing Dexterous Hand-Object Manipulation
Figure 1: DexterCap captures dexterous manipulation of a Rubik’s Cube. Top: raw multi-camera footage showing character-c
 *Figure 1: DexterCap captures dexterous manipulation of a Rubik’s Cube. Top: raw multi-camera footage showing character-c* DexterCap는 문자 코드화된 마커 패치를 사용하는 저비용 광학 모션 캡처 시스템으로, 심한 자기 폐색 상황에서도 손가락의 섬세한 조작 동작을 정확하게 추적하며 최소한의 수동 작업으로 자동 재구성 파이프라인을 제공한다.
DexterCap은 문자 코드화 마커와 자동화 파이프라인을 통해 저비용으로도 섬세한 손 조작을 정확하게 캡처할 수 있음을 보여주며, 공개된 DexterHand 데이터셋과 함께 손-물체 상호작용 연구의 중요한 리소스로 기여한다.
EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video
Figure 1: EgoDex is a large-scale egocentric dataset that focuses on human dexterous manipulation.
 *Figure 1: EgoDex is a large-scale egocentric dataset that focuses on human dexterous manipulation.* Apple Vision Pro를 활용하여 829시간의 3D 손 추적 주석이 포함된 대규모 자아중심 비디오 데이터셋 EgoDex를 수집하고, 이를 통해 기술적 조작 모방 학습을 위한 벤치마크를 제시한다.
EgoDex는 기술적 조작 학습을 위한 획기적인 대규모 데이터셋을 제공하며, 웨어러블 기술의 실제 활용을 통해 로봇 조작 분야의 '인터넷 규모 데이터' 시대를 개척한다. 데이터셋의 규모와 정밀도는 탁월하나, 실제 로봇 정책 전이의 실효성 검증이 후속 과제로 남아있다.
HandX: Scaling Bimanual Motion and Interaction Generation
Figure 1. (a) We introduce HandX, a large-scale dataset of bimanual and dexterous motions paired with fine-grained textu
 *Figure 1. (a) We introduce HandX, a large-scale dataset of bimanual and dexterous motions paired with fine-grained textu* HandX는 양손의 섬세한 움직임과 상호작용을 생성하기 위한 통합 기반을 제공하는 대규모 dataset, annotation 전략, 그리고 평가 방법론을 제시한다.
HandX는 bimanual hand motion generation의 significant gap을 체계적으로 해결하는 comprehensive framework를 제시하며, large-scale dataset, scalable annotation 전략, 그리고 detailed benchmarking을 통해 손 움직임 합성 분야의 새로운 표준을 제시한다. 실제 humanoid deployment까지 입증한 점에서 학술적, 실용적 가치가 높다.
HumanoidGen: Data Generation for Bimanual Dexterous Manipulation via LLM Reasoning
Figure 1: The overview of HumanoidGen. It includes spatial annotations, scene generation, constraint
 *Figure 1: The overview of HumanoidGen. It includes spatial annotations, scene generation, constraint* HumanoidGen은 LLM 추론과 원자적 손 동작을 활용하여 휴머노이드 로봇의 양손 정교한 조작을 위한 시뮬레이션 데이터와 시연을 자동으로 생성하는 프레임워크이다. MCTS 기반 추론 강화를 통해 장시간 작업과 불충분한 주석에서의 계획 능력을 개선한다.
HumanoidGen은 LLM 기반 자동화, 원자적 손 동작 설계, MCTS 강화 추론의 조합으로 휴머노이드 로봇의 양손 정교한 조작 데이터 생성에 새로운 접근법을 제시하며, HGen-Bench 벤치마크와 함께 데이터 스케일링의 성능 향상을 실증하여 실무적 가치가 높다. 다만 공간 주석의 수동 작성 부담과 sim-to-real 검증 부재가 확장성을 제한한다.
HumanoidVLM: Vision-Language-Guided Impedance Control for Contact-Rich Humanoid Manipulation
Figure 1: Overall architecture of the proposed HumanoidVLM framework.
 *Figure 1: Overall architecture of the proposed HumanoidVLM framework.* HumanoidVLM은 vision-language model과 retrieval-augmented generation을 결합하여 휴머노이드 로봇이 egocentric 이미지로부터 task-specific impedance parameters와 gripper configuration을 자동으로 선택하는 적응형 조작 프레임워크이다.
본 논문은 VLM과 RAG를 humanoid manipulation에 효과적으로 적용하여 semantic perception과 compliant control을 처음 체계적으로 연결했으며, 높은 retrieval 정확도와 실제 로봇 실험을 통해 타당성을 입증했다. 다만 고정된 database 규모와 sensor 제약이 향후 확장성을 제한하는 점이 개선 대상이다.
Lightning Grasp: High Performance Procedural Grasp Synthesis with Contact Fields
Figure 1: Lightning Grasp is a high-performance procedural (analytical) grasp synthesis algorithm.
 *Figure 3: Contact Field and Its Interaction with Objects. A contact field is a collection of vectors in* Lightning Grasp는 Contact Field라는 새로운 데이터 구조를 도입하여 기하학적 계산과 최적화 과정을 분리함으로써 다지형 손을 위한 고속의 절차적 파지 합성을 실현한다.
Lightning Grasp는 Contact Field라는 우아한 추상화를 통해 파지 합성의 근본적 병목을 해결하고 획기적인 속도 향상을 달성한 혁신적 기여로, 절차적 파지 합성의 새로운 표준을 제시한다.
OSMO: Open-Source Tactile Glove for Human-to-Robot Skill Transfer
Fig. 1: (A) The OSMO tactile glove for collecting in-the-wild
 *Fig. 1: (A) The OSMO tactile glove for collecting in-the-wild* OSMO는 인간의 촉각 데이터를 캡처하는 오픈소스 웨어러블 촉각 장갑으로, 촉각-시각 embodiment 격차를 최소화하여 인간 시연만으로 로봇 접촉 조작 정책을 학습할 수 있게 한다.
OSMO는 웨어러블 촉각 센싱 분야에서 주목할 만한 하드웨어 기여를 하며, 인간-로봇 skill transfer에서 촉각 정보의 중요성을 실증적으로 입증했다. 완전 공개 설계와 다양한 hand-tracking 호환성은 커뮤니티 영향력을 높일 것으로 예상되나, 단일 작업 평가와 로봇 플랫폼 제한성이 일반화 가능성에 대한 의문을 남긴다.
UniDex: A Robot Foundation Suite for Universal Dexterous Hand Control from Egocentric Human Videos

Figure 1. We introduce UniDex, a robot foundation suite for heterogeneous dexterous hand embodiments. We first curate Un
 *Figure 1. We introduce UniDex, a robot foundation suite for heterogeneous dexterous hand embodiments. We first curate Un* 인간 자기중심 비디오로부터 8종 로봇 핸드에 대한 범용 손재주 제어를 위해 50K+ 궤적 데이터셋(UniDex-Dataset), 통합 액션 공간(FAAS), 3D VLA 정책(UniDex-VLA)을 제시하는 로봇 파운데이션 스위트이다.
UniDex는 손재주 로봇 손 제어를 위한 첫 포괄적 파운데이션 스위트로, 대규모 다중 손 데이터셋, 혁신적인 FAAS 액션 공간, 강력한 3D VLA 정책을 통합하여 일반화와 전이 학습에서 뛰어난 성과를 달성했다.
Unified Human-Scene Interaction via Prompted Chain-of-Contacts
Figure 1: UniHSI facilitates unified and long-horizon control in response to natural language com-
 *Figure 2: Comprehensive Overview of UniHSI. The entire pipeline comprises two principal com-* UniHSI는 Large Language Model을 활용하여 자연어 명령을 Chain of Contacts (CoC)로 변환하고, 통합 컨트롤러를 통해 다양한 인간-장면 상호작용을 물리적으로 타당하게 수행하는 프레임워크를 제안한다.
UniHSI는 Chain of Contacts라는 새로운 상호작용 표현과 LLM 기반 계획 생성으로 자연어 명령 기반의 다양하고 장기간의 인간-장면 상호작용을 통합적으로 제어하는 혁신적 프레임워크이며, ICLR 2024 발표 논문으로서 embodied AI 분야에 의미 있는 기여를 제시한다.
A Rapid Deployment Pipeline for Autonomous Humanoid Grasping Based on Foundation Models
Fig. 1. The three-stage pipeline for rapid deployment of humanoid grasping.
 *Fig. 1. The three-stage pipeline for rapid deployment of humanoid grasping.* Foundation model들(YOLOv8, SAM 3D, FoundationPose)을 통합하여 휴머노이드 로봇의 새로운 물체 조작 배포 시간을 1-2일에서 약 30분으로 단축하는 end-to-end 파이프라인을 제시한다.
Foundation model들의 효과적 통합으로 휴머노이드 로봇 배포 시간을 획기적으로 단축한 실용적이고 우수한 논문이며, 자동 주석, zero-shot 3D 재구성, zero-shot pose tracking을 연계한 modular 설계가 산업 적용성을 높인다. 다만 제한된 물체 유형과 환경 조건에서의 검증이 일반화 가능성을 판단하기 위해 추가 필요하다.
Alter-Art: Exploring Embodied Artistic Creation through a Robot Avatar
Figure 1: Some snapshots of applications in artistic scenarios: theatre (top),
 *Figure 1: Some snapshots of applications in artistic scenarios: theatre (top),* 본 논문은 반인간형 로봇 Alter-Ego를 통한 원격 몰입 예술 창작 패러다임인 Alter-Art를 제안한다. 무용, 연극, 회화 세 가지 예술 영역에서 전문 예술가들이 로봇 신체에 내재되어 창작하는 경험을 탐구하며, 구체적 현존감 형성과 로봇의 물리적 제약이 창작 과정에 미치는 영향을 분석한다.
본 논문은 로봇 예술의 새로운 패러다임인 Alter-Art를 명확히 정의하고, 실제 예술가들과의 협력을 통해 embodied creative experience의 가능성을 설득력 있게 시연한다. 로봇을 기계가 아닌 신체적 확장으로 재구성하는 철학적 관점과 구체적 기술 플랫폼의 통합이 돋보인다. 다만 표본 규모의 제한, 정성적 방법론의 보강 필요, 기술 세부사항의 추가 설명 등이 개선 과제이나, 사회 로봇과 telepresence 연구에 중요한 개념적 기여를 제시한다.
RAPT: Model-Predictive Out-of-Distribution Detection and Failure Diagnosis for Sim-to-Real Humanoid Robots

Fig. 1: RAPT overview. Real-world out-of-distribution (OOD) scenarios during humanoid deployment. RAPT detects anomalies
 *Fig. 1: RAPT overview. Real-world out-of-distribution (OOD) scenarios during humanoid deployment. RAPT detects anomalies* RAPT는 시뮬레이션 환경에서 학습한 인간형 로봇 제어 정책의 현실 배포 시 out-of-distribution(OOD) 상태를 감지하고 실패 원인을 진단하는 경량의 자기감독 모니터링 시스템이다.
RAPT는 humanoid robot 배포의 실제적 난제인 silent failure 감지와 근본 원인 분석을 동시에 해결하는 실용적이고 혁신적인 방법으로, 50Hz 고주파 제어 호환성과 interpretable diagnosis를 통해 Sim-to-Real gap 문제의 새로운 패러다임을 제시한다.
RL from Physical Feedback: Aligning Large Motion Models with Humanoid Control
 *Figure 2: Overview of RLPF, which consists of three key components: i) Motion Tracking Policy* 본 논문은 텍스트 기반 인간 동작을 실제 휴머노이드 로봇에 실행 가능한 형태로 변환하는 문제를 해결하기 위해, 물리 시뮬레이터에서의 피드백을 기반으로 대규모 모션 생성 모델을 강화학습으로 미세조정하는 RLPF 프레임워크를 제안한다.
본 논문은 text-to-motion 생성 모델과 로봇 제어 간의 오랜 간극을 물리적 피드백 기반 RL로 체계적으로 해결하는 창의적 접근을 제시하며, 실제 로봇 배포 성공을 통해 실용적 가치를 입증했다. 다만 계산 효율성과 평가 범위 확대에 대한 추가 연구가 필요하다.
SafeFlow: Real-Time Text-Driven Humanoid Whole-Body Control via Physics-Guided Rectified Flow and Selective Safety Gating
 *Fig. 2.* SafeFlow는 physics-guided rectified flow matching과 3단계 안전 게이팅을 결합하여 텍스트 명령 기반 휴머노이드 전신 제어에서 물리적으로 실현 불가능한 동작 생성 문제를 해결한다.
SafeFlow는 physics-guided generation과 hierarchical safety gating을 효과적으로 결합하여 텍스트 기반 휴머노이드 제어의 안전성과 실행 가능성을 동시에 달성한 실질적으로 중요한 연구이며, Unitree G1에서의 광범위한 실험 검증으로 실제 로봇 배포의 가능성을 보여준다.
SENTINEL: A Fully End-to-End Language-Action Model for Humanoid Whole Body Control
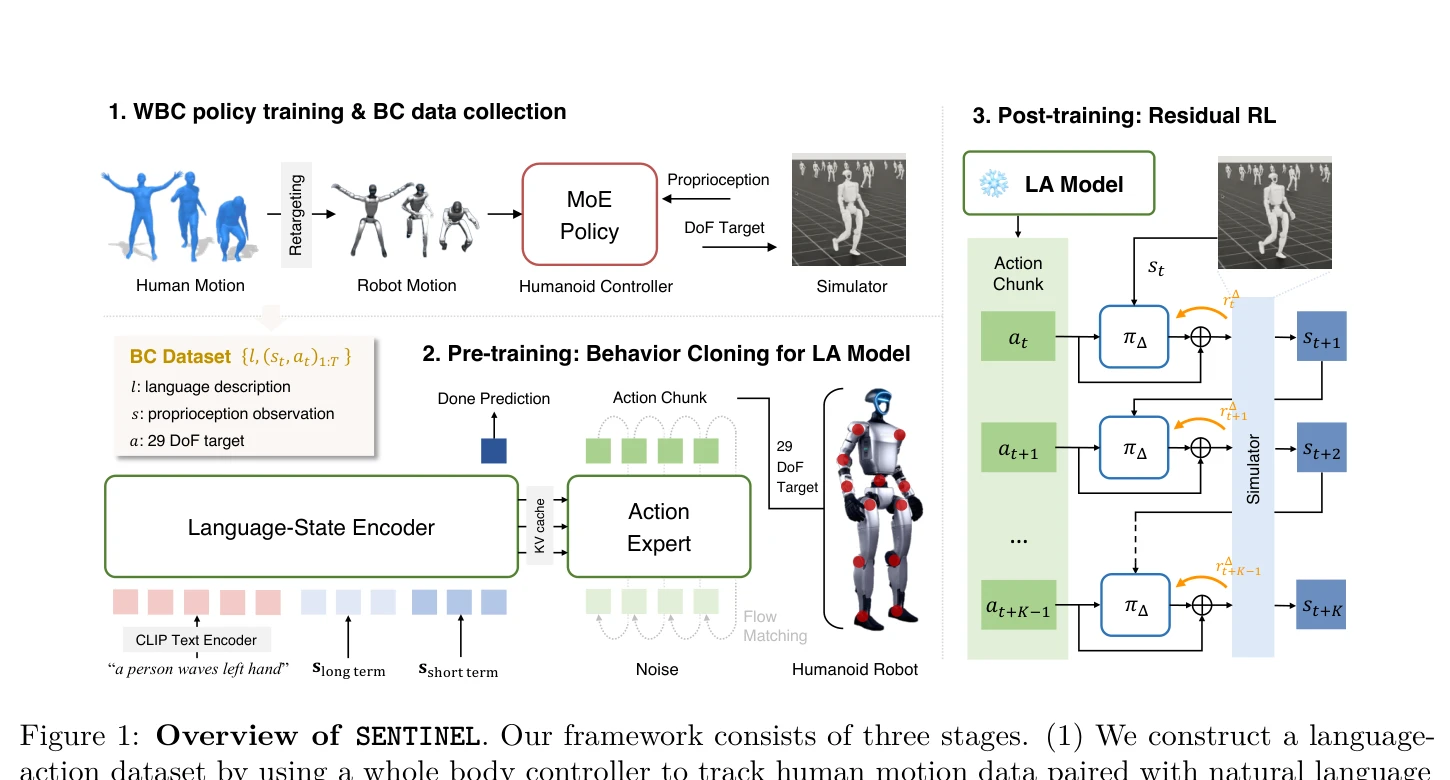
Figure 1: Overview of SENTINEL. Our framework consists of three stages. (1) We construct a language-
 *Figure 1: Overview of SENTINEL. Our framework consists of three stages. (1) We construct a language-* SENTINEL은 언어 명령을 휴머노이드 로봇의 저수준 제어 신호로 직접 변환하는 완전 end-to-end 언어-행동 모델로, flow matching을 통해 행동 청크를 생성하고 실제 배포를 위해 잔여 강화학습으로 정제한다.
SENTINEL은 언어-조건부 휴머노이드 제어를 위한 완전 end-to-end 접근의 첫 사례로, 중간 표현을 제거하고 flow matching과 residual RL을 결합한 창의적인 방법론을 제시한다. 시뮬레이션과 실제 로봇 모두에서의 성공적인 배포는 본 접근의 타당성을 입증하며, 향후 구체화 AI 발전에 중요한 기초를 마련한다.
AGILE: A Comprehensive Workflow for Humanoid Loco-Manipulation Learning
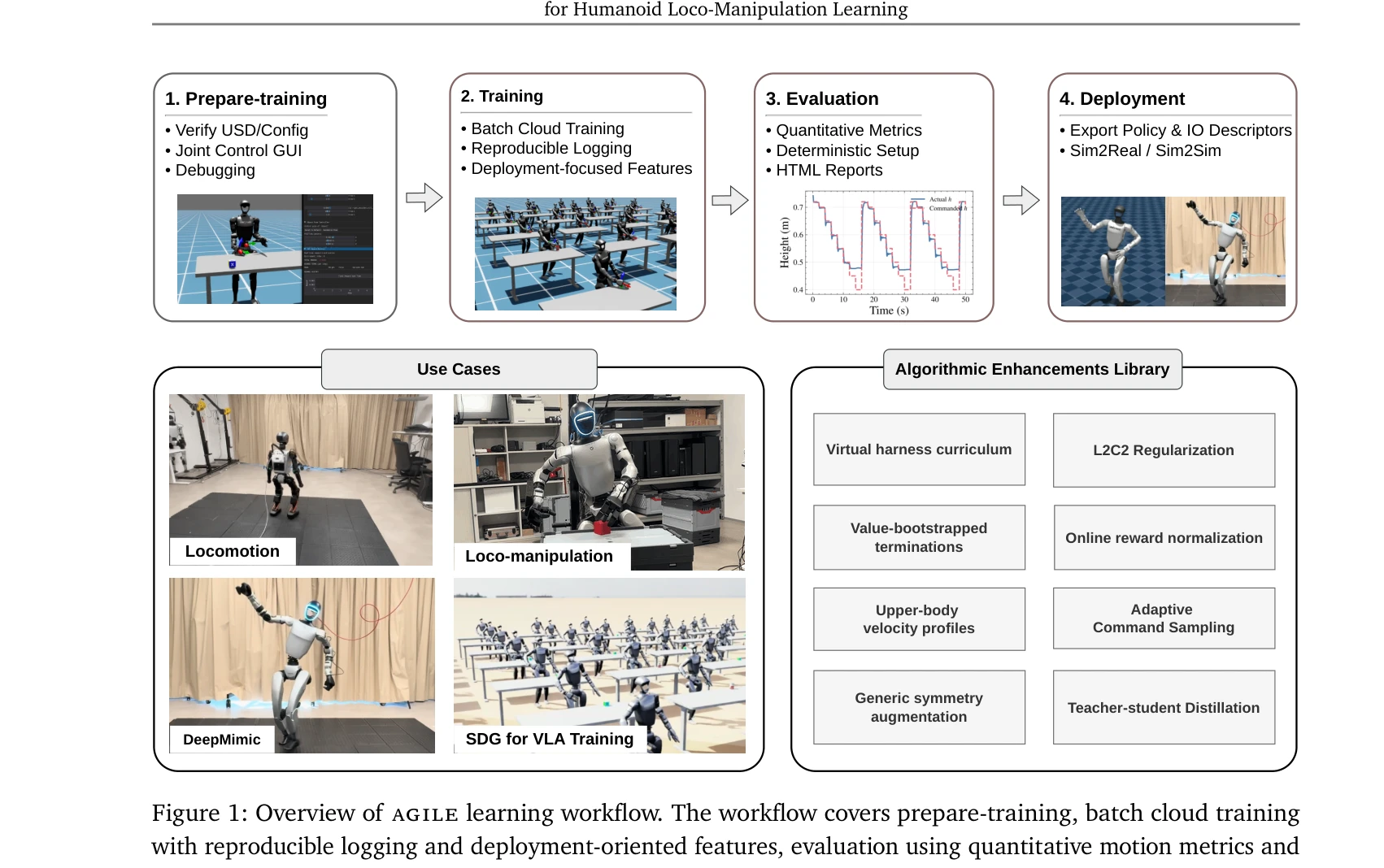
Figure 1: Overview of agile learning workflow. The workflow covers prepare-training, batch cloud training
 *Figure 1: Overview of agile learning workflow. The workflow covers prepare-training, batch cloud training* AGILE는 휴머노이드 로봇의 강화학습 정책 개발을 위한 엔드투엔드 워크플로우로, 환경 검증, 재현 가능한 학습, 통합 평가, 디스크립터 기반 배포의 4단계를 표준화하여 시뮬레이션-실세계 전이의 신뢰성을 향상시킨다.
AGILE는 휴머노이드 RL의 실제 배포 단계에서 야기되는 현실적 문제들을 직시하고 이를 해결하기 위한 체계적인 엔지니어링 워크플로우를 제시한다. 알고리즘 혁신보다는 infrastructure 중심이지만, 재현성, 신뢰성, 배포 가능성 측면에서 매우 실용적이며 5개 작업과 2개 플랫폼에서의 성공적인 sim-to-real 전이로 효과를 입증했다.
CLONE: Closed-Loop Whole-Body Humanoid Teleoperation for Long-Horizon Tasks
CLONE은 MoE 기반 폐루프 제어 시스템으로 MR 헤드셋의 헤드와 손 추적만으로 휴머노이드 로봇의 전신 협응 동작을 정밀하게 원격 조종하고 장시간 작업에서 위치 드리프트를 최소화한다.
CLONE은 MoE 기반 폐루프 제어와 최소 입력 인터페이스를 결합하여 휴머노이드 텔레오퍼레이션의 근본적 제약을 해결한 선도적 연구로, 전신 협응과 장시간 정밀 제어를 동시에 달성한 최초의 실제 시스템 구현이다.
CLoSD: Closing the Loop between Simulation and Diffusion for multi-task character control
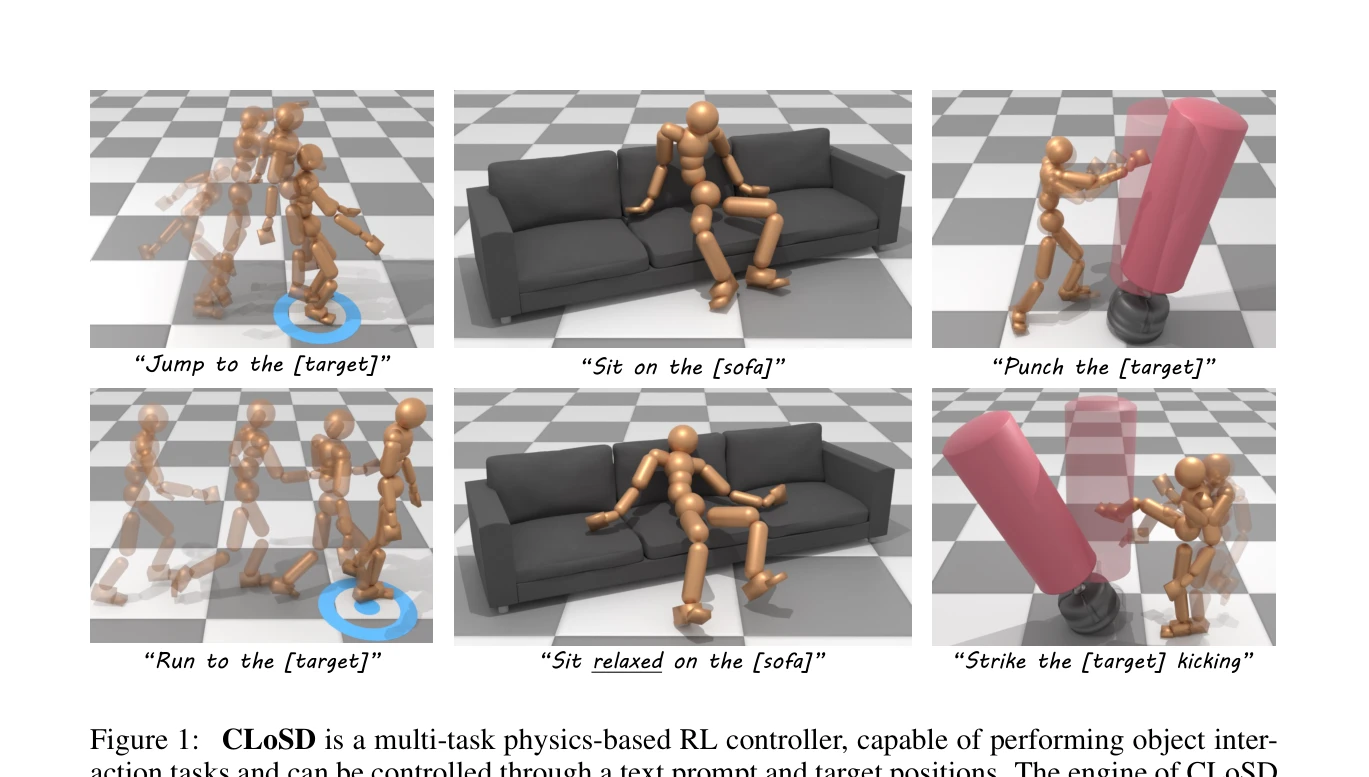
Figure 1: CLoSD is a multi-task physics-based RL controller, capable of performing object inter-
 *Figure 1: CLoSD is a multi-task physics-based RL controller, capable of performing object inter-* CLoSD는 motion diffusion 모델과 RL 기반 physics 시뮬레이션을 폐쇄 루프로 연결하여, 텍스트 프롬프트와 타겟 위치로 제어되는 다중 태스크 캐릭터 제어를 실현한다.
CLoSD는 diffusion 기반 계획과 RL 기반 추적을 폐쇄 루프로 통합하여 텍스트 제어와 물리적 그럴듯성을 동시에 달성하는 창의적인 접근법을 제시하며, 실시간 다중 태스크 캐릭터 제어의 새로운 가능성을 보여준다.
Commanding Humanoid by Free-form Language: A Large Language Action Model with Unified Motion Vocabulary

Figure 1. An illustration of Humanoid-LLA. Given a high-level
 *Figure 1. An illustration of Humanoid-LLA. Given a high-level* 자유형식 자연언어 명령을 인간형 로봇의 신체 전체 제어로 매핑하는 Large Language Action Model(Humanoid-LLA)을 제안하며, 통합 모션 어휘, 어휘-지향 컨트롤러 증류, 강화학습 기반 파인튜닝을 통해 언어 일반화와 물리적 타당성을 동시에 달성한다.
Humanoid-LLA는 통합 모션 어휘, 어휘-지향 증류, 강화학습 파인튜닝을 통합하여 자유형식 언어에서 물리적으로 실행 가능한 인간형 로봇 제어로의 매핑을 최초로 달성한 중요한 기여이며, 실세계 검증과 명확한 기술 혁신으로 인간-로봇 상호작용 분야의 중대한 진전을 나타낸다.
ECHO: Edge-Cloud Humanoid Orchestration for Language-to-Motion Control
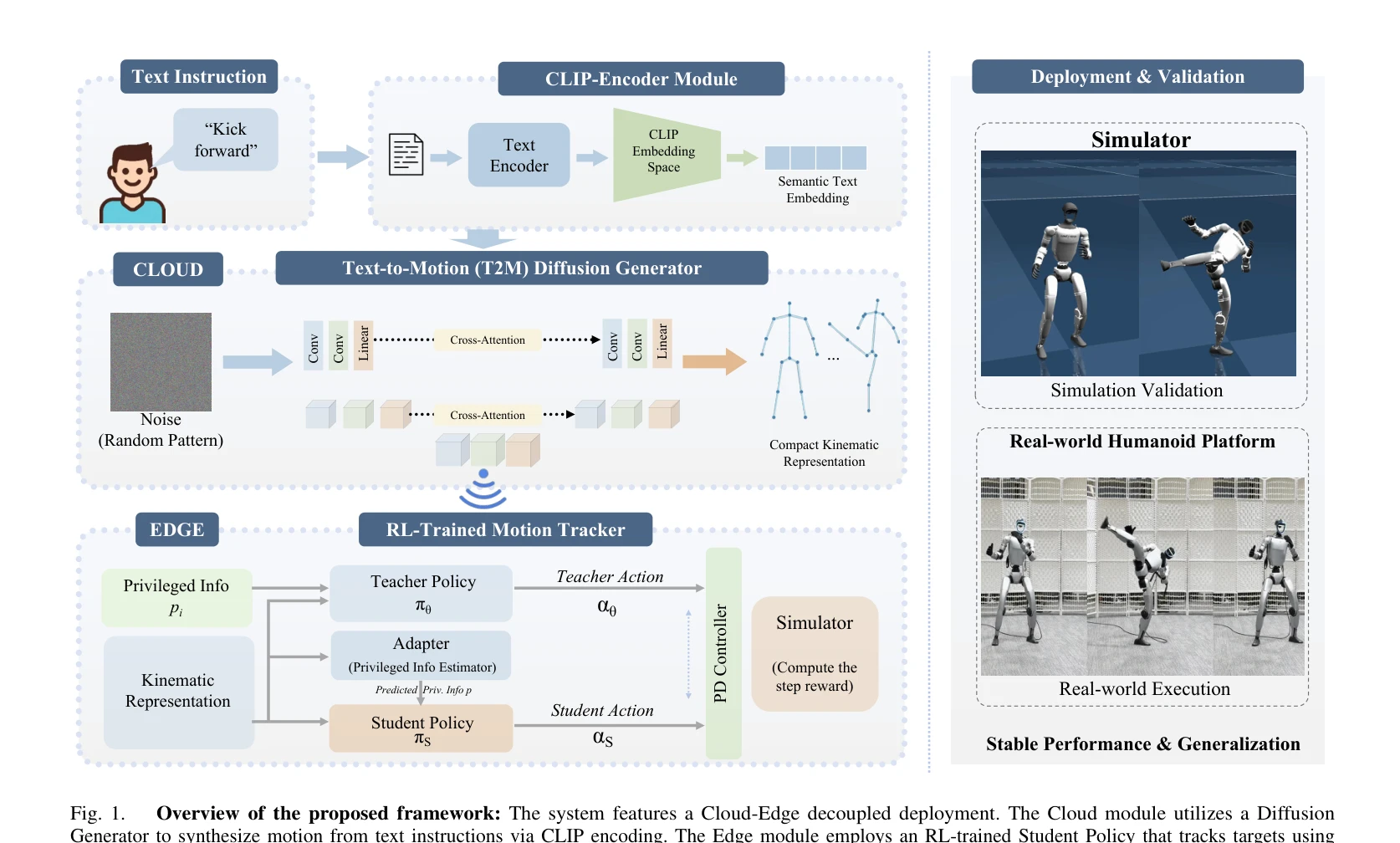
Fig. 1.
 *Fig. 1.* ECHO는 자연어 명령으로 휴머노이드 로봇을 제어하는 엣지-클라우드 프레임워크로, 클라우드의 diffusion 기반 text-to-motion 생성기와 엣지의 RL 트래커를 로봇 네이티브 38차원 표현으로 연결하여 실시간 폐루프 실행을 실현한다.
ECHO는 생성과 실행의 명확한 분리, robot-native 표현 설계, 실세계 배포 달성을 통해 언어-기반 휴머노이드 제어 분야에서 modularity와 deployability의 새로운 기준을 제시하는 의미 있는 연구이다.
Endowing GPT-4 with a Humanoid Body: Building the Bridge Between Off-the-Shelf VLMs and the Physical World
Figure 1: BiBo is a humanoid agent powered by an off-the-shelf VLM. It consists of an embodied
 *Figure 1: BiBo is a humanoid agent powered by an off-the-shelf VLM. It consists of an embodied* off-the-shelf VLM(GPT-4)을 humanoid agent의 제어에 활용하기 위해 embodied instruction compiler와 diffusion-based motion executor로 구성된 BiBo 프레임워크를 제안하고, 이를 통해 대규모 데이터 수집 없이 개방형 환경에서의 유연한 상호작용을 가능하게 함.
본 논문은 off-the-shelf VLM과 humanoid control을 연결하는 창의적인 프레임워크를 제시하고, structured representation과 LDM의 novel application을 통해 기술적 기여를 하였으며, 실제 데이터 수집의 병목을 해소하려는 실질적 의의가 있음. 다만 실제 물리 환경에서의 검증과 robustness 분석이 보강된다면 더욱 강력한 작업이 될 것으로 예상됨.
From Language to Locomotion: Retargeting-free Humanoid Control via Motion Latent Guidance
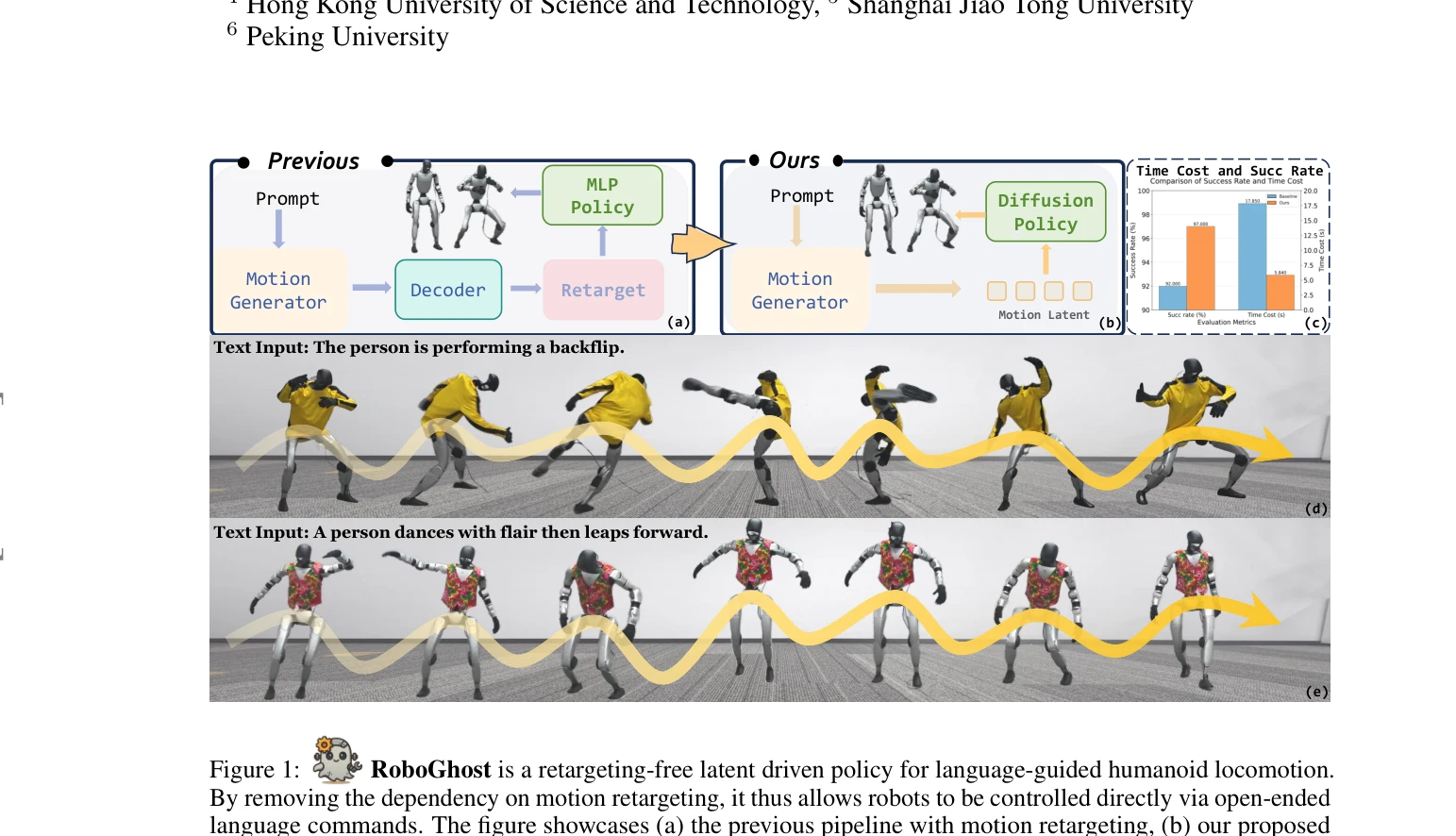
Figure 1:
 *Figure 2: Overview of RoboGhost. We propose a two-stage approach: a motion latent is first generated, then a* RoboGhost는 언어 지시를 humanoid 로봇의 실행 가능한 동작으로 직접 변환하는 retargeting-free 프레임워크로, motion latent을 조건으로 하는 diffusion-based policy를 통해 기존의 다단계 파이프라인의 누적 오류와 지연을 제거한다.
RoboGhost는 language-guided humanoid 제어의 근본적인 파이프라인 재설계를 통해 기존의 다단계 접근의 한계를 효과적으로 해결하며, 실제 로봇 배포에서 우수한 성능을 입증한 매우 영향력 있는 연구이다. 다만 해석성 강화와 복잡한 task로의 확장이 후속 과제로 남아있다.
From Motion to Behavior: Hierarchical Modeling of Humanoid Generative Behavior Control
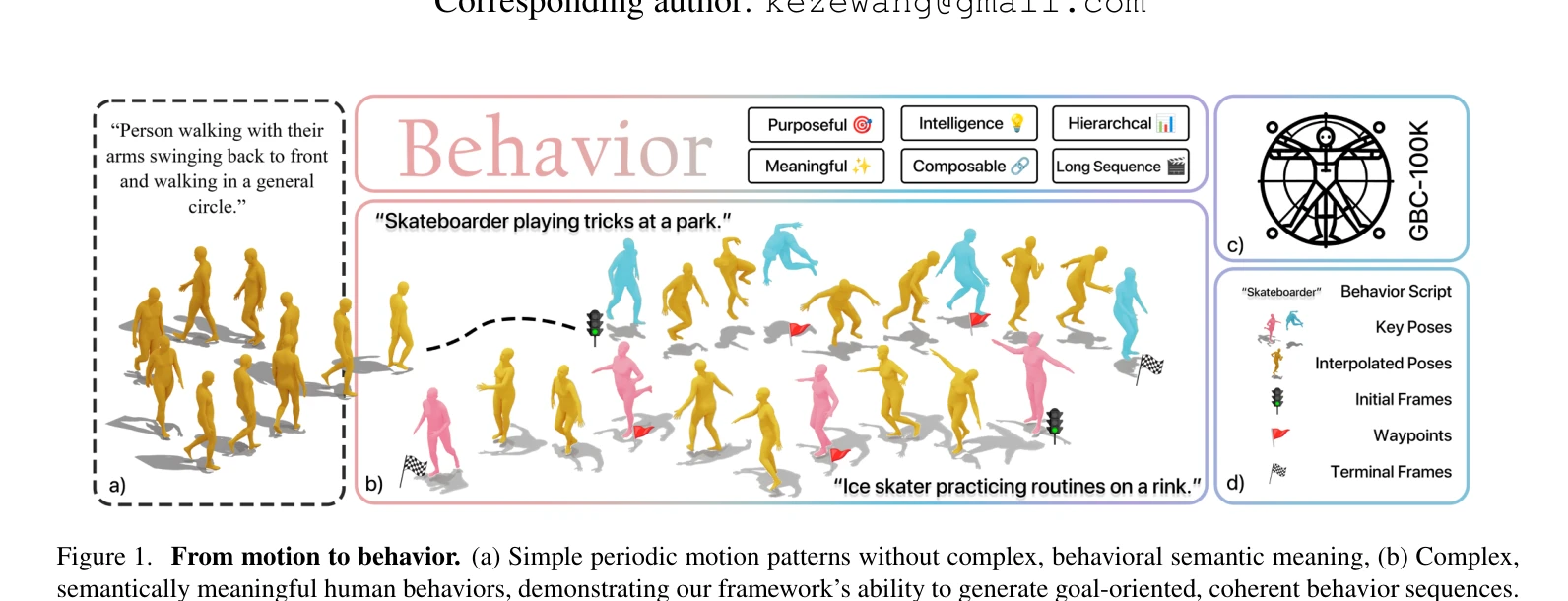
Figure 1. From motion to behavior. (a) Simple periodic motion patterns without complex, behavioral semantic meaning, (b)
 *Figure 1. From motion to behavior. (a) Simple periodic motion patterns without complex, behavioral semantic meaning, (b)* 인간의 고수준 의도를 반영하는 계층적 행동 계획과 LLM을 결합하여 장기간의 물리적으로 타당한 인간 행동을 생성하는 통합 프레임워크 PHYLOMAN을 제시하고, 이를 위해 다층 텍스트 주석이 포함된 GBC-100K 대규모 데이터셋을 구축했다.
본 논문은 인간 행동 생성에 LLM 기반 계획과 물리적 제어를 혁신적으로 통합하고 대규모 주석 데이터셋을 제공함으로써 장기간 의도 지향적 행동 생성의 새로운 기준을 제시한다. 기술적 우수성, 실무적 가치, 그리고 체계적인 실험 검증으로 인해 컴퓨터 비전 및 로봇공학 커뮤니티에 상당한 영향을 미칠 것으로 예상된다.
FRoM-W1: Towards General Humanoid Whole-Body Control with Language Instructions
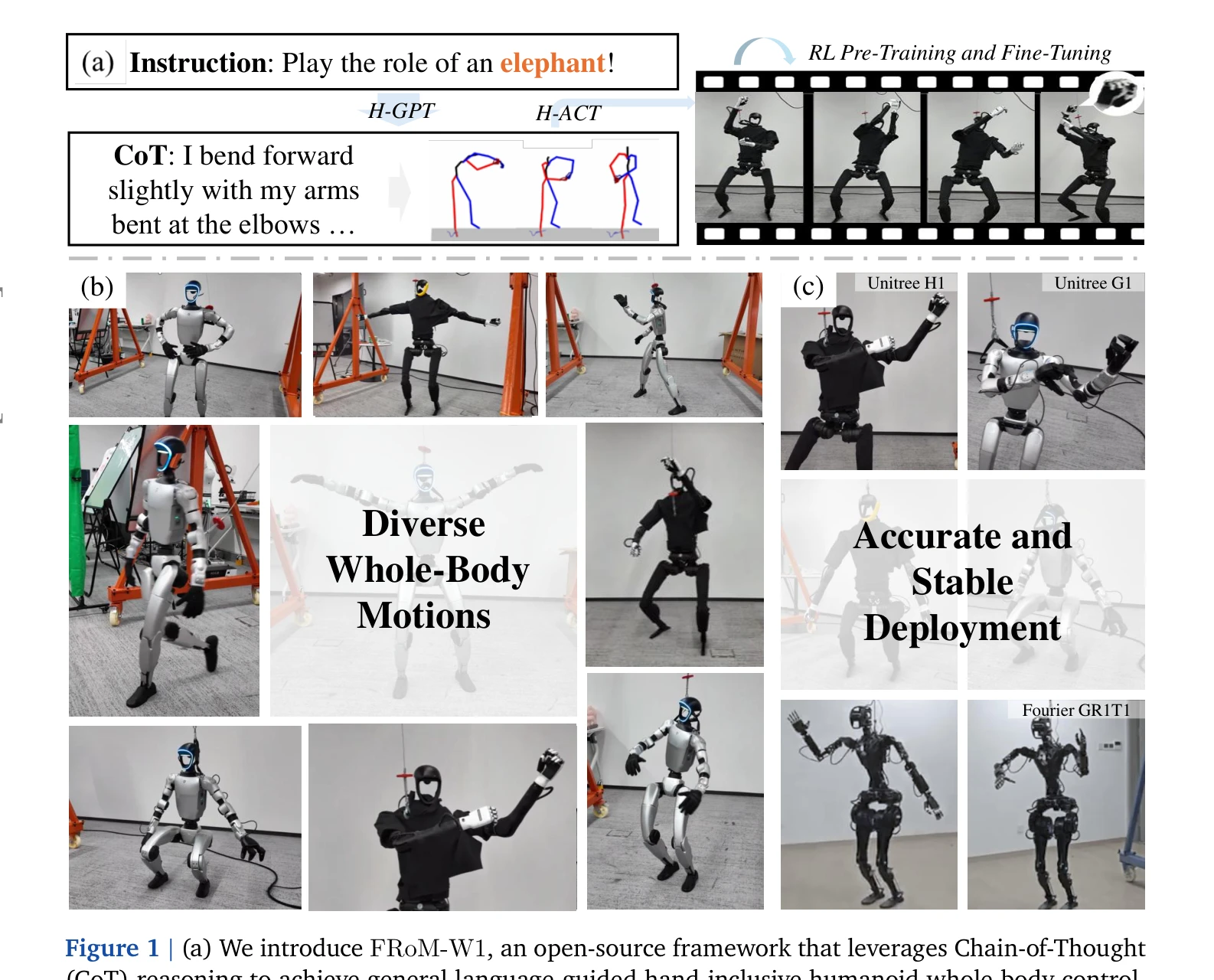
Figure 1 | (a) We introduce FRoM-W1, an open-source framework that leverages Chain-of-Thought
 *Figure 2 | The inference pipeline of FRoM-W1. (a) H-GPT first translates language instructions* FRoM-W1은 자연어 지시문으로부터 휴머노이드 로봇의 전신 움직임을 제어하는 오픈소스 프레임워크로, H-GPT 모델과 H-ACT 모듈의 2단계 구조로 언어 이해와 안정적인 로봇 실행을 동시에 달성한다.
FRoM-W1은 자연어 기반 휴머노이드 전신 제어라는 중요한 문제를 Chain-of-Thought와 2단계 RL 전략으로 창의적으로 해결하며, 완전 오픈소스 제공과 실제 로봇 실증을 통해 높은 실용성과 재현성을 보여준다.
Heracles: Bridging Precise Tracking and Generative Synthesis for General Humanoid Control

Figure 1: Heracles synthesizes diverse, anthropomorphic recovery motions via state-conditioned diffusion. In
 *Figure 1: Heracles synthesizes diverse, anthropomorphic recovery motions via state-conditioned diffusion. In* Heracles는 state-conditioned diffusion 미들웨어를 통해 정밀한 모션 추적과 생성적 적응을 통합하여 휴머노이드 로봇이 극단적인 외부 교란 상황에서도 자연스러운 복구 동작을 수행하도록 한다.
Heracles는 state-conditioned diffusion을 활용한 혁신적인 제어 미들웨어를 제시하여 휴머노이드 로봇의 정밀 추적과 생성적 적응성의 오래된 딜레마를 우아하게 해결하며, 물리적 로봇 실험을 통한 강건한 성능 검증으로 실질적 가치를 입증한다.
High-Speed and Impact Resilient Teleoperation of Humanoid Robots
Fig. 1.
 *Fig. 1.* 본 논문은 7개의 IMU 기반 캘리브레이션 무료 모션 캡처, low-latency kinematics streaming toolbox, 고대역폭 cycloidal actuator를 통합하여 휴머노이드 로봇의 고속 및 충격 강건 텔레오퍼레이션을 실현한다.
본 논문은 최소 센서 기반 모션 캡처, low-latency streaming, cycloidal actuator를 통합하여 휴머노이드 로봇의 고속 충격 강건 텔레오퍼레이션을 처음으로 실제 구현 및 검증했으며, 간단하면서도 효과적인 설계로 실용적 가치가 높다. 다만 플랫폼 특화성과 환경 다양성 평가 부재가 한계이다.
LangWBC: Language-directed Humanoid Whole-Body Control via End-to-end Learning

Fig. 1:
 *Fig. 2.* 자연언어 명령을 humanoid robot의 전신 제어 동작으로 직접 변환하는 end-to-end 학습 프레임워크를 제시한다. Reinforcement learning으로 학습한 teacher policy와 CVAE 기반 student policy를 결합하여 언어-행동의 통합 latent space를 구성한다.
본 논문은 humanoid 전신 제어의 오랜 난제인 언어-행동 갭을 end-to-end learning으로 직접 해결하며, CVAE 기반의 unified latent space 구성으로 동작 다양성과 부드러운 전환을 동시에 달성한 점이 우수하다. 실제 로봇 검증과 강건성 입증을 통해 현실 적용 가능성을 보였으나, 데이터셋 의존성과 다양한 플랫폼 일반화에 대한 추가 검증이 필요하다.
Learning Humanoid End-Effector Control for Open-Vocabulary Visual Loco-Manipulation

Fig. 1: We build capability for a humanoid to autonomously loco-manipulate novel objects in novel scenes using onboard
 *Fig. 2: Overall architecture for our proposed modular system for open-vocabulary object grasping. Given a free-form* HERO 시스템은 정확한 end-effector 추적 정책과 대규모 비전 모델을 결합하여 휴머노이드 로봇이 미지의 환경에서 임의의 일상용품을 자율적으로 집을 수 있게 한다. End-effector 추적 오차를 3.2배 감소시키고 83.8%의 성공률을 달성했다.
본 논문은 정확한 end-effector 제어의 기술적 난제를 classical robotics와 학습 기반 모듈의 창의적 결합으로 해결하고, 이를 통해 humanoid의 실제 환경 object manipulation을 처음으로 현실화했다. 모듈식 설계로 대규모 실제 데이터 수집 없이도 open-vocabulary 일반화를 달성한 점이 특히 의미 있으며, 83.8%의 실제 환경 성공률은 해당 분야의 significant advance를 나타낸다.
OmniClone: Engineering a Robust, All-Rounder Whole-Body Humanoid Teleoperation System
Fig. 1: OmniClone achieves well-balanced, high-fidelity whole-body tracking across all MPJPE dimensions on OmniBench whi
 *Fig. 1: OmniClone achieves well-balanced, high-fidelity whole-body tracking across all MPJPE dimensions on OmniBench whi* OmniClone은 단일 소비자 GPU에서 전신 휴머노이드 텔레오퍼레이션을 실현하는 시스템으로, OmniBench 진단 벤치마크를 통해 기존 시스템의 동작별 성능 격차를 노출하고 이를 바탕으로 최적화된 정책과 시스템 기술을 통합하여 MPJPE를 66% 이상 감소시켰다.
OmniClone은 진단적 벤치마킹과 시스템 공학을 결합하여 실용적이면서도 강력한 휴머노이드 텔레오퍼레이션 시스템을 제시한다. OmniBench는 기존 평가 방식의 근본적 한계를 지적하고 이를 기반으로 한 체계적 개선이 뒤따르는 점, 그리고 소비자 GPU로 SOTA 성능을 달성하면서도 높은 접근성을 제공하는 점에서 학술적, 실용적 가치가 모두 높다.
OmniXtreme: Breaking the Generality Barrier in High-Dynamic Humanoid Control
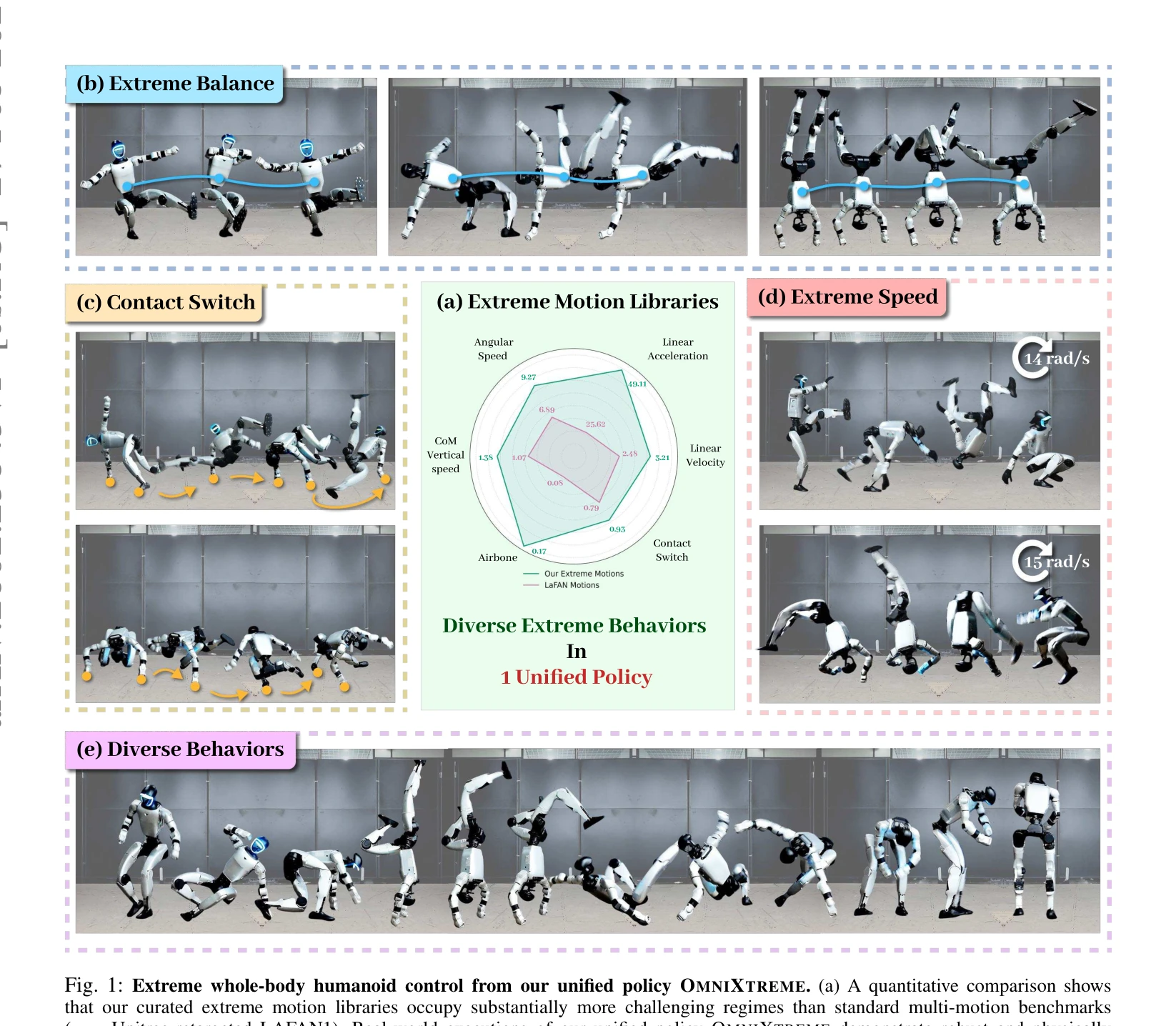
Fig. 1: Extreme whole-body humanoid control from our unified policy OMNIXTREME. (a) A quantitative comparison shows
 *Fig. 1: Extreme whole-body humanoid control from our unified policy OMNIXTREME. (a) A quantitative comparison shows* OmniXtreme는 flow-matching 기반의 생성형 정책과 actuation-aware residual RL을 결합하여 고동역 인간형 로봇의 다양한 극단적 동작을 고충실도로 추적할 수 있는 확장 가능한 프레임워크를 제시한다.
OmniXtreme은 humanoid 동작 제어의 long-standing fidelity-scalability trade-off를 해결하기 위해 생성형 모델과 actuation-aware 정제라는 두 가지 보완적 기법을 창의적으로 결합한 강력한 프레임워크이며, 실제 로봇에서 극단적 동작의 성공적 실행으로 그 유효성을 입증했다.
TWIST: Teleoperated Whole-Body Imitation System
Figure 1: The Teleoperated Whole-Body Imitation System (TWIST) is a system that teleoperates humanoid
 *Figure 1: The Teleoperated Whole-Body Imitation System (TWIST) is a system that teleoperates humanoid* TWIST는 모션 캡처 데이터의 실시간 리타겟팅과 RL+BC 기반의 통합 신경망 컨트롤러를 통해 휴머노이드 로봇의 전신 협응 제어를 실현하는 원격 조종 시스템이다.
TWIST는 전신 협응 휴머노이드 원격 조종의 오래된 과제를 teacher-student 프레임워크와 데이터 혼합 전략으로 우아하게 해결하며, 단일 신경망으로 다양한 협응 기술을 실현한 의미 있는 기여이다.
PaCo-VLA: Passivity-Shielded Compliance Prior for Contact-Rich Vision-Language-Action Manipulation
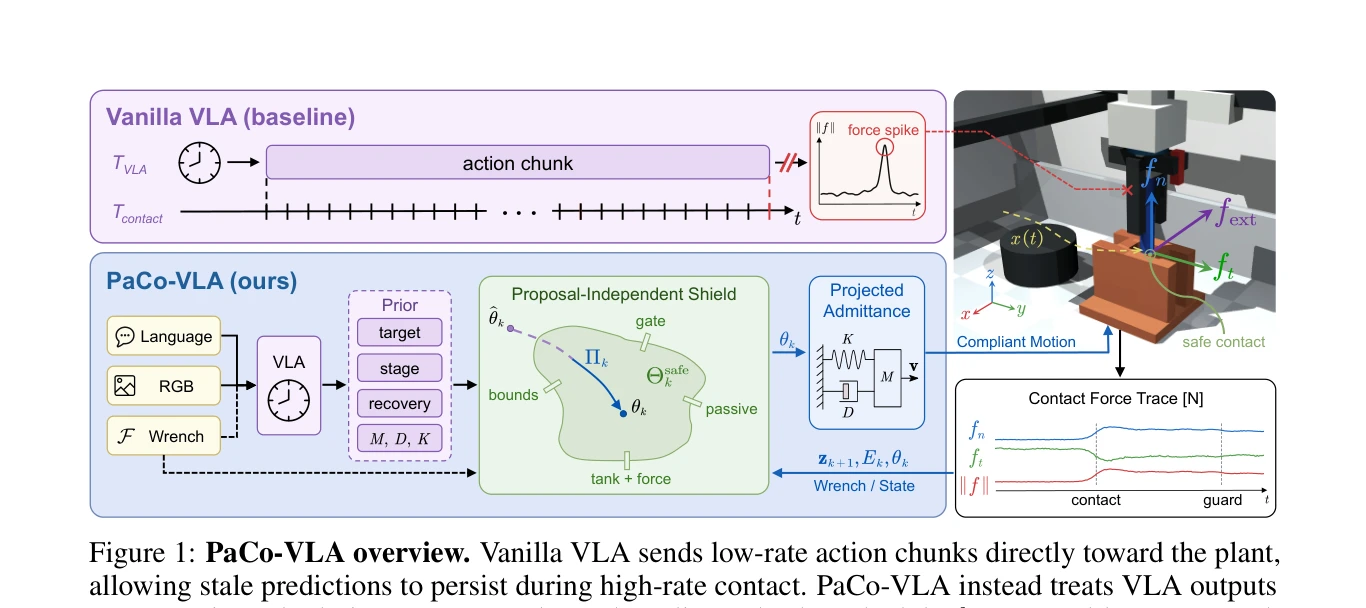
Figure 1: PaCo-VLA overview. Vanilla VLA sends low-rate action chunks directly toward the plant,
 *Figure 2: Runtime shield mechanisms. (a) Box projection maps unfiltered proposals into Θbox;* 본 논문은 Vision-Language-Action (VLA) 모델을 contact-rich manipulation 작업에 안전하게 적용하기 위해 PaCo-VLA라는 passivity-shielded compliance prior를 제안한다. VLA의 저주기 출력을 직접 모터 명령으로 사용하지 않고, 대신 high-frequency proposal-independent passivity shield를 통해 semantic proposal을 filtering하여 contact dynamics의 안전성을 보장한다.
본 논문은 VLA의 semantic generalization과 contact-rich manipulation의 safety requirement를 reconcile하는 실질적이고 principled된 framework를 제시한다. Passivity-shielded interface와 paired counterfactual evaluation protocol은 methodologically 견고하며, zero passivity violation과 superior precision의 실험 결과는 접근법의 실효성을 입증한다. 다만 task diversity 제한과 보다 일반적인 compliance model에 대한 확장성 논의가 있으면 더욱 강화될 것이다.
Whole-Body Inverse Kinematics with Graph Diffusion
Fig. 1.
 *Fig. 1.* 이 논문은 역기구학(inverse kinematics) 문제를 구조-인식형 그래프 확산 프레임워크인 GraphDiff-IK로 해결한다. 로봇의 URDF로부터 구성한 kinematic graph를 기반으로 조건부 그래프 diffusion process를 통해 직접 joint configuration을 생성하며, 단일 팔 로봇부터 dual-arm, 토소를 가진 전신 로봇까지 통일된 방식으로 지원한다.
GraphDiff-IK는 구조-인식형 graph diffusion을 IK에 적용하여 다양한 로봇 형태의 통일된 처리, 다중 해 생성, 높은 정확도를 동시에 달성한 혁신적 접근법이다. 실제 로봇 플랫폼에서의 광범위한 검증과 우수한 성능으로, 현대 고도-자유도 로봇 제어에 실질적 기여가 기대된다.
Real-Time Polygonal Semantic Mapping for Humanoid Robot Stair Climbing
Fig. 1: Planar polygon semantic mapping results of spiral
 *Fig. 2: Overview of the Planar Polygonal Semantic Mapping System Framework. The system inputs are depth images and* 인형로봇의 계단 등반을 위해 GPU 가속 anisotropic diffusion 필터링과 RANSAC 기반 평면 추출을 활용한 실시간 다각형 의미 맵핑 알고리즘을 제시한다.
본 논문은 GPU 가속을 활용한 anisotropic diffusion 필터링과 RANSAC 기반 다각형 추출을 결합하여 인형로봇의 복잡한 지형 네비게이션을 위한 실시간 의미 맵핑 문제를 효과적으로 해결했다. 시뮬레이션과 실제 센서 데이터 간의 성능 격차를 줄이고 로봇의 안전한 보행 계획을 지원하는 실용적인 시스템으로서의 가치가 크다.
RoboMirror: Understand Before You Imitate for Video to Humanoid Locomotion

Figure 1. RoboMirror makes humanoid understand before imitating. It acts like a mirror, which can not only infer and rep
 *Figure 1. RoboMirror makes humanoid understand before imitating. It acts like a mirror, which can not only infer and rep* RoboMirror는 VLM을 활용하여 비디오에서 visual motion intent를 추출하고 diffusion-based policy로 직접 인간형 로봇의 보행을 제어하는 retargeting-free 프레임워크이다. 기존의 pose estimation-retargeting 파이프라인을 우회하고 egocentric/third-person 비디오로부터 시맨틱하게 정렬된 보행을 생성한다.
RoboMirror는 인간형 로봇 제어에 시각적 이해라는 자연스러운 패러다임을 도입하고, retargeting-free 아키텍처로 지연시간을 획기적으로 단축하면서 성능을 향상시킨 의미 있는 기여이다. 다만 sim-to-real 검증 부재와 VLM 의존성 문제는 실용화를 위해 추가 연구가 필요함을 시사한다.
VIGOR: Visual Goal-In-Context Inference for Unified Humanoid Fall Safety
Fig. 1. Vision-enabled unified fall safety for humanoids. A single learned policy integrates fall mitigation and stand-u
 *Fig. 1. Vision-enabled unified fall safety for humanoids. A single learned policy integrates fall mitigation and stand-u* 휴머노이드 로봇의 넘어짐 안전성을 위해 teacher-student 증류 방식으로 egocentric depth와 proprioception만 사용하여 시각적 goal-in-context 표현을 학습하는 통합 접근법을 제시한다.
휴머노이드의 통합적 fall safety를 시각 기반으로 해결하는 창의적 접근으로, factorized data generation과 goal-in-context representation의 개념이 우수하며 zero-shot transfer 결과가 인상적이다. 다만 실제 환경 적용성을 더 광범위하게 검증할 필요가 있다.
ClimbingCap: Multi-Modal Dataset and Method for Rock Climbing in World Coordinate
Figure 1. Overview. To address the challenging problem of global climbing motion recovery, we collect the dataset Ascend
 *Figure 1. Overview. To address the challenging problem of global climbing motion recovery, we collect the dataset Ascend* ClimbingCap은 RGB와 LiDAR 멀티모달 데이터를 활용하여 암벽 등반 동작을 글로벌 좌표계에서 정확하게 복원하는 방법을 제안하며, 대규모 도전적 등반 동작 데이터셋 AscendMotion을 구축했다.
ClimbingCap은 미개발 분야인 등반 동작 캡처에 대해 대규모 고품질 데이터셋과 멀티모달 별도 좌표 복원 방식의 창의적 방법론을 제시하여 높은 독창성과 실질적 기여도를 보여준다. 광범위한 실험 검증과 공개 예정인 데이터셋·코드는 커뮤니티 기여도 높으나, 환경 일반화와 단일 모달 방식의 개발이 후속 과제다.
CRISP: Contact-Guided Real2Sim from Monocular Video with Planar Scene Primitives
 *Figure 2: CRISP pipeline. Given a casual RGB video (left), CRISP reconstructs scene geometry* 단안 비디오에서 planar primitive 기반 scene geometry 복원과 human motion 추정을 통해 물리 시뮬레이션 가능한 human-scene reconstruction을 수행하는 real-to-sim 파이프라인을 제안한다.
CRISP는 planar primitive 기반의 간단하면서도 효과적인 real-to-sim 파이프라인으로, 기존 human-scene reconstruction의 근본적 문제(simulation incompatibility)를 physics 기반 검증으로 해결하며, substantial empirical improvement와 in-the-wild generalization을 통해 embodied AI 분야에 실질적 기여를 한다.
Efficient and Scalable Monocular Human-Object Interaction Motion Reconstruction
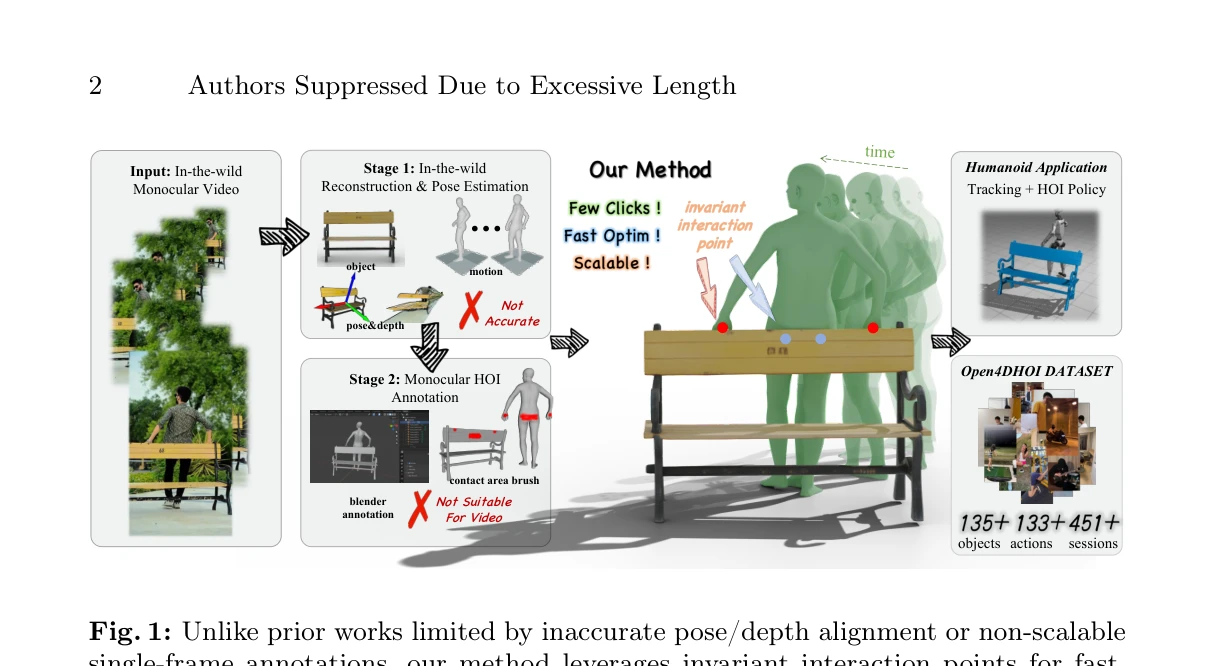
Fig. 1: Unlike prior works limited by inaccurate pose/depth alignment or non-scalable
 *Fig. 1: Unlike prior works limited by inaccurate pose/depth alignment or non-scalable* 단안 비디오에서 4D 인간-물체 상호작용(HOI) 데이터를 효율적으로 추출하기 위해 sparse contact annotation paradigm과 human-in-the-loop 데이터 엔진을 제안하고, 4DHOISolver 최적화 프레임워크를 통해 시공간적으로 일관성 있는 재구성을 수행한다.
이 논문은 단안 비디오에서 4D HOI 데이터 수집의 annotation 병목을 sparse contact point와 human-in-the-loop 엔진으로 혁신적으로 해결하고, 4DHOISolver를 통해 시공간적 일관성을 유지하면서 대규모 고품질 데이터셋 Open4DHOI를 구축했다. 로봇 학습의 데이터 병목을 실질적으로 해결하는 높은 실용성과 완성도로 컴퓨터 비전 및 로봇 학습 분야에 중대한 기여를 한다.
EmbodMocap: In-the-Wild 4D Human-Scene Reconstruction for Embodied Agents
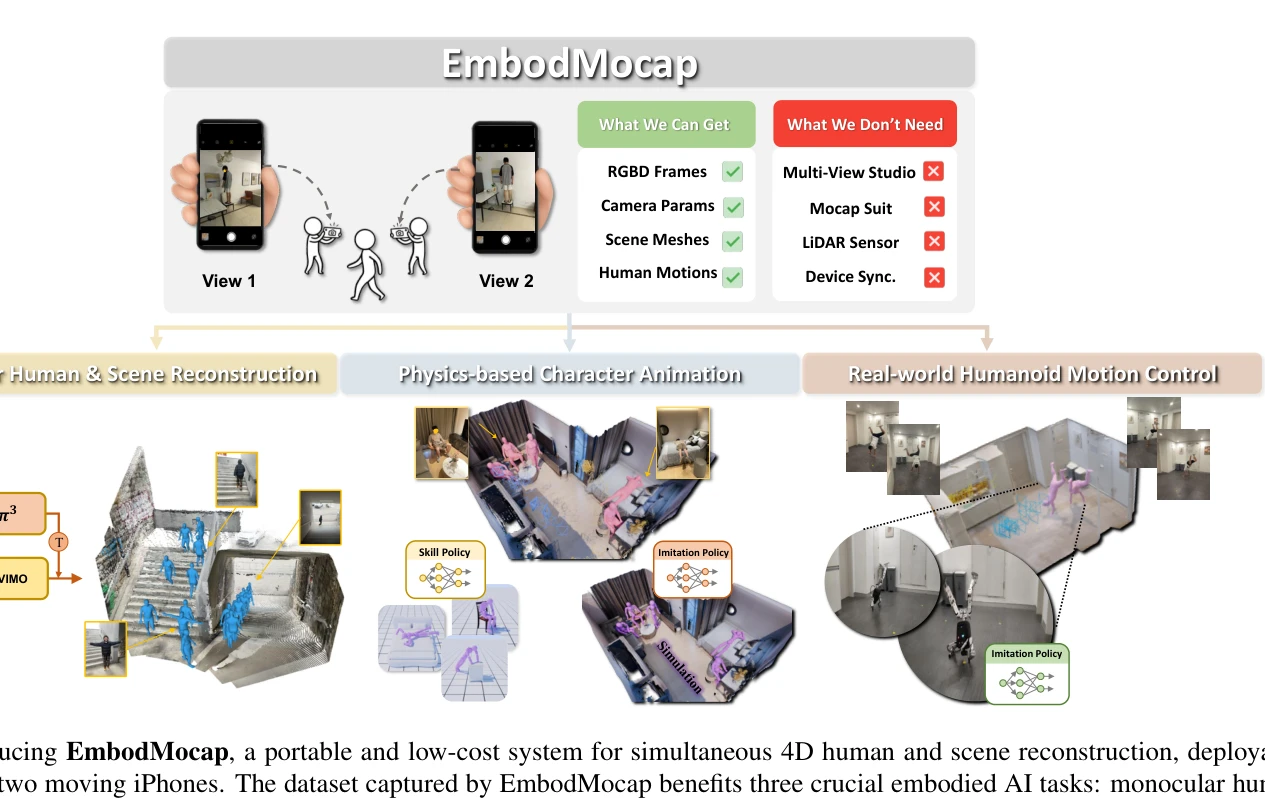
Figure 1. Introducing EmbodMocap, a portable and low-cost system for simultaneous 4D human and scene reconstruction, dep
 *Figure 1. Introducing EmbodMocap, a portable and low-cost system for simultaneous 4D human and scene reconstruction, dep* EmbodMocap은 두 개의 이동하는 iPhone을 사용하여 실외 환경에서 메트릭 스케일의 인간 동작과 3D 장면을 동시에 재구성하는 저비용 데이터 수집 파이프라인을 제안한다. 이 시스템은 모노큘러 재구성, 물리 기반 캐릭터 애니메이션, 로봇 제어 등 세 가지 embodied AI 작업을 지원한다.
EmbodMocap은 embodied AI 연구의 실질적 장애물인 고비용 데이터 수집을 혁신적으로 해결하는 실용적이고 확장 가능한 시스템을 제시한다. Dual-view RGB-D의 joint optimization이라는 기술적 통찰력과 함께 monocular reconstruction, physics-based animation, robot control까지 포괄적으로 검증한 점에서 높은 가치를 지닌다.
FRAME: Floor-aligned Representation for Avatar Motion from Egocentric Video
Figure 1. We introduce a large scale egocentric dataset (b) collected with a custom-made wearable capture rig (a). With
 *Figure 1. We introduce a large scale egocentric dataset (b) collected with a custom-made wearable capture rig (a). With * VR/AR 환경에서 일인칭 시점의 스테레오 카메라와 헤드 트래킹을 활용하여 신체 자세를 추정하는 FRAME 아키텍처를 제안하며, 대규모 실제 데이터셋을 수집하여 합성 데이터 사전학습의 필요성을 제거했다.
일인칭 모션 캡처의 핵심 문제들(합성 데이터 의존성, 하지 정확도, 아티팩트)을 대규모 실제 데이터셋과 기하학적으로 명시적인 아키텍처로 체계적으로 해결하며, 실시간 성능과 높은 일반화 능력을 동시에 달성한 실용성 높은 연구다.
Hiking in the Wild: A Scalable Perceptive Parkour Framework for Humanoids
Fig. 1: Hiking in the Wild. Our framework enables a humanoid robot to traverse diverse terrains in both indoor and outdo
 *Fig. 2: System overview. Our framework trains an end-to-end policy using simulated depth and proprioception. To ensure* 이 논문은 깊이 카메라와 proprioception을 직접 joint actions으로 변환하는 end-to-end RL 프레임워크를 제시하여, 외부 상태 추정 없이 humanoid 로봇이 복잡한 비정형 지형에서 최대 2.5 m/s의 속도로 안전하게 이동할 수 있게 한다.
이 논문은 humanoid 로봇의 야외 주행을 위한 실용적이고 확장 가능한 end-to-end RL 프레임워크를 제시하며, Terrain Edge Detection, Foot Volume Points, Flat Patch Sampling 등 novel 메커니즘으로 safety와 reward hacking 문제를 효과적으로 해결한다. Open-source 배포와 실제 로봇 검증을 통해 높은 재현성과 실용성을 입증한 우수한 연구이다.
HumanoidPano: Hybrid Spherical Panoramic-LiDAR Cross-Modal Perception for Humanoid Robots
Figure 1. The humanoid robot autonomously navigates complex environments using HumanoidPano, which fuses panoramic visio
 *Figure 1. The humanoid robot autonomously navigates complex environments using HumanoidPano, which fuses panoramic visio* 인간형 로봇의 자아-폐색 및 제한된 시야 문제를 해결하기 위해 파노라마 비전과 LiDAR를 융합하는 HumanoidPano 프레임워크를 제안하며, Spherical Geometry-aware Constraints와 Spatial Deformable Attention을 통해 기하학적으로 정렬된 크로스모달 인식을 구현한다.
HumanoidPano는 인간형 로봇의 고유한 구조적 제약을 심층적으로 고려하여 panoramic vision과 LiDAR를 기하학적으로 정렬하는 혁신적인 프레임워크로, 실제 로봇 플랫폼에서의 검증과 state-of-the-art 성능으로 embodied AI 분야에 새로운 패러다임을 제시한다.
HUMOTO: A 4D Dataset of Mocap Human Object Interactions
Figure 1. Overview of the HUMOTO dataset. The dataset contains mocap 4D human-object interaction animations with multipl
 *Figure 1. Overview of the HUMOTO dataset. The dataset contains mocap 4D human-object interaction animations with multipl* HUMOTO는 735개 시퀀스(7,875초)의 고충실도 모션캡처 4D 인간-객체 상호작용 데이터셋으로, 63개의 정밀 모델링 객체와 상세한 손 동작을 포함하며 LLM 기반 스크립팅과 다중센서 캡처로 복잡한 다중-객체 상호작용을 정확히 기록한다.
HUMOTO는 고충실도 다중-객체 인간-객체 상호작용 데이터셋으로서, Scene-Driven LLM Scripting과 다중센서 캡처 기술의 창의적 결합을 통해 기존 데이터셋의 한계를 효과적으로 해결하였으며, 정량적 평가 메트릭 도입으로 HOI 데이터셋 분야에 기여한 가치 있는 자산이다.
LookOut: Real-World Humanoid Egocentric Navigation

Figure 1. Problem formulation. Given a posed egocentric video (black-outlined frustums, with frames shown in detail on t
 *Figure 1. Problem formulation. Given a posed egocentric video (black-outlined frustums, with frames shown in detail on t* Project Aria 안경을 이용한 데이터 수집 파이프라인과 함께, 동적 장애물이 있는 실제 환경에서 egocentric 비디오로부터 미래의 6D 헤드 포즈(위치 및 회전)를 예측하는 LookOut 모델을 제안한다.
인간형 egocentric 네비게이션의 동적 환경 처리, 능동적 정보 수집 모델링, 그리고 실용적 데이터 수집 파이프라인을 종합적으로 해결한 포괄적 기여로, Project Aria를 활용한 혁신적 데이터 수집 방식과 현실성 높은 4시간 AND 데이터셋이 향후 연구에 큰 영향을 미칠 것으로 기대된다.
MeshMimic: Geometry-Aware Humanoid Motion Learning through 3D Scene Reconstruction
Figure 1: MeshMimic: monocular video-to-humanoid robots. From ordinary consumer monocular videos (no
 *Figure 1: MeshMimic: monocular video-to-humanoid robots. From ordinary consumer monocular videos (no* MeshMimic은 단일 모노큘러 비디오에서 3D 장면 재구성을 통해 휴머노이드 로봇이 복잡한 지형과의 상호작용을 학습할 수 있는 프레임워크이다. Kinematic Consistency Optimization과 contact-aware retargeting을 통해 모션-지형 결합 상호작용을 정확하게 전달한다.
MeshMimic은 3D 비전과 구체화된 지능을 창의적으로 결합하여 비용 효율적이고 확장 가능한 휴머노이드 로봇 훈련 방식을 제시한다. 물리적 일관성 최적화와 접촉 인식 retargeting을 통해 복잡한 지형에서의 안정적인 상호작용을 실현함으로써 로봇 제어 분야에 상당한 기여를 한다.
PHUMA: Physically-Grounded Humanoid Locomotion Dataset
Figure 1: Physical reliability of Humanoid-X vs. PHUMA. Each column illustrates four failure
 *Figure 1: Physical reliability of Humanoid-X vs. PHUMA. Each column illustrates four failure* PHUMA는 대규모 인터넷 비디오로부터 인간다운 보행을 위한 물리적으로 타당한 휴머노이드 모션 데이터셋을 구축하며, 데이터 큐레이션과 physics-constrained retargeting을 통해 floating, penetration, foot skating 등의 물리적 artifacts를 제거한다.
PHUMA는 대규모 비디오 기반 모션 데이터의 물리적 신뢰성 문제를 체계적으로 해결하는 실용적인 데이터셋이며, physics-constrained retargeting 방법론과 실증적 성능 향상을 통해 휴머노이드 보행 학습 분야에 명확한 기여를 제시한다.
Simulating Infant First-Person Sensorimotor Experience via Motion Retargeting from Babies to Humanoids
 *Fig. 2.* 본 논문은 영아의 단일 비디오로부터 3D 신체 자세를 추정하고 이를 iCub, pyCub, EMFANT, MIMo 등의 휴머노이드 로봇에 매핑하여 고유수용감각, 촉각, 시각 등 다중감각 스트림을 시뮬레이션하는 motion retargeting 프레임워크를 제시한다.
본 논문은 영아 발달 연구와 로보틱스의 교점에서 motion retargeting에 다중감각 시뮬레이션을 결합한 창의적이고 기술적으로 건전한 작업이다. Sub-centimeter 정확도와 실제 및 가상 휴머노이드 플랫폼에서의 입증은 강점이나, 단일 영상 검증과 영아 모델 부재로 인한 일반화 가능성 제약이 한계이다. 코드 공개 및 명확한 방법론 제시는 높이 평가되며, 발달과학과 신경발달 진단 응용의 미래 잠재력이 있다.
A Hybrid Autoencoder for Robust Heightmap Generation from Fused Lidar and Depth Data for Humanoid Robot Locomotion
 *Figure 3. The structure is designed to bridge this gap by ex-* 이 논문은 humanoid robot의 unstructured environment 이동을 위해 LiDAR과 depth camera 데이터를 fuse하여 heightmap을 생성하는 hybrid encoder-decoder 아키텍처를 제안한다. CNN 기반 spatial feature extraction과 GRU 기반 temporal consistency를 결합한 접근으로, multimodal fusion이 단일 센서 대비 7.2~9.9% 재구성 정확도 개선을 달성한다.
이 논문은 multimodal sensor fusion과 temporal modeling을 통해 humanoid robot의 heightmap 재구성 정확도를 체계적으로 개선하며, spherical projection 기반 LiDAR 처리와 heightmap 그리드 해상도 최적화 등의 실질적 contribution을 제공한다. 다만 실제 robot platform에서의 locomotion 성능 향상을 정량적으로 입증하고, 다양한 환경 및 센서 조합에 대한 robust성을 검증해야 impact가 높아질 수 있다.
Residual Off-Policy RL for Finetuning Behavior Cloning Policies
 *Fig. 2. Off-policy residual fine-tuning (ResFiT): A two-phase approach using online RL to improve BC policies. First, we* Behavior Cloning(BC) 정책을 기반으로 Residual Off-Policy RL을 적용하여 샘플 효율적으로 조작 정책을 개선하며, 고자유도 이족 로봇에서의 첫 실시간 RL 학습을 달성했다.
BC와 off-policy RL을 residual learning으로 효과적으로 결합하여, 고자유도 실시간 로봇 학습의 실용적 경로를 제시했다. 블랙박스 방식의 일반성과 첫 휴머노이드 RL 실증이 로봇 학습 분야에 의미 있는 기여를 이룬다.
UniTracker: Learning Universal Whole-Body Motion Tracker for Humanoid Robots

Fig. 1: We deploy our UniTracker on a real humanoid robot,
 *Fig. 2: An overview of UniTracker: In Stage 1, we train a teacher policy using oracle states via goal-conditioned* UniTracker는 CVAE 기반 세 단계 학습 프레임워크를 통해 부분 관측 조건에서도 다양하고 일관성 있는 전신 동작 추적을 실현하는 휴머노이드 로봇 제어 정책이다.
UniTracker는 CVAE 기반 증류와 전역 맥락 정렬을 통해 기존 teacher-student 프레임워크의 핵심 한계를 우아하게 해결하며, 실제 로봇에서 8,000개 이상의 동작 추적을 성공시킨 강력한 기여이다. 방법론의 창의성, 실제 배포 검증, 그리고 실용적 영향 면에서 높은 평가를 받을 만한 논문이다.
WHOLE: World-Grounded Hand-Object Lifted from Egocentric Videos

Figure 1. Given a metric-SLAMed egocentric video of a person interacting with the scene and the corresponding object tem
 *Figure 2. Reconstruction Using the Generative Motion Prior. Given a metric-SLAMed egocentric videos, and the object temp* WHOLE는 손잡이와 물체의 상호작용을 joint generative motion prior를 통해 이용하여 egocentric 비디오에서 world space로의 hand-object 궤적을 holistically 재구성한다.
WHOLE는 hand-object interaction을 joint generative prior로 모델링하여 egocentric video에서 globally consistent world-space trajectories를 복원하는 혁신적 접근으로, 기존 isolated method들의 inconsistency 문제를 근본적으로 해결하며 practical application에 중요한 기여를 한다.
EGM: Efficiently Learning General Motion Tracking Policy for High Dynamic Humanoid Whole-Body Control

Figure 1: We deploy a unified student policy trained with EGM in the simulation environment, achieving high robust
 *Figure 2: Overview of the EGM framework. First, large-scale Mocap datasets are retargeted to Humanoid, then a small* EGM은 Bin-based Cross-motion Curriculum Adaptive Sampling과 Composite Decoupled Mixture-of-Experts 아키텍처를 통해 4.08시간의 소량 데이터로 49.25시간의 다양한 모션을 효율적으로 추적하는 일반화된 휴머노이드 제어 정책을 학습한다.
EGM은 Bin-based adaptive sampling과 CDMoE 아키텍처의 새로운 조합으로 humanoid motion tracking의 데이터 효율성과 dynamic motion 성능을 획기적으로 개선하며, 소량 데이터 학습의 실용성을 입증하는 강력한 기여를 제시한다.
FARM: Frame-Accelerated Augmentation and Residual Mixture-of-Experts for Physics-Based High-Dynamic Humanoid Control
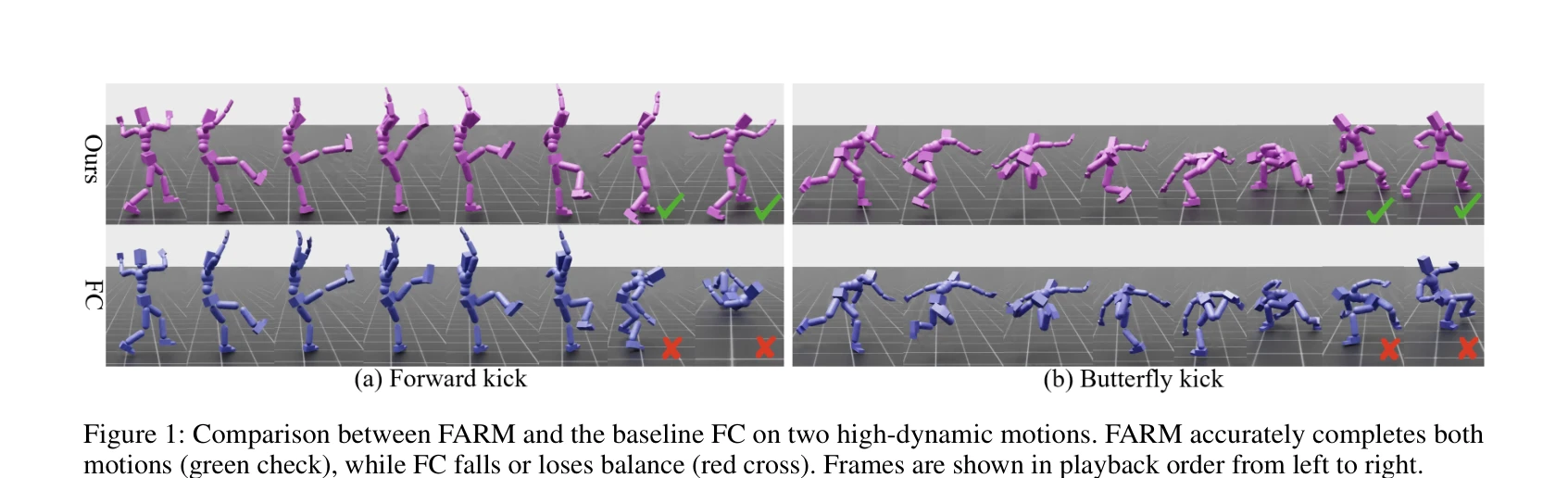
Figure 1: Comparison between FARM and the baseline FC on two high-dynamic motions. FARM accurately completes both
 *Figure 2: Overview of the FARM pipeline. Failure cases are* FARM은 frame-accelerated augmentation과 residual mixture-of-experts를 결합하여 저역학(low-dynamic) 동작에서의 높은 정확도를 유지하면서 고역학(high-dynamic) 인간형 동작 제어 성능을 크게 향상시키는 프레임워크이다.
FARM은 간단하면서도 효과적인 frame-accelerated augmentation과 동적 용량 할당 메커니즘으로 범용 인간형 제어의 실질적 한계를 해결하며, 첫번째 공개 고역학 벤치마크 제시와 함께 물리 기반 인간형 제어 분야에 중요한 기여를 한다.
From Experts to a Generalist: Toward General Whole-Body Control for Humanoid Robots
 *Figure 2: Overview of the BumbleBee framework. The left section illustrates the data curation stage, which* BumbleBee는 motion clustering과 sim-to-real adaptation을 결합하여 humanoid robot의 일반적인 whole-body control을 달성하는 expert-generalist 학습 프레임워크이다. 여러 motion cluster에서 전문가 정책을 훈련한 후 이를 통합 generalist controller로 distill한다.
BumbleBee는 motion clustering과 expert-generalist distillation을 통해 humanoid robot의 일반적인 whole-body control 문제를 효과적으로 해결하며, sim-to-real adaptation과 결합하여 실제 세계에서 agile하고 robust한 control을 달성한 우수한 연구이다. 기술적 창의성과 실험적 검증이 뛰어나고 robotics 분야에 의미 있는 기여를 한다.
Humanoid World Models: Open World Foundation Models for Humanoid Robotics
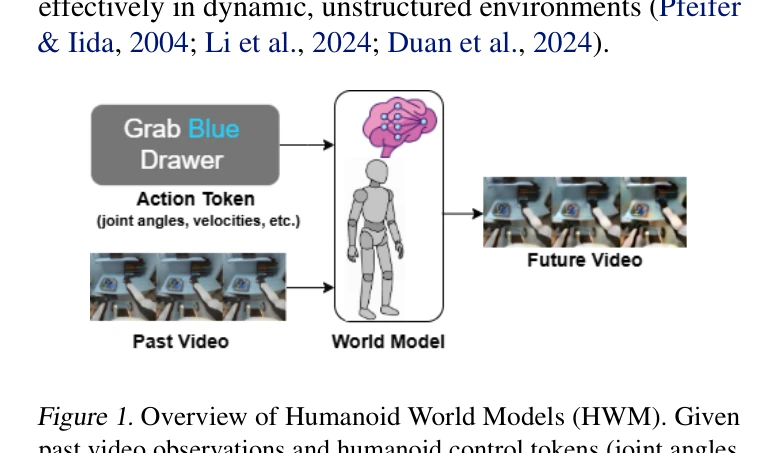
Figure 1. Overview of Humanoid World Models (HWM). Given
 *Figure 1. Overview of Humanoid World Models (HWM). Given* Humanoid World Models (HWM)는 100시간의 humanoid 시연 데이터로 학습된 경량 오픈소스 모델로, egocentric 비디오를 humanoid control token으로 조건화하여 미래 프레임을 예측한다. Masked Transformer와 Flow-Matching 두 가지 생성 모델을 탐색하며 parameter-sharing 기법으로 33-53% 크기 감소를 달성했다.
이 논문은 humanoid 로봇을 위한 경량의 접근 가능한 world model이라는 명확한 필요를 직면하고, Masked Transformer와 Flow-Matching 두 패러다임을 체계적으로 비교하며 parameter-sharing 효율성을 입증한 실질적 기여를 한다. 다만 downstream task 평가와 실제 로봇 실험을 통한 효과 검증이 추가되면 영향력이 더욱 커질 것으로 예상된다.
InterMimic: Towards Universal Whole-Body Control for Physics-Based Human-Object Interactions
Figure 1. InterMimic enables physically simulated humans to perform interactions with dynamic and diverse objects. It su
 *Figure 2. Our two-stage pipeline: (i) training each teacher pol-* InterMimic은 교사-학생 증류 및 RL 미세조정을 통해 불완전한 MoCap 데이터로부터 다양한 동적 객체와의 전신 상호작용을 학습할 수 있는 물리 기반 제어 정책 프레임워크이다.
InterMimic은 불완전한 대규모 MoCap 데이터로부터 다양한 동적 객체와의 전신 상호작용을 학습하는 첫 통합 프레임워크로, 교사-학생 증류와 RL 미세조정의 창의적 결합을 통해 물리 기반 상호작용 애니메이션의 새로운 기준을 제시한다.
Learning to Control Physically-simulated 3D Characters via Generating and Mimicking 2D Motions
Figure 1. The proposed Mimic2DM effectively learns character controllers for diverse motion types, including dynamic hum
 *Figure 1. The proposed Mimic2DM effectively learns character controllers for diverse motion types, including dynamic hum* Mimic2DM은 비디오에서 추출한 2D 키포인트 궤적만을 사용하여 물리 기반 3D 캐릭터 제어 정책을 직접 학습하는 모션 모방 프레임워크이며, 재투영 오차 최소화와 RL을 통해 2D 데이터로부터 물리적으로 타당한 3D 동작을 합성한다.
Mimic2DM은 접근성 높은 2D 데이터로부터 물리 기반 3D 캐릭터 제어를 학습하는 실질적이고 혁신적인 방법으로, 기존의 희소한 3D MoCap 데이터 의존성을 크게 완화하며 다양한 도메인에서 우수한 성능을 보여준다.
Scaling Large Motion Models with Million-Level Human Motions
Figure 1: TOP: While existing models perform well on
 *Figure 1: TOP: While existing models perform well on* LLM의 성공에 영감을 받아 백만 단위 규모의 대규모 모션 데이터셋 MotionLib를 구축하고, 이를 기반으로 Being-M0 모델을 훈련하여 대규모 모션 생성 모델의 확장성을 입증하는 연구이다.
이 논문은 모션 생성 분야에서 대규모 데이터와 모델 확장의 중요성을 처음으로 체계적으로 입증하며, MotionLib와 2D-LFQ 기술을 통해 실질적인 기여를 제공한다. 모션 생성 모델 개발의 새로운 기준을 제시하고 향후 연구의 견고한 기초를 마련한 중요한 연구이다.
Taming Diffusion Probabilistic Models for Character Control
 *Figure 2: Conditional Autoregressive Motion Diffusion Model* Transformer 기반 Conditional Autoregressive Motion Diffusion Model (CAMDM)을 제안하여 사용자의 동적 제어 신호에 실시간으로 반응하면서 고품질의 다양한 캐릭터 애니메이션을 생성한다.
Diffusion model을 실시간 캐릭터 컨트롤에 적용하기 위한 체계적이고 실용적인 해결책을 제시한 우수한 논문으로, 별도 조건 토큰화와 classifier-free guidance의 novel한 조합이 다양성과 제어 안정성을 동시에 달성하며, 단일 모델의 다중 스타일 지원은 산업 응용 가치가 높다.
Diffusion Forcing for Multi-Agent Interaction Sequence Modeling

Figure 1. A Generative Model for Multi-Agent Interaction. We propose Multi-Agent Diffusion Forcing Transformer (MAGNet),
 *Figure 1. A Generative Model for Multi-Agent Interaction. We propose Multi-Agent Diffusion Forcing Transformer (MAGNet),* MAGNet은 diffusion forcing을 활용한 통합 autoregressive diffusion framework로, 다양한 multi-agent interaction 시나리오를 하나의 모델로 처리하며 dyadic부터 polyadic 상황까지 확장 가능한 long-horizon motion generation을 수행한다.
MAGNet은 multi-agent motion generation의 근본적인 문제인 task fragmentation을 해결하는 우아한 통합 프레임워크를 제시하며, relational representation과 diffusion forcing의 조합으로 polyadic scenario까지 자연스럽게 확장 가능한 점이 탁월하다. 다만 polyadic scenario의 정량적 평가 강화와 practical deployment에 필요한 robustness 평가가 향후 과제이다.
Example-based Motion Synthesis via Generative Motion Matching
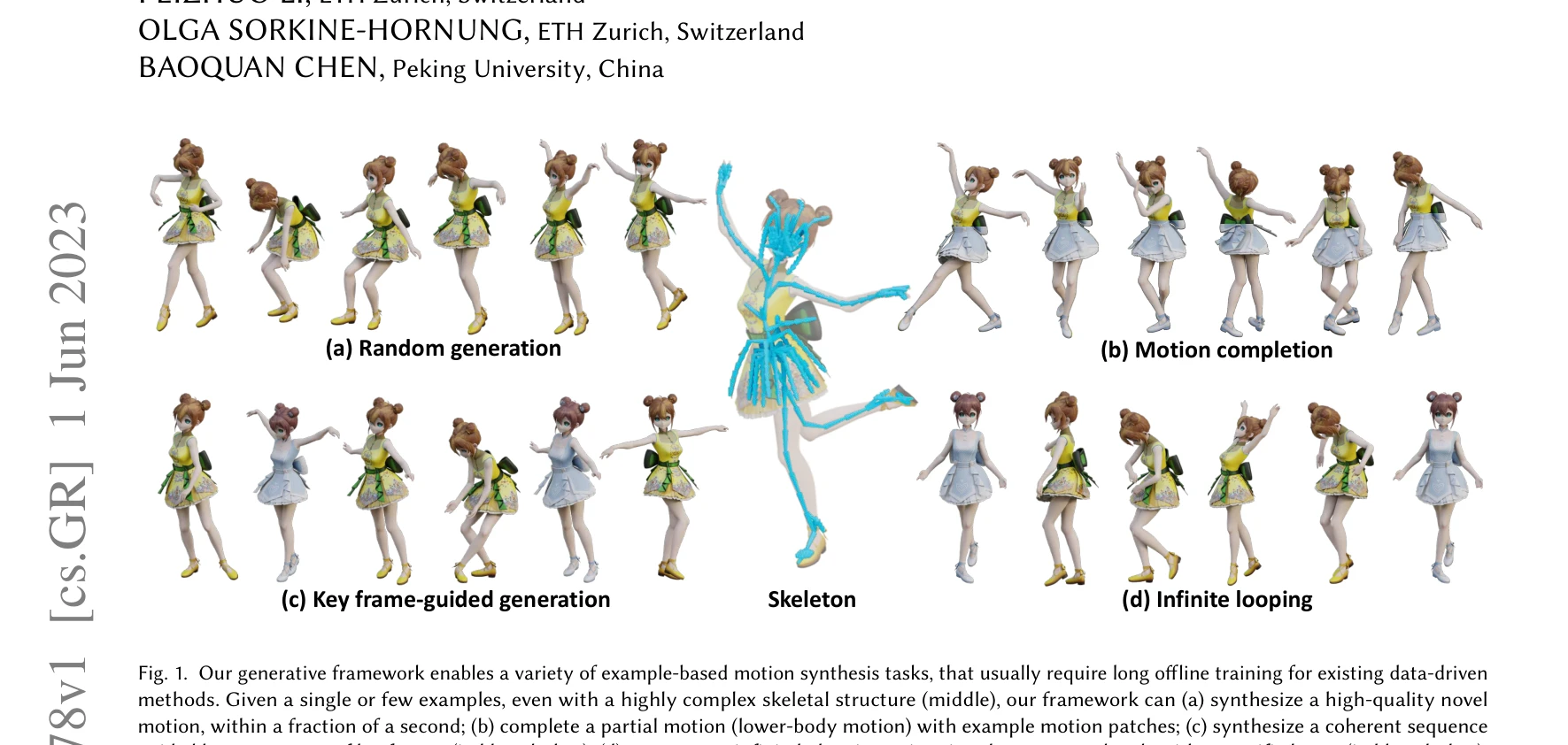
Fig. 1. Our generative framework enables a variety of example-based motion synthesis tasks, that usually require long of
 *Fig. 2. Multi-stage motion synthesis. Starting from the coarsest stage, the generative motion matching at each stage 𝑠ta* GenMM은 단일 또는 소수의 예제 모션으로부터 다양한 모션을 생성하는 학습 불필요한 생성 모델로, Motion Matching의 품질을 유지하면서 Bidirectional similarity를 생성 비용 함수로 활용하여 다단계 프레임워크로 점진적으로 모션을 정제한다.
GenMM은 Motion Matching의 우수한 품질을 유지하면서 학습 불필요한 생성 모델을 구현한 창의적인 접근법으로, 산업 실무에서 즉시 적용 가능한 실용성과 복잡한 스켈레톤에 대한 강력한 확장성을 제공하는 매우 가치 있는 연구이다.
Feature-Based vs. GAN-Based Learning from Demonstrations: When and Why
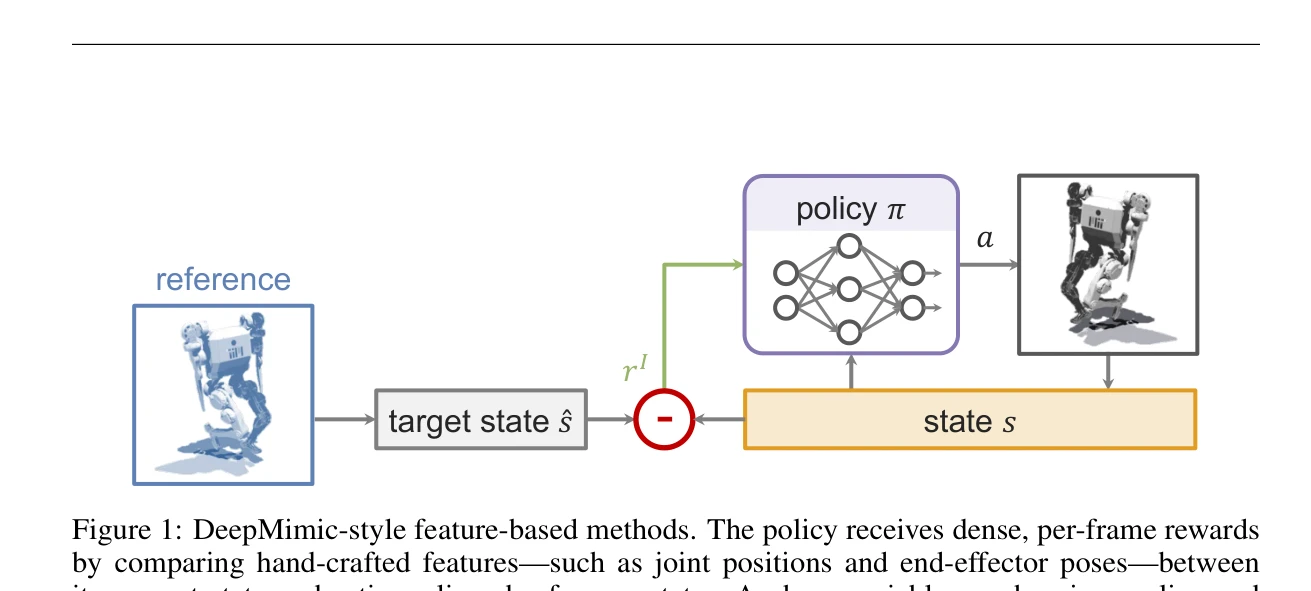
Figure 1: DeepMimic-style feature-based methods. The policy receives dense, per-frame rewards
 *Figure 1: DeepMimic-style feature-based methods. The policy receives dense, per-frame rewards* Feature-based와 GAN-based 학습 방법론을 비교 분석하여, 각 접근법의 장단점을 명확히 하고 작업별 우선순위에 따른 방법 선택 프레임워크를 제시한다.
이 survey는 시연 학습의 두 주요 패러다임을 원칙적으로 비교하고, 실무자들이 작업 특성에 맞는 방법을 선택할 수 있도록 하는 개념적 프레임워크를 제공하는 가치 있는 기여이다. 구조화된 모션 표현의 수렴점을 강조함으로써 향후 연구의 방향성을 제시한다.
Flexible Motion In-betweening with Diffusion Models
Figure 1: Flexible motion in-betweening given a text prompt and spatio-temporally sparse keyframes. From left to right:
 *Figure 1: Flexible motion in-betweening given a text prompt and spatio-temporally sparse keyframes. From left to right: * CondMDI는 diffusion model 기반의 통합된 모션 인-비트위닝 방법으로, 텍스트 조건과 함께 유연한 keyframe 제약을 받아 다양하고 정밀한 인간 모션을 생성한다.
CondMDI는 masked conditional diffusion model을 통해 motion in-betweening의 오랜 한계를 효과적으로 해결하며, 유연한 제약 처리와 텍스트 조건의 통합으로 실무적 가치가 높고 기술적으로도 우수한 기여를 제시한다.
Generative World Modelling for Humanoids: 1X World Model Challenge Technical Report
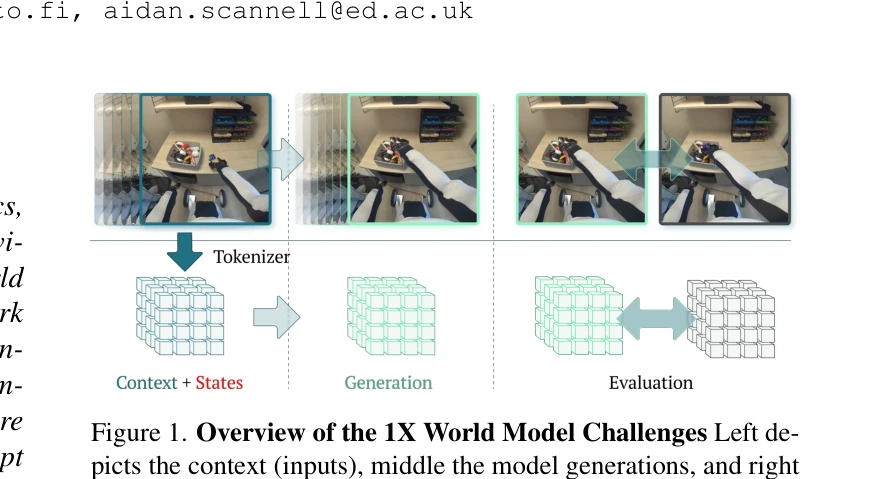
Figure 1. Overview of the 1X World Model Challenges Left de-
 *Figure 1. Overview of the 1X World Model Challenges Left de-* 1X World Model Challenge에서 humanoid 로봇의 미래 상태 예측을 위해 Wan 2.2 TI2V-5B를 video-state-conditioned 프레임 예측으로 적응시키고, Spatio-Temporal Transformer를 압축 트랙용으로 훈련하여 두 트랙 모두에서 1위를 달성했다.
본 논문은 대규모 foundation model을 robot state 조건화로 효과적으로 적응시키고, pixel space와 discrete latent space에서 모두 최고 성능을 달성함으로써 실제 humanoid 로봇 world modeling의 새로운 벤치마크를 제시했다. 방법론의 명확한 설명과 포괄적인 ablation study는 향후 world model 연구에 큰 기여가 될 것으로 예상된다.
GENMO: A GENeralist Model for Human MOtion
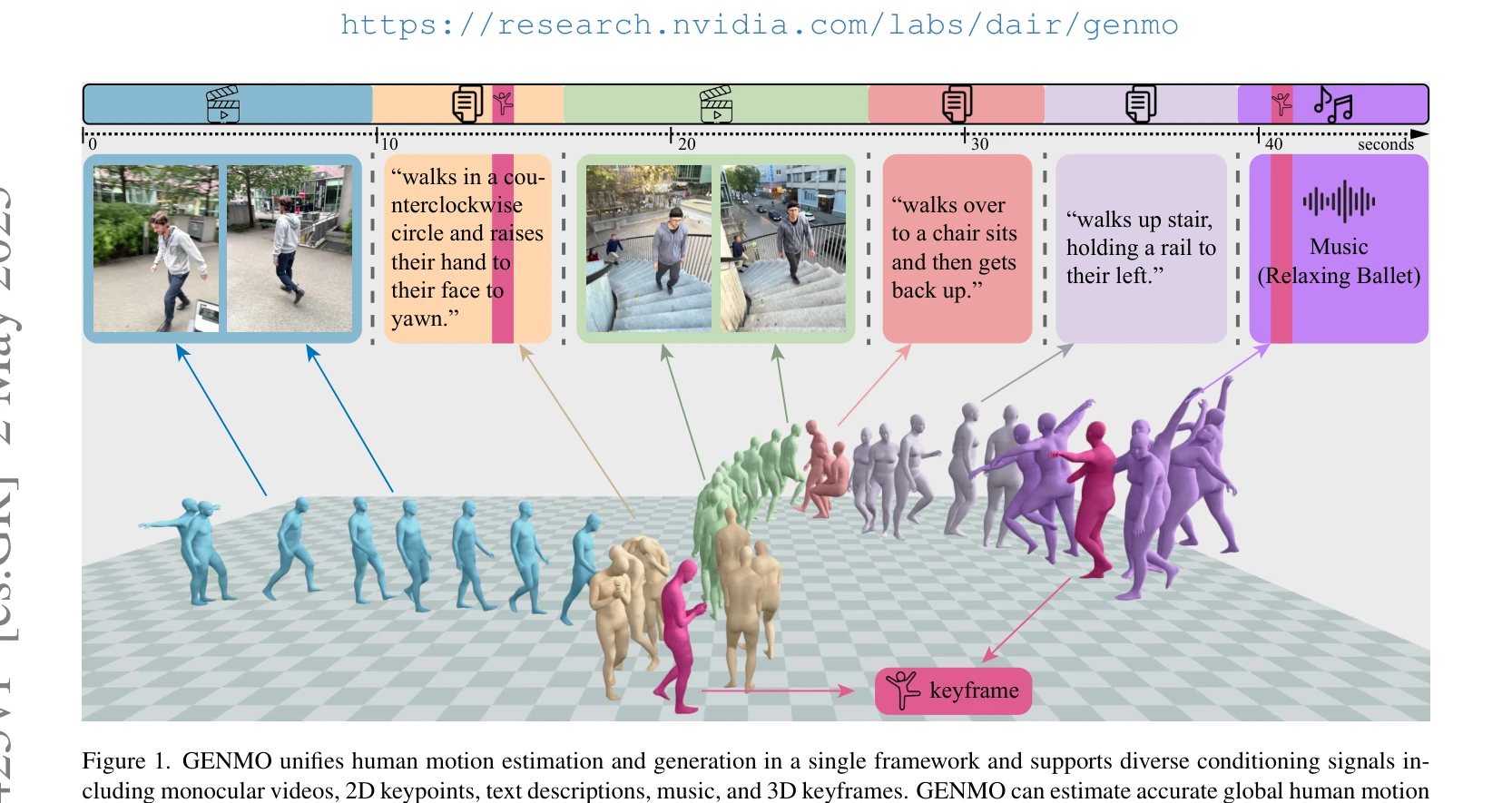
Figure 1. GENMO unifies human motion estimation and generation in a single framework and supports diverse conditioning s
 *Figure 1. GENMO unifies human motion estimation and generation in a single framework and supports diverse conditioning s* GENMO는 인간 동작 추정과 생성을 단일 프레임워크에서 통합하는 generalist 모델로, 동작 추정을 제약 조건이 있는 동작 생성으로 재구성하여 정확한 추정과 다양한 생성을 동시에 달성한다.
GENMO는 동작 추정과 생성의 오랫동안의 분리를 혁신적으로 통합하는 첫 번째 generalist 모델로, dual-mode 훈련과 estimation-guided 목표를 통해 두 작업 간 상승 효과를 효과적으로 달성하며, 다양한 benchmark에서 state-of-the-art 성능을 입증한다.
Guided Motion Diffusion for Controllable Human Motion Synthesis
Figure 1. Our proposed Guided Motion Diffusion (GMD) can generate high-quality and diverse motions given a text prompt a
 *Figure 2. We tackle the problem of spatially conditioned motion* Guided Motion Diffusion (GMD)는 자연어 설명과 공간적 제약(궤적, 키프레임, 장애물 회피)을 동시에 고려하여 인간의 모션을 합성하는 diffusion model 기반 방법을 제안한다.
GMD는 모션 생성의 중요한 미충족 요구(공간적 제약 통합)를 새로운 관점에서 해결하며, emphasis projection과 dense signal propagation이라는 두 가지 우아하고 일반적인 기법으로 강력한 성과를 달성한 고품질의 논문이다.
Kimodo: Scaling Controllable Human Motion Generation
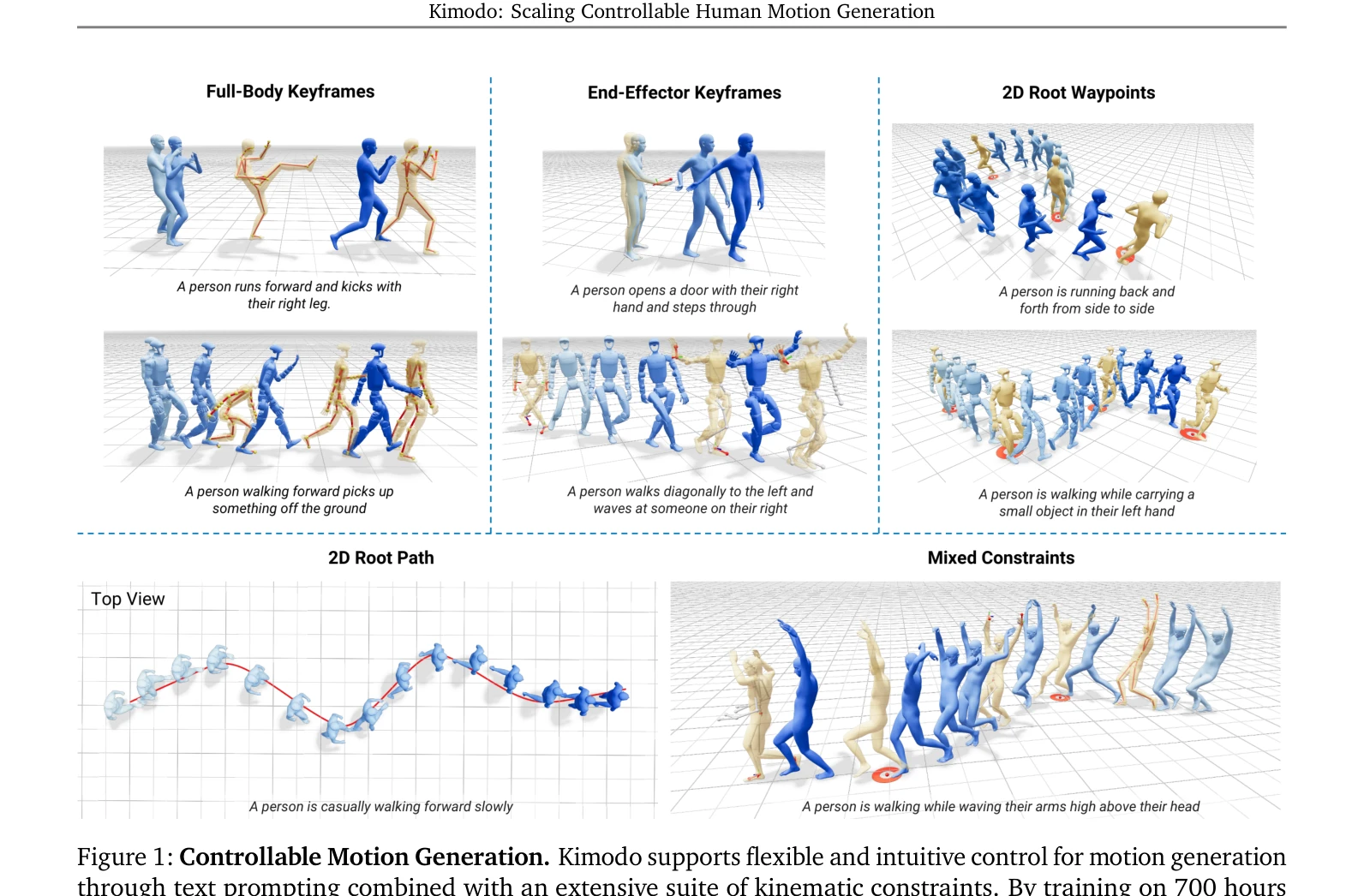
Figure 1: Controllable Motion Generation. Kimodo supports flexible and intuitive control for motion generation
 *Figure 1: Controllable Motion Generation. Kimodo supports flexible and intuitive control for motion generation* NVIDIA의 Kimodo는 700시간의 광학 모션캡처 데이터로 학습한 kinematic motion diffusion model로, 텍스트 프롬프트 및 포괄적인 운동학 제약 조건을 통해 고품질 인간 모션을 생성한다.
Kimodo는 대규모 모션캡처 데이터와 혁신적인 두 단계 diffusion 아키텍처를 결합하여 현실적이고 제어 가능한 인간 모션 생성을 달성한 중요한 기여이며, 로봇공학과 콘텐츠 생성 분야에서 실질적인 응용 가치를 제시한다.
MaskedMimic: Unified Physics-Based Character Control Through Masked Motion Inpainting

Fig. 1. We present MaskedMimic, a versatile control model that enables physically simulated characters to generate diver
 *Fig. 1. We present MaskedMimic, a versatile control model that enables physically simulated characters to generate diver* MaskedMimic은 motion inpainting 문제로 physics-based character control을 재정의하여, 마스킹된 keyframe, text, object 등 다양한 partial 조건으로부터 통합된 단일 모델이 전신 물리 기반 애니메이션을 생성할 수 있게 한다.
MaskedMimic은 motion inpainting이라는 우아한 재정의를 통해 physics-based character control의 versatility 문제를 근본적으로 해결하며, 단일 unified model로 diverse control modalities를 지원하는 breakthrough를 이루었다. 실제 응용 및 확장성 측면에서의 평가는 필요하지만, character animation의 패러다임을 크게 전환할 수 있는 높은 impact의 연구이다.
OmniControl: Control Any Joint at Any Time for Human Motion Generation

Figure 1: OmniControl can generate realistic human motions given a text prompt and flexible
 *Figure 1: OmniControl can generate realistic human motions given a text prompt and flexible* OmniControl은 diffusion 기반 text-conditioned 인간 동작 생성 모델에 flexible spatial control signals을 통합하는 방법으로, 단일 모델로 임의의 관절을 임의의 시간에 제어할 수 있다.
OmniControl은 기존 방법의 근본적 제약을 global coordinate 변환과 dual guidance로 해결하며, 단일 모델로 임의의 관절 제어를 가능하게 한 significant contribution이다. 실용적 응용성과 성능 면에서 human motion generation 분야의 중요한 진전을 이루었다.
PhysDiff: Physics-Guided Human Motion Diffusion Model
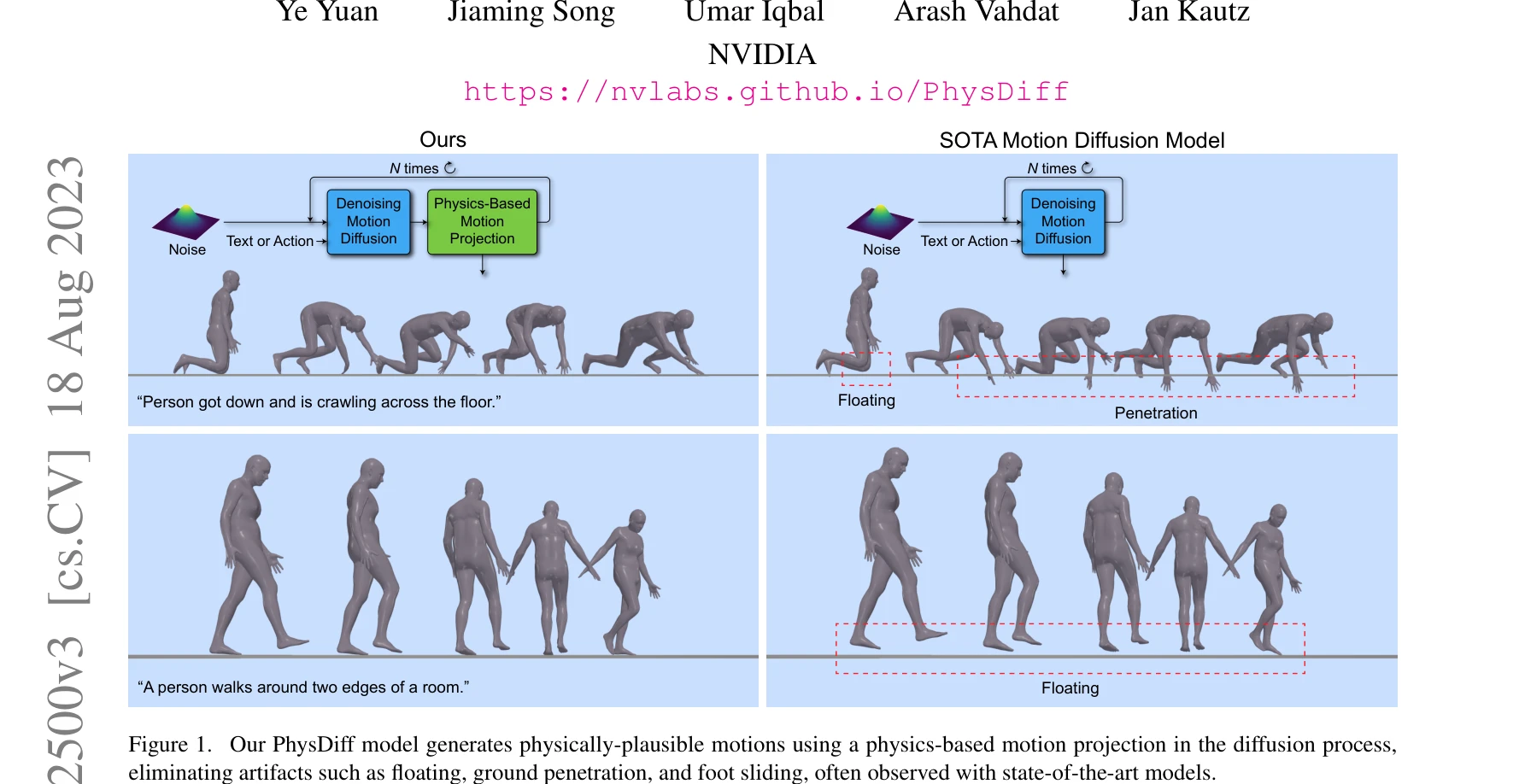
Figure 1. Our PhysDiff model generates physically-plausible motions using a physics-based motion projection in the diffu
 *Figure 1. Our PhysDiff model generates physically-plausible motions using a physics-based motion projection in the diffu* PhysDiff는 diffusion 과정에 물리 기반 motion projection 모듈을 통합하여 physically-plausible human motion을 생성하는 physics-guided motion diffusion 모델이다. 기존 motion diffusion 모델의 floating, foot sliding, ground penetration 같은 물리적 artifacts를 제거한다.
PhysDiff는 human motion generation에 physics 제약을 systematically 통합하여 physically-plausible motion 생성의 핵심 문제를 해결한 혁신적 연구이다. Iterative projection 전략과 철저한 실험 분석이 학계에 중요한 기여를 제공하며, 실제 animation/VR 응용의 현실화를 크게 앞당긴다.
TEDi: Temporally-Entangled Diffusion for Long-Term Motion Synthesis
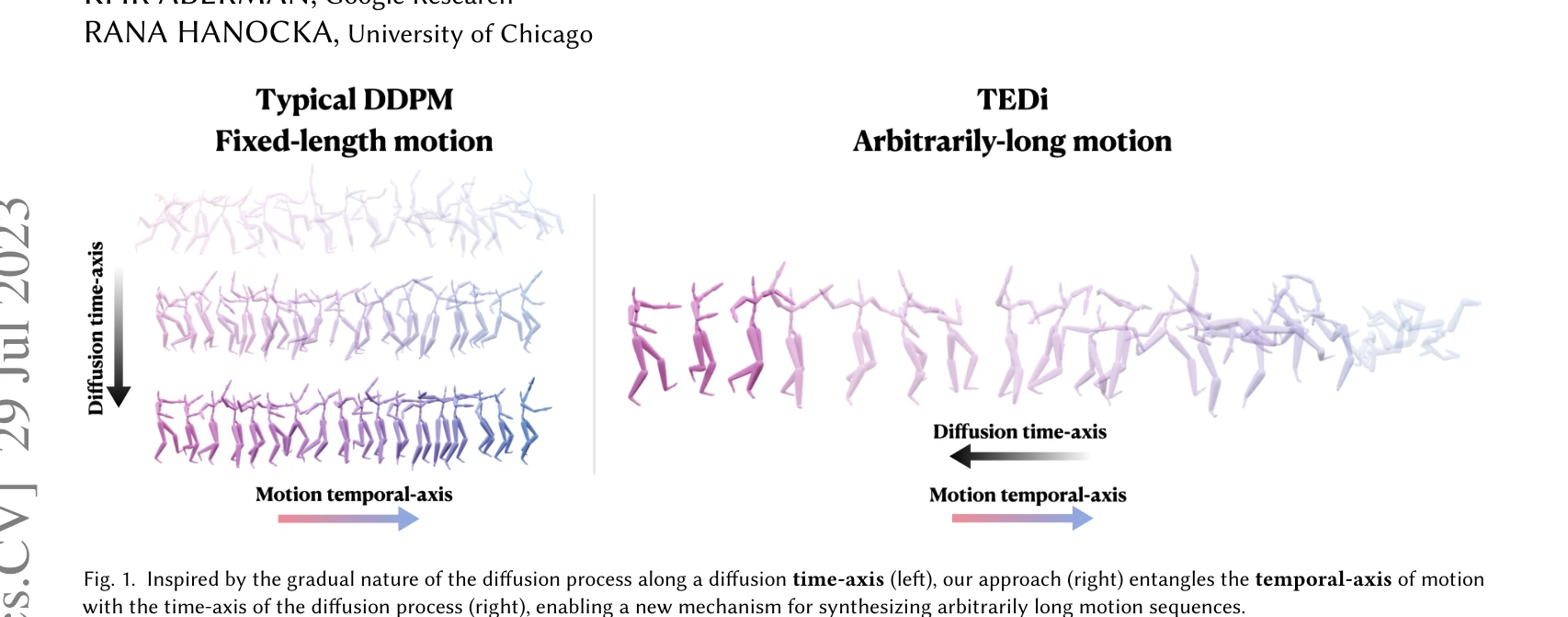
Fig. 1. Inspired by the gradual nature of the diffusion process along a diffusion time-axis (left), our approach (right)
 *Fig. 1. Inspired by the gradual nature of the diffusion process along a diffusion time-axis (left), our approach (right)* TEDi는 Denoising Diffusion Probabilistic Models (DDPM)의 점진적 생성 개념을 모션 시퀀스의 시간축에 적용하여, 두 축을 얽혀 있게(entangle) 함으로써 임의 길이의 장기 모션 생성을 가능하게 한다. 시간에 따라 변하는 노이즈 레벨을 가진 모션 버퍼를 반복적으로 제거하는 자동회귀 메커니즘을 통해 연속적인 프레임 스트림을 생성한다.
TEDi는 diffusion 모델의 시간축과 모션 시퀀스의 시간축을 창의적으로 얽혀 있게 함으로써 장기 모션 생성의 근본적인 문제를 우아하게 해결한 혁신적 작업이다. 임의 길이 생성, stitching 제거, 대화형 제어 등 기존 방법들의 한계를 동시에 극복하며, 명확한 설명과 견고한 기술적 기초로 높은 평가를 받을 만하다.
GENMO: A GENeralist Model for Human MOtion
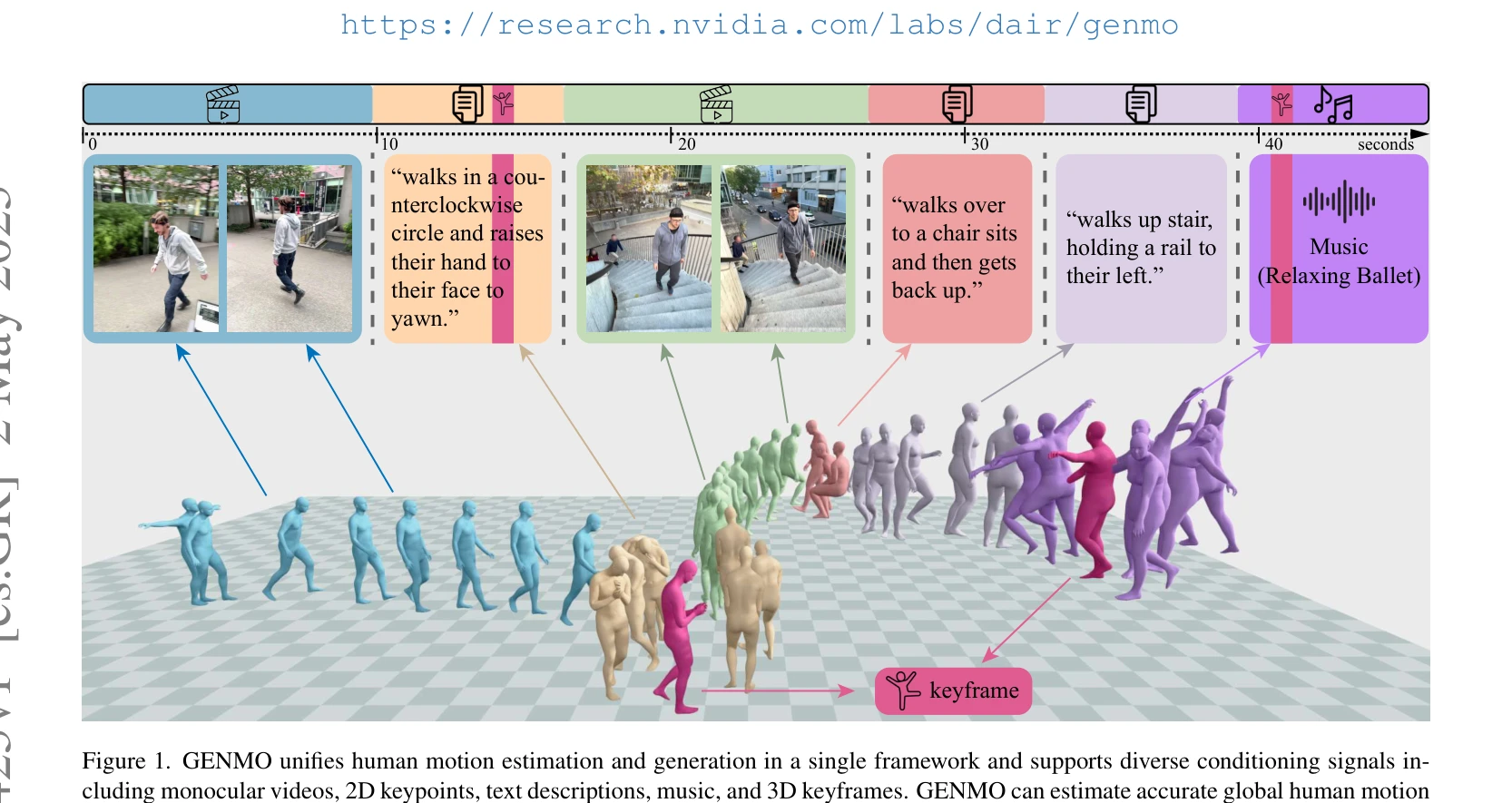
Figure 1. GENMO unifies human motion estimation and generation in a single framework and supports diverse conditioning s
 *Figure 1. GENMO unifies human motion estimation and generation in a single framework and supports diverse conditioning s* 본 논문은 인간 모션 생성과 추정을 단일 diffusion 기반 프레임워크에서 통합하는 GENMO를 제안한다. 모션 추정을 제약이 있는 모션 생성으로 재정의하고, dual-mode 학습 패러다임을 통해 정확한 global motion estimation과 다양한 모션 생성을 동시에 달성한다.
본 논문은 인간 모션 생성과 추정을 통합하는 새로운 관점과 실용적인 솔루션을 제시하는 강력한 연구이다. Dual-mode training paradigm과 estimation-guided objective는 창의적이며, 다양한 조건 신호의 유연한 처리는 실제 애플리케이션에서 높은 가치를 가진다. 다만 상세한 정량적 평가와 계산 효율성 분석의 강화가 필요하다.
GMT: General Motion Tracking for Humanoid Whole-Body Control

Figure 1: We deploy the general unified motion tracking policy on a medium-sized humanoid robot.
 *Figure 3: An overview of GMT. Here gt denotes the motion target frame, ot denotes proprioceptive* GMT는 humanoid 로봇이 다양한 전신 모션을 추적할 수 있도록 하는 통합 정책을 학습하는 프레임워크로, Adaptive Sampling 전략과 Motion Mixture-of-Experts 아키텍처를 핵심 요소로 제안한다.
GMT는 humanoid 로봇의 general motion tracking에 대한 실질적인 해결책을 제시하며, Adaptive Sampling과 Motion MoE라는 두 가지 실용적 기법으로 기존의 산발적 접근들을 통합한 우수한 연구이다. 실제 로봇 배포 성공과 상태-최첨단 성능은 높은 가치를 제시하지만, 더 광범위한 하드웨어 검증과 이론적 분석 강화가 필요하다.
Iterative Closed-Loop Motion Synthesis for Scaling the Capabilities of Humanoid Control
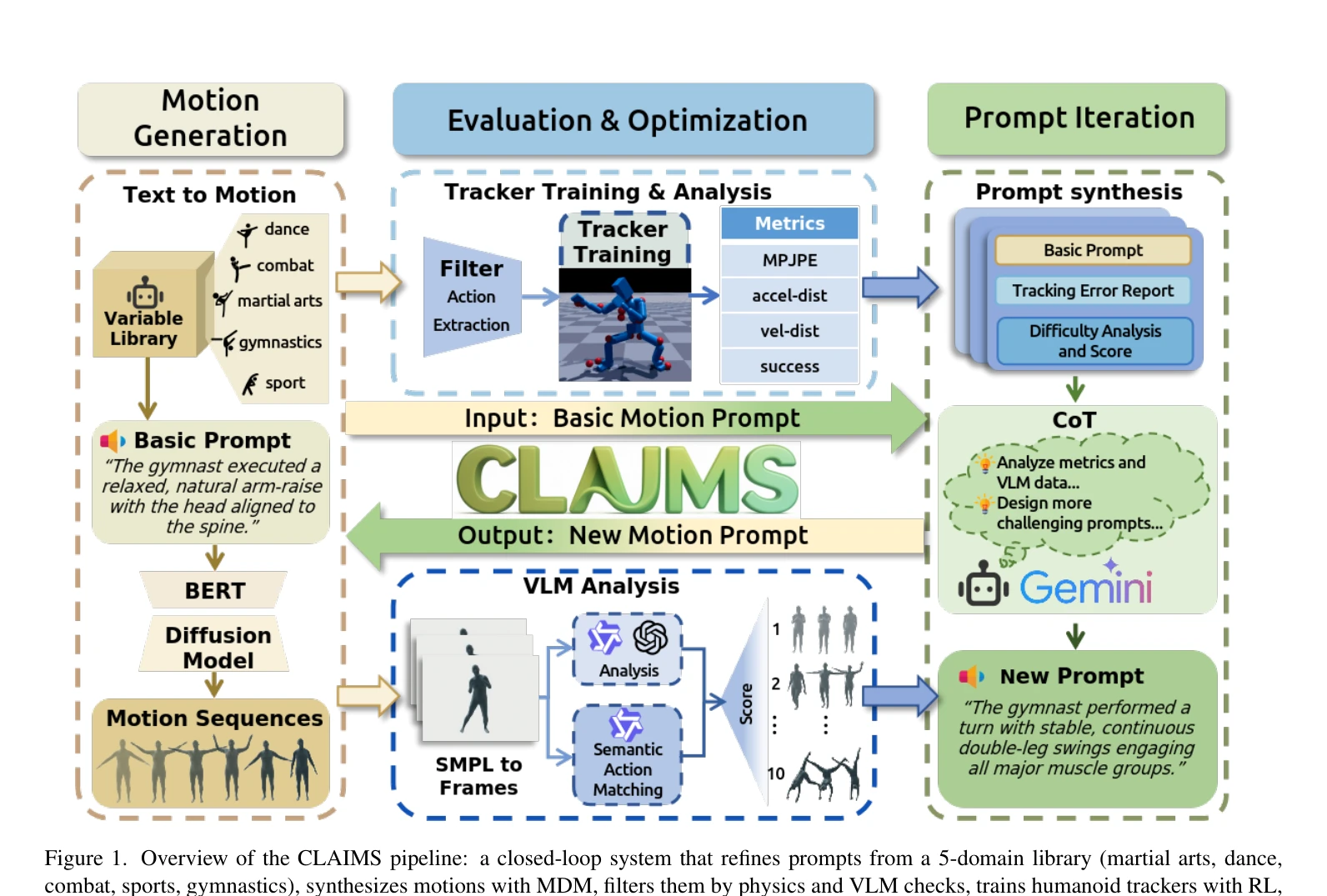
Figure 1. Overview of the CLAIMS pipeline: a closed-loop system that refines prompts from a 5-domain library (martial ar
 *Figure 1. Overview of the CLAIMS pipeline: a closed-loop system that refines prompts from a 5-domain library (martial ar* 본 논문은 폐쇄 루프 자동화 모션 데이터 생성 및 반복 프레임워크(CLAIMS)를 제안하여 고정된 난이도 분포의 데이터셋 한계를 극복하고, 휴머노이드 제어 정책의 성능 상한을 향상시킨다.
본 논문은 동적 난이도 적응을 통해 휴머노이드 제어의 고질적인 문제(고정 데이터 분포, 높은 데이터 수집 비용)를 혁신적으로 해결하며, 폐쇄 루프 프레임워크의 개념과 실제 구현이 모두 우수하다. 특히 AMASS의 1/10 데이터로 45% 실패율 감소라는 실질적 성과와 다양한 벤치마크에서의 일반화 능력은 이 분야에 상당한 실용적 기여를 제공한다.
KungfuBot2: Learning Versatile Motion Skills for Humanoid Whole-Body Control
Fig. 1: Humanoid learning versatile motion skills. We deploy VMS on the Unitree G1 humanoid robot, demonstrating its cap
 *Fig. 2: Framework of VMS. The large-scale motion capture dataset is first retargeted to the humanoid skeleton using an I* VMS는 Orthogonal Mixture-of-Experts (OMoE) 아키텍처와 하이브리드 추적 목표를 결합하여 단일 정책으로 다양한 동작을 수행하는 휴머노이드 로봇 제어기를 제시한다. 장시간 시퀀스에서 안정적인 성능과 높은 동작 충실도를 달성한다.
VMS는 OMoE 아키텍처와 하이브리드 추적 목표의 조합으로 실용적 휴머노이드 제어의 주요 과제들을 효과적으로 해결하며, 대규모 데이터 기반의 체계적 방법론과 실로봇 검증을 통해 범용 휴머노이드 제어의 기초 플랫폼으로서 높은 가치를 보여준다.
Learning Smooth Humanoid Locomotion through Lipschitz-Constrained Policies

Fig. 1: Lipschitz-constrained policies (LCP) provide a simple and general method for training policies to produce smooth
 *Fig. 2: Lipschitz continuity is a method of quantifying the* 본 논문은 Reinforcement Learning으로 훈련한 humanoid robot의 locomotion policy에 Lipschitz 제약을 부여하여 smooth behavior를 자동으로 유도하는 Lipschitz-Constrained Policies (LCP) 방법을 제안한다.
Lipschitz constraint을 통한 smooth policy 학습은 이론적으로 명확하고 실용적이며, 기존의 복잡한 smoothing 기법들을 단순하고 미분 가능한 방식으로 대체하는 우수한 기여이다. 실제 humanoid robot에서의 검증과 재현성 있는 공개 코드 공개로 high impact을 기대할 수 있다.
TeleGate: Whole-Body Humanoid Teleoperation via Gated Expert Selection with Motion Prior
Fig. 1.
 *Fig. 1.* TeleGate는 가벼운 gating network를 통해 multiple domain-specific expert policies를 동적으로 선택하여 humanoid robot의 real-time whole-body teleoperation을 수행하며, VAE 기반 motion prior를 도입하여 미래 정보 없이도 점프나 일어서기 같은 동적 동작을 예측적으로 제어한다.
TeleGate는 gated expert selection과 VAE 기반 motion prior를 결합하여 제한된 데이터로도 높은 정밀도의 real-time whole-body humanoid teleoperation을 실현하는 혁신적인 프레임워크이며, Unitree G1에서의 성공적인 physical deployment로 실제 적용 가능성을 입증했다.
TokenHSI: Unified Synthesis of Physical Human-Scene Interactions through Task Tokenization
Figure 1. Introducing TokenHSI, a unified model that enables physics-based characters to perform diverse human-scene int
 *Figure 1. Introducing TokenHSI, a unified model that enables physics-based characters to perform diverse human-scene int* TokenHSI는 transformer 기반의 통합 정책으로 humanoid 고유감각을 공유 토큰으로 모델링하고 task 토큰과 masking mechanism으로 결합하여 다양한 인간-장면 상호작용(HSI) 기술을 단일 네트워크에서 통합한다.
TokenHSI는 독립적 proprioception tokenizer와 masking mechanism을 통해 다중 HSI 기술을 단일 네트워크에서 효과적으로 통합하고, 변수 길이 입력을 활용한 효율적 정책 적응까지 실현한 혁신적인 접근법으로, 컴퓨터 애니메이션과 embodied AI 분야에서 실질적인 기여를 한다.
Track Any Motions under Any Disturbances

Fig. 1: (a) The humanoid tracks diverse, highly dynamic, and contact-rich motions using a single policy. (b) The humanoi
 *Fig. 1: (a) The humanoid tracks diverse, highly dynamic, and contact-rich motions using a single policy. (b) The humanoi* Any2Track는 휴머노이드 로봇이 다양한 동작을 추적하면서 동시에 지형, 외력, 물리적 성질 변화 등 실제 환경 교란에 적응할 수 있도록 하는 두 단계 강화학습 프레임워크를 제안한다.
Any2Track는 동역학 적응성을 명시적으로 재정의하고 이를 기본 추적 능력과 분리하여 학습하는 혁신적 접근을 제시하며, Unitree G1에서 zero-shot sim2real 전이를 달성하여 실제 휴머노이드 로봇의 실용화에 중요한 기여를 한다.
Switch: Learning Agile Skills Switching for Humanoid Robots
 *Fig. 2: The Switch system: (a) We retarget human motion capture skills onto the robot. We then construct a skill graph w* Switch는 Skill Graph를 기반으로 humanoid robot이 임의의 시점에서 다양한 동작 기술들 사이를 자유롭게 전환할 수 있는 계층적 전신 제어 시스템을 제시한다.
Switch는 Skill Graph라는 단순하면서도 효과적인 구조와 online graph search 기반의 동적 재계획을 통해 humanoid robot의 skill switching 문제를 실용적으로 해결한 의미 있는 연구이며, 실제 로봇 플랫폼에서의 검증으로 높은 적용 가치를 보여준다.
Track Any Motions under Any Disturbances

Fig. 1: (a) The humanoid tracks diverse, highly dynamic, and contact-rich motions using a single policy. (b) The humanoi
 *Fig. 1: (a) The humanoid tracks diverse, highly dynamic, and contact-rich motions using a single policy. (b) The humanoi* 이 논문은 humanoid 로봇이 다양하고 동적이며 접촉이 많은 동작을 추적하면서 동시에 지형, 외력, 물리적 속성 변화 등의 실세계 교란에 강건하게 적응할 수 있도록 하는 Any2Track을 제안한다. AnyTracker와 AnyAdapter 두 가지 주요 컴포넌트로 구성된 2단계 RL 프레임워크를 통해 단일 정책으로 다양한 동작을 추적하면서도 온라인 동역학 적응성을 달성한다.
본 논문은 humanoid motion tracking의 오랜 과제인 다양한 동작 추적과 실세계 교란 적응을 동시에 해결하는 포괄적인 솔루션을 제시한다. 2단계 RL 프레임워크의 설계가 체계적이며, 실제 하드웨어 배포를 통한 성능 입증이 설득력 있다. 다만 단일 플랫폼에만의 평가와 계산 효율성 분석 부재가 한계이지만, 이 분야에 상당한 기여를 하는 우수한 연구로 평가된다.
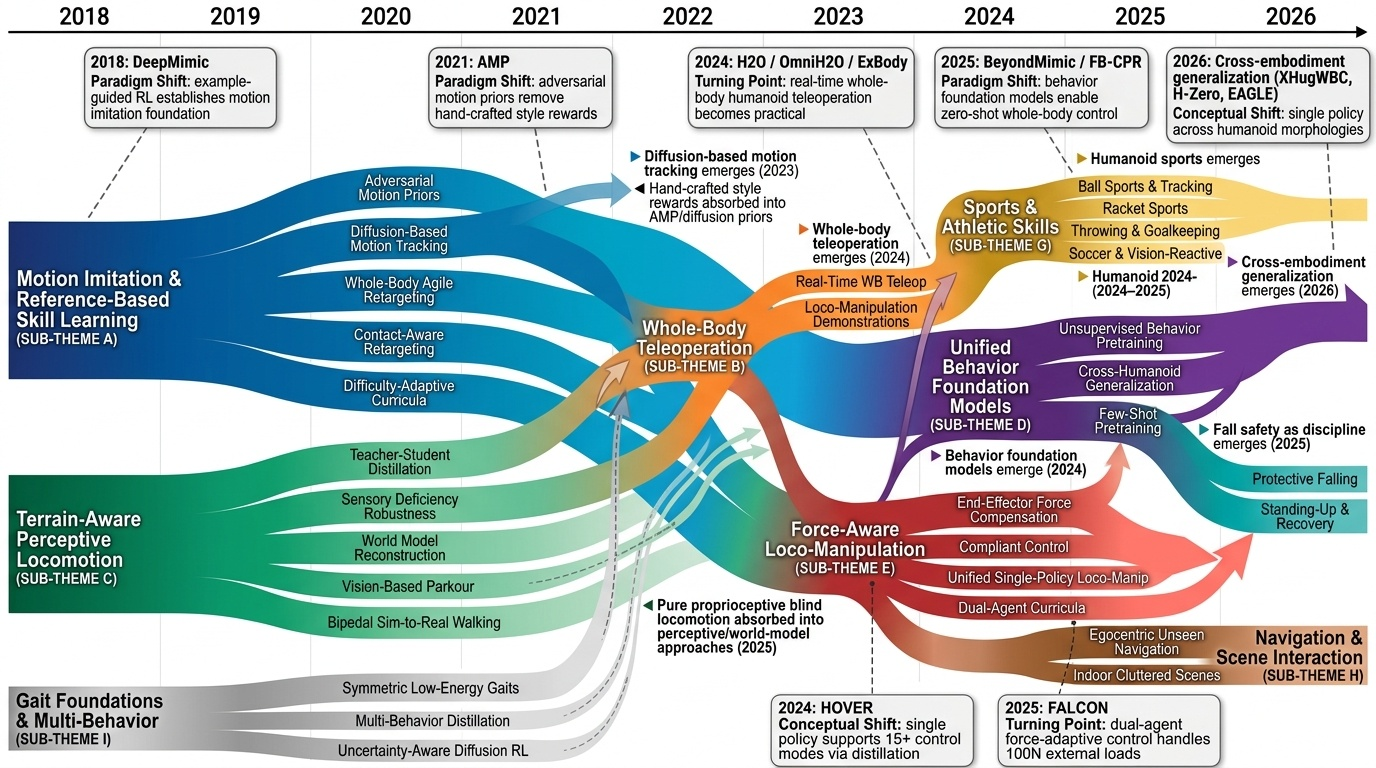
Category Overview
휴머노이드 로봇의 강화학습 기반 다족 보행 제어(Reinforcement Learning Legged Robot Control) 분야는 인간 수준의 운동 능력을 갖춘 로봇 개발을 목표로 하는 첨단 연구 영역이다. 확산 모델(Diffusion Model) 기반 모션 추적, 다양한 데이터셋을 활용한 비지도학습 사전학습, 그리고 역학적으로 일관성 있는 조작 제어(Loco-Manipulation Control) 등 여러 하위 주제가 이 분야를 구성하고 있다[1614][1615]. 특히 인간 모션의 모방학습(Motion Imitation Learning)과 실시간 원격 조종(Real-Time Whole-Body Teleoperation)은 휴머노이드 로봇의 실용성을 극대화하는 핵심 기술로, 텔레오퍼레이션 시스템과 차별화된 모션 스타일을 학습하는 데 주력하고 있다[1426][1451][1498]. 또한 낙상 회복(Fall Recovery), 지형 적응형 보행(Terrain Locomotion), 그리고 접촉력 인식 제어(Contact-Aware Control) 등 안전성과 강건성을 강화하는 연구들이 활발히 진행 중이다[1649][1657][1661]. 비전 기반 운동 인식(Vision-Based Motion Perception)과 월드 모델(World Model)을 통한 환경 이해, 그리고 커리큘럼 학습(Curriculum Learning) 방식의 적응형 제어 알고리즘이 통합되면서 복잡한 환경에서의 자율 운동 능력이 급속도로 향상되고 있다[1617][1652][1655].
- Diffusion-Based Motion Tracking: Diffusion-Based Motion Tracking은 확산 모델(Diffusion Model)을 기반으로 다리 있는 휴머노이드 로봇이 인간의 동작을 추적하고 모방하도록 학습하는 강화학습 방법론입니다. [1426]의 HumanPlus와 [1498]의 OmniH2O 연구는 휴머노이드 로봇이 인간의 전신 동작을 실시간으로 섀도잉(Shadowing)하고 모방할 수 있도록 확산 모델 기반의 모션 추적 기법을 적용했습니다. [1650]의 Robot Drummer와 [1653]의 RobotDancing 논문들은 리듬감 있는 드럼 연주와 댄싱 같은 복잡한 신체 제어 태스크(Task)에서 잔차 행동 강화학습(Residual-Action RL)을 결합하여 로봇의 동작 추적 정확도를 향상시켰습니다. 이러한 접근 방식은 [1751]의 시각적 모방(Visual Imitation)과 [1759]의 순차적 전신 제어(Sequential Whole-Body Control) 연구로 확장되어, 로봇이 다양한 맥락(Context)에서 인간 수준의 동작 반응성을 달성할 수 있게 합니다. 궁극적으로 확산 기반 모션 추적은 휴머노이드 로봇의 지능형 동작 학습을 위한 핵심 기술로 자리잡고 있습니다.
- Unsupervised Behavior Pre-Training with Diverse Datasets: 비지도 학습(Unsupervised Learning)을 기반으로 한 다양한 데이터셋을 활용한 다리 있는 로봇의 행동 사전학습(Behavior Pre-Training)은 강화학습 기반 로봇 제어의 중요한 연구 분야이다. 이 분야는 시뮬레이션 환경에서 대규모 행동 데이터를 수집하여 로봇의 기초 모델(Foundation Model)을 구축하고, 이를 통해 실제 로봇이 다양한 태스크에 빠르게 적응할 수 있도록 하는 것을 목표로 한다[1761][1821]. 행동 기초 모델과 스킬 블렌딩(Skill Blending), 대칭성 동등성(Symmetry Equivariance) 등의 기술을 활용하여 휴머노이드 로봇(Humanoid Robot)의 전신 제어(Whole-Body Control)와 이족 보행(Locomotion)을 효율적으로 학습할 수 있다[1678][1854]. 또한 데이터 효율성(Data Efficiency)을 높이기 위해 고유감각(Proprioceptive) 정보와 시뮬레이션 사전학습(Simulation Pre-training)을 결합한 방법론들이 제안되었으며[1627][1680], 이러한 접근 방식들은 크로스-휴머노이드 전이(Cross-Humanoid Transfer)와 일반화된 제어(Generalized Control)의 실현을 가능하게 한다[1665].
- End-Effector Force Compensation: # End-Effector Force Compensation 강화학습 기반 다리로봇의 End-Effector Force Compensation은 로봇의 말단 장치(End-Effector)에 작용하는 외력을 정확히 제어하고 보상하기 위한 기술 분야입니다. 이 분야는 로봇이 복잡한 환경에서 조작(Manipulation) 작업을 수행하면서 동시에 안정적인 보행(Locomotion)을 유지해야 하는 문제를 다룹니다. [1668]의 SEEC와 [1922]의 FALCON 연구들은 모델 강화 잔차(Model-Enhanced Residual) 제어와 Force-Adaptive 강화학습을 통해 말단 장치의 힘을 적응적으로 보상하는 방법을 제시합니다. [1923]의 FAME와 [2017]의 HWC-Loco는 조작 범위를 확대하기 위해 전신 제어(Whole-Body Control)와 계층적 제어(Hierarchical Control) 구조를 활용한 힘 보상 전략을 개발했습니다. 이러한 기술들은 로봇이 다양한 외부 힘에 대응하면서 높은 안정성과 정확성을 유지하도록 하며, 실제 세계의 조작 작업에서 로봇의 적응 능력을 크게 향상시킵니다.
- Adversarial Motion Prior Locomotion: # Adversarial Motion Prior Locomotion 적대적 동작 사전(Adversarial Motion Prior)을 활용한 다리 로봇 제어는 시뮬레이션과 실제 환경 간의 차이를 극복하고 강건한 보행 정책을 학습하는 방법론입니다. [1792]와 [2072]에서 보여주듯이, 적대적 학습 프레임워크를 통해 판별자(discriminator)가 생성한 동작과 실제 인간 동작을 구별하도록 강제함으로써 사실적이고 자연스러운 보행 기술을 습득하게 됩니다. 이러한 접근법은 도메인 랜더마이제이션(domain randomization)과 결합되어 [1675]와 [1712]에서 제시된 바와 같이 시뮬레이션에서 학습한 정책을 실제 휴머노이드 로봇으로 성공적으로 전이할 수 있게 합니다. [2073]과 [2401]의 연구들은 다양한 신체 구조와 환경 조건에서 동작 사전을 적응적으로 학습하여 로봇의 범용성을 높이는 방법을 제시합니다. 이를 통해 휴머노이드 로봇들은 인간 참조 데이터(human reference data)를 기반으로 더욱 정교하고 안정적인 전신 보행 능력(whole-body locomotion)을 갖추게 됩니다.
- Perceptive Terrain Navigation under Sensory Deficiency: 이 분야는 감각 능력이 제한된 환경에서 다리 로봇이 지형을 인지하고 자율적으로 이동하는 기술을 다룹니다. 비전(vision) 센서의 부재나 불완전한 감각 정보 상황에서 강화학습(Reinforcement Learning)을 통해 로봇의 보행 능력을 학습하는 것이 핵심 과제입니다[1746][1850]. 실시간 지형 적응(Real-Time Terrain Adaptation)과 복잡한 환경 네비게이션(Complex Terrain Navigation)을 위해 컨트라스티브 표현 학습(Contrastive Representation Learning)이나 혼합 잔차 전문가(Mixture of Residual Experts) 같은 고급 기술들이 적용되고 있습니다[1939][2105]. 또한 시뮬레이션-투-리얼 전이(Sim-to-Real Transfer)와 다양한 모프 구조(Morphologies)에 대한 영점 복구(Zero-Shot Recovery) 등의 일반화 문제도 중요하게 연구되고 있습니다[2068]. 이러한 연구들은 극한의 파쿠르(Parkour) 같은 동적 운동부터 일상적인 보행까지 인간형 로봇(Humanoid Robot)의 적응 능력을 향상시키는 데 기여합니다.
- Loco-Manipulation Demonstration Retargeting: # Loco-Manipulation Demonstration Retargeting 로코-조작(Loco-Manipulation) 시연 재타게팅은 인간의 이동과 조작 동작을 휴머노이드 로봇으로 전이하는 기술로, 강화학습과 모방학습을 결합하여 복잡한 전신 제어를 실현한다. [1614]와 [1860]에서 보듯이 물리적 제약 조건을 만족하면서 인간의 시연(Demonstration) 데이터로부터 학습하는 접근법이 핵심이다. [1891]의 DynaRetarget과 [1969]의 HDMI 같은 연구들은 동역학적으로 실현 가능한(Dynamically-Feasible) 동작 재타게팅(Retargeting)을 위해 샘플링 기반 최적화와 상호작용 제어(Interactive Control)를 활용한다. [2055]와 [2103]은 개방어휘(Open-Vocabulary) 작업 이해와 인간-로봇 간 손(Hand) 조작 일반화를 통해 실세계 적용성을 확대하고 있다. 이러한 기술들은 [2115]의 OKAMI처럼 비디오 시연으로부터 직접 조작 능력을 습득하는 엔드-투-엔드(End-to-End) 학습 패러다임으로 발전하고 있다.
- Reference-Based Motion Skill Learning: Reference-Based Motion Skill Learning은 참조 동작(reference motion)을 기반으로 강화학습 에이전트가 자연스럽고 사실적인 동작을 습득하는 방법론입니다. 이 접근법은 모션 캡처 데이터나 전문가 시연(demonstration)과 같은 참조 동작을 활용하여 학습 신호를 제공하고, Adversarial Motion Prior(AMP) 기법을 통해 물리 기반 시뮬레이션 환경에서 고품질의 동작 스타일을 학습하도록 합니다[1801]. DeepMimic[1862]과 같은 대표적 연구는 예제 기반 강화학습(example-guided deep reinforcement learning)을 통해 복잡한 동작 모방을 달성했으며, 이러한 방법들은 Adversarial Skill Embeddings(ASE)를 이용하여 대규모로 재사용 가능한 스킬을 학습할 수 있도록 확장되었습니다[1809]. 또한 StyleLoco[1695]와 같은 생성형 적대적 증류(generative adversarial distillation) 기법은 자연스러운 보행 움직임의 스타일을 학습하고, Physics-Guided RL[1755]은 물리 기반 제약 조건을 반영하여 민첩한 휴머노이드 로봇 제어를 가능하게 합니다. 이러한 Reference-Based Motion Skill Learning 방법론들은 이족 로봇 캐릭터의 설계 및 제어에도 적용되어 현실성 높은 동작 생성을 실현하고 있습니다[1865].
- Egocentric Navigation in Unseen Environments: Egocentric Navigation in Unseen Environments는 사족 로봇(legged robot)이 자신의 시각 정보를 바탕으로 미지의 환경에서 자율적으로 네비게이션하는 기술을 다룬다. 이 분야는 로봇의 자기중심적 관점(egocentric perspective)에서 수집된 센서 정보를 활용하여 충돌 회피(collision avoidance)와 경로 계획(path planning)을 동시에 수행한다. [1807]에서 제시된 ARMOR와 [2057]의 인간 데이터 기반 학습 접근법은 강화학습(reinforcement learning)을 통해 실제 환경의 복잡성에 대응하는 정책(policy)을 개발한다. [1978]의 파쿠르 프레임워크와 [2122]의 다중 환경 통일 정책은 다양한 지형과 장애물 환경에서 로봇의 일반화 능력(generalization)을 향상시킨다. 이러한 연구들은 미분화된 환경에서의 안전한 로봇 이동을 가능하게 하는 핵심 기술로 주목받고 있다.
- Uncertainty-Aware Diffusion RL Control: Uncertainty-Aware Diffusion RL Control은 다리 로봇의 제어에서 불확실성을 명시적으로 모델링하면서 Diffusion 모델 기반의 강화학습(Reinforcement Learning)을 적용하는 기술입니다. 이 접근법은 부분 관찰(Partial Observations) 환경에서 휴머노이드 로봇의 보행을 학습하거나 [1667], 복잡한 다중 접촉 조작 작업(Multi-Support Manipulation)에서 모방학습(Imitation Learning)을 수행할 때 [1931] 특히 유용합니다. Diffusion 모델의 점진적 생성 과정과 불확실성 정량화를 결합함으로써 로봇은 예측 불가능한 환경에서 더욱 안정적이고 적응적인 정책을 학습할 수 있습니다. 또한 이 방법은 대규모 사전학습(Large-Scale Pretraining)과 실제 로봇 제어 사이의 격차를 줄이는 데 [2154] 기여하며, 쌍방향 인식(Dual Planning and Policy Awareness) 메커니즘을 통해 시간적 일관성을 보장합니다. 결과적으로 Uncertainty-Aware Diffusion RL은 고차원적이고 복잡한 휴머노이드 로봇 제어 문제에서 강력한 성능을 제공합니다.
- Fall Recovery & Upright Stabilization: 이족 휴머노이드 로봇의 낙상 복구(Fall Recovery) 및 직립 안정화(Upright Stabilization)는 강화학습 기반 다리 로봇 제어의 핵심 과제입니다. 부분 관측(Partial Observation) 환경에서의 강화학습 성공 [1696]부터 일반화된 휴머노이드 보행 제어 [1760]에 이르기까지, 다양한 로봇 동작 시나리오에서 강건한 정책(Policy)을 학습하는 것이 중요합니다. 특히 자가 보호 낙상 정책(Self-Protective Falling Policy) 발견 [1880]과 고역학 휴머노이드를 위한 다단계 커리큘럼 학습(Multi-Stage Curriculum Learning) [1976]은 로봇의 안전성을 보장하는 데 필수적입니다. 소수의 시연(Demonstration)으로부터 통합 낙상 안전 정책(Unified Fall-Safety Policy)을 학습하는 방법론 [2171]과 다중 기술 전환의 부드러운 수행을 위한 강건한 정책 게이팅(Robust Policy Gating) [2408]은 실제 로봇 응용에 필요한 실용적 기술들입니다.
- Real-Time Whole-Body Teleoperation for Humanoids: 실시간 전신 원격 조종(Real-Time Whole-Body Teleoperation)은 강화학습 기반의 휴머노이드 로봇 제어에서 인간의 의도를 로봇이 즉각적으로 모방하고 실행하는 기술을 다룹니다. 이 분야의 연구들은 인간과 로봇 간의 운동학적 차이를 극복하고, 폐쇄루프(Closed-Loop) 피드백을 통해 안정적인 제어를 구현하는 데 중점을 두고 있습니다. [1451]과 [1839]는 각각 실시간 전신 원격 조종 학습과 장시간 운영을 위한 폐쇄루프 제어 방식을 제시하고 있으며, [1842]는 전역 운동 추적(Global Motion Tracking)을 위한 방법론을 제안합니다. [2107]과 [2163]은 모의환경에서 실제 환경으로의 전이(Sim-to-Real Transfer)와 모방 학습(Imitation Learning)을 통해 실용적인 휴머노이드 제어 시스템을 구축하고 있습니다. 이러한 연구들의 결합은 복잡한 인간형 로봇의 원격 조종을 더욱 직관적이고 안정적으로 만드는 데 기여합니다.
- Gait Symmetry & Speed-Appropriate Control: 보행 대칭성과 속도 적응 제어(Gait Symmetry & Speed-Appropriate Control)는 강화학습 기반 다리 로봇 제어에서 효율적이고 안정적인 운동을 실현하는 핵심 기술이다. [2065]와 [3356]의 연구는 대칭적이고 저에너지 보행(Symmetric and Low-energy Locomotion)을 학습하여 로봇의 에너지 효율성을 극대화하고 자연스러운 동작을 구현하는 방법을 제시한다. [1940]에서는 다중 단계 커리큘럼(Multi-Phase Curriculum) 기반의 보행 조건부 강화학습(Gait-Conditioned Reinforcement Learning)을 통해 다양한 속도에서 적응적인 제어를 달성한다. [1635]와 [2384]는 축소 모델(Reduced-Order Model)과 수동 신체 역학(Passive Body Dynamics)을 활용한 모델 기반 강화학습(Model-Based Reinforcement Learning) 접근법으로, 계산 효율성을 높이면서도 보행 대칭성을 유지할 수 있음을 보여준다. 이러한 기법들은 로봇의 주행 속도와 지형에 맞춘 적응형 보행 제어를 가능하게 하여 실제 환경에서의 응용성을 크게 향상시킨다.
- Teacher-Student Terrain Locomotion: Teacher-Student Terrain Locomotion(교사-학생 지형 보행)은 강화학습(Reinforcement Learning)을 통해 다리 로봇이 복잡한 지형에서 안정적으로 움직이도록 학습하는 기술입니다. 이 접근법은 숙련된 교사 정책(teacher policy)이 학생 정책(student policy)을 지도하는 모방학습(imitation learning) 및 증류(distillation) 기법을 활용하여 샘플 효율성과 학습 안정성을 동시에 향상시킵니다. [1692]의 Stage-Conditioned Imitation과 [1881]의 Distillation-PPO는 단계별 조건화(stage-conditioned)와 정책 증류를 통해 인간형 로봇(humanoid robot)의 견고한 보행 제어를 실현하는 방법을 제시합니다. [2108]의 Multi-task Deep Reinforcement Learning은 다양한 지형 환경에서 다중 작업(multi-task) 학습을 통해 일반화 능력을 강화하며, [2071]과 같은 정보 탐색(information seeking) 기법은 로봇이 의사결정 과정에서 필요한 환경 정보를 효율적으로 수집하도록 학습합니다. 이러한 기술들의 통합은 레그드 로봇의 보행 제어 분야에서 실제 환경 적응 능력을 획기적으로 향상시키고 있습니다.
- World Model Terrain Estimation: World Model Terrain Estimation은 강화학습 기반 다리 로봇 제어에서 지면의 특성을 추정하고 이를 세계 모델(world model)에 반영하여 로봇의 주행 성능을 향상시키는 기술입니다. 이 접근법은 로봇이 실시간으로 지형 정보를 감지하고 학습하여 불규칙한 환경에서도 안정적인 보행을 수행할 수 있도록 합니다. [1914]와 [3354]의 연구들은 휴머노이드 로봇의 안전하고 쾌적한 보행(safe and comfortable locomotion)을 위해 환경과의 상호작용을 모델링하는 end-to-end reinforcement learning 방식을 제시합니다. [2131]에서 제안된 physics augmentation 기법은 물리 기반의 지형 특성을 정책 학습에 직접 통합하여 샘플 효율성을 높입니다. 이러한 기술들은 데이터 스케일링과 모델 스케일링 [1745]을 통해 더욱 강화되며, 로봇이 복잡한 지형에서의 주행 성능을 지속적으로 개선할 수 있게 합니다.
- Vision-Based Humanoid Parkour: Vision-Based Humanoid Parkour는 인간형 로봇(Humanoid Robot)이 카메라와 같은 시각 센서를 활용하여 복잡한 파쿠르(Parkour) 동작을 학습하고 수행하는 분야입니다. 강화학습(Reinforcement Learning) 기반의 제어 기법을 통해 로봇이 높은 곳으로 뛰어오르기, 벽 타기, 장애물 넘기 등의 동적 인간 기술(Dynamic Human Skills)을 습득하도록 훈련합니다. [1999]와 [2134]의 연구들은 시각 정보를 바탕으로 환경을 인식하면서 파쿠르 운동의 연쇄적 동작(Chaining Dynamic Skills)을 수행하는 방법론을 제시하고 있습니다. [1974]에서 제안된 계층적 비전-언어 계획(Hierarchical Vision-Language Planning) 기법은 다단계 인간형 조작(Multi-Step Humanoid Manipulation) 작업에서 로봇의 의사결정 능력을 향상시킵니다. 이러한 연구들은 확산 정책(Diffusion Policy)과 같은 고급 제어 알고리즘을 결합하여 로봇의 일반화 성능(Generalizability)을 극대화하고 있습니다.
- Difficulty-Adaptive Motion Imitation Curricula: 난이도 적응형 모션 모방 커리큘럼(Difficulty-Adaptive Motion Imitation Curricula)은 강화학습 기반의 다리 로봇 제어에서 복잡한 동작을 단계적으로 학습하는 방법론입니다. [1816]의 연구에서는 휴머노이드 로봇의 모션 모방 학습 벤치마킹을 통해 동작의 난이도를 체계적으로 평가하고 조정하는 방식을 제시하고 있습니다. [1390]과 [2053]의 연구들은 각각 온몸 신체 제어(whole-body control)와 배드민턴 같은 고난이도 스포츠 기술 학습을 통해 점진적 난이도 상향이 얼마나 효과적인지 보여줍니다. 이러한 커리큘럼 학습 방식은 로봇이 단순한 기초 동작부터 시작하여 복잡한 운동 능력까지 효율적으로 습득하도록 돕습니다. [3321]의 물리 인식 모션 재타게팅(physics-aware motion retargeting) 연구도 실제 물리 환경에서의 적응적 학습을 강조하며, 이는 난이도 조절 커리큘럼의 실무 적용성을 높입니다.
- Human-Inspired Fall Protection: 인간형 로봇의 넘어짐 방지 및 보호 제어(fall protection)는 실제 환경에서 로봇의 안전성을 보장하는 핵심 기술이다. [1649]는 강화학습을 통해 로봇이 부드럽고 세련된 방식으로 넘어지는 동작을 학습하여 충격을 최소화하는 접근법을 제시한다. [1661]의 SafeFall 프레임워크는 휴머노이드 로봇이 위험한 상황에서 스스로를 보호하는 제어 정책(control policy)을 습득하도록 설계되었다. [1747]과 [2150]은 시각 정보(visual input)와 신체 구조의 공동 최적화(co-design)를 통해 더욱 견고한 낙상 대응 능력을 구현하는 통합적 접근법을 보여준다. 이러한 연구들은 인간의 본능적 낙상 반응을 모방하여 로봇의 내구성과 안전성을 동시에 향상시키는 데 기여한다.
- Few-Shot Robot Skill Pretraining: Few-Shot Robot Skill Pretraining은 제한된 데이터와 학습 시간으로 다리 로봇(legged robot)이 새로운 기술을 빠르게 습득하도록 하는 강화학습 기법입니다. 이는 사전학습(pretraining)된 기초 정책(policy)을 활용하여 샘플 효율성(sample efficiency)을 크게 향상시키며, 실제 로봇 환경에서의 적응(adaptation)을 가능하게 합니다. [1652]에서는 로봇이 자동으로 실제 환경에 정책을 적응시키는 방법을 제시했으며, [1962]에서는 휴머노이드 로봇(humanoid robot) 간의 사전학습을 통해 적응형 학습(few-shot adaptation)의 효율성을 입증했습니다. [1943]과 [3319]는 행동 복제(behavior cloning) 프레임워크와 멀티스킬 제너레이티브 컨트롤러(multi-skill generative controller)를 통해 전신 협조 제어(whole-body coordinated control)와 다양한 보행 기술(locomotion skill) 학습을 통합적으로 다루고 있습니다. 이러한 접근법들은 로봇의 일반화 능력(generalization capability)을 향상시켜 현실의 복잡한 작업 환경에서 효과적으로 작동할 수 있도록 합니다.
- Bipedal Sim-to-Real Terrain Walking: 이족 로봇(bipedal robot)의 시뮬레이션-실제 환경 전환(sim-to-real transfer) 기술은 복잡한 지형에서의 보행 제어를 학습하는 데 핵심적인 역할을 한다. [1657]에서 제시된 연구는 순응형 및 불규칙한 지형(compliant and uneven terrain)에서 휴머노이드 로봇의 견고한 보행을 위해 강화학습(reinforcement learning)을 적용하여 실제 환경 적응성을 크게 향상시켰다. [1818]의 버클리 휴머노이드는 학습 기반 협력제어(learning-based co-control) 연구 플랫폼으로서 전신 로봇 제어(whole-body robot control)의 실질적 구현을 가능하게 했다. [2007]의 휴머노이드벤치(HumanoidBench)는 전신 학습(whole-body learning) 벤치마크를 제공하여 다양한 알고리즘의 성능을 체계적으로 평가할 수 있는 표준화된 환경을 구축했다. [2110]에서는 단거리 보행(short-range locomotion) 학습에 행진 동작(marching)에서 벗어난 새로운 보행 패턴을 도입하여 보행의 자연성과 효율성을 개선했다.
- Humanoid Ball Sports Skills: 휴머노이드 로봇의 공 스포츠 기술(Humanoid Ball Sports Skills) 학습은 강화학습(Reinforcement Learning)을 기반으로 복잡한 동작 제어를 실현하는 분야입니다. 이 분야는 데모(Demonstration)로부터 농구 상호작용 기술(Basketball Interaction Skills)을 모방(Mimic)하는 접근법[1679]부터 장시간 지평선(Long-Horizon) 정책 구성(Policy Composition)을 통한 바스켓 동작 학습[2066]까지 다양한 방법론을 포함합니다. 특히 외부 방해(Disturbances) 상황에서도 안정적으로 임의의 동작(Any Motions)을 추적(Track)할 수 있는 강건한(Robust) 제어 기술이 핵심입니다[2158]. 이러한 기술들은 시뮬레이션 환경에서의 학습 효율성을 높이고 실제 로봇 플랫폼으로의 전이(Transfer)를 가능하게 합니다. 휴머노이드 로봇이 인간 수준의 공 스포츠 기술을 습득하기 위해서는 정책 학습(Policy Learning), 동작 모방(Motion Imitation), 그리고 적응형 제어(Adaptive Control)의 통합이 필수적입니다.
- Full-Body Throwing & Goalkeeping Skills: Full-Body Throwing & Goalkeeping Skills는 다리가 있는 휴머노이드 로봇이 팔과 몸 전체를 협력하여 던지기(throwing)와 골키퍼(goalkeeper) 같은 고도의 동적 제어(dynamic control) 기술을 습득하는 강화학습(reinforcement learning) 분야입니다. [1757]에서는 다리 조작기(legged manipulators)를 이용한 전신 동적 던지기 기술을 개발하여 복잡한 물체 투사(object projection) 작업을 수행하며, [1994]는 위치 조건부 작업(position conditioned task)에서 학습하는 휴머노이드 골키퍼 모델을 제시합니다. [1694]의 물체 균형 잡기(object balancing) 기술과 같이 이러한 기술들은 로봇의 안정성(stability)과 정확도(accuracy)를 동시에 요구합니다. 이 분야의 발전은 로봇이 스포츠나 산업 현장에서 인간 수준의 민첩한 움직임(agile movement)을 구현하는 데 중요한 기초가 됩니다.
- Contact-Aware Human-to-Robot Motion Retargeting: Contact-Aware Human-to-Robot Motion Retargeting은 인간의 동작을 다리 로봇(legged robot)으로 전달할 때 접촉(contact) 정보를 고려하는 기술입니다. 이는 인간과 로봇의 신체 구조 차이를 극복하면서도 동작의 본질적인 특성을 보존하기 위해 접촉 상태와 힘(force)을 명시적으로 고려합니다 [1785]. Implicit Kinodynamic Motion Retargeting [2021]과 같은 방식들은 로봇의 동역학(kinodynamics)을 자동으로 학습하여 인간의 동작을 더욱 자연스럽게 재현합니다. 또한 Interactive Whole-Body Control [2030]을 통해 환경과의 상호작용 과정에서 동작 적응이 이루어지며, Safe Human-to-Humanoid Motion Imitation [2385]에서는 제어 장벽 함수(control barrier function)를 활용하여 안전성을 보장합니다. 강화학습(reinforcement learning) 기반의 접근 방식은 이러한 복잡한 재타겟팅 문제를 효율적으로 해결할 수 있습니다.
- Dual-Agent Curriculum Learning: 듀얼-에이전트 커리큘럼 학습(Dual-Agent Curriculum Learning)은 강화학습 기반의 다리형 로봇 제어에서 두 개의 에이전트가 상호작용하며 점진적으로 학습 난이도를 조절하는 방식입니다. [1964]에서 제안된 HAFO는 힘 적응 제어(Force-Adaptive Control) 프레임워크로 로봇이 환경과의 상호작용을 통해 동적으로 제어 전략을 조정합니다. [2032]의 JAEGER는 듀얼-레벨 인간형 로봇 전신 제어기(Dual-Level Humanoid Whole-Body Controller)로 상위 계층과 하위 계층의 에이전트 간 협력을 통해 복잡한 운동 제어를 수행합니다. [2036]은 운동학 인식 다중 정책 강화학습(Kinematics-Aware Multi-Policy Reinforcement Learning)을 활용하여 로봇의 기하학적 제약을 고려한 학습을 진행합니다. [2094]의 기계적 지능 인식 커리큘럼 학습(Mechanical Intelligence-Aware Curriculum Reinforcement Learning)은 로봇의 물리적 특성을 학습 과정에 반영하여 더욱 효율적인 제어 정책을 수립합니다.
- Visual-Motor Terrain Perception: Visual-Motor Terrain Perception(시각-운동 지형 인식)은 강화학습 기반 다족 로봇 제어에서 환경의 지형 정보를 시각적으로 인식하고 이를 바탕으로 운동 제어를 수행하는 분야입니다. 이러한 접근 방식은 로봇이 복잡한 지형에서 안정적으로 이동하기 위해 카메라나 센서로부터 획득한 시각 정보(visual input)를 실시간으로 처리하여 모터 명령(motor command)으로 변환합니다. [1975]의 계층적 시각-운동 제어(hierarchical visuomotor control) 기법과 [2080]의 복잡한 지형에서의 통합 기술 개발(integrative skill development) 연구는 인간형 로봇이 다양한 환경에 적응하는 능력을 향상시키는 데 중점을 두고 있습니다. 또한 [2074]에서 다루는 반응형 기술 학습(reactive skill learning)과 [2389]의 다중 기술 지속 학습(multi-skill continual learning)은 로봇이 여러 운동 과제를 통합적으로 학습하면서 지형 인식 능력을 동시에 개선하는 방법을 제시합니다. 이러한 연구들은 로봇의 자율성(autonomy)과 환경 적응성(environmental adaptability)을 크게 향상시키는 데 기여하고 있습니다.
- Single-Stage Proprioceptive Motion Skill Integration: # Single-Stage Proprioceptive Motion Skill Integration 단일 단계 고유감각 기반 동작 기술 통합(Single-Stage Proprioceptive Motion Skill Integration)은 강화학습을 통해 로봇이 센서 피드백(sensor feedback)만을 활용하여 복잡한 운동 기술을 직접 학습하고 통합하는 방식입니다. [1617]의 저저수준 제어기(low-level controller) 연구와 [1655]의 동작 추적(motion tracking) 기술은 고유감각 정보(proprioceptive information)를 기반으로 하는 단일 신경망 구조의 효율성을 보여줍니다. 이 접근법은 복잡한 계층적 제어 구조를 제거하면서도 안정적이고 강건한(robust) 움직임을 달성할 수 있으며, [2063]의 축구 기술 학습 연구는 이러한 통합 접근법이 다양한 실제 운동(locomotion) 과제에 적용 가능함을 입증합니다. 단일 단계 통합 방식은 학습 시간 단축, 시뮬레이션 전이(sim-to-real transfer) 성능 향상, 그리고 계산 효율성(computational efficiency) 측면에서 장점을 제공합니다.
- Multi-Behavior Adaptive Control: 다중 행동 적응형 제어(Multi-Behavior Adaptive Control)는 휴머노이드 로봇이 다양한 작업과 환경 변화에 유연하게 대응할 수 있도록 하는 강화학습 기반의 제어 기법입니다. 이는 사전학습(Pre-training)과 미세조정(Fine-tuning) 단계를 통해 로봇이 여러 행동 양식을 효율적으로 학습하고, 이를 새로운 상황에 맞게 적응시키는 방식으로 작동합니다[1621]. 특히 현실 세계의 휴머노이드 로봇에 적용할 때 일어나기(Getting-Up), 걷기, 균형잡기 등 다양한 기본 행동들을 습득하고 실제 환경에서 안정적으로 수행하는 것이 핵심 과제입니다[2051]. 행동 증류(Behavior Distillation) 기법을 활용하면 여러 전문화된 정책(Policy)들의 지식을 통합하여 하나의 적응형 제어 시스템으로 통합할 수 있습니다[2153]. 이러한 접근 방식은 로봇이 제한된 계산 자원 내에서도 복잡한 환경 변화에 신속하게 대응하고, 서로 다른 행동 간의 전환을 매끄럽게 수행할 수 있게 합니다.
- Whole-Body Agile Motion Retargeting: 전신 민첩 동작 재타겟팅(Whole-Body Agile Motion Retargeting)은 강화학습 기반 다리 로봇 제어에서 인간의 표현력 있는 동작을 로봇이 물리적으로 실현 가능한 형태로 변환하는 기술 영역입니다. [1681]의 자기감독 동작 적응(Self-supervised Motion Adaptation) 방법론은 대규모 모션 캡처 데이터 없이도 로봇의 신체 특성에 맞춘 동작 학습을 가능하게 합니다. [1795]에서는 이질적 신체 구조를 가진 휴머노이드 로봇에서 민첩성(Agility)과 안정성(Stability)의 균형을 유지하면서 다양한 제어 목표를 달성하는 방법을 제시합니다. [1918]의 고급 표현 휴머노이드 전신 제어 기술은 복잡한 제스처, 댄싱, 스포츠 동작 등 고차원의 동작 표현을 로봇 플랫폼에 효율적으로 재타겟팅합니다. 이러한 기술들은 심층 강화학습(Deep Reinforcement Learning)과 동작 재매핑(Motion Retargeting) 알고리즘의 결합을 통해 로봇의 자율적 운동 능력을 비약적으로 향상시킵니다.
- Whole-Body Tennis Motion Planning: 휴머노이드 로봇의 전신 테니스 동작 계획은 복잡한 신체 제어와 고속의 동적 움직임을 요구하는 도전적인 문제입니다. 강화학습(Reinforcement Learning)을 활용한 계층적 계획 방식을 통해 핀, 탁구, 배드민턴 등 다양한 라켓 스포츠 동작을 학습하고 실행할 수 있습니다. [1682]에서는 확장 가능한 전신 기술(Scalable Whole-Body Skills) 습득을 위한 SMASH 방법론을 제시하며, [1979]의 HITTER 시스템은 계층적 계획(Hierarchical Planning)을 통해 탁구 로봇의 성능을 향상시킵니다. [2003]의 다단계 강화학습(Multi-Stage Reinforcement Learning) 접근법은 배드민턴 동작의 복합성을 단계적으로 해결함으로써 높은 정확도의 라켓 스포츠 실행을 가능하게 합니다. 이러한 연구들은 로봇이 인간 수준의 민첩한 스포츠 동작을 습득하는 데 중요한 기초를 제공합니다.
- Compliant End-Effector Force Control: 순응형 말단 집행기 힘 제어(Compliant End-Effector Force Control)는 강화학습 기반 다리 로봇 제어에서 환경과의 접촉 시 유연성과 안정성을 동시에 확보하는 핵심 기술이다. 이는 로봇의 말단 집행기(end-effector)가 일정한 힘 범위 내에서 능동적으로 순응(compliance)하도록 제어함으로써, 경직된 제어 방식보다 안전하고 자연스러운 상호작용을 가능하게 한다. SoftMimic [1684]과 CHIP [1836] 연구들은 모방 학습(imitation learning)과 적응적 순응성(adaptive compliance)을 통해 휴머노이드 로봇의 전신 제어에서 우수한 성능을 입증했다. GentleHumanoid [1953]는 상체 순응성 학습에 중점을 두어 접촉 반응 작업(contact-rich tasks)에서의 안정성을 향상시켰다. 이러한 접근 방식들은 로봇이 복잡한 물리적 상호작용 환경에서 견고하고 부드러운 제어를 실현할 수 있도록 하며, 실제 산업 및 일상 환경 배포에서의 안전성 요구사항을 충족시킨다.
- Indoor Cluttered Scene Navigation: 실내 복잡한 환경에서의 로봇 네비게이션(Navigation)은 강화학습 기반의 다리 로봇 제어 분야에서 중요한 연구 주제이다. 이 영역은 장애물 회피(Collision Avoidance)와 동시에 목표 지점에 도달해야 하는 복합적인 과제를 다루며, 휴머노이드 로봇(Humanoid Robot)의 동적 안정성을 유지하면서 효율적인 이동을 실현하는 것을 목표로 한다. [1845]에서는 복잡한 실내 장면에서 충돌 없이 이동하는 휴머노이드 로봇의 순회 능력을 구현하였으며, [2082]에서는 장기간의 복합적인 과제 수행을 위한 통합 정책(Unified Policy)을 학습하는 방식을 제시하였다. 이러한 연구들은 심층 강화학습(Deep Reinforcement Learning)과 시뮬레이션-현실 전이(Sim-to-Real Transfer)를 활용하여 현실 세계의 동적이고 불규칙한 환경에 적응하는 로봇의 자율성(Autonomy)을 향상시키고 있다.
- Unified Loco-Manipulation Single Policy: # 통합 이동-조작 단일 정책 (3편) 휴머노이드 로봇의 이동(locomotion)과 조작(manipulation) 작업을 하나의 정책(single policy)으로 통합 제어하는 강화학습 기반 접근법입니다. [1863]은 단일 시연(demonstration)으로부터 시작하여 일반화 가능한 휴머노이드 제어 정책을 학습하는 방법을 제시하며, [2126]은 동역학적으로 실현 가능한 전신 궤적(whole-body trajectory) 모방을 통해 기술 습득(skill learning)을 최적화합니다. [2165]은 이동과 조작 작업을 미세 단위로 제어하는 통합 제어기(unified controller)를 개발하여 복잡한 다중 작업 시나리오에서의 성능을 향상시킵니다. 이러한 연구들은 보강 학습(reinforcement learning)과 모방 학습(imitation learning)을 결합하여 로봇의 자율성과 적응성을 동시에 증진시키는 것을 목표로 합니다.
⚠ 갭: 대규모 병렬 시뮬레이션 기반 학습이 주류가 되었음에도 실제 로봇 배포 시 발생하는 신뢰성·안전성·책임 귀속 문제에 대한 체계적 연구와 표준화가 부재하다.
🏛 정책: RL 기반 로봇 제어 정책의 산업 현장 배포를 위한 검증·인증 체계를 국제 표준화 기구와 협력하여 선도적으로 개발해야 한다.
BEHAVIOR Robot Suite: Streamlining Real-World Whole-Body Manipulation for Everyday Household Activities
Figure 1: Everyday household activities enabled by BEHAVIOR ROBOT SUITE (BRS), show-
 *Figure 1: Everyday household activities enabled by BEHAVIOR ROBOT SUITE (BRS), show-* BEHAVIOR Robot Suite (BRS)는 가정용 일상 작업을 수행하기 위한 양팔 협력, 안정적 네비게이션, 광범위한 말단 장치 도달성을 갖춘 전신 조작 로봇을 위한 통합 프레임워크를 제시한다. JoyLo 원격 조작 인터페이스와 WB-VIMA 시각운동 정책 학습 알고리즘을 통해 실세계 가정 작업 수행을 가능하게 한다.
BEHAVIOR Robot Suite는 가정용 일상 작업을 위한 전신 조작 로봇의 완전한 생태계를 제시하는 포괄적 연구로, JoyLo의 창의적인 저비용 설계와 WB-VIMA의 계층적 자동회귀 정책 학습이 결합되어 실세계 가정 로봇의 실질적 진전을 이룬다. 특히 하드웨어, 데이터 수집, 알고리즘을 완전히 오픈소스화함으로써 커뮤니티 확산 가능성이 높으며, 다중 도메인의 체계적 통합을 통해 로봇 학습 연구에 의미 있는 기여를 한다.
Quasi-Direct Drive for Low-Cost Compliant Robotic Manipulation
Fig. 1.
 *Fig. 1.* Quasi-Direct Drive 구동방식을 기반으로 한 저비용 7-DOF 로봇 팔 Blue를 제안하여 인간 환경에서 안전하고 힘 제어 가능한 조작을 가능하게 함.
이 논문은 인간 환경에서 필요한 저비용 compliant 로봇의 설계 패러다임을 재정의하고 Quasi-Direct Drive 방식을 통해 이를 실현한 획기적 연구로, AI 기반 로봇 학습의 대규모 보급을 가능하게 하는 중요한 플랫폼을 제시함.
Reinforcement Learning with Data Bootstrapping for Dynamic Subgoal Pursuit in Humanoid Robot Navigation
 *Fig. 2. Overall structure of the proposed hierarchical framework for humanoid navigation. The high-level RL-based planne* Humanoid robot navigation을 위해 고수준 RL 기반 동적 subgoal 생성기와 저수준 MPC 기반 보행 제어기를 결합한 계층적 프레임워크를 제안하며, data bootstrapping 기법으로 학습을 안정화한다.
Bipedal robot navigation을 위한 RL과 MPC의 계층적 결합은 창의적이며, data bootstrapping을 통한 학습 안정화는 실질적 기여이나, 시뮬레이션 환경만의 검증과 동적 환경 미평가가 실제 적용까지의 간격을 남긴다.
SEEC: Stable End-Effector Control with Model-Enhanced Residual Learning for Humanoid Loco-Manipulation
 *Fig. 2: System framework overview of SEEC. Our SEEC framework decouples the humanoid loco-manipulation controller into u* SEEC는 model-enhanced residual learning을 통해 휴머노이드 로봇의 보행 중 팔 end-effector를 안정적으로 제어하는 프레임워크로, 하지 유도 교란에 대해 모델 기반 보상 신호를 RL 정책에 통합한다.
SEEC는 모델 기반 제어의 정밀성과 RL의 적응성을 효과적으로 결합하며, perturbation 생성을 통한 모듈식 설계로 미학습 제어기에도 robust하게 전이되는 점에서 높은 독창성을 보인다. 실제 휴머노이드 로봇 배포와 다양한 loco-manipulation 작업 검증으로 실용성도 입증하였다.
Sim-to-Real Learning for Humanoid Box Loco-Manipulation
Fig. 1: We learn box loco-manipulation policies in simulation
 *Fig. 1: We learn box loco-manipulation policies in simulation* 본 연구는 인간형 로봇 Digit의 박스 집기 및 운반 작업을 위해 강화학습 기반의 sim-to-real 접근법을 제시하며, 5가지 분리된 정책(걷기, 서기, 집기, 박스 들고 걷기, 박스 들고 서기)을 학습하여 실제 하드웨어에서 성공적으로 전이했다.
본 논문은 인간형 이족 로봇의 복합적인 loco-manipulation 작업에 대한 첫 sim-to-real RL 성공 사례를 제시하며, 실용적인 보상 함수 설계와 action space 선택을 통해 자연스러운 동작을 학습했다는 점에서 의의가 있다. 다만 phase 관리의 경직성과 박스 pose 추정 오차 등 개선의 여지가 있어 기술적으로는 중간 수준이지만 실제 하드웨어 적용이라는 중요한 성과와 명확한 기여로 높은 가치를 가진다.
SPARK: Safe Protective and Assistive Robot Kit
 *Figure 3: SPARK system framework.* SPARK는 휴머노이드 로봇의 안전한 자율 제어와 원격 조종을 위한 포괄적인 벤치마크 프레임워크로, 모듈식 안전 제어 알고리즘과 시뮬레이션 환경을 제공하여 비전문가도 안전 컨트롤러를 효율적으로 설계하고 배포할 수 있도록 지원한다.
SPARK는 휴머노이드 로봇의 안전한 제어를 위한 실질적이고 체계적인 프레임워크를 제시하는 높은 가치의 연구로, 모듈식 설계, 벤치마크 제공, 실제 배포 검증을 통해 안전 로봇 연구를 가속화할 수 있는 견고한 기반을 마련했다.
EgoMI: Learning Active Vision and Whole-Body Manipulation from Egocentric Human Demonstrations
Fig. 1: Overview of the EgoMI framework. EgoMI captures egocentric human demonstrations with synchronized head and hand
 *Fig. 1: Overview of the EgoMI framework. EgoMI captures egocentric human demonstrations with synchronized head and hand* EgoMI는 인간의 동시화된 머리 및 손 움직임을 포착하는 egocentric 데이터 수집 프레임워크로, SPARKS 메모리 메커니즘을 통해 급속한 시점 변화를 처리하여 반인간형 로봇으로 zero-shot 전이를 달성한다.
EgoMI는 인간의 active vision과 manipulation을 동시에 포착하는 창의적 프레임워크로, SPARKS 메커니즘을 통해 급속한 시점 변화를 우아하게 처리하며 zero-shot transfer를 달성해 imitation learning의 embodiment gap 문제에 실질적 솔루션을 제시한다.
Emergent Active Perception and Dexterity of Simulated Humanoids from Visual Reinforcement Learning
Figure 1. Perceptive Dexterous Control (PDC) enables a humanoid equipped with egocentric vision to search for, reach, gr
 *Figure 1. Perceptive Dexterous Control (PDC) enables a humanoid equipped with egocentric vision to search for, reach, gr* 본 논문은 egocentric vision만을 사용하여 simulated humanoid가 복잡한 household tasks를 수행하도록 하는 Perceptive Dexterous Control (PDC) 프레임워크를 제안하며, visual perception을 task specification의 인터페이스로 활용하여 active search 등의 emergent behaviors를 유도한다.
본 논문은 egocentric vision을 유일한 정보원으로 하는 humanoid whole-body dexterous control의 실현이라는 도전적 문제를 perception-as-interface 패러다임과 hierarchical RL을 통해 창의적으로 해결하며, emergent active search behaviors의 명시적 입증을 통해 vision-driven control의 이점을 새롭게 조명한다.
EMP: Executable Motion Prior for Humanoid Robot Standing Upper-body Motion Imitation
 *Fig. 2: Overview of our framework. Motion Retargeting (section III): We train a graph convolution retargeting network to* 휴머노이드 로봇이 서 있는 자세를 유지하면서 인간의 상체 동작을 모방하기 위해 강화학습과 Executable Motion Prior(EMP) 모듈을 결합한 프레임워크를 제안한다.
이 논문은 RL과 동작 prior를 결합하여 휴머노이드 로봇의 안정적인 상체 동작 모방을 실현하는 실용적인 솔루션을 제시하며, 실제 로봇 배포를 통해 그 효과를 입증한 우수한 연구이다.
ExtremControl: Low-Latency Humanoid Teleoperation with Direct Extremity Control
Fig. 1: The humanoid robot (Unitree G1) demonstrates a diverse set of loco-manipulation tasks under teleoperation: (a) r
 *Fig. 1: The humanoid robot (Unitree G1) demonstrates a diverse set of loco-manipulation tasks under teleoperation: (a) r* ExtremControl은 SE(3) 포즈 기반의 직접 제어와 velocity feedforward 제어를 통해 humanoid teleoperation의 지연시간을 50ms까지 단축하는 저지연 전신 제어 프레임워크이다.
ExtremControl은 velocity feedforward와 direct extremity control을 결합하여 humanoid teleoperation의 지연시간을 4배 단축하고 고속 반응 작업을 실현한 혁신적 연구로, 실제 로봇에서의 높은 응답성 달성과 통합된 시스템 구현으로 실용적 가치가 우수하다.
FALCON: Learning Force-Adaptive Humanoid Loco-Manipulation
Figure 1: FALCON enables versatile forceful loco-manipulation tasks for humanoids: (a) Transporting Pay-
 *Figure 2: Overview of FALCON. (a) Two agents with different sub-tasks are jointly trained with* FALCON은 이중 에이전트 강화학습 프레임워크로, 하체의 안정적 보행과 상체의 정밀한 말단 장치 위치 추적을 분리하여 학습함으로써 휴머노이드 로봇이 0-100N의 큰 외부 힘에 적응하면서 강제적 작업을 수행하도록 한다.
FALCON은 휴머노이드의 강제적 로코-조작 문제를 이중 에이전트 분해와 힘 커리큘럼 설계로 효과적으로 해결하며, 다중 플랫폼 배포와 2배의 추적 정확도 향상을 입증함으로써 실용적 가치가 높다. 다만 sim-to-real 갭 극복 메커니즘과 극단적 환경 강건성에 대한 분석이 더 필요하다.
FAME: Force-Adaptive RL for Expanding the Manipulation Envelope of a Full-Scale Humanoid
Fig. 1: FAME overview and real demonstration. Left: FAME conditions a standing policy on an upper-body context encoder t
 *Fig. 2: Overview of the proposed standing framework. During training (top), an upper-body dynamics encoder processes* FAME는 양팔 조작 시 외부 손 힘으로 인한 균형 교란을 해결하기 위해, 상체 관절 구성과 양팔 상호작용 힘을 인코딩하는 latent context에 조건화된 RL 정책을 학습한다.
FAME는 latent context adaptation을 양팔 조작 중 balance 문제에 창의적으로 적용하며, 센서 불필요 배포와 실세계 검증으로 실용적 기여를 한다. 다만 sim-to-real 격차와 힘 추정 정확도 분석이 보강되면 더욱 강력해질 것이다.
HAIC: Humanoid Agile Object Interaction Control via Dynamics-Aware World Model
 *Fig. 3: Overview of our Dynamics-aware World Model. It predicts object* HAIC는 humanoid 로봇이 독립적인 동역학을 가진 미작동(underactuated) 물체와 상호작용할 수 있도록 dynamics-aware world model을 통해 proprioception만으로 고차 가속도를 예측하고 기하학적 projection을 통해 시각 blind spot에서도 강건한 제어를 실현한다.
본 논문은 humanoid 로봇의 underactuated 물체 상호작용이라는 현실적으로 중요한 문제를 proprioception 기반의 창의적인 dynamics prediction과 geometric projection으로 우아하게 해결하며, 실제 로봇에서 SOTA 성능을 입증한 매우 강력한 기여이다.
HiWET: Hierarchical World-Frame End-Effector Tracking for Long-Horizon Humanoid Loco-Manipulation
Fig. 1.
 *Fig. 2.* HiWET는 휴머노이드 로봇의 장기 조작 작업을 위해 세계 좌표계 기준 end-effector 추적을 명시적으로 수행하는 계층적 강화학습 프레임워크를 제안한다. Kinematic Manifold Prior를 통해 탐색 공간을 감소시키고 동역학적 안정성을 유지하면서 정밀한 추적을 달성한다.
HiWET는 world-frame 중심 재정의와 Kinematic Manifold Prior를 통해 휴머노이드 조작에서 정밀하고 안정적인 추적을 실현한 창의적 연구이다. 실제 로봇 검증과 12.4 mm의 추적 정확도로 실질적 기여를 입증하였으며, 계층적 설계와 명시적 공간 인터페이스는 장기 로컬로조작 문제의 효과적 해결 방안을 제시한다.
HMC: Learning Heterogeneous Meta-Control for Contact-Rich Loco-Manipulation
Fig. 1: Rolling out HMC for contact-rich tasks on a humanoid robot. Compared to na¨ıve position-only policies [5, 26,
 *Fig. 2: System overview. HMC-Controller accepts inputs from either a VR-based teleoperation system or HMC-Policy* 로봇의 접촉이 많은 조작 작업을 위해 위치, 임피던스, 하이브리드 힘-위치 제어를 적응적으로 혼합하는 HMC(Heterogeneous Meta-Control) 프레임워크를 제안하며, mixture-of-experts 라우팅을 통해 대규모 위치 데이터와 미세한 힘 인식 시연으로부터 학습한다.
HMC는 실제 접촉이 많은 조작 작업의 도전을 체계적으로 해결하는 실용적이고 혁신적인 프레임워크로, 통합된 제어 인터페이스와 이질적 정책 설계가 50% 이상의 성능 향상을 달성하며 로코-조작 분야에 의미 있는 기여를 제시한다.
Humanoid Robot Acrobatics Utilizing Complete Articulated Rigid Body Dynamics
 *Figure 2: Jump phases. Magenta: Launch phase, blue: flight* 고도화된 동적 동작을 수행하는 휴머노이드 로봇을 위해 완전한 articulated rigid body dynamics를 기반으로 하는 제어 아키텍처를 제시하며, trajectory optimization과 whole-body control을 model abstraction으로 중개하여 아크로바틱 동작을 실현한다.
휴머노이드 로봇의 고도 동적 제어에 대한 개념적·이론적 기여도가 높고 control architecture가 체계적이나, 시뮬레이션 검증에 한정되고 optimization 방법론 세부사항이 부족하여 실질적 영향력에는 제약이 있다.
HWC-Loco: A Hierarchical Whole-Body Control Approach to Robust Humanoid Locomotion
HWC-Loco는 휴머노이드 로봇의 견고한 이동을 위해 계층적 정책 구조로 목표 추적과 안전 복구 간의 trade-off를 동적으로 해결하는 강화학습 기반 전신 제어 알고리즘이다.
HWC-Loco는 휴머노이드 로봇 제어의 현실적 과제인 sim2real gap과 안전성 대 성능의 trade-off를 효과적으로 해결하는 혁신적인 계층적 제어 프레임워크이며, 광범위한 실험 검증을 통해 실용적 가치를 입증했다.
HYPERmotion: Learning Hybrid Behavior Planning for Autonomous Loco-manipulation
Figure 1: HYPERmotion enables the humanoid robot to learn, plan, and select behaviors to
 *Figure 2: Overview of HYPERmotion.We decompose the framework into four sectors: Motion* HYPERmotion은 강화학습과 최적화를 결합하여 휴머노이드 로봇이 자연어 명령으로부터 복잡한 로코-조작 작업을 자율적으로 수행할 수 있도록 하는 계층적 행동 계획 프레임워크이다. LLM과 VLM을 활용하여 의미론적 지시를 원시 행동 기술로 변환하고 동적 환경에서 형태론적 선택을 수행한다.
HYPERmotion은 고자유도 휴머노이드 로봇의 자율적 로코-조작을 자연어 명령으로부터 수행하는 포괄적이고 실용적인 프레임워크를 제시하며, 특히 LLM/VLM과 로봇 제어의 통합, 실제 로봇 배포 실현은 해당 분야에서 의미 있는 진전을 보여준다. 다만 계산 복잡도, 환경 적응성, 완전한 자동화 측면에서 개선 여지가 있다.
Learning Adaptive Neural Teleoperation for Humanoid Robots: From Inverse Kinematics to End-to-End Control
Figure 1: Neural teleoperation policy architecture. The network takes VR controller poses (14-dim), joint states (28-
 *Figure 1: Neural teleoperation policy architecture. The network takes VR controller poses (14-dim), joint states (28-* VR 텔레오퍼레이션에서 전통적인 IK+PD 파이프라인을 RL 기반 신경망 정책으로 대체하여 힘 적응, 궤적 부드러움, 사용자 적응을 동시에 달성하는 학습 기반 프레임워크를 제안한다.
학습 기반 신경망 정책으로 VR 텔레오퍼레이션의 근본적 한계를 해결하고 명확한 성능 향상을 보여주는 실질적으로 가치 있는 연구이며, 모방 학습과 교과 학습의 조합 설계가 우수하다.
Learning Humanoid Arm Motion via Centroidal Momentum Regularized Multi-Agent Reinforcement Learning
 *Fig. 2: Overview of our limb-level multi-agent reinforcement learning framework with CAM regularization. Separate actor-* 인간의 팔 스윙 운동에서 영감을 받아, centroidal angular momentum (CAM) 추적 보상을 통해 다리와 팔을 별도의 에이전트로 취급하는 multi-agent RL 프레임워크를 제시하여 휴머노이드 로봇의 협응 제어를 달성한다.
본 논문은 centroidal dynamics의 물리적 의미와 생역학적 원리를 CTDE 기반 multi-agent RL과 효과적으로 결합하여, 휴머노이드 로봇의 자연스러운 팔 스윙과 향상된 균형 제어를 달성한 독창적이고 실용적인 연구이다.
MetaWorld-X: Hierarchical World Modeling via VLM-Orchestrated Experts for Humanoid Loco-Manipulation
 *Fig. 2: MetaWorld-X achieves natural humanoid control through the dynamic orchestration of expert policies guided by a* 휴머노이드 로봇의 복잡한 로코-매니퓰레이션 제어를 Specialized Expert Policy(SEP)와 VLM 기반 Intelligent Routing Mechanism(IRM)으로 분해-통합하는 계층적 프레임워크를 제안한다. 인간 모션 프라이어와 의미적 라우팅을 결합하여 자연스럽고 안정적인 동작을 생성한다.
MetaWorld-X는 human motion priors, world models, VLM 기반 의미적 라우팅을 창의적으로 결합하여 고자유도 휴머노이드 로코-매니퓰레이션 제어의 중요한 문제(스킬 간섭, 부자연스러운 동작, 낮은 일반화)를 효과적으로 해결한다. Humanoid-bench에서의 강력한 실험 결과와 명확한 방법론 제시에도 불구하고, 실제 로봇 검증 부재가 임팩트를 제한한다.
Mobile-TeleVision: Predictive Motion Priors for Humanoid Whole-Body Control
Fig. 1: Humanoid robot doing whole-body tasks that require both precise manipulation and robust locomotion. The robot
 *Fig. 2: The training pipeline consists of three stages: (a) preprocessing of the motion dataset by mapping local rotatio* 휴머노이드 로봇의 전신 제어를 위해 상체 조작과 하체 보행을 분리하고, CVAE 기반 Predictive Motion Priors (PMP)를 사용하여 상체의 정밀한 조작과 하체의 강건한 보행을 동시에 달성한다.
상체 정밀 조작과 하체 강건 보행이라는 근본적으로 다른 요구를 효과적으로 분리하면서도 CVAE 기반 motion prior를 통해 통합하는 창의적 접근으로, 고 DoF 팔 제어에서 기존 전신 RL 방법을 명확히 능가한다. 실세계 텔레오퍼레이션 가능성까지 보여주어 실용성이 높은 연구이다.
MorphoGuard: A Morphology-Based Whole-Body Interactive Motion Controller
Figure 1: Schematic of morphology-based whole-body motion control (MorphoGuard). (A) An example of a robot
 *Figure 1: Schematic of morphology-based whole-body motion control (MorphoGuard). (A) An example of a robot* 로봇의 형태학적 표현을 기반으로 Material Point Method를 활용하여 전신 제어 네트워크 MorphoGuard를 제안. 복잡한 다중 접촉 조합을 명시적으로 관리하며 1cm의 접촉점 관리 오차를 달성.
복잡한 다중 접촉 조합을 관리하는 로봇 전신 제어의 미해결 문제를 형태학적 표현과 Material Point Method의 창의적 결합으로 우아하게 해결했으며, 높은 정확도의 실험 결과를 보여준다. 다만 단일 플랫폼 실험과 일반화 가능성에 대한 검증이 보완되면 더욱 강력한 기여가 될 것으로 기대된다.
TOP: Time Optimization Policy for Stable and Accurate Standing Manipulation with Humanoid Robots
Fig. 1: Illustration of different methods. A: Whole-body RL
 *Fig. 2: The overall architecture. (A) Training a latent code zt based on VAE structure to represent diverse upper-body m* 이 논문은 휴머노이드 로봇의 안정적인 서서하기 조작을 위해 상체 동작의 시간 궤적을 최적화하는 Time Optimization Policy (TOP)을 제안한다. 상체의 빠른 움직임으로 인한 모멘텀을 줄여 균형, 정확성, 시간 효율성을 동시에 달성한다.
이 논문은 상체 동작 시간 최적화라는 직관적이면서도 효과적인 아이디어로 휴머노이드 서서하기 조작의 안정성-정확성-효율성 trade-off 문제를 창의적으로 해결한다. 이론과 실험이 잘 결합되어 있으며, humanoid 로봇 제어 분야에 실질적인 기여를 제공한다.
Humanoid Robot Teleoperation for Nonprehensile Transportation: A Multiple-Constraint Safety-Critical Control Framework
 *Figure 2. Dual-arm reachability maps of the custom-built humanoid robot platform.* 본 논문은 인간형 로봇의 비파지형 물체 운반 원격조종 작업에서 다중 제약 조건 간 충돌과 안전 문제를 해결하기 위해 계층적 3단계 구조의 Multiple-Constraint Safety-Critical Control Framework (MC-SCCF)를 제안한다. 상층부는 미분가능한 도달가능성 대리 모델과 개선된 control barrier function 기반 안전 속도 필터로 작업공간 경계에서의 안전성을 보장하고, 중층부는 사용자 명령을 자세 결합 참조 궤적으로 매핑하여 물체의 미끄러짐과 넘어짐을 방지하며, 하층부는 QP 기반 역운동학 해석기로 자체 충돌 회피와 조정된 운동을 달성한다.
본 논문은 인간형 로봇의 복잡한 비파지형 운반 작업에서 다중 충돌 제약을 체계적으로 해결하기 위한 계층적 MC-SCCF를 제시하며, 미분가능한 도달가능성 대리 모델과 개선된 control barrier function 기반의 안전 속도 필터는 기술적 참신성을 보여준다. 시뮬레이션과 물리적 로봇 실험으로 유효성을 입증했으나, 대리 모델의 일반화 가능성, 환경 변수 견고성, 계산 성능 벤치마크 등에 대한 상세 분석이 보완되면 더욱 강화될 수 있다.
GenerativeMPC: VLM-RAG-guided Whole-Body MPC with Virtual Impedance for Bimanual Mobile Manipulation
 *Fig. 3.* GenerativeMPC는 Vision-Language Model과 Retrieval-Augmented Generation을 활용하여 의미론적 장면 이해를 물리적 제어 파라미터로 변환하고, Whole-Body MPC와 통합 임피던스-어드미턴스 제어기를 통해 양팔 이동형 조작 로봇의 안전하고 맥락인식적인 제어를 실현한다.
GenerativeMPC는 의미론적 이해와 물리적 안전성을 체계적으로 통합하는 창의적 접근으로, VLM-RAG 기반 파라미터 생성과 경험 메모리의 신규 활용을 통해 양팔 이동형 조작 로봇의 인간중심 자율성을 크게 향상시킨다. 광범위한 시뮬레이션 및 실제 검증으로 신뢰성을 입증했으나, 실제 플랫폼 실험 확대와 분포 외 robustness 분석이 추가 필요하다.
Humanoid Robot Teleoperation for Nonprehensile Transportation: A Multiple-Constraint Safety-Critical Control Framework
 *Figure 2. Dual-arm reachability maps of the custom-built humanoid robot platform.* 본 논문은 인간형 로봇의 비파지 운송 작업을 위한 텔레조작 시스템에서 다층적 안전 제약 조건을 동시에 만족하는 Multiple-Constraint Safety-Critical Control Framework (MC-SCCF)를 제안한다. 계층적 3계층 아키텍처를 통해 작업공간 경계, 물체 역학 안전성, 로봇 운동학 제약을 통합하여 관리한다.
본 논문은 인간형 로봇 텔레조작을 위한 실질적이고 중요한 문제를 다루며, 미분 가능한 도달 가능성 평가, 개선된 CBF, 3계층 계층적 제어 프레임워크 등 기술적으로 건실한 해결책을 제시한다. 하드웨어 실증 결과는 실용성을 보여주나, 모델링 불확실성 강건성과 동적 환경 적응성에 대한 깊이 있는 분석이 추가되면 더욱 완성도 높은 연구가 될 것으로 판단된다.
Constrained Whole-Body Tracking for Humanoid Robots
Figure 1: Where does safety fit into a learning-based humanoid motion tracking stack? We approach
 *Figure 1: Where does safety fit into a learning-based humanoid motion tracking stack? We approach* 본 논문은 강화학습 기반 인간형 로봇의 전신 모션 추적 제어에서 안전 제약조건을 실시간으로 강제하는 ConstrainedMimic 프레임워크를 제시한다. operational space control과 control barrier functions을 결합하여 kinematics와 dynamics 차원에서 실행시간 제약조건을 만족시킨다.
본 논문은 humanoid 전신 제어에서 contact-constrained 동역학을 통한 체계적이고 실용적인 안전 강제 방법을 제시한다. Kinematics와 dynamics 양단 필터링, task-consistent 설계, 실시간 실행 가능성은 주목할 만하나, 실하드웨어 검증과 충돌 모델 확장이 필요하다.
SPARK: Safe Protective and Assistive Robot Kit
Figure 1: Scenarios of safe humanoid control achieved with SPARK. Left top figure: A real Unitree G1 humanoid robot avoi
 *Figure 1: Scenarios of safe humanoid control achieved with SPARK. Left top figure: A real Unitree G1 humanoid robot avoi* 본 논문은 인형 로봇의 안전한 자율주행 및 원격 조종을 위한 종합적인 벤치마크 및 도구 모음인 SPARK를 제시한다. 모듈 방식의 composable, extensible, deployable 설계를 통해 사용자가 커스텀 안전 조건과 작업 목표를 쉽게 구성하고 실제 로봇에 배포할 수 있도록 한다.
SPARK는 인형 로봇의 안전한 배포를 위한 실질적이고 실용적인 솔루션을 제시하는 고가치의 도구 논문이다. Composable, extensible, deployable 설계 원칙을 통해 기존 개별 알고리즘들의 통합과 재사용성을 크게 향상시켰으며, 시뮬레이션-실제 로봇 간의 연결고리를 제공한다. 다만 새로운 알고리즘 기여보다는 engineering 측면의 도구 개발에 초점이 있으므로 이론적 혁신성은 제한적이다. 로봇 안전 연구 커뮤니티에 실질적인 가치를 제공할 수 있는 고품질의 플랫폼 논문이다.
BiCoord: 장기간 시공간 협응 양팔 조작 벤치마크
Figure 1: Overview of BiCoord. (a) The data generation pipeline. (b) An example trajectory of Cook task is exhibited. Ea
 *Figure 1: Overview of BiCoord. (a) The data generation pipeline. (b) An example trajectory of Cook task is exhibited. Ea* 본 논문은 장기간 고도로 협응되는 양팔 조작 작업을 평가하기 위한 벤치마크 BiCoord를 제안한다. 기존 벤치마크는 단기간의 느슨한 협응 작업만 포함하는 반면, BiCoord는 연속적 팔 의존성과 동적 역할 교환이 필요한 복잡한 다단계 작업들을 제공한다.
본 논문은 양팔 조작 연구의 중요한 공백을 채우는 포괄적이고 잘 설계된 벤치마크를 제시한다. 장기간 고결합 작업, 명시적인 협응 특성 정의, 다각적 정량 메트릭 등이 커뮤니티에 상당한 기여를 할 것으로 기대된다.
Sumo: 동적이고 일반화 가능한 전신 이동-조작 제어
 *Fig. 2: System overview: Our method takes a hierarchical* 본 논문은 사전 학습된 전신 제어 정책과 테스트 시점 샘플 기반 계획을 계층적으로 결합하여 사족 로봇과 인형 로봇이 동적으로 대형 무거운 물체를 조작할 수 있게 하는 Sumo 프레임워크를 제시한다. 이 방법은 재학습 없이 다양한 물체와 작업에 일반화되며, 비용 함수만 변경하여 테스트 시점에 유연하게 적응할 수 있다.
본 논문은 강화학습과 샘플 기반 MPC를 계층적으로 결합하는 우아한 방식으로 동적 전신 로코-조작을 처음 구현했으며, Spot 실제 로봇에서의 인상적인 결과와 일반화 가능성은 로봇 조작 분야에 의미 있는 기여를 한다. 테스트 시점 유연성과 훈련 없는 적응은 실무 적용에 큰 가치가 있다.
BiCoord: 장기간 시공간 협응 양팔 조작 벤치마크
Figure 1: Overview of BiCoord. (a) The data generation pipeline. (b) An example trajectory of Cook task is exhibited. Ea
 *Figure 1: Overview of BiCoord. (a) The data generation pipeline. (b) An example trajectory of Cook task is exhibited. Ea* 본 논문은 장시간의 강한 시공간 협응을 요구하는 양팔 조작 작업을 평가하기 위한 BiCoord 벤치마크를 제시한다. 기존 벤치마크의 단기 및 약결합 작업의 한계를 극복하고자 phased coupling, spatial-temporal constraint, predictive coordination 특성을 반영한 과제를 설계했으며, 시간적·공간적·시공간 복합 메트릭을 제안한다.
BiCoord는 양팔 로봇 조작 분야에서 기존의 단기 약결합 벤치마크의 공백을 효과적으로 메우며, 장시간 강결합 협응 작업 평가를 위한 체계적 프레임워크를 제공한다. 새로운 메트릭과 포괄적 실험을 통해 현존 정책의 한계를 명확히 드러내고 향후 협응 인식 모델 개발에 의미 있는 기준점을 제시한다. 다만 시뮬레이션의 물리적 한계, 실제 로봇으로의 전이 가능성 검증, 그리고 협응 특화 학습 방법의 부재는 보완이 필요한 부분이다.
Sumo: 동적이고 일반화 가능한 전신 이동-조작 제어
 *Fig. 2: System overview: Our method takes a hierarchical* 본 논문은 사전학습된 전신 제어 정책과 테스트 시점 샘플 기반 계획을 계층적으로 결합하는 Sumo 프레임워크를 제안한다. 이를 통해 사족 및 인형 로봇이 동적으로 대형 중량 물체를 조작할 수 있으며, 재학습 없이 다양한 물체와 작업에 일반화된다.
Sumo는 동적 전신 조작이라는 도전적 과제에서 실용적이고 일반화 가능한 해결책을 제시한다. 계층적 프레임워크의 설계가 우수하고 실제 로봇 검증이 설득력 있으며, 재학습 없는 적응 능력이 인상적이다. 다만 인형 로봇 실제 검증과 더 광범위한 물체 기하학적 다양성 시험이 있으면 영향력이 더욱 클 것이다.
DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
Figure 1: DreamDojo overview. DreamDojo acquires comprehensive physical knowledge from large-scale
 *Figure 1: DreamDojo overview. DreamDojo acquires comprehensive physical knowledge from large-scale* 44k시간의 대규모 인간 동영상으로부터 연속 잠재 행동(continuous latent actions)을 통일된 프록시로 사용하여 학습한 DreamDojo는 로봇의 손재주 제어와 물리 이해를 갖춘 기초 세계 모델로, 실시간 텔레오퍼레이션과 모델 기반 계획을 가능하게 한다.
DreamDojo는 대규모 인간 동영상과 연속 잠재 행동의 혁신적 결합으로 로봇 세계 모델의 스케일과 일반화 능력을 획기적으로 향상시킨 중요한 기여이다. 실시간 성능과 다양한 실제 응용 가능성이 입증되었으나, embodiment gap 완전 해결과 극도의 장기 예측에 대한 추가 검증이 필요하다.
Physically Consistent Humanoid Loco-Manipulation using Latent Diffusion Models
Fig. 1: A loco-manipulation task achieved with our approach.
 *Fig. 2: Pipeline overview.* 본 논문은 Latent Diffusion Model(LDM)을 활용하여 인간-물체 상호작용 장면을 생성하고, 이로부터 추출한 접촉 위치와 로봇 구성을 whole-body trajectory optimization에 활용하여 인형로봇의 물리적으로 일관성 있는 장기 조작 계획을 수립한다.
본 논문은 LDM과 foundation model을 창의적으로 결합하여 인형로봇의 장기 로코-조작 계획 문제를 새로운 방식으로 접근하며, 광범위한 실험과 분석을 통해 방법론의 유효성을 입증했다. 다만 실제 로봇 검증과 일부 모듈의 정확성 개선이 필요하다.
RL from Physical Feedback: Aligning Large Motion Models with Humanoid Control
 *Figure 2: Overview of RLPF, which consists of three key components: i) Motion Tracking Policy* 본 논문은 텍스트 기반 인간 동작을 실제 휴머노이드 로봇에 실행 가능한 형태로 변환하는 문제를 해결하기 위해, 물리 시뮬레이터에서의 피드백을 기반으로 대규모 모션 생성 모델을 강화학습으로 미세조정하는 RLPF 프레임워크를 제안한다.
본 논문은 text-to-motion 생성 모델과 로봇 제어 간의 오랜 간극을 물리적 피드백 기반 RL로 체계적으로 해결하는 창의적 접근을 제시하며, 실제 로봇 배포 성공을 통해 실용적 가치를 입증했다. 다만 계산 효율성과 평가 범위 확대에 대한 추가 연구가 필요하다.
RoboMirror: Understand Before You Imitate for Video to Humanoid Locomotion
Figure 1. RoboMirror makes humanoid understand before imitating. It acts like a mirror, which can not only infer and rep
 *Figure 1. RoboMirror makes humanoid understand before imitating. It acts like a mirror, which can not only infer and rep* RoboMirror는 VLM을 활용하여 비디오에서 visual motion intent를 추출하고 diffusion-based policy로 직접 인간형 로봇의 보행을 제어하는 retargeting-free 프레임워크이다. 기존의 pose estimation-retargeting 파이프라인을 우회하고 egocentric/third-person 비디오로부터 시맨틱하게 정렬된 보행을 생성한다.
RoboMirror는 인간형 로봇 제어에 시각적 이해라는 자연스러운 패러다임을 도입하고, retargeting-free 아키텍처로 지연시간을 획기적으로 단축하면서 성능을 향상시킨 의미 있는 기여이다. 다만 sim-to-real 검증 부재와 VLM 의존성 문제는 실용화를 위해 추가 연구가 필요함을 시사한다.
RoboStriker: Hierarchical Decision-Making for Autonomous Humanoid Boxing

Figure 1. Real-world clips of humanoid boxing using RoboStriker,
 *Figure 2. Overview of RoboStriker. Stage I pretrains a motion tracker to produce physically plausible humanoid behaviors* RoboStriker는 인간 수준의 경쟁력 있는 휴머노이드 권투를 위해 높은 수준의 전략 추론과 낮은 수준의 물리적 실행을 분리하는 3단계 계층적 프레임워크를 제안한다. Motion capture 데이터로부터 학습된 동작 라이브러리를 구조화된 잠재 공간으로 압축한 후, Latent-Space NFSP를 통해 다중 에이전트 경쟁 학습을 수행한다.
RoboStriker는 embodied MARL의 근본적 모순을 처음으로 공식화하고 계층적 분해를 통해 실질적으로 해결하는 주요 기여를 제시한다. 물리 시뮬레이션과 실제 로봇에서 권투라는 도전적 작업을 성공적으로 달성하여, 추상 게임에서 물리 기반 로봇 시스템으로 MARL을 확장하는 중요한 마일스톤을 제공한다.
SafeHumanoid: VLM-RAG-driven Control of Upper Body Impedance for Humanoid Robot
Figure 1: Egocentric perception and semantic-to-safety
 *Figure 1: Egocentric perception and semantic-to-safety* SafeHumanoid는 Vision Language Model(VLM)과 Retrieval-Augmented Generation(RAG)을 활용하여 휴머노이드 로봇의 임피던스와 속도를 동적으로 조정하는 시스템으로, 인간-로봇 상호작용 시 안전성과 작업 완료를 동시에 달성한다.
SafeHumanoid는 의미론적 추론과 임피던스 제어의 혁신적 결합으로 인간-로봇 협력의 안전성을 크게 향상시키는 제안이지만, 추론 지연시간과 실시간성은 실제 배포를 위해 해결해야 할 주요 과제이다.
Vision in Action: Learning Active Perception from Human Demonstrations
Figure 1: Vision in Action (ViA) uses an active head
 *Figure 1: Vision in Action (ViA) uses an active head* ViA는 6-DoF 로봇 넥과 VR 텔레오퍼레이션 인터페이스를 통해 인간의 능동적 지각 전략을 직접 학습하여 이중팔 조작 로봇의 성능을 향상시키는 시스템이다.
ViA는 능동적 지각, VR 텔레오퍼레이션, 이중팔 조작을 효과적으로 통합한 혁신적 시스템으로, 중간 3D 표현을 통한 지연 시간 해결과 공유 관찰 공간 개념이 특히 창의적이며, 시각적 폐색이 있는 복잡한 실제 작업에서 실질적인 성능 향상을 달성했다.
WHOLE: World-Grounded Hand-Object Lifted from Egocentric Videos
Figure 1. Given a metric-SLAMed egocentric video of a person interacting with the scene and the corresponding object tem
 *Figure 2. Reconstruction Using the Generative Motion Prior. Given a metric-SLAMed egocentric videos, and the object temp* WHOLE는 손잡이와 물체의 상호작용을 joint generative motion prior를 통해 이용하여 egocentric 비디오에서 world space로의 hand-object 궤적을 holistically 재구성한다.
WHOLE는 hand-object interaction을 joint generative prior로 모델링하여 egocentric video에서 globally consistent world-space trajectories를 복원하는 혁신적 접근으로, 기존 isolated method들의 inconsistency 문제를 근본적으로 해결하며 practical application에 중요한 기여를 한다.
$Ψ_0$: An Open Foundation Model Towards Universal Humanoid Loco-Manipulation
 *Fig. 2: Model Training and Deployment: First, we pre-train the VLM on the EgoDex [20] dataset to autoregressively predic* Ψ0는 인간 중심 egocentric 비디오로 VLM을 사전학습한 후 humanoid 로봇 데이터로 flow-based action expert를 post-train하는 2단계 학습 패러다임을 통해 humanoid loco-manipulation을 위한 foundation model을 제안한다.
Ψ0는 인간-humanoid embodiment gap을 극복하기 위한 명확한 2단계 학습 패러다임과 고품질 데이터 선택의 중요성을 새롭게 제시하며, 10배 이상의 데이터 효율 개선으로 humanoid loco-manipulation 분야에 significant contribution을 제공한다.
Being-H0: Vision-Language-Action Pretraining from Large-Scale Human Videos
Figure 1: Being-H0 acquires dexterous manipulation skills by learning from large-scale human videos in the
 *Figure 1: Being-H0 acquires dexterous manipulation skills by learning from large-scale human videos in the* Being-H0는 대규모 인간 비디오로부터 학습한 민첩한 Vision-Language-Action 모델로, physical instruction tuning 패러다임을 통해 인간의 손 동작을 명시적으로 모델링하여 로봇 조작 작업으로 전이한다.
Being-H0는 대규모 인간 비디오로부터 민첩한 로봇 조작을 학습하는 새로운 패러다임을 제시하며, physical instruction tuning과 part-level motion tokenization을 통해 기존 VLA의 데이터 부족 문제를 혁신적으로 해결한다. 명시적 동작 모델링 접근법과 UniHand 데이터셋은 로봇 공학 분야에 중요한 기여를 제공한다.
BiGym: A Demo-Driven Mobile Bi-Manual Manipulation Benchmark
Figure 1: BiGym focuses on mobile manipulation with home assistance humanoids. We provide 40
 *Figure 1: BiGym focuses on mobile manipulation with home assistance humanoids. We provide 40* BiGym은 인간이 수집한 데모를 포함한 40개의 다양한 이족 이족 조작 작업을 제공하는 모바일 휴머노이드 로봇 학습 벤치마크로, Imitation Learning과 Demo-Driven RL 알고리즘을 평가할 수 있게 설계되었다.
BiGym은 인간이 수집한 현실적 다중양식 데모와 모바일 이족 조작의 복잡성을 체계적으로 다루는 최초의 종합 벤치마크로, Imitation Learning과 Demo-Driven RL 연구에 중요한 기여를 한다. 다만 실제 로봇 검증과 환경 다양성 확대가 향후 영향력 확대를 위해 필요하다.
Bunny-VisionPro: Real-Time Bimanual Dexterous Teleoperation for Imitation Learning
Figure 1: System Overview and Task Suits. (a) Hand poses captured by Apple Vision Pro are con-
 *Figure 1: System Overview and Task Suits. (a) Hand poses captured by Apple Vision Pro are con-* Apple Vision Pro의 손 추적 기능을 활용하여 양손 민첩한 조작이 가능한 실시간 텔레오퍼레이션 시스템 Bunny-VisionPro를 제시하며, 저비용 햅틱 피드백과 충돌/특이점 회피를 통해 모방 학습용 고품질 시연 데이터를 수집한다.
Vision Pro를 활용한 양손 민첩 텔레오퍼레이션에서 실시간 성능, 안전성, 몰입감을 동시에 달성한 혁신적 시스템으로, 장시간 복잡 조작의 시연 수집을 통해 모방 학습의 새로운 가능성을 제시하는 높은 기술적·응용적 가치의 연구다.
Coordinated Humanoid Manipulation with Choice Policies
Fig. 1: Coordinated Humanoid Manipulation. We present a teleoperation system and a policy learning framework for
 *Fig. 1: Coordinated Humanoid Manipulation. We present a teleoperation system and a policy learning framework for* 휴머노이드 로봇의 전신 협조 조작을 위해 모듈식 텔레오퍼레이션 인터페이스와 Choice Policy라는 모방 학습 방식을 결합한 시스템을 제시한다. Choice Policy는 다중 후보 행동을 생성하고 점수를 학습하여 멀티모달 행동을 효율적으로 모델링한다.
이 논문은 휴머노이드 전신 조작을 위한 실용적이고 확장 가능한 시스템을 제시하며, Choice Policy는 멀티모달 행동 모델링에서 효율성과 표현력의 균형을 잘 달성했다. 모듈식 텔레오퍼레이션과 함께 실제 로봇 작업에서의 성공적 검증은 고가치의 실제 기여를 보여준다.
Deep Imitation Learning for Humanoid Loco-manipulation through Human Teleoperation
Fig. 1: Overview of TRILL. TRILL addresses the challenge of learning
 *Fig. 1: Overview of TRILL. TRILL addresses the challenge of learning* 본 논문은 VR 텔레오퍼레이션을 통해 수집한 인간 시연 데이터로부터 humanoid 로봇의 loco-manipulation 능력을 deep imitation learning으로 학습하는 TRILL 프레임워크를 제시한다. Whole-body control 기반의 계층적 정책 구조를 통해 높은 자유도 humanoid의 복잡한 동작을 데이터 효율적으로 학습할 수 있다.
본 논문은 humanoid loco-manipulation을 위한 데이터 효율적 deep imitation learning 방법을 제시하며, whole-body control과의 영리한 결합을 통해 높은 자유도 시스템의 안정성과 학습 효율성을 동시에 달성했다. 실제 humanoid 로봇에서 처음으로 성공적으로 복잡한 manipulation을 학습한 선도적 성과로, 앞으로 humanoid의 자율 능력 향상에 중요한 기여를 할 것으로 예상된다.
DexCap: Scalable and Portable Mocap Data Collection System for Dexterous Manipulation
Fig. 1: DEXCAP facilitates the in-the-wild collection of high-quality human hand motion capture data and 3D observations
 *Fig. 1: DEXCAP facilitates the in-the-wild collection of high-quality human hand motion capture data and 3D observations* DexCap은 SLAM과 전자기장을 활용한 휴대용 손 모션캡처 시스템이며, DexIL은 이 데이터로부터 역운동학과 point cloud 기반 모방학습을 통해 로봇이 손가락 조작을 직접 학습하도록 하는 알고리즘이다.
DexCap과 DexIL은 휴대용 mocap 시스템과 embodiment gap을 극복하는 imitation learning을 처음으로 통합하여 in-the-wild 환경에서 로봇 손가락 조작 학습을 가능하게 한 우수한 기여이며, 6가지 조작 작업에서 일관된 성과를 보여준다.
DexMimicGen: Automated Data Generation for Bimanual Dexterous Manipulation via Imitation Learning
Fig. 1: DexMimicGen Overview. DexMimicGen offers an efficient pipeline
 *Fig. 1: DexMimicGen Overview. DexMimicGen offers an efficient pipeline* DexMimicGen은 소수의 인간 시연으로부터 simulation에서 자동으로 대규모 궤적 데이터를 생성하여 양손 dexterous 로봇 조작 학습을 위한 imitation learning 데이터 수집 병목을 해결하는 시스템이다.
DexMimicGen은 양손 dexterous 로봇 조작을 위한 자동 데이터 생성의 실질적인 해결책을 제시하며, MimicGen을 의미 있게 확장하고 실제 humanoid 배포로 그 효과를 입증했으나, 한계된 실제 작업 검증과 일반화 능력 평가가 필요하다.
DynaRetarget: Dynamically-Feasible Retargeting using Sampling-Based Trajectory Optimization
Fig. 1: Real-world humanoid loco-manipulation behaviors enabled by DynaRetarget. Demonstrations retargeted using our fra
 *Fig. 2: DynaRetarget overview. Given a human–object demonstration, we first perform IK-based retargeting to obtain a kin* DynaRetarget은 Sampling-Based Trajectory Optimization (SBTO)을 통해 운동학적으로 부정확한 인간 동작을 휴머노이드 로봇이 동적으로 실행 가능한 loco-manipulation 행동으로 변환하는 완전한 파이프라인을 제시한다.
DynaRetarget은 sampling-based trajectory optimization의 incremental horizon 확장 개념을 통해 humanoid loco-manipulation retargeting의 동적 실행 가능성 문제를 효과적으로 해결하며, 광범위한 실험과 실제 로봇 배포를 통해 그 효과를 입증한 의미 있는 기여이다.
Ego-Vision World Model for Humanoid Contact Planning
 *Fig. 2: World Model Training Pipeline. The pipeline begins with the offline data collection process shown in (a), where * 휴머노이드 로봇이 접촉을 활용하는 지능형 계획을 수립하기 위해 학습된 world model을 sampling-based MPC와 결합한 프레임워크를 제안하며, 오프라인 데이터셋으로부터 압축된 latent space에서 미래 결과를 예측한다.
휴머노이드의 접촉 활용 계획을 위해 world model과 value-guided MPC를 효과적으로 결합하여 샘플 효율성과 다중 작업 능력을 동시에 달성한 우수한 연구로, 실제 로봇 배포를 통해 실용성을 입증했으나 계획 수평선 제약과 시뮬-현실 갭에 대한 추가 분석이 필요하다.
EgoDemoGen: Egocentric Demonstration Generation for Viewpoint Generalization in Robotic Manipulation
 *Figure 2. Overview of EgoDemoGen. Given source demonstrations from a standard egocentric viewpoint, we generate novel de* EgoDemoGen은 egocentric viewpoint 변화에 대응하는 로봇 조작 정책의 일반화를 위해, 궤적 전송과 영상 합성을 통해 새로운 egocentric 관점에서 정렬된 observation-action 시연을 생성하는 프레임워크이다.
본 논문은 egocentric viewpoint 변화의 특수성을 명확히 인식하고, 궤적 전송과 영상 합성을 통합하는 EgoDemoGen 프레임워크를 제시하여 로봇 조작의 viewpoint 일반화 문제를 근본적으로 해결한다. 실험적으로 시뮬레이션과 실제 로봇 환경에서 일관된 성능 향상을 보여주며, 로봇 학습의 실용적 적용에 중요한 기여를 한다.
EgoHumanoid: Unlocking In-the-Wild Loco-Manipulation with Robot-Free Egocentric Demonstration
Fig. 1: Introducing EGOHUMANOID, the first investigation on human-to-humanoid transfer for whole-body loco-manipulation.
 *Fig. 1: Introducing EGOHUMANOID, the first investigation on human-to-humanoid transfer for whole-body loco-manipulation.* EgoHumanoid는 로봇 없이 수집한 대규모 인간 egocentric 시연과 제한된 로봇 데이터를 co-train하여 휴머노이드 로봇이 다양한 현실 환경에서 loco-manipulation을 수행하도록 하는 첫 번째 프레임워크이다. View alignment와 action alignment로 구성된 embodiment 정렬 파이프라인을 통해 인간-로봇 간의 신체 형태, 관점, 동역학의 차이를 극복한다.
EgoHumanoid는 휴머노이드 loco-manipulation 분야에서 human egocentric data 활용의 새로운 가능성을 체계적으로 보여주는 획기적인 작업이다. Practical embodiment alignment pipeline, 현실 환경에서의 강력한 성능 개선(51%), 그리고 scalability 분석은 향후 humanoid 로봇 학습의 중요한 방향을 제시한다.
EgoMimic: Scaling Imitation Learning via Egocentric Video
Fig. 1: EgoMimic unlocks human embodiment data—egocentric videos paired with 3D hand tracks—as a new scalable data sourc
 *Fig. 1: EgoMimic unlocks human embodiment data—egocentric videos paired with 3D hand tracks—as a new scalable data sourc* EgoMimic은 Project Aria 안경을 통해 수집한 인간의 일인칭 시점 비디오와 3D 손 추적 데이터를 로봇 조작 학습에 활용하는 전체 스택 프레임워크로, 인간과 로봇 데이터를 동등한 embodied demonstration으로 취급하여 통합 정책을 학습한다.
EgoMimic은 인간의 일인칭 시점 데이터를 로봇 학습에 동등하게 활용하는 혁신적 접근으로, 실제 조작 작업에서 뛰어난 성능 개선과 일반화를 입증했으며, 수동적 대규모 데이터 수집의 가능성을 열어 로봇 학습의 확장성 문제 해결에 크게 기여한다.
EgoVLA: Learning Vision-Language-Action Models from Egocentric Human Videos
Figure 1: EgoVLA. Our vision-language-action model learns manipulation skills from egocentric human
 *Figure 1: EgoVLA. Our vision-language-action model learns manipulation skills from egocentric human* egocentric human 비디오로부터 Vision-Language-Action (VLA) 모델을 학습하여 로봇 조작 정책을 획득하고, Inverse Kinematics과 retargeting을 통해 인간 행동을 로봇 행동으로 변환한다.
본 논문은 egocentric human 비디오를 활용한 VLA 학습이라는 혁신적 접근으로 로봇 데이터 수집의 확장성 문제를 효과적으로 해결하며, unified action space 설계와 종합적인 벤치마크 제안을 통해 높은 실용성과 학술적 기여를 제시한다.
GraspDreamer: 생성형 인간 시연 기반 기능적 파지 모방 학습
Fig. 1: GraspDreamer leverages human demonstrations syn-
 *Fig. 1: GraspDreamer leverages human demonstrations syn-* Visual Generative Model (VGM)으로 생성한 인간 시연 비디오로부터 기능적 파지를 학습하여 실제 데이터 수집 없이 제로샷 로봇 파지를 가능하게 하는 GraspDreamer 방법을 제안한다. 인터넷 규모의 사전학습 데이터에 인코딩된 인간-물체 상호작용 프라이어를 활용하여 데이터 효율성과 일반화 성능을 동시에 달성한다.
GraspDreamer는 VGM의 생성 능력을 창의적으로 활용하여 기능적 파지의 데이터 수집 부담을 획기적으로 감소시키면서도 다양한 로봇 플랫폼에 일반화되는 실용적 솔루션을 제시한다. 공개 벤치마크와 실세계 실험의 광범위한 검증으로 방법의 유효성을 충실히 입증하였다.
H-RDT: Human Manipulation Enhanced Bimanual Robotic Manipulation
Figure 1: Overview of H-RDT. A human-to-robotics diffusion transformer with two-stage training.
 *Figure 1: Overview of H-RDT. A human-to-robotics diffusion transformer with two-stage training.* H-RDT는 대규모 egocentric 인간 조작 데이터로 사전학습하고 모듈식 action encoder/decoder를 통해 다양한 로봇에 fine-tuning하는 두 단계 diffusion transformer 기반 접근법으로, 로봇 조작 학습을 향상시킨다.
H-RDT는 대규모 egocentric human manipulation 데이터의 가치를 체계적으로 입증하면서, 모듈식 전이 구조를 통해 diverse robot platform으로의 확장 가능성을 보여준 혁신적 연구이다. 광범위한 실험과 강력한 empirical 결과가 robotic manipulation 학습의 data scarcity 문제 해결에 실질적인 기여를 하고 있다.
HDMI: Learning Interactive Humanoid Whole-Body Control from Human Videos
Fig. 1: HDMI enables humanoid robots to acquire diverse whole-body interaction skills directly from human videos. (a)
 *Fig. 2: HDMI is a general framework for interactive skill learning. Monocular RGB videos are processed into a structured* HDMI는 단일 모노큘러 RGB 비디오에서 인간의 상호작용을 추출하여 휴머노이드 로봇이 물체와의 전신 상호작용 기술을 학습하는 프레임워크이다. Robot-object co-tracking을 통해 강화학습 정책을 훈련하고 실제 로봇에 제로샷 배포한다.
HDMI는 휴머노이드 로봇의 전신 물체 상호작용을 위한 일반적이고 실용적인 프레임워크로, 인간 비디오 활용이라는 확장 가능한 데이터 소스와 함께 robot-object co-tracking이라는 우아한 문제 설정을 통해 실제 로봇에서 강력한 성능을 달성했으며, 휴머노이드 로보틱스 분야에 의미 있는 기여를 한다.
Humanoid Policy ~ Human Policy
Figure 1: This paper advocates high-quality human data as a data source for cross-embodiment
 *Figure 1: This paper advocates high-quality human data as a data source for cross-embodiment* 휴머노이드 로봇 조작 정책 학습을 위해 대규모 자아중심 인간 데모를 cross-embodiment 학습 데이터로 활용하고, Human Action Transformer (HAT)를 통해 인간과 로봇을 통합된 상태-행동 공간에서 다양한 embodiment으로 모델링한다.
로봇 조작 학습에서 대규모 인간 데이터 활용의 실질적 가치를 입증한 의미 있는 연구로, 통합된 state-action space와 체계적인 co-training 전략을 통해 embodiment 간극을 효과적으로 해소했으며, PH2D 데이터셋과 HAT 모델의 공개를 통해 cross-embodiment 학습 커뮤니티에 중요한 기여를 할 것으로 기대된다.
HumanoidExo: Scalable Whole-Body Humanoid Manipulation via Wearable Exoskeleton
Figure 1. HumanoidExo, a wearable exoskeleton system that transfers human motion to whole-body humanoid data. HumanoidEx
 *Figure 1. HumanoidExo, a wearable exoskeleton system that transfers human motion to whole-body humanoid data. HumanoidEx* 웨어러블 외골격(exoskeleton)을 통해 인간의 전신 동작을 휴머노이드 로봇 데이터로 변환하는 HumanoidExo 시스템을 제안하여, 휴머노이드 정책 학습을 위한 대규모 다양한 데이터셋 수집의 병목을 해결한다.
HumanoidExo는 웨어러블 외골격을 통한 전신 휴머노이드 데이터 수집의 첫 성공적 사례로, 기존 방법의 상지 집중 문제를 극복하고 embodiment gap을 최소화한 혁신적 접근이다. 실험 결과가 제한적이고 기술적 깊이가 다소 부족하지만, 휴머노이드 정책 학습의 데이터 병목 문제 해결이라는 실질적 기여와 높은 실용성으로 인해 로보틱스 분야에 의미 있는 진전을 제시한다.
HumanoidVLM: Vision-Language-Guided Impedance Control for Contact-Rich Humanoid Manipulation
Figure 1: Overall architecture of the proposed HumanoidVLM framework.
 *Figure 1: Overall architecture of the proposed HumanoidVLM framework.* HumanoidVLM은 vision-language model과 retrieval-augmented generation을 결합하여 휴머노이드 로봇이 egocentric 이미지로부터 task-specific impedance parameters와 gripper configuration을 자동으로 선택하는 적응형 조작 프레임워크이다.
본 논문은 VLM과 RAG를 humanoid manipulation에 효과적으로 적용하여 semantic perception과 compliant control을 처음 체계적으로 연결했으며, 높은 retrieval 정확도와 실제 로봇 실험을 통해 타당성을 입증했다. 다만 고정된 database 규모와 sensor 제약이 향후 확장성을 제한하는 점이 개선 대상이다.
HumDex: Humanoid Dexterous Manipulation Made Easy
Fig. 1: The HumDex System. Our portable teleoperation system enables efficient collection of high-quality dexterous
 *Fig. 1: The HumDex System. Our portable teleoperation system enables efficient collection of high-quality dexterous* IMU 기반 모션 트래킹을 활용한 휴머노이드 전신 손재주 조작 텔레오퍼레이션 시스템으로, learning-based hand retargeting과 human 데이터 사전학습을 통해 최소 데이터로 높은 일반화 성능을 달성한다.
IMU 기반 휴대용 텔레오퍼레이션과 learning-based hand retargeting, human 데이터 활용의 three-pronged 접근으로 humanoid 손재주 조작 데이터 수집의 오래된 병목을 효과적으로 해결한 높은 수준의 시스템 논문이다. 재현성 높은 설계와 충분한 실험 검증으로 실제 영향력이 클 것으로 예상된다.
Learning Humanoid End-Effector Control for Open-Vocabulary Visual Loco-Manipulation
Fig. 1: We build capability for a humanoid to autonomously loco-manipulate novel objects in novel scenes using onboard
 *Fig. 2: Overall architecture for our proposed modular system for open-vocabulary object grasping. Given a free-form* HERO 시스템은 정확한 end-effector 추적 정책과 대규모 비전 모델을 결합하여 휴머노이드 로봇이 미지의 환경에서 임의의 일상용품을 자율적으로 집을 수 있게 한다. End-effector 추적 오차를 3.2배 감소시키고 83.8%의 성공률을 달성했다.
본 논문은 정확한 end-effector 제어의 기술적 난제를 classical robotics와 학습 기반 모듈의 창의적 결합으로 해결하고, 이를 통해 humanoid의 실제 환경 object manipulation을 처음으로 현실화했다. 모듈식 설계로 대규모 실제 데이터 수집 없이도 open-vocabulary 일반화를 달성한 점이 특히 의미 있으며, 83.8%의 실제 환경 성공률은 해당 분야의 significant advance를 나타낸다.
LeVERB: Humanoid Whole-Body Control with Latent Vision-Language Instruction
Figure 1: Overview of our contributions. Top: we create a photorealistic and dynamically accurate
 *Figure 1: Overview of our contributions. Top: we create a photorealistic and dynamically accurate* LeVERB는 humanoid 로봇의 전신 제어를 위해 vision-language 입력을 latent action 공간으로 인코딩하는 계층적 프레임워크를 제안하며, 150개 이상의 task로 구성된 첫 번째 sim-to-real 준비 벤치마크를 제시한다.
LeVERB는 humanoid WBC를 위한 vision-language 제어에서 중요한 진전을 이루었으며, 첫 latent instruction-following framework와 comprehensive sim-to-real 벤치마크를 제시하여 이 분야의 기초를 다졌다. 다만 실제 배포 성능의 추가 개선과 더 광범위한 task 평가를 통한 검증이 필요하다.
ManiSkill-HAB: A Benchmark for Low-Level Manipulation in Home Rearrangement Tasks
 *Figure 2: Interact benchmark comparing MS-HAB (ours) with Habitat. Each data point is annotated* MS-HAB는 GPU 가속화된 Home Assistant Benchmark의 구현으로, 현실적인 저수준 조작과 빠른 시뮬레이션 속도(4300 SPS)를 지원하며 대규모 데이터셋 생성을 위한 자동화된 궤적 필터링 시스템을 제공한다.
MS-HAB는 현실적인 저수준 조작 제어, 고속 GPU 시뮬레이션, 그리고 자동화된 데이터 생성을 통합하여 가정용 로봇 조작 연구의 중요한 벤치마크를 제공하며, 광범위한 기반선과 투명한 평가 지표는 후속 연구에 큰 가치를 제공한다.
Masquerade: Learning from In-the-wild Human Videos using Data-Editing
Fig. 1: Overview of Masquerade. Left: Large-scale in-the-wild egocentric human videos are edited to obtain “robotized”
 *Fig. 1: Overview of Masquerade. Left: Large-scale in-the-wild egocentric human videos are edited to obtain “robotized”* Masquerade는 in-the-wild 인간 영상을 데이터 편집을 통해 로봇화된 시연으로 변환하고, 이를 통해 사전학습된 visual encoder로 로봇 조작 정책을 학습하는 방법을 제안한다. 675K 프레임의 편집된 인간 영상으로 사전학습 후 50개의 로봇 시연으로 fine-tuning하여 기존 방법 대비 5-6배 향상된 성능을 달성한다.
Masquerade는 visual embodiment gap을 명시적으로 해결하면서 대규모 in-the-wild 인간 영상을 로봇 학습에 활용하는 창의적이고 실용적인 방법론을 제시한다. 적절한 평가와 ablation으로 핵심 설계 선택의 효과를 입증했으며, 로봇 데이터 부족 문제를 완화하는 데 의미 있는 기여를 한다.
MimicDroid: In-Context Learning for Humanoid Robot Manipulation from Human Play Videos
Fig. 1: Overview. MIMICDROID enables few-shot learning for humanoid manipulation by training solely on human play
 *Fig. 1: Overview. MIMICDROID enables few-shot learning for humanoid manipulation by training solely on human play* MimicDroid는 인간의 자유로운 상호작용 비디오(human play videos)만을 학습 데이터로 사용하여 휴머노이드 로봇이 In-Context Learning(ICL)을 통해 새로운 조작 작업을 효율적으로 수행하도록 한다.
MimicDroid는 human play videos라는 현실적이고 확장 가능한 데이터 소스를 활용하여 휴머노이드 로봇의 In-Context Learning 기반 조작을 실현한 혁신적인 연구이며, 명확한 방법론, 강력한 실증적 결과, 그리고 공개 벤치마크를 통해 로봇 학습 분야에 실질적인 기여를 한다.
MobileH2R: Learning Generalizable Human to Mobile Robot Handover Exclusively from Scalable and Diverse Synthetic Data
Figure 1. The overview of MobileH2R. We propose a framework for generalizable human-to-mobile-robot handover, including
 *Figure 1. The overview of MobileH2R. We propose a framework for generalizable human-to-mobile-robot handover, including * MobileH2R는 대규모 다양한 합성 데이터만을 사용하여 모바일 로봇이 인간으로부터 물체를 받을 수 있도록 학습하는 프레임워크를 제시한다. 인간의 전신 동작 생성, 안전한 시연 자동 생성, 4D imitation learning을 통합하여 베이스-암 협조 제어가 가능한 일반화된 정책을 학습한다.
MobileH2R는 모바일 로봇의 인간-로봇 handover 문제를 체계적으로 해결하는 포괄적이고 확장 가능한 프레임워크를 제시한다. 합성 데이터의 생성, 안전한 시연 자동 생성, 통합 학습이라는 세 요소를 정교하게 설계하여 +15% 이상의 성능 향상을 달성했으며, 대규모 데이터의 효과를 실증한 점에서 실무적 가치가 높다.
Object-Centric Dexterous Manipulation from Human Motion Data
Figure 1: Our system uses human hand motion capture data and deep reinforcement learning to train
 *Figure 2: Overview of our framework. (A) Training: Firstly, we use human motion capture data to* 인간의 손 모션 캡처 데이터를 활용하여 로봇 다지털 조작을 학습하는 계층적 정책 학습 프레임워크를 제안한다. 고수준의 손목 궤적 생성 모델과 저수준의 손가락 제어기를 조합하여 embodiment gap을 극복한다.
본 논문은 인간 wrist 모션의 embodiment 불변성을 창의적으로 활용하여 embodiment gap 문제를 해결하고, 계층적 학습 프레임워크로 복잡한 다지털 조작을 효과적으로 학습한다. 실세계 전이와 일반화 능력 모두 입증하여 로봇 조작 분야에 significant한 기여를 한다.
OKAMI: Teaching Humanoid Robots Manipulation Skills through Single Video Imitation
 *Figure 2: Overview of OKAMI. OKAMI is a two-staged method that enables a humanoid robot to imitate a* OKAMI는 단일 RGB-D 비디오 시연으로부터 인형 로봇의 조작 기술을 학습하도록 하는 방법으로, object-aware retargeting을 통해 인간의 움직임을 로봇 기구학에 맞게 변환하면서 테스트 시 객체 위치에 적응한다.
OKAMI는 object-aware retargeting이라는 핵심 개념으로 단일 비디오로부터 인형 로봇의 조작 학습을 효과적으로 해결하며, 실제 하드웨어에서 강한 일반화 능력을 입증하여 로봇 학습의 실용성을 크게 향상시킨다.
Open-TeleVision: Teleoperation with Immersive Active Visual Feedback
Figure 1: Autonomous and teleoperated sessions using our setup. a-e: robots executing long-
 *Figure 2: Teleoperated data collection and learning setup. Left: our teleoperation system. VR* Apple VisionPro 등 VR 기기를 활용하여 스테레오 영상 피드백과 로봇 헤드의 능동적 카메라 제어를 통해 직관적이고 몰입감 있는 원격 조종 시스템을 구현하고, 이를 통해 수집한 데이터로 모방 학습 정책을 훈련하여 복잡한 조작 작업을 자동화함.
본 논문은 VR 기반 능동적 헤드 카메라와 스테레오 영상 피드백을 통해 직관적이고 몰입감 있는 원격 조종 시스템을 제시하며, 이를 통해 수집한 데이터로 복잡한 조작 작업을 성공적으로 자동화할 수 있음을 입증함으로써 로봇 학습 데이터 수집 분야에 실질적인 기여를 함.
Opening the Sim-to-Real Door for Humanoid Pixel-to-Action Policy Transfer
Figure 1: DoorMan, a simulation-trained, RGB-only humanoid loco-manipulation policy, opens diverse, real-world doors.
 *Figure 2: DoorMan training pipeline. All phases are done interactively with IsaacLab. In Phase 1, we train a* GPU 가속 포토리얼리스틱 시뮬레이션과 teacher-student-bootstrap 학습 프레임워크를 통해 순수 RGB 시각만 사용하여 인간형 로봇이 다양한 문을 열 수 있는 sim-to-real 정책을 개발했다.
순수 RGB 시각만을 사용하여 다양한 실제 문을 여는 인간형 로봇 정책을 시뮬레이션에서만 훈련하여 영점 샷 전이에 성공한 획기적인 연구로, staged-reset 탐색과 GRPO 기반 bootstrapping 등의 novel 방법론이 실질적 성능 개선을 입증한다.
TrajBooster: Boosting Humanoid Whole-Body Manipulation via Trajectory-Centric Learning
Fig. 1: Overview of framework. Our proposed TrajBooster uses abundant existing robot manipulation datasets. It retargets
 *Fig. 1: Overview of framework. Our proposed TrajBooster uses abundant existing robot manipulation datasets. It retargets* TrajBooster는 휠드 휴머노이드에서 추출한 다양한 궤적 데이터를 이족 휴머노이드(Unitree G1)로 전이학습하여, 부족한 이족 휴머노이드 데이터를 보충하고 Vision-Language-Action 모델의 성능을 향상시키는 실시간-시뮬레이션-실시간 파이프라인이다.
TrajBooster는 형태학적으로 다른 로봇 간 전이학습이라는 어려운 문제에 대해 실용적이고 효과적인 해결책을 제시한다. 최소한의 실제 데이터만으로도 이족 휴머노이드의 광범위한 전신 조작을 가능하게 한 점에서 로봇 학습의 실용성 측면에서 매우 중요한 기여를 한다.
ULTRA: Unified Multimodal Control for Autonomous Humanoid Whole-Body Loco-Manipulation
Fig. 1: ULTRA is an all-in-one controller for humanoid loco-manipulation that supports: Top. dense motion tracking
 *Fig. 1: ULTRA is an all-in-one controller for humanoid loco-manipulation that supports: Top. dense motion tracking* 물리 기반 신경 retargeting과 unified multimodal controller를 결합하여 humanoid 로봇이 dense reference tracking과 sparse goal-conditioning을 모두 지원하며, egocentric 시각 인지 기반 자율적 전신 loco-manipulation을 수행할 수 있는 프레임워크이다.
이 논문은 humanoid loco-manipulation의 두 가지 근본적인 병목(물리적 retargeting과 통합 컨트롤)을 체계적으로 해결하며, physics-driven retargeting과 multimodal distillation의 조합으로 실제 배포 환경에서의 자율성을 크게 향상시킨다. 특히 unified framework로 diverse 조건 신호를 처리하고 real-world 평가를 제시한 점에서 학술적 및 실용적 의의가 높다.
UniDex: A Robot Foundation Suite for Universal Dexterous Hand Control from Egocentric Human Videos
Figure 1. We introduce UniDex, a robot foundation suite for heterogeneous dexterous hand embodiments. We first curate Un
 *Figure 1. We introduce UniDex, a robot foundation suite for heterogeneous dexterous hand embodiments. We first curate Un* 인간 자기중심 비디오로부터 8종 로봇 핸드에 대한 범용 손재주 제어를 위해 50K+ 궤적 데이터셋(UniDex-Dataset), 통합 액션 공간(FAAS), 3D VLA 정책(UniDex-VLA)을 제시하는 로봇 파운데이션 스위트이다.
UniDex는 손재주 로봇 손 제어를 위한 첫 포괄적 파운데이션 스위트로, 대규모 다중 손 데이터셋, 혁신적인 FAAS 액션 공간, 강력한 3D VLA 정책을 통합하여 일반화와 전이 학습에서 뛰어난 성과를 달성했다.
SynAgent: Generalizable Cooperative Humanoid Manipulation via Solo-to-Cooperative Agent Synergy
Fig. 1. Features of SynAgent. As the first model to address trajectory-following object manipulation with multiple human
 *Fig. 1. Features of SynAgent. As the first model to address trajectory-following object manipulation with multiple human* SynAgent는 단일 에이전트 기술을 다중 에이전트 협력 조작으로 전이하는 Solo-to-Cooperative Agent Synergy 패러다임을 통해, 휴머노이드 로봇의 협력 조작 학습 데이터 부족 문제를 해결하고 다양한 물체 기하학에 일반화하는 통합 프레임워크를 제시한다.
SynAgent는 HOHI 데이터 부족 문제를 창의적으로 해결하고, Solo-to-Cooperative Agent Synergy 패러다임을 통해 다중 에이전트 협력 조작의 확장성과 일반화를 크게 향상시킨 중요한 기여를 한다. 다만 실제 로봇 환경 검증과 더 많은 에이전트로의 확장성 증명이 필요하다.
HumanEgo: Zero-Shot Robot Learning from Minutes of Human Egocentric Videos
HumanEgo는 인간의 자아중심 영상(egocentric video)으로부터 로봇 조작 정책을 학습하는 프레임워크로서, Interaction-Centric Tokens(ICT)를 통해 구체화 격차(embodiment gap)를 해결하고 flow matching 정책과 조밀한 보조 목표들을 결합하여 30분의 인간 영상만으로 92.5% 성공률을 달성한다.
HumanEgo는 인간 자아중심 영상으로부터 로봇 정책을 학습하는 문제에 명확한 해결책을 제시한다. Interaction-Centric Tokens를 통한 혁신적 표현과 조밀한 보조 감시의 조합은 기술적으로 타당하며, 30분 영상으로 92.5% 성공률과 zero-shot 전이 능력은 실용적 의의가 크다. 다만 Aria 센서 의존도와 제한된 작업 평가 범위가 일반화 가능성에 의문을 제기한다.
Learning Human-Intention Priors from Large-Scale Human Demonstrations for Robotic Manipulation
Figure 1: Overview of the HA-2.2M curation pipeline. Large-scale unlabeled human demonstration
 *Figure 1: Overview of the HA-2.2M curation pipeline. Large-scale unlabeled human demonstration* 본 논문은 대규모 인간 시연 영상으로부터 로봇 조작을 위한 인간-의도 사전을 학습하는 MoT-HRA 프레임워크를 제안한다. 220만 에피소드의 HA-2.2M 데이터셋을 구성하고, 3D 궤적 예측, MANO 스타일 손 모션 모델링, 로봇 행동 변환의 3단계 계층적 구조로 인간 시연의 재사용 가능한 부분을 보존하면서 로봇 특화 제어를 학습한다.
본 논문은 대규모 인간 시연으로부터 로봇 조작을 학습하는 실질적 도전에 대해 잘 정의된 계층적 접근을 제시한다. 220만 에피소드 HA-2.2M 데이터셋과 MoT-HRA의 knowledge insulation 설계는 인간 행동의 재사용 가능한 구조를 보존하면서 로봇 특화 제어를 학습하는 점에서 기여도가 있다. 다만 데이터셋 필터링 정확성, 실제 로봇 평가의 포괄성, 계산 효율성 분석이 강화될 필요가 있다.
Humanoid Policy ~ Human Policy
Figure 1: This paper advocates high-quality human data as a data source for cross-embodiment
 *Figure 3: Overview of HAT. Human Action Transformer (HAT) learns a robot policy by modeling* 이 논문은 humanoid 로봇의 조작 정책 학습에 대규모 egocentric human demonstration을 활용하는 cross-embodiment 학습 방법을 제안한다. PH2D 데이터셋과 Human Action Transformer (HAT)를 통해 human과 robot 간의 embodiment gap을 완화하고 데이터 수집 효율을 크게 개선한다.
이 논문은 humanoid robot manipulation 학습을 위해 대규모 human data를 효율적으로 활용하는 실용적이고 창의적인 방안을 제시한다. PH2D 데이터셋의 규모와 품질, HAT의 unified design, 그리고 실로봇 검증이 기여도 있으나, 평가 범위 확장과 다양한 플랫폼으로의 일반화 검증이 필요하다.
Expressive Whole-Body Control for Humanoid Robots
Fig. 1: Our Robot demonstrates diverse and expressive whole-body movements in different scenarios. Top Row: The robot is
 *Fig. 2: Overview of our framework. Our framework is able to train on data from various sources such as static human moti* 인간형 로봇이 인간의 모션 캡처 데이터를 학습하여 표현력 있는 전신 움직임을 수행하도록 강화학습 기반의 제어 정책을 제안하며, 상체는 참조 모션을 모방하되 하체는 속도 명령만 따르도록 제약을 완화하여 실제 로봇에서의 동작을 가능하게 함.
본 논문은 인간 모션 캡처 데이터를 실제 인간형 로봇에 효과적으로 적용하는 창의적인 문제 분해 방식과 차등적 제약 설계로, 학습 기반 인간형 로봇 제어 분야에서 처음으로 다양한 표현력 있는 동작을 실현함. 명확한 동기, 실제 로봇 검증, 그리고 우수한 성과에도 불구하고 기술적 신규성이 개별 컴포넌트 수준에서는 제한적이며, 하체 표현력과 다양한 작업 확장에 대한 연구가 필요함.
Benchmarking Humanoid Imitation Learning with Motion Difficulty
Figure 1. Our Motion Difficulty Score (MDS) accurately quanti-
 *Figure 1. Our Motion Difficulty Score (MDS) accurately quanti-* 본 논문은 인간형 로봇의 동작 모방 학습에서 정책 성능과 동작 난이도를 분리하여 평가하기 위해 Motion Difficulty Score (MDS)를 제안하며, 이를 통해 실패가 학습 부족인지 본질적으로 어려운 동작인지를 구분할 수 있게 한다.
본 논문은 동작 모방 학습에서 오래된 문제(정책 성능 vs 동작 난이도의 혼동)를 처음으로 명확히 정의하고 수학적으로 해결하는 창의적인 접근을 제시하며, MD-AMASS 구성과 광범위한 실증 검증을 통해 실용적 가치를 입증한다. 다만 실제 로봇 환경으로의 확장과 일반화 가능성에 대한 추가 검증이 요구된다.
Human-Humanoid Robots Cross-Embodiment Behavior-Skill Transfer Using Decomposed Adversarial Learning from Demonstration
Fig. 1: Human can serve as the prototype of diverse humanoid robots, efficiently learning generalized loco-manipulation
 *Fig. 2: Schematic overview of the cross-embodiment loco-manipulation skill transfer framework. 1) Human embodiment* Unified Digital Human (UDH) 모델을 공통 프로토타입으로 사용하여 인간 시연에서 행동 원시 요소를 학습하고, 분해된 adversarial imitation learning과 kinematic motion retargeting을 통해 다양한 휴머노이드 로봇 플랫폼으로 로코-매니퓰레이션 스킬을 효율적으로 전이한다.
본 논문은 UDH를 중심으로 한 창의적인 교차 embodiment 프레임워크를 제시하며, functional decomposition과 adversarial imitation learning의 결합, 그리고 interaction graph 기반 계획을 통해 휴머노이드 로봇의 로코-매니퓰레이션 스킬 전이 문제를 실질적으로 해결하는 중요한 기여를 한다.
Learning Human-Like Badminton Skills for Humanoid Robots
Fig. 1: Real-world Deployment of the System. We present a learning-based framework that enables a humanoid to perform ag
 *Fig. 2: Overview of the Framework. The pipeline progressively transforms a kinematic imitator into a dynamic striker thr* 휴머노이드 로봇이 배드민턴 기술을 습득하도록 하는 Imitation-to-Interaction 점진적 강화학습 프레임워크를 제안하며, 시뮬레이션에서 실제 로봇으로의 제로샷 sim-to-real 전이를 달성했다.
휴머노이드 로봇 스포츠 제어의 새로운 경계를 개척한 혁신적 연구로, Imitation-to-Interaction 프레임워크와 manifold expansion 전략은 희소한 전문가 데이터에서 고도로 정밀하고 인간다운 운동을 학습하는 강력한 솔루션을 제시한다. 제로샷 sim-to-real 전이의 성공은 실용적 가치가 높으나, 상대방 상호작용과 환경 변동성 측면의 제한이 남아 있다.
Learning to Control Physically-simulated 3D Characters via Generating and Mimicking 2D Motions
Figure 1. The proposed Mimic2DM effectively learns character controllers for diverse motion types, including dynamic hum
 *Figure 1. The proposed Mimic2DM effectively learns character controllers for diverse motion types, including dynamic hum* Mimic2DM은 비디오에서 추출한 2D 키포인트 궤적만을 사용하여 물리 기반 3D 캐릭터 제어 정책을 직접 학습하는 모션 모방 프레임워크이며, 재투영 오차 최소화와 RL을 통해 2D 데이터로부터 물리적으로 타당한 3D 동작을 합성한다.
Mimic2DM은 접근성 높은 2D 데이터로부터 물리 기반 3D 캐릭터 제어를 학습하는 실질적이고 혁신적인 방법으로, 기존의 희소한 3D MoCap 데이터 의존성을 크게 완화하며 다양한 도메인에서 우수한 성능을 보여준다.
PDF-HR: Pose Distance Fields for Humanoid Robots
Fig. 1: We present PDF-HR, which learns the manifold of plausible G1 poses as a zero-level set. Left: The fϕ is trained
 *Fig. 1: We present PDF-HR, which learns the manifold of plausible G1 poses as a zero-level set. Left: The fϕ is trained * Humanoid 로봇을 위한 pose distance field인 PDF-HR을 제안하여, 학습된 로봇 포즈 분포를 연속 미분 가능한 manifold로 표현하고 포즈의 plausibility를 평가한다.
이 논문은 humanoid robotics에 implicit manifold representation을 처음 적용하여 scarce data 문제를 효과적으로 해결하고, lightweight하면서도 재사용 가능한 pose prior를 제안한 점에서 높은 학술적 기여를 한다. 다양한 task에서 일관된 성능 향상을 보이며 실용적 가치도 우수하나, corpus 의존성과 temporal modeling의 미흡이 향후 개선 과제이다.
ReActor: Reinforcement Learning for Physics-Aware Motion Retargeting
Fig. 1. Physics-aware retargeting of human motion (left) onto two humanoid robots (middle) and a quadruped (right) with
 *Fig. 1. Physics-aware retargeting of human motion (left) onto two humanoid robots (middle) and a quadruped (right) with * 본 논문은 인간의 모션캡처 데이터를 상이한 형태의 휴머노이드 및 사족로봇으로 리타게팅하기 위한 이중수준 최적화 프레임워크를 제안한다. 상단 수준에서는 리타게팅 매개변수를 최적화하고, 하단 수준에서는 reinforcement learning을 통해 tracking policy를 학습하여 물리 기반의 artifact-free한 모션을 생성한다.
본 논문은 motion retargeting을 bilevel optimization과 RL의 조합으로 재정의하여 물리적으로 타당하고 artifact-free한 모션을 생성하는 강력한 프레임워크를 제시한다. Sparse correspondence만으로 다양한 morphology를 지원하며, 시뮬레이션 기반 검증과 제한적 hardware 결과를 제공한다. 계산 효율성과 hardware 검증의 확장이 향후 과제이지만, 로보틱스와 애니메이션 분야의 motion retargeting 문제에 대한 중요한 기여로 평가된다.
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Figure 1: Data Pyramid for Robot Foundation Model
 *Figure 1: Data Pyramid for Robot Foundation Model* GR00T N1은 Vision-Language-Action (VLA) 모델로, dual-system 아키텍처를 통해 다양한 휴머노이드 로봇을 제어할 수 있는 오픈 소스 기초 모델이다. 웹 데이터, 인간 비디오, 합성 데이터, 실제 로봇 궤적을 계층적으로 조합하여 학습한다.
GR00T N1은 휴머노이드 로봇 기초 모델 개발에서 중요한 진전을 이루었으며, data pyramid 전략과 dual-system 아키텍처의 혁신적 설계가 돋보인다. 오픈소스 공개와 실제 로봇 검증을 통해 로봇 학습 커뮤니티에 실질적 기여를 할 것으로 기대된다.
PvP: Data-Efficient Humanoid Robot Learning with Proprioceptive-Privileged Contrastive Representations
Figure 1. (a) PvP employs contrastive learning between proprioceptive and privileged states to learn compact and task-re
 *Figure 1. (a) PvP employs contrastive learning between proprioceptive and privileged states to learn compact and task-re* PvP는 고유 감각(proprioceptive)과 특권 상태(privileged state) 사이의 대조 학습을 활용하여 휴머노이드 로봇의 전신 제어(WBC) 학습의 샘플 효율성을 크게 향상시킨다.
PvP는 proprioceptive-privileged 대조 학습이라는 직관적이면서도 효과적인 방법으로 휴머노이드 로봇 학습의 샘플 효율성을 크게 향상시키며, SRL4Humanoid 프레임워크는 해당 분야의 표준 도구로서 상당한 기여를 한다.
Scalable and General Whole-Body Control for Cross-Humanoid Locomotion
Figure 1. Zero-shot generalization and real-world humanoid capabilities enabled by XHugWBC’s generalist policy. First ro
 *Figure 2. Training framework of XHugWBC. (a) Data generation: physics-consistent morphological randomization produces di* XHugWBC는 물리적으로 일관성 있는 형태학적 랜덤화, 의미론적으로 정렬된 관찰-행동 공간, 그래프 기반 정책 아키텍처를 통해 단일 정책으로 다양한 인간형 로봇에 대한 제로샷 제너럴화를 실현하는 교차-신체 전신 제어 프레임워크이다.
본 논문은 물리적으로 일관성 있는 형태 랜덤화와 의미론적 정렬을 통해 단일 정책의 다중 인간형 로봇 제너럴화를 처음으로 달성했으며, 7개 실제 로봇에서의 강건한 제로샷 성능과 시뮬레이션 확장성으로 로봇 학습의 현실적 가치를 입증했다.
SENTINEL: A Fully End-to-End Language-Action Model for Humanoid Whole Body Control
Figure 1: Overview of SENTINEL. Our framework consists of three stages. (1) We construct a language-
 *Figure 1: Overview of SENTINEL. Our framework consists of three stages. (1) We construct a language-* SENTINEL은 언어 명령을 휴머노이드 로봇의 저수준 제어 신호로 직접 변환하는 완전 end-to-end 언어-행동 모델로, flow matching을 통해 행동 청크를 생성하고 실제 배포를 위해 잔여 강화학습으로 정제한다.
SENTINEL은 언어-조건부 휴머노이드 제어를 위한 완전 end-to-end 접근의 첫 사례로, 중간 표현을 제거하고 flow matching과 residual RL을 결합한 창의적인 방법론을 제시한다. 시뮬레이션과 실제 로봇 모두에서의 성공적인 배포는 본 접근의 타당성을 입증하며, 향후 구체화 AI 발전에 중요한 기초를 마련한다.
SkillBlender: Towards Versatile Humanoid Whole-Body Loco-Manipulation via Skill Blending
 *Figure 2: Overview of SkillBlender. We first pretrain goal-conditioned primitive expert skills that are* SkillBlender는 사전학습된 목표조건부 원시 기술들을 동적으로 혼합하여 휴머노이드 로봇이 복잡한 전신 조작-이동 작업을 최소한의 보상 엔지니어링으로 수행할 수 있게 하는 계층적 강화학습 프레임워크이다.
SkillBlender는 휴머노이드 로봇의 다용도적 조작-이동 능력 개발에 대한 우아하고 실용적인 해결책을 제시하며, 포괄적인 벤치마크와 함께 향후 휴머노이드 연구의 중요한 기초가 될 가능성이 높다.
SLAC: Simulation-Pretrained Latent Action Space for Whole-Body Real-World RL
Figure 1: SLAC uses a task-agnostic action space trained in low-fidelity simulation (left) to learn
 *Figure 1: SLAC uses a task-agnostic action space trained in low-fidelity simulation (left) to learn* SLAC는 저충실도 시뮬레이터에서 학습한 task-agnostic 잠재 행동 공간을 사용하여 고자유도 모바일 매니퓨레이터가 실제 환경에서 효율적이고 안전하게 강화학습으로 접촉이 풍부한 전신 조작 작업을 학습할 수 있게 한다.
SLAC는 저충실도 시뮬레이션 기반 latent action space pretraining과 실제 환경 강화학습을 결합하여 고자유도 모바일 매니퓨레이터의 복잡한 접촉 조작 작업을 안전하고 효율적으로 학습할 수 있게 하는 혁신적인 접근법을 제시하며, 1시간 미만의 실제 상호작용만으로 의미 있는 성과를 달성함으로써 실제 로봇 학습의 실용성을 크게 향상시킨다.
UniTracker: Learning Universal Whole-Body Motion Tracker for Humanoid Robots
Fig. 1: We deploy our UniTracker on a real humanoid robot,
 *Fig. 2: An overview of UniTracker: In Stage 1, we train a teacher policy using oracle states via goal-conditioned* UniTracker는 CVAE 기반 세 단계 학습 프레임워크를 통해 부분 관측 조건에서도 다양하고 일관성 있는 전신 동작 추적을 실현하는 휴머노이드 로봇 제어 정책이다.
UniTracker는 CVAE 기반 증류와 전역 맥락 정렬을 통해 기존 teacher-student 프레임워크의 핵심 한계를 우아하게 해결하며, 실제 로봇에서 8,000개 이상의 동작 추적을 성공시킨 강력한 기여이다. 방법론의 창의성, 실제 배포 검증, 그리고 실용적 영향 면에서 높은 평가를 받을 만한 논문이다.
Zero-Shot Whole-Body Humanoid Control via Behavioral Foundation Models
Figure 1 META MOTIVO is the first behavioral foundation model for humanoid agents that can solve whole-body control task
 *Figure 1 META MOTIVO is the first behavioral foundation model for humanoid agents that can solve whole-body control task* Forward-Backward representations with Conditional-Policy Regularization (FB-CPR)을 통해 unlabeled behavior dataset으로 unsupervised RL을 정규화하여, humanoid agent의 zero-shot whole-body control을 가능하게 하는 behavioral foundation model Meta Motivo를 개발했다.
FB-CPR은 unsupervised RL의 exploration 한계를 behavior dataset 정규화로 창의적으로 해결하고, 복잡한 humanoid 제어에서 zero-shot generalization을 달성한 기술적으로 견실하고 의미 있는 연구이다. 재현성 보장과 다양한 평가는 강점이나, 데이터셋 의존성과 실제 로봇 검증 부재는 향후 개선이 필요하다.
ZeroWBC: Learning Natural Visuomotor Humanoid Control Directly from Human Egocentric Video
Fig. 1: Overview of the ZeroWBC framework. We propose a novel framework that learns natural humanoid visuomotor control
 *Fig. 1: Overview of the ZeroWBC framework. We propose a novel framework that learns natural humanoid visuomotor control* ZeroWBC는 인간의 일인칭 비디오와 모션 캡처 데이터로부터 휴머노이드 로봇의 전신 제어 정책을 직접 학습하는 프레임워크로, 로봇 원격조종 데이터 수집 없이 자연스러운 장면 상호작용을 가능하게 한다.
ZeroWBC는 휴머노이드 로봇의 원격조종 데이터 수집 문제를 근본적으로 해결하며, 인간 영상 데이터로부터 자연스럽고 다양한 전신 제어를 구현하는 혁신적인 프레임워크이다. 강력한 실험 검증과 실제 로봇 성공사례는 제시되어 있으나, 추가 플랫폼 일반화와 동적 환경 적응성에 대한 평가가 향후 필요하다.
AGILE: A Comprehensive Workflow for Humanoid Loco-Manipulation Learning
Figure 1: Overview of agile learning workflow. The workflow covers prepare-training, batch cloud training
 *Figure 1: Overview of agile learning workflow. The workflow covers prepare-training, batch cloud training* AGILE는 휴머노이드 로봇의 강화학습 정책 개발을 위한 엔드투엔드 워크플로우로, 환경 검증, 재현 가능한 학습, 통합 평가, 디스크립터 기반 배포의 4단계를 표준화하여 시뮬레이션-실세계 전이의 신뢰성을 향상시킨다.
AGILE는 휴머노이드 RL의 실제 배포 단계에서 야기되는 현실적 문제들을 직시하고 이를 해결하기 위한 체계적인 엔지니어링 워크플로우를 제시한다. 알고리즘 혁신보다는 infrastructure 중심이지만, 재현성, 신뢰성, 배포 가능성 측면에서 매우 실용적이며 5개 작업과 2개 플랫폼에서의 성공적인 sim-to-real 전이로 효과를 입증했다.
BFM-Zero: A Promptable Behavioral Foundation Model for Humanoid Control Using Unsupervised Reinforcement Learning
Figure 1: BFM-Zero enables versatile and robust whole-body skills. (A-C) Diverse zero-shot inference
 *Figure 2: An overview of the BFM-Zero framework. After the pre-training stage, BFM-Zero forms a latent* BFM-Zero는 unsupervised RL과 Forward-Backward 모델을 활용하여 휴머노이드 로봇의 다양한 제어 작업을 단일 정책으로 수행할 수 있는 promptable behavioral foundation model을 제시한다. 공유 잠재 공간에 모션, 목표, 보상을 임베딩하여 zero-shot 추론과 few-shot 적응을 가능하게 한다.
BFM-Zero는 unsupervised RL을 통해 휴머노이드 로봇의 실제 배포에서 처음으로 promptable foundation model을 성공적으로 구현하였으며, zero-shot 다중 작업 수행과 few-shot 적응의 균형을 이루는 실용적 솔루션을 제시한다. 이는 로봇 제어의 패러다임 전환을 제시하는 중요한 기여이다.
Coordinated Humanoid Robot Locomotion with Symmetry Equivariant Reinforcement Learning Policy
Figure 1: The overall architecture of SE-Policy. (a) Left: the architecture of the actor and critic model. (b) upper rig
 *Figure 1: The overall architecture of SE-Policy. (a) Left: the architecture of the actor and critic model. (b) upper rig* 인간의 신경계에서 영감을 받은 Symmetry Equivariant Policy (SE-Policy)를 제안하여, 휴머노이드 로봇의 형태적 대칭성을 DRL 프레임워크에 엄격하게 임베딩함으로써 조정되고 균형잡힌 보행을 실현한다.
SE-Policy는 휴머노이드 로봇의 형태적 대칭성을 엄격한 네트워크 제약으로 구현하여 추가 하이퍼파라미터 없이 40% 성능 향상을 달성한 혁신적인 방법이며, 실제 로봇 배포를 통해 실용성을 입증했다는 점에서 높은 기여도를 가진다.
EGM: Efficiently Learning General Motion Tracking Policy for High Dynamic Humanoid Whole-Body Control
Figure 1: We deploy a unified student policy trained with EGM in the simulation environment, achieving high robust
 *Figure 2: Overview of the EGM framework. First, large-scale Mocap datasets are retargeted to Humanoid, then a small* EGM은 Bin-based Cross-motion Curriculum Adaptive Sampling과 Composite Decoupled Mixture-of-Experts 아키텍처를 통해 4.08시간의 소량 데이터로 49.25시간의 다양한 모션을 효율적으로 추적하는 일반화된 휴머노이드 제어 정책을 학습한다.
EGM은 Bin-based adaptive sampling과 CDMoE 아키텍처의 새로운 조합으로 humanoid motion tracking의 데이터 효율성과 dynamic motion 성능을 획기적으로 개선하며, 소량 데이터 학습의 실용성을 입증하는 강력한 기여를 제시한다.
Embodiment-Aware Generalist Specialist Distillation for Unified Humanoid Whole-Body Control
Fig. 1: In this work, we propose a distillation framework that yields a single whole-body controller that runs on hetero
 *Fig. 2: Method Overview. (a) Unified command interface. The command vector ct comprises task commands vt (linear* EAGLE는 다양한 휴머노이드 로봇을 단일 정책으로 제어하기 위한 embodiment-aware generalist-specialist distillation 프레임워크로, 반복적인 전문가 미세조정과 일반화 정책으로의 지식 증류를 통해 여러 이종 로봇에서 보행, 스쿼팅, 기울임 등 다양한 whole-body 제어를 가능하게 한다.
EAGLE는 generalist-specialist distillation을 통해 이종 휴머노이드의 통합 제어라는 어려운 문제에 대한 실증적 해결책을 제시하며, 시뮬레이션과 실제 하드웨어에서의 광범위한 검증으로 fleet-level 휴머노이드 제어의 실현 가능성을 보여주는 의미 있는 기여다.
FARM: Frame-Accelerated Augmentation and Residual Mixture-of-Experts for Physics-Based High-Dynamic Humanoid Control
Figure 1: Comparison between FARM and the baseline FC on two high-dynamic motions. FARM accurately completes both
 *Figure 2: Overview of the FARM pipeline. Failure cases are* FARM은 frame-accelerated augmentation과 residual mixture-of-experts를 결합하여 저역학(low-dynamic) 동작에서의 높은 정확도를 유지하면서 고역학(high-dynamic) 인간형 동작 제어 성능을 크게 향상시키는 프레임워크이다.
FARM은 간단하면서도 효과적인 frame-accelerated augmentation과 동적 용량 할당 메커니즘으로 범용 인간형 제어의 실질적 한계를 해결하며, 첫번째 공개 고역학 벤치마크 제시와 함께 물리 기반 인간형 제어 분야에 중요한 기여를 한다.
From Experts to a Generalist: Toward General Whole-Body Control for Humanoid Robots
 *Figure 2: Overview of the BumbleBee framework. The left section illustrates the data curation stage, which* BumbleBee는 motion clustering과 sim-to-real adaptation을 결합하여 humanoid robot의 일반적인 whole-body control을 달성하는 expert-generalist 학습 프레임워크이다. 여러 motion cluster에서 전문가 정책을 훈련한 후 이를 통합 generalist controller로 distill한다.
BumbleBee는 motion clustering과 expert-generalist distillation을 통해 humanoid robot의 일반적인 whole-body control 문제를 효과적으로 해결하며, sim-to-real adaptation과 결합하여 실제 세계에서 agile하고 robust한 control을 달성한 우수한 연구이다. 기술적 창의성과 실험적 검증이 뛰어나고 robotics 분야에 의미 있는 기여를 한다.
From Motion to Behavior: Hierarchical Modeling of Humanoid Generative Behavior Control
Figure 1. From motion to behavior. (a) Simple periodic motion patterns without complex, behavioral semantic meaning, (b)
 *Figure 1. From motion to behavior. (a) Simple periodic motion patterns without complex, behavioral semantic meaning, (b)* 인간의 고수준 의도를 반영하는 계층적 행동 계획과 LLM을 결합하여 장기간의 물리적으로 타당한 인간 행동을 생성하는 통합 프레임워크 PHYLOMAN을 제시하고, 이를 위해 다층 텍스트 주석이 포함된 GBC-100K 대규모 데이터셋을 구축했다.
본 논문은 인간 행동 생성에 LLM 기반 계획과 물리적 제어를 혁신적으로 통합하고 대규모 주석 데이터셋을 제공함으로써 장기간 의도 지향적 행동 생성의 새로운 기준을 제시한다. 기술적 우수성, 실무적 가치, 그리고 체계적인 실험 검증으로 인해 컴퓨터 비전 및 로봇공학 커뮤니티에 상당한 영향을 미칠 것으로 예상된다.
GMT: General Motion Tracking for Humanoid Whole-Body Control
Figure 1: We deploy the general unified motion tracking policy on a medium-sized humanoid robot.
 *Figure 3: An overview of GMT. Here gt denotes the motion target frame, ot denotes proprioceptive* GMT는 humanoid 로봇이 다양한 전신 모션을 추적할 수 있도록 하는 통합 정책을 학습하는 프레임워크로, Adaptive Sampling 전략과 Motion Mixture-of-Experts 아키텍처를 핵심 요소로 제안한다.
GMT는 humanoid 로봇의 general motion tracking에 대한 실질적인 해결책을 제시하며, Adaptive Sampling과 Motion MoE라는 두 가지 실용적 기법으로 기존의 산발적 접근들을 통합한 우수한 연구이다. 실제 로봇 배포 성공과 상태-최첨단 성능은 높은 가치를 제시하지만, 더 광범위한 하드웨어 검증과 이론적 분석 강화가 필요하다.
HoRD: Robust Humanoid Control via History-Conditioned Reinforcement Learning and Online Distillation
Figure 1. Framework overview. Two-stage teacher–student learning pipeline for robust humanoid control under partial obse
 *Figure 1. Framework overview. Two-stage teacher–student learning pipeline for robust humanoid control under partial obse* HoRD는 history-conditioned reinforcement learning과 online distillation을 결합한 두 단계 학습 프레임워크로, 휴머노이드 로봇이 도메인 시프트 상황에서 강건한 제어를 수행하도록 한다.
HoRD는 history-conditioned 동역학 추론과 sparse 명령 처리라는 두 가지 핵심 혁신을 통해 휴머노이드 제어의 강건성과 일반화 문제를 효과적으로 해결하며, 광범위한 실험 검증과 데이터셋 공개로 실용적 가치를 입증한다.
HOVER: Versatile Neural Whole-Body Controller for Humanoid Robots
Fig. 1: HOVER enables versatile humanoid control with a unified
 *Fig. 1: HOVER enables versatile humanoid control with a unified* HOVER는 키네매틱 위치 추적, 조인트 각도 추적, 루트 추적을 포함한 15개 이상의 제어 모드를 지원하는 통합 신경망 제어기로, 정책 증류를 통해 다양한 제어 모드를 단일 정책으로 통합하여 휴머노이드 로봇의 다목적 전신 제어를 실현한다.
HOVER는 휴머노이드 전신 제어의 다중 모드 통합이라는 실질적이고 중요한 문제를 정책 증류 기반의 우아한 해결책으로 제시하며, 시뮬레이션과 실제 로봇에서 모두 검증된 견고한 성과를 보여준다. 다만 실제 환경의 복잡한 작업에 대한 적응성과 계산 효율성에 대한 심화 분석이 더해지면 완성도가 높아질 수 있다.
In-N-On: Scaling Egocentric Manipulation with in-the-wild and on-task Data
Figure 1. This paper investigates large-scale pre-training and post-training with egocentric human data. We curate a lar
 *Figure 1. This paper investigates large-scale pre-training and post-training with egocentric human data. We curate a lar* 이 논문은 1,000시간 이상의 in-the-wild 에고센트릭 데이터와 on-task 데이터를 결합하여 대규모 휴머노이드 조작 정책 Human0을 학습하고, domain adaptation을 통해 인간과 로봇 간의 도메인 갭을 최소화한다.
이 논문은 in-the-wild와 on-task 인간 데이터를 체계적으로 결합하는 새로운 data recipe를 제시하고, 대규모 PHSD 데이터셋과 Human0 모델을 통해 실제 휴머노이드 로봇에서 language following, few-shot learning, robustness 개선을 달성함으로써 로봇 조작 학습의 확장성에 중요한 기여를 한다.
InterMimic: Towards Universal Whole-Body Control for Physics-Based Human-Object Interactions
Figure 1. InterMimic enables physically simulated humans to perform interactions with dynamic and diverse objects. It su
 *Figure 2. Our two-stage pipeline: (i) training each teacher pol-* InterMimic은 교사-학생 증류 및 RL 미세조정을 통해 불완전한 MoCap 데이터로부터 다양한 동적 객체와의 전신 상호작용을 학습할 수 있는 물리 기반 제어 정책 프레임워크이다.
InterMimic은 불완전한 대규모 MoCap 데이터로부터 다양한 동적 객체와의 전신 상호작용을 학습하는 첫 통합 프레임워크로, 교사-학생 증류와 RL 미세조정의 창의적 결합을 통해 물리 기반 상호작용 애니메이션의 새로운 기준을 제시한다.
InterPrior: Scaling Generative Control for Physics-Based Human-Object Interactions
Figure 1. InterPrior is a versatile generative controller instantiated as a goal-conditioned policy that controls a simu
 *Figure 1. InterPrior is a versatile generative controller instantiated as a goal-conditioned policy that controls a simu* InterPrior는 대규모 모방 사전학습과 강화학습 미세조정을 통해 물리 기반 인간-객체 상호작용을 위한 확장 가능한 생성형 제어기를 학습하는 프레임워크로, 고수준 의도로부터 자연스러운 전신 협응과 조작을 생성한다.
InterPrior는 distillation과 RL의 시너지를 통해 물리 기반 인간-객체 상호작용의 확장 가능한 생성형 제어 문제를 우아하게 해결하며, 다양한 목표 형식 지원, 강력한 실패 회복, 미분포 일반화 능력으로 인해 휴머노이드 로봇 제어 분야의 실질적 진전을 이루었다.
KungfuBot2: Learning Versatile Motion Skills for Humanoid Whole-Body Control
Fig. 1: Humanoid learning versatile motion skills. We deploy VMS on the Unitree G1 humanoid robot, demonstrating its cap
 *Fig. 2: Framework of VMS. The large-scale motion capture dataset is first retargeted to the humanoid skeleton using an I* VMS는 Orthogonal Mixture-of-Experts (OMoE) 아키텍처와 하이브리드 추적 목표를 결합하여 단일 정책으로 다양한 동작을 수행하는 휴머노이드 로봇 제어기를 제시한다. 장시간 시퀀스에서 안정적인 성능과 높은 동작 충실도를 달성한다.
VMS는 OMoE 아키텍처와 하이브리드 추적 목표의 조합으로 실용적 휴머노이드 제어의 주요 과제들을 효과적으로 해결하며, 대규모 데이터 기반의 체계적 방법론과 실로봇 검증을 통해 범용 휴머노이드 제어의 기초 플랫폼으로서 높은 가치를 보여준다.
LangWBC: Language-directed Humanoid Whole-Body Control via End-to-end Learning
Fig. 1:
 *Fig. 2.* 자연언어 명령을 humanoid robot의 전신 제어 동작으로 직접 변환하는 end-to-end 학습 프레임워크를 제시한다. Reinforcement learning으로 학습한 teacher policy와 CVAE 기반 student policy를 결합하여 언어-행동의 통합 latent space를 구성한다.
본 논문은 humanoid 전신 제어의 오랜 난제인 언어-행동 갭을 end-to-end learning으로 직접 해결하며, CVAE 기반의 unified latent space 구성으로 동작 다양성과 부드러운 전환을 동시에 달성한 점이 우수하다. 실제 로봇 검증과 강건성 입증을 통해 현실 적용 가능성을 보였으나, 데이터셋 의존성과 다양한 플랫폼 일반화에 대한 추가 검증이 필요하다.
Learning Athletic Humanoid Tennis Skills from Imperfect Human Motion Data (LATENT)
Figure 1 (a) The humanoid performs multi-shot rallies with a human player using different stroke types across various co
 *Figure 2 Overview of LATENT. (a) We pre-train a motion tracker on collected imperfect human motion data. (b) We construc* LATENT는 불완전한 인간 모션 데이터(5시간 분량의 테니스 프리미브)로부터 수정 가능한 잠재 행동 공간을 구성하고, 고수준 정책으로 이를 보정·합성하여 휴머노이드 로봇이 인간과의 멀티샷 테니스 랠리를 수행하도록 학습하는 시스템이다.
본 논문은 불완전한 모션 데이터로부터 athletic humanoid 스포츠 기술을 학습하는 실질적이고 창의적인 시스템을 제시하며, correctable latent space와 latent action barrier라는 두 가지 novel design으로 imperfect data의 한계를 효과적으로 극복했다. Real-world humanoid 로봇에서 인간과의 멀티샷 테니스 랠리를 성공적으로 구현한 점이 이 분야의 중요한 이정표이다.
OmniXtreme: Breaking the Generality Barrier in High-Dynamic Humanoid Control
Fig. 1: Extreme whole-body humanoid control from our unified policy OMNIXTREME. (a) A quantitative comparison shows
 *Fig. 1: Extreme whole-body humanoid control from our unified policy OMNIXTREME. (a) A quantitative comparison shows* OmniXtreme는 flow-matching 기반의 생성형 정책과 actuation-aware residual RL을 결합하여 고동역 인간형 로봇의 다양한 극단적 동작을 고충실도로 추적할 수 있는 확장 가능한 프레임워크를 제시한다.
OmniXtreme은 humanoid 동작 제어의 long-standing fidelity-scalability trade-off를 해결하기 위해 생성형 모델과 actuation-aware 정제라는 두 가지 보완적 기법을 창의적으로 결합한 강력한 프레임워크이며, 실제 로봇에서 극단적 동작의 성공적 실행으로 그 유효성을 입증했다.
TokenHSI: Unified Synthesis of Physical Human-Scene Interactions through Task Tokenization
Figure 1. Introducing TokenHSI, a unified model that enables physics-based characters to perform diverse human-scene int
 *Figure 1. Introducing TokenHSI, a unified model that enables physics-based characters to perform diverse human-scene int* TokenHSI는 transformer 기반의 통합 정책으로 humanoid 고유감각을 공유 토큰으로 모델링하고 task 토큰과 masking mechanism으로 결합하여 다양한 인간-장면 상호작용(HSI) 기술을 단일 네트워크에서 통합한다.
TokenHSI는 독립적 proprioception tokenizer와 masking mechanism을 통해 다중 HSI 기술을 단일 네트워크에서 효과적으로 통합하고, 변수 길이 입력을 활용한 효율적 정책 적응까지 실현한 혁신적인 접근법으로, 컴퓨터 애니메이션과 embodied AI 분야에서 실질적인 기여를 한다.
UniAct: Unified Motion Generation and Action Streaming for Humanoid Robots
Figure 1. UniAct, a unified framework for multimodal motion generation and action streaming. UniAct enables humanoid rob
 *Figure 1. UniAct, a unified framework for multimodal motion generation and action streaming. UniAct enables humanoid rob* UniAct는 MLLM과 causal streaming pipeline을 결합한 두 단계 프레임워크로, 인간형 로봇이 언어, 음악, 궤적 등 다양한 multimodal 명령을 sub-500ms 지연시간으로 실행할 수 있게 한다.
UniAct는 MLLM과 robust tracking을 unified framework로 통합하여 실제 humanoid robot에서 multimodal instruction following을 low latency로 달성한 의미 있는 연구이며, UA-Net 데이터셋 기여와 함께 embodied AI 분야에서 중요한 진전을 나타낸다.
Switch: Learning Agile Skills Switching for Humanoid Robots
 *Fig. 2: The Switch system: (a) We retarget human motion capture skills onto the robot. We then construct a skill graph w* Switch는 Skill Graph를 기반으로 humanoid robot이 임의의 시점에서 다양한 동작 기술들 사이를 자유롭게 전환할 수 있는 계층적 전신 제어 시스템을 제시한다.
Switch는 Skill Graph라는 단순하면서도 효과적인 구조와 online graph search 기반의 동적 재계획을 통해 humanoid robot의 skill switching 문제를 실용적으로 해결한 의미 있는 연구이며, 실제 로봇 플랫폼에서의 검증으로 높은 적용 가치를 보여준다.
CF-VLA: Efficient Coarse-to-Fine Action Generation for Vision-Language-Action Policies
Figure 1: Teaser of CF-VLA. Standard flow matching requires multiple iterative steps to recover action structure from un
 *Figure 1: Teaser of CF-VLA. Standard flow matching requires multiple iterative steps to recover action structure from un* 본 논문은 flow matching 기반 VLA 정책의 비효율성을 해결하기 위해 coarse-to-fine 두 단계 생성 프레임워크를 제안한다. 첫 번째 단계에서는 Gaussian 노이즈를 action-prior-guided 초기화로 변환하고, 두 번째 단계에서는 단일 스텝 국소 정교화를 수행하여 추론 지연시간을 75.4% 감소시키면서 성능을 유지한다.
CF-VLA는 flow-based VLA 정책의 구조적 비효율성을 명확하게 파악하고, coarse-to-fine 분해를 통해 실용적이고 효과적인 해결책을 제시한다. 75.4%의 지연시간 감소와 실로봇 83.0% 성공률은 강력한 경험적 검증을 보여주며, 방법의 플러그-앤-플레이 특성으로 인해 광범위한 적용성을 가진다. 다만 이론적 분석과 더 깊은 통찰이 추가되면 더욱 완성도 있는 연구가 될 것이다.
Shape Your Body: Value Gradients for Multi-Embodiment Robot Design
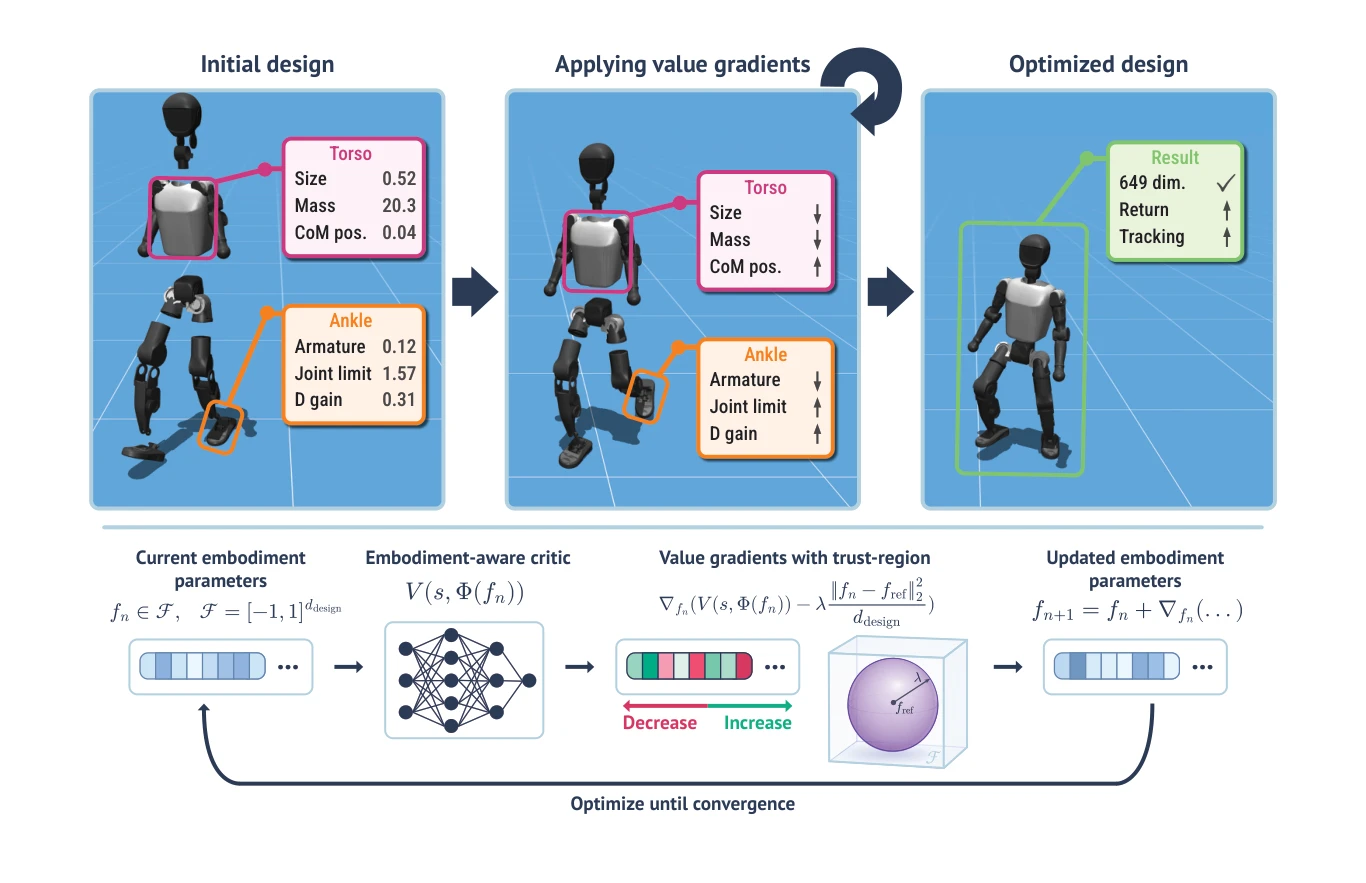
Figure 1: Shape Your Body. We first train an embodiment-aware policy and value function with
 *Figure 1: Shape Your Body. We first train an embodiment-aware policy and value function with* 본 논문은 다중 체형을 학습한 가치함수를 재사용 가능한 설계 모델로 변환하는 방법을 제안한다. 사전 학습된 embodiment-aware value function에서 gradient를 계산하여 새로운 로봇 설계를 최적화함으로써 매번 새로운 RL 학습 루프를 실행할 필요를 제거한다.
본 논문은 다중 체형 가치함수를 재사용 가능한 설계 도구로 변환하는 실용적이고 혁신적인 방법을 제시한다. 대규모 embodiment 공간에서의 효율적 최적화, 강력한 실험 검증, 그리고 설계 분석 기능이 주요 강점이다. 다만 현실 로봇 검증과 극단적 체형 외삽에 대한 분석이 보완된다면 더욱 완성도 있는 작업이 될 것이다.
HumanPlus: Humanoid Shadowing and Imitation from Humans
Figure 1: Stanford HumanPlus Robot. We present a full-stack system for humanoid robots to learn motion and
 *Figure 3: Shadowing and Retargeting. Our system uses one RGB camera for body and hand pose estimation.* 휴머노이드 로봇이 단일 RGB 카메라를 사용하여 인간의 동작을 실시간으로 따라할 수 있는 shadowing 시스템과, 수집된 데이터로부터 자율적인 작업 기술을 학습하는 imitation learning 파이프라인을 제시하는 전체 스택 시스템이다.
본 논문은 휴머노이드 로봇의 인간 데이터 활용이라는 오랫동안의 과제에 대해 실용적이고 완성도 높은 end-to-end 시스템을 제시했으며, RGB 카메라 기반 shadowing의 단순성과 효율성, 그리고 다양한 자율 작업의 성공적 구현은 로봇 공학 분야에 실질적인 기여를 한다.
OmniH2O: Universal and Dexterous Human-to-Humanoid Whole-Body Teleoperation and Learning
Figure 1: (a) OmniH2O enables teleoperating a full-size humanoid robot (Unitree H1) to complete tasks that
 *Figure 1: (a) OmniH2O enables teleoperating a full-size humanoid robot (Unitree H1) to complete tasks that* OmniH2O는 kinematic pose를 보편적 제어 인터페이스로 사용하여 VR, RGB 카메라, 음성 명령 등 다양한 입력을 통해 전신 인형 로봇을 조작하고 자율 작업을 수행할 수 있는 학습 기반 시스템이다.
OmniH2O는 kinematic pose 기반의 보편적 제어 인터페이스와 정교한 sim-to-real 파이프라인을 통해 인형 로봇의 전신 로코-조작을 처음으로 체계적으로 해결한 연구이며, 공개 데이터셋과 다양한 실제 작업 시연으로 높은 실무 가치를 제공한다.
Preference-Conditioned Multi-Objective RL for Integrated Command Tracking and Force Compliance in Humanoid Locomotion
Fig. 1: Preference-conditioned locomotion: A single policy realizes behaviors from
 *Fig. 1: Preference-conditioned locomotion: A single policy realizes behaviors from* 인간형 로봇의 명령 추적과 외력 순응을 동시에 달성하기 위해 선호도 조건부 MORL 프레임워크를 제안하며, 단일 정책으로 추적-순응 간의 연속적인 trade-off를 구현한다.
본 논문은 선호도 조건부 MORL을 통해 인간형 로봇 보행의 핵심 trade-off를 명시적으로 해결하는 창의적 접근법을 제시하며, velocity-resistance 모델링이라는 우아한 통합 기법과 실세계 검증을 통해 실제 배치 가능성을 입증한다. 다만 범위 제한(수평 평면, 선형 모델)과 단일 플랫폼 실험이 일반화 가능성에 대한 의문을 남긴다.
ResMimic: From General Motion Tracking to Humanoid Whole-body Loco-Manipulation via Residual Learning
Fig. 1: We deploy ResMimic on a Unitree G1 humanoid to demonstrate diverse whole-body loco-manipulation capabilities.
 *Fig. 3: Overview of ResMimic : (1) A general motion tracking policy is trained on large-scale human motion data to serve* ResMimic는 일반 모션 추적(GMT) 정책을 기반으로 효율적인 잔차 정책(residual policy)을 학습하여 인간형 로봇의 정밀한 전신 이동-조작 능력을 실현하는 이단계 잔차학습 프레임워크이다.
ResMimic는 대규모 사전훈련 GMT 정책과 효율적 잔차 정책의 결합으로 인간형 로봇의 정밀한 전신 이동-조작을 실현한 혁신적 프레임워크이며, 맞춤형 보상 설계와 광범위한 실증으로 인간형 로봇 제어 분야에 중요한 기여를 한다.
Robot Drummer: Learning Rhythmic Skills for Humanoid Drumming
Fig. 1: The humanoid robot demonstrates expressive drumming skills across three songs: In the top row, the robot plays j
 *Fig. 3: Overview of the Robot Drummer: Starting from a raw MIDI drum track (left), each note-onset is first mapped to a* 본 논문은 인문형 로봇이 MIDI 악보를 기반으로 드럼을 연주하는 기술을 제시하며, Rhythmic Contact Chain 표현과 temporal decomposition을 활용한 reinforcement learning 프레임워크를 제안한다.
본 논문은 humanoid robotics에서 process-driven 창의적 작업으로의 확장을 의미 있게 시연하며, Rhythmic Contact Chain과 temporal decomposition이라는 실용적 기법을 통해 장시간 정밀 제어 문제를 효과적으로 해결한다. 30개 이상의 곡에서의 성공적 성과와 신흥 인간형 전략의 발현은 RL 기반 로봇 제어의 창의적 응용 가능성을 강력하게 보여준다.
RobotDancing: Residual-Action Reinforcement Learning Enables Robust Long-Horizon Humanoid Motion Tracking
Fig. 1.
 *Fig. 1.* RobotDancing은 잔차 동작(residual action) 강화학습을 통해 인간형 로봇이 장기간 고역동 춤 동작을 추적할 수 있도록 하는 프레임워크로, 모델-실제 간의 동역학 불일치를 명시적으로 보정한다.
RobotDancing은 잔차 동작 학습과 이원 샘플링 전략을 통해 인간형 로봇의 장기 고역동 모션 추적 문제를 우아하게 해결하며, 실제 로봇으로의 영점 전달 성공은 실무적 가치가 높다.
RuN: Residual Policy for Natural Humanoid Locomotion
 *Fig. 2: Overview of the RuN framework. (a) Motion Retargeting: Raw human motions are converted into a kinematically feas* RuN은 Conditional Motion Generator를 통한 운동학적 모션 프라이어와 강화학습 기반 residual policy를 분리하여, 인형로봇의 자연스러운 보행-달리기 전환을 실현하는 decoupled residual learning 프레임워크이다.
RuN은 humanoid locomotion 제어의 근본적인 복잡성을 elegant하게 해결한 well-motivated 프레임워크로, decoupled residual learning 접근이 학습 효율성과 최종 성능을 모두 개선하며 실제 로봇에서 검증된 강력한 방법론이다.
SafeFlow: Real-Time Text-Driven Humanoid Whole-Body Control via Physics-Guided Rectified Flow and Selective Safety Gating
 *Fig. 2.* SafeFlow는 physics-guided rectified flow matching과 3단계 안전 게이팅을 결합하여 텍스트 명령 기반 휴머노이드 전신 제어에서 물리적으로 실현 불가능한 동작 생성 문제를 해결한다.
SafeFlow는 physics-guided generation과 hierarchical safety gating을 효과적으로 결합하여 텍스트 기반 휴머노이드 제어의 안전성과 실행 가능성을 동시에 달성한 실질적으로 중요한 연구이며, Unitree G1에서의 광범위한 실험 검증으로 실제 로봇 배포의 가능성을 보여준다.
SimGenHOI: Physically Realistic Whole-Body Humanoid-Object Interaction via Generative Modeling and Reinforcement Learning
Figure 1: With the condition of text prompt, object geometry,
 *Figure 2: Our proposed framework uses a diffusion model for key action generation and reinforcement learning to train* SimGenHOI는 Diffusion Transformers 기반의 생성 모델과 강화학습 기반의 접촉-인식 제어 정책을 결합하여 물리적으로 현실적인 인간형 로봇-객체 상호작용을 생성하는 통합 프레임워크이다. 상호 미세조정 전략을 통해 생성 모델과 제어 정책이 반복적으로 서로를 개선하여 장기 조작 과제의 성공률을 높인다.
본 논문은 생성 모델과 강화학습의 상호 보완적 강점을 효과적으로 결합하여 물리적으로 현실적인 장기 인간형 로봇-객체 상호작용 생성이라는 중요한 문제를 해결하였다. 특히 상호 미세조정 전략과 key action 기반 패러다임은 높은 독창성을 보여주며, 광범위한 실험을 통해 방법의 효과를 입증했으나 sim-to-real 검증이 부족한 점이 아쉽다.
SONIC: Supersizing Motion Tracking for Natural Humanoid Whole-Body Control
Figure 1: SONIC enables diverse humanoid tasks through a universal control policy that handles diverse input
 *Figure 1: SONIC enables diverse humanoid tasks through a universal control policy that handles diverse input* 인간의 모션 캡처 데이터를 활용한 motion tracking을 기반 작업으로 삼아 42M 파라미터의 대규모 humanoid controller를 학습하고, kinematic planner와 unified token space를 통해 다양한 제어 인터페이스를 지원하는 자연스러운 전신 움직임 제어 시스템을 제시한다.
이 논문은 humanoid control에 대규모 스케일링을 성공적으로 적용한 첫 사례로, motion tracking을 foundation task로 선정하고 100M 프레임 데이터와 42M 파라미터로 학습하여 강력한 generalization을 보인다. Kinematic planner와 unified token space를 통해 다양한 제어 인터페이스를 단일 정책으로 통합함으로써 실제 응용 가능성을 입증했으며, 체계적인 ablation과 comprehensive evaluation은 연구의 엄밀성을 보강한다.
TACT: Humanoid Whole-body Contact Manipulation through Deep Imitation Learning with Tactile Modality
 *Fig. 2. Humanoid control system for whole-body contact manipulation with tactile feedback.* 인간형 로봇이 촉각 센서를 활용한 모방 학습(imitation learning)을 통해 전신 접촉 조작을 수행할 수 있도록 하는 TACT(tactile-modality extended ACT) 제어 시스템을 제안하였다.
본 연구는 촉각 센서를 Transformer 기반 모방 학습에 성공적으로 통합하여 생활 규모 인간형 로봇의 섬세한 전신 접촉 조작을 최초로 실증했으며, 모델 기반 제어와 학습 기반 제어의 창의적 결합으로 신뢰성과 유연성을 동시에 확보한 의미 있는 기여이다.
The Duke Humanoid: Design and Control For Energy Efficient Bipedal Locomotion Using Passive Dynamics
Fig. 1: Duke Humanoid v1.0: a) The frontal plane symmetry
 *Fig. 1: Duke Humanoid v1.0: a) The frontal plane symmetry* Duke Humanoid은 동적 보행이 가능한 오픈소스 10-DoF 인형로봇으로, 패시브 다이내믹스를 활용하는 reinforcement learning 정책을 통해 에너지 효율적인 이족 보행을 달성한다.
이 논문은 오픈소스 인형로봇 플랫폼과 패시브 다이내믹스 기반 에너지 효율 개선을 결합하여 humanoid 보행 연구에 실질적 기여를 한다. 특히 reinforcement learning 내 passive dynamics의 명시적 활용과 zero-shot 배포 검증은 학술적·실용적 가치가 높으나, 속도 범위와 일반화 능력의 검증이 더 필요하다.
Thor: Towards Human-Level Whole-Body Reactions for Intense Contact-Rich Environments
Fig. 1. Humanoids performing tasks involving forceful interactions with the
 *Fig. 2.* Thor는 humanoid 로봇이 강한 접촉 상호작용 환경에서 인간 수준의 전신 반응을 생성하도록 하는 프레임워크로, force-adaptive torso-tilt (FAT2) 보상 함수와 decoupled reinforcement learning 아키텍처를 제안한다.
Thor는 decoupled RL 아키텍처와 인간 생체역학 기반 FAT2 보상 함수를 통해 humanoid의 강력한 힘 상호작용 능력을 크게 향상시킨 우수한 연구로, 실세계 성능 검증과 다양한 작업 시연을 통해 높은 실용적 가치를 입증했다.
Visual Imitation Enables Contextual Humanoid Control
 *Figure 2: VideoMimic Real-to-Sim. A casually captured phone video provides the only input. We first* VIDEOMIMIC는 단순한 휴대폰 영상에서 인간-환경 4D 기하학을 공동 재구성하고, 이를 시뮬레이션에서 RL 정책으로 학습한 후 실제 휴머노이드 로봇에 배포하는 real-to-sim-to-real 파이프라인이다.
이 논문은 일상 영상으로부터 휴머노이드 로봇의 문맥-인식 제어를 가능하게 하는 실용적이고 확장 가능한 파이프라인을 제시하며, 공동 4D 재구성과 RL 기반 정책 증류의 조합으로 높은 독창성을 보인다. 실제 로봇 배포 성공은 연구의 가치를 크게 높이나, 환경 표현의 제한성과 동역학 정확도 측면에서 개선 여지가 있다.
VisualMimic: Visual Humanoid Loco-Manipulation via Motion Tracking and Generation
 *Fig. 2: VisualMimic consists of two training stages: 1) training a general keypoint tracker, where a teacher motion trac* VisualMimic은 egocentric vision과 hierarchical whole-body control을 결합한 sim-to-real 프레임워크로, 인간의 동작 데이터로 학습한 task-agnostic keypoint tracker와 task-specific visuomotor policy를 통해 humanoid robot의 loco-manipulation을 실현한다.
VisualMimic은 teacher-student distillation의 창의적 이중 적용과 human motion statistics 기반 제약으로 humanoid loco-manipulation의 현실적 과제를 효과적으로 해결하며, 다양한 작업에서 zero-shot real-world transfer를 입증한 매우 의미 있는 연구이다.
WoCoCo: Learning Whole-Body Humanoid Control with Sequential Contacts
Figure 1: An overview of WoCoCo and tasks. (A) We decompose the task into separate contact
 *Figure 1: An overview of WoCoCo and tasks. (A) We decompose the task into separate contact* WoCoCo는 순차적 접촉(sequential contacts)을 포함한 전신 휴머노이드 제어를 학습하기 위한 통합 RL 프레임워크로, 작업을 접촉 단계별로 분해하여 task-agnostic 보상 설계와 sim-to-real 파이프라인을 제시한다.
WoCoCo는 순차적 접촉을 포함한 휴머노이드 제어 문제에 대해 개념적으로 우아하고 실용적인 RL 프레임워크를 제시하며, 4가지 도전적 작업의 현실 검증을 통해 높은 응용 가치를 입증한다. 다만 접촉 계획의 자동 생성 및 더 복잡한 작업 환경으로의 확장은 향후 연구 방향이다.
ZEST: Zero-shot Embodied Skill Transfer for Athletic Robot Control
Fig. 1. Hardware deployment of ZEST across diverse data sources and robot morphologies. In order of appearance from top
 *Fig. 3. Overview of ZEST, which consists of three main stages. (1) Reference data: A diverse set of motions from MoCap, * ZEST는 모션 캡처, 비디오, 애니메이션 등 다양한 출처의 데이터로부터 RL을 통해 인간형 로봇 제어 정책을 학습하고, 시뮬레이션에서만 훈련하여 하드웨어에 Zero-shot 배포하는 motion-imitation 프레임워크이다.
ZEST는 다양한 비정형 데이터 소스로부터 인간형 로봇의 일반적 제어 정책을 학습하고 zero-shot 배포하는 혁신적 프레임워크로, 실제 하드웨어에서의 광범위한 성공적 검증을 통해 로봇 제어의 실용성과 확장성을 크게 향상시킨 매우 중요한 기여이다.
AGILOped: Agile Open-Source Humanoid Robot for Research
Fig. 1: The kinematics, CAD model and constructed version of AGILOped.
 *Fig. 1: The kinematics, CAD model and constructed version of AGILOped.* AGILOped는 오픈소스 휴머노이드 로봇으로서 높은 성능과 접근성 사이의 간극을 해소하며, 3D 프린팅과 상용 부품을 활용해 6,380 USD의 저렴한 가격으로 동적 운동 능력을 제공한다.
AGILOped는 오픈소스, 저가격, 높은 성능을 결합한 획기적인 휴머노이드 로봇으로, 휴머노이드 로봇 연구의 진입장벽을 크게 낮추고 학계의 민주화를 촉진하는 중요한 기여를 한다.
Architecture Is All You Need: Diversity-Enabled Sweet Spots for Robust Humanoid Locomotion
 *Fig. 2. Training and Deployment Overview: both actor and critic are two-stage architectures each with their own percepti* 휴머노이드 로봇의 견고한 보행을 위해 빠른 고주파 안정화 제어기와 느린 저주파 지각 정책을 분리하는 계층화 제어 구조(LCA)가 단일 end-to-end 설계보다 우월함을 보였다.
휴머노이드 로봇 제어에서 네트워크 복잡도보다 구조적 설계(계층화 다중 주파수)가 견고성의 핵심임을 명확히 입증한 중요한 연구로, 최소한의 아키텍처로 복잡한 실제 환경 과제를 해결함으로써 로봇 제어 설계의 원칙을 제시한다.
Being-M0.5: A Real-Time Controllable Vision-Language-Motion Model
Figure 1: Leveraging our million-scale dataset HuMo100M, we present Being-M0.5, the first real-time, control-
 *Figure 1: Leveraging our million-scale dataset HuMo100M, we present Being-M0.5, the first real-time, control-* Being-M0.5는 HuMo100M이라는 백만 규모의 대규모 데이터셋을 기반으로 한 최초의 실시간 제어 가능 vision-language-motion model로, part-aware residual quantization을 통해 신체 각 부위에 대한 세밀한 제어를 가능하게 한다.
Being-M0.5는 HuMo100M과 part-aware residual quantization이라는 두 가지 주요 혁신을 통해 motion generation의 제어 가능성과 실시간 성능 문제를 동시에 해결하며, 대규모 데이터셋과 모델 설계 통찰력으로 실제 응용 배포의 새로운 기준을 제시한다.
BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion
Figure 1: Overview of the proposed versatile humanoid control framework. (A) Scalable
 *Figure 1: Overview of the proposed versatile humanoid control framework. (A) Scalable* BeyondMimic은 인간 모션 데이터로부터 학습한 compact motion-tracking 공식과 classifier guidance를 활용한 diffusion model을 결합하여, 휴머노이드 로봇이 학습 중 보지 못한 다양한 작업을 zero-shot으로 수행할 수 있는 통합 제어 프레임워크를 제시한다.
BeyondMimic은 motion tracking RL의 민첩성과 diffusion 모델의 유연성을 효과적으로 결합하여, 휴머노이드 로봇 제어의 장기적 과제인 자연스러움, 민첩성, versatility를 동시에 달성하는 강력한 프레임워크를 제시한다. 실제 로봇 배포와 zero-shot task 일반화 시연은 로보틱스 커뮤니티에 상당한 기여를 한다.
Commanding Humanoid by Free-form Language: A Large Language Action Model with Unified Motion Vocabulary
Figure 1. An illustration of Humanoid-LLA. Given a high-level
 *Figure 1. An illustration of Humanoid-LLA. Given a high-level* 자유형식 자연언어 명령을 인간형 로봇의 신체 전체 제어로 매핑하는 Large Language Action Model(Humanoid-LLA)을 제안하며, 통합 모션 어휘, 어휘-지향 컨트롤러 증류, 강화학습 기반 파인튜닝을 통해 언어 일반화와 물리적 타당성을 동시에 달성한다.
Humanoid-LLA는 통합 모션 어휘, 어휘-지향 증류, 강화학습 파인튜닝을 통합하여 자유형식 언어에서 물리적으로 실행 가능한 인간형 로봇 제어로의 매핑을 최초로 달성한 중요한 기여이며, 실세계 검증과 명확한 기술 혁신으로 인간-로봇 상호작용 분야의 중대한 진전을 나타낸다.
DreamControl: Human-Inspired Whole-Body Humanoid Control for Scene Interaction via Guided Diffusion
Fig. 1: Unitree G1 humanoid performing various skills trained via
 *Fig. 2: DreamControl Overview: (A) we first generate text and spatiotemporally guided human motion trajectories using di* DreamControl은 human motion 기반 diffusion prior를 RL과 결합하여 humanoid robot의 whole-body 조작 작업을 학습하는 방법론을 제안한다.
DreamControl은 human motion diffusion prior와 RL의 장점을 효과적으로 결합하여 humanoid robot의 whole-body manipulation을 학습하는 창의적이고 실용적인 방법론을 제시하며, 실제 로봇에서의 다양한 작업 수행으로 그 가치를 입증했다.
ECHO: Edge-Cloud Humanoid Orchestration for Language-to-Motion Control
Fig. 1.
 *Fig. 1.* ECHO는 자연어 명령으로 휴머노이드 로봇을 제어하는 엣지-클라우드 프레임워크로, 클라우드의 diffusion 기반 text-to-motion 생성기와 엣지의 RL 트래커를 로봇 네이티브 38차원 표현으로 연결하여 실시간 폐루프 실행을 실현한다.
ECHO는 생성과 실행의 명확한 분리, robot-native 표현 설계, 실세계 배포 달성을 통해 언어-기반 휴머노이드 제어 분야에서 modularity와 deployability의 새로운 기준을 제시하는 의미 있는 연구이다.
Embedding Classical Balance Control Principles in Reinforcement Learning for Humanoid Recovery
Fig. 1.
 *Fig. 1.* 고전적 균형 제어 원리(capture point, center-of-mass, centroidal momentum)를 강화학습의 privileged critic 입력과 보상 형성에 직접 임베딩하여, 인간형 로봇의 낙상 회복을 위한 통합 정책을 학습한다. 단일 정책으로 발목/엉덩이 전략, 보정 스텝, 다중접촉 일어서기를 포괄하며 93.4% 회복률을 달성한다.
본 논문은 고전적 균형 제어 원리를 강화학습에 체계적으로 임베딩하는 creative한 접근으로, ablation을 통해 이 구조의 필수성을 입증하고 93.4% 회복률로 강력한 실증 결과를 제시한다. 다만 하드웨어 검증 규모와 다양한 환경에서의 일반화 평가가 보강되면 더욱 설득력 있을 것이다.
Embrace Collisions: Humanoid Shadowing for Deployable Contact-Agnostics Motions
Fig. 1: We present a unified humanoid motion interface and a zero-shot sim-to-real reinforcement learning framework, so
 *Fig. 1: We present a unified humanoid motion interface and a zero-shot sim-to-real reinforcement learning framework, so * 본 논문은 휴머노이드 로봇이 온몸의 모든 신체 부위를 사용하여 환경과 상호작용하는 접촉-무관(contact-agnostic) 동작을 수행할 수 있도록 하는 통합 제어 프레임워크를 제안한다. GPU 가속 rigid-body simulator와 reinforcement learning을 활용하여 시뮬레이션에서 학습한 정책을 실제 로봇에 zero-shot으로 배포할 수 있음을 시연한다.
본 논문은 접촉-무관 극단 동작을 지원하는 humanoid 제어의 중요한 진전을 이루었으며, 새로운 motion interface와 training 기법이 창의적이다. 다만 실험 검증과 기술 상세 설명이 더 필요하고, project website 의존도가 높아 독립적 평가에 제약이 있다.
FRoM-W1: Towards General Humanoid Whole-Body Control with Language Instructions
Figure 1 | (a) We introduce FRoM-W1, an open-source framework that leverages Chain-of-Thought
 *Figure 2 | The inference pipeline of FRoM-W1. (a) H-GPT first translates language instructions* FRoM-W1은 자연어 지시문으로부터 휴머노이드 로봇의 전신 움직임을 제어하는 오픈소스 프레임워크로, H-GPT 모델과 H-ACT 모듈의 2단계 구조로 언어 이해와 안정적인 로봇 실행을 동시에 달성한다.
FRoM-W1은 자연어 기반 휴머노이드 전신 제어라는 중요한 문제를 Chain-of-Thought와 2단계 RL 전략으로 창의적으로 해결하며, 완전 오픈소스 제공과 실제 로봇 실증을 통해 높은 실용성과 재현성을 보여준다.
H2-COMPACT: Human-Humanoid Co-Manipulation via Adaptive Contact Trajectory Policies
Fig. 1: Real-world human–humanoid co-manipulation. The human leads the humanoid robot—unaware of the route or
 *Fig. 2: H²-COMPACT’s pipeline: raw force/torque and RGB inputs are cleaned by SAM2 and WHAM, then passed through* 힘각 센서 기반 haptic intent inference와 reinforcement learning 기반 locomotion policy를 계층적으로 결합하여 인간-휴머노이드 협력 물체 운반을 실현한다.
Haptic-based intent inference와 force-adaptive legged locomotion의 계층적 결합으로 인간-휴머노이드 협력 물체 운반의 새로운 패러다임을 제시하며, motion-capture free 데이터 수집과 sim-to-real 검증을 통해 실용성 높은 연구로 평가된다.
Hierarchical Intention-Aware Expressive Motion Generation for Humanoid Robots
Fig. 1: Overall framework of the proposed work. (a) The high-level system architecture. Multimodal inputs XI = (Vin, Lin
 *Fig. 1: Overall framework of the proposed work. (a) The high-level system architecture. Multimodal inputs XI = (Vin, Lin* 본 논문은 Vision Language Model의 의도 추론과 diffusion 기반 동작 생성을 결합한 계층적 프레임워크 HIAER을 제안하여, 인간의 사회적 의도와 감정 맥락을 파악하고 실시간으로 표현적인 로봇 동작을 생성한다.
본 논문은 VLM의 고수준 사회적 추론과 diffusion 기반 동작 생성을 의도적으로 결합하여 인간-로봇 상호작용의 폐쇄 루프를 완성한 점에서 높은 가치를 지니며, 물리 로봇 실증을 통해 실현 가능성을 보여준다.
Hold My Beer: Learning Gentle Humanoid Locomotion and End-Effector Stabilization Control
Figure 1: Learning Gentle Humanoid Locomotion and End-Effector Stabilization Control with
 *Figure 1: Learning Gentle Humanoid Locomotion and End-Effector Stabilization Control with* 휴머노이드 로봇이 음료를 들고 걸을 때 흘리지 않도록 상체와 하체를 분리된 에이전트로 제어하는 SoFTA 프레임워크를 제안하여, 느린 보행 제어와 빠른 end-effector 안정화를 동시에 달성한다.
이 논문은 휴머노이드의 보행 중 end-effector 안정화라는 중요하면서도 미해결 문제를 frequency separation과 decoupled control로 우아하게 해결한 창의적 접근법을 제시하며, 실세계 배포로 실용성을 입증한 뛰어난 연구이다.
HOMIE: Humanoid Loco-Manipulation with Isomorphic Exoskeleton Cockpit
Fig. 1: HOMIE empowers the humanoid robot to execute various loco-manipulation tasks in the real world. (a): Squatting t
 *Fig. 2: System Overview. (a): how an operator uses the exoskeleton-based hardware system to control humanoid robots in t* HOMIE는 강화학습 기반 신체 제어, 동형 외골격 팔, 모션센싱 장갑을 통합한 반자율 원격조종 시스템으로, 단일 작업자가 휴머노이드 로봇의 전신 보행-조작 작업을 정밀하게 제어할 수 있게 함
HOMIE는 RL 기반 적응형 보행 제어와 저비용 동형 하드웨어를 혁신적으로 결합하여 휴머노이드 로봇의 전신 원격조종을 현실화한 획기적 시스템으로, 비용 효율성과 성능에서 기존 솔루션을 크게 초월하며 실용적 가치가 높음
HuBE: Cross-Embodiment Human-like Behavior Execution for Humanoid Robots
Fig. 1.
 *Fig. 1.* HuBE는 인간 행동의 유사성(similarity)과 적절성(appropriateness)을 모두 만족하는 이족 로봇용 양단계 폐루프 프레임워크를 제안하며, 뼈 스케일링 기반 데이터 증강을 통해 이기종 로봇 간 교차-구현체(cross-embodiment) 적응을 실현한다.
HuBE는 인간형 로봇 행동 생성에 행동 적절성 개념을 처음 체계적으로 도입하고, 폐루프 아키텍처와 bone scaling 기반 교차-구현체 적응을 통해 실무적 가치 높은 솔루션을 제시한다. 다만 LLM 주석 신뢰성 검증과 더 광범위한 플랫폼 실험이 진행된다면 영향력이 한층 강화될 것으로 예상된다.
HuMam: Humanoid Motion Control via End-to-End Deep Reinforcement Learning with Mamba
Figure 1: Overall architecture of the proposed humanoid locomotion framework. At each time step, robot-centric and exter
 *Figure 1: Overall architecture of the proposed humanoid locomotion framework. At each time step, robot-centric and exter* HuMam은 Mamba 인코더를 백본으로 사용하는 end-to-end 강화학습 기반 휴머노이드 로봇 보행 제어 프레임워크로, 로봇 중심 상태와 목표 발걸음을 효율적으로 융합하여 안정적이고 에너지 효율적인 제어를 실현한다.
HuMam은 Mamba를 활용한 휴머노이드 보행 제어의 첫 성공 사례로, 학습 효율성과 에너지 효율성을 동시에 개선하는 실질적 기여를 한다. 다만 시뮬레이션 기반 결과와 단일 플랫폼 검증의 제약이 있어 실제 응용 가능성 입증을 위한 추가 연구가 필요하다.
Humanoid Hanoi: Investigating Shared Whole-Body Control for Skill-Based Box Rearrangement
 *Fig. 2: Independently trained high-level skills generate task-level commands that are executed through a shared, task-ag* 휴머노이드 로봇의 장기 박스 재배열 작업을 위해 공유된 task-agnostic WBC를 통해 재사용 가능한 스킬들을 조합하는 skill-based framework를 제안하고, 분포 이동으로 인한 강건성 저하를 데이터 집계를 통해 해결한다.
본 논문은 공유 WBC를 통한 모듈식 스킬 조합 아키텍처의 systematic exploration과 데이터 집계 기반 robustness 개선이라는 실용적 기여를 제시하며, Humanoid Hanoi 벤치마크를 통해 long-horizon 장기 자율 실행의 가능성을 입증한다. 다만 high-level planning, 계산 scalability, sim-to-real gap에 대한 심화 분석은 부족하다.
Humanoid Locomotion as Next Token Prediction
Figure 1: A humanoid that walks in San Francisco. We deploy our policy to various locations in San Francisco over
 *Figure 2: Humanoid locomotion as next token prediction. We collect a dataset on trajectories from various sources, such* Humanoid 로봇 제어를 언어 모델의 next token prediction처럼 다루어, causal transformer를 통해 sensorimotor 궤적을 자동 회귀적으로 예측한다. 시뮬레이션, 모션캡처, 유튜브 영상 등 다양한 소스의 불완전한 데이터로 학습하여 실제 humanoid 로봇이 zero-shot으로 샌프란시스코에서 보행할 수 있게 한다.
본 논문은 언어 모델의 next token prediction 패러다임을 humanoid 제어에 창의적으로 적용하여, 불완전한 다중 소스 데이터로 학습한 모델이 실제 환경에서 zero-shot 보행을 가능하게 함을 입증했다. 생성 모델 기반의 로봇 제어 학습에 대한 유망한 방향을 제시하며, 실제 배포 결과는 매우 인상적이다.
Humanoid Manipulation Interface: Humanoid Whole-Body Manipulation from Robot-Free Demonstrations
Fig. 1: Humanoid Manipulation Interface (HuMI). Left: Our portable, robot-free data collection facilitates skill transfe
 *Fig. 1: Humanoid Manipulation Interface (HuMI). Left: Our portable, robot-free data collection facilitates skill transfe* HuMI는 로봇 없이 휴대용 하드웨어로 수집한 인간 전신 동작 데이터를 이용해 인형형 로봇에게 다양한 전신 조작 기술을 학습시키는 프레임워크이다. 계층적 학습 파이프라인과 IK 기반 적응을 통해 인간-로봇 간 신체형 차이를 극복하고 70% 성공률을 달성한다.
HuMI는 로봇 없는 휴대용 데이터 수집과 계층적 학습을 결합하여 인형형 로봇의 전신 조작을 효율적으로 학습시키는 혁신적인 프레임워크이다. 3배 높은 데이터 수집 효율과 미지 환경에서의 강한 일반화는 로봇 학습의 실용성을 크게 향상시키며, 신체형 차이 극복을 위한 체계적 접근법이 학문적 기여도 크다.
iCub3 Avatar System: Enabling Remote Fully-Immersive Embodiment of Humanoid Robots
원격 위치에서 휴머노이드 로봇 iCub3을 구현화(embodiment)하는 완전한 아바타 시스템을 제시하며, 수백 km 떨어진 위치에서의 이동, 조작, 음성, 표정 제어와 시각, 청각, 촉각, 무게감 피드백을 통합한다.
본 논문은 휴머노이드 아바타의 완전한 신체 제어와 다중 감각 피드백을 통합하여 원격 현존감을 실현한 획기적인 시스템을 제시하며, 실제 환경에서의 대규모 검증을 통해 그 실용성을 입증했다. 네트워크 지연 처리와 embodiment 평가의 정량화 측면에서 개선의 여지가 있으나, 전체적으로 로보틱스와 텔레현존 분야에 중요한 기여를 한다.
KungfuBot: Physics-Based Humanoid Whole-Body Control for Learning Highly-Dynamic Skills
Figure 1: An overview of PBHC that includes three core components: (a) motion extraction from
 *Figure 1: An overview of PBHC that includes three core components: (a) motion extraction from* 본 논문은 물리 기반 인간형 로봇 제어 프레임워크(PBHC)를 제안하여 쿵푸, 댄싱 등 고도로 동적인 인간 행동을 모방하도록 학습하는 방법을 제시한다. 다단계 모션 처리와 적응형 모션 추적을 통해 기존 방법보다 현저히 낮은 추적 오차를 달성하고 실제 로봇에 배포된다.
본 논문은 물리 기반 모션 처리, 적응형 bi-level optimization 커리큘럼, 비대칭 actor-critic 구조를 결합한 포괄적 프레임워크로 고도로 동적인 인간형 로봇 제어 문제를 체계적으로 해결한다. 실제 로봇 배포 성공과 기존 방법 대비 현저한 성능 향상은 강력한 기술적 기여를 입증하며, 인간형 로봇의 동적 행동 학습 분야에서 중요한 진전을 이룬다.
Learning Humanoid Standing-up Control across Diverse Postures
Fig. 1: Overview. (a) Our proposed framework HOST enables the humanoid robot to learn standing-up control via reinforcem
 *Fig. 1: Overview. (a) Our proposed framework HOST enables the humanoid robot to learn standing-up control via reinforcem* HoST는 강화학습 기반 프레임워크로 휴머노이드 로봇이 다양한 자세에서 일어서는 동작을 학습하고 실제 환경에서 robust하게 수행할 수 있도록 한다.
이 논문은 휴머노이드 로봇의 standing-up control이라는 실질적 문제를 RL 기반으로 체계적으로 해결하며, 사전 궤적 없이 diverse posture에서의 실제 배포를 성공적으로 달성한 의미 있는 기여로, 실제 로봇 시스템의 자율성 향상에 중요한 발걸음이다.
Learning Motion Skills with Adaptive Assistive Curriculum Force in Humanoid Robots
Fig. 1.
 *Fig. 1.* 인간의 학습 방식을 모방한 적응형 보조력(Adaptive Assistive Curriculum Force, A2CF)을 제안하여 휴머노이드 로봇의 복잡한 동작 학습을 가속화하는 이중-에이전트 강화학습 프레임워크를 제시한다.
인간의 자연스러운 학습 과정에서 영감을 얻은 적응형 보조력 메커니즘으로 휴머노이드 로봇의 복잡한 동작 학습을 획기적으로 가속화한 논문이며, 실제 로봇 실험을 통한 검증과 명확한 성과 지표가 높은 실용적 가치를 제공한다.
Learning Sim-to-Real Humanoid Locomotion in 15 Minutes
Figure 1: Summary of results. We introduce a simple recipe based on off-policy RL algorithms, i.e.,
 *Figure 1: Summary of results. We introduce a simple recipe based on off-policy RL algorithms, i.e.,* 이 논문은 FastSAC와 FastTD3라는 off-policy RL 알고리즘을 기반으로 단일 RTX 4090 GPU에서 15분 이내에 humanoid 로봇의 보행 정책을 학습할 수 있는 실용적인 레시피를 제시한다.
이 논문은 off-policy RL을 humanoid 제어에 효과적으로 적용하기 위한 실용적이고 체계적인 레시피를 제공하며, 15분의 빠른 훈련 시간과 실제 로봇 배포를 통해 sim-to-real 개발 사이클의 혁신을 보여준다. 오픈소스 구현 제공으로 산업 및 학계에 즉시 영향을 미칠 수 있다.
Learning with pyCub: A Simulation and Exercise Framework for Humanoid Robotics
Fig. 1. An example of the simulation environment showing the iCub humanoid robot,
 *Fig. 1. An example of the simulation environment showing the iCub humanoid robot,* pyCub는 humanoid robot iCub의 Python 기반 physics 시뮬레이션 프레임워크로, YARP 미들웨어 없이 학생들이 humanoid robotics의 기초를 배울 수 있는 교육용 연습 문제들을 제공한다.
pyCub는 humanoid robotics 교육 접근성의 실질적 장벽을 Python과 단순화된 아키텍처로 제거한 가치 있는 오픈소스 프레임워크이며, 실제 교육 과정 검증과 완전한 공개를 통해 학술 커뮤니티에 즉시 활용 가능한 자원을 제공한다.
LiPS: Large-Scale Humanoid Robot Reinforcement Learning with Parallel-Series Structures
 *Fig. 4: Illustration of LiPS Simulation Training and Real-World Deployment Process.* LiPS는 GPU 기반 병렬 훈련 환경에서 URDF 형식의 휴머노이드 로봇을 위한 강화학습 방법으로, 멀티-리지드바디 폐루프 동역학 모델링을 통해 시뮬레이션-현실 간 격차를 줄인다.
LiPS는 휴머노이드 로봇의 GPU 병렬 강화학습에서 sim2real 격차를 크게 줄이는 실질적이고 실용적인 방법으로, URDF 기반 복잡한 로봇 제어 연구에 중요한 기여를 한다. 다만 광범위한 실제 로봇 검증과 다양한 시뮬레이션 플랫폼으로의 확장 연구가 필요하다.
Load-Aware Locomotion Control for Humanoid Robots in Industrial Transportation Tasks
Fig. 1. Overview of the proposed load-aware humanoid loco-manipulation framework. Upper-body manipulation is generated b
 *Fig. 1. Overview of the proposed load-aware humanoid loco-manipulation framework. Upper-body manipulation is generated b* 산업용 휴머노이드 로봇의 다양한 하중 조건에서 안정적 보행을 위해 분리-협조 구조의 로코-매니퓰레이션 아키텍처를 제안하며, RL 기반 하체 제어와 상태 추정기를 통해 시뮬레이션 학습 후 실제 로봇에 파인튜닝 없이 배포 성공.
산업용 휴머노이드의 실질적 과제인 하중 변화 조건에서의 로코-매니퓰레이션을 분리-협조 구조와 상태 추정으로 체계적으로 해결하며, 시뮬레이션 학습 후 무튜닝 실배포 성공은 높은 실무 가치를 입증한다.
MaskedManipulator: Versatile Whole-Body Manipulation
Figure 1: MaskedManipulator enables physics-based humanoids to perform intricate, object interactions from sparse spatio
 *Figure 1: MaskedManipulator enables physics-based humanoids to perform intricate, object interactions from sparse spatio* MaskedManipulator는 대규모 모션 캡처 데이터로 학습한 추적 컨트롤러에서 증류한 생성적 제어 정책으로, 사용자가 객체 포즈나 신체 포즈 같은 고수준 목표를 지정하여 물리 기반 전신 조작 행동을 생성한다.
MaskedManipulator는 두 단계 증류 프레임워크를 통해 정교한 물리 기반 전신 조작을 희소한 고수준 목표로 제어 가능하도록 함으로써, 캐릭터 애니메이션과 인간형 로봇 제어 분야의 중요한 진전을 이룬다. 대규모 모션 캡처 데이터 활용과 유연성-정밀도 균형 달성이 특히 주목할 만하나, 실제 로봇 적용 평가와 일반화 성능 분석이 보완되면 더욱 완성도 높은 기여가 될 것이다.
Olaf: Bringing an Animated Character to Life in the Physical World
Fig. 1: Olaf Robot.
 *Fig. 1: Olaf Robot.* 애니메이션 캐릭터 올라프를 실제 물리 로봇으로 구현하기 위해 RL 기반 제어와 혁신적인 기계설계를 결합한 연구이다. 비물리적 움직임과 부자연스러운 비율을 가진 캐릭터를 believable하게 현실화했다.
애니메이션 캐릭터를 물리 로봇으로 현실화하는 문제에 대해 기계설계와 제어 알고리즘을 창의적으로 결합한 우수한 연구이며, thermal awareness와 impact reduction 같은 실무적 고려사항을 RL에 반영한 점이 특히 주목할 만하다.
OmniClone: Engineering a Robust, All-Rounder Whole-Body Humanoid Teleoperation System
Fig. 1: OmniClone achieves well-balanced, high-fidelity whole-body tracking across all MPJPE dimensions on OmniBench whi
 *Fig. 1: OmniClone achieves well-balanced, high-fidelity whole-body tracking across all MPJPE dimensions on OmniBench whi* OmniClone은 단일 소비자 GPU에서 전신 휴머노이드 텔레오퍼레이션을 실현하는 시스템으로, OmniBench 진단 벤치마크를 통해 기존 시스템의 동작별 성능 격차를 노출하고 이를 바탕으로 최적화된 정책과 시스템 기술을 통합하여 MPJPE를 66% 이상 감소시켰다.
OmniClone은 진단적 벤치마킹과 시스템 공학을 결합하여 실용적이면서도 강력한 휴머노이드 텔레오퍼레이션 시스템을 제시한다. OmniBench는 기존 평가 방식의 근본적 한계를 지적하고 이를 기반으로 한 체계적 개선이 뒤따르는 점, 그리고 소비자 GPU로 SOTA 성능을 달성하면서도 높은 접근성을 제공하는 점에서 학술적, 실용적 가치가 모두 높다.
OmniControl: Control Any Joint at Any Time for Human Motion Generation
Figure 1: OmniControl can generate realistic human motions given a text prompt and flexible
 *Figure 1: OmniControl can generate realistic human motions given a text prompt and flexible* OmniControl은 diffusion 기반 text-conditioned 인간 동작 생성 모델에 flexible spatial control signals을 통합하는 방법으로, 단일 모델로 임의의 관절을 임의의 시간에 제어할 수 있다.
OmniControl은 기존 방법의 근본적 제약을 global coordinate 변환과 dual guidance로 해결하며, 단일 모델로 임의의 관절 제어를 가능하게 한 significant contribution이다. 실용적 응용성과 성능 면에서 human motion generation 분야의 중요한 진전을 이루었다.
Perpetual Humanoid Control for Real-time Simulated Avatars
Figure 1: We propose a motion imitator that can naturally recover from falls and walk to far-away reference motion, perp
 *Figure 1: We propose a motion imitator that can naturally recover from falls and walk to far-away reference motion, perp* Physics 기반 humanoid controller인 Perpetual Humanoid Controller (PHC)는 noisy input과 unexpected falls에 강건하면서 10,000개의 motion clips을 학습할 수 있으며, 새로운 Progressive Multiplicative Control Policy (PMCP)를 통해 catastrophic forgetting 없이 대규모 motion database에서 학습 가능하다.
이 논문은 external force 제거와 PMCP라는 novel mechanism으로 physics-based motion imitation의 scalability 문제를 효과적으로 해결하며, natural fail-state recovery와 noisy input 강건성으로 실제 video 기반 avatar application에 처음으로 실용적인 solution을 제공한다.
Towards Adaptable Humanoid Control via Adaptive Motion Tracking
Fig. 1: Overview. Our method, AdaMimic (adaptive motion tracking), achieves agile humanoid whole-body adaptation from on
 *Fig. 2: Method overview. (a) Human motions are reconstructed into SMPL motions via GVHMR [21] and retargeted to the huma* AdaMimic은 단일 참조 동작으로부터 휴머노이드 로봇의 적응형 제어를 가능하게 하는 동작 추적 알고리즘으로, 키프레임 기반 데이터 증강과 단계적 어댑터 학습을 통해 정확한 모방과 광범위한 적응성을 동시에 달성한다.
AdaMimic은 단일 참조 동작으로부터 고정밀 모방과 광범위 적응성을 동시에 달성하는 혁신적 접근으로, 두 단계 학습과 이중 어댑터 구조의 새로운 설계가 의미 있으며, 실제 로봇에서의 광범위한 검증이 제시되어 실용성이 높다.
Towards Motion Turing Test: Evaluating Human-Likeness in Humanoid Robots
Figure 1.
 *Figure 1.* Motion Turing Test라는 개념을 제시하여 인간관찰자가 키네마틱 정보만으로 휴머노이드 로봇과 인간의 자세를 구분할 수 있는지를 평가하고, 이를 위해 1,000개의 모션 시퀀스로 구성된 HHMotion 데이터셋과 human-likeness 예측 기준선 모델을 제안한다.
Motion Turing Test라는 명확한 개념 정의와 이를 뒷받침하는 포괄적인 HHMotion 데이터셋은 휴머노이드 로봇 모션 평가 분야에 중요한 기여를 한다. SMPL-X 기반 appearance-agnostic 평가 방식과 500시간의 대규모 인간 주석은 높은 신뢰성을 제공하며, 제안된 PTR-Net이 VLM 기반 방법들을 능가한 결과는 전문화된 모션 평가 모델의 필요성을 입증한다.
TWIST2: Scalable, Portable, and Holistic Humanoid Data Collection System
Fig. 1: We introduce TWIST2, a holistic humanoid data collection system designed with scalability and portability. TWIST
 *Fig. 1: We introduce TWIST2, a holistic humanoid data collection system designed with scalability and portability. TWIST* TWIST2는 mocap 없이 VR 기반의 포터블한 휴머노이드 텔레오퍼레이션 시스템으로, 전신 제어를 유지하면서 확장 가능한 데이터 수집을 가능하게 한다. 수집한 데이터로 hierarchical visuomotor policy를 학습하여 자율적인 전신 제어를 구현한다.
TWIST2는 휴머노이드 로봇의 대규모 데이터 수집 병목을 실질적으로 해결하는 혁신적인 시스템으로, 포터블성과 전신 제어의 오래된 trade-off를 극복했다. 완전 오픈소스 공개와 실증적 성과(whole-body dexterous manipulation, kick-T task)는 휴머노이드 로봇 학습 커뮤니티에 즉각적인 영향을 미칠 수 있는 중대한 기여다.
Learn Weightlessness: Imitate Non-Self-Stabilizing Motions on Humanoid Robot
Fig. 1: Our work introduces a human-inspired weightlessness mechanism that controls robot joints to selectively relax wh
 *Fig. 1: Our work introduces a human-inspired weightlessness mechanism that controls robot joints to selectively relax wh* 휴머노이드 로봇이 비자기안정화(non-self-stabilizing) 동작을 수행할 때 인간의 '무중력 상태' 메커니즘을 모방하여 특정 관절을 선택적으로 이완시킴으로써 환경과의 물리적 접촉을 통해 동작을 완성하는 방법을 제안한다.
본 논문은 인간의 생물학적 메커니즘을 로봇 제어에 창의적으로 적용하여 비자기안정화 동작이라는 미해결 문제를 해결하는 우수한 연구이며, Unitree G1에서의 실제 검증과 다양한 환경에 대한 일반화 성능은 로봇 공학의 실질적 진전을 보여준다.
HOIST: Humanoid Optimization with Imitation and Sample-efficient Tuning for Manipulating Suspended Loads
 *Figure 4: Overview of the HOIST pipeline. VR teleoperation provides hoisting demonstrations to* 본 논문은 인도형(underactuated) 부유 하중(suspended load)을 조작하는 휴머노이드 로봇을 위한 HOIST를 제시한다. VR 원격 조종 데이터로부터 vision-language-action(VLA) 정책을 미세조정하고, whole-body controller를 통해 실행한 후, iterative batched reinforcement learning으로 배치 정확도와 정지 행동을 개선한다.
HOIST는 휴머노이드 로봇을 이용한 underactuated material-handling이라는 새로운 실제 문제를 잘 정의하고, imitation learning과 reinforcement learning을 실용적으로 결합한 효과적인 해결 방안을 제시한다. VR teleoperation 기반의 데이터 수집부터 whole-body control과 sample-efficient RL까지 완전한 파이프라인을 구현하고, 시뮬레이션과 실제 로봇 모두에서 검증한 점이 강점이다. 다만 일반화 능력 검증과 안전 보장의 명시적 분석이 부족하고, 더 다양한 시나리오에서의 평가가 필요하다.
Humanoid Locomotion as Next Token Prediction
 *Figure 2: Humanoid locomotion as next token prediction. We collect a dataset on trajectories from various sources, such* 이 논문은 인간형 로봇의 보행 제어를 언어 모델링의 next token prediction 문제로 재해석한 연구이다. causal transformer를 이용해 sensorimotor trajectories를 자동회귀적으로 예측하되, 불완전한 모달리티(예: 액션 없는 비디오)도 활용할 수 있도록 설계했다.
이 논문은 언어 모델링 패러다임을 로봇 제어에 효과적으로 적용한 강력한 연구이다. 제로샷 실제 환경 배포, 불완전한 데이터의 창의적 활용, 다양한 소스 통합 등에서 명확한 기여를 보여주며, 기술적으로도 건전하고 실험 결과도 설득력 있다.
Learning Human-to-Humanoid Real-Time Whole-Body Teleoperation
Fig. 1:
 *Fig. 4: Overview of H2O: (a) Retargeting (Section IV): H2O first aligns the SMPL body model to a humanoid’s structure* RGB 카메라만을 사용하여 실시간으로 전신 휴머노이드 로봇을 원격조종할 수 있는 RL 기반 프레임워크 H2O를 제시하며, 'sim-to-data' 프로세스로 인간 동작을 로봇 친화적으로 필터링하고 sim-to-real 전이를 달성했다.
본 논문은 인간-휴머노이드 상호작용의 새로운 패러다임을 제시하며, 'sim-to-data' 필터링과 효과적인 sim-to-real 전이를 통해 RL 기반 전신 원격조종을 처음 실현했다는 점에서 획기적 기여이다. 대규모 데이터셋 생성, RGB 카메라 기반 제어, 다양한 동작 실현 등에서 높은 완성도를 보여주며, 향후 로봇 원격조종 및 자율 시스템 학습의 중요한 토대가 될 것으로 예상된다.
Semantic Co-Speech Gesture Synthesis and Real-Time Control for Humanoid Robots
Figure 1: System Overview: Training and Inference Pipeline.
 *Figure 1: System Overview: Training and Inference Pipeline.* 이 연구는 음성 입력으로부터 의미론적으로 적절한 제스처를 생성하고 실시간으로 휴머노이드 로봇에 배포하는 end-to-end 프레임워크를 제시한다. LLM과 Motion-GPT를 활용한 제스처 생성과 imitation learning 기반의 MotionTracker 제어 정책을 통합하여 의미 있는 비언어적 소통을 실현한다.
이 논문은 음성 기반 의미론적 제스처 생성과 실시간 로봇 배포를 통합한 의미 있는 연구로, LLM, Motion-GPT, imitation learning을 창의적으로 결합하여 완전한 end-to-end 파이프라인을 실현했다. 다만 평가의 정량성 강화와 다양한 환경에서의 robustness 검증이 필요하다.
SignBot: Learning Human-to-Humanoid Sign Language Interaction
 *Fig. 2: Overview of SignBot: The framework consists of three stages: (1) Motion Retargeting aligns human sign language* SignBot은 수화 언어를 인식하고 생성할 수 있는 인간형 로봇을 위한 프레임워크로, motion retargeting, policy training, 그리고 generative interaction을 통합하여 청각장애인과의 자연스러운 상호작용을 실현한다.
SignBot은 embodied humanoid robot에서 처음으로 자동화된 sign language interaction을 구현한 혁신적 연구로, 청각장애인 커뮤니티의 의사소통 접근성 향상에 실질적 기여를 한다. 다만 hand retargeting 기술의 상세 설명과 더 광범위한 실세계 평가가 보완되면 영향력이 더욱 증대될 것으로 예상된다.
TextOp: Real-time Interactive Text-Driven Humanoid Robot Motion Generation and Control
 *Fig. 2: Overview of TextOp’s framework. The framework consists of three main parts: (a) Interactive Motion Generation,* TextOp는 streaming 자연어 명령으로 인간형 로봇의 운동을 실시간으로 생성하고 제어하는 프레임워크로, 고수준의 autoregressive motion diffusion 모델과 저수준의 motion tracking policy를 결합하여 실행 중 동적으로 명령 수정을 지원한다.
TextOp는 실시간 interactive motion generation과 robust physical control을 성공적으로 통합하여 자연어 기반 humanoid 제어의 새로운 paradigm을 제시한 뛰어난 연구이며, 실제 로봇 실험을 통해 실현 가능성을 검증했다. 다만 플랫폼 특화성과 데이터셋 의존성을 개선한다면 더욱 광범위한 영향을 미칠 수 있을 것으로 예상된다.
A Rapid Instrument Exchange System for Humanoid Robots in Minimally Invasive Surgery
Figure 1. Overview of the immersive teleoperated surgical instrument rapid exchange system (a)
 *Figure 1. Overview of the immersive teleoperated surgical instrument rapid exchange system (a)* 휴머노이드 로봇의 이중 팔 구성을 활용하여 HMD 기반 몰입형 원격조작과 단축 컴플라이언트 도킹 메커니즘을 통합한 최소침습 수술용 고속 기구 교환 시스템을 제안한다.
휴머노이드 로봇을 최소침습 수술에 실질적으로 적용하기 위한 핵심 기술 과제를 체계적으로 해결하였으며, HMD 기반 몰입형 원격조작과 맞춤형 도킹 메커니즘의 통합이 효과적임을 입증한 중요한 연구이다.
ARMADA: Augmented Reality for Robot Manipulation and Robot-Free Data Acquisition
Fig. 1: Overview. (A) Human demonstrators wearing Apple Vision Pro can
 *Fig. 1: Overview. (A) Human demonstrators wearing Apple Vision Pro can* Apple Vision Pro의 AR을 활용하여 물리적 로봇 없이 로봇 조작 데이터를 수집하는 ARMADA 시스템을 제시하며, 실시간 로봇 피드백이 데이터 품질을 1.3%에서 71.1%로 향상시킨다.
ARMADA는 AR 기술을 창의적으로 활용하여 로봇 데이터 수집의 실제적 병목을 해결하는 혁신적 시스템을 제시하며, 실시간 피드백의 극적인 효과를 실증함으로써 대규모 로봇 학습의 새로운 가능성을 열었다.
CHILD (Controller for Humanoid Imitation and Live Demonstration): a Whole-Body Humanoid Teleoperation System
Fig. 1. Overview of CHILD humanoid teleoperation system.
 *Fig. 1. Overview of CHILD humanoid teleoperation system.* CHILD는 베이비 캐리어 크기의 컴팩트한 텔레오퍼레이션 장치로, 직접 관절 매핑을 통해 휴머노이드 로봇의 전신 관절 수준 제어를 가능하게 하는 시스템이다.
이 논문은 전신 humanoid 텔레오퍼레이션을 위한 직접 관절 매핑 방식을 최초로 제시하였으며, 베이비 캐리어를 활용한 혁신적이고 저비용의 하드웨어 설계와 오픈소스 공개를 통해 robotics 커뮤니티에 실질적인 기여를 제공한다.
CLONE: Closed-Loop Whole-Body Humanoid Teleoperation for Long-Horizon Tasks
CLONE은 MoE 기반 폐루프 제어 시스템으로 MR 헤드셋의 헤드와 손 추적만으로 휴머노이드 로봇의 전신 협응 동작을 정밀하게 원격 조종하고 장시간 작업에서 위치 드리프트를 최소화한다.
CLONE은 MoE 기반 폐루프 제어와 최소 입력 인터페이스를 결합하여 휴머노이드 텔레오퍼레이션의 근본적 제약을 해결한 선도적 연구로, 전신 협응과 장시간 정밀 제어를 동시에 달성한 최초의 실제 시스템 구현이다.
CLOT: Closed-Loop Global Motion Tracking for Whole-Body Humanoid Teleoperation
Fig. 1: Long-horizon whole-body teleoperation with global pose closed-loop feedback. The proposed framework achieves
 *Fig. 1: Long-horizon whole-body teleoperation with global pose closed-loop feedback. The proposed framework achieves* CLOT는 고주파 로컬라이제이션 피드백을 통해 폐루프 전역 자세 추적을 달성하는 실시간 인간형 로봇 원격조종 시스템으로, 장시간 운영 중 누적되는 전역 드리프트 문제를 해결한다.
CLOT는 폐루프 전역 제어와 Observation Pre-shift 데이터 기반 무작위화 전략을 통해 장시간 드리프트 없는 인간형 로봇 원격조종을 달성한 혁신적 시스템으로, 실제 인간형 로봇에서의 포괄적 검증과 고품질 데이터셋 공개는 이 분야의 중요한 기여이다.
EMOTION: Expressive Motion Sequence Generation for Humanoid Robots with In-Context Learning
Fig. 1. Overview of the EMOTION framework.
 *Fig. 1. Overview of the EMOTION framework.* EMOTION은 대규모 언어 모델(LLM)의 문맥 학습 능력을 활용하여 인간형 로봇이 표정, 제스처, 신체 움직임 등 자연스러운 비언어적 의사소통을 수행할 수 있도록 하는 프레임워크이다. 온라인 사용자 연구를 통해 생성된 모션이 인간 수행자와 동등하거나 우수함을 입증했다.
EMOTION은 LLM의 in-context learning을 창의적으로 활용하여 인간형 로봇의 표현적 모션 생성을 자동화한 실질적 솔루션을 제시한다. 사용자 연구를 통한 검증과 인간 피드백 통합 방식은 실용성을 높이나, 다양한 제스처에 대한 성능 편차와 실제 상호작용 환경 테스트의 필요성이 향후 과제로 남아 있다.
High-Speed and Impact Resilient Teleoperation of Humanoid Robots
Fig. 1.
 *Fig. 1.* 본 논문은 7개의 IMU 기반 캘리브레이션 무료 모션 캡처, low-latency kinematics streaming toolbox, 고대역폭 cycloidal actuator를 통합하여 휴머노이드 로봇의 고속 및 충격 강건 텔레오퍼레이션을 실현한다.
본 논문은 최소 센서 기반 모션 캡처, low-latency streaming, cycloidal actuator를 통합하여 휴머노이드 로봇의 고속 충격 강건 텔레오퍼레이션을 처음으로 실제 구현 및 검증했으며, 간단하면서도 효과적인 설계로 실용적 가치가 높다. 다만 플랫폼 특화성과 환경 다양성 평가 부재가 한계이다.
Learning to Look Around: Enhancing Teleoperation and Learning with a Human-like Actuated Neck
Figure 1: A teleoperation system featuring an actuated neck and dexterous arms, enabling human-like manipu-
 *Figure 1: A teleoperation system featuring an actuated neck and dexterous arms, enabling human-like manipu-* 인간의 자연스러운 머리 움직임을 모방하는 5-DOF actuated neck을 원격 조종 시스템에 통합하여 작업자의 직관성 향상, 인지 부하 감소, 자율 정책 학습 개선을 달성하는 연구이다.
이 논문은 인간의 자연스러운 지각 능력을 원격 조종 시스템에 구현한 혁신적 접근으로, 직관성 향상과 자율 정책 학습 개선에 대한 실증적 증거를 제시한다. 다만 평가 작업의 범위 확대와 기술적 한계 개선을 통해 더욱 강화될 수 있다.
MOSAIC: Bridging the Sim-to-Real Gap in Generalist Humanoid Motion Tracking and Teleoperation with Rapid Residual Adaptation
 *Fig. 2: MOSAIC System Overview. MOSAIC consists of a unified training–deployment pipeline for humanoid motion tracking* MOSAIC는 강화학습을 통해 학습한 범용 humanoid 동작 추적기와 빠른 residual 적응 메커니즘을 결합하여 시뮬레이션과 실제 로봇 간의 gap을 줄이고 장시간의 텔레오퍼레이션을 안정적으로 지원하는 시스템이다.
MOSAIC는 시뮬레이션-실제 로봇 간 격차를 체계적으로 해결하기 위해 텔레오퍼레이션 지향의 RL 설계와 residual adaptation을 결합한 실용적이고 잘 설계된 시스템으로, RobotBridge 프레임워크와 함께 공개되어 재현성과 확장성을 크게 향상시킨다. 다만 완전한 zero-shot adaptation과 다양한 embodiment에 대한 더욱 강력한 일반화가 향후 과제이다.
TWIST: Teleoperated Whole-Body Imitation System
Figure 1: The Teleoperated Whole-Body Imitation System (TWIST) is a system that teleoperates humanoid
 *Figure 1: The Teleoperated Whole-Body Imitation System (TWIST) is a system that teleoperates humanoid* TWIST는 모션 캡처 데이터의 실시간 리타겟팅과 RL+BC 기반의 통합 신경망 컨트롤러를 통해 휴머노이드 로봇의 전신 협응 제어를 실현하는 원격 조종 시스템이다.
TWIST는 전신 협응 휴머노이드 원격 조종의 오래된 과제를 teacher-student 프레임워크와 데이터 혼합 전략으로 우아하게 해결하며, 단일 신경망으로 다양한 협응 기술을 실현한 의미 있는 기여이다.
Learning Versatile Humanoid Manipulation with Touch Dreaming
Fig. 1: Our system enables versatile, contact-rich, and dexterous humanoid manipulation. A: long-horizon, multi-stage ma
 *Fig. 1: Our system enables versatile, contact-rich, and dexterous humanoid manipulation. A: long-horizon, multi-stage ma* 휴머노이드 로봇의 접촉-풍부한 조작을 위해 VR 텔레오퍼레이션 기반 데이터 수집과 터치 감각을 핵심 모달리티로 하는 Humanoid Transformer with Touch Dreaming (HTD)을 제안한다.
본 논문은 터치를 핵심 모달리티로 하는 Touch Dreaming 기법과 통합된 실세계 데이터 수집 시스템으로 휴머노이드 접촉-풍부한 조작의 실현 가능성을 강력하게 입증한다. 다섯 가지 다양한 실제 작업에서 90.9% 성능 개선을 달성하며, 잠재 공간 예측의 효과성을 명확히 보여주는 높은 질의 연구이다.
Learning Whole-Body Humanoid Locomotion via Motion Generation and Motion Tracking
 *Fig. 2. Overview of the training framework. (a) Data Collection & Curation: whole-body robot motions are obtained from h* Diffusion 기반 motion generation과 RL 기반 motion tracking을 결합하여 지형 인식 whole-body humanoid locomotion을 실현하고 Unitree G1 로봇에 실제 배포했다.
이 논문은 diffusion-based motion generation과 RL-based tracking을 결합하여 실제 humanoid 로봇에서 처음으로 whole-body terrain-aware locomotion을 성공적으로 구현한 획기적 연구이다. 강력한 hardware 검증과 명확한 방법론을 통해 높은 수준의 완성도를 보여주며, humanoid 로봇 제어 분야에 의미 있는 기여를 제시한다.
Simulating Infant First-Person Sensorimotor Experience via Motion Retargeting from Babies to Humanoids
 *Fig. 2.* 본 논문은 영아의 단일 비디오로부터 3D 신체 자세를 추정하고 이를 iCub, pyCub, EMFANT, MIMo 등의 휴머노이드 로봇에 매핑하여 고유수용감각, 촉각, 시각 등 다중감각 스트림을 시뮬레이션하는 motion retargeting 프레임워크를 제시한다.
본 논문은 영아 발달 연구와 로보틱스의 교점에서 motion retargeting에 다중감각 시뮬레이션을 결합한 창의적이고 기술적으로 건전한 작업이다. Sub-centimeter 정확도와 실제 및 가상 휴머노이드 플랫폼에서의 입증은 강점이나, 단일 영상 검증과 영아 모델 부재로 인한 일반화 가능성 제약이 한계이다. 코드 공개 및 명확한 방법론 제시는 높이 평가되며, 발달과학과 신경발달 진단 응용의 미래 잠재력이 있다.
PhysHMR: Learning Humanoid Control Policies from Vision for Physically Plausible Human Motion Reconstruction
Fig. 1. Given a monocular video (a), (b) kinematic-based methods (e.g., GVHMR [Shen et al. 2024]) often cannot produce p
 *Fig. 1. Given a monocular video (a), (b) kinematic-based methods (e.g., GVHMR [Shen et al. 2024]) often cannot produce p* PhysHMR은 모노큘러 비디오로부터 물리적으로 타당한 인간 동작 재구성을 위해 비전-기반 휴머노이드 제어 정책을 직접 학습하는 통합 프레임워크이다. 기존의 두 단계 방식(운동학 기반 추정 + 물리 후처리)과 달리, 시각 정보와 물리 제약을 단일 정책 네트워크에서 함께 추론한다.
PhysHMR은 시각-기반 제어와 물리 추론을 통합하는 창의적 접근으로 모노큘러 비디오 기반 인간 동작 재구성의 근본적 문제를 해결한다. 우수한 물리적 타당성 개선과 실질적 응용 가치로 컴퓨터 비전과 그래픽스 분야에 의미 있는 기여를 한다.
PhysHSI: Towards a Real-World Generalizable and Natural Humanoid-Scene Interaction System
Fig. 1: Our system PhysHSI enables humanoid robots to perform diverse real-world interactions indoors and outdoors with
 *Fig. 2: Overview of PhysHSI. (a) Dataset Preparation: Human motions from a MoCap dataset are retargeted to humanoid moti* PhysHSI는 humanoid 로봇이 실제 환경에서 물체 운반, 앉기, 누우기 등 다양한 상호작용을 자연스럽고 일반화 가능하게 수행할 수 있도록 하는 통합 시스템으로, simulation 기반 AMP 정책 학습과 실시간 LiDAR-camera 기반 객체 인식 모듈을 결합한다.
PhysHSI는 AMP 기반 motion learning과 hybrid sensor fusion을 통합하여 humanoid의 실세계 scene interaction을 처음 실현한 high-impact system으로, 자연스러운 동작과 robust generalization을 동시에 달성했으나, annotation 자동화와 marker-free perception 확대가 실용 배포의 과제이다.
RAPT: Model-Predictive Out-of-Distribution Detection and Failure Diagnosis for Sim-to-Real Humanoid Robots
Fig. 1: RAPT overview. Real-world out-of-distribution (OOD) scenarios during humanoid deployment. RAPT detects anomalies
 *Fig. 1: RAPT overview. Real-world out-of-distribution (OOD) scenarios during humanoid deployment. RAPT detects anomalies* RAPT는 시뮬레이션 환경에서 학습한 인간형 로봇 제어 정책의 현실 배포 시 out-of-distribution(OOD) 상태를 감지하고 실패 원인을 진단하는 경량의 자기감독 모니터링 시스템이다.
RAPT는 humanoid robot 배포의 실제적 난제인 silent failure 감지와 근본 원인 분석을 동시에 해결하는 실용적이고 혁신적인 방법으로, 50Hz 고주파 제어 호환성과 interpretable diagnosis를 통해 Sim-to-Real gap 문제의 새로운 패러다임을 제시한다.
RPL: Learning Robust Humanoid Perceptive Locomotion on Challenging Terrains
Fig. 1.
 *Fig. 2.* RPL은 두 단계 학습 프레임워크로 terrain-specific 전문가 정책을 depth 카메라 기반 transformer 정책으로 증류하여, 복잡한 지형에서 payload를 탑재한 상태의 견고한 다방향 인형로봇 보행을 실현한다.
본 논문은 다단계 학습과 효율적 시뮬레이션을 통해 인형로봇의 복잡 지형 다방향 보행 문제를 체계적으로 해결하며, 특히 비대칭 다중 센서 입력 처리 기법과 payload 견고성 검증에서 실질적 기여를 제시한다.
VIRAL: Visual Sim-to-Real at Scale for Humanoid Loco-Manipulation

Figure 1. Center: Unitree G1 humanoid performing loco-manipulation, walking between tables to place and pick objects for
 *Figure 2. VIRAL teacher-student pipeline. Phase 1: In simulation, a privileged RL teacher policy πteacher receives full-* VIRAL은 humanoid robot의 loco-manipulation을 시뮬레이션에서 학습하고 zero-shot으로 실제 로봇에 배포하는 visual sim-to-real 프레임워크이며, teacher-student 구조와 대규모 GPU 컴퓨팅을 활용하여 RGB 기반 정책을 통해 54개 사이클의 연속적인 객체 이동을 달성했다.
본 논문은 humanoid loco-manipulation에 대한 시뮬레이션 기반 접근의 실현 가능성을 대규모 GPU 컴퓨팅과 체계적인 설계를 통해 실증한 중요한 연구로, teacher-student 프레임워크와 visual domain randomization의 조합이 zero-shot sim-to-real 전이를 가능하게 함을 보여준다.
ARMOR: Egocentric Perception for Humanoid Robot Collision Avoidance and Motion Planning
Fig. 1: ARMOR presents a novel egocentric wearable perception hardware and software system for humanoid robots (left).
 *Fig. 3: ARMOR’s egocentric perception hardware in simu-* 휴머노이드 로봇의 팔과 손에 분산 배치된 ToF 센서 기반의 자아중심 지각 시스템 ARMOR과 transformer 기반 모방학습 정책을 제시하여 밀집 환경에서의 충돌 회피 및 동작 계획을 수행한다.
휴머노이드 로봇의 지각-계획 문제를 분산 ToF 센서와 인간 중심의 imitation learning으로 창의적으로 해결하며, 실제 배포와 의미 있는 성능 향상으로 실용성 높은 연구이다. 다만 센서 배치 최적화와 sim-to-real gap 논의 강화가 필요하다.
CRISP: Contact-Guided Real2Sim from Monocular Video with Planar Scene Primitives
 *Figure 2: CRISP pipeline. Given a casual RGB video (left), CRISP reconstructs scene geometry* 단안 비디오에서 planar primitive 기반 scene geometry 복원과 human motion 추정을 통해 물리 시뮬레이션 가능한 human-scene reconstruction을 수행하는 real-to-sim 파이프라인을 제안한다.
CRISP는 planar primitive 기반의 간단하면서도 효과적인 real-to-sim 파이프라인으로, 기존 human-scene reconstruction의 근본적 문제(simulation incompatibility)를 physics 기반 검증으로 해결하며, substantial empirical improvement와 in-the-wild generalization을 통해 embodied AI 분야에 실질적 기여를 한다.
DexHub and DART: Towards Internet Scale Robot Data Collection
Fig. 1: We present DART, Dexterous Augmented Reality Teleoperation system, enabling intuitive, low-latency teleoperation
 *Fig. 1: We present DART, Dexterous Augmented Reality Teleoperation system, enabling intuitive, low-latency teleoperation* DART는 클라우드 기반 시뮬레이션과 AR을 활용한 군중기반 로봇 데이터 수집 플랫폼이며, DexHub는 수집된 데이터를 저장하는 공개 클라우드 데이터베이스이다.
본 논문은 AR과 클라우드 시뮬레이션을 창의적으로 결합하여 로봇 데이터 수집의 실질적 문제(지연, 피로, 확장성)를 해결하는 DART 플랫폼을 제시하며, DexHub를 통해 커뮤니티 규모의 데이터 생태계 구축을 시도한 점에서 높은 기여도를 가진다.
DPL: Depth-only Perceptive Humanoid Locomotion via Realistic Depth Synthesis and Cross-Attention Terrain Reconstruction
Fig. 1: Overview of the proposed teacher–student distillation framework for humanoid perceptive locomotion. (A) The stud
 *Fig. 1: Overview of the proposed teacher–student distillation framework for humanoid perceptive locomotion. (A) The stud* 휴머노이드 로봇의 깊이 이미지만을 사용한 지형 인식 보행을 위해, 현실적인 깊이 합성과 cross-attention transformer를 결합하여 사전 학습된 blind policy를 기반으로 효율적인 정책 학습을 가능하게 한다.
이 논문은 humanoid 로봇의 깊이 기반 보행에서 sim-to-real gap과 효율성 문제를 체계적으로 해결하는 통합 프레임워크를 제시하며, self-occlusion-aware 깊이 합성, cross-modal transformer, end-to-end fine-tuning의 조합으로 높은 독창성과 실용성을 달성했다. 실제 로봇 검증과 명확한 기술 기여가 돋보이는 우수한 연구이다.
EgoActor: Grounding Task Planning into Spatial-aware Egocentric Actions for Humanoid Robots via Visual-Language Models
Fig. 1: Overview of EgoActor, which can control a humanoid robot by jointly predicting movement, active perception,
 *Fig. 1: Overview of EgoActor, which can control a humanoid robot by jointly predicting movement, active perception,* EgoActor는 VLM 기반의 통합 모델로서 고수준 자연어 명령어를 휴머노이드 로봇의 저수준 공간 인식 동작(보행, 조작, 지각, 인간-로봇 상호작용)으로 직접 변환하는 EgoActing 태스크를 제안한다.
EgoActor는 VLM을 활용한 휴머노이드 로봇 제어에서 보행, 조작, 지각, 상호작용을 통합하는 새로운 접근을 제시하며, 광범위한 실제 및 시뮬레이션 검증을 통해 그 가능성을 입증한다. 오픈소스 공개와 함께 휴머노이드 구체화 AI의 실질적 발전에 기여할 것으로 예상된다.
Gallant: Voxel Grid-based Humanoid Locomotion and Local-navigation across 3D Constrained Terrains
Figure 1. Overview. Gallant enables a single policy with voxel grids to traverse diverse 3D constrained terrains: (a) as
 *Figure 1. Overview. Gallant enables a single policy with voxel grids to traverse diverse 3D constrained terrains: (a) as* Gallant는 Voxel Grid 기반의 LiDAR 인식과 z-grouped 2D CNN을 활용하여 인간형 로봇이 계단, 천장, 측면 장애물 등 3D 제약 지형을 단일 정책으로 횡단할 수 있게 하는 프레임워크이다.
Gallant는 Voxel Grid와 효율적 CNN을 결합하여 인간형 로봇의 3D 지형 인식 문제를 체계적으로 해결하고, 고충실도 시뮬레이션과 end-to-end 최적화로 sim-to-real 일관성을 달성한 임팩트 있는 연구이다. 다만 실시간 성능과 지형 일반화의 추가 검증이 필요하다.
GaussGym: An open-source real-to-sim framework for learning locomotion from pixels
Figure 1: GaussGym constructs photorealistic worlds from various data sources and renders them
 *Figure 1: GaussGym constructs photorealistic worlds from various data sources and renders them* 3D Gaussian Splatting을 IsaacGym 같은 벡터화된 물리 시뮬레이터에 통합하여 초당 100,000스텝 이상의 고속 시뮬레이션과 높은 시각적 충실도를 동시에 달성하는 포토리얼리스틱 로봇 시뮬레이션 프레임워크를 제시한다.
본 논문은 3D Gaussian Splatting을 물리 시뮬레이터와 통합하여 고속성과 시각적 충실도를 동시에 달성한 획기적인 작업으로, 포토리얼리스틱 로봇 학습에 새로운 가능성을 열었다. 오픈소스 공개와 광범위한 데이터 지원으로 향후 연구의 기반이 될 것으로 기대된다.
Generalizable Geometric Prior and Recurrent Spiking Feature Learning for Humanoid Robot Manipulation
Fig. 1. Overview of our framework. By integrating geometric common-
 *Fig. 1. Overview of our framework. By integrating geometric common-* RGMP-S는 기하학적 선행 정보와 spiking 신경망을 결합하여 인간형 로봇 조작을 위한 고수준 의미론적 추론과 저수준 동작 생성을 동시에 달성하는 프레임워크다.
RGMP-S는 기하학적 추론과 spiking neural network을 창의적으로 결합하여 인간형 로봇 조작에서 기술 가능성 검증과 데이터 효율성이라는 두 가지 근본적 도전을 동시에 해결한다. 다양한 실제 로봇 플랫폼에서의 광범위한 검증과 19% 성능 향상, 5배 데이터 효율성 개선은 높은 실용적 가치를 입증한다.
Generative World Modelling for Humanoids: 1X World Model Challenge Technical Report
Figure 1. Overview of the 1X World Model Challenges Left de-
 *Figure 1. Overview of the 1X World Model Challenges Left de-* 1X World Model Challenge에서 humanoid 로봇의 미래 상태 예측을 위해 Wan 2.2 TI2V-5B를 video-state-conditioned 프레임 예측으로 적응시키고, Spatio-Temporal Transformer를 압축 트랙용으로 훈련하여 두 트랙 모두에서 1위를 달성했다.
본 논문은 대규모 foundation model을 robot state 조건화로 효과적으로 적응시키고, pixel space와 discrete latent space에서 모두 최고 성능을 달성함으로써 실제 humanoid 로봇 world modeling의 새로운 벤치마크를 제시했다. 방법론의 명확한 설명과 포괄적인 ablation study는 향후 world model 연구에 큰 기여가 될 것으로 예상된다.
Hiking in the Wild: A Scalable Perceptive Parkour Framework for Humanoids
Fig. 1: Hiking in the Wild. Our framework enables a humanoid robot to traverse diverse terrains in both indoor and outdo
 *Fig. 2: System overview. Our framework trains an end-to-end policy using simulated depth and proprioception. To ensure* 이 논문은 깊이 카메라와 proprioception을 직접 joint actions으로 변환하는 end-to-end RL 프레임워크를 제시하여, 외부 상태 추정 없이 humanoid 로봇이 복잡한 비정형 지형에서 최대 2.5 m/s의 속도로 안전하게 이동할 수 있게 한다.
이 논문은 humanoid 로봇의 야외 주행을 위한 실용적이고 확장 가능한 end-to-end RL 프레임워크를 제시하며, Terrain Edge Detection, Foot Volume Points, Flat Patch Sampling 등 novel 메커니즘으로 safety와 reward hacking 문제를 효과적으로 해결한다. Open-source 배포와 실제 로봇 검증을 통해 높은 재현성과 실용성을 입증한 우수한 연구이다.
Humanoid World Models: Open World Foundation Models for Humanoid Robotics
Figure 1. Overview of Humanoid World Models (HWM). Given
 *Figure 1. Overview of Humanoid World Models (HWM). Given* Humanoid World Models (HWM)는 100시간의 humanoid 시연 데이터로 학습된 경량 오픈소스 모델로, egocentric 비디오를 humanoid control token으로 조건화하여 미래 프레임을 예측한다. Masked Transformer와 Flow-Matching 두 가지 생성 모델을 탐색하며 parameter-sharing 기법으로 33-53% 크기 감소를 달성했다.
이 논문은 humanoid 로봇을 위한 경량의 접근 가능한 world model이라는 명확한 필요를 직면하고, Masked Transformer와 Flow-Matching 두 패러다임을 체계적으로 비교하며 parameter-sharing 효율성을 입증한 실질적 기여를 한다. 다만 downstream task 평가와 실제 로봇 실험을 통한 효과 검증이 추가되면 영향력이 더욱 커질 것으로 예상된다.
Iterative Closed-Loop Motion Synthesis for Scaling the Capabilities of Humanoid Control
Figure 1. Overview of the CLAIMS pipeline: a closed-loop system that refines prompts from a 5-domain library (martial ar
 *Figure 1. Overview of the CLAIMS pipeline: a closed-loop system that refines prompts from a 5-domain library (martial ar* 본 논문은 폐쇄 루프 자동화 모션 데이터 생성 및 반복 프레임워크(CLAIMS)를 제안하여 고정된 난이도 분포의 데이터셋 한계를 극복하고, 휴머노이드 제어 정책의 성능 상한을 향상시킨다.
본 논문은 동적 난이도 적응을 통해 휴머노이드 제어의 고질적인 문제(고정 데이터 분포, 높은 데이터 수집 비용)를 혁신적으로 해결하며, 폐쇄 루프 프레임워크의 개념과 실제 구현이 모두 우수하다. 특히 AMASS의 1/10 데이터로 45% 실패율 감소라는 실질적 성과와 다양한 벤치마크에서의 일반화 능력은 이 분야에 상당한 실용적 기여를 제공한다.
Kimodo: Scaling Controllable Human Motion Generation
Figure 1: Controllable Motion Generation. Kimodo supports flexible and intuitive control for motion generation
 *Figure 1: Controllable Motion Generation. Kimodo supports flexible and intuitive control for motion generation* NVIDIA의 Kimodo는 700시간의 광학 모션캡처 데이터로 학습한 kinematic motion diffusion model로, 텍스트 프롬프트 및 포괄적인 운동학 제약 조건을 통해 고품질 인간 모션을 생성한다.
Kimodo는 대규모 모션캡처 데이터와 혁신적인 두 단계 diffusion 아키텍처를 결합하여 현실적이고 제어 가능한 인간 모션 생성을 달성한 중요한 기여이며, 로봇공학과 콘텐츠 생성 분야에서 실질적인 응용 가치를 제시한다.
Learning Humanoid Navigation from Human Data
Fig. 1.
 *Fig. 1.* 인간 보행 데이터 5시간으로만 학습하여 휴머노이드 로봇이 미지의 환경을 자율 내비게이션할 수 있는 EgoNav 시스템을 제안. 360° 시각 메모리와 diffusion model을 통해 다중모달 궤적 분포를 생성하고 로봇에 직접 배포 가능.
인간 보행 데이터로부터 로봇 데이터 없이 휴머노이드 내비게이션을 학습하는 혁신적 접근으로, 360° visual memory와 diffusion model의 조합으로 다중모달 예측과 실시간 성능을 동시에 달성했다. 실제 로봇 배포 데모는 임팩트 있지만 정량적 성능 평가 확대와 다양한 로봇 및 환경에서의 일반화 검증이 필요하다.
Learning Whole-Body Human-Humanoid Interaction from Human-Human Demonstrations
Figure 1. From HHI to HHoI with simulation and real-robot results. Left: PAIR (Physics-Aware Interaction Retargeting) co
 *Figure 2. PAIR preserves physical consistency where naive meth-* 휴먼-휴먼 인터랙션(HHI) 데이터를 물리적 일관성을 보존하면서 휴먼-휴모이드 인터랙션(HHoI)으로 변환하는 PAIR와, 시간적 의도와 공간적 선택을 분리하여 상호작용적 이해를 갖춘 D-STAR 정책을 제안한다.
이 논문은 HHI에서 HHoI로의 데이터 변환 문제를 물리적 일관성 관점에서 체계적으로 해결하고, 시공간 분리를 통해 상호작용 정책의 반응성을 크게 향상시키는 혁신적인 접근을 제시한다. 시뮬레이션과 실제 로봇 검증을 통해 실용성을 입증하였으나, 더 다양한 상호작용 시나리오와 플랫폼으로의 확장이 필요하다.
Now You See That: Learning End-to-End Humanoid Locomotion from Raw Pixels
Fig. 1: Overview. Our end-to-end vision-based humanoid locomotion policy enables robust traversal across diverse challen
 *Fig. 1: Overview. Our end-to-end vision-based humanoid locomotion policy enables robust traversal across diverse challen* Raw 깊이 이미지로부터 end-to-end 휴머노이드 로봇 보행을 학습하기 위해, 현실적인 depth 센서 시뮬레이션과 vision-aware behavior distillation, 그리고 terrain-specific multi-critic/multi-discriminator 학습을 결합한 프레임워크를 제시한다.
본 논문은 휴머노이드 로봇의 vision-based 보행에서 sim-to-real gap과 다양한 terrain 통합 학습의 근본적인 두 과제를 체계적으로 해결하며, 현실적인 센서 모델링과 behavior distillation, terrain-specific 학습을 결합한 창의적인 프레임워크를 제시한다. 두 개의 실제 로봇 플랫폼에서 극한 장애물부터 fine-grained 작업까지 광범위한 성능 검증을 통해 학술적·실무적 가치가 높다.
Omni-Perception: Omnidirectional Collision Avoidance for Legged Locomotion in Dynamic Environments
Figure 1: Validation scenarios for the Omni-Perception framework. Effective omnidirectional collision avoid-
 *Figure 1: Validation scenarios for the Omni-Perception framework. Effective omnidirectional collision avoid-* 본 논문은 LiDAR 포인트 클라우드를 직접 처리하는 end-to-end 강화학습 정책 Omni-Perception을 제안하여 동적 환경에서 다리 로봇의 전방향 충돌 회피를 실현한다. PD-RiskNet이라는 새로운 지각 모듈을 통해 시공간적 LiDAR 데이터를 해석하여 환경 위험을 평가한다.
본 논문은 다리 로봇의 동적 환경 네비게이션에 LiDAR을 직접 활용한 end-to-end 학습 프레임워크라는 참신한 접근을 제시하며, 실용적인 시뮬레이션 툴킷과 함께 강건한 sim-to-real 전이를 입증한다. 다만 기술 상세 공개 수준과 극단 환경 검증 보강이 필요하다.
One Policy but Many Worlds: A Scalable Unified Policy for Versatile Humanoid Locomotion
 *Figure 2: Framework of DreamPolicy. The system is decomposed into two parts: (1) Terrain-aware* DreamPolicy는 Humanoid Motion Imagery (HMI)를 생성하는 terrain-aware autoregressive diffusion planner와 HMI-conditioned RL policy를 결합하여, 단일 정책으로 다양한 지형에서 humanoid 로봇의 이동을 학습하고 미지의 시나리오로 zero-shot 일반화를 달성하는 통합 프레임워크이다.
DreamPolicy는 offline data와 diffusion-based trajectory synthesis를 통합하여 humanoid 이동의 확장성 문제를 창의적으로 해결하고, 실제 로봇 응용에 실질적 가치를 제공하는 강력한 프레임워크이다. 다만 sim-to-real 검증과 computational 효율성 분석이 보완되면 더욱 견고한 기여가 될 것이다.
One-shot Adaptation of Humanoid Whole-body Motion with Walking Priors
Figure 1. Sampled frames from motion sequences of a humanoid (Unitree H1) performing four distinct actions in sim-to-sim
 *Figure 2. Given a sequence of walking motion pose skeletons and a target sequence comprising non-walking motions, we emp* 단일 비보행 대상 샘플과 보행 사전 지식을 활용하여 휴머노이드 전신 운동을 원샷 적응하는 데이터 효율적 방법을 제안한다. Order-preserving optimal transport를 통해 보행과 비보행 시퀀스 간 거리를 계산하고 geodesic 보간으로 중간 포즈를 생성한 후 강화학습으로 정책을 적응한다.
휴머노이드 전신 운동에 원샷 학습을 효과적으로 적용하고, order-preserving optimal transport와 manifold 최적화를 통해 경량의 데이터 효율적 솔루션을 제시하는 높은 가치의 연구이다. 다만 실제 로봇 검증과 더 다양한 보조 모션 확장이 후속 과제이다.
TTT-Parkour: Rapid Test-Time Training for Perceptive Robot Parkour
 *Fig. 2: TTT-Parkour. Our framework consists of three stages: (1) Pre-training: A general policy is pre-trained on divers* 본 논문은 RGB-D 입력으로부터 고충실도 메시 재구성을 통해 미지의 복잡한 지형에서 휴머노이드 로봇의 빠른 테스트 시간 파인튜닝(TTT)을 가능하게 하는 real-to-sim-to-real 프레임워크를 제안한다.
본 논문은 피드포워드 기하 재구성과 빠른 테스트 시간 파인튜닝을 통합하여 휴머노이드 로봇의 미지 복잡 지형 순회 능력을 획기적으로 향상시키는 실용적이고 혁신적인 프레임워크를 제시한다. 10분 이내의 완전 파이프라인과 강건한 sim-to-real 전이는 로봇 배포의 현실성을 크게 높인다.
Global-Local Attention Decomposition for Terrain Encoding in Humanoid Perceptive Locomotion
Fig. 1. Real-world locomotion results on the Unitree G1 humanoid robot. A
 *Fig. 2.* 본 논문은 인간형 로봇의 지형 인식 보행을 위해 Global-Local Attention Decomposition (GLAD)이라는 새로운 terrain encoder를 제안한다. 광범위한 지형 맥락 이해와 정확한 발판 선택이라는 두 가지 지각 목표를 명시적으로 분리함으로써 sparse-foothold terrain에서의 안정적인 보행을 달성한다.
본 논문은 인간형 로봇의 sparse-foothold 보행을 위해 attention mechanism의 역할을 명시적으로 분리하는 GLAD를 제안하며, 이론적 동기부여가 명확하고 실제 로봇 배포에서 우수한 성능을 달성했다는 점에서 의미 있는 기여를 한다. 다만, 더 철저한 ablation study와 기존 방법과의 정량적 비교가 보충되면 더욱 강력한 논문이 될 것이다.
Learning Humanoid Navigation from Human Data
Fig. 1.
 *Fig. 2. Overview of the proposed method: A rolling buffer of 32 segmented* 본 논문은 인간의 보행 데이터 5시간만을 활용하여 휴머노이드 로봇이 미지의 환경에서 자율적으로 내비게이션할 수 있는 EgoNav 시스템을 제안한다. 로봇 데이터 없이 순수 인간 데이터만으로 학습한 모델을 Unitree G1 휴머노이드에 제로샷 배포하여 실제 환경에서의 효과를 입증한다.
EgoNav는 인간 보행 데이터만으로 휴머노이드 로봇 내비게이션을 가능하게 하는 혁신적 접근을 제시하며, diffusion model 기반 다중 모달 궤적 생성과 실시간 추론의 결합, 실제 미지 환경에서의 제로샷 배포 성공은 로봇 내비게이션 분야에 상당한 기여를 한다. 다만 학습 데이터 규모와 극한 환경 견고성의 검증이 추가되면 더욱 강력한 논문이 될 수 있다.
Physics-Based Motion Imitation with Adversarial Differential Discriminators
Fig. 1. We propose an adversarial multi-objective optimization technique that enables physically simulated characters to
 *Fig. 1. We propose an adversarial multi-objective optimization technique that enables physically simulated characters to* Physics-based 캐릭터 애니메이션을 위해 Adversarial Differential Discriminator (ADD)를 통해 수동 보상 함수 설계 없이 다중 목표 최적화를 자동으로 수행하는 방법을 제시한다. 단일 positive sample(영점 벡터)만으로도 효과적으로 여러 목표를 동적으로 균형잡아 고난도 동작을 모방할 수 있다.
본 논문은 다중 목표 최적화의 자동화를 위해 창의적인 adversarial discriminator 설계를 제시하며, physics-based 캐릭터 애니메이션에서 수동 보상 함수 설계 제거를 통해 일반화 가능성을 크게 향상시킨다. 핵심 아이디어의 단순성과 광범위한 적용 가능성이 강점이다.
PRIMAL: Physically Reactive and Interactive Motor Model for Avatar Learning
Figure 1. PRIMAL is a novel generative real-time 3D character animation system that works in Unreal Engine. The avatar r
 *Figure 1. PRIMAL is a novel generative real-time 3D character animation system that works in Unreal Engine. The avatar r* PRIMAL은 두 단계 학습 패러다임으로 아바타의 모터 시스템을 generative motion model로 구현하여, 물리적으로 반응성 있고 제어 가능하며 실시간 상호작용이 가능한 3D 캐릭터 애니메이션을 실현한다.
PRIMAL은 짧은 시간 척도에서의 physics 지배성이라는 통찰력으로 unsupervised diffusion model을 통해 실시간 반응성과 물리적 사실성을 동시에 달성한 혁신적 접근이며, Unreal Engine 구현으로 실제 응용 가능성을 입증한 탁월한 연구이다.
StyleLoco: Generative Adversarial Distillation for Natural Humanoid Robot Locomotion

Fig. 1.
 *Fig. 1.* StyleLoco는 강화학습의 민첩성과 모션캡처 데이터의 자연스러움을 결합하기 위해 다중 discriminator를 활용한 Generative Adversarial Distillation (GAD) 프레임워크를 제안하여 인간형 로봇의 자연스러운 보행을 실현한다.
StyleLoco는 인간형 로봇 보행의 오랜 딜레마를 해결하는 창의적인 프레임워크를 제시하며, 다중 discriminator를 통한 이질적 소스의 결합과 실제 로봇에서의 성공적인 배포는 높은 실용 가치를 입증한다.
Taming Diffusion Probabilistic Models for Character Control
 *Figure 2: Conditional Autoregressive Motion Diffusion Model* Transformer 기반 Conditional Autoregressive Motion Diffusion Model (CAMDM)을 제안하여 사용자의 동적 제어 신호에 실시간으로 반응하면서 고품질의 다양한 캐릭터 애니메이션을 생성한다.
Diffusion model을 실시간 캐릭터 컨트롤에 적용하기 위한 체계적이고 실용적인 해결책을 제시한 우수한 논문으로, 별도 조건 토큰화와 classifier-free guidance의 novel한 조합이 다양성과 제어 안정성을 동시에 달성하며, 단일 모델의 다중 스타일 지원은 산업 응용 가치가 높다.
Walk the PLANC: Physics-Guided RL for Agile Humanoid Locomotion on Constrained Footholds
Fig. 1. Model-guided RL traversing constrained footholds on the Unitree G1
 *Fig. 2. A visual depiction of the model-guided RL architecture used to achieve stepping stones. The left column shows th* 이 논문은 감소된 차수의 발판 계획기와 Control Lyapunov Function (CLF) 기반 보상을 통해 물리학 기반 구조로 강화학습을 안내하여, 제한된 발판에서 인간형 로봇의 정밀한 보행을 달성한다.
본 논문은 물리 기반 구조와 강화학습을 효과적으로 결합하여 stepping-stone 보행의 정밀성과 강건성 문제를 우아하게 해결하였으며, 하드웨어 검증과 오픈소스 공개를 통해 높은 실용적 가치를 제공한다.
AMOR: Adaptive Character Control through Multi-Objective Reinforcement Learning
Fig. 1. Our method uses multi-objective reinforcement learning to enable on-the-fly tuning of reward weights post-traini
 *Fig. 1. Our method uses multi-objective reinforcement learning to enable on-the-fly tuning of reward weights post-traini* 본 논문은 Multi-Objective Reinforcement Learning(MORL)을 활용하여 보상 함수의 가중치를 학습 후 조정할 수 있는 AMOR 프레임워크를 제안하며, 이를 통해 물리 기반 캐릭터 제어의 반복 튜닝 시간을 단축하고 실제 로봇으로의 전이를 용이하게 한다.
본 논문은 MORL을 물리 기반 캐릭터 제어에 창의적으로 적용하여 훈련 후 가중치 조정을 가능하게 함으로써 개발 워크플로우를 크게 개선하고, 실제 로봇 적용에서의 sim-to-real 전이를 용이하게 하는 실용적이고 혁신적인 접근법을 제시한다.
AMP: Adversarial Motion Priors for Stylized Physics-Based Character Control
 *Fig. 2. Schematic overview of the system. Given a motion dataset defining a* 물리 기반 캐릭터 애니메이션에서 adversarial motion prior를 학습하여 비구조화된 모션 클립 데이터셋으로부터 자동으로 스타일을 추출하고, 간단한 보상 함수로 정의된 고수준 태스크 목표를 달성하면서도 자연스러운 움직임을 생성하는 방법을 제안한다.
본 논문은 adversarial motion prior를 통해 비구조화 모션 데이터의 자동 활용을 실현한 물리 기반 캐릭터 애니메이션 분야의 중요한 기여로, 모션 선택 메커니즘 설계의 부담을 제거하면서도 최첨단 성능을 달성하며 게임, 영상, 로봇 등 다양한 응용 분야에 실질적 가치를 제공한다.
ASE: Large-Scale Reusable Adversarial Skill Embeddings for Physically Simulated Characters
Fig. 1. Our framework enables physically simulated characters to learn versatile and reusable skill embeddings from larg
 *Fig. 1. Our framework enables physically simulated characters to learn versatile and reusable skill embeddings from larg* 대규모 비정형 모션 데이터셋으로부터 adversarial imitation learning과 unsupervised reinforcement learning을 결합하여 물리 시뮬레이션 캐릭터의 재사용 가능한 스킬 임베딩을 학습하는 데이터 기반 프레임워크를 제시한다. 학습된 스킬 임베딩은 다양한 새로운 과제에 효과적으로 전이되며 자연스러운 행동을 합성한다.
본 논문은 adversarial imitation learning과 information maximization을 결합하여 대규모 비정형 모션 데이터로부터 재사용 가능한 스킬 임베딩을 학습하는 혁신적인 프레임워크를 제시한다. 십 년 규모의 대규모 사전 학습과 탁월한 전이 성능으로 물리 기반 캐릭터 애니메이션 분야에 significant contribution을 제공한다.
DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills
Fig. 1. Highly dynamic skills learned by imitating reference motion capture clips using our method, executed by physical
 *Fig. 1. Highly dynamic skills learned by imitating reference motion capture clips using our method, executed by physical* Motion capture 데이터를 활용한 example-guided reinforcement learning으로 물리 기반 캐릭터 애니메이션을 학습하는 방법을 제안하며, 모션 모방과 task 목표를 결합하여 강건하고 다양한 기술을 수행하는 제어 정책을 학습한다.
본 논문은 개별 기술의 novel 한 조합보다는 physics-based character animation에서의 효과적 시스템 설계를 통해 실질적 가치를 제시하며, 광범위한 실증 결과로 방법의 실용성과 확장성을 강력히 입증한 매우 영향력 있는 기여이다.
Design and Control of a Bipedal Robotic Character
Fig. 1.
 *Fig. 2.* 이 논문은 표현력 있는 예술적 동작과 강건한 동적 이동성을 결합한 이족 로봇 캐릭터의 설계 및 제어 시스템을 제시한다. Reinforcement Learning 기반 제어 구조와 실시간 애니메이션 엔진을 통해 로봇이 연극적 성능을 수행할 수 있도록 한다.
이 논문은 이족 로봇의 표현성과 동적 능력을 통합하는 혁신적인 설계 및 제어 파이프라인을 제시하며, 애니메이션과 로봇 공학의 교점에서 새로운 패러다임을 제안한다. 엔터테인ment 로보틱스와 휴먼-로봇 상호작용 분야에 중요한 기여를 하면서도 실제 시스템 구현을 통해 실용성을 입증했다.
Diffusion Forcing for Multi-Agent Interaction Sequence Modeling
Figure 1. A Generative Model for Multi-Agent Interaction. We propose Multi-Agent Diffusion Forcing Transformer (MAGNet),
 *Figure 1. A Generative Model for Multi-Agent Interaction. We propose Multi-Agent Diffusion Forcing Transformer (MAGNet),* MAGNet은 diffusion forcing을 활용한 통합 autoregressive diffusion framework로, 다양한 multi-agent interaction 시나리오를 하나의 모델로 처리하며 dyadic부터 polyadic 상황까지 확장 가능한 long-horizon motion generation을 수행한다.
MAGNet은 multi-agent motion generation의 근본적인 문제인 task fragmentation을 해결하는 우아한 통합 프레임워크를 제시하며, relational representation과 diffusion forcing의 조합으로 polyadic scenario까지 자연스럽게 확장 가능한 점이 탁월하다. 다만 polyadic scenario의 정량적 평가 강화와 practical deployment에 필요한 robustness 평가가 향후 과제이다.
Do You Have Freestyle? Expressive Humanoid Locomotion via Audio Control
Figure 1.
 *Figure 1.* RoboPerform은 오디오를 직접 제어 신호로 사용하여 음악에 맞춰 춤을 추거나 음성에 맞춰 제스처를 생성하는 휴머노이드 로봇 제어 프레임워크로, 명시적 모션 재구성을 제거하여 저지연 및 고충실도를 달성한다.
RoboPerform은 오디오 제어 신호를 휴머노이드 로봇 모션에 직접 통합하는 novel한 접근으로, retargeting-free 설계와 content-style decomposition을 통해 저지연 고충실도 실시간 성능을 달성한 의미 있는 기여이다. 다만 실제 로봇 배포 및 sim-to-real 검증이 추가되면 실용성이 더욱 강화될 것이다.
Example-based Motion Synthesis via Generative Motion Matching
Fig. 1. Our generative framework enables a variety of example-based motion synthesis tasks, that usually require long of
 *Fig. 2. Multi-stage motion synthesis. Starting from the coarsest stage, the generative motion matching at each stage 𝑠ta* GenMM은 단일 또는 소수의 예제 모션으로부터 다양한 모션을 생성하는 학습 불필요한 생성 모델로, Motion Matching의 품질을 유지하면서 Bidirectional similarity를 생성 비용 함수로 활용하여 다단계 프레임워크로 점진적으로 모션을 정제한다.
GenMM은 Motion Matching의 우수한 품질을 유지하면서 학습 불필요한 생성 모델을 구현한 창의적인 접근법으로, 산업 실무에서 즉시 적용 가능한 실용성과 복잡한 스켈레톤에 대한 강력한 확장성을 제공하는 매우 가치 있는 연구이다.
GENMO: A GENeralist Model for Human MOtion
Figure 1. GENMO unifies human motion estimation and generation in a single framework and supports diverse conditioning s
 *Figure 1. GENMO unifies human motion estimation and generation in a single framework and supports diverse conditioning s* GENMO는 인간 동작 추정과 생성을 단일 프레임워크에서 통합하는 generalist 모델로, 동작 추정을 제약 조건이 있는 동작 생성으로 재구성하여 정확한 추정과 다양한 생성을 동시에 달성한다.
GENMO는 동작 추정과 생성의 오랫동안의 분리를 혁신적으로 통합하는 첫 번째 generalist 모델로, dual-mode 훈련과 estimation-guided 목표를 통해 두 작업 간 상승 효과를 효과적으로 달성하며, 다양한 benchmark에서 state-of-the-art 성능을 입증한다.
MaskedMimic: Unified Physics-Based Character Control Through Masked Motion Inpainting
Fig. 1. We present MaskedMimic, a versatile control model that enables physically simulated characters to generate diver
 *Fig. 1. We present MaskedMimic, a versatile control model that enables physically simulated characters to generate diver* MaskedMimic은 motion inpainting 문제로 physics-based character control을 재정의하여, 마스킹된 keyframe, text, object 등 다양한 partial 조건으로부터 통합된 단일 모델이 전신 물리 기반 애니메이션을 생성할 수 있게 한다.
MaskedMimic은 motion inpainting이라는 우아한 재정의를 통해 physics-based character control의 versatility 문제를 근본적으로 해결하며, 단일 unified model로 diverse control modalities를 지원하는 breakthrough를 이루었다. 실제 응용 및 확장성 측면에서의 평가는 필요하지만, character animation의 패러다임을 크게 전환할 수 있는 높은 impact의 연구이다.
PhysDiff: Physics-Guided Human Motion Diffusion Model
Figure 1. Our PhysDiff model generates physically-plausible motions using a physics-based motion projection in the diffu
 *Figure 1. Our PhysDiff model generates physically-plausible motions using a physics-based motion projection in the diffu* PhysDiff는 diffusion 과정에 물리 기반 motion projection 모듈을 통합하여 physically-plausible human motion을 생성하는 physics-guided motion diffusion 모델이다. 기존 motion diffusion 모델의 floating, foot sliding, ground penetration 같은 물리적 artifacts를 제거한다.
PhysDiff는 human motion generation에 physics 제약을 systematically 통합하여 physically-plausible motion 생성의 핵심 문제를 해결한 혁신적 연구이다. Iterative projection 전략과 철저한 실험 분석이 학계에 중요한 기여를 제공하며, 실제 animation/VR 응용의 현실화를 크게 앞당긴다.
TEDi: Temporally-Entangled Diffusion for Long-Term Motion Synthesis
Fig. 1. Inspired by the gradual nature of the diffusion process along a diffusion time-axis (left), our approach (right)
 *Fig. 1. Inspired by the gradual nature of the diffusion process along a diffusion time-axis (left), our approach (right)* TEDi는 Denoising Diffusion Probabilistic Models (DDPM)의 점진적 생성 개념을 모션 시퀀스의 시간축에 적용하여, 두 축을 얽혀 있게(entangle) 함으로써 임의 길이의 장기 모션 생성을 가능하게 한다. 시간에 따라 변하는 노이즈 레벨을 가진 모션 버퍼를 반복적으로 제거하는 자동회귀 메커니즘을 통해 연속적인 프레임 스트림을 생성한다.
TEDi는 diffusion 모델의 시간축과 모션 시퀀스의 시간축을 창의적으로 얽혀 있게 함으로써 장기 모션 생성의 근본적인 문제를 우아하게 해결한 혁신적 작업이다. 임의 길이 생성, stitching 제거, 대화형 제어 등 기존 방법들의 한계를 동시에 극복하며, 명확한 설명과 견고한 기술적 기초로 높은 평가를 받을 만하다.
GENMO: A GENeralist Model for Human MOtion
Figure 1. GENMO unifies human motion estimation and generation in a single framework and supports diverse conditioning s
 *Figure 1. GENMO unifies human motion estimation and generation in a single framework and supports diverse conditioning s* 본 논문은 인간 모션 생성과 추정을 단일 diffusion 기반 프레임워크에서 통합하는 GENMO를 제안한다. 모션 추정을 제약이 있는 모션 생성으로 재정의하고, dual-mode 학습 패러다임을 통해 정확한 global motion estimation과 다양한 모션 생성을 동시에 달성한다.
본 논문은 인간 모션 생성과 추정을 통합하는 새로운 관점과 실용적인 솔루션을 제시하는 강력한 연구이다. Dual-mode training paradigm과 estimation-guided objective는 창의적이며, 다양한 조건 신호의 유연한 처리는 실제 애플리케이션에서 높은 가치를 가진다. 다만 상세한 정량적 평가와 계산 효율성 분석의 강화가 필요하다.
PILOT: A Perceptive Integrated Low-level Controller for Loco-manipulation over Unstructured Scenes
Fig. 1. Method overview of PILOT. We propose a unified single-stage reinforcement learning framework that seamlessly int
 *Fig. 1. Method overview of PILOT. We propose a unified single-stage reinforcement learning framework that seamlessly int* PILOT는 humanoid robot의 loco-manipulation을 위한 통합 단계 RL 프레임워크로, 지각 기반 locomotion과 전신 제어를 단일 policy로 통합하여 비정형 지형에서 안정적인 작업 실행을 가능하게 한다.
PILOT는 humanoid loco-manipulation 문제에 대한 통합적이고 실용적인 해결책을 제시하며, cross-modal perception과 MoE 구조를 통해 기술적 기여와 실제 로봇 구현의 성공적 사례를 보여준다.
Robust and Generalized Humanoid Motion Tracking
 *Fig. 2: Overview of the proposed whole-body control pipeline. A history encoder extracts a dynamics embedding from* 휴머노이드 로봇의 일반적인 전신 제어를 위해 dynamics-conditioned command aggregation 프레임워크를 제안하며, 인과적 temporal encoder와 multi-head cross-attention을 결합하여 노이즈가 있는 참조 동작에 강건하게 대응한다.
본 논문은 dynamics-conditioned command aggregation이라는 우아한 설계를 통해 컴팩트한 데이터셋으로도 강건한 일반화 휴머노이드 전신 제어를 달성하며, 낙하 회복의 통합과 실제 로봇 배포 검증으로 높은 실용성을 보여준다.
CReF: Cross-modal and Recurrent Fusion for Depth-conditioned Humanoid Locomotion
Fig. 1.
 *Fig. 2.* CReF는 cross-modal attention과 gated residual fusion을 활용하여 raw depth 입력으로부터 직접 locomotion-relevant 특징을 학습하는 단일 단계 depth-conditioned humanoid locomotion 프레임워크로, 명시적 기하학적 중간 표현 없이 zero-shot sim-to-real transfer를 달성한다.
CReF는 명시적 기하학적 중간 표현을 제거하고 cross-modal attention과 gated recurrent fusion을 통해 raw depth로부터 직접 locomotion-relevant features를 학습하는 혁신적 접근법으로, zero-shot sim-to-real transfer와 다양한 실제 환경에서의 강건한 성능을 통해 humanoid locomotion 분야에 significant contribution을 제시한다.
Learning Soccer Skills for Humanoid Robots: A Progressive Perception-Action Framework
 *Fig. 2: Overview of the Perception-Action integrated Decision-making (PAiD) framework. Our pipeline progressively acquir* 본 논문은 humanoid robot이 human-like kicking과 whole-body balance를 동시에 수행하는 soccer skill을 습득하기 위해, 세 단계로 구성된 Perception-Action integrated Decision-making (PAiD) 프레임워크를 제안한다.
본 논문은 humanoid robot의 복잡한 embodied skill 습득을 위한 체계적인 progressive framework를 제시하며, motion tracking-perception integration-sim-to-real transfer의 세 단계 분해를 통해 기존 방식의 training instability와 reward conflict를 효과적으로 해결한다. 91.3% 성공률의 robust real-world kicking 성능과 diverse condition에서의 일관성은 제안 방법의 효과를 입증하며, divide-and-conquer 전략은 향후 complex embodied skill 습득의 scalable framework로 활용 가능하다.
Learning Visuotactile Skills with Two Multifingered Hands
Fig. 1. An overview of our system setup and learned visuotactile skills on four tasks. (a) Our hardware and teleoperatio
 *Fig. 1. An overview of our system setup and learned visuotactile skills on four tasks. (a) Our hardware and teleoperatio* VR 기반 저가형 텔레오퍼레이션 시스템 HATO와 촉각 센서가 장착된 의족 손을 활용하여 양손 다중지 조작 로봇이 시각-촉각 데이터로부터 인간 수준의 민첩한 조작 기술을 학습하는 시스템을 제시한다.
본 논문은 양손 다중지 조작 분야에서 하드웨어 혁신(의족 재목적화)과 접근성 높은 텔레오퍼레이션 시스템(HATO)을 통해 visuotactile learning의 새로운 경계를 개척했다. 촉각 센싱의 중요성을 실증적으로 보여주고 효율적 데이터 수집 및 정책 학습을 달성하여 로봇 조작 분야에 상당한 기여를 한다.
Towards Proprioception-Aware Embodied Planning for Dual-Arm Humanoid Robots
Fig. 1: DualTHOR is a novel simulator specifically tai-
 *Fig. 1: DualTHOR is a novel simulator specifically tai-* 이 논문은 이중팔 휴머노이드 로봇의 장기 계획을 위해 DualTHOR 시뮬레이터와 고유감각(proprioception)을 인식하는 Proprio-MLLM을 제안하며, 기존 MLLM의 구현화 인식 부족을 해결한다.
이 논문은 이중팔 휴머노이드 로봇의 장기 계획을 위한 체계적인 시뮬레이션 플랫폼과 고유감각 기반 MLLM을 제시함으로써 구현화 AI 분야에 중요한 기여를 한다. 실제 로봇에서의 성능 검증과 더 복잡한 협력 작업 확장이 이루어진다면 더욱 영향력 있는 연구가 될 것이다.
PIMBS: Efficient Body Schema Learning for Musculoskeletal Humanoids with Physics-Informed Neural Networks
Fig. 1.
 *Fig. 1.* Physics-Informed Neural Networks (PINNs) 개념을 적용하여 근골격 휴머노이드 로봇의 신체 스키마를 적은 데이터로 효율적으로 학습하는 PIMBS 방법을 제안한다.
이 논문은 Physics-Informed Neural Networks를 근골격 로봇의 신체 스키마 학습에 창의적으로 적용하여 적은 데이터로도 효율적인 학습을 가능하게 하는 실용적이고 혁신적인 방법을 제시한다. 시뮬레이션과 실제 로봇 실험을 통한 검증으로 제안 방법의 타당성을 충분히 입증했다.
Cost-Matching Model Predictive Control for Efficient Reinforcement Learning in Humanoid Locomotion
Fig. 1: Cost-Matching MPC-RL framework for humanoids.
 *Fig. 1: Cost-Matching MPC-RL framework for humanoids.* 인간형 로봇 보행 제어를 위해 MPC를 RL로 학습할 때 반복적인 MPC 해결의 계산 부담을 제거하는 Cost-Matching MPC 방법을 제안한다. 매개변수화된 MPC의 비용-미래가치(cost-to-go)와 실제 측정된 리턴값의 불일치를 최소화하여 효율적으로 학습한다.
본 논문은 MPC-RL의 계산 병목을 해결하는 창의적인 cost-matching 방법을 제시하며, 복잡한 인간형 로봇 제어 문제에 체계적으로 적용한 우수한 연구다. 다만 실제 로봇 검증의 부재가 임팩트를 제한하므로, 향후 sim-to-real 전이 연구가 필요하다.
HAFO: A Force-Adaptive Control Framework for Humanoid Robots in Intense Interaction Environments
Fig 1: Overview of the HAFO model. (a) Policy Training. A dual-agent strategy with
 *Fig 1: Overview of the HAFO model. (a) Policy Training. A dual-agent strategy with* HAFO는 dual-agent RL 프레임워크를 통해 humanoid robot의 하체 보행과 상체 조작을 동시에 최적화하여 강한 외력 상호작용 환경에서 안정적이고 정밀한 제어를 달성한다.
HAFO는 spring-damper 모델과 dual-agent RL의 결합으로 humanoid robot의 강한 외력 적응 제어에서 새로운 기준을 제시하며, 특히 로프 현수라는 novel 응용에서 안정적 제어를 최초 달성한 의미 있는 연구다.
JAEGER: Dual-Level Humanoid Whole-Body Controller
Figure 1: Some real-world demonstrations of JAEGER deployed on the H1-2. For the root-based
 *Figure 2: The framework of JAEGER. The left shows the retargeting network, which uses an MLP* JAEGER는 인간형 로봇의 상체와 하체를 독립적인 두 개의 컨트롤러로 분리하여 제어하는 dual-level whole-body controller를 제안하며, root velocity tracking(coarse-grained)과 local joint angle tracking(fine-grained) 제어를 모두 지원한다.
JAEGER는 상하체 분리 설계와 MLP 기반 retargeting, 체계화된 curriculum learning을 통해 인간형 로봇의 whole-body control 문제에 대한 실질적이고 창의적인 해결책을 제시하며, 실제 환경에서의 검증을 통해 높은 실용성을 입증한다.
Kinematics-Aware Multi-Policy Reinforcement Learning for Force-Capable Humanoid Loco-Manipulation
Fig. 1. System architecture of the proposed training pipeline. The diagram illustrates the integration of the upper-body
 *Fig. 1. System architecture of the proposed training pipeline. The diagram illustrates the integration of the upper-body* 본 논문은 휴머노이드 로봇의 고부하 산업 작업 수행을 위해 kinematics 사전 정보를 활용한 휴리스틱 보상함수, force-based curriculum learning, delta-command 정책을 통합한 3단계 RL 기반 loco-manipulation 프레임워크를 제안한다.
본 논문은 휴머노이드 로봇의 고부하 loco-manipulation을 위해 kinematics 정보 활용, curriculum learning, modular 정책 조정을 결합한 체계적이고 실용적인 RL 프레임워크를 제시하며, 실제 로봇 실험으로 강력한 성능을 입증했다. 다만 단일 플랫폼 검증과 실제 산업 환경 적응성 평가 보강이 필요하다.
Mechanical Intelligence-Aware Curriculum Reinforcement Learning for Humanoids with Parallel Actuation
Fig. 1: BRUCE [2] hardware with three distinct parallel mechanisms, which
 *Fig. 1: BRUCE [2] hardware with three distinct parallel mechanisms, which* 본 논문은 병렬 구동 메커니즘을 완전히 시뮬레이션하여 학습한 RL 정책을 휴머노이드 로봇 BRUCE에 배포하며, 기존의 직렬 근사 방식과 달리 폐곡선 운동학 제약을 GPU 가속 MJX로 네이티브 구현한다.
본 논문은 병렬 메커니즘의 기계적 특성을 완전히 시뮬레이션하여 RL 학습에 반영하는 혁신적 접근법을 제시하며, 실제 하드웨어 검증을 통해 이 방식의 실질적 성능 이득을 명확히 보여줌으로써 휴머노이드 로봇 제어 분야에 중요한 기여를 한다.
Reinforcement Learning Enabled Adaptive Multi-Task Control for Bipedal Soccer Robots
 *Fig. 3: Multi-Task RL Control Architecture for Tinker.* 이 논문은 이족 로봇 축구에서 기본 보행과 복잡한 작업(공 찾기, 킥, 낙상 회복)의 깊은 결합 문제를 해결하기 위해 CPG 기반 feedforward oscillator와 RL 기반 residual action을 결합한 모듈식 강화학습 제어 프레임워크를 제안한다.
이 논문은 이족 로봇 축구의 핵심 과제들을 체계적으로 해결하는 효과적인 모듈식 제어 프레임워크를 제시하며, CPG-residual 하이브리드 제어와 posture 기반 상태 전환 메커니즘은 높은 독창성을 보여준다. 다만 실제 하드웨어 검증 부재와 타 방법론과의 비교 분석 부족이 영향력을 제한하며, 이들이 보충된다면 이족 로봇 제어 분야에서 실질적 기여를 할 수 있을 것으로 판단된다.
PolySim: Bridging the Sim-to-Real Gap for Humanoid Control via Multi-Simulator Dynamics Randomization
 *Fig. 2: Visual illustration of PolySim. The pink star denotes* PolySim은 여러 이질적인 시뮬레이터를 병렬로 활용하여 훈련하는 플랫폼으로, 단일 시뮬레이터의 귀납적 편향을 완화하고 현실 세계로의 전이 갭을 줄인다.
PolySim은 다중 시뮬레이터 병렬 훈련을 통해 simulator inductive bias를 근본적으로 완화하는 혁신적 접근법이며, 견고한 이론적 근거와 실제 배포 성공으로 humanoid control의 현실 전이 문제 해결에 중요한 기여를 한다.
Retargeting Matters: General Motion Retargeting for Humanoid Motion Tracking
 *Fig. 2: General Motion Retargeting (GMR) Pipeline.* 인간-휴머노이드 로봇 간 embodiment gap을 해결하기 위해 모션 retargeting 품질이 정책 성능에 미치는 영향을 체계적으로 평가하고, retargeting artifacts를 줄이는 새로운 방법 GMR을 제안한다.
본 연구는 humanoid motion tracking에서 그동안 간과되어온 retargeting 품질의 중요성을 체계적으로 입증하고, GMR을 통해 실질적 개선을 달성했다. 광범위한 평가 프레임워크와 명확한 발견은 향후 humanoid 학습 연구에 중요한 지침을 제공한다.
Success in Humanoid Reinforcement Learning under Partial Observation
Figure 1 summarizes the training performance under three partial observability configurations:
 *Figure 1 summarizes the training performance under three partial observability configurations:* 부분 관찰 환경에서 고정 길이 과거 관찰 시퀀스를 병렬로 처리하는 novel history encoder를 제안하여, Gymnasium Humanoid-v4 환경에서 부분 관찰 하에서의 안정적인 humanoid 정책 학습을 처음으로 성공시켰다.
본 연구는 부분 관찰 환경에서의 고차원 humanoid 제어라는 미해결 문제를 처음으로 성공적으로 해결하며, 병렬 history encoder를 통해 기존 RNN 기반 메모리 방법들을 압도적으로 능가한다. 다만 방법론의 구체적 설명이 부족하고 실제 로봇 검증이 필요하다.
Unleashing Humanoid Reaching Potential via Real-world-Ready Skill Space
Fig. 1: (a) The humanoid showcases multiple real-world-ready primitive skills, including locomotion and body-pose-adjust
 *Fig. 1: (a) The humanoid showcases multiple real-world-ready primitive skills, including locomotion and body-pose-adjust* 휴머노이드 로봇의 대규모 도달 공간 확보를 위해 사전 학습된 원시 스킬들을 통합하는 Real-world-Ready Skill Space (R2S2)를 제안하며, CVAE 기반의 통일된 신경 스킬 표현을 통해 효율적이고 sim2real 전이 가능한 전신 제어를 실현한다.
이 논문은 휴머노이드 로봇의 대규모 도달 공간 실현이라는 중요한 문제를 실용적 관점에서 해결하며, 이질적 스킬 통합과 CVAE 기반 신경 스킬 표현이라는 참신한 기술을 통해 보상 엔지니어링 최소화와 강한 sim2real 전이를 동시에 달성한 우수한 연구이다.
X-Loco: Towards Generalist Humanoid Locomotion Control via Synergetic Policy Distillation
Fig. 1: X-Loco achieves vision-based generalist humanoid locomotion control. Relying solely on velocity commands without
 *Fig. 2: Overview of X-Loco. (a) X-Loco integrates the capabilities of three specialist policies into a vision-based gene* X-Loco는 시너지 정책 증류를 통해 세 개의 전문가 정책(upright locomotion, fall recovery, whole-body coordination)을 단일 비전 기반 범용 정책으로 통합하여, 속도 명령만으로 다양한 휴머노이드 보행 스킬을 수행하는 프레임워크이다.
X-Loco는 policy distillation을 통해 다양한 휴머노이드 로콜로모션 스킬을 효과적으로 통합하는 혁신적인 접근법을 제시하며, CASS, SAR, SFI 등의 설계 요소들이 이론적으로 잘 동기부여되고 실제 로봇 배포로 검증되어 휴머노이드 로봇 제어 분야에 중요한 기여를 한다.
A Survey of Behavior Foundation Model: Next-Generation Whole-Body Control System of Humanoid Robots
본 논문은 휴머노이드 로봇의 전신 제어(WBC)를 위한 행동 기초 모델(BFM)의 발전과 응용을 종합적으로 조사하며, 대규모 사전학습을 통해 재사용 가능한 행동 기초를 학습하여 다양한 작업에 빠르게 적응할 수 있는 차세대 제어 시스템을 제시한다.
본 논문은 휴머노이드 로봇 제어의 역사적 진화를 명확히 하고 BFM을 차세대 통합 제어 패러다임으로 체계적으로 정의하여, 로봇 제어 커뮤니티에 명확한 비전과 구조화된 개요를 제공하는 가치 높은 조사 논문이다. 다만 구체적인 기술적 혁신과 실세계 검증 결과는 추가 개발이 필요하다.
Being-0: A Humanoid Robotic Agent with Vision-Language Models and Modular Skills
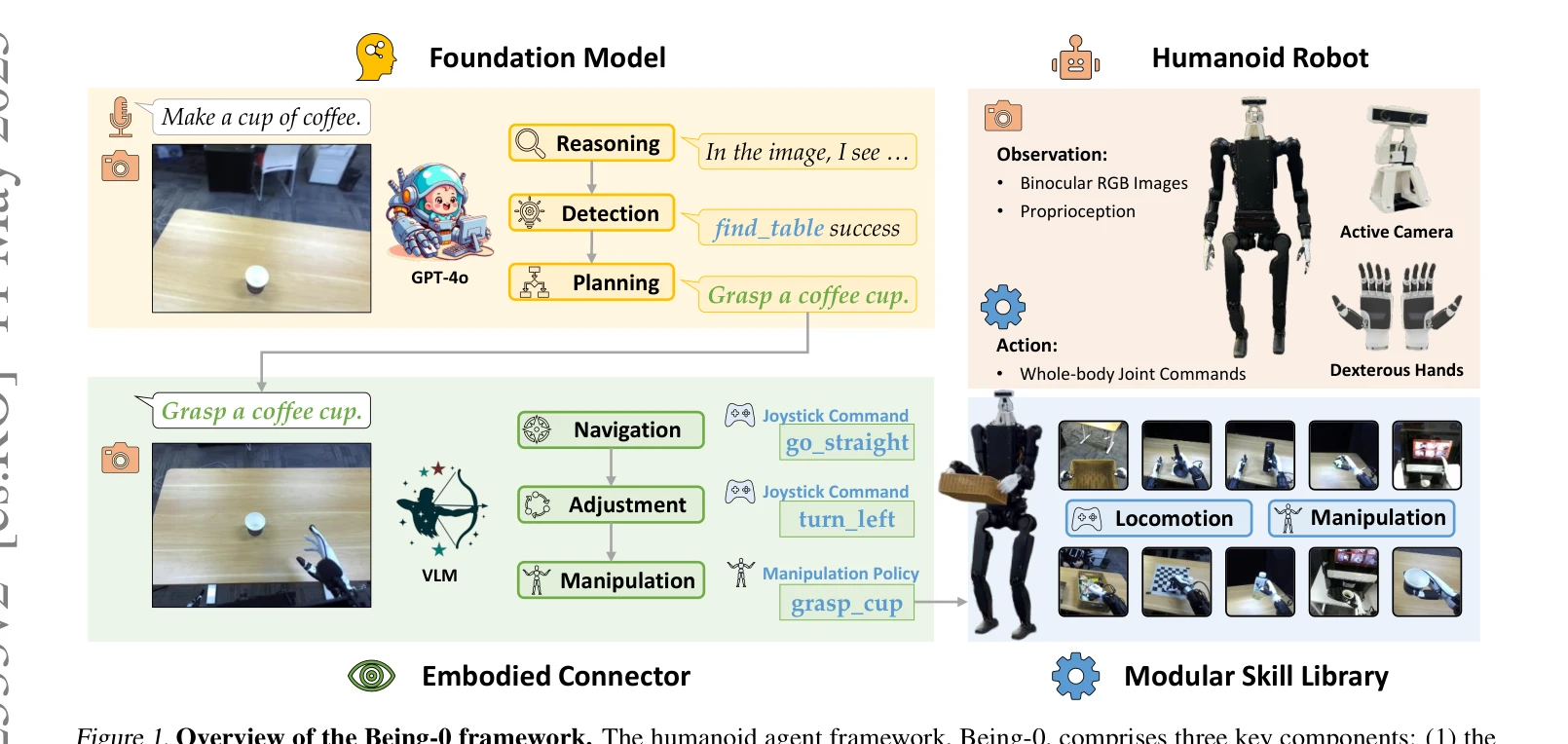
Figure 1. Overview of the Being-0 framework. The humanoid agent framework, Being-0, comprises three key components: (1)
 *Figure 1. Overview of the Being-0 framework. The humanoid agent framework, Being-0, comprises three key components: (1) * Being-0는 Foundation Model, VLM 기반 Connector, 모듈식 스킬 라이브러리를 계층적으로 통합하여 인간형 로봇이 복잡한 장기 과제를 수행할 수 있도록 하는 프레임워크이다. Connector 모듈이 언어 기반 계획을 실행 가능한 스킬 명령으로 변환하고 보행과 조작을 동적으로 조율한다.
Being-0는 인간형 로봇을 위한 실용적이고 효율적인 hierarchical agent 프레임워크로, Connector 모듈을 통한 창의적인 중간층 설계와 실제 하드웨어 구현으로 embodied AI 분야에 의미 있는 기여를 한다. 높은 완수율과 4.2배 효율성 향상은 제안 방식의 효과를 입증하지만, FM의 클라우드 의존성과 실내 중심 평가는 실용성 확대를 위한 개선 과제이다.
Development of an Intuitive GUI for Non-Expert Teleoperation of Humanoid Robots
Figure 1: Visual of kid-size humanoid robot navigating a replica of the FIRA obstacle run event.
 *Figure 1: Visual of kid-size humanoid robot navigating a replica of the FIRA obstacle run event.* FIRA HuroCup 경기에서 비전문가 운영자가 인형형 로봇을 텔레조작할 수 있도록 사용자 친화적인 GUI를 개발했다. HTML, CSS, JavaScript를 사용하여 직관적인 인터페이스를 반복적으로 설계하고 테스트했다.
본 연구는 경합 환경에서 실제로 필요한 비전문가 중심의 텔로봇 GUI를 반복적 개발 방식으로 체계적으로 구축한 의미 있는 실무 기여이다. 다만 외부 사용자 평가 부재로 주장의 일반화 가능성이 제한되며, 향후 형식적인 사용성 평가를 통한 정량적 검증이 필요하다.
Dexterity from Smart Lenses: Multi-Fingered Robot Manipulation with In-the-Wild Human Demonstrations

Fig. 1: AINA is a framework for learning multi-fingered policies from in-the-wild human data collected with smart glasse
 *Fig. 1: AINA is a framework for learning multi-fingered policies from in-the-wild human data collected with smart glasse* Aria Gen 2 스마트 글래스로 수집한 in-the-wild 인간 영상만으로 로봇용 다중 손가락 조작 정책을 학습하는 AINA 프레임워크를 제안한다. 이는 로봇 데이터나 시뮬레이션 없이도 직접 배포 가능한 3D point-based 정책을 생성한다.
이 논문은 스마트 글래스의 고급 센싱 능력을 창의적으로 활용하여 순수 인간 비디오만으로 다중 손가락 로봇 조작 정책을 학습하는 실질적이고 확장 가능한 해법을 제시한다. 강력한 실증 결과와 명확한 방법론으로 인간-로봇 모방 학습 분야에 상당한 진전을 이루었으며, 로봇 조작의 대규모 실용화를 향한 중요한 한 걸음을 제공한다.
Discovering Self-Protective Falling Policy for Humanoid Robot via Deep Reinforcement Learning

Fig. 1.
 *Fig. 1.* Deep Reinforcement Learning과 Curriculum Learning을 이용하여 인간형 로봇이 낙상 상황에서 자체적으로 보호 행동을 발견하도록 학습시키며, 팔을 삼각형 구조로 형성하여 낙상 손상을 최소화하는 방법을 제시한다.
이 논문은 DRL과 Curriculum Learning을 통해 인간형 로봇이 자신의 물리적 특성에 맞는 낙상 보호 정책을 자율적으로 발견하도록 하는 혁신적 접근을 제시하며, 실제 로봇 플랫폼으로의 성공적 전이와 포괄적 벤치마크 구성으로 인간형 로봇의 안전성 향상에 중요한 기여를 한다.
Embracing Evolution: A Call for Body-Control Co-Design in Embodied Humanoid Robot
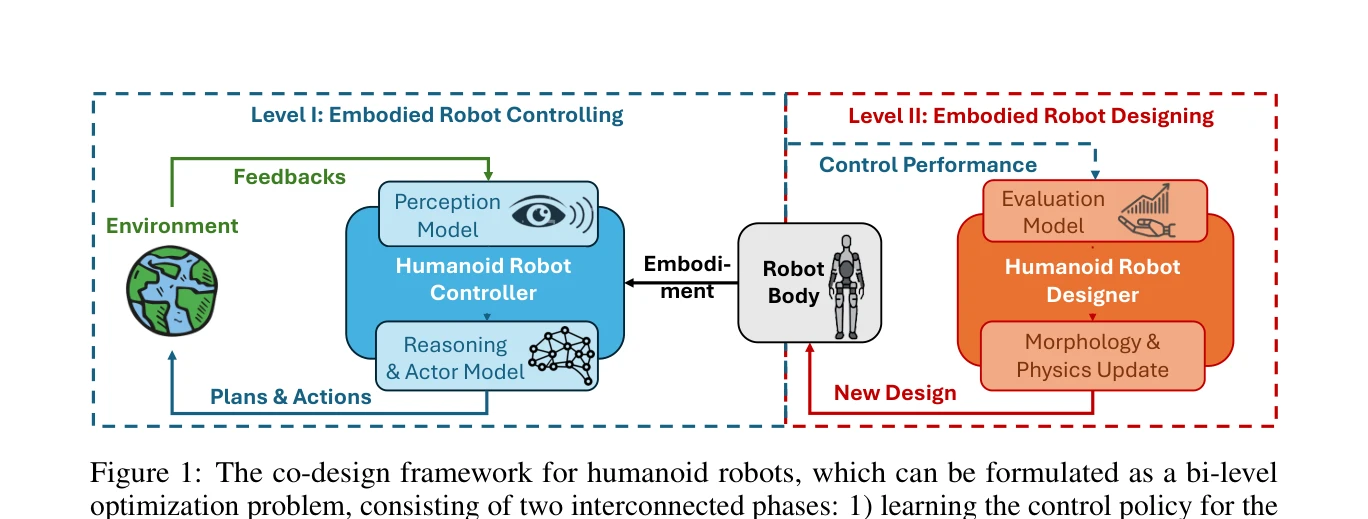
Figure 1: The co-design framework for humanoid robots, which can be formulated as a bi-level
 *Figure 1: The co-design framework for humanoid robots, which can be formulated as a bi-level* 인간형 로봇의 제어 정책과 물리적 구조를 동시에 진화시키는 co-design 메커니즘을 제안하며, 이를 bi-level 최적화 문제로 공식화하여 embodied intelligence 달성의 필수 요소임을 주장하는 위치 논문이다.
본 논문은 인간형 로봇의 embodied intelligence 달성을 위해 co-design의 필수성을 체계적으로 주장하고 실행 가능한 방법론을 제시하는 영향력 있는 위치 논문이다. 다만 구체적인 실험 검증과 정량적 성능 평가를 통한 후속 연구로 보강될 필요가 있다.
Hierarchical Planning and Control for Box Loco-Manipulation
Fig. 1. We develop loco-manipulation skills for box-carrying physics-based characters. This is achieved via a
 *Fig. 2. System overview. We design four motion primitives for locomotion and manipulation which can be* 물리 기반 시뮬레이션 인간 캐릭터가 box rearrangement 작업을 수행하기 위해 계획, diffusion model, 강화학습을 계층적으로 조합하는 시스템을 제시한다.
본 논문은 물리 기반 캐릭터 애니메이션에서 loco-manipulation의 도전적인 문제를 diffusion model과 RL을 계층적으로 조합하여 우아하게 해결하며, 높은 기술적 완성도와 실용적 가치를 동시에 갖춘 우수한 연구이다.
HiFAR: Multi-Stage Curriculum Learning for High-Dynamics Humanoid Fall Recovery
Fig. 1.
 *Fig. 1.* HiFAR는 다단계 커리큘럼 학습 프레임워크를 통해 휴머노이드 로봇의 자율적 낙상 회복을 학습하는 방법을 제시하며, 저차원 태스크에서 시작하여 고차원 배포 시나리오로 점진적으로 확장한다.
HiFAR은 다단계 커리큘럼 학습과 KSI, reward shaping을 효과적으로 결합하여 복잡한 고차원 낙상 회복 문제를 체계적으로 해결하며, 실제 로봇 검증을 통해 높은 실용성과 견고성을 입증한 우수한 연구이다.
Unified Humanoid Fall-Safety Policy from a Few Demonstrations
Fig. 1.
 *Fig. 1.* 휴머노이드 로봇이 균형을 잃었을 때 안전하게 넘어지고 빠르게 일어날 수 있도록, 스파스한 인간 시연과 reinforcement learning, diffusion 기반 메모리를 결합하여 낙상 예방·충격 완화·회복을 통합하는 단일 정책을 학습한다.
본 논문은 휴머노이드 낙상 완화와 회복을 명시적으로 통합하는 첫 성공적인 통합 정책을 제시하며, 스파스 인간 시연과 RL, diffusion model을 창의적으로 결합하여 안전한 다중 모달 행동을 학습한다. Unitree G1에서의 견고한 sim-to-real 전이와 일관된 성능은 실제 환경에서의 로봇 안전성을 크게 향상시킬 가능성을 보여준다.
Simulator Adaptation for Sim-to-Real Learning of Legged Locomotion via Proprioceptive Distribution Matching
 *Fig. 3: A Unitree Go2 quadruped used in sim-to-real experiments.* 본 논문은 Sim-to-Real 학습에서 시뮬레이터를 적응시키기 위해 proprioceptive distribution matching을 제안하며, 모션 캡처나 시간 정렬 없이 hardware와 simulation의 dynamics 불일치를 해결한다.
본 논문은 실무적 제약을 해결하는 실용적이고 우아한 솔루션을 제시하며, proprioceptive distribution matching은 기존의 복잡한 state-matching 방식을 효과적으로 대체할 수 있는 가치 있는 기여다. 다만 평가가 단일 로봇 플랫폼과 제한된 hardware data에서만 수행되어 일반화 가능성을 더 광범위하게 검증할 필요가 있다.
RPG: Robust Policy Gating for Smooth Multi-Skill Transitions in Humanoid Fighting
Fig. 1.
 *Fig. 1.* 본 논문은 RPG(Robust Policy Gating)라는 하이브리드 전문가 정책 프레임워크를 제안하여 인형형 로봇이 다양한 격투 기술 간 매끄럽고 안정적인 전환을 통해 장시간 동적 격투를 수행할 수 있도록 함.
본 논문은 RPG 프레임워크를 통해 인형형 로봇의 다중 격투 기술 매끄러운 전환 문제를 효과적으로 해결하였으며, policy-transition randomization과 temporal randomization의 결합은 기술 전환 강건성 확보에 창의적 기여를 함. 실세계 로봇 검증과 게임 인터페이스 설계로 실용성이 높으나, 기술 범주 확장 및 다양한 로봇 플랫폼 검증이 필요함.
PPF: Pre-training and Preservative Fine-tuning of Humanoid Locomotion via Model-Assumption-based Regularization
Fig. 1.
 *Fig. 1.* 본 연구는 모델 기반 제어기의 모방학습(Pre-training)과 강화학습을 결합하되, 모델 가정이 성립하는 상태에서만 정규화하는 MAR(Model-Assumption-based Regularization)을 통해 인간형 로봇의 보행 정책을 학습하는 PPF 프레임워크를 제안한다.
본 논문은 모델 기반과 학습 기반 제어의 장점을 결합하면서 재앙적 망각을 완화하는 MAR이라는 창신적 정규화 기법을 제안하며, 실제 인간형 로봇에서 1.5 m/s의 고속 보행과 다양한 지형 강건성을 달성하여 실용적 가치가 높다.
FLAM: Foundation Model-Based Body Stabilization for Humanoid Locomotion and Manipulation
Fig. 1.
 *Fig. 1.* FLAM은 인간 동작 재구성 모델 기반의 안정화 보상 함수를 설계하여 휴머노이드 로봇의 전신 제어에서 신체 안정성을 명시적으로 고려하는 강화학습 방법이다. 로봇 자세를 3D 가상 인간 모델에 매핑한 후 안정화된 자세를 재구성하여 보상을 계산함으로써 학습 과정을 가속화한다.
FLAM은 인간 동작 foundation model을 창의적으로 활용하여 휴머노이드 로봇의 안정성 문제를 해결한 효과적인 방법이다. 강화학습의 샘플 효율성 문제를 개선하고 다양한 작업에서 우수한 성능을 보여주며, 향후 로봇 제어의 중요한 기초를 제공할 수 있다.
Learning Aerodynamics for the Control of Flying Humanoid Robots
Fig. 1: Design of the iRonCub-Mk1 physical prototype. Front (a) and rear (b) pictures of the
 *Fig. 1: Design of the iRonCub-Mk1 physical prototype. Front (a) and rear (b) pictures of the* 비행 인간형 로봇의 공기역학 모델링을 위해 CFD 시뮬레이션, 풍동 실험, 딥러닝을 결합한 포괄적 접근 방식을 제시하고, 제트 엔진을 장착한 iRonCub-Mk1 로봇을 설계·제작하여 비행 제어를 구현한다.
인간형 로봇의 비행 능력 확보를 위해 공기역학 모델링과 제어를 종합적으로 다룬 기술적·과학적으로 의미 있는 연구이며, 다중 모드 로봇의 미래 설계에 중요한 기여를 제시한다. 다만 실제 비행 실험 검증과 학습 모델의 일반화 성능 평가가 후속 과제이다.
Learning Getting-Up Policies for Real-World Humanoid Robots
Fig. 1: HUMANUP provides a simple and general two-stage training method for humanoid getting-up tasks, which can be
 *Fig. 2: HUMANUP system overview. Our getting-up policy (Sec. III-A) is trained in simulation using two-stage RL training* 휴머노이드 로봇의 낙상 복구를 위해 두 단계 강화학습 프레임워크(HUMANUP)를 제시하여 다양한 자세와 지형에서 일어나는 동작을 학습하고 실제 G1 로봇에 배포했다.
휴머노이드 로봇 낙상 복구는 중요하면서도 미탐색된 문제이며, 이 논문은 작업 특성을 정확히 파악하고 실용적 커리큘럼 학습을 통해 인간 규모 로봇에서 처음 성공적인 실제 배포를 시연했다. 기술적 기여도 있지만 평가 범위의 한계와 설계 선택의 일반화 가능성에 대한 추가 검증이 필요하다.
Towards Adaptive Humanoid Control via Multi-Behavior Distillation and Reinforced Fine-Tuning
Figure 1: Comparison between multi-task RL and our pro-
 *Figure 2: Overview of the proposed two-stage framework Adaptive Humanoid Control. In the first stage, we train two separ* 휴머노이드 로봇이 다양한 이족보행 행동(서기, 걷기, 뛰기, 점프)을 학습할 수 있도록 다중행동 증류(multi-behavior distillation)와 강화학습 미세조정을 통해 적응형 제어기를 개발한다.
다중행동 증류와 강화학습 미세조정을 결합한 2단계 프레임워크는 휴머노이드 로봇의 적응형 제어라는 중요한 문제에 대한 실용적이고 효과적인 해결책을 제시하며, 시뮬레이션과 실로봇 실험을 통해 그 타당성을 입증했다.
Predictive Sampling: Real-time Behaviour Synthesis with MuJoCo
 *Figure 3 | Graphical User Interface. The left tab includes modules for Tasks and the Agent. In the* MuJoCo 물리 엔진 기반의 실시간 예측 제어 프레임워크 MJPC를 소개하고, 간단한 샘플링 기반 알고리즘인 Predictive Sampling이 기존의 더 복잡한 알고리즘들과 경쟁력 있음을 보여준다.
본 논문은 새로운 알고리즘적 기여보다는 실용적이고 접근 가능한 도구의 개발과 제공에 중점을 두며, 예측 제어의 대중화와 연구 생산성 향상이라는 중요한 목표를 달성한다. Predictive Sampling의 실험적 경쟁력은 흥미로우나 이론적 분석이 보완되면 더욱 강력한 기여가 될 것이다.
Quantum deep reinforcement learning for humanoid robot navigation task
 *Fig. 4. Return of Classical SAC versus Quantum SAC in the Walker2d-v4* 이 논문은 Soft Actor-Critic(SAC) 알고리즘을 parameterized quantum circuit으로 구현한 quantum deep reinforcement learning(QDRL)을 humanoid robot navigation 작업에 적용하여, 고차원 상태-행동 공간에서 고전적 RL보다 92% 더 적은 스텝으로 8% 높은 성능을 달성했다.
이 논문은 humanoid robot navigation이라는 도전적 고차원 문제에 QDRL을 처음 적용한 의미 있는 연구로, 양자 컴퓨팅의 실용적 잠재력을 보여주지만, 시뮬레이션 환경 제한과 실제 양자 하드웨어 부재로 인해 근본적인 양자 이점의 증명은 아직 불완전하다.
StageACT: Stage-Conditioned Imitation for Robust Humanoid Door Opening

Fig. 1: Autonomous door opening by the G1 humanoid robot in a real-world office. Time-synchronized front (top) and back
 *Fig. 3: The StageACT framework combines stage-level guidance with low-* StageACT는 휴머노이드 로봇의 도어 오픈 작업을 위해 저수준 정책에 작업 단계(task stage) 정보를 조건으로 추가한 단계-조건부 모방 학습 프레임워크를 제안하며, 부분 관찰성 환경에서 강건성을 크게 향상시킨다.
이 논문은 휴머노이드 도어 오픈이라는 도전적인 실제 문제에서 단순하지만 효과적인 단계 조건화 방식으로 현저한 성능 향상을 달성했으며, 장 지평선 부분 관찰 작업에 대한 실질적 시사점을 제공한다. 다만 일반화와 신뢰성 관점에서 추가 검증이 필요하고, 수동 라벨링 프로세스의 자동화가 필요하다.
Teleoperation of Humanoid Robots: A Survey
 *Fig. 2: Schematic architecture for teleoperating a humanoid.* 이 논문은 인간형 로봇의 원격 조종(teleoperation) 분야에 대한 포괄적인 서베이로, 시스템 아키텍처, 기술 및 방법론적 진전, 실제 응용 분야를 종합적으로 분석한다.
이 서베이는 humanoid robot teleoperation의 포괄적이고 최신의 개요를 제공하며, 복잡한 시스템을 명확한 아키텍처로 정리하고 다양한 기술적 도전과 솔루션을 체계적으로 분석한다. 해당 분야의 연구자와 실무자들에게 매우 유용한 참고 자료이지만, 구체적인 기술 혁신보다는 기존 연구의 종합과 정리에 초점을 두고 있다.
Distillation-PPO: A Novel Two-Stage Reinforcement Learning Framework for Humanoid Robot Perceptive Locomotion
Fig. 1: We demonstrate the walking capabilities of the humanoid robot Tien Kung on
 *Fig. 2: The training framework of Distillation-PPO adopts a symmetric structure for both the teacher and student network* 인문형 로봇의 지각 기반 보행을 위해 교사 정책과 강화학습을 결합한 2단계 프레임워크 Distillation-PPO (D-PPO)를 제안하며, 시뮬레이션에서의 안정성과 실제 로봇의 강건성을 동시에 확보한다.
본 논문은 강화학습과 지식 증류의 강점을 결합한 균형잡힌 접근법으로, 시뮬레이션과 실제 로봇 양쪽에서 검증된 실질적 성과를 보여준다. 다만 이론적 분석이 부족하고 단일 로봇 플랫폼의 실험만 제시된 점이 아쉽지만, 인문형 로봇 보행 제어의 실질적 문제 해결에 기여하는 의미 있는 연구다.
Learning to Look: Seeking Information for Decision Making via Policy Factorization

Figure 1: DISaM for tasks with information-seeking behavior. To make the right decision in a
 *Figure 1: DISaM for tasks with information-seeking behavior. To make the right decision in a* 로봇이 조작 작업을 수행하기 위해 필요한 정보를 능동적으로 탐색하는 문제를 factorized Contextual MDP로 정의하고, 정보 탐색 정책과 정보 활용 정책으로 분리된 dual-policy 솔루션 DISaM을 제안한다.
정보 탐색과 조작의 분리를 통해 장지평 POMDP를 효율적으로 해결하는 우아한 솔루션을 제시하며, 광범위한 실험 검증으로 실용성을 입증한 강력한 논문이다. 다만 다단계 탐색 최적화와 완전 자동학습 가능성 탐색이 향후 과제이다.
Multi-task Deep Reinforcement Learning with PopArt
 *Figure 2: Atari-57 (unclipped): Median human normalised* Multi-task Deep Reinforcement Learning에서 task 간의 reward scale과 sparsity 차이로 인한 불균형 문제를 PopArt 정규화를 통해 해결하여, 57개 Atari 게임을 단일 정책으로 인간 수준 이상의 성능으로 학습.
PopArt를 multi-task RL에 적용한 실용적이고 효과적인 솔루션으로, 단일 정책이 다양한 task에서 인간 수준 성능을 달성한 것은 RL 분야의 중요한 이정표다. 명확한 문제 정의, 우아한 솔루션, 그리고 강력한 실험 결과로 높은 가치의 논문이다.
NoMaD: Goal Masked Diffusion Policies for Navigation and Exploration
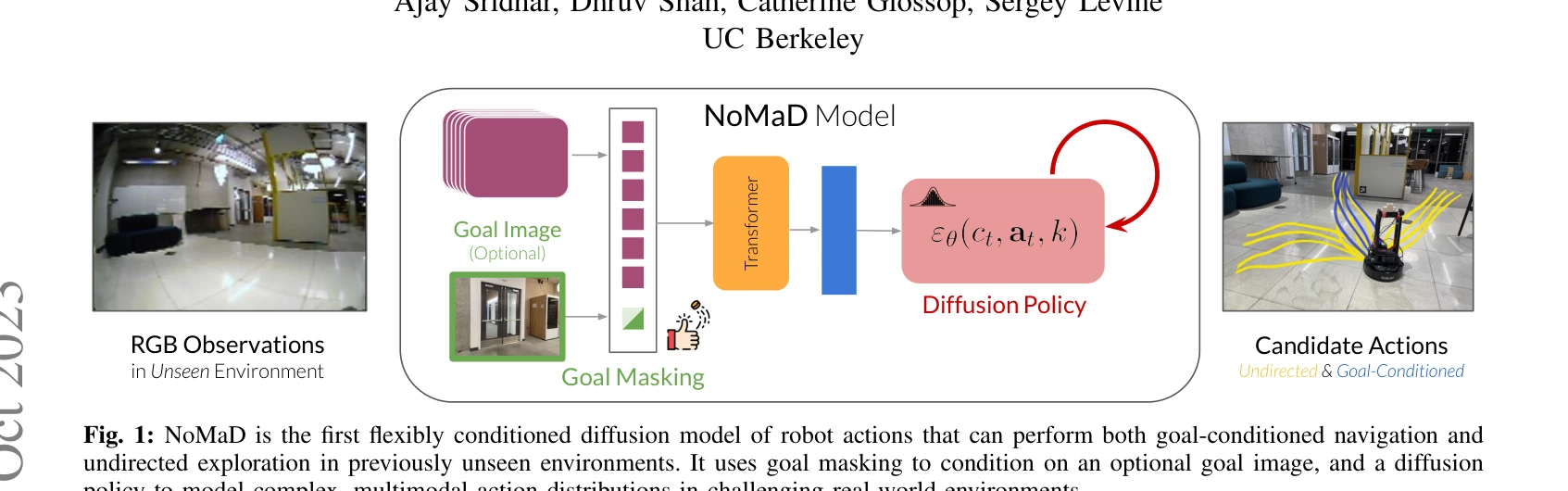
Fig. 1: NoMaD is the first flexibly conditioned diffusion model of robot actions that can perform both goal-conditioned
 *Fig. 1: NoMaD is the first flexibly conditioned diffusion model of robot actions that can perform both goal-conditioned * NoMaD는 goal masking을 활용한 unified diffusion policy로 로봇의 목표 지향 네비게이션과 목표 무관 탐색을 단일 모델로 처리하며, Transformer 기반 정책과 diffusion model decoder를 결합하여 미지의 환경에서 효과적인 네비게이션을 구현한다.
NoMaD는 goal masking과 diffusion policy를 결합하여 exploration과 goal-seeking을 통합한 혁신적 아키텍처를 제시하며, ViNT 대비 25% 이상의 성능 향상과 15배 효율성 개선을 실제 로봇에서 달성하여 로봇 네비게이션 분야에 상당한 기여를 한다.
Sentinel-VLA: A Metacognitive VLA Model with Active Status Monitoring for Dynamic Reasoning and Error Recovery
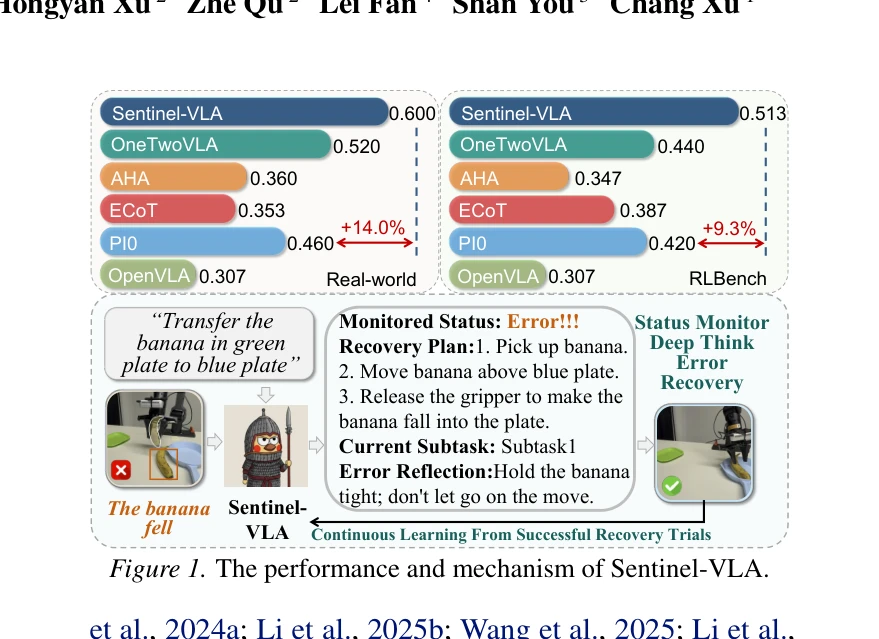
Figure 1. The performance and mechanism of Sentinel-VLA.
 *Figure 1. The performance and mechanism of Sentinel-VLA.* 본 논문은 embodied manipulation을 위한 metacognitive VLA 모델인 Sentinel-VLA를 제안한다. 실시간 실행 상태를 모니터링하는 sentinel 모듈을 통해 필요할 때만 동적 추론과 에러 복구를 수행하는 온디맨드 추론 메커니즘을 특징으로 한다.
Sentinel-VLA는 metacognitive 접근을 통해 VLA 모델의 추론, 상태 모니터링, 에러 복구라는 세 가지 핵심 문제를 통합적으로 해결하는 창의적인 방안을 제시한다. 특히 온디맨드 추론 메커니즘과 자동화된 대규모 데이터 생성 파이프라인의 조합, 그리고 orthogonal constraint을 이용한 지속적 학습 방식은 기술적으로 견고하며 실세계 성능 향상(30%)으로 실증되었다. 다만 에러 감지의 한계 분석과 트리거 기준의 명확한 정의가 보강되면 더욱 완성도 높을 것이다.
Stability of Control Lyapunov Function Guided Reinforcement Learning
Fig. 1.
 *Fig. 1.* 본 논문은 Control Lyapunov Function (CLF)을 기반으로 한 강화학습(CLF-RL)으로 학습된 제어 정책의 이론적 안정성을 분석한다. 연속·이산 시간 모두에서 최적 제어 문제로 재정의하여 지수 안정성을 증명하고, 이를 수치 검증 및 휴머노이드 로봇의 주기 보행 실험으로 검증한다.
본 논문은 CLF-RL의 실제 성공을 이론으로 뒷받침하는 중요한 기여로, 지수 안정성 증명이 명확하고 연속·이산 시간 모두에서 포괄적으로 다루어졌다. 다만 지역 안정성 한정, CLF 구성 방법의 실용성 부재, 제한된 실험 검증이 한계이나, 제어 이론과 RL의 격차를 줄이는 가치 있는 첫 걸음이다.
World Models for Robotic Manipulation: A Survey
 *Fig. 2. Representation spectrum of world models. The five families are ordered by increasing structured inductive bias, * 로봇 조작을 위한 world model에 대한 포괄적 서베이다. 세 가지 질문(어떤 미래 표현을 예측하는가, 예측을 행동에 어떻게 연결하는가, 학습 파이프라인의 어느 단계에서 사용되는가)을 중심으로 action-conditioned predictive system으로서의 world model을 정의하고, 다섯 가지 표현 계열과 기능적 분류를 제시한다.
이 서베이는 로봇 조작 분야에서 fragmented된 world model 문헌을 통합하는 중요한 기여다. 세 가지 직교 축의 framework와 명확한 operational definition은 향후 연구의 설계 선택을 가이드할 수 있으며, 34개 dataset 검토와 종합 평가 프로토콜은 실질적 가치를 제공한다. 다만 closed-loop 평가 부족과 contact modeling 등 조작 고유의 도전이 여전히 미해결되어 있고, 개념적 경계의 모호성도 완전히 제거되지 않았다. 전체적으로 조작 중심의 predictive modeling을 이해하는 데 필수적인 참고문헌이지만, 구체적인 기술 혁신보다는 종합 정리의 성격이 강하다.
Teleoperation of Humanoid Robots: A Survey
 *Fig. 2: Schematic architecture for teleoperating a humanoid.* 본 논문은 humanoid robot teleoperation에 대한 포괄적인 survey로, 원격 환경에서 인간의 인지 능력과 humanoid robot의 물리적 능력을 통합하는 teleoperation 시스템의 아키텍처, 기술적 조화, 그리고 응용 분야를 체계적으로 분석한다. Teleoperation system의 전체 파이프라인과 각 구성 요소를 상세히 제시하며, 통신 지연, 제어, retargeting, 인간-로봇 상호작용 등 다층적 도전 과제들을 다룬다.
본 논문은 humanoid robot teleoperation 분야의 첫 번째 포괄적 survey로, 시스템 아키텍처, 기술적 도전 과제, 그리고 실제 응용을 통합적으로 다룬다. 웹 기반 자료까지 제공하여 학계의 접근성을 높였으나, 이론적 깊이와 정량적 성능 비교 분석이 추가되면 더욱 강화될 수 있다. 고위험 원격 작업의 안전성과 효율성이 중요해지는 시대에 매우 시의적절하고 가치 있는 기여이다.
Symphony: A Heuristic Normalized Calibrated Advantage Actor and Critic Algorithm in application for Humanoid Robots
Fig. 1: a) x
 *Fig. 4: Swaddling Regularization with β as temperature.* Symphony는 휴머노이드 로봇을 안전하게 훈련하기 위해 Swaddling 정규화, Fading Replay Buffer, Temporal Advantage를 결합한 결정론적 Actor-Critic 알고리즘이다. 제한된 parametric noise와 action strength 조절을 통해 sample efficiency, safety, smooth motion을 동시에 달성한다.
Symphony는 실제 휴머노이드 로봇 훈련의 실질적 문제들(safety, efficiency, smoothness)을 종합적으로 해결하는 창의적인 heuristic 알고리즘이다. 그러나 이론적 기초와 실증적 검증이 부족하여 학술적 엄밀성과 재현성 면에서 개선이 필요하다.
PyRoki: A Modular Toolkit for Robot Kinematic Optimization
Fig. 1: PyRoki is a modular, extensible, and cross-platform toolkit for kinematic optimization. We unify problems
 *Fig. 1: PyRoki is a modular, extensible, and cross-platform toolkit for kinematic optimization. We unify problems* PyRoki는 역기구학, 궤적 최적화, 모션 리타게팅 등 다양한 로봇 운동학 최적화 문제를 통합적으로 해결하는 모듈식, 확장 가능하며 CPU/GPU/TPU에서 실행되는 크로스 플랫폼 툴킷이다.
PyRoki는 로봇 운동학 최적화를 위한 통합된 모듈식 프레임워크로서 파편화된 기존 도구들의 문제를 효과적으로 해결하고, CPU/GPU/TPU 크로스 플랫폼 지원과 cuRobo 대비 1.4-1.7배 성능 향상을 달성하였다. 인터랙티브 시각화와 사용 편의성을 갖춘 실용적인 오픈소스 도구로서 높은 연구 및 산업 가치가 있다.
Robust and Versatile Bipedal Jumping Control through Reinforcement Learning
Fig. 1: Representative dynamic jumping maneuvers performed by a bipedal robot Cassie using the proposed goal-conditioned
 *Fig. 1: Representative dynamic jumping maneuvers performed by a bipedal robot Cassie using the proposed goal-conditioned* Reinforcement learning과 새로운 정책 구조를 활용하여 이족 로봇 Cassie가 다양한 착지 위치와 방향으로 점프하는 강건하고 다목적인 동적 점프 제어를 실현했다.
이족 로봇의 동적 점프 제어에서 RL과 새로운 정책 구조를 결합하여 기존 방법을 크게 뛰어넘는 실제 세계 성과를 달성한 우수한 연구이며, 다목적 강건한 로봇 제어의 새로운 가능성을 보여준다.
SteadyTray: Learning Object Balancing Tasks in Humanoid Tray Transport via Residual Reinforcement Learning
 *Fig. 2: Overview of the ReST-RL framework. Base Policy Training: A locomotion policy is first trained to carry a tray wh* ReST-RL은 사전학습된 이족 보행 정책에 잔차 모듈을 추가하여 휴머노이드 로봇이 동적 보행 중 트레이 위의 불안정한 물체를 안정적으로 운반할 수 있도록 하는 계층적 강화학습 아키텍처이다.
ReST-RL은 보행 안정성을 보존하면서 payload 안정화를 분리 학습하는 우아한 설계로, 휴머노이드 로봇의 실제 서비스 응용(식음료 배송, 의료 기구 운반)에 필수적인 신뢰성 높은 물체 운반을 처음 성공적으로 시연했다.
Whole-Body Dynamic Throwing with Legged Manipulators
Fig. 1: Our robot throwing policies demonstrated on real hardware (top) and in simulation (bottom) showing complex full-
 *Fig. 1: Our robot throwing policies demonstrated on real hardware (top) and in simulation (bottom) showing complex full-* 다리가 있는 로봇의 전신 동역학을 활용하여 강화학습 기반의 3D 목표지점으로의 정확한 투척을 학습하는 방법을 제시하고, 시뮬레이션에서 학습한 정책을 실제 휴머노이드 로봇으로 전이시켰다.
본 논문은 전신 동역학을 활용한 3D 임의 목표 투척이라는 명확한 혁신과 적응형 커리큘럼이라는 기술적 기여로 로봇 조작 연구의 새로운 방향을 제시했으나, 실제 로봇 전이의 완전성 부족과 일반화 범위 제약이 실용적 임팩트를 다소 제한한다.
A Hierarchical, Model-Based System for High-Performance Humanoid Soccer
Fig. 1: Overview of the ARTEMIS humanoid soccer system. A). Two ARTEMIS humanoid robots competing for ball possession du
 *Fig. 2: System architecture of the ARTEMIS humanoid platform. The perception layer provides object detections, proximity* RoboCup 2024 우승팀의 완전히 통합된 성인용 휴머노이드 축구 로봇 시스템으로, QDD 액추에이터 기반 하드웨어와 계층적 perception-planning-control 아키텍처를 결합하여 동적이고 전술적으로 효과적인 게임플레이를 실현했다.
QDD 액추에이터 기반 하드웨어와 perception-planning-control의 tight integration을 통해 RoboCup 우승을 달성한 고성숙도의 시스템으로, 동적 휴머노이드 제어와 실시간 자율 네비게이션의 실제 구현 사례로서 상당한 실질적 가치를 제공한다.
DecARt Leg: Design and Evaluation of a Novel Humanoid Robot Leg with Decoupled Actuation for Agile Locomotion
Fig. 1. The concept of DecARt Leg design: decoupled actuation, all motors
 *Fig. 1. The concept of DecARt Leg design: decoupled actuation, all motors* 본 논문은 decoupled actuation을 활용하면서도 인간형 다리의 외형을 유지하는 DecARt Leg을 제안하며, FAST(Fastest Achievable Swing Time) 메트릭을 통해 agile locomotion 능력을 평가한다.
본 논문은 humanoid robotics의 오랜 설계 갈등(efficiency vs. human-like appearance)을 새로운 kinematic approach로 해결하려는 의미 있는 시도이며, FAST 메트릭 제안과 함께 충분한 설계 혁신성을 보여준다. 다만 preliminary hardware 수준의 검증에 그쳐 실제 성능 우위를 완전히 입증하지는 못한 한계가 있다.
Humanoid Goalkeeper: Learning from Position Conditioned Task-Motion Constraints
Fig. 1: We present Humanoid Goalkeeper, capable of performing goalkeeping tasks across various regions with a wide opera
 *Fig. 2: Method framework: We train our policy using an end-to-end* 인간형 로봇의 골키퍼 역할을 위해 위치 조건부 task-motion constraints를 학습하는 end-to-end RL 프레임워크를 제시하며, 인간 모션 프라이어를 adversarial scheme으로 통합하여 자동화되고 인간다운 전신 동작을 생성한다.
본 논문은 position-conditioned adversarial motion priors를 통해 humanoid 로봇의 자동화되고 인간다운 골키퍼 능력을 처음으로 시연한 의미 있는 연구이며, 실제 하드웨어 배포와 task 일반화를 통해 실용성을 입증했으나, 정량적 분석과 ablation study가 강화될 필요가 있다.
InEKFormer: A Hybrid State Estimator for Humanoid Robots
Fig. 1.
 *Fig. 1.* InEKFormer는 Invariant Extended Kalman Filter(InEKF)와 Transformer 네트워크를 결합한 하이브리드 상태 추정 방법으로, 인간형 로봇의 floating base 상태를 정확하게 추정한다.
본 논문은 InEKF와 Transformer를 내부적으로 결합한 novel hybrid 방법을 제시하고 인간형 로봇에 처음 적용함으로써 상태 추정 분야에 기여하나, autoregressive 학습의 안정성 문제와 일반화에 대한 보다 심층적인 분석이 필요하다.
X2-N: A Transformable Wheel-legged Humanoid Robot with Dual-mode Locomotion and Manipulation
Fig. 1: Illustration of X2-N in dual locomotion modes with
 *Fig. 1: Illustration of X2-N in dual locomotion modes with* X2-N은 휠-레그 하이브리드 모드와 휴머노이드 풋 모드를 유연하게 변환하며 운영할 수 있는 고자유도 로봇으로, RL 기반 통합 제어 프레임워크로 효율적 이동과 정교한 조작을 동시에 수행한다.
X2-N은 휠-레그와 휴머노이드 로봇의 장점을 창의적으로 통합한 혁신적 플랫폼으로, Joint reuse 기반의 우아한 메커니즘 설계와 RL·모델 기반 제어의 효과적 결합을 통해 실용성 높은 솔루션을 제시한다.
A Hierarchical Framework for Humanoid Locomotion with Supernumerary Limbs
 *Figure 3.1: Training performance of the PPO agent over 500 million environment steps. (a)* 본 논문은 초과 사지(Supernumerary Limbs, SLs)로 증강된 인형로봇(humanoid robot)의 안정적인 보행을 위해 계층적 제어 프레임워크를 제안한다. 학습 기반의 저수준 보행 정책과 모델 기반의 고수준 동적 균형 제어기를 결합한 분리된 접근방식을 통해 SLs로부터의 동적 교란을 효과적으로 완화한다.
본 논문은 계층적 제어 프레임워크를 통해 초과 사지 장착 인형로봇의 안정적 보행 문제를 창의적으로 해결한다. DRL 기반 보행 정책과 model-based 균형 제어의 결합은 기술적으로 타당하며 47% DTW 개선이라는 정량적 성과를 달성한다. 다만 시뮬레이션 한정 평가와 실제 하드웨어 검증 부재가 실용적 기여도를 제한한다.
Reduced-Order Model-Guided Reinforcement Learning for Demonstration-Free Humanoid Locomotion
Figure 1: Overview of the ROM-GRL framework. In Stage 1, a 4-DOF ROM policy is trained in Box2D: the policy
 *Figure 1: Overview of the ROM-GRL framework. In Stage 1, a 4-DOF ROM policy is trained in Box2D: the policy* ROM-GRL은 모션캡처 데이터 없이 4-DOF reduced-order model로 생성한 gait template을 이용해 full-body humanoid 정책을 학습하는 2단계 강화학습 프레임워크이다. Adversarial discriminator를 통해 ROM의 5-dimensional gait feature 분포를 따르도록 유도하여 자연스러운 보행을 실현한다.
ROM-GRL은 reduced-order model을 creative하게 활용해 motion capture 의존성을 제거하면서 자연스럽고 안정적인 humanoid 보행을 달성하는 novel 프레임워크이다. 보상 설계와 모방 학습 간 간격을 효과적으로 줄였으나, 제한된 속도 범위와 실제 로봇 검증 부재가 일반화 가능성의 의문을 남긴다.
Biomechanical Comparisons Reveal Divergence of Human and Humanoid Gaits
Fig. 1: Joint mapping between humanoid robot and human.
 *Fig. 2: Comparison of lower-limb joint angles, moments, and* 본 논문은 Gait Divergence Analysis Framework (GDAF)를 제안하여 인간과 휴머노이드 로봇의 보행 간 생체역학적 차이를 정량적으로 분석하고, 28개 속도에서 수집한 공개 데이터셋과 분석 도구를 제공한다.
본 논문은 휴머노이드 보행 평가를 위한 첫 번째 체계적 생체역학 분석 프레임워크와 완전 공개 데이터셋을 제시하여 로봇 보행 개선의 정량적 기준과 도구를 확보하게 하는 점에서 의의가 크며, 방법론적 투명성과 재현가능성이 우수하나 단일 플랫폼과 보행 환경 제약이 일반화 가능성을 다소 제한한다.
Gait-Conditioned Reinforcement Learning with Multi-Phase Curriculum for Humanoid Locomotion
Fig. 1: Human-like multi-gait locomotion on the Unitree G1
 *Fig. 1: Human-like multi-gait locomotion on the Unitree G1* 인간에게서 영감을 얻은 보상 형성과 gait-conditioned reward routing을 통해 단일 recurrent policy에서 서서기, 걷기, 달리기 및 전환을 학습하는 통합 reference-free RL 프레임워크를 제시한다.
이 논문은 gait-conditioned reward routing과 생물역학 기반 보상 설계를 통해 MoCap 없이 자연스러운 다중 gait 학습을 가능하게 하는 우아한 프레임워크를 제시하며, 실제 인간형 로봇에서의 검증으로 실용성을 입증한다.
Learning Symmetric and Low-energy Locomotion
Fig. 1. Locomotion Controller trained for different creatures. (a) Biped walking. (b) Quadruped galloping. (c) Hexapod W
 *Fig. 1. Locomotion Controller trained for different creatures. (a) Biped walking. (b) Quadruped galloping. (c) Hexapod W* Deep Reinforcement Learning에 미러 대칭 손실 함수와 커리큘럼 학습을 적용하여 모션 캡처 데이터 없이 자연스럽고 저에너지의 대칭적인 로코모션을 학습하는 방법을 제안한다.
본 논문은 미러 대칭 손실과 adaptive curriculum learning을 결합하여 DRL 기반 로코모션 학습의 오래된 문제(부자연스러움, 고에너지)를 우아하게 해결하며, 다양한 형태에 일반화 가능한 점에서 높은 독창성과 실용성을 갖춘 우수한 연구이다.
Optimizing Bipedal Locomotion for The 100m Dash With Comparison to Human Running
 *Fig. 3: The top 5 most efficient freq (above) and ratio* 이 논문은 이족 로봇 Cassie의 고속 주행 보행을 위해 보행 매개변수(stride frequency, swing ratio)를 체계적으로 최적화하고, 그 결과를 인간의 주행 역학과 비교하며, 최종적으로 100m 대시 기네스 월드레코드를 달성한 완전한 컨트롤러를 제시한다.
이 논문은 이족 로봇의 고속 주행을 위한 보행 매개변수의 첫 체계적 최적화를 제시하고, 인간 주행 역학과의 흥미로운 비교를 통해 이론적 깊이를 제공하며, 기네스 월드레코드 달성으로 실질적 임팩트를 입증한 우수한 연구이다.
Evolving the Complete Muscle: Efficient Morphology-Control Co-design for Musculoskeletal Locomotion
Fig. 1: Conceptual overview of Spectral Design Evolution
 *Fig. 1: Conceptual overview of Spectral Design Evolution* 본 논문은 근육-골격 로봇의 근력, 속도, 경직도를 동시에 진화시키는 Complete Musculoskeletal Morphological Evolution Space를 제시하고, 이를 효율적으로 탐색하기 위해 bilateral symmetry prior와 PCA를 결합한 Spectral Design Evolution(SDE) 프레임워크를 제안한다.
본 논문은 근육-골격 로봇의 형태-제어 공동 설계에 강도, 속도, 경직도의 포괄적 진화를 처음으로 도입하고, SDE의 spectral manifold 접근법으로 차원 폭발 문제를 효과적으로 해결하여 높은 샘플 효율성과 로컬로모션 성능을 달성한 의미있는 기여이나, 다양한 태스크와 형태학에 대한 일반화 검증이 필요하다.
Model-Based Reinforcement Learning Exploits Passive Body Dynamics for High-Performance Biped Robot Locomotion
Figure 1: Biped robot and model. (A) Lower body model based on muscu-
본 연구는 수동적 신체 역학(스프링, 높은 백드라이버빌리티 등)을 가진 이족 로봇이 Model-Based Deep Reinforcement Learning을 통해 고성능 보행·주행 운동을 효율적으로 습득할 수 있음을 보여준다. 수동 요소가 시스템의 어트랙터를 활용하여 안정적이고 에너지 효율적인 운동을 생성한다.
본 논문은 embodied AI의 핵심인 수동 신체 역학의 학습 효율성을 엄밀하게 입증한 중요한 연구로, Model-Based RL과 생체역학 설계의 시너지를 명확히 보여준다. 시뮬레이터 기반 검증이라는 한계가 있지만, 미래 로봇 설계 원칙에 유의미한 통찰을 제공한다.
Learning Symmetric and Low-energy Locomotion
Fig. 1. Locomotion Controller trained for different creatures. (a) Biped walking. (b) Quadruped galloping. (c) Hexapod W
 *Fig. 1. Locomotion Controller trained for different creatures. (a) Biped walking. (b) Quadruped galloping. (c) Hexapod W* 본 논문은 심층 강화학습(DRL)을 사용하여 motion capture나 finite state machine 없이 대칭적이고 저에너지의 자연스러운 로코모션을 학습하는 방법을 제안한다. 손실 함수에 미러 대칭성 손실항을 추가하고, 점진적으로 물리적 보조를 완화하는 curriculum learning 방법을 통해 다양한 형태의 캐릭터(이족, 사족, 육족)에서 효과적인 보행 제어기를 자동으로 생성할 수 있음을 보여준다.
본 논문은 강화학습 기반 로코모션 학습에서 미러 대칭성 손실과 curriculum learning이라는 두 가지 간단하면서도 효과적인 기법을 통해 자연스럽고 에너지 효율적인 보행을 달성한 우수한 연구이다. 특히 motion capture나 형태 특정 지식 없이 다양한 캐릭터에 적용 가능한 일반성과 생물학적으로 타당한 결과는 의미있는 기여이나, 이론적 근거와 더 복잡한 운동에 대한 검증이 보완된다면 더욱 강력한 연구가 될 것이다.
Reference-Free Sampling-Based Model Predictive Control
Fig. 1: Our reference-free sampling-based MPC framework
 *Fig. 1: Our reference-free sampling-based MPC framework* 본 논문은 사전정의된 보행 패턴이나 접촉 시퀀스 없이 MPPI 기반의 샘플링 기반 MPC 프레임워크를 제안하여 emergent locomotion을 실현한다. Cubic Hermite spline 파라미터화를 통해 위치와 속도 제어점을 동시에 최적화하여 실시간 CPU 기반 제어를 가능하게 한다.
본 논문은 참조 없는 emergent locomotion 발현, 극도의 샘플 효율성, 그리고 실시간 CPU 제어라는 세 가지 측면에서 우수한 기여를 제시한다. Cubic Hermite spline 파라미터화와 diffusion annealing의 조합은 창의적이며, Go2 로봇의 실제 검증은 신뢰성을 높인다. 다만 현실 로봇 검증의 범위 확대와 sim-to-real 갭 분석이 필요하다.
VB-Com: Learning Vision-Blind Composite Humanoid Locomotion Against Deficient Perception
Fig. 1: Overview. VB-Com enables humanoid robots (move direction in orange arrorw) to traverse dynamic terrains and obst
 *Fig. 1: Overview. VB-Com enables humanoid robots (move direction in orange arrorw) to traverse dynamic terrains and obst* VB-Com은 휴머노이드 로봇이 시각 정보의 결손에 대응하기 위해 시각 기반 정책과 고유감각 기반의 맹목 정책을 동적으로 전환하는 복합 제어 프레임워크를 제안한다.
VB-Com은 휴머노이드 로봇의 지각 견고성 문제를 정책 합성으로 우아하게 해결하며, return estimator 기반 동적 선택 메커니즘은 창의적이고 실용적이다. 동적 지형 및 지각 노이즈 시나리오의 체계적 구성과 두 휴머노이드 플랫폼에서의 검증이 강점이나, 실제 배포 결과 확장과 일반화 능력 분석이 보강되면 더욱 설득력 있을 것이다.
Advancing Humanoid Locomotion: Mastering Challenging Terrains with Denoising World Model Learning
Fig. 1: Extensive showcase of locomotion skills using the proposed framework. Displayed is a sequence illustrating a hum
 *Fig. 1: Extensive showcase of locomotion skills using the proposed framework. Displayed is a sequence illustrating a hum* Denoising World Model Learning (DWL)이라는 end-to-end 강화학습 프레임워크를 통해 휴머노이드 로봇이 눈덮인 언덕, 계단, 불규칙한 지형 등 현실의 복잡한 지형을 처음으로 마스터했으며, zero-shot sim-to-real transfer로 같은 신경망을 모든 시나리오에서 구동한다.
DWL은 휴머노이드 로봇의 현실 복잡 지형 보행 문제를 처음으로 해결한 혁신적 연구이며, noisy observation으로부터 true state를 복원하는 encoder-decoder 기반 denoising 접근과 2-DoF ankle mechanism의 하드웨어 혁신이 결합되어 높은 영향력을 기대할 수 있다.
APEX: Learning Adaptive High-Platform Traversal for Humanoid Robots
Fig. 1: The robot adaptively traverses high platforms of up to 0.8 m (≈114% of leg length) by leveraging diverse full-bo
 *Fig. 1: The robot adaptively traverses high platforms of up to 0.8 m (≈114% of leg length) by leveraging diverse full-bo* APEX는 humanoid 로봇이 다리 길이의 114%에 달하는 높은 플랫폼을 traversal할 수 있도록 하는 시스템으로, ratchet progress reward를 통해 학습한 6가지 기술(climb-up, climb-down, stand-up, lie-down, walking, crawling)을 하나의 정책으로 통합한다.
APEX는 humanoid 로봇의 고플랫폼 traversal에 대한 실질적 해결책을 제시하는 논문으로, 새로운 ratchet progress reward 공식과 다중기술 통합 framework가 창의적이며, 실제 로봇에서 다리 길이의 114%에 달하는 높이를 달성한 점이 매우 인상적이다. 다만 평가 환경이 상대적으로 제한적이고 더 복잡한 실제 환경으로의 확장성에 대한 검증이 필요하다.
BeamDojo: Learning Agile Humanoid Locomotion on Sparse Footholds
Fig. 1: Our proposed framework, BEAMDOJO, enables agile and robust humanoid locomotion across challenging sparse foothol
 *Fig. 1: Our proposed framework, BEAMDOJO, enables agile and robust humanoid locomotion across challenging sparse foothol* BeamDojo는 샘플링 기반의 다각형 발 보상 함수와 이중 critic 아키텍처를 결합한 2단계 강화학습 프레임워크로, 휴머노이드 로봇이 디딤돌과 같은 드문 디딤점을 가진 복잡한 지형에서 민첩하고 정밀한 보행을 학습하게 한다.
BeamDojo는 휴머노이드 로봇의 다각형 발 기하학을 명시적으로 처리하고 2단계 훈련으로 표본 효율성을 높인 혁신적인 프레임워크로, 시뮬레이션과 실제 로봇 실험을 통해 sparse foothold에서의 민첩한 보행 능력을 입증하여 로봇 보행 제어 분야에 중요한 기여를 한다.
CMR: Contractive Mapping Embeddings for Robust Humanoid Locomotion on Unstructured Terrains
Fig. 1: The left panel illustrates diverse types of challenging
 *Fig. 2: Overview of the CMR framework. Noisy ob-* CMR은 관찰 노이즈에 강건한 휴머노이드 로봇 보행을 위해 contrastive representation learning과 Lipschitz regularization을 결합하여 disturbance를 attenuate하는 latent space를 학습하는 프레임워크이다.
CMR은 contraction mapping theorem을 휴머노이드 로봇 제어에 엄밀하게 도입하여 이론적 근거와 실증적 성능을 모두 제시한 강한 논문이다. 다양한 지형에서의 노이즈 robustness 개선과 기존 파이프라인과의 용이한 통합이 주요 강점이나, 실제 로봇 검증과 노이즈 모델 확장이 필요하다.
Contrastive Representation Learning for Robust Sim-to-Real Transfer of Adaptive Humanoid Locomotion
Fig. 1: Our policy, trained via contrastive knowledge distillation, enables
 *Fig. 2: Overview of our proposed training framework. An asymmetric Actor-* Contrastive learning을 이용해 시뮬레이션의 특권 정보(terrain heightmap)를 순수 proprioceptive policy에 증류시켜 지각의 선견성을 얻으면서도 배포 시 지각 센서의 비용을 피한다. Adaptive gait clock을 통해 고정된 클럭 보행과 불안정한 자유 클럭 보행 사이의 근본적 trade-off를 해결한다.
이 논문은 contrastive learning을 통해 시뮬레이션 특권 정보를 proprioceptive policy에 효과적으로 증류하여 지각 센서 없이도 선견성 있는 제어를 달성하는 창의적 해결책을 제시한다. Zero-shot sim-to-real 전이로 극도로 도전적인 지형에서의 강건한 보행을 실증함으로써 인간형 로봇 실용화의 중요한 진전을 보여준다.
Deep Whole-body Parkour
Fig. 1: Deep Whole-Body Parkour. Our framework enables a humanoid robot to autonomously traverse challenging obstacles
 *Fig. 2: Data-driven whole-body control framework. Real-world environment scans and human demonstrations are processed an* 본 연구는 외부 센싱(depth perception)을 whole-body motion tracking에 통합하여 인간형 로봇이 불규칙한 지형에서 vaulting, dive-rolling 등의 동적 parkour 움직임을 수행하도록 하는 프레임워크를 제시한다.
본 논문은 두 상충하는 제어 패러다임을 창의적으로 통합하여 humanoid robot의 traversability를 획기적으로 확장했으며, custom motion-terrain dataset과 최적화된 ray-casting algorithm은 기술적 기여도 충실하다. sim-to-real gap 해소와 실제 동작 검증으로 실무적 가치가 높으나, dataset 확장성과 타 robot morphology 적용에 개선 여지가 있다.
E-SDS: Environment-aware See it, Do it, Sorted - Automated Environment-Aware Reinforcement Learning for Humanoid Locomotion
Fig. 1. E-SDS pipeline showing the automated reward generation and refinement.
 *Fig. 1. E-SDS pipeline showing the automated reward generation and refinement.* E-SDS는 Vision-Language Model과 실시간 지형 센서 분석을 통합하여 휴머노이드 로봇의 환경 인식 보행 정책을 자동으로 학습할 수 있는 프레임워크를 제시한다. 환경 통계 기반 보상 함수 자동 생성으로 수동 엔지니어링 시간을 대폭 단축하면서도 더 강건한 보행 정책을 실현한다.
E-SDS는 VLM 기반 자동 보상 설계와 환경 인식 지각형 제어를 혁신적으로 통합하여 휴머노이드 보행의 자동화 및 강건성을 획기적으로 개선했다. 다만 최신 VLM 모델 의존성, 계산 비용, 실제 하드웨어 검증 부재 등은 실용화를 위한 과제로 남아있다.
FocusNav: Spatial Selective Attention with Waypoint Guidance for Humanoid Local Navigation
Fig. 1: Snapshots of dynamic obstacle avoidance on stairs.
 *Fig. 4: Overview of the FocusNav framework. (a) Multi-modal perception encoder fuses spatially aligned LiDAR and depth* FocusNav는 인간형 로봇의 국소 항법을 위해 Waypoint-Guided Spatial Cross-Attention (WGSCA)와 Stability-Aware Selective Gating (SASG) 모듈을 결합한 공간 선택적 주의 프레임워크를 제안한다. 예측된 무충돌 경로점을 기준으로 환경 지각을 동적으로 조정하여 불안정 시 원거리 정보를 제거함으로써 동적·복잡한 환경에서의 견고한 항법을 달성한다.
FocusNav는 생물학적 영감과 기술적 혁신을 결합하여 인간형 로봇의 복잡한 동적 환경 항법이라는 중대한 과제를 체계적으로 해결한다. WGSCA와 SASG 모듈의 설계가 우수하고 실제 로봇 실험으로 검증되었으나, 단일 플랫폼 실험과 수동 파라미터 조정이라는 제약이 있다.
Gait-Adaptive Perceptive Humanoid Locomotion with Real-Time Under-Base Terrain Reconstruction
Fig. 1: Full-sized humanoid robot Oli performing gait-
 *Fig. 2: Overview of the proposed Successive Teacher–Student (S-TS) framework and deployment pipeline. A teacher–student* 인간형 로봇의 복잡한 지형 보행을 위해 하향식 깊이 카메라로 촬영한 영상을 U-Net으로 높이맵으로 재구성하고, 이를 통합 정책에 입력하여 관절 제어와 보행 주기를 동시에 적응시키는 지각 기반 보행 프레임워크를 제시한다.
인간형 로봇의 복잡 지형 보행이라는 중요한 문제를 하향식 깊이 카메라와 U-Net 기반 높이맵 재구성, 통합 적응형 정책의 조합으로 창의롭게 해결하였으며, 실제 로봇에서 계단 오르내림과 갭 횡단을 성공적으로 시연하여 높은 실용적 가치를 보인다.
Humanoid Whole-Body Locomotion on Narrow Terrain via Dynamic Balance and Reinforcement Learning
Fig. 1: The locomotion capabilities of full-sized Humanoid without vision or LiDAR sensors. (a) Narrow Path (25cm):
 *Fig. 1: The locomotion capabilities of full-sized Humanoid without vision or LiDAR sensors. (a) Narrow Path (25cm):* ZMP(Zero Moment Point) 기반 리워드와 강화학습을 결합한 동적 균형 메커니즘을 도입하여, 휴머노이드 로봇이 외부 센서 없이 고유감각만으로 좁은 경로와 예상 못한 장애물이 있는 극단적 지형을 안정적으로 통과하도록 하는 전신 보행 알고리즘을 제안한다.
본 논문은 고전적 ZMP 개념을 현대 강화학습에 효과적으로 통합하여 외부 센서 없이 극단적 지형 통과 능력을 확보한 의미 있는 기여를 한다. 실제 full-sized 휴머노이드 로봇에서의 광범위한 실증이 강점이나, 다양한 로봇 플랫폼과 극단적 지형에 대한 일반화 가능성 검증이 필요하다.
Learning Bipedal Locomotion on Gear-Driven Humanoid Robot Using Foot-Mounted IMUs
Fig. 1: Upper: A photo (left) and kinematic model (right)
 *Fig. 1: Upper: A photo (left) and kinematic model (right)* 고기어비 액추에이터와 토크 센서가 없는 휴머노이드 로봇의 이족 보행 학습을 위해 발목 장착 IMU를 활용하는 Sim-to-Real RL 프레임워크를 제안하고, 대칭 데이터 증강과 random network distillation을 통해 불규칙한 지형에서의 안정화를 향상시킨다.
본 논문은 저비용 고기어비 액추에이터 로봇의 Sim-to-Real 학습에서 발목 IMU 센서를 혁신적으로 활용하여 복잡한 모델링을 회피하면서도 강건한 이족 보행을 달성한다. 하드웨어 검증과 실제 성능 개선이 입증되었으나, 다양한 로봇 플랫폼으로의 일반화 가능성과 기여도 분석이 향후 강화될 필요가 있다.
Learning Human-Humanoid Coordination for Collaborative Object Carrying
Fig. 1: COLA provides a proprioception-only policy that enables compliant human-humanoid collaboration for carrying dive
 *Fig. 2: Overview of COLA. Our Policy mainly consists of three steps: (i) We train a base whole-body control policy to pr* COLA는 proprioception만을 사용하는 reinforcement learning 기반의 정책으로, humanoid 로봇이 인간과 협력하여 물체를 운반할 때 적응적이고 안정적인 whole-body coordination을 가능하게 한다.
COLA는 humanoid-human collaborative carrying이라는 실용적 과제에 대해 proprioception-only 정책으로 완전한 솔루션을 제시하며, three-step training framework와 implicit force modeling을 통해 높은 독창성을 보여준다. 시뮬레이션과 실제 환경에서 동시에 검증된 결과는 실제 배포 가능성을 시사하며, human user study를 통한 compliant collaboration 확인으로 실무적 가치를 입증한다.
Learning Humanoid Locomotion with Perceptive Internal Model
Fig. 1: We propose a perceptive humanoid locomotion policy capable of mastering various challenging terrains. This polic
 *Fig. 2: Overview of our framework. Within PIM, we integrate perceptive information into the state predictor to achieve m* 인간형 로봇의 안정적인 이동을 위해 온보드 elevation map을 기반으로 한 Perceptive Internal Model (PIM)을 제안하며, HIM을 확장하여 지각 정보를 통합한 단일 단계 학습 방법을 제시한다.
본 논문은 elevation map 기반 지각 모듈을 HIM과 통합하여 인간형 로봇의 복잡한 지형 네비게이션을 단일 단계로 효율적으로 학습하는 실질적이고 우수한 방법을 제시하며, 다양한 로봇과 지형에서의 광범위한 검증을 통해 실용성을 입증한다.
Learning to Get Up Across Morphologies: Zero-Shot Recovery with a Unified Humanoid Policy
Fig. 1. Visual of diverse humanoid morphologies. Ordered by size (left: smallest, right:
 *Fig. 1. Visual of diverse humanoid morphologies. Ordered by size (left: smallest, right:* 7개의 다양한 휴머노이드 로봇(높이 0.48-0.81m, 무게 2.8-7.9kg)에서 낙상 복구를 수행할 수 있는 단일 통합 DRL 정책을 제시하며, 로봇 특화 학습 없이 미학습 로봇에 86±7% 성공률로 제로샷 전이가 가능함을 보였다.
이 논문은 휴머노이드 낙상 복구라는 구체적 과제에서 형태-불가지론적 다중 로봇 제어의 실현 가능성을 처음 입증하며, 포괄적 실험과 높은 제로샷 성능으로 일반화된 로봇 제어의 기초를 마련한다. 다만 시뮬레이션 기반 검증과 실제 전이 실험이 부재한 점이 한계이지만, 오픈소스 공개와 체계적 분석은 해당 분야에 실질적 기여를 한다.
MoRE: Mixture of Residual Experts for Humanoid Lifelike Gaits Learning on Complex Terrains
Fig. 1. Our framework leverages a two-stage training pipeline and the mixture
 *Fig. 2.* 휴머노이드 로봇이 복잡한 지형을 인간다운 보행으로 횡단하기 위해 Mixture of Residual Experts (MoRE)와 다중 판별자를 활용한 2단계 RL 학습 프레임워크를 제안한다.
본 논문은 복잡 지형 횡단과 인간다운 다중 보행 학습을 동시에 달성하는 통합적 프레임워크를 제시하며, MoE 기반 residual 접근법과 다중 판별자 활용으로 방법론적 독창성을 보인다. 실제 로봇 배포 검증과 함께 기술적으로 견고하고 실무적 중요성이 높은 연구이다.
Traversing Narrow Paths: A Two-Stage Reinforcement Learning Framework for Robust and Safe Humanoid Walking
Fig. 1: Overview. The proposed framework uses 3D-LIPM
 *Fig. 1: Overview. The proposed framework uses 3D-LIPM* 이 논문은 humanoid 로봇이 좁은 경로를 안전하게 통과하도록 하는 두 단계 reinforcement learning 프레임워크를 제안하며, physics-기반 LIPM foothold planner와 RL 기반 foothold tracker/modifier를 결합한다.
이 논문은 physics-기반 모델과 reinforcement learning을 창의적으로 결합하여 안전하고 해석 가능한 narrow path traversal을 달성했으며, 실제 humanoid robot에서 높은 성공률로 검증함으로써 로봇 제어의 실질적 응용 가치를 입증했다.
CART: Context-Aware Terrain Adaptation using Temporal Sequence Selection for Legged Robots
 *Fig. 2: Overview of the Pipeline: CART inputs a stream of RGBD images Sv, friction meshes Sm using [19], and propriocept* CART는 사족 로봇의 지형 적응을 위해 시각 정보와 고유감각(proprioception)을 통합하여 맥락을 파악하고, 시간 수열 선택을 통해 로봇의 안정성을 향상시키는 고수준 제어기이다.
CART는 시각과 고유감각의 불일치 문제를 명시적으로 인식하고 이를 해결하기 위한 창의적인 맥락 기반 제어 프레임워크를 제시하며, 시뮬레이션과 실제 환경 모두에서 안정성 개선을 입증한 의미 있는 연구이다. 다만 평가 범위 확대와 방법론의 일반화 가능성 검증이 필요하다.
Deep Whole-body Parkour
Fig. 1: Deep Whole-Body Parkour. Our framework enables a humanoid robot to autonomously traverse challenging obstacles
 *Fig. 2: Data-driven whole-body control framework. Real-world environment scans and human demonstrations are processed an* 이 논문은 exteroceptive perception을 whole-body motion tracking에 통합하여 humanoid robot이 복잡한 지형에서 vault, dive-rolling 등의 다중 접촉 parkour 기술을 수행하도록 하는 프레임워크를 제시한다. 기존의 locomotion-centric 접근과 environment-agnostic 동작 추적을 결합하여 지각 기반의 일반적 동작 제어를 실현한다.
이 논문은 humanoid robot 제어의 두 주요 패러다임을 창의적으로 통합하여 지형 인식 능력과 복잡한 전신 동작을 동시에 달성하는 실질적인 솔루션을 제시한다. 커스텀 dataset curation, 최적화된 parallel simulation, 견고한 폐루프 제어 통합을 통해 vault와 dive-rolling 같은 고도로 동적인 parkour 기술을 실제 humanoid에서 구현했다는 점에서 의의가 크다.
Reinforcement Learning for Versatile, Dynamic, and Robust Bipedal Locomotion Control
이족 로봇의 다양한 동적 보행 기술(걷기, 뛰기, 점프)을 통합적으로 제어하기 위해 dual-history 아키텍처를 갖춘 심화강화학습 프레임워크를 제시하고, 시뮬레이션에서 실제 로봇(Cassie)으로 무튜닝 전이 배포를 성공시켰다.
이족 로봇 제어라는 도전적 과제에서 dual-history 아키텍처와 task randomization을 통해 통합 RL 프레임워크를 달성하고, 광범위한 실제 로봇 실험으로 다양한 동적 보행 기술의 강건한 구현을 입증한 우수한 연구이다. 다만 아키텍처 설계 선택의 이론적 근거 강화와 다른 플랫폼으로의 확장성 검증이 필요하다.
Robust Humanoid Walking on Compliant and Uneven Terrain with Deep Reinforcement Learning
Fig. 1: HRP-5P humanoid bipedal locomotion (clockwise) on flat rigid
 *Fig. 1: HRP-5P humanoid bipedal locomotion (clockwise) on flat rigid* Deep RL을 이용하여 humanoid robot HRP-5P가 시뮬레이션에서 terrain randomization으로 학습한 정책을 실제 환경의 compliant하고 uneven한 terrain에서도 robust하게 보행하도록 하는 연구이다.
Life-sized humanoid의 challenging terrain 보행을 위한 deep RL 기반 접근법의 실제 구현을 성공적으로 입증했으며, sim-to-real transfer와 adaptive gait control의 효과를 명확히 보여준 의미 있는 연구이다. 다만 clock control 정책의 실제 적용 효과 검증과 failure case 분석이 보강되면 더욱 완성도 높은 작업이 될 수 있다.
SKATER: Synthesized Kinematics for Advanced Traversing Efficiency on a Humanoid Robot via Roller Skate Swizzles
Fig. 1: The SKATER system: a humanoid robot equipped
 *Fig. 1: The SKATER system: a humanoid robot equipped* 휴머노이드 로봇의 발에 4개의 수동 바퀴를 장착하고 Deep Reinforcement Learning을 통해 롤러스케이팅 스위즐 보행을 학습시켜 전통적인 보행 대비 충격력 75.86%, 에너지 소비 63.34% 감소를 달성했다.
휴머노이드 로봇의 에너지 효율과 관절 수명 향상을 위해 롤러스케이팅이라는 창의적인 솔루션을 제시하고, DRL 기반 제어 프레임워크를 통해 현실적인 구현을 달성한 혁신적 연구이다. 85~76% 수준의 높은 성능 개선과 sim-to-real 전이의 성공은 로봇 운동 제어 분야에 실질적 기여를 한다.
A Framework for Optimal Ankle Design of Humanoid Robots
Fig. 1: Examples of two-degrees-of-freedom ankle mechanisms.
 *Fig. 1: Examples of two-degrees-of-freedom ankle mechanisms.* 휴머노이드 로봇의 발목 설계를 위한 통합 프레임워크를 제시하며, SPU 및 RSU 병렬 메커니즘에 대한 다목적 최적화를 통해 최적 구성을 도출한다.
본 논문은 휴머노이드 로봇 발목 설계의 오랜 난제인 아키텍처 선택과 파라미터 최적화를 체계적이고 정량적으로 해결하는 통합 프레임워크를 제시하며, 실제 로봇 재설계를 통한 유의미한 성능 개선으로 실용성을 입증하였다.
A Gait Driven Reinforcement Learning Framework for Humanoid Robots
 *Fig. 2: A real-time-gait-driven training framework.* 본 논문은 humanoid robot의 bipedal gait 학습을 위해 실시간 gait planner와 structured reward composition을 결합한 reinforcement learning framework를 제시한다.
본 논문은 model-based planning과 data-driven learning을 효과적으로 결합하여 humanoid robot의 bipedal gait 학습을 위한 실용적인 framework를 제시한다. H-LIP 기반 decoupling과 structured reward composition의 조합이 학습 효율성과 periodicity를 동시에 향상시키는 점에서 기술적 독창성이 있으나, 물리 실험 검증과 복잡한 환경 적응성 평가가 추가되면 더욱 강화될 것이다.
A Unified and General Humanoid Whole-Body Controller for Versatile Locomotion
Fig. 1: Humanoid capabilities supported by HUGWBC. First row: HUGWBC allows four standard gaits - walking, jumping, stan
HugWBC는 시뮬레이션에서 학습한 통일된 강화학습 기반 정책으로 휴머노이드 로봇이 걷기, 뛰기, 서기, 깡충뛰기 등 다양한 보행 행동을 자유롭게 조절 가능하도록 하며, 상반신 외부 제어 개입도 지원하는 전신 컨트롤러이다.
HugWBC는 확장된 명령 공간과 intervention training 기법을 통해 휴머노이드 로봇의 다양한 보행과 로코-조작을 통합적으로 제어하는 첫 번째 전신 컨트롤러로서, 우수한 추적 성능과 강건성으로 휴머노이드 로봇의 실용 능력을 크게 향상시키는 의미 있는 기여이다.
Berkeley Humanoid: A Research Platform for Learning-based Control
Figure 1: Design, training, and sim-to-real deployment of our custom-built humanoid with a
 *Figure 1: Design, training, and sim-to-real deployment of our custom-built humanoid with a* 학습 기반 제어를 위해 특별히 설계된 저비용 중형 휴머노이드 로봇 플랫폼인 Berkeley Humanoid를 제시하며, 좁은 sim-to-real 갭과 높은 신뢰성으로 다양한 지형에서 동적 보행을 실현한다.
Berkeley Humanoid는 학습 기반 휴머노이드 제어 연구를 위한 실용적이고 비용 효율적인 플랫폼으로, 하드웨어와 제어 알고리즘의 통합 설계를 통해 중요한 sim-to-real 문제를 해결한 가치 있는 기여이다. Open-source 공개 계획은 커뮤니티 연구를 촉진할 것으로 예상된다.
Booster Gym: An End-to-End Reinforcement Learning Framework for Humanoid Robot Locomotion
Fig. 1: Training, testing, and deployment on Booster T1
 *Fig. 1: Training, testing, and deployment on Booster T1* Booster Gym은 시뮬레이션에서 실제 로봇까지 humanoid robot locomotion을 위한 RL 기반 정책을 훈련하고 배포하는 end-to-end 프레임워크를 제시한다. 이 프레임워크는 domain randomization, 보상 함수 설계, parallel structures 처리 등을 포함하며 Booster T1 로봇에서 omnidirectional walking, disturbance resistance, terrain adaptability를 달성했다.
이 논문은 humanoid robot locomotion의 RL 기반 훈련과 배포를 위한 실용적이고 완전한 오픈소스 프레임워크를 제시하며, 다중 시뮬레이터 검증과 실제 로봇 배포를 통해 실용성을 입증한다. 학술적 기여는 제한적이지만 로보틱스 커뮤니티에 즉시 활용 가능한 도구를 제공하는 점에서 가치 있다.
CAD-Driven Co-Design for Flight-Ready Jet-Powered Humanoids
 *Fig. 2: CAD assemblies of the links being modified. 1: Jetpack Turbine Angle; 2: Jetpack Turbine offset distance; 3: Jet* CAD 기반 설계-제어 공동 최적화 프레임워크를 통해 제트 추진 휴머노이드 로봇의 형태와 MPC 제어 파라미터를 동시에 최적화하여 비행 가능한 구성을 도출한다.
본 논문은 CAD 기반 설계-제어 공동 최적화를 제트 추진 항공 휴머노이드에 적용한 것으로, 대규모 형태 공간 탐색과 비행 성능 평가를 체계적으로 통합한 점에서 기여가 크다. 다만 선형화된 제어와 제한된 평가 시나리오는 실제 적용의 견고성을 위해 추가 검증이 필요하다.
ECO: Energy-Constrained Optimization with Reinforcement Learning for Humanoid Walking
Fig. 1: Comparison between the proposed constrained RL frame-
 *Fig. 1: Comparison between the proposed constrained RL frame-* ECO는 에너지 소비를 보상 함수의 가중치가 아닌 명시적 부등식 제약 조건으로 reformulate한 constrained RL 프레임워크로, 휴머노이드 로봇의 에너지 효율적 보행을 달성한다.
ECO는 에너지 최적화를 constrained RL로 reformulate한 novel한 접근법으로 휴머노이드 보행의 에너지 효율성에서 획기적 성과를 달성했으며, 실제 로봇 플랫폼 검증과 constrained RL에 대한 실증적 분석은 로봇 공학 및 최적 제어 커뮤니티에 중대한 기여를 한다.
Evolutionary Continuous Adaptive RL-Powered Co-Design for Humanoid Chin-Up Performance
 *Fig. 2: Overview of the EA-CoRL framework methodology.* EA-CoRL은 진화 알고리즘과 강화학습을 결합하여 휴머노이드 로봇의 하드웨어 설계(기어비)와 제어 정책을 동시에 최적화하는 프레임워크이며, RH5 로봇의 턱걸이 작업 성공을 통해 검증되었다.
EA-CoRL은 continuous adaptive 정책 최적화를 통해 RL 기반 co-design의 실질적 문제를 해결한 창의적 프레임워크이며, 이전 불가능했던 고난도 동적 작업 실현의 가능성을 보였다. 다만 실제 하드웨어 검증과 설계 공간 확장이 이루어진다면 실용적 영향력이 더욱 크게 증대될 것으로 예상된다.
Full-Order Sampling-Based MPC for Torque-Level Locomotion Control via Diffusion-Style Annealing
Fig. 1: Diffusion-inspired annealing for legged MPC (DIAL-
 *Fig. 1: Diffusion-inspired annealing for legged MPC (DIAL-* DIAL-MPC는 diffusion 프로세스의 iterative refinement 아이디어를 sampling-based MPC에 적용하여 full-order 사족 로봇의 torque-level 제어를 실시간으로 수행하는 training-free 방법이다.
본 논문은 MPPI와 diffusion의 수학적 연결을 통해 sampling-based MPC의 근본적 한계를 새로운 각도로 접근하며, diffusion-inspired annealing이라는 창의적 방법으로 full-order 사족 로봇의 실시간 제어를 training-free로 달성한 의미있는 기여이다.
Humanoid-Gym: Reinforcement Learning for Humanoid Robot with Zero-Shot Sim2Real Transfer
Fig. 1: Humanoid-Gym enables users to train their policies
 *Fig. 2: Pipeline of Humanoid-Gym. Initially, we employ* Humanoid-Gym은 Nvidia Isaac Gym 기반의 강화학습 프레임워크로, 인간형 로봇의 보행 기술을 훈련하고 zero-shot sim-to-real 전이를 통해 실제 환경으로 직접 배포할 수 있도록 설계되었다.
Humanoid-Gym은 인간형 로봇의 zero-shot sim-to-real 전이를 체계적으로 구현한 최초의 공개 프레임워크로, 실제 로봇에서 입증된 높은 실용성과 함께 로봇 학습 커뮤니티에 중요한 기여를 제공한다. 다만 평가 환경과 로봇 종류의 다양성 확대를 통해 결과의 보편성을 강화할 필요가 있다.
HumanoidBench: Simulated Humanoid Benchmark for Whole-Body Locomotion and Manipulation
Fig. 1:
 *Fig. 1:* HumanoidBench는 이족 로봇의 전신 조작과 이동 능력을 평가하기 위한 시뮬레이션 벤치마크로, 손가락이 있는 손과 다양한 27개의 도전적인 작업을 포함한다.
HumanoidBench는 이족 로봇의 전신 제어 문제를 포괄적으로 다루는 첫 번째 벤치마크로서, 로봇 학습 커뮤니티에 중요한 평가 플랫폼을 제공하며, 계층적 학습 접근법의 효과성을 입증하여 향후 이족 로봇 알고리즘 연구의 방향을 제시한다.
MASH: Cooperative-Heterogeneous Multi-Agent Reinforcement Learning for Single Humanoid Robot Locomotion
Fig. 1. MARL model for a single humanoid robot’s locomotion
 *Fig. 1. MARL model for a single humanoid robot’s locomotion* 단일 인간형 로봇의 보행을 위해 각 팔다리를 독립 에이전트로 모델링하여 Cooperative-Heterogeneous MARL을 적용하는 MASH 프레임워크를 제안한다. 이는 전역 비평가를 공유하며 협력학습을 통해 전신 조화 능력을 향상시킨다.
MASH는 MARL 원칙을 단일 인간형 로봇에 창의적으로 적용하여 전신 조화 보행 학습을 효과적으로 개선한 의미 있는 기여이다. 다만 실제 로봇 검증과 알고리즘 세부사항 명확화가 필요하다.
No More Marching: Learning Humanoid Locomotion for Short-Range SE(2) Targets
Fig. 1: Overview of our approach for short-range SE(2)-target
 *Fig. 1: Overview of our approach for short-range SE(2)-target* 본 논문은 휴머노이드 로봇의 단거리 SE(2) 목표 위치 도달을 위해 constellation 기반 보상 함수를 활용한 강화학습 접근법을 제시하며, 속도 추적 기반의 기존 방법들이 생성하는 비효율적인 행진 동작을 제거한다.
이 논문은 단거리 SE(2) 목표 도달이라는 실제 작업에 특화된 새로운 보상 함수와 RL 접근법을 제시하며, 직관적인 설계와 sim-to-real 전이 성공으로 휴머노이드 로봇의 실무 적용 가능성을 크게 향상시킨다.
Towards bridging the gap: Systematic sim-to-real transfer for diverse legged robots
Figure 1. Comparison of real and simulated robot trajectories
 *Figure 1. Comparison of real and simulated robot trajectories* 이족 로봇의 시뮬레이션-실제 전이 문제를 해결하기 위해 강화학습과 영구자석 동기 전동기(PMSM)의 물리 기반 에너지 모델을 통합한 프레임워크를 제안하며, 최소한의 파라미터로 현실성을 확보하면서 에너지 효율성을 달성한다.
이 논문은 물리 기반 모델링과 강화학습을 체계적으로 결합하여 실제 다리 로봇의 시뮬레이션 전이 문제를 효과적으로 해결하며, 광범위한 플랫폼 검증과 에너지 효율성 개선으로 높은 실용성과 신뢰성을 입증한다.
Adaptive LIPM-based trajectory planning for energy-efficient bipedal locomotion on inclined terrains
 *Fig. 3 Shows the structure and snapshots of the simulation* 경사지면에서 이족 보행 로봇의 안정적이고 에너지 효율적인 보행을 위해 Slope Adaptive LIPM (SA-LIPM)을 기반으로 궤적 계획을 수행하고, 12-DOF 하체 로봇에서 ZMP 안정성, COM 궤적, 관절별 에너지 소비를 상세히 분석한다.
본 논문은 경사지에서 이족 로봇의 보행 안정성과 에너지 효율성을 SA-LIPM 기반으로 체계적으로 분석한 중요한 연구이며, 관절별 에너지 감사를 통해 휴머노이드 로봇 설계에 실질적인 지침을 제공한다. 다만 더 가파른 경사와 실제 하드웨어 검증이 필요하다.
Residual Off-Policy RL for Finetuning Behavior Cloning Policies
 *Fig. 2. Off-policy residual fine-tuning (ResFiT): A two-phase approach using online RL to improve BC policies. First, we* Behavior Cloning(BC) 정책을 기반으로 Residual Off-Policy RL을 적용하여 샘플 효율적으로 조작 정책을 개선하며, 고자유도 이족 로봇에서의 첫 실시간 RL 학습을 달성했다.
BC와 off-policy RL을 residual learning으로 효과적으로 결합하여, 고자유도 실시간 로봇 학습의 실용적 경로를 제시했다. 블랙박스 방식의 일반성과 첫 휴머노이드 RL 실증이 로봇 학습 분야에 의미 있는 기여를 이룬다.
SkillMimic: Learning Basketball Interaction Skills from Demonstrations
Figure 1. We propose a novel approach that for the first time enables physically simulated humanoids to learn a variety
 *Figure 2. Concept of SkillMimic. We define an interaction skill as* SkillMimic은 skill-specific reward 설계 없이 통합된 HOI imitation reward를 사용하여 단일 policy로 다양한 농구 상호작용 기술을 학습하고 합성할 수 있는 data-driven 프레임워크다.
SkillMimic은 skill-specific reward 제거를 통해 상호작용 기술 학습의 실용성을 혁신적으로 개선했으며, contact graph와 통합 HOI reward 설계는 기술적으로 견고하고 농구 데이터셋 기여와 함께 이 분야의 significant advance를 이룬다.
Learning Smooth Humanoid Locomotion through Lipschitz-Constrained Policies
Fig. 1: Lipschitz-constrained policies (LCP) provide a simple and general method for training policies to produce smooth
 *Fig. 2: Lipschitz continuity is a method of quantifying the* 본 논문은 Reinforcement Learning으로 훈련한 humanoid robot의 locomotion policy에 Lipschitz 제약을 부여하여 smooth behavior를 자동으로 유도하는 Lipschitz-Constrained Policies (LCP) 방법을 제안한다.
Lipschitz constraint을 통한 smooth policy 학습은 이론적으로 명확하고 실용적이며, 기존의 복잡한 smoothing 기법들을 단순하고 미분 가능한 방식으로 대체하는 우수한 기여이다. 실제 humanoid robot에서의 검증과 재현성 있는 공개 코드 공개로 high impact을 기대할 수 있다.
Learning to Ball: Composing Policies for Long-Horizon Basketball Moves
Fig. 1. We introduce a novel policy integration framework to enable the composition of drastically different motor skill
 *Fig. 1. We introduce a novel policy integration framework to enable the composition of drastically different motor skill* 농구 동작과 같은 다단계 장기 과제에서 정의되지 않은 중간 상태를 가진 이질적인 스킬들을 seamlessly 합성하기 위해 policy integration framework와 soft routing을 제안한다.
본 논문은 ill-defined 중간 subtask를 다루기 위한 혁신적인 policy integration framework를 제시하며, soft routing과 adaptive fine-tuning을 통해 다단계 장기 과제에서 이질 스킬의 seamless 합성을 실현한다. 실시간 사용자 명령 기반의 자유로운 농구 플레이와 높은 슈팅 정확도는 제안 방법의 유효성을 강력히 입증하나, 시뮬레이션 환경 한정과 방법의 일반화 가능성이 향후 과제이다.
TD-GRPC: Temporal Difference Learning with Group Relative Policy Constraint for Humanoid Locomotion
 *Fig. 2: Overview of TD-GRPC for Humanoid Locomotion: Starting from an initial state s0 encoded into latent state z0 with* 본 논문은 Humanoid Locomotion을 위해 TD-MPC 프레임워크에 Group Relative Policy Optimization (GRPO)와 trust-region constraint를 통합한 TD-GRPC를 제안하여, off-policy 학습의 불안정성과 policy mismatch 문제를 해결한다.
본 논문은 GRPO와 trust-region constraint를 통합한 TD-GRPC를 제안하여 humanoid locomotion의 off-policy 학습 안정성을 효과적으로 개선한 의미 있는 연구이나, 실제 로봇 검증과 이론적 분석 심화, 그리고 더 광범위한 task 평가가 필요하다.
Track Any Motions under Any Disturbances
Fig. 1: (a) The humanoid tracks diverse, highly dynamic, and contact-rich motions using a single policy. (b) The humanoi
 *Fig. 1: (a) The humanoid tracks diverse, highly dynamic, and contact-rich motions using a single policy. (b) The humanoi* Any2Track는 휴머노이드 로봇이 다양한 동작을 추적하면서 동시에 지형, 외력, 물리적 성질 변화 등 실제 환경 교란에 적응할 수 있도록 하는 두 단계 강화학습 프레임워크를 제안한다.
Any2Track는 동역학 적응성을 명시적으로 재정의하고 이를 기본 추적 능력과 분리하여 학습하는 혁신적 접근을 제시하며, Unitree G1에서 zero-shot sim2real 전이를 달성하여 실제 휴머노이드 로봇의 실용화에 중요한 기여를 한다.
Being-H0.7: A Latent World-Action Model from Egocentric Videos
 *Figure 2: Latent reasoning and latent world-action model. Left: Learnable latent queries are inserted* 이 논문은 egocentric video로부터 학습된 latent world-action model인 Being-H0.7을 제시한다. 행동 생성 사이에 학습 가능한 latent query를 추론 인터페이스로 도입하고, future-informed dual-branch 설계를 통해 미래 프레임 생성 없이 세계 모델의 예측 능력을 VLA의 효율성과 결합한다.
Being-H0.7은 world-action modeling을 latent 공간으로 재정의하여 미래 예측의 이득을 유지하면서도 픽셀 생성의 비효율성을 제거한 강력한 기여를 한다. Future-informed dual-branch 설계와 latent query 기반 인터페이스는 창의적이고 효과적이며, 광범위한 시뮬레이션 및 실제 로봇 평가에서 일관된 성능 향상을 입증한다. 다만 posterior branch의 정당성, latent 구조의 이론적 근거, 그리고 일부 하이퍼파라미터 선택의 명확화가 필요하다.
Track Any Motions under Any Disturbances
Fig. 1: (a) The humanoid tracks diverse, highly dynamic, and contact-rich motions using a single policy. (b) The humanoi
 *Fig. 1: (a) The humanoid tracks diverse, highly dynamic, and contact-rich motions using a single policy. (b) The humanoi* 이 논문은 humanoid 로봇이 다양하고 동적이며 접촉이 많은 동작을 추적하면서 동시에 지형, 외력, 물리적 속성 변화 등의 실세계 교란에 강건하게 적응할 수 있도록 하는 Any2Track을 제안한다. AnyTracker와 AnyAdapter 두 가지 주요 컴포넌트로 구성된 2단계 RL 프레임워크를 통해 단일 정책으로 다양한 동작을 추적하면서도 온라인 동역학 적응성을 달성한다.
본 논문은 humanoid motion tracking의 오랜 과제인 다양한 동작 추적과 실세계 교란 적응을 동시에 해결하는 포괄적인 솔루션을 제시한다. 2단계 RL 프레임워크의 설계가 체계적이며, 실제 하드웨어 배포를 통한 성능 입증이 설득력 있다. 다만 단일 플랫폼에만의 평가와 계산 효율성 분석 부재가 한계이지만, 이 분야에 상당한 기여를 하는 우수한 연구로 평가된다.
RGMP: Recurrent Geometric-prior Multimodal Policy for Generalizable Humanoid Robot Manipulation
Figure 1: Overview of our framework. By applying seman-
 *Figure 2: Pipeline of RGMP. Upon receiving a speech command, the robot utilizes GSS to identify and localize the target* 기하학적 추론과 데이터 효율성을 결합한 RGMP는 humanoid robot 조작을 위해 Geometric-prior Skill Selector와 Adaptive Recursive Gaussian Network를 통합하여 87% 성공률과 5배 데이터 효율을 달성한다.
RGMP는 기하학적 추론과 데이터 효율성의 결합을 통해 humanoid robot 조작의 중요한 문제를 해결하며, GSS와 ARGN의 설계가 정교하고 실제 로봇에서 strong empirical result를 달성한 우수한 연구이다. 다만 기하학적 제약의 자동화와 더 광범위한 실증 평가가 이루어진다면 더욱 강력할 것으로 판단된다.
Cognition to Control - Multi-Agent Learning for Human-Humanoid Collaborative Transport
Fig. 1: Demonstration of human-robot collaboration via cognition-to-control hierarchy: (a) the humanoid and human partne
 *Fig. 3: The proposed hierarchical HRC framework for humanoid-object coordination, partitioning decision-making into thre* 인간-휴머노이드 협업 운반을 위한 3계층 Cognition-to-Control 프레임워크로, VLM 기반 의미론적 추론, Markov potential game 기반 MARL 조정, 전신 제어를 통합하여 역할의 자동 형성과 강건한 협업을 실현한다.
인간-로봇 협업의 근본적인 인지-제어 단절 문제를 3계층 구조로 체계적으로 해결하고, Markov potential game MARL을 통해 명시적 역할 할당 없이 협업 역할이 자동 형성되는 novel 접근법을 제시한다. 실험 결과는 강건성과 유효성을 잘 보여주지만, 작업 다양성 및 환경 조건 범위 확대가 필요하다.
Hand-Eye Autonomous Delivery: Learning Humanoid Navigation, Locomotion and Reaching
 *Figure 2: System overview: HEAD consists of a high-level policy with two modules, navigation* 인간 모션 캡처와 에고센트릭 비전 데이터로부터 휴머노이드 로봇의 네비게이션, 로코모션, 리칭 능력을 학습하는 HEAD 프레임워크를 제안한다. 고수준 정책이 손과 눈의 목표 위치를 명령하고 저수준 whole-body controller가 추적하는 모듈식 접근법을 채택한다.
HEAD는 모듈식 설계와 sparse 3-point tracking을 통해 휴머노이드 로봇의 통합적 navigation, locomotion, reaching을 효과적으로 학습하는 창의적인 접근을 제시하며, 실제 로봇에서의 동작 검증으로 실용성을 입증한다. 다만 human 데이터 의존성과 정제 비용, 환경 일반화 가능성에 대한 추가 분석이 필요하다.
Hierarchical visuomotor control of humanoids
Figure 1:
 *Figure 4: Schematic of the architecture: a high-level controller (HL) selects among multiple low-* 인간형 로봇의 고차원 시각-운동 제어를 위해 저수준 모터 제어기와 고수준 작업 조정기를 계층적으로 구성하는 아키텍처를 제안한다. Motion capture 데이터로 사전학습된 저수준 sub-policy들을 고수준 controller가 시각 정보에 기반해 동적으로 선택하여 복잡한 humanoid 제어를 수행한다.
Motion capture 기반 저수준 제어와 시각-메모리 기반 고수준 조정을 결합하여 고복잡도 humanoid의 integrated visuomotor 제어를 달성한 우수한 연구로, 신경과학적 영감과 실제 구현의 균형이 잘 맞으며 ICLR 발표에 적합한 수준의 기여를 제시한다.
INTENTION: Inferring Tendencies of Humanoid Robot Motion Through Interactive Intuition and Grounded VLM
Fig. 1: INTENTION enables the humanoid robot to learn, plan,
 *Fig. 1: INTENTION enables the humanoid robot to learn, plan,* INTENTION은 Vision-Language Models 기반의 Intuitive Perceptor와 Memory Graph를 통합하여 휴머노이드 로봇이 상호작용 경험으로부터 직관적 물리 이해를 학습하고 새로운 조작 작업에 자율적으로 적응하는 프레임워크를 제안한다.
INTENTION은 VLM 기반 지각과 상호작용 메모리를 결합하여 휴머노이드 로봇의 적응형 조작을 혁신적으로 제시하는 연구로, 개념과 설계는 우수하나 실험적 검증과 기술적 세부 구현의 엄밀성 강화가 필요하다.
Learning Vision-Driven Reactive Soccer Skills for Humanoid Robots
Figure 1 System overview. The real-world robot is equipped with an onboard camera for visual perception. Image
 *Figure 1 System overview. The real-world robot is equipped with an onboard camera for visual perception. Image* 본 논문은 시각 인식과 모션 제어를 직접 통합한 통합 강화학습 기반 컨트롤러를 통해 인형 로봇이 반응형 축구 기술을 습득할 수 있도록 하는 방법을 제시한다. Adversarial Motion Priors를 시각 기반 동적 제어 환경으로 확장하여 실제 RoboCup 경기에서 강력한 반응성을 보여준다.
본 논문은 Adversarial Motion Priors를 시각 기반 동적 제어로 성공적으로 확장하여, 강화학습 기반 인형 로봇이 실세계 축구 환경에서 반응형 행동을 자동으로 습득할 수 있음을 처음으로 입증했다. RoboCup 2025 우승이라는 실제 경쟁 성과는 제시된 방법론의 실용성과 견고성을 강력하게 검증한다.
Let Humanoids Hike! Integrative Skill Development on Complex Trails
Figure 1. We propose training humanoids to hike complex trails, driving integrative skill development across visual perc
 *Figure 1. We propose training humanoids to hike complex trails, driving integrative skill development across visual perc* 휴머노이드 로봇이 복잡한 산길을 자율적으로 하이킹하도록 학습시키기 위해 시각 인식, 의사결정, 운동 실행을 통합하는 LEGO-H 프레임워크를 제안한다. TC-ViT와 Hierarchical Latent Matching을 통해 네비게이션과 로코모션을 단일 학습 체계로 통합한다.
본 논문은 하이킹을 새로운 벤치마크로 제시하고 TC-ViT와 HLM 기반 LEGO-H 프레임워크를 통해 네비게이션과 로코모션의 통합이라는 오래된 문제에 혁신적으로 접근한다. 다만 시뮬레이션 중심의 평가가 실제 배포 가능성의 의문을 남기지만, 휴머노이드 로봇 자율성 개발을 위한 강력한 기초 제시로서 충분히 의미 있는 기여이다.
Trinity: A Modular Humanoid Robot AI System
Fig. 1: Overview of the Modular Humanoid Robot AI System. In this system, task instructions are processed by both a visi
 *Fig. 1: Overview of the Modular Humanoid Robot AI System. In this system, task instructions are processed by both a visi* LLM, VLM, RL을 통합한 모듈식 인간형 로봇 AI 시스템 Trinity를 제안하여 복잡한 환경에서 효율적인 제어를 실현한다. 계층적 아키텍처를 통해 언어 이해, 시각 인식, 동작 제어를 조화롭게 수행한다.
Trinity는 RL, LLM, VLM을 효과적으로 통합한 혁신적 인간형 로봇 AI 시스템으로, 모듈식 설계를 통해 유연성과 해석성을 확보하고 실제 로봇에서의 동작을 입증함으로써 구현적 가치가 높다. 다만 sim-to-real 갭과 모듈 간 상호작용의 견고성에 대한 심화 분석이 필요하다.
Tree Learning: A Multi-Skill Continual Learning Framework for Humanoid Robots
 *Figure 2: Tree Learning for Unitree G1.* Tree Learning은 humanoid robot을 위한 multi-skill continual learning 프레임워크로, hierarchical parameter inheritance mechanism을 통해 catastrophic forgetting을 방지하면서 새로운 스킬을 효율적으로 확장한다.
Tree Learning은 biological hierarchy inspired architecture를 통해 humanoid robot의 multi-skill continual learning에서 catastrophic forgetting을 근본적으로 해결하면서 경량 배포를 가능하게 하는 창의적인 솔루션이다. 다만 real-world 환경에서의 실제 검증과 더 복잡한 skill 상호작용에 대한 확장성이 향후 과제이다.
Trinity: A Modular Humanoid Robot AI System
Fig. 1: Overview of the Modular Humanoid Robot AI System. In this system, task instructions are processed by both a visi
 *Fig. 1: Overview of the Modular Humanoid Robot AI System. In this system, task instructions are processed by both a visi* Trinity는 LLM, VLM, RL을 모듈식 계층 구조로 통합하여 humanoid robot을 제어하는 종합 AI 시스템이다. 각 모듈이 독립적으로 최적화되면서도 협력하여 복잡한 환경에서 humanoid robot의 효율적인 제어를 실현한다.
Trinity는 RL, LLM, VLM을 모듈식 계층 구조로 통합하여 humanoid robot의 복잡한 제어 문제를 체계적으로 해결하는 혁신적인 접근법을 제시한다. Full-scale humanoid robot에 대한 종합 검증과 loco-manipulation 성능이 주요 강점이나, 더 광범위한 작업에 대한 평가와 sim-to-real transfer 성능의 명확한 분석이 필요하다. 전반적으로 humanoid robotics 분야의 중요한 진전을 대표하는 양질의 시스템 논문이다.
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots

Fig. 1: Overview of RoboCasa. RoboCasa is a simulation framework for training generalist robot agents. Four pillars unde
 *Fig. 1: Overview of RoboCasa. RoboCasa is a simulation framework for training generalist robot agents. Four pillars unde* RoboCasa는 kitchen 환경에 중점을 둔 대규모 로봇 시뮬레이션 프레임워크로, 생성형 AI를 활용하여 다양한 3D 자산과 task를 확보하고 100K 이상의 synthetic trajectory로 generalist robot 학습을 가능하게 한다.
RoboCasa는 generative AI를 활용하여 robot learning을 위한 대규모 realistic simulation을 구축한 의미 있는 contribution이며, 실제 real-world transfer 성공을 보여줌으로써 sim-to-real robot learning의 실질적 경로를 제시한다. 다만 현재 kitchen 환경 집중과 제한된 real-world 검증은 향후 개선이 필요하다.
Thinking in 360°: Humanoid Visual Search in the Wild
Figure 1. We pose a fundamental question: can an AI agent actively search for objects or paths in a 3D world like a huma
 *Figure 1. We pose a fundamental question: can an AI agent actively search for objects or paths in a 3D world like a huma* 인간처럼 360° 파노라마 환경에서 머리 회전을 통해 능동적으로 물체를 탐색하거나 경로를 찾는 embodied 시각 탐색 에이전트를 제안하고, 실내 장면을 넘어 지하철역·쇼핑몰·거리 등 복잡한 현실 환경을 대상으로 한 H*Bench 벤치마크를 구축했다.
humanoid visual search라는 새로운 embodied AI 문제를 정의하고 현실적이고 도전적인 H*Bench 벤치마크를 제시함으로써 MLLM 기반 에이전트의 공간 추론 능력을 체계적으로 평가할 수 있는 기틀을 마련했으며, SFT와 RL을 통한 성능 향상을 보여주되 남은 큰 도전과제도 명확히 규명한 높은 가치의 연구이다.
Collision-Free Humanoid Traversal in Cluttered Indoor Scenes
Fig. 1: Using a single generalist policy, our humanoid robot achieves collision-free traversal in cluttered indoor envir
 *Fig. 2: Overall pipeline. We learn a visuomotor policy that maps diverse obstacle geometries and spatial layouts to* 인간형 로봇이 어수선한 실내 환경에서 장애물을 피하며 이동할 수 있도록 Humanoid Potential Field (HumanoidPF)를 제안하고, 하이브리드 장면 생성 방식과 RL 기반 학습으로 현실 세계에 성공적으로 전이시킨 연구이다.
이 논문은 humanoid 로봇의 현실적 실내 이동이라는 중요한 문제를 체계적으로 처음 다루면서, HumanoidPF라는 창의적이고 효과적인 표현 방식과 하이브리드 scene generation을 통해 실제 로봇에의 성공적 전이를 보여준다. 기술적 깊이, 실험의 포괄성, 그리고 실용적 가치 측면에서 humanoid robotics 분야에 상당한 기여를 하는 우수한 연구이다.
Dribble Master: Learning Agile Humanoid Dribbling through Legged Locomotion
Fig. 1: Dribble Master: Humanoid robot learning to dribble under various tasks. (a): The robot receives ball velocity co
 *Fig. 1: Dribble Master: Humanoid robot learning to dribble under various tasks. (a): The robot receives ball velocity co* 두 단계 curriculum learning과 virtual camera 모델을 이용하여 humanoid 로봇이 시뮬레이션에서 학습한 드리블링 정책을 실제 로봇에 성공적으로 전이하는 방법을 제안한다.
본 논문은 humanoid 로봇의 지속적이고 민첩한 드리블링을 최초로 실현한 의미 있는 연구로, 현실적 시각 제약 모델링과 실제 로봇 전이 성공은 높은 가치가 있다. 다만 정량적 평가와 방법의 일반화 가능성 검증이 보강되면 더욱 완성도 있을 것이다.
Humanoid Agent via Embodied Chain-of-Action Reasoning with Multimodal Foundation Models for Zero-Shot Loco-Manipulation
Fig. 1.
 *Fig. 1.* 인형로봇의 전신 보행-조작을 위해 기초 모델의 추론 능력과 Embodied Chain-of-Action (CoA) 메커니즘을 통합한 제로샷 에이전트 프레임워크를 제시한다. 고수준 인간 지시를 affordance 분석, 공간 추론, 전신 동작 추론을 통해 체계적인 보행 및 조작 원시 동작 수열로 분해한다.
본 논문은 Foundation model의 추론 능력을 인형로봇 보행-조작에 처음 통합한 의미 있는 기여이며, CoA Reasoning 메커니즘을 통해 자연어 지시를 물리적으로 실현 가능한 동작 수열로 변환하는 새로운 접근을 제시한다. 실제 인형로봇에서 강건한 제로샷 일반화를 입증한 점에서 높은 실용적 가치를 갖는다.
LHM-Humanoid: Learning a Unified Policy for Long-Horizon Humanoid Whole-Body Loco-Manipulation in Diverse Messy Environments
Fig. 1: Overview of LHM-Humanoid. Our system solves long-horizon loco-manipulation tasks
 *Fig. 1: Overview of LHM-Humanoid. Our system solves long-horizon loco-manipulation tasks* LHM-Humanoid는 다양한 혼란스러운 환경에서 장시간 인간형 로봇이 복수 객체를 반복적으로 집기, 운반, 배치하는 작업을 단일 통합 정책으로 수행하는 벤치마크와 학습 프레임워크를 제시한다.
본 논문은 장시간 혼란스러운 환경에서의 인간형 로봇 로코-조작이라는 도전적인 새로운 문제를 정의하고 이중 교사 증류 프레임워크로 효과적으로 해결하며, 350개 다양한 장면의 종합 벤치마크를 제공하여 로봇 일반화 연구에 의미 있는 기여를 한다.
MolmoSpaces: A Large-Scale Open Ecosystem for Robot Navigation and Manipulation
Figure 1 MolmoSpaces is an open ecosystem consisting of a large number of simulation environments, 3D articulated object
 *Figure 1 MolmoSpaces is an open ecosystem consisting of a large number of simulation environments, 3D articulated object* 로봇 네비게이션과 매니퓰레이션을 위한 230k개 이상의 다양한 실내 환경, 130k개의 주석이 달린 객체 자산, 42M개의 안정적인 그래스프를 포함하는 대규모 오픈 에코시스템 MolmoSpaces를 제시하고, 이를 통해 로봇 정책의 일반화 능력을 평가할 수 있는 벤치마크를 구축했다.
MolmoSpaces는 로봇 학습의 평가 기준이 되어 왔던 장면과 객체의 규모 제약을 크게 확장하며, simulator-agnostic 설계와 강한 시뮬-투-리얼 상관관계 검증으로 실무적 신뢰성을 확보한 중요한 오픈 인프라이다. 다만 task 복잡도와 시각적 현실성에서 아직 개선의 여지가 있다.
Robot Crash Course: Learning Soft and Stylized Falling
 *Fig. 2: Method Overview. We leverage reinforcement learn-* 이 논문은 양족 로봇의 낙하 현상 자체에 초점을 맞춰, 충격을 최소화하면서 사용자가 지정한 목표 자세에 도달하도록 하는 강화학습 기반 낙하 정책을 제안한다.
이 논문은 로봇 낙하를 예방이 아닌 제어 대상으로 재정의하는 독창적 관점을 제시하며, RL 기반 다목적 보상 함수와 샘플링 전략으로 범용적 해결책을 제공한다. 실제 양족 로봇에서 부드럽고 스타일화된 낙하를 시연한 점에서 높은 의의가 있으나, 정량적 평가 확대와 다양한 로봇 플랫폼 검증이 필요하다.
SafeFall: Learning Protective Control for Humanoid Robots
Fig. 1.
 *Fig. 1.* SafeFall은 휴머노이드 로봇의 낙상을 예측하고 손상 최소화 제어를 학습하는 프레임워크로, GRU 기반 낙상 예측기와 강화학습 정책을 결합하여 로봇의 구조적 취약성을 고려한 보호 행동을 실행한다.
SafeFall은 휴머노이드 로봇의 실제 배포를 가로막던 낙상 손상 문제를 처음으로 체계적으로 해결하는 프레임워크로, 강화학습과 손상 인식 설계를 결합하여 의미 있는 성능 개선을 달성했으며, 기존 제어기와의 무간섭 통합으로 즉시 실용성이 높다.
VIGOR: Visual Goal-In-Context Inference for Unified Humanoid Fall Safety
Fig. 1. Vision-enabled unified fall safety for humanoids. A single learned policy integrates fall mitigation and stand-u
 *Fig. 1. Vision-enabled unified fall safety for humanoids. A single learned policy integrates fall mitigation and stand-u* 휴머노이드 로봇의 넘어짐 안전성을 위해 teacher-student 증류 방식으로 egocentric depth와 proprioception만 사용하여 시각적 goal-in-context 표현을 학습하는 통합 접근법을 제시한다.
휴머노이드의 통합적 fall safety를 시각 기반으로 해결하는 창의적 접근으로, factorized data generation과 goal-in-context representation의 개념이 우수하며 zero-shot transfer 결과가 인상적이다. 다만 실제 환경 적용성을 더 광범위하게 검증할 필요가 있다.
Dexterous Safe Control for Humanoids in Cluttered Environments via Projected Safe Set Algorithm
Figure 1: Application of dexterous safe control for humanoids in cluttered environments. (a) A safe teleoperation task w
 *Figure 1: Application of dexterous safe control for humanoids in cluttered environments. (a) A safe teleoperation task w* 인간형 로봇이 복잡한 환경에서 다중 충돌 회피를 수행할 때 발생하는 제어 제약의 불가능성 문제를 해결하기 위해 Projected Safe Set Algorithm (p-SSA)을 제안한다.
밀집된 환경에서 인간형 로봇의 섬세한 다중 충돌 회피라는 현실적이고 중요한 문제를 처음 체계적으로 다루었으며, p-SSA 알고리즘은 실제 로봇 배포에 즉시 활용 가능한 실용적 해결책을 제시한다. 이론적 보장은 제한적이지만 광범위한 실증 검증과 무매개변수 일반화 능력이 인간형 로봇 안전 제어의 중요한 진전을 보여준다.
LEGO: Latent-space Exploration for Geometry-aware Optimization of Humanoid Kinematic Design
Fig. 1: Total pipeline for humanoid kinematic structure optimization. First, a dataset of robots is converted to a unifi
 *Fig. 1: Total pipeline for humanoid kinematic structure optimization. First, a dataset of robots is converted to a unifi* LEGO는 기존 로봇 설계 데이터와 인간 모션 데이터를 활용하여 humanoid 로봇의 kinematic 구조를 자동으로 최적화하는 데이터 기반 설계 프레임워크이다. Screw theory 기반 표현과 isometric manifold learning을 통해 compact한 latent space를 구성하고 gradient-free optimization으로 최적 설계를 탐색한다.
본 논문은 screw theory, isometric manifold learning, motion retargeting을 통합한 혁신적인 data-driven 로봇 설계 프레임워크를 제시하며, 실제 하드웨어 프로토타입 검증으로 실용성을 입증한 의미 있는 연구이다. 다만 제한된 학습 데이터와 특정 morphology에의 국한이 일반화 관점에서의 한계이나, 로봇 설계 자동화 분야에 중요한 기여를 제공한다.
Toward Humanoid Brain-Body Co-design: Joint Optimization of Control and Morphology for Fall Recovery
 *Fig. 2: The RoboCraft framework.* 본 논문은 humanoid 로봇의 fall recovery 능력을 향상시키기 위해 제어 정책과 신체 형태를 동시에 최적화하는 RoboCraft 프레임워크를 제안한다. 공유 제어 정책의 사전학습과 설계 공간 탐색을 결합하여 효율적인 co-design을 실현한다.
본 논문은 복잡한 humanoid 로봇에 대한 실질적이고 확장 가능한 co-design 프레임워크를 처음 제시하며, 다중 설계 사전학습 정책과 우선순위 버퍼를 통한 효율적 최적화로 형태 최적화의 중요성을 명확히 입증했다. 시뮬레이션 기반 한계에도 불구하고 embodied AI 분야의 중요한 진전을 나타낸다.
A Foot Resistive Force Model for Legged Locomotion on Muddy Terrains
 *Fig. 2 shows a set of snapshots of foot-mud interactions.* 진흙 지형에서 다리 로봇의 발-진흙 상호작용을 모델링하는 저항력 모델을 제시하고, 이를 바탕으로 변형 가능한 로봇 발을 설계하여 이동성과 에너지 효율을 향상시킨다.
본 논문은 진흙 지형에서 다리 로봇의 발-진흙 상호작용에 대한 첫 번째 포괄적 물리 기반 모델을 제시하며, 이를 바탕으로 설계된 변형 발의 성능 향상을 실험으로 검증함으로써 로봇 이동성 연구에 중요한 기여를 한다.
Bipedal-Walking-Dynamics Model on Granular Terrains
Figure 1. Schematic of the bipedal walking model with foot sinkage and slip on granular media. (a)
 *Figure 1. Schematic of the bipedal walking model with foot sinkage and slip on granular media. (a)* 본 논문은 모래와 같은 입자성 지형에서 이족 로봇의 보행 동역학을 모델링하기 위해 발의 침하(sinkage)와 슬립(slip)을 고려한 3개의 추가 자유도를 도입한 동적 발-지형 상호작용 모델을 제시한다.
본 논문은 입자성 지형에서의 이족 보행 동역학 모델링에 있어 발의 침하와 슬립을 처음으로 명시적으로 다룬 중요한 기여를 제시하며, 실험 검증을 통해 모델의 신뢰성을 입증했다. 제안된 모델은 granular terrain에서의 로봇 보행 제어 및 최적화를 위한 필수적인 기초 도구로서 높은 가치를 가진다.
Robot Trains Robot: Automatic Real-World Policy Adaptation and Learning for Humanoids
Figure 1: Robot Trains Robot (RTR). We pro-
 *Figure 1: Robot Trains Robot (RTR). We pro-* 로봇 팔(teacher)이 휴머노이드 로봇(student)을 지원하고 가이드하는 Robot-Trains-Robot(RTR) 프레임워크를 제안하여, 안전하고 효율적인 실제 환경에서의 휴머노이드 학습을 가능하게 한다. Dynamics-encoded latent variable 최적화를 통한 sim-to-real 전이 방법을 함께 제안한다.
실제 환경에서의 휴머노이드 학습이라는 중요하면서도 실제로 구현되지 않았던 문제에 대해, 혁신적인 teacher-robot 지원 방식과 효율적 sim-to-real 알고리즘을 결합하여 실질적인 해결책을 제시한다. 실험적 검증과 전반적 설계의 견고성이 우수하지만, 제한된 플랫폼과 태스크에서의 검증이라는 한계가 있다.
Scaling Large Motion Models with Million-Level Human Motions
Figure 1: TOP: While existing models perform well on
 *Figure 1: TOP: While existing models perform well on* LLM의 성공에 영감을 받아 백만 단위 규모의 대규모 모션 데이터셋 MotionLib를 구축하고, 이를 기반으로 Being-M0 모델을 훈련하여 대규모 모션 생성 모델의 확장성을 입증하는 연구이다.
이 논문은 모션 생성 분야에서 대규모 데이터와 모델 확장의 중요성을 처음으로 체계적으로 입증하며, MotionLib와 2D-LFQ 기술을 통해 실질적인 기여를 제공한다. 모션 생성 모델 개발의 새로운 기준을 제시하고 향후 연구의 견고한 기초를 마련한 중요한 연구이다.
Behavior Foundation Model for Humanoid Robots
Fig. 1: Behavior Foundation Model enables humanoid robots to perform a variety of behaviors in a zero-shot manner,
 *Fig. 2: Overview of BFM Implementation. (a) Human motion dataset is retargeted to humanoid robots for proxy agent* 본 논문은 휴머노이드 로봇의 다양한 제어 태스크에 일반화 가능한 행동 기반 파운데이션 모델(BFM)을 제안하며, masked online distillation과 CVAE를 결합하여 대규모 행동 데이터셋으로 사전학습한다.
본 논문은 휴머노이드 로봇 제어의 통합 행동 학습 패러다임을 명확히 제시하고 masked online distillation과 CVAE를 통한 실제적 구현으로 다양한 제어 모드 지원과 빠른 신행동 습득을 실현했으며, 시뮬레이션과 실제 플랫폼 양쪽에서 광범위하게 검증하여 범용 휴머노이드 제어의 새로운 방향을 제시한다.
DreamGen: Unlocking Generalization in Robot Learning through Video World Models
 *Figure 2: DREAMGEN Overview. We begin by fine-tuning a video world model on teleoperated robot trajectories.* DreamGen은 비디오 월드 모델(video world model)을 활용하여 최소한의 원격조종 데이터로부터 로봇 정책을 학습하는 4단계 파이프라인으로, 신규 행동과 환경에 대한 일반화를 달성한다.
DreamGen은 비디오 월드 모델을 로봇 학습의 효율적인 데이터 생성 도구로 재정의하여, 최소한의 원격조종 데이터로 다양한 행동과 환경 일반화를 달성하는 혁신적이고 실용적인 접근법을 제시한다. 다중 embodiment 실세계 검증과 DreamGen Bench라는 체계적 평가 도구까지 제공하여 로봇 학습 확장의 새로운 방향을 제시한다.
FastTD3: Simple, Fast, and Capable Reinforcement Learning for Humanoid Control
 *Figure 3: Summary of results. FastTD3 is a simple, fast, and capable RL algorithm that significantly* FastTD3는 병렬 시뮬레이션, 대배치 업데이트, 분포 기반 크리틱 등의 간단한 수정을 통해 TD3를 최적화하여 humanoid 로봇 제어 태스크를 단일 A100 GPU에서 3시간 이내에 학습하는 빠르고 효율적인 오프-정책 강화학습 알고리즘을 제시한다.
FastTD3는 기존 기법의 조합이지만 humanoid robotics에서 실무적으로 매우 유용한 간단하고 빠른 솔루션을 제공하며, 오픈소스 구현을 통해 RL 연구 커뮤니티의 접근성을 크게 향상시킨다. 다만 알고리즘 혁신보다는 엔지니어링 최적화에 중점을 두고 있어 과학적 원창성은 제한적이다.
GBC: Generalized Behavior-Cloning Framework for Whole-Body Humanoid Imitation
Fig. 1. GBC data processing pipeline. MoCap data (angle-axis representation)
 *Fig. 1. GBC data processing pipeline. MoCap data (angle-axis representation)* GBC는 이질적인 휴머노이드 로봇들을 위한 통합 행동 모방 프레임워크로, differentiable IK 기반 데이터 파이프라인, DAgger-MMPPO 알고리즘, MMTransformer 아키텍처를 결합하여 인간 모션캡처 데이터를 다양한 로봇에 자동으로 재타겟팅하고 학습한다.
본 논문은 이질적 휴머노이드 로봇들의 행동 모방을 위한 첫 번째 통합 프레임워크를 제시하며, differentiable IK, MMTransformer, DAgger-MMPPO 알고리즘을 결합하여 데이터 처리부터 정책 학습까지 일원화된 솔루션을 제공한다. 오픈소스 플랫폼 제공과 다중 로봇 검증을 통해 실용성과 확장성을 입증했으나, 실제 로봇 배포 성능 및 동적 환경에서의 강건성에 대한 검증이 후속과제이다.
H-Zero: Cross-Humanoid Locomotion Pretraining Enables Few-shot Novel Embodiment Transfer
Fig. 1: Left: We propose a locomotion pretraining pipeline for humanoids by mixing multiple randomized embodiments
 *Fig. 2: Method overview. a) The policy is pretrained by learning on a diverse set of humanoid embodiments through* H-Zero는 다양한 휴머노이드 로봇 embodiment에서 사전학습된 일반화된 이동 정책을 학습하여 미지의 로봇으로의 제로샷 및 소수샷 전이를 가능하게 하는 파이프라인이다.
H-Zero는 unified control semantics를 통해 실용적이고 확장 가능한 cross-embodiment 이동 제어 솔루션을 제시하며, 30분의 미세조정으로 신규 로봇에 적응할 수 있는 점에서 현실 배포 관점에서 큰 의의가 있다. 다만 embodiment 선택의 체계화와 더 다양한 형태의 로봇으로의 일반화 능력 검증이 필요하다.
HumanX: Toward Agile and Generalizable Humanoid Interaction Skills from Human Videos
Fig. 1: HumanX enables diverse interaction skills through two core components. XGen synthesizes and augments humanoid in
 *Fig. 1: HumanX enables diverse interaction skills through two core components. XGen synthesizes and augments humanoid in* HumanX는 인간 비디오로부터 휴머노이드 로봇의 상호작용 스킬을 학습하는 전체 스택 프레임워크로, XGen 데이터 생성 파이프라인과 XMimic 모방 학습 프레임워크의 두 가지 핵심 컴포넌트를 통합하여 과제별 보상 설계 없이 일반화 가능한 현실 세계 스킬을 습득한다.
HumanX는 물리 기반 데이터 합성과 일반화 우선 모방 학습을 결합하여 단일 비디오로부터 현실 세계 휴머노이드 로봇의 다양한 상호작용 스킬을 효율적으로 습득하는 획기적인 방법론을 제시하며, 8배 이상의 일반화 성능 향상과 적응형 행동 시연으로 로보틱스 분야에 상당한 기여를 한다.
Learning from Massive Human Videos for Universal Humanoid Pose Control
Figure 1. Overview. We introduce Humanoid-X, a large-scale dataset to facilitate humanoid robot learning from massive hu
 *Figure 2. Learning Humanoid Pose Control from Massive Videos. We mine massive human-centric video clips V from the Inter* Humanoid-X는 인터넷의 160,000개 이상의 인간 동영상으로부터 20백만 개의 휴머노이드 로봇 동작을 수집한 대규모 데이터셋이며, UH-1 모델을 통해 텍스트 명령을 휴머노이드 로봇의 제어 신호로 변환하는 범용 언어 조건부 제어를 실현한다.
본 논문은 휴머노이드 로봇 제어에 인터넷 비디오 빅데이터를 최초로 체계적으로 적용하고, 대규모 데이터셋과 범용 모델을 구축함으로써 로봇 학습의 확장성 문제를 실질적으로 해결한 중요한 기여를 한다. 시뮬레이션과 실세계 실험을 통한 검증이 충분하며 기술적·실무적 가치가 높다.
Natural Humanoid Robot Locomotion with Generative Motion Prior
본 논문은 Generative Motion Prior (GMP)를 활용하여 인간의 자연스러운 보행 데이터로부터 휴머노이드 로봇의 자연스러운 보행을 학습하는 방법을 제안한다. 기존의 adversarial motion prior 대신 frozen generative model을 사용하여 fine-grained motion-level 감독을 제공함으로써 학습 안정성과 해석 가능성을 향상시킨다.
본 논문은 generative motion prior를 활용한 혁신적 접근으로 humanoid robot의 자연스러운 보행 학습 문제를 효과적으로 해결하며, adversarial training의 불안정성을 제거하고 fine-grained guidance를 제공함으로써 motion naturalness에서 SOTA 성능을 달성한다. 다만 real-world 실험 확대와 다양한 환경에서의 일반화 능력 검증이 필요하다.
MuGen: Multi-Skill Generative Locomotion Controller for Humanoid Robots
Fig. 1: MuGen enables multi-skill humanoid locomotion by learning a generative controller. (a-d): A simulated humanoid t
 *Fig. 2: System overview 1) Motion Skill Embedding: states and reference motions are encoded into continuous representati* MuGen은 VQ-VAE와 model-based reinforcement learning을 결합하여 인간의 모션 데이터로부터 인형형 로봇의 다중 기술 보행 제어기를 학습하는 데이터 기반 프레임워크이다. Teacher-student learning과 새로운 policy distillation 전략을 통해 시뮬레이션에서 학습한 모션을 실제 로봇에 배포할 수 있게 한다.
MuGen은 VQ-VAE, model-based RL, teacher-student learning을 통합하여 인형형 로봇의 다중 기술 보행을 학습하고 배포하는 체계적이고 기술적으로 건전한 접근을 제시한다. 실제 Unitree G1 로봇에서의 검증과 미학습 모션에 대한 강건한 일반화 능력을 보여주었으나, sim-to-real gap의 완전한 해결, 데이터셋 규모/다양성의 상세 분석, 계산 복잡도 평가 등에서 개선이 필요하다. 전반적으로 인형형 로봇 제어 분야에 의미 있는 기여를 한 견실한 연구이다.
SCDP: Learning Humanoid Locomotion from Partial Observations via Mixed-Observation Distillation
Fig. 1: Deployment of Sensor-Conditioned Diffusion Policies
 *Fig. 2: Sensor-Conditioned Diffusion Policies (SCDP) architecture and training framework. The state-action diffusion* 온보드 센서만으로 휴머노이드 보행을 학습하기 위해 mixed-observation distillation을 사용하는 SCDP(Sensor-Conditioned Diffusion Policies)를 제안하며, diffusion model이 센서 이력에 조건화되면서 privileged 미래 상태-행동 궤적을 예측하도록 학습한다.
Mixed-observation distillation은 개념적으로 우수한 해결책이며, 실로봇 배포까지 달성한 점이 높게 평가된다. 다만 일반화 범위와 센서 robustness 측면의 추가 검증이 필요하며, IROS 채택으로 인정된 견고한 연구이다.
SoccerDiffusion: Toward Learning End-to-End Humanoid Robot Soccer from Gameplay Recordings
SoccerDiffusion은 transformer 기반 diffusion model을 활용하여 RoboCup 경기 녹화 데이터로부터 휴머노이드 로봇 축구의 end-to-end 제어 정책을 학습하고, distillation 기법으로 실시간 추론을 가능하게 한다.
본 논문은 실제 RoboCup 경기 데이터로부터 humanoid robot soccer 정책을 학습하는 실질적 시도로, transformer 기반 diffusion model과 distillation 기법의 조합으로 end-to-end 학습과 실시간 추론을 동시에 달성했다. 고수준 전략 행동은 제한적이지만 저수준 운동 행동의 효과적 학습과 공개 데이터셋 제공으로 향후 로봇 학습 연구의 견고한 기초를 마련했다.
Spectral Normalization for Lipschitz-Constrained Policies on Learning Humanoid Locomotion
Fig. 1.
 *Fig. 1.* 본 논문은 인간형 로봇의 보행 학습에서 Spectral Normalization (SN)을 사용하여 Lipschitz 연속성을 효율적으로 강제하고, 기존의 gradient penalty 기반 방법보다 GPU 메모리 오버헤드를 줄이면서도 유사한 성능을 달성한다.
본 논문은 Spectral Normalization이라는 기존 기법을 로봇 정책 학습의 대역폭 제약 문제에 창의적으로 적용하여, 계산 효율성과 성능을 모두 달성한 실용적인 솔루션을 제시한다. 시뮬레이션과 실제 로봇 양쪽에서의 검증으로 신뢰성을 높였으며, sim-to-real 전이 문제 해결에 중요한 기여를 한다.
AMO: Adaptive Motion Optimization for Hyper-Dexterous Humanoid Whole-Body Control
Fig. 1: AMO enables hyper-dexterous whole-body movements for humanoid robots. (a): The robot picks and places a can on
 *Fig. 2: System overview. The system is decomposed into four stages: 1. AMO module training by collecting AMO dataset* AMO는 sim-to-real RL과 trajectory optimization을 결합하여 29-DoF 인형로봇의 실시간 적응형 전신 제어를 구현하며, hybrid dataset 구성과 O.O.D. 명령에 대한 강건한 일반화를 통해 기존 방법의 운동 공간 제한을 극복한다.
AMO는 hybrid motion synthesis와 O.O.D. robust 정책 학습을 통해 인형로봇의 운동 공간을 획기적으로 확대한 혁신적 연구로, MoCap과 trajectory optimization의 상보적 장점을 효과적으로 결합하며 sim-to-real transfer와 실시간 적응형 제어에서 탁월한 성과를 보여준다.
Benchmarking Potential Based Rewards for Learning Humanoid Locomotion
Fig. 1: The potential based (left), direct (middle), and base-
 *Fig. 2: A visualization of a tracking reward in both direct-* 본 논문은 humanoid 로봇의 고차원 보행 학습에서 potential-based reward shaping (PBRS)과 direct reward shaping (DRS)을 벤치마크하여, PBRS가 수렴 속도에서는 한계적 이점만 제공하지만 보상 척도에 대해 훨씬 더 견고하다는 것을 실증적으로 입증한다.
본 논문은 고차원 로보틱 시스템에서 PBRS의 실제 효과를 실증적으로 검증한 중요한 케이스 스터디로, 보상 함수 설계의 실무적 지침(특히 견고성 측면)을 제공한다. 다만 단일 태스크 벤치마크와 이론-실전 간 격차의 원인 분석이 보강된다면 더욱 강력한 기여가 될 것이다.
Bridging the Sim-to-Real Gap for Athletic Loco-Manipulation
Fig. 1: Sim-to-real transfer of athletic loco-manipulation.
 *Fig. 2: Unsupervised Actuator Network (UAN) approach for real-to-sim-to-real. Our training pipeline involves three steps* 로봇의 운동 조작 작업에서 시뮬레이션-현실 간 격차를 줄이기 위해 실제 데이터로부터 액추에이터 동역학을 학습하는 Unsupervised Actuator Net (UAN)과 참조 궤적을 탐색 힌트로 활용하는 두 단계 학습 파이프라인을 제안한다.
본 논문은 토크 센싱 없는 UAN으로 복잡한 액추에이터 동역학을 학습하고, 참조 궤적을 탐색 힌트로 활용하는 우아한 두 단계 파이프라인으로 운동 로봇의 시뮬-현실 전이 문제를 체계적으로 해결했다. 실제 사족 조작 로봇에서 다양한 운동 작업의 성공적 구현으로 높은 실용성을 보여주며, RL 기반 로보틱스 분야에 기여도 높은 연구이다.
DoublyAware: Dual Planning and Policy Awareness for Temporal Difference Learning in Humanoid Locomotion
Fig. 1: Overview of DoublyAware: Disjoint uncertainty decomposi-
 *Fig. 1: Overview of DoublyAware: Disjoint uncertainty decomposi-* DoublyAware는 TD-MPC 프레임워크에서 불확실성을 planning uncertainty와 policy uncertainty로 명시적으로 분해하여, conformal prediction과 Group-Relative Policy Constraint를 통해 휴머노이드 로봇의 샘플 효율적이고 안정적인 학습을 실현한다.
본 논문은 MBRL의 핵심 문제인 불확실성을 planning과 policy로 분해하고 각각에 맞는 엄밀한 해법(conformal prediction, GRPC)을 제시함으로써 개념적 명확성과 기술적 우수성을 동시에 달성했다. 휴머노이드 로봇 제어라는 도전적 문제에서 실증적 개선을 보여주었으나, 실제 로봇 검증과 계산 비용 분석이 보완되면 더욱 강력한 기여가 될 것으로 판단된다.
DreamControl-v2: Simpler and Scalable Autonomous Humanoid Skills via Trainable Guided Diffusion Priors
Fig. 1: DreamControl-v2 enables scalable and autonomous humanoid skill acquisition. We demonstrate diverse real-world sk
 *Fig. 2: DreamControl-v2 Overview. Our four-stage pipeline enables humanoid whole-body manipulation: (1) large-scale huma* humanoid 로봇의 복잡한 manipulation 작업을 위해 guided diffusion 모델을 로봇의 motion space에 직접 학습하여, 다양한 인간과 로봇 데이터를 통합하고 RL 정책을 자동으로 생성하는 확장 가능한 프레임워크를 제시한다.
DreamControl-v2는 robot-space diffusion prior 훈련이라는 명확한 아이디어로 기존의 확장성 문제를 근본적으로 해결하며, 자동화된 파이프라인과 다양한 skill 습득을 통해 humanoid 로봇의 자율적 loco-manipulation에 실질적인 진전을 이루었다. 다만 다중 로봇 embodiment 일반화와 실제 환경에서의 광범위한 검증이 추가되면 더욱 강력한 기여가 될 것이다.
Flow Matching Imitation Learning for Multi-Support Manipulation
Figure 1.
 *Figure 1.* 본 논문은 Flow Matching 생성 모델을 활용하여 휴머노이드 로봇이 팔을 추가 지지점으로 사용하는 다중 접촉 조작 작업을 모방 학습으로 학습할 수 있는 통합 접근법을 제시한다. Talos 로봇에서 상자 밀기 및 식기세척기 문 닫기 작업을 성공적으로 수행하며, 공유 자율성 모드를 통해 인간 조작자를 지원한다.
본 논문은 Flow Matching을 실제 휴머노이드 로봇의 다중 접촉 조작 학습에 처음 적용한 혁신적 연구로, 이론적 기여와 실제 구현이 잘 결합되어 있다. 공유 자율성 모드를 통한 실용적 응용 가치와 생성 모델의 로봇 적용 가능성을 명확히 입증한다.
Learning Perceptive Humanoid Locomotion over Challenging Terrain

Fig. 1: Deployment to outdoor environments. We deployed the model in outdoor challenging terrains. Our controller can
 *Fig. 2: Training of Humanoid Perception Controller consists of two stages: (1) Oracle Policy Training generates referenc* 인간형 로봇이 소음이 있는 센서 데이터로부터 지형을 인식하고 거친 지형을 안정적으로 보행할 수 있도록, teacher-student distillation과 variational information bottleneck을 결합한 세계 모델 기반 방법을 제안한다.
본 논문은 teacher-student distillation과 world model 기반 센서 디노이징을 효과적으로 결합하여 인간형 로봇의 실제 환경 보행 성능을 크게 향상시켰다. 2 km의 다양한 지형 횡단 성과와 체계적인 방법론은 높은 기술적 가치를 가지며, 실제 로봇 배포를 위한 중요한 진전을 보여준다.
Mobi-$π$: Mobilizing Your Robot Learning Policy
Figure 1: Introducing policy mobilization. (a) Assume a visuomotor policy π trained from one or a set of limited camera
 *Figure 1: Introducing policy mobilization. (a) Assume a visuomotor policy π trained from one or a set of limited camera * 모바일 로봇에서 제한된 관점으로 학습된 조작 정책을 배포할 때 발생하는 분포 외 문제를 해결하기 위해, 정책과 호환되는 로봇 베이스 포즈를 찾는 '정책 모빌라이제이션' 문제를 제시하고 3D Gaussian Splatting과 샘플링 기반 최적화를 통해 해결한다.
본 논문은 모바일 조작 로봇에서 기존 정책의 재사용성을 크게 향상시키는 정책 모빌라이제이션이라는 새로운 문제를 정의하고, 3D Gaussian Splatting과 최적화 기법을 활용한 실용적 해법을 제시했다. 시뮬레이션과 실제 환경에서의 광범위한 검증을 통해 방법론의 유효성을 입증하였으며, 제시된 프레임워크는 향후 모바일 조작 연구의 중요한 기준이 될 것으로 기대된다.
Towards Bridging the Gap between Large-Scale Pretraining and Efficient Finetuning for Humanoid Control
Figure 1: Large-scale pretraIning and efficient FineTuning (LIFT) Framework. In stage (i), we
 *Figure 1: Large-scale pretraIning and efficient FineTuning (LIFT) Framework. In stage (i), we* 대규모 병렬 시뮬레이션에서 SAC 기반 정책 사전학습과 물리-정보 기반 세계 모델을 활용한 효율적 미세조정을 결합하여 휴머노이드 로봇의 시뮬-투-리얼 전이와 안전한 적응을 실현한다.
본 논문은 대규모 시뮬레이션 효율성과 샘플-효율적 적응을 효과적으로 결합하고, 안전성을 강조한 미세조정 전략으로 휴머노이드 제어의 실질적 도전을 해결한다. 실로봇 검증과 공개 코드는 로보틱스 커뮤니티에 즉시 활용 가능한 기초를 제공한다.
Robot Learning from Human Videos: A Survey
 *Figure 2. Taxonomy of robot learning from human videos.* 본 논문은 로봇이 인간 영상 시연으로부터 조작 기술을 습득하는 방법에 대한 포괄적 리뷰로서, task·observation·action 레벨에서의 계층적 전이 경로를 제시하고 데이터 기초를 체계적으로 분석한다. 인간 영상 기반 학습이 기존 로봇 텔레작동에 비해 5-10배 이상의 데이터 효율성을 제공함을 강조한다.
본 survey는 로봇 학습 분야에서 인간 영상 기반 스킬 획득이라는 급성장하는 분야에 대해 처음으로 체계적이고 포괄적인 분류 체계를 제시하며, 다각적인 비교 분석과 대규모 데이터 통계를 바탕으로 현재 연구 경관을 명확히 조망한다. 실제 데이터 효율성 개선(5-10배)이 실증되어 있어 학술적·실무적 중요성이 높으나, 정량적 성능 비교와 새로운 메서드 제시가 없는 순수 리뷰 논문이라는 한계가 있다.
Mobi-$π$: Mobilizing Your Robot Learning Policy
Figure 1: Introducing policy mobilization. (a) Assume a visuomotor policy π trained from one or a set of limited camera
 *Figure 1: Introducing policy mobilization. (a) Assume a visuomotor policy π trained from one or a set of limited camera * 본 논문은 제한된 카메라 뷰포인트에서 학습된 visuomotor 조작 정책을 모바일 로봇 플랫폼에서 실행 가능하게 하는 "policy mobilization" 문제를 정의하고, 3D Gaussian Splatting과 sampling-based optimization을 활용하여 최적의 로봇 베이스 포즈를 찾는 방법을 제안한다.
Policy mobilization을 명확히 정의하고 3D Gaussian Splatting 기반의 실질적 해결책을 제시한 우수한 연구이다. 기존 stationary robot 정책의 모바일 로봇 배포 문제를 elegant하게 해결하며, Mobi-π 프레임워크를 통해 체계적 평가가 가능하도록 한 점이 특히 가치있다. 다만 실환경 실험 규모 확대와 더 정교한 method 개발이 추가되면 영향력을 더욱 높일 수 있을 것으로 기대된다.
Sim-to-Real of Humanoid Locomotion Policies via Joint Torque Space Perturbation Injection
Fig. 1: Snapshots of training, sim-to-sim transfer, and sim-to-real transfer. This work proposes a novel sim-to-real met
 *Fig. 2: Overview of the training framework: The dynamics* 본 논문은 기존 domain randomization의 한계를 극복하기 위해 상태 의존적인 joint torque space perturbation을 주입하여 humanoid 로봇의 sim-to-real 전이를 개선하는 방법을 제안한다.
본 논문은 domain randomization의 근본적 한계를 creative하게 해결하고 full-sized humanoid 로봇에서 실증적 검증을 통해 sim-to-real 전이 분야에 유의미한 기여를 한다. 다만 방법의 일반화 가능성과 실제 배포 시나리오에서의 추가 고려사항에 대한 더 깊은 분석이 있으면 완성도가 높아질 수 있다.
The Role of Domain Randomization in Training Diffusion Policies for Whole-Body Humanoid Control
Figure 1: Proposed method. First, a robust and stable RL policy is trained using AMP under ex-
 *Figure 2: Evaluation of Diffusion Policies in a non-randomized target environment. Top: A plot dis-* 본 논문은 Humanoid 로봇의 전신 제어를 위해 Diffusion Policies를 훈련할 때 Domain Randomization의 역할을 조사하며, 조작 작업보다 보행 작업이 훨씬 더 큰 규모와 다양성의 데이터셋을 요구함을 보여준다.
본 논문은 humanoid 제어를 위한 Diffusion Policies의 데이터 요구사항에 대한 첫 체계적 ablation 연구로서, Domain Randomization의 중요성을 명확히 입증하고 조작-보행 작업 간의 근본적 차이를 정량화한다. 다만 실제 로봇 검증과 복잡한 작업으로의 확장이 필요하다.
Whole-body Humanoid Robot Locomotion with Human Reference
Fig. 1: The top image displays the humanoid robot Adam walking on unseen terrain,
 *Fig. 1: The top image displays the humanoid robot Adam walking on unseen terrain,* 인간의 보행 데이터를 활용한 모방 학습 프레임워크를 통해 풀사이즈 휴머노이드 로봇 Adam이 인간 수준의 보행 성능을 달성하는 방법을 제시한다.
휴머노이드 로봇 제어의 오래된 과제(복잡한 보상 함수, Sim2Real 간극)를 인간 모방 학습으로 효과적으로 해결하고 풀사이즈 로봇에서 첫 성공을 달성한 중요한 연구이다. 다만 정량적 평가 지표 부족과 경쟁 로봇과의 비교 분석이 보강되면 더욱 강력한 논문이 될 수 있다.
Adversarial Locomotion and Motion Imitation for Humanoid Policy Learning
인간형 로봇의 상반신과 하반신의 서로 다른 역할을 분리하여 학습하는 대적적 학습 프레임워크 ALMI를 제안하고, 시뮬레이션과 실제 로봇에서 강건한 보행과 정확한 모션 추적을 달성한다.
상반신과 하반신의 역할 분리를 adversarial learning으로 구현한 novel framework이며, 이론적 수렴 보장과 실제 로봇 구현의 성공이 결합되어 높은 실용성을 보유하고 있다. 대규모 dataset 공개로 향후 연구의 기반을 제공하는 점도 의미 있다.
Keep on Going: Learning Robust Humanoid Motion Skills via Selective Adversarial Training
 *Figure 2: Overview of the SA2RT. The SAP identifies vulnerabilities in motion states and generates adversarial samples b* 인간형 로봇의 장시간 안정적 운영을 위해 선택적 적대적 공격(SA2RT)을 통한 견고한 동작 제어 정책을 학습하는 방법을 제안한다. 공격 예산 제약 하에서 취약한 상태와 행동을 찾아 표적화된 섭동을 가하여 정책을 강화한다.
본 논문은 선택적 적대적 공격을 통해 인간형 로봇의 동작 견고성을 체계적으로 강화하는 혁신적인 방법을 제시하며, 실제 로봇 플랫폼에서 40% 성공률 향상 등 괄목할 만한 성과를 입증했다. 다만 단일 로봇 플랫폼 실험과 공격 예산 설정의 일반화 측면에서 개선의 여지가 있다.
Learning to Walk and Fly with Adversarial Motion Priors
 *Fig. 2: The discriminator learns to distinguish between samples* 본 논문은 Adversarial Motion Priors(AMP)와 강화학습을 결합하여 항공 인형로봇(aerial humanoid robot)이 인간 같은 보행과 비행 사이를 자동으로 전환하도록 학습하는 방법을 제시한다. 복잡한 보상 함수 없이 동작 데이터셋을 모방하면서 과제를 수행하며, 환경 피드백에 따라 locomotion 모드가 자발적으로 전환된다.
본 논문은 AMP와 강화학습의 결합을 통해 항공 인형로봇의 multimodal locomotion에서 자동 mode-switching이라는 미해결 문제를 우아하게 해결한 높은 수준의 연구이다. 비록 시뮬레이션 환경에 한정되어 있지만, 기술적 혁신성, 문제 해결의 우수성, 그리고 실제 응용 가능성 측면에서 로봇공학 분야에 의미 있는 기여를 한다.
Learning to Walk in Costume: Adversarial Motion Priors for Aesthetically Constrained Humanoids
Fig. 1: Cosmo: an entertainment humanoid robot with covers
 *Fig. 1: Cosmo: an entertainment humanoid robot with covers* 미적 설계 제약이 있는 엔터테인먼트 휴머노이드 로봇 Cosmo를 위해 Adversarial Motion Priors (AMP)를 기반으로 한 강화학습 보행 시스템을 제시하며, 극단적인 질량 분포와 움직임 제약 하에서도 자연스러운 보행 행동을 학습할 수 있음을 보여준다.
본 논문은 엔터테인먼트 로봇의 미적 설계 제약이라는 실제적이고 새로운 도전 문제를 다루면서 AMP 기반 학습을 성공적으로 적용한 의미 있는 연구이다. 극단적인 질량 분포와 제한된 감각 조건에서의 안정적인 sim-to-real 보행 달성은 인상적이지만, 특정 로봇 플랫폼에 대한 높은 맞춤화와 실험의 범위 제한이 일반화 가능성을 감소시킨다.
HALO: Hybrid Auto-encoded Locomotion with Learned Latent Dynamics, Poincaré Maps, and Regions of Attraction
Figure 1: Autoencoders enable learning of a reduced-order dynamics model in a latent space.
 *Figure 1: Autoencoders enable learning of a reduced-order dynamics model in a latent space.* HALO는 autoencoder와 Poincaré map을 결합하여 다리 로봇 같은 hybrid 동역학 시스템의 주기적 운동을 저차원 latent space에서 학습하고 분석하는 프레임워크이다. Latent space에서 Lyapunov 분석을 수행하여 region of attraction을 구성하고 이를 전체 시스템으로 복원한다.
HALO는 hybrid locomotion dynamics의 안정성 분석을 위해 autoencoder와 Poincaré map을 창의적으로 결합한 우수한 연구이며, latent space의 안정성 속성이 전체 시스템으로 이전된다는 것을 실험적으로 입증한다. 이론과 실험의 균형이 좋으나, 복잡한 시스템에서의 reconstruction 오차 처리와 robust 안정성 보장에 대한 더 깊은 분석이 필요하다.
Multi-Gait Learning for Humanoid Robots Using Reinforcement Learning with Selective Adversarial Motion Prior
Fig. 1.
 *Fig. 1.* 본 논문은 humanoid robot이 보행, 거위걸음, 달리기, 계단 오르기, 점프 등 5가지 서로 다른 보행 방식을 통일된 강화학습 프레임워크로 학습할 수 있도록 하는 선택적 Adversarial Motion Prior (AMP) 전략을 제안한다.
본 논문은 humanoid robot의 다중 보행 학습에서 AMP의 선택적 적용이라는 창의적인 아이디어를 제시하고, 통일된 강화학습 프레임워크로 5가지 이질적 보행을 성공적으로 학습 및 실로봇 배포한 것으로 실무적 가치가 높다. 다만 선택 기준의 일반화 부족과 단일 로봇 플랫폼 검증이라는 한계가 있어 추가 확장 연구가 필요하다.
SMAP: Self-supervised Motion Adaptation for Physically Plausible Humanoid Whole-body Control
 *Figure 3: Pipeline of SMAP* 본 논문은 인간 모션과 휴머노이드 로봇의 이질적 행동 공간 간 차이를 해결하기 위해 Vector-Quantized Periodic Autoencoder 기반의 Humanoid-Adapter를 제안하여 인간 모션을 물리적으로 타당한 로봇 모션으로 적응시키고, Teacher-Student 증류 학습을 통해 안정적인 전신 제어 정책을 학습한다.
본 논문은 인간-로봇 모션 이질성이라는 실질적 문제를 Vector-Quantized Periodic Autoencoder와 디커플된 보상을 통해 체계적으로 해결하며, 시뮬레이션과 실제 로봇 실험을 통해 방법의 효과성을 충분히 입증한다. 다만 특정 로봇 플랫폼에 한정된 검증과 일반화 가능성에 대한 추가 분석이 있으면 더욱 강력한 논문이 될 것으로 예상된다.
Agility Meets Stability: Versatile Humanoid Control with Heterogeneous Data
Fig. 1: Introducing AMS (Agility Meets Stability), one single policy that performs diverse motions with stability and ag
 *Fig. 2: Overview of AMS. (a) The general whole-body tracking pipeline retargets human MoCap data to reference motions* AMS는 휴먼 모션캡처 데이터와 합성 밸런스 데이터를 결합하여 단일 정책으로 민첩한 동작과 극한의 밸런스 유지를 동시에 수행할 수 있는 휴머노이드 제어 프레임워크다.
본 논문은 휴머노이드 로봇 제어의 오랫동안의 과제인 민첩성과 안정성의 통합을 처음으로 체계적으로 해결하며, 이질적 데이터와 하이브리드 보상 설계를 통한 창의적 접근과 실제 로봇에서의 강력한 성과를 보여준다.
Chasing Stability: Humanoid Running via Control Lyapunov Function Guided Reinforcement Learning
Fig. 1: Overview of our approach. Trajectory optimization
 *Fig. 1: Overview of our approach. Trajectory optimization* 본 논문은 Control Lyapunov Function(CLF)의 안정성 조건을 RL 보상에 임베딩하여 휴머노이드 로봇의 달리기를 실현하는 CLF-RL 방법을 제시한다. 이는 휴머노이드가 비행 및 단일 지지 상(flight and single support phases)를 포함한 동적 달리기를 수행하도록 한다.
본 논문은 고전 제어 이론(CLF)과 최신 RL을 매우 효과적으로 통합하여, 휴머노이드 로봇의 동적 달리기 제어를 위한 원리 기반의 체계적 프레임워크를 제시한다. 실제 하드웨어에서의 안정적 배포와 강건한 추적 성능은 높은 실용적 가치를 입증한다.
ExBody2: Advanced Expressive Humanoid Whole-Body Control
Fig. 1: Humanoid robot executing various expressive whole-body motions in the real world. The robot can (a) walk with a
 *Fig. 1: Humanoid robot executing various expressive whole-body motions in the real world. The robot can (a) walk with a * ExBody2는 휴머노이드 로봇이 인간의 모션 캡처 데이터와 시뮬레이션 데이터를 학습하여 표현력 있는 전신 동작을 수행하도록 하는 프레임워크이며, 자동화된 데이터 필터링과 teacher-student 기반의 decoupled motion-velocity 제어 전략을 통해 실제 로봇에 배포 가능하게 함.
ExBody2는 자동화된 데이터 필터링, generalist-specialist 파이프라인, decoupled motion-velocity 제어라는 세 가지 명확한 혁신을 통해 휴머노이드 로봇의 표현력 있는 전신 제어 문제를 체계적으로 해결하며, 실제 로봇에서의 다양한 동작 성공 시연으로 실질적 기여를 입증한 우수한 연구임.
SMASH: Mastering Scalable Whole-Body Skills for Humanoid Ping-Pong with Egocentric Vision
Fig. 1: SMASH: Our system enables the first outdoor humanoid ping-pong player and the first whole-body smash on a humano
 *Fig. 2: Overview of SMASH. Our system connects scalable motion generation, task-aligned policy learning, and egocentric* 휴머노이드 로봇의 탁구 게임을 위해 확장 가능한 전신 동작 학습과 자체 에고센트릭 비전을 통합한 SMASH 시스템을 제시하며, 외부 카메라나 모션 캡처 없이 실외에서 연속적인 탁구 스트라이킹을 처음으로 달성했다.
이 논문은 휴머노이드 탁구에서 에고센트릭 온보드 지각과 전신 협응 제어를 통합한 최초의 자율 시스템을 구현함으로써 로봇 동적 상호작용 연구에 중요한 기여를 하였다. Motion VAE 기반 동작 확장과 task-aligned motion matching이라는 확장 가능한 방법론은 다른 동적 로봇 과제에도 적용 가능한 잠재력이 있다.
HITTER: A HumanoId Table TEnnis Robot via Hierarchical Planning and Learning
Fig. 1: Humanoid table tennis rallies. Our system enables both humanoid-humanoid (left) and humanoid-human (right) match
 *Fig. 2: System overview. (a) The racket is mounted on the robot’s right wrist using a 3D-printed connector, and the ball* 휴머노이드 로봇이 탁구를 하기 위한 계층적 프레임워크를 제시하며, model-based planner와 RL 기반 whole-body controller를 통합하여 sub-second 반응 시간 내에 초당 5 m/s 이상의 볼을 처리한다.
본 논문은 humanoid table tennis를 통해 고속 동적 환경에서의 전신 제어 및 상호작용을 처음으로 성공적으로 시연하였으며, 계층적 planning-control 통합과 minimal human references를 통한 우아한 접근법이 인상적이다. 실제 세계 검증(106 연속 샷)은 방법론의 실용성을 강력히 입증한다.
Humanoid Whole-Body Badminton via Multi-Stage Reinforcement Learning
 *Fig. 2: System overview. (a) Training: PPO learns a single policy πWBC using Privileged Critic Obs together with Actor* 이 논문은 다단계 강화학습 커리큘럼을 통해 휴머노이드 로봇이 배드민턴을 하도록 학습하는 통합 전신 제어기를 제시하며, 시뮬레이션과 실제 로봇 모두에서 1초 이내의 반응 시간으로 19.1 m/s의 셔틀콕 속도를 달성했다.
이 논문은 휴머노이드 로봇의 고속 동적 상호작용 능력을 크게 진전시키며, 잘 설계된 3단계 커리큘럼과 실제 배포 성공이 인상적이다. 다만 예측 없는 변형의 실제 검증 부족과 현재 제한된 시험 환경이 향후 개선 과제이다.
HUSKY: Humanoid Skateboarding System via Physics-Aware Whole-Body Control
Fig. 1: Overview. (a) Our proposed framework HUSKY enables the humanoid robot to perform complete real-world skateboardi
 *Fig. 1: Overview. (a) Our proposed framework HUSKY enables the humanoid robot to perform complete real-world skateboardi* HUSKY는 humanoid 로봇이 skateboard 위에서 안정적으로 skating을 수행하기 위한 physics-aware whole-body control 프레임워크이며, lean-to-steer 제약과 hybrid contact dynamics를 명시적으로 모델링하여 AMP 기반 pushing과 physics-guided steering을 통합한다.
HUSKY는 humanoid skateboarding이라는 도전적인 문제를 physics-aware modeling과 hybrid control framework를 통해 창의적으로 해결한 고품질 연구이며, explicit system modeling과 DRL의 결합으로 real-world에서의 stable skateboarding을 실현한 점에서 significant contribution을 제시한다.
SoftMimic: Learning Compliant Whole-body Control from Examples
 *Fig. 2: Soft Whole-body Control via Compliant Motion Augmentation. Left: Given an original reference motion (qref) and a* SoftMimic은 역기구학 솔버를 이용해 순응적 동작 데이터셋을 생성하고 강화학습으로 학습하여, 인간형 로봇이 외부 힘에 순응하면서도 균형을 유지하는 제어 정책을 학습하는 프레임워크이다.
SoftMimic은 역기구학 기반 데이터 증강과 강화학습을 창의적으로 결합하여 인간형 로봇의 순응적 제어라는 중요한 문제를 체계적으로 해결하며, 이론과 실제 로봇 실험으로 그 효과를 입증한 우수한 연구이다.
A Humanoid Visual-Tactile-Action Dataset for Contact-Rich Manipulation
Fig. 1.
 *Fig. 1.* 인형로봇의 시각-촉각-행동 다중모달 데이터셋을 제시하여 접촉 기반 조작, 특히 부드러운 물체 조작을 위한 로봇 학습을 지원한다.
본 논문은 접촉 기반 조작 연구의 중요한 격차를 메우기 위해 인형로봇 기반의 고밀도 시각-촉각-행동 데이터셋을 처음으로 제시하며, 고해상도 촉각 신호의 필요성을 명확하게 입증하는 가치 있는 기여다.
CHIP: Adaptive Compliance for Humanoid Control through Hindsight Perturbation
Fig. 1: CHIP enables humanoid robots to perform manipulation tasks that require force control, such as wiping a whiteboa
 *Fig. 1: CHIP enables humanoid robots to perform manipulation tasks that require force control, such as wiping a whiteboa* CHIP는 hindsight perturbation을 통해 humanoid robot이 민첩한 움직임을 유지하면서도 적응적 compliance를 갖춘 forceful manipulation을 수행할 수 있게 하는 plug-and-play 모듈이다.
CHIP는 humanoid의 agile motion과 compliant manipulation을 양립시키는 우아한 해결책으로, hindsight perturbation이라는 핵심 아이디어의 단순함과 기존 framework와의 호환성이 강점이다. 다만 실제 로봇 검증과 force control의 정량적 분석이 보완되면 더욱 완성도 있는 연구가 될 것이다.
Embracing Bulky Objects with Humanoid Robots: Whole-Body Manipulation with Reinforcement Learning
Fig. 1.
 *Fig. 1.* 본 논문은 인간의 동작 사전(human motion prior)과 neural signed distance field(NSDF)를 통합한 강화학습 프레임워크를 제안하여 휴머노이드 로봇이 팔과 몸통을 조율해 부피가 큰 물체를 전신으로 포용하고 운반할 수 있도록 하는 방법을 제시한다.
본 논문은 휴머노이드 로봇의 전신 물체 포용 조작을 위한 최초의 RL 프레임워크를 제시하며, 인간 모션 사전과 NSDF의 통합을 통해 학습 효율성과 접촉 강건성을 동시에 달성한 혁신적인 연구다. 시뮬레이션과 실제 로봇 실험을 통한 검증이 충분하고 실용적 가치가 높다.
GentleHumanoid: Learning Upper-body Compliance for Contact-rich Human and Object Interaction
Fig. 1: GentleHumanoid learns a universal whole-body control policy with upper-body compliance and tunable force limits.
 *Fig. 1: GentleHumanoid learns a universal whole-body control policy with upper-body compliance and tunable force limits.* GentleHumanoid는 impedance control을 whole-body motion tracking 정책에 통합하여 humanoid 로봇의 상체 compliance를 학습하는 프레임워크이다. 이는 human motion data에서 샘플링한 spring-based formulation을 통해 resistive contact와 guiding contact를 통일적으로 모델링한다.
GentleHumanoid는 humanoid 로봇의 안전한 human-robot physical interaction을 위한 실질적이고 창의적인 솔루션을 제시한다. Unified spring-based formulation과 human motion data 기반 contact modeling의 조합은 novel하며, 실제 Unitree G1에서의 검증과 custom pressure-sensing 평가 방법론은 논문의 신뢰성을 높인다.
Humanoids in Hospitals: A Technical Study of Humanoid Robot Surrogates for Dexterous Medical Interventions
Fig. 1: Teleoperated humanoid robot in diverse medical scenarios. The following were performed with the presented
 *Fig. 1: Teleoperated humanoid robot in diverse medical scenarios. The following were performed with the presented* 본 연구는 Unitree G1 인간형 로봇에 대한 원격조종 시스템을 개발하여 7가지 의료 시술(신체검진, 응급 개입, 정밀 바늘 작업)을 수행할 수 있는 가능성을 탐색적으로 검증했다.
본 연구는 인간형 로봇의 의료 활용 가능성을 처음으로 체계적으로 탐색한 획기적인 연구로, innovative teleoperation 시스템과 실제 임상 작업 검증을 통해 향후 의료 로봇 통합의 토대를 마련했다. 다만 힘 출력과 센서 한계로 인한 현실적 과제 해결이 임상 배포를 위한 핵심 과제이다.
Multimodal Quad‐Finger Soft Robotic Hand With Dual‐Chamber Origami Actuator for Large‐Workspace Manipulation
 *Figure 5b,c,e,f, respectively, illustrate the 3D fingertip trajectories* 본 연구는 이중 챔버 SCOP actuator를 이용한 4지 소프트 로봇 핸드(QDO hand)를 제시하며, 양압과 음압 조절을 통해 축 방향 신축과 양방향 굽힘 등 다양한 운동 양식을 구현하여 5.2배 확대된 작업 공간을 달성한다.
본 논문은 이중 챔버 SCOP actuator와 DCI-FLMG 제어 방식을 통해 소프트 로봇 핸드의 작업 공간 확대와 다중 운동 양식을 동시에 달성한 혁신적 연구이며, 인간-로봇 협업과 복잡한 환경에서의 조작 능력 향상에 크게 기여할 것으로 기대된다.
Stability-Aware Retargeting for Humanoid Multi-Contact Teleoperation
Figure 1: Robot performing a teleoperated manipulation task, in
 *Figure 1: Robot performing a teleoperated manipulation task, in* 휴머노이드 로봇의 다중 접촉 텔레오퍼레이션 중 안정성을 향상시키기 위해 Centroidal stability 기반 retargeting을 제안하며, Linear Program 민감도 분석을 통해 효율적으로 안정성 여유 기울기를 계산한다.
다중 접촉 텔레오퍼레이션에 centroidal 안정성 분석을 효과적으로 통합하고 LP 민감도를 통한 새로운 기울기 계산 방법을 제시하며, 시뮬레이션과 하드웨어 검증으로 실용성을 입증한 견고한 기여.
Task and Motion Planning for Humanoid Loco-manipulation
Fig. 1: Overview of the proposed framework. Second panel: the task and the scene are translated into our symbolic framew
 *Fig. 1: Overview of the proposed framework. Second panel: the task and the scene are translated into our symbolic framew* 본 논문은 접촉 모드의 통일된 표현을 통해 로봇 이동과 조작을 함께 계획하는 최적화 기반 TAMP 프레임워크를 제시하며, 인형로봇의 장시간 복잡한 로코-조작 행동 생성을 가능하게 한다.
본 논문은 인형로봇의 동적 로코-조작 계획이라는 도전적 문제에 대해 접촉 수준의 통일된 기호 표현을 통해 이론적으로 견고한 TAMP 솔루션을 제시하며, 전신 동역학과 구동 제약을 포함한 점에서 학술적 기여도가 높다. 다만 실제 로봇 실험 검증과 대규모 문제에 대한 계산 효율 평가가 추가되면 영향력을 더욱 높일 수 있을 것으로 판단된다.
ToddlerBot: Open-Source ML-Compatible Humanoid Platform for Loco-Manipulation
Figure 1: ToddlerBot is an open-source humanoid platform for large-scale, high-quality data collec-
 *Figure 1: ToddlerBot is an open-source humanoid platform for large-scale, high-quality data collec-* ToddlerBot은 머신러닝 기반 로봇 정책 학습을 위해 설계된 저비용, 오픈소스 미니어처 인형로봇으로, 시뮬레이션과 실제 환경 모두에서 고품질 데이터 수집을 가능하게 하며 zero-shot sim-to-real 정책 전이를 지원한다.
ToddlerBot은 ML-compatible 설계, 높은 자유도, 완벽한 재현성, 그리고 저비용이라는 독특한 조합으로 로봇공학 연구를 민주화하는 중요한 플랫폼이며, 시뮬레이션-실제 데이터 수집과 정책 학습을 위한 실질적인 도구를 제공한다.
Whole-Body Bilateral Teleoperation with Multi-Stage Object Parameter Estimation for Wheeled Humanoid Locomanipulation
Fig. 1: Lifting and delivering a heavy water bottle (∼1/3 of robot’s weight)
 *Fig. 2: Overview of the whole-body bilateral teleoperation framework. (Left) A human pilot controls a wheeled humanoid w* 휠 달린 인간형 로봇의 원격조종 시스템에 다단계 물체 관성 매개변수 온라인 추정을 통합하여, 무거운 물체의 들기·운반 작업을 동적으로 수행할 수 있는 프레임워크를 제시한다.
본 논문은 VLM과 hierarchical sampling을 결합한 혁신적 물체 매개변수 추정과 이를 bilateral teleoperation에 통합함으로써 로봇의 무거운 부하 취급 능력을 획기적으로 향상시켰다. 시스템 설계, 기술 구현, 실험 검증 모두 우수하며 로봇 조작 작업의 실용화에 중요한 기여를 한다.
A Closed-Form Geometric Retargeting Solver for Upper Body Humanoid Robot Teleoperation
Fig. 1: We propose SEW-Mimic for retargeting human shoulder, elbow, and wrist (SEW) keypoints analytically to robot
 *Fig. 1: We propose SEW-Mimic for retargeting human shoulder, elbow, and wrist (SEW) keypoints analytically to robot* SEW-Mimic은 인간의 어깨, 팔꿈치, 손목(SEW) 키포인트를 7-DoF 로봇 팔의 관절각으로 변환하는 폐형식(closed-form) 기하학적 역운동학 솔버로, 3kHz의 고속 추론과 최적성 보장을 제공한다.
SEW-Mimic은 인간형 로봇 텔레오퍼레이션의 근본적 병목(계산 지연, 팔꿈치 제어 불일치)을 폐형식 기하학적 해석으로 우아하게 해결하며, 실증적 성과와 다중 플랫폼 검증으로 실무 임팩트가 높은 기여이다.
DemoHLM: From One Demonstration to Generalizable Humanoid Loco-Manipulation
Figure 1: Overview of DemoHLM. For each task, we collect a single demonstration via VR teleoperation
 *Figure 1: Overview of DemoHLM. For each task, we collect a single demonstration via VR teleoperation* DemoHLM은 단일 시뮬레이션 데모로부터 합성 데이터를 생성하여 휴머노이드 로봇의 일반화된 로코-매니퓰레이션 정책을 학습하는 프레임워크이다. 계층적 제어 구조를 통해 저수준 전신 제어기와 고수준 조작 정책을 통합하여 실제 로봇에 시뮬레이션-현실 전이를 달성한다.
본 논문은 MimicGen 개념을 휴머노이드 로코-매니퓰레이션으로 확장하여 단일 데모로부터 확장 가능한 데이터 생성을 실현하고, 계층적 제어 구조를 통해 현실 로봇에 효과적인 시뮬레이션-현실 전이를 달성했다. 데이터 효율성과 다중 작업 일반화 측면에서 강력한 기여를 제공하며, 실제 로봇 검증이 완전하여 실질적 가치가 높다.
Demonstrating Berkeley Humanoid Lite: An Open-source, Accessible, and Customizable 3D-printed Humanoid Robot
Fig. 1.
 *Fig. 1.* Berkeley Humanoid Lite는 3D-printed cycloidal gearbox를 활용한 오픈소스 휴머노이드 로봇으로, $5,000 이하의 저비용으로 데스크톱 3D프린터와 e-commerce 부품으로 제작 가능하며 강화학습 기반 locomotion controller를 통해 sim-to-real transfer를 입증했다.
Berkeley Humanoid Lite는 3D-printed cycloidal gear 기반 저비용 휴머노이드 로봇의 설계와 구현을 통해 로봇 연구의 접근성을 획기적으로 낮추고, 완전 오픈소스 공개 정책으로 커뮤니티 주도의 발전을 가능하게 했다. Reinforcement learning 기반 locomotion control의 성공적인 sim-to-real transfer는 플랫폼의 실용성을 입증하며, 향후 휴머노이드 로봇 연구의 민주화를 주도할 초석이 될 가능성이 크다.
Dexterous Teleoperation of 20-DoF ByteDexter Hand via Human Motion Retargeting
Figure 1 Our hand-arm teleoperation system achieves dexterous in-hand manipulation, including multi-object grasping,
 *Figure 2 An overview of the proposed hand-arm teleoperation system. The teleoperation interface consists of a Meta* ByteDexter라는 20-DoF 링크구동 로봇 손과 optimization 기반 motion retargeting을 이용하여 인간의 손 움직임을 실시간으로 로봇에 재현하는 원격조종 시스템을 제시한다.
ByteDexter 시스템은 linkage-driven 손의 mechanical design, fast kinematics solver, 그리고 optimization 기반 motion retargeting을 정교하게 통합하여 고-DoF 로봇 손의 원격조종을 실현하는 의미 있는 기여를 제시한다. 실시간 제어와 고품질 demonstration data 생성이라는 실용적 가치가 높지만, 다양한 task 환경에서의 general robustness와 imitation learning 결과의 실증이 필요하다.
Human-Robot Collaboration for the Remote Control of Mobile Humanoid Robots with Torso-Arm Coordination
Fig. 1: The experimental setup consists of two workspaces. The robotic workspace features a shelf unit with four shelves
 *Fig. 1: The experimental setup consists of two workspaces. The robotic workspace features a shelf unit with four shelves* 원격 제어되는 모바일 휴머노이드 로봇의 몸통-팔 협력 제어를 위해 인간-로봇 협업(HRC) 방법들을 제안하고, 사용자 연구(N=17)를 통해 자동 및 수동 제어 방식의 효과를 비교 평가한다.
원격 조종 휴머노이드 로봇의 몸통-팔 협력 문제에 대한 체계적이고 실용적인 HRC 솔루션을 제시하며, 사용자 중심의 평가를 통해 상황별 최적 제어 방식을 제공하는 의의 있는 연구이다. 다만 표본 크기와 실제 환경 검증의 확대가 필요하다.
LapSurgie: Humanoid Robots Performing Surgery via Teleoperated Handheld Laparoscopy
 *Fig. 2: The overview of the humanoid-based laparoscopic framework. The target tool pose Ptt is mapped from the control* LapSurgie는 인문형 로봇이 원격 조종을 통해 상용 복강경 수술 도구를 직접 조작할 수 있게 하는 최초의 텔레오퍼레이션 프레임워크로, 원격 중심 운동(RCM) 제약을 만족하는 역매핑 전략과 스테레오 비전 피드백을 통합한다.
LapSurgie는 인문형 로봇을 수술 영역에 처음 적용하고 RCM 제약 기반 역매핑 제어를 통해 상용 복강경 도구의 직관적 조작을 실현한 혁신적 연구로, 의료 자원 부족 지역에서의 로봇 수술 접근성 확대에 중요한 기여를 한다. 다만 임상 수준의 검증과 기술적 성숙도 향상이 필요하다.
Learning Differentiable Reachability Maps for Optimization-based Humanoid Motion Generation
Fig. 1.
 *Fig. 1.* 본 논문은 humanoid robot의 motion generation을 위해 differentiable reachability map을 학습하는 새로운 방법을 제안한다. 이 맵은 task space에서 정의된 스칼라 함수로서, robot end-effector이 도달 가능한 영역에서만 양수값을 가지며, task space 좌표에 대해 미분가능하여 continuous optimization의 제약조건으로 직접 사용될 수 있다.
본 논문은 humanoid motion planning의 computational bottleneck을 해결하기 위해 differentiable reachability map이라는 혁신적 표현을 제안하며, binary classification 기반의 학습 방법론은 기존 방식의 한계를 잘 극복한다. 다만 실제 실험 결과와 성능 평가에 대한 상세한 검증이 필요하다.
Opt2Skill: Imitating Dynamically-feasible Whole-Body Trajectories for Versatile Humanoid Loco-Manipulation
Fig. 1. The proposed Opt2Skill framework enables a Digit humanoid robot to
 *Fig. 1. The proposed Opt2Skill framework enables a Digit humanoid robot to* Opt2Skill은 Differential Dynamic Programming (DDP)로 생성한 동역학적으로 실현 가능한 궤적을 Reinforcement Learning (RL)으로 모방하게 함으로써 인간형 로봇의 다양한 로코-조작 작업을 효과적으로 수행하는 통합 파이프라인이다.
Opt2Skill은 model-based trajectory optimization과 reinforcement learning을 효과적으로 결합하여 인간형 로봇의 동역학적으로 실현 가능한 다양한 로코-조작 작업을 체계적으로 해결하며, 실제 하드웨어 전이까지 성공한 중요한 기여로, 토크 정보 활용과 광범위한 실험 검증을 통해 높은 과학적 가치를 갖춘다.
ULC: A Unified and Fine-Grained Controller for Humanoid Loco-Manipulation
Fig. 1: Diverse loco-manipulation capabilities enabled by ULC. The humanoid robot demonstrates various coordinated whole
 *Fig. 1: Diverse loco-manipulation capabilities enabled by ULC. The humanoid robot demonstrates various coordinated whole* ULC는 인간형 로봇의 보행-조작을 위해 상체와 하체 제어를 통합한 단일 정책 프레임워크로, sequential skill acquisition, residual action modeling, 다항식 보간 등의 기술을 통해 추적 정확도, 넓은 작업 공간, 견고성을 동시에 달성한다.
ULC는 humanoid loco-manipulation 분야에서 통합 제어의 실행 가능성을 처음으로 대규모 실험으로 입증한 의미 있는 논문이며, sequential skill acquisition, residual action modeling, deployment-realistic training 등의 체계적인 기술 조합으로 높은 추적 성능과 넓은 작업 공간을 동시에 달성했다. 다만 단일 하드웨어 플랫폼에만 검증되었고 시뮬레이션 기반 훈련의 현실 일반화 가능성에 대한 상세 분석이 부족한 점이 한계이다.
Stabilizing Humanoid Robot Trajectory Generation via Physics-Informed Learning and Control-Informed Steering
Fig. 1: Our method used to execute various walking direc-
 *Fig. 1: Our method used to execute various walking direc-* 인간형 로봇의 궤적 생성에 물리 기반 학습과 제어 기반 보정을 결합하여 모방학습의 안정성을 향상시키는 방법을 제안한다. Physics-informed loss와 PI 제어기를 통해 물리 법칙 위반을 줄이고 실제 로봇에서의 안정성을 개선한다.
본 논문은 물리 기반 학습과 제어 이론을 효과적으로 결합하여 인간형 로봇 궤적 생성의 실제 안정성을 향상시키는 실질적이고 모듈식의 접근법을 제시한다. 특히 미분가능한 물리 제약 인코딩과 추론 단계의 PI 제어 보정은 구현이 간단하면서도 실증적 효과가 크며, 실제 로봇 검증으로 산업 적용 가능성을 보여준다.
STATE-NAV: Stability-Aware Traversability Estimation for Bipedal Navigation on Rough Terrain
Figure 1: Overall diagram of the proposed traversability estimation and the navigation framework. A transformer-based bi
 *Figure 1: Overall diagram of the proposed traversability estimation and the navigation framework. A transformer-based bi* 이족 로봇의 불안정성을 예측하는 TravFormer 신경망을 개발하고, 안정성 기반 명령 속도를 traversability로 정의하여 거친 지형에서의 안전하고 효율적인 네비게이션을 실현한다.
이 논문은 이족 로봇의 안정성 기반 traversability 추정이라는 중요하면서도 미개척된 문제를 처음 체계적으로 다루며, BSFA 특성 식별부터 TravFormer 개발, 계층적 네비게이션 프레임워크까지 일관된 기술적 기여를 제시한다. 시뮬레이션과 실제 로봇 실험을 통한 검증이 견고하고, 안정성 기반 속도 표현이라는 혁신적 설계로 가중치 재조정 문제를 해결하여 실용적 가치가 높다.
Unveiling the Impact of Data and Model Scaling on High-Level Control for Humanoid Robots
Fig. 1. We present the large-scale, high-quality robot motion dataset
 *Fig. 1. We present the large-scale, high-quality robot motion dataset* 대규모 인간 모션 데이터를 활용하여 자동 파이프라인으로 생성한 Humanoid-Union 데이터셋(260시간)과 이를 기반으로 하는 SCHUR 프레임워크를 제안하여 텍스트 기반 휴머노이드 로봇 모션 생성의 확장성을 달성했다.
본 논문은 대규모 자동화 파이프라인으로 고품질 로봇 모션 데이터셋을 구축하고, FSQ VAE 및 LLaMA 기반 SCHUR 프레임워크로 효과적인 data/model scaling을 달성하여 휴머노이드 로봇의 텍스트 기반 고수준 제어의 실질적 발전을 보여준다.
AME-2: Agile and Generalized Legged Locomotion via Attention-Based Neural Map Encoding
Fig. 1. Our method enables agile and generalized legged locomotion across diverse terrains with onboard sensing and comp
 *Fig. 1. Our method enables agile and generalized legged locomotion across diverse terrains with onboard sensing and comp* AME-2는 Attention 기반 맵 인코더를 통합한 통합 RL 프레임워크로, 민첩성과 일반화를 동시에 달성하는 사족/이족 로봇 보행 제어 방법이다. 학습 기반의 불확실성 인식 elevation mapping 파이프라인과 teacher-student 학습 체계를 통해 sim-to-real 이전을 개선한다.
AME-2는 Attention 기반 맵 인코더와 불확실성 인식 elevation mapping을 통해 agile과 generalized 보행을 통합적으로 달성하는 우수한 프레임워크이며, quadruped과 biped 양쪽에서 실증된 강력한 일반화 능력과 sim-to-real 이전 효과를 입증함으로써 legged locomotion 분야에 중요한 기여를 한다.
DiffCoTune: Differentiable Co-Tuning for Cross-domain Robot Control
Fig. 1: Overview of the proposed automated co-tuning approach for
 *Fig. 1: Overview of the proposed automated co-tuning approach for* 로봇 컨트롤러의 시뮬레이션-실제 환경 간 성능 격차를 해결하기 위해 differentiable simulator를 활용한 gradient 기반 co-tuning 프레임워크를 제안하며, 컨트롤러와 시뮬레이터 매개변수를 동시에 최적화하여 적은 시행횟수로 체계적인 도메인 전이를 가능하게 한다.
본 논문은 로봇 도메인 전이의 실질적 문제를 differentiable simulator 기반의 우아한 co-tuning 프레임워크로 해결하며, 다양한 컨트롤러와 시스템에서의 광범위한 실험을 통해 실용성을 입증한 기여도 높은 연구이다.
End-to-End Humanoid Robot Safe and Comfortable Locomotion Policy
Fig. 1.
 *Fig. 1.* 휴머노이드 로봇의 안전하고 편안한 네비게이션을 위해 LiDAR 포인트 클라우드를 모터 커맨드로 직접 매핑하는 end-to-end 정책을 제시하며, CMDP 프레임워크에서 CBF 원리를 비용 함수로 변환하여 P3O로 안전 제약을 강제한다.
본 논문은 LiDAR 기반 end-to-end 정책, CBF-CMDP-P3O 통합 프레임워크, HRI 기반 편안함 설계를 통해 휴머노이드 로봇의 안전하고 사회적으로 수용 가능한 네비게이션 문제를 종합적으로 해결한 강력한 기여를 제시한다. 형식적 안전 보장과 실제 배포의 균형을 잘 맞추었으며, 다만 비선형 동역학과 도메인 갭 분석 강화가 필요하다.
FastStair: Learning to Run Up Stairs with Humanoid Robots
Fig. 1.
 *Fig. 2.* FastStair는 model-based foothold planner와 model-free RL을 통합하여 humanoid robot의 고속 계단 등반을 실현하는 다단계 학습 프레임워크이다. DCM 기반 planner로 탐색을 안내하고 speed-specialized experts와 LoRA를 통해 보수성을 완화한다.
FastStair는 model-based 안정성과 learning-based 민첩성의 근본적 상충을 다단계 학습과 LoRA 기반 통합으로 우아하게 해결한 혁신적 프레임워크이다. 실제 로봇 배포와 경쟁 우승으로 실용성이 입증되었다.
Learning a Vision-Based Footstep Planner for Hierarchical Walking Control
Fig. 1.
 *Fig. 2.* 본 논문은 단일 깊이 카메라와 reinforcement learning 기반의 계층적 제어 프레임워크를 통해 쌍족 로봇이 비정형 지형에서 실시간 발걸음 계획을 수행하도록 하는 시각 기반 발걸음 계획기를 제시한다. Angular Momentum Linear Inverted Pendulum 모델을 활용하여 저차원 상태 표현을 구성하고 상위 레벨의 RL 발걸음 계획기와 하위 레벨의 Operational Space Controller를 통합한다.
본 논문은 RL 기반 발걸음 계획을 ALIP 모델과 깊이 카메라 vision으로 통합한 실질적인 계층적 제어 프레임워크를 제시하며, 실제 로봇 하드웨어에서의 검증을 통해 실용성을 입증한다. 다만 ALIP 모델의 표현력 한계와 복잡한 지형에서의 성능 저하가 명확하게 드러나 향후 더 정교한 모델이나 end-to-end 학습 접근의 필요성을 시사한다.
Learning agile and dynamic motor skills for legged robots
 *Fig. 5. Training control policies in simulation. The policy net-* 본 논문은 시뮬레이션에서 reinforcement learning으로 사족 로봇의 제어 정책을 학습하고 현실의 ANYmal 로봇에 전이하는 방법을 제시하여, 고속 주행과 낙하 복구 등의 동적 운동 기술을 달성했다.
본 논문은 사족 로봇의 동적 제어에 reinforcement learning과 domain randomization을 효과적으로 결합하여 시뮬레이션-현실 전이 문제를 체계적으로 해결했으며, 실제 고급 로봇 플랫폼에서 이전에 달성하지 못한 수준의 운동 기술을 구현함으로써 로봇 제어 분야에 중요한 기여를 했다.
Learning Agile Striker Skills for Humanoid Soccer Robots from Noisy Sensory Input
 *Fig. 2: Left: The network architectures for the teacher and the student network; Right: Multi-stage training framework: * 이 논문은 reinforcement learning 기반의 4단계 학습 프레임워크를 통해 인간형 로봇이 노이즈가 있는 센서 입력에서도 강건한 볼 킹킹 기술을 습득하도록 하는 시스템을 제시한다.
이 논문은 noisy perception 환경에서 인간형 로봇의 복잡한 동적 기술을 학습하는 현실적이고 체계적인 프레임워크를 제시하며, 4단계 curriculum, 현실적 지각 모델링, constrained RL 적응의 조합으로 sim-to-real gap을 효과적으로 감소시켰다. 실제 로봇 실험 결과와 포괄적 ablation 연구는 제안 방법의 타당성을 잘 입증하고 있으나, 단일 로봇 플랫폼 평가와 66.7% 성공률이 실무 적용성을 위해서는 추가 개선이 필요하다.
Learning Social Navigation from Positive and Negative Demonstrations and Rule-Based Specifications
Fig. 1: Overview of the proposed framework. A. Reward learning: (a) density-based reward maps are constructed from
 *Fig. 1: Overview of the proposed framework. A. Reward learning: (a) density-based reward maps are constructed from* 본 논문은 긍정적 및 부정적 시연과 규칙 기반 명세로부터 학습한 밀도 기반 보상을 결합하여 동적 인간 환경에서 안전성과 적응성의 균형을 맞춘 모바일 로봇 네비게이션 정책을 개발한다.
본 논문은 데이터 기반 보상과 규칙 기반 안전 명제의 효과적인 통합을 통해 동적 인간 환경에서의 로봇 네비게이션을 다루는 실용적이고 신뢰할 수 있는 해결책을 제시하며, teacher-student 증류 및 불확실성 추정 기법을 포함한 방법론적 기여와 함께 실제 인간 참여자 실험으로 검증한 점에서 높은 가치를 갖는다.
PACE: Physics Augmentation for Coordinated End-to-end Reinforcement Learning toward Versatile Humanoid Table Tennis
Fig. 1.
 *Fig. 2.* 본 논문은 휴머노이드 로봇의 탁구 경기를 위해 학습된 예측기와 물리 기반 보상을 결합한 end-to-end RL 프레임워크 PACE를 제안하여, 전신 협응 제어와 민첩한 풋워크를 동시에 달성한다.
본 논문은 학습된 예측기와 physics-augmented 보상 설계를 통해 휴머노이드 탁구의 end-to-end RL을 성공적으로 구현한 강력한 작업이며, 시뮬레이션과 실제 하드웨어 모두에서 높은 성능을 입증하여 로봇 동적 제어의 실질적 진전을 보여준다.
Learning Humanoid Locomotion with Perceptive Internal Model
Fig. 1: We propose a perceptive humanoid locomotion policy capable of mastering various challenging terrains. This polic
 *Fig. 1: We propose a perceptive humanoid locomotion policy capable of mastering various challenging terrains. This polic* 본 논문은 휴머노이드 로봇의 불안정한 형태학적 특성으로 인해 필수적인 지각 정보를 효과적으로 통합하기 위해 Perceptive Internal Model (PIM)을 제안한다. 로봇 중심의 elevation map을 기반으로 하는 이 방법은 깊이 맵이나 포인트 클라우드 직접 인코딩과 달리 시뮬레이션에서 최소한의 계산 비용으로 3시간 내에 정책 학습을 완료할 수 있다.
본 논문은 로봇 중심 elevation map 기반 지각 정보 통합을 통해 휴머노이드 로봇의 안정적인 복잡 지형 주행을 실현하는 실질적이고 효율적인 방법을 제시한다. 단일 단계 훈련으로 우수한 성능을 달성하며 다양한 로봇 플랫폼에 검증된 점이 강점이나, 실제 환경 적용 시 elevation map 구성 오류에 대한 견고성 분석이 보완되면 더욱 완성도 있는 연구가 될 것이다.
Learning Humanoid Locomotion with World Model Reconstruction
Fig. 1: Deployment to outdoor environments. We deployed the model in an outdoor environment covered in ice and snow.
 *Fig. 2: Illustration of the World Model Reconstruction framework. Our framework explicitly reconstructs world state from* 본 논문은 humanoid robot의 blind locomotion을 위해 World Model Reconstruction (WMR)을 제안한다. 센서 노이즈로부터 world state를 명시적으로 재구성하고, gradient cutoff를 통해 estimator와 policy를 독립적으로 학습시킴으로써 실제 복잡한 지형에서의 견고한 주행을 실현한다.
본 논문은 humanoid 로봇의 blind locomotion을 위한 명시적 world model reconstruction의 효과를 체계적으로 입증하고, gradient cutoff 메커니즘을 통해 estimation과 policy learning의 충돌을 창의적으로 해결한다. 단일 학습 단계로 복잡한 실제 지형에서의 장거리 주행을 달성한 것은 실질적 임팩트가 크며, 3.2 km hike의 구체적 성과는 방법의 실효성을 명확히 보여준다. 다만 단일 로봇 플랫폼 실험과 failure case 분석의 부족이 아쉬우나, 전체적으로 humanoid locomotion 분야에 의미있는 기여를 하는 고품질 연구이다.
The MIT Humanoid Robot: Design, Motion Planning, and Control For Acrobatic Behaviors
Fig. 1.
 *Fig. 1.* MIT 휴머노이드 로봇이 고도의 동역학 운동(백플립, 전플립, 회전 점프)을 수행하기 위해 맞춤형 액추에이터 설계, actuator-aware kino-dynamic 모션 플래닝, 그리고 MPC와 WBIC을 통합한 착지 제어 시스템을 제시한다.
본 논문은 humanoid 로봇의 고도의 동역학 운동을 실현하기 위해 하드웨어, 모션 플래닝, 제어를 통합적으로 설계한 체계적인 접근법을 제시하며, 맞춤형 액추에이터 개발과 정밀한 검증을 통해 높은 신뢰성을 확보한 우수한 연구이다.
Whole-body Multi-contact Motion Control for Humanoid Robots Based on Distributed Tactile Sensors
Fig. 1. Control system for whole-body multi-contact motion in a humanoid robot.
 *Fig. 1. Control system for whole-body multi-contact motion in a humanoid robot.* 휴머노이드 로봇이 분산 촉각 센서를 장착하여 팔꿈치, 무릎 등 중간 영역의 접촉을 포함한 전신 다중 접촉 모션을 제어하는 방법을 개발했다.
본 논문은 distributed tactile sensor를 활용하여 휴머노이드 로봇의 전신 다중 접촉 모션을 처음으로 실현한 의미 있는 연구로, 방법론과 검증이 체계적이나 autonomous planning 미흡이 제한적이다.
A Whole-Body Motion Imitation Framework from Human Data for Full-Size Humanoid Robot
 *Fig. 2.* 전신 동작 모방을 위해 contact-aware 전신 모션 리타겟팅과 비선형 중심 MPC를 결합한 휴머노이드 로봇 제어 프레임워크를 제안한다. 실제 휴머노이드 로봇에서 인간의 다양한 전신 동작을 정확하고 안정적으로 모방할 수 있음을 입증한다.
Contact-aware motion retargeting과 nonlinear centroidal MPC를 체계적으로 결합하여 실제 휴머노이드 로봇에서 정확하고 안정적인 전신 모션 모방을 달성한 강력한 연구이다. 실제 로봇 플랫폼에서의 광범위한 검증은 실용적 가치를 높이나, 고속 동작 확장 및 강건성 분석에서 추가 개선이 필요하다.
Implicit Kinodynamic Motion Retargeting for Human-to-humanoid Imitation Learning
 *Fig. 2: Overall pipeline for our proposed framework. We model motion retargeting as a sequence-to-sequence mapping from * 본 논문은 인간의 모션을 휴머노이드 로봇이 실행 가능한 모션으로 변환하는 Implicit Kinodynamic Motion Retargeting (IKMR) 프레임워크를 제안하며, 기존 frame-by-frame 방식의 비효율성을 극복하고 대규모 모션을 실시간으로 처리한다.
본 논문은 motion retargeting에 implicit neural network을 처음 도입하여 scalability 문제를 혁신적으로 해결하고, kinematics과 dynamics를 체계적으로 통합함으로써 physically feasible한 대규모 모션 자동 변환을 실현한 의미 있는 기여이며, 실제 휴머노이드 로봇 배포 검증으로 실용성을 입증했다.
iRonCub 3: The Jet-Powered Flying Humanoid Robot
 *Fig. 2.* iRonCub 3는 제트 터빈 4개를 장착한 완전 인형형 비행 로봇으로, 시뮬레이션 검증 후 최초로 수직 이착륙에 성공했다.
iRonCub 3는 인형형 로봇 비행의 기술적 난제(제어, 추정, 기계 통합)를 체계적으로 해결하고 최초 비행 실증을 달성했으나, 고등 기동과 조작 능력 통합은 향후 과제다.
It Takes Two: Learning Interactive Whole-Body Control Between Humanoid Robots
 *Figure 2: Overview of the proposed Harmanoid framework. It contains two key components: (i) contact-aware motion retarge* Harmanoid는 두 개의 휴머노이드 로봇 간 상호작용 동작을 모방하는 프레임워크로, 접촉 인식 motion retargeting과 상호작용 기반 motion controller를 통해 키네마틱 충실도와 물리적 현실성을 동시에 보존한다.
Harmanoid는 다중 휴머노이드 상호작용 동작 모방의 명확한 문제를 체계적으로 해결하며, contact-aware retargeting과 interaction-aware control의 결합으로 고립 문제를 효과적으로 극복하는 첫 프레임워크이다. 종합적인 실험과 우수한 성능으로 humanoid robotics 분야에 중요한 기여를 하나, sim-to-real 검증 부재와 2-agent 제한이 실제 적용의 완전성을 제약한다.
Safe Human-to-Humanoid Motion Imitation Using Control Barrier Functions
Fig. 1: Overview of the proposed safe human-to-humanoid motion imitation framework.
 *Fig. 1: Overview of the proposed safe human-to-humanoid motion imitation framework.* 비전 기반 motion retargeting과 Control Barrier Function을 결합하여 휴머노이드 로봇이 인간의 동작을 모방하면서 자기 충돌과 인간-로봇 충돌을 실시간으로 회피할 수 있는 안전 프레임워크를 제시한다.
비전 기반 motion imitation에 CBF를 체계적으로 도입하여 실시간 안전 필터링을 구현한 실질적 기여이며, 충돌 회피와 responsiveness의 균형을 QP로 효과적으로 달성했다. 다만 시뮬레이션만 제시되고 하드웨어 검증이 필요하며, 설계 parameter 튜닝과 일반화 가능성 개선이 추후 과제이다.
A Behavior Architecture for Fast Humanoid Robot Door Traversals
Figure 1: The Nadia humanoid robot performing a right pull lever handle door traversal using cycloidal drive forearms an
 *Figure 2: An all inclusive overview of the parts involved in this work.* 휴머노이드 로봇의 다양한 도어 통과 작업을 수행하기 위해 GPU 가속 인식, Behavior Tree 기반 행동 조정 시스템, 전신 제어기를 통합한 아키텍처를 제시한다. 실제 Nadia 휴머노이드 로봇에서 빠른 도어 통과 성능을 달성했다.
이족 휴머노이드의 도어 통과라는 미개발 영역을 처음 체계적으로 다루고, 실제 로봇에서 동작하는 통합 시스템을 구현한 의미 있는 연구이다. 행동 저작의 속도와 재사용성 향상, 다층적 시스템 설계 관점에서 독창성과 실용성이 우수하나, 단일 플랫폼 검증과 일반화 가능성에 대한 보완이 필요하다.
Generalizable Humanoid Manipulation with 3D Diffusion Policies

Fig. 1: Humanoid manipulation in diverse unseen scenarios. With our system, we are able to 1) collect human-like
 *Fig. 1: Humanoid manipulation in diverse unseen scenarios. With our system, we are able to 1) collect human-like* 이 논문은 단일 장면에서 수집한 데이터만으로 휴머노이드 로봇이 다양한 미지의 실제 환경에서 자율적으로 조작 작업을 수행하도록 하는 3D Diffusion Policy 기반 시스템을 제시한다.
이 논문은 휴머노이드 로봇의 장면 일반화 조작이라는 미해결 문제를 최초로 해결하며, 개선된 3D Diffusion Policy와 완전한 실제 환경 시스템을 통해 단일 장면 데이터만으로 다양한 미지 환경에서의 자율 작동을 달성한 의미 있는 기여를 제시한다.
Hierarchical Vision-Language Planning for Multi-Step Humanoid Manipulation
Fig. 1: Our hierarchical humanoid manipulation system autonomously executes a multi-step rearrangement task. The robot f
 *Fig. 2: Overview of the proposed hierarchical framework for autonomous multi-step humanoid manipulation. The system* 인간형 로봇의 복잡한 다단계 조작 작업을 위해 저수준 RL 추적 제어기, 중수준 모방학습 기반 스킬 정책, 고수준 VLM 기반 계획 및 모니터링으로 구성된 3계층 계층적 프레임워크를 제시한다.
본 논문은 humanoid 로봇의 자율적 다단계 조작을 위해 VLM 기반 계획 및 모니터링을 기존 2계층 제어에 추가하는 실용적인 접근을 제시하며, 실제 로봇 시험으로 기술적 가능성을 입증했다. 다만 73% 성공률과 단일 작업 검증은 추후 개선이 필요한 부분이다.
Humanoid Parkour Learning
Figure 1: We present a single vision-based end-to-end whole-body-control parkour policy for humanoid robots
 *Figure 1: We present a single vision-based end-to-end whole-body-control parkour policy for humanoid robots* 본 논문은 시각 기반 end-to-end 제어 정책을 통해 인간형 로봇이 모션 프리어 없이 다양한 파쿠르 기술(점프, 허들 뛰기, 갭 넘기 등)을 수행할 수 있도록 학습하는 통합 프레임워크를 제시한다.
본 논문은 모션 프리어 없이 인간형 로봇이 다양한 파쿠르 기술을 통합적으로 학습하고 실제 배포할 수 있게 하는 혁신적 프레임워크를 제시하며, fractal noise를 통한 자연스러운 보행 유도와 효율적인 vision 정책 증류 기법으로 로봇 운동 능력의 경계를 의미 있게 확장한다.
Perceptive Humanoid Parkour: Chaining Dynamic Human Skills via Motion Matching
Fig. 1: Perceptive Humanoid Parkour (PHP) enables a Unitree G1 humanoid robot to execute highly dynamic, long-horizon
 *Fig. 2: Perceptive Humanoid Parkour overview. Atomic parkour skills are composed into long-horizon kinematic reference* Motion matching을 통해 인간의 동작 데이터를 원자적 기술로 합성하고, DAgger와 RL을 결합한 teacher-student 파이프라인으로 단일 깊이 기반 정책으로 증류하여 휴머노이드 로봇이 복잡한 장애물 코스에서 자율적으로 장시간 파쿠르를 수행하도록 한다.
본 연구는 motion matching과 hybrid DAgger-RL 증류를 통해 희소한 인간 동작 데이터로부터 복잡한 파쿠르 기술을 효과적으로 합성 및 학습하여 휴머노이드 로봇의 동적 환경 적응 능력을 획기적으로 향상시켰으며, 실제 로봇에서의 강인한 구현과 zero-shot sim-to-real 전이는 높은 실용적 가치를 입증한다.
Humanoid Parkour Learning
Figure 1: We present a single vision-based end-to-end whole-body-control parkour policy for humanoid robots
 *Figure 1: We present a single vision-based end-to-end whole-body-control parkour policy for humanoid robots* 본 논문은 인간형 로봇이 motion prior 없이 end-to-end vision-based 정책으로 다양한 parkour 기술을 학습할 수 있는 프레임워크를 제시한다. Fractal noise를 활용한 terrain randomization과 DAgger를 통한 vision policy 증류로 sim-to-real transfer를 달성하며, 실제 로봇에서 0.42m 점프, 0.8m gap 통과, 1.8m/s 주행 등을 성공한다.
본 논문은 인간형 로봇의 parkour learning에서 motion prior 제거와 fractal noise 기반 자동 foot-raising 유도라는 중요한 기여를 제시한다. 3단계 훈련 파이프라인과 DAgger 증류를 통한 sim-to-real transfer는 기술적으로 견고하며, 실제 로봇에서의 다양한 성공 사례는 실용적 가치가 높다. 다만 직선 track 제약, 정량적 평가 부족, 일반화 가능성 검증 미흡이 한계이나, 인간형 로봇의 agile locomotion 분야에 상당한 진전을 이루었다.
General Humanoid Whole-Body Control via Pretraining and Fast Adaptation
 *Figure 2: An overview of FAST. Our framework consists of three stages. (1) We construct a curated* FAST는 대규모 사전학습과 경량 잔여 정책 적응을 결합하여 인간형 로봇의 일반적인 전신 제어를 가능하게 하는 프레임워크이다. Center-of-Mass-Aware Control과 Parseval-Guided Residual Policy Adaptation을 통해 분포 외 동작에 대한 빠른 적응과 안정적인 균형을 동시에 달성한다.
FAST는 실용적인 제약 조건 하에서 인간형 로봇의 일반적이고 견고한 전신 제어를 달성하는 잘 설계된 프레임워크이며, Center-of-Mass-Aware 제어와 Parseval-Guided 잔여 적응의 조합은 분포 외 동작 적응에서 새로운 접근 방식을 제시한다.
HuB: Learning Extreme Humanoid Balance
Figure 1: Extreme Balance Tasks. HuB enables humanoids to perform extreme quasi-static balance tasks
 *Figure 2: HuB Overview. To tackle the challenges of extreme balance tasks on humanoids, HuB integrates* HuB는 휴머노이드 로봇이 제한된 한 발로 서기나 높은 킥과 같은 극도의 준정적 균형 작업을 수행할 수 있도록 하는 통합 프레임워크이며, 참조 동작 정제, 균형 인식 정책 학습, sim-to-real 강건성 훈련의 세 가지 구성 요소로 이루어져 있다.
HuB는 휴머노이드의 극한 균형 제어라는 도전적 문제에 대해 참조 정제, 정책 학습, sim-to-real 전이의 세 가지 핵심 요소를 체계적으로 통합한 포괄적 솔루션을 제시하며, 실제 하드웨어에서 인상적인 성능을 달성하여 로봇 제어 분야에 의미 있는 기여를 한다.
TeleGate: Whole-Body Humanoid Teleoperation via Gated Expert Selection with Motion Prior
Fig. 1.
 *Fig. 1.* TeleGate는 가벼운 gating network를 통해 multiple domain-specific expert policies를 동적으로 선택하여 humanoid robot의 real-time whole-body teleoperation을 수행하며, VAE 기반 motion prior를 도입하여 미래 정보 없이도 점프나 일어서기 같은 동적 동작을 예측적으로 제어한다.
TeleGate는 gated expert selection과 VAE 기반 motion prior를 결합하여 제한된 데이터로도 높은 정밀도의 real-time whole-body humanoid teleoperation을 실현하는 혁신적인 프레임워크이며, Unitree G1에서의 성공적인 physical deployment로 실제 적용 가능성을 입증했다.
HuB: Learning Extreme Humanoid Balance
Figure 1: Extreme Balance Tasks. HuB enables humanoids to perform extreme quasi-static balance tasks
 *Figure 1: Extreme Balance Tasks. HuB enables humanoids to perform extreme quasi-static balance tasks* 본 논문은 휴머노이드 로봇이 극단적인 균형 잡기 태스크(Swallow Balance, Bruce Lee's Kick 등)를 수행하도록 하기 위해 세 가지 핵심 문제(참조 동작 오류, 형태학적 불일치, sim-to-real 갭)를 각각 해결하는 통합 프레임워크 HuB를 제시한다. 이를 통해 Unitree G1 휴머노이드 로봇에서 강한 외부 충격에도 안정적으로 균형을 유지하는 정책을 학습할 수 있음을 입증했다.
본 논문은 휴머노이드의 극단적 균형 제어라는 도전적인 문제에 대해 잘 동기부여되고 체계적으로 설계된 솔루션을 제시한다. 세 가지 핵심 장애물(참조 오류, morphological mismatch, sim-to-real 갭)을 각각 겨냥한 모듈식 접근법과 실제 하드웨어에서의 강력한 실험 검증이 강점이다. 다만 다른 휴머노이드 플랫폼으로의 일반화 가능성과 학습 효율성 측면에서 추가 논의가 필요하다.
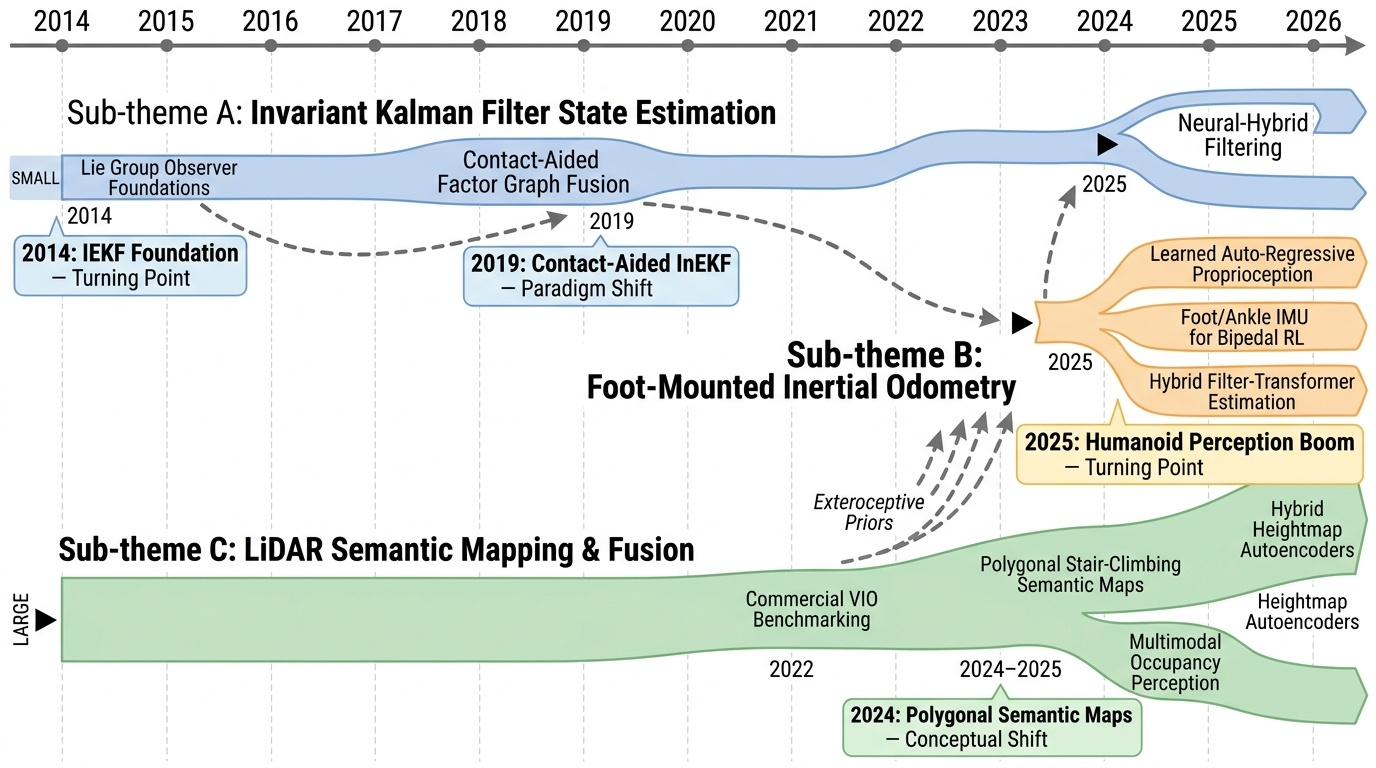
Category Overview
# Robot State Estimation and Mapping (12편) 개요 휴머노이드 로봇의 안정적인 동작을 위해서는 정확한 상태 추정(State Estimation)과 환경 인식(Environmental Perception)이 필수적이다. 본 카테고리는 센서 융합, 지도 작성, 보행 추정 등 다양한 기술을 통해 휴머노이드 로봇이 주변 환경을 인지하고 자신의 위치와 자세를 파악하는 방법들을 다룬다. 고전적인 Extended Kalman Filter(EKF) 기반 접근법부터 최신 딥러닝 기반 방법까지, 로봇의 제약된 계산 환경에서 실시간으로 동작 가능한 솔루션들을 제시한다[1710][1849][2023]. 특히 카메라, 라이다(LiDAR), 고유감각 센서(Proprioceptive Sensor) 등 다양한 센서로부터 정보를 통합하여 강건한 상태 추정을 달성하는 연구들[1802][1810][2078]과 함께, 의미론적 지도 생성(Semantic Mapping)과 점유 격자(Occupancy Grid) 기술을 활용한 환경 인식 연구[1633][1998][2010]가 포함된다. 이러한 기술들은 복잡한 실내 환경에서의 계단 오르기, 비틀린 지형 보행 등 휴머노이드 로봇의 적응형 보행(Adaptive Locomotion) 구현의 토대가 되며[1619][2048], 궁극적으로 로봇의 자율성과 안전성을 향상시킨다.
⚠ 갭: 극한 환경(진흙, 모래, 미끄러운 면, 수중 등)에서의 상태 추정 성능 및 센서 고장 시 폴트 톨러런스 메커니즘에 대한 연구가 현저히 부족하다.
🏛 정책: 재난 대응 로봇의 열악한 환경 운용을 위한 강건 상태 추정 기술 개발을 국방·소방·재난 관련 기관과의 협력 과제로 추진해야 한다.
PolygMap: A Perceptive Locomotion Framework for Humanoid Robot Stair Climbing
 *Fig. 2: The system integrates joint recorders, depth sensing and LIO estimator. Robot pose is obtained via fusing forwar* PolygMap은 LiDAR, RGB-D 카메라, IMU를 융합하여 실시간 다각형 계단 평면 의미지도를 구축하고, 이를 기반으로 인간형 로봇의 계단 등반을 위한 발디딤 계획을 수행하는 지각 기반 보행 계획 프레임워크이다.
PolygMap은 다중 센서 융합을 통해 계단 환경의 인식 불확실성을 효과적으로 대응하고, 실시간 의미지도 생성과 안전 제약 기반 발디딤 계획을 실현함으로써 인간형 로봇의 신뢰성 있는 계단 등반을 달성했다. 실제 환경 검증과 NVIDIA Orin 구현을 통해 실용성을 입증한 점에서 높은 가치가 있으나, 특정 표면 재질에 대한 견고성 개선과 더 높은 갱신률이 향후 과제이다.
Real-Time Polygonal Semantic Mapping for Humanoid Robot Stair Climbing
Fig. 1: Planar polygon semantic mapping results of spiral
 *Fig. 2: Overview of the Planar Polygonal Semantic Mapping System Framework. The system inputs are depth images and* 인형로봇의 계단 등반을 위해 GPU 가속 anisotropic diffusion 필터링과 RANSAC 기반 평면 추출을 활용한 실시간 다각형 의미 맵핑 알고리즘을 제시한다.
본 논문은 GPU 가속을 활용한 anisotropic diffusion 필터링과 RANSAC 기반 다각형 추출을 결합하여 인형로봇의 복잡한 지형 네비게이션을 위한 실시간 의미 맵핑 문제를 효과적으로 해결했다. 시뮬레이션과 실제 센서 데이터 간의 성능 격차를 줄이고 로봇의 안전한 보행 계획을 지원하는 실용적인 시스템으로서의 가치가 크다.
Whole-Body Bilateral Teleoperation with Multi-Stage Object Parameter Estimation for Wheeled Humanoid Locomanipulation
Fig. 1: Lifting and delivering a heavy water bottle (∼1/3 of robot’s weight)
 *Fig. 2: Overview of the whole-body bilateral teleoperation framework. (Left) A human pilot controls a wheeled humanoid w* 휠 달린 인간형 로봇의 원격조종 시스템에 다단계 물체 관성 매개변수 온라인 추정을 통합하여, 무거운 물체의 들기·운반 작업을 동적으로 수행할 수 있는 프레임워크를 제시한다.
본 논문은 VLM과 hierarchical sampling을 결합한 혁신적 물체 매개변수 추정과 이를 bilateral teleoperation에 통합함으로써 로봇의 무거운 부하 취급 능력을 획기적으로 향상시켰다. 시스템 설계, 기술 구현, 실험 검증 모두 우수하며 로봇 조작 작업의 실용화에 중요한 기여를 한다.
An Empirical Evaluation of Four Off-the-Shelf Proprietary Visual-Inertial Odometry Systems
Fig. 1. The custom-built capture rig for benchmarking 6-DoF motion tracking
 *Fig. 1. The custom-built capture rig for benchmarking 6-DoF motion tracking* Apple ARKit, Google ARCore, Intel RealSense T265, Stereolabs ZED 2 등 4개의 상용 VIO 시스템을 실내외 환경에서 실험하여 6-DoF 위치 추정 성능을 벤치마크 비교한 연구이다.
본 연구는 산업 및 로봇 분야에서 광범위하게 사용되는 상용 VIO 시스템의 실제 성능을 최초로 체계적으로 벤치마킹한 중요한 기여이며, 실내외 도전적 환경에서의 포괄적 평가를 통해 연구자와 엔지니어에게 실용적인 참고 자료를 제공한다.
ClimbingCap: Multi-Modal Dataset and Method for Rock Climbing in World Coordinate
Figure 1. Overview. To address the challenging problem of global climbing motion recovery, we collect the dataset Ascend
 *Figure 1. Overview. To address the challenging problem of global climbing motion recovery, we collect the dataset Ascend* ClimbingCap은 RGB와 LiDAR 멀티모달 데이터를 활용하여 암벽 등반 동작을 글로벌 좌표계에서 정확하게 복원하는 방법을 제안하며, 대규모 도전적 등반 동작 데이터셋 AscendMotion을 구축했다.
ClimbingCap은 미개발 분야인 등반 동작 캡처에 대해 대규모 고품질 데이터셋과 멀티모달 별도 좌표 복원 방식의 창의적 방법론을 제시하여 높은 독창성과 실질적 기여도를 보여준다. 광범위한 실험 검증과 공개 예정인 데이터셋·코드는 커뮤니티 기여도 높으나, 환경 일반화와 단일 모달 방식의 개발이 후속 과제다.
DIJIT: A Robotic Head for an Active Observer
Fig. 1.
 *Fig. 1.* 인간의 시각 체계를 모방한 생체모방 쌍안 로봇 헤드 DIJIT를 제시하며, 9개의 기계적 자유도와 4개의 광학적 자유도를 통해 능동적 시각 연구와 인간 시각의 안구-머리 운동을 탐구한다.
DIJIT은 인간 시각의 핵심 특성을 종합적으로 구현한 최초의 로봇 헤드로, 생체모방 설계와 실제 saccade 성능 평가를 통해 능동 시각 연구의 새로운 플랫폼을 제공한다. 완전 공개된 설계와 체계적인 비교 분석은 후속 로봇 시각 연구에 중요한 기여를 할 수 있다.
Efficient and Scalable Monocular Human-Object Interaction Motion Reconstruction
Fig. 1: Unlike prior works limited by inaccurate pose/depth alignment or non-scalable
 *Fig. 1: Unlike prior works limited by inaccurate pose/depth alignment or non-scalable* 단안 비디오에서 4D 인간-물체 상호작용(HOI) 데이터를 효율적으로 추출하기 위해 sparse contact annotation paradigm과 human-in-the-loop 데이터 엔진을 제안하고, 4DHOISolver 최적화 프레임워크를 통해 시공간적으로 일관성 있는 재구성을 수행한다.
이 논문은 단안 비디오에서 4D HOI 데이터 수집의 annotation 병목을 sparse contact point와 human-in-the-loop 엔진으로 혁신적으로 해결하고, 4DHOISolver를 통해 시공간적 일관성을 유지하면서 대규모 고품질 데이터셋 Open4DHOI를 구축했다. 로봇 학습의 데이터 병목을 실질적으로 해결하는 높은 실용성과 완성도로 컴퓨터 비전 및 로봇 학습 분야에 중대한 기여를 한다.
EmbodMocap: In-the-Wild 4D Human-Scene Reconstruction for Embodied Agents
Figure 1. Introducing EmbodMocap, a portable and low-cost system for simultaneous 4D human and scene reconstruction, dep
 *Figure 1. Introducing EmbodMocap, a portable and low-cost system for simultaneous 4D human and scene reconstruction, dep* EmbodMocap은 두 개의 이동하는 iPhone을 사용하여 실외 환경에서 메트릭 스케일의 인간 동작과 3D 장면을 동시에 재구성하는 저비용 데이터 수집 파이프라인을 제안한다. 이 시스템은 모노큘러 재구성, 물리 기반 캐릭터 애니메이션, 로봇 제어 등 세 가지 embodied AI 작업을 지원한다.
EmbodMocap은 embodied AI 연구의 실질적 장애물인 고비용 데이터 수집을 혁신적으로 해결하는 실용적이고 확장 가능한 시스템을 제시한다. Dual-view RGB-D의 joint optimization이라는 기술적 통찰력과 함께 monocular reconstruction, physics-based animation, robot control까지 포괄적으로 검증한 점에서 높은 가치를 지닌다.
FRAME: Floor-aligned Representation for Avatar Motion from Egocentric Video
Figure 1. We introduce a large scale egocentric dataset (b) collected with a custom-made wearable capture rig (a). With
 *Figure 1. We introduce a large scale egocentric dataset (b) collected with a custom-made wearable capture rig (a). With * VR/AR 환경에서 일인칭 시점의 스테레오 카메라와 헤드 트래킹을 활용하여 신체 자세를 추정하는 FRAME 아키텍처를 제안하며, 대규모 실제 데이터셋을 수집하여 합성 데이터 사전학습의 필요성을 제거했다.
일인칭 모션 캡처의 핵심 문제들(합성 데이터 의존성, 하지 정확도, 아티팩트)을 대규모 실제 데이터셋과 기하학적으로 명시적인 아키텍처로 체계적으로 해결하며, 실시간 성능과 높은 일반화 능력을 동시에 달성한 실용성 높은 연구다.
Gallant: Voxel Grid-based Humanoid Locomotion and Local-navigation across 3D Constrained Terrains
Figure 1. Overview. Gallant enables a single policy with voxel grids to traverse diverse 3D constrained terrains: (a) as
 *Figure 1. Overview. Gallant enables a single policy with voxel grids to traverse diverse 3D constrained terrains: (a) as* Gallant는 Voxel Grid 기반의 LiDAR 인식과 z-grouped 2D CNN을 활용하여 인간형 로봇이 계단, 천장, 측면 장애물 등 3D 제약 지형을 단일 정책으로 횡단할 수 있게 하는 프레임워크이다.
Gallant는 Voxel Grid와 효율적 CNN을 결합하여 인간형 로봇의 3D 지형 인식 문제를 체계적으로 해결하고, 고충실도 시뮬레이션과 end-to-end 최적화로 sim-to-real 일관성을 달성한 임팩트 있는 연구이다. 다만 실시간 성능과 지형 일반화의 추가 검증이 필요하다.
Humanoid Occupancy: Enabling A Generalized Multimodal Occupancy Perception System on Humanoid Robots
Figure 1: Schematic diagram of the Humanoid Occupancy system.
 *Figure 1: Schematic diagram of the Humanoid Occupancy system.* 휴머노이드 로봇을 위한 일반화된 다중모달 occupancy 인식 시스템을 제시하며, 하드웨어 설계, 데이터셋 구축, 다중모달 fusion 네트워크를 통합한 완전한 환경 인식 프레임워크를 제공한다.
본 논문은 휴머노이드 로봇의 독특한 구조적 도전과제를 해결하는 실질적이고 포괄적인 occupancy 기반 인식 시스템을 제시하며, 첫 번째 휴머노이드 로봇 특화 데이터셋 제공으로 해당 분야에 중요한 기여를 한다.
HumanoidPano: Hybrid Spherical Panoramic-LiDAR Cross-Modal Perception for Humanoid Robots
Figure 1. The humanoid robot autonomously navigates complex environments using HumanoidPano, which fuses panoramic visio
 *Figure 1. The humanoid robot autonomously navigates complex environments using HumanoidPano, which fuses panoramic visio* 인간형 로봇의 자아-폐색 및 제한된 시야 문제를 해결하기 위해 파노라마 비전과 LiDAR를 융합하는 HumanoidPano 프레임워크를 제안하며, Spherical Geometry-aware Constraints와 Spatial Deformable Attention을 통해 기하학적으로 정렬된 크로스모달 인식을 구현한다.
HumanoidPano는 인간형 로봇의 고유한 구조적 제약을 심층적으로 고려하여 panoramic vision과 LiDAR를 기하학적으로 정렬하는 혁신적인 프레임워크로, 실제 로봇 플랫폼에서의 검증과 state-of-the-art 성능으로 embodied AI 분야에 새로운 패러다임을 제시한다.
LookOut: Real-World Humanoid Egocentric Navigation
Figure 1. Problem formulation. Given a posed egocentric video (black-outlined frustums, with frames shown in detail on t
 *Figure 1. Problem formulation. Given a posed egocentric video (black-outlined frustums, with frames shown in detail on t* Project Aria 안경을 이용한 데이터 수집 파이프라인과 함께, 동적 장애물이 있는 실제 환경에서 egocentric 비디오로부터 미래의 6D 헤드 포즈(위치 및 회전)를 예측하는 LookOut 모델을 제안한다.
인간형 egocentric 네비게이션의 동적 환경 처리, 능동적 정보 수집 모델링, 그리고 실용적 데이터 수집 파이프라인을 종합적으로 해결한 포괄적 기여로, Project Aria를 활용한 혁신적 데이터 수집 방식과 현실성 높은 4시간 AND 데이터셋이 향후 연구에 큰 영향을 미칠 것으로 기대된다.
MeshMimic: Geometry-Aware Humanoid Motion Learning through 3D Scene Reconstruction
Figure 1: MeshMimic: monocular video-to-humanoid robots. From ordinary consumer monocular videos (no
 *Figure 1: MeshMimic: monocular video-to-humanoid robots. From ordinary consumer monocular videos (no* MeshMimic은 단일 모노큘러 비디오에서 3D 장면 재구성을 통해 휴머노이드 로봇이 복잡한 지형과의 상호작용을 학습할 수 있는 프레임워크이다. Kinematic Consistency Optimization과 contact-aware retargeting을 통해 모션-지형 결합 상호작용을 정확하게 전달한다.
MeshMimic은 3D 비전과 구체화된 지능을 창의적으로 결합하여 비용 효율적이고 확장 가능한 휴머노이드 로봇 훈련 방식을 제시한다. 물리적 일관성 최적화와 접촉 인식 retargeting을 통해 복잡한 지형에서의 안정적인 상호작용을 실현함으로써 로봇 제어 분야에 상당한 기여를 한다.
Omni-Perception: Omnidirectional Collision Avoidance for Legged Locomotion in Dynamic Environments
Figure 1: Validation scenarios for the Omni-Perception framework. Effective omnidirectional collision avoid-
 *Figure 1: Validation scenarios for the Omni-Perception framework. Effective omnidirectional collision avoid-* 본 논문은 LiDAR 포인트 클라우드를 직접 처리하는 end-to-end 강화학습 정책 Omni-Perception을 제안하여 동적 환경에서 다리 로봇의 전방향 충돌 회피를 실현한다. PD-RiskNet이라는 새로운 지각 모듈을 통해 시공간적 LiDAR 데이터를 해석하여 환경 위험을 평가한다.
본 논문은 다리 로봇의 동적 환경 네비게이션에 LiDAR을 직접 활용한 end-to-end 학습 프레임워크라는 참신한 접근을 제시하며, 실용적인 시뮬레이션 툴킷과 함께 강건한 sim-to-real 전이를 입증한다. 다만 기술 상세 공개 수준과 극단 환경 검증 보강이 필요하다.
A Rapid Deployment Pipeline for Autonomous Humanoid Grasping Based on Foundation Models
Fig. 1. The three-stage pipeline for rapid deployment of humanoid grasping.
 *Fig. 1. The three-stage pipeline for rapid deployment of humanoid grasping.* Foundation model들(YOLOv8, SAM 3D, FoundationPose)을 통합하여 휴머노이드 로봇의 새로운 물체 조작 배포 시간을 1-2일에서 약 30분으로 단축하는 end-to-end 파이프라인을 제시한다.
Foundation model들의 효과적 통합으로 휴머노이드 로봇 배포 시간을 획기적으로 단축한 실용적이고 우수한 논문이며, 자동 주석, zero-shot 3D 재구성, zero-shot pose tracking을 연계한 modular 설계가 산업 적용성을 높인다. 다만 제한된 물체 유형과 환경 조건에서의 검증이 일반화 가능성을 판단하기 위해 추가 필요하다.
Global-Local Attention Decomposition for Terrain Encoding in Humanoid Perceptive Locomotion
Fig. 1. Real-world locomotion results on the Unitree G1 humanoid robot. A
 *Fig. 2.* 본 논문은 인간형 로봇의 지형 인식 보행을 위해 Global-Local Attention Decomposition (GLAD)이라는 새로운 terrain encoder를 제안한다. 광범위한 지형 맥락 이해와 정확한 발판 선택이라는 두 가지 지각 목표를 명시적으로 분리함으로써 sparse-foothold terrain에서의 안정적인 보행을 달성한다.
본 논문은 인간형 로봇의 sparse-foothold 보행을 위해 attention mechanism의 역할을 명시적으로 분리하는 GLAD를 제안하며, 이론적 동기부여가 명확하고 실제 로봇 배포에서 우수한 성능을 달성했다는 점에서 의미 있는 기여를 한다. 다만, 더 철저한 ablation study와 기존 방법과의 정량적 비교가 보충되면 더욱 강력한 논문이 될 것이다.
DIJIT: A Robotic Head for an Active Observer
Fig. 1.
 *Fig. 1.* 본 논문은 능동적 관찰자 역할을 수행하는 이동형 로봇을 위해 설계된 이중 카메라 로봇 헤드 DIJIT를 제시한다. DIJIT는 9개의 기계적 자유도와 4개의 광학적 자유도를 갖추고 있으며, 인간의 시각 체계와 유사한 범위와 속도의 카메라 운동이 가능하다.
DIJIT는 인간의 시각 체계를 포괄적으로 모방한 잘 설계된 로봇 헤드로, active vision 연구와 인간-기계 시각 비교를 위한 가치 있는 플랫폼을 제공한다. 특히 완전한 자유도 구현과 실용적인 saccade 제어 방법은 주목할 만하며, 오픈소스 공개로 인한 접근성도 강점이다.
A Hybrid Autoencoder for Robust Heightmap Generation from Fused Lidar and Depth Data for Humanoid Robot Locomotion
 *Figure 3. The structure is designed to bridge this gap by ex-* 이 논문은 humanoid robot의 unstructured environment 이동을 위해 LiDAR과 depth camera 데이터를 fuse하여 heightmap을 생성하는 hybrid encoder-decoder 아키텍처를 제안한다. CNN 기반 spatial feature extraction과 GRU 기반 temporal consistency를 결합한 접근으로, multimodal fusion이 단일 센서 대비 7.2~9.9% 재구성 정확도 개선을 달성한다.
이 논문은 multimodal sensor fusion과 temporal modeling을 통해 humanoid robot의 heightmap 재구성 정확도를 체계적으로 개선하며, spherical projection 기반 LiDAR 처리와 heightmap 그리드 해상도 최적화 등의 실질적 contribution을 제공한다. 다만 실제 robot platform에서의 locomotion 성능 향상을 정량적으로 입증하고, 다양한 환경 및 센서 조합에 대한 robust성을 검증해야 impact가 높아질 수 있다.
Sampling-Based System Identification with Active Exploration for Legged Robot Sim2Real Learning
Figure 1: SPI-Active enables high-fidelity Sim-to-Real transfer across diverse locomotion tasks. To highlight
 *Figure 2: Overview of SPI-Active. Data Collection: Collect real-world trajectories using RL policies or* SPI-Active는 legged robot의 물리 파라미터를 샘플링 기반으로 식별하고 Fisher Information 최대화를 통한 active exploration으로 sim-to-real 갭을 최소화하는 two-stage 프레임워크이다.
이 논문은 legged robot의 sim-to-real 갭 해결을 위한 원리적이고 실용적인 system identification 프레임워크를 제시하며, Fisher Information 기반 active exploration 전략의 창의적 적용으로 고정밀 locomotion 작업에서 현저한 성능 향상을 달성했다.
AutoOdom: Learning Auto-regressive Proprioceptive Odometry for Legged Locomotion
Fig. 1. Overview of the AutoOdom system.
 *Fig. 1. Overview of the AutoOdom system.* AutoOdom은 자동회귀 학습을 기반으로 하는 2단계 훈련 패러다임으로 다리 로봇의 고유감각 주행거리 추정 성능을 크게 향상시킨 시스템이다. 대규모 시뮬레이션 데이터로 비선형 동역학을 학습하고 제한된 실제 데이터로 sim-to-real 갭을 해결한다.
AutoOdom은 자동회귀 학습과 효율적인 2단계 훈련으로 proprioceptive odometry의 중요한 한계를 해결하며, 강력한 실험 결과와 포괄적 ablation 연구로 견고한 기여를 제시한다. 다만 특정 로봇 플랫폼 검증과 다양한 환경으로의 일반화 가능성 확인이 후속 과제다.
InEKFormer: A Hybrid State Estimator for Humanoid Robots
Fig. 1.
 *Fig. 1.* InEKFormer는 Invariant Extended Kalman Filter(InEKF)와 Transformer 네트워크를 결합한 하이브리드 상태 추정 방법으로, 인간형 로봇의 floating base 상태를 정확하게 추정한다.
본 논문은 InEKF와 Transformer를 내부적으로 결합한 novel hybrid 방법을 제시하고 인간형 로봇에 처음 적용함으로써 상태 추정 분야에 기여하나, autoregressive 학습의 안정성 문제와 일반화에 대한 보다 심층적인 분석이 필요하다.
Learning a Vision-Based Footstep Planner for Hierarchical Walking Control
Fig. 1.
 *Fig. 2.* 본 논문은 단일 깊이 카메라와 reinforcement learning 기반의 계층적 제어 프레임워크를 통해 쌍족 로봇이 비정형 지형에서 실시간 발걸음 계획을 수행하도록 하는 시각 기반 발걸음 계획기를 제시한다. Angular Momentum Linear Inverted Pendulum 모델을 활용하여 저차원 상태 표현을 구성하고 상위 레벨의 RL 발걸음 계획기와 하위 레벨의 Operational Space Controller를 통합한다.
본 논문은 RL 기반 발걸음 계획을 ALIP 모델과 깊이 카메라 vision으로 통합한 실질적인 계층적 제어 프레임워크를 제시하며, 실제 로봇 하드웨어에서의 검증을 통해 실용성을 입증한다. 다만 ALIP 모델의 표현력 한계와 복잡한 지형에서의 성능 저하가 명확하게 드러나 향후 더 정교한 모델이나 end-to-end 학습 접근의 필요성을 시사한다.
Learning agile and dynamic motor skills for legged robots
 *Fig. 5. Training control policies in simulation. The policy net-* 본 논문은 시뮬레이션에서 reinforcement learning으로 사족 로봇의 제어 정책을 학습하고 현실의 ANYmal 로봇에 전이하는 방법을 제시하여, 고속 주행과 낙하 복구 등의 동적 운동 기술을 달성했다.
본 논문은 사족 로봇의 동적 제어에 reinforcement learning과 domain randomization을 효과적으로 결합하여 시뮬레이션-현실 전이 문제를 체계적으로 해결했으며, 실제 고급 로봇 플랫폼에서 이전에 달성하지 못한 수준의 운동 기술을 구현함으로써 로봇 제어 분야에 중요한 기여를 했다.
Learning Bipedal Locomotion on Gear-Driven Humanoid Robot Using Foot-Mounted IMUs
Fig. 1: Upper: A photo (left) and kinematic model (right)
 *Fig. 1: Upper: A photo (left) and kinematic model (right)* 고기어비 액추에이터와 토크 센서가 없는 휴머노이드 로봇의 이족 보행 학습을 위해 발목 장착 IMU를 활용하는 Sim-to-Real RL 프레임워크를 제안하고, 대칭 데이터 증강과 random network distillation을 통해 불규칙한 지형에서의 안정화를 향상시킨다.
본 논문은 저비용 고기어비 액추에이터 로봇의 Sim-to-Real 학습에서 발목 IMU 센서를 혁신적으로 활용하여 복잡한 모델링을 회피하면서도 강건한 이족 보행을 달성한다. 하드웨어 검증과 실제 성능 개선이 입증되었으나, 다양한 로봇 플랫폼으로의 일반화 가능성과 기여도 분석이 향후 강화될 필요가 있다.
Learning Humanoid Locomotion with Perceptive Internal Model
Fig. 1: We propose a perceptive humanoid locomotion policy capable of mastering various challenging terrains. This polic
 *Fig. 2: Overview of our framework. Within PIM, we integrate perceptive information into the state predictor to achieve m* 인간형 로봇의 안정적인 이동을 위해 온보드 elevation map을 기반으로 한 Perceptive Internal Model (PIM)을 제안하며, HIM을 확장하여 지각 정보를 통합한 단일 단계 학습 방법을 제시한다.
본 논문은 elevation map 기반 지각 모듈을 HIM과 통합하여 인간형 로봇의 복잡한 지형 네비게이션을 단일 단계로 효율적으로 학습하는 실질적이고 우수한 방법을 제시하며, 다양한 로봇과 지형에서의 광범위한 검증을 통해 실용성을 입증한다.
Bipedal-Walking-Dynamics Model on Granular Terrains
Figure 1. Schematic of the bipedal walking model with foot sinkage and slip on granular media. (a)
 *Figure 1. Schematic of the bipedal walking model with foot sinkage and slip on granular media. (a)* 본 논문은 모래와 같은 입자성 지형에서 이족 로봇의 보행 동역학을 모델링하기 위해 발의 침하(sinkage)와 슬립(slip)을 고려한 3개의 추가 자유도를 도입한 동적 발-지형 상호작용 모델을 제시한다.
본 논문은 입자성 지형에서의 이족 보행 동역학 모델링에 있어 발의 침하와 슬립을 처음으로 명시적으로 다룬 중요한 기여를 제시하며, 실험 검증을 통해 모델의 신뢰성을 입증했다. 제안된 모델은 granular terrain에서의 로봇 보행 제어 및 최적화를 위한 필수적인 기초 도구로서 높은 가치를 가진다.
Model-Based Reinforcement Learning Exploits Passive Body Dynamics for High-Performance Biped Robot Locomotion
Figure 1: Biped robot and model. (A) Lower body model based on muscu-
본 연구는 수동적 신체 역학(스프링, 높은 백드라이버빌리티 등)을 가진 이족 로봇이 Model-Based Deep Reinforcement Learning을 통해 고성능 보행·주행 운동을 효율적으로 습득할 수 있음을 보여준다. 수동 요소가 시스템의 어트랙터를 활용하여 안정적이고 에너지 효율적인 운동을 생성한다.
본 논문은 embodied AI의 핵심인 수동 신체 역학의 학습 효율성을 엄밀하게 입증한 중요한 연구로, Model-Based RL과 생체역학 설계의 시너지를 명확히 보여준다. 시뮬레이터 기반 검증이라는 한계가 있지만, 미래 로봇 설계 원칙에 유의미한 통찰을 제공한다.
Learning Humanoid Locomotion with Perceptive Internal Model
Fig. 1: We propose a perceptive humanoid locomotion policy capable of mastering various challenging terrains. This polic
 *Fig. 1: We propose a perceptive humanoid locomotion policy capable of mastering various challenging terrains. This polic* 본 논문은 휴머노이드 로봇의 불안정한 형태학적 특성으로 인해 필수적인 지각 정보를 효과적으로 통합하기 위해 Perceptive Internal Model (PIM)을 제안한다. 로봇 중심의 elevation map을 기반으로 하는 이 방법은 깊이 맵이나 포인트 클라우드 직접 인코딩과 달리 시뮬레이션에서 최소한의 계산 비용으로 3시간 내에 정책 학습을 완료할 수 있다.
본 논문은 로봇 중심 elevation map 기반 지각 정보 통합을 통해 휴머노이드 로봇의 안정적인 복잡 지형 주행을 실현하는 실질적이고 효율적인 방법을 제시한다. 단일 단계 훈련으로 우수한 성능을 달성하며 다양한 로봇 플랫폼에 검증된 점이 강점이나, 실제 환경 적용 시 elevation map 구성 오류에 대한 견고성 분석이 보완되면 더욱 완성도 있는 연구가 될 것이다.
The invariant extended Kalman filter as a stable observer
Invariant Extended Kalman Filter (IEKF)를 Lie group 위의 결정론적 비선형 관찰자로 분석하여, 표준 선형 조건 하에서 임의의 궤적 주변에서의 국소 안정성을 증명한다.
본 논문은 IEKF의 수렴성을 엄밀히 증명하고 일반적인 시스템 클래스를 특성화함으로써 비선형 관찰자 이론에 중요한 기여를 하며, navigation 응용에서의 우수한 실제 성능을 이론적으로 정당화한다.
Contact-Aided Invariant Extended Kalman Filtering for Robot State Estimation
Figure 1: A Cassie-series biped robot is used for both simulation and experimental results. The robot was developed by A
 *Figure 1: A Cassie-series biped robot is used for both simulation and experimental results. The robot was developed by A* Lie군 이론과 불변 관찰자 설계를 기반으로 IMU와 접촉 센서 데이터를 융합하는 Contact-Aided Invariant Extended Kalman Filter (InEKF)를 개발하여 이족 로봇의 자세와 속도를 추정한다.
이 논문은 Lie군 기반 불변 관찰자 이론을 legged robot의 접촉-관성 상태 추정에 체계적으로 적용하여, 기존 EKF의 수렴성과 일관성 문제를 근본적으로 해결한 중요한 기여를 제시한다. 이론적 엄밀성과 실험적 검증, 오픈소스 구현까지 겸비한 완성도 높은 연구로, 자율 legged robot의 장시간 안정 운영을 위한 핵심 기술이다.
HAIC: Humanoid Agile Object Interaction Control via Dynamics-Aware World Model
 *Fig. 3: Overview of our Dynamics-aware World Model. It predicts object* HAIC는 humanoid 로봇이 독립적인 동역학을 가진 미작동(underactuated) 물체와 상호작용할 수 있도록 dynamics-aware world model을 통해 proprioception만으로 고차 가속도를 예측하고 기하학적 projection을 통해 시각 blind spot에서도 강건한 제어를 실현한다.
본 논문은 humanoid 로봇의 underactuated 물체 상호작용이라는 현실적으로 중요한 문제를 proprioception 기반의 창의적인 dynamics prediction과 geometric projection으로 우아하게 해결하며, 실제 로봇에서 SOTA 성능을 입증한 매우 강력한 기여이다.
Legged Robot State-Estimation Through Combined Forward Kinematic and Preintegrated Contact Factors
 *Fig. 2: An example factor graph for the proposed system. Forward kinematic* 시각 추적 손실 시에도 작동하는 다리 로봇 상태 추정 기법으로, Forward Kinematic 인수와 Preintegrated Contact 인수를 Factor Graph에 통합하여 엔코더 측정과 접촉 정보를 활용한다.
본 논문은 Factor Graph 프레임워크에 Forward Kinematic 및 Preintegrated Contact 인수를 처음 도입하여 시각 손실 상황에서도 다리 로봇의 상태를 추정할 수 있는 실용적 기법을 제시했으며, 이론적 엄밀성과 실제 로봇 구현 양면에서 견고한 기여를 하지만, 실험의 규모가 제한적이고 일반화 가능성 검증이 필요하다.
Asymptotically Stable Gait Generation and Instantaneous Walkability Determination for Planar Almost Linear Biped with Knees
Figure 1 shows the model of the planar 6-DOF biped robot
 *Figure 1 shows the model of the planar 6-DOF biped robot* 거의 선형 역학 모델을 갖는 무릎 관절이 있는 평면 이족보행 로봇에서 Taylor 전개를 이용한 선형화를 통해 수치 적분 없이 점프로 안정적인 보행을 생성하고 즉각적인 보행 가능성 판정을 수행한다.
이 논문은 거의 선형 역학을 갖는 무릎 관절 이족보행 로봇에서 선형화를 통한 실시간 보행 가능성 판정이라는 실용적으로 중요한 문제를 해결하며, 차원 축소 및 근사 정확도 분석에서 상세한 기여를 제공한다. 다만 AL3 로봇의 특수성과 실제 로봇 검증 부족이 일반화 가능성을 제한한다.
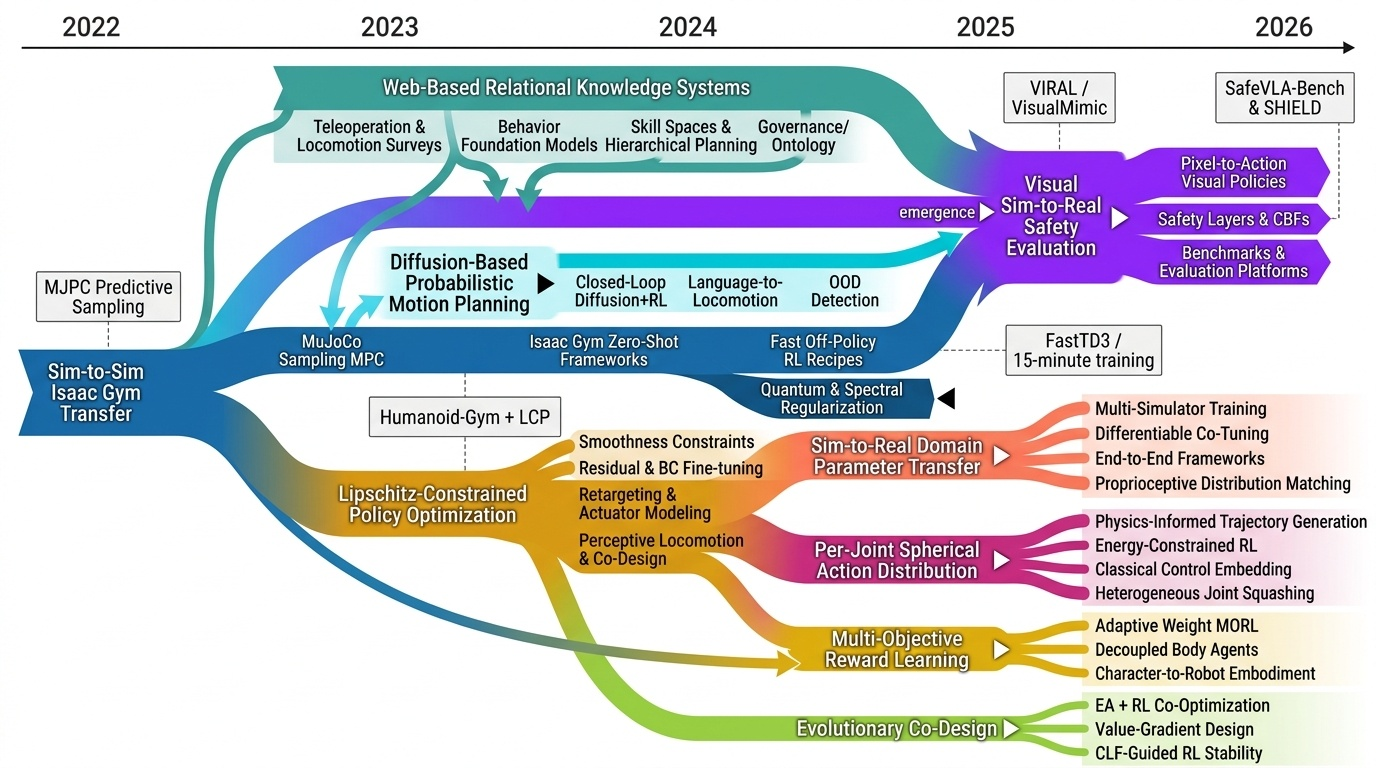
Category Overview
# Sim-to-Real Policy Transfer Methods 카테고리 개요 휴머노이드 로봇의 시뮬레이션에서 실제 환경으로의 정책 전이(Sim-to-Real Policy Transfer)는 현대 로봇공학의 핵심 과제이다. 본 카테고리는 강화학습(Reinforcement Learning), 모방학습(Imitation Learning), 그리고 도메인 적응(Domain Adaptation) 기법을 통해 이 격차를 해소하는 51편의 연구를 다룬다. 주요 접근 방식은 도메인 랜더마이제이션(Domain Randomization), 리스칙 제약 정책 최적화(Lipschitz-Constrained Policy Optimization), 확산 기반 확률적 계획(Diffusion-Based Probabilistic Motion Planning) 등을 포함한다. 시각 기반 정책 학습[1612][1749][1753]은 카메라 입력으로부터 직접 제어 신호를 생성하는 방식으로, 현실의 복잡한 시각 환경에 대응하기 위해 설계되었다. 물리 기반 안정화 및 안전성 검증[1671][1688][1691]은 제어 배리어 함수(Control Barrier Functions)와 스펙트럼 정규화(Spectral Normalization)를 활용하여 실제 배포 시 로봇의 안정성을 보장한다. 도메인 파라미터 전이(Domain Parameter Transfer)[1620], Sim-to-Sim 전이[1647], 그리고 행동 복제 미세조정(Behavior Cloning Finetuning)[1639]은 시뮬레이션과 실제 간 물리적 특성 차이를 극복하는 기법들이다. 이중 목적 보상 학습(Multi-Objective Reward Learning)[1800]과 진화적 로봇 설계(Evolutionary Co-Design)[1817]는 단일 목표가 아닌 복합적 성능 지표를 동시에 최적화하는 방법론을 제시한다. 모션 재타겟팅(Motion Retargeting)[1641], 원격조작(Teleoperation)[1707], 그리고 종합 워크플로우 기법[1794]은 인간의 시연(Demonstration)으로부터 휴머노이드 정책을 효율적으로 학습하는 실무적 방안을 제공한다. 양자 강화학습[1629], 예측적 샘플링[1622], 그리고 분포 외 탐지(Out-of-Distribution Detection)[1632] 등 최신 기술들은 정책 전이의 견고성과 신뢰성을 한층 강화하고 있다.
- Visual Sim-to-Real Safety Evaluation: Visual Sim-to-Real Safety Evaluation은 시뮬레이션 환경에서 학습한 시각 기반 정책(visual policy)을 실제 로봇에 안전하게 전이하기 위한 평가 방법론을 다룬다. 이 분야는 픽셀 입력(pixel input)으로부터 로봇 제어 명령을 직접 생성하는 end-to-end 학습 접근법의 안전성을 검증하는 데 중점을 두고 있다. [1671]과 [1749]에서 보듯이, 안전 제약(safety constraints)과 대규모 시뮬레이션 환경을 통해 휴머노이드 로봇의 복합적인 작업(loco-manipulation) 수행 능력을 안전하게 평가하고 검증한다. [1794]와 [2125]와 같은 연구들은 구조화된 평가 워크플로우(evaluation workflow)와 고충실도 시뮬레이션 플랫폼(high-fidelity simulation)을 제공함으로써 시뮬레이션과 현실 간의 간격(sim-to-real gap)을 줄이고 정책 전이의 신뢰성을 높인다. 궁극적으로 Visual Sim-to-Real Safety Evaluation은 로봇 학습의 민주화(democratization)를 실현하면서도 실제 환경에서의 안전성을 보장하는 핵심 기술이다.
- Web-Based Relational Knowledge Systems: # Web-Based Relational Knowledge Systems (웹 기반 관계형 지식 시스템) Web-Based Relational Knowledge Systems는 로봇의 시뮬레이션에서 실제 환경으로의 정책 전이(Sim-to-Real Policy Transfer)를 위해 웹 기반의 관계형 지식을 활용하는 방법론을 다룹니다. 이러한 시스템은 인간-로봇 상호작용(Human-Robot Interaction), 행동 모방 학습(Behavior Imitation Learning), 그리고 계층적 제어 구조(Hierarchical Control)를 통해 로봇의 일반화 능력을 향상시킵니다. [1707]과 [3366]에서 다루는 원격 조종(Teleoperation) 기술은 실제 로봇 데이터 수집의 핵심 방법으로, 웹 기반 플랫폼을 통해 전 세계적으로 협력할 수 있는 환경을 제공합니다. [1744]와 [1973]의 연구들은 인간의 시연 데이터를 기반으로 한 학습(Learning from Demonstrations)과 복잡한 조작 작업의 계층적 계획(Hierarchical Planning)을 결합하여 현실 세계에 적용 가능한 로봇 제어 정책을 개발합니다. [1782]와 [1928]에서 제시된 기초 모델(Foundation Model) 기반의 접근과 특징 기반 학습(Feature-Based Learning) 방식은 다양한 로봇 플랫폼 간의 지식 재사용성(Knowledge Transferability)을 극대화하여 시뮬레이션 환경에서 습득한 정책의 현실 적용 성공률을 높입니다.
- Sim-to-Sim Isaac Gym Transfer: Sim-to-Sim Isaac Gym Transfer는 시뮬레이션 환경 간의 정책 이전 기법으로, 주로 물리 시뮬레이터 간의 차이를 극복하여 로봇 제어 정책을 효과적으로 전달하는 방법을 다룹니다. 이 분야의 연구들은 Isaac Gym과 같은 고성능 시뮬레이션 플랫폼을 활용하여 휴머노이드 로봇(humanoid robot)의 보행 제어와 네비게이션 학습을 가속화합니다[2006]. 심화된 강화학습(deep reinforcement learning) 기법과 샘플링 기반 모델 예측 제어(sampling-based model predictive control) 방식을 결합하여 현실적인 로봇 동작을 빠르게 생성할 수 있습니다[1622][1938]. 스펙트럼 정규화(spectral normalization)와 포텐셜 기반 보상(potential-based rewards) 같은 고급 기법들은 정책의 안정성과 수렴 속도를 향상시킵니다[1688][1817]. 특히 최근 연구들은 15분 이내의 단시간 학습으로 실제 로봇 동작이 가능한 수준의 정책을 획득하는 성과를 보여주고 있습니다[2061].
- Lipschitz-Constrained Policy Optimization: Lipschitz-Constrained Policy Optimization은 시뮬레이션과 실제 환경 간의 갭(sim-to-real gap)을 줄이기 위한 중요한 방법론입니다. 이 기법은 정책(policy)의 Lipschitz 상수를 제약함으로써 입력의 작은 변화에 대한 출력의 급격한 변화를 방지하고, 따라서 시뮬레이션에서 학습된 정책이 실제 로봇 환경에서도 안정적으로 작동하도록 합니다[2062]. 행동 모방(behavior cloning)과 같은 기초 정책을 미세 조정(finetuning)할 때 오프-정책 강화학습(off-policy RL)과 결합되어 성능을 향상시키며[1639], 인간형 로봇(humanoid)의 보행(locomotion)이나 손가락 조작(multi-fingered manipulation)과 같은 복잡한 제어 문제에 특히 효과적입니다[1871][2060]. 또한 모션 재타겟팅(motion retargeting)이나 진화 기반 신체-제어 공설계(body-control co-design) 등의 기법과 함께 사용되어, 더욱 견고한 정책 전이를 가능하게 합니다[1641][1910]. 이러한 접근 방식은 로봇 학습의 현실성과 적용 가능성을 크게 향상시키는 핵심 기술입니다.
- Sim-to-Real Domain Parameter Transfer: Sim-to-Real Domain Parameter Transfer는 시뮬레이션 환경에서 학습한 정책(policy)을 실제 로봇에 적용할 때 발생하는 도메인 갭(domain gap)을 줄이기 위해 시뮬레이터의 물리 파라미터(physics parameters)를 체계적으로 조정하는 방법론입니다. [1620]과 [1877]에서 볼 수 있듯이, 이러한 접근법은 마찰력, 질량, 관성 모멘트 등의 시뮬레이션 파라미터를 최적화하여 시뮬레이션과 현실 환경의 물리적 특성을 더욱 일치시킵니다. [2155]와 [2386]의 연구들은 체계적인 파라미터 전이(parameter transfer) 전략을 통해 휴머노이드 로봇과 다리 로봇(legged robots)의 운동 제어에서 높은 성공률을 달성하고 있습니다. 이 기법은 강화학습(reinforcement learning) 기반의 로봇 제어 정책 개발에서 시뮬레이션 단계의 효율성을 극대화하면서도 현실 세계 적용성을 보장하는 핵심 기술로 평가됩니다.
- Per-Joint Spherical Action Distribution: Per-Joint Spherical Action Distribution은 로봇의 각 관절(joint)에 대해 구면 공간(spherical space)에서 행동 분포를 정의하는 심 투 리얼 정책 이전(Sim-to-Real Policy Transfer) 기법입니다. 이 방법은 시뮬레이션 환경에서 학습한 강화학습(Reinforcement Learning) 정책을 실제 로봇에 안정적으로 전이할 때, 각 관절의 토크(torque) 또는 속도(velocity) 명령을 구면 분포로 모델링하여 물리적 제약을 효과적으로 반영합니다. [1691]과 [1905]에서 보이는 바와 같이, 인간형 로봇(humanoid robot)의 궤적 생성(trajectory generation)과 고전적 균형 제어(balance control) 원리를 강화학습에 통합할 때 이러한 구면 분포 기반 접근이 안정성을 크게 향상시킵니다. [1894]와 [3310]의 연구들은 에너지 제약(energy constraint)과 동적 제약(dynamic constraint)을 강화학습 프레임워크에 포함시킬 때, Per-Joint Spherical Action Distribution이 현실 세계의 제약 조건을 더 정확하게 모델링할 수 있음을 입증했습니다. 이 기법은 로봇의 각 관절이 독립적인 구면 분포를 가지면서도 전체 시스템의 물리적 일관성을 유지하는 데 특히 효과적입니다.
- Diffusion-Based Probabilistic Motion Planning: Diffusion-Based Probabilistic Motion Planning은 확산 모델(diffusion model)을 활용하여 로봇의 움직임을 확률적으로 계획하는 방법론입니다. 이 접근법은 시뮬레이션과 실제 환경 간의 갭을 줄이기 위해 확률적 의사결정을 통합하며, 분포 외(out-of-distribution) 상황에서도 안정적인 정책 이전(policy transfer)을 가능하게 합니다. [1632]에서는 모델 예측 제어(model-predictive control)와 분포 외 탐지(out-of-distribution detection)를 결합하여 로봇의 실패 상황을 사전에 예방하는 방법을 제시합니다. [1841]은 시뮬레이션과 확산 모델 간의 루프를 닫음으로써 더욱 정교한 동작 생성을 실현하며, [1935]는 언어 지시(language instruction)로부터 인형로봇(humanoid) 제어까지 시뮬레이션 기반 학습을 확장하는 재타겟팅 프리(retargeting-free) 방식을 제안합니다. 이러한 방법들은 심층 강화학습(deep reinforcement learning)과 확률적 모델링을 결합하여 로봇 제어의 일반화 능력을 향상시킵니다.
- Multi-Objective Reward Learning for Robotics: 로봇 제어에서 다중 목표 보상 학습(Multi-Objective Reward Learning for Robotics)은 시뮬레이션에서 학습한 정책을 실제 로봇에 적용할 때 여러 개의 상충하는 목표들을 동시에 만족시키는 방법론을 다룬다. [1800]의 AMOR은 적응형 캐릭터 제어(Adaptive Character Control)를 통해 다양한 제어 목표를 균형있게 달성하는 접근법을 제시한다. [1982]의 연구에서는 부드러운 인간형 로봇 보행(Gentle Humanoid Locomotion)과 말단 장치 제어(End-Effector Control)를 동시에 학습하면서 현실 세계의 제약 조건을 고려한 정책 전이를 구현한다. [2116]의 Olaf 프로젝트는 애니메이션 캐릭터를 실제 물리 환경에서 구현하기 위해 여러 목표 간의 우선순위 조정과 보상 가중치 최적화(Reward Weight Optimization)를 활용한다.
- Evolutionary Co-Design of Robot Morphology: 로봇 형태 학습(Robot Morphology)의 진화적 공동 설계(Evolutionary Co-Design)는 로봇의 신체 구조와 제어 정책을 동시에 최적화하는 방법론입니다. 이 분야에서는 강화학습(Reinforcement Learning)과 진화 알고리즘(Evolutionary Algorithm)을 결합하여 로봇의 물리적 형태와 행동 제어를 상호작용적으로 개선합니다. [1916]과 [3325]의 연구들은 로봇이 다양한 신체 구조를 가질 때 최적의 정책을 학습하고, 역으로 학습된 정책에 맞춰 신체 형태를 설계하는 적응형 방법을 제시합니다. 특히 [3327]은 제어 리아푼노프 함수(Control Lyapunov Function)를 활용하여 이러한 공동 설계 과정에서 시스템의 안정성(Stability)을 보장하는 기법을 다룹니다. 이러한 접근 방식은 실제 로봇 시스템에서 시뮬레이션 환경의 성능을 물리적 세계로 효과적으로 이전하는 Sim-to-Real transfer의 성공률을 높입니다.
⚠ 갭: 시뮬레이터의 물리 충실도와 학습 속도 간의 트레이드오프를 체계적으로 분석하고 특정 응용 분야에 적합한 시뮬레이터 선택 가이드라인이 부재하다.
🏛 정책: 고충실도 오픈소스 시뮬레이터 개발 및 공유를 국가 연구 인프라로 지정하고, 산학연 공동 활용 플랫폼 구축을 지원해야 한다.
A Hierarchical Framework for Humanoid Locomotion with Supernumerary Limbs
 *Figure 2.1: The composite robot model used in the simulation, illustrating (a) the Unitree H1* 초과 사지(Supernumerary Limbs)가 장착된 인형형 로봇의 안정적인 보행을 위해 학습 기반 저수준 보행 제어와 모델 기반 고수준 동적 평형 제어를 결합한 계층적 제어 아키텍처를 제시한다.
본 논문은 초과 사지가 장착된 인형형 로봇의 보행 안정성 문제를 해결하기 위해 계층적 제어 구조를 통해 학습 기반과 모델 기반 제어를 효과적으로 결합한 독창적인 접근법을 제시하며, 47% DTW 거리 감소 등 정량적 성과를 입증했다. 다만 실제 하드웨어 검증과 복잡한 환경에서의 평가가 필요하다.
Deep Reinforcement Learning for Bipedal Locomotion: A Brief Survey
Fig. 1: Representative bipedal and humanoid robots illustrat-
본 논문은 bipedal robot의 locomotion을 위한 Deep Reinforcement Learning(DRL) 기반 프레임워크를 체계적으로 분류, 비교, 분석하는 survey이며, end-to-end와 hierarchical 제어 방식으로 구분하여 각 프레임워크의 구성, 강점, 한계를 평가한다.
본 survey는 DRL 기반 bipedal locomotion 분야의 fragmented 연구를 체계적으로 정리하고 unified framework을 향한 명확한 research agenda를 제시하는 가치 있는 종합 분석이다. End-to-end와 hierarchical 분류 체계, learning paradigm 비교, hybrid 아키텍처 평가는 이 분야의 종사자들에게 실질적인 guidance를 제공하며, 향후 generalisable bipedal locomotion 개발의 기초를 마련한다.
Teleoperation of Humanoid Robots: A Survey
 *Fig. 2: Schematic architecture for teleoperating a humanoid.* 이 논문은 인간형 로봇의 원격 조종(teleoperation) 분야에 대한 포괄적인 서베이로, 시스템 아키텍처, 기술 및 방법론적 진전, 실제 응용 분야를 종합적으로 분석한다.
이 서베이는 humanoid robot teleoperation의 포괄적이고 최신의 개요를 제공하며, 복잡한 시스템을 명확한 아키텍처로 정리하고 다양한 기술적 도전과 솔루션을 체계적으로 분석한다. 해당 분야의 연구자와 실무자들에게 매우 유용한 참고 자료이지만, 구체적인 기술 혁신보다는 기존 연구의 종합과 정리에 초점을 두고 있다.
Unleashing Humanoid Reaching Potential via Real-world-Ready Skill Space
Fig. 1: (a) The humanoid showcases multiple real-world-ready primitive skills, including locomotion and body-pose-adjust
 *Fig. 1: (a) The humanoid showcases multiple real-world-ready primitive skills, including locomotion and body-pose-adjust* 휴머노이드 로봇의 대규모 도달 공간 확보를 위해 사전 학습된 원시 스킬들을 통합하는 Real-world-Ready Skill Space (R2S2)를 제안하며, CVAE 기반의 통일된 신경 스킬 표현을 통해 효율적이고 sim2real 전이 가능한 전신 제어를 실현한다.
이 논문은 휴머노이드 로봇의 대규모 도달 공간 실현이라는 중요한 문제를 실용적 관점에서 해결하며, 이질적 스킬 통합과 CVAE 기반 신경 스킬 표현이라는 참신한 기술을 통해 보상 엔지니어링 최소화와 강한 sim2real 전이를 동시에 달성한 우수한 연구이다.
A Survey of Behavior Foundation Model: Next-Generation Whole-Body Control System of Humanoid Robots
본 논문은 휴머노이드 로봇의 전신 제어(WBC)를 위한 행동 기초 모델(BFM)의 발전과 응용을 종합적으로 조사하며, 대규모 사전학습을 통해 재사용 가능한 행동 기초를 학습하여 다양한 작업에 빠르게 적응할 수 있는 차세대 제어 시스템을 제시한다.
본 논문은 휴머노이드 로봇 제어의 역사적 진화를 명확히 하고 BFM을 차세대 통합 제어 패러다임으로 체계적으로 정의하여, 로봇 제어 커뮤니티에 명확한 비전과 구조화된 개요를 제공하는 가치 높은 조사 논문이다. 다만 구체적인 기술적 혁신과 실세계 검증 결과는 추가 개발이 필요하다.
Being-0: A Humanoid Robotic Agent with Vision-Language Models and Modular Skills
Figure 1. Overview of the Being-0 framework. The humanoid agent framework, Being-0, comprises three key components: (1)
 *Figure 1. Overview of the Being-0 framework. The humanoid agent framework, Being-0, comprises three key components: (1) * Being-0는 Foundation Model, VLM 기반 Connector, 모듈식 스킬 라이브러리를 계층적으로 통합하여 인간형 로봇이 복잡한 장기 과제를 수행할 수 있도록 하는 프레임워크이다. Connector 모듈이 언어 기반 계획을 실행 가능한 스킬 명령으로 변환하고 보행과 조작을 동적으로 조율한다.
Being-0는 인간형 로봇을 위한 실용적이고 효율적인 hierarchical agent 프레임워크로, Connector 모듈을 통한 창의적인 중간층 설계와 실제 하드웨어 구현으로 embodied AI 분야에 의미 있는 기여를 한다. 높은 완수율과 4.2배 효율성 향상은 제안 방식의 효과를 입증하지만, FM의 클라우드 의존성과 실내 중심 평가는 실용성 확대를 위한 개선 과제이다.
Beyond Tools and Persons: Who Are They? Classifying Robots and AI Agents for Proportional Governance
Figure 1: The CPST Integration Space.
 *Figure 1: The CPST Integration Space.* CPST(Cyber-Physical-Social-Thinking) 공간 이론에 기반한 로봇과 AI 에이전트의 분류 프레임워크를 제안하여, 기존의 '도구' vs '인격' 이분법적 법적 범주의 한계를 극복하고 비례적 거버넌스를 위한 온톨로지를 제시한다.
본 논문은 AI 및 로봇 거버넌스의 근본적 온톨로지 문제를 CPST 이론으로 해결하려는 야심찬 시도로, 기존 위험도/안전성 중심의 규제에서 엔티티 특성 중심으로의 패러다임 전환을 제시한다. 다만 평가 지표의 정량화, 국제 표준화의 현실성, 신기술 추적 메커니즘에 대한 더 깊은 논의가 필요하다.
Feature-Based vs. GAN-Based Learning from Demonstrations: When and Why
Figure 1: DeepMimic-style feature-based methods. The policy receives dense, per-frame rewards
 *Figure 1: DeepMimic-style feature-based methods. The policy receives dense, per-frame rewards* Feature-based와 GAN-based 학습 방법론을 비교 분석하여, 각 접근법의 장단점을 명확히 하고 작업별 우선순위에 따른 방법 선택 프레임워크를 제시한다.
이 survey는 시연 학습의 두 주요 패러다임을 원칙적으로 비교하고, 실무자들이 작업 특성에 맞는 방법을 선택할 수 있도록 하는 개념적 프레임워크를 제공하는 가치 있는 기여이다. 구조화된 모션 표현의 수렴점을 강조함으로써 향후 연구의 방향성을 제시한다.
Hierarchical Planning and Control for Box Loco-Manipulation
Fig. 1. We develop loco-manipulation skills for box-carrying physics-based characters. This is achieved via a
 *Fig. 2. System overview. We design four motion primitives for locomotion and manipulation which can be* 물리 기반 시뮬레이션 인간 캐릭터가 box rearrangement 작업을 수행하기 위해 계획, diffusion model, 강화학습을 계층적으로 조합하는 시스템을 제시한다.
본 논문은 물리 기반 캐릭터 애니메이션에서 loco-manipulation의 도전적인 문제를 diffusion model과 RL을 계층적으로 조합하여 우아하게 해결하며, 높은 기술적 완성도와 실용적 가치를 동시에 갖춘 우수한 연구이다.
Teleoperation of Humanoid Robots: A Survey
 *Fig. 2: Schematic architecture for teleoperating a humanoid.* 본 논문은 humanoid robot teleoperation에 대한 포괄적인 survey로, 원격 환경에서 인간의 인지 능력과 humanoid robot의 물리적 능력을 통합하는 teleoperation 시스템의 아키텍처, 기술적 조화, 그리고 응용 분야를 체계적으로 분석한다. Teleoperation system의 전체 파이프라인과 각 구성 요소를 상세히 제시하며, 통신 지연, 제어, retargeting, 인간-로봇 상호작용 등 다층적 도전 과제들을 다룬다.
본 논문은 humanoid robot teleoperation 분야의 첫 번째 포괄적 survey로, 시스템 아키텍처, 기술적 도전 과제, 그리고 실제 응용을 통합적으로 다룬다. 웹 기반 자료까지 제공하여 학계의 접근성을 높였으나, 이론적 깊이와 정량적 성능 비교 분석이 추가되면 더욱 강화될 수 있다. 고위험 원격 작업의 안전성과 효율성이 중요해지는 시대에 매우 시의적절하고 가치 있는 기여이다.
Physics-Informed Neural Networks with Unscented Kalman Filter for Sensorless Joint Torque Estimation in Humanoid Robots
 *Fig. 2: Block diagram of the multi-layer torque control architecture implemented on the ergoCub humanoid robot. The* 본 논문은 Physics-Informed Neural Networks (PINNs)와 Unscented Kalman Filter (UKF)를 결합하여 휴머노이드 로봇의 관절 토크 센서 없이 전신 토크 제어를 수행하는 프레임워크를 제시한다. 이 방식은 마찰 모델링과 토크 추정을 통합하여 실시간 토크 제어 아키텍처를 구현한다.
본 논문은 PINNs과 UKF의 혁신적 통합을 통해 센서 없는 토크 제어라는 실질적 문제를 해결하며, ergoCub에서의 엄밀한 실험 검증과 확장성 시연으로 휴머노이드 로봇의 실시간 준수 제어를 위한 강력한 기초를 제공한다.
PhysHMR: Learning Humanoid Control Policies from Vision for Physically Plausible Human Motion Reconstruction
Fig. 1. Given a monocular video (a), (b) kinematic-based methods (e.g., GVHMR [Shen et al. 2024]) often cannot produce p
 *Fig. 1. Given a monocular video (a), (b) kinematic-based methods (e.g., GVHMR [Shen et al. 2024]) often cannot produce p* PhysHMR은 모노큘러 비디오로부터 물리적으로 타당한 인간 동작 재구성을 위해 비전-기반 휴머노이드 제어 정책을 직접 학습하는 통합 프레임워크이다. 기존의 두 단계 방식(운동학 기반 추정 + 물리 후처리)과 달리, 시각 정보와 물리 제약을 단일 정책 네트워크에서 함께 추론한다.
PhysHMR은 시각-기반 제어와 물리 추론을 통합하는 창의적 접근으로 모노큘러 비디오 기반 인간 동작 재구성의 근본적 문제를 해결한다. 우수한 물리적 타당성 개선과 실질적 응용 가치로 컴퓨터 비전과 그래픽스 분야에 의미 있는 기여를 한다.
PvP: Data-Efficient Humanoid Robot Learning with Proprioceptive-Privileged Contrastive Representations
Figure 1. (a) PvP employs contrastive learning between proprioceptive and privileged states to learn compact and task-re
 *Figure 1. (a) PvP employs contrastive learning between proprioceptive and privileged states to learn compact and task-re* PvP는 고유 감각(proprioceptive)과 특권 상태(privileged state) 사이의 대조 학습을 활용하여 휴머노이드 로봇의 전신 제어(WBC) 학습의 샘플 효율성을 크게 향상시킨다.
PvP는 proprioceptive-privileged 대조 학습이라는 직관적이면서도 효과적인 방법으로 휴머노이드 로봇 학습의 샘플 효율성을 크게 향상시키며, SRL4Humanoid 프레임워크는 해당 분야의 표준 도구로서 상당한 기여를 한다.
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Fig. 1: Overview of RoboCasa. RoboCasa is a simulation framework for training generalist robot agents. Four pillars unde
 *Fig. 1: Overview of RoboCasa. RoboCasa is a simulation framework for training generalist robot agents. Four pillars unde* RoboCasa는 kitchen 환경에 중점을 둔 대규모 로봇 시뮬레이션 프레임워크로, 생성형 AI를 활용하여 다양한 3D 자산과 task를 확보하고 100K 이상의 synthetic trajectory로 generalist robot 학습을 가능하게 한다.
RoboCasa는 generative AI를 활용하여 robot learning을 위한 대규모 realistic simulation을 구축한 의미 있는 contribution이며, 실제 real-world transfer 성공을 보여줌으로써 sim-to-real robot learning의 실질적 경로를 제시한다. 다만 현재 kitchen 환경 집중과 제한된 real-world 검증은 향후 개선이 필요하다.
RoboPlayground: 구조화된 물리 도메인을 통한 로봇 평가 민주화
Fig. 1: Language-Guided Task Generation in Structured Physical Domains. Natural language instructions are compiled into
 *Fig. 1: Language-Guided Task Generation in Structured Physical Domains. Natural language instructions are compiled into * 자연어로 로봇 조작 작업을 정의하고 재현 가능한 작업 명세로 컴파일하는 RoboPlayground 프레임워크를 제안하며, 고정 벤치마크에서 드러나지 않는 일반화 실패를 언어 기반 작업 변형을 통해 발견한다.
RoboPlayground는 로봇 평가의 민주화와 접근성을 크게 향상시키는 혁신적 접근법으로, 언어 기반 구조화된 작업 변형을 통해 고정 벤치마크가 놓치는 정책의 실제 약점을 드러낸다는 점에서 중요한 기여다. 다만 도메인 제한과 대규모 crowd-sourced 평가의 품질 관리가 실무 적용의 과제다.
RoboStriker: Hierarchical Decision-Making for Autonomous Humanoid Boxing
Figure 1. Real-world clips of humanoid boxing using RoboStriker,
 *Figure 2. Overview of RoboStriker. Stage I pretrains a motion tracker to produce physically plausible humanoid behaviors* RoboStriker는 인간 수준의 경쟁력 있는 휴머노이드 권투를 위해 높은 수준의 전략 추론과 낮은 수준의 물리적 실행을 분리하는 3단계 계층적 프레임워크를 제안한다. Motion capture 데이터로부터 학습된 동작 라이브러리를 구조화된 잠재 공간으로 압축한 후, Latent-Space NFSP를 통해 다중 에이전트 경쟁 학습을 수행한다.
RoboStriker는 embodied MARL의 근본적 모순을 처음으로 공식화하고 계층적 분해를 통해 실질적으로 해결하는 주요 기여를 제시한다. 물리 시뮬레이션과 실제 로봇에서 권투라는 도전적 작업을 성공적으로 달성하여, 추상 게임에서 물리 기반 로봇 시스템으로 MARL을 확장하는 중요한 마일스톤을 제공한다.
RPL: Learning Robust Humanoid Perceptive Locomotion on Challenging Terrains
Fig. 1.
 *Fig. 2.* RPL은 두 단계 학습 프레임워크로 terrain-specific 전문가 정책을 depth 카메라 기반 transformer 정책으로 증류하여, 복잡한 지형에서 payload를 탑재한 상태의 견고한 다방향 인형로봇 보행을 실현한다.
본 논문은 다단계 학습과 효율적 시뮬레이션을 통해 인형로봇의 복잡 지형 다방향 보행 문제를 체계적으로 해결하며, 특히 비대칭 다중 센서 입력 처리 기법과 payload 견고성 검증에서 실질적 기여를 제시한다.
SHIELD: Safety on Humanoids via CBFs In Expectation on Learned Dynamics
Fig. 1. A humanoid robot implementing the SHIELD architecture au-
 *Fig. 1. A humanoid robot implementing the SHIELD architecture au-* SHIELD는 학습 기반 휴머노이드 로봇 컨트롤러에 안전 계층을 추가하여 실시간 제약 조건 명시와 확률적 안전 보장을 동시에 제공하는 프레임워크이다. 동적 잔차 모델과 확률적 이산 시간 제어 배리어 함수(S-DTCBF)를 통해 기존 블랙박스 RL 정책을 재학습 없이 안전화한다.
SHIELD는 학습 기반 humanoid 컨트롤러의 실제 배포를 위한 현실적이고 실용적인 안전 보장 방법을 제시하며, 데이터 기반과 모델 기반 방법의 간격을 효과적으로 연결한다. 실제 로봇 실험 검증과 함께 이론적 안전 보장을 제공하여 로봇 안전 연구에 상당한 기여를 한다.
Sim-and-Real Co-Training: A Simple Recipe for Vision-Based Robotic Manipulation
Fig. 1: Sim-and-Real Co-Training. We show how co-training
 *Fig. 1: Sim-and-Real Co-Training. We show how co-training* 시뮬레이션 데이터와 실제 로봇 데이터를 혼합하여 학습하는 sim-and-real co-training 전략을 체계적으로 연구하고, 비전 기반 로봇 조작 작업에서 실제 데이터만 사용하는 것 대비 평균 38% 성능 향상을 달성했다.
본 논문은 sim-and-real co-training의 실용성을 체계적으로 검증하여 실제 로봇 학습의 데이터 효율성 문제에 직접적인 해결책을 제시하며, 명확한 실험 설계와 실무적 가이드라인으로 로봇 커뮤니티에 높은 가치를 제공한다.
SLAC: Simulation-Pretrained Latent Action Space for Whole-Body Real-World RL
Figure 1: SLAC uses a task-agnostic action space trained in low-fidelity simulation (left) to learn
 *Figure 1: SLAC uses a task-agnostic action space trained in low-fidelity simulation (left) to learn* SLAC는 저충실도 시뮬레이터에서 학습한 task-agnostic 잠재 행동 공간을 사용하여 고자유도 모바일 매니퓨레이터가 실제 환경에서 효율적이고 안전하게 강화학습으로 접촉이 풍부한 전신 조작 작업을 학습할 수 있게 한다.
SLAC는 저충실도 시뮬레이션 기반 latent action space pretraining과 실제 환경 강화학습을 결합하여 고자유도 모바일 매니퓨레이터의 복잡한 접촉 조작 작업을 안전하고 효율적으로 학습할 수 있게 하는 혁신적인 접근법을 제시하며, 1시간 미만의 실제 상호작용만으로 의미 있는 성과를 달성함으로써 실제 로봇 학습의 실용성을 크게 향상시킨다.
VIRAL: Visual Sim-to-Real at Scale for Humanoid Loco-Manipulation
Figure 1. Center: Unitree G1 humanoid performing loco-manipulation, walking between tables to place and pick objects for
 *Figure 2. VIRAL teacher-student pipeline. Phase 1: In simulation, a privileged RL teacher policy πteacher receives full-* VIRAL은 humanoid robot의 loco-manipulation을 시뮬레이션에서 학습하고 zero-shot으로 실제 로봇에 배포하는 visual sim-to-real 프레임워크이며, teacher-student 구조와 대규모 GPU 컴퓨팅을 활용하여 RGB 기반 정책을 통해 54개 사이클의 연속적인 객체 이동을 달성했다.
본 논문은 humanoid loco-manipulation에 대한 시뮬레이션 기반 접근의 실현 가능성을 대규모 GPU 컴퓨팅과 체계적인 설계를 통해 실증한 중요한 연구로, teacher-student 프레임워크와 visual domain randomization의 조합이 zero-shot sim-to-real 전이를 가능하게 함을 보여준다.
VisualMimic: Visual Humanoid Loco-Manipulation via Motion Tracking and Generation
 *Fig. 2: VisualMimic consists of two training stages: 1) training a general keypoint tracker, where a teacher motion trac* VisualMimic은 egocentric vision과 hierarchical whole-body control을 결합한 sim-to-real 프레임워크로, 인간의 동작 데이터로 학습한 task-agnostic keypoint tracker와 task-specific visuomotor policy를 통해 humanoid robot의 loco-manipulation을 실현한다.
VisualMimic은 teacher-student distillation의 창의적 이중 적용과 human motion statistics 기반 제약으로 humanoid loco-manipulation의 현실적 과제를 효과적으로 해결하며, 다양한 작업에서 zero-shot real-world transfer를 입증한 매우 의미 있는 연구이다.
AGILE: A Comprehensive Workflow for Humanoid Loco-Manipulation Learning
Figure 1: Overview of agile learning workflow. The workflow covers prepare-training, batch cloud training
 *Figure 1: Overview of agile learning workflow. The workflow covers prepare-training, batch cloud training* AGILE는 휴머노이드 로봇의 강화학습 정책 개발을 위한 엔드투엔드 워크플로우로, 환경 검증, 재현 가능한 학습, 통합 평가, 디스크립터 기반 배포의 4단계를 표준화하여 시뮬레이션-실세계 전이의 신뢰성을 향상시킨다.
AGILE는 휴머노이드 RL의 실제 배포 단계에서 야기되는 현실적 문제들을 직시하고 이를 해결하기 위한 체계적인 엔지니어링 워크플로우를 제시한다. 알고리즘 혁신보다는 infrastructure 중심이지만, 재현성, 신뢰성, 배포 가능성 측면에서 매우 실용적이며 5개 작업과 2개 플랫폼에서의 성공적인 sim-to-real 전이로 효과를 입증했다.
AME-2: Agile and Generalized Legged Locomotion via Attention-Based Neural Map Encoding
Fig. 1. Our method enables agile and generalized legged locomotion across diverse terrains with onboard sensing and comp
 *Fig. 1. Our method enables agile and generalized legged locomotion across diverse terrains with onboard sensing and comp* AME-2는 Attention 기반 맵 인코더를 통합한 통합 RL 프레임워크로, 민첩성과 일반화를 동시에 달성하는 사족/이족 로봇 보행 제어 방법이다. 학습 기반의 불확실성 인식 elevation mapping 파이프라인과 teacher-student 학습 체계를 통해 sim-to-real 이전을 개선한다.
AME-2는 Attention 기반 맵 인코더와 불확실성 인식 elevation mapping을 통해 agile과 generalized 보행을 통합적으로 달성하는 우수한 프레임워크이며, quadruped과 biped 양쪽에서 실증된 강력한 일반화 능력과 sim-to-real 이전 효과를 입증함으로써 legged locomotion 분야에 중요한 기여를 한다.
DexHub and DART: Towards Internet Scale Robot Data Collection
Fig. 1: We present DART, Dexterous Augmented Reality Teleoperation system, enabling intuitive, low-latency teleoperation
 *Fig. 1: We present DART, Dexterous Augmented Reality Teleoperation system, enabling intuitive, low-latency teleoperation* DART는 클라우드 기반 시뮬레이션과 AR을 활용한 군중기반 로봇 데이터 수집 플랫폼이며, DexHub는 수집된 데이터를 저장하는 공개 클라우드 데이터베이스이다.
본 논문은 AR과 클라우드 시뮬레이션을 창의적으로 결합하여 로봇 데이터 수집의 실질적 문제(지연, 피로, 확장성)를 해결하는 DART 플랫폼을 제시하며, DexHub를 통해 커뮤니티 규모의 데이터 생태계 구축을 시도한 점에서 높은 기여도를 가진다.
E-SDS: Environment-aware See it, Do it, Sorted - Automated Environment-Aware Reinforcement Learning for Humanoid Locomotion
Fig. 1. E-SDS pipeline showing the automated reward generation and refinement.
 *Fig. 1. E-SDS pipeline showing the automated reward generation and refinement.* E-SDS는 Vision-Language Model과 실시간 지형 센서 분석을 통합하여 휴머노이드 로봇의 환경 인식 보행 정책을 자동으로 학습할 수 있는 프레임워크를 제시한다. 환경 통계 기반 보상 함수 자동 생성으로 수동 엔지니어링 시간을 대폭 단축하면서도 더 강건한 보행 정책을 실현한다.
E-SDS는 VLM 기반 자동 보상 설계와 환경 인식 지각형 제어를 혁신적으로 통합하여 휴머노이드 보행의 자동화 및 강건성을 획기적으로 개선했다. 다만 최신 VLM 모델 의존성, 계산 비용, 실제 하드웨어 검증 부재 등은 실용화를 위한 과제로 남아있다.
End-to-End Humanoid Robot Safe and Comfortable Locomotion Policy
Fig. 1.
 *Fig. 1.* 휴머노이드 로봇의 안전하고 편안한 네비게이션을 위해 LiDAR 포인트 클라우드를 모터 커맨드로 직접 매핑하는 end-to-end 정책을 제시하며, CMDP 프레임워크에서 CBF 원리를 비용 함수로 변환하여 P3O로 안전 제약을 강제한다.
본 논문은 LiDAR 기반 end-to-end 정책, CBF-CMDP-P3O 통합 프레임워크, HRI 기반 편안함 설계를 통해 휴머노이드 로봇의 안전하고 사회적으로 수용 가능한 네비게이션 문제를 종합적으로 해결한 강력한 기여를 제시한다. 형식적 안전 보장과 실제 배포의 균형을 잘 맞추었으며, 다만 비선형 동역학과 도메인 갭 분석 강화가 필요하다.
Genie Sim 3.0 : A High-Fidelity Comprehensive Simulation Platform for Humanoid Robot
Fig. 1: Overview of Genie Sim 3.0. Genie Sim 3.0 is a full-cycle robotic simulation platform that integrates environment
 *Fig. 1: Overview of Genie Sim 3.0. Genie Sim 3.0 is a full-cycle robotic simulation platform that integrates environment* Genie Sim 3.0은 LLM 기반 장면 생성, VLM 기반 자동 평가, 10,000시간 이상의 합성 데이터를 제공하는 휴머노이드 로봇 통합 시뮬레이션 플랫폼이다.
Genie Sim 3.0은 LLM/VLM과 로봇 시뮬레이션을 통합한 혁신적 플랫폼으로, 자동화된 장면 생성, 대규모 합성 데이터, 다차원 평가 벤치마크를 통해 로봇 학습 개발 사이클을 크게 가속화할 수 있는 높은 기여도의 연구이다.
Keep on Going: Learning Robust Humanoid Motion Skills via Selective Adversarial Training
 *Figure 2: Overview of the SA2RT. The SAP identifies vulnerabilities in motion states and generates adversarial samples b* 인간형 로봇의 장시간 안정적 운영을 위해 선택적 적대적 공격(SA2RT)을 통한 견고한 동작 제어 정책을 학습하는 방법을 제안한다. 공격 예산 제약 하에서 취약한 상태와 행동을 찾아 표적화된 섭동을 가하여 정책을 강화한다.
본 논문은 선택적 적대적 공격을 통해 인간형 로봇의 동작 견고성을 체계적으로 강화하는 혁신적인 방법을 제시하며, 실제 로봇 플랫폼에서 40% 성공률 향상 등 괄목할 만한 성과를 입증했다. 다만 단일 로봇 플랫폼 실험과 공격 예산 설정의 일반화 측면에서 개선의 여지가 있다.
Learning Social Navigation from Positive and Negative Demonstrations and Rule-Based Specifications
Fig. 1: Overview of the proposed framework. A. Reward learning: (a) density-based reward maps are constructed from
 *Fig. 1: Overview of the proposed framework. A. Reward learning: (a) density-based reward maps are constructed from* 본 논문은 긍정적 및 부정적 시연과 규칙 기반 명세로부터 학습한 밀도 기반 보상을 결합하여 동적 인간 환경에서 안전성과 적응성의 균형을 맞춘 모바일 로봇 네비게이션 정책을 개발한다.
본 논문은 데이터 기반 보상과 규칙 기반 안전 명제의 효과적인 통합을 통해 동적 인간 환경에서의 로봇 네비게이션을 다루는 실용적이고 신뢰할 수 있는 해결책을 제시하며, teacher-student 증류 및 불확실성 추정 기법을 포함한 방법론적 기여와 함께 실제 인간 참여자 실험으로 검증한 점에서 높은 가치를 갖는다.
Learning to Look: Seeking Information for Decision Making via Policy Factorization
Figure 1: DISaM for tasks with information-seeking behavior. To make the right decision in a
 *Figure 1: DISaM for tasks with information-seeking behavior. To make the right decision in a* 로봇이 조작 작업을 수행하기 위해 필요한 정보를 능동적으로 탐색하는 문제를 factorized Contextual MDP로 정의하고, 정보 탐색 정책과 정보 활용 정책으로 분리된 dual-policy 솔루션 DISaM을 제안한다.
정보 탐색과 조작의 분리를 통해 장지평 POMDP를 효율적으로 해결하는 우아한 솔루션을 제시하며, 광범위한 실험 검증으로 실용성을 입증한 강력한 논문이다. 다만 다단계 탐색 최적화와 완전 자동학습 가능성 탐색이 향후 과제이다.
ManiSkill-HAB: A Benchmark for Low-Level Manipulation in Home Rearrangement Tasks
 *Figure 2: Interact benchmark comparing MS-HAB (ours) with Habitat. Each data point is annotated* MS-HAB는 GPU 가속화된 Home Assistant Benchmark의 구현으로, 현실적인 저수준 조작과 빠른 시뮬레이션 속도(4300 SPS)를 지원하며 대규모 데이터셋 생성을 위한 자동화된 궤적 필터링 시스템을 제공한다.
MS-HAB는 현실적인 저수준 조작 제어, 고속 GPU 시뮬레이션, 그리고 자동화된 데이터 생성을 통합하여 가정용 로봇 조작 연구의 중요한 벤치마크를 제공하며, 광범위한 기반선과 투명한 평가 지표는 후속 연구에 큰 가치를 제공한다.
MolmoSpaces: A Large-Scale Open Ecosystem for Robot Navigation and Manipulation
Figure 1 MolmoSpaces is an open ecosystem consisting of a large number of simulation environments, 3D articulated object
 *Figure 1 MolmoSpaces is an open ecosystem consisting of a large number of simulation environments, 3D articulated object* 로봇 네비게이션과 매니퓰레이션을 위한 230k개 이상의 다양한 실내 환경, 130k개의 주석이 달린 객체 자산, 42M개의 안정적인 그래스프를 포함하는 대규모 오픈 에코시스템 MolmoSpaces를 제시하고, 이를 통해 로봇 정책의 일반화 능력을 평가할 수 있는 벤치마크를 구축했다.
MolmoSpaces는 로봇 학습의 평가 기준이 되어 왔던 장면과 객체의 규모 제약을 크게 확장하며, simulator-agnostic 설계와 강한 시뮬-투-리얼 상관관계 검증으로 실무적 신뢰성을 확보한 중요한 오픈 인프라이다. 다만 task 복잡도와 시각적 현실성에서 아직 개선의 여지가 있다.
OmniXtreme: Breaking the Generality Barrier in High-Dynamic Humanoid Control
Fig. 1: Extreme whole-body humanoid control from our unified policy OMNIXTREME. (a) A quantitative comparison shows
 *Fig. 1: Extreme whole-body humanoid control from our unified policy OMNIXTREME. (a) A quantitative comparison shows* OmniXtreme는 flow-matching 기반의 생성형 정책과 actuation-aware residual RL을 결합하여 고동역 인간형 로봇의 다양한 극단적 동작을 고충실도로 추적할 수 있는 확장 가능한 프레임워크를 제시한다.
OmniXtreme은 humanoid 동작 제어의 long-standing fidelity-scalability trade-off를 해결하기 위해 생성형 모델과 actuation-aware 정제라는 두 가지 보완적 기법을 창의적으로 결합한 강력한 프레임워크이며, 실제 로봇에서 극단적 동작의 성공적 실행으로 그 유효성을 입증했다.
Opening the Sim-to-Real Door for Humanoid Pixel-to-Action Policy Transfer
Figure 1: DoorMan, a simulation-trained, RGB-only humanoid loco-manipulation policy, opens diverse, real-world doors.
 *Figure 2: DoorMan training pipeline. All phases are done interactively with IsaacLab. In Phase 1, we train a* GPU 가속 포토리얼리스틱 시뮬레이션과 teacher-student-bootstrap 학습 프레임워크를 통해 순수 RGB 시각만 사용하여 인간형 로봇이 다양한 문을 열 수 있는 sim-to-real 정책을 개발했다.
순수 RGB 시각만을 사용하여 다양한 실제 문을 여는 인간형 로봇 정책을 시뮬레이션에서만 훈련하여 영점 샷 전이에 성공한 획기적인 연구로, staged-reset 탐색과 GRPO 기반 bootstrapping 등의 novel 방법론이 실질적 성능 개선을 입증한다.
Toward Reliable Sim-to-Real Predictability for MoE-based Robust Quadrupedal Locomotion
Fig. 1:
 *Fig. 1:* 본 논문은 Mixture-of-Experts (MoE) 기반 사족 로봇 이동 정책과 sim-to-real 전이 가능성을 정량화하는 RoboGauge 평가 프레임워크를 통합하여 신뢰할 수 있는 시뮬레이션-실제 간 갭을 해소하는 통합 프레임워크를 제시한다.
본 논문은 MoE 기반 정책과 RoboGauge 평가 프레임워크를 통합하여 sim-to-real 갭 문제를 체계적으로 해결하고, 극한 지형에서 4 m/s의 견고한 이동 성능을 입증함으로써 사족 로봇 이동 제어 분야에 유의미한 기여를 한다.
RPG: Robust Policy Gating for Smooth Multi-Skill Transitions in Humanoid Fighting
Fig. 1.
 *Fig. 1.* 본 논문은 RPG(Robust Policy Gating)라는 하이브리드 전문가 정책 프레임워크를 제안하여 인형형 로봇이 다양한 격투 기술 간 매끄럽고 안정적인 전환을 통해 장시간 동적 격투를 수행할 수 있도록 함.
본 논문은 RPG 프레임워크를 통해 인형형 로봇의 다중 격투 기술 매끄러운 전환 문제를 효과적으로 해결하였으며, policy-transition randomization과 temporal randomization의 결합은 기술 전환 강건성 확보에 창의적 기여를 함. 실세계 로봇 검증과 게임 인터페이스 설계로 실용성이 높으나, 기술 범주 확장 및 다양한 로봇 플랫폼 검증이 필요함.
Constrained Whole-Body Tracking for Humanoid Robots
Figure 1: Where does safety fit into a learning-based humanoid motion tracking stack? We approach
 *Figure 1: Where does safety fit into a learning-based humanoid motion tracking stack? We approach* 본 논문은 강화학습 기반 인간형 로봇의 전신 모션 추적 제어에서 안전 제약조건을 실시간으로 강제하는 ConstrainedMimic 프레임워크를 제시한다. operational space control과 control barrier functions을 결합하여 kinematics와 dynamics 차원에서 실행시간 제약조건을 만족시킨다.
본 논문은 humanoid 전신 제어에서 contact-constrained 동역학을 통한 체계적이고 실용적인 안전 강제 방법을 제시한다. Kinematics와 dynamics 양단 필터링, task-consistent 설계, 실시간 실행 가능성은 주목할 만하나, 실하드웨어 검증과 충돌 모델 확장이 필요하다.
HOIST: Humanoid Optimization with Imitation and Sample-efficient Tuning for Manipulating Suspended Loads
 *Figure 4: Overview of the HOIST pipeline. VR teleoperation provides hoisting demonstrations to* 본 논문은 인도형(underactuated) 부유 하중(suspended load)을 조작하는 휴머노이드 로봇을 위한 HOIST를 제시한다. VR 원격 조종 데이터로부터 vision-language-action(VLA) 정책을 미세조정하고, whole-body controller를 통해 실행한 후, iterative batched reinforcement learning으로 배치 정확도와 정지 행동을 개선한다.
HOIST는 휴머노이드 로봇을 이용한 underactuated material-handling이라는 새로운 실제 문제를 잘 정의하고, imitation learning과 reinforcement learning을 실용적으로 결합한 효과적인 해결 방안을 제시한다. VR teleoperation 기반의 데이터 수집부터 whole-body control과 sample-efficient RL까지 완전한 파이프라인을 구현하고, 시뮬레이션과 실제 로봇 모두에서 검증한 점이 강점이다. 다만 일반화 능력 검증과 안전 보장의 명시적 분석이 부족하고, 더 다양한 시나리오에서의 평가가 필요하다.
PaCo-VLA: Passivity-Shielded Compliance Prior for Contact-Rich Vision-Language-Action Manipulation
Figure 1: PaCo-VLA overview. Vanilla VLA sends low-rate action chunks directly toward the plant,
 *Figure 2: Runtime shield mechanisms. (a) Box projection maps unfiltered proposals into Θbox;* 본 논문은 Vision-Language-Action (VLA) 모델을 contact-rich manipulation 작업에 안전하게 적용하기 위해 PaCo-VLA라는 passivity-shielded compliance prior를 제안한다. VLA의 저주기 출력을 직접 모터 명령으로 사용하지 않고, 대신 high-frequency proposal-independent passivity shield를 통해 semantic proposal을 filtering하여 contact dynamics의 안전성을 보장한다.
본 논문은 VLA의 semantic generalization과 contact-rich manipulation의 safety requirement를 reconcile하는 실질적이고 principled된 framework를 제시한다. Passivity-shielded interface와 paired counterfactual evaluation protocol은 methodologically 견고하며, zero passivity violation과 superior precision의 실험 결과는 접근법의 실효성을 입증한다. 다만 task diversity 제한과 보다 일반적인 compliance model에 대한 확장성 논의가 있으면 더욱 강화될 것이다.
SafeVLA-Bench: A Benchmark for the Success-Safety Gap in Vision-Language-Action Models
Figure 1: SafeVLA-Bench overview. SafeVLA-Bench combines task-aware STL safety specifica-
 *Figure 1: SafeVLA-Bench overview. SafeVLA-Bench combines task-aware STL safety specifica-* 본 논문은 VLA 벤치마크에서 높은 작업 성공률이 안전한 실행을 보장하지 않는 문제를 지적하고, SafeVLA-Bench를 제시하여 Signal Temporal Logic (STL) 기반의 형식화된 안전 사양과 Success-But-Unsafe (SBU), Violation Severity Index (VSI) 메트릭을 통해 성공-안전 간극을 정량화한다.
SafeVLA-Bench는 VLA 벤치마크에서 간과되어 온 성공-안전 간극을 명확히 드러내고, 형식화되고 이식 가능한 평가 프레임워크를 제공함으로써 로봇 안전 연구에 중요한 기여를 한다. 다만 시뮬레이터 충실도, 임계값 보정의 한계, 현실 환경 검증 부재 등의 제약이 있다.
Physics-Based Motion Imitation with Adversarial Differential Discriminators
Fig. 1. We propose an adversarial multi-objective optimization technique that enables physically simulated characters to
 *Fig. 1. We propose an adversarial multi-objective optimization technique that enables physically simulated characters to* Physics-based 캐릭터 애니메이션을 위해 Adversarial Differential Discriminator (ADD)를 통해 수동 보상 함수 설계 없이 다중 목표 최적화를 자동으로 수행하는 방법을 제시한다. 단일 positive sample(영점 벡터)만으로도 효과적으로 여러 목표를 동적으로 균형잡아 고난도 동작을 모방할 수 있다.
본 논문은 다중 목표 최적화의 자동화를 위해 창의적인 adversarial discriminator 설계를 제시하며, physics-based 캐릭터 애니메이션에서 수동 보상 함수 설계 제거를 통해 일반화 가능성을 크게 향상시킨다. 핵심 아이디어의 단순성과 광범위한 적용 가능성이 강점이다.
Robot Drummer: Learning Rhythmic Skills for Humanoid Drumming
Fig. 1: The humanoid robot demonstrates expressive drumming skills across three songs: In the top row, the robot plays j
 *Fig. 3: Overview of the Robot Drummer: Starting from a raw MIDI drum track (left), each note-onset is first mapped to a* 본 논문은 인문형 로봇이 MIDI 악보를 기반으로 드럼을 연주하는 기술을 제시하며, Rhythmic Contact Chain 표현과 temporal decomposition을 활용한 reinforcement learning 프레임워크를 제안한다.
본 논문은 humanoid robotics에서 process-driven 창의적 작업으로의 확장을 의미 있게 시연하며, Rhythmic Contact Chain과 temporal decomposition이라는 실용적 기법을 통해 장시간 정밀 제어 문제를 효과적으로 해결한다. 30개 이상의 곡에서의 성공적 성과와 신흥 인간형 전략의 발현은 RL 기반 로봇 제어의 창의적 응용 가능성을 강력하게 보여준다.
StyleLoco: Generative Adversarial Distillation for Natural Humanoid Robot Locomotion
Fig. 1.
 *Fig. 1.* StyleLoco는 강화학습의 민첩성과 모션캡처 데이터의 자연스러움을 결합하기 위해 다중 discriminator를 활용한 Generative Adversarial Distillation (GAD) 프레임워크를 제안하여 인간형 로봇의 자연스러운 보행을 실현한다.
StyleLoco는 인간형 로봇 보행의 오랜 딜레마를 해결하는 창의적인 프레임워크를 제시하며, 다중 discriminator를 통한 이질적 소스의 결합과 실제 로봇에서의 성공적인 배포는 높은 실용 가치를 입증한다.
Agility Meets Stability: Versatile Humanoid Control with Heterogeneous Data
Fig. 1: Introducing AMS (Agility Meets Stability), one single policy that performs diverse motions with stability and ag
 *Fig. 2: Overview of AMS. (a) The general whole-body tracking pipeline retargets human MoCap data to reference motions* AMS는 휴먼 모션캡처 데이터와 합성 밸런스 데이터를 결합하여 단일 정책으로 민첩한 동작과 극한의 밸런스 유지를 동시에 수행할 수 있는 휴머노이드 제어 프레임워크다.
본 논문은 휴머노이드 로봇 제어의 오랫동안의 과제인 민첩성과 안정성의 통합을 처음으로 체계적으로 해결하며, 이질적 데이터와 하이브리드 보상 설계를 통한 창의적 접근과 실제 로봇에서의 강력한 성과를 보여준다.
AMOR: Adaptive Character Control through Multi-Objective Reinforcement Learning
Fig. 1. Our method uses multi-objective reinforcement learning to enable on-the-fly tuning of reward weights post-traini
 *Fig. 1. Our method uses multi-objective reinforcement learning to enable on-the-fly tuning of reward weights post-traini* 본 논문은 Multi-Objective Reinforcement Learning(MORL)을 활용하여 보상 함수의 가중치를 학습 후 조정할 수 있는 AMOR 프레임워크를 제안하며, 이를 통해 물리 기반 캐릭터 제어의 반복 튜닝 시간을 단축하고 실제 로봇으로의 전이를 용이하게 한다.
본 논문은 MORL을 물리 기반 캐릭터 제어에 창의적으로 적용하여 훈련 후 가중치 조정을 가능하게 함으로써 개발 워크플로우를 크게 개선하고, 실제 로봇 적용에서의 sim-to-real 전이를 용이하게 하는 실용적이고 혁신적인 접근법을 제시한다.
Contrastive Representation Learning for Robust Sim-to-Real Transfer of Adaptive Humanoid Locomotion
Fig. 1: Our policy, trained via contrastive knowledge distillation, enables
 *Fig. 2: Overview of our proposed training framework. An asymmetric Actor-* Contrastive learning을 이용해 시뮬레이션의 특권 정보(terrain heightmap)를 순수 proprioceptive policy에 증류시켜 지각의 선견성을 얻으면서도 배포 시 지각 센서의 비용을 피한다. Adaptive gait clock을 통해 고정된 클럭 보행과 불안정한 자유 클럭 보행 사이의 근본적 trade-off를 해결한다.
이 논문은 contrastive learning을 통해 시뮬레이션 특권 정보를 proprioceptive policy에 효과적으로 증류하여 지각 센서 없이도 선견성 있는 제어를 달성하는 창의적 해결책을 제시한다. Zero-shot sim-to-real 전이로 극도로 도전적인 지형에서의 강건한 보행을 실증함으로써 인간형 로봇 실용화의 중요한 진전을 보여준다.
Hold My Beer: Learning Gentle Humanoid Locomotion and End-Effector Stabilization Control
Figure 1: Learning Gentle Humanoid Locomotion and End-Effector Stabilization Control with
 *Figure 1: Learning Gentle Humanoid Locomotion and End-Effector Stabilization Control with* 휴머노이드 로봇이 음료를 들고 걸을 때 흘리지 않도록 상체와 하체를 분리된 에이전트로 제어하는 SoFTA 프레임워크를 제안하여, 느린 보행 제어와 빠른 end-effector 안정화를 동시에 달성한다.
이 논문은 휴머노이드의 보행 중 end-effector 안정화라는 중요하면서도 미해결 문제를 frequency separation과 decoupled control로 우아하게 해결한 창의적 접근법을 제시하며, 실세계 배포로 실용성을 입증한 뛰어난 연구이다.
Learning Symmetric and Low-energy Locomotion
Fig. 1. Locomotion Controller trained for different creatures. (a) Biped walking. (b) Quadruped galloping. (c) Hexapod W
 *Fig. 1. Locomotion Controller trained for different creatures. (a) Biped walking. (b) Quadruped galloping. (c) Hexapod W* Deep Reinforcement Learning에 미러 대칭 손실 함수와 커리큘럼 학습을 적용하여 모션 캡처 데이터 없이 자연스럽고 저에너지의 대칭적인 로코모션을 학습하는 방법을 제안한다.
본 논문은 미러 대칭 손실과 adaptive curriculum learning을 결합하여 DRL 기반 로코모션 학습의 오래된 문제(부자연스러움, 고에너지)를 우아하게 해결하며, 다양한 형태에 일반화 가능한 점에서 높은 독창성과 실용성을 갖춘 우수한 연구이다.
Learning to Ball: Composing Policies for Long-Horizon Basketball Moves
Fig. 1. We introduce a novel policy integration framework to enable the composition of drastically different motor skill
 *Fig. 1. We introduce a novel policy integration framework to enable the composition of drastically different motor skill* 농구 동작과 같은 다단계 장기 과제에서 정의되지 않은 중간 상태를 가진 이질적인 스킬들을 seamlessly 합성하기 위해 policy integration framework와 soft routing을 제안한다.
본 논문은 ill-defined 중간 subtask를 다루기 위한 혁신적인 policy integration framework를 제시하며, soft routing과 adaptive fine-tuning을 통해 다단계 장기 과제에서 이질 스킬의 seamless 합성을 실현한다. 실시간 사용자 명령 기반의 자유로운 농구 플레이와 높은 슈팅 정확도는 제안 방법의 유효성을 강력히 입증하나, 시뮬레이션 환경 한정과 방법의 일반화 가능성이 향후 과제이다.
Olaf: Bringing an Animated Character to Life in the Physical World
Fig. 1: Olaf Robot.
 *Fig. 1: Olaf Robot.* 애니메이션 캐릭터 올라프를 실제 물리 로봇으로 구현하기 위해 RL 기반 제어와 혁신적인 기계설계를 결합한 연구이다. 비물리적 움직임과 부자연스러운 비율을 가진 캐릭터를 believable하게 현실화했다.
애니메이션 캐릭터를 물리 로봇으로 현실화하는 문제에 대해 기계설계와 제어 알고리즘을 창의적으로 결합한 우수한 연구이며, thermal awareness와 impact reduction 같은 실무적 고려사항을 RL에 반영한 점이 특히 주목할 만하다.
Unified Humanoid Fall-Safety Policy from a Few Demonstrations
Fig. 1.
 *Fig. 1.* 휴머노이드 로봇이 균형을 잃었을 때 안전하게 넘어지고 빠르게 일어날 수 있도록, 스파스한 인간 시연과 reinforcement learning, diffusion 기반 메모리를 결합하여 낙상 예방·충격 완화·회복을 통합하는 단일 정책을 학습한다.
본 논문은 휴머노이드 낙상 완화와 회복을 명시적으로 통합하는 첫 성공적인 통합 정책을 제시하며, 스파스 인간 시연과 RL, diffusion model을 창의적으로 결합하여 안전한 다중 모달 행동을 학습한다. Unitree G1에서의 견고한 sim-to-real 전이와 일관된 성능은 실제 환경에서의 로봇 안전성을 크게 향상시킬 가능성을 보여준다.
Learning Symmetric and Low-energy Locomotion
Fig. 1. Locomotion Controller trained for different creatures. (a) Biped walking. (b) Quadruped galloping. (c) Hexapod W
 *Fig. 1. Locomotion Controller trained for different creatures. (a) Biped walking. (b) Quadruped galloping. (c) Hexapod W* 본 논문은 심층 강화학습(DRL)을 사용하여 motion capture나 finite state machine 없이 대칭적이고 저에너지의 자연스러운 로코모션을 학습하는 방법을 제안한다. 손실 함수에 미러 대칭성 손실항을 추가하고, 점진적으로 물리적 보조를 완화하는 curriculum learning 방법을 통해 다양한 형태의 캐릭터(이족, 사족, 육족)에서 효과적인 보행 제어기를 자동으로 생성할 수 있음을 보여준다.
본 논문은 강화학습 기반 로코모션 학습에서 미러 대칭성 손실과 curriculum learning이라는 두 가지 간단하면서도 효과적인 기법을 통해 자연스럽고 에너지 효율적인 보행을 달성한 우수한 연구이다. 특히 motion capture나 형태 특정 지식 없이 다양한 캐릭터에 적용 가능한 일반성과 생물학적으로 타당한 결과는 의미있는 기여이나, 이론적 근거와 더 복잡한 운동에 대한 검증이 보완된다면 더욱 강력한 연구가 될 것이다.
PolySim: Bridging the Sim-to-Real Gap for Humanoid Control via Multi-Simulator Dynamics Randomization
 *Fig. 2: Visual illustration of PolySim. The pink star denotes* PolySim은 여러 이질적인 시뮬레이터를 병렬로 활용하여 훈련하는 플랫폼으로, 단일 시뮬레이터의 귀납적 편향을 완화하고 현실 세계로의 전이 갭을 줄인다.
PolySim은 다중 시뮬레이터 병렬 훈련을 통해 simulator inductive bias를 근본적으로 완화하는 혁신적 접근법이며, 견고한 이론적 근거와 실제 배포 성공으로 humanoid control의 현실 전이 문제 해결에 중요한 기여를 한다.
Sim-to-Real of Humanoid Locomotion Policies via Joint Torque Space Perturbation Injection
Fig. 1: Snapshots of training, sim-to-sim transfer, and sim-to-real transfer. This work proposes a novel sim-to-real met
 *Fig. 2: Overview of the training framework: The dynamics* 본 논문은 기존 domain randomization의 한계를 극복하기 위해 상태 의존적인 joint torque space perturbation을 주입하여 humanoid 로봇의 sim-to-real 전이를 개선하는 방법을 제안한다.
본 논문은 domain randomization의 근본적 한계를 creative하게 해결하고 full-sized humanoid 로봇에서 실증적 검증을 통해 sim-to-real 전이 분야에 유의미한 기여를 한다. 다만 방법의 일반화 가능성과 실제 배포 시나리오에서의 추가 고려사항에 대한 더 깊은 분석이 있으면 완성도가 높아질 수 있다.
Booster Gym: An End-to-End Reinforcement Learning Framework for Humanoid Robot Locomotion
Fig. 1: Training, testing, and deployment on Booster T1
 *Fig. 1: Training, testing, and deployment on Booster T1* Booster Gym은 시뮬레이션에서 실제 로봇까지 humanoid robot locomotion을 위한 RL 기반 정책을 훈련하고 배포하는 end-to-end 프레임워크를 제시한다. 이 프레임워크는 domain randomization, 보상 함수 설계, parallel structures 처리 등을 포함하며 Booster T1 로봇에서 omnidirectional walking, disturbance resistance, terrain adaptability를 달성했다.
이 논문은 humanoid robot locomotion의 RL 기반 훈련과 배포를 위한 실용적이고 완전한 오픈소스 프레임워크를 제시하며, 다중 시뮬레이터 검증과 실제 로봇 배포를 통해 실용성을 입증한다. 학술적 기여는 제한적이지만 로보틱스 커뮤니티에 즉시 활용 가능한 도구를 제공하는 점에서 가치 있다.
DiffCoTune: Differentiable Co-Tuning for Cross-domain Robot Control
Fig. 1: Overview of the proposed automated co-tuning approach for
 *Fig. 1: Overview of the proposed automated co-tuning approach for* 로봇 컨트롤러의 시뮬레이션-실제 환경 간 성능 격차를 해결하기 위해 differentiable simulator를 활용한 gradient 기반 co-tuning 프레임워크를 제안하며, 컨트롤러와 시뮬레이터 매개변수를 동시에 최적화하여 적은 시행횟수로 체계적인 도메인 전이를 가능하게 한다.
본 논문은 로봇 도메인 전이의 실질적 문제를 differentiable simulator 기반의 우아한 co-tuning 프레임워크로 해결하며, 다양한 컨트롤러와 시스템에서의 광범위한 실험을 통해 실용성을 입증한 기여도 높은 연구이다.
Towards bridging the gap: Systematic sim-to-real transfer for diverse legged robots
Figure 1. Comparison of real and simulated robot trajectories
 *Figure 1. Comparison of real and simulated robot trajectories* 이족 로봇의 시뮬레이션-실제 전이 문제를 해결하기 위해 강화학습과 영구자석 동기 전동기(PMSM)의 물리 기반 에너지 모델을 통합한 프레임워크를 제안하며, 최소한의 파라미터로 현실성을 확보하면서 에너지 효율성을 달성한다.
이 논문은 물리 기반 모델링과 강화학습을 체계적으로 결합하여 실제 다리 로봇의 시뮬레이션 전이 문제를 효과적으로 해결하며, 광범위한 플랫폼 검증과 에너지 효율성 개선으로 높은 실용성과 신뢰성을 입증한다.
Simulator Adaptation for Sim-to-Real Learning of Legged Locomotion via Proprioceptive Distribution Matching
 *Fig. 3: A Unitree Go2 quadruped used in sim-to-real experiments.* 본 논문은 Sim-to-Real 학습에서 시뮬레이터를 적응시키기 위해 proprioceptive distribution matching을 제안하며, 모션 캡처나 시간 정렬 없이 hardware와 simulation의 dynamics 불일치를 해결한다.
본 논문은 실무적 제약을 해결하는 실용적이고 우아한 솔루션을 제시하며, proprioceptive distribution matching은 기존의 복잡한 state-matching 방식을 효과적으로 대체할 수 있는 가치 있는 기여다. 다만 평가가 단일 로봇 플랫폼과 제한된 hardware data에서만 수행되어 일반화 가능성을 더 광범위하게 검증할 필요가 있다.
Predictive Sampling: Real-time Behaviour Synthesis with MuJoCo
 *Figure 3 | Graphical User Interface. The left tab includes modules for Tasks and the Agent. In the* MuJoCo 물리 엔진 기반의 실시간 예측 제어 프레임워크 MJPC를 소개하고, 간단한 샘플링 기반 알고리즘인 Predictive Sampling이 기존의 더 복잡한 알고리즘들과 경쟁력 있음을 보여준다.
본 논문은 새로운 알고리즘적 기여보다는 실용적이고 접근 가능한 도구의 개발과 제공에 중점을 두며, 예측 제어의 대중화와 연구 생산성 향상이라는 중요한 목표를 달성한다. Predictive Sampling의 실험적 경쟁력은 흥미로우나 이론적 분석이 보완되면 더욱 강력한 기여가 될 것이다.
Quantum deep reinforcement learning for humanoid robot navigation task
 *Fig. 4. Return of Classical SAC versus Quantum SAC in the Walker2d-v4* 이 논문은 Soft Actor-Critic(SAC) 알고리즘을 parameterized quantum circuit으로 구현한 quantum deep reinforcement learning(QDRL)을 humanoid robot navigation 작업에 적용하여, 고차원 상태-행동 공간에서 고전적 RL보다 92% 더 적은 스텝으로 8% 높은 성능을 달성했다.
이 논문은 humanoid robot navigation이라는 도전적 고차원 문제에 QDRL을 처음 적용한 의미 있는 연구로, 양자 컴퓨팅의 실용적 잠재력을 보여주지만, 시뮬레이션 환경 제한과 실제 양자 하드웨어 부재로 인해 근본적인 양자 이점의 증명은 아직 불완전하다.
Reinforcement Learning for Versatile, Dynamic, and Robust Bipedal Locomotion Control
이족 로봇의 다양한 동적 보행 기술(걷기, 뛰기, 점프)을 통합적으로 제어하기 위해 dual-history 아키텍처를 갖춘 심화강화학습 프레임워크를 제시하고, 시뮬레이션에서 실제 로봇(Cassie)으로 무튜닝 전이 배포를 성공시켰다.
이족 로봇 제어라는 도전적 과제에서 dual-history 아키텍처와 task randomization을 통해 통합 RL 프레임워크를 달성하고, 광범위한 실제 로봇 실험으로 다양한 동적 보행 기술의 강건한 구현을 입증한 우수한 연구이다. 다만 아키텍처 설계 선택의 이론적 근거 강화와 다른 플랫폼으로의 확장성 검증이 필요하다.
RobotDancing: Residual-Action Reinforcement Learning Enables Robust Long-Horizon Humanoid Motion Tracking
Fig. 1.
 *Fig. 1.* RobotDancing은 잔차 동작(residual action) 강화학습을 통해 인간형 로봇이 장기간 고역동 춤 동작을 추적할 수 있도록 하는 프레임워크로, 모델-실제 간의 동역학 불일치를 명시적으로 보정한다.
RobotDancing은 잔차 동작 학습과 이원 샘플링 전략을 통해 인간형 로봇의 장기 고역동 모션 추적 문제를 우아하게 해결하며, 실제 로봇으로의 영점 전달 성공은 실무적 가치가 높다.
Robust and Versatile Bipedal Jumping Control through Reinforcement Learning
Fig. 1: Representative dynamic jumping maneuvers performed by a bipedal robot Cassie using the proposed goal-conditioned
 *Fig. 1: Representative dynamic jumping maneuvers performed by a bipedal robot Cassie using the proposed goal-conditioned* Reinforcement learning과 새로운 정책 구조를 활용하여 이족 로봇 Cassie가 다양한 착지 위치와 방향으로 점프하는 강건하고 다목적인 동적 점프 제어를 실현했다.
이족 로봇의 동적 점프 제어에서 RL과 새로운 정책 구조를 결합하여 기존 방법을 크게 뛰어넘는 실제 세계 성과를 달성한 우수한 연구이며, 다목적 강건한 로봇 제어의 새로운 가능성을 보여준다.
Robust Humanoid Walking on Compliant and Uneven Terrain with Deep Reinforcement Learning
Fig. 1: HRP-5P humanoid bipedal locomotion (clockwise) on flat rigid
 *Fig. 1: HRP-5P humanoid bipedal locomotion (clockwise) on flat rigid* Deep RL을 이용하여 humanoid robot HRP-5P가 시뮬레이션에서 terrain randomization으로 학습한 정책을 실제 환경의 compliant하고 uneven한 terrain에서도 robust하게 보행하도록 하는 연구이다.
Life-sized humanoid의 challenging terrain 보행을 위한 deep RL 기반 접근법의 실제 구현을 성공적으로 입증했으며, sim-to-real transfer와 adaptive gait control의 효과를 명확히 보여준 의미 있는 연구이다. 다만 clock control 정책의 실제 적용 효과 검증과 failure case 분석이 보강되면 더욱 완성도 높은 작업이 될 수 있다.
Sampling-Based System Identification with Active Exploration for Legged Robot Sim2Real Learning
Figure 1: SPI-Active enables high-fidelity Sim-to-Real transfer across diverse locomotion tasks. To highlight
 *Figure 2: Overview of SPI-Active. Data Collection: Collect real-world trajectories using RL policies or* SPI-Active는 legged robot의 물리 파라미터를 샘플링 기반으로 식별하고 Fisher Information 최대화를 통한 active exploration으로 sim-to-real 갭을 최소화하는 two-stage 프레임워크이다.
이 논문은 legged robot의 sim-to-real 갭 해결을 위한 원리적이고 실용적인 system identification 프레임워크를 제시하며, Fisher Information 기반 active exploration 전략의 창의적 적용으로 고정밀 locomotion 작업에서 현저한 성능 향상을 달성했다.
SoccerDiffusion: Toward Learning End-to-End Humanoid Robot Soccer from Gameplay Recordings
SoccerDiffusion은 transformer 기반 diffusion model을 활용하여 RoboCup 경기 녹화 데이터로부터 휴머노이드 로봇 축구의 end-to-end 제어 정책을 학습하고, distillation 기법으로 실시간 추론을 가능하게 한다.
본 논문은 실제 RoboCup 경기 데이터로부터 humanoid robot soccer 정책을 학습하는 실질적 시도로, transformer 기반 diffusion model과 distillation 기법의 조합으로 end-to-end 학습과 실시간 추론을 동시에 달성했다. 고수준 전략 행동은 제한적이지만 저수준 운동 행동의 효과적 학습과 공개 데이터셋 제공으로 향후 로봇 학습 연구의 견고한 기초를 마련했다.
Spectral Normalization for Lipschitz-Constrained Policies on Learning Humanoid Locomotion
Fig. 1.
 *Fig. 1.* 본 논문은 인간형 로봇의 보행 학습에서 Spectral Normalization (SN)을 사용하여 Lipschitz 연속성을 효율적으로 강제하고, 기존의 gradient penalty 기반 방법보다 GPU 메모리 오버헤드를 줄이면서도 유사한 성능을 달성한다.
본 논문은 Spectral Normalization이라는 기존 기법을 로봇 정책 학습의 대역폭 제약 문제에 창의적으로 적용하여, 계산 효율성과 성능을 모두 달성한 실용적인 솔루션을 제시한다. 시뮬레이션과 실제 로봇 양쪽에서의 검증으로 신뢰성을 높였으며, sim-to-real 전이 문제 해결에 중요한 기여를 한다.
StageACT: Stage-Conditioned Imitation for Robust Humanoid Door Opening
Fig. 1: Autonomous door opening by the G1 humanoid robot in a real-world office. Time-synchronized front (top) and back
 *Fig. 3: The StageACT framework combines stage-level guidance with low-* StageACT는 휴머노이드 로봇의 도어 오픈 작업을 위해 저수준 정책에 작업 단계(task stage) 정보를 조건으로 추가한 단계-조건부 모방 학습 프레임워크를 제안하며, 부분 관찰성 환경에서 강건성을 크게 향상시킨다.
이 논문은 휴머노이드 도어 오픈이라는 도전적인 실제 문제에서 단순하지만 효과적인 단계 조건화 방식으로 현저한 성능 향상을 달성했으며, 장 지평선 부분 관찰 작업에 대한 실질적 시사점을 제공한다. 다만 일반화와 신뢰성 관점에서 추가 검증이 필요하고, 수동 라벨링 프로세스의 자동화가 필요하다.
The Role of Domain Randomization in Training Diffusion Policies for Whole-Body Humanoid Control
Figure 1: Proposed method. First, a robust and stable RL policy is trained using AMP under ex-
 *Figure 2: Evaluation of Diffusion Policies in a non-randomized target environment. Top: A plot dis-* 본 논문은 Humanoid 로봇의 전신 제어를 위해 Diffusion Policies를 훈련할 때 Domain Randomization의 역할을 조사하며, 조작 작업보다 보행 작업이 훨씬 더 큰 규모와 다양성의 데이터셋을 요구함을 보여준다.
본 논문은 humanoid 제어를 위한 Diffusion Policies의 데이터 요구사항에 대한 첫 체계적 ablation 연구로서, Domain Randomization의 중요성을 명확히 입증하고 조작-보행 작업 간의 근본적 차이를 정량화한다. 다만 실제 로봇 검증과 복잡한 작업으로의 확장이 필요하다.
Walk the PLANC: Physics-Guided RL for Agile Humanoid Locomotion on Constrained Footholds
Fig. 1. Model-guided RL traversing constrained footholds on the Unitree G1
 *Fig. 2. A visual depiction of the model-guided RL architecture used to achieve stepping stones. The left column shows th* 이 논문은 감소된 차수의 발판 계획기와 Control Lyapunov Function (CLF) 기반 보상을 통해 물리학 기반 구조로 강화학습을 안내하여, 제한된 발판에서 인간형 로봇의 정밀한 보행을 달성한다.
본 논문은 물리 기반 구조와 강화학습을 효과적으로 결합하여 stepping-stone 보행의 정밀성과 강건성 문제를 우아하게 해결하였으며, 하드웨어 검증과 오픈소스 공개를 통해 높은 실용적 가치를 제공한다.
Whole-body Humanoid Robot Locomotion with Human Reference
Fig. 1: The top image displays the humanoid robot Adam walking on unseen terrain,
 *Fig. 1: The top image displays the humanoid robot Adam walking on unseen terrain,* 인간의 보행 데이터를 활용한 모방 학습 프레임워크를 통해 풀사이즈 휴머노이드 로봇 Adam이 인간 수준의 보행 성능을 달성하는 방법을 제시한다.
휴머노이드 로봇 제어의 오래된 과제(복잡한 보상 함수, Sim2Real 간극)를 인간 모방 학습으로 효과적으로 해결하고 풀사이즈 로봇에서 첫 성공을 달성한 중요한 연구이다. 다만 정량적 평가 지표 부족과 경쟁 로봇과의 비교 분석이 보강되면 더욱 강력한 논문이 될 수 있다.
Whole-Body Model-Predictive Control of Legged Robots with MuJoCo
Fig. 1.
 *Fig. 1.* MuJoCo 물리엔진과 iterative LQR (iLQR) 알고리즘을 결합하여 사족 및 인형로봇의 전신 모델예측제어(MPC)를 실시간으로 수행하고, 간단한 방법으로도 현실 세계에 효과적으로 적용 가능함을 입증하는 연구이다.
이 논문은 복잡한 최적화 이론 대신 표준 도구들의 조합으로 현실 세계 다리로봇 제어를 성공시킨 우수한 실증 연구이며, 공개된 코드와 상세한 구현 정보로 커뮤니티 연구 가속화에 큰 기여할 것으로 기대된다.
AMO: Adaptive Motion Optimization for Hyper-Dexterous Humanoid Whole-Body Control
Fig. 1: AMO enables hyper-dexterous whole-body movements for humanoid robots. (a): The robot picks and places a can on
 *Fig. 2: System overview. The system is decomposed into four stages: 1. AMO module training by collecting AMO dataset* AMO는 sim-to-real RL과 trajectory optimization을 결합하여 29-DoF 인형로봇의 실시간 적응형 전신 제어를 구현하며, hybrid dataset 구성과 O.O.D. 명령에 대한 강건한 일반화를 통해 기존 방법의 운동 공간 제한을 극복한다.
AMO는 hybrid motion synthesis와 O.O.D. robust 정책 학습을 통해 인형로봇의 운동 공간을 획기적으로 확대한 혁신적 연구로, MoCap과 trajectory optimization의 상보적 장점을 효과적으로 결합하며 sim-to-real transfer와 실시간 적응형 제어에서 탁월한 성과를 보여준다.
Architecture Is All You Need: Diversity-Enabled Sweet Spots for Robust Humanoid Locomotion
 *Fig. 2. Training and Deployment Overview: both actor and critic are two-stage architectures each with their own percepti* 휴머노이드 로봇의 견고한 보행을 위해 빠른 고주파 안정화 제어기와 느린 저주파 지각 정책을 분리하는 계층화 제어 구조(LCA)가 단일 end-to-end 설계보다 우월함을 보였다.
휴머노이드 로봇 제어에서 네트워크 복잡도보다 구조적 설계(계층화 다중 주파수)가 견고성의 핵심임을 명확히 입증한 중요한 연구로, 최소한의 아키텍처로 복잡한 실제 환경 과제를 해결함으로써 로봇 제어 설계의 원칙을 제시한다.
BeamDojo: Learning Agile Humanoid Locomotion on Sparse Footholds
Fig. 1: Our proposed framework, BEAMDOJO, enables agile and robust humanoid locomotion across challenging sparse foothol
 *Fig. 1: Our proposed framework, BEAMDOJO, enables agile and robust humanoid locomotion across challenging sparse foothol* BeamDojo는 샘플링 기반의 다각형 발 보상 함수와 이중 critic 아키텍처를 결합한 2단계 강화학습 프레임워크로, 휴머노이드 로봇이 디딤돌과 같은 드문 디딤점을 가진 복잡한 지형에서 민첩하고 정밀한 보행을 학습하게 한다.
BeamDojo는 휴머노이드 로봇의 다각형 발 기하학을 명시적으로 처리하고 2단계 훈련으로 표본 효율성을 높인 혁신적인 프레임워크로, 시뮬레이션과 실제 로봇 실험을 통해 sparse foothold에서의 민첩한 보행 능력을 입증하여 로봇 보행 제어 분야에 중요한 기여를 한다.
Benchmarking Humanoid Imitation Learning with Motion Difficulty
Figure 1. Our Motion Difficulty Score (MDS) accurately quanti-
 *Figure 1. Our Motion Difficulty Score (MDS) accurately quanti-* 본 논문은 인간형 로봇의 동작 모방 학습에서 정책 성능과 동작 난이도를 분리하여 평가하기 위해 Motion Difficulty Score (MDS)를 제안하며, 이를 통해 실패가 학습 부족인지 본질적으로 어려운 동작인지를 구분할 수 있게 한다.
본 논문은 동작 모방 학습에서 오래된 문제(정책 성능 vs 동작 난이도의 혼동)를 처음으로 명확히 정의하고 수학적으로 해결하는 창의적인 접근을 제시하며, MD-AMASS 구성과 광범위한 실증 검증을 통해 실용적 가치를 입증한다. 다만 실제 로봇 환경으로의 확장과 일반화 가능성에 대한 추가 검증이 요구된다.
Benchmarking Potential Based Rewards for Learning Humanoid Locomotion
Fig. 1: The potential based (left), direct (middle), and base-
 *Fig. 2: A visualization of a tracking reward in both direct-* 본 논문은 humanoid 로봇의 고차원 보행 학습에서 potential-based reward shaping (PBRS)과 direct reward shaping (DRS)을 벤치마크하여, PBRS가 수렴 속도에서는 한계적 이점만 제공하지만 보상 척도에 대해 훨씬 더 견고하다는 것을 실증적으로 입증한다.
본 논문은 고차원 로보틱 시스템에서 PBRS의 실제 효과를 실증적으로 검증한 중요한 케이스 스터디로, 보상 함수 설계의 실무적 지침(특히 견고성 측면)을 제공한다. 다만 단일 태스크 벤치마크와 이론-실전 간 격차의 원인 분석이 보강된다면 더욱 강력한 기여가 될 것이다.
Berkeley Humanoid: A Research Platform for Learning-based Control
Figure 1: Design, training, and sim-to-real deployment of our custom-built humanoid with a
 *Figure 1: Design, training, and sim-to-real deployment of our custom-built humanoid with a* 학습 기반 제어를 위해 특별히 설계된 저비용 중형 휴머노이드 로봇 플랫폼인 Berkeley Humanoid를 제시하며, 좁은 sim-to-real 갭과 높은 신뢰성으로 다양한 지형에서 동적 보행을 실현한다.
Berkeley Humanoid는 학습 기반 휴머노이드 제어 연구를 위한 실용적이고 비용 효율적인 플랫폼으로, 하드웨어와 제어 알고리즘의 통합 설계를 통해 중요한 sim-to-real 문제를 해결한 가치 있는 기여이다. Open-source 공개 계획은 커뮤니티 연구를 촉진할 것으로 예상된다.
DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills
Fig. 1. Highly dynamic skills learned by imitating reference motion capture clips using our method, executed by physical
 *Fig. 1. Highly dynamic skills learned by imitating reference motion capture clips using our method, executed by physical* Motion capture 데이터를 활용한 example-guided reinforcement learning으로 물리 기반 캐릭터 애니메이션을 학습하는 방법을 제안하며, 모션 모방과 task 목표를 결합하여 강건하고 다양한 기술을 수행하는 제어 정책을 학습한다.
본 논문은 개별 기술의 novel 한 조합보다는 physics-based character animation에서의 효과적 시스템 설계를 통해 실질적 가치를 제시하며, 광범위한 실증 결과로 방법의 실용성과 확장성을 강력히 입증한 매우 영향력 있는 기여이다.
Discovering Self-Protective Falling Policy for Humanoid Robot via Deep Reinforcement Learning
Fig. 1.
 *Fig. 1.* Deep Reinforcement Learning과 Curriculum Learning을 이용하여 인간형 로봇이 낙상 상황에서 자체적으로 보호 행동을 발견하도록 학습시키며, 팔을 삼각형 구조로 형성하여 낙상 손상을 최소화하는 방법을 제시한다.
이 논문은 DRL과 Curriculum Learning을 통해 인간형 로봇이 자신의 물리적 특성에 맞는 낙상 보호 정책을 자율적으로 발견하도록 하는 혁신적 접근을 제시하며, 실제 로봇 플랫폼으로의 성공적 전이와 포괄적 벤치마크 구성으로 인간형 로봇의 안전성 향상에 중요한 기여를 한다.
Distillation-PPO: A Novel Two-Stage Reinforcement Learning Framework for Humanoid Robot Perceptive Locomotion
Fig. 1: We demonstrate the walking capabilities of the humanoid robot Tien Kung on
 *Fig. 2: The training framework of Distillation-PPO adopts a symmetric structure for both the teacher and student network* 인문형 로봇의 지각 기반 보행을 위해 교사 정책과 강화학습을 결합한 2단계 프레임워크 Distillation-PPO (D-PPO)를 제안하며, 시뮬레이션에서의 안정성과 실제 로봇의 강건성을 동시에 확보한다.
본 논문은 강화학습과 지식 증류의 강점을 결합한 균형잡힌 접근법으로, 시뮬레이션과 실제 로봇 양쪽에서 검증된 실질적 성과를 보여준다. 다만 이론적 분석이 부족하고 단일 로봇 플랫폼의 실험만 제시된 점이 아쉽지만, 인문형 로봇 보행 제어의 실질적 문제 해결에 기여하는 의미 있는 연구다.
DoublyAware: Dual Planning and Policy Awareness for Temporal Difference Learning in Humanoid Locomotion
Fig. 1: Overview of DoublyAware: Disjoint uncertainty decomposi-
 *Fig. 1: Overview of DoublyAware: Disjoint uncertainty decomposi-* DoublyAware는 TD-MPC 프레임워크에서 불확실성을 planning uncertainty와 policy uncertainty로 명시적으로 분해하여, conformal prediction과 Group-Relative Policy Constraint를 통해 휴머노이드 로봇의 샘플 효율적이고 안정적인 학습을 실현한다.
본 논문은 MBRL의 핵심 문제인 불확실성을 planning과 policy로 분해하고 각각에 맞는 엄밀한 해법(conformal prediction, GRPC)을 제시함으로써 개념적 명확성과 기술적 우수성을 동시에 달성했다. 휴머노이드 로봇 제어라는 도전적 문제에서 실증적 개선을 보여주었으나, 실제 로봇 검증과 계산 비용 분석이 보완되면 더욱 강력한 기여가 될 것으로 판단된다.
Dribble Master: Learning Agile Humanoid Dribbling through Legged Locomotion
Fig. 1: Dribble Master: Humanoid robot learning to dribble under various tasks. (a): The robot receives ball velocity co
 *Fig. 1: Dribble Master: Humanoid robot learning to dribble under various tasks. (a): The robot receives ball velocity co* 두 단계 curriculum learning과 virtual camera 모델을 이용하여 humanoid 로봇이 시뮬레이션에서 학습한 드리블링 정책을 실제 로봇에 성공적으로 전이하는 방법을 제안한다.
본 논문은 humanoid 로봇의 지속적이고 민첩한 드리블링을 최초로 실현한 의미 있는 연구로, 현실적 시각 제약 모델링과 실제 로봇 전이 성공은 높은 가치가 있다. 다만 정량적 평가와 방법의 일반화 가능성 검증이 보강되면 더욱 완성도 있을 것이다.
EMP: Executable Motion Prior for Humanoid Robot Standing Upper-body Motion Imitation
 *Fig. 2: Overview of our framework. Motion Retargeting (section III): We train a graph convolution retargeting network to* 휴머노이드 로봇이 서 있는 자세를 유지하면서 인간의 상체 동작을 모방하기 위해 강화학습과 Executable Motion Prior(EMP) 모듈을 결합한 프레임워크를 제안한다.
이 논문은 RL과 동작 prior를 결합하여 휴머노이드 로봇의 안정적인 상체 동작 모방을 실현하는 실용적인 솔루션을 제시하며, 실제 로봇 배포를 통해 그 효과를 입증한 우수한 연구이다.
FastTD3: Simple, Fast, and Capable Reinforcement Learning for Humanoid Control
 *Figure 3: Summary of results. FastTD3 is a simple, fast, and capable RL algorithm that significantly* FastTD3는 병렬 시뮬레이션, 대배치 업데이트, 분포 기반 크리틱 등의 간단한 수정을 통해 TD3를 최적화하여 humanoid 로봇 제어 태스크를 단일 A100 GPU에서 3시간 이내에 학습하는 빠르고 효율적인 오프-정책 강화학습 알고리즘을 제시한다.
FastTD3는 기존 기법의 조합이지만 humanoid robotics에서 실무적으로 매우 유용한 간단하고 빠른 솔루션을 제공하며, 오픈소스 구현을 통해 RL 연구 커뮤니티의 접근성을 크게 향상시킨다. 다만 알고리즘 혁신보다는 엔지니어링 최적화에 중점을 두고 있어 과학적 원창성은 제한적이다.
Full-Order Sampling-Based MPC for Torque-Level Locomotion Control via Diffusion-Style Annealing
Fig. 1: Diffusion-inspired annealing for legged MPC (DIAL-
 *Fig. 1: Diffusion-inspired annealing for legged MPC (DIAL-* DIAL-MPC는 diffusion 프로세스의 iterative refinement 아이디어를 sampling-based MPC에 적용하여 full-order 사족 로봇의 torque-level 제어를 실시간으로 수행하는 training-free 방법이다.
본 논문은 MPPI와 diffusion의 수학적 연결을 통해 sampling-based MPC의 근본적 한계를 새로운 각도로 접근하며, diffusion-inspired annealing이라는 창의적 방법으로 full-order 사족 로봇의 실시간 제어를 training-free로 달성한 의미있는 기여이다.
Gait-Conditioned Reinforcement Learning with Multi-Phase Curriculum for Humanoid Locomotion
Fig. 1: Human-like multi-gait locomotion on the Unitree G1
 *Fig. 1: Human-like multi-gait locomotion on the Unitree G1* 인간에게서 영감을 얻은 보상 형성과 gait-conditioned reward routing을 통해 단일 recurrent policy에서 서서기, 걷기, 달리기 및 전환을 학습하는 통합 reference-free RL 프레임워크를 제시한다.
이 논문은 gait-conditioned reward routing과 생물역학 기반 보상 설계를 통해 MoCap 없이 자연스러운 다중 gait 학습을 가능하게 하는 우아한 프레임워크를 제시하며, 실제 인간형 로봇에서의 검증으로 실용성을 입증한다.
GBC: Generalized Behavior-Cloning Framework for Whole-Body Humanoid Imitation
Fig. 1. GBC data processing pipeline. MoCap data (angle-axis representation)
 *Fig. 1. GBC data processing pipeline. MoCap data (angle-axis representation)* GBC는 이질적인 휴머노이드 로봇들을 위한 통합 행동 모방 프레임워크로, differentiable IK 기반 데이터 파이프라인, DAgger-MMPPO 알고리즘, MMTransformer 아키텍처를 결합하여 인간 모션캡처 데이터를 다양한 로봇에 자동으로 재타겟팅하고 학습한다.
본 논문은 이질적 휴머노이드 로봇들의 행동 모방을 위한 첫 번째 통합 프레임워크를 제시하며, differentiable IK, MMTransformer, DAgger-MMPPO 알고리즘을 결합하여 데이터 처리부터 정책 학습까지 일원화된 솔루션을 제공한다. 오픈소스 플랫폼 제공과 다중 로봇 검증을 통해 실용성과 확장성을 입증했으나, 실제 로봇 배포 성능 및 동적 환경에서의 강건성에 대한 검증이 후속과제이다.
Generalizable Humanoid Manipulation with 3D Diffusion Policies
Fig. 1: Humanoid manipulation in diverse unseen scenarios. With our system, we are able to 1) collect human-like
 *Fig. 1: Humanoid manipulation in diverse unseen scenarios. With our system, we are able to 1) collect human-like* 이 논문은 단일 장면에서 수집한 데이터만으로 휴머노이드 로봇이 다양한 미지의 실제 환경에서 자율적으로 조작 작업을 수행하도록 하는 3D Diffusion Policy 기반 시스템을 제시한다.
이 논문은 휴머노이드 로봇의 장면 일반화 조작이라는 미해결 문제를 최초로 해결하며, 개선된 3D Diffusion Policy와 완전한 실제 환경 시스템을 통해 단일 장면 데이터만으로 다양한 미지 환경에서의 자율 작동을 달성한 의미 있는 기여를 제시한다.
HuMam: Humanoid Motion Control via End-to-End Deep Reinforcement Learning with Mamba
Figure 1: Overall architecture of the proposed humanoid locomotion framework. At each time step, robot-centric and exter
 *Figure 1: Overall architecture of the proposed humanoid locomotion framework. At each time step, robot-centric and exter* HuMam은 Mamba 인코더를 백본으로 사용하는 end-to-end 강화학습 기반 휴머노이드 로봇 보행 제어 프레임워크로, 로봇 중심 상태와 목표 발걸음을 효율적으로 융합하여 안정적이고 에너지 효율적인 제어를 실현한다.
HuMam은 Mamba를 활용한 휴머노이드 보행 제어의 첫 성공 사례로, 학습 효율성과 에너지 효율성을 동시에 개선하는 실질적 기여를 한다. 다만 시뮬레이션 기반 결과와 단일 플랫폼 검증의 제약이 있어 실제 응용 가능성 입증을 위한 추가 연구가 필요하다.
Humanoid-Gym: Reinforcement Learning for Humanoid Robot with Zero-Shot Sim2Real Transfer
Fig. 1: Humanoid-Gym enables users to train their policies
 *Fig. 2: Pipeline of Humanoid-Gym. Initially, we employ* Humanoid-Gym은 Nvidia Isaac Gym 기반의 강화학습 프레임워크로, 인간형 로봇의 보행 기술을 훈련하고 zero-shot sim-to-real 전이를 통해 실제 환경으로 직접 배포할 수 있도록 설계되었다.
Humanoid-Gym은 인간형 로봇의 zero-shot sim-to-real 전이를 체계적으로 구현한 최초의 공개 프레임워크로, 실제 로봇에서 입증된 높은 실용성과 함께 로봇 학습 커뮤니티에 중요한 기여를 제공한다. 다만 평가 환경과 로봇 종류의 다양성 확대를 통해 결과의 보편성을 강화할 필요가 있다.
HumanoidBench: Simulated Humanoid Benchmark for Whole-Body Locomotion and Manipulation
Fig. 1:
 *Fig. 1:* HumanoidBench는 이족 로봇의 전신 조작과 이동 능력을 평가하기 위한 시뮬레이션 벤치마크로, 손가락이 있는 손과 다양한 27개의 도전적인 작업을 포함한다.
HumanoidBench는 이족 로봇의 전신 제어 문제를 포괄적으로 다루는 첫 번째 벤치마크로서, 로봇 학습 커뮤니티에 중요한 평가 플랫폼을 제공하며, 계층적 학습 접근법의 효과성을 입증하여 향후 이족 로봇 알고리즘 연구의 방향을 제시한다.
Kinematics-Aware Multi-Policy Reinforcement Learning for Force-Capable Humanoid Loco-Manipulation
Fig. 1. System architecture of the proposed training pipeline. The diagram illustrates the integration of the upper-body
 *Fig. 1. System architecture of the proposed training pipeline. The diagram illustrates the integration of the upper-body* 본 논문은 휴머노이드 로봇의 고부하 산업 작업 수행을 위해 kinematics 사전 정보를 활용한 휴리스틱 보상함수, force-based curriculum learning, delta-command 정책을 통합한 3단계 RL 기반 loco-manipulation 프레임워크를 제안한다.
본 논문은 휴머노이드 로봇의 고부하 loco-manipulation을 위해 kinematics 정보 활용, curriculum learning, modular 정책 조정을 결합한 체계적이고 실용적인 RL 프레임워크를 제시하며, 실제 로봇 실험으로 강력한 성능을 입증했다. 다만 단일 플랫폼 검증과 실제 산업 환경 적응성 평가 보강이 필요하다.
Learning Agile Striker Skills for Humanoid Soccer Robots from Noisy Sensory Input
 *Fig. 2: Left: The network architectures for the teacher and the student network; Right: Multi-stage training framework: * 이 논문은 reinforcement learning 기반의 4단계 학습 프레임워크를 통해 인간형 로봇이 노이즈가 있는 센서 입력에서도 강건한 볼 킹킹 기술을 습득하도록 하는 시스템을 제시한다.
이 논문은 noisy perception 환경에서 인간형 로봇의 복잡한 동적 기술을 학습하는 현실적이고 체계적인 프레임워크를 제시하며, 4단계 curriculum, 현실적 지각 모델링, constrained RL 적응의 조합으로 sim-to-real gap을 효과적으로 감소시켰다. 실제 로봇 실험 결과와 포괄적 ablation 연구는 제안 방법의 타당성을 잘 입증하고 있으나, 단일 로봇 플랫폼 평가와 66.7% 성공률이 실무 적용성을 위해서는 추가 개선이 필요하다.
Learning Sim-to-Real Humanoid Locomotion in 15 Minutes
Figure 1: Summary of results. We introduce a simple recipe based on off-policy RL algorithms, i.e.,
 *Figure 1: Summary of results. We introduce a simple recipe based on off-policy RL algorithms, i.e.,* 이 논문은 FastSAC와 FastTD3라는 off-policy RL 알고리즘을 기반으로 단일 RTX 4090 GPU에서 15분 이내에 humanoid 로봇의 보행 정책을 학습할 수 있는 실용적인 레시피를 제시한다.
이 논문은 off-policy RL을 humanoid 제어에 효과적으로 적용하기 위한 실용적이고 체계적인 레시피를 제공하며, 15분의 빠른 훈련 시간과 실제 로봇 배포를 통해 sim-to-real 개발 사이클의 혁신을 보여준다. 오픈소스 구현 제공으로 산업 및 학계에 즉시 영향을 미칠 수 있다.
Learning to Get Up Across Morphologies: Zero-Shot Recovery with a Unified Humanoid Policy
Fig. 1. Visual of diverse humanoid morphologies. Ordered by size (left: smallest, right:
 *Fig. 1. Visual of diverse humanoid morphologies. Ordered by size (left: smallest, right:* 7개의 다양한 휴머노이드 로봇(높이 0.48-0.81m, 무게 2.8-7.9kg)에서 낙상 복구를 수행할 수 있는 단일 통합 DRL 정책을 제시하며, 로봇 특화 학습 없이 미학습 로봇에 86±7% 성공률로 제로샷 전이가 가능함을 보였다.
이 논문은 휴머노이드 낙상 복구라는 구체적 과제에서 형태-불가지론적 다중 로봇 제어의 실현 가능성을 처음 입증하며, 포괄적 실험과 높은 제로샷 성능으로 일반화된 로봇 제어의 기초를 마련한다. 다만 시뮬레이션 기반 검증과 실제 전이 실험이 부재한 점이 한계이지만, 오픈소스 공개와 체계적 분석은 해당 분야에 실질적 기여를 한다.
Learning to Walk in Costume: Adversarial Motion Priors for Aesthetically Constrained Humanoids
Fig. 1: Cosmo: an entertainment humanoid robot with covers
 *Fig. 1: Cosmo: an entertainment humanoid robot with covers* 미적 설계 제약이 있는 엔터테인먼트 휴머노이드 로봇 Cosmo를 위해 Adversarial Motion Priors (AMP)를 기반으로 한 강화학습 보행 시스템을 제시하며, 극단적인 질량 분포와 움직임 제약 하에서도 자연스러운 보행 행동을 학습할 수 있음을 보여준다.
본 논문은 엔터테인먼트 로봇의 미적 설계 제약이라는 실제적이고 새로운 도전 문제를 다루면서 AMP 기반 학습을 성공적으로 적용한 의미 있는 연구이다. 극단적인 질량 분포와 제한된 감각 조건에서의 안정적인 sim-to-real 보행 달성은 인상적이지만, 특정 로봇 플랫폼에 대한 높은 맞춤화와 실험의 범위 제한이 일반화 가능성을 감소시킨다.
LiPS: Large-Scale Humanoid Robot Reinforcement Learning with Parallel-Series Structures
 *Fig. 4: Illustration of LiPS Simulation Training and Real-World Deployment Process.* LiPS는 GPU 기반 병렬 훈련 환경에서 URDF 형식의 휴머노이드 로봇을 위한 강화학습 방법으로, 멀티-리지드바디 폐루프 동역학 모델링을 통해 시뮬레이션-현실 간 격차를 줄인다.
LiPS는 휴머노이드 로봇의 GPU 병렬 강화학습에서 sim2real 격차를 크게 줄이는 실질적이고 실용적인 방법으로, URDF 기반 복잡한 로봇 제어 연구에 중요한 기여를 한다. 다만 광범위한 실제 로봇 검증과 다양한 시뮬레이션 플랫폼으로의 확장 연구가 필요하다.
MASH: Cooperative-Heterogeneous Multi-Agent Reinforcement Learning for Single Humanoid Robot Locomotion
Fig. 1. MARL model for a single humanoid robot’s locomotion
 *Fig. 1. MARL model for a single humanoid robot’s locomotion* 단일 인간형 로봇의 보행을 위해 각 팔다리를 독립 에이전트로 모델링하여 Cooperative-Heterogeneous MARL을 적용하는 MASH 프레임워크를 제안한다. 이는 전역 비평가를 공유하며 협력학습을 통해 전신 조화 능력을 향상시킨다.
MASH는 MARL 원칙을 단일 인간형 로봇에 창의적으로 적용하여 전신 조화 보행 학습을 효과적으로 개선한 의미 있는 기여이다. 다만 실제 로봇 검증과 알고리즘 세부사항 명확화가 필요하다.
Mechanical Intelligence-Aware Curriculum Reinforcement Learning for Humanoids with Parallel Actuation
Fig. 1: BRUCE [2] hardware with three distinct parallel mechanisms, which
 *Fig. 1: BRUCE [2] hardware with three distinct parallel mechanisms, which* 본 논문은 병렬 구동 메커니즘을 완전히 시뮬레이션하여 학습한 RL 정책을 휴머노이드 로봇 BRUCE에 배포하며, 기존의 직렬 근사 방식과 달리 폐곡선 운동학 제약을 GPU 가속 MJX로 네이티브 구현한다.
본 논문은 병렬 메커니즘의 기계적 특성을 완전히 시뮬레이션하여 RL 학습에 반영하는 혁신적 접근법을 제시하며, 실제 하드웨어 검증을 통해 이 방식의 실질적 성능 이득을 명확히 보여줌으로써 휴머노이드 로봇 제어 분야에 중요한 기여를 한다.
No More Marching: Learning Humanoid Locomotion for Short-Range SE(2) Targets
Fig. 1: Overview of our approach for short-range SE(2)-target
 *Fig. 1: Overview of our approach for short-range SE(2)-target* 본 논문은 휴머노이드 로봇의 단거리 SE(2) 목표 위치 도달을 위해 constellation 기반 보상 함수를 활용한 강화학습 접근법을 제시하며, 속도 추적 기반의 기존 방법들이 생성하는 비효율적인 행진 동작을 제거한다.
이 논문은 단거리 SE(2) 목표 도달이라는 실제 작업에 특화된 새로운 보상 함수와 RL 접근법을 제시하며, 직관적인 설계와 sim-to-real 전이 성공으로 휴머노이드 로봇의 실무 적용 가능성을 크게 향상시킨다.
Towards Bridging the Gap between Large-Scale Pretraining and Efficient Finetuning for Humanoid Control
Figure 1: Large-scale pretraIning and efficient FineTuning (LIFT) Framework. In stage (i), we
 *Figure 1: Large-scale pretraIning and efficient FineTuning (LIFT) Framework. In stage (i), we* 대규모 병렬 시뮬레이션에서 SAC 기반 정책 사전학습과 물리-정보 기반 세계 모델을 활용한 효율적 미세조정을 결합하여 휴머노이드 로봇의 시뮬-투-리얼 전이와 안전한 적응을 실현한다.
본 논문은 대규모 시뮬레이션 효율성과 샘플-효율적 적응을 효과적으로 결합하고, 안전성을 강조한 미세조정 전략으로 휴머노이드 제어의 실질적 도전을 해결한다. 실로봇 검증과 공개 코드는 로보틱스 커뮤니티에 즉시 활용 가능한 기초를 제공한다.
Track Any Motions under Any Disturbances
Fig. 1: (a) The humanoid tracks diverse, highly dynamic, and contact-rich motions using a single policy. (b) The humanoi
 *Fig. 1: (a) The humanoid tracks diverse, highly dynamic, and contact-rich motions using a single policy. (b) The humanoi* Any2Track는 휴머노이드 로봇이 다양한 동작을 추적하면서 동시에 지형, 외력, 물리적 성질 변화 등 실제 환경 교란에 적응할 수 있도록 하는 두 단계 강화학습 프레임워크를 제안한다.
Any2Track는 동역학 적응성을 명시적으로 재정의하고 이를 기본 추적 능력과 분리하여 학습하는 혁신적 접근을 제시하며, Unitree G1에서 zero-shot sim2real 전이를 달성하여 실제 휴머노이드 로봇의 실용화에 중요한 기여를 한다.
HALO: Hybrid Auto-encoded Locomotion with Learned Latent Dynamics, Poincaré Maps, and Regions of Attraction
Figure 1: Autoencoders enable learning of a reduced-order dynamics model in a latent space.
 *Figure 1: Autoencoders enable learning of a reduced-order dynamics model in a latent space.* HALO는 autoencoder와 Poincaré map을 결합하여 다리 로봇 같은 hybrid 동역학 시스템의 주기적 운동을 저차원 latent space에서 학습하고 분석하는 프레임워크이다. Latent space에서 Lyapunov 분석을 수행하여 region of attraction을 구성하고 이를 전체 시스템으로 복원한다.
HALO는 hybrid locomotion dynamics의 안정성 분석을 위해 autoencoder와 Poincaré map을 창의적으로 결합한 우수한 연구이며, latent space의 안정성 속성이 전체 시스템으로 이전된다는 것을 실험적으로 입증한다. 이론과 실험의 균형이 좋으나, 복잡한 시스템에서의 reconstruction 오차 처리와 robust 안정성 보장에 대한 더 깊은 분석이 필요하다.
ReActor: Reinforcement Learning for Physics-Aware Motion Retargeting
Fig. 1. Physics-aware retargeting of human motion (left) onto two humanoid robots (middle) and a quadruped (right) with
 *Fig. 1. Physics-aware retargeting of human motion (left) onto two humanoid robots (middle) and a quadruped (right) with * 본 논문은 인간의 모션캡처 데이터를 상이한 형태의 휴머노이드 및 사족로봇으로 리타게팅하기 위한 이중수준 최적화 프레임워크를 제안한다. 상단 수준에서는 리타게팅 매개변수를 최적화하고, 하단 수준에서는 reinforcement learning을 통해 tracking policy를 학습하여 물리 기반의 artifact-free한 모션을 생성한다.
본 논문은 motion retargeting을 bilevel optimization과 RL의 조합으로 재정의하여 물리적으로 타당하고 artifact-free한 모션을 생성하는 강력한 프레임워크를 제시한다. Sparse correspondence만으로 다양한 morphology를 지원하며, 시뮬레이션 기반 검증과 제한적 hardware 결과를 제공한다. 계산 효율성과 hardware 검증의 확장이 향후 과제이지만, 로보틱스와 애니메이션 분야의 motion retargeting 문제에 대한 중요한 기여로 평가된다.
Track Any Motions under Any Disturbances
Fig. 1: (a) The humanoid tracks diverse, highly dynamic, and contact-rich motions using a single policy. (b) The humanoi
 *Fig. 1: (a) The humanoid tracks diverse, highly dynamic, and contact-rich motions using a single policy. (b) The humanoi* 이 논문은 humanoid 로봇이 다양하고 동적이며 접촉이 많은 동작을 추적하면서 동시에 지형, 외력, 물리적 속성 변화 등의 실세계 교란에 강건하게 적응할 수 있도록 하는 Any2Track을 제안한다. AnyTracker와 AnyAdapter 두 가지 주요 컴포넌트로 구성된 2단계 RL 프레임워크를 통해 단일 정책으로 다양한 동작을 추적하면서도 온라인 동역학 적응성을 달성한다.
본 논문은 humanoid motion tracking의 오랜 과제인 다양한 동작 추적과 실세계 교란 적응을 동시에 해결하는 포괄적인 솔루션을 제시한다. 2단계 RL 프레임워크의 설계가 체계적이며, 실제 하드웨어 배포를 통한 성능 입증이 설득력 있다. 다만 단일 플랫폼에만의 평가와 계산 효율성 분석 부재가 한계이지만, 이 분야에 상당한 기여를 하는 우수한 연구로 평가된다.
Symphony: A Heuristic Normalized Calibrated Advantage Actor and Critic Algorithm in application for Humanoid Robots
Fig. 1: a) x
 *Fig. 4: Swaddling Regularization with β as temperature.* Symphony는 휴머노이드 로봇을 안전하게 훈련하기 위해 Swaddling 정규화, Fading Replay Buffer, Temporal Advantage를 결합한 결정론적 Actor-Critic 알고리즘이다. 제한된 parametric noise와 action strength 조절을 통해 sample efficiency, safety, smooth motion을 동시에 달성한다.
Symphony는 실제 휴머노이드 로봇 훈련의 실질적 문제들(safety, efficiency, smoothness)을 종합적으로 해결하는 창의적인 heuristic 알고리즘이다. 그러나 이론적 기초와 실증적 검증이 부족하여 학술적 엄밀성과 재현성 면에서 개선이 필요하다.
PyRoki: A Modular Toolkit for Robot Kinematic Optimization
Fig. 1: PyRoki is a modular, extensible, and cross-platform toolkit for kinematic optimization. We unify problems
 *Fig. 1: PyRoki is a modular, extensible, and cross-platform toolkit for kinematic optimization. We unify problems* PyRoki는 역기구학, 궤적 최적화, 모션 리타게팅 등 다양한 로봇 운동학 최적화 문제를 통합적으로 해결하는 모듈식, 확장 가능하며 CPU/GPU/TPU에서 실행되는 크로스 플랫폼 툴킷이다.
PyRoki는 로봇 운동학 최적화를 위한 통합된 모듈식 프레임워크로서 파편화된 기존 도구들의 문제를 효과적으로 해결하고, CPU/GPU/TPU 크로스 플랫폼 지원과 cuRobo 대비 1.4-1.7배 성능 향상을 달성하였다. 인터랙티브 시각화와 사용 편의성을 갖춘 실용적인 오픈소스 도구로서 높은 연구 및 산업 가치가 있다.
SEEC: Stable End-Effector Control with Model-Enhanced Residual Learning for Humanoid Loco-Manipulation
 *Fig. 2: System framework overview of SEEC. Our SEEC framework decouples the humanoid loco-manipulation controller into u* SEEC는 model-enhanced residual learning을 통해 휴머노이드 로봇의 보행 중 팔 end-effector를 안정적으로 제어하는 프레임워크로, 하지 유도 교란에 대해 모델 기반 보상 신호를 RL 정책에 통합한다.
SEEC는 모델 기반 제어의 정밀성과 RL의 적응성을 효과적으로 결합하며, perturbation 생성을 통한 모듈식 설계로 미학습 제어기에도 robust하게 전이되는 점에서 높은 독창성을 보인다. 실제 휴머노이드 로봇 배포와 다양한 loco-manipulation 작업 검증으로 실용성도 입증하였다.
SKATER: Synthesized Kinematics for Advanced Traversing Efficiency on a Humanoid Robot via Roller Skate Swizzles
Fig. 1: The SKATER system: a humanoid robot equipped
 *Fig. 1: The SKATER system: a humanoid robot equipped* 휴머노이드 로봇의 발에 4개의 수동 바퀴를 장착하고 Deep Reinforcement Learning을 통해 롤러스케이팅 스위즐 보행을 학습시켜 전통적인 보행 대비 충격력 75.86%, 에너지 소비 63.34% 감소를 달성했다.
휴머노이드 로봇의 에너지 효율과 관절 수명 향상을 위해 롤러스케이팅이라는 창의적인 솔루션을 제시하고, DRL 기반 제어 프레임워크를 통해 현실적인 구현을 달성한 혁신적 연구이다. 85~76% 수준의 높은 성능 개선과 sim-to-real 전이의 성공은 로봇 운동 제어 분야에 실질적 기여를 한다.
Stabilizing Humanoid Robot Trajectory Generation via Physics-Informed Learning and Control-Informed Steering
Fig. 1: Our method used to execute various walking direc-
 *Fig. 1: Our method used to execute various walking direc-* 인간형 로봇의 궤적 생성에 물리 기반 학습과 제어 기반 보정을 결합하여 모방학습의 안정성을 향상시키는 방법을 제안한다. Physics-informed loss와 PI 제어기를 통해 물리 법칙 위반을 줄이고 실제 로봇에서의 안정성을 개선한다.
본 논문은 물리 기반 학습과 제어 이론을 효과적으로 결합하여 인간형 로봇 궤적 생성의 실제 안정성을 향상시키는 실질적이고 모듈식의 접근법을 제시한다. 특히 미분가능한 물리 제약 인코딩과 추론 단계의 PI 제어 보정은 구현이 간단하면서도 실증적 효과가 크며, 실제 로봇 검증으로 산업 적용 가능성을 보여준다.
Control of Humanoid Robots with Parallel Mechanisms using Differential Actuation Models
 *Fig. 3: Planar 4-bar mechanism, with the serial link rotating* Cassie 영감의 휴머노이드 로봇에 사용되는 병렬 구동 메커니즘에 대한 미분가능한 해석 모델을 제시하여 정확한 비선형 전달 특성을 효율적으로 계산 가능하게 한다.
Parallel actuation 메커니즘의 정확한 모델링을 minimal하고 미분가능한 형식으로 구현하여 현대 제어 및 학습 알고리즘에 실용적으로 통합 가능하게 한 의미 있는 기여다. 하드웨어 검증으로 이론의 실효성을 입증했으나, 보다 일반적인 mechanism 설계에 대한 확장성 검증이 추가로 필요하다.
Cost-Matching Model Predictive Control for Efficient Reinforcement Learning in Humanoid Locomotion
Fig. 1: Cost-Matching MPC-RL framework for humanoids.
 *Fig. 1: Cost-Matching MPC-RL framework for humanoids.* 인간형 로봇 보행 제어를 위해 MPC를 RL로 학습할 때 반복적인 MPC 해결의 계산 부담을 제거하는 Cost-Matching MPC 방법을 제안한다. 매개변수화된 MPC의 비용-미래가치(cost-to-go)와 실제 측정된 리턴값의 불일치를 최소화하여 효율적으로 학습한다.
본 논문은 MPC-RL의 계산 병목을 해결하는 창의적인 cost-matching 방법을 제시하며, 복잡한 인간형 로봇 제어 문제에 체계적으로 적용한 우수한 연구다. 다만 실제 로봇 검증의 부재가 임팩트를 제한하므로, 향후 sim-to-real 전이 연구가 필요하다.
ECO: Energy-Constrained Optimization with Reinforcement Learning for Humanoid Walking
Fig. 1: Comparison between the proposed constrained RL frame-
 *Fig. 1: Comparison between the proposed constrained RL frame-* ECO는 에너지 소비를 보상 함수의 가중치가 아닌 명시적 부등식 제약 조건으로 reformulate한 constrained RL 프레임워크로, 휴머노이드 로봇의 에너지 효율적 보행을 달성한다.
ECO는 에너지 최적화를 constrained RL로 reformulate한 novel한 접근법으로 휴머노이드 보행의 에너지 효율성에서 획기적 성과를 달성했으며, 실제 로봇 플랫폼 검증과 constrained RL에 대한 실증적 분석은 로봇 공학 및 최적 제어 커뮤니티에 중대한 기여를 한다.
Embedding Classical Balance Control Principles in Reinforcement Learning for Humanoid Recovery
Fig. 1.
 *Fig. 1.* 고전적 균형 제어 원리(capture point, center-of-mass, centroidal momentum)를 강화학습의 privileged critic 입력과 보상 형성에 직접 임베딩하여, 인간형 로봇의 낙상 회복을 위한 통합 정책을 학습한다. 단일 정책으로 발목/엉덩이 전략, 보정 스텝, 다중접촉 일어서기를 포괄하며 93.4% 회복률을 달성한다.
본 논문은 고전적 균형 제어 원리를 강화학습에 체계적으로 임베딩하는 creative한 접근으로, ablation을 통해 이 구조의 필수성을 입증하고 93.4% 회복률로 강력한 실증 결과를 제시한다. 다만 하드웨어 검증 규모와 다양한 환경에서의 일반화 평가가 보강되면 더욱 설득력 있을 것이다.
Explosive Output to Enhance Jumping Ability: A Variable Reduction Ratio Design Paradigm for Humanoid Robots Knee Joint
Fig. 1: Motor torque performance envelope (TPE) and power
 *Fig. 1: Motor torque performance envelope (TPE) and power* 휴머노이드 로봇의 점프 능력을 향상시키기 위해 무릎 관절이 신장할수록 감속비가 동적으로 감소하는 EVRR-K(Explosive Variable Reduction Ratio Knee) 설계 패러다임을 제안한다.
무릎 관절의 동적 감속비 개념을 신창의적으로 도입하여 전기 구동 휴머노이드의 점프 성능을 획기적으로 개선한 우수한 연구다. 이론 분석, 메커니즘 설계, 실험 검증이 체계적으로 이루어져 있으며, 달성한 점프 성능(0.5m 수직, 1.1m 수평)은 기존 전기 로봇 대비 최고 수준이다.
FastStair: Learning to Run Up Stairs with Humanoid Robots
Fig. 1.
 *Fig. 2.* FastStair는 model-based foothold planner와 model-free RL을 통합하여 humanoid robot의 고속 계단 등반을 실현하는 다단계 학습 프레임워크이다. DCM 기반 planner로 탐색을 안내하고 speed-specialized experts와 LoRA를 통해 보수성을 완화한다.
FastStair는 model-based 안정성과 learning-based 민첩성의 근본적 상충을 다단계 학습과 LoRA 기반 통합으로 우아하게 해결한 혁신적 프레임워크이다. 실제 로봇 배포와 경쟁 우승으로 실용성이 입증되었다.
Learning Adaptive Neural Teleoperation for Humanoid Robots: From Inverse Kinematics to End-to-End Control
Figure 1: Neural teleoperation policy architecture. The network takes VR controller poses (14-dim), joint states (28-
 *Figure 1: Neural teleoperation policy architecture. The network takes VR controller poses (14-dim), joint states (28-* VR 텔레오퍼레이션에서 전통적인 IK+PD 파이프라인을 RL 기반 신경망 정책으로 대체하여 힘 적응, 궤적 부드러움, 사용자 적응을 동시에 달성하는 학습 기반 프레임워크를 제안한다.
학습 기반 신경망 정책으로 VR 텔레오퍼레이션의 근본적 한계를 해결하고 명확한 성능 향상을 보여주는 실질적으로 가치 있는 연구이며, 모방 학습과 교과 학습의 조합 설계가 우수하다.
PACE: Physics Augmentation for Coordinated End-to-end Reinforcement Learning toward Versatile Humanoid Table Tennis
Fig. 1.
 *Fig. 2.* 본 논문은 휴머노이드 로봇의 탁구 경기를 위해 학습된 예측기와 물리 기반 보상을 결합한 end-to-end RL 프레임워크 PACE를 제안하여, 전신 협응 제어와 민첩한 풋워크를 동시에 달성한다.
본 논문은 학습된 예측기와 physics-augmented 보상 설계를 통해 휴머노이드 탁구의 end-to-end RL을 성공적으로 구현한 강력한 작업이며, 시뮬레이션과 실제 하드웨어 모두에서 높은 성능을 입증하여 로봇 동적 제어의 실질적 진전을 보여준다.
TOP: Time Optimization Policy for Stable and Accurate Standing Manipulation with Humanoid Robots
Fig. 1: Illustration of different methods. A: Whole-body RL
 *Fig. 2: The overall architecture. (A) Training a latent code zt based on VAE structure to represent diverse upper-body m* 이 논문은 휴머노이드 로봇의 안정적인 서서하기 조작을 위해 상체 동작의 시간 궤적을 최적화하는 Time Optimization Policy (TOP)을 제안한다. 상체의 빠른 움직임으로 인한 모멘텀을 줄여 균형, 정확성, 시간 효율성을 동시에 달성한다.
이 논문은 상체 동작 시간 최적화라는 직관적이면서도 효과적인 아이디어로 휴머노이드 서서하기 조작의 안정성-정확성-효율성 trade-off 문제를 창의적으로 해결한다. 이론과 실험이 잘 결합되어 있으며, humanoid 로봇 제어 분야에 실질적인 기여를 제공한다.
Reinforcement Learning Enabled Adaptive Multi-Task Control for Bipedal Soccer Robots
 *Fig. 3: Multi-Task RL Control Architecture for Tinker.* 이 논문은 이족 로봇 축구에서 기본 보행과 복잡한 작업(공 찾기, 킥, 낙상 회복)의 깊은 결합 문제를 해결하기 위해 CPG 기반 feedforward oscillator와 RL 기반 residual action을 결합한 모듈식 강화학습 제어 프레임워크를 제안한다.
이 논문은 이족 로봇 축구의 핵심 과제들을 체계적으로 해결하는 효과적인 모듈식 제어 프레임워크를 제시하며, CPG-residual 하이브리드 제어와 posture 기반 상태 전환 메커니즘은 높은 독창성을 보여준다. 다만 실제 하드웨어 검증 부재와 타 방법론과의 비교 분석 부족이 영향력을 제한하며, 이들이 보충된다면 이족 로봇 제어 분야에서 실질적 기여를 할 수 있을 것으로 판단된다.
Constraint-Enhanced Reinforcement Learning Based on Dynamic Decoupled Spherical Radial Squashing
본 논문은 강화학습에서 이질적(heterogeneous) 관절별 액추에이터 속도 제약을 정확히 처리하는 Dynamic Decoupled Spherical Radial Squashing (DD-SRad) 기법을 제안한다. 기존의 isotropic spherical 방법은 ℓ∞ 박스 형태의 제약을 ℓ2 공 형태로 압축하여 실현 가능 집합을 손실하는 반면, DD-SRad는 차원별 적응 반경(per-dimension adaptive radius)을 독립적으로 계산하여 정확한 ℓ∞ 커버리지를 달성한다.
본 논문은 이질적 속도 제약을 가진 강화학습 문제에 대해 이론적으로 건전하고 실무적으로 효과적인 해결책을 제시한다. 기하학적 직관, 엄밀한 정리, 광범위한 실증이 결합되어 있으며, 실 로봇 배포 경로를 명확히 제시하는 점이 돋보인다. 다만 UI=0 미분 불가능성, 제한된 실험 범위, 수렴성 증명 부재가 소수의 약점이나 전반적으로 게재 가치가 충분하다.
Physics-Informed Neural Networks with Unscented Kalman Filter for Sensorless Joint Torque Estimation in Humanoid Robots
 *Fig. 4: CoM tracking comparison: RNEA-PINN (left) vs. UKF-PINN (right). Green rectangles indicate external contacts.* 본 논문은 휴머노이드 로봇의 joint torque 센서를 사용하지 않고 토크 제어를 수행하기 위해 PINN을 활용한 마찰 모델링과 UKF 기반 joint torque 추정을 통합하는 프레임워크를 제시한다. 이 접근법은 high-ratio harmonic drive를 탑재한 전기 모터 시스템에서 실시간 sensorless torque control을 가능하게 한다.
본 논문은 PINN과 UKF를 통합한 sensorless torque control 프레임워크를 제시하며, 휴머노이드 로봇 제어에서 실질적인 advances를 제공한다. 기술적으로 견고하고 실험적으로 검증되었으나, 실험 범위의 제한과 계산 효율성에 대한 분석 부족이 영향을 미친다. 전반적으로 robotics 커뮤니티에 가치 있는 기여를 한다.
RAPT: Model-Predictive Out-of-Distribution Detection and Failure Diagnosis for Sim-to-Real Humanoid Robots
Fig. 1: RAPT overview. Real-world out-of-distribution (OOD) scenarios during humanoid deployment. RAPT detects anomalies
 *Fig. 1: RAPT overview. Real-world out-of-distribution (OOD) scenarios during humanoid deployment. RAPT detects anomalies* RAPT는 시뮬레이션 환경에서 학습한 인간형 로봇 제어 정책의 현실 배포 시 out-of-distribution(OOD) 상태를 감지하고 실패 원인을 진단하는 경량의 자기감독 모니터링 시스템이다.
RAPT는 humanoid robot 배포의 실제적 난제인 silent failure 감지와 근본 원인 분석을 동시에 해결하는 실용적이고 혁신적인 방법으로, 50Hz 고주파 제어 호환성과 interpretable diagnosis를 통해 Sim-to-Real gap 문제의 새로운 패러다임을 제시한다.
CLoSD: Closing the Loop between Simulation and Diffusion for multi-task character control
Figure 1: CLoSD is a multi-task physics-based RL controller, capable of performing object inter-
 *Figure 1: CLoSD is a multi-task physics-based RL controller, capable of performing object inter-* CLoSD는 motion diffusion 모델과 RL 기반 physics 시뮬레이션을 폐쇄 루프로 연결하여, 텍스트 프롬프트와 타겟 위치로 제어되는 다중 태스크 캐릭터 제어를 실현한다.
CLoSD는 diffusion 기반 계획과 RL 기반 추적을 폐쇄 루프로 통합하여 텍스트 제어와 물리적 그럴듯성을 동시에 달성하는 창의적인 접근법을 제시하며, 실시간 다중 태스크 캐릭터 제어의 새로운 가능성을 보여준다.
From Language to Locomotion: Retargeting-free Humanoid Control via Motion Latent Guidance
Figure 1:
 *Figure 2: Overview of RoboGhost. We propose a two-stage approach: a motion latent is first generated, then a* RoboGhost는 언어 지시를 humanoid 로봇의 실행 가능한 동작으로 직접 변환하는 retargeting-free 프레임워크로, motion latent을 조건으로 하는 diffusion-based policy를 통해 기존의 다단계 파이프라인의 누적 오류와 지연을 제거한다.
RoboGhost는 language-guided humanoid 제어의 근본적인 파이프라인 재설계를 통해 기존의 다단계 접근의 한계를 효과적으로 해결하며, 실제 로봇 배포에서 우수한 성능을 입증한 매우 영향력 있는 연구이다. 다만 해석성 강화와 복잡한 task로의 확장이 후속 과제로 남아있다.
Heracles: Bridging Precise Tracking and Generative Synthesis for General Humanoid Control
Figure 1: Heracles synthesizes diverse, anthropomorphic recovery motions via state-conditioned diffusion. In
 *Figure 1: Heracles synthesizes diverse, anthropomorphic recovery motions via state-conditioned diffusion. In* Heracles는 state-conditioned diffusion 미들웨어를 통해 정밀한 모션 추적과 생성적 적응을 통합하여 휴머노이드 로봇이 극단적인 외부 교란 상황에서도 자연스러운 복구 동작을 수행하도록 한다.
Heracles는 state-conditioned diffusion을 활용한 혁신적인 제어 미들웨어를 제시하여 휴머노이드 로봇의 정밀 추적과 생성적 적응성의 오래된 딜레마를 우아하게 해결하며, 물리적 로봇 실험을 통한 강건한 성능 검증으로 실질적 가치를 입증한다.
One Policy but Many Worlds: A Scalable Unified Policy for Versatile Humanoid Locomotion
 *Figure 2: Framework of DreamPolicy. The system is decomposed into two parts: (1) Terrain-aware* DreamPolicy는 Humanoid Motion Imagery (HMI)를 생성하는 terrain-aware autoregressive diffusion planner와 HMI-conditioned RL policy를 결합하여, 단일 정책으로 다양한 지형에서 humanoid 로봇의 이동을 학습하고 미지의 시나리오로 zero-shot 일반화를 달성하는 통합 프레임워크이다.
DreamPolicy는 offline data와 diffusion-based trajectory synthesis를 통합하여 humanoid 이동의 확장성 문제를 창의적으로 해결하고, 실제 로봇 응용에 실질적 가치를 제공하는 강력한 프레임워크이다. 다만 sim-to-real 검증과 computational 효율성 분석이 보완되면 더욱 견고한 기여가 될 것이다.
TEDi: Temporally-Entangled Diffusion for Long-Term Motion Synthesis
Fig. 1. Inspired by the gradual nature of the diffusion process along a diffusion time-axis (left), our approach (right)
 *Fig. 1. Inspired by the gradual nature of the diffusion process along a diffusion time-axis (left), our approach (right)* TEDi는 Denoising Diffusion Probabilistic Models (DDPM)의 점진적 생성 개념을 모션 시퀀스의 시간축에 적용하여, 두 축을 얽혀 있게(entangle) 함으로써 임의 길이의 장기 모션 생성을 가능하게 한다. 시간에 따라 변하는 노이즈 레벨을 가진 모션 버퍼를 반복적으로 제거하는 자동회귀 메커니즘을 통해 연속적인 프레임 스트림을 생성한다.
TEDi는 diffusion 모델의 시간축과 모션 시퀀스의 시간축을 창의적으로 얽혀 있게 함으로써 장기 모션 생성의 근본적인 문제를 우아하게 해결한 혁신적 작업이다. 임의 길이 생성, stitching 제거, 대화형 제어 등 기존 방법들의 한계를 동시에 극복하며, 명확한 설명과 견고한 기술적 기초로 높은 평가를 받을 만하다.
Residual Off-Policy RL for Finetuning Behavior Cloning Policies
 *Fig. 2. Off-policy residual fine-tuning (ResFiT): A two-phase approach using online RL to improve BC policies. First, we* Behavior Cloning(BC) 정책을 기반으로 Residual Off-Policy RL을 적용하여 샘플 효율적으로 조작 정책을 개선하며, 고자유도 이족 로봇에서의 첫 실시간 RL 학습을 달성했다.
BC와 off-policy RL을 residual learning으로 효과적으로 결합하여, 고자유도 실시간 로봇 학습의 실용적 경로를 제시했다. 블랙박스 방식의 일반성과 첫 휴머노이드 RL 실증이 로봇 학습 분야에 의미 있는 기여를 이룬다.
Retargeting Matters: General Motion Retargeting for Humanoid Motion Tracking
 *Fig. 2: General Motion Retargeting (GMR) Pipeline.* 인간-휴머노이드 로봇 간 embodiment gap을 해결하기 위해 모션 retargeting 품질이 정책 성능에 미치는 영향을 체계적으로 평가하고, retargeting artifacts를 줄이는 새로운 방법 GMR을 제안한다.
본 연구는 humanoid motion tracking에서 그동안 간과되어온 retargeting 품질의 중요성을 체계적으로 입증하고, GMR을 통해 실질적 개선을 달성했다. 광범위한 평가 프레임워크와 명확한 발견은 향후 humanoid 학습 연구에 중요한 지침을 제공한다.
SkillMimic: Learning Basketball Interaction Skills from Demonstrations
Figure 1. We propose a novel approach that for the first time enables physically simulated humanoids to learn a variety
 *Figure 2. Concept of SkillMimic. We define an interaction skill as* SkillMimic은 skill-specific reward 설계 없이 통합된 HOI imitation reward를 사용하여 단일 policy로 다양한 농구 상호작용 기술을 학습하고 합성할 수 있는 data-driven 프레임워크다.
SkillMimic은 skill-specific reward 제거를 통해 상호작용 기술 학습의 실용성을 혁신적으로 개선했으며, contact graph와 통합 HOI reward 설계는 기술적으로 견고하고 농구 데이터셋 기여와 함께 이 분야의 significant advance를 이룬다.
Bridging the Sim-to-Real Gap for Athletic Loco-Manipulation
Fig. 1: Sim-to-real transfer of athletic loco-manipulation.
 *Fig. 2: Unsupervised Actuator Network (UAN) approach for real-to-sim-to-real. Our training pipeline involves three steps* 로봇의 운동 조작 작업에서 시뮬레이션-현실 간 격차를 줄이기 위해 실제 데이터로부터 액추에이터 동역학을 학습하는 Unsupervised Actuator Net (UAN)과 참조 궤적을 탐색 힌트로 활용하는 두 단계 학습 파이프라인을 제안한다.
본 논문은 토크 센싱 없는 UAN으로 복잡한 액추에이터 동역학을 학습하고, 참조 궤적을 탐색 힌트로 활용하는 우아한 두 단계 파이프라인으로 운동 로봇의 시뮬-현실 전이 문제를 체계적으로 해결했다. 실제 사족 조작 로봇에서 다양한 운동 작업의 성공적 구현으로 높은 실용성을 보여주며, RL 기반 로보틱스 분야에 기여도 높은 연구이다.
Dexterity from Smart Lenses: Multi-Fingered Robot Manipulation with In-the-Wild Human Demonstrations
Fig. 1: AINA is a framework for learning multi-fingered policies from in-the-wild human data collected with smart glasse
 *Fig. 1: AINA is a framework for learning multi-fingered policies from in-the-wild human data collected with smart glasse* Aria Gen 2 스마트 글래스로 수집한 in-the-wild 인간 영상만으로 로봇용 다중 손가락 조작 정책을 학습하는 AINA 프레임워크를 제안한다. 이는 로봇 데이터나 시뮬레이션 없이도 직접 배포 가능한 3D point-based 정책을 생성한다.
이 논문은 스마트 글래스의 고급 센싱 능력을 창의적으로 활용하여 순수 인간 비디오만으로 다중 손가락 로봇 조작 정책을 학습하는 실질적이고 확장 가능한 해법을 제시한다. 강력한 실증 결과와 명확한 방법론으로 인간-로봇 모방 학습 분야에 상당한 진전을 이루었으며, 로봇 조작의 대규모 실용화를 향한 중요한 한 걸음을 제공한다.
Embracing Evolution: A Call for Body-Control Co-Design in Embodied Humanoid Robot
Figure 1: The co-design framework for humanoid robots, which can be formulated as a bi-level
 *Figure 1: The co-design framework for humanoid robots, which can be formulated as a bi-level* 인간형 로봇의 제어 정책과 물리적 구조를 동시에 진화시키는 co-design 메커니즘을 제안하며, 이를 bi-level 최적화 문제로 공식화하여 embodied intelligence 달성의 필수 요소임을 주장하는 위치 논문이다.
본 논문은 인간형 로봇의 embodied intelligence 달성을 위해 co-design의 필수성을 체계적으로 주장하고 실행 가능한 방법론을 제시하는 영향력 있는 위치 논문이다. 다만 구체적인 실험 검증과 정량적 성능 평가를 통한 후속 연구로 보강될 필요가 있다.
Learning Perceptive Humanoid Locomotion over Challenging Terrain
Fig. 1: Deployment to outdoor environments. We deployed the model in outdoor challenging terrains. Our controller can
 *Fig. 2: Training of Humanoid Perception Controller consists of two stages: (1) Oracle Policy Training generates referenc* 인간형 로봇이 소음이 있는 센서 데이터로부터 지형을 인식하고 거친 지형을 안정적으로 보행할 수 있도록, teacher-student distillation과 variational information bottleneck을 결합한 세계 모델 기반 방법을 제안한다.
본 논문은 teacher-student distillation과 world model 기반 센서 디노이징을 효과적으로 결합하여 인간형 로봇의 실제 환경 보행 성능을 크게 향상시켰다. 2 km의 다양한 지형 횡단 성과와 체계적인 방법론은 높은 기술적 가치를 가지며, 실제 로봇 배포를 위한 중요한 진전을 보여준다.
Learning Smooth Humanoid Locomotion through Lipschitz-Constrained Policies
Fig. 1: Lipschitz-constrained policies (LCP) provide a simple and general method for training policies to produce smooth
 *Fig. 2: Lipschitz continuity is a method of quantifying the* 본 논문은 Reinforcement Learning으로 훈련한 humanoid robot의 locomotion policy에 Lipschitz 제약을 부여하여 smooth behavior를 자동으로 유도하는 Lipschitz-Constrained Policies (LCP) 방법을 제안한다.
Lipschitz constraint을 통한 smooth policy 학습은 이론적으로 명확하고 실용적이며, 기존의 복잡한 smoothing 기법들을 단순하고 미분 가능한 방식으로 대체하는 우수한 기여이다. 실제 humanoid robot에서의 검증과 재현성 있는 공개 코드 공개로 high impact을 기대할 수 있다.
Multi-task Deep Reinforcement Learning with PopArt
 *Figure 2: Atari-57 (unclipped): Median human normalised* Multi-task Deep Reinforcement Learning에서 task 간의 reward scale과 sparsity 차이로 인한 불균형 문제를 PopArt 정규화를 통해 해결하여, 57개 Atari 게임을 단일 정책으로 인간 수준 이상의 성능으로 학습.
PopArt를 multi-task RL에 적용한 실용적이고 효과적인 솔루션으로, 단일 정책이 다양한 task에서 인간 수준 성능을 달성한 것은 RL 분야의 중요한 이정표다. 명확한 문제 정의, 우아한 솔루션, 그리고 강력한 실험 결과로 높은 가치의 논문이다.
NoMaD: Goal Masked Diffusion Policies for Navigation and Exploration
Fig. 1: NoMaD is the first flexibly conditioned diffusion model of robot actions that can perform both goal-conditioned
 *Fig. 1: NoMaD is the first flexibly conditioned diffusion model of robot actions that can perform both goal-conditioned * NoMaD는 goal masking을 활용한 unified diffusion policy로 로봇의 목표 지향 네비게이션과 목표 무관 탐색을 단일 모델로 처리하며, Transformer 기반 정책과 diffusion model decoder를 결합하여 미지의 환경에서 효과적인 네비게이션을 구현한다.
NoMaD는 goal masking과 diffusion policy를 결합하여 exploration과 goal-seeking을 통합한 혁신적 아키텍처를 제시하며, ViNT 대비 25% 이상의 성능 향상과 15배 효율성 개선을 실제 로봇에서 달성하여 로봇 네비게이션 분야에 상당한 기여를 한다.
TD-GRPC: Temporal Difference Learning with Group Relative Policy Constraint for Humanoid Locomotion
 *Fig. 2: Overview of TD-GRPC for Humanoid Locomotion: Starting from an initial state s0 encoded into latent state z0 with* 본 논문은 Humanoid Locomotion을 위해 TD-MPC 프레임워크에 Group Relative Policy Optimization (GRPO)와 trust-region constraint를 통합한 TD-GRPC를 제안하여, off-policy 학습의 불안정성과 policy mismatch 문제를 해결한다.
본 논문은 GRPO와 trust-region constraint를 통합한 TD-GRPC를 제안하여 humanoid locomotion의 off-policy 학습 안정성을 효과적으로 개선한 의미 있는 연구이나, 실제 로봇 검증과 이론적 분석 심화, 그리고 더 광범위한 task 평가가 필요하다.
Being-H0.7: A Latent World-Action Model from Egocentric Videos
 *Figure 2: Latent reasoning and latent world-action model. Left: Learnable latent queries are inserted* 이 논문은 egocentric video로부터 학습된 latent world-action model인 Being-H0.7을 제시한다. 행동 생성 사이에 학습 가능한 latent query를 추론 인터페이스로 도입하고, future-informed dual-branch 설계를 통해 미래 프레임 생성 없이 세계 모델의 예측 능력을 VLA의 효율성과 결합한다.
Being-H0.7은 world-action modeling을 latent 공간으로 재정의하여 미래 예측의 이득을 유지하면서도 픽셀 생성의 비효율성을 제거한 강력한 기여를 한다. Future-informed dual-branch 설계와 latent query 기반 인터페이스는 창의적이고 효과적이며, 광범위한 시뮬레이션 및 실제 로봇 평가에서 일관된 성능 향상을 입증한다. 다만 posterior branch의 정당성, latent 구조의 이론적 근거, 그리고 일부 하이퍼파라미터 선택의 명확화가 필요하다.
Sentinel-VLA: A Metacognitive VLA Model with Active Status Monitoring for Dynamic Reasoning and Error Recovery
Figure 1. The performance and mechanism of Sentinel-VLA.
 *Figure 1. The performance and mechanism of Sentinel-VLA.* 본 논문은 embodied manipulation을 위한 metacognitive VLA 모델인 Sentinel-VLA를 제안한다. 실시간 실행 상태를 모니터링하는 sentinel 모듈을 통해 필요할 때만 동적 추론과 에러 복구를 수행하는 온디맨드 추론 메커니즘을 특징으로 한다.
Sentinel-VLA는 metacognitive 접근을 통해 VLA 모델의 추론, 상태 모니터링, 에러 복구라는 세 가지 핵심 문제를 통합적으로 해결하는 창의적인 방안을 제시한다. 특히 온디맨드 추론 메커니즘과 자동화된 대규모 데이터 생성 파이프라인의 조합, 그리고 orthogonal constraint을 이용한 지속적 학습 방식은 기술적으로 견고하며 실세계 성능 향상(30%)으로 실증되었다. 다만 에러 감지의 한계 분석과 트리거 기준의 명확한 정의가 보강되면 더욱 완성도 높을 것이다.
Evolutionary Continuous Adaptive RL-Powered Co-Design for Humanoid Chin-Up Performance
 *Fig. 2: Overview of the EA-CoRL framework methodology.* EA-CoRL은 진화 알고리즘과 강화학습을 결합하여 휴머노이드 로봇의 하드웨어 설계(기어비)와 제어 정책을 동시에 최적화하는 프레임워크이며, RH5 로봇의 턱걸이 작업 성공을 통해 검증되었다.
EA-CoRL은 continuous adaptive 정책 최적화를 통해 RL 기반 co-design의 실질적 문제를 해결한 창의적 프레임워크이며, 이전 불가능했던 고난도 동적 작업 실현의 가능성을 보였다. 다만 실제 하드웨어 검증과 설계 공간 확장이 이루어진다면 실용적 영향력이 더욱 크게 증대될 것으로 예상된다.
Shape Your Body: Value Gradients for Multi-Embodiment Robot Design
Figure 1: Shape Your Body. We first train an embodiment-aware policy and value function with
 *Figure 1: Shape Your Body. We first train an embodiment-aware policy and value function with* 본 논문은 다중 체형을 학습한 가치함수를 재사용 가능한 설계 모델로 변환하는 방법을 제안한다. 사전 학습된 embodiment-aware value function에서 gradient를 계산하여 새로운 로봇 설계를 최적화함으로써 매번 새로운 RL 학습 루프를 실행할 필요를 제거한다.
본 논문은 다중 체형 가치함수를 재사용 가능한 설계 도구로 변환하는 실용적이고 혁신적인 방법을 제시한다. 대규모 embodiment 공간에서의 효율적 최적화, 강력한 실험 검증, 그리고 설계 분석 기능이 주요 강점이다. 다만 현실 로봇 검증과 극단적 체형 외삽에 대한 분석이 보완된다면 더욱 완성도 있는 작업이 될 것이다.
Stability of Control Lyapunov Function Guided Reinforcement Learning
Fig. 1.
 *Fig. 1.* 본 논문은 Control Lyapunov Function (CLF)을 기반으로 한 강화학습(CLF-RL)으로 학습된 제어 정책의 이론적 안정성을 분석한다. 연속·이산 시간 모두에서 최적 제어 문제로 재정의하여 지수 안정성을 증명하고, 이를 수치 검증 및 휴머노이드 로봇의 주기 보행 실험으로 검증한다.
본 논문은 CLF-RL의 실제 성공을 이론으로 뒷받침하는 중요한 기여로, 지수 안정성 증명이 명확하고 연속·이산 시간 모두에서 포괄적으로 다루어졌다. 다만 지역 안정성 한정, CLF 구성 방법의 실용성 부재, 제한된 실험 검증이 한계이나, 제어 이론과 RL의 격차를 줄이는 가치 있는 첫 걸음이다.
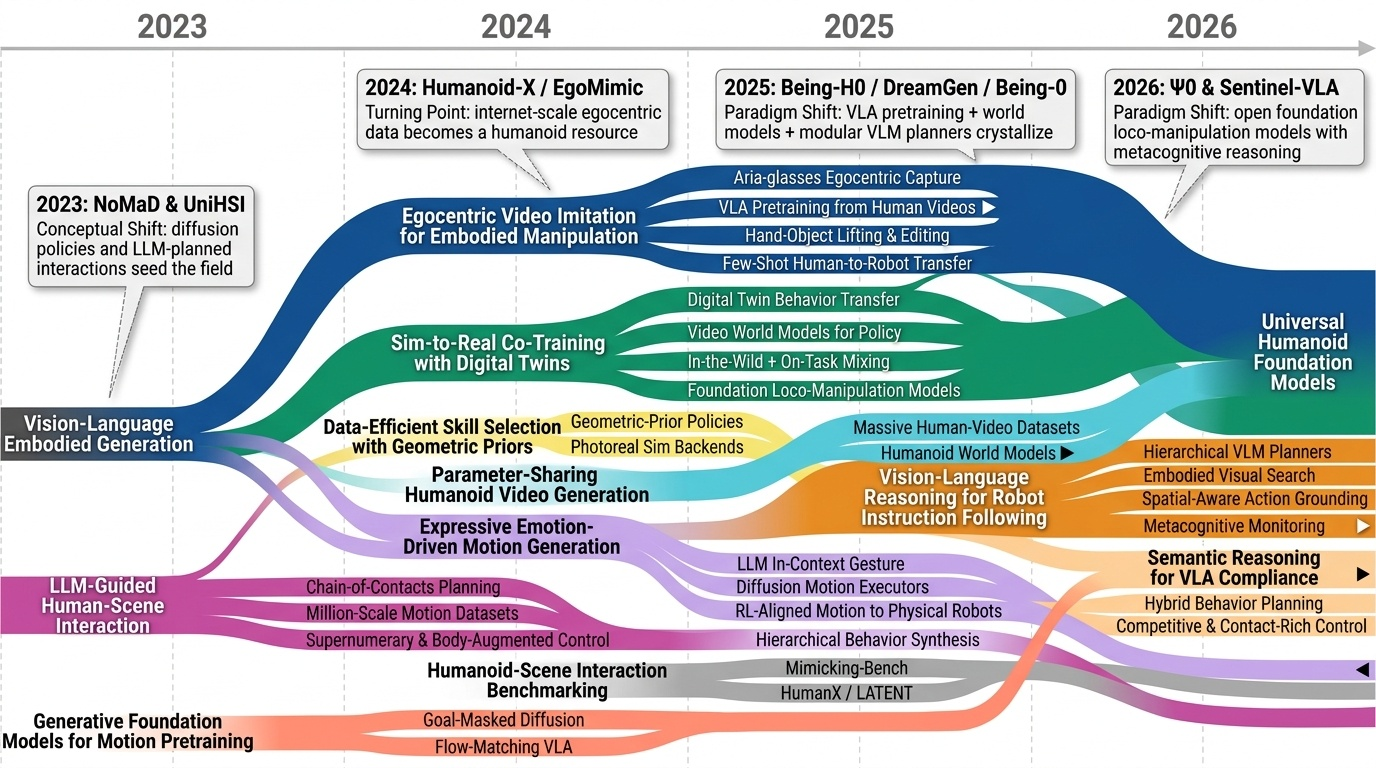
Category Overview
Vision-Language Embodied Motion Control은 시각 정보와 언어 이해를 결합하여 휴머노이드 로봇의 전신(whole-body) 제어를 실현하는 분야이다. 이 카테고리는 대규모 인간 동작 데이터(large-scale human motion data) 학습, 시뮬레이션-실제 환경의 공동 훈련(Sim-to-Real co-training), 그리고 시각-언어-행동(Vision-Language-Action) 사전학습을 통해 로봇의 일반화 능력을 향상시키는 연구들을 포함한다[1666][1673][1814]. 에고센트릭 비디오 모방(egocentric video imitation)과 기하학적 선행지식(geometric priors)을 활용한 데이터 효율적 기술 학습[1758][1642], 그리고 대규모 언어 모델(LLM) 기반의 자연어 명령어 추종(instruction following) 및 의미론적 추론(semantic reasoning)이 핵심 기술이다[1847][1815]. 또한 디지털 트윈(digital twins)을 통한 협력 학습, 감정 표현 동작 생성(emotion-driven motion generation), 그리고 휴머노이드-장면 상호작용 벤치마킹(humanoid-scene interaction benchmarking)을 통해 로봇의 표현력과 환경 적응성을 강화한다[1812][1669][1713]. 이러한 기초 모델(foundation models) 기반 접근 방식은 로봇의 자율적 스킬 습득과 실시간 제어 능력을 확보하는 데 필수적이다[1772][1815].
- Egocentric Video Imitation for Embodied Manipulation: # Egocentric Video Imitation for Embodied Manipulation 본 연구 분야는 일인칭 시점(egocentric view)의 비디오에서 인간의 조작 행동을 학습하여 로봇이 실제 환경에서 물체를 조작하도록 하는 기술을 다룬다. [1903]의 EgoMimic과 [1904]의 EgoVLA는 대규모 일인칭 비디오 데이터를 활용한 모방 학습(imitation learning) 및 비전-언어-행동(vision-language-action) 모델 개발에 초점을 맞추고 있다. [1758]의 WHOLE과 [1899]의 EgoDemoGen은 일인칭 비디오에서 손-물체 상호작용(hand-object interaction)을 추출하고 이를 다양한 시점에서 활용 가능하도록 변환하는 기술을 제시한다. [1957]의 GraspDreamer와 [1961]의 H-RDT는 생성형 모델과 인간 조작 데이터를 결합하여 양팔 로봇(bimanual robot)의 파지(grasping) 및 조작 능력을 향상시킨다. 이러한 접근 방식들은 로봇이 인간의 일상적 행동을 효과적으로 모방하여 실제 환경에서의 조작 작업을 수행할 수 있도록 한다.
- Sim-to-Real Co-Training with Digital Twins: Sim-to-Real Co-Training with Digital Twins는 시뮬레이션(Simulation) 환경과 실제(Real-world) 환경을 동시에 활용하여 로봇의 비전-언어 기반 구현화 동작 제어(Vision-Language Embodied Motion Control)를 학습하는 기술을 다룹니다. 이 방법은 디지털 트윈(Digital Twin) 기술을 통해 시뮬레이션 환경에서 대규모의 훈련 데이터를 수집하면서 동시에 실제 로봇 환경에서의 학습을 병행함으로써 시뮬레이션-현실 간 격차(Sim-to-Real Gap)를 효과적으로 해소합니다 [1673]. DreamDojo와 DreamControl-v2 같은 연구들은 대규모 데이터셋과 제너럴리스트 로봇 월드 모델(Generalist Robot World Model)을 구축하여 범용 로봇 학습의 확장성을 입증했습니다 [1355][1885]. 또한 EgoHumanoid와 Human-Humanoid Robots Cross-Embodiment 연구들은 휴머노이드 로봇의 조작 능력과 운동 기술 전이(Skill Transfer)를 실현하여 현실 환경에서의 적응력 있는 로봇 제어를 가능하게 합니다 [1901][1989]. 이러한 접근 방식은 로봇이 인간 수준의 행동을 학습하고 복잡한 멀티태스킹 환경에서 일반화 능력을 획득하도록 지원합니다.
- Vision-Language Reasoning for Robot Instruction Following: 비전-언어 추론을 통한 로봇 명령 수행(Vision-Language Reasoning for Robot Instruction Following)은 인간의 자연어 지시를 시각 정보와 결합하여 휴머노이드 로봇이 복잡한 작업을 자율적으로 수행하도록 하는 기술 분야이다. [1992], [2025]와 같은 연구들은 embodied chain-of-action reasoning과 motion tendency inference를 통해 로봇이 인간의 의도를 정확하게 이해하고 이를 구체적인 행동으로 변환하는 방법을 제시한다. [1713], [1844]의 논문들은 360도 시각 탐색과 멀티-에이전트 학습을 활용하여 로봇이 동적인 환경에서 효과적으로 지시를 따를 수 있도록 개선하고 있다. [2161], [3306] 연구는 modular AI system과 latent world-action model을 통해 egocentric video로부터 학습된 표현을 로봇 제어에 직접 적용하는 통합 시스템을 구축한다. 이러한 접근 방식들은 vision-language model의 의미 이해 능력과 로봇의 embodied experience를 결합함으로써 보다 자연스럽고 효율적인 인간-로봇 상호작용을 실현한다.
- Expressive Emotion-Driven Motion Generation: # Expressive Emotion-Driven Motion Generation 감정 기반의 표현력 있는 동작 생성(Expressive Emotion-Driven Motion Generation)은 인간형 로봇(Humanoid Robots)이 음성, 텍스트, 감정 신호 등 다양한 모달리티(Modality)를 기반으로 자연스럽고 감정이 담긴 동작을 생성하는 기술을 다룬다. 이 분야는 대규모 언어 모델(Large Language Models, LLMs)과 확산 모델(Diffusion Models)을 활용하여 의미론적 제스처(Semantic Gestures), 전신 제어(Whole-Body Control), 그리고 행동 계층화(Hierarchical Behavior Modeling)를 통합하는 방식으로 발전하고 있다 [1912] [1937]. 강화학습(Reinforcement Learning)과 물리적 피드백(Physical Feedback)을 결합하여 실제 로봇 환경에서의 모션 정렬(Motion Alignment)을 달성하고, 자유형식 언어 명령어(Free-form Language Commands)로 로봇의 전체 신체 동작을 제어할 수 있게 하는 연구들이 진행 중이다 [1847] [1968]. 이러한 기술은 인간-로봇 상호작용(Human-Robot Interaction)에서 더욱 자연스럽고 표현력 있는 커뮤니케이션을 가능하게 하며, 실시간 제어(Real-Time Control) 능력을 갖춘 통합 시스템 개발을 목표로 한다.
- Parameter-Sharing Humanoid Video Generation: 파라미터 공유 휴머노이드 비디오 생성(Parameter-Sharing Humanoid Video Generation)은 단일 모델이 다양한 휴머노이드 로봇의 동작을 생성하고 제어할 수 있는 기술입니다. 이 접근 방식은 여러 로봇 플랫폼 간 공통 파라미터를 활용하여 일반화 성능을 향상시키고, 각 로봇별로 별도의 모델을 학습해야 하는 비효율성을 제거합니다[1934][2005]. 대규모 인간 비디오 데이터와 월드 모델(world models)을 활용하여 범용 휴머노이드 정책(universal humanoid policy)을 학습하고, 실시간 동작 생성 능력을 확보할 수 있습니다[2050]. 또한 협력적 조작(cooperative manipulation)이나 중력 환경 제어 등 복잡한 태스크 수행을 위해 파라미터 공유 구조가 효과적으로 활용됩니다[2403][2410]. 이러한 기술은 휴머노이드 로봇의 실제 배포와 다양한 환경에서의 적응성을 크게 개선하여 로봇 제어의 일반화 문제를 해결하는 핵심 연구 방향입니다.
- LLM-Guided Human-Scene Interaction: LLM(Large Language Model) 기반 인간-장면 상호작용 제어는 자연어 지시사항을 통해 인간형 로봇(humanoid robot)이나 가상 캐릭터가 환경과 상호작용하도록 유도하는 기술입니다. [1815]는 실시간 제어 가능한 Vision-Language-Motion 모델을 제시하여 시각 정보와 언어 명령을 통합적으로 처리합니다. [2170]에서는 Prompted Chain-of-Contact 접근법으로 인간-장면 상호작용을 통합된 프레임워크로 다루며, 접촉 순서와 동작 시퀀스를 체계적으로 계획합니다. [1666]의 대규모 모션 모델(motion model)은 백만 개 수준의 인간 동작 데이터를 학습하여 다양한 상호작용 시나리오에 대응합니다. [010]과 [2015]는 각각 계층적 로코모션(locomotion) 프레임워크와 대규모 인간-물체 상호작용 데이터셋(HUMOTO)을 제공하여 현실감 있는 동작 생성을 지원합니다.
- Data-Efficient Skill Selection with Geometric Priors: 기하학적 선행정보(geometric priors)를 활용한 데이터 효율적 기술 선택은 비전-언어 구현화 동작 제어 분야에서 샘플 효율성을 크게 향상시키는 방법론입니다. [1642]에서 제시된 반복 기하학적 선행정보 다중모달 정책(Recurrent Geometric-prior Multimodal Policy, RGMP)은 기하학적 제약조건을 명시적으로 인코딩하여 로봇 제어의 학습 효율을 개선합니다. [1644]의 RoboCasa는 대규모 시뮬레이션 환경에서 일상적 작업에 대한 다양한 기술을 학습할 수 있는 플랫폼을 제공하며, 이를 통해 기하학적 선행정보의 일반화 성능을 검증합니다. [1946]에서 제안된 일반화 가능한 기하학적 선행정보와 반복 스파이킹 특징(Generalizable Geometric Prior and Recurrent Spiking Feature)은 신경형 컴퓨팅(neuromorphic computing) 패러다임을 결합하여 더욱 효율적인 기술 학습을 실현합니다. 이러한 접근법들은 제한된 데이터 환경에서도 로봇의 다양한 조작 기술(manipulation skills)을 빠르게 습득할 수 있도록 함으로써 실제 로봇 응용의 실용성을 높입니다.
- Semantic Reasoning for VLA Compliance: 의미론적 추론을 통한 VLA(Vision-Language Agent) 준수는 로봇의 자율 운동 제어에서 시각-언어 정보를 의미 있게 해석하고 이를 실제 행동으로 변환하는 핵심 기술이다. [1648]의 계층적 의사결정(Hierarchical Decision-Making) 접근법과 [2018]의 하이브리드 행동 계획(Hybrid Behavior Planning)은 복잡한 환경에서 로봇이 고수준의 언어 지시와 저수준의 제어 신호를 통합하여 작동하도록 한다. [3320]의 연구는 접촉 기반 작업(Contact-Rich Manipulation)에서 수동성 차폐 규정(Passivity-Shielded Compliance Prior)을 통해 물리적 제약 조건을 만족하면서도 의미론적 목표를 달성하는 방식을 제시한다. [3331]의 월드 모델(World Models) 기반 접근은 로봇이 환경을 내부적으로 표현하고 예측함으로써 더욱 견고한 의미 이해와 계획 수립을 가능하게 한다. 이러한 기술들은 자율 로봇 시스템이 인간의 의도를 정확히 파악하고 안전하고 효율적으로 실행하는 데 필수적이다.
- Humanoid-Scene Interaction Benchmarking: 인간형 로봇(Humanoid Robot)이 실제 환경에서 다양한 물체 및 장면과 상호작용하는 능력을 평가하기 위한 벤치마크 연구들입니다. [2013]은 민첩하고 일반화 가능한 인간형 로봇의 상호작용 능력을 목표로 하며, [2047]은 테니스와 같은 운동 기술 학습을 통해 실제 인간의 움직임을 모방하는 방법을 제시합니다. [2100]은 인간형 로봇이 다양한 장면에서 일반화된 상호작용 능력을 갖추도록 하는 벤치마크(Mimicking-Bench)를 제안합니다. 이러한 연구들은 Vision-Language 모델과 결합하여 로봇이 시각 정보와 언어 지시를 통해 복잡한 장면 상호작용(Scene Interaction)을 수행하도록 학습시킵니다. 궁극적으로 이러한 벤치마킹 작업은 실제 세계에서 인간처럼 작동할 수 있는 범용 인간형 로봇 개발의 기초를 마련합니다.
- Generative Foundation Models for Motion Pretraining: 생성형 기초 모델을 활용한 동작 사전학습(Motion Pretraining)은 비전-언어 구체화된 동작 제어(Vision-Language Embodied Motion Control) 분야에서 중요한 연구 방향입니다. 물리 기반 인간 동작 제어에서 생성적 제어(Generative Control)의 확장성을 다루는 [2027]과 같은 연구들은 복잡한 동작 생성을 위한 사전학습 프레임워크를 제시합니다. 마스크된 확산 정책(Masked Diffusion Policies)을 기반으로 네비게이션과 탐색(Navigation and Exploration) 작업을 수행하는 [2111]의 접근법은 목표 지향적 동작 학습의 새로운 패러다임을 보여줍니다. 또한 [3308]에서 제안하는 단계적 행동 생성(Coarse-to-Fine Action Generation) 방식은 시각-언어 기반 에이전트(Vision-Language Agent)의 효율성을 크게 향상시킵니다. 이러한 연구들은 사전학습된 생성 모델이 다양한 로봇 작업과 체화된 AI(Embodied AI) 응용에 어떻게 적용될 수 있는지를 보여주는 중요한 사례들입니다.
- Vision-Language Multimodal Whole-Body Control: 비전-언어 기반 인간형 로봇의 전신 제어(Whole-Body Control)는 로봇이 시각 정보와 언어 명령을 통합하여 복잡한 동작을 수행하도록 하는 기술입니다. 행동 기초 모델(Behavior Foundation Model)은 대규모 데이터셋으로부터 학습된 사전학습 모델로서, 다양한 로봇 제어 작업에 일반화되는 능력을 제공합니다[1812]. 적응형 동작 추적(Adaptive Motion Tracking) 기법은 환경 변화와 로봇의 물리적 특성에 따라 제어 정책을 동적으로 조정하여 강건성을 향상시킵니다[2152]. 이러한 접근 방식들은 멀티모달 입력(Multimodal Input)을 활용하여 로봇의 이해도와 실행 능력을 동시에 높입니다. 인간형 로봇의 전신 제어 기술은 산업 자동화, 재난 대응, 일상 서비스 등 다양한 실제 응용 분야에서 활용될 수 있습니다.
⚠ 갭: VLA 모델의 성능과 안전성 간의 간극(Success-But-Unsafe 문제)을 체계적으로 평가하고 해결하는 연구가 이제 막 시작되었으며, 특히 접촉이 많은 조작 작업에서의 안전 보장 방법론이 미성숙하다.
🏛 정책: VLA 기반 휴머노이드 로봇의 공공 환경 도입 전 안전성 검증 의무화 규정을 선제적으로 마련하고 관련 평가 방법론 연구를 집중 지원해야 한다.
A Hierarchical Framework for Humanoid Locomotion with Supernumerary Limbs
 *Figure 2.1: The composite robot model used in the simulation, illustrating (a) the Unitree H1* 초과 사지(Supernumerary Limbs)가 장착된 인형형 로봇의 안정적인 보행을 위해 학습 기반 저수준 보행 제어와 모델 기반 고수준 동적 평형 제어를 결합한 계층적 제어 아키텍처를 제시한다.
본 논문은 초과 사지가 장착된 인형형 로봇의 보행 안정성 문제를 해결하기 위해 계층적 제어 구조를 통해 학습 기반과 모델 기반 제어를 효과적으로 결합한 독창적인 접근법을 제시하며, 47% DTW 거리 감소 등 정량적 성과를 입증했다. 다만 실제 하드웨어 검증과 복잡한 환경에서의 평가가 필요하다.
Scaling Large Motion Models with Million-Level Human Motions
Figure 1: TOP: While existing models perform well on
 *Figure 1: TOP: While existing models perform well on* LLM의 성공에 영감을 받아 백만 단위 규모의 대규모 모션 데이터셋 MotionLib를 구축하고, 이를 기반으로 Being-M0 모델을 훈련하여 대규모 모션 생성 모델의 확장성을 입증하는 연구이다.
이 논문은 모션 생성 분야에서 대규모 데이터와 모델 확장의 중요성을 처음으로 체계적으로 입증하며, MotionLib와 2D-LFQ 기술을 통해 실질적인 기여를 제공한다. 모션 생성 모델 개발의 새로운 기준을 제시하고 향후 연구의 견고한 기초를 마련한 중요한 연구이다.
Being-M0.5: A Real-Time Controllable Vision-Language-Motion Model
Figure 1: Leveraging our million-scale dataset HuMo100M, we present Being-M0.5, the first real-time, control-
 *Figure 1: Leveraging our million-scale dataset HuMo100M, we present Being-M0.5, the first real-time, control-* Being-M0.5는 HuMo100M이라는 백만 규모의 대규모 데이터셋을 기반으로 한 최초의 실시간 제어 가능 vision-language-motion model로, part-aware residual quantization을 통해 신체 각 부위에 대한 세밀한 제어를 가능하게 한다.
Being-M0.5는 HuMo100M과 part-aware residual quantization이라는 두 가지 주요 혁신을 통해 motion generation의 제어 가능성과 실시간 성능 문제를 동시에 해결하며, 대규모 데이터셋과 모델 설계 통찰력으로 실제 응용 배포의 새로운 기준을 제시한다.
Do You Have Freestyle? Expressive Humanoid Locomotion via Audio Control
Figure 1.
 *Figure 1.* RoboPerform은 오디오를 직접 제어 신호로 사용하여 음악에 맞춰 춤을 추거나 음성에 맞춰 제스처를 생성하는 휴머노이드 로봇 제어 프레임워크로, 명시적 모션 재구성을 제거하여 저지연 및 고충실도를 달성한다.
RoboPerform은 오디오 제어 신호를 휴머노이드 로봇 모션에 직접 통합하는 novel한 접근으로, retargeting-free 설계와 content-style decomposition을 통해 저지연 고충실도 실시간 성능을 달성한 의미 있는 기여이다. 다만 실제 로봇 배포 및 sim-to-real 검증이 추가되면 실용성이 더욱 강화될 것이다.
Efficient and Scalable Monocular Human-Object Interaction Motion Reconstruction
Fig. 1: Unlike prior works limited by inaccurate pose/depth alignment or non-scalable
 *Fig. 1: Unlike prior works limited by inaccurate pose/depth alignment or non-scalable* 단안 비디오에서 4D 인간-물체 상호작용(HOI) 데이터를 효율적으로 추출하기 위해 sparse contact annotation paradigm과 human-in-the-loop 데이터 엔진을 제안하고, 4DHOISolver 최적화 프레임워크를 통해 시공간적으로 일관성 있는 재구성을 수행한다.
이 논문은 단안 비디오에서 4D HOI 데이터 수집의 annotation 병목을 sparse contact point와 human-in-the-loop 엔진으로 혁신적으로 해결하고, 4DHOISolver를 통해 시공간적 일관성을 유지하면서 대규모 고품질 데이터셋 Open4DHOI를 구축했다. 로봇 학습의 데이터 병목을 실질적으로 해결하는 높은 실용성과 완성도로 컴퓨터 비전 및 로봇 학습 분야에 중대한 기여를 한다.
Example-based Motion Synthesis via Generative Motion Matching
Fig. 1. Our generative framework enables a variety of example-based motion synthesis tasks, that usually require long of
 *Fig. 2. Multi-stage motion synthesis. Starting from the coarsest stage, the generative motion matching at each stage 𝑠ta* GenMM은 단일 또는 소수의 예제 모션으로부터 다양한 모션을 생성하는 학습 불필요한 생성 모델로, Motion Matching의 품질을 유지하면서 Bidirectional similarity를 생성 비용 함수로 활용하여 다단계 프레임워크로 점진적으로 모션을 정제한다.
GenMM은 Motion Matching의 우수한 품질을 유지하면서 학습 불필요한 생성 모델을 구현한 창의적인 접근법으로, 산업 실무에서 즉시 적용 가능한 실용성과 복잡한 스켈레톤에 대한 강력한 확장성을 제공하는 매우 가치 있는 연구이다.
Flexible Motion In-betweening with Diffusion Models
Figure 1: Flexible motion in-betweening given a text prompt and spatio-temporally sparse keyframes. From left to right:
 *Figure 1: Flexible motion in-betweening given a text prompt and spatio-temporally sparse keyframes. From left to right: * CondMDI는 diffusion model 기반의 통합된 모션 인-비트위닝 방법으로, 텍스트 조건과 함께 유연한 keyframe 제약을 받아 다양하고 정밀한 인간 모션을 생성한다.
CondMDI는 masked conditional diffusion model을 통해 motion in-betweening의 오랜 한계를 효과적으로 해결하며, 유연한 제약 처리와 텍스트 조건의 통합으로 실무적 가치가 높고 기술적으로도 우수한 기여를 제시한다.
HUMOTO: A 4D Dataset of Mocap Human Object Interactions
Figure 1. Overview of the HUMOTO dataset. The dataset contains mocap 4D human-object interaction animations with multipl
 *Figure 1. Overview of the HUMOTO dataset. The dataset contains mocap 4D human-object interaction animations with multipl* HUMOTO는 735개 시퀀스(7,875초)의 고충실도 모션캡처 4D 인간-객체 상호작용 데이터셋으로, 63개의 정밀 모델링 객체와 상세한 손 동작을 포함하며 LLM 기반 스크립팅과 다중센서 캡처로 복잡한 다중-객체 상호작용을 정확히 기록한다.
HUMOTO는 고충실도 다중-객체 인간-객체 상호작용 데이터셋으로서, Scene-Driven LLM Scripting과 다중센서 캡처 기술의 창의적 결합을 통해 기존 데이터셋의 한계를 효과적으로 해결하였으며, 정량적 평가 메트릭 도입으로 HOI 데이터셋 분야에 기여한 가치 있는 자산이다.
OmniControl: Control Any Joint at Any Time for Human Motion Generation
Figure 1: OmniControl can generate realistic human motions given a text prompt and flexible
 *Figure 1: OmniControl can generate realistic human motions given a text prompt and flexible* OmniControl은 diffusion 기반 text-conditioned 인간 동작 생성 모델에 flexible spatial control signals을 통합하는 방법으로, 단일 모델로 임의의 관절을 임의의 시간에 제어할 수 있다.
OmniControl은 기존 방법의 근본적 제약을 global coordinate 변환과 dual guidance로 해결하며, 단일 모델로 임의의 관절 제어를 가능하게 한 significant contribution이다. 실용적 응용성과 성능 면에서 human motion generation 분야의 중요한 진전을 이루었다.
Unified Human-Scene Interaction via Prompted Chain-of-Contacts
Figure 1: UniHSI facilitates unified and long-horizon control in response to natural language com-
 *Figure 2: Comprehensive Overview of UniHSI. The entire pipeline comprises two principal com-* UniHSI는 Large Language Model을 활용하여 자연어 명령을 Chain of Contacts (CoC)로 변환하고, 통합 컨트롤러를 통해 다양한 인간-장면 상호작용을 물리적으로 타당하게 수행하는 프레임워크를 제안한다.
UniHSI는 Chain of Contacts라는 새로운 상호작용 표현과 LLM 기반 계획 생성으로 자연어 명령 기반의 다양하고 장기간의 인간-장면 상호작용을 통합적으로 제어하는 혁신적 프레임워크이며, ICLR 2024 발표 논문으로서 embodied AI 분야에 의미 있는 기여를 제시한다.
Deep Reinforcement Learning for Bipedal Locomotion: A Brief Survey
Fig. 1: Representative bipedal and humanoid robots illustrat-
본 논문은 bipedal robot의 locomotion을 위한 Deep Reinforcement Learning(DRL) 기반 프레임워크를 체계적으로 분류, 비교, 분석하는 survey이며, end-to-end와 hierarchical 제어 방식으로 구분하여 각 프레임워크의 구성, 강점, 한계를 평가한다.
본 survey는 DRL 기반 bipedal locomotion 분야의 fragmented 연구를 체계적으로 정리하고 unified framework을 향한 명확한 research agenda를 제시하는 가치 있는 종합 분석이다. End-to-end와 hierarchical 분류 체계, learning paradigm 비교, hybrid 아키텍처 평가는 이 분야의 종사자들에게 실질적인 guidance를 제공하며, 향후 generalisable bipedal locomotion 개발의 기초를 마련한다.
SafeHumanoid: VLM-RAG-driven Control of Upper Body Impedance for Humanoid Robot
Figure 1: Egocentric perception and semantic-to-safety
 *Figure 1: Egocentric perception and semantic-to-safety* SafeHumanoid는 Vision Language Model(VLM)과 Retrieval-Augmented Generation(RAG)을 활용하여 휴머노이드 로봇의 임피던스와 속도를 동적으로 조정하는 시스템으로, 인간-로봇 상호작용 시 안전성과 작업 완료를 동시에 달성한다.
SafeHumanoid는 의미론적 추론과 임피던스 제어의 혁신적 결합으로 인간-로봇 협력의 안전성을 크게 향상시키는 제안이지만, 추론 지연시간과 실시간성은 실제 배포를 위해 해결해야 할 주요 과제이다.
Thinking in 360°: Humanoid Visual Search in the Wild
Figure 1. We pose a fundamental question: can an AI agent actively search for objects or paths in a 3D world like a huma
 *Figure 1. We pose a fundamental question: can an AI agent actively search for objects or paths in a 3D world like a huma* 인간처럼 360° 파노라마 환경에서 머리 회전을 통해 능동적으로 물체를 탐색하거나 경로를 찾는 embodied 시각 탐색 에이전트를 제안하고, 실내 장면을 넘어 지하철역·쇼핑몰·거리 등 복잡한 현실 환경을 대상으로 한 H*Bench 벤치마크를 구축했다.
humanoid visual search라는 새로운 embodied AI 문제를 정의하고 현실적이고 도전적인 H*Bench 벤치마크를 제시함으로써 MLLM 기반 에이전트의 공간 추론 능력을 체계적으로 평가할 수 있는 기틀을 마련했으며, SFT와 RL을 통한 성능 향상을 보여주되 남은 큰 도전과제도 명확히 규명한 높은 가치의 연구이다.
Being-0: A Humanoid Robotic Agent with Vision-Language Models and Modular Skills
Figure 1. Overview of the Being-0 framework. The humanoid agent framework, Being-0, comprises three key components: (1)
 *Figure 1. Overview of the Being-0 framework. The humanoid agent framework, Being-0, comprises three key components: (1) * Being-0는 Foundation Model, VLM 기반 Connector, 모듈식 스킬 라이브러리를 계층적으로 통합하여 인간형 로봇이 복잡한 장기 과제를 수행할 수 있도록 하는 프레임워크이다. Connector 모듈이 언어 기반 계획을 실행 가능한 스킬 명령으로 변환하고 보행과 조작을 동적으로 조율한다.
Being-0는 인간형 로봇을 위한 실용적이고 효율적인 hierarchical agent 프레임워크로, Connector 모듈을 통한 창의적인 중간층 설계와 실제 하드웨어 구현으로 embodied AI 분야에 의미 있는 기여를 한다. 높은 완수율과 4.2배 효율성 향상은 제안 방식의 효과를 입증하지만, FM의 클라우드 의존성과 실내 중심 평가는 실용성 확대를 위한 개선 과제이다.
Beyond Tools and Persons: Who Are They? Classifying Robots and AI Agents for Proportional Governance
Figure 1: The CPST Integration Space.
 *Figure 1: The CPST Integration Space.* CPST(Cyber-Physical-Social-Thinking) 공간 이론에 기반한 로봇과 AI 에이전트의 분류 프레임워크를 제안하여, 기존의 '도구' vs '인격' 이분법적 법적 범주의 한계를 극복하고 비례적 거버넌스를 위한 온톨로지를 제시한다.
본 논문은 AI 및 로봇 거버넌스의 근본적 온톨로지 문제를 CPST 이론으로 해결하려는 야심찬 시도로, 기존 위험도/안전성 중심의 규제에서 엔티티 특성 중심으로의 패러다임 전환을 제시한다. 다만 평가 지표의 정량화, 국제 표준화의 현실성, 신기술 추적 메커니즘에 대한 더 깊은 논의가 필요하다.
Cognition to Control - Multi-Agent Learning for Human-Humanoid Collaborative Transport
Fig. 1: Demonstration of human-robot collaboration via cognition-to-control hierarchy: (a) the humanoid and human partne
 *Fig. 3: The proposed hierarchical HRC framework for humanoid-object coordination, partitioning decision-making into thre* 인간-휴머노이드 협업 운반을 위한 3계층 Cognition-to-Control 프레임워크로, VLM 기반 의미론적 추론, Markov potential game 기반 MARL 조정, 전신 제어를 통합하여 역할의 자동 형성과 강건한 협업을 실현한다.
인간-로봇 협업의 근본적인 인지-제어 단절 문제를 3계층 구조로 체계적으로 해결하고, Markov potential game MARL을 통해 명시적 역할 할당 없이 협업 역할이 자동 형성되는 novel 접근법을 제시한다. 실험 결과는 강건성과 유효성을 잘 보여주지만, 작업 다양성 및 환경 조건 범위 확대가 필요하다.
Development of an Intuitive GUI for Non-Expert Teleoperation of Humanoid Robots
Figure 1: Visual of kid-size humanoid robot navigating a replica of the FIRA obstacle run event.
 *Figure 1: Visual of kid-size humanoid robot navigating a replica of the FIRA obstacle run event.* FIRA HuroCup 경기에서 비전문가 운영자가 인형형 로봇을 텔레조작할 수 있도록 사용자 친화적인 GUI를 개발했다. HTML, CSS, JavaScript를 사용하여 직관적인 인터페이스를 반복적으로 설계하고 테스트했다.
본 연구는 경합 환경에서 실제로 필요한 비전문가 중심의 텔로봇 GUI를 반복적 개발 방식으로 체계적으로 구축한 의미 있는 실무 기여이다. 다만 외부 사용자 평가 부재로 주장의 일반화 가능성이 제한되며, 향후 형식적인 사용성 평가를 통한 정량적 검증이 필요하다.
DIJIT: A Robotic Head for an Active Observer
Fig. 1.
 *Fig. 1.* 인간의 시각 체계를 모방한 생체모방 쌍안 로봇 헤드 DIJIT를 제시하며, 9개의 기계적 자유도와 4개의 광학적 자유도를 통해 능동적 시각 연구와 인간 시각의 안구-머리 운동을 탐구한다.
DIJIT은 인간 시각의 핵심 특성을 종합적으로 구현한 최초의 로봇 헤드로, 생체모방 설계와 실제 saccade 성능 평가를 통해 능동 시각 연구의 새로운 플랫폼을 제공한다. 완전 공개된 설계와 체계적인 비교 분석은 후속 로봇 시각 연구에 중요한 기여를 할 수 있다.
Discovering Self-Protective Falling Policy for Humanoid Robot via Deep Reinforcement Learning
Fig. 1.
 *Fig. 1.* Deep Reinforcement Learning과 Curriculum Learning을 이용하여 인간형 로봇이 낙상 상황에서 자체적으로 보호 행동을 발견하도록 학습시키며, 팔을 삼각형 구조로 형성하여 낙상 손상을 최소화하는 방법을 제시한다.
이 논문은 DRL과 Curriculum Learning을 통해 인간형 로봇이 자신의 물리적 특성에 맞는 낙상 보호 정책을 자율적으로 발견하도록 하는 혁신적 접근을 제시하며, 실제 로봇 플랫폼으로의 성공적 전이와 포괄적 벤치마크 구성으로 인간형 로봇의 안전성 향상에 중요한 기여를 한다.
EgoActor: Grounding Task Planning into Spatial-aware Egocentric Actions for Humanoid Robots via Visual-Language Models
Fig. 1: Overview of EgoActor, which can control a humanoid robot by jointly predicting movement, active perception,
 *Fig. 1: Overview of EgoActor, which can control a humanoid robot by jointly predicting movement, active perception,* EgoActor는 VLM 기반의 통합 모델로서 고수준 자연어 명령어를 휴머노이드 로봇의 저수준 공간 인식 동작(보행, 조작, 지각, 인간-로봇 상호작용)으로 직접 변환하는 EgoActing 태스크를 제안한다.
EgoActor는 VLM을 활용한 휴머노이드 로봇 제어에서 보행, 조작, 지각, 상호작용을 통합하는 새로운 접근을 제시하며, 광범위한 실제 및 시뮬레이션 검증을 통해 그 가능성을 입증한다. 오픈소스 공개와 함께 휴머노이드 구체화 AI의 실질적 발전에 기여할 것으로 예상된다.
Embracing Evolution: A Call for Body-Control Co-Design in Embodied Humanoid Robot
Figure 1: The co-design framework for humanoid robots, which can be formulated as a bi-level
 *Figure 1: The co-design framework for humanoid robots, which can be formulated as a bi-level* 인간형 로봇의 제어 정책과 물리적 구조를 동시에 진화시키는 co-design 메커니즘을 제안하며, 이를 bi-level 최적화 문제로 공식화하여 embodied intelligence 달성의 필수 요소임을 주장하는 위치 논문이다.
본 논문은 인간형 로봇의 embodied intelligence 달성을 위해 co-design의 필수성을 체계적으로 주장하고 실행 가능한 방법론을 제시하는 영향력 있는 위치 논문이다. 다만 구체적인 실험 검증과 정량적 성능 평가를 통한 후속 연구로 보강될 필요가 있다.
Humanoid Agent via Embodied Chain-of-Action Reasoning with Multimodal Foundation Models for Zero-Shot Loco-Manipulation
Fig. 1.
 *Fig. 1.* 인형로봇의 전신 보행-조작을 위해 기초 모델의 추론 능력과 Embodied Chain-of-Action (CoA) 메커니즘을 통합한 제로샷 에이전트 프레임워크를 제시한다. 고수준 인간 지시를 affordance 분석, 공간 추론, 전신 동작 추론을 통해 체계적인 보행 및 조작 원시 동작 수열로 분해한다.
본 논문은 Foundation model의 추론 능력을 인형로봇 보행-조작에 처음 통합한 의미 있는 기여이며, CoA Reasoning 메커니즘을 통해 자연어 지시를 물리적으로 실현 가능한 동작 수열로 변환하는 새로운 접근을 제시한다. 실제 인형로봇에서 강건한 제로샷 일반화를 입증한 점에서 높은 실용적 가치를 갖는다.
INTENTION: Inferring Tendencies of Humanoid Robot Motion Through Interactive Intuition and Grounded VLM
Fig. 1: INTENTION enables the humanoid robot to learn, plan,
 *Fig. 1: INTENTION enables the humanoid robot to learn, plan,* INTENTION은 Vision-Language Models 기반의 Intuitive Perceptor와 Memory Graph를 통합하여 휴머노이드 로봇이 상호작용 경험으로부터 직관적 물리 이해를 학습하고 새로운 조작 작업에 자율적으로 적응하는 프레임워크를 제안한다.
INTENTION은 VLM 기반 지각과 상호작용 메모리를 결합하여 휴머노이드 로봇의 적응형 조작을 혁신적으로 제시하는 연구로, 개념과 설계는 우수하나 실험적 검증과 기술적 세부 구현의 엄밀성 강화가 필요하다.
Multi-task Deep Reinforcement Learning with PopArt
 *Figure 2: Atari-57 (unclipped): Median human normalised* Multi-task Deep Reinforcement Learning에서 task 간의 reward scale과 sparsity 차이로 인한 불균형 문제를 PopArt 정규화를 통해 해결하여, 57개 Atari 게임을 단일 정책으로 인간 수준 이상의 성능으로 학습.
PopArt를 multi-task RL에 적용한 실용적이고 효과적인 솔루션으로, 단일 정책이 다양한 task에서 인간 수준 성능을 달성한 것은 RL 분야의 중요한 이정표다. 명확한 문제 정의, 우아한 솔루션, 그리고 강력한 실험 결과로 높은 가치의 논문이다.
Towards Proprioception-Aware Embodied Planning for Dual-Arm Humanoid Robots
Fig. 1: DualTHOR is a novel simulator specifically tai-
 *Fig. 1: DualTHOR is a novel simulator specifically tai-* 이 논문은 이중팔 휴머노이드 로봇의 장기 계획을 위해 DualTHOR 시뮬레이터와 고유감각(proprioception)을 인식하는 Proprio-MLLM을 제안하며, 기존 MLLM의 구현화 인식 부족을 해결한다.
이 논문은 이중팔 휴머노이드 로봇의 장기 계획을 위한 체계적인 시뮬레이션 플랫폼과 고유감각 기반 MLLM을 제시함으로써 구현화 AI 분야에 중요한 기여를 한다. 실제 로봇에서의 성능 검증과 더 복잡한 협력 작업 확장이 이루어진다면 더욱 영향력 있는 연구가 될 것이다.
Trinity: A Modular Humanoid Robot AI System
Fig. 1: Overview of the Modular Humanoid Robot AI System. In this system, task instructions are processed by both a visi
 *Fig. 1: Overview of the Modular Humanoid Robot AI System. In this system, task instructions are processed by both a visi* LLM, VLM, RL을 통합한 모듈식 인간형 로봇 AI 시스템 Trinity를 제안하여 복잡한 환경에서 효율적인 제어를 실현한다. 계층적 아키텍처를 통해 언어 이해, 시각 인식, 동작 제어를 조화롭게 수행한다.
Trinity는 RL, LLM, VLM을 효과적으로 통합한 혁신적 인간형 로봇 AI 시스템으로, 모듈식 설계를 통해 유연성과 해석성을 확보하고 실제 로봇에서의 동작을 입증함으로써 구현적 가치가 높다. 다만 sim-to-real 갭과 모듈 간 상호작용의 견고성에 대한 심화 분석이 필요하다.
Being-H0.7: A Latent World-Action Model from Egocentric Videos
 *Figure 2: Latent reasoning and latent world-action model. Left: Learnable latent queries are inserted* 이 논문은 egocentric video로부터 학습된 latent world-action model인 Being-H0.7을 제시한다. 행동 생성 사이에 학습 가능한 latent query를 추론 인터페이스로 도입하고, future-informed dual-branch 설계를 통해 미래 프레임 생성 없이 세계 모델의 예측 능력을 VLA의 효율성과 결합한다.
Being-H0.7은 world-action modeling을 latent 공간으로 재정의하여 미래 예측의 이득을 유지하면서도 픽셀 생성의 비효율성을 제거한 강력한 기여를 한다. Future-informed dual-branch 설계와 latent query 기반 인터페이스는 창의적이고 효과적이며, 광범위한 시뮬레이션 및 실제 로봇 평가에서 일관된 성능 향상을 입증한다. 다만 posterior branch의 정당성, latent 구조의 이론적 근거, 그리고 일부 하이퍼파라미터 선택의 명확화가 필요하다.
Sentinel-VLA: A Metacognitive VLA Model with Active Status Monitoring for Dynamic Reasoning and Error Recovery
Figure 1. The performance and mechanism of Sentinel-VLA.
 *Figure 1. The performance and mechanism of Sentinel-VLA.* 본 논문은 embodied manipulation을 위한 metacognitive VLA 모델인 Sentinel-VLA를 제안한다. 실시간 실행 상태를 모니터링하는 sentinel 모듈을 통해 필요할 때만 동적 추론과 에러 복구를 수행하는 온디맨드 추론 메커니즘을 특징으로 한다.
Sentinel-VLA는 metacognitive 접근을 통해 VLA 모델의 추론, 상태 모니터링, 에러 복구라는 세 가지 핵심 문제를 통합적으로 해결하는 창의적인 방안을 제시한다. 특히 온디맨드 추론 메커니즘과 자동화된 대규모 데이터 생성 파이프라인의 조합, 그리고 orthogonal constraint을 이용한 지속적 학습 방식은 기술적으로 견고하며 실세계 성능 향상(30%)으로 실증되었다. 다만 에러 감지의 한계 분석과 트리거 기준의 명확한 정의가 보강되면 더욱 완성도 높을 것이다.
DIJIT: A Robotic Head for an Active Observer
Fig. 1.
 *Fig. 1.* 본 논문은 능동적 관찰자 역할을 수행하는 이동형 로봇을 위해 설계된 이중 카메라 로봇 헤드 DIJIT를 제시한다. DIJIT는 9개의 기계적 자유도와 4개의 광학적 자유도를 갖추고 있으며, 인간의 시각 체계와 유사한 범위와 속도의 카메라 운동이 가능하다.
DIJIT는 인간의 시각 체계를 포괄적으로 모방한 잘 설계된 로봇 헤드로, active vision 연구와 인간-기계 시각 비교를 위한 가치 있는 플랫폼을 제공한다. 특히 완전한 자유도 구현과 실용적인 saccade 제어 방법은 주목할 만하며, 오픈소스 공개로 인한 접근성도 강점이다.
Trinity: A Modular Humanoid Robot AI System
Fig. 1: Overview of the Modular Humanoid Robot AI System. In this system, task instructions are processed by both a visi
 *Fig. 1: Overview of the Modular Humanoid Robot AI System. In this system, task instructions are processed by both a visi* Trinity는 LLM, VLM, RL을 모듈식 계층 구조로 통합하여 humanoid robot을 제어하는 종합 AI 시스템이다. 각 모듈이 독립적으로 최적화되면서도 협력하여 복잡한 환경에서 humanoid robot의 효율적인 제어를 실현한다.
Trinity는 RL, LLM, VLM을 모듈식 계층 구조로 통합하여 humanoid robot의 복잡한 제어 문제를 체계적으로 해결하는 혁신적인 접근법을 제시한다. Full-scale humanoid robot에 대한 종합 검증과 loco-manipulation 성능이 주요 강점이나, 더 광범위한 작업에 대한 평가와 sim-to-real transfer 성능의 명확한 분석이 필요하다. 전반적으로 humanoid robotics 분야의 중요한 진전을 대표하는 양질의 시스템 논문이다.
DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
Figure 1: DreamDojo overview. DreamDojo acquires comprehensive physical knowledge from large-scale
 *Figure 1: DreamDojo overview. DreamDojo acquires comprehensive physical knowledge from large-scale* 44k시간의 대규모 인간 동영상으로부터 연속 잠재 행동(continuous latent actions)을 통일된 프록시로 사용하여 학습한 DreamDojo는 로봇의 손재주 제어와 물리 이해를 갖춘 기초 세계 모델로, 실시간 텔레오퍼레이션과 모델 기반 계획을 가능하게 한다.
DreamDojo는 대규모 인간 동영상과 연속 잠재 행동의 혁신적 결합으로 로봇 세계 모델의 스케일과 일반화 능력을 획기적으로 향상시킨 중요한 기여이다. 실시간 성능과 다양한 실제 응용 가능성이 입증되었으나, embodiment gap 완전 해결과 극도의 장기 예측에 대한 추가 검증이 필요하다.
HumanPlus: Humanoid Shadowing and Imitation from Humans
Figure 1: Stanford HumanPlus Robot. We present a full-stack system for humanoid robots to learn motion and
 *Figure 3: Shadowing and Retargeting. Our system uses one RGB camera for body and hand pose estimation.* 휴머노이드 로봇이 단일 RGB 카메라를 사용하여 인간의 동작을 실시간으로 따라할 수 있는 shadowing 시스템과, 수집된 데이터로부터 자율적인 작업 기술을 학습하는 imitation learning 파이프라인을 제시하는 전체 스택 시스템이다.
본 논문은 휴머노이드 로봇의 인간 데이터 활용이라는 오랫동안의 과제에 대해 실용적이고 완성도 높은 end-to-end 시스템을 제시했으며, RGB 카메라 기반 shadowing의 단순성과 효율성, 그리고 다양한 자율 작업의 성공적 구현은 로봇 공학 분야에 실질적인 기여를 한다.
OmniH2O: Universal and Dexterous Human-to-Humanoid Whole-Body Teleoperation and Learning
Figure 1: (a) OmniH2O enables teleoperating a full-size humanoid robot (Unitree H1) to complete tasks that
 *Figure 1: (a) OmniH2O enables teleoperating a full-size humanoid robot (Unitree H1) to complete tasks that* OmniH2O는 kinematic pose를 보편적 제어 인터페이스로 사용하여 VR, RGB 카메라, 음성 명령 등 다양한 입력을 통해 전신 인형 로봇을 조작하고 자율 작업을 수행할 수 있는 학습 기반 시스템이다.
OmniH2O는 kinematic pose 기반의 보편적 제어 인터페이스와 정교한 sim-to-real 파이프라인을 통해 인형 로봇의 전신 로코-조작을 처음으로 체계적으로 해결한 연구이며, 공개 데이터셋과 다양한 실제 작업 시연으로 높은 실무 가치를 제공한다.
PvP: Data-Efficient Humanoid Robot Learning with Proprioceptive-Privileged Contrastive Representations
Figure 1. (a) PvP employs contrastive learning between proprioceptive and privileged states to learn compact and task-re
 *Figure 1. (a) PvP employs contrastive learning between proprioceptive and privileged states to learn compact and task-re* PvP는 고유 감각(proprioceptive)과 특권 상태(privileged state) 사이의 대조 학습을 활용하여 휴머노이드 로봇의 전신 제어(WBC) 학습의 샘플 효율성을 크게 향상시킨다.
PvP는 proprioceptive-privileged 대조 학습이라는 직관적이면서도 효과적인 방법으로 휴머노이드 로봇 학습의 샘플 효율성을 크게 향상시키며, SRL4Humanoid 프레임워크는 해당 분야의 표준 도구로서 상당한 기여를 한다.
Robot Trains Robot: Automatic Real-World Policy Adaptation and Learning for Humanoids
Figure 1: Robot Trains Robot (RTR). We pro-
 *Figure 1: Robot Trains Robot (RTR). We pro-* 로봇 팔(teacher)이 휴머노이드 로봇(student)을 지원하고 가이드하는 Robot-Trains-Robot(RTR) 프레임워크를 제안하여, 안전하고 효율적인 실제 환경에서의 휴머노이드 학습을 가능하게 한다. Dynamics-encoded latent variable 최적화를 통한 sim-to-real 전이 방법을 함께 제안한다.
실제 환경에서의 휴머노이드 학습이라는 중요하면서도 실제로 구현되지 않았던 문제에 대해, 혁신적인 teacher-robot 지원 방식과 효율적 sim-to-real 알고리즘을 결합하여 실질적인 해결책을 제시한다. 실험적 검증과 전반적 설계의 견고성이 우수하지만, 제한된 플랫폼과 태스크에서의 검증이라는 한계가 있다.
Scalable and General Whole-Body Control for Cross-Humanoid Locomotion
Figure 1. Zero-shot generalization and real-world humanoid capabilities enabled by XHugWBC’s generalist policy. First ro
 *Figure 2. Training framework of XHugWBC. (a) Data generation: physics-consistent morphological randomization produces di* XHugWBC는 물리적으로 일관성 있는 형태학적 랜덤화, 의미론적으로 정렬된 관찰-행동 공간, 그래프 기반 정책 아키텍처를 통해 단일 정책으로 다양한 인간형 로봇에 대한 제로샷 제너럴화를 실현하는 교차-신체 전신 제어 프레임워크이다.
본 논문은 물리적으로 일관성 있는 형태 랜덤화와 의미론적 정렬을 통해 단일 정책의 다중 인간형 로봇 제너럴화를 처음으로 달성했으며, 7개 실제 로봇에서의 강건한 제로샷 성능과 시뮬레이션 확장성으로 로봇 학습의 현실적 가치를 입증했다.
SCDP: Learning Humanoid Locomotion from Partial Observations via Mixed-Observation Distillation
Fig. 1: Deployment of Sensor-Conditioned Diffusion Policies
 *Fig. 2: Sensor-Conditioned Diffusion Policies (SCDP) architecture and training framework. The state-action diffusion* 온보드 센서만으로 휴머노이드 보행을 학습하기 위해 mixed-observation distillation을 사용하는 SCDP(Sensor-Conditioned Diffusion Policies)를 제안하며, diffusion model이 센서 이력에 조건화되면서 privileged 미래 상태-행동 궤적을 예측하도록 학습한다.
Mixed-observation distillation은 개념적으로 우수한 해결책이며, 실로봇 배포까지 달성한 점이 높게 평가된다. 다만 일반화 범위와 센서 robustness 측면의 추가 검증이 필요하며, IROS 채택으로 인정된 견고한 연구이다.
Sim-and-Real Co-Training: A Simple Recipe for Vision-Based Robotic Manipulation
Fig. 1: Sim-and-Real Co-Training. We show how co-training
 *Fig. 1: Sim-and-Real Co-Training. We show how co-training* 시뮬레이션 데이터와 실제 로봇 데이터를 혼합하여 학습하는 sim-and-real co-training 전략을 체계적으로 연구하고, 비전 기반 로봇 조작 작업에서 실제 데이터만 사용하는 것 대비 평균 38% 성능 향상을 달성했다.
본 논문은 sim-and-real co-training의 실용성을 체계적으로 검증하여 실제 로봇 학습의 데이터 효율성 문제에 직접적인 해결책을 제시하며, 명확한 실험 설계와 실무적 가이드라인으로 로봇 커뮤니티에 높은 가치를 제공한다.
SkillBlender: Towards Versatile Humanoid Whole-Body Loco-Manipulation via Skill Blending
 *Figure 2: Overview of SkillBlender. We first pretrain goal-conditioned primitive expert skills that are* SkillBlender는 사전학습된 목표조건부 원시 기술들을 동적으로 혼합하여 휴머노이드 로봇이 복잡한 전신 조작-이동 작업을 최소한의 보상 엔지니어링으로 수행할 수 있게 하는 계층적 강화학습 프레임워크이다.
SkillBlender는 휴머노이드 로봇의 다용도적 조작-이동 능력 개발에 대한 우아하고 실용적인 해결책을 제시하며, 포괄적인 벤치마크와 함께 향후 휴머노이드 연구의 중요한 기초가 될 가능성이 높다.
SkillMimic: Learning Basketball Interaction Skills from Demonstrations
Figure 1. We propose a novel approach that for the first time enables physically simulated humanoids to learn a variety
 *Figure 2. Concept of SkillMimic. We define an interaction skill as* SkillMimic은 skill-specific reward 설계 없이 통합된 HOI imitation reward를 사용하여 단일 policy로 다양한 농구 상호작용 기술을 학습하고 합성할 수 있는 data-driven 프레임워크다.
SkillMimic은 skill-specific reward 제거를 통해 상호작용 기술 학습의 실용성을 혁신적으로 개선했으며, contact graph와 통합 HOI reward 설계는 기술적으로 견고하고 농구 데이터셋 기여와 함께 이 분야의 significant advance를 이룬다.
SLAC: Simulation-Pretrained Latent Action Space for Whole-Body Real-World RL
Figure 1: SLAC uses a task-agnostic action space trained in low-fidelity simulation (left) to learn
 *Figure 1: SLAC uses a task-agnostic action space trained in low-fidelity simulation (left) to learn* SLAC는 저충실도 시뮬레이터에서 학습한 task-agnostic 잠재 행동 공간을 사용하여 고자유도 모바일 매니퓨레이터가 실제 환경에서 효율적이고 안전하게 강화학습으로 접촉이 풍부한 전신 조작 작업을 학습할 수 있게 한다.
SLAC는 저충실도 시뮬레이션 기반 latent action space pretraining과 실제 환경 강화학습을 결합하여 고자유도 모바일 매니퓨레이터의 복잡한 접촉 조작 작업을 안전하고 효율적으로 학습할 수 있게 하는 혁신적인 접근법을 제시하며, 1시간 미만의 실제 상호작용만으로 의미 있는 성과를 달성함으로써 실제 로봇 학습의 실용성을 크게 향상시킨다.
Visual Imitation Enables Contextual Humanoid Control
 *Figure 2: VideoMimic Real-to-Sim. A casually captured phone video provides the only input. We first* VIDEOMIMIC는 단순한 휴대폰 영상에서 인간-환경 4D 기하학을 공동 재구성하고, 이를 시뮬레이션에서 RL 정책으로 학습한 후 실제 휴머노이드 로봇에 배포하는 real-to-sim-to-real 파이프라인이다.
이 논문은 일상 영상으로부터 휴머노이드 로봇의 문맥-인식 제어를 가능하게 하는 실용적이고 확장 가능한 파이프라인을 제시하며, 공동 4D 재구성과 RL 기반 정책 증류의 조합으로 높은 독창성을 보인다. 실제 로봇 배포 성공은 연구의 가치를 크게 높이나, 환경 표현의 제한성과 동역학 정확도 측면에서 개선 여지가 있다.
Zero-Shot Whole-Body Humanoid Control via Behavioral Foundation Models
Figure 1 META MOTIVO is the first behavioral foundation model for humanoid agents that can solve whole-body control task
 *Figure 1 META MOTIVO is the first behavioral foundation model for humanoid agents that can solve whole-body control task* Forward-Backward representations with Conditional-Policy Regularization (FB-CPR)을 통해 unlabeled behavior dataset으로 unsupervised RL을 정규화하여, humanoid agent의 zero-shot whole-body control을 가능하게 하는 behavioral foundation model Meta Motivo를 개발했다.
FB-CPR은 unsupervised RL의 exploration 한계를 behavior dataset 정규화로 창의적으로 해결하고, 복잡한 humanoid 제어에서 zero-shot generalization을 달성한 기술적으로 견실하고 의미 있는 연구이다. 재현성 보장과 다양한 평가는 강점이나, 데이터셋 의존성과 실제 로봇 검증 부재는 향후 개선이 필요하다.
ZEST: Zero-shot Embodied Skill Transfer for Athletic Robot Control
Fig. 1. Hardware deployment of ZEST across diverse data sources and robot morphologies. In order of appearance from top
 *Fig. 3. Overview of ZEST, which consists of three main stages. (1) Reference data: A diverse set of motions from MoCap, * ZEST는 모션 캡처, 비디오, 애니메이션 등 다양한 출처의 데이터로부터 RL을 통해 인간형 로봇 제어 정책을 학습하고, 시뮬레이션에서만 훈련하여 하드웨어에 Zero-shot 배포하는 motion-imitation 프레임워크이다.
ZEST는 다양한 비정형 데이터 소스로부터 인간형 로봇의 일반적 제어 정책을 학습하고 zero-shot 배포하는 혁신적 프레임워크로, 실제 하드웨어에서의 광범위한 성공적 검증을 통해 로봇 제어의 실용성과 확장성을 크게 향상시킨 매우 중요한 기여이다.
$Ψ_0$: An Open Foundation Model Towards Universal Humanoid Loco-Manipulation
 *Fig. 2: Model Training and Deployment: First, we pre-train the VLM on the EgoDex [20] dataset to autoregressively predic* Ψ0는 인간 중심 egocentric 비디오로 VLM을 사전학습한 후 humanoid 로봇 데이터로 flow-based action expert를 post-train하는 2단계 학습 패러다임을 통해 humanoid loco-manipulation을 위한 foundation model을 제안한다.
Ψ0는 인간-humanoid embodiment gap을 극복하기 위한 명확한 2단계 학습 패러다임과 고품질 데이터 선택의 중요성을 새롭게 제시하며, 10배 이상의 데이터 효율 개선으로 humanoid loco-manipulation 분야에 significant contribution을 제공한다.
ARMADA: Augmented Reality for Robot Manipulation and Robot-Free Data Acquisition
Fig. 1: Overview. (A) Human demonstrators wearing Apple Vision Pro can
 *Fig. 1: Overview. (A) Human demonstrators wearing Apple Vision Pro can* Apple Vision Pro의 AR을 활용하여 물리적 로봇 없이 로봇 조작 데이터를 수집하는 ARMADA 시스템을 제시하며, 실시간 로봇 피드백이 데이터 품질을 1.3%에서 71.1%로 향상시킨다.
ARMADA는 AR 기술을 창의적으로 활용하여 로봇 데이터 수집의 실제적 병목을 해결하는 혁신적 시스템을 제시하며, 실시간 피드백의 극적인 효과를 실증함으로써 대규모 로봇 학습의 새로운 가능성을 열었다.
BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion
Figure 1: Overview of the proposed versatile humanoid control framework. (A) Scalable
 *Figure 1: Overview of the proposed versatile humanoid control framework. (A) Scalable* BeyondMimic은 인간 모션 데이터로부터 학습한 compact motion-tracking 공식과 classifier guidance를 활용한 diffusion model을 결합하여, 휴머노이드 로봇이 학습 중 보지 못한 다양한 작업을 zero-shot으로 수행할 수 있는 통합 제어 프레임워크를 제시한다.
BeyondMimic은 motion tracking RL의 민첩성과 diffusion 모델의 유연성을 효과적으로 결합하여, 휴머노이드 로봇 제어의 장기적 과제인 자연스러움, 민첩성, versatility를 동시에 달성하는 강력한 프레임워크를 제시한다. 실제 로봇 배포와 zero-shot task 일반화 시연은 로보틱스 커뮤니티에 상당한 기여를 한다.
BFM-Zero: A Promptable Behavioral Foundation Model for Humanoid Control Using Unsupervised Reinforcement Learning
Figure 1: BFM-Zero enables versatile and robust whole-body skills. (A-C) Diverse zero-shot inference
 *Figure 2: An overview of the BFM-Zero framework. After the pre-training stage, BFM-Zero forms a latent* BFM-Zero는 unsupervised RL과 Forward-Backward 모델을 활용하여 휴머노이드 로봇의 다양한 제어 작업을 단일 정책으로 수행할 수 있는 promptable behavioral foundation model을 제시한다. 공유 잠재 공간에 모션, 목표, 보상을 임베딩하여 zero-shot 추론과 few-shot 적응을 가능하게 한다.
BFM-Zero는 unsupervised RL을 통해 휴머노이드 로봇의 실제 배포에서 처음으로 promptable foundation model을 성공적으로 구현하였으며, zero-shot 다중 작업 수행과 few-shot 적응의 균형을 이루는 실용적 솔루션을 제시한다. 이는 로봇 제어의 패러다임 전환을 제시하는 중요한 기여이다.
BiGym: A Demo-Driven Mobile Bi-Manual Manipulation Benchmark
Figure 1: BiGym focuses on mobile manipulation with home assistance humanoids. We provide 40
 *Figure 1: BiGym focuses on mobile manipulation with home assistance humanoids. We provide 40* BiGym은 인간이 수집한 데모를 포함한 40개의 다양한 이족 이족 조작 작업을 제공하는 모바일 휴머노이드 로봇 학습 벤치마크로, Imitation Learning과 Demo-Driven RL 알고리즘을 평가할 수 있게 설계되었다.
BiGym은 인간이 수집한 현실적 다중양식 데모와 모바일 이족 조작의 복잡성을 체계적으로 다루는 최초의 종합 벤치마크로, Imitation Learning과 Demo-Driven RL 연구에 중요한 기여를 한다. 다만 실제 로봇 검증과 환경 다양성 확대가 향후 영향력 확대를 위해 필요하다.
Coordinated Humanoid Robot Locomotion with Symmetry Equivariant Reinforcement Learning Policy
Figure 1: The overall architecture of SE-Policy. (a) Left: the architecture of the actor and critic model. (b) upper rig
 *Figure 1: The overall architecture of SE-Policy. (a) Left: the architecture of the actor and critic model. (b) upper rig* 인간의 신경계에서 영감을 받은 Symmetry Equivariant Policy (SE-Policy)를 제안하여, 휴머노이드 로봇의 형태적 대칭성을 DRL 프레임워크에 엄격하게 임베딩함으로써 조정되고 균형잡힌 보행을 실현한다.
SE-Policy는 휴머노이드 로봇의 형태적 대칭성을 엄격한 네트워크 제약으로 구현하여 추가 하이퍼파라미터 없이 40% 성능 향상을 달성한 혁신적인 방법이며, 실제 로봇 배포를 통해 실용성을 입증했다는 점에서 높은 기여도를 가진다.
Deep Imitation Learning for Humanoid Loco-manipulation through Human Teleoperation
Fig. 1: Overview of TRILL. TRILL addresses the challenge of learning
 *Fig. 1: Overview of TRILL. TRILL addresses the challenge of learning* 본 논문은 VR 텔레오퍼레이션을 통해 수집한 인간 시연 데이터로부터 humanoid 로봇의 loco-manipulation 능력을 deep imitation learning으로 학습하는 TRILL 프레임워크를 제시한다. Whole-body control 기반의 계층적 정책 구조를 통해 높은 자유도 humanoid의 복잡한 동작을 데이터 효율적으로 학습할 수 있다.
본 논문은 humanoid loco-manipulation을 위한 데이터 효율적 deep imitation learning 방법을 제시하며, whole-body control과의 영리한 결합을 통해 높은 자유도 시스템의 안정성과 학습 효율성을 동시에 달성했다. 실제 humanoid 로봇에서 처음으로 성공적으로 복잡한 manipulation을 학습한 선도적 성과로, 앞으로 humanoid의 자율 능력 향상에 중요한 기여를 할 것으로 예상된다.
DemoHLM: From One Demonstration to Generalizable Humanoid Loco-Manipulation
Figure 1: Overview of DemoHLM. For each task, we collect a single demonstration via VR teleoperation
 *Figure 1: Overview of DemoHLM. For each task, we collect a single demonstration via VR teleoperation* DemoHLM은 단일 시뮬레이션 데모로부터 합성 데이터를 생성하여 휴머노이드 로봇의 일반화된 로코-매니퓰레이션 정책을 학습하는 프레임워크이다. 계층적 제어 구조를 통해 저수준 전신 제어기와 고수준 조작 정책을 통합하여 실제 로봇에 시뮬레이션-현실 전이를 달성한다.
본 논문은 MimicGen 개념을 휴머노이드 로코-매니퓰레이션으로 확장하여 단일 데모로부터 확장 가능한 데이터 생성을 실현하고, 계층적 제어 구조를 통해 현실 로봇에 효과적인 시뮬레이션-현실 전이를 달성했다. 데이터 효율성과 다중 작업 일반화 측면에서 강력한 기여를 제공하며, 실제 로봇 검증이 완전하여 실질적 가치가 높다.
DexMimicGen: Automated Data Generation for Bimanual Dexterous Manipulation via Imitation Learning
Fig. 1: DexMimicGen Overview. DexMimicGen offers an efficient pipeline
 *Fig. 1: DexMimicGen Overview. DexMimicGen offers an efficient pipeline* DexMimicGen은 소수의 인간 시연으로부터 simulation에서 자동으로 대규모 궤적 데이터를 생성하여 양손 dexterous 로봇 조작 학습을 위한 imitation learning 데이터 수집 병목을 해결하는 시스템이다.
DexMimicGen은 양손 dexterous 로봇 조작을 위한 자동 데이터 생성의 실질적인 해결책을 제시하며, MimicGen을 의미 있게 확장하고 실제 humanoid 배포로 그 효과를 입증했으나, 한계된 실제 작업 검증과 일반화 능력 평가가 필요하다.
Dexterity from Smart Lenses: Multi-Fingered Robot Manipulation with In-the-Wild Human Demonstrations
Fig. 1: AINA is a framework for learning multi-fingered policies from in-the-wild human data collected with smart glasse
 *Fig. 1: AINA is a framework for learning multi-fingered policies from in-the-wild human data collected with smart glasse* Aria Gen 2 스마트 글래스로 수집한 in-the-wild 인간 영상만으로 로봇용 다중 손가락 조작 정책을 학습하는 AINA 프레임워크를 제안한다. 이는 로봇 데이터나 시뮬레이션 없이도 직접 배포 가능한 3D point-based 정책을 생성한다.
이 논문은 스마트 글래스의 고급 센싱 능력을 창의적으로 활용하여 순수 인간 비디오만으로 다중 손가락 로봇 조작 정책을 학습하는 실질적이고 확장 가능한 해법을 제시한다. 강력한 실증 결과와 명확한 방법론으로 인간-로봇 모방 학습 분야에 상당한 진전을 이루었으며, 로봇 조작의 대규모 실용화를 향한 중요한 한 걸음을 제공한다.
DreamControl-v2: Simpler and Scalable Autonomous Humanoid Skills via Trainable Guided Diffusion Priors
Fig. 1: DreamControl-v2 enables scalable and autonomous humanoid skill acquisition. We demonstrate diverse real-world sk
 *Fig. 2: DreamControl-v2 Overview. Our four-stage pipeline enables humanoid whole-body manipulation: (1) large-scale huma* humanoid 로봇의 복잡한 manipulation 작업을 위해 guided diffusion 모델을 로봇의 motion space에 직접 학습하여, 다양한 인간과 로봇 데이터를 통합하고 RL 정책을 자동으로 생성하는 확장 가능한 프레임워크를 제시한다.
DreamControl-v2는 robot-space diffusion prior 훈련이라는 명확한 아이디어로 기존의 확장성 문제를 근본적으로 해결하며, 자동화된 파이프라인과 다양한 skill 습득을 통해 humanoid 로봇의 자율적 loco-manipulation에 실질적인 진전을 이루었다. 다만 다중 로봇 embodiment 일반화와 실제 환경에서의 광범위한 검증이 추가되면 더욱 강력한 기여가 될 것이다.
DreamControl: Human-Inspired Whole-Body Humanoid Control for Scene Interaction via Guided Diffusion
Fig. 1: Unitree G1 humanoid performing various skills trained via
 *Fig. 2: DreamControl Overview: (A) we first generate text and spatiotemporally guided human motion trajectories using di* DreamControl은 human motion 기반 diffusion prior를 RL과 결합하여 humanoid robot의 whole-body 조작 작업을 학습하는 방법론을 제안한다.
DreamControl은 human motion diffusion prior와 RL의 장점을 효과적으로 결합하여 humanoid robot의 whole-body manipulation을 학습하는 창의적이고 실용적인 방법론을 제시하며, 실제 로봇에서의 다양한 작업 수행으로 그 가치를 입증했다.
DreamGen: Unlocking Generalization in Robot Learning through Video World Models
 *Figure 2: DREAMGEN Overview. We begin by fine-tuning a video world model on teleoperated robot trajectories.* DreamGen은 비디오 월드 모델(video world model)을 활용하여 최소한의 원격조종 데이터로부터 로봇 정책을 학습하는 4단계 파이프라인으로, 신규 행동과 환경에 대한 일반화를 달성한다.
DreamGen은 비디오 월드 모델을 로봇 학습의 효율적인 데이터 생성 도구로 재정의하여, 최소한의 원격조종 데이터로 다양한 행동과 환경 일반화를 달성하는 혁신적이고 실용적인 접근법을 제시한다. 다중 embodiment 실세계 검증과 DreamGen Bench라는 체계적 평가 도구까지 제공하여 로봇 학습 확장의 새로운 방향을 제시한다.
DynaRetarget: Dynamically-Feasible Retargeting using Sampling-Based Trajectory Optimization
Fig. 1: Real-world humanoid loco-manipulation behaviors enabled by DynaRetarget. Demonstrations retargeted using our fra
 *Fig. 2: DynaRetarget overview. Given a human–object demonstration, we first perform IK-based retargeting to obtain a kin* DynaRetarget은 Sampling-Based Trajectory Optimization (SBTO)을 통해 운동학적으로 부정확한 인간 동작을 휴머노이드 로봇이 동적으로 실행 가능한 loco-manipulation 행동으로 변환하는 완전한 파이프라인을 제시한다.
DynaRetarget은 sampling-based trajectory optimization의 incremental horizon 확장 개념을 통해 humanoid loco-manipulation retargeting의 동적 실행 가능성 문제를 효과적으로 해결하며, 광범위한 실험과 실제 로봇 배포를 통해 그 효과를 입증한 의미 있는 기여이다.
EgoHumanoid: Unlocking In-the-Wild Loco-Manipulation with Robot-Free Egocentric Demonstration
Fig. 1: Introducing EGOHUMANOID, the first investigation on human-to-humanoid transfer for whole-body loco-manipulation.
 *Fig. 1: Introducing EGOHUMANOID, the first investigation on human-to-humanoid transfer for whole-body loco-manipulation.* EgoHumanoid는 로봇 없이 수집한 대규모 인간 egocentric 시연과 제한된 로봇 데이터를 co-train하여 휴머노이드 로봇이 다양한 현실 환경에서 loco-manipulation을 수행하도록 하는 첫 번째 프레임워크이다. View alignment와 action alignment로 구성된 embodiment 정렬 파이프라인을 통해 인간-로봇 간의 신체 형태, 관점, 동역학의 차이를 극복한다.
EgoHumanoid는 휴머노이드 loco-manipulation 분야에서 human egocentric data 활용의 새로운 가능성을 체계적으로 보여주는 획기적인 작업이다. Practical embodiment alignment pipeline, 현실 환경에서의 강력한 성능 개선(51%), 그리고 scalability 분석은 향후 humanoid 로봇 학습의 중요한 방향을 제시한다.
Embodiment-Aware Generalist Specialist Distillation for Unified Humanoid Whole-Body Control
Fig. 1: In this work, we propose a distillation framework that yields a single whole-body controller that runs on hetero
 *Fig. 2: Method Overview. (a) Unified command interface. The command vector ct comprises task commands vt (linear* EAGLE는 다양한 휴머노이드 로봇을 단일 정책으로 제어하기 위한 embodiment-aware generalist-specialist distillation 프레임워크로, 반복적인 전문가 미세조정과 일반화 정책으로의 지식 증류를 통해 여러 이종 로봇에서 보행, 스쿼팅, 기울임 등 다양한 whole-body 제어를 가능하게 한다.
EAGLE는 generalist-specialist distillation을 통해 이종 휴머노이드의 통합 제어라는 어려운 문제에 대한 실증적 해결책을 제시하며, 시뮬레이션과 실제 하드웨어에서의 광범위한 검증으로 fleet-level 휴머노이드 제어의 실현 가능성을 보여주는 의미 있는 기여다.
Emergent Active Perception and Dexterity of Simulated Humanoids from Visual Reinforcement Learning
Figure 1. Perceptive Dexterous Control (PDC) enables a humanoid equipped with egocentric vision to search for, reach, gr
 *Figure 1. Perceptive Dexterous Control (PDC) enables a humanoid equipped with egocentric vision to search for, reach, gr* 본 논문은 egocentric vision만을 사용하여 simulated humanoid가 복잡한 household tasks를 수행하도록 하는 Perceptive Dexterous Control (PDC) 프레임워크를 제안하며, visual perception을 task specification의 인터페이스로 활용하여 active search 등의 emergent behaviors를 유도한다.
본 논문은 egocentric vision을 유일한 정보원으로 하는 humanoid whole-body dexterous control의 실현이라는 도전적 문제를 perception-as-interface 패러다임과 hierarchical RL을 통해 창의적으로 해결하며, emergent active search behaviors의 명시적 입증을 통해 vision-driven control의 이점을 새롭게 조명한다.
GBC: Generalized Behavior-Cloning Framework for Whole-Body Humanoid Imitation
Fig. 1. GBC data processing pipeline. MoCap data (angle-axis representation)
 *Fig. 1. GBC data processing pipeline. MoCap data (angle-axis representation)* GBC는 이질적인 휴머노이드 로봇들을 위한 통합 행동 모방 프레임워크로, differentiable IK 기반 데이터 파이프라인, DAgger-MMPPO 알고리즘, MMTransformer 아키텍처를 결합하여 인간 모션캡처 데이터를 다양한 로봇에 자동으로 재타겟팅하고 학습한다.
본 논문은 이질적 휴머노이드 로봇들의 행동 모방을 위한 첫 번째 통합 프레임워크를 제시하며, differentiable IK, MMTransformer, DAgger-MMPPO 알고리즘을 결합하여 데이터 처리부터 정책 학습까지 일원화된 솔루션을 제공한다. 오픈소스 플랫폼 제공과 다중 로봇 검증을 통해 실용성과 확장성을 입증했으나, 실제 로봇 배포 성능 및 동적 환경에서의 강건성에 대한 검증이 후속과제이다.
Generalizable Humanoid Manipulation with 3D Diffusion Policies
Fig. 1: Humanoid manipulation in diverse unseen scenarios. With our system, we are able to 1) collect human-like
 *Fig. 1: Humanoid manipulation in diverse unseen scenarios. With our system, we are able to 1) collect human-like* 이 논문은 단일 장면에서 수집한 데이터만으로 휴머노이드 로봇이 다양한 미지의 실제 환경에서 자율적으로 조작 작업을 수행하도록 하는 3D Diffusion Policy 기반 시스템을 제시한다.
이 논문은 휴머노이드 로봇의 장면 일반화 조작이라는 미해결 문제를 최초로 해결하며, 개선된 3D Diffusion Policy와 완전한 실제 환경 시스템을 통해 단일 장면 데이터만으로 다양한 미지 환경에서의 자율 작동을 달성한 의미 있는 기여를 제시한다.
H-Zero: Cross-Humanoid Locomotion Pretraining Enables Few-shot Novel Embodiment Transfer
Fig. 1: Left: We propose a locomotion pretraining pipeline for humanoids by mixing multiple randomized embodiments
 *Fig. 2: Method overview. a) The policy is pretrained by learning on a diverse set of humanoid embodiments through* H-Zero는 다양한 휴머노이드 로봇 embodiment에서 사전학습된 일반화된 이동 정책을 학습하여 미지의 로봇으로의 제로샷 및 소수샷 전이를 가능하게 하는 파이프라인이다.
H-Zero는 unified control semantics를 통해 실용적이고 확장 가능한 cross-embodiment 이동 제어 솔루션을 제시하며, 30분의 미세조정으로 신규 로봇에 적응할 수 있는 점에서 현실 배포 관점에서 큰 의의가 있다. 다만 embodiment 선택의 체계화와 더 다양한 형태의 로봇으로의 일반화 능력 검증이 필요하다.
Human-Humanoid Robots Cross-Embodiment Behavior-Skill Transfer Using Decomposed Adversarial Learning from Demonstration
Fig. 1: Human can serve as the prototype of diverse humanoid robots, efficiently learning generalized loco-manipulation
 *Fig. 2: Schematic overview of the cross-embodiment loco-manipulation skill transfer framework. 1) Human embodiment* Unified Digital Human (UDH) 모델을 공통 프로토타입으로 사용하여 인간 시연에서 행동 원시 요소를 학습하고, 분해된 adversarial imitation learning과 kinematic motion retargeting을 통해 다양한 휴머노이드 로봇 플랫폼으로 로코-매니퓰레이션 스킬을 효율적으로 전이한다.
본 논문은 UDH를 중심으로 한 창의적인 교차 embodiment 프레임워크를 제시하며, functional decomposition과 adversarial imitation learning의 결합, 그리고 interaction graph 기반 계획을 통해 휴머노이드 로봇의 로코-매니퓰레이션 스킬 전이 문제를 실질적으로 해결하는 중요한 기여를 한다.
Humanoid Policy ~ Human Policy
Figure 1: This paper advocates high-quality human data as a data source for cross-embodiment
 *Figure 1: This paper advocates high-quality human data as a data source for cross-embodiment* 휴머노이드 로봇 조작 정책 학습을 위해 대규모 자아중심 인간 데모를 cross-embodiment 학습 데이터로 활용하고, Human Action Transformer (HAT)를 통해 인간과 로봇을 통합된 상태-행동 공간에서 다양한 embodiment으로 모델링한다.
로봇 조작 학습에서 대규모 인간 데이터 활용의 실질적 가치를 입증한 의미 있는 연구로, 통합된 state-action space와 체계적인 co-training 전략을 통해 embodiment 간극을 효과적으로 해소했으며, PH2D 데이터셋과 HAT 모델의 공개를 통해 cross-embodiment 학습 커뮤니티에 중요한 기여를 할 것으로 기대된다.
HumanoidExo: Scalable Whole-Body Humanoid Manipulation via Wearable Exoskeleton
Figure 1. HumanoidExo, a wearable exoskeleton system that transfers human motion to whole-body humanoid data. HumanoidEx
 *Figure 1. HumanoidExo, a wearable exoskeleton system that transfers human motion to whole-body humanoid data. HumanoidEx* 웨어러블 외골격(exoskeleton)을 통해 인간의 전신 동작을 휴머노이드 로봇 데이터로 변환하는 HumanoidExo 시스템을 제안하여, 휴머노이드 정책 학습을 위한 대규모 다양한 데이터셋 수집의 병목을 해결한다.
HumanoidExo는 웨어러블 외골격을 통한 전신 휴머노이드 데이터 수집의 첫 성공적 사례로, 기존 방법의 상지 집중 문제를 극복하고 embodiment gap을 최소화한 혁신적 접근이다. 실험 결과가 제한적이고 기술적 깊이가 다소 부족하지만, 휴머노이드 정책 학습의 데이터 병목 문제 해결이라는 실질적 기여와 높은 실용성으로 인해 로보틱스 분야에 의미 있는 진전을 제시한다.
In-N-On: Scaling Egocentric Manipulation with in-the-wild and on-task Data
Figure 1. This paper investigates large-scale pre-training and post-training with egocentric human data. We curate a lar
 *Figure 1. This paper investigates large-scale pre-training and post-training with egocentric human data. We curate a lar* 이 논문은 1,000시간 이상의 in-the-wild 에고센트릭 데이터와 on-task 데이터를 결합하여 대규모 휴머노이드 조작 정책 Human0을 학습하고, domain adaptation을 통해 인간과 로봇 간의 도메인 갭을 최소화한다.
이 논문은 in-the-wild와 on-task 인간 데이터를 체계적으로 결합하는 새로운 data recipe를 제시하고, 대규모 PHSD 데이터셋과 Human0 모델을 통해 실제 휴머노이드 로봇에서 language following, few-shot learning, robustness 개선을 달성함으로써 로봇 조작 학습의 확장성에 중요한 기여를 한다.
Learning Human-Like Badminton Skills for Humanoid Robots
Fig. 1: Real-world Deployment of the System. We present a learning-based framework that enables a humanoid to perform ag
 *Fig. 2: Overview of the Framework. The pipeline progressively transforms a kinematic imitator into a dynamic striker thr* 휴머노이드 로봇이 배드민턴 기술을 습득하도록 하는 Imitation-to-Interaction 점진적 강화학습 프레임워크를 제안하며, 시뮬레이션에서 실제 로봇으로의 제로샷 sim-to-real 전이를 달성했다.
휴머노이드 로봇 스포츠 제어의 새로운 경계를 개척한 혁신적 연구로, Imitation-to-Interaction 프레임워크와 manifold expansion 전략은 희소한 전문가 데이터에서 고도로 정밀하고 인간다운 운동을 학습하는 강력한 솔루션을 제시한다. 제로샷 sim-to-real 전이의 성공은 실용적 가치가 높으나, 상대방 상호작용과 환경 변동성 측면의 제한이 남아 있다.
Learning Humanoid End-Effector Control for Open-Vocabulary Visual Loco-Manipulation
Fig. 1: We build capability for a humanoid to autonomously loco-manipulate novel objects in novel scenes using onboard
 *Fig. 2: Overall architecture for our proposed modular system for open-vocabulary object grasping. Given a free-form* HERO 시스템은 정확한 end-effector 추적 정책과 대규모 비전 모델을 결합하여 휴머노이드 로봇이 미지의 환경에서 임의의 일상용품을 자율적으로 집을 수 있게 한다. End-effector 추적 오차를 3.2배 감소시키고 83.8%의 성공률을 달성했다.
본 논문은 정확한 end-effector 제어의 기술적 난제를 classical robotics와 학습 기반 모듈의 창의적 결합으로 해결하고, 이를 통해 humanoid의 실제 환경 object manipulation을 처음으로 현실화했다. 모듈식 설계로 대규모 실제 데이터 수집 없이도 open-vocabulary 일반화를 달성한 점이 특히 의미 있으며, 83.8%의 실제 환경 성공률은 해당 분야의 significant advance를 나타낸다.
Learning to Look Around: Enhancing Teleoperation and Learning with a Human-like Actuated Neck
Figure 1: A teleoperation system featuring an actuated neck and dexterous arms, enabling human-like manipu-
 *Figure 1: A teleoperation system featuring an actuated neck and dexterous arms, enabling human-like manipu-* 인간의 자연스러운 머리 움직임을 모방하는 5-DOF actuated neck을 원격 조종 시스템에 통합하여 작업자의 직관성 향상, 인지 부하 감소, 자율 정책 학습 개선을 달성하는 연구이다.
이 논문은 인간의 자연스러운 지각 능력을 원격 조종 시스템에 구현한 혁신적 접근으로, 직관성 향상과 자율 정책 학습 개선에 대한 실증적 증거를 제시한다. 다만 평가 작업의 범위 확대와 기술적 한계 개선을 통해 더욱 강화될 수 있다.
Let Humanoids Hike! Integrative Skill Development on Complex Trails
Figure 1. We propose training humanoids to hike complex trails, driving integrative skill development across visual perc
 *Figure 1. We propose training humanoids to hike complex trails, driving integrative skill development across visual perc* 휴머노이드 로봇이 복잡한 산길을 자율적으로 하이킹하도록 학습시키기 위해 시각 인식, 의사결정, 운동 실행을 통합하는 LEGO-H 프레임워크를 제안한다. TC-ViT와 Hierarchical Latent Matching을 통해 네비게이션과 로코모션을 단일 학습 체계로 통합한다.
본 논문은 하이킹을 새로운 벤치마크로 제시하고 TC-ViT와 HLM 기반 LEGO-H 프레임워크를 통해 네비게이션과 로코모션의 통합이라는 오래된 문제에 혁신적으로 접근한다. 다만 시뮬레이션 중심의 평가가 실제 배포 가능성의 의문을 남기지만, 휴머노이드 로봇 자율성 개발을 위한 강력한 기초 제시로서 충분히 의미 있는 기여이다.
LHM-Humanoid: Learning a Unified Policy for Long-Horizon Humanoid Whole-Body Loco-Manipulation in Diverse Messy Environments
Fig. 1: Overview of LHM-Humanoid. Our system solves long-horizon loco-manipulation tasks
 *Fig. 1: Overview of LHM-Humanoid. Our system solves long-horizon loco-manipulation tasks* LHM-Humanoid는 다양한 혼란스러운 환경에서 장시간 인간형 로봇이 복수 객체를 반복적으로 집기, 운반, 배치하는 작업을 단일 통합 정책으로 수행하는 벤치마크와 학습 프레임워크를 제시한다.
본 논문은 장시간 혼란스러운 환경에서의 인간형 로봇 로코-조작이라는 도전적인 새로운 문제를 정의하고 이중 교사 증류 프레임워크로 효과적으로 해결하며, 350개 다양한 장면의 종합 벤치마크를 제공하여 로봇 일반화 연구에 의미 있는 기여를 한다.
MimicDroid: In-Context Learning for Humanoid Robot Manipulation from Human Play Videos
Fig. 1: Overview. MIMICDROID enables few-shot learning for humanoid manipulation by training solely on human play
 *Fig. 1: Overview. MIMICDROID enables few-shot learning for humanoid manipulation by training solely on human play* MimicDroid는 인간의 자유로운 상호작용 비디오(human play videos)만을 학습 데이터로 사용하여 휴머노이드 로봇이 In-Context Learning(ICL)을 통해 새로운 조작 작업을 효율적으로 수행하도록 한다.
MimicDroid는 human play videos라는 현실적이고 확장 가능한 데이터 소스를 활용하여 휴머노이드 로봇의 In-Context Learning 기반 조작을 실현한 혁신적인 연구이며, 명확한 방법론, 강력한 실증적 결과, 그리고 공개 벤치마크를 통해 로봇 학습 분야에 실질적인 기여를 한다.
Mobi-$π$: Mobilizing Your Robot Learning Policy
Figure 1: Introducing policy mobilization. (a) Assume a visuomotor policy π trained from one or a set of limited camera
 *Figure 1: Introducing policy mobilization. (a) Assume a visuomotor policy π trained from one or a set of limited camera * 모바일 로봇에서 제한된 관점으로 학습된 조작 정책을 배포할 때 발생하는 분포 외 문제를 해결하기 위해, 정책과 호환되는 로봇 베이스 포즈를 찾는 '정책 모빌라이제이션' 문제를 제시하고 3D Gaussian Splatting과 샘플링 기반 최적화를 통해 해결한다.
본 논문은 모바일 조작 로봇에서 기존 정책의 재사용성을 크게 향상시키는 정책 모빌라이제이션이라는 새로운 문제를 정의하고, 3D Gaussian Splatting과 최적화 기법을 활용한 실용적 해법을 제시했다. 시뮬레이션과 실제 환경에서의 광범위한 검증을 통해 방법론의 유효성을 입증하였으며, 제시된 프레임워크는 향후 모바일 조작 연구의 중요한 기준이 될 것으로 기대된다.
MobileH2R: Learning Generalizable Human to Mobile Robot Handover Exclusively from Scalable and Diverse Synthetic Data
Figure 1. The overview of MobileH2R. We propose a framework for generalizable human-to-mobile-robot handover, including
 *Figure 1. The overview of MobileH2R. We propose a framework for generalizable human-to-mobile-robot handover, including * MobileH2R는 대규모 다양한 합성 데이터만을 사용하여 모바일 로봇이 인간으로부터 물체를 받을 수 있도록 학습하는 프레임워크를 제시한다. 인간의 전신 동작 생성, 안전한 시연 자동 생성, 4D imitation learning을 통합하여 베이스-암 협조 제어가 가능한 일반화된 정책을 학습한다.
MobileH2R는 모바일 로봇의 인간-로봇 handover 문제를 체계적으로 해결하는 포괄적이고 확장 가능한 프레임워크를 제시한다. 합성 데이터의 생성, 안전한 시연 자동 생성, 통합 학습이라는 세 요소를 정교하게 설계하여 +15% 이상의 성능 향상을 달성했으며, 대규모 데이터의 효과를 실증한 점에서 실무적 가치가 높다.
TWIST2: Scalable, Portable, and Holistic Humanoid Data Collection System
Fig. 1: We introduce TWIST2, a holistic humanoid data collection system designed with scalability and portability. TWIST
 *Fig. 1: We introduce TWIST2, a holistic humanoid data collection system designed with scalability and portability. TWIST* TWIST2는 mocap 없이 VR 기반의 포터블한 휴머노이드 텔레오퍼레이션 시스템으로, 전신 제어를 유지하면서 확장 가능한 데이터 수집을 가능하게 한다. 수집한 데이터로 hierarchical visuomotor policy를 학습하여 자율적인 전신 제어를 구현한다.
TWIST2는 휴머노이드 로봇의 대규모 데이터 수집 병목을 실질적으로 해결하는 혁신적인 시스템으로, 포터블성과 전신 제어의 오래된 trade-off를 극복했다. 완전 오픈소스 공개와 실증적 성과(whole-body dexterous manipulation, kick-T task)는 휴머노이드 로봇 학습 커뮤니티에 즉각적인 영향을 미칠 수 있는 중대한 기여다.
Learning Versatile Humanoid Manipulation with Touch Dreaming
Fig. 1: Our system enables versatile, contact-rich, and dexterous humanoid manipulation. A: long-horizon, multi-stage ma
 *Fig. 1: Our system enables versatile, contact-rich, and dexterous humanoid manipulation. A: long-horizon, multi-stage ma* 휴머노이드 로봇의 접촉-풍부한 조작을 위해 VR 텔레오퍼레이션 기반 데이터 수집과 터치 감각을 핵심 모달리티로 하는 Humanoid Transformer with Touch Dreaming (HTD)을 제안한다.
본 논문은 터치를 핵심 모달리티로 하는 Touch Dreaming 기법과 통합된 실세계 데이터 수집 시스템으로 휴머노이드 접촉-풍부한 조작의 실현 가능성을 강력하게 입증한다. 다섯 가지 다양한 실제 작업에서 90.9% 성능 개선을 달성하며, 잠재 공간 예측의 효과성을 명확히 보여주는 높은 질의 연구이다.
MuGen: Multi-Skill Generative Locomotion Controller for Humanoid Robots
Fig. 1: MuGen enables multi-skill humanoid locomotion by learning a generative controller. (a-d): A simulated humanoid t
 *Fig. 2: System overview 1) Motion Skill Embedding: states and reference motions are encoded into continuous representati* MuGen은 VQ-VAE와 model-based reinforcement learning을 결합하여 인간의 모션 데이터로부터 인형형 로봇의 다중 기술 보행 제어기를 학습하는 데이터 기반 프레임워크이다. Teacher-student learning과 새로운 policy distillation 전략을 통해 시뮬레이션에서 학습한 모션을 실제 로봇에 배포할 수 있게 한다.
MuGen은 VQ-VAE, model-based RL, teacher-student learning을 통합하여 인형형 로봇의 다중 기술 보행을 학습하고 배포하는 체계적이고 기술적으로 건전한 접근을 제시한다. 실제 Unitree G1 로봇에서의 검증과 미학습 모션에 대한 강건한 일반화 능력을 보여주었으나, sim-to-real gap의 완전한 해결, 데이터셋 규모/다양성의 상세 분석, 계산 복잡도 평가 등에서 개선이 필요하다. 전반적으로 인형형 로봇 제어 분야에 의미 있는 기여를 한 견실한 연구이다.
Robot Learning from Human Videos: A Survey
 *Figure 2. Taxonomy of robot learning from human videos.* 본 논문은 로봇이 인간 영상 시연으로부터 조작 기술을 습득하는 방법에 대한 포괄적 리뷰로서, task·observation·action 레벨에서의 계층적 전이 경로를 제시하고 데이터 기초를 체계적으로 분석한다. 인간 영상 기반 학습이 기존 로봇 텔레작동에 비해 5-10배 이상의 데이터 효율성을 제공함을 강조한다.
본 survey는 로봇 학습 분야에서 인간 영상 기반 스킬 획득이라는 급성장하는 분야에 대해 처음으로 체계적이고 포괄적인 분류 체계를 제시하며, 다각적인 비교 분석과 대규모 데이터 통계를 바탕으로 현재 연구 경관을 명확히 조망한다. 실제 데이터 효율성 개선(5-10배)이 실증되어 있어 학술적·실무적 중요성이 높으나, 정량적 성능 비교와 새로운 메서드 제시가 없는 순수 리뷰 논문이라는 한계가 있다.
Shape Your Body: Value Gradients for Multi-Embodiment Robot Design
Figure 1: Shape Your Body. We first train an embodiment-aware policy and value function with
 *Figure 1: Shape Your Body. We first train an embodiment-aware policy and value function with* 본 논문은 다중 체형을 학습한 가치함수를 재사용 가능한 설계 모델로 변환하는 방법을 제안한다. 사전 학습된 embodiment-aware value function에서 gradient를 계산하여 새로운 로봇 설계를 최적화함으로써 매번 새로운 RL 학습 루프를 실행할 필요를 제거한다.
본 논문은 다중 체형 가치함수를 재사용 가능한 설계 도구로 변환하는 실용적이고 혁신적인 방법을 제시한다. 대규모 embodiment 공간에서의 효율적 최적화, 강력한 실험 검증, 그리고 설계 분석 기능이 주요 강점이다. 다만 현실 로봇 검증과 극단적 체형 외삽에 대한 분석이 보완된다면 더욱 완성도 있는 작업이 될 것이다.
Humanoid Policy ~ Human Policy
Figure 1: This paper advocates high-quality human data as a data source for cross-embodiment
 *Figure 3: Overview of HAT. Human Action Transformer (HAT) learns a robot policy by modeling* 이 논문은 humanoid 로봇의 조작 정책 학습에 대규모 egocentric human demonstration을 활용하는 cross-embodiment 학습 방법을 제안한다. PH2D 데이터셋과 Human Action Transformer (HAT)를 통해 human과 robot 간의 embodiment gap을 완화하고 데이터 수집 효율을 크게 개선한다.
이 논문은 humanoid robot manipulation 학습을 위해 대규모 human data를 효율적으로 활용하는 실용적이고 창의적인 방안을 제시한다. PH2D 데이터셋의 규모와 품질, HAT의 unified design, 그리고 실로봇 검증이 기여도 있으나, 평가 범위 확장과 다양한 플랫폼으로의 일반화 검증이 필요하다.
Mobi-$π$: Mobilizing Your Robot Learning Policy
Figure 1: Introducing policy mobilization. (a) Assume a visuomotor policy π trained from one or a set of limited camera
 *Figure 1: Introducing policy mobilization. (a) Assume a visuomotor policy π trained from one or a set of limited camera * 본 논문은 제한된 카메라 뷰포인트에서 학습된 visuomotor 조작 정책을 모바일 로봇 플랫폼에서 실행 가능하게 하는 "policy mobilization" 문제를 정의하고, 3D Gaussian Splatting과 sampling-based optimization을 활용하여 최적의 로봇 베이스 포즈를 찾는 방법을 제안한다.
Policy mobilization을 명확히 정의하고 3D Gaussian Splatting 기반의 실질적 해결책을 제시한 우수한 연구이다. 기존 stationary robot 정책의 모바일 로봇 배포 문제를 elegant하게 해결하며, Mobi-π 프레임워크를 통해 체계적 평가가 가능하도록 한 점이 특히 가치있다. 다만 실환경 실험 규모 확대와 더 정교한 method 개발이 추가되면 영향력을 더욱 높일 수 있을 것으로 기대된다.
Expressive Whole-Body Control for Humanoid Robots
Fig. 1: Our Robot demonstrates diverse and expressive whole-body movements in different scenarios. Top Row: The robot is
 *Fig. 2: Overview of our framework. Our framework is able to train on data from various sources such as static human moti* 인간형 로봇이 인간의 모션 캡처 데이터를 학습하여 표현력 있는 전신 움직임을 수행하도록 강화학습 기반의 제어 정책을 제안하며, 상체는 참조 모션을 모방하되 하체는 속도 명령만 따르도록 제약을 완화하여 실제 로봇에서의 동작을 가능하게 함.
본 논문은 인간 모션 캡처 데이터를 실제 인간형 로봇에 효과적으로 적용하는 창의적인 문제 분해 방식과 차등적 제약 설계로, 학습 기반 인간형 로봇 제어 분야에서 처음으로 다양한 표현력 있는 동작을 실현함. 명확한 동기, 실제 로봇 검증, 그리고 우수한 성과에도 불구하고 기술적 신규성이 개별 컴포넌트 수준에서는 제한적이며, 하체 표현력과 다양한 작업 확장에 대한 연구가 필요함.
Realistic Lip Motion Generation Based on 3D Dynamic Viseme and Coarticulation Modeling for Human-Robot Interaction
Fig. 1.
 *Fig. 1.* 인간-로봇 상호작용을 위해 3D 동적 비셈(viseme)과 공명음현상(coarticulation) 모델링 기반의 입술 운동 생성 프레임워크를 제안하며, 고차원 공간 입술 운동을 14-DOF 로봇 입술 구동 시스템으로 변환한다.
본 연구는 3D 동적 비셈과 중국어 언어학적 특성을 결합하여 입술 동기화의 근본적 한계를 해결한 학제적 기여로, 경량하고 실용적인 로봇 배포 프레임워크를 통해 인간-로봇 상호작용의 자연성을 크게 향상시킨다.
RL from Physical Feedback: Aligning Large Motion Models with Humanoid Control
 *Figure 2: Overview of RLPF, which consists of three key components: i) Motion Tracking Policy* 본 논문은 텍스트 기반 인간 동작을 실제 휴머노이드 로봇에 실행 가능한 형태로 변환하는 문제를 해결하기 위해, 물리 시뮬레이터에서의 피드백을 기반으로 대규모 모션 생성 모델을 강화학습으로 미세조정하는 RLPF 프레임워크를 제안한다.
본 논문은 text-to-motion 생성 모델과 로봇 제어 간의 오랜 간극을 물리적 피드백 기반 RL로 체계적으로 해결하는 창의적 접근을 제시하며, 실제 로봇 배포 성공을 통해 실용적 가치를 입증했다. 다만 계산 효율성과 평가 범위 확대에 대한 추가 연구가 필요하다.
Semantic Co-Speech Gesture Synthesis and Real-Time Control for Humanoid Robots
Figure 1: System Overview: Training and Inference Pipeline.
 *Figure 1: System Overview: Training and Inference Pipeline.* 이 연구는 음성 입력으로부터 의미론적으로 적절한 제스처를 생성하고 실시간으로 휴머노이드 로봇에 배포하는 end-to-end 프레임워크를 제시한다. LLM과 Motion-GPT를 활용한 제스처 생성과 imitation learning 기반의 MotionTracker 제어 정책을 통합하여 의미 있는 비언어적 소통을 실현한다.
이 논문은 음성 기반 의미론적 제스처 생성과 실시간 로봇 배포를 통합한 의미 있는 연구로, LLM, Motion-GPT, imitation learning을 창의적으로 결합하여 완전한 end-to-end 파이프라인을 실현했다. 다만 평가의 정량성 강화와 다양한 환경에서의 robustness 검증이 필요하다.
SignBot: Learning Human-to-Humanoid Sign Language Interaction
 *Fig. 2: Overview of SignBot: The framework consists of three stages: (1) Motion Retargeting aligns human sign language* SignBot은 수화 언어를 인식하고 생성할 수 있는 인간형 로봇을 위한 프레임워크로, motion retargeting, policy training, 그리고 generative interaction을 통합하여 청각장애인과의 자연스러운 상호작용을 실현한다.
SignBot은 embodied humanoid robot에서 처음으로 자동화된 sign language interaction을 구현한 혁신적 연구로, 청각장애인 커뮤니티의 의사소통 접근성 향상에 실질적 기여를 한다. 다만 hand retargeting 기술의 상세 설명과 더 광범위한 실세계 평가가 보완되면 영향력이 더욱 증대될 것으로 예상된다.
TextOp: Real-time Interactive Text-Driven Humanoid Robot Motion Generation and Control
 *Fig. 2: Overview of TextOp’s framework. The framework consists of three main parts: (a) Interactive Motion Generation,* TextOp는 streaming 자연어 명령으로 인간형 로봇의 운동을 실시간으로 생성하고 제어하는 프레임워크로, 고수준의 autoregressive motion diffusion 모델과 저수준의 motion tracking policy를 결합하여 실행 중 동적으로 명령 수정을 지원한다.
TextOp는 실시간 interactive motion generation과 robust physical control을 성공적으로 통합하여 자연어 기반 humanoid 제어의 새로운 paradigm을 제시한 뛰어난 연구이며, 실제 로봇 실험을 통해 실현 가능성을 검증했다. 다만 플랫폼 특화성과 데이터셋 의존성을 개선한다면 더욱 광범위한 영향을 미칠 수 있을 것으로 예상된다.
Commanding Humanoid by Free-form Language: A Large Language Action Model with Unified Motion Vocabulary
Figure 1. An illustration of Humanoid-LLA. Given a high-level
 *Figure 1. An illustration of Humanoid-LLA. Given a high-level* 자유형식 자연언어 명령을 인간형 로봇의 신체 전체 제어로 매핑하는 Large Language Action Model(Humanoid-LLA)을 제안하며, 통합 모션 어휘, 어휘-지향 컨트롤러 증류, 강화학습 기반 파인튜닝을 통해 언어 일반화와 물리적 타당성을 동시에 달성한다.
Humanoid-LLA는 통합 모션 어휘, 어휘-지향 증류, 강화학습 파인튜닝을 통합하여 자유형식 언어에서 물리적으로 실행 가능한 인간형 로봇 제어로의 매핑을 최초로 달성한 중요한 기여이며, 실세계 검증과 명확한 기술 혁신으로 인간-로봇 상호작용 분야의 중대한 진전을 나타낸다.
ECHO: Edge-Cloud Humanoid Orchestration for Language-to-Motion Control
Fig. 1.
 *Fig. 1.* ECHO는 자연어 명령으로 휴머노이드 로봇을 제어하는 엣지-클라우드 프레임워크로, 클라우드의 diffusion 기반 text-to-motion 생성기와 엣지의 RL 트래커를 로봇 네이티브 38차원 표현으로 연결하여 실시간 폐루프 실행을 실현한다.
ECHO는 생성과 실행의 명확한 분리, robot-native 표현 설계, 실세계 배포 달성을 통해 언어-기반 휴머노이드 제어 분야에서 modularity와 deployability의 새로운 기준을 제시하는 의미 있는 연구이다.
EMOTION: Expressive Motion Sequence Generation for Humanoid Robots with In-Context Learning
Fig. 1. Overview of the EMOTION framework.
 *Fig. 1. Overview of the EMOTION framework.* EMOTION은 대규모 언어 모델(LLM)의 문맥 학습 능력을 활용하여 인간형 로봇이 표정, 제스처, 신체 움직임 등 자연스러운 비언어적 의사소통을 수행할 수 있도록 하는 프레임워크이다. 온라인 사용자 연구를 통해 생성된 모션이 인간 수행자와 동등하거나 우수함을 입증했다.
EMOTION은 LLM의 in-context learning을 창의적으로 활용하여 인간형 로봇의 표현적 모션 생성을 자동화한 실질적 솔루션을 제시한다. 사용자 연구를 통한 검증과 인간 피드백 통합 방식은 실용성을 높이나, 다양한 제스처에 대한 성능 편차와 실제 상호작용 환경 테스트의 필요성이 향후 과제로 남아 있다.
Endowing GPT-4 with a Humanoid Body: Building the Bridge Between Off-the-Shelf VLMs and the Physical World
Figure 1: BiBo is a humanoid agent powered by an off-the-shelf VLM. It consists of an embodied
 *Figure 1: BiBo is a humanoid agent powered by an off-the-shelf VLM. It consists of an embodied* off-the-shelf VLM(GPT-4)을 humanoid agent의 제어에 활용하기 위해 embodied instruction compiler와 diffusion-based motion executor로 구성된 BiBo 프레임워크를 제안하고, 이를 통해 대규모 데이터 수집 없이 개방형 환경에서의 유연한 상호작용을 가능하게 함.
본 논문은 off-the-shelf VLM과 humanoid control을 연결하는 창의적인 프레임워크를 제시하고, structured representation과 LDM의 novel application을 통해 기술적 기여를 하였으며, 실제 데이터 수집의 병목을 해소하려는 실질적 의의가 있음. 다만 실제 물리 환경에서의 검증과 robustness 분석이 보강된다면 더욱 강력한 작업이 될 것으로 예상됨.
From Language to Locomotion: Retargeting-free Humanoid Control via Motion Latent Guidance
Figure 1:
 *Figure 2: Overview of RoboGhost. We propose a two-stage approach: a motion latent is first generated, then a* RoboGhost는 언어 지시를 humanoid 로봇의 실행 가능한 동작으로 직접 변환하는 retargeting-free 프레임워크로, motion latent을 조건으로 하는 diffusion-based policy를 통해 기존의 다단계 파이프라인의 누적 오류와 지연을 제거한다.
RoboGhost는 language-guided humanoid 제어의 근본적인 파이프라인 재설계를 통해 기존의 다단계 접근의 한계를 효과적으로 해결하며, 실제 로봇 배포에서 우수한 성능을 입증한 매우 영향력 있는 연구이다. 다만 해석성 강화와 복잡한 task로의 확장이 후속 과제로 남아있다.
From Motion to Behavior: Hierarchical Modeling of Humanoid Generative Behavior Control
Figure 1. From motion to behavior. (a) Simple periodic motion patterns without complex, behavioral semantic meaning, (b)
 *Figure 1. From motion to behavior. (a) Simple periodic motion patterns without complex, behavioral semantic meaning, (b)* 인간의 고수준 의도를 반영하는 계층적 행동 계획과 LLM을 결합하여 장기간의 물리적으로 타당한 인간 행동을 생성하는 통합 프레임워크 PHYLOMAN을 제시하고, 이를 위해 다층 텍스트 주석이 포함된 GBC-100K 대규모 데이터셋을 구축했다.
본 논문은 인간 행동 생성에 LLM 기반 계획과 물리적 제어를 혁신적으로 통합하고 대규모 주석 데이터셋을 제공함으로써 장기간 의도 지향적 행동 생성의 새로운 기준을 제시한다. 기술적 우수성, 실무적 가치, 그리고 체계적인 실험 검증으로 인해 컴퓨터 비전 및 로봇공학 커뮤니티에 상당한 영향을 미칠 것으로 예상된다.
FRoM-W1: Towards General Humanoid Whole-Body Control with Language Instructions
Figure 1 | (a) We introduce FRoM-W1, an open-source framework that leverages Chain-of-Thought
 *Figure 2 | The inference pipeline of FRoM-W1. (a) H-GPT first translates language instructions* FRoM-W1은 자연어 지시문으로부터 휴머노이드 로봇의 전신 움직임을 제어하는 오픈소스 프레임워크로, H-GPT 모델과 H-ACT 모듈의 2단계 구조로 언어 이해와 안정적인 로봇 실행을 동시에 달성한다.
FRoM-W1은 자연어 기반 휴머노이드 전신 제어라는 중요한 문제를 Chain-of-Thought와 2단계 RL 전략으로 창의적으로 해결하며, 완전 오픈소스 제공과 실제 로봇 실증을 통해 높은 실용성과 재현성을 보여준다.
Harmon: Whole-Body Motion Generation of Humanoid Robots from Language Descriptions
 *Fig. 2 depicts our proposed method, HARMON. Firstly, we generate human motion based on the* 인간 모션 데이터셋으로부터 사전학습된 프라이어를 활용하고 Vision Language Model을 통해 손가락과 머리 모션을 생성·편집하여 휴머노이드 로봇의 자연스러운 전신 모션을 언어 설명으로부터 생성한다.
이 논문은 인간 모션 프라이어와 VLM의 상식적 추론을 창의적으로 결합하여 언어로부터 자연스러운 휴머노이드 모션을 생성하는 실용적인 방법을 제시하며, 실제 로봇 실험과 높은 사용자 평가로 그 유효성을 입증했다.
Hierarchical Intention-Aware Expressive Motion Generation for Humanoid Robots
Fig. 1: Overall framework of the proposed work. (a) The high-level system architecture. Multimodal inputs XI = (Vin, Lin
 *Fig. 1: Overall framework of the proposed work. (a) The high-level system architecture. Multimodal inputs XI = (Vin, Lin* 본 논문은 Vision Language Model의 의도 추론과 diffusion 기반 동작 생성을 결합한 계층적 프레임워크 HIAER을 제안하여, 인간의 사회적 의도와 감정 맥락을 파악하고 실시간으로 표현적인 로봇 동작을 생성한다.
본 논문은 VLM의 고수준 사회적 추론과 diffusion 기반 동작 생성을 의도적으로 결합하여 인간-로봇 상호작용의 폐쇄 루프를 완성한 점에서 높은 가치를 지니며, 물리 로봇 실증을 통해 실현 가능성을 보여준다.
iCub3 Avatar System: Enabling Remote Fully-Immersive Embodiment of Humanoid Robots
원격 위치에서 휴머노이드 로봇 iCub3을 구현화(embodiment)하는 완전한 아바타 시스템을 제시하며, 수백 km 떨어진 위치에서의 이동, 조작, 음성, 표정 제어와 시각, 청각, 촉각, 무게감 피드백을 통합한다.
본 논문은 휴머노이드 아바타의 완전한 신체 제어와 다중 감각 피드백을 통합하여 원격 현존감을 실현한 획기적인 시스템을 제시하며, 실제 환경에서의 대규모 검증을 통해 그 실용성을 입증했다. 네트워크 지연 처리와 embodiment 평가의 정량화 측면에서 개선의 여지가 있으나, 전체적으로 로보틱스와 텔레현존 분야에 중요한 기여를 한다.
Implicit Kinodynamic Motion Retargeting for Human-to-humanoid Imitation Learning
 *Fig. 2: Overall pipeline for our proposed framework. We model motion retargeting as a sequence-to-sequence mapping from * 본 논문은 인간의 모션을 휴머노이드 로봇이 실행 가능한 모션으로 변환하는 Implicit Kinodynamic Motion Retargeting (IKMR) 프레임워크를 제안하며, 기존 frame-by-frame 방식의 비효율성을 극복하고 대규모 모션을 실시간으로 처리한다.
본 논문은 motion retargeting에 implicit neural network을 처음 도입하여 scalability 문제를 혁신적으로 해결하고, kinematics과 dynamics를 체계적으로 통합함으로써 physically feasible한 대규모 모션 자동 변환을 실현한 의미 있는 기여이며, 실제 휴머노이드 로봇 배포 검증으로 실용성을 입증했다.
LangWBC: Language-directed Humanoid Whole-Body Control via End-to-end Learning
Fig. 1:
 *Fig. 2.* 자연언어 명령을 humanoid robot의 전신 제어 동작으로 직접 변환하는 end-to-end 학습 프레임워크를 제시한다. Reinforcement learning으로 학습한 teacher policy와 CVAE 기반 student policy를 결합하여 언어-행동의 통합 latent space를 구성한다.
본 논문은 humanoid 전신 제어의 오랜 난제인 언어-행동 갭을 end-to-end learning으로 직접 해결하며, CVAE 기반의 unified latent space 구성으로 동작 다양성과 부드러운 전환을 동시에 달성한 점이 우수하다. 실제 로봇 검증과 강건성 입증을 통해 현실 적용 가능성을 보였으나, 데이터셋 의존성과 다양한 플랫폼 일반화에 대한 추가 검증이 필요하다.
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Figure 1: Data Pyramid for Robot Foundation Model
 *Figure 1: Data Pyramid for Robot Foundation Model* GR00T N1은 Vision-Language-Action (VLA) 모델로, dual-system 아키텍처를 통해 다양한 휴머노이드 로봇을 제어할 수 있는 오픈 소스 기초 모델이다. 웹 데이터, 인간 비디오, 합성 데이터, 실제 로봇 궤적을 계층적으로 조합하여 학습한다.
GR00T N1은 휴머노이드 로봇 기초 모델 개발에서 중요한 진전을 이루었으며, data pyramid 전략과 dual-system 아키텍처의 혁신적 설계가 돋보인다. 오픈소스 공개와 실제 로봇 검증을 통해 로봇 학습 커뮤니티에 실질적 기여를 할 것으로 기대된다.
Quantum deep reinforcement learning for humanoid robot navigation task
 *Fig. 4. Return of Classical SAC versus Quantum SAC in the Walker2d-v4* 이 논문은 Soft Actor-Critic(SAC) 알고리즘을 parameterized quantum circuit으로 구현한 quantum deep reinforcement learning(QDRL)을 humanoid robot navigation 작업에 적용하여, 고차원 상태-행동 공간에서 고전적 RL보다 92% 더 적은 스텝으로 8% 높은 성능을 달성했다.
이 논문은 humanoid robot navigation이라는 도전적 고차원 문제에 QDRL을 처음 적용한 의미 있는 연구로, 양자 컴퓨팅의 실용적 잠재력을 보여주지만, 시뮬레이션 환경 제한과 실제 양자 하드웨어 부재로 인해 근본적인 양자 이점의 증명은 아직 불완전하다.
ZeroWBC: Learning Natural Visuomotor Humanoid Control Directly from Human Egocentric Video
Fig. 1: Overview of the ZeroWBC framework. We propose a novel framework that learns natural humanoid visuomotor control
 *Fig. 1: Overview of the ZeroWBC framework. We propose a novel framework that learns natural humanoid visuomotor control* ZeroWBC는 인간의 일인칭 비디오와 모션 캡처 데이터로부터 휴머노이드 로봇의 전신 제어 정책을 직접 학습하는 프레임워크로, 로봇 원격조종 데이터 수집 없이 자연스러운 장면 상호작용을 가능하게 한다.
ZeroWBC는 휴머노이드 로봇의 원격조종 데이터 수집 문제를 근본적으로 해결하며, 인간 영상 데이터로부터 자연스럽고 다양한 전신 제어를 구현하는 혁신적인 프레임워크이다. 강력한 실험 검증과 실제 로봇 성공사례는 제시되어 있으나, 추가 플랫폼 일반화와 동적 환경 적응성에 대한 평가가 향후 필요하다.
Behavior Foundation Model for Humanoid Robots
Fig. 1: Behavior Foundation Model enables humanoid robots to perform a variety of behaviors in a zero-shot manner,
 *Fig. 2: Overview of BFM Implementation. (a) Human motion dataset is retargeted to humanoid robots for proxy agent* 본 논문은 휴머노이드 로봇의 다양한 제어 태스크에 일반화 가능한 행동 기반 파운데이션 모델(BFM)을 제안하며, masked online distillation과 CVAE를 결합하여 대규모 행동 데이터셋으로 사전학습한다.
본 논문은 휴머노이드 로봇 제어의 통합 행동 학습 패러다임을 명확히 제시하고 masked online distillation과 CVAE를 통한 실제적 구현으로 다양한 제어 모드 지원과 빠른 신행동 습득을 실현했으며, 시뮬레이션과 실제 플랫폼 양쪽에서 광범위하게 검증하여 범용 휴머노이드 제어의 새로운 방향을 제시한다.
HoRD: Robust Humanoid Control via History-Conditioned Reinforcement Learning and Online Distillation
Figure 1. Framework overview. Two-stage teacher–student learning pipeline for robust humanoid control under partial obse
 *Figure 1. Framework overview. Two-stage teacher–student learning pipeline for robust humanoid control under partial obse* HoRD는 history-conditioned reinforcement learning과 online distillation을 결합한 두 단계 학습 프레임워크로, 휴머노이드 로봇이 도메인 시프트 상황에서 강건한 제어를 수행하도록 한다.
HoRD는 history-conditioned 동역학 추론과 sparse 명령 처리라는 두 가지 핵심 혁신을 통해 휴머노이드 제어의 강건성과 일반화 문제를 효과적으로 해결하며, 광범위한 실험 검증과 데이터셋 공개로 실용적 가치를 입증한다.
Learning Vision-Driven Reactive Soccer Skills for Humanoid Robots
Figure 1 System overview. The real-world robot is equipped with an onboard camera for visual perception. Image
 *Figure 1 System overview. The real-world robot is equipped with an onboard camera for visual perception. Image* 본 논문은 시각 인식과 모션 제어를 직접 통합한 통합 강화학습 기반 컨트롤러를 통해 인형 로봇이 반응형 축구 기술을 습득할 수 있도록 하는 방법을 제시한다. Adversarial Motion Priors를 시각 기반 동적 제어 환경으로 확장하여 실제 RoboCup 경기에서 강력한 반응성을 보여준다.
본 논문은 Adversarial Motion Priors를 시각 기반 동적 제어로 성공적으로 확장하여, 강화학습 기반 인형 로봇이 실세계 축구 환경에서 반응형 행동을 자동으로 습득할 수 있음을 처음으로 입증했다. RoboCup 2025 우승이라는 실제 경쟁 성과는 제시된 방법론의 실용성과 견고성을 강력하게 검증한다.
LeVERB: Humanoid Whole-Body Control with Latent Vision-Language Instruction
Figure 1: Overview of our contributions. Top: we create a photorealistic and dynamically accurate
 *Figure 1: Overview of our contributions. Top: we create a photorealistic and dynamically accurate* LeVERB는 humanoid 로봇의 전신 제어를 위해 vision-language 입력을 latent action 공간으로 인코딩하는 계층적 프레임워크를 제안하며, 150개 이상의 task로 구성된 첫 번째 sim-to-real 준비 벤치마크를 제시한다.
LeVERB는 humanoid WBC를 위한 vision-language 제어에서 중요한 진전을 이루었으며, 첫 latent instruction-following framework와 comprehensive sim-to-real 벤치마크를 제시하여 이 분야의 기초를 다졌다. 다만 실제 배포 성능의 추가 개선과 더 광범위한 task 평가를 통한 검증이 필요하다.
Natural Humanoid Robot Locomotion with Generative Motion Prior
본 논문은 Generative Motion Prior (GMP)를 활용하여 인간의 자연스러운 보행 데이터로부터 휴머노이드 로봇의 자연스러운 보행을 학습하는 방법을 제안한다. 기존의 adversarial motion prior 대신 frozen generative model을 사용하여 fine-grained motion-level 감독을 제공함으로써 학습 안정성과 해석 가능성을 향상시킨다.
본 논문은 generative motion prior를 활용한 혁신적 접근으로 humanoid robot의 자연스러운 보행 학습 문제를 효과적으로 해결하며, adversarial training의 불안정성을 제거하고 fine-grained guidance를 제공함으로써 motion naturalness에서 SOTA 성능을 달성한다. 다만 real-world 실험 확대와 다양한 환경에서의 일반화 능력 검증이 필요하다.
Towards Adaptable Humanoid Control via Adaptive Motion Tracking
Fig. 1: Overview. Our method, AdaMimic (adaptive motion tracking), achieves agile humanoid whole-body adaptation from on
 *Fig. 2: Method overview. (a) Human motions are reconstructed into SMPL motions via GVHMR [21] and retargeted to the huma* AdaMimic은 단일 참조 동작으로부터 휴머노이드 로봇의 적응형 제어를 가능하게 하는 동작 추적 알고리즘으로, 키프레임 기반 데이터 증강과 단계적 어댑터 학습을 통해 정확한 모방과 광범위한 적응성을 동시에 달성한다.
AdaMimic은 단일 참조 동작으로부터 고정밀 모방과 광범위 적응성을 동시에 달성하는 혁신적 접근으로, 두 단계 학습과 이중 어댑터 구조의 새로운 설계가 의미 있으며, 실제 로봇에서의 광범위한 검증이 제시되어 실용성이 높다.
Towards Bridging the Gap between Large-Scale Pretraining and Efficient Finetuning for Humanoid Control
Figure 1: Large-scale pretraIning and efficient FineTuning (LIFT) Framework. In stage (i), we
 *Figure 1: Large-scale pretraIning and efficient FineTuning (LIFT) Framework. In stage (i), we* 대규모 병렬 시뮬레이션에서 SAC 기반 정책 사전학습과 물리-정보 기반 세계 모델을 활용한 효율적 미세조정을 결합하여 휴머노이드 로봇의 시뮬-투-리얼 전이와 안전한 적응을 실현한다.
본 논문은 대규모 시뮬레이션 효율성과 샘플-효율적 적응을 효과적으로 결합하고, 안전성을 강조한 미세조정 전략으로 휴머노이드 제어의 실질적 도전을 해결한다. 실로봇 검증과 공개 코드는 로보틱스 커뮤니티에 즉시 활용 가능한 기초를 제공한다.
UniAct: Unified Motion Generation and Action Streaming for Humanoid Robots
Figure 1. UniAct, a unified framework for multimodal motion generation and action streaming. UniAct enables humanoid rob
 *Figure 1. UniAct, a unified framework for multimodal motion generation and action streaming. UniAct enables humanoid rob* UniAct는 MLLM과 causal streaming pipeline을 결합한 두 단계 프레임워크로, 인간형 로봇이 언어, 음악, 궤적 등 다양한 multimodal 명령을 sub-500ms 지연시간으로 실행할 수 있게 한다.
UniAct는 MLLM과 robust tracking을 unified framework로 통합하여 실제 humanoid robot에서 multimodal instruction following을 low latency로 달성한 의미 있는 연구이며, UA-Net 데이터셋 기여와 함께 embodied AI 분야에서 중요한 진전을 나타낸다.
PhysHSI: Towards a Real-World Generalizable and Natural Humanoid-Scene Interaction System
Fig. 1: Our system PhysHSI enables humanoid robots to perform diverse real-world interactions indoors and outdoors with
 *Fig. 2: Overview of PhysHSI. (a) Dataset Preparation: Human motions from a MoCap dataset are retargeted to humanoid moti* PhysHSI는 humanoid 로봇이 실제 환경에서 물체 운반, 앉기, 누우기 등 다양한 상호작용을 자연스럽고 일반화 가능하게 수행할 수 있도록 하는 통합 시스템으로, simulation 기반 AMP 정책 학습과 실시간 LiDAR-camera 기반 객체 인식 모듈을 결합한다.
PhysHSI는 AMP 기반 motion learning과 hybrid sensor fusion을 통합하여 humanoid의 실세계 scene interaction을 처음 실현한 high-impact system으로, 자연스러운 동작과 robust generalization을 동시에 달성했으나, annotation 자동화와 marker-free perception 확대가 실용 배포의 과제이다.
SafeFlow: Real-Time Text-Driven Humanoid Whole-Body Control via Physics-Guided Rectified Flow and Selective Safety Gating
 *Fig. 2.* SafeFlow는 physics-guided rectified flow matching과 3단계 안전 게이팅을 결합하여 텍스트 명령 기반 휴머노이드 전신 제어에서 물리적으로 실현 불가능한 동작 생성 문제를 해결한다.
SafeFlow는 physics-guided generation과 hierarchical safety gating을 효과적으로 결합하여 텍스트 기반 휴머노이드 제어의 안전성과 실행 가능성을 동시에 달성한 실질적으로 중요한 연구이며, Unitree G1에서의 광범위한 실험 검증으로 실제 로봇 배포의 가능성을 보여준다.
SENTINEL: A Fully End-to-End Language-Action Model for Humanoid Whole Body Control
Figure 1: Overview of SENTINEL. Our framework consists of three stages. (1) We construct a language-
 *Figure 1: Overview of SENTINEL. Our framework consists of three stages. (1) We construct a language-* SENTINEL은 언어 명령을 휴머노이드 로봇의 저수준 제어 신호로 직접 변환하는 완전 end-to-end 언어-행동 모델로, flow matching을 통해 행동 청크를 생성하고 실제 배포를 위해 잔여 강화학습으로 정제한다.
SENTINEL은 언어-조건부 휴머노이드 제어를 위한 완전 end-to-end 접근의 첫 사례로, 중간 표현을 제거하고 flow matching과 residual RL을 결합한 창의적인 방법론을 제시한다. 시뮬레이션과 실제 로봇 모두에서의 성공적인 배포는 본 접근의 타당성을 입증하며, 향후 구체화 AI 발전에 중요한 기초를 마련한다.
SONIC: Supersizing Motion Tracking for Natural Humanoid Whole-Body Control
Figure 1: SONIC enables diverse humanoid tasks through a universal control policy that handles diverse input
 *Figure 1: SONIC enables diverse humanoid tasks through a universal control policy that handles diverse input* 인간의 모션 캡처 데이터를 활용한 motion tracking을 기반 작업으로 삼아 42M 파라미터의 대규모 humanoid controller를 학습하고, kinematic planner와 unified token space를 통해 다양한 제어 인터페이스를 지원하는 자연스러운 전신 움직임 제어 시스템을 제시한다.
이 논문은 humanoid control에 대규모 스케일링을 성공적으로 적용한 첫 사례로, motion tracking을 foundation task로 선정하고 100M 프레임 데이터와 42M 파라미터로 학습하여 강력한 generalization을 보인다. Kinematic planner와 unified token space를 통해 다양한 제어 인터페이스를 단일 정책으로 통합함으로써 실제 응용 가능성을 입증했으며, 체계적인 ablation과 comprehensive evaluation은 연구의 엄밀성을 보강한다.
Unveiling the Impact of Data and Model Scaling on High-Level Control for Humanoid Robots
Fig. 1. We present the large-scale, high-quality robot motion dataset
 *Fig. 1. We present the large-scale, high-quality robot motion dataset* 대규모 인간 모션 데이터를 활용하여 자동 파이프라인으로 생성한 Humanoid-Union 데이터셋(260시간)과 이를 기반으로 하는 SCHUR 프레임워크를 제안하여 텍스트 기반 휴머노이드 로봇 모션 생성의 확장성을 달성했다.
본 논문은 대규모 자동화 파이프라인으로 고품질 로봇 모션 데이터셋을 구축하고, FSQ VAE 및 LLaMA 기반 SCHUR 프레임워크로 효과적인 data/model scaling을 달성하여 휴머노이드 로봇의 텍스트 기반 고수준 제어의 실질적 발전을 보여준다.
Advancing Humanoid Locomotion: Mastering Challenging Terrains with Denoising World Model Learning
Fig. 1: Extensive showcase of locomotion skills using the proposed framework. Displayed is a sequence illustrating a hum
 *Fig. 1: Extensive showcase of locomotion skills using the proposed framework. Displayed is a sequence illustrating a hum* Denoising World Model Learning (DWL)이라는 end-to-end 강화학습 프레임워크를 통해 휴머노이드 로봇이 눈덮인 언덕, 계단, 불규칙한 지형 등 현실의 복잡한 지형을 처음으로 마스터했으며, zero-shot sim-to-real transfer로 같은 신경망을 모든 시나리오에서 구동한다.
DWL은 휴머노이드 로봇의 현실 복잡 지형 보행 문제를 처음으로 해결한 혁신적 연구이며, noisy observation으로부터 true state를 복원하는 encoder-decoder 기반 denoising 접근과 2-DoF ankle mechanism의 하드웨어 혁신이 결합되어 높은 영향력을 기대할 수 있다.
CReF: Cross-modal and Recurrent Fusion for Depth-conditioned Humanoid Locomotion
Fig. 1.
 *Fig. 2.* CReF는 cross-modal attention과 gated residual fusion을 활용하여 raw depth 입력으로부터 직접 locomotion-relevant 특징을 학습하는 단일 단계 depth-conditioned humanoid locomotion 프레임워크로, 명시적 기하학적 중간 표현 없이 zero-shot sim-to-real transfer를 달성한다.
CReF는 명시적 기하학적 중간 표현을 제거하고 cross-modal attention과 gated recurrent fusion을 통해 raw depth로부터 직접 locomotion-relevant features를 학습하는 혁신적 접근법으로, zero-shot sim-to-real transfer와 다양한 실제 환경에서의 강건한 성능을 통해 humanoid locomotion 분야에 significant contribution을 제시한다.
EmbodMocap: In-the-Wild 4D Human-Scene Reconstruction for Embodied Agents
Figure 1. Introducing EmbodMocap, a portable and low-cost system for simultaneous 4D human and scene reconstruction, dep
 *Figure 1. Introducing EmbodMocap, a portable and low-cost system for simultaneous 4D human and scene reconstruction, dep* EmbodMocap은 두 개의 이동하는 iPhone을 사용하여 실외 환경에서 메트릭 스케일의 인간 동작과 3D 장면을 동시에 재구성하는 저비용 데이터 수집 파이프라인을 제안한다. 이 시스템은 모노큘러 재구성, 물리 기반 캐릭터 애니메이션, 로봇 제어 등 세 가지 embodied AI 작업을 지원한다.
EmbodMocap은 embodied AI 연구의 실질적 장애물인 고비용 데이터 수집을 혁신적으로 해결하는 실용적이고 확장 가능한 시스템을 제시한다. Dual-view RGB-D의 joint optimization이라는 기술적 통찰력과 함께 monocular reconstruction, physics-based animation, robot control까지 포괄적으로 검증한 점에서 높은 가치를 지닌다.
FARM: Frame-Accelerated Augmentation and Residual Mixture-of-Experts for Physics-Based High-Dynamic Humanoid Control
Figure 1: Comparison between FARM and the baseline FC on two high-dynamic motions. FARM accurately completes both
 *Figure 2: Overview of the FARM pipeline. Failure cases are* FARM은 frame-accelerated augmentation과 residual mixture-of-experts를 결합하여 저역학(low-dynamic) 동작에서의 높은 정확도를 유지하면서 고역학(high-dynamic) 인간형 동작 제어 성능을 크게 향상시키는 프레임워크이다.
FARM은 간단하면서도 효과적인 frame-accelerated augmentation과 동적 용량 할당 메커니즘으로 범용 인간형 제어의 실질적 한계를 해결하며, 첫번째 공개 고역학 벤치마크 제시와 함께 물리 기반 인간형 제어 분야에 중요한 기여를 한다.
From Experts to a Generalist: Toward General Whole-Body Control for Humanoid Robots
 *Figure 2: Overview of the BumbleBee framework. The left section illustrates the data curation stage, which* BumbleBee는 motion clustering과 sim-to-real adaptation을 결합하여 humanoid robot의 일반적인 whole-body control을 달성하는 expert-generalist 학습 프레임워크이다. 여러 motion cluster에서 전문가 정책을 훈련한 후 이를 통합 generalist controller로 distill한다.
BumbleBee는 motion clustering과 expert-generalist distillation을 통해 humanoid robot의 일반적인 whole-body control 문제를 효과적으로 해결하며, sim-to-real adaptation과 결합하여 실제 세계에서 agile하고 robust한 control을 달성한 우수한 연구이다. 기술적 창의성과 실험적 검증이 뛰어나고 robotics 분야에 의미 있는 기여를 한다.
Generative World Modelling for Humanoids: 1X World Model Challenge Technical Report
Figure 1. Overview of the 1X World Model Challenges Left de-
 *Figure 1. Overview of the 1X World Model Challenges Left de-* 1X World Model Challenge에서 humanoid 로봇의 미래 상태 예측을 위해 Wan 2.2 TI2V-5B를 video-state-conditioned 프레임 예측으로 적응시키고, Spatio-Temporal Transformer를 압축 트랙용으로 훈련하여 두 트랙 모두에서 1위를 달성했다.
본 논문은 대규모 foundation model을 robot state 조건화로 효과적으로 적응시키고, pixel space와 discrete latent space에서 모두 최고 성능을 달성함으로써 실제 humanoid 로봇 world modeling의 새로운 벤치마크를 제시했다. 방법론의 명확한 설명과 포괄적인 ablation study는 향후 world model 연구에 큰 기여가 될 것으로 예상된다.
GMT: General Motion Tracking for Humanoid Whole-Body Control
Figure 1: We deploy the general unified motion tracking policy on a medium-sized humanoid robot.
 *Figure 3: An overview of GMT. Here gt denotes the motion target frame, ot denotes proprioceptive* GMT는 humanoid 로봇이 다양한 전신 모션을 추적할 수 있도록 하는 통합 정책을 학습하는 프레임워크로, Adaptive Sampling 전략과 Motion Mixture-of-Experts 아키텍처를 핵심 요소로 제안한다.
GMT는 humanoid 로봇의 general motion tracking에 대한 실질적인 해결책을 제시하며, Adaptive Sampling과 Motion MoE라는 두 가지 실용적 기법으로 기존의 산발적 접근들을 통합한 우수한 연구이다. 실제 로봇 배포 성공과 상태-최첨단 성능은 높은 가치를 제시하지만, 더 광범위한 하드웨어 검증과 이론적 분석 강화가 필요하다.
Guided Motion Diffusion for Controllable Human Motion Synthesis
Figure 1. Our proposed Guided Motion Diffusion (GMD) can generate high-quality and diverse motions given a text prompt a
 *Figure 2. We tackle the problem of spatially conditioned motion* Guided Motion Diffusion (GMD)는 자연어 설명과 공간적 제약(궤적, 키프레임, 장애물 회피)을 동시에 고려하여 인간의 모션을 합성하는 diffusion model 기반 방법을 제안한다.
GMD는 모션 생성의 중요한 미충족 요구(공간적 제약 통합)를 새로운 관점에서 해결하며, emphasis projection과 dense signal propagation이라는 두 가지 우아하고 일반적인 기법으로 강력한 성과를 달성한 고품질의 논문이다.
HuBE: Cross-Embodiment Human-like Behavior Execution for Humanoid Robots
Fig. 1.
 *Fig. 1.* HuBE는 인간 행동의 유사성(similarity)과 적절성(appropriateness)을 모두 만족하는 이족 로봇용 양단계 폐루프 프레임워크를 제안하며, 뼈 스케일링 기반 데이터 증강을 통해 이기종 로봇 간 교차-구현체(cross-embodiment) 적응을 실현한다.
HuBE는 인간형 로봇 행동 생성에 행동 적절성 개념을 처음 체계적으로 도입하고, 폐루프 아키텍처와 bone scaling 기반 교차-구현체 적응을 통해 실무적 가치 높은 솔루션을 제시한다. 다만 LLM 주석 신뢰성 검증과 더 광범위한 플랫폼 실험이 진행된다면 영향력이 한층 강화될 것으로 예상된다.
Humanoid Locomotion as Next Token Prediction
Figure 1: A humanoid that walks in San Francisco. We deploy our policy to various locations in San Francisco over
 *Figure 2: Humanoid locomotion as next token prediction. We collect a dataset on trajectories from various sources, such* Humanoid 로봇 제어를 언어 모델의 next token prediction처럼 다루어, causal transformer를 통해 sensorimotor 궤적을 자동 회귀적으로 예측한다. 시뮬레이션, 모션캡처, 유튜브 영상 등 다양한 소스의 불완전한 데이터로 학습하여 실제 humanoid 로봇이 zero-shot으로 샌프란시스코에서 보행할 수 있게 한다.
본 논문은 언어 모델의 next token prediction 패러다임을 humanoid 제어에 창의적으로 적용하여, 불완전한 다중 소스 데이터로 학습한 모델이 실제 환경에서 zero-shot 보행을 가능하게 함을 입증했다. 생성 모델 기반의 로봇 제어 학습에 대한 유망한 방향을 제시하며, 실제 배포 결과는 매우 인상적이다.
Humanoid World Models: Open World Foundation Models for Humanoid Robotics
Figure 1. Overview of Humanoid World Models (HWM). Given
 *Figure 1. Overview of Humanoid World Models (HWM). Given* Humanoid World Models (HWM)는 100시간의 humanoid 시연 데이터로 학습된 경량 오픈소스 모델로, egocentric 비디오를 humanoid control token으로 조건화하여 미래 프레임을 예측한다. Masked Transformer와 Flow-Matching 두 가지 생성 모델을 탐색하며 parameter-sharing 기법으로 33-53% 크기 감소를 달성했다.
이 논문은 humanoid 로봇을 위한 경량의 접근 가능한 world model이라는 명확한 필요를 직면하고, Masked Transformer와 Flow-Matching 두 패러다임을 체계적으로 비교하며 parameter-sharing 효율성을 입증한 실질적 기여를 한다. 다만 downstream task 평가와 실제 로봇 실험을 통한 효과 검증이 추가되면 영향력이 더욱 커질 것으로 예상된다.
Iterative Closed-Loop Motion Synthesis for Scaling the Capabilities of Humanoid Control
Figure 1. Overview of the CLAIMS pipeline: a closed-loop system that refines prompts from a 5-domain library (martial ar
 *Figure 1. Overview of the CLAIMS pipeline: a closed-loop system that refines prompts from a 5-domain library (martial ar* 본 논문은 폐쇄 루프 자동화 모션 데이터 생성 및 반복 프레임워크(CLAIMS)를 제안하여 고정된 난이도 분포의 데이터셋 한계를 극복하고, 휴머노이드 제어 정책의 성능 상한을 향상시킨다.
본 논문은 동적 난이도 적응을 통해 휴머노이드 제어의 고질적인 문제(고정 데이터 분포, 높은 데이터 수집 비용)를 혁신적으로 해결하며, 폐쇄 루프 프레임워크의 개념과 실제 구현이 모두 우수하다. 특히 AMASS의 1/10 데이터로 45% 실패율 감소라는 실질적 성과와 다양한 벤치마크에서의 일반화 능력은 이 분야에 상당한 실용적 기여를 제공한다.
Learning from Massive Human Videos for Universal Humanoid Pose Control
Figure 1. Overview. We introduce Humanoid-X, a large-scale dataset to facilitate humanoid robot learning from massive hu
 *Figure 2. Learning Humanoid Pose Control from Massive Videos. We mine massive human-centric video clips V from the Inter* Humanoid-X는 인터넷의 160,000개 이상의 인간 동영상으로부터 20백만 개의 휴머노이드 로봇 동작을 수집한 대규모 데이터셋이며, UH-1 모델을 통해 텍스트 명령을 휴머노이드 로봇의 제어 신호로 변환하는 범용 언어 조건부 제어를 실현한다.
본 논문은 휴머노이드 로봇 제어에 인터넷 비디오 빅데이터를 최초로 체계적으로 적용하고, 대규모 데이터셋과 범용 모델을 구축함으로써 로봇 학습의 확장성 문제를 실질적으로 해결한 중요한 기여를 한다. 시뮬레이션과 실세계 실험을 통한 검증이 충분하며 기술적·실무적 가치가 높다.
Learning Humanoid Navigation from Human Data
Fig. 1.
 *Fig. 1.* 인간 보행 데이터 5시간으로만 학습하여 휴머노이드 로봇이 미지의 환경을 자율 내비게이션할 수 있는 EgoNav 시스템을 제안. 360° 시각 메모리와 diffusion model을 통해 다중모달 궤적 분포를 생성하고 로봇에 직접 배포 가능.
인간 보행 데이터로부터 로봇 데이터 없이 휴머노이드 내비게이션을 학습하는 혁신적 접근으로, 360° visual memory와 diffusion model의 조합으로 다중모달 예측과 실시간 성능을 동시에 달성했다. 실제 로봇 배포 데모는 임팩트 있지만 정량적 성능 평가 확대와 다양한 로봇 및 환경에서의 일반화 검증이 필요하다.
One-shot Adaptation of Humanoid Whole-body Motion with Walking Priors
Figure 1. Sampled frames from motion sequences of a humanoid (Unitree H1) performing four distinct actions in sim-to-sim
 *Figure 2. Given a sequence of walking motion pose skeletons and a target sequence comprising non-walking motions, we emp* 단일 비보행 대상 샘플과 보행 사전 지식을 활용하여 휴머노이드 전신 운동을 원샷 적응하는 데이터 효율적 방법을 제안한다. Order-preserving optimal transport를 통해 보행과 비보행 시퀀스 간 거리를 계산하고 geodesic 보간으로 중간 포즈를 생성한 후 강화학습으로 정책을 적응한다.
휴머노이드 전신 운동에 원샷 학습을 효과적으로 적용하고, order-preserving optimal transport와 manifold 최적화를 통해 경량의 데이터 효율적 솔루션을 제시하는 높은 가치의 연구이다. 다만 실제 로봇 검증과 더 다양한 보조 모션 확장이 후속 과제이다.
PDF-HR: Pose Distance Fields for Humanoid Robots
Fig. 1: We present PDF-HR, which learns the manifold of plausible G1 poses as a zero-level set. Left: The fϕ is trained
 *Fig. 1: We present PDF-HR, which learns the manifold of plausible G1 poses as a zero-level set. Left: The fϕ is trained * Humanoid 로봇을 위한 pose distance field인 PDF-HR을 제안하여, 학습된 로봇 포즈 분포를 연속 미분 가능한 manifold로 표현하고 포즈의 plausibility를 평가한다.
이 논문은 humanoid robotics에 implicit manifold representation을 처음 적용하여 scarce data 문제를 효과적으로 해결하고, lightweight하면서도 재사용 가능한 pose prior를 제안한 점에서 높은 학술적 기여를 한다. 다양한 task에서 일관된 성능 향상을 보이며 실용적 가치도 우수하나, corpus 의존성과 temporal modeling의 미흡이 향후 개선 과제이다.
Perpetual Humanoid Control for Real-time Simulated Avatars
Figure 1: We propose a motion imitator that can naturally recover from falls and walk to far-away reference motion, perp
 *Figure 1: We propose a motion imitator that can naturally recover from falls and walk to far-away reference motion, perp* Physics 기반 humanoid controller인 Perpetual Humanoid Controller (PHC)는 noisy input과 unexpected falls에 강건하면서 10,000개의 motion clips을 학습할 수 있으며, 새로운 Progressive Multiplicative Control Policy (PMCP)를 통해 catastrophic forgetting 없이 대규모 motion database에서 학습 가능하다.
이 논문은 external force 제거와 PMCP라는 novel mechanism으로 physics-based motion imitation의 scalability 문제를 효과적으로 해결하며, natural fail-state recovery와 noisy input 강건성으로 실제 video 기반 avatar application에 처음으로 실용적인 solution을 제공한다.
PHUMA: Physically-Grounded Humanoid Locomotion Dataset
Figure 1: Physical reliability of Humanoid-X vs. PHUMA. Each column illustrates four failure
 *Figure 1: Physical reliability of Humanoid-X vs. PHUMA. Each column illustrates four failure* PHUMA는 대규모 인터넷 비디오로부터 인간다운 보행을 위한 물리적으로 타당한 휴머노이드 모션 데이터셋을 구축하며, 데이터 큐레이션과 physics-constrained retargeting을 통해 floating, penetration, foot skating 등의 물리적 artifacts를 제거한다.
PHUMA는 대규모 비디오 기반 모션 데이터의 물리적 신뢰성 문제를 체계적으로 해결하는 실용적인 데이터셋이며, physics-constrained retargeting 방법론과 실증적 성능 향상을 통해 휴머노이드 보행 학습 분야에 명확한 기여를 제시한다.
Towards Motion Turing Test: Evaluating Human-Likeness in Humanoid Robots
Figure 1.
 *Figure 1.* Motion Turing Test라는 개념을 제시하여 인간관찰자가 키네마틱 정보만으로 휴머노이드 로봇과 인간의 자세를 구분할 수 있는지를 평가하고, 이를 위해 1,000개의 모션 시퀀스로 구성된 HHMotion 데이터셋과 human-likeness 예측 기준선 모델을 제안한다.
Motion Turing Test라는 명확한 개념 정의와 이를 뒷받침하는 포괄적인 HHMotion 데이터셋은 휴머노이드 로봇 모션 평가 분야에 중요한 기여를 한다. SMPL-X 기반 appearance-agnostic 평가 방식과 500시간의 대규모 인간 주석은 높은 신뢰성을 제공하며, 제안된 PTR-Net이 VLM 기반 방법들을 능가한 결과는 전문화된 모션 평가 모델의 필요성을 입증한다.
Learn Weightlessness: Imitate Non-Self-Stabilizing Motions on Humanoid Robot
Fig. 1: Our work introduces a human-inspired weightlessness mechanism that controls robot joints to selectively relax wh
 *Fig. 1: Our work introduces a human-inspired weightlessness mechanism that controls robot joints to selectively relax wh* 휴머노이드 로봇이 비자기안정화(non-self-stabilizing) 동작을 수행할 때 인간의 '무중력 상태' 메커니즘을 모방하여 특정 관절을 선택적으로 이완시킴으로써 환경과의 물리적 접촉을 통해 동작을 완성하는 방법을 제안한다.
본 논문은 인간의 생물학적 메커니즘을 로봇 제어에 창의적으로 적용하여 비자기안정화 동작이라는 미해결 문제를 해결하는 우수한 연구이며, Unitree G1에서의 실제 검증과 다양한 환경에 대한 일반화 성능은 로봇 공학의 실질적 진전을 보여준다.
SynAgent: Generalizable Cooperative Humanoid Manipulation via Solo-to-Cooperative Agent Synergy
Fig. 1. Features of SynAgent. As the first model to address trajectory-following object manipulation with multiple human
 *Fig. 1. Features of SynAgent. As the first model to address trajectory-following object manipulation with multiple human* SynAgent는 단일 에이전트 기술을 다중 에이전트 협력 조작으로 전이하는 Solo-to-Cooperative Agent Synergy 패러다임을 통해, 휴머노이드 로봇의 협력 조작 학습 데이터 부족 문제를 해결하고 다양한 물체 기하학에 일반화하는 통합 프레임워크를 제시한다.
SynAgent는 HOHI 데이터 부족 문제를 창의적으로 해결하고, Solo-to-Cooperative Agent Synergy 패러다임을 통해 다중 에이전트 협력 조작의 확장성과 일반화를 크게 향상시킨 중요한 기여를 한다. 다만 실제 로봇 환경 검증과 더 많은 에이전트로의 확장성 증명이 필요하다.
Humanoid Locomotion as Next Token Prediction
 *Figure 2: Humanoid locomotion as next token prediction. We collect a dataset on trajectories from various sources, such* 이 논문은 인간형 로봇의 보행 제어를 언어 모델링의 next token prediction 문제로 재해석한 연구이다. causal transformer를 이용해 sensorimotor trajectories를 자동회귀적으로 예측하되, 불완전한 모달리티(예: 액션 없는 비디오)도 활용할 수 있도록 설계했다.
이 논문은 언어 모델링 패러다임을 로봇 제어에 효과적으로 적용한 강력한 연구이다. 제로샷 실제 환경 배포, 불완전한 데이터의 창의적 활용, 다양한 소스 통합 등에서 명확한 기여를 보여주며, 기술적으로도 건전하고 실험 결과도 설득력 있다.
Learning Humanoid Locomotion with World Model Reconstruction
Fig. 1: Deployment to outdoor environments. We deployed the model in an outdoor environment covered in ice and snow.
 *Fig. 2: Illustration of the World Model Reconstruction framework. Our framework explicitly reconstructs world state from* 본 논문은 humanoid robot의 blind locomotion을 위해 World Model Reconstruction (WMR)을 제안한다. 센서 노이즈로부터 world state를 명시적으로 재구성하고, gradient cutoff를 통해 estimator와 policy를 독립적으로 학습시킴으로써 실제 복잡한 지형에서의 견고한 주행을 실현한다.
본 논문은 humanoid 로봇의 blind locomotion을 위한 명시적 world model reconstruction의 효과를 체계적으로 입증하고, gradient cutoff 메커니즘을 통해 estimation과 policy learning의 충돌을 창의적으로 해결한다. 단일 학습 단계로 복잡한 실제 지형에서의 장거리 주행을 달성한 것은 실질적 임팩트가 크며, 3.2 km hike의 구체적 성과는 방법의 실효성을 명확히 보여준다. 다만 단일 로봇 플랫폼 실험과 failure case 분석의 부족이 아쉬우나, 전체적으로 humanoid locomotion 분야에 의미있는 기여를 하는 고품질 연구이다.
Learning Humanoid Navigation from Human Data
Fig. 1.
 *Fig. 2. Overview of the proposed method: A rolling buffer of 32 segmented* 본 논문은 인간의 보행 데이터 5시간만을 활용하여 휴머노이드 로봇이 미지의 환경에서 자율적으로 내비게이션할 수 있는 EgoNav 시스템을 제안한다. 로봇 데이터 없이 순수 인간 데이터만으로 학습한 모델을 Unitree G1 휴머노이드에 제로샷 배포하여 실제 환경에서의 효과를 입증한다.
EgoNav는 인간 보행 데이터만으로 휴머노이드 로봇 내비게이션을 가능하게 하는 혁신적 접근을 제시하며, diffusion model 기반 다중 모달 궤적 생성과 실시간 추론의 결합, 실제 미지 환경에서의 제로샷 배포 성공은 로봇 내비게이션 분야에 상당한 기여를 한다. 다만 학습 데이터 규모와 극한 환경 견고성의 검증이 추가되면 더욱 강력한 논문이 될 수 있다.
Physically Consistent Humanoid Loco-Manipulation using Latent Diffusion Models
Fig. 1: A loco-manipulation task achieved with our approach.
 *Fig. 2: Pipeline overview.* 본 논문은 Latent Diffusion Model(LDM)을 활용하여 인간-물체 상호작용 장면을 생성하고, 이로부터 추출한 접촉 위치와 로봇 구성을 whole-body trajectory optimization에 활용하여 인형로봇의 물리적으로 일관성 있는 장기 조작 계획을 수립한다.
본 논문은 LDM과 foundation model을 창의적으로 결합하여 인형로봇의 장기 로코-조작 계획 문제를 새로운 방식으로 접근하며, 광범위한 실험과 분석을 통해 방법론의 유효성을 입증했다. 다만 실제 로봇 검증과 일부 모듈의 정확성 개선이 필요하다.
RoboMirror: Understand Before You Imitate for Video to Humanoid Locomotion
Figure 1. RoboMirror makes humanoid understand before imitating. It acts like a mirror, which can not only infer and rep
 *Figure 1. RoboMirror makes humanoid understand before imitating. It acts like a mirror, which can not only infer and rep* RoboMirror는 VLM을 활용하여 비디오에서 visual motion intent를 추출하고 diffusion-based policy로 직접 인간형 로봇의 보행을 제어하는 retargeting-free 프레임워크이다. 기존의 pose estimation-retargeting 파이프라인을 우회하고 egocentric/third-person 비디오로부터 시맨틱하게 정렬된 보행을 생성한다.
RoboMirror는 인간형 로봇 제어에 시각적 이해라는 자연스러운 패러다임을 도입하고, retargeting-free 아키텍처로 지연시간을 획기적으로 단축하면서 성능을 향상시킨 의미 있는 기여이다. 다만 sim-to-real 검증 부재와 VLM 의존성 문제는 실용화를 위해 추가 연구가 필요함을 시사한다.
Vision in Action: Learning Active Perception from Human Demonstrations
Figure 1: Vision in Action (ViA) uses an active head
 *Figure 1: Vision in Action (ViA) uses an active head* ViA는 6-DoF 로봇 넥과 VR 텔레오퍼레이션 인터페이스를 통해 인간의 능동적 지각 전략을 직접 학습하여 이중팔 조작 로봇의 성능을 향상시키는 시스템이다.
ViA는 능동적 지각, VR 텔레오퍼레이션, 이중팔 조작을 효과적으로 통합한 혁신적 시스템으로, 중간 3D 표현을 통한 지연 시간 해결과 공유 관찰 공간 개념이 특히 창의적이며, 시각적 폐색이 있는 복잡한 실제 작업에서 실질적인 성능 향상을 달성했다.
WHOLE: World-Grounded Hand-Object Lifted from Egocentric Videos
Figure 1. Given a metric-SLAMed egocentric video of a person interacting with the scene and the corresponding object tem
 *Figure 2. Reconstruction Using the Generative Motion Prior. Given a metric-SLAMed egocentric videos, and the object temp* WHOLE는 손잡이와 물체의 상호작용을 joint generative motion prior를 통해 이용하여 egocentric 비디오에서 world space로의 hand-object 궤적을 holistically 재구성한다.
WHOLE는 hand-object interaction을 joint generative prior로 모델링하여 egocentric video에서 globally consistent world-space trajectories를 복원하는 혁신적 접근으로, 기존 isolated method들의 inconsistency 문제를 근본적으로 해결하며 practical application에 중요한 기여를 한다.
Being-H0: Vision-Language-Action Pretraining from Large-Scale Human Videos
Figure 1: Being-H0 acquires dexterous manipulation skills by learning from large-scale human videos in the
 *Figure 1: Being-H0 acquires dexterous manipulation skills by learning from large-scale human videos in the* Being-H0는 대규모 인간 비디오로부터 학습한 민첩한 Vision-Language-Action 모델로, physical instruction tuning 패러다임을 통해 인간의 손 동작을 명시적으로 모델링하여 로봇 조작 작업으로 전이한다.
Being-H0는 대규모 인간 비디오로부터 민첩한 로봇 조작을 학습하는 새로운 패러다임을 제시하며, physical instruction tuning과 part-level motion tokenization을 통해 기존 VLA의 데이터 부족 문제를 혁신적으로 해결한다. 명시적 동작 모델링 접근법과 UniHand 데이터셋은 로봇 공학 분야에 중요한 기여를 제공한다.
DexCap: Scalable and Portable Mocap Data Collection System for Dexterous Manipulation
Fig. 1: DEXCAP facilitates the in-the-wild collection of high-quality human hand motion capture data and 3D observations
 *Fig. 1: DEXCAP facilitates the in-the-wild collection of high-quality human hand motion capture data and 3D observations* DexCap은 SLAM과 전자기장을 활용한 휴대용 손 모션캡처 시스템이며, DexIL은 이 데이터로부터 역운동학과 point cloud 기반 모방학습을 통해 로봇이 손가락 조작을 직접 학습하도록 하는 알고리즘이다.
DexCap과 DexIL은 휴대용 mocap 시스템과 embodiment gap을 극복하는 imitation learning을 처음으로 통합하여 in-the-wild 환경에서 로봇 손가락 조작 학습을 가능하게 한 우수한 기여이며, 6가지 조작 작업에서 일관된 성과를 보여준다.
DexterCap: An Affordable and Automated System for Capturing Dexterous Hand-Object Manipulation
Figure 1: DexterCap captures dexterous manipulation of a Rubik’s Cube. Top: raw multi-camera footage showing character-c
 *Figure 1: DexterCap captures dexterous manipulation of a Rubik’s Cube. Top: raw multi-camera footage showing character-c* DexterCap는 문자 코드화된 마커 패치를 사용하는 저비용 광학 모션 캡처 시스템으로, 심한 자기 폐색 상황에서도 손가락의 섬세한 조작 동작을 정확하게 추적하며 최소한의 수동 작업으로 자동 재구성 파이프라인을 제공한다.
DexterCap은 문자 코드화 마커와 자동화 파이프라인을 통해 저비용으로도 섬세한 손 조작을 정확하게 캡처할 수 있음을 보여주며, 공개된 DexterHand 데이터셋과 함께 손-물체 상호작용 연구의 중요한 리소스로 기여한다.
EGM: Efficiently Learning General Motion Tracking Policy for High Dynamic Humanoid Whole-Body Control
Figure 1: We deploy a unified student policy trained with EGM in the simulation environment, achieving high robust
 *Figure 2: Overview of the EGM framework. First, large-scale Mocap datasets are retargeted to Humanoid, then a small* EGM은 Bin-based Cross-motion Curriculum Adaptive Sampling과 Composite Decoupled Mixture-of-Experts 아키텍처를 통해 4.08시간의 소량 데이터로 49.25시간의 다양한 모션을 효율적으로 추적하는 일반화된 휴머노이드 제어 정책을 학습한다.
EGM은 Bin-based adaptive sampling과 CDMoE 아키텍처의 새로운 조합으로 humanoid motion tracking의 데이터 효율성과 dynamic motion 성능을 획기적으로 개선하며, 소량 데이터 학습의 실용성을 입증하는 강력한 기여를 제시한다.
EgoDemoGen: Egocentric Demonstration Generation for Viewpoint Generalization in Robotic Manipulation
 *Figure 2. Overview of EgoDemoGen. Given source demonstrations from a standard egocentric viewpoint, we generate novel de* EgoDemoGen은 egocentric viewpoint 변화에 대응하는 로봇 조작 정책의 일반화를 위해, 궤적 전송과 영상 합성을 통해 새로운 egocentric 관점에서 정렬된 observation-action 시연을 생성하는 프레임워크이다.
본 논문은 egocentric viewpoint 변화의 특수성을 명확히 인식하고, 궤적 전송과 영상 합성을 통합하는 EgoDemoGen 프레임워크를 제시하여 로봇 조작의 viewpoint 일반화 문제를 근본적으로 해결한다. 실험적으로 시뮬레이션과 실제 로봇 환경에서 일관된 성능 향상을 보여주며, 로봇 학습의 실용적 적용에 중요한 기여를 한다.
EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video
Figure 1: EgoDex is a large-scale egocentric dataset that focuses on human dexterous manipulation.
 *Figure 1: EgoDex is a large-scale egocentric dataset that focuses on human dexterous manipulation.* Apple Vision Pro를 활용하여 829시간의 3D 손 추적 주석이 포함된 대규모 자아중심 비디오 데이터셋 EgoDex를 수집하고, 이를 통해 기술적 조작 모방 학습을 위한 벤치마크를 제시한다.
EgoDex는 기술적 조작 학습을 위한 획기적인 대규모 데이터셋을 제공하며, 웨어러블 기술의 실제 활용을 통해 로봇 조작 분야의 '인터넷 규모 데이터' 시대를 개척한다. 데이터셋의 규모와 정밀도는 탁월하나, 실제 로봇 정책 전이의 실효성 검증이 후속 과제로 남아있다.
EgoMI: Learning Active Vision and Whole-Body Manipulation from Egocentric Human Demonstrations
Fig. 1: Overview of the EgoMI framework. EgoMI captures egocentric human demonstrations with synchronized head and hand
 *Fig. 1: Overview of the EgoMI framework. EgoMI captures egocentric human demonstrations with synchronized head and hand* EgoMI는 인간의 동시화된 머리 및 손 움직임을 포착하는 egocentric 데이터 수집 프레임워크로, SPARKS 메모리 메커니즘을 통해 급속한 시점 변화를 처리하여 반인간형 로봇으로 zero-shot 전이를 달성한다.
EgoMI는 인간의 active vision과 manipulation을 동시에 포착하는 창의적 프레임워크로, SPARKS 메커니즘을 통해 급속한 시점 변화를 우아하게 처리하며 zero-shot transfer를 달성해 imitation learning의 embodiment gap 문제에 실질적 솔루션을 제시한다.
EgoMimic: Scaling Imitation Learning via Egocentric Video
Fig. 1: EgoMimic unlocks human embodiment data—egocentric videos paired with 3D hand tracks—as a new scalable data sourc
 *Fig. 1: EgoMimic unlocks human embodiment data—egocentric videos paired with 3D hand tracks—as a new scalable data sourc* EgoMimic은 Project Aria 안경을 통해 수집한 인간의 일인칭 시점 비디오와 3D 손 추적 데이터를 로봇 조작 학습에 활용하는 전체 스택 프레임워크로, 인간과 로봇 데이터를 동등한 embodied demonstration으로 취급하여 통합 정책을 학습한다.
EgoMimic은 인간의 일인칭 시점 데이터를 로봇 학습에 동등하게 활용하는 혁신적 접근으로, 실제 조작 작업에서 뛰어난 성능 개선과 일반화를 입증했으며, 수동적 대규모 데이터 수집의 가능성을 열어 로봇 학습의 확장성 문제 해결에 크게 기여한다.
EgoVLA: Learning Vision-Language-Action Models from Egocentric Human Videos
Figure 1: EgoVLA. Our vision-language-action model learns manipulation skills from egocentric human
 *Figure 1: EgoVLA. Our vision-language-action model learns manipulation skills from egocentric human* egocentric human 비디오로부터 Vision-Language-Action (VLA) 모델을 학습하여 로봇 조작 정책을 획득하고, Inverse Kinematics과 retargeting을 통해 인간 행동을 로봇 행동으로 변환한다.
본 논문은 egocentric human 비디오를 활용한 VLA 학습이라는 혁신적 접근으로 로봇 데이터 수집의 확장성 문제를 효과적으로 해결하며, unified action space 설계와 종합적인 벤치마크 제안을 통해 높은 실용성과 학술적 기여를 제시한다.
GraspDreamer: 생성형 인간 시연 기반 기능적 파지 모방 학습
Fig. 1: GraspDreamer leverages human demonstrations syn-
 *Fig. 1: GraspDreamer leverages human demonstrations syn-* Visual Generative Model (VGM)으로 생성한 인간 시연 비디오로부터 기능적 파지를 학습하여 실제 데이터 수집 없이 제로샷 로봇 파지를 가능하게 하는 GraspDreamer 방법을 제안한다. 인터넷 규모의 사전학습 데이터에 인코딩된 인간-물체 상호작용 프라이어를 활용하여 데이터 효율성과 일반화 성능을 동시에 달성한다.
GraspDreamer는 VGM의 생성 능력을 창의적으로 활용하여 기능적 파지의 데이터 수집 부담을 획기적으로 감소시키면서도 다양한 로봇 플랫폼에 일반화되는 실용적 솔루션을 제시한다. 공개 벤치마크와 실세계 실험의 광범위한 검증으로 방법의 유효성을 충실히 입증하였다.
H-RDT: Human Manipulation Enhanced Bimanual Robotic Manipulation
Figure 1: Overview of H-RDT. A human-to-robotics diffusion transformer with two-stage training.
 *Figure 1: Overview of H-RDT. A human-to-robotics diffusion transformer with two-stage training.* H-RDT는 대규모 egocentric 인간 조작 데이터로 사전학습하고 모듈식 action encoder/decoder를 통해 다양한 로봇에 fine-tuning하는 두 단계 diffusion transformer 기반 접근법으로, 로봇 조작 학습을 향상시킨다.
H-RDT는 대규모 egocentric human manipulation 데이터의 가치를 체계적으로 입증하면서, 모듈식 전이 구조를 통해 diverse robot platform으로의 확장 가능성을 보여준 혁신적 연구이다. 광범위한 실험과 강력한 empirical 결과가 robotic manipulation 학습의 data scarcity 문제 해결에 실질적인 기여를 하고 있다.
Hand-Eye Autonomous Delivery: Learning Humanoid Navigation, Locomotion and Reaching
 *Figure 2: System overview: HEAD consists of a high-level policy with two modules, navigation* 인간 모션 캡처와 에고센트릭 비전 데이터로부터 휴머노이드 로봇의 네비게이션, 로코모션, 리칭 능력을 학습하는 HEAD 프레임워크를 제안한다. 고수준 정책이 손과 눈의 목표 위치를 명령하고 저수준 whole-body controller가 추적하는 모듈식 접근법을 채택한다.
HEAD는 모듈식 설계와 sparse 3-point tracking을 통해 휴머노이드 로봇의 통합적 navigation, locomotion, reaching을 효과적으로 학습하는 창의적인 접근을 제시하며, 실제 로봇에서의 동작 검증으로 실용성을 입증한다. 다만 human 데이터 의존성과 정제 비용, 환경 일반화 가능성에 대한 추가 분석이 필요하다.
HandX: Scaling Bimanual Motion and Interaction Generation
Figure 1. (a) We introduce HandX, a large-scale dataset of bimanual and dexterous motions paired with fine-grained textu
 *Figure 1. (a) We introduce HandX, a large-scale dataset of bimanual and dexterous motions paired with fine-grained textu* HandX는 양손의 섬세한 움직임과 상호작용을 생성하기 위한 통합 기반을 제공하는 대규모 dataset, annotation 전략, 그리고 평가 방법론을 제시한다.
HandX는 bimanual hand motion generation의 significant gap을 체계적으로 해결하는 comprehensive framework를 제시하며, large-scale dataset, scalable annotation 전략, 그리고 detailed benchmarking을 통해 손 움직임 합성 분야의 새로운 표준을 제시한다. 실제 humanoid deployment까지 입증한 점에서 학술적, 실용적 가치가 높다.
HDMI: Learning Interactive Humanoid Whole-Body Control from Human Videos
Fig. 1: HDMI enables humanoid robots to acquire diverse whole-body interaction skills directly from human videos. (a)
 *Fig. 2: HDMI is a general framework for interactive skill learning. Monocular RGB videos are processed into a structured* HDMI는 단일 모노큘러 RGB 비디오에서 인간의 상호작용을 추출하여 휴머노이드 로봇이 물체와의 전신 상호작용 기술을 학습하는 프레임워크이다. Robot-object co-tracking을 통해 강화학습 정책을 훈련하고 실제 로봇에 제로샷 배포한다.
HDMI는 휴머노이드 로봇의 전신 물체 상호작용을 위한 일반적이고 실용적인 프레임워크로, 인간 비디오 활용이라는 확장 가능한 데이터 소스와 함께 robot-object co-tracking이라는 우아한 문제 설정을 통해 실제 로봇에서 강력한 성능을 달성했으며, 휴머노이드 로보틱스 분야에 의미 있는 기여를 한다.
Kimodo: Scaling Controllable Human Motion Generation
Figure 1: Controllable Motion Generation. Kimodo supports flexible and intuitive control for motion generation
 *Figure 1: Controllable Motion Generation. Kimodo supports flexible and intuitive control for motion generation* NVIDIA의 Kimodo는 700시간의 광학 모션캡처 데이터로 학습한 kinematic motion diffusion model로, 텍스트 프롬프트 및 포괄적인 운동학 제약 조건을 통해 고품질 인간 모션을 생성한다.
Kimodo는 대규모 모션캡처 데이터와 혁신적인 두 단계 diffusion 아키텍처를 결합하여 현실적이고 제어 가능한 인간 모션 생성을 달성한 중요한 기여이며, 로봇공학과 콘텐츠 생성 분야에서 실질적인 응용 가치를 제시한다.
Learning to Control Physically-simulated 3D Characters via Generating and Mimicking 2D Motions
Figure 1. The proposed Mimic2DM effectively learns character controllers for diverse motion types, including dynamic hum
 *Figure 1. The proposed Mimic2DM effectively learns character controllers for diverse motion types, including dynamic hum* Mimic2DM은 비디오에서 추출한 2D 키포인트 궤적만을 사용하여 물리 기반 3D 캐릭터 제어 정책을 직접 학습하는 모션 모방 프레임워크이며, 재투영 오차 최소화와 RL을 통해 2D 데이터로부터 물리적으로 타당한 3D 동작을 합성한다.
Mimic2DM은 접근성 높은 2D 데이터로부터 물리 기반 3D 캐릭터 제어를 학습하는 실질적이고 혁신적인 방법으로, 기존의 희소한 3D MoCap 데이터 의존성을 크게 완화하며 다양한 도메인에서 우수한 성능을 보여준다.
Learning Whole-Body Human-Humanoid Interaction from Human-Human Demonstrations
Figure 1. From HHI to HHoI with simulation and real-robot results. Left: PAIR (Physics-Aware Interaction Retargeting) co
 *Figure 2. PAIR preserves physical consistency where naive meth-* 휴먼-휴먼 인터랙션(HHI) 데이터를 물리적 일관성을 보존하면서 휴먼-휴모이드 인터랙션(HHoI)으로 변환하는 PAIR와, 시간적 의도와 공간적 선택을 분리하여 상호작용적 이해를 갖춘 D-STAR 정책을 제안한다.
이 논문은 HHI에서 HHoI로의 데이터 변환 문제를 물리적 일관성 관점에서 체계적으로 해결하고, 시공간 분리를 통해 상호작용 정책의 반응성을 크게 향상시키는 혁신적인 접근을 제시한다. 시뮬레이션과 실제 로봇 검증을 통해 실용성을 입증하였으나, 더 다양한 상호작용 시나리오와 플랫폼으로의 확장이 필요하다.
LookOut: Real-World Humanoid Egocentric Navigation
Figure 1. Problem formulation. Given a posed egocentric video (black-outlined frustums, with frames shown in detail on t
 *Figure 1. Problem formulation. Given a posed egocentric video (black-outlined frustums, with frames shown in detail on t* Project Aria 안경을 이용한 데이터 수집 파이프라인과 함께, 동적 장애물이 있는 실제 환경에서 egocentric 비디오로부터 미래의 6D 헤드 포즈(위치 및 회전)를 예측하는 LookOut 모델을 제안한다.
인간형 egocentric 네비게이션의 동적 환경 처리, 능동적 정보 수집 모델링, 그리고 실용적 데이터 수집 파이프라인을 종합적으로 해결한 포괄적 기여로, Project Aria를 활용한 혁신적 데이터 수집 방식과 현실성 높은 4시간 AND 데이터셋이 향후 연구에 큰 영향을 미칠 것으로 기대된다.
MaskedManipulator: Versatile Whole-Body Manipulation
Figure 1: MaskedManipulator enables physics-based humanoids to perform intricate, object interactions from sparse spatio
 *Figure 1: MaskedManipulator enables physics-based humanoids to perform intricate, object interactions from sparse spatio* MaskedManipulator는 대규모 모션 캡처 데이터로 학습한 추적 컨트롤러에서 증류한 생성적 제어 정책으로, 사용자가 객체 포즈나 신체 포즈 같은 고수준 목표를 지정하여 물리 기반 전신 조작 행동을 생성한다.
MaskedManipulator는 두 단계 증류 프레임워크를 통해 정교한 물리 기반 전신 조작을 희소한 고수준 목표로 제어 가능하도록 함으로써, 캐릭터 애니메이션과 인간형 로봇 제어 분야의 중요한 진전을 이룬다. 대규모 모션 캡처 데이터 활용과 유연성-정밀도 균형 달성이 특히 주목할 만하나, 실제 로봇 적용 평가와 일반화 성능 분석이 보완되면 더욱 완성도 높은 기여가 될 것이다.
Masquerade: Learning from In-the-wild Human Videos using Data-Editing
Fig. 1: Overview of Masquerade. Left: Large-scale in-the-wild egocentric human videos are edited to obtain “robotized”
 *Fig. 1: Overview of Masquerade. Left: Large-scale in-the-wild egocentric human videos are edited to obtain “robotized”* Masquerade는 in-the-wild 인간 영상을 데이터 편집을 통해 로봇화된 시연으로 변환하고, 이를 통해 사전학습된 visual encoder로 로봇 조작 정책을 학습하는 방법을 제안한다. 675K 프레임의 편집된 인간 영상으로 사전학습 후 50개의 로봇 시연으로 fine-tuning하여 기존 방법 대비 5-6배 향상된 성능을 달성한다.
Masquerade는 visual embodiment gap을 명시적으로 해결하면서 대규모 in-the-wild 인간 영상을 로봇 학습에 활용하는 창의적이고 실용적인 방법론을 제시한다. 적절한 평가와 ablation으로 핵심 설계 선택의 효과를 입증했으며, 로봇 데이터 부족 문제를 완화하는 데 의미 있는 기여를 한다.
Object-Centric Dexterous Manipulation from Human Motion Data
Figure 1: Our system uses human hand motion capture data and deep reinforcement learning to train
 *Figure 2: Overview of our framework. (A) Training: Firstly, we use human motion capture data to* 인간의 손 모션 캡처 데이터를 활용하여 로봇 다지털 조작을 학습하는 계층적 정책 학습 프레임워크를 제안한다. 고수준의 손목 궤적 생성 모델과 저수준의 손가락 제어기를 조합하여 embodiment gap을 극복한다.
본 논문은 인간 wrist 모션의 embodiment 불변성을 창의적으로 활용하여 embodiment gap 문제를 해결하고, 계층적 학습 프레임워크로 복잡한 다지털 조작을 효과적으로 학습한다. 실세계 전이와 일반화 능력 모두 입증하여 로봇 조작 분야에 significant한 기여를 한다.
OKAMI: Teaching Humanoid Robots Manipulation Skills through Single Video Imitation
 *Figure 2: Overview of OKAMI. OKAMI is a two-staged method that enables a humanoid robot to imitate a* OKAMI는 단일 RGB-D 비디오 시연으로부터 인형 로봇의 조작 기술을 학습하도록 하는 방법으로, object-aware retargeting을 통해 인간의 움직임을 로봇 기구학에 맞게 변환하면서 테스트 시 객체 위치에 적응한다.
OKAMI는 object-aware retargeting이라는 핵심 개념으로 단일 비디오로부터 인형 로봇의 조작 학습을 효과적으로 해결하며, 실제 하드웨어에서 강한 일반화 능력을 입증하여 로봇 학습의 실용성을 크게 향상시킨다.
Open-TeleVision: Teleoperation with Immersive Active Visual Feedback
Figure 1: Autonomous and teleoperated sessions using our setup. a-e: robots executing long-
 *Figure 2: Teleoperated data collection and learning setup. Left: our teleoperation system. VR* Apple VisionPro 등 VR 기기를 활용하여 스테레오 영상 피드백과 로봇 헤드의 능동적 카메라 제어를 통해 직관적이고 몰입감 있는 원격 조종 시스템을 구현하고, 이를 통해 수집한 데이터로 모방 학습 정책을 훈련하여 복잡한 조작 작업을 자동화함.
본 논문은 VR 기반 능동적 헤드 카메라와 스테레오 영상 피드백을 통해 직관적이고 몰입감 있는 원격 조종 시스템을 제시하며, 이를 통해 수집한 데이터로 복잡한 조작 작업을 성공적으로 자동화할 수 있음을 입증함으로써 로봇 학습 데이터 수집 분야에 실질적인 기여를 함.
TrajBooster: Boosting Humanoid Whole-Body Manipulation via Trajectory-Centric Learning
Fig. 1: Overview of framework. Our proposed TrajBooster uses abundant existing robot manipulation datasets. It retargets
 *Fig. 1: Overview of framework. Our proposed TrajBooster uses abundant existing robot manipulation datasets. It retargets* TrajBooster는 휠드 휴머노이드에서 추출한 다양한 궤적 데이터를 이족 휴머노이드(Unitree G1)로 전이학습하여, 부족한 이족 휴머노이드 데이터를 보충하고 Vision-Language-Action 모델의 성능을 향상시키는 실시간-시뮬레이션-실시간 파이프라인이다.
TrajBooster는 형태학적으로 다른 로봇 간 전이학습이라는 어려운 문제에 대해 실용적이고 효과적인 해결책을 제시한다. 최소한의 실제 데이터만으로도 이족 휴머노이드의 광범위한 전신 조작을 가능하게 한 점에서 로봇 학습의 실용성 측면에서 매우 중요한 기여를 한다.
UniDex: A Robot Foundation Suite for Universal Dexterous Hand Control from Egocentric Human Videos
Figure 1. We introduce UniDex, a robot foundation suite for heterogeneous dexterous hand embodiments. We first curate Un
 *Figure 1. We introduce UniDex, a robot foundation suite for heterogeneous dexterous hand embodiments. We first curate Un* 인간 자기중심 비디오로부터 8종 로봇 핸드에 대한 범용 손재주 제어를 위해 50K+ 궤적 데이터셋(UniDex-Dataset), 통합 액션 공간(FAAS), 3D VLA 정책(UniDex-VLA)을 제시하는 로봇 파운데이션 스위트이다.
UniDex는 손재주 로봇 손 제어를 위한 첫 포괄적 파운데이션 스위트로, 대규모 다중 손 데이터셋, 혁신적인 FAAS 액션 공간, 강력한 3D VLA 정책을 통합하여 일반화와 전이 학습에서 뛰어난 성과를 달성했다.
HumanEgo: Zero-Shot Robot Learning from Minutes of Human Egocentric Videos
HumanEgo는 인간의 자아중심 영상(egocentric video)으로부터 로봇 조작 정책을 학습하는 프레임워크로서, Interaction-Centric Tokens(ICT)를 통해 구체화 격차(embodiment gap)를 해결하고 flow matching 정책과 조밀한 보조 목표들을 결합하여 30분의 인간 영상만으로 92.5% 성공률을 달성한다.
HumanEgo는 인간 자아중심 영상으로부터 로봇 정책을 학습하는 문제에 명확한 해결책을 제시한다. Interaction-Centric Tokens를 통한 혁신적 표현과 조밀한 보조 감시의 조합은 기술적으로 타당하며, 30분 영상으로 92.5% 성공률과 zero-shot 전이 능력은 실용적 의의가 크다. 다만 Aria 센서 의존도와 제한된 작업 평가 범위가 일반화 가능성에 의문을 제기한다.
Learning Human-Intention Priors from Large-Scale Human Demonstrations for Robotic Manipulation
Figure 1: Overview of the HA-2.2M curation pipeline. Large-scale unlabeled human demonstration
 *Figure 1: Overview of the HA-2.2M curation pipeline. Large-scale unlabeled human demonstration* 본 논문은 대규모 인간 시연 영상으로부터 로봇 조작을 위한 인간-의도 사전을 학습하는 MoT-HRA 프레임워크를 제안한다. 220만 에피소드의 HA-2.2M 데이터셋을 구성하고, 3D 궤적 예측, MANO 스타일 손 모션 모델링, 로봇 행동 변환의 3단계 계층적 구조로 인간 시연의 재사용 가능한 부분을 보존하면서 로봇 특화 제어를 학습한다.
본 논문은 대규모 인간 시연으로부터 로봇 조작을 학습하는 실질적 도전에 대해 잘 정의된 계층적 접근을 제시한다. 220만 에피소드 HA-2.2M 데이터셋과 MoT-HRA의 knowledge insulation 설계는 인간 행동의 재사용 가능한 구조를 보존하면서 로봇 특화 제어를 학습하는 점에서 기여도가 있다. 다만 데이터셋 필터링 정확성, 실제 로봇 평가의 포괄성, 계산 효율성 분석이 강화될 필요가 있다.
PICO: Reconstructing 3D People In Contact with Objects
Figure 1. We present PICO, a novel framework for joint human-object reconstruction in 3D. PICO includes PICO-db, a uniqu
 *Figure 1. We present PICO, a novel framework for joint human-object reconstruction in 3D. PICO includes PICO-db, a uniqu* 단일 이미지에서 신체-물체 접촉 정보를 활용하여 3D 인간-물체 상호작용을 복원하는 PICO 프레임워크를 제시하며, 이를 위해 신체와 물체 모두에 밀집된 3D 접촉 주석이 있는 PICO-db 데이터셋을 수집했다.
본 논문은 신체-물체 접촉이라는 새로운 관점에서 3D HOI 문제를 체계적으로 다루며, PICO-db라는 고가치 데이터셋과 확장 가능한 PICO-fit 방법을 통해 현실의 다양한 물체 클래스에 일반화되는 실용적인 해결책을 제시한다.
ResMimic: From General Motion Tracking to Humanoid Whole-body Loco-Manipulation via Residual Learning
Fig. 1: We deploy ResMimic on a Unitree G1 humanoid to demonstrate diverse whole-body loco-manipulation capabilities.
 *Fig. 3: Overview of ResMimic : (1) A general motion tracking policy is trained on large-scale human motion data to serve* ResMimic는 일반 모션 추적(GMT) 정책을 기반으로 효율적인 잔차 정책(residual policy)을 학습하여 인간형 로봇의 정밀한 전신 이동-조작 능력을 실현하는 이단계 잔차학습 프레임워크이다.
ResMimic는 대규모 사전훈련 GMT 정책과 효율적 잔차 정책의 결합으로 인간형 로봇의 정밀한 전신 이동-조작을 실현한 혁신적 프레임워크이며, 맞춤형 보상 설계와 광범위한 실증으로 인간형 로봇 제어 분야에 중요한 기여를 한다.
A Survey of Behavior Foundation Model: Next-Generation Whole-Body Control System of Humanoid Robots
본 논문은 휴머노이드 로봇의 전신 제어(WBC)를 위한 행동 기초 모델(BFM)의 발전과 응용을 종합적으로 조사하며, 대규모 사전학습을 통해 재사용 가능한 행동 기초를 학습하여 다양한 작업에 빠르게 적응할 수 있는 차세대 제어 시스템을 제시한다.
본 논문은 휴머노이드 로봇 제어의 역사적 진화를 명확히 하고 BFM을 차세대 통합 제어 패러다임으로 체계적으로 정의하여, 로봇 제어 커뮤니티에 명확한 비전과 구조화된 개요를 제공하는 가치 높은 조사 논문이다. 다만 구체적인 기술적 혁신과 실세계 검증 결과는 추가 개발이 필요하다.
AMP: Adversarial Motion Priors for Stylized Physics-Based Character Control
 *Fig. 2. Schematic overview of the system. Given a motion dataset defining a* 물리 기반 캐릭터 애니메이션에서 adversarial motion prior를 학습하여 비구조화된 모션 클립 데이터셋으로부터 자동으로 스타일을 추출하고, 간단한 보상 함수로 정의된 고수준 태스크 목표를 달성하면서도 자연스러운 움직임을 생성하는 방법을 제안한다.
본 논문은 adversarial motion prior를 통해 비구조화 모션 데이터의 자동 활용을 실현한 물리 기반 캐릭터 애니메이션 분야의 중요한 기여로, 모션 선택 메커니즘 설계의 부담을 제거하면서도 최첨단 성능을 달성하며 게임, 영상, 로봇 등 다양한 응용 분야에 실질적 가치를 제공한다.
ASE: Large-Scale Reusable Adversarial Skill Embeddings for Physically Simulated Characters
Fig. 1. Our framework enables physically simulated characters to learn versatile and reusable skill embeddings from larg
 *Fig. 1. Our framework enables physically simulated characters to learn versatile and reusable skill embeddings from larg* 대규모 비정형 모션 데이터셋으로부터 adversarial imitation learning과 unsupervised reinforcement learning을 결합하여 물리 시뮬레이션 캐릭터의 재사용 가능한 스킬 임베딩을 학습하는 데이터 기반 프레임워크를 제시한다. 학습된 스킬 임베딩은 다양한 새로운 과제에 효과적으로 전이되며 자연스러운 행동을 합성한다.
본 논문은 adversarial imitation learning과 information maximization을 결합하여 대규모 비정형 모션 데이터로부터 재사용 가능한 스킬 임베딩을 학습하는 혁신적인 프레임워크를 제시한다. 십 년 규모의 대규모 사전 학습과 탁월한 전이 성능으로 물리 기반 캐릭터 애니메이션 분야에 significant contribution을 제공한다.
CRISP: Contact-Guided Real2Sim from Monocular Video with Planar Scene Primitives
 *Figure 2: CRISP pipeline. Given a casual RGB video (left), CRISP reconstructs scene geometry* 단안 비디오에서 planar primitive 기반 scene geometry 복원과 human motion 추정을 통해 물리 시뮬레이션 가능한 human-scene reconstruction을 수행하는 real-to-sim 파이프라인을 제안한다.
CRISP는 planar primitive 기반의 간단하면서도 효과적인 real-to-sim 파이프라인으로, 기존 human-scene reconstruction의 근본적 문제(simulation incompatibility)를 physics 기반 검증으로 해결하며, substantial empirical improvement와 in-the-wild generalization을 통해 embodied AI 분야에 실질적 기여를 한다.
HumanX: Toward Agile and Generalizable Humanoid Interaction Skills from Human Videos
Fig. 1: HumanX enables diverse interaction skills through two core components. XGen synthesizes and augments humanoid in
 *Fig. 1: HumanX enables diverse interaction skills through two core components. XGen synthesizes and augments humanoid in* HumanX는 인간 비디오로부터 휴머노이드 로봇의 상호작용 스킬을 학습하는 전체 스택 프레임워크로, XGen 데이터 생성 파이프라인과 XMimic 모방 학습 프레임워크의 두 가지 핵심 컴포넌트를 통합하여 과제별 보상 설계 없이 일반화 가능한 현실 세계 스킬을 습득한다.
HumanX는 물리 기반 데이터 합성과 일반화 우선 모방 학습을 결합하여 단일 비디오로부터 현실 세계 휴머노이드 로봇의 다양한 상호작용 스킬을 효율적으로 습득하는 획기적인 방법론을 제시하며, 8배 이상의 일반화 성능 향상과 적응형 행동 시연으로 로보틱스 분야에 상당한 기여를 한다.
KungfuBot: Physics-Based Humanoid Whole-Body Control for Learning Highly-Dynamic Skills
Figure 1: An overview of PBHC that includes three core components: (a) motion extraction from
 *Figure 1: An overview of PBHC that includes three core components: (a) motion extraction from* 본 논문은 물리 기반 인간형 로봇 제어 프레임워크(PBHC)를 제안하여 쿵푸, 댄싱 등 고도로 동적인 인간 행동을 모방하도록 학습하는 방법을 제시한다. 다단계 모션 처리와 적응형 모션 추적을 통해 기존 방법보다 현저히 낮은 추적 오차를 달성하고 실제 로봇에 배포된다.
본 논문은 물리 기반 모션 처리, 적응형 bi-level optimization 커리큘럼, 비대칭 actor-critic 구조를 결합한 포괄적 프레임워크로 고도로 동적인 인간형 로봇 제어 문제를 체계적으로 해결한다. 실제 로봇 배포 성공과 기존 방법 대비 현저한 성능 향상은 강력한 기술적 기여를 입증하며, 인간형 로봇의 동적 행동 학습 분야에서 중요한 진전을 이룬다.
Learning Athletic Humanoid Tennis Skills from Imperfect Human Motion Data (LATENT)
Figure 1 (a) The humanoid performs multi-shot rallies with a human player using different stroke types across various co
 *Figure 2 Overview of LATENT. (a) We pre-train a motion tracker on collected imperfect human motion data. (b) We construc* LATENT는 불완전한 인간 모션 데이터(5시간 분량의 테니스 프리미브)로부터 수정 가능한 잠재 행동 공간을 구성하고, 고수준 정책으로 이를 보정·합성하여 휴머노이드 로봇이 인간과의 멀티샷 테니스 랠리를 수행하도록 학습하는 시스템이다.
본 논문은 불완전한 모션 데이터로부터 athletic humanoid 스포츠 기술을 학습하는 실질적이고 창의적인 시스템을 제시하며, correctable latent space와 latent action barrier라는 두 가지 novel design으로 imperfect data의 한계를 효과적으로 극복했다. Real-world humanoid 로봇에서 인간과의 멀티샷 테니스 랠리를 성공적으로 구현한 점이 이 분야의 중요한 이정표이다.
MaskedMimic: Unified Physics-Based Character Control Through Masked Motion Inpainting
Fig. 1. We present MaskedMimic, a versatile control model that enables physically simulated characters to generate diver
 *Fig. 1. We present MaskedMimic, a versatile control model that enables physically simulated characters to generate diver* MaskedMimic은 motion inpainting 문제로 physics-based character control을 재정의하여, 마스킹된 keyframe, text, object 등 다양한 partial 조건으로부터 통합된 단일 모델이 전신 물리 기반 애니메이션을 생성할 수 있게 한다.
MaskedMimic은 motion inpainting이라는 우아한 재정의를 통해 physics-based character control의 versatility 문제를 근본적으로 해결하며, 단일 unified model로 diverse control modalities를 지원하는 breakthrough를 이루었다. 실제 응용 및 확장성 측면에서의 평가는 필요하지만, character animation의 패러다임을 크게 전환할 수 있는 높은 impact의 연구이다.
Mimicking-Bench: A Benchmark for Generalizable Humanoid-Scene Interaction Learning via Human Mimicking
Figure 1. Mimicking-Bench is the first benchmark for learning generalizable humanoid-scene interaction skills via mimick
 *Figure 1. Mimicking-Bench is the first benchmark for learning generalizable humanoid-scene interaction skills via mimick* 인간의 모션 데이터를 활용한 휴머노이드 로봇의 3D 장면 상호작용 학습을 위한 첫 번째 종합 벤치마크인 Mimicking-Bench를 제시하며, 23K개의 인간 상호작용 모션과 11K개의 다양한 객체 형상을 포함한다.
Mimicking-Bench는 인간 모션 데이터의 대규모 다양성을 활용한 휴머노이드-장면 상호작용 학습을 위한 첫 종합 벤치마크로, 신체 모방 기반의 로봇 스킬 학습 연구를 체계적으로 진행할 수 있는 중요한 기여를 제공한다.
Perceptive Humanoid Parkour: Chaining Dynamic Human Skills via Motion Matching
Fig. 1: Perceptive Humanoid Parkour (PHP) enables a Unitree G1 humanoid robot to execute highly dynamic, long-horizon
 *Fig. 2: Perceptive Humanoid Parkour overview. Atomic parkour skills are composed into long-horizon kinematic reference* Motion matching을 통해 인간의 동작 데이터를 원자적 기술로 합성하고, DAgger와 RL을 결합한 teacher-student 파이프라인으로 단일 깊이 기반 정책으로 증류하여 휴머노이드 로봇이 복잡한 장애물 코스에서 자율적으로 장시간 파쿠르를 수행하도록 한다.
본 연구는 motion matching과 hybrid DAgger-RL 증류를 통해 희소한 인간 동작 데이터로부터 복잡한 파쿠르 기술을 효과적으로 합성 및 학습하여 휴머노이드 로봇의 동적 환경 적응 능력을 획기적으로 향상시켰으며, 실제 로봇에서의 강인한 구현과 zero-shot sim-to-real 전이는 높은 실용적 가치를 입증한다.
Learning Whole-Body Humanoid Locomotion via Motion Generation and Motion Tracking
 *Fig. 2. Overview of the training framework. (a) Data Collection & Curation: whole-body robot motions are obtained from h* Diffusion 기반 motion generation과 RL 기반 motion tracking을 결합하여 지형 인식 whole-body humanoid locomotion을 실현하고 Unitree G1 로봇에 실제 배포했다.
이 논문은 diffusion-based motion generation과 RL-based tracking을 결합하여 실제 humanoid 로봇에서 처음으로 whole-body terrain-aware locomotion을 성공적으로 구현한 획기적 연구이다. 강력한 hardware 검증과 명확한 방법론을 통해 높은 수준의 완성도를 보여주며, humanoid 로봇 제어 분야에 의미 있는 기여를 제시한다.
PRIMAL: Physically Reactive and Interactive Motor Model for Avatar Learning
Figure 1. PRIMAL is a novel generative real-time 3D character animation system that works in Unreal Engine. The avatar r
 *Figure 1. PRIMAL is a novel generative real-time 3D character animation system that works in Unreal Engine. The avatar r* PRIMAL은 두 단계 학습 패러다임으로 아바타의 모터 시스템을 generative motion model로 구현하여, 물리적으로 반응성 있고 제어 가능하며 실시간 상호작용이 가능한 3D 캐릭터 애니메이션을 실현한다.
PRIMAL은 짧은 시간 척도에서의 physics 지배성이라는 통찰력으로 unsupervised diffusion model을 통해 실시간 반응성과 물리적 사실성을 동시에 달성한 혁신적 접근이며, Unreal Engine 구현으로 실제 응용 가능성을 입증한 탁월한 연구이다.
SimGenHOI: Physically Realistic Whole-Body Humanoid-Object Interaction via Generative Modeling and Reinforcement Learning
Figure 1: With the condition of text prompt, object geometry,
 *Figure 2: Our proposed framework uses a diffusion model for key action generation and reinforcement learning to train* SimGenHOI는 Diffusion Transformers 기반의 생성 모델과 강화학습 기반의 접촉-인식 제어 정책을 결합하여 물리적으로 현실적인 인간형 로봇-객체 상호작용을 생성하는 통합 프레임워크이다. 상호 미세조정 전략을 통해 생성 모델과 제어 정책이 반복적으로 서로를 개선하여 장기 조작 과제의 성공률을 높인다.
본 논문은 생성 모델과 강화학습의 상호 보완적 강점을 효과적으로 결합하여 물리적으로 현실적인 장기 인간형 로봇-객체 상호작용 생성이라는 중요한 문제를 해결하였다. 특히 상호 미세조정 전략과 key action 기반 패러다임은 높은 독창성을 보여주며, 광범위한 실험을 통해 방법의 효과를 입증했으나 sim-to-real 검증이 부족한 점이 아쉽다.
StyleLoco: Generative Adversarial Distillation for Natural Humanoid Robot Locomotion
Fig. 1.
 *Fig. 1.* StyleLoco는 강화학습의 민첩성과 모션캡처 데이터의 자연스러움을 결합하기 위해 다중 discriminator를 활용한 Generative Adversarial Distillation (GAD) 프레임워크를 제안하여 인간형 로봇의 자연스러운 보행을 실현한다.
StyleLoco는 인간형 로봇 보행의 오랜 딜레마를 해결하는 창의적인 프레임워크를 제시하며, 다중 discriminator를 통한 이질적 소스의 결합과 실제 로봇에서의 성공적인 배포는 높은 실용 가치를 입증한다.
Taming Diffusion Probabilistic Models for Character Control
 *Figure 2: Conditional Autoregressive Motion Diffusion Model* Transformer 기반 Conditional Autoregressive Motion Diffusion Model (CAMDM)을 제안하여 사용자의 동적 제어 신호에 실시간으로 반응하면서 고품질의 다양한 캐릭터 애니메이션을 생성한다.
Diffusion model을 실시간 캐릭터 컨트롤에 적용하기 위한 체계적이고 실용적인 해결책을 제시한 우수한 논문으로, 별도 조건 토큰화와 classifier-free guidance의 novel한 조합이 다양성과 제어 안정성을 동시에 달성하며, 단일 모델의 다중 스타일 지원은 산업 응용 가치가 높다.
UniTracker: Learning Universal Whole-Body Motion Tracker for Humanoid Robots
Fig. 1: We deploy our UniTracker on a real humanoid robot,
 *Fig. 2: An overview of UniTracker: In Stage 1, we train a teacher policy using oracle states via goal-conditioned* UniTracker는 CVAE 기반 세 단계 학습 프레임워크를 통해 부분 관측 조건에서도 다양하고 일관성 있는 전신 동작 추적을 실현하는 휴머노이드 로봇 제어 정책이다.
UniTracker는 CVAE 기반 증류와 전역 맥락 정렬을 통해 기존 teacher-student 프레임워크의 핵심 한계를 우아하게 해결하며, 실제 로봇에서 8,000개 이상의 동작 추적을 성공시킨 강력한 기여이다. 방법론의 창의성, 실제 배포 검증, 그리고 실용적 영향 면에서 높은 평가를 받을 만한 논문이다.
CLoSD: Closing the Loop between Simulation and Diffusion for multi-task character control
Figure 1: CLoSD is a multi-task physics-based RL controller, capable of performing object inter-
 *Figure 1: CLoSD is a multi-task physics-based RL controller, capable of performing object inter-* CLoSD는 motion diffusion 모델과 RL 기반 physics 시뮬레이션을 폐쇄 루프로 연결하여, 텍스트 프롬프트와 타겟 위치로 제어되는 다중 태스크 캐릭터 제어를 실현한다.
CLoSD는 diffusion 기반 계획과 RL 기반 추적을 폐쇄 루프로 통합하여 텍스트 제어와 물리적 그럴듯성을 동시에 달성하는 창의적인 접근법을 제시하며, 실시간 다중 태스크 캐릭터 제어의 새로운 가능성을 보여준다.
Diffusion Forcing for Multi-Agent Interaction Sequence Modeling
Figure 1. A Generative Model for Multi-Agent Interaction. We propose Multi-Agent Diffusion Forcing Transformer (MAGNet),
 *Figure 1. A Generative Model for Multi-Agent Interaction. We propose Multi-Agent Diffusion Forcing Transformer (MAGNet),* MAGNet은 diffusion forcing을 활용한 통합 autoregressive diffusion framework로, 다양한 multi-agent interaction 시나리오를 하나의 모델로 처리하며 dyadic부터 polyadic 상황까지 확장 가능한 long-horizon motion generation을 수행한다.
MAGNet은 multi-agent motion generation의 근본적인 문제인 task fragmentation을 해결하는 우아한 통합 프레임워크를 제시하며, relational representation과 diffusion forcing의 조합으로 polyadic scenario까지 자연스럽게 확장 가능한 점이 탁월하다. 다만 polyadic scenario의 정량적 평가 강화와 practical deployment에 필요한 robustness 평가가 향후 과제이다.
Feature-Based vs. GAN-Based Learning from Demonstrations: When and Why
Figure 1: DeepMimic-style feature-based methods. The policy receives dense, per-frame rewards
 *Figure 1: DeepMimic-style feature-based methods. The policy receives dense, per-frame rewards* Feature-based와 GAN-based 학습 방법론을 비교 분석하여, 각 접근법의 장단점을 명확히 하고 작업별 우선순위에 따른 방법 선택 프레임워크를 제시한다.
이 survey는 시연 학습의 두 주요 패러다임을 원칙적으로 비교하고, 실무자들이 작업 특성에 맞는 방법을 선택할 수 있도록 하는 개념적 프레임워크를 제공하는 가치 있는 기여이다. 구조화된 모션 표현의 수렴점을 강조함으로써 향후 연구의 방향성을 제시한다.
GENMO: A GENeralist Model for Human MOtion
Figure 1. GENMO unifies human motion estimation and generation in a single framework and supports diverse conditioning s
 *Figure 1. GENMO unifies human motion estimation and generation in a single framework and supports diverse conditioning s* GENMO는 인간 동작 추정과 생성을 단일 프레임워크에서 통합하는 generalist 모델로, 동작 추정을 제약 조건이 있는 동작 생성으로 재구성하여 정확한 추정과 다양한 생성을 동시에 달성한다.
GENMO는 동작 추정과 생성의 오랫동안의 분리를 혁신적으로 통합하는 첫 번째 generalist 모델로, dual-mode 훈련과 estimation-guided 목표를 통해 두 작업 간 상승 효과를 효과적으로 달성하며, 다양한 benchmark에서 state-of-the-art 성능을 입증한다.
InterMimic: Towards Universal Whole-Body Control for Physics-Based Human-Object Interactions
Figure 1. InterMimic enables physically simulated humans to perform interactions with dynamic and diverse objects. It su
 *Figure 2. Our two-stage pipeline: (i) training each teacher pol-* InterMimic은 교사-학생 증류 및 RL 미세조정을 통해 불완전한 MoCap 데이터로부터 다양한 동적 객체와의 전신 상호작용을 학습할 수 있는 물리 기반 제어 정책 프레임워크이다.
InterMimic은 불완전한 대규모 MoCap 데이터로부터 다양한 동적 객체와의 전신 상호작용을 학습하는 첫 통합 프레임워크로, 교사-학생 증류와 RL 미세조정의 창의적 결합을 통해 물리 기반 상호작용 애니메이션의 새로운 기준을 제시한다.
InterPrior: Scaling Generative Control for Physics-Based Human-Object Interactions
Figure 1. InterPrior is a versatile generative controller instantiated as a goal-conditioned policy that controls a simu
 *Figure 1. InterPrior is a versatile generative controller instantiated as a goal-conditioned policy that controls a simu* InterPrior는 대규모 모방 사전학습과 강화학습 미세조정을 통해 물리 기반 인간-객체 상호작용을 위한 확장 가능한 생성형 제어기를 학습하는 프레임워크로, 고수준 의도로부터 자연스러운 전신 협응과 조작을 생성한다.
InterPrior는 distillation과 RL의 시너지를 통해 물리 기반 인간-객체 상호작용의 확장 가능한 생성형 제어 문제를 우아하게 해결하며, 다양한 목표 형식 지원, 강력한 실패 회복, 미분포 일반화 능력으로 인해 휴머노이드 로봇 제어 분야의 실질적 진전을 이루었다.
Learning Perceptive Humanoid Locomotion over Challenging Terrain
Fig. 1: Deployment to outdoor environments. We deployed the model in outdoor challenging terrains. Our controller can
 *Fig. 2: Training of Humanoid Perception Controller consists of two stages: (1) Oracle Policy Training generates referenc* 인간형 로봇이 소음이 있는 센서 데이터로부터 지형을 인식하고 거친 지형을 안정적으로 보행할 수 있도록, teacher-student distillation과 variational information bottleneck을 결합한 세계 모델 기반 방법을 제안한다.
본 논문은 teacher-student distillation과 world model 기반 센서 디노이징을 효과적으로 결합하여 인간형 로봇의 실제 환경 보행 성능을 크게 향상시켰다. 2 km의 다양한 지형 횡단 성과와 체계적인 방법론은 높은 기술적 가치를 가지며, 실제 로봇 배포를 위한 중요한 진전을 보여준다.
NoMaD: Goal Masked Diffusion Policies for Navigation and Exploration
Fig. 1: NoMaD is the first flexibly conditioned diffusion model of robot actions that can perform both goal-conditioned
 *Fig. 1: NoMaD is the first flexibly conditioned diffusion model of robot actions that can perform both goal-conditioned * NoMaD는 goal masking을 활용한 unified diffusion policy로 로봇의 목표 지향 네비게이션과 목표 무관 탐색을 단일 모델로 처리하며, Transformer 기반 정책과 diffusion model decoder를 결합하여 미지의 환경에서 효과적인 네비게이션을 구현한다.
NoMaD는 goal masking과 diffusion policy를 결합하여 exploration과 goal-seeking을 통합한 혁신적 아키텍처를 제시하며, ViNT 대비 25% 이상의 성능 향상과 15배 효율성 개선을 실제 로봇에서 달성하여 로봇 네비게이션 분야에 상당한 기여를 한다.
PhysDiff: Physics-Guided Human Motion Diffusion Model
Figure 1. Our PhysDiff model generates physically-plausible motions using a physics-based motion projection in the diffu
 *Figure 1. Our PhysDiff model generates physically-plausible motions using a physics-based motion projection in the diffu* PhysDiff는 diffusion 과정에 물리 기반 motion projection 모듈을 통합하여 physically-plausible human motion을 생성하는 physics-guided motion diffusion 모델이다. 기존 motion diffusion 모델의 floating, foot sliding, ground penetration 같은 물리적 artifacts를 제거한다.
PhysDiff는 human motion generation에 physics 제약을 systematically 통합하여 physically-plausible motion 생성의 핵심 문제를 해결한 혁신적 연구이다. Iterative projection 전략과 철저한 실험 분석이 학계에 중요한 기여를 제공하며, 실제 animation/VR 응용의 현실화를 크게 앞당긴다.
CF-VLA: Efficient Coarse-to-Fine Action Generation for Vision-Language-Action Policies
Figure 1: Teaser of CF-VLA. Standard flow matching requires multiple iterative steps to recover action structure from un
 *Figure 1: Teaser of CF-VLA. Standard flow matching requires multiple iterative steps to recover action structure from un* 본 논문은 flow matching 기반 VLA 정책의 비효율성을 해결하기 위해 coarse-to-fine 두 단계 생성 프레임워크를 제안한다. 첫 번째 단계에서는 Gaussian 노이즈를 action-prior-guided 초기화로 변환하고, 두 번째 단계에서는 단일 스텝 국소 정교화를 수행하여 추론 지연시간을 75.4% 감소시키면서 성능을 유지한다.
CF-VLA는 flow-based VLA 정책의 구조적 비효율성을 명확하게 파악하고, coarse-to-fine 분해를 통해 실용적이고 효과적인 해결책을 제시한다. 75.4%의 지연시간 감소와 실로봇 83.0% 성공률은 강력한 경험적 검증을 보여주며, 방법의 플러그-앤-플레이 특성으로 인해 광범위한 적용성을 가진다. 다만 이론적 분석과 더 깊은 통찰이 추가되면 더욱 완성도 있는 연구가 될 것이다.
GENMO: A GENeralist Model for Human MOtion
Figure 1. GENMO unifies human motion estimation and generation in a single framework and supports diverse conditioning s
 *Figure 1. GENMO unifies human motion estimation and generation in a single framework and supports diverse conditioning s* 본 논문은 인간 모션 생성과 추정을 단일 diffusion 기반 프레임워크에서 통합하는 GENMO를 제안한다. 모션 추정을 제약이 있는 모션 생성으로 재정의하고, dual-mode 학습 패러다임을 통해 정확한 global motion estimation과 다양한 모션 생성을 동시에 달성한다.
본 논문은 인간 모션 생성과 추정을 통합하는 새로운 관점과 실용적인 솔루션을 제시하는 강력한 연구이다. Dual-mode training paradigm과 estimation-guided objective는 창의적이며, 다양한 조건 신호의 유연한 처리는 실제 애플리케이션에서 높은 가치를 가진다. 다만 상세한 정량적 평가와 계산 효율성 분석의 강화가 필요하다.
RGMP: Recurrent Geometric-prior Multimodal Policy for Generalizable Humanoid Robot Manipulation
Figure 1: Overview of our framework. By applying seman-
 *Figure 2: Pipeline of RGMP. Upon receiving a speech command, the robot utilizes GSS to identify and localize the target* 기하학적 추론과 데이터 효율성을 결합한 RGMP는 humanoid robot 조작을 위해 Geometric-prior Skill Selector와 Adaptive Recursive Gaussian Network를 통합하여 87% 성공률과 5배 데이터 효율을 달성한다.
RGMP는 기하학적 추론과 데이터 효율성의 결합을 통해 humanoid robot 조작의 중요한 문제를 해결하며, GSS와 ARGN의 설계가 정교하고 실제 로봇에서 strong empirical result를 달성한 우수한 연구이다. 다만 기하학적 제약의 자동화와 더 광범위한 실증 평가가 이루어진다면 더욱 강력할 것으로 판단된다.
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Fig. 1: Overview of RoboCasa. RoboCasa is a simulation framework for training generalist robot agents. Four pillars unde
 *Fig. 1: Overview of RoboCasa. RoboCasa is a simulation framework for training generalist robot agents. Four pillars unde* RoboCasa는 kitchen 환경에 중점을 둔 대규모 로봇 시뮬레이션 프레임워크로, 생성형 AI를 활용하여 다양한 3D 자산과 task를 확보하고 100K 이상의 synthetic trajectory로 generalist robot 학습을 가능하게 한다.
RoboCasa는 generative AI를 활용하여 robot learning을 위한 대규모 realistic simulation을 구축한 의미 있는 contribution이며, 실제 real-world transfer 성공을 보여줌으로써 sim-to-real robot learning의 실질적 경로를 제시한다. 다만 현재 kitchen 환경 집중과 제한된 real-world 검증은 향후 개선이 필요하다.
VIRAL: Visual Sim-to-Real at Scale for Humanoid Loco-Manipulation
Figure 1. Center: Unitree G1 humanoid performing loco-manipulation, walking between tables to place and pick objects for
 *Figure 2. VIRAL teacher-student pipeline. Phase 1: In simulation, a privileged RL teacher policy πteacher receives full-* VIRAL은 humanoid robot의 loco-manipulation을 시뮬레이션에서 학습하고 zero-shot으로 실제 로봇에 배포하는 visual sim-to-real 프레임워크이며, teacher-student 구조와 대규모 GPU 컴퓨팅을 활용하여 RGB 기반 정책을 통해 54개 사이클의 연속적인 객체 이동을 달성했다.
본 논문은 humanoid loco-manipulation에 대한 시뮬레이션 기반 접근의 실현 가능성을 대규모 GPU 컴퓨팅과 체계적인 설계를 통해 실증한 중요한 연구로, teacher-student 프레임워크와 visual domain randomization의 조합이 zero-shot sim-to-real 전이를 가능하게 함을 보여준다.
DPL: Depth-only Perceptive Humanoid Locomotion via Realistic Depth Synthesis and Cross-Attention Terrain Reconstruction
Fig. 1: Overview of the proposed teacher–student distillation framework for humanoid perceptive locomotion. (A) The stud
 *Fig. 1: Overview of the proposed teacher–student distillation framework for humanoid perceptive locomotion. (A) The stud* 휴머노이드 로봇의 깊이 이미지만을 사용한 지형 인식 보행을 위해, 현실적인 깊이 합성과 cross-attention transformer를 결합하여 사전 학습된 blind policy를 기반으로 효율적인 정책 학습을 가능하게 한다.
이 논문은 humanoid 로봇의 깊이 기반 보행에서 sim-to-real gap과 효율성 문제를 체계적으로 해결하는 통합 프레임워크를 제시하며, self-occlusion-aware 깊이 합성, cross-modal transformer, end-to-end fine-tuning의 조합으로 높은 독창성과 실용성을 달성했다. 실제 로봇 검증과 명확한 기술 기여가 돋보이는 우수한 연구이다.
GaussGym: An open-source real-to-sim framework for learning locomotion from pixels
Figure 1: GaussGym constructs photorealistic worlds from various data sources and renders them
 *Figure 1: GaussGym constructs photorealistic worlds from various data sources and renders them* 3D Gaussian Splatting을 IsaacGym 같은 벡터화된 물리 시뮬레이터에 통합하여 초당 100,000스텝 이상의 고속 시뮬레이션과 높은 시각적 충실도를 동시에 달성하는 포토리얼리스틱 로봇 시뮬레이션 프레임워크를 제시한다.
본 논문은 3D Gaussian Splatting을 물리 시뮬레이터와 통합하여 고속성과 시각적 충실도를 동시에 달성한 획기적인 작업으로, 포토리얼리스틱 로봇 학습에 새로운 가능성을 열었다. 오픈소스 공개와 광범위한 데이터 지원으로 향후 연구의 기반이 될 것으로 기대된다.
Generalizable Geometric Prior and Recurrent Spiking Feature Learning for Humanoid Robot Manipulation
Fig. 1. Overview of our framework. By integrating geometric common-
 *Fig. 1. Overview of our framework. By integrating geometric common-* RGMP-S는 기하학적 선행 정보와 spiking 신경망을 결합하여 인간형 로봇 조작을 위한 고수준 의미론적 추론과 저수준 동작 생성을 동시에 달성하는 프레임워크다.
RGMP-S는 기하학적 추론과 spiking neural network을 창의적으로 결합하여 인간형 로봇 조작에서 기술 가능성 검증과 데이터 효율성이라는 두 가지 근본적 도전을 동시에 해결한다. 다양한 실제 로봇 플랫폼에서의 광범위한 검증과 19% 성능 향상, 5배 데이터 효율성 개선은 높은 실용적 가치를 입증한다.
Now You See That: Learning End-to-End Humanoid Locomotion from Raw Pixels
Fig. 1: Overview. Our end-to-end vision-based humanoid locomotion policy enables robust traversal across diverse challen
 *Fig. 1: Overview. Our end-to-end vision-based humanoid locomotion policy enables robust traversal across diverse challen* Raw 깊이 이미지로부터 end-to-end 휴머노이드 로봇 보행을 학습하기 위해, 현실적인 depth 센서 시뮬레이션과 vision-aware behavior distillation, 그리고 terrain-specific multi-critic/multi-discriminator 학습을 결합한 프레임워크를 제시한다.
본 논문은 휴머노이드 로봇의 vision-based 보행에서 sim-to-real gap과 다양한 terrain 통합 학습의 근본적인 두 과제를 체계적으로 해결하며, 현실적인 센서 모델링과 behavior distillation, terrain-specific 학습을 결합한 창의적인 프레임워크를 제시한다. 두 개의 실제 로봇 플랫폼에서 극한 장애물부터 fine-grained 작업까지 광범위한 성능 검증을 통해 학술적·실무적 가치가 높다.
TTT-Parkour: Rapid Test-Time Training for Perceptive Robot Parkour
 *Fig. 2: TTT-Parkour. Our framework consists of three stages: (1) Pre-training: A general policy is pre-trained on divers* 본 논문은 RGB-D 입력으로부터 고충실도 메시 재구성을 통해 미지의 복잡한 지형에서 휴머노이드 로봇의 빠른 테스트 시간 파인튜닝(TTT)을 가능하게 하는 real-to-sim-to-real 프레임워크를 제안한다.
본 논문은 피드포워드 기하 재구성과 빠른 테스트 시간 파인튜닝을 통합하여 휴머노이드 로봇의 미지 복잡 지형 순회 능력을 획기적으로 향상시키는 실용적이고 혁신적인 프레임워크를 제시한다. 10분 이내의 완전 파이프라인과 강건한 sim-to-real 전이는 로봇 배포의 현실성을 크게 높인다.
RoboPlayground: 구조화된 물리 도메인을 통한 로봇 평가 민주화
Fig. 1: Language-Guided Task Generation in Structured Physical Domains. Natural language instructions are compiled into
 *Fig. 1: Language-Guided Task Generation in Structured Physical Domains. Natural language instructions are compiled into * 자연어로 로봇 조작 작업을 정의하고 재현 가능한 작업 명세로 컴파일하는 RoboPlayground 프레임워크를 제안하며, 고정 벤치마크에서 드러나지 않는 일반화 실패를 언어 기반 작업 변형을 통해 발견한다.
RoboPlayground는 로봇 평가의 민주화와 접근성을 크게 향상시키는 혁신적 접근법으로, 언어 기반 구조화된 작업 변형을 통해 고정 벤치마크가 놓치는 정책의 실제 약점을 드러낸다는 점에서 중요한 기여다. 다만 도메인 제한과 대규모 crowd-sourced 평가의 품질 관리가 실무 적용의 과제다.
RoboStriker: Hierarchical Decision-Making for Autonomous Humanoid Boxing
Figure 1. Real-world clips of humanoid boxing using RoboStriker,
 *Figure 2. Overview of RoboStriker. Stage I pretrains a motion tracker to produce physically plausible humanoid behaviors* RoboStriker는 인간 수준의 경쟁력 있는 휴머노이드 권투를 위해 높은 수준의 전략 추론과 낮은 수준의 물리적 실행을 분리하는 3단계 계층적 프레임워크를 제안한다. Motion capture 데이터로부터 학습된 동작 라이브러리를 구조화된 잠재 공간으로 압축한 후, Latent-Space NFSP를 통해 다중 에이전트 경쟁 학습을 수행한다.
RoboStriker는 embodied MARL의 근본적 모순을 처음으로 공식화하고 계층적 분해를 통해 실질적으로 해결하는 주요 기여를 제시한다. 물리 시뮬레이션과 실제 로봇에서 권투라는 도전적 작업을 성공적으로 달성하여, 추상 게임에서 물리 기반 로봇 시스템으로 MARL을 확장하는 중요한 마일스톤을 제공한다.
SHIELD: Safety on Humanoids via CBFs In Expectation on Learned Dynamics
Fig. 1. A humanoid robot implementing the SHIELD architecture au-
 *Fig. 1. A humanoid robot implementing the SHIELD architecture au-* SHIELD는 학습 기반 휴머노이드 로봇 컨트롤러에 안전 계층을 추가하여 실시간 제약 조건 명시와 확률적 안전 보장을 동시에 제공하는 프레임워크이다. 동적 잔차 모델과 확률적 이산 시간 제어 배리어 함수(S-DTCBF)를 통해 기존 블랙박스 RL 정책을 재학습 없이 안전화한다.
SHIELD는 학습 기반 humanoid 컨트롤러의 실제 배포를 위한 현실적이고 실용적인 안전 보장 방법을 제시하며, 데이터 기반과 모델 기반 방법의 간격을 효과적으로 연결한다. 실제 로봇 실험 검증과 함께 이론적 안전 보장을 제공하여 로봇 안전 연구에 상당한 기여를 한다.
StageACT: Stage-Conditioned Imitation for Robust Humanoid Door Opening
Fig. 1: Autonomous door opening by the G1 humanoid robot in a real-world office. Time-synchronized front (top) and back
 *Fig. 3: The StageACT framework combines stage-level guidance with low-* StageACT는 휴머노이드 로봇의 도어 오픈 작업을 위해 저수준 정책에 작업 단계(task stage) 정보를 조건으로 추가한 단계-조건부 모방 학습 프레임워크를 제안하며, 부분 관찰성 환경에서 강건성을 크게 향상시킨다.
이 논문은 휴머노이드 도어 오픈이라는 도전적인 실제 문제에서 단순하지만 효과적인 단계 조건화 방식으로 현저한 성능 향상을 달성했으며, 장 지평선 부분 관찰 작업에 대한 실질적 시사점을 제공한다. 다만 일반화와 신뢰성 관점에서 추가 검증이 필요하고, 수동 라벨링 프로세스의 자동화가 필요하다.
Task and Motion Planning for Humanoid Loco-manipulation
Fig. 1: Overview of the proposed framework. Second panel: the task and the scene are translated into our symbolic framew
 *Fig. 1: Overview of the proposed framework. Second panel: the task and the scene are translated into our symbolic framew* 본 논문은 접촉 모드의 통일된 표현을 통해 로봇 이동과 조작을 함께 계획하는 최적화 기반 TAMP 프레임워크를 제시하며, 인형로봇의 장시간 복잡한 로코-조작 행동 생성을 가능하게 한다.
본 논문은 인형로봇의 동적 로코-조작 계획이라는 도전적 문제에 대해 접촉 수준의 통일된 기호 표현을 통해 이론적으로 견고한 TAMP 솔루션을 제시하며, 전신 동역학과 구동 제약을 포함한 점에서 학술적 기여도가 높다. 다만 실제 로봇 실험 검증과 대규모 문제에 대한 계산 효율 평가가 추가되면 영향력을 더욱 높일 수 있을 것으로 판단된다.
Coordinated Humanoid Manipulation with Choice Policies
Fig. 1: Coordinated Humanoid Manipulation. We present a teleoperation system and a policy learning framework for
 *Fig. 1: Coordinated Humanoid Manipulation. We present a teleoperation system and a policy learning framework for* 휴머노이드 로봇의 전신 협조 조작을 위해 모듈식 텔레오퍼레이션 인터페이스와 Choice Policy라는 모방 학습 방식을 결합한 시스템을 제시한다. Choice Policy는 다중 후보 행동을 생성하고 점수를 학습하여 멀티모달 행동을 효율적으로 모델링한다.
이 논문은 휴머노이드 전신 조작을 위한 실용적이고 확장 가능한 시스템을 제시하며, Choice Policy는 멀티모달 행동 모델링에서 효율성과 표현력의 균형을 잘 달성했다. 모듈식 텔레오퍼레이션과 함께 실제 로봇 작업에서의 성공적 검증은 고가치의 실제 기여를 보여준다.
Genie Sim 3.0 : A High-Fidelity Comprehensive Simulation Platform for Humanoid Robot
Fig. 1: Overview of Genie Sim 3.0. Genie Sim 3.0 is a full-cycle robotic simulation platform that integrates environment
 *Fig. 1: Overview of Genie Sim 3.0. Genie Sim 3.0 is a full-cycle robotic simulation platform that integrates environment* Genie Sim 3.0은 LLM 기반 장면 생성, VLM 기반 자동 평가, 10,000시간 이상의 합성 데이터를 제공하는 휴머노이드 로봇 통합 시뮬레이션 플랫폼이다.
Genie Sim 3.0은 LLM/VLM과 로봇 시뮬레이션을 통합한 혁신적 플랫폼으로, 자동화된 장면 생성, 대규모 합성 데이터, 다차원 평가 벤치마크를 통해 로봇 학습 개발 사이클을 크게 가속화할 수 있는 높은 기여도의 연구이다.
Heracles: Bridging Precise Tracking and Generative Synthesis for General Humanoid Control
Figure 1: Heracles synthesizes diverse, anthropomorphic recovery motions via state-conditioned diffusion. In
 *Figure 1: Heracles synthesizes diverse, anthropomorphic recovery motions via state-conditioned diffusion. In* Heracles는 state-conditioned diffusion 미들웨어를 통해 정밀한 모션 추적과 생성적 적응을 통합하여 휴머노이드 로봇이 극단적인 외부 교란 상황에서도 자연스러운 복구 동작을 수행하도록 한다.
Heracles는 state-conditioned diffusion을 활용한 혁신적인 제어 미들웨어를 제시하여 휴머노이드 로봇의 정밀 추적과 생성적 적응성의 오래된 딜레마를 우아하게 해결하며, 물리적 로봇 실험을 통한 강건한 성능 검증으로 실질적 가치를 입증한다.
HiWET: Hierarchical World-Frame End-Effector Tracking for Long-Horizon Humanoid Loco-Manipulation
Fig. 1.
 *Fig. 2.* HiWET는 휴머노이드 로봇의 장기 조작 작업을 위해 세계 좌표계 기준 end-effector 추적을 명시적으로 수행하는 계층적 강화학습 프레임워크를 제안한다. Kinematic Manifold Prior를 통해 탐색 공간을 감소시키고 동역학적 안정성을 유지하면서 정밀한 추적을 달성한다.
HiWET는 world-frame 중심 재정의와 Kinematic Manifold Prior를 통해 휴머노이드 조작에서 정밀하고 안정적인 추적을 실현한 창의적 연구이다. 실제 로봇 검증과 12.4 mm의 추적 정확도로 실질적 기여를 입증하였으며, 계층적 설계와 명시적 공간 인터페이스는 장기 로컬로조작 문제의 효과적 해결 방안을 제시한다.
HumanoidGen: Data Generation for Bimanual Dexterous Manipulation via LLM Reasoning
Figure 1: The overview of HumanoidGen. It includes spatial annotations, scene generation, constraint
 *Figure 1: The overview of HumanoidGen. It includes spatial annotations, scene generation, constraint* HumanoidGen은 LLM 추론과 원자적 손 동작을 활용하여 휴머노이드 로봇의 양손 정교한 조작을 위한 시뮬레이션 데이터와 시연을 자동으로 생성하는 프레임워크이다. MCTS 기반 추론 강화를 통해 장시간 작업과 불충분한 주석에서의 계획 능력을 개선한다.
HumanoidGen은 LLM 기반 자동화, 원자적 손 동작 설계, MCTS 강화 추론의 조합으로 휴머노이드 로봇의 양손 정교한 조작 데이터 생성에 새로운 접근법을 제시하며, HGen-Bench 벤치마크와 함께 데이터 스케일링의 성능 향상을 실증하여 실무적 가치가 높다. 다만 공간 주석의 수동 작성 부담과 sim-to-real 검증 부재가 확장성을 제한한다.
HYPERmotion: Learning Hybrid Behavior Planning for Autonomous Loco-manipulation
Figure 1: HYPERmotion enables the humanoid robot to learn, plan, and select behaviors to
 *Figure 2: Overview of HYPERmotion.We decompose the framework into four sectors: Motion* HYPERmotion은 강화학습과 최적화를 결합하여 휴머노이드 로봇이 자연어 명령으로부터 복잡한 로코-조작 작업을 자율적으로 수행할 수 있도록 하는 계층적 행동 계획 프레임워크이다. LLM과 VLM을 활용하여 의미론적 지시를 원시 행동 기술로 변환하고 동적 환경에서 형태론적 선택을 수행한다.
HYPERmotion은 고자유도 휴머노이드 로봇의 자율적 로코-조작을 자연어 명령으로부터 수행하는 포괄적이고 실용적인 프레임워크를 제시하며, 특히 LLM/VLM과 로봇 제어의 통합, 실제 로봇 배포 실현은 해당 분야에서 의미 있는 진전을 보여준다. 다만 계산 복잡도, 환경 적응성, 완전한 자동화 측면에서 개선 여지가 있다.
Learning to Look: Seeking Information for Decision Making via Policy Factorization
Figure 1: DISaM for tasks with information-seeking behavior. To make the right decision in a
 *Figure 1: DISaM for tasks with information-seeking behavior. To make the right decision in a* 로봇이 조작 작업을 수행하기 위해 필요한 정보를 능동적으로 탐색하는 문제를 factorized Contextual MDP로 정의하고, 정보 탐색 정책과 정보 활용 정책으로 분리된 dual-policy 솔루션 DISaM을 제안한다.
정보 탐색과 조작의 분리를 통해 장지평 POMDP를 효율적으로 해결하는 우아한 솔루션을 제시하며, 광범위한 실험 검증으로 실용성을 입증한 강력한 논문이다. 다만 다단계 탐색 최적화와 완전 자동학습 가능성 탐색이 향후 과제이다.
MetaWorld-X: Hierarchical World Modeling via VLM-Orchestrated Experts for Humanoid Loco-Manipulation
 *Fig. 2: MetaWorld-X achieves natural humanoid control through the dynamic orchestration of expert policies guided by a* 휴머노이드 로봇의 복잡한 로코-매니퓰레이션 제어를 Specialized Expert Policy(SEP)와 VLM 기반 Intelligent Routing Mechanism(IRM)으로 분해-통합하는 계층적 프레임워크를 제안한다. 인간 모션 프라이어와 의미적 라우팅을 결합하여 자연스럽고 안정적인 동작을 생성한다.
MetaWorld-X는 human motion priors, world models, VLM 기반 의미적 라우팅을 창의적으로 결합하여 고자유도 휴머노이드 로코-매니퓰레이션 제어의 중요한 문제(스킬 간섭, 부자연스러운 동작, 낮은 일반화)를 효과적으로 해결한다. Humanoid-bench에서의 강력한 실험 결과와 명확한 방법론 제시에도 불구하고, 실제 로봇 검증 부재가 임팩트를 제한한다.
MorphoGuard: A Morphology-Based Whole-Body Interactive Motion Controller
Figure 1: Schematic of morphology-based whole-body motion control (MorphoGuard). (A) An example of a robot
 *Figure 1: Schematic of morphology-based whole-body motion control (MorphoGuard). (A) An example of a robot* 로봇의 형태학적 표현을 기반으로 Material Point Method를 활용하여 전신 제어 네트워크 MorphoGuard를 제안. 복잡한 다중 접촉 조합을 명시적으로 관리하며 1cm의 접촉점 관리 오차를 달성.
복잡한 다중 접촉 조합을 관리하는 로봇 전신 제어의 미해결 문제를 형태학적 표현과 Material Point Method의 창의적 결합으로 우아하게 해결했으며, 높은 정확도의 실험 결과를 보여준다. 다만 단일 플랫폼 실험과 일반화 가능성에 대한 검증이 보완되면 더욱 강력한 기여가 될 것으로 기대된다.
TD-GRPC: Temporal Difference Learning with Group Relative Policy Constraint for Humanoid Locomotion
 *Fig. 2: Overview of TD-GRPC for Humanoid Locomotion: Starting from an initial state s0 encoded into latent state z0 with* 본 논문은 Humanoid Locomotion을 위해 TD-MPC 프레임워크에 Group Relative Policy Optimization (GRPO)와 trust-region constraint를 통합한 TD-GRPC를 제안하여, off-policy 학습의 불안정성과 policy mismatch 문제를 해결한다.
본 논문은 GRPO와 trust-region constraint를 통합한 TD-GRPC를 제안하여 humanoid locomotion의 off-policy 학습 안정성을 효과적으로 개선한 의미 있는 연구이나, 실제 로봇 검증과 이론적 분석 심화, 그리고 더 광범위한 task 평가가 필요하다.
GenerativeMPC: VLM-RAG-guided Whole-Body MPC with Virtual Impedance for Bimanual Mobile Manipulation
 *Fig. 3.* GenerativeMPC는 Vision-Language Model과 Retrieval-Augmented Generation을 활용하여 의미론적 장면 이해를 물리적 제어 파라미터로 변환하고, Whole-Body MPC와 통합 임피던스-어드미턴스 제어기를 통해 양팔 이동형 조작 로봇의 안전하고 맥락인식적인 제어를 실현한다.
GenerativeMPC는 의미론적 이해와 물리적 안전성을 체계적으로 통합하는 창의적 접근으로, VLM-RAG 기반 파라미터 생성과 경험 메모리의 신규 활용을 통해 양팔 이동형 조작 로봇의 인간중심 자율성을 크게 향상시킨다. 광범위한 시뮬레이션 및 실제 검증으로 신뢰성을 입증했으나, 실제 플랫폼 실험 확대와 분포 외 robustness 분석이 추가 필요하다.
PaCo-VLA: Passivity-Shielded Compliance Prior for Contact-Rich Vision-Language-Action Manipulation
Figure 1: PaCo-VLA overview. Vanilla VLA sends low-rate action chunks directly toward the plant,
 *Figure 2: Runtime shield mechanisms. (a) Box projection maps unfiltered proposals into Θbox;* 본 논문은 Vision-Language-Action (VLA) 모델을 contact-rich manipulation 작업에 안전하게 적용하기 위해 PaCo-VLA라는 passivity-shielded compliance prior를 제안한다. VLA의 저주기 출력을 직접 모터 명령으로 사용하지 않고, 대신 high-frequency proposal-independent passivity shield를 통해 semantic proposal을 filtering하여 contact dynamics의 안전성을 보장한다.
본 논문은 VLA의 semantic generalization과 contact-rich manipulation의 safety requirement를 reconcile하는 실질적이고 principled된 framework를 제시한다. Passivity-shielded interface와 paired counterfactual evaluation protocol은 methodologically 견고하며, zero passivity violation과 superior precision의 실험 결과는 접근법의 실효성을 입증한다. 다만 task diversity 제한과 보다 일반적인 compliance model에 대한 확장성 논의가 있으면 더욱 강화될 것이다.
SafeVLA-Bench: A Benchmark for the Success-Safety Gap in Vision-Language-Action Models
Figure 1: SafeVLA-Bench overview. SafeVLA-Bench combines task-aware STL safety specifica-
 *Figure 1: SafeVLA-Bench overview. SafeVLA-Bench combines task-aware STL safety specifica-* 본 논문은 VLA 벤치마크에서 높은 작업 성공률이 안전한 실행을 보장하지 않는 문제를 지적하고, SafeVLA-Bench를 제시하여 Signal Temporal Logic (STL) 기반의 형식화된 안전 사양과 Success-But-Unsafe (SBU), Violation Severity Index (VSI) 메트릭을 통해 성공-안전 간극을 정량화한다.
SafeVLA-Bench는 VLA 벤치마크에서 간과되어 온 성공-안전 간극을 명확히 드러내고, 형식화되고 이식 가능한 평가 프레임워크를 제공함으로써 로봇 안전 연구에 중요한 기여를 한다. 다만 시뮬레이터 충실도, 임계값 보정의 한계, 현실 환경 검증 부재 등의 제약이 있다.
Whole-Body Inverse Kinematics with Graph Diffusion
Fig. 1.
 *Fig. 1.* 이 논문은 역기구학(inverse kinematics) 문제를 구조-인식형 그래프 확산 프레임워크인 GraphDiff-IK로 해결한다. 로봇의 URDF로부터 구성한 kinematic graph를 기반으로 조건부 그래프 diffusion process를 통해 직접 joint configuration을 생성하며, 단일 팔 로봇부터 dual-arm, 토소를 가진 전신 로봇까지 통일된 방식으로 지원한다.
GraphDiff-IK는 구조-인식형 graph diffusion을 IK에 적용하여 다양한 로봇 형태의 통일된 처리, 다중 해 생성, 높은 정확도를 동시에 달성한 혁신적 접근법이다. 실제 로봇 플랫폼에서의 광범위한 검증과 우수한 성능으로, 현대 고도-자유도 로봇 제어에 실질적 기여가 기대된다.
World Models for Robotic Manipulation: A Survey
 *Fig. 2. Representation spectrum of world models. The five families are ordered by increasing structured inductive bias, * 로봇 조작을 위한 world model에 대한 포괄적 서베이다. 세 가지 질문(어떤 미래 표현을 예측하는가, 예측을 행동에 어떻게 연결하는가, 학습 파이프라인의 어느 단계에서 사용되는가)을 중심으로 action-conditioned predictive system으로서의 world model을 정의하고, 다섯 가지 표현 계열과 기능적 분류를 제시한다.
이 서베이는 로봇 조작 분야에서 fragmented된 world model 문헌을 통합하는 중요한 기여다. 세 가지 직교 축의 framework와 명확한 operational definition은 향후 연구의 설계 선택을 가이드할 수 있으며, 34개 dataset 검토와 종합 평가 프로토콜은 실질적 가치를 제공한다. 다만 closed-loop 평가 부족과 contact modeling 등 조작 고유의 도전이 여전히 미해결되어 있고, 개념적 경계의 모호성도 완전히 제거되지 않았다. 전체적으로 조작 중심의 predictive modeling을 이해하는 데 필수적인 참고문헌이지만, 구체적인 기술 혁신보다는 종합 정리의 성격이 강하다.